






An Improved S2A-Net Algorithm for Ship Object Detection in Optical Remote Sensing Images

 , , and
, , and
Abstract
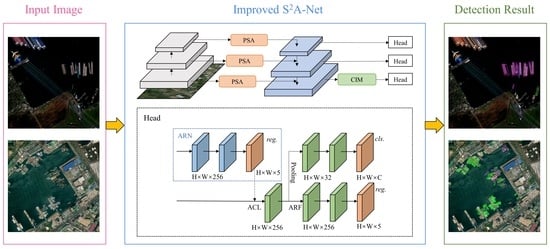
:
1. Introduction
- (1)
- On the basis of origin S2A-Net, pyramid squeeze attention is embedded in order to accentuate salient features within the images, which empowers the network to more effectively discern critical information within input data, thereby substantially bolstering its overall performance.
- (2)
- The context information module was meticulously devised to augment the network’s proficiency in comprehending contextual intricacies, thereby bolstering the neural network’s task comprehension and enabling it to better handle remote sensing image detection tasks.
- (3)
- An image weight sampling strategy is proposed, which can improve the training opportunities for small and difficult samples, so as to alleviate the problem of unbalanced distribution of ship categories to a certain extent.
2. Datasets
3. Methodology
3.1. S2A-Net Algorithm
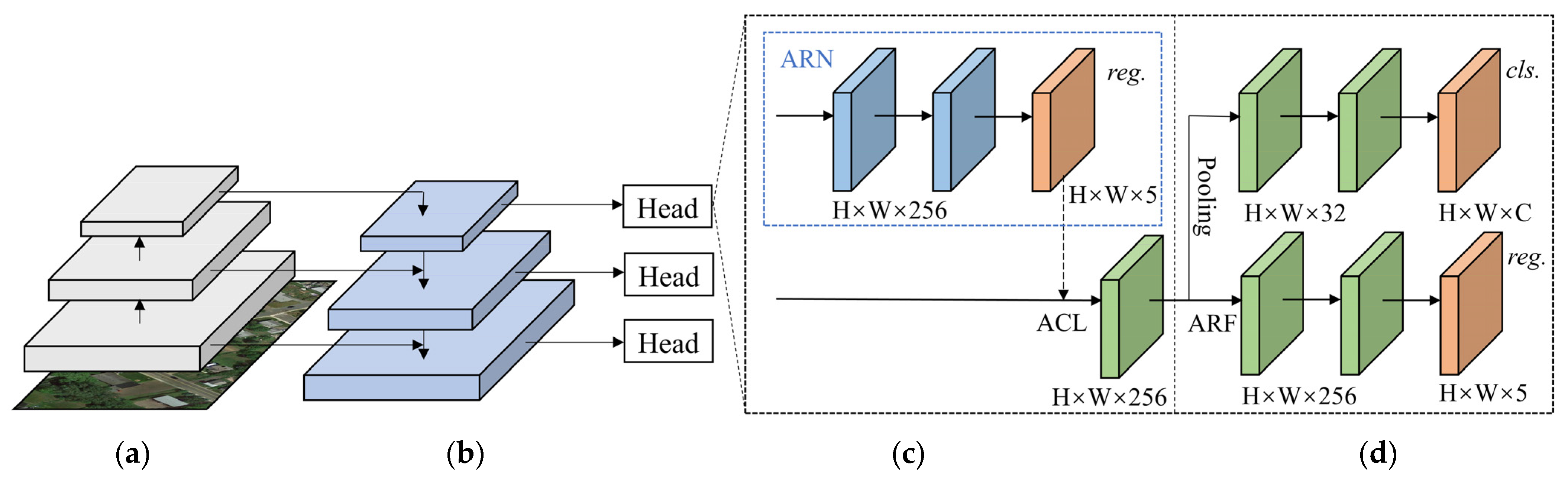
3.2. Improved Network Structure
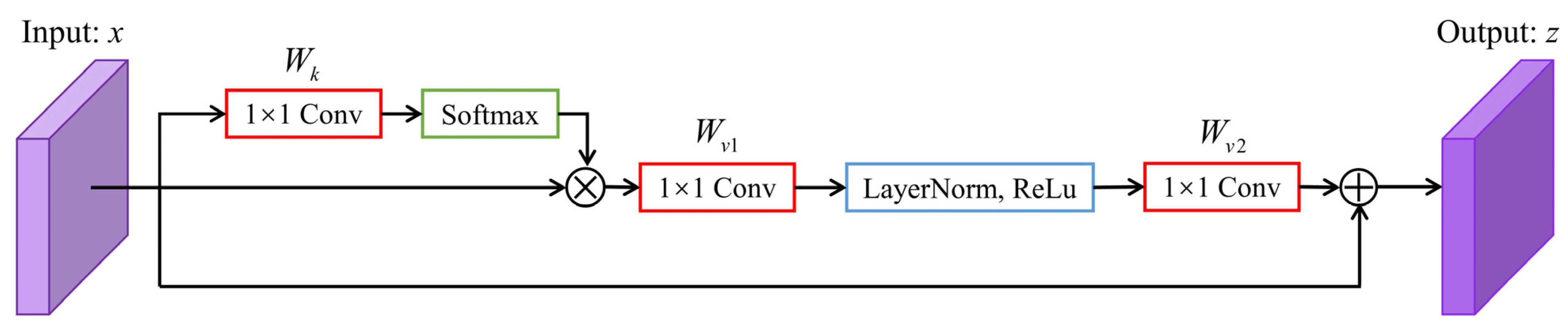
3.2.1. Pyramid Squeeze Attention (PSA)
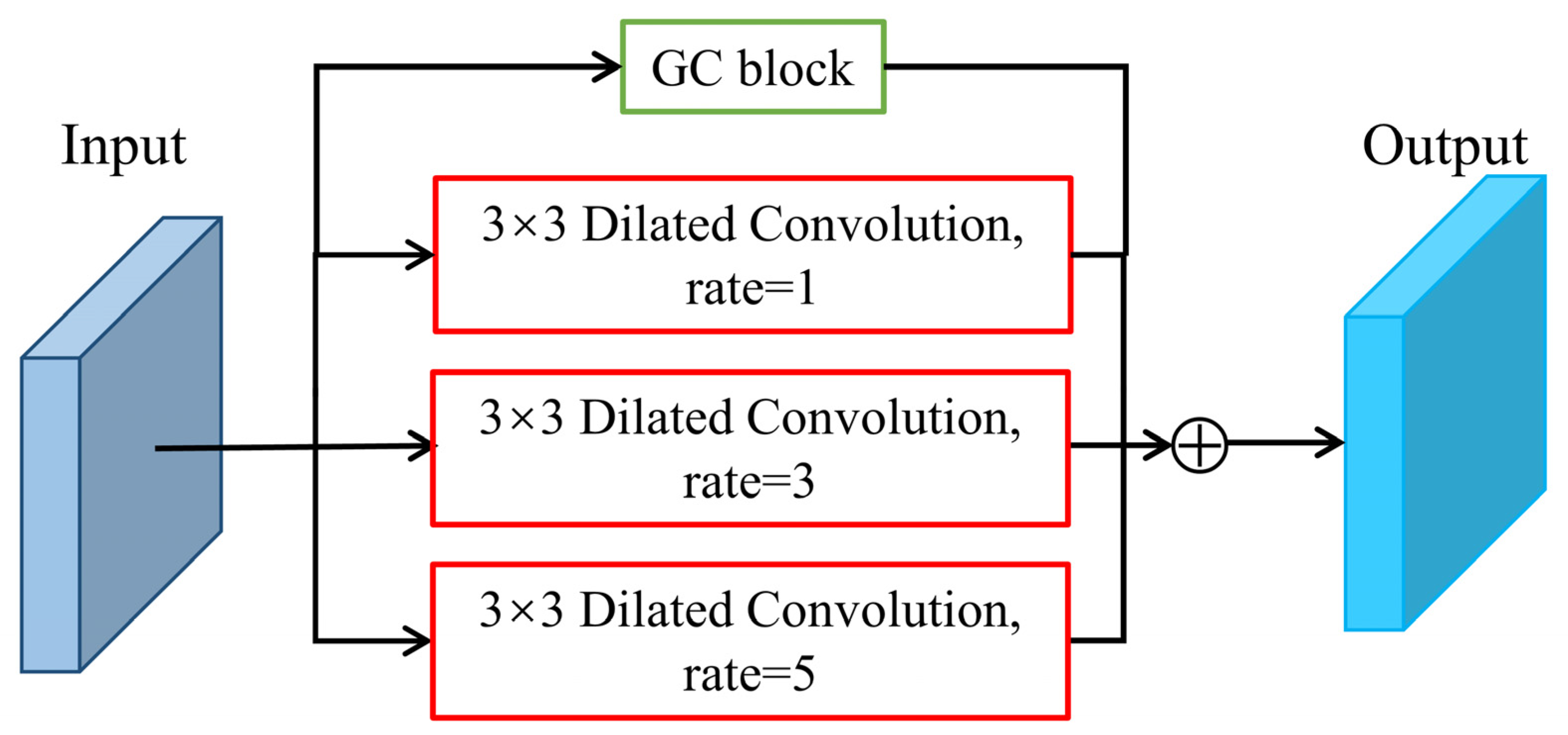
3.2.2. Context Information Module (CIM)
3.3. Improved Training Strategy
3.3.1. Remote Sensing Image Dehazing
3.3.2. Image Weights Sampling Strategy
4. Results and Discussion
4.1. Evaluation Metric
