

A Multi-Modality Fusion and Gated Multi-Filter U-Net for Water Area Segmentation in Remote Sensing

Abstract
1. Introduction
- We release the Water Index and Polarization Information multi-modality dataset for water area segmentation in remote sensing. The proposed datasets are the first ever to provide both the water index modal and the corresponding polarization information modal. Specifically, the dataset contains the Cloud-Free Labels automatically obtained by the proposed Multi-Model Decision Fusion algorithm, which can effectively alleviate the problem of labeled sample scarcity.
- We propose a multi-modality fusion and gated multi-filter U-shaped convolutional neural network that introduces the GCT skip connection for adaptively focusing on more meaningful channels and that incorporates the proposed gated multi-filter inception module for fully utilizing the multi-modality information and handling the challenge due to the variety of water body sizes and shapes.
- Extensive experiments on three benchmarks, including WIPI (water index and SAR images), Chengdu (multispectral images) and GF2020 (optical images) datasets demonstrated that our MFGF-UNet model achieves favorable performance with lower complexity and better robustness against six competing approaches.
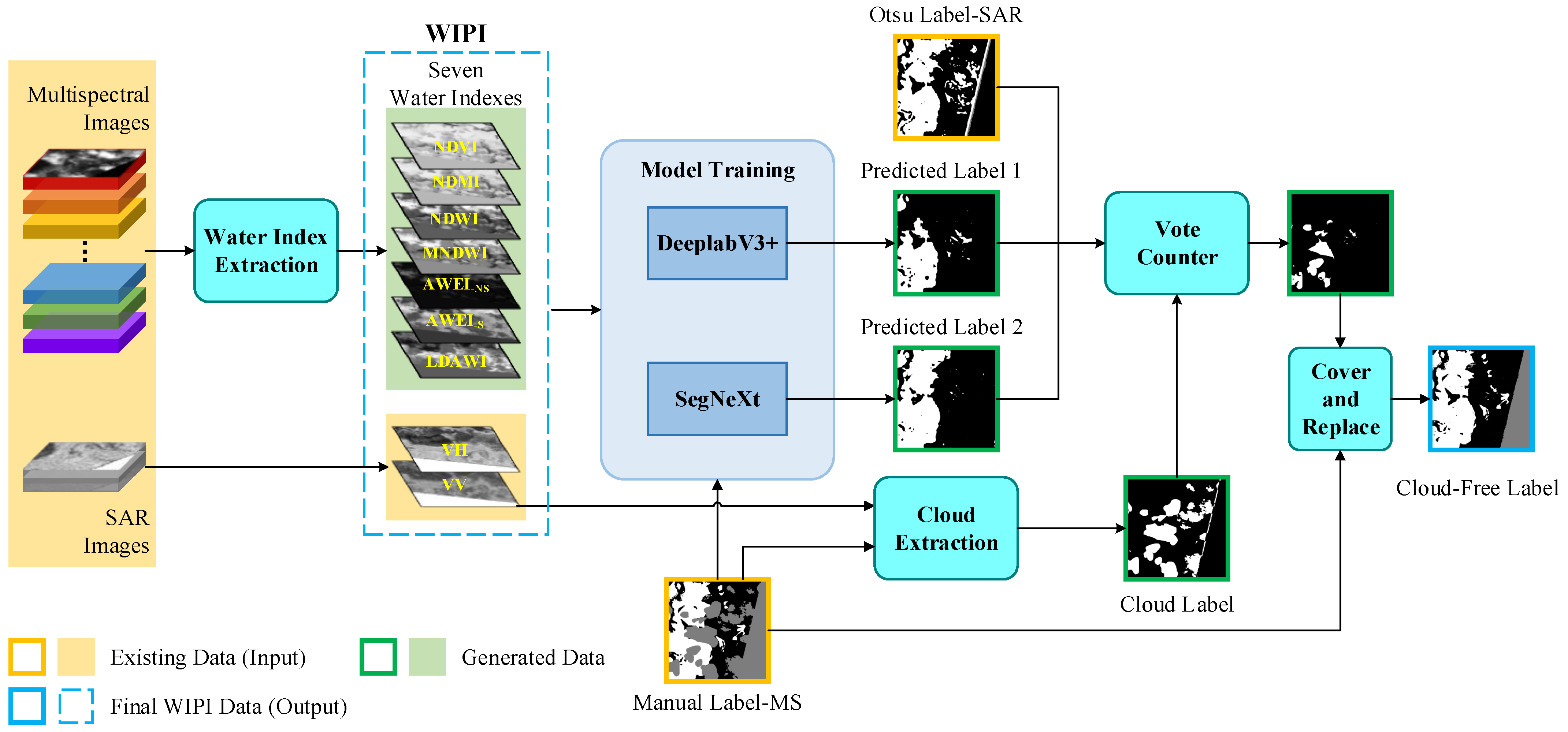
2. WIPI Multi-Modality Dataset Construction
2.1. Original Sen1Floods11 Dataset
2.2. Water Index Extraction
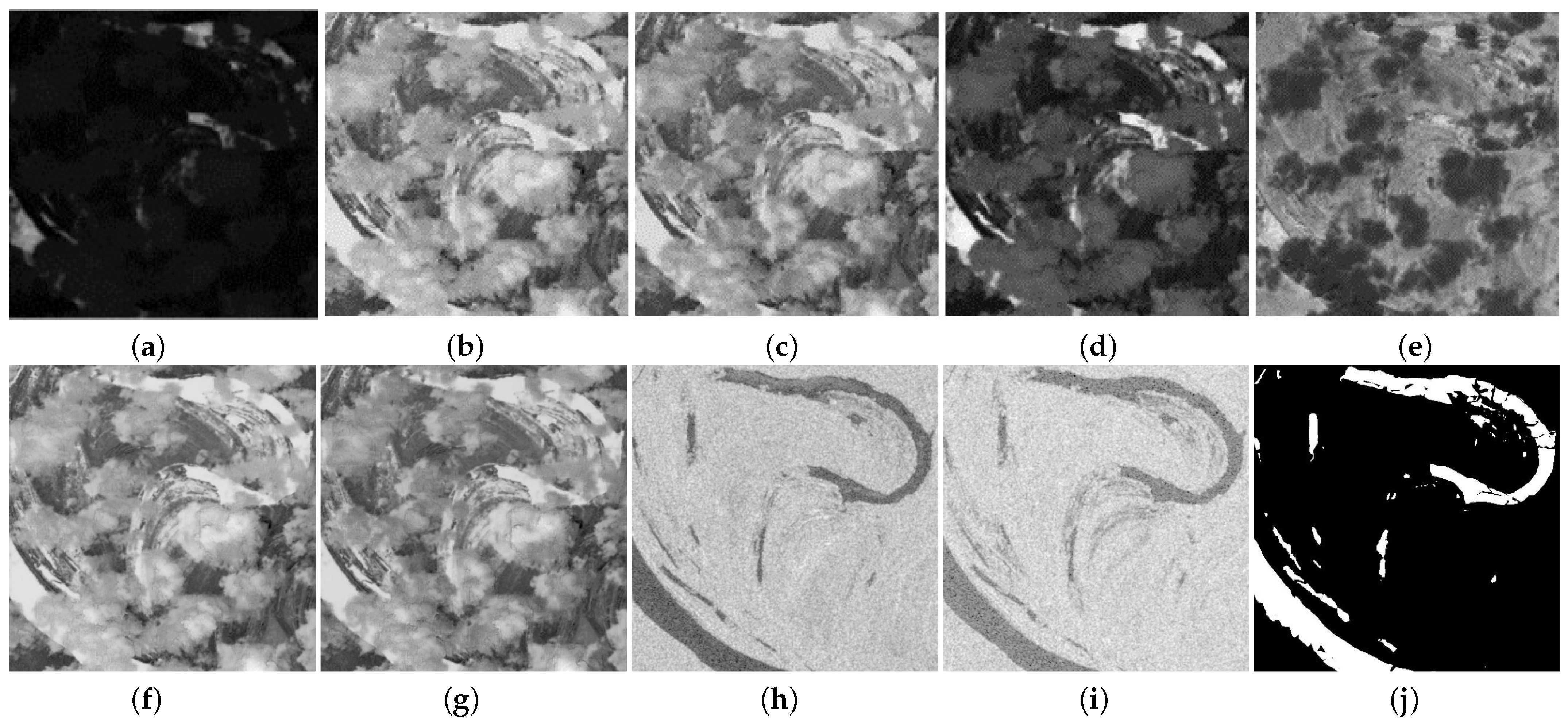
2.3. Obtaining Cloud-Free Labels
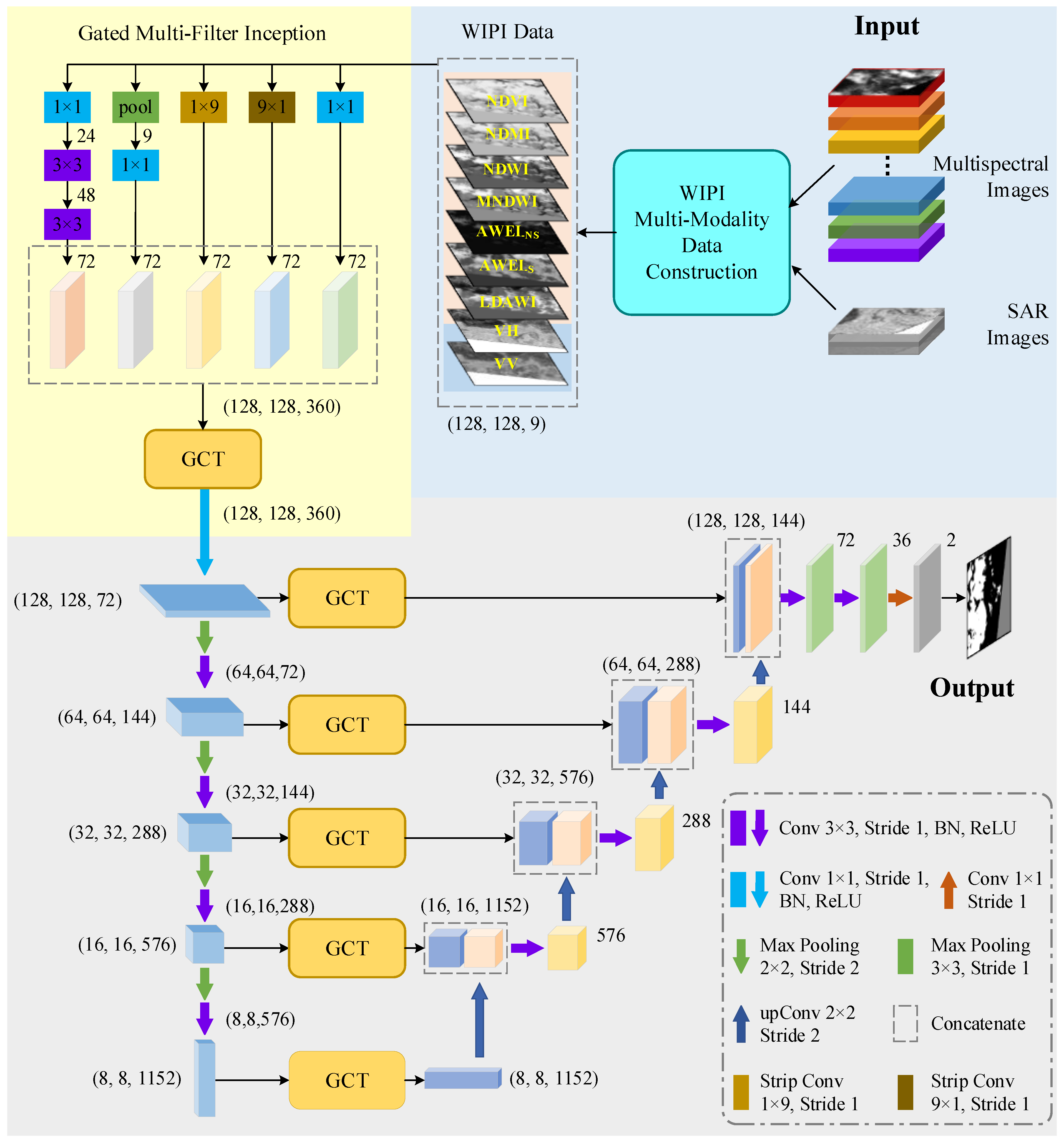
3. Methodology
3.1. U-Shaped Encoder-Decoder
3.2. Skip Connections with Channel Attention
3.3. Gated Multi-Filter Inception Module
4. Experiments
4.1. Dataset and Pre-Processing
4.2. Experimental Setup and Evaluation Metrics
