
Rapid Large-Scale Wetland Inventory Update Using Multi-Source Remote Sensing




Abstract
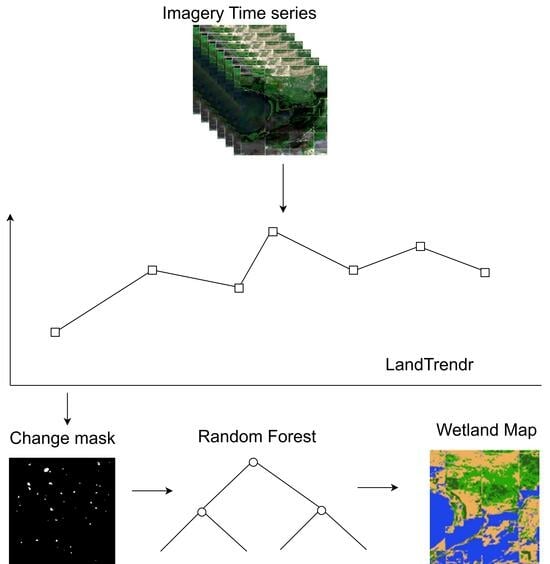
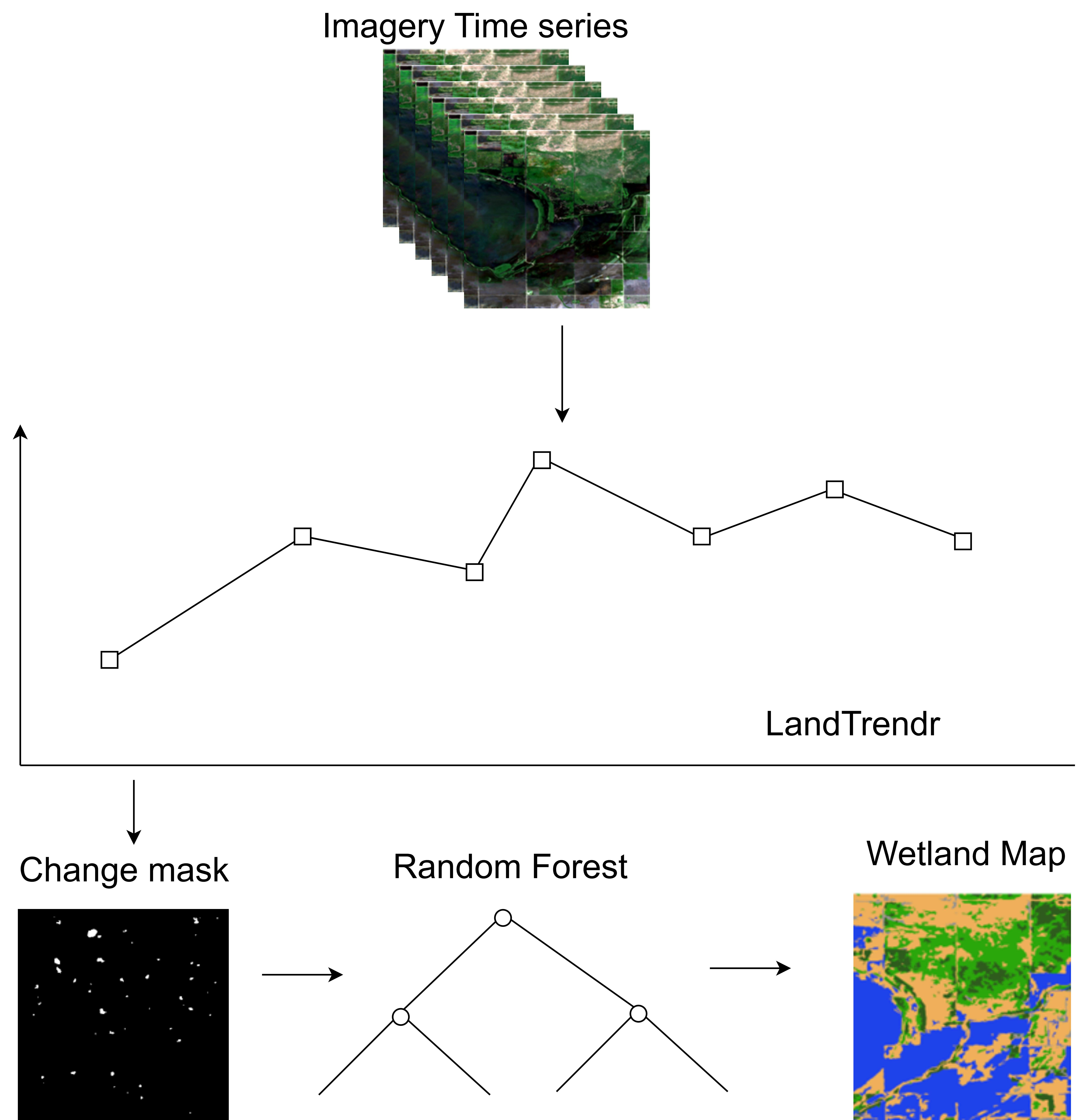
:
1. Introduction
- (1)
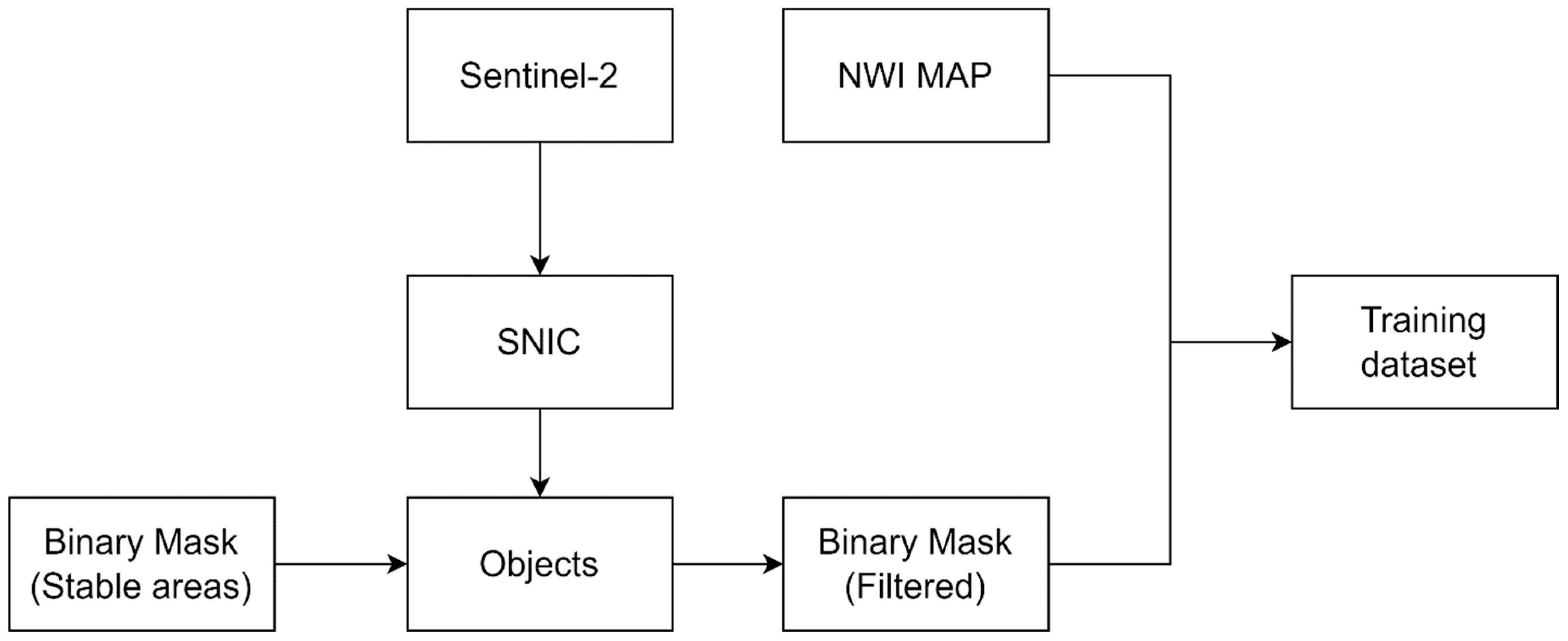
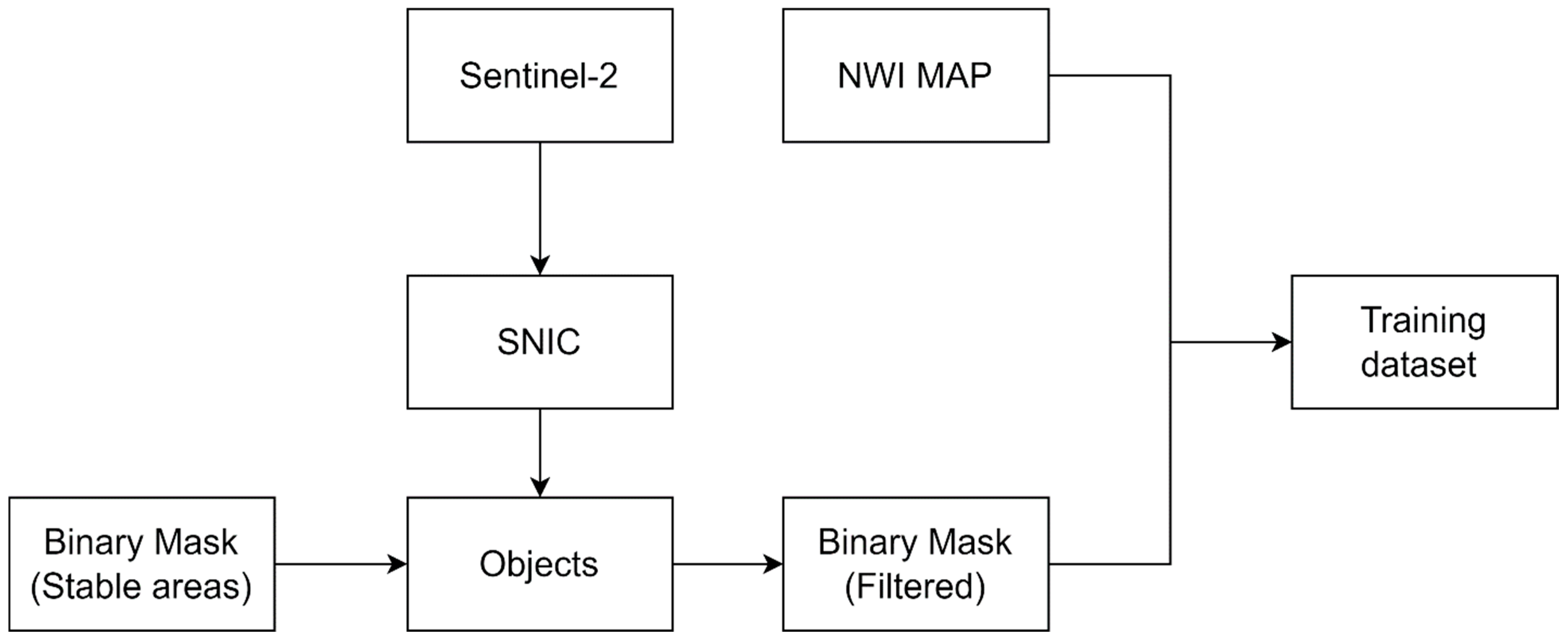
- Extract training samples from an existing wetland map of Minnesota. This is achieved by using LandTrendr to identify areas in the study area which are least likely to have undergone significant changes over a time period which we refer to as “stable”. The consistency of the identified areas is further improved by using clusters (objects) to further filter out pixels in these stable areas. Finally, a database of training samples is then extracted.
- (2)
- Use the extracted training samples to classify wetlands in Minnesota, leveraging SAR, multispectral and topographic data.
- (3)
- Produce an updated fine-resolution statewide wetland inventory map.
- (4)
- Secondarily, we assess the impact of increased water content on classification performance.
