


A Global-Information-Constrained Deep Learning Network for Digital Elevation Model Super-Resolution


Abstract
1. Introduction
- (1)
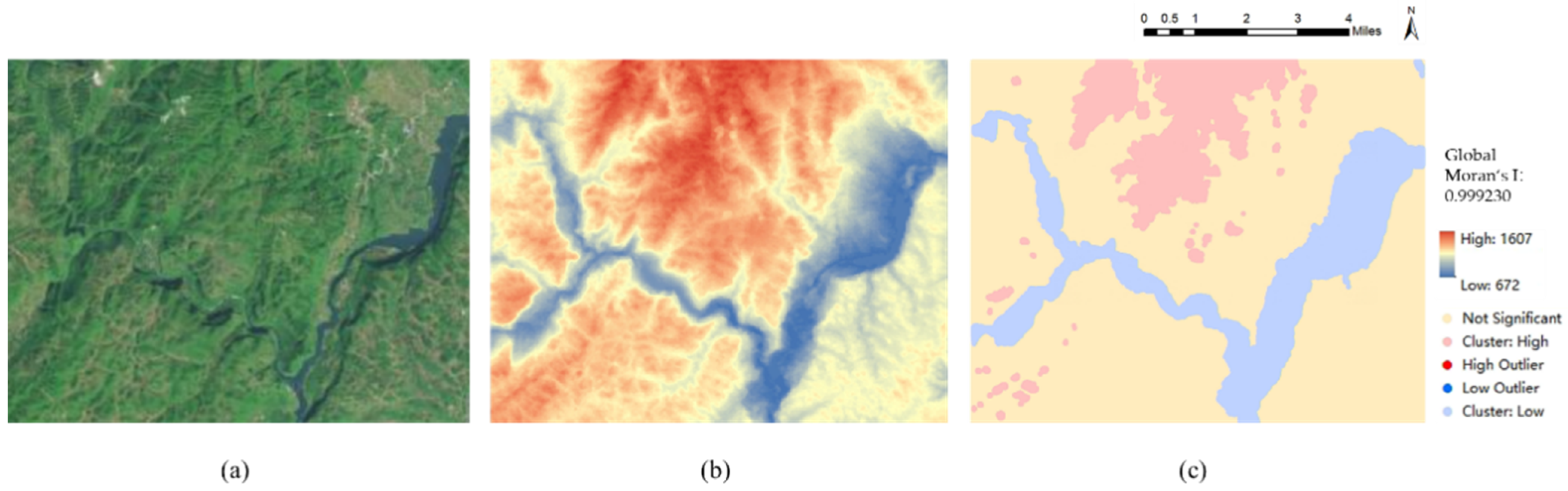
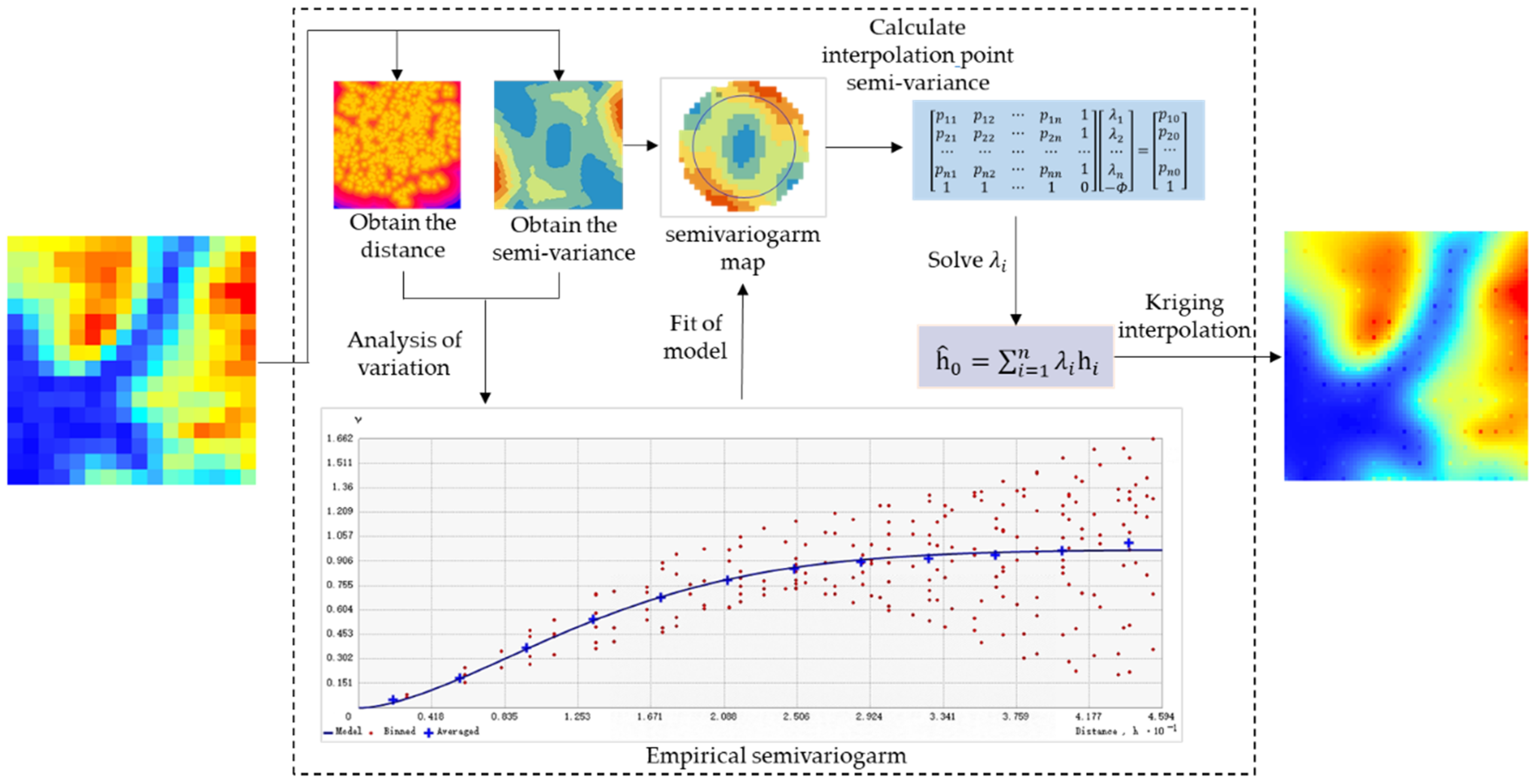
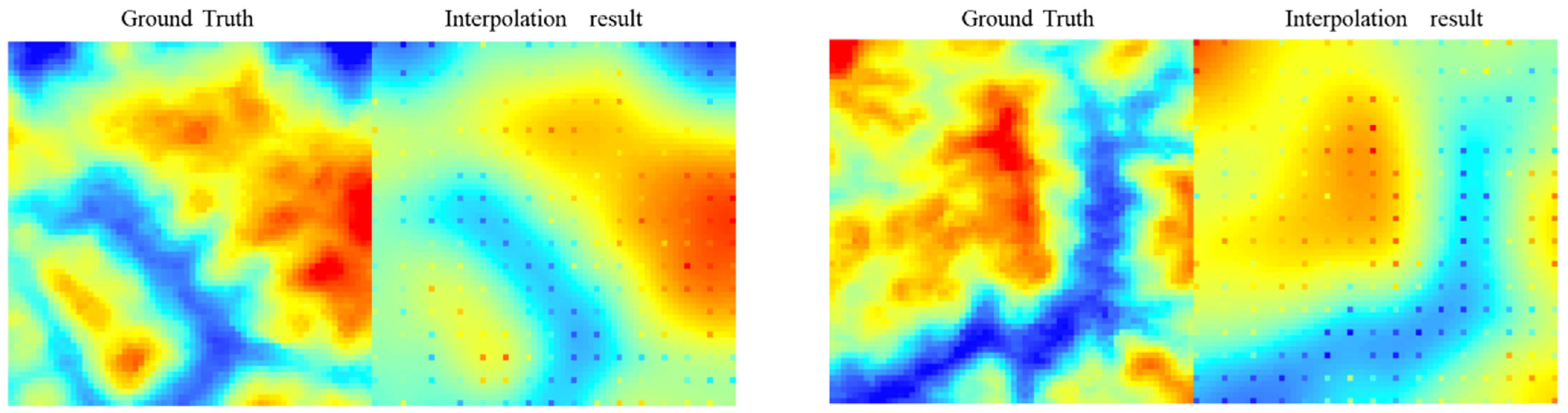
- As a supplement method of DEM SR, the constraints provided by spatial autocorrelation can directly provide the DEM SR results with a certain degree of accuracy for the model. For example, the Kriging method [30] is used to find the spatial interpolation kernel that conforms to the target region by calculating the relationship between the spatial distance and the semi-variogram, and its interpolation results are highly accurate.
- (2)
- The results generated under the spatial autocorrelation rule are involved in the final results of the DEM SR, which is based on constraining the parameter flow direction of the learnable convolution kernel throughout the whole network, which indirectly supplements the global information for the model.
- We propose a global-information-constrained deep learning network for DEM SR (GISR) that can optimize the DEM SR process toward generating global terrain features and achieving advanced results. Specifically, compared with the traditional bicubic Kriging interpolation method and existing neural network methods (TfaSR [31], SRResNet [32], and SRCNN [33]), the RMSE of our results is improved by 20% to 200%, and the MAE of our results is improved by 20% to 300%.
