1. Introduction
High-spatial-resolution remote sensing data have shown great potential for application in areas such as precision agricultural monitoring [
1,
2,
3], urban and rural regional planning, road traffic management [
4,
5], high precision navigation maps [
6,
7,
8], environmental disaster assessment [
9,
10], forestry measurement [
11,
12,
13], and military construction. Buildings, as the main body in urban construction, occupy a more important component in high-resolution remote sensing images. In urban scenes, buildings are used as an important assessment indicator to understand the development status of cities due to their wide distribution in urban areas. And because of the rich information on buildings contained in high-resolution remote sensing images, the extraction of buildings using high-resolution remote sensing images has become a current research hotspot [
14,
15].
At present, image semantic segmentation algorithms based on deep learning are widely used in building extraction applications, but due to the irregular distribution and large number of building data in large urban scenes obtained by sensors, the rapid production of building samples has become a challenge. The existing building semantic segmentation model requires a large number of labelled training samples as a priori knowledge in order to obtain more satisfactory accuracy results. In terms of producing training samples, the current mainstream approach is based on manual labelling, however, high-resolution building labelling in complex scenes requires a huge time cost, resulting in the acquisition speed of high-quality labels lagging far behind that of remote sensing data, which hinders the automatic extraction of remote sensing information [
16].
In order to simplify the labelling process of training samples, researchers have carried out research on automatic or semi-automatic sample generation methods and have proposed semi-supervised learning strategies. The semi-supervised learning-based image semantic segmentation method uses a limited number of real samples as training data, and then makes full use of the limited labelled data and the weakly labelled data generated by unsupervised classification methods for model training, reducing the cost of acquiring accurately labelled data.
In order to secure the number of training samples to increase sample diversity and thus improve training accuracy results, many studies have explored the use of a small number of real labels to label unlabelled data, thereby expanding the number of weakly labelled samples available for training. Weakly annotated samples are often the result of feature extraction and classification of multi-source remote sensing data, benefiting from the ability of multi-source remote sensing data to provide a true visual representation of surface targets.
For example, Han et al. proposed a semi-supervised generation framework combining deep learning features, self-labelling techniques, and discriminative evaluation methods for the task of scene classification and labelling datasets, which can learn valuable information from unlabelled samples and improve classification capabilities [
17]. Wang et al. formulated high-spatial-resolution remote sensing image classification as a semi-supervised depth metric learning problem, which considers group images and single images for the label consistency of unlabelled data [
18]. Kaiser et al. [
19] used vectorised weakly labelled samples from Open Street Map for house and road extraction, and Kang et al. created pseudo-labelled sample remote sensing using non-deep learning methods to improve the deep learning-based segmentation of small labelled datasets [
20]. Xu et al. [
21] trained the deep convolutional neural network (DCNN) model to obtain the spatial distribution of rice and maize in Liaoning Province using the results of the traditional classifier support vector machine (SVM) to classify images as weak samples and analysed the applicability of weak samples. Hong et al. [
22] used a cross-modal deep learning framework to expand a small number of labels into a large number of labelled samples for the classification of hyperspectral images, effectively improving the efficiency of label expansion. Wang et al. [
23] used self-training to achieve the label expansion of unlabelled scene images and further improved the quality of labelled samples of scene images by constraining the initial weights of the expanded labelled samples. Zhu et al. [
24] considered the influence of different structural models to extract scene image features and trained two different structural classification models to simultaneously assign labels to unlabelled scene images to enhance the stability of the predicted labelling results of unlabelled samples. Ding et al. [
25,
26,
27] and Zhang et al. [
28] designed a graph convolutional neural network framework for hyperspectral image classification, which uses superpixels to cluster local spectral features, and uses the clustering results as the nodes of the graph convolution, then uses the graph convