
Low-Rank Constrained Attention-Enhanced Multiple Spatial–Spectral Feature Fusion for Small Sample Hyperspectral Image Classification


Abstract
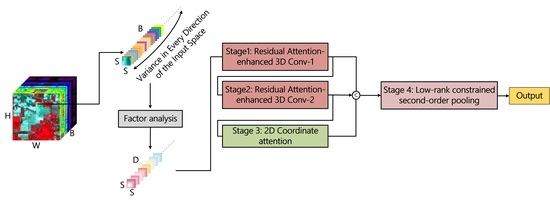
1. Introduction
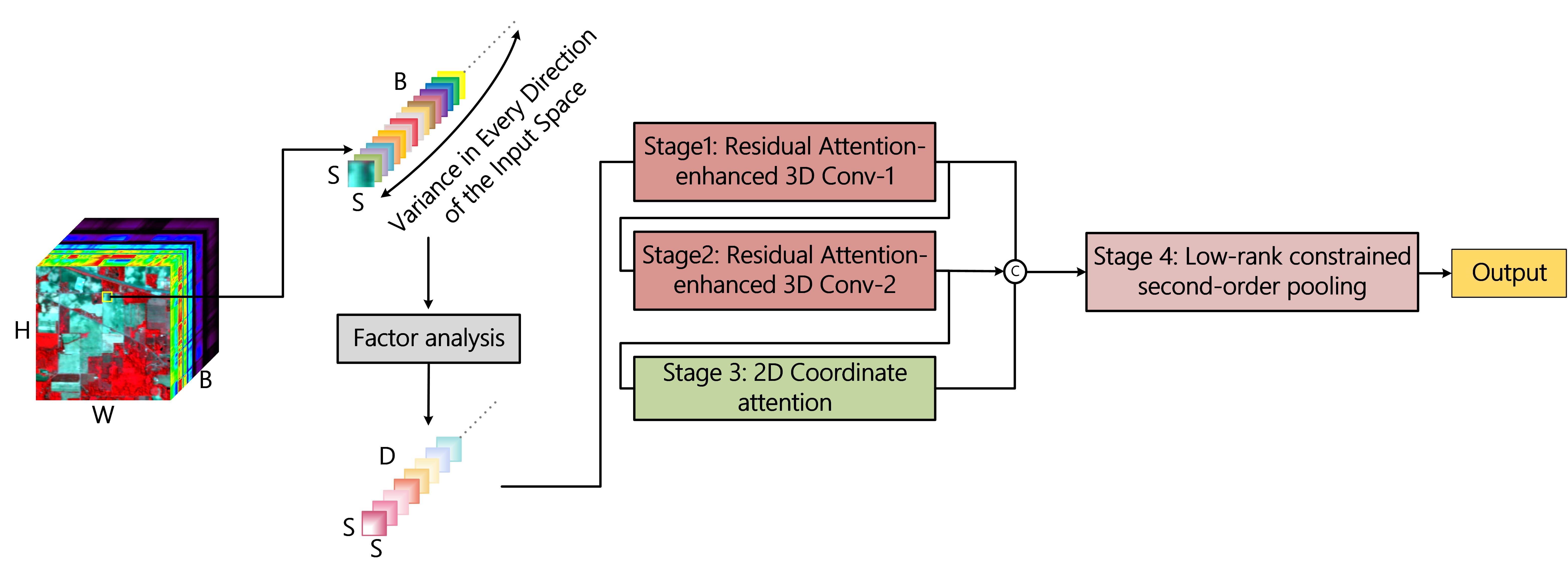
- To fit the small sample dilemma, a few components that can model the hyperspectral data are first extracted using factor analysis to reduce data redundancy. One single vanilla 3D convolutional layer is utilized to primarily investigate spatial–spectral features, and the features are then further refined based on an attention-like manner.
- Complementary position-sensitive and channel correlation information are provided by coordinate attention. The multi-level features extracted by 3D convolution and 2D attention are then unified and aggregated by a simple and effective composite residual structure. Finally, a compact vector of second-order statistics is learned for each class using low-rank second-order pooling to achieve classification.
- Extensive experiments have been performed using four representative hyperspectral datasets with varying spatial–spectral characteristics. Using only five samples of each class for training, the LAMFN outperforms several recently released well-designed models with smaller parameter size and shorter running time.
2. Related Research
2.1. Mixed CNN Model
2.2. Attention Mechanism
3. Methods
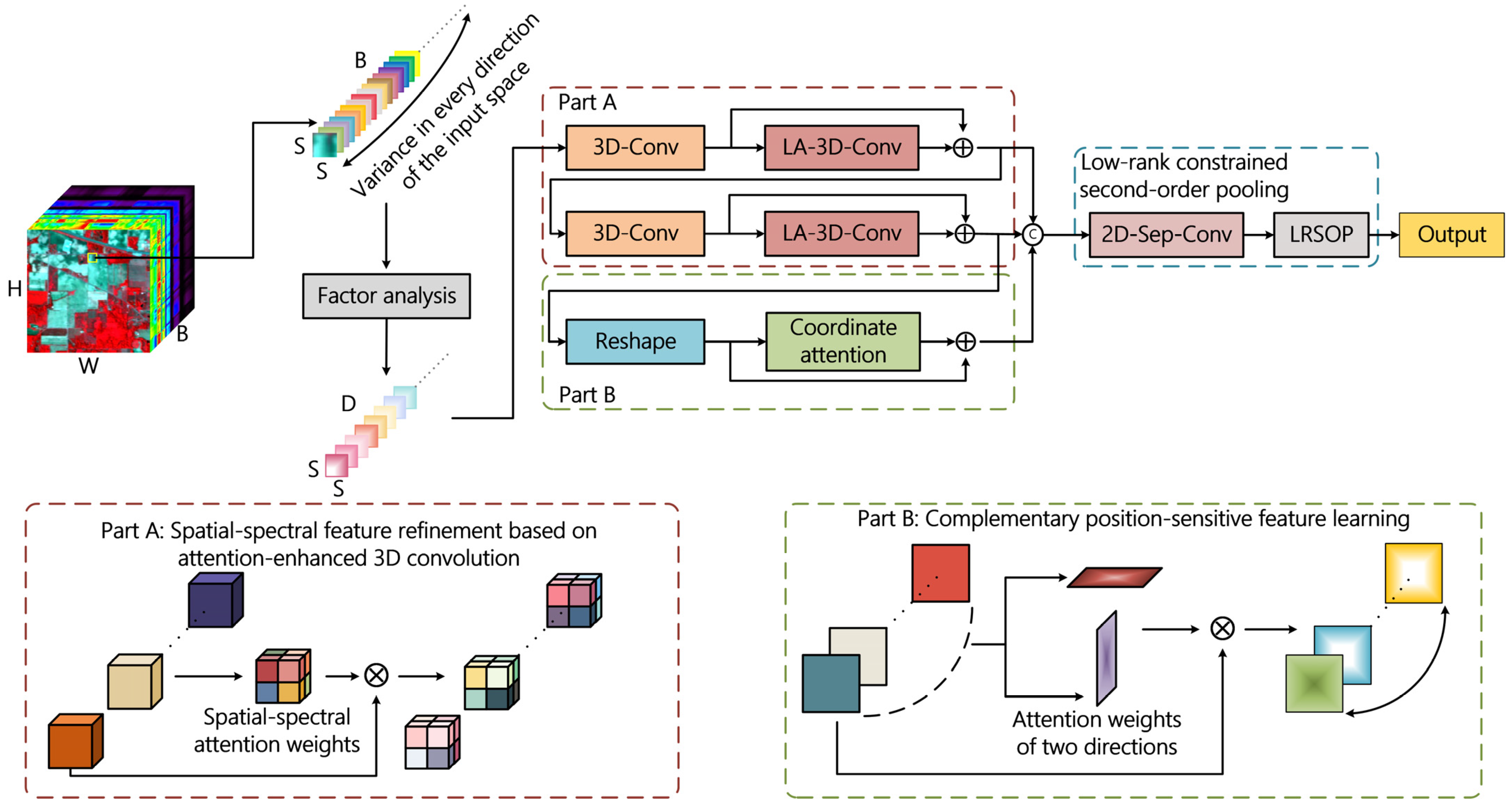
3.1. Network Structure
3.2. Hyperspectral Data Pre-Processing Based on Factor Analysis
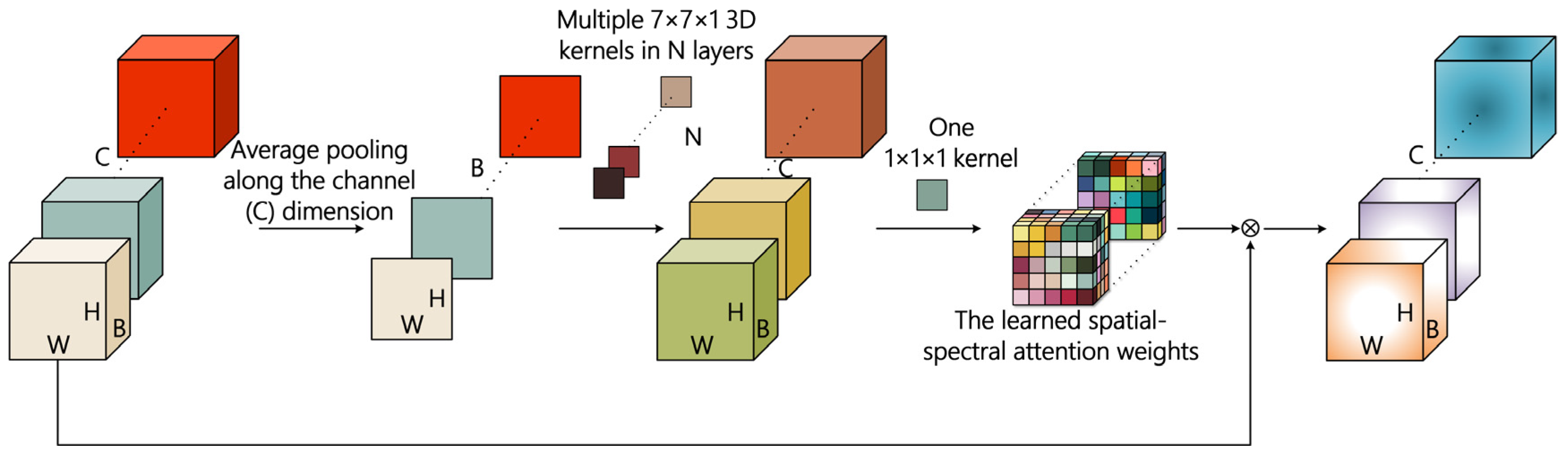
3.3. Light-Weight Attention-Enhanced Spatial–Spectral Feature Learning
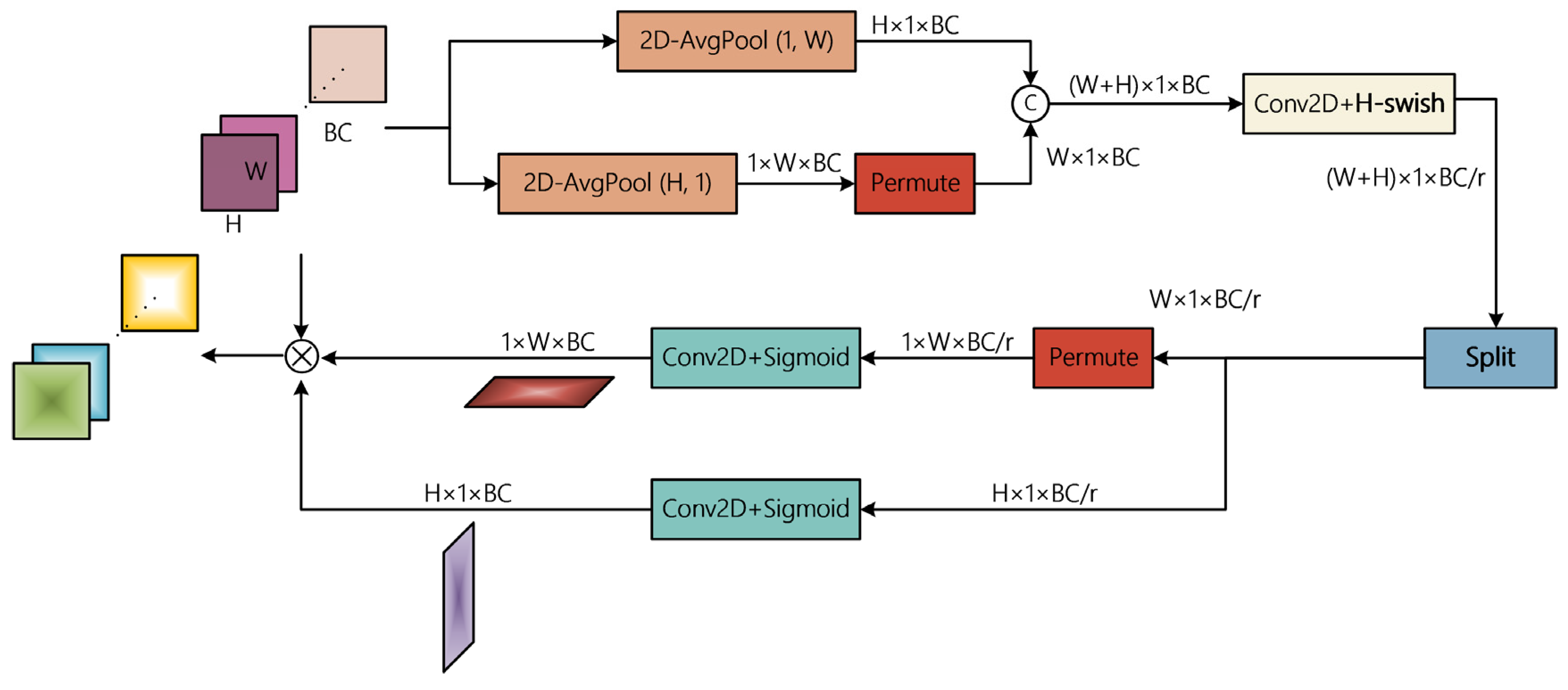
3.4. Spatial Feature Refinement Based on Coordinate Attention
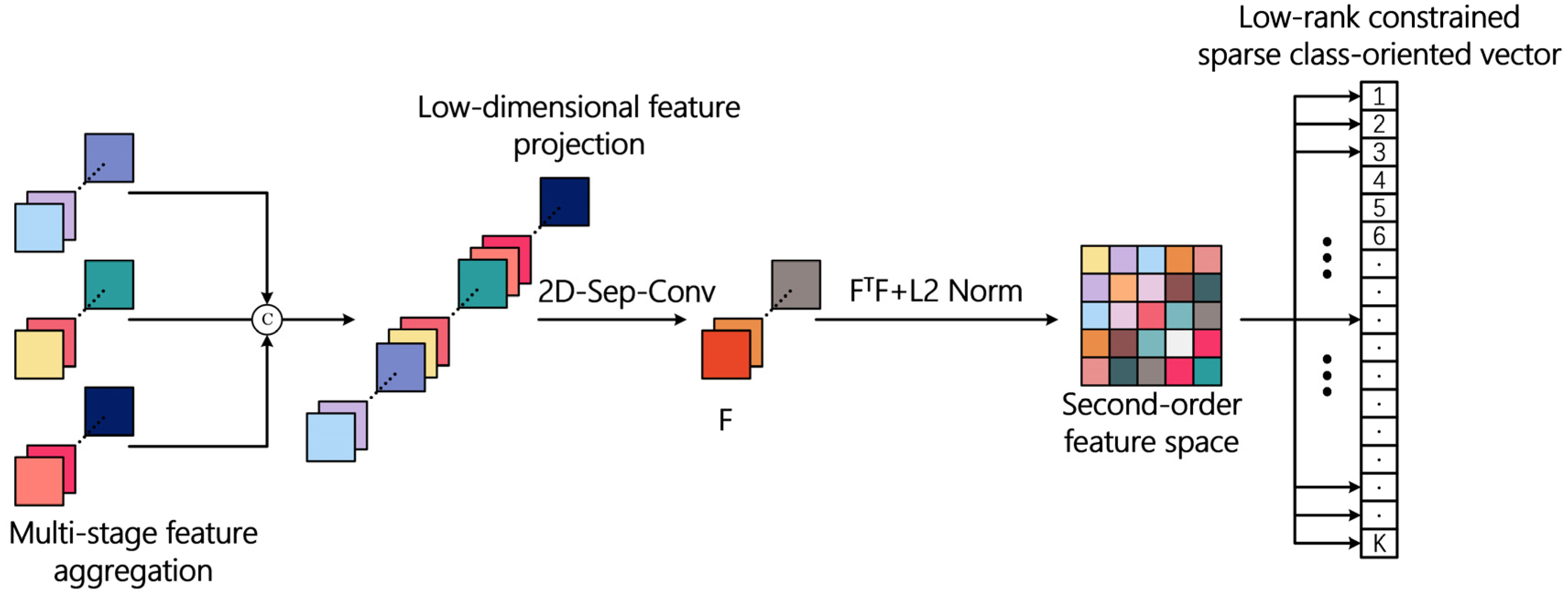
3.5. Low-Rank Constrained Second-Order Pooling for Final Classification
4. Experimental Results and Analysis
4.1. Experimental Datasets
- IP is a classical dataset that is widely used to evaluate HSIC algorithms. Since its spatial resolution is low and many mixed pixels exist, the IP dataset can test the effectiveness of the algorithm in extracting robust features. The remaining three datasets have large image sizes and high spatial resolution.
- PC has an original size of . However, some areas have no information and they have been discarded. The processed PC dataset still has a large image size, which is . This scene contains many objects with similar textures and colors that often appear in urban areas.
- The HU dataset was originally released during the 2013 Data Fusion Contest by the Image Analysis and Data Fusion Technical Committee of the IEEE Geoscience and Remote Sensing Society, so it is also named “2013_IEEE_GRSS_DF_Contest”. This dataset is challenging due to its large image size and sparse distribution of available samples.
- The WHU dataset is a recently released hyperspectral dataset collected by unmanned aerial vehicles (UAVs) with extremely high spatial resolution [59]. The ground objects include 22 plant species with similar colors and textures, which greatly challenges the classification algorithm.
4.2. Contrast Models
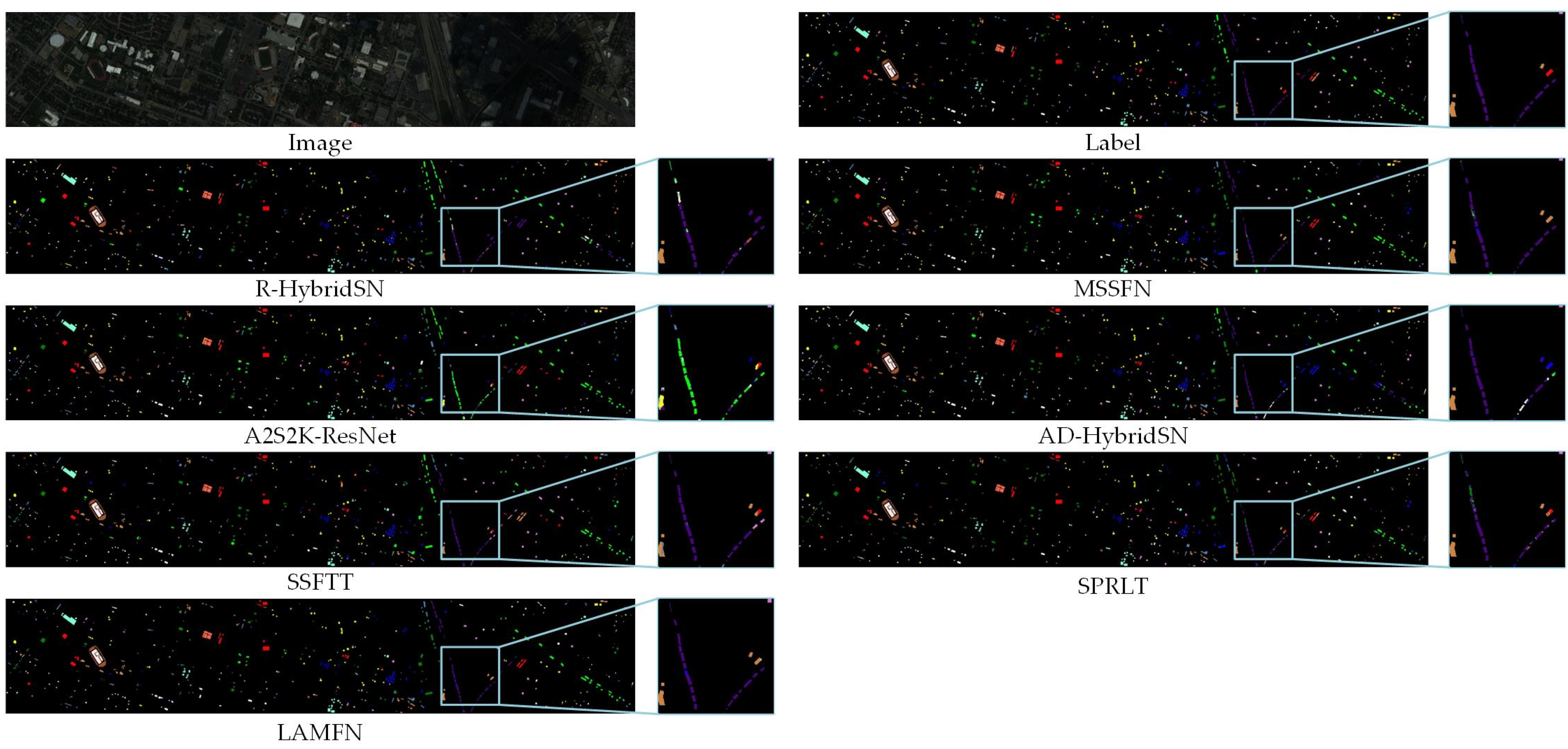
- R-HybridSN and MSSFN are both residual CNN models, which are focused on small sample HSIC tasks. R-HybridSN adopts residual learning and depth separable convolution to refine the feature learning process. MSSFN further improves the classification accuracy using cascaded feature fusion patterns and second-order pooling.
- A2S2K-ResNet and AD-HybridSN are two convolution-attention fusion models. AD-HybridSN is a mixed CNN model. Attention modules are inserted after each convolutional layer to achieve spatial–spectral feature refinement. A2S2K-ResNet adopted selective kernel attention in the first layer and efficient channel feature attention in the successive layers.
- SSFTT and SPRLT are two very recently proposed transformer-based HSIC models. SPRLT adopts a spatial partition restore (SPR) module that is designed to split the input patch into several overlapping continuous sub-patches as sequential. SSFTT use 3D convolution and 2D convolution to build prior spatial–spectral feature space for subsequent transformer block. Both of them improve the applicability of transformer block in HSIC tasks by designing a novel feature organization approach.
4.3. Experimental Setup
4.4. Comparison with the Contrast Models
- Various methods show distinct generalization properties for different datasets. For example, the experimental results of R-HybridSN and SPRLT with larger model sizes are not ideal for the four datasets, which indicates the over-fitting phenomenon is prominent. On the contrary, MSSFN and SSFTT performed relatively better. It is believed that the parameter number is the superficial reason, while the real reason is the difference in feature extraction ability and parameter redundancy caused by the model structure.
- Two transformer-based models, SSFTT and SPRLT, can achieve comparable results with other models in PC and WHU, but the results in IP and HU are not ideal. Since patch-based structures are adopted, the global feature learning ability of the self-attention module is limited to a large extent. Therefore, the VIT-based approaches may consider continued improvements in data organization.
- Quantitative experimental results demonstrate the effectiveness of LAMFN. In the four datasets, the proposed method achieved the highest OA and kappa. Compared with the second-best model, MSSFN, the OA of LAMFN has improved by 0.82%, 1.12%, 1.67%, and 0.89% in IP, PC, HU, and WHU datasets, respectively. The AA value of LAMFN was slightly lower than MSSFN in the WHU dataset.
- Although the LAMFN achieved the best OA value in four datasets, it achieved the lowest standard deviation in only two datasets, namely PC and WHU. The stability of the LAMFN for some datasets needs to be further improved.
4.5. Running Time Analysis
5. Discussion
5.1. Model Design Analysis of LAMFN
- When the number of bands is 16, FA achieves the overall best accuracy (measured in average) in the four datasets. By increasing the number of bands, only the accuracy in the IP data set continues to improve, while the accuracy of the other datasets tends to decrease. Compared with PCA, the FA dimension reduction method achieves the optimal factor number earlier.
- FA significantly outperforms the PCA method when the number of bands is 16. In both IP and WHU datasets, FA has an absolute advantage. However, FA achieves slightly lower accuracy in the PC dataset than using PCA. As the number of bands increases, the accuracy obtained by PCA improves significantly in IP and to a lesser extent in other datasets. Overall, there is a large gap between PCA and FA methods.
- PCA significantly outperforms FA in terms of resolving time. When the band number is 16, the resolving time of FA is 28.0 s slower than that of PCA. When the number of bands is taken as 24, the gap increases to 59.8 s. The slowdown is due to the fact that the FA takes into account the covariance of all input pixels. The extended solution time when the number of bands is taken as 16 is acceptable, given the resulting accuracy improvement.
5.2. Comparison with Advanced Semi-Supervised Methods
- The DFSL is a cross-domain meta-learning method. Firstly, the model is pre-trained in the source domain dataset to obtain the metric space. Then, the well-trained model extracts robust features, and the final classification can be achieved by a simple linear classifier using very few samples.
- The DMVL is a contrastive learning method. The two successive spectral vectors within each pixel are used for generating positive and negative samples for contrastive pretraining.
- The UM2L is an end-to-end cross-domain meta-learning method. The pretraining phase was performed in an unsupervised manner with multi-view constrained contrast learning.