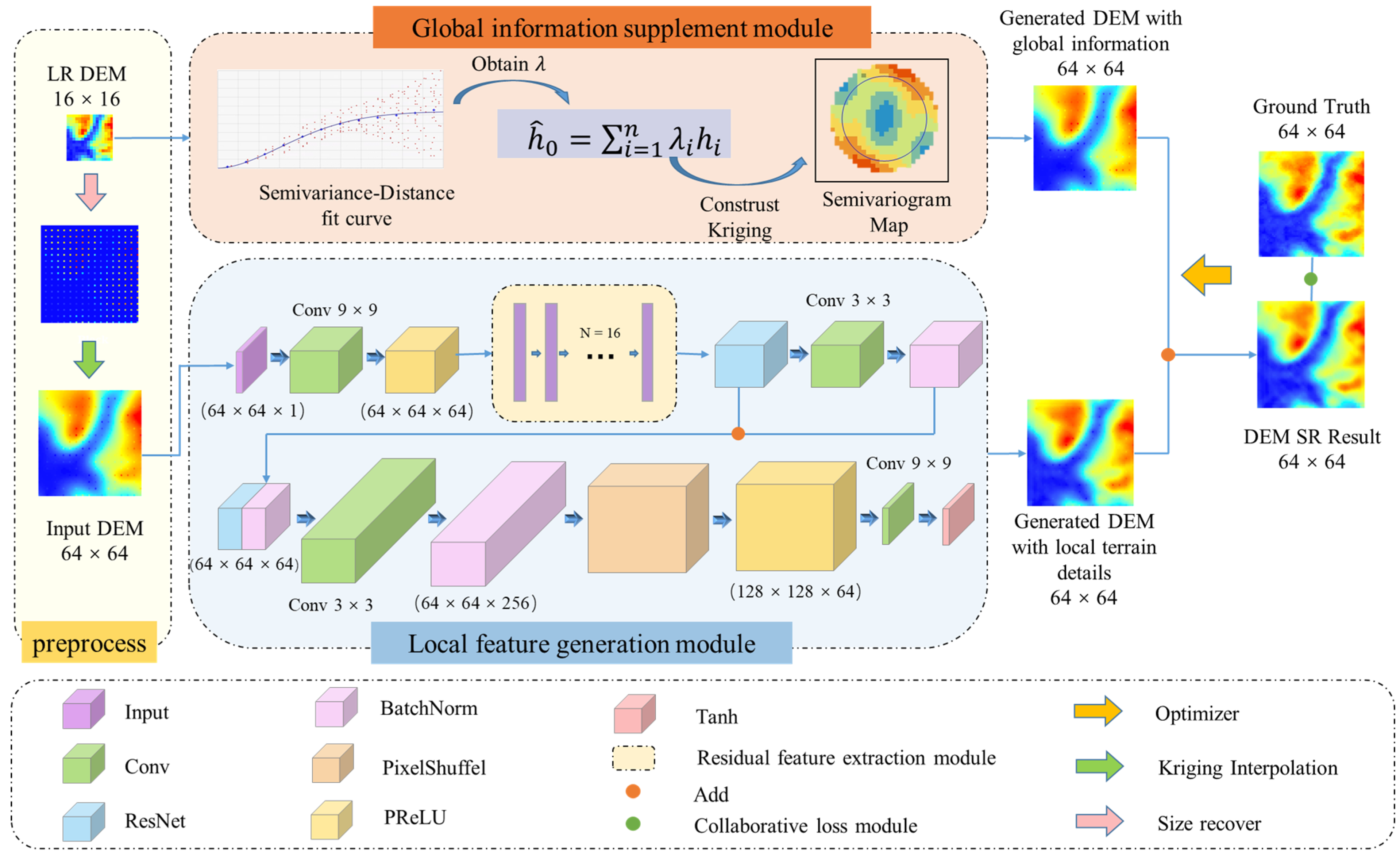
- We use the Kriging interpolation method, which accounts for spatial autocorrelation, to construct the global information supplement module. The module directly fuses the global information of the interpolation method and indirectly supplements the global information by affecting the loss to generate a DEM more similar to the real terrain distribution.
2. Related Work
2.1. Super-Resolution (SR) Based on Traditional Spatial Interpolation Methods
2.2. DEM SR Based on Deep Learning Methods
3. Methods
3.1. Global Information Supplement Module
3.2. Local Feature Generation Module
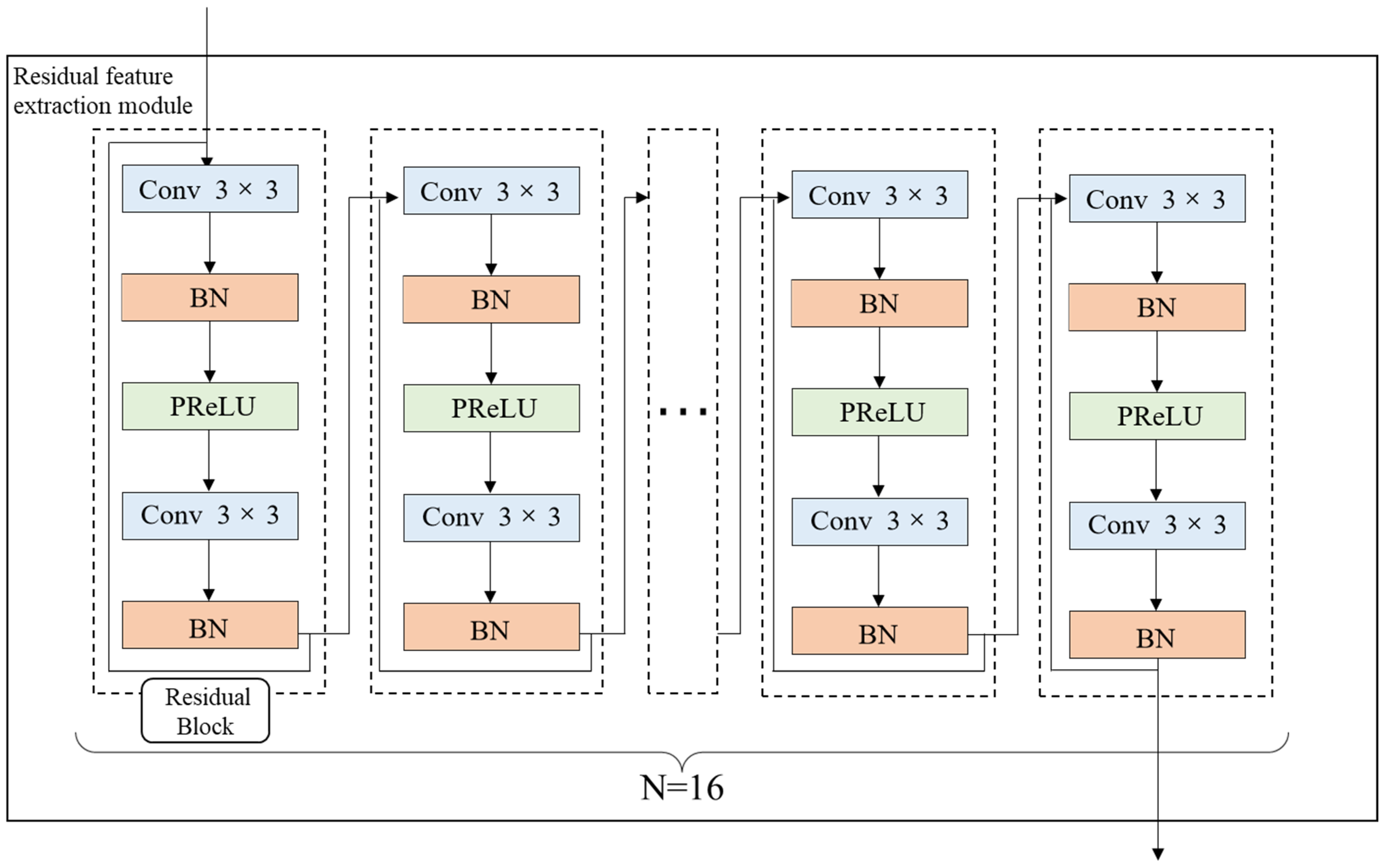
3.2.1. The Concept of the Residual Feature Extraction Module
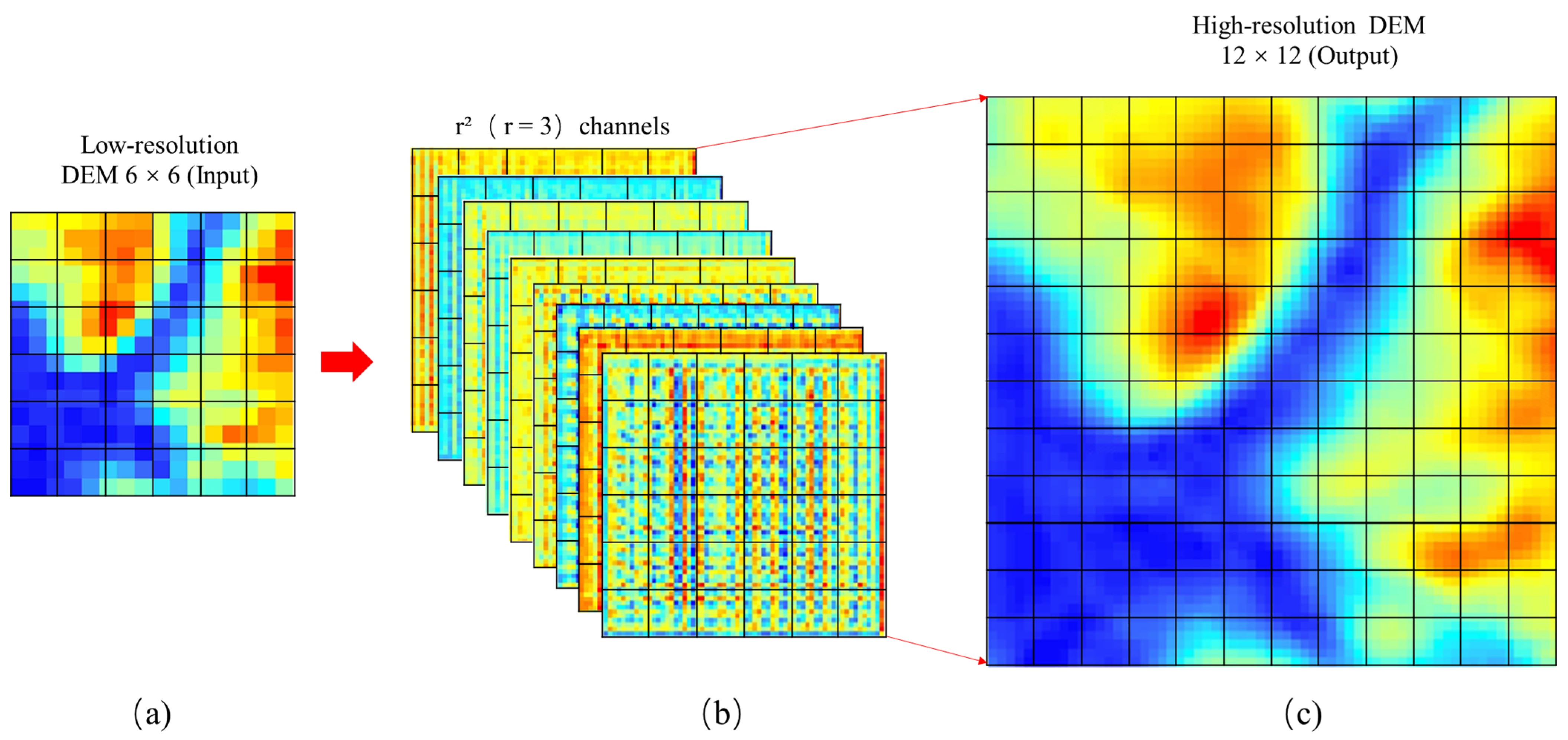
3.2.2. The Concept of PixelShuffle
3.3. Collaborative Loss
3.3.1. Elevation Loss
3.3.2. Feature Loss
4. Experiments
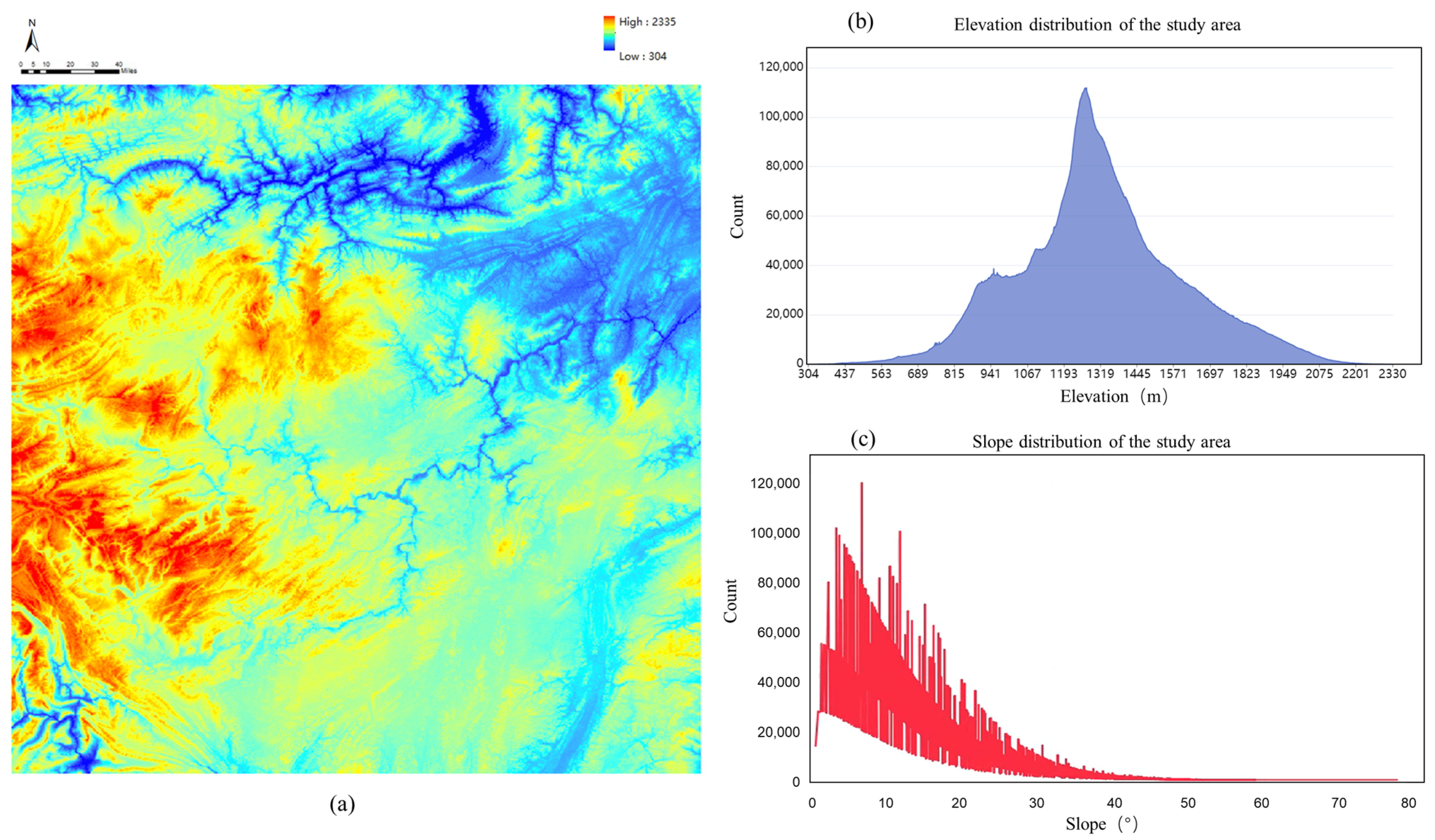
4.1. Experimental Setup
4.2. Training
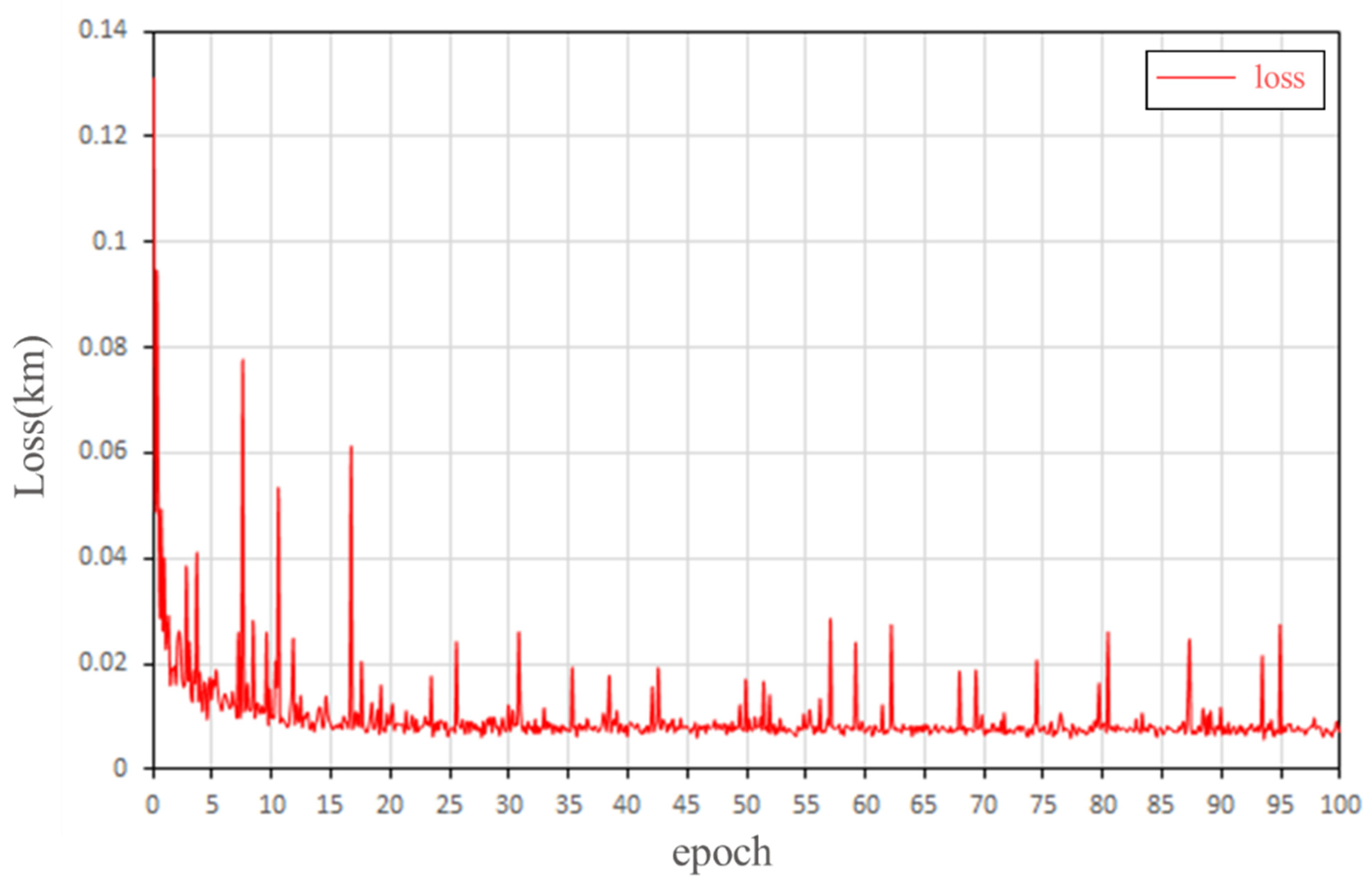
- ①
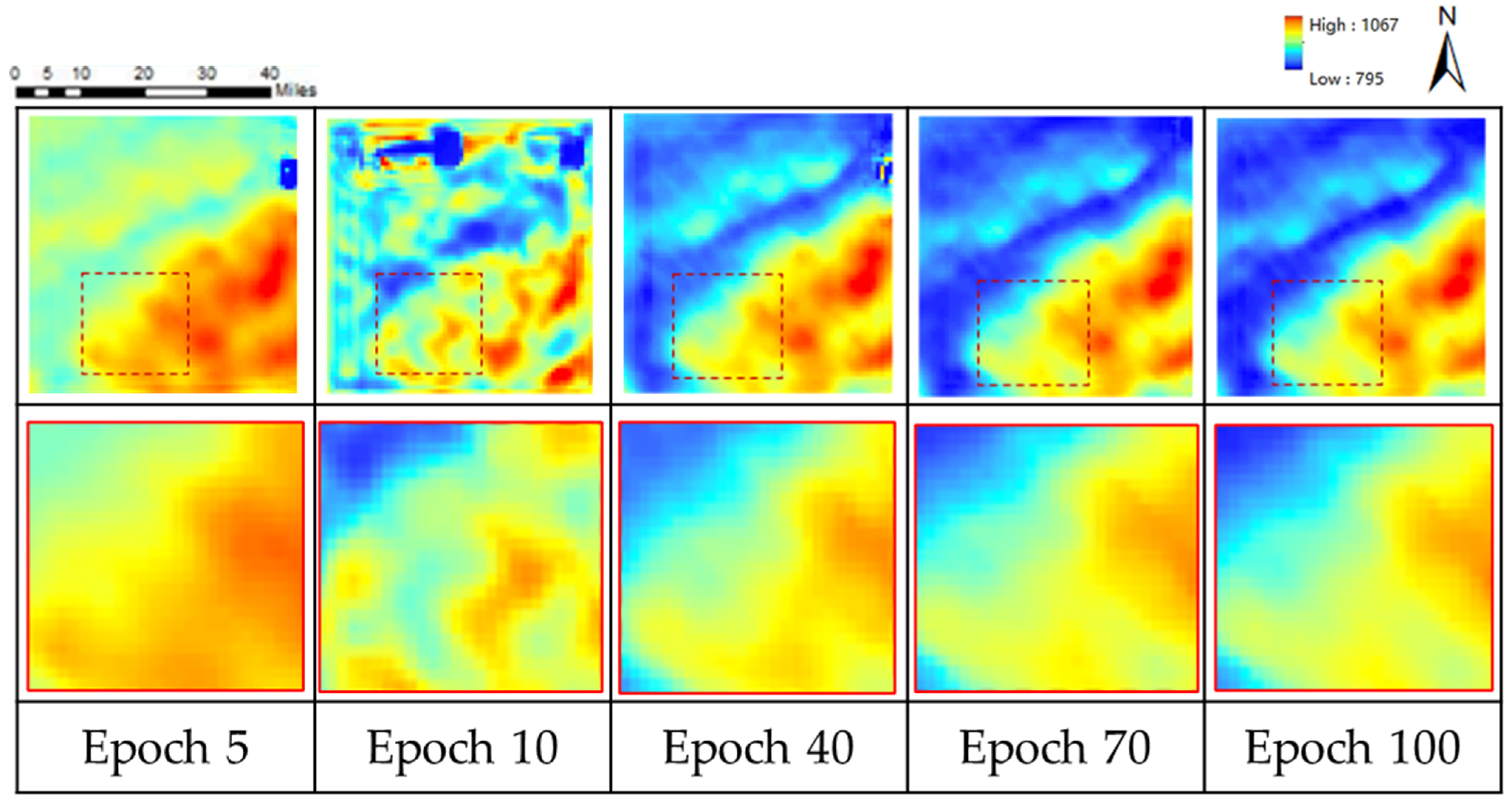
- Figure 8 shows a downward trend, which decreases rapidly in the early stage and gradually flattens in the late stage. This phenomenon shows that our model can effectively capture the depth of the spatial terrain characteristics of the samples.
- ②
- During the whole training process, the loss fluctuates up and down. At the initial stage of training, the initial waveform fluctuates greatly. When the training epoch increases, the performance of the DEM generation tends to be stable, and the fluctuation amplitude becomes smaller. There are two reasons for loss fluctuation: (1) In the training process, the randomly selected samples come from different regions, and their elevation drop and terrain complexity are different, leading to the instability of loss. (2) The preprocessing effect of some regions with too complex terrain is not good (Figure 9), resulting in a large loss value of the generated results, which makes the loss fluctuate. It is proved by experiments that the results of training after removing the problematic samples from the preprocessing are almost the same as those of training with all samples.
5. Results and Discussions
5.1. Results
5.1.1. Overall Accuracy
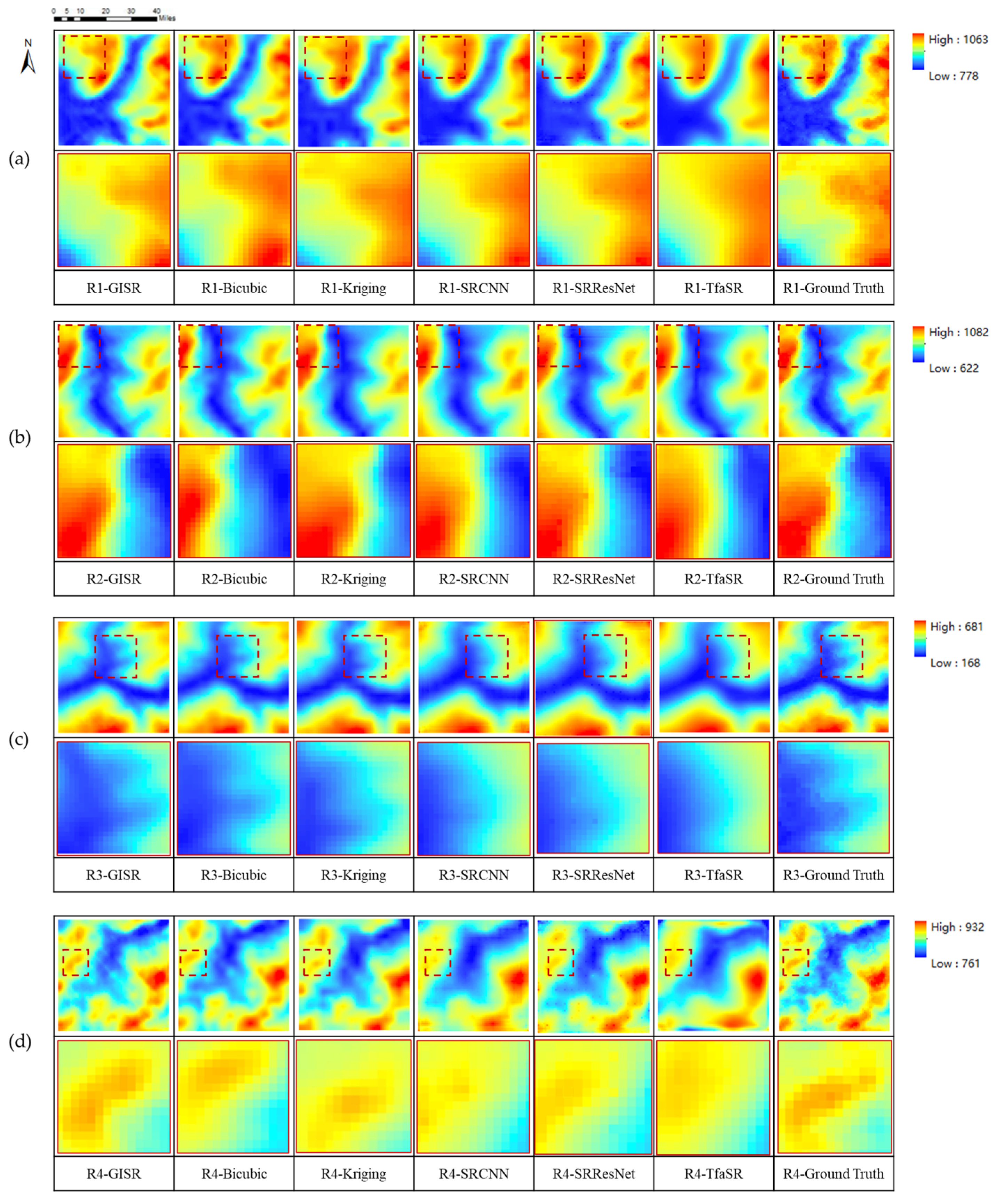
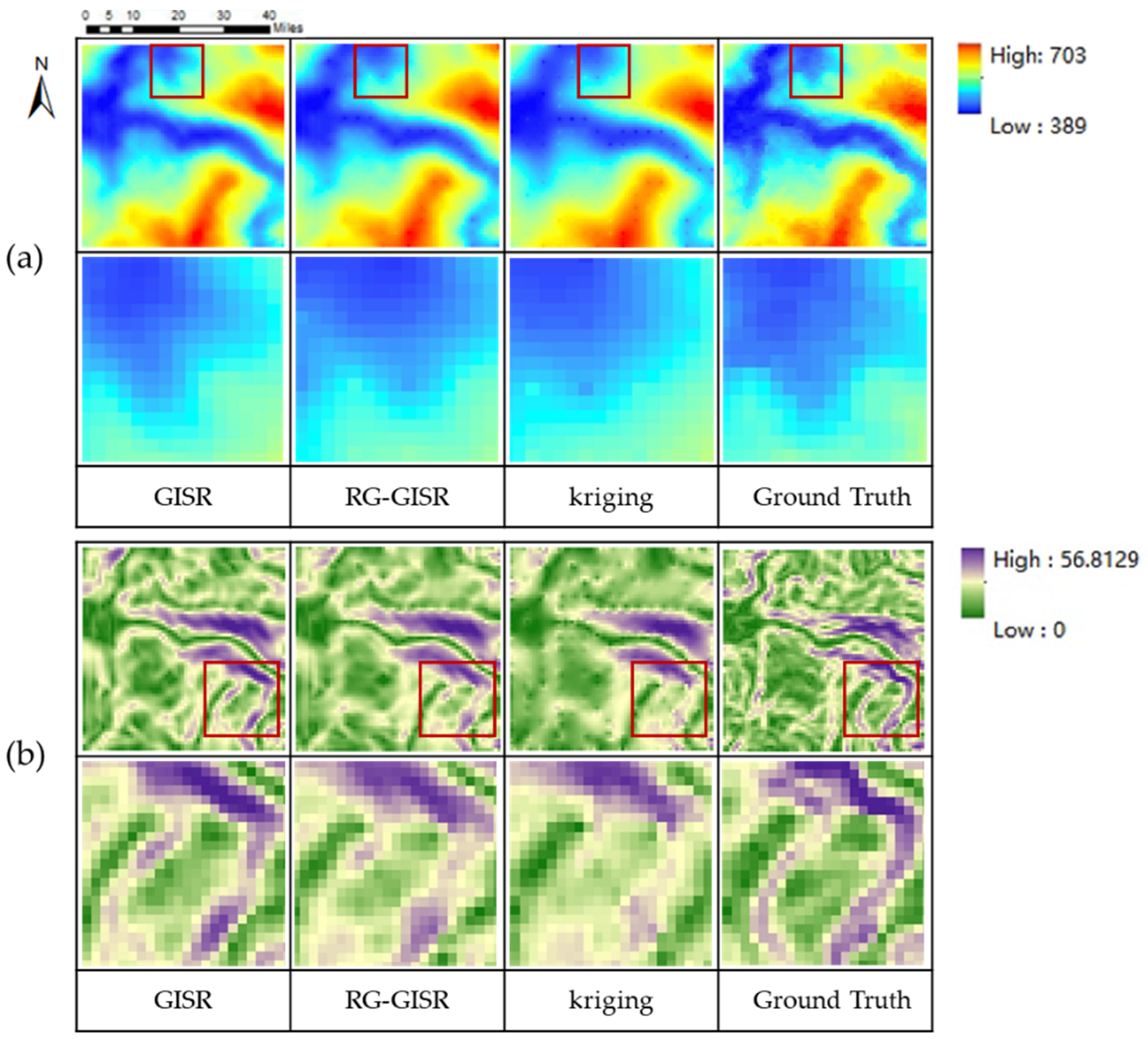
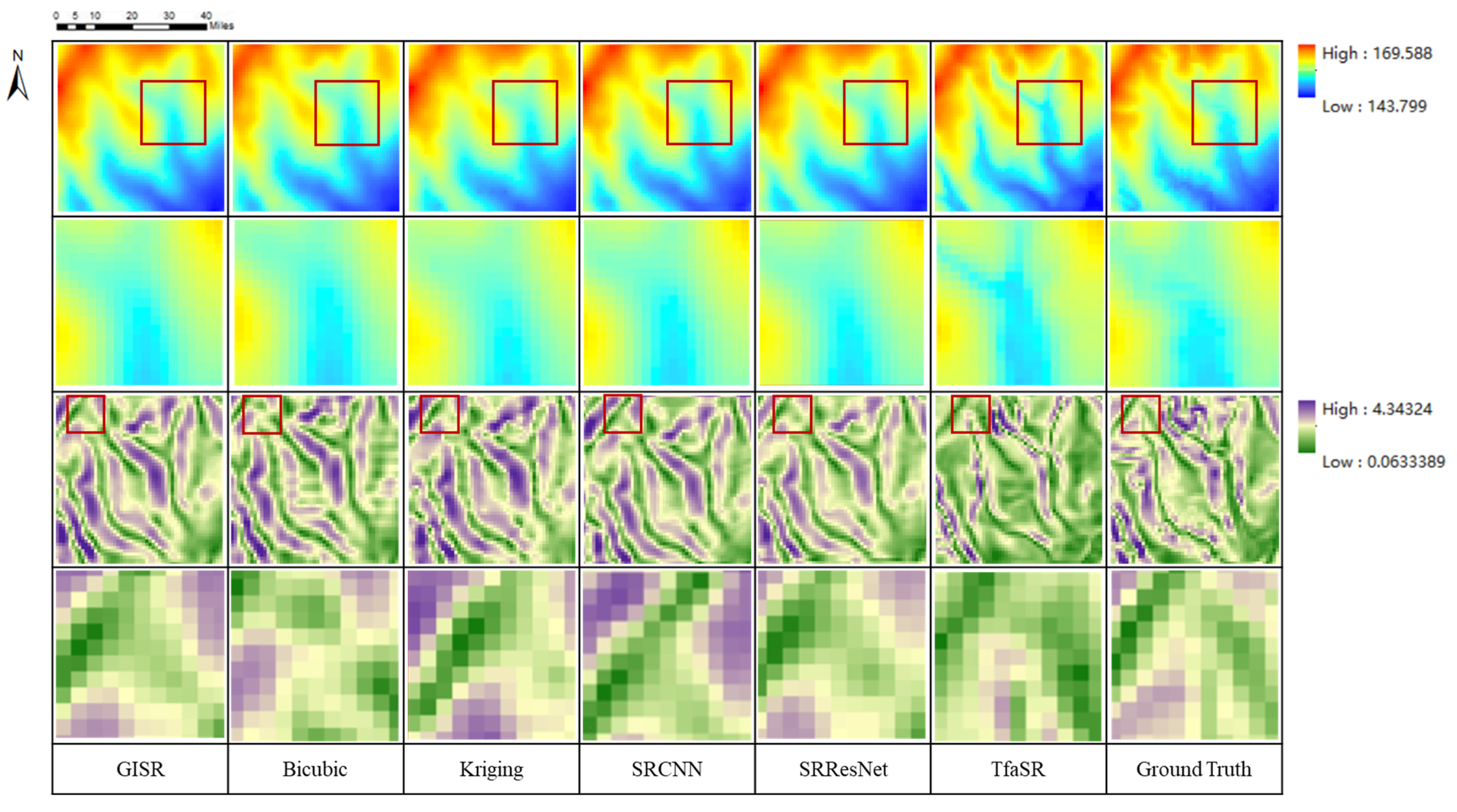