4.2. Remote Sensing Image Dehazing Experiment
4.3. Ablation Study of Ship Detection
4.4. Discussions of Model Parameter Setting
4.4.1. The Setting of the Convolution Kernel Size of PSA
4.4.2. CIM Ablation Study
4.4.3. The Calculation Form of ci in Image Weights Sampling Strategy
4.5. Detection Results and Comparisons
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, F.; Liu, J.; Sun, H.; Wang, T.; Wang, X. Research Progress on Vessel Detection Using Optical Remote Sensing Image. Opt. Precis. Eng. 2021, 29, 916–931. [Google Scholar] [CrossRef]
- Pegler, K.; Coleman, D.; Zhang, Y.; Pelot, R. The Potential for Using Very High Spatial Resolution Imagery for Marine Search and Rescue Surveillance. Geocarto Int. 2003, 18, 35–39. [Google Scholar] [CrossRef]
- Bouma, H.; Dekker, R.; Schoemaker, R.; Mohamoud, A. Segmentation and Wake Removal of Seafaring Vessels in Optical Satellite Images. In Proceedings of the Electro-Optical Remote Sensing, Photonic Technologies, and Applications VII, and Military Applications in Hyperspectral Imaging and High Spatial Resolution Sensing, Dresden, Germany, 15 October 2013. [Google Scholar] [CrossRef]
- Arguedas, V. Texture-based Vessel Classifier for Electro-optical Satellite Imagery. In Proceedings of the IEEE International Conference on Image Processing, Quebec, QC, Canada, 27–30 September 2015. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot MultiBox Detector. arXiv 2015. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X. HSF-Net: Multiscale Deep Feature Embedding for Ship Detection in Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning Roi Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined Single-stage Detector with Feature Refinement for Rotating Object. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602511. [Google Scholar] [CrossRef]
- Zhou, Y.; Ye, Q.; Qiu, Q.; Jiao, J. Oriented Response Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing Plain Vision Transformer Toward Remote Sensing Foundation Model. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5607315. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. arXiv 2023. [Google Scholar] [CrossRef]
- Pu, Y.; Wang, Y.; Xia, Z.; Han, Y.; Wang, Y.; Gan, W.; Wang, Z.; Song, S.; Huang, G. Adaptive Rotated Convolution for Rotated Object Detection. arXiv 2023. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-resolution Remote Sensing Imagery. ISPRS-J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local Networks Meet Squeeze-excitation Networks and Beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, C.; Liu, R.; Zhang, L.; Guo, X.; Tao, D. Self-augmented Unpaired Image Dehazing via Density and Depth Decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Boat Types Recognition|Kaggle. Available online: https://www.kaggle.com/datasets/clorichel/boat-types-recognition?resource=download (accessed on 30 April 2023).