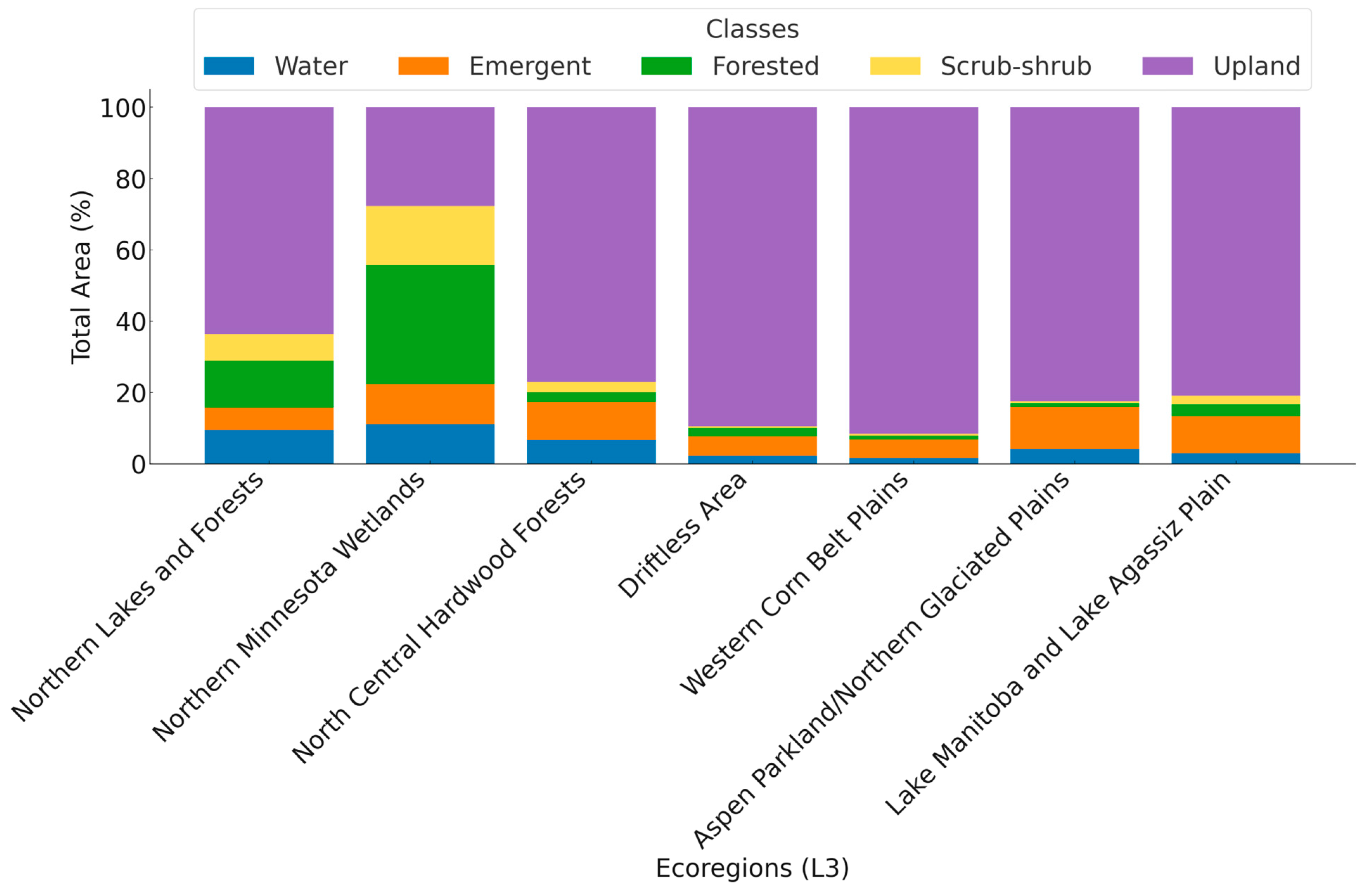
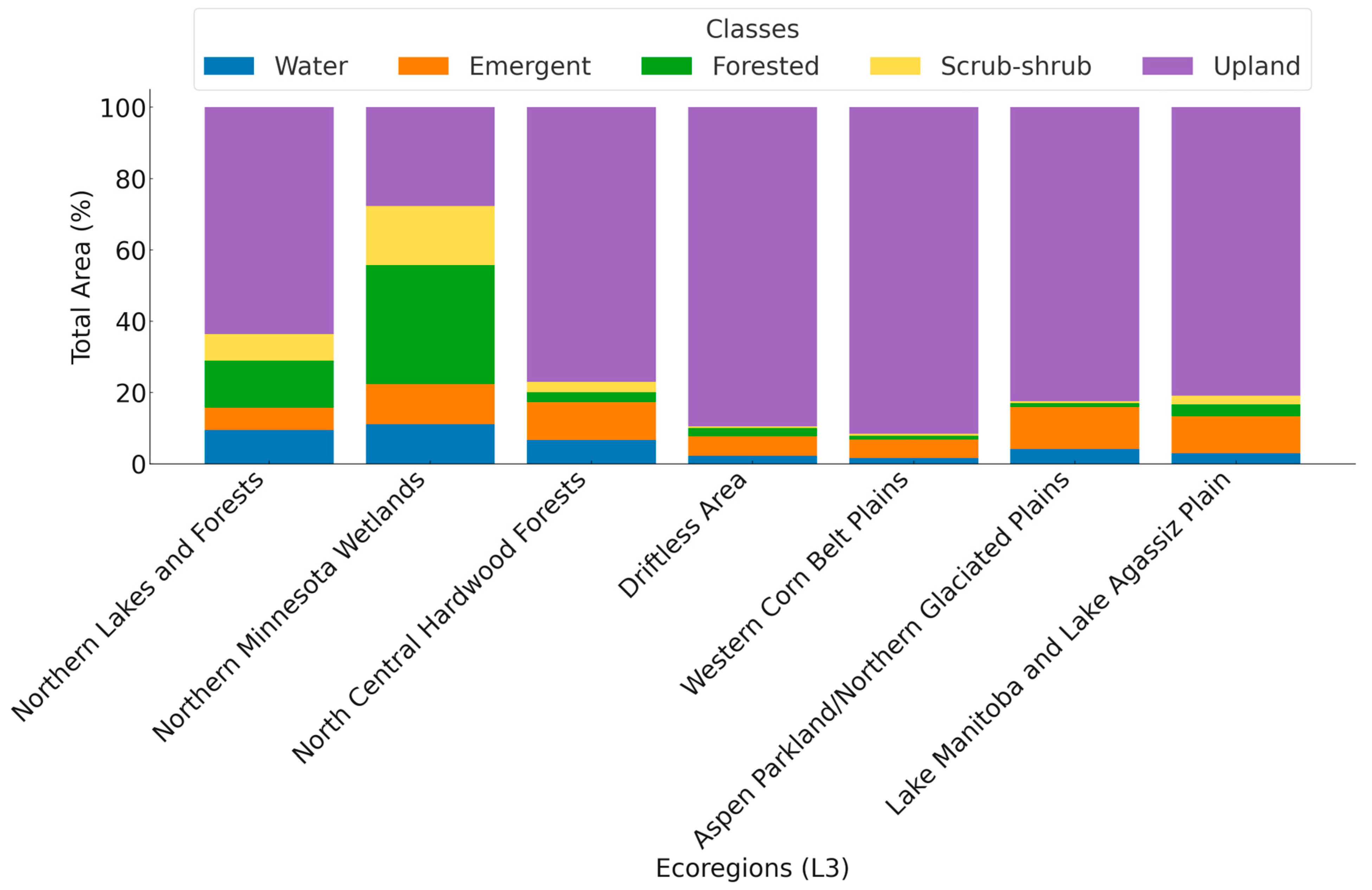
2. Study Area
3. Data
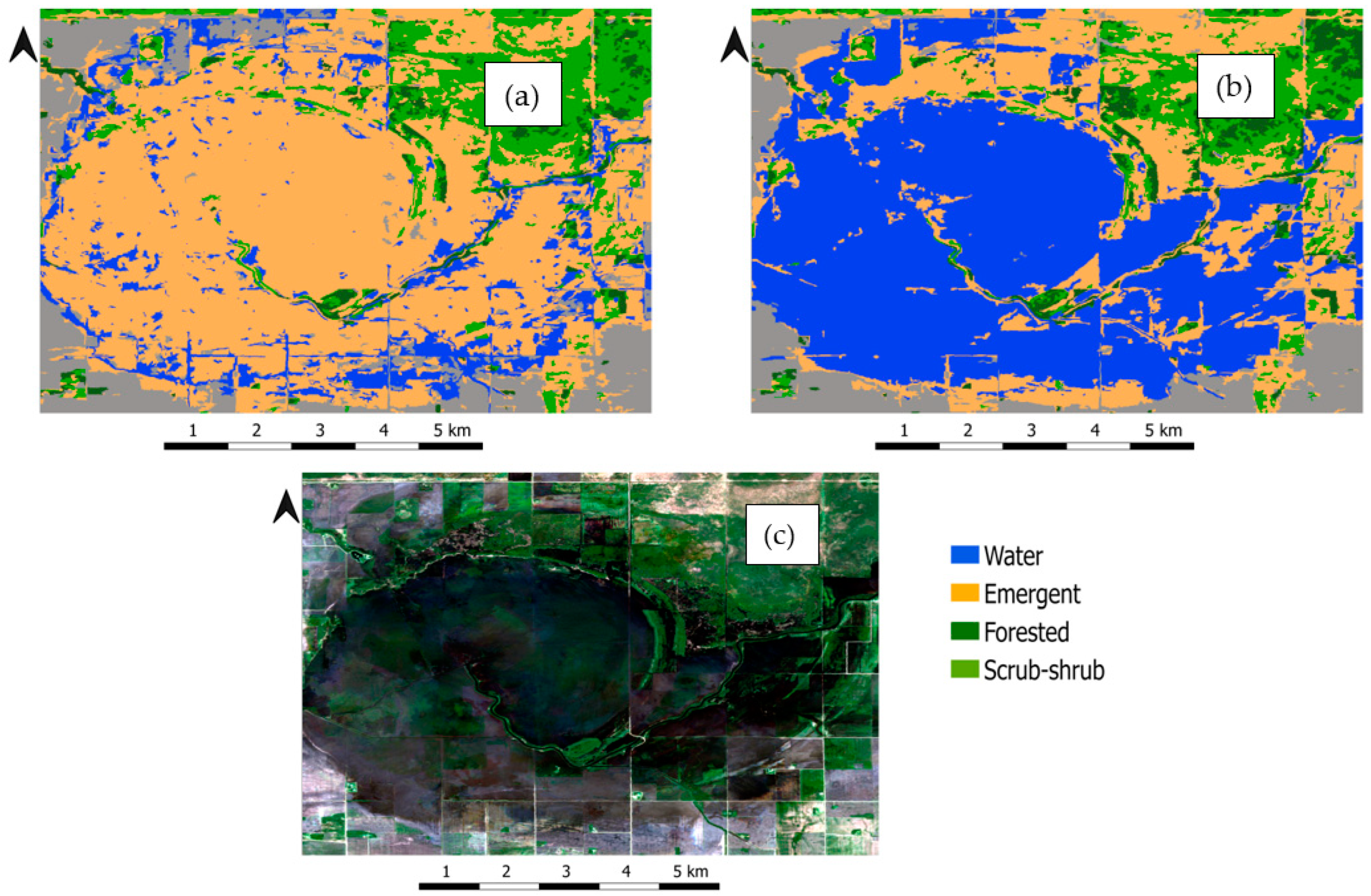
3.1. National Wetland Inventory Map
3.2. Imagery Input
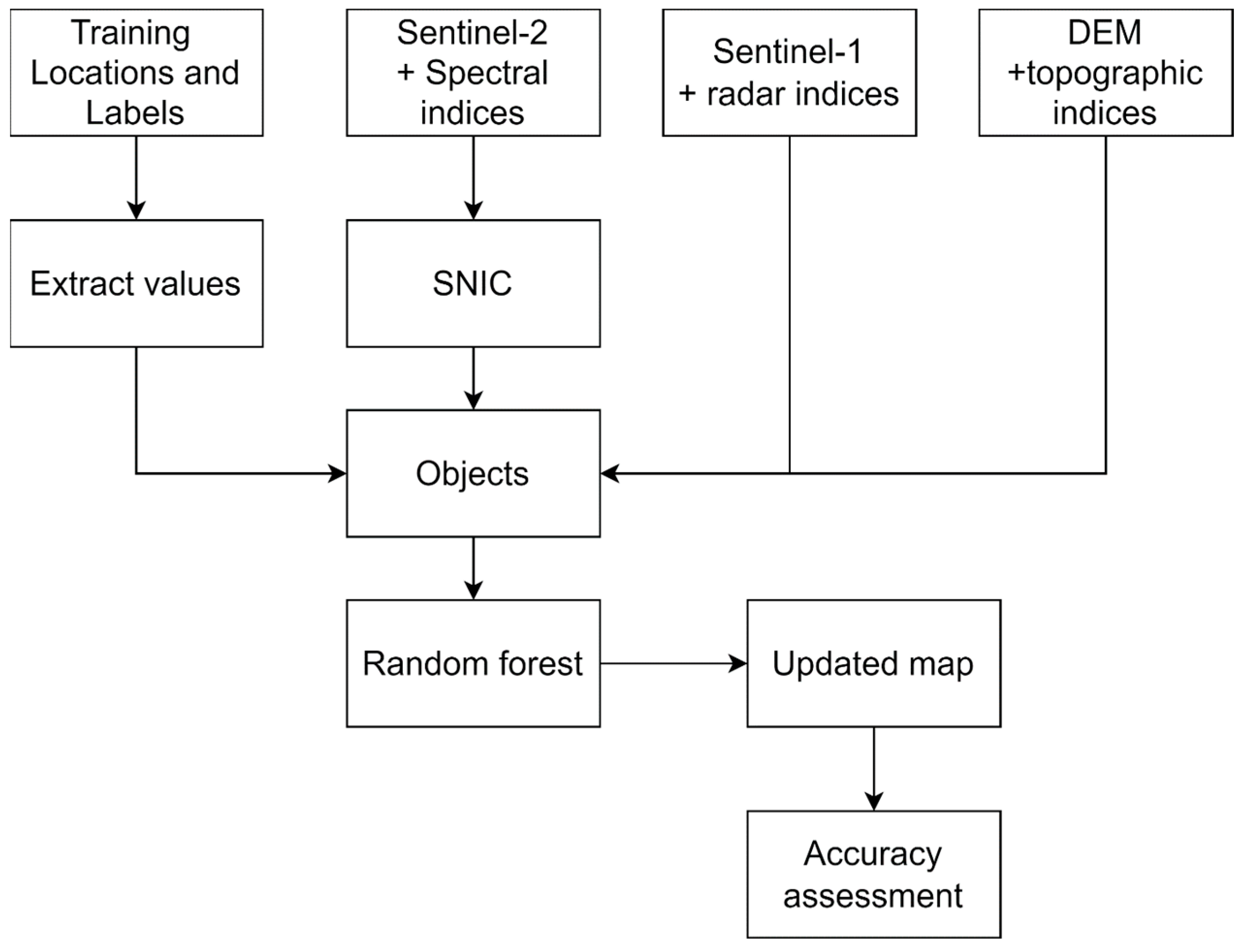
4. Method
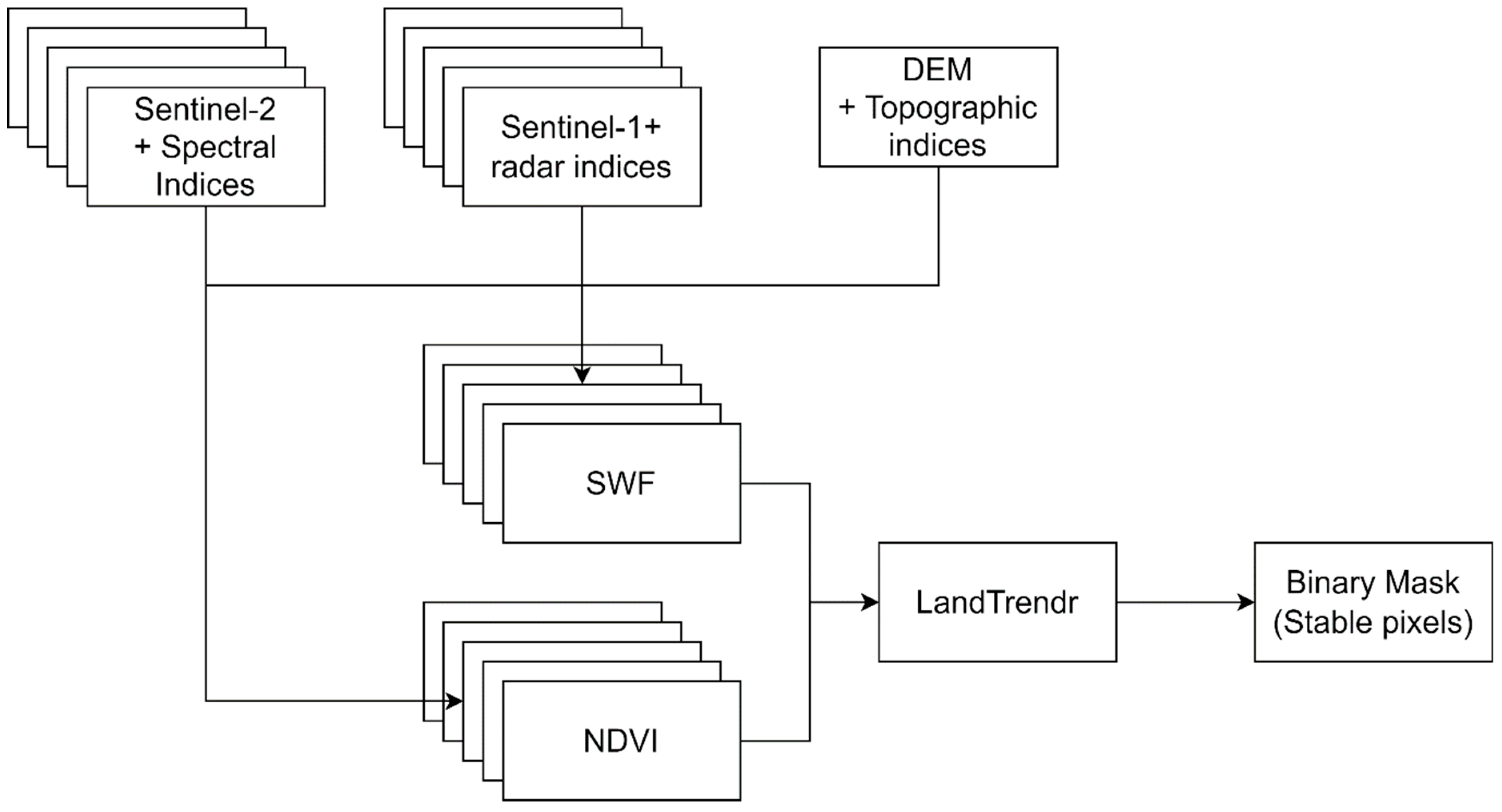
4.1. Stable Pixels Identification
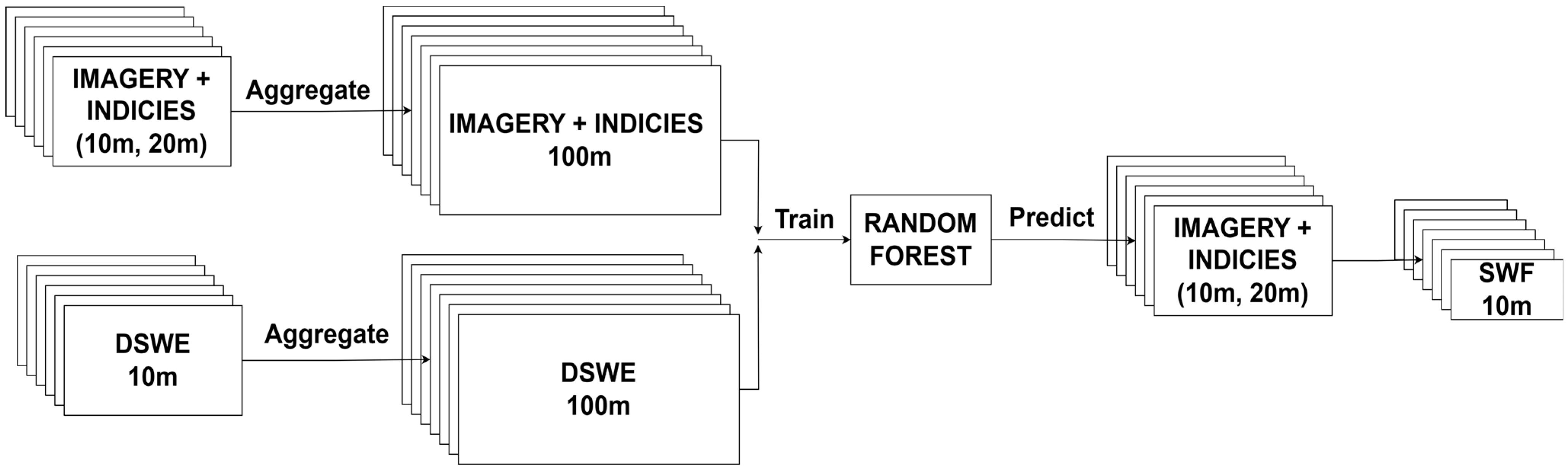
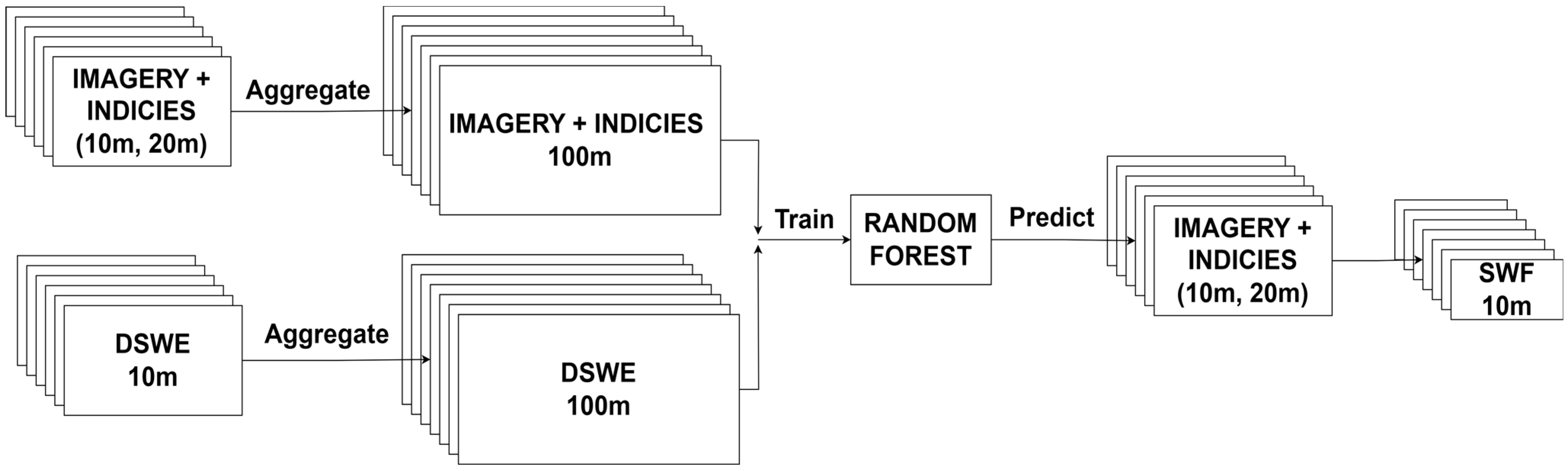
4.1.1. Sub-Pixel Water Fraction (SWF)
4.1.2. LandTrendr
4.2. Training Sample Selection
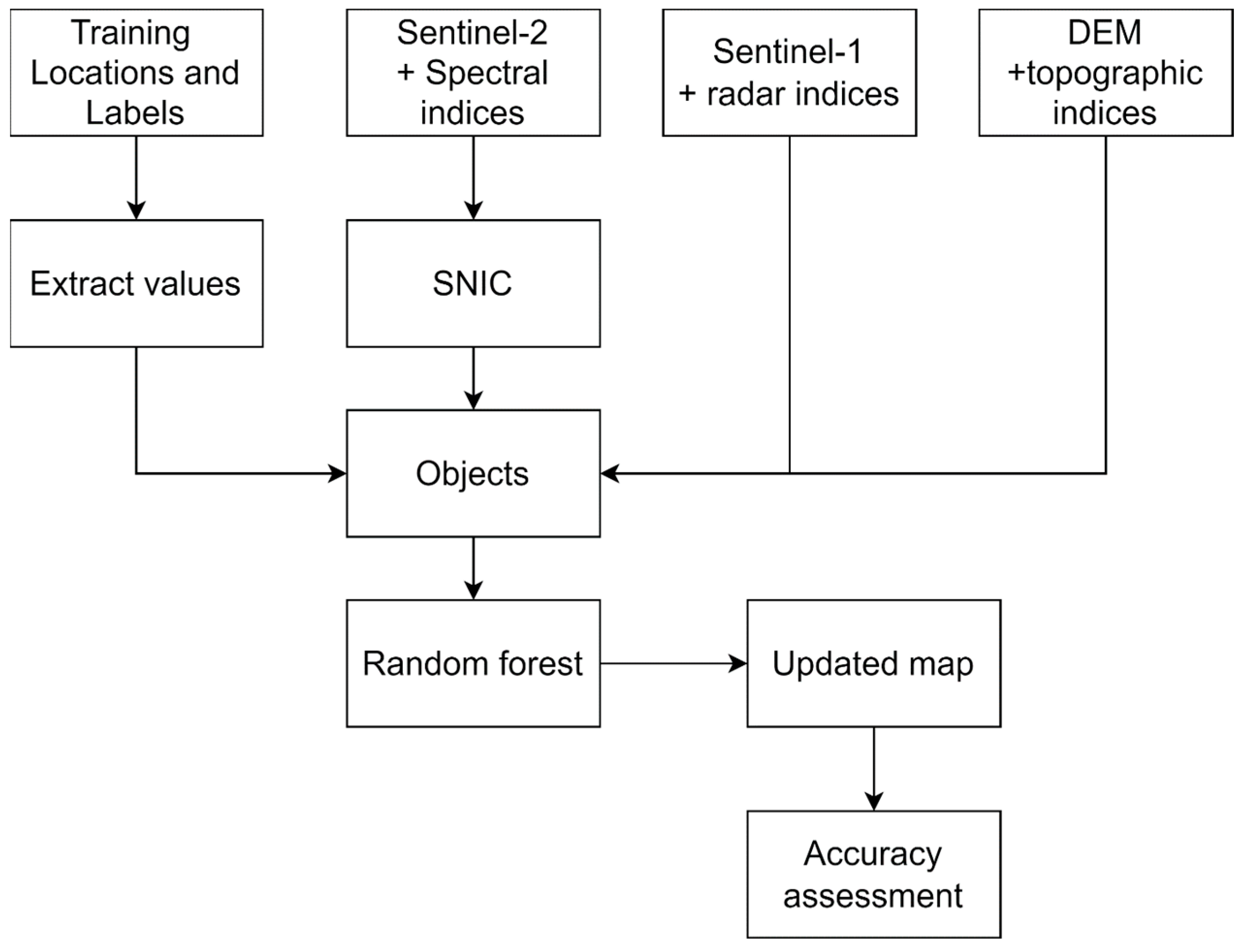
4.3. Classification
Accuracy Assessment and Evaluation Metrics
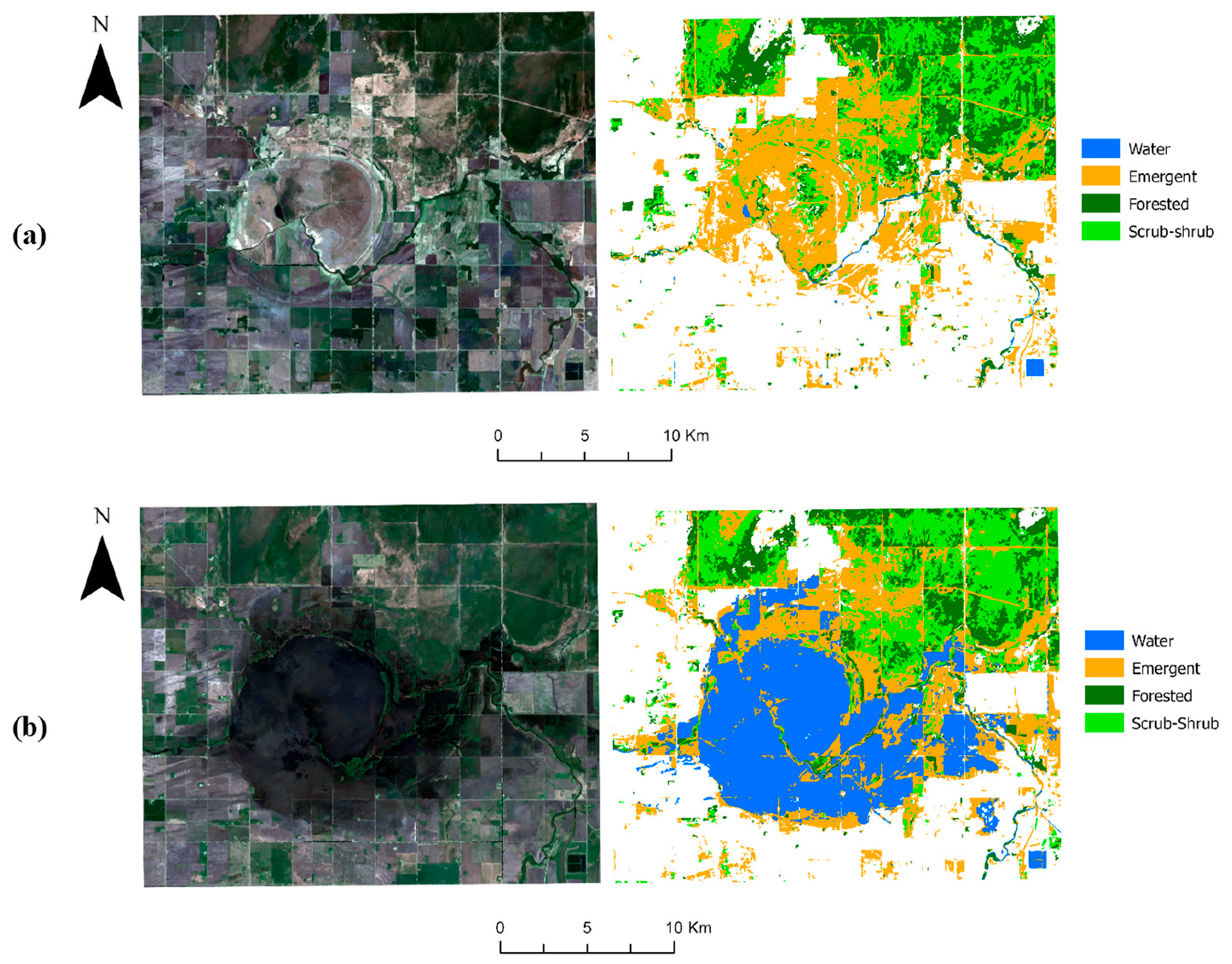
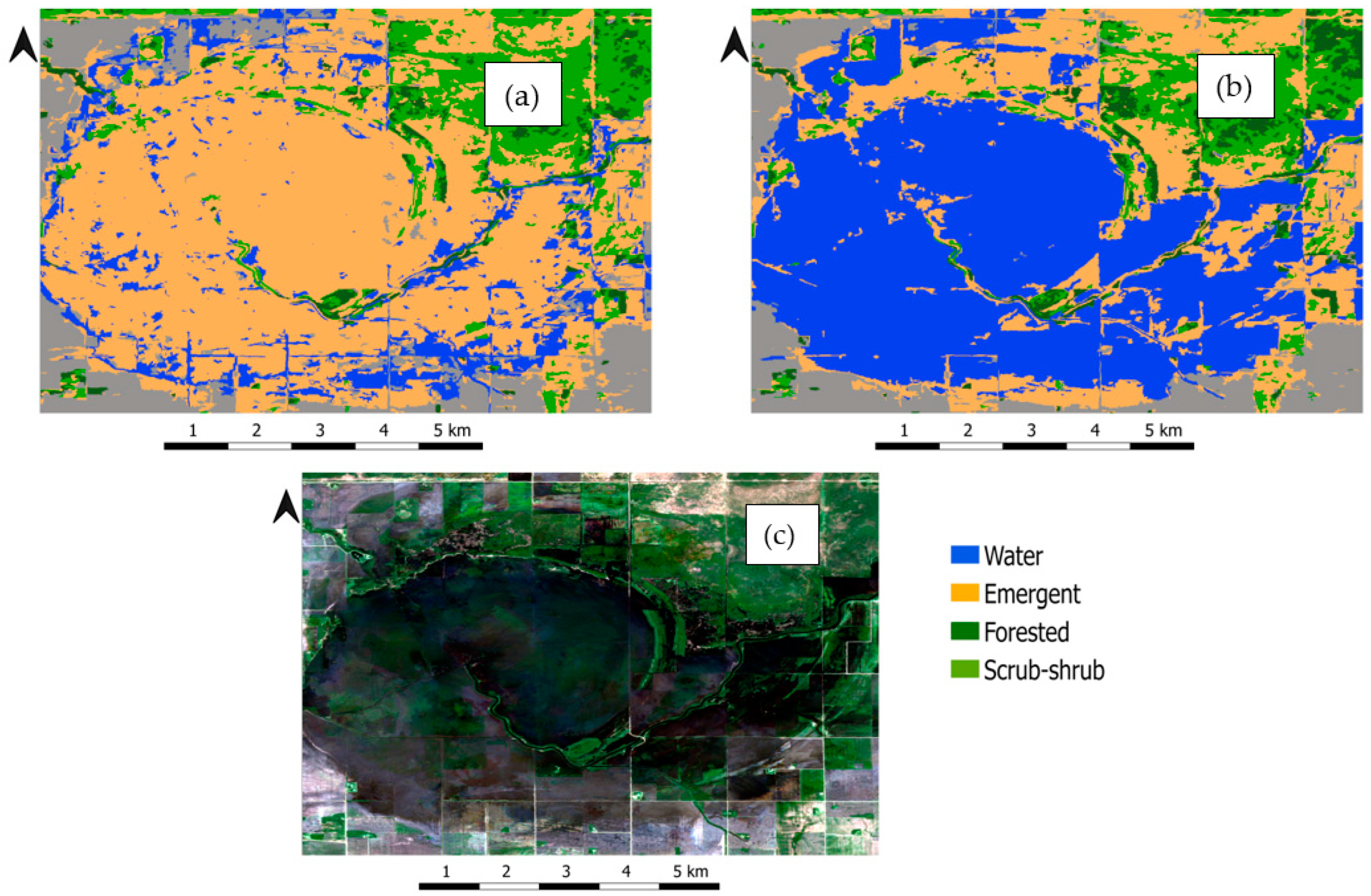
5. Results
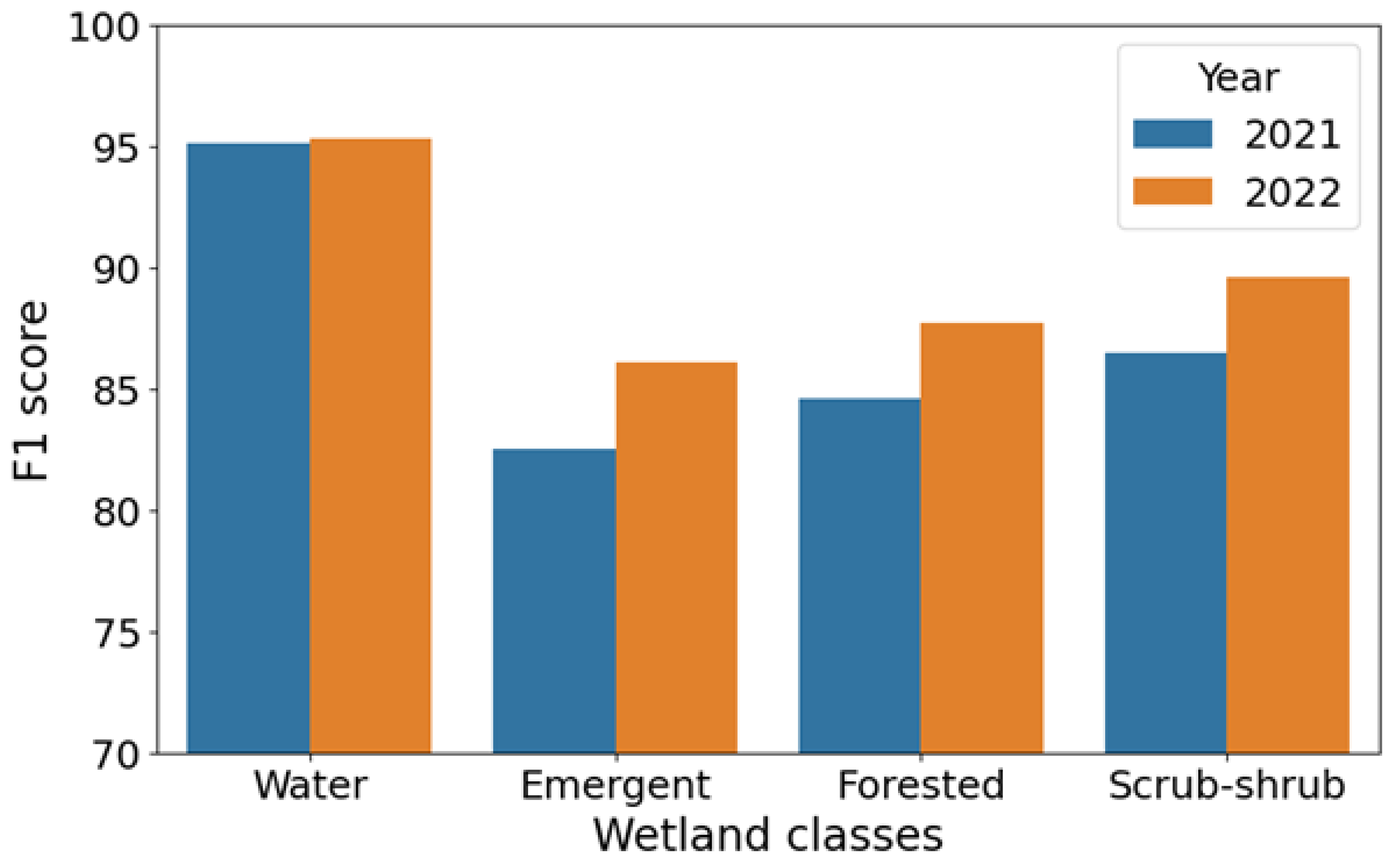
5.1. Quantitative Assessment
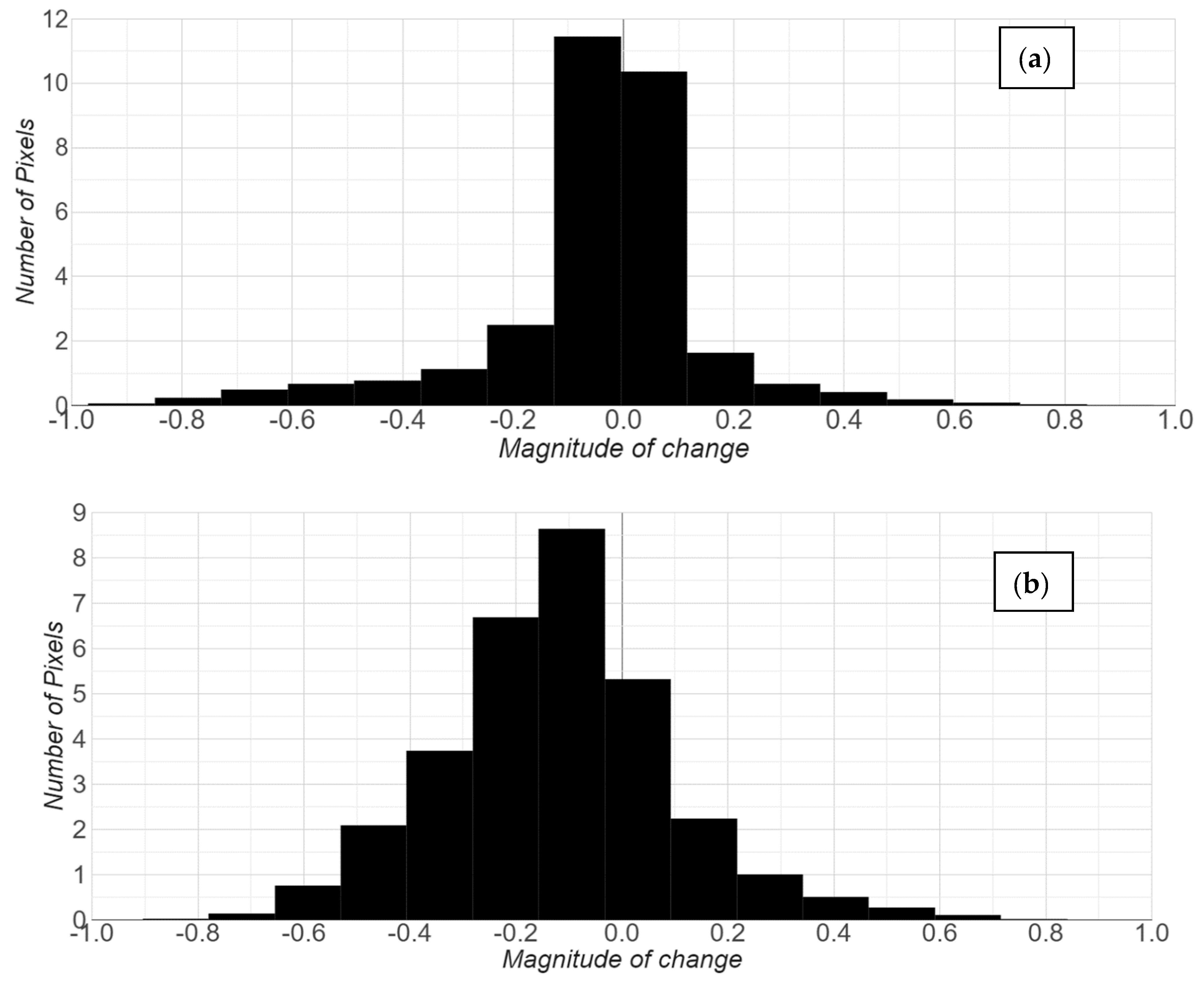
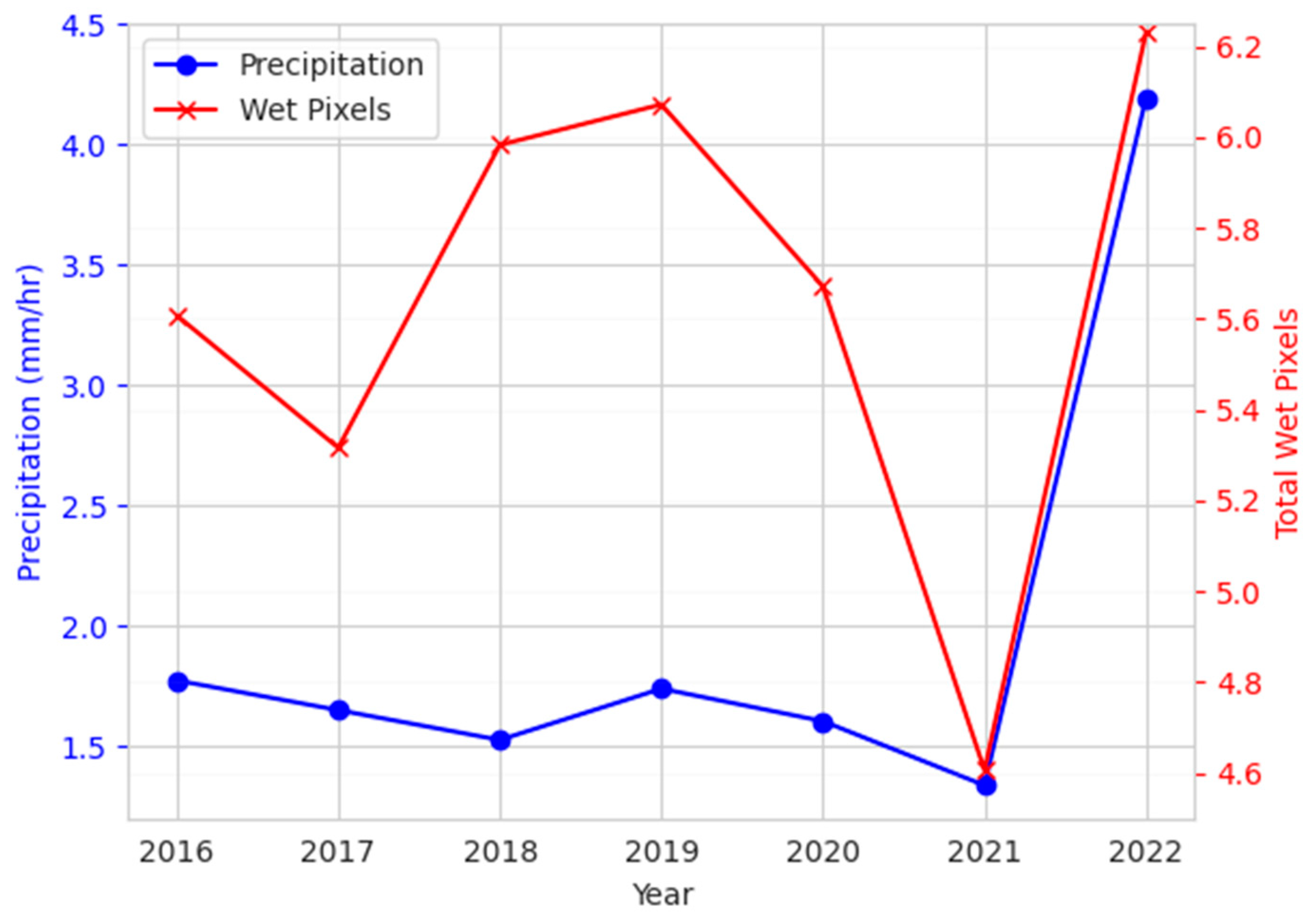
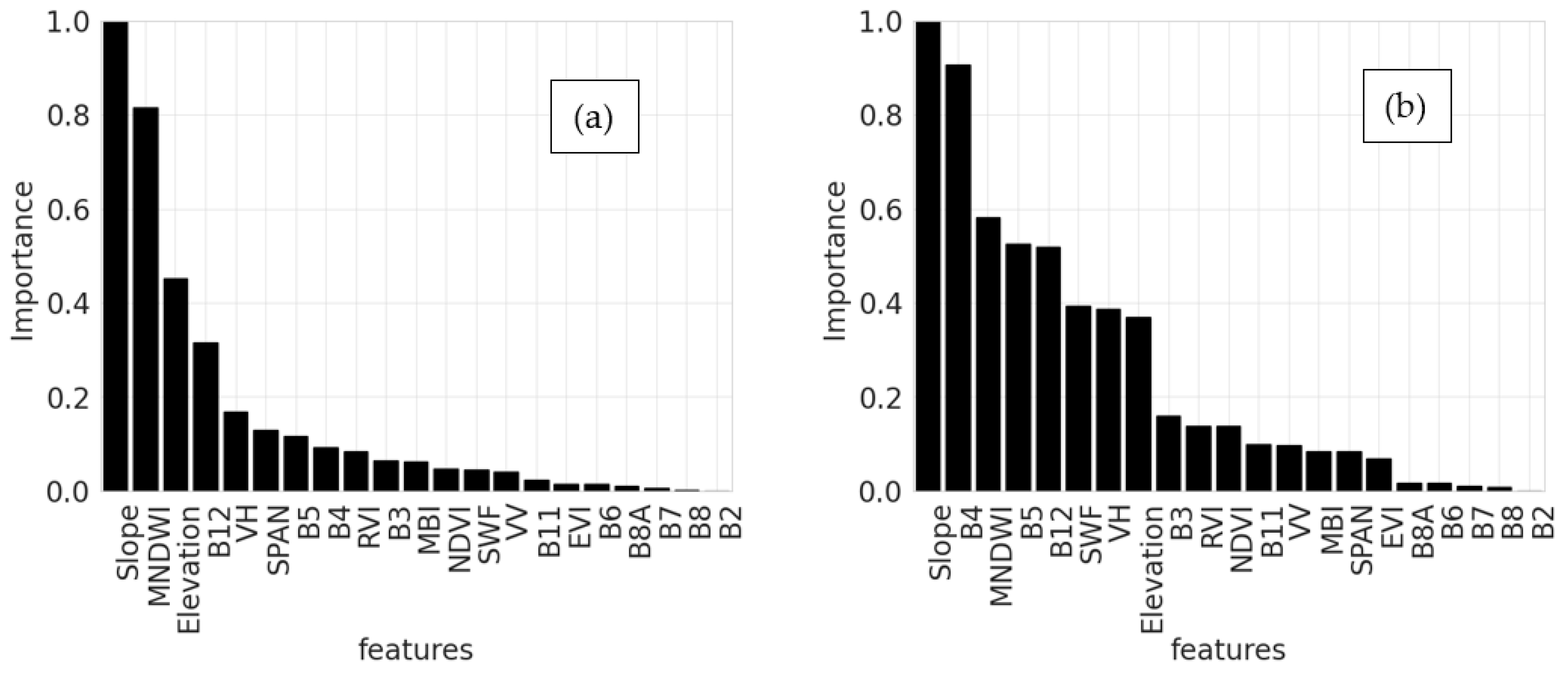
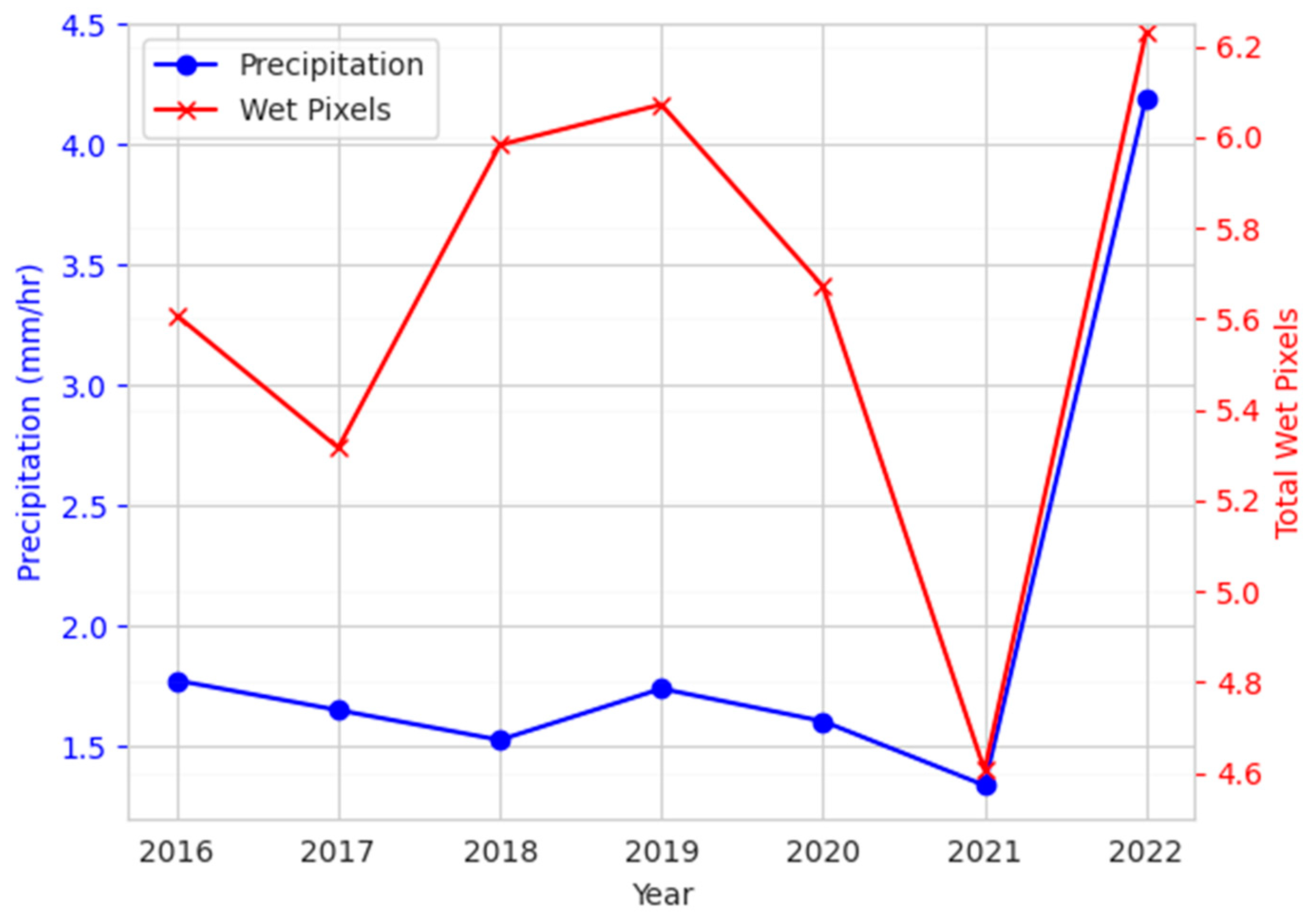
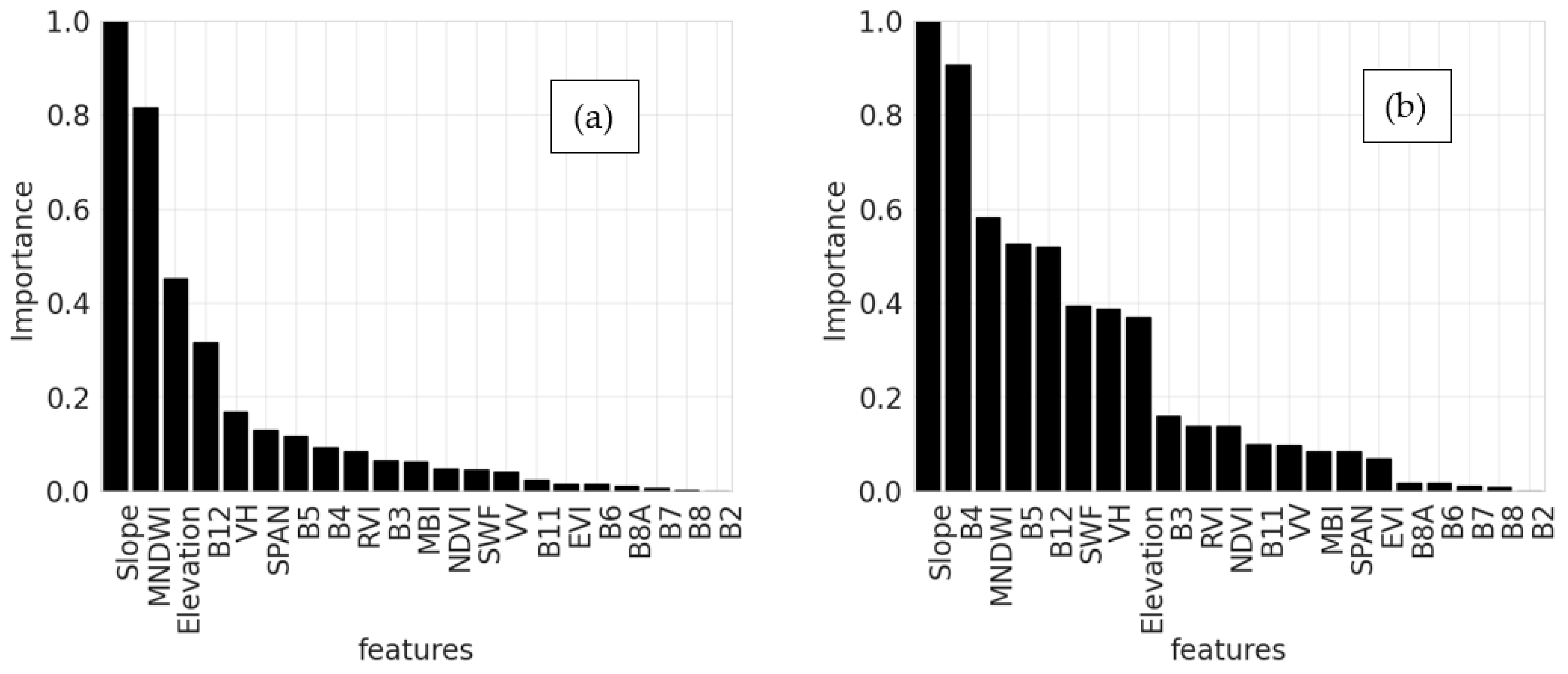
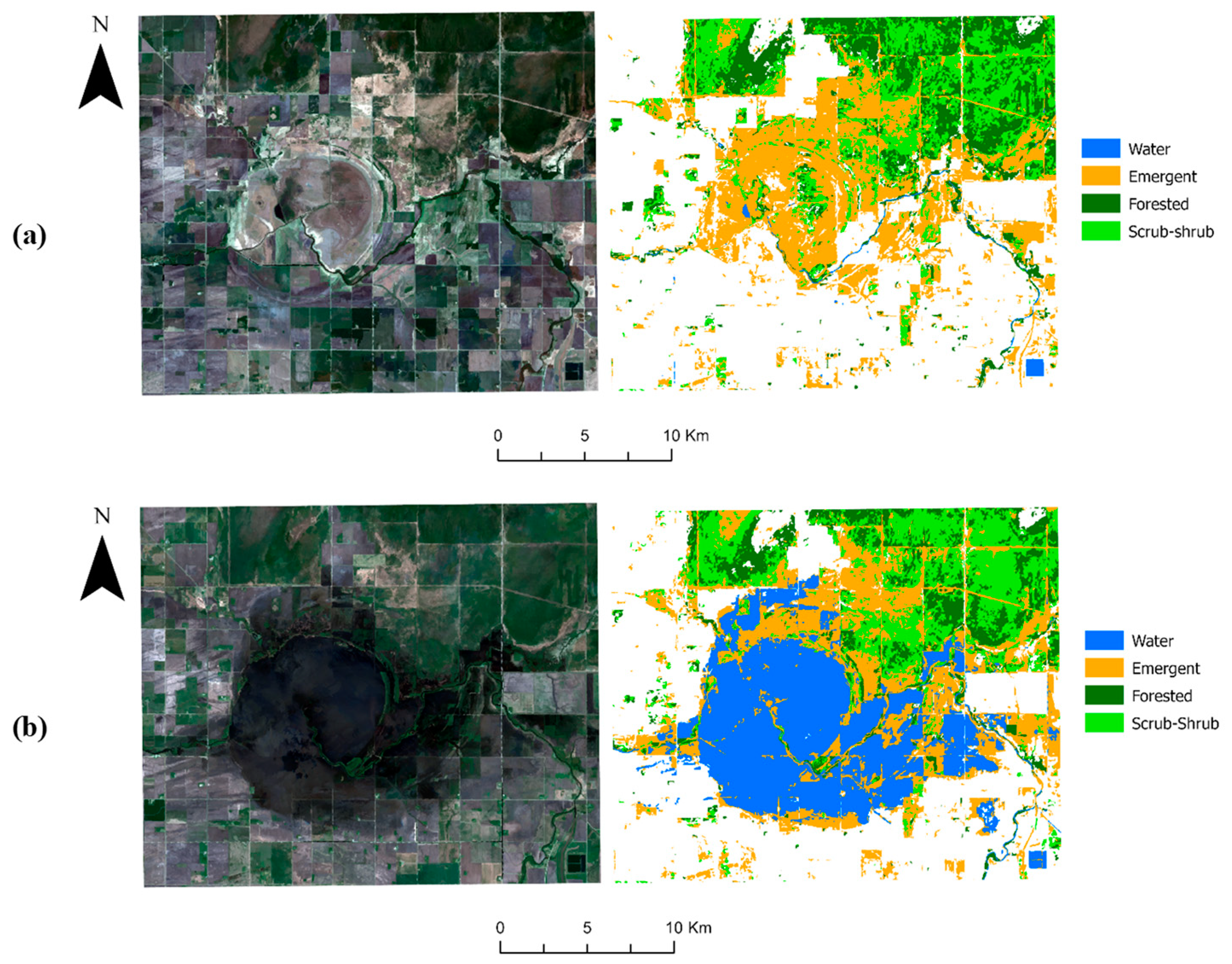
5.2. Effect of SWF Index
6. Discussion
6.1. Dataset Generation Using Change Detection
6.2. Effect of SWF Index