5.1.2. Visual Assessment
5.1.3. Terrain Parameter Maintenance
5.2. Discussion
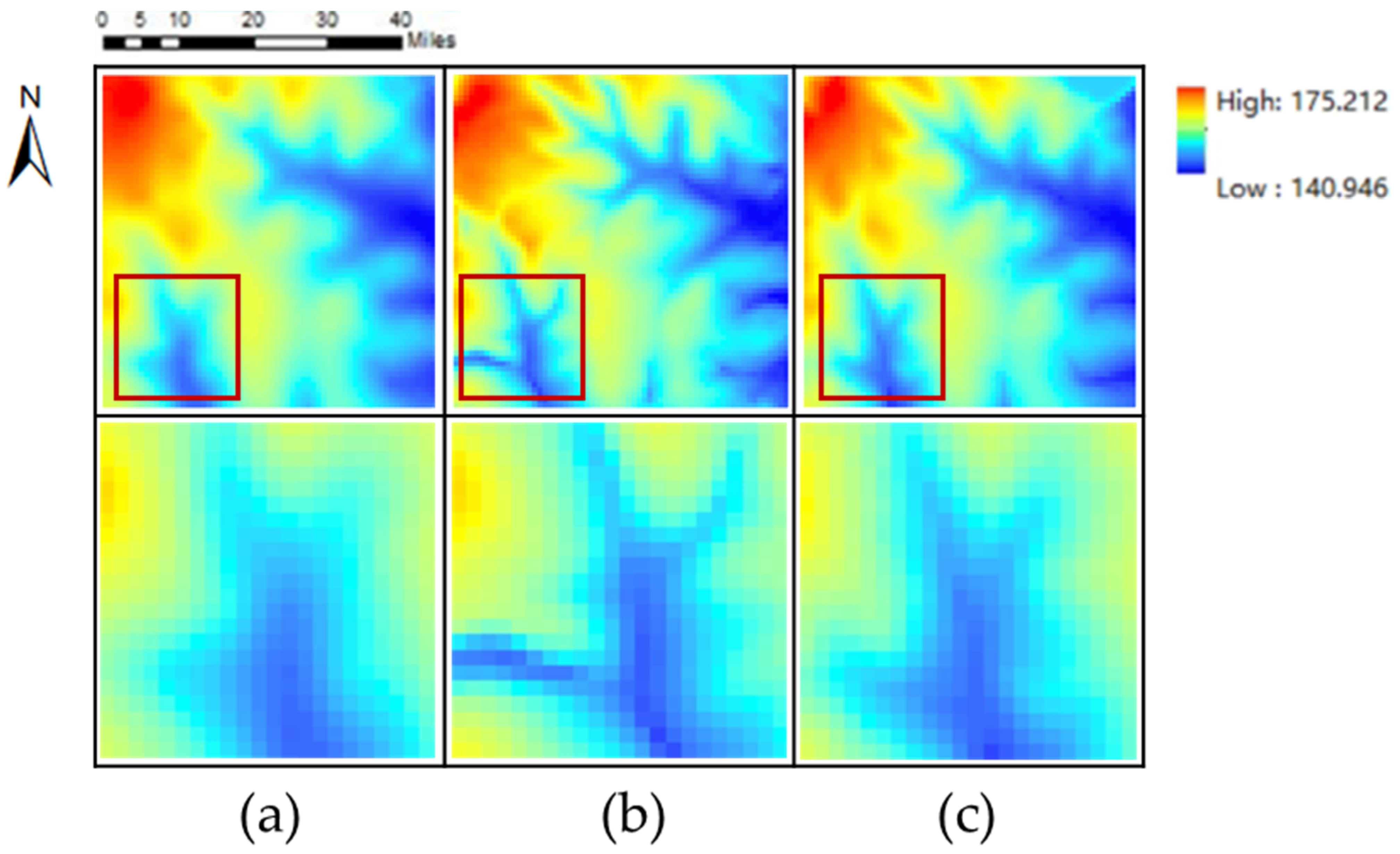
5.2.1. The Impact of the Global Information Supplement Module
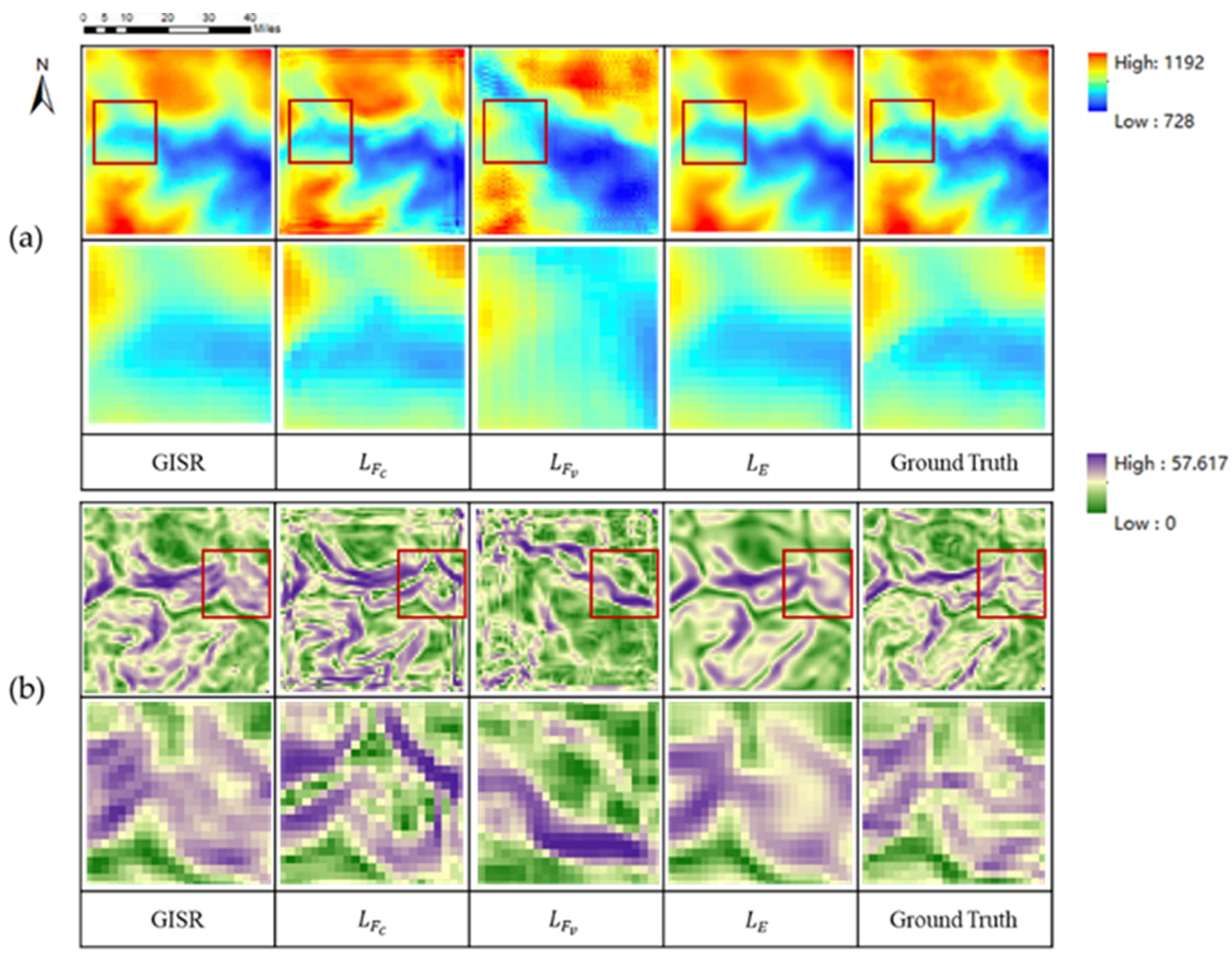
5.2.2. Effectiveness of the Collaborative Loss
5.2.3. The Application of Other Dataset
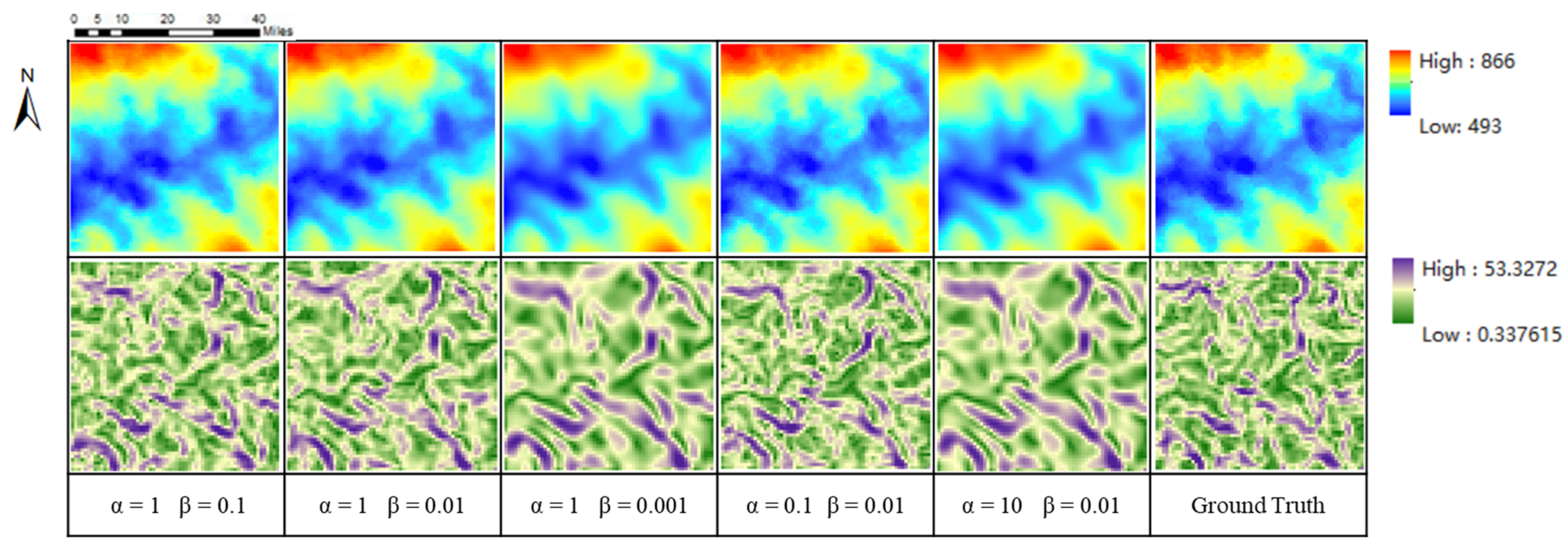
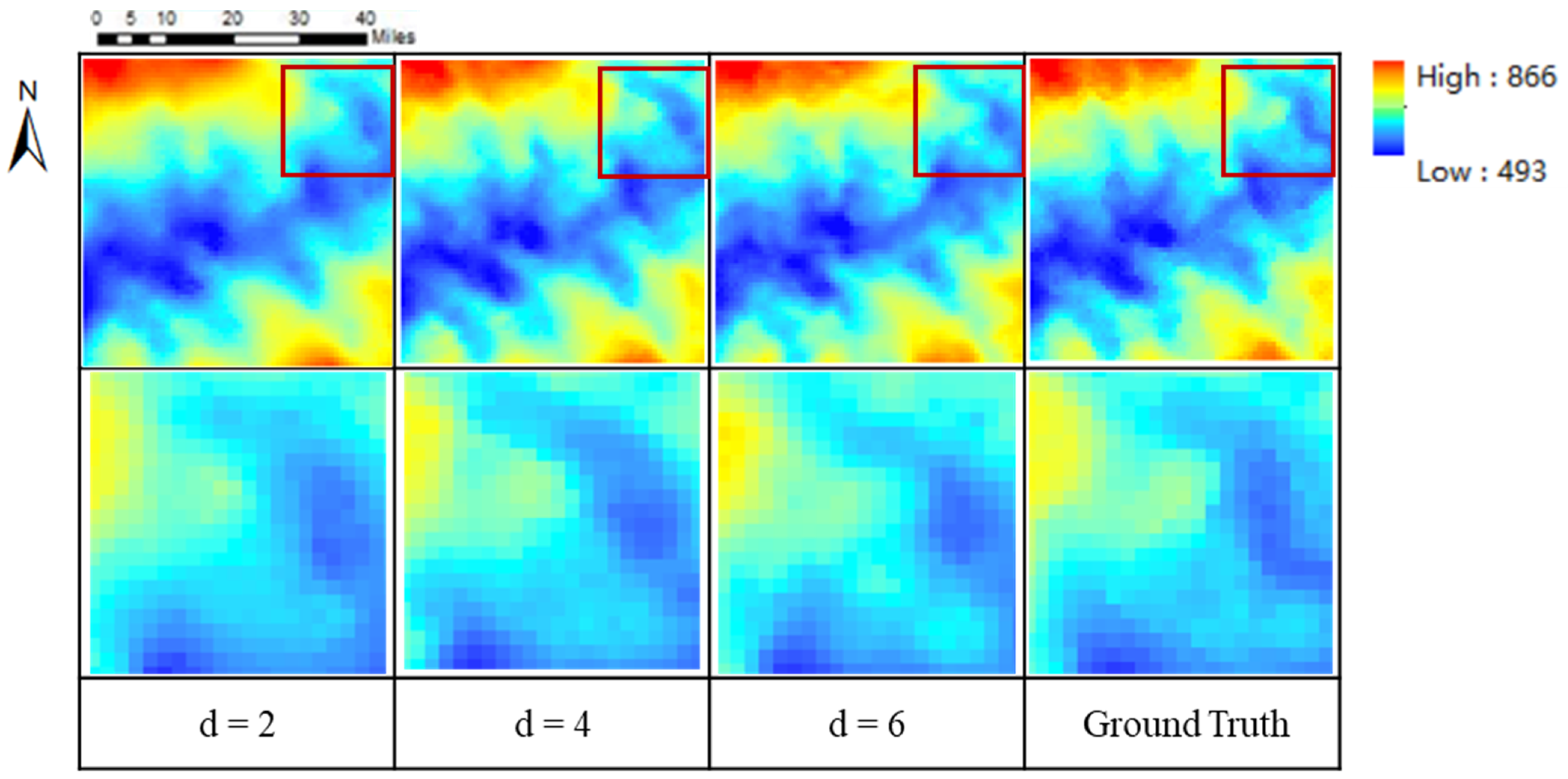
5.2.4. The Impact of the Different Down Sampling Factors
5.2.5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DEM | digital elevation model |
| LR DEM | low-resolution digital elevation model |
| HR DEM | high-resolution digital elevation model |
| SR | super-resolution |
| DEM SR | digital elevation model super-resolution |
| RMSE | root means square error |
| MAE | mean absolute error |
| CNN | convolutional neural network |
| SRCNN | super-resolution convolutional neural network |
| SRResNet | super-resolution residual network |
| TfaSR | terrain feature-aware super-resolution model |
| GISR | global-information-constrained digital elevation model super-resolution |
| LISA | local indicators of spatial association |
| IDW | inverse distance weighted |
| FCN | fully convolutional networks |
| CEDGANs | conditional encoder-decoder generative adversarial neural networks |
| EDEM-SR | enhanced double-filter deep residual neural network |
| PReLU | parametric rectified linear unit |
| ReLU | rectified linear unit |
| LReLU | leaky rectified linear unit |
| BN | batch normalization |
| ResNet | residual network |
| PS | Pixelshuffle |
| VGG | visual geometry group |
| RG-GISR | GISR of removing the global information supplement module |
| SSIM | structure similarity index measure |
| RSPCN | recursive sub-pixel convolutional neural networks |
| ZSSR | zero-shot super-resolution |
References
- Passalacqua, P.; Tarolli, P.; Foufoula-Georgiou, E. Testing space-scale methodologies for automatic geomorphic feature extraction from lidar in a complex mountainous landscape. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Kenward, T.; Lettenmaier, D.P.; Wood, E.F.; Fielding, E. Effects of digital elevation model accuracy on hydrologic predictions. Remote Sens. Environ. 2000, 74, 432–444. [Google Scholar] [CrossRef]
- Huang, C.; Chen, Y.; Wu, J. DEM-based modification of pixel-swapping algorithm for enhancing floodplain inundation mapping. Int. J. Remote Sens. 2014, 35, 365–381. [Google Scholar] [CrossRef]
- Kellndorfer, J.; Walker, W.; Pierce, L.; Dobson, C.; Fites, J.A.; Hunsaker, C.; Vona, J.; Clutter, M. Vegetation height estimation from shuttle radar topography mission and national elevation datasets. Remote Sens. Environ. 2004, 93, 339–358. [Google Scholar] [CrossRef]
- Chen, D.; Zhong, Y.; Zheng, Z.; Ma, A.; Lu, X. Urban road mapping based on an end-to-end road vectorization mapping network framework. ISPRS J. Photogramm. Remote Sens. 2021, 178, 345–365. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, X.; Xu, Z. Convolutional Neural Network Based Dem Super Resolution. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 247–250. [Google Scholar] [CrossRef]
- Zhu, D.; Cheng, X.; Zhang, F.; Yao, X.; Gao, Y.; Liu, Y. Spatial interpolation using conditional generative adversarial neural networks. Int. J. Geogr. Inf. Sci. 2020, 34, 735–758. [Google Scholar] [CrossRef]
- Han, D. Comparison of commonly used image interpolation methods. In Proceedings of the Conference of the 2nd International Conference on Computer Science and Electronics Engineering (ICCSEE 2013), Paris, France, 22–23 March 2013; pp. 1556–1559. [Google Scholar]
- Zhang, Y.; Yu, W. Comparison of DEM Super-Resolution Methods Based on Interpolation and Neural Networks. Sensors 2022, 22, 745. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D. A review of comparative studies of spatial interpolation methods in environmental sciences: Performance and impact factors. Ecol. Inform. 2011, 6, 228–241. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Musakwa, W.; Van Niekerk, A. Monitoring urban sprawl and sustainable urban development using the Moran Index: A case study of Stellenbosch, South Africa. Int. J. Appl. Geospat. Res. (IJAGR) 2014, 5, 1–20. [Google Scholar] [CrossRef]
- Zhou, A.; Chen, Y.; Wilson, J.P.; Su, H.; Xiong, Z.; Cheng, Q. An Enhanced Double-Filter Deep Residual Neural Network for Generating Super Resolution DEMs. Remote Sens. 2021, 13, 3089. [Google Scholar] [CrossRef]
- Knudsen, E.I. Fundamental components of attention. Annu. Rev. Neurosci. 2007, 30, 57–78. [Google Scholar] [CrossRef]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Pashler, H.; Johnston, J.C.; Ruthruff, E. Attention and performance. Annu. Rev. Psychol. 2001, 52, 629. [Google Scholar] [CrossRef]