- Mittal, A.; Soundararajan, R.; Bovik, A. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Choi, L.; You, J.; Bovik, A. Referenceless Prediction of Perceptual Fog Density and Perceptual Image Defogging. IEEE Trans. Image Process 2015, 24, 3888–3901. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-stage Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S. Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking Rotated Object Detection with Gaussian Wasserstein Distance Loss. arXiv 2021. [Google Scholar] [CrossRef]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning High-precision Bounding Box for Rotated Object Detection via Kullback-leibler Divergence. arXiv 2021. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Ps | Mb | Fb | Tb | Es | Lc | Dc | Ws | Os | |
|---|---|---|---|---|---|---|---|---|---|---|
| Training set | Number | 792 | 7434 | 4791 | 1472 | 1485 | 3428 | 10,627 | 761 | 2314 |
| Proportion | 2.2% | 22.5% | 14.5% | 4.5% | 4.5% | 10.4% | 32.1% | 2.3% | 7.0% | |
| Testing set | Number | 121 | 1393 | 1061 | 250 | 300 | 602 | 1962 | 101 | 601 |
| Proportion | 1.9% | 21.8% | 16.6% | 3.9% | 4.7% | 9.4% | 30.7% | 1.6% | 9.4% | |
| Training Set (before Dehazing) | Training Set (after Dehazing) | Testing Set (before Dehazing) | Testing Set (after Dehazing) | |
|---|---|---|---|---|
| NIQE | 11.15 | 10.37 | 10.06 | 9.15 |
| FADE | 0.84 | 0.45 | 0.63 | 0.33 |
| S2A-Net | PSA | CIM | D4 Image Dehazing | Image Weights Sampling | mAP/% |
|---|---|---|---|---|---|
| √ | 71.67 | ||||
| √ | √ | 72.84 | |||
| √ | √ | √ | 74.47 | ||
| √ | √ | √ | √ | 74.73 | |
| √ | √ | √ | √ | √ | 77.27 |
| Ps | Mb | Fb | Tb | Es | Lc | Dc | Ws | Os | mAP/% | |
|---|---|---|---|---|---|---|---|---|---|---|
| S2A-Net | 63.8 | 72.0 | 58.3 | 76.1 | 78.4 | 86.8 | 87.0 | 84.6 | 38.0 | 71.67 |
| Improved S2A-Net | 68.3 | 86.9 | 74.6 | 76.6 | 80.4 | 89.1 | 88.6 | 76.9 | 54.2 | 77.27 |
| Ps | Mb | Fb | Tb | Es | Lc | Dc | Ws | Os | mAP/% | |
|---|---|---|---|---|---|---|---|---|---|---|
| First | 66.8 | 73.7 | 60.6 | 78.9 | 82.4 | 88.6 | 88.1 | 85.1 | 49.9 | 74.89 |
| Second | 67.7 | 73.2 | 60.0 | 77.7 | 84.3 | 88.8 | 87.9 | 83.7 | 48.0 | 74.60 |
| Third | 67.8 | 73.2 | 61.6 | 79.1 | 85.0 | 89.0 | 87.8 | 82.3 | 46.8 | 74.73 |
| Ps | Mb | Fb | Tb | Es | Lc | Dc | Ws | Os | mAP/% | |
|---|---|---|---|---|---|---|---|---|---|---|
| (1, 3, 5, 7) | 65.7 | 67.8 | 53.9 | 74.3 | 74.5 | 86.1 | 86.9 | 83.7 | 38.5 | 70.16 |
