







MOON: A Subspace-Based Multi-Branch Network for Object Detection in Remotely Sensed Images


Abstract
:
1. Introduction
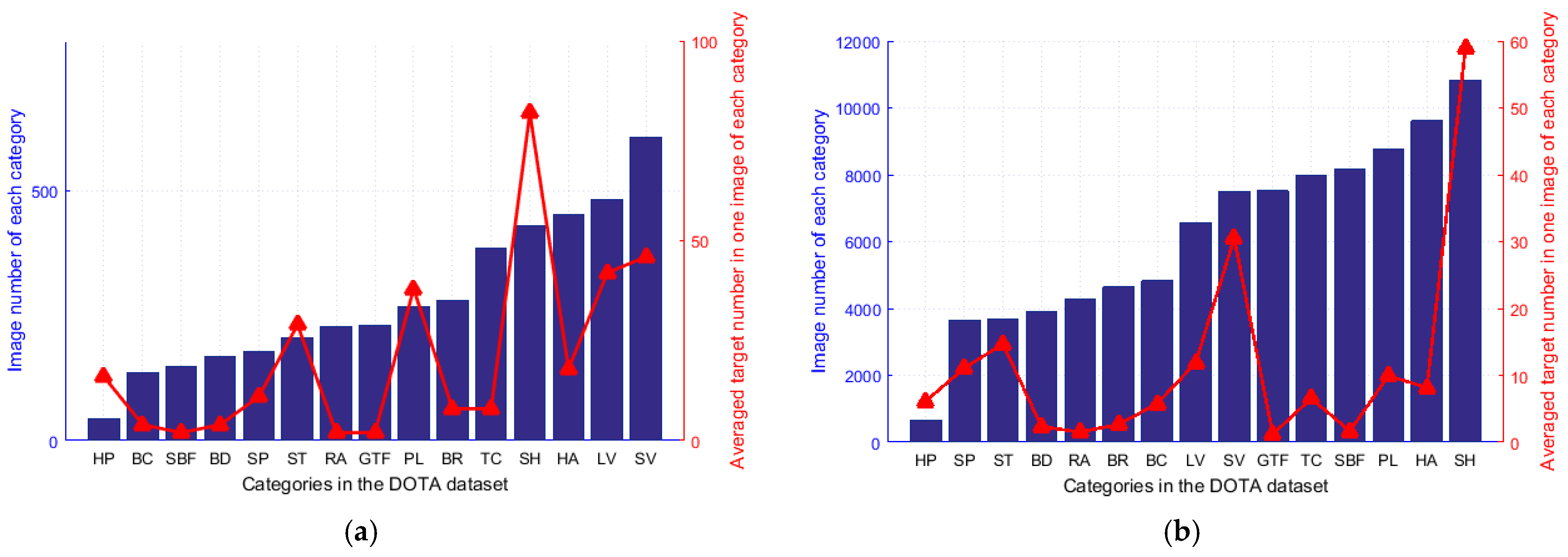
- To our best knowledge, this is the first time that the long-tail problem in object detection for remotely sensed images is focused to solve the high imbalance of sample data between different categories;
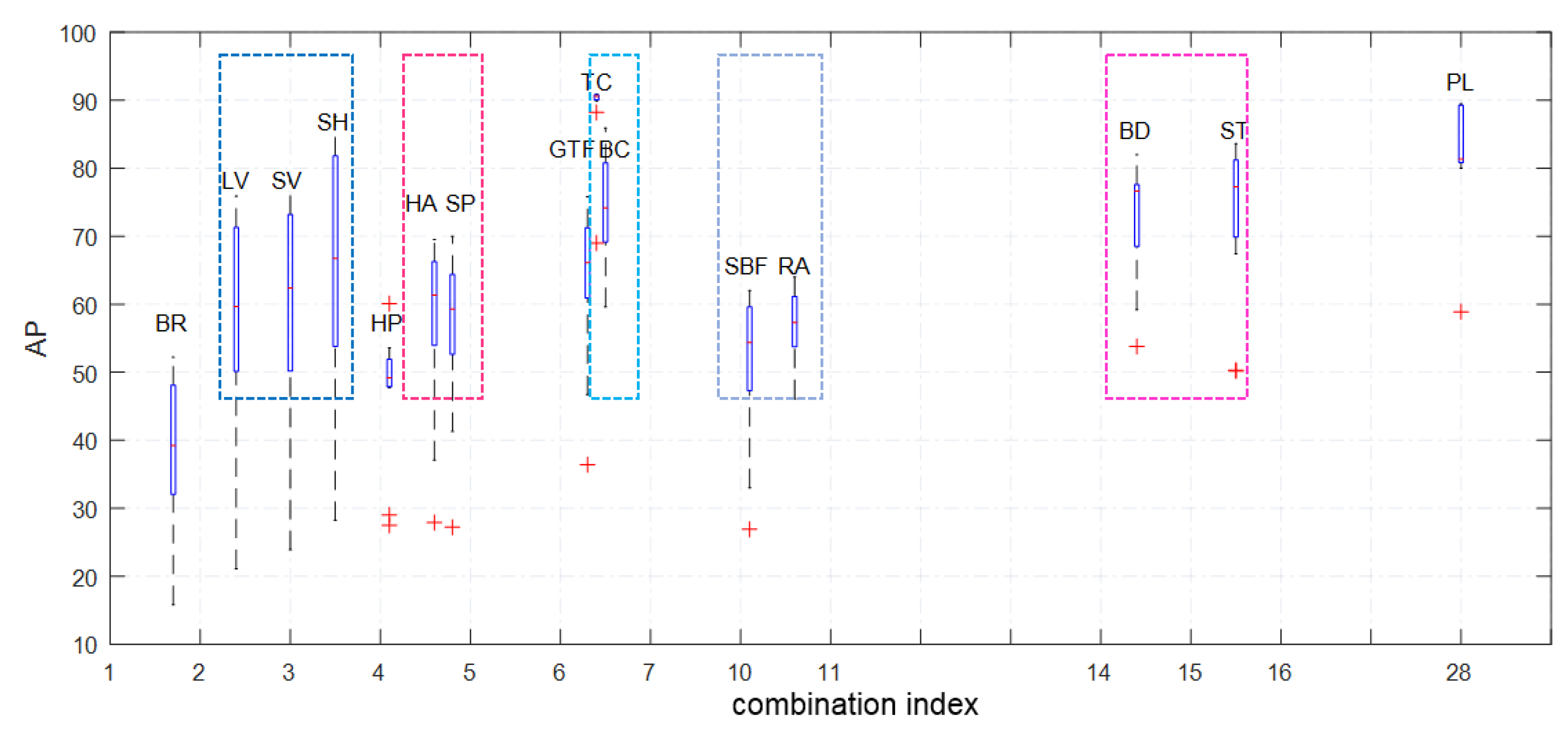
- A new framework of subspace-based object detection for remotely sensed images is proposed, in which a new combination index is defined to quantify certain similarities between different categories, and a new subspace-dividing strategy is also proposed to divide the entire sample space and balance the amounts of sample data between different subspaces;
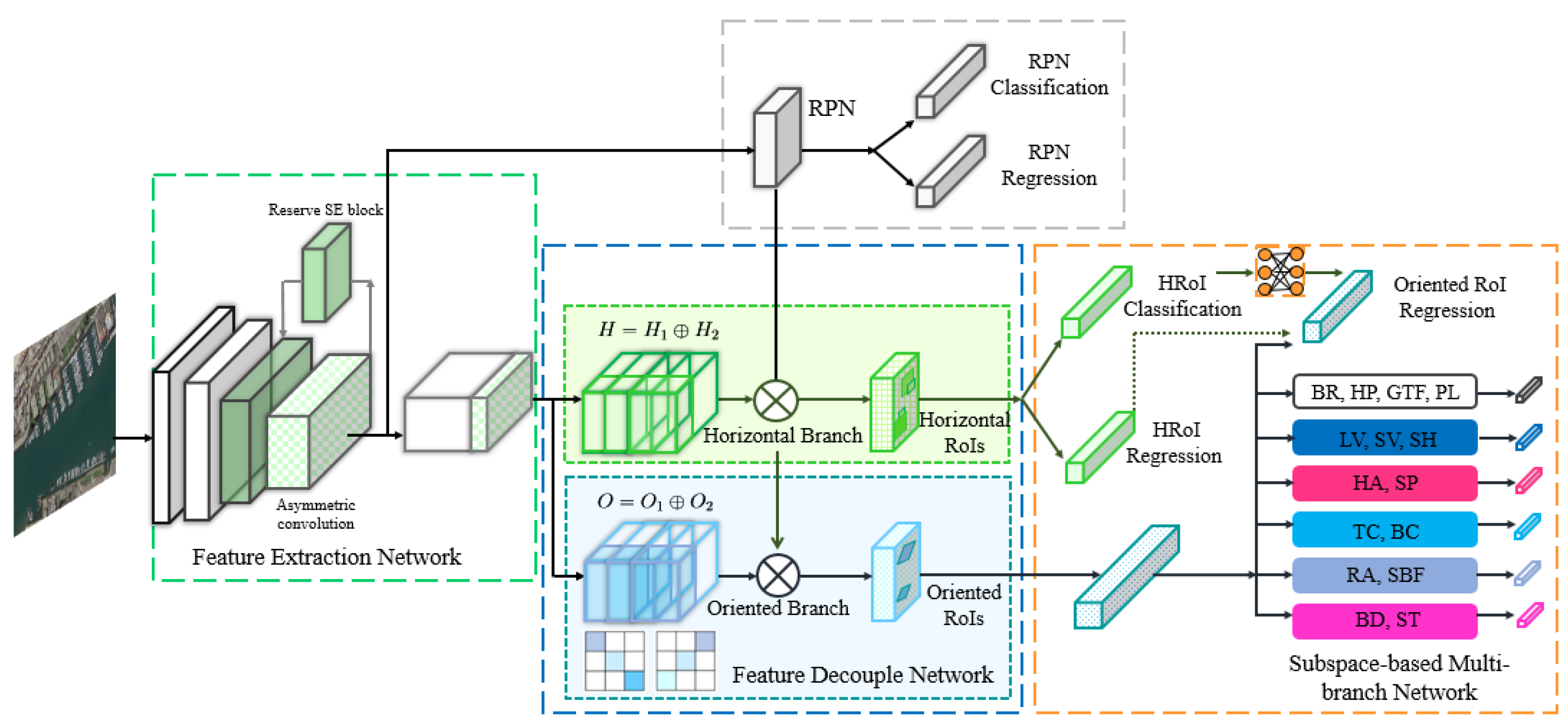
- A new subspace-based loss function is designed to account for the relationship between targets in one subspace and across different subspaces, and a subspace-based multi-branch network is constructed to ensure the subspace-aware regression, combined with a specially designed module to decouple the learning of horizontal and rotated features.
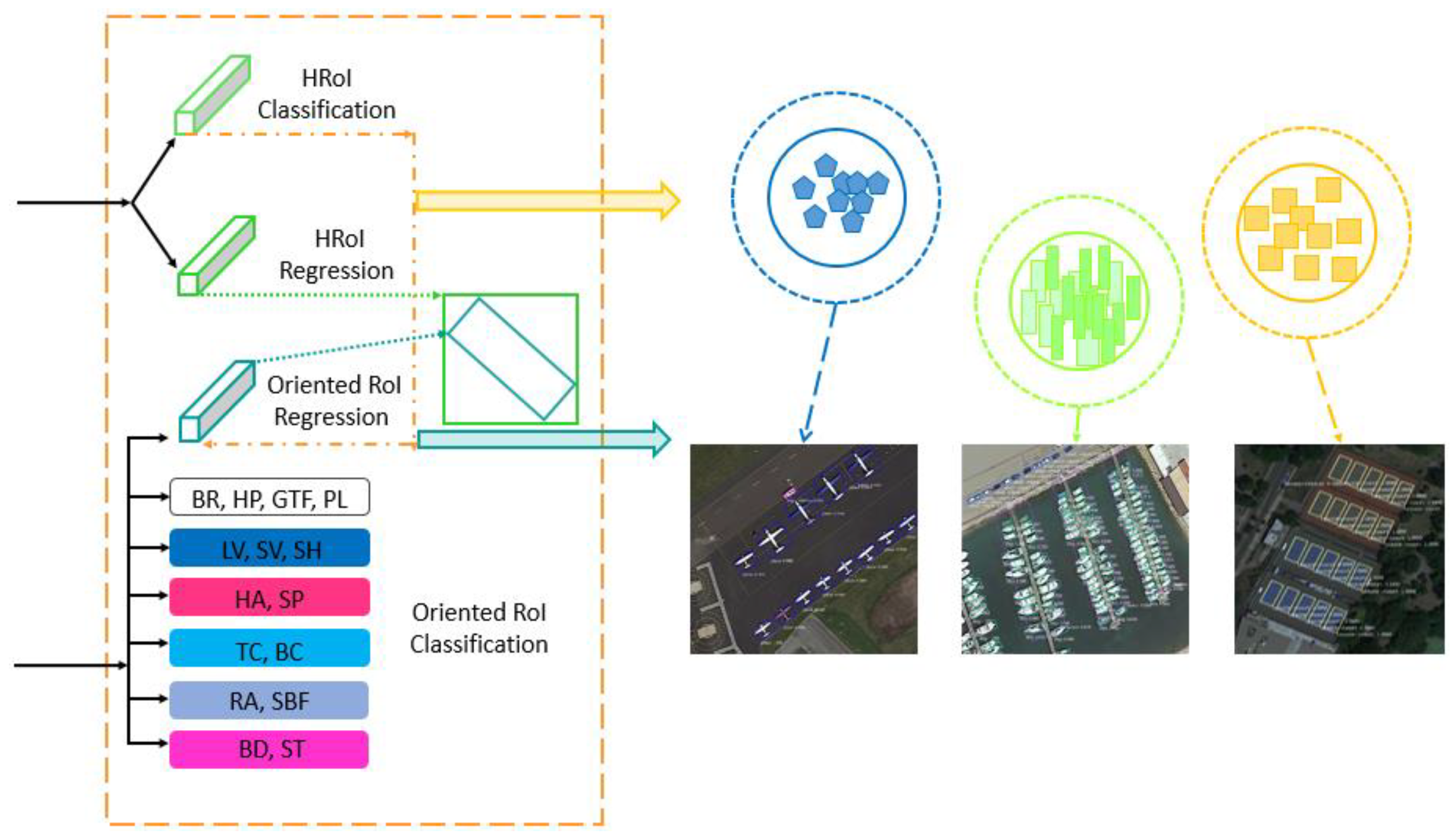
2. Proposed Method
2.1. Problem Formulation
2.2. Combination Index and Subspace Division
2.3. Subspace-Based Multi-branch Network
2.4. Subspace-Based Loss Function
3. Experiments and Discussion
3.1. Datasets and Implements
3.2. Comparison with SOTA on the DOTA Dataset
3.3. Comparision for the Long-Tail Problem
3.4. Ablation Studies
3.5. Effect of Each Part of the Multi-branch Network
3.6. Effect of Each Part of the Subspace-based Loss Function
3.7. Comparison on HRSC2016 Dataset