6.3. Scalability
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Test 1: If (MNDWI > 0.124) set the ones digit (i.e., 00001)
- Test 2: If (MBSRV > MBSRN) set the tens digit (i.e., 00010)
- Test 3: If (AWESH > 0.0) set the hundreds digit (i.e., 00100)
- Test 4: If (MNDWI > −0.44 && B5 < 900 && B4 < 1500 & NDVI < 0.7) set the thousands digit (i.e., 01000)
- Test 5: If (MNDWI > −0.5 && B5 < 3000 && B7 < 1000 && B4 < 2500 && B1 < 1000) set the ten-thousands digit (i.e., 10000)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Value Assigned | Bit Value |
|---|---|
| Not Water (0) | 00000 |
| 00001 | |
| 00010 | |
| 00100 | |
| 01000 | |
| Water—High Confidence (1) | 01111 |
| 10111 | |
| 11011 | |
| 11101 | |
| 11110 | |
| 11111 | |
| Water—Moderate Confidence (2) | 00111 |
| 01011 | |
| 01101 | |
| 01110 | |
| 10011 | |
| 10101 | |
| 10110 | |
| 11001 | |
| 11010 | |
| 11100 | |
| Potential Wetland (3) | 11000 |
| Low Confidence Water or Wetland (4) | 00011 |
| 00101 | |
| 00110 | |
| 01001 | |
| 01010 | |
| 01100 | |
| 10000 | |
| 10001 | |
| 10010 | |
| 10100 |
- If (percent-slope >= 30% slope) and the initial DSWE is High Confidence Water (1), the final DSWE is set to 0 otherwise set it to initial DSWE;
- If (percent-slope >= 30% slope) and the initial DSWE is Moderate Confidence Water (2), the final DSWE is set 0 otherwise set it to initial DSWE;
- If (percent-slope >= 20% slope) and the initial DSWE is Potential Wetland (3), the final DSWE is set to 0 otherwise set it to initial DSWE;
- If (percent-slope >= 10% slope) and the initial DSWE is Low Confidence Water or Wetland (4), the final DSWE is set to 0 otherwise set it to initial DSWE.