- Demiray, B.Z.; Sit, M.; Demir, I. D-SRGAN: DEM super-resolution with generative adversarial networks. SN Comput. Sci. 2021, 2, 48. [Google Scholar] [CrossRef]
- Getis, A. Spatial autocorrelation. In Handbook of Applied Spatial Analysis; Springer: Berlin/Heidelberg, Germany, 2010; pp. 255–278. [Google Scholar]
- Chen, T.-J.; Chuang, K.-S.; Wu, J.; Chen, S.C.; Hwang, M.; Jan, M.-L. A novel image quality index using Moran I statistics. Phys. Med. Biol. 2003, 48, N131. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–19 June 2016; pp. 770–778. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–19 June 2016; pp. 1874–1883. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 20–23 June 2017; pp. 764–773. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 17 October 2019; pp. 6411–6420. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2018; pp. 4055–4064. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; 30. [Google Scholar]
- Cressie, N. The origins of kriging. Math. Geol. 1990, 22, 239–252. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, W.; Zhu, D. Terrain feature-aware deep learning network for digital elevation model superresolution. ISPRS J. Photogramm. Remote Sens. 2022, 189, 143–162. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 18–22 June 2017; pp. 4681–4690. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Atkinson, P.M.; Lloyd, C.D. Geostatistics and spatial interpolation. In The SAGE Handbook of Spatial Analysis; SAGE: Newcastle upon Tyne, UK, 2009; pp. 159–181. [Google Scholar]
- Shepard, D. A two-dimensional interpolation function for irregularly-spaced data. In Proceedings of the 1968 23rd ACM National Conference, New York, NY, USA, 27–29 August 1968; pp. 517–524. [Google Scholar]
- Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A brief review of nearest neighbor algorithm for learning and classification. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 1255–1260. [Google Scholar]
- Bhatia, N. Survey of nearest neighbor techniques. arXiv 2010, arXiv:1007.0085. [Google Scholar]
- McKinley, S.; Levine, M. Cubic spline interpolation. Coll. Redw. 1998, 45, 1049–1060. [Google Scholar]
- Wahba, G. Spline interpolation and smoothing on the sphere. SIAM J. Sci. Stat. Comput. 1981, 2, 5–16. [Google Scholar] [CrossRef]