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot Multibox Detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-Head R-CNN: In Defense of Two-Stage Object Detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, l.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2019; pp. 150–165. [Google Scholar]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: To-wards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented Object Detection in Aerial Images with Box Boundary-aware Vectors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 2150–2159. [Google Scholar]
- Zhang, H.; Xu, Z.; Han, X.; Sun, W. Refining FFT-based Heatmap for the Detection of Cluster Distributed Targets in Satellite Images. In Proceedings of the British Machine Vision Conference, Online, 22–25 November 2021. [Google Scholar]
- Zhang, H.; Leng, W.; Han, X.; Sun, W. Category-Oriented Adversarial Data Augmentation via Statistic Similarity for Satellite Images. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision, Shenzhen, China, 14–17 October 2022; Springer: Cham, Switzerland, 2022; pp. 473–483. [Google Scholar]
- Dai, L.; Liu, H.; Tang, H.; Wu, Z.; Song, P. Ao2-detr: Arbitrary-oriented Object Detection Transformer. In IEEE Transactions on Circuits and Systems for Video Technology; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Zhang, Y.; Liu, X.; Wa, S.; Chen, S.; Ma, Q. Gansformer: A Detection Network for Aerial Images with High Performance Combining Convolutional Network and Transformer. Remote Sens. 2022, 14, 923. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Y.; Zeng, Y. Transformer with Transfer CNN for Remote-Sensing-Image Object Detection. Remote Sens. 2022, 14, 984. [Google Scholar] [CrossRef]
- Liu, X.; Ma, S.; He, L.; Wang, C.; Chen, Z. Hybrid Network Model: Transconvnet for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 2090. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, Z.; Han, X.; Sun, W. Data Augmentation Using Bitplane Information Recombination Model. IEEE Trans. Image Process. 2022, 31, 3713–3725. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; p. 11. [Google Scholar]