References
- Federal Geographic Data Committee. Classification of Wetlands and Deepwater Habitats of the United States, 2nd ed.; FGDC-STD-004-2013; Federal Geographic Data Committee: Reston, VA, USA, 2013.
- U.S. Army Corps of Engineers. Corps of Engineers Wetlands Delineation Manual; U.S. Army Corps of Engineers: Washington, DC, USA, 1987; 143p. [Google Scholar]
- Steve, K.M.; Doug, N.J.; Andrea, B.L. Minnesota Wetland Inventory: User Guide and Summary Statistics; Minnesota Department of Natural Resources: St. Paul, MN, USA, 2019; 68p. [Google Scholar]
- van Asselen, S.; Verburg, P.H.; Vermaat, J.E.; Janse, J.H. Drivers of Wetland Conversion: A Global Meta-Analysis. PLoS ONE 2013, 8, e81292. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, K.R.; Akter, S.; Marandi, A.; Schüth, C. A Simple and Robust Wetland Classification Approach by Using Optical Indices, Unsupervised and Supervised Machine Learning Algorithms. Remote Sens. Appl. Soc. Environ. 2021, 23, 100569. [Google Scholar] [CrossRef]
- Johnston, C. Human Impacts to Minnesota Wetlands. J. Minn. Acad. Sci. 1989, 55, 120–124. [Google Scholar]
- Hu, X.; Zhang, P.; Zhang, Q.; Wang, J. Improving Wetland Cover Classification Using Artificial Neural Networks with Ensemble Techniques. GIScience Remote Sens. 2021, 58, 603–623. [Google Scholar] [CrossRef]
- Holtgrave, A.-K.; Förster, M.; Greifeneder, F.; Notarnicola, C.; Kleinschmit, B. Estimation of Soil Moisture in Vegetation-Covered Floodplains with Sentinel-1 SAR Data Using Support Vector Regression. PFG 2018, 86, 85–101. [Google Scholar] [CrossRef]
- Paloscia, S. A Summary of Experimental Results to Assess the Contribution of SAR for Mapping Vegetation Biomass and Soil Moisture. Can. J. Remote Sens. 2002, 28, 246–261. [Google Scholar] [CrossRef]
- Li, J.; Chen, W. A Rule-Based Method for Mapping Canada’s Wetlands Using Optical, Radar and DEM Data. Int. J. Remote Sens. 2005, 26, 5051–5069. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Brisco, B.; Granger, J.; Mohammadimanesh, F.; Salehi, B.; Homayouni, S.; Bourgeau-Chavez, L. The Third Generation of Pan-Canadian Wetland Map at 10 m Resolution Using Multisource Earth Observation Data on Cloud Computing Platform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8789–8803. [Google Scholar] [CrossRef]
- Amani, M.; Ghorbanian, A.; Ahmadi, S.A.; Kakooei, M.; Moghimi, A.; Mirmazloumi, S.M.; Moghaddam, S.H.A.; Mahdavi, S.; Ghahremanloo, M.; Parsian, S.; et al. Google Earth Engine Cloud Computing Platform for Remote Sensing Big Data Applications: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5326–5350. [Google Scholar] [CrossRef]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.; Adeli, S.; Brisco, B. Google Earth Engine for Geo-Big Data Applications: A Meta-Analysis and Systematic Review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Khazaei, M.; Alavipanah, S.K.; Weng, Q. Google Earth Engine for Large-Scale Land Use and Land Cover Mapping: An Object-Based Classification Approach Using Spectral, Textural and Topographical Factors. GIScience Remote Sens. 2021, 58, 914–928. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Fu, B.; Lan, F.; Xie, S.; Liu, M.; He, H.; Li, Y.; Liu, L.; Huang, L.; Fan, D.; Gao, E.; et al. Spatio-Temporal Coupling Coordination Analysis between Marsh Vegetation and Hydrology Change from 1985 to 2019 Using LandTrendr Algorithm and Google Earth Engine. Ecol. Indic. 2022, 137, 108763. [Google Scholar] [CrossRef]
- Valenti, V.L.; Carcelen, E.C.; Lange, K.; Russo, N.J.; Chapman, B. Leveraging Google Earth Engine User Interface for Semiautomated Wetland Classification in the Great Lakes Basin at 10 m with Optical and Radar Geospatial Datasets. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6008–6018. [Google Scholar] [CrossRef]
- Wagle, N.; Acharya, T.D.; Kolluru, V.; Huang, H.; Lee, D.H. Multi-Temporal Land Cover Change Mapping Using Google Earth Engine and Ensemble Learning Methods. Appl. Sci. 2020, 10, 8083. [Google Scholar] [CrossRef]
- Paris, C.; Bruzzone, L.; Fernández-Prieto, D. A Novel Approach to the Unsupervised Update of Land-Cover Maps by Classification of Time Series of Multispectral Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4259–4277. [Google Scholar] [CrossRef]
- Demir, B.; Bovolo, F.; Bruzzone, L. Updating Land-Cover Maps by Classification of Image Time Series: A Novel Change-Detection-Driven Transfer Learning Approach. IEEE Trans. Geosci. Remote Sens. 2013, 51, 300–312. [Google Scholar] [CrossRef]
- Chen, X.; Chen, J.; Shi, Y.; Yamaguchi, Y. An Automated Approach for Updating Land Cover Maps Based on Integrated Change Detection and Classification Methods. ISPRS J. Photogramm. Remote Sens. 2012, 71, 86–95. [Google Scholar] [CrossRef]
- Jia, K.; Liang, S.; Wei, X.; Zhang, L.; Yao, Y.; Gao, S. Automatic Land-Cover Update Approach Integrating Iterative Training Sample Selection and a Markov Random Field Model. Remote Sens. Lett. 2014, 5, 148–156. [Google Scholar] [CrossRef]
- Kloiber, S.M.; Macleod, R.D.; Smith, A.J.; Knight, J.F.; Huberty, B.J. A Semi-Automated, Multi-Source Data Fusion Update of a Wetland Inventory for East-Central Minnesota, USA. Wetlands 2015, 35, 335–348. [Google Scholar] [CrossRef]
- Paris, C.; Bruzzone, L. A Novel Approach to the Unsupervised Extraction of Reliable Training Samples From Thematic Products. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1930–1948. [Google Scholar] [CrossRef]
- Xian, G.; Homer, C.; Fry, J. Updating the 2001 National Land Cover Database Land Cover Classification to 2006 by Using Landsat Imagery Change Detection Methods. Remote Sens. Environ. 2009, 113, 1133–1147. [Google Scholar] [CrossRef]
- Minnesota Department of Natural Resources Minnesota, National Wetland Inventory. Available online: https://gisdata.mn.gov/dataset/water-nat-wetlands-inv-2009-2014 (accessed on 10 May 2023).
- Minnesota Department of Natural Resources. Minnesota Annual Precipitation Normal: 1991–2020 and the Change from 1981–2010. Available online: https://www.dnr.state.mn.us/climate/summaries_and_publications/minnesota-annual-precipitation-normal-1991-2020.html (accessed on 10 May 2023).
- Lothspeich, A.C.; Knight, J.F. The Applicability of LandTrendr to Surface Water Dynamics: A Case Study of Minnesota from 1984 to 2019 Using Google Earth Engine. Remote Sens. 2022, 14, 2662. [Google Scholar] [CrossRef]
- Yin, F.; Lewis, P.E.; Gómez-Dans, J.L. Bayesian Atmospheric Correction over Land: Sentinel-2/MSI and Landsat 8/OLI. Geosci. Model Dev. 2022, 15, 7933–7976. [Google Scholar] [CrossRef]
- Brisco, B.; Short, N.; van der Sanden, J.; Landry, R.; Raymond, D. A Semi-Automated Tool for Surface Water Mapping with RADARSAT-1. Can. J. Remote Sens. 2009, 35, 336–344. [Google Scholar] [CrossRef]
- Vanderhoof, M.K.; Alexander, L.; Christensen, J.; Solvik, K.; Nieuwlandt, P.; Sagehorn, M. High-Frequency Time Series Comparison of Sentinel-1 and Sentinel-2 Satellites for Mapping Open and Vegetated Water across the United States (2017–2021). Remote Sens. Environ. 2023, 288, 113498. [Google Scholar] [CrossRef] [PubMed]
- Charbonneau, F.; Trudel, M.; Fernandes, R. Use of Dual Polarization and Multi-Incidence SAR for Soil Permeability Mapping. In Proceedings of the 2005 Advanced Synthetic Aperture Radar (ASAR) Workshop, St-Hubert, QC, Canada, 15–17 November 2005; pp. 15–17. [Google Scholar]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting Trends in Forest Disturbance and Recovery Using Yearly Landsat Time Series: 1. LandTrendr—Temporal Segmentation Algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Yang, Y.; Erskine, P.D.; Lechner, A.M.; Mulligan, D.; Zhang, S.; Wang, Z. Detecting the Dynamics of Vegetation Disturbance and Recovery in Surface Mining Area via Landsat Imagery and LandTrendr Algorithm. J. Clean. Prod. 2018, 178, 353–362. [Google Scholar] [CrossRef]
- Chai, X.R.; Li, M.; Wang, G.W. Characterizing Surface Water Changes across the Tibetan Plateau Based on Landsat Time Series and LandTrendr Algorithm. Eur. J. Remote Sens. 2022, 55, 251–262. [Google Scholar] [CrossRef]
- DeVries, B.; Huang, C.; Lang, M.W.; Jones, J.W.; Huang, W.; Creed, I.F.; Carroll, M.L. Automated Quantification of Surface Water Inundation in Wetlands Using Optical Satellite Imagery. Remote Sens. 2017, 9, 807. [Google Scholar] [CrossRef]
- Jones, J.W. Efficient Wetland Surface Water Detection and Monitoring via Landsat: Comparison with in Situ Data from the Everglades Depth Estimation Network. Remote Sens. 2015, 7, 12503–12538. [Google Scholar] [CrossRef]
- U.S. Geological Survey. Landsat Dynamic Surface Water Extent (DSWE) Algorithm Description Document (ADD) Version 1.0; U.S. Geological Survey: Reston, VI, USA, 2018.
- U.S. Geological Survey. Landsat Dynamic Surface Water Extent (DSWE) Product Guide Version 2.0; U.S. Geological Survey: Reston, VI, USA, 2022.
- Kennedy, R.E.; Yang, Z.; Gorelick, N.; Braaten, J.; Cavalcante, L.; Cohen, W.B.; Healey, S. Implementation of the LandTrendr Algorithm on Google Earth Engine. Remote Sens. 2018, 10, 691. [Google Scholar] [CrossRef]
- Achanta, R.; Susstrunk, S. Superpixels and Polygons Using Simple Non-Iterative Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4651–4660. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 6, 2274–2282. [Google Scholar] [CrossRef]
- Dewitz, J. National Land Cover Database (NLCD) 2019 Products. U.S. Geological Survey. 2021. Available online: https://www.sciencebase.gov/catalog/item/5f21cef582cef313ed940043 (accessed on 10 May 2023).