- SC-EADNet combines contrastive learning with well-designed multiscale residual depth-separable convolutional networks.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Deep learning techniques to classify agricultural crops through UAV imagery: A review. Neural Comput. Appl. 2022, 34, 9511–9536. [Google Scholar] [CrossRef] [PubMed]
- Wambugu, N.; Chen, Y.; Xiao, Z.; Tan, K.; Wei, M.; Liu, X.; Li, J. Hyperspectral image classification on insufficient-sample and feature learning using deep neural networks: A review. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102603. [Google Scholar] [CrossRef]
- Vali, A.; Comai, S.; Matteucci, M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep: Overview and Toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]
- Ghamisi, P.; Maggiori, E.; Li, S.; Souza, R.; Tarablaka, Y.; Moser, G.; Giorgi, A.D.; Fang, L.; Chen, Y.; Chi, M.; et al. New Frontiers in Spectral–Spatial Hyperspectral Image Classification: The Latest Advances Based on Mathematical Morphology, Markov Random Fields, Segmentation, Sparse Representation, and Deep Learning. IEEE Geosci. Remote Sens. Mag. 2018, 6, 10–43. [Google Scholar] [CrossRef]
- Li, X.; Liu, B.; Zhang, K.; Chen, H.; Cao, W.; Liu, W.; Tao, D. Multi-view learning for hyperspectral image classification: An overview. Neurocomputing 2022, 500, 499–517. [Google Scholar] [CrossRef]
- Jia, S.; Jiang, S.; Lin, Z.; Li, N.; Xu, M.; Yu, S. A survey: Deep learning for hyperspectral image classification with few labeled samples. Neurocomputing 2021, 448, 179–204. [Google Scholar] [CrossRef]
- Ahmad, M.; Shabbir, S.; Raza, R.A.; Mazzara, M.; Distefano, S.; Khan, A.M. Artifacts of different dimension reduction methods on hybrid CNN feature hierarchy for Hyperspectral Image Classification. Optik 2021, 246, 167757. [Google Scholar] [CrossRef]
- Mohan, A.; Venkatesan, M. HybridCNN based hyperspectral image classification using multiscale spatiospectral features. Infrared Phys. Technol. 2020, 108, 103326. [Google Scholar] [CrossRef]
- Luo, F.L.; Du, B.; Zhang, L.P.; Zhang, L.F.; Tao, D.C. Feature Learning Using Spatial-Spectral Hypergraph Discriminant Analysis for Hyperspectral Image. IEEE Trans. Cybern. 2019, 49, 2406–2419. [Google Scholar] [CrossRef]
- Fu, H.; Sun, G.; Ren, J.; Zhang, A.; Jia, X. Fusion of PCA and Segmented-PCA Domain Multiscale 2-D-SSA for Effective Spectral-Spatial Feature Extraction and Data Classification in Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5500214. [Google Scholar] [CrossRef]
- Huang, H.; Shi, G.Y.; He, H.B.; Duan, Y.L.; Luo, F.L. Dimensionality Reduction of Hyperspectral Imagery Based on Spatial-spectral Manifold Learning. IEEE Trans. Cybern. 2020, 50, 2604–2616. [Google Scholar] [CrossRef] [PubMed]
- Shi, G.; Huang, H.; Liu, J.; Li, Z.; Wang, L. Spatial-Spectral Multiple Manifold Discriminant Analysis for Dimensionality Reduction of Hyperspectral Imagery. Remote Sens. 2019, 11, 2414. [Google Scholar] [CrossRef]
- Ahmad, M.; Shabbir, S.; Roy, S.K.; Hong, D.; Wu, X.; Yao, J.; Khan, A.M.; Mazzara, M.; Distefano, S.; Chanussot, J. Hyperspectral Image Classification—Traditional to Deep Models: A Survey for Future Prospects. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 968–999. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Li, Z.; Wang, T.; Li, W.; Du, Q.; Wang, C.; Liu, C.; Shi, X. Deep Multilayer Fusion Dense Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1258–1270. [Google Scholar] [CrossRef]
- Roy, S.K.; Chatterjee, S.; Bhattacharyya, S.; Chaudhuri, B.B.; Platoš, J. Lightweight Spectral–Spatial Squeeze-and-Excitation Residual Bag-of-Features Learning for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5277–5290. [Google Scholar] [CrossRef]
- Liu, B.; Yu, A.; Gao, K.; Wang, Y.; Yu, X.; Zhang, P. Multiscale nested U-Net for small sample classification of hyperspectral images. J Appl. Remote Sens. 2022, 16, 016506. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Going Deeper with Contextual CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef]
- Wang, W.; Dou, S.; Jiang, Z.; Sun, L. A Fast Dense Spectral–Spatial Convolution Network Framework for Hyperspectral Images Classification. Remote Sens. 2018, 10, 1068. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Feng, F.; Wang, S.; Wang, C.; Zhang, J. Learning Deep Hierarchical Spatial-Spectral Features for Hyperspectral Image Classification Based on Residual 3D-2D CNN. Sensors 2019, 19, 5276. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Valente, J.; van der Voort, M.; Tekinerdogan, B. Effect of Attention Mechanism in Deep Learning-Based Remote Sensing Image Processing: A Systematic Literature Review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Learning to Pay Attention on Spectral Domain: A Spectral Attention Module-Based Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 110–122. [Google Scholar] [CrossRef]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 449–462. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, F.; Feng, F.; Wang, C. Spatial-Spectral Feature Refinement for Hyperspectral Image Classification Based on Attention-Dense 3D-2D-CNN. Sensors 2020, 20, 5191. [Google Scholar] [CrossRef]