- Wang, M.; Yu, J.; Xue, J.H.; Sun, W. Denoising of Hyperspectral Images Using Group Low-Rank Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4420–4427. [Google Scholar] [CrossRef]
- Han, X.; Yu, J.; Xue, J.H.; Sun, W. Spectral Super-resolution for RGB Images Using Class-based BP Neural Networks. In Proceedings of the Digital Image Computing: Techniques and Applications, Canberra, ACT, Australia, 10–13 December 2018; pp. 721–727. [Google Scholar]
- Han, X.; Yu, J.; Luo, J.; Sun, W. Hyperspectral and Multispectral Image Fusion using Cluster-based Multi-branch BP Neural Networks. Remote Sens. 2019, 11, 1173. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. A Subspace-Based Change Detection Method for Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 815–830. [Google Scholar] [CrossRef]
- Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, l.; Wang, Z.; Wei, Y. Circle Loss: A Unified Perspective of Pair Similarity Optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6398–6407. [Google Scholar]
- Ranjan, R.; Castillo, C.D.; Chellappa, R. L2-constrained Softmax Loss for Discriminative Face Verification. arXiv 2017, arXiv:1703.09507. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep Hypersphere Embedding for Face Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive Margin Softmax for Face Verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Wang, J.; Zhou, F.; Wen, S.; Liu, X.; Lin, Y. Deep Metric Learning with Angular Loss. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2612–2620. [Google Scholar]