4.3. Ablation Studies
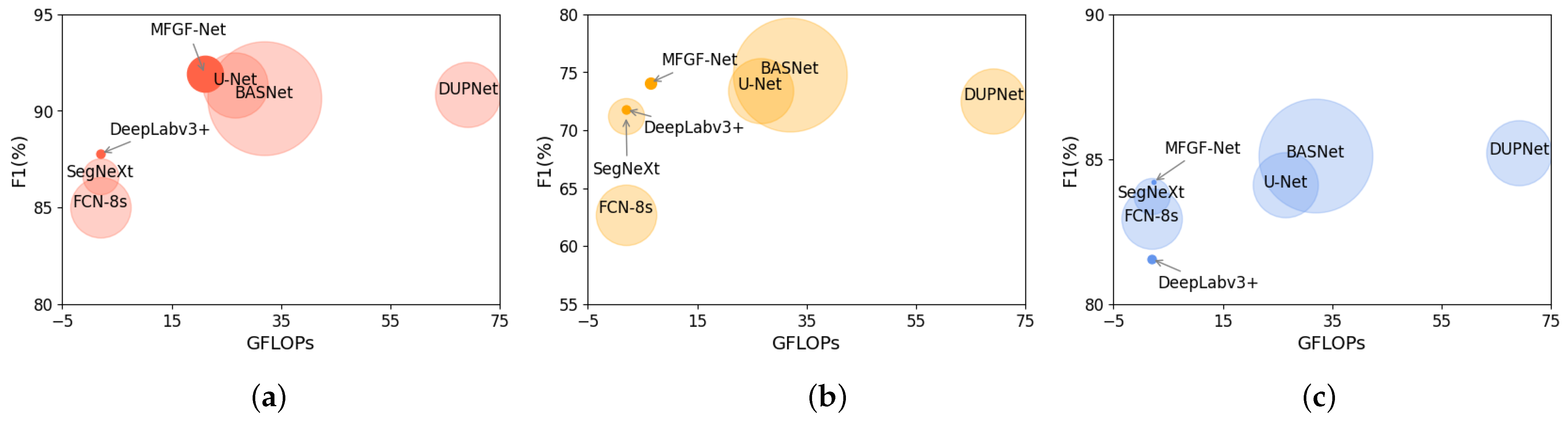
4.4. Comprehensive Comparison with Other Methods
4.5. Evaluation of Model Robustness
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Description of Sen1Floods11 Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Value | Format | Bands | |
|---|---|---|---|---|
| SAR | Unit:dB | GeoTIFF 512 × 512 2 bands Float32 | 0:VV 1:VH | |
| MSI | Unit: TOA reflectance (scaled by 10,000) | 0: B1 (Coastal) | 7: B8 (NIR) | |
| 1: B2 (Blue) | 8: B8A (Narrow NIR) | |||
| 2: B3 (Green) | 9: B9 (Water Vapor) | |||
GeoTIFF 512 × 512 13 bands UInt16 | 3: B4 (Red) | 10: B10 (Cirrus) | ||
| 4: B5 (RedEdge-1) | 11: B11 (SWIR-1) | |||
| 5: B6 (RedEdge-2) | 12: B12 (SWIR-2) | |||
| 6: B7 (RedEdge-3) | ||||
Appendix A.2. Description of the Seven Water Indexes Used
| Index | Name | Formula | Description |
|---|---|---|---|
| 1 | Normalized Difference Vegetation Index (NDVI) [40] | (B8 − B4)/(B8 + B4) | High values indicate dense tree canopies, while low or negative values indicate urban areas or water bodies. |
| 2 | Normalized Difference Moisture Index (NDMI) [41] | (B8A − B11)/(B8A + B11) | Vegetation with higher values is relatively moist. |
| 3 | Normalized Difference Water Index (NDWI) [26] | (B3 − B8)/(B3 + B8) | Highlights water bodies, suppresses vegetation information; susceptible to the influence of object shadows. |
| 4 | Modified Normalized Difference Water Index (MNDWI) [27] | (B3 − B11)/(B3 + B11) | Eliminates the influence of buildings and land, highlights water bodies; easily affected by shadows of objects. |
| 5 | Automated Water Extraction Index (Non-Shadow, AWEI) [42] | (4B3 − 4B11)/(0.25B8 + 2.75B12) | Removes black buildings that are easily misclassified as water bodies. |