- Gao, S.; Gruev, V. Bilinear and bicubic interpolation methods for division of focal plane polarimeters. Opt. Express 2011, 19, 26161–26173. [Google Scholar] [CrossRef]
- De Boor, C. Bicubic spline interpolation. J. Math. Phys. 1962, 41, 212–218. [Google Scholar] [CrossRef]
- Wackernagel, H. Ordinary kriging. In Multivariate Geostatistics; Springer: Berlin/Heidelberg, Germany, 2003; pp. 79–88. [Google Scholar]
- Hutchinson, M.; Gessler, P. Splines—More than just a smooth interpolator. Geoderma 1994, 62, 45–67. [Google Scholar] [CrossRef]
- Sun, M.; Song, Z.; Jiang, X.; Pan, J.; Pang, Y. Learning pooling for convolutional neural network. Neurocomputing 2017, 224, 96–104. [Google Scholar] [CrossRef]
- Yu, D.; Wang, H.; Chen, P.; Wei, Z. Mixed pooling for convolutional neural networks. In Proceedings of the International Conference on Rough Sets and Knowledge Yechnology, Shanghai, China, 24–26 October 2014; pp. 364–375. [Google Scholar]
- Tang, J.; Xia, H.; Zhang, J.; Qiao, J.; Yu, W. Deep forest regression based on cross-layer full connection. Neural Comput. Appl. 2021, 33, 9307–9328. [Google Scholar] [CrossRef]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2015; pp. 1520–1528. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2015; pp. 1026–1034. [Google Scholar]
- Demiray, B.Z.; Sit, M.; Demir, I. DEM Super-Resolution with EfficientNetV2. arXiv 2021, arXiv:2109.09661. [Google Scholar]
- Lin, X.; Zhang, Q.; Wang, H.; Yao, C.; Chen, C.; Cheng, L.; Li, Z. A DEM Super-Resolution Reconstruction Network Combining Internal and External Learning. Remote Sens. 2022, 14, 2181. [Google Scholar] [CrossRef]
- Zhang, R.; Bian, S.; Li, H. RSPCN: Super-Resolution of Digital Elevation Model Based on Recursive Sub-Pixel Convolutional Neural Networks. ISPRS Int. J. Geo-Inf. 2021, 10, 501. [Google Scholar] [CrossRef]
- He, P.; Cheng, Y.; Qi, M.; Cao, Z.; Zhang, H.; Ma, S.; Yao, S.; Wang, Q. Super-Resolution of Digital Elevation Model with Local Implicit Function Representation. In Proceedings of the 2022 International Conference on Machine Learning and Intelligent Systems Engineering (MLISE), Seoul, Korea, 8–11 November 2022; pp. 111–116. [Google Scholar]
- Koenig, W.D. Spatial autocorrelation of ecological phenomena. Trends Ecol. Evol. 1999, 14, 22–26. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2015; pp. 448–456. [Google Scholar]