| (5, 7, 9, 11) | 67.9 | 65.8 | 57.0 | 74.1 | 76.9 | 86.6 | 87.2 | 84.4 | 42.8 | 71.41 |
| (3, 5, 7, 9) | 63.0 | 73.0 | 60.7 | 76.1 | 77.5 | 87.5 | 87.9 | 84.8 | 45.1 | 72.84 |
| S2A-Net + PSA | GC Block | Dilated Convolution | mAP/% |
|---|---|---|---|
| √ | 72.84 | ||
| √ | √ | 72.92 | |
| √ | √ | 73.24 | |
| √ | √ | √ | 74.47 |
| Ps | Mb | Fb | Tb | Es | Lc | Dc | Ws | Os | mAP/% | |
|---|---|---|---|---|---|---|---|---|---|---|
| 68.9 | 85.3 | 72.2 | 72.1 | 79.6 | 88.9 | 87.9 | 76.0 | 55.7 | 76.31 | |
| 67.9 | 86.5 | 73.5 | 76.9 | 78.1 | 88.9 | 88.3 | 78.1 | 55.4 | 77.08 | |
| 68.3 | 86.9 | 74.6 | 76.6 | 80.4 | 89.1 | 88.6 | 76.9 | 54.2 | 77.27 |
| Ps | Mb | Fb | Tb | Es | Lc | Dc | Ws | Os | mAP/% | |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5 | 62.1 | 60.6 | 66.5 | 70.3 | 74.6 | 88.6 | 87.7 | 80.9 | 32.6 | 69.30 |
| Cascade R-CNN | 59.7 | 50.0 | 52.6 | 62.7 | 67.5 | 78.0 | 78.6 | 67.0 | 28.9 | 60.50 |
| FCOS | 40.9 | 48.4 | 41.6 | 58.0 | 65.3 | 76.6 | 75.8 | 63.0 | 13.9 | 53.72 |
| ATSS | 48.2 | 49.9 | 44.6 | 61.5 | 66.4 | 79.0 | 82.4 | 67.4 | 15.4 | 57.19 |
| GWD | 35.0 | 58.0 | 44.4 | 65.8 | 72.3 | 73.3 | 76.0 | 51.3 | 23.1 | 55.50 |
| KLD | 40.8 | 62.7 | 46.4 | 65.4 | 71.9 | 75.0 | 74.9 | 56.0 | 24.1 | 57.44 |
| Gliding Vertex | 69.7 | 74.2 | 53.5 | 74.1 | 78.5 | 75.6 | 75.5 | 51.0 | 44.0 | 66.25 |
| Improved S2A-Net | 68.3 | 86.9 | 74.6 | 76.6 | 80.4 | 89.1 | 88.6 | 76.9 | 54.2 | 77.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Chen, M.; Hou, S.; Wang, Y.; Luo, Q.; Wang, C. An Improved S2A-Net Algorithm for Ship Object Detection in Optical Remote Sensing Images. Remote Sens. 2023, 15, 4559. https://doi.org/10.3390/rs15184559
Li J, Chen M, Hou S, Wang Y, Luo Q, Wang C. An Improved S2A-Net Algorithm for Ship Object Detection in Optical Remote Sensing Images. Remote Sensing. 2023; 15(18):4559. https://doi.org/10.3390/rs15184559
Chicago/Turabian StyleLi, Jianfeng, Mingxu Chen, Siyuan Hou, Yongling Wang, Qinghua Luo, and Chenxu Wang. 2023. "An Improved S2A-Net Algorithm for Ship Object Detection in Optical Remote Sensing Images" Remote Sensing 15, no. 18: 4559. https://doi.org/10.3390/rs15184559
APA StyleLi, J., Chen, M., Hou, S., Wang, Y., Luo, Q., & Wang, C. (2023). An Improved S2A-Net Algorithm for Ship Object Detection in Optical Remote Sensing Images. Remote Sensing, 15(18), 4559. https://doi.org/10.3390/rs15184559