| 6 | Automated Water Extraction Index (Shadow, AWEI) [42] | B2 + 2.5B3 − 1.5 (B8 + B11) − 0.25B12 | Suitable for scenes with a high amount of shadow. |
| 7 | Linear Discriminant Analysis Water Index (LDAWI) [43] | 1.7204 + 171B3 + 3B4 − 70B8 − 45B11 − 71B12 | Suitable for scenes where there is a large difference in spectral distribution between non-water and water bodies. |
References
- Liu, Z.; Chen, X.; Zhou, S.; Yu, H.; Guo, J.; Liu, Y. DUPnet: Water Body Segmentation with Dense Block and Multi-Scale Spatial Pyramid Pooling for Remote Sensing Images. Remote Sens. 2022, 14, 5567. [Google Scholar] [CrossRef]
- Konapala, G.; Kumar, S.V.; Ahmad, S.K. Exploring Sentinel-1 and Sentinel-2 diversity for flood inundation mapping using deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 180, 163–173. [Google Scholar] [CrossRef]
- Li, Y.; Dang, B.; Zhang, Y.; Du, Z. Water body classification from high-resolution optical remote sensing imagery: Achievements and perspectives. ISPRS J. Photogramm. Remote Sens. 2022, 187, 306–327. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Y. Water Body Extraction in Remote Sensing Imagery Using Domain Adaptation-Based Network Embedding Selective Self-Attention and Multi-Scale Feature Fusion. Remote Sens. 2022, 14, 3538. [Google Scholar] [CrossRef]
- Shen, X.; Wang, D.; Mao, K.; Anagnostou, E.; Hong, Y. Inundation extent mapping by synthetic aperture radar: A review. Remote Sens. 2019, 11, 879. [Google Scholar] [CrossRef]
- Longfei, S.; Zhengxuan, L.; Fei, G.; Min, Y. A review of remote sensing image water extraction. Remote Sens. Nat. Resour. 2021, 33, 9–11. [Google Scholar]
- Cao, M.; Mao, K.; Shen, X.; Xu, T.; Yan, Y.; Yuan, Z. Monitoring the spatial and temporal variations in the water surface and floating algal bloom areas in Dongting Lake using a long-term MODIS image time series. Remote Sens. 2020, 12, 3622. [Google Scholar] [CrossRef]