- Dong, Z.; Cai, Y.; Cai, Z.; Liu, X.; Yang, Z.; Zhuge, M. Cooperative Spectral–Spatial Attention Dense Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 18, 866–870. [Google Scholar] [CrossRef]
- Xue, Z.; Zhang, M.; Liu, Y.; Du, P. Attention-Based Second-Order Pooling Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9600–9615. [Google Scholar] [CrossRef]
- Cheng, S.; Wang, L.; Du, A. Asymmetric coordinate attention spectral-spatial feature fusion network for hyperspectral image classification. Sci. Rep. 2021, 11, 17408. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518615. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Xue, Z.; Xu, Q.; Zhang, M. Local Transformer with Spatial Partition Restore for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4307–4325. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Ding, X.; Zhang, X.; Zhou, Y.; Han, J.; Ding, G.; Sun, J. Scaling Up Your Kernels to 31 × 31: Revisiting Large Kernel Design in CNNs. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhu, W.; Zhao, C.; Feng, S.; Qin, B. Multiscale short and long range graph convolutional network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5535815. [Google Scholar] [CrossRef]
- Feng, F.; Zhang, Y.; Zhang, J.; Liu, B. Small Sample Hyperspectral Image Classification Based on Cascade Fusion of Mixed Spatial-Spectral Features and Second-Order Pooling. Remote Sens. 2022, 14, 505. [Google Scholar] [CrossRef]
- Roy, S.K.; Kar, P.; Hong, D.; Wu, X.; Plaza, A.; Chanussot, J. Revisiting Deep Hyperspectral Feature Extraction Networks via Gradient Centralized Convolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5516619. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Unsupervised Spectral–Spatial Feature Learning via Deep Residual Conv–Deconv Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 391–406. [Google Scholar] [CrossRef]
- Zhu, M.; Fan, J.; Yang, Q.; Chen, T. SC-EADNet: A Self-Supervised Contrastive Efficient Asymmetric Dilated Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5519517. [Google Scholar] [CrossRef]
- Liu, B.; Yu, A.; Yu, X.; Wang, R.; Gao, K.; Guo, W. Deep Multiview Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7758–7772. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2290–2304. [Google Scholar] [CrossRef]
- Gao, K.; Liu, B.; Yu, X.; Qin, J.; Zhang, P.; Tan, X. Deep Relation Network for Hyperspectral Image Few-Shot Classification. Remote Sens. 2020, 12, 923. [Google Scholar] [CrossRef]
- Gao, K.; Liu, B.; Yu, X.; Yu, A. Unsupervised Meta Learning with Multiview Constraints for Hyperspectral Image Small Sample Set Classification. IEEE Trans. Image Process. 2022, 31, 3449–3462. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Li, N.; Zhao, H.; Jia, G. Dimensional reduction method based on factor analysis model for hyperspectral data. J. Image Graph. 2011, 16, 2030–2035. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Gao, Z.; Wu, Y.; Zhang, X.; Dai, J.; Jia, Y.; Harandi, M. Revisiting Bilinear Pooling: A Coding Perspective. In Proceedings of the AAAI 2020—34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; Volume 34, pp. 3954–3961. [Google Scholar]
- Kong, S.; Fowlkes, C. Low-Rank Bilinear Pooling for Fine-Grained Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7025–7034. [Google Scholar]
- Xue, Z.; Zhang, M. Multiview Low-Rank Hybrid Dilated Network for SAR Target Recognition Using Limited Training Samples. IEEE Access 2020, 8, 227847–227856. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Roy, S.K.; Manna, S.; Song, T.; Bruzzone, L. Attention-Based Adaptive Spectral–Spatial Kernel ResNet for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7831–7843. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Output Shape | Kernel Size | Filters or Other Parameter | |
|---|---|---|---|---|
| Input | (15, 15, 16, 1) | |||
| Stage 1: Spatial–spectral feature learning | 3D-Conv-BN-Relu | (15, 15, 16, 16) | (3, 3, 3) | 16 |
| LA-3D-Conv | (15, 15, 16, 16) | (7, 7, 1) × 2 (1, 1, 1) × 1 | 16 × 2 1 | |
| Residual structure and BN layer | (15, 15, 16, 16) | |||
| Stage 2: Spatial–spectral feature learning | 3D-Conv-BN-Relu | (15, 15, 16, 16) | (3, 3, 3) | 16 |
| LA-3D-Conv | (15, 15, 16, 16) | (7, 7, 1) × 2 (1, 1, 1) × 1 | 16 × 2 1 | |
| Residual structure and BN layer | (15, 15, 16, 16) | |||
| Stage 3: Complementary position information embedding | Reshape | (15, 15, 256) | ||
| Coordinate attention | (15, 15, 256) | (1, 1) × 3 | 64, 256, 256 | |
| Residual structure and BN layer | (15, 15, 256) | |||