- Fan, E. Extended tanh-function method and its applications to nonlinear equations. Phys. Lett. A 2000, 277, 212–218. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning 2013, Atlanta, GA, USA, 16–21 June 2013; p. 3. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 2010, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bolstad, P.V.; Stowe, T. An evaluation of DEM accuracy: Elevation, slope, and aspect. Photogramm. Eng. Remote Sens. 1994, 60, 1327–1332. [Google Scholar]
- Wang, S.; Rehman, A.; Wang, Z.; Ma, S.; Gao, W. SSIM-motivated rate-distortion optimization for video coding. IEEE Trans. Circuits Syst. Video Technol. 2011, 22, 516–529. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Method | MAE | RMSE | SSIM | ||
|---|---|---|---|---|---|---|
| Elevation | Slope | Elevation | Slope | |||
| R1 | Bicubic [40] | 14.958 | 6.405 | 21.120 | 8.547 | 0.789 |
| Kriging [42] | 9.870 | 6.310 | 13.143 | 8.163 | 0.851 | |
| SRResNet [32] | 7.493 | 5.124 | 10.165 | 6.684 | 0.890 | |
| SRCNN [6] | 7.560 | 5.235 | 9.926 | 6.971 | 0.859 | |
| TfaSR [31] | 10.730 | 6.565 | 13.908 | 8.665 | 0.793 | |
| GISR | 6.365 | 4.503 | 8.236 | 5.824 | 0.919 | |
| R2 | Bicubic | 25.064 | 8.289 | 35.994 | 11.374 | 0.835 |
| Kriging | 11.546 | 6.562 | 16.193 | 8.831 | 0.913 | |
| SRResNet | 8.553 | 5.235 | 11.630 | 6.665 | 0.927 | |
| SRCNN | 9.221 | 5.644 | 12.728 | 7.225 | 0.945 | |
| TfaSR | 12.578 | 6.773 | 16.598 | 8.587 | 0.905 | |
| GISR | 6.232 | 4.424 | 8.364 | 5.581 | 0.971 | |
| R3 | Bicubic | 22.462 | 7.148 | 27.365 | 9.165 | 0.847 |
| Kriging | 13.217 | 7.884 | 17.526 | 8.981 | 0.872 | |
| SRResNet | 16.568 | 6.825 | 25.054 | 8.919 | 0.901 | |
| SRCNN | 11.343 | 6.181 | 14.379 | 7.839 | 0.935 | |
| TfaSR | 14.122 | 7.041 | 17.449 | 8.763 | 0.908 | |
| GISR | 7.785 | 4.628 | 9.865 | 5.910 | 0.956 | |
| R4 | Bicubic | 11.002 | 5.460 | 14.577 | 7.118 | 0.705 |
| Kriging | 9.276 | 6.659 | 12.153 | 7.885 | 0.676 | |
| SRResNet | 7.146 | 5.029 | 9.606 | 6.439 | 0.791 | |
| SRCNN | 8.151 | 6.048 | 10.438 | 7.684 | 0.770 | |
| TfaSR | 10.840 | 6.675 | 14.017 | 8.551 | 0.548 | |
| GISR | 4.871 | 3.854 | 6.316 | 4.951 | 0.885 | |
| GISR | RG-GISR | Kriging | ||
|---|---|---|---|---|
| MAE | Elevation | 6.250 | 8.432 | 7.521 |
| Slope | 4.845 | 5.010 | 5.873 | |
| RMSE | Elevation | 8.178 | 10.387 | 10.121 |