- Shetty, S.; Gupta, P.K.; Belgiu, M.; Srivastav, S. Assessing the effect of training sampling design on the performance of machine learning classifiers for land cover mapping using multi-temporal remote sensing data and google earth engine. Remote Sens. 2021, 13, 1433. [Google Scholar] [CrossRef]
- Razaque, A.; Ben Haj Frej, M.; Almi’ani, M.; Alotaibi, M.; Alotaibi, B. Improved support vector machine enabled radial basis function and linear variants for remote sensing image classification. Sensors 2021, 21, 4431. [Google Scholar] [CrossRef]
- Li, A.; Fan, M.; Qin, G.; Xu, Y.; Wang, H. Comparative analysis of machine learning algorithms in automatic identification and extraction of water boundaries. Appl. Sci. 2021, 11, 10062. [Google Scholar] [CrossRef]
- Acharya, T.D.; Subedi, A.; Lee, D.H. Evaluation of machine learning algorithms for surface water extraction in a Landsat 8 scene of Nepal. Sensors 2019, 19, 2769. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Cui, M.; Li, K.; Chen, J.; Yu, W. CM-Unet: A novel remote sensing image segmentation method based on improved U-Net. IEEE Access 2023, 11, 56994–57005. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote. Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional Nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. Segnext: Rethinking convolutional attention design for semantic segmentation. arXiv 2022, arXiv:2209.08575. [Google Scholar]