| Multi-stage fusion | Concatenation (Stage 1 and Stage2 also reshaped) | (15, 15, 768) | ||
| Stage 4: Low-rank constrained classification based on second-order features | Sep-Conv-BN-Relu | (15, 15, 64) | (3, 3) | 64 |
| Reshape | (225, 64) | |||
| Second-order pooling | (64, 64) | |||
| L2 normalization | (64, 64) | |||
| Low-rank constrained classification layer | Number of classes | rank = 16 | ||
| Parameter number: 157,826 (takes IP dataset as an example) | ||||
| IP | PC | Houston | WHU | |
|---|---|---|---|---|
| Spectral Range (μm) | 0.4–2.5 | 0.43–0.86 | 0.38–1.05 | 0.4–1.0 |
| Number of Bands | 200 | 102 | 144 | 270 |
| Data Size | 145 × 145 | 1096 × 715 | 349 × 1905 | 940 × 475 |
| Spatial Resolution (m) | 20 | 1.3 | 2.5 | 0.043 |
| Number of Classes | 16 | 9 | 15 | 22 |
| Number of Labeled Data | 10,249 | 148,152 | 15,029 | 386,693 |
| Number of Training Data | 80 | 45 | 75 | 110 |
| No. | Residual CNN | Attention-Based CNN | Transformer Models | Proposed | |||
|---|---|---|---|---|---|---|---|
| R- HybridSN | MSSFN | A2S2K- ResNet | AD- HybridSN | SSFTT | SPRLT | LAMFN | |
| 1 | 96.10 | 99.76 | 96.34 | 98.05 | 98.29 | 96.83 | 98.78 |
| 2 | 50.39 | 69.28 | 40.77 | 54.34 | 49.09 | 59.72 | 64.40 |
| 3 | 48.62 | 67.14 | 48.17 | 69.02 | 56.28 | 60.40 | 66.02 |
| 4 | 80.43 | 93.45 | 81.42 | 82.24 | 90.39 | 93.06 | 90.95 |
| 5 | 75.25 | 82.43 | 69.27 | 76.46 | 75.67 | 81.80 | 83.37 |
| 6 | 92.87 | 96.47 | 88.84 | 94.44 | 92.76 | 95.90 | 96.72 |
| 7 | 100.00 | 100.00 | 99.13 | 100.00 | 100.00 | 100.00 | 99.57 |
| 8 | 96.00 | 98.20 | 86.17 | 95.52 | 95.50 | 92.09 | 99.70 |
| 9 | 100.00 | 99.33 | 99.33 | 100.00 | 100.00 | 98.67 | 100.00 |
| 10 | 63.42 | 69.60 | 56.85 | 55.18 | 72.03 | 68.79 | 74.01 |
| 11 | 55.03 | 63.98 | 45.03 | 47.78 | 57.29 | 54.36 | 67.36 |
| 12 | 53.74 | 67.11 | 52.13 | 47.79 | 49.88 | 66.89 | 80.43 |
| 13 | 99.65 | 99.55 | 97.90 | 99.25 | 98.50 | 99.35 | 98.55 |
| 14 | 81.13 | 95.02 | 84.69 | 84.65 | 84.38 | 89.32 | 93.01 |
| 15 | 76.30 | 92.41 | 79.97 | 79.48 | 82.26 | 92.34 | 86.90 |
| 16 | 98.64 | 98.86 | 96.93 | 96.82 | 90.91 | 99.32 | 98.30 |
| Kappa | 62.32 ± 2.53 | 74.58 ± 3.21 | 57.05 ± 6.73 | 62.62 ± 2.85 | 64.86 ± 3.64 | 68.70 ± 2.49 | 75.41 ± 3.44 |
| OA | 66.34 ± 2.42 | 77.33 ± 2.89 | 61.35 ± 6.28 | 66.40 ± 2.79 | 68.68 ± 3.46 | 71.95 ± 2.37 | 78.15 ± 3.14 |
| AA | 79.22 ± 1.44 | 87.04 ± 1.59 | 76.43 ± 5.32 | 80.06 ± 1.92 | 80.83 ± 1.93 | 84.30 ± 1.13 | 87.38 ± 1.55 |
| No. | Residual CNN | Attention-Based CNN | Transformer Models | Proposed | |||
|---|---|---|---|---|---|---|---|
| R- HybridSN | MSSFN | A2S2K- ResNet | AD- HybridSN | SSFTT | SPRLT | LAMFN | |
| 1 | 98.00 | 99.40 | 99.14 | 99.52 | 98.37 | 99.16 | 99.60 |
| 2 | 79.98 | 84.07 | 84.66 | 84.61 | 81.79 | 84.58 | 84.73 |
| 3 | 87.49 | 81.90 | 96.05 | 87.06 | 88.28 | 83.06 | 88.96 |
| 4 | 86.09 | 98.61 | 93.13 | 97.93 | 95.81 | 72.31 | 95.24 |
| 5 | 80.53 | 82.87 | 88.70 | 84.80 | 88.93 | 85.93 | 90.47 |
| 6 | 86.43 | 91.71 | 96.06 | 93.88 | 83.48 | 87.62 | 98.41 |
| 7 | 90.03 | 91.08 | 83.36 | 91.08 | 91.09 | 87.93 | 89.72 |
| 8 | 94.52 | 98.38 | 96.77 | 96.79 | 98.64 | 95.71 | 98.78 |
| 9 | 77.07 | 86.12 | 98.03 | 88.44 | 92.01 | 91.89 | 91.59 |
| Kappa | 90.69 ± 2.55 | 94.44 ± 1.82 | 94.49 ± 1.71 | 94.42 ± 1.28 | 93.68 ± 1.64 | 92.40 ± 2.78 | 96.01 ± 0.84 |
| OA | 93.34 ± 1.91 | 96.06 ± 1.30 | 96.09 ± 1.23 | 96.04 ± 0.92 | 95.51 ± 1.17 | 94.59 ± 2.03 | 97.18 ± 0.60 |
| AA | 86.68 ± 1.07 | 90.46 ± 2.85 | 92.88 ± 1.47 | 91.57 ± 1.45 | 90.93 ± 2.12 | 87.58 ± 3.64 | 93.05 ± 1.12 |
| No. | Residual CNN | Attention-Based CNN | Transformer Models | Proposed | |||
|---|---|---|---|---|---|---|---|
| R- HybridSN | MSSFN | A2S2K- ResNet | AD- HybridSN | SSFTT | SPRLT | LAMFN | |
| 1 | 72.05 | 84.91 | 82.10 | 77.44 | 76.37 | 86.93 | 86.89 |
| 2 | 78.49 | 84.45 | 78.59 | 81.68 | 81.00 | 80.32 | 83.96 |
| 3 | 91.45 | 98.03 | 88.15 | 97.12 | 98.24 | 99.54 | 98.37 |
| 4 | 79.48 | 88.35 | 90.66 | 81.44 | 81.32 | 86.19 | 90.40 |
| 5 | 89.30 | 92.78 | 79.89 | 96.98 | 98.01 | 99.69 | 98.48 |
| 6 | 88.38 | 85.09 | 77.03 | 88.38 | 88.22 | 93.47 | 86.97 |
| 7 | 41.76 | 70.89 | 62.91 | 67.17 | 66.80 | 56.35 | 71.10 |
| 8 | 52.46 | 52.97 | 45.81 | 49.50 | 42.99 | 58.07 | 54.87 |
| 9 | 47.89 | 69.03 | 59.37 | 61.11 | 50.22 | 37.67 | 67.64 |
| 10 | 58.36 | 76.38 | 41.87 | 63.53 | 62.12 | 62.52 | 73.40 |
| 11 | 57.83 | 73.72 | 47.46 | 70.67 | 74.19 | 64.67 | 84.37 |
| 12 | 68.45 | 74.90 | 45.82 | 71.95 | 65.13 | 57.56 | 73.08 |
| 13 | 87.78 | 82.50 | 90.91 | 94.70 | 90.60 | 67.89 | 92.72 |
| 14 | 100.00 | 100.00 | 97.07 | 99.93 | 99.76 | 100.00 | 100.00 |
| 15 | 99.05 | 96.41 | 92.41 | 99.88 | 98.09 | 99.53 | 96.05 |
| Kappa | 67.18 ± 1.90 | 78.04 ± 2.19 | 65.47 ± 3.94 | 74.50 ± 2.95 | 72.20 ± 2.46 | 70.97 ± 2.09 | 79.84 ± 2.82 |
| OA | 69.56 ± 1.77 | 79.68 ± 2.03 | 68.01 ± 3.63 | 76.35 ± 2.75 | 74.26 ± 2.29 | 73.11 ± 1.95 | 81.35 ± 2.61 |