| Slope | 6.148 | 6.411 | 7.550 |
| Loss Scheme | MAE | RMSE | SSIM | |||||
|---|---|---|---|---|---|---|---|---|
| Elevation | Slope | Elevation | Slope | |||||
| Ⅰ | √ | × | × | 4.735 | 3.826 | 6.352 | 4.853 | 0.914 |
| Ⅱ | × | √ | × | 33.594 | 11.345 | 40.298 | 14.180 | 0.826 |
| Ⅲ | × | × | √ | 51.082 | 10.936 | 62.618 | 13.686 | 0.582 |
| Ⅳ | √ | √ | √ | 6.922 | 4.303 | 8.990 | 5.484 | 0.951 |
| α | β | MAE | RMSE | SSIM | ||
|---|---|---|---|---|---|---|
| Elevation | Slope | Elevation | Slope | |||
| 1 | 0.1 | 6.729 | 6.060 | 8.446 | 7.712 | 0.904 |
| 1 | 0.01 | 5.702 | 5.797 | 7.333 | 7.302 | 0.934 |
| 1 | 0.001 | 4.926 | 5.059 | 6.438 | 6.441 | 0.913 |
| 0.1 | 0.01 | 7.437 | 6.030 | 9.069 | 7.549 | 0.903 |
| 1 | 0.01 | 5.702 | 5.797 | 7.333 | 7.302 | 0.934 |
| 10 | 0.01 | 5.240 | 5.050 | 6.789 | 6.413 | 0.914 |
| Method | MAE | RMSE | SSIM | ||
|---|---|---|---|---|---|
| Elevation | Slope | Elevation | Slope | ||
| Bicubic [46] | 11.108 | 0.468 | 14.679 | 0.635 | 0.8268 |
| Kriging [49] | 4.552 | 0.350 | 5.932 | 0.478 | 0.9480 |
| SRResNet [37] | 4.731 | 0.349 | 7.799 | 0.495 | 0.9344 |
| SRCNN [38] | 6.194 | 0.350 | 7.873 | 0.477 | 0.9399 |
| TfaSR [36] | 9.070 | 0.535 | 11.758 | 0.758 | 0.8956 |
| GISR | 4.372 | 0.315 | 5.866 | 0.439 | 0.9561 |
| Scale | Elevation | SSIM | |
|---|---|---|---|
| MAE | RMSE | ||
| 2 | 4.434 | 5.701 | 0.935 |
| 4 | 5.702 | 7.333 | 0.913 |
| 6 | 7.147 | 8.976 | 0.874 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, X.; Ma, X.; Li, H.; Chen, Z. A Global-Information-Constrained Deep Learning Network for Digital Elevation Model Super-Resolution. Remote Sens. 2023, 15, 305. https://doi.org/10.3390/rs15020305
Han X, Ma X, Li H, Chen Z. A Global-Information-Constrained Deep Learning Network for Digital Elevation Model Super-Resolution. Remote Sensing. 2023; 15(2):305. https://doi.org/10.3390/rs15020305
Chicago/Turabian StyleHan, Xiaoyi, Xiaochuan Ma, Houpu Li, and Zhanlong Chen. 2023. "A Global-Information-Constrained Deep Learning Network for Digital Elevation Model Super-Resolution" Remote Sensing 15, no. 2: 305. https://doi.org/10.3390/rs15020305
APA StyleHan, X., Ma, X., Li, H., & Chen, Z. (2023). A Global-Information-Constrained Deep Learning Network for Digital Elevation Model Super-Resolution. Remote Sensing, 15(2), 305. https://doi.org/10.3390/rs15020305