- Dingle Robertson, L.; King, D.J.; Davies, C. Object-Based Image Analysis of Optical and Radar Variables for Wetland Evaluation. Int. J. Remote Sens. 2015, 36, 5811–5841. [Google Scholar] [CrossRef]
- Knight, J.; Corcoran, J.; Rampi, L.; Pelletier, K. Theory and Applications of Object-Based Image Analysis and Emerging Methods in Wetland Mapping. Remote Sens. Wetl. Appl. Adv. 2015, 574. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Amani, M.; Salehi, B.; Mahdavi, S.; Granger, J.; Brisco, B. Wetland Classification in Newfoundland and Labrador Using Multi-Source SAR and Optical Data Integration. GIScience Remote Sens. 2017, 54, 779–796. [Google Scholar] [CrossRef]
- Han, Z.; Gao, Y.; Jiang, X.; Wang, J.; Li, W. Multisource Remote Sensing Classification for Coastal Wetland Using Feature Intersecting Learning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 21642096. [Google Scholar] [CrossRef]
- Mao, D.; Wang, Z.; Du, B.; Li, L.; Tian, Y.; Jia, M.; Zeng, Y.; Song, K.; Jiang, M.; Wang, Y. National Wetland Mapping in China: A New Product Resulting from Object-Based and Hierarchical Classification of Landsat 8 OLI Images. ISPRS J. Photogramm. Remote Sens. 2020, 164, 11–25. [Google Scholar] [CrossRef]
- Mohseni, F.; Amani, M.; Mohammadpour, P.; Kakooei, M.; Jin, S.; Moghimi, A. Wetland Mapping in Great Lakes Using Sentinel-1/2 Time-Series Imagery and DEM Data in Google Earth Engine. Remote Sens. 2023, 15, 3495. [Google Scholar] [CrossRef]
- Corcoran, J.; Knight, J.; Brisco, B.; Kaya, S.; Cull, A.; Murnaghan, K. The Integration of Optical, Topographic, and Radar Data for Wetland Mapping in Northern Minnesota. Can. J. Remote Sens. 2011, 37, 564–582. [Google Scholar] [CrossRef]
- Igwe, V.; Salehi, B.; Mahdianpari, M. State-wide wetland inventory map of Minnesota using multi-source and multi-Temporzalremote sensing data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, V-3–2022, 411–416. [Google Scholar] [CrossRef]
- Ye, S.; Pontius, R.G.; Rakshit, R. A Review of Accuracy Assessment for Object-Based Image Analysis: From per-Pixel to per-Polygon Approaches. ISPRS J. Photogramm. Remote Sens. 2018, 141, 137–147. [Google Scholar] [CrossRef]
- Minnesota State Climatology Office Wet Conditions Return. 2022. Available online: https://www.dnr.state.mn.us/climate/journal/wet-conditions-return-2022.html (accessed on 11 April 2023).
- Raschka, S.; Patterson, J.; Nolet, C. Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence. Information 2020, 11, 193. [Google Scholar] [CrossRef]






| Features | Source | Resolution (m) | Time Series | Parameters |
|---|---|---|---|---|
| Multispectral | Sentinel-2 (BOA) | 10, 20 | 2016–2022 | Blue, Green Red, Red Edge 1, Red Edge 2, Red Edge 3, Near-infrared (NIR), Red Edge 4, Short-wave infrared (SWIR 1, SWIR 2) |
| SAR | Sentinel-1 Backscatter | 10 | 2016–2022 | Vertical transmit/vertical receive (VV) polarization backscatter coefficient, vertical transmit/horizontal receive (VH) polarization backscatter coefficient |
| Elevation | USGS 3DEP | 10 | Elevation |
| Features | Source | Resolution (m) | Time Series | Parameters |
|---|---|---|---|---|
| Spectral Indices | Sentinel-2 (BOA) | 10 | 2016–2022 | Modified normalized difference water index (MNDWI), normalized difference vegetation index (NDVI), multi-band spectral relationship visible (MNSRV), multi-band spectral relationship near-infrared (MBSRN), automated water extent shadow (AWESH) |
| Radar Indices | Sentinel-1 Backscatter | 10 | 2016–2022 | Ratio, span |
| Elevation | USGS 3DEP 10-m | 10 | Slope |
| Parameter | Description | Values |
|---|---|---|
| Max Segments | The maximum number of segments allowed in the temporal fitting. | 4 |
| Spike Threshold | Threshold for dampening spikes. | 0.5 |
| Vertex Count Overshoot | The number of vertices by which the initial model can exceed the maximum segments before pruning. | 2 |
| Prevent One Year Recovery | Prevent segments that are a one-year recovery back to a previous level. | FALSE |
| Recovery Threshold | Segment slopes are limited to a rate of less than 1/Recovery Threshold. | 0.25 |
| p-value Threshold | Maximum p-value of the best model. | 0.1 |
| Best Model Proportion | Defines the best model as that with the most vertices with a p-value that is at most this proportion away from the model with the lowest p-value. | 1 |
| Min Observations Needed | Minimum number of observations in the time series for the model to fit. | 6 |
| Features | Source | Resolution (m) | Year | Parameters |
|---|---|---|---|---|
| Spectral Indices | Sentinel-2 (BOA) | 10 | 2022 | Modified normalized difference water index (MNDWI), sub-pixel water fraction (SWF), normalized difference vegetation index (NDVI), enhanced vegetation index (EVI), modified built-up index (MBI) |
| Radar Indices | Sentinel-1 Backscatter | 10 | 2022 | Span, radar vegetation index (RVI) |
| Elevation | USGS 3DEP 10-m | 10 | Slope |
| Baseline Method | Predicted Labels | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Wetland | Upland | ||||||||
| Water | Emergent | Forested | Scrub-Shrub | Urban | Forested | Agriculture | |||
| (a) | |||||||||
| Reference labels | Wetland | Water | 0.93 | 0.06 | 0.01 | ||||
| Emergent | 0.12 | 0.82 | 0.05 | ||||||
| Forested | 0.01 | 0.77 | 0.17 | 0.04 | |||||
| Scrub-shrub | 0.01 | 0.34 | 0.16 | 0.49 | |||||
| Upland | Urban | 1 | |||||||
| Forested | 0.02 | 0.11 | 0.02 | 0.82 | 0.02 | ||||
| Agriculture | 0.06 | 0.01 | 0.01 | 0.03 | 0.88 | ||||
| (b) | |||||||||
| Reference labels | Wetland | Water | 0.90 | 0.09 | 0.02 | ||||
| Emergent | 0.06 | 0.88 | 0.06 | ||||||
| Forested | 0.01 | 0.89 | 0.07 | 0.02 | |||||
| Scrub-shrub | 0.21 | 0.1 | 0.68 | ||||||
| Upland | Urban | 1 | |||||||
| Forested | 0.01 | 0.05 | 0.92 | 0.02 | |||||
| Agriculture | 0.04 | 0.01 | 0.01 | 0.04 | 0.91 | ||||
| Type | Classes | Baseline Method | Proposed Method | ||||
|---|---|---|---|---|---|---|---|
| PA (%) | UA (%) | F1 (%) | PA (%) | UA (%) | F1 (%) | ||
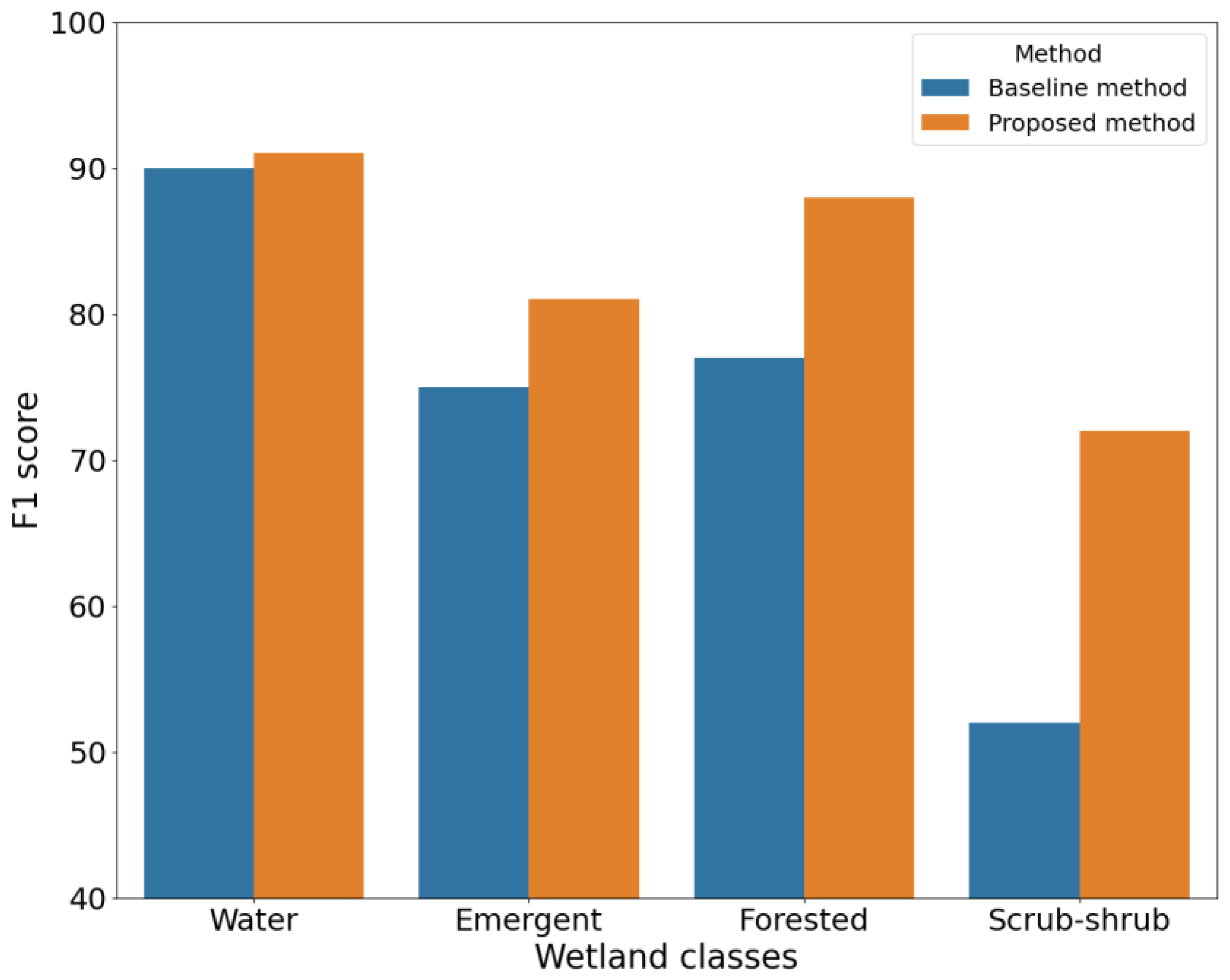
| Wetland | Water | 93 | 87 | 90 | 90 | 93 | 91 |
| Emergent | 82 | 69 | 75 | 88 | 76 | 81 | |
| Forested | 77 | 77 | 77 | 89 | 87 | 88 | |
| Scrub Shrub | 49 | 56 | 52 | 68 | 76 | 72 | |
| Upland | Urban | 100 | 97 | 99 | 100 | 99 | 99 |
| Forested | 82 | 92 | 87 | 92 | 93 | 93 | |
| Agriculture | 89 | 98 | 93 | 91 | 98 | 94 | |
| OA (%) | 82 | 89 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Igwe, V.; Salehi, B.; Mahdianpari, M. Rapid Large-Scale Wetland Inventory Update Using Multi-Source Remote Sensing. Remote Sens. 2023, 15, 4960. https://doi.org/10.3390/rs15204960
Igwe V, Salehi B, Mahdianpari M. Rapid Large-Scale Wetland Inventory Update Using Multi-Source Remote Sensing. Remote Sensing. 2023; 15(20):4960. https://doi.org/10.3390/rs15204960
Chicago/Turabian StyleIgwe, Victor, Bahram Salehi, and Masoud Mahdianpari. 2023. "Rapid Large-Scale Wetland Inventory Update Using Multi-Source Remote Sensing" Remote Sensing 15, no. 20: 4960. https://doi.org/10.3390/rs15204960
APA StyleIgwe, V., Salehi, B., & Mahdianpari, M. (2023). Rapid Large-Scale Wetland Inventory Update Using Multi-Source Remote Sensing. Remote Sensing, 15(20), 4960. https://doi.org/10.3390/rs15204960