- Akiva, P.; Purri, M.; Dana, K.; Tellman, B.; Anderson, T. H2O-Net: Self-supervised flood segmentation via adversarial domain adaptation and label refinement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 111–122. [Google Scholar]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Guan, Q.; Huang, Y.; Zhong, Z.; Zheng, Z.; Zheng, L.; Yang, Y. Diagnose like a radiologist: Attention guided convolutional neural network for thorax disease classification. arXiv 2018, arXiv:1801.09927. [Google Scholar]
- Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional shapecontextnet for point cloud recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4606–4615. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. Vl-bert: Pre-training of generic visual-linguistic representations. arXiv 2019, arXiv:1908.08530. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Bonafilia, D.; Tellman, B.; Anderson, T.; Issenberg, E. Sen1Floods11: A georeferenced dataset to train and test deep learning flood algorithms for sentinel-1. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 210–211. [Google Scholar]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Jackson, R.D. Remote sensing of biotic and abiotic plant stress. Annu. Rev. Phytopathol. 1986, 24, 265–287. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated Water Extraction Index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Fisher, A.; Flood, N.; Danaher, T. Comparing Landsat water index methods for automated water classification in eastern Australia. Remote Sens. Environ. 2016, 175, 167–182. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, ICML, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; JMLR Workshop and Conference Proceedings. pp. 315–323. [Google Scholar]
- Yang, Z.; Zhu, L.; Wu, Y.; Yang, Y. Gated channel transformation for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11794–11803. [Google Scholar]