- Wang, X.; Han, X.; Huang, W.; Dong, D.; Scott, M.R. Multi-similarity Loss with General Pair Weighting for Deep Metric Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5022–5030. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Yan, J.; Guo, Y. Learning Modulated Loss for Rotated Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 2458–2466. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense Label Encoding for Boundary Discontinuity Free Rotation Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15819–15829. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain Adaptive Faster R-CNN for Object Detection in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Ouyang, W.; Wang, X.; Zhang, C.; Yang, X. Factors in Finetuning Deep Model for Object Detection with Long-Tail Distribution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 864–873. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1911–1920. [Google Scholar]
- De Brabandere, B.; Neven, D.; Van Gool, L. Semantic Instance Segmentation with a Discriminative Loss Function. arXiv 2017, arXiv:1708.02551. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Zhang, S.; You, C.; Vidal, R.; Li, C.G. Learning a Self-expressive Network for Subspace Clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12393–12403. [Google Scholar]
- Lu, C.; Feng, J.; Lin, Z.; Mei, T.; Yan, S. Subspace Clustering by Block Diagonal Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 487–501. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated Region based CNN for Ship Detection. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.S.; Bai, X.; Yang, W.; Yang, M. Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7778–7796. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.; Gong, C.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Li, B.; Liu, Y.; Wang, X. Gradient Harmonized Single-Stage Detector. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, USA, 26 January 2019; Volume 33, pp. 8577–8584. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2CNN | 88.5 | 71.2 | 31.7 | 59.3 | 51.9 | 56.2 | 57.3 | 90.8 | 72.8 | 67.4 | 56.7 | 52.8 | 53.1 | 51.9 | 53.6 | 60.7 |
| RRPN | 80.9 | 65.8 | 35.3 | 67.4 | 59.9 | 50.9 | 55.8 | 90.7 | 66.9 | 72.4 | 55.1 | 52.2 | 55.1 | 53.4 | 48.2 | 61.0 |
| LR-O | 81.1 | 77.1 | 32.3 | 72.6 | 48.5 | 49.4 | 50.5 | 89.9 | 72.6 | 73.7 | 61.4 | 58.7 | 54.8 | 59.0 | 48.7 | 62.0 |
| DCN | 80.8 | 77.7 | 37.2 | 75.8 | 58.8 | 51.1 | 63.5 | 88.2 | 75.5 | 78.0 | 57.8 | 64.0 | 57.9 | 59.5 | 49.7 | 65.0 |
| Mask RCNN | 89.2 | 76.3 | 50.8 | 66.2 | 78.2 | 75.9 | 86.1 | 90.2 | 81.0 | 81.9 | 45.9 | 57.4 | 64.8 | 63.0 | 47.7 | 70.3 |
| HTC | 89.3 | 77.0 | 52.2 | 66.0 | 77.9 | 75.6 | 86.9 | 90.5 | 80.6 | 80.5 | 48.7 | 57.2 | 69.5 | 64.6 | 52.5 | 71.3 |
| R3Det | 89.5 | 82.0 | 48.5 | 62.5 | 70.5 | 74.3 | 77.5 | 90.8 | 81.4 | 83.5 | 62.0 | 59.8 | 65.4 | 67.5 | 60.1 | 71.7 |
| BBAvector | 88.4 | 80.0 | 50.7 | 62.2 | 78.4 | 79.0 | 87.9 | 90.9 | 83.6 | 84.4 | 54.1 | 60.2 | 65.2 | 64.3 | 55.7 | 72.3 |
| RT (baseline) | 88.3 | 77.0 | 51.6 | 69.6 | 77.5 | 77.2 | 87.1 | 90.8 | 84.9 | 83.1 | 53.0 | 63.8 | 74.5 | 68.8 | 59.2 | 73.8 |
| MOON | 89.0 | 84.4 | 54.4 | 77.2 | 78.4 | 77.8 | 87.7 | 90.8 | 87.6 | 85.3 | 63.9 | 67.6 | 77.2 | 70.6 | 63.4 | 77.0 |
| MOON (MS + RR) | 89.1 | 85.7 | 56.6 | 80.3 | 79.1 | 84.9 | 88.0 | 90.9 | 87.6 | 87.6 | 69.5 | 70.7 | 78.3 | 78.4 | 69.4 | 79.8 |
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RT (baseline) | 88.3 | 77.0 | 51.6 | 69.6 | 77.5 | 77.2 | 87.1 | 90.8 | 84.9 | 83.1 | 53.0 | 63.8 | 74.5 | 68.8 | 59.2 | 73.8 |
| RT + focal loss | 88.7 | 82.6 | 54.1 | 72.0 | 77.4 | 77.5 | 87.4 | 90.9 | 86.8 | 85.2 | 62.7 | 59.3 | 76.1 | 68.7 | 59.4 | 75.2 |