| AA | 74.18 ± 1.49 | 82.03 ± 1.69 | 72.00 ± 3.77 | 80.10 ± 2.31 | 78.20 ± 1.90 | 76.69 ± 1.71 | 83.89 ± 2.17 |
| No. | Residual CNN | Attention-Based CNN | Transformer Models | Proposed | |||
|---|---|---|---|---|---|---|---|
| R- HybridSN | MSSFN | A2S2K- ResNet | AD- HybridSN | SSFTT | SPRLT | LAMFN | |
| 1 | 83.77 | 75.44 | 73.07 | 80.63 | 82.23 | 81.02 | 85.62 |
| 2 | 57.62 | 75.88 | 68.98 | 80.79 | 71.03 | 67.99 | 73.99 |
| 3 | 75.19 | 81.19 | 81.64 | 75.22 | 83.52 | 77.88 | 83.27 |
| 4 | 86.41 | 94.92 | 69.54 | 91.49 | 84.56 | 79.06 | 95.71 |
| 5 | 60.50 | 93.54 | 68.35 | 86.23 | 78.71 | 74.74 | 92.79 |
| 6 | 90.24 | 93.03 | 86.38 | 89.97 | 89.12 | 78.05 | 93.61 |
| 7 | 51.49 | 66.98 | 40.20 | 63.94 | 46.70 | 42.38 | 68.29 |
| 8 | 60.11 | 62.97 | 37.14 | 66.06 | 58.84 | 28.80 | 56.19 |
| 9 | 93.01 | 92.89 | 90.29 | 92.75 | 90.60 | 92.36 | 94.21 |
| 10 | 42.60 | 83.75 | 65.16 | 66.84 | 47.48 | 52.29 | 80.02 |
| 11 | 57.00 | 73.57 | 46.42 | 59.18 | 43.88 | 26.08 | 74.74 |
| 12 | 44.28 | 74.67 | 60.33 | 52.24 | 49.06 | 52.68 | 73.47 |
| 13 | 43.62 | 57.55 | 52.50 | 52.48 | 49.24 | 44.83 | 62.05 |
| 14 | 77.41 | 83.49 | 71.25 | 88.72 | 65.27 | 60.21 | 86.35 |
| 15 | 96.04 | 99.71 | 91.35 | 95.88 | 98.77 | 86.61 | 98.01 |
| 16 | 84.32 | 95.58 | 82.85 | 86.34 | 89.98 | 76.09 | 95.13 |
| 17 | 86.42 | 90.99 | 77.52 | 77.88 | 83.36 | 69.19 | 89.62 |
| 18 | 91.74 | 97.83 | 87.08 | 95.80 | 89.78 | 58.14 | 95.87 |
| 19 | 82.70 | 92.61 | 78.80 | 87.64 | 73.48 | 47.68 | 85.53 |
| 20 | 80.82 | 95.99 | 77.49 | 88.50 | 59.88 | 79.99 | 93.66 |
| 21 | 75.28 | 97.43 | 78.16 | 89.52 | 83.08 | 67.69 | 97.30 |
| 22 | 76.49 | 94.62 | 86.33 | 86.78 | 85.59 | 87.03 | 94.14 |
| Kappa | 71.88 ± 2.62 | 83.84 ± 2.12 | 64.27 ± 4.13 | 78.47 ± 2.69 | 71.16 ± 3.98 | 64.05 ± 5.56 | 84.90 ± 1.82 |
| OA | 77.06 ± 2.23 | 87.04 ± 1.79 | 69.71 ± 3.98 | 82.61 ± 2.26 | 76.38 ± 3.68 | 70.07 ± 5.17 | 87.93 ± 1.49 |
| AA | 72.59 ± 2.28 | 85.21 ± 1.29 | 71.40 ± 2.74 | 79.77 ± 2.71 | 72.92 ± 1.44 | 65.03 ± 3.59 | 84.98 ± 1.31 |
| Model | R- HybridSN | MSSFN | A2S2K- ResNet | AD- HybridSN | SSFTT | SPRLT | LAMFN |
|---|---|---|---|---|---|---|---|
| Input size | 15 × 15 × 16 | 15 × 15 × 16 | 9 × 9 × 200 | 15 × 15 × 16 | 13 × 13 × 30 | 9 × 9 × 200 | 15 × 15 × 16 |
| Parameter | 719,112 | 159,012 | 373,184 | 366,662 | 148,488 | 839,728 | 157,826 |
| Training Time (s) | 16.6 | 24.8 | 341.4 | 20.0 | 3.0 | 239.3 | 29.1 |
| Testing Time (s) | 49.2 | 60.7 | 116.0 | 76.5 | 16.9 | 184.0 | 103.9 |
| Model | Description | IP | PC | Houston | WHU |
|---|---|---|---|---|---|
| LAMFN | proposed | 78.15 | 97.18 | 81.35 | 87.93 |
| C1 | Replacing FA with PCA | 74.74 | 97.27 | 81.14 | 84.36 |
| C2 | Replacing LA-3D-Conv with residual 3D-Conv | 77.07 | 96.98 | 80.23 | 87.02 |
| C3 | Without CA | 77.06 | 97.05 | 80.94 | 86.96 |
| C4 | Replacing LRSOP with GAP | 77.39 | 95.66 | 79.01 | 87.67 |
| C5 | Replacing LRSOP with SOP | 77.35 | 96.99 | 80.87 | 86.56 |
| Band | IP | PC | Houston | WHU | ||||
|---|---|---|---|---|---|---|---|---|
| FA | PCA | FA | PCA | FA | PCA | FA | PCA | |
| 12 | 77.70 | 72.62 | 97.18 | 97.27 | 81.18 | 80.31 | 87.27 | 84.08 |
| 16 | 78.15 | 74.74 | 97.18 | 97.27 | 81.35 | 81.14 | 87.93 | 84.36 |
| 20 | 77.63 | 71.87 | 96.86 | 97.24 | 81.77 | 80.89 | 86.80 | 83.80 |
| 24 | 78.07 | 73.00 | 97.07 | 96.83 | 80.59 | 81.16 | 87.06 | 84.16 |
| 28 | 77.41 | 72.47 | 96.94 | 96.56 | 80.49 | 79.87 | 86.73 | 86.14 |
| 12 | 16 | 20 | 24 | 28 | |
|---|---|---|---|---|---|
| PCA | 3.0 | 3.0 | 3.7 | 5.0 | 4.0 |
| FA | 34.8 | 31.0 | 49.0 | 64.8 | 63.9 |
| Model | IP | PC | Houston |
|---|---|---|---|
| LAMFN | 78.15 | 97.18 | 81.35 |
| DFSL | 63.11 | 94.90 | 69.29 |
| DMVL | 78.01 | 78.55 | |
| UM2L | 72.09 | 94.27 | |
| SC-EADNet | 82.69 | 80.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, F.; Zhang, Y.; Zhang, J.; Liu, B. Low-Rank Constrained Attention-Enhanced Multiple Spatial–Spectral Feature Fusion for Small Sample Hyperspectral Image Classification. Remote Sens. 2023, 15, 304. https://doi.org/10.3390/rs15020304
Feng F, Zhang Y, Zhang J, Liu B. Low-Rank Constrained Attention-Enhanced Multiple Spatial–Spectral Feature Fusion for Small Sample Hyperspectral Image Classification. Remote Sensing. 2023; 15(2):304. https://doi.org/10.3390/rs15020304
Chicago/Turabian StyleFeng, Fan, Yongsheng Zhang, Jin Zhang, and Bing Liu. 2023. "Low-Rank Constrained Attention-Enhanced Multiple Spatial–Spectral Feature Fusion for Small Sample Hyperspectral Image Classification" Remote Sensing 15, no. 2: 304. https://doi.org/10.3390/rs15020304
APA StyleFeng, F., Zhang, Y., Zhang, J., & Liu, B. (2023). Low-Rank Constrained Attention-Enhanced Multiple Spatial–Spectral Feature Fusion for Small Sample Hyperspectral Image Classification. Remote Sensing, 15(2), 304. https://doi.org/10.3390/rs15020304