- Yuan, K.; Zhuang, X.; Schaefer, G.; Feng, J.; Guan, L.; Fang, H. Deep-learning-based multispectral satellite image segmentation for water body detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7422–7434. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Diao, W.; Lu, X.; Yang, Z.; Zhang, Y.; Xiang, D.; Yan, C.; Guo, J.; et al. Automated high-resolution earth observation image interpretation: Outcome of the 2020 Gaofen challenge. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8922–8940. [Google Scholar] [CrossRef]








| Dataset | Image Size | Number of Images in Dataset | |||
|---|---|---|---|---|---|
| Total | Train Set | Val Set | Test Set | ||
| WIPI | (512, 512, 9) | 446 | 221 | 85 | 140 |
| Chengdu | (512, 512, 5) | 1681 | 1008 | 336 | 337 |
| GF2020 | (492, 492, 3) | 1000 | 600 | 200 | 200 |
| Method | Enc-Dec | Inception | GCT | ACC (%) | MIoU (%) | F1 (%) | Param (M) | GFLOPs |
|---|---|---|---|---|---|---|---|---|
| AS1 | ✓ | 98.09 (±0.04) | 83.92 (±0.31) | 91.26 (±0.18) (↓0.65) | 27.36 | 15.74 | ||
| AS2 | ✓ | ✓ | 98.21 (±0.01) | 84.82 (±0.15) | 91.79 (±0.08) (↓0.12) | 27.53 | 21.04 | |
| AS3 | ✓ | ✓ | 98.13 (±0.03) | 84.21 (±0.28) | 91.43 (±0.16) (↓0.48) | 27.37 | 15.75 | |
| MFGF-UNet | ✓ | ✓ | ✓ | 98.22 (±0.01) | 85.03 (±0.18) | 91.91 (±0.11) | 27.53 | 21.05 |
| Method | Modality | Channel No. | ACC (%) | MIoU (%) | F1 (%) | Param (M) | GFLOPs |
|---|---|---|---|---|---|---|---|
| MFGF-UNet | SAR | 2 | 95.52 (±0.06) | 63.18 (±0.60) | 77.68 (±0.79) (↓14.23) | 1.36 | 1.04 |
| MSI | 13 | 97.55 (±0.04) | 79.79 (±0.29) | 88.76 (±0.18) (↓3.15) | 57.43 | 43.79 | |
| WI | 7 | 97.79 (±0.05) | 81.38 (±0.39) | 89.73 (±0.24) (↓2.18) | 16.65 | 12.71 | |
| WIPI | 9 | 98.22 (±0.01) | 85.03 (±0.18) | 91.91 (±0.11) | 27.53 | 21.04 |
| Method | Dataset | Channel No. | ACC (%) | MIoU (%) | F1 (%) | Param (M) | GFLOPs |
|---|---|---|---|---|---|---|---|