| RT + GHM | 88.7 | 77.4 | 53.9 | 77.4 | 77.6 | 77.6 | 87.7 | 90.8 | 86.8 | 85.6 | 61.9 | 60.1 | 76.1 | 70.5 | 64.3 | 75.8 |
| MOON | 89.0 | 84.4 | 54.4 | 77.2 | 78.4 | 77.8 | 87.7 | 90.8 | 87.6 | 85.3 | 63.9 | 67.6 | 77.2 | 70.6 | 63.4 | 77.0 |
| Method | m-net | s-loss | mAP |
|---|---|---|---|
| RT (Baseline) | 72.9 | ||
| RT + m-net | √ | 74.1 | |
| RT + s-loss | √ | 74.7 | |
| MOON (RT + m-net + s-loss) | √ | √ | 75.2 |
| Method | Decouple | Crisscross | mAP |
|---|---|---|---|
| RT (Baseline) | 72.9 | ||
| RT + Decouple | √ | 73.8 | |
| RT + Crisscross | √ | 73.3 | |
| MOON (RT + Decouple + Crisscross) | √ | √ | 74.1 |
| Method | SC | SR | mAP |
|---|---|---|---|
| RT (Baseline) | 72.9 | ||
| RT + SC | √ | 73.9 | |
| RT + SR | √ | 73.8 | |
| MOON (RT + SC + SR) | √ | √ | 74.7 |
| Method | mAP |
|---|---|
| RC2 | 75.7 |
| R2PN | 79.6 |
| R2CNN | 79.7 |
| RT | 80.1 |
| BBAvector | 82.8 |
| MOON | 84.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Leng, W.; Han, X.; Sun, W. MOON: A Subspace-Based Multi-Branch Network for Object Detection in Remotely Sensed Images. Remote Sens. 2023, 15, 4201. https://doi.org/10.3390/rs15174201
Zhang H, Leng W, Han X, Sun W. MOON: A Subspace-Based Multi-Branch Network for Object Detection in Remotely Sensed Images. Remote Sensing. 2023; 15(17):4201. https://doi.org/10.3390/rs15174201
Chicago/Turabian StyleZhang, Huan, Wei Leng, Xiaolin Han, and Weidong Sun. 2023. "MOON: A Subspace-Based Multi-Branch Network for Object Detection in Remotely Sensed Images" Remote Sensing 15, no. 17: 4201. https://doi.org/10.3390/rs15174201
APA StyleZhang, H., Leng, W., Han, X., & Sun, W. (2023). MOON: A Subspace-Based Multi-Branch Network for Object Detection in Remotely Sensed Images. Remote Sensing, 15(17), 4201. https://doi.org/10.3390/rs15174201