| FCN-8s [12] | Sen1Floods11 | 15 | 96.04 (±0.28) | 68.12 (±1.91) | 81.02 (±1.36) | 46.25 | 2.01 |
| WIPI | 9 | 96.83 (±0.06) | 73.95 (±0.62) | 85.02 (±0.41) (↑4.00) | 46.24 | 1.98 | |
| U-Net [14] | Sen1Floods11 | 15 | 96.53 (±0.46) | 72.84 (±2.47) | 84.26 (±1.64) | 49.89 | 26.91 |
| WIPI | 9 | 98.09 (±0.04) | 84.07 (±0.21) | 91.35 (±0.12 (↑7.09)) | 49.89 | 26.69 | |
| DeepLabv3+ [19] | Sen1Floods11 | 15 | 96.43 (±0.34) | 71.88 (±1.91) | 83.62 (±1.28) | 6.43 | 2.10 |
| WIPI | 9 | 97.37 (±0.03) | 78.22 (±0.33) | 87.78 (±0.21) (↑4.16) | 6.43 | 2.09 | |
| BASNet [20] | Sen1Floods11 | 15 | 97.30 (±0.06) | 78.14 (±0.17) | 87.73 (±0.10) | 87.08 | 31.99 |
| WIPI | 9 | 97.91 (±0.07) | 82.92 (±0.45) | 90.66 (±0.27) (↑2.93) | 87.07 | 31.93 | |
| DUPNet [1] | Sen1Floods11 | 15 | 95.16 (±0.24) | 66.06 (±1.18) | 79.55 (±0.86) | 49.87 | 69.20 |
| WIPI | 9 | 98.01 (±0.07) | 83.23 (±0.66) | 90.85 (±0.40) (↑11.30) | 49.86 | 69.17 | |
| SegNeXt [24] | Sen1Floods11 | 15 | 96.67 (±0.10) | 72.15 (±1.08) | 83.81 (±0.73) | 27.54 | 2.02 |
| WIPI | 9 | 97.11 (±0.17) | 76.38 (±1.21) | 86.60 (±0.78) (↑2.79) | 27.54 | 2.01 | |
| MFGF-UNet (ours) | Sen1Floods11 | 15 | 96.11 (±0.53) | 70.52 (±2.64) | 82.68 (±1.84) | 76.46 | 58.37 |
| WIPI | 9 | 98.22 (±0.01) | 85.03 (±0.18) | 91.91 (±0.11) (↑9.23) | 27.53 | 21.05 |
| Method | Dataset | ACC (%) | MIoU (%) | F1 (%) | Params (M) | GFLOPs |
|---|---|---|---|---|---|---|
| FCN-8s [12] | Chengdu | 98.56 (±0.01) | 45.78 (±0.76) | 62.71 (±0.64) | 46.25 | 1.96 |
| GF2020 | 93.12 (±0.01) | 70.83 (±0.22) | 82.93 (±0.15) | 46.25 | 1.95 | |
| U-Net [14] | Chengdu | 98.91 (±0.01) | 58.02 (±0.61) | 73.42 (±0.49) | 49.88 | 26.54 |
| GF2020 | 93.69 (±0.11) | 72.72 (±0.77) | 84.10 (±0.51) | 49.88 | 26.46 | |
| DeepLabv3+ [19] | Chengdu | 98.86 (±0.01) | 55.96 (±0.50) | 71.76 (±0.41) | 6.43 | 2.09 |
| GF2020 | 92.56 (±0.16) | 68.86 (±0.90) | 81.55 (±0.63) | 6.43 | 2.09 | |
| BASNet [20] | Chengdu | 98.90 (±0.01) | 59.69 (±0.12) | 74.75 (±0.09) | 87.07 | 31.89 |
| GF2020 | 93.45 (±0.16) | 74.11 (±0.35) | 85.13 (±0.23) | 87.07 | 31.87 | |
| DUPNet [1] | Chengdu | 98.87 (±0.01) | 56.87 (±0.72) | 72.50 (±0.58) | 49.86 | 69.16 |
| GF2020 | 93.79 (±0.06) | 74.27 (±0.09) | 85.23 (±0.06) | 49.86 | 69.15 | |
| SegNeXt [24] | Chengdu | 98.84 (±0.01) | 55.29 (±0.13) | 71.21 (±0.11) | 27.54 | 2.01 |
| GF2020 | 93.06 (±0.09) | 72.03 (±0.26) | 83.74 (±0.17) | 27.54 | 2.01 | |
| MFGF-UNet | Chengdu | 98.91 (±0.01) | 58.85 (±0.10) | 74.09 (±0.08) | 8.50 | 6.49 |
| GF2020 | 93.63 (±0.09) | 72.73 (±0.45) | 84.21 (±0.30) | 3.06 | 2.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Zhang, C.; Chen, C.; Hao, H.; Li, W.; Jiao, L. A Multi-Modality Fusion and Gated Multi-Filter U-Net for Water Area Segmentation in Remote Sensing. Remote Sens. 2024, 16, 419. https://doi.org/10.3390/rs16020419
Wang R, Zhang C, Chen C, Hao H, Li W, Jiao L. A Multi-Modality Fusion and Gated Multi-Filter U-Net for Water Area Segmentation in Remote Sensing. Remote Sensing. 2024; 16(2):419. https://doi.org/10.3390/rs16020419
Chicago/Turabian StyleWang, Rongfang, Chenchen Zhang, Chao Chen, Hongxia Hao, Weibin Li, and Licheng Jiao. 2024. "A Multi-Modality Fusion and Gated Multi-Filter U-Net for Water Area Segmentation in Remote Sensing" Remote Sensing 16, no. 2: 419. https://doi.org/10.3390/rs16020419
APA StyleWang, R., Zhang, C., Chen, C., Hao, H., Li, W., & Jiao, L. (2024). A Multi-Modality Fusion and Gated Multi-Filter U-Net for Water Area Segmentation in Remote Sensing. Remote Sensing, 16(2), 419. https://doi.org/10.3390/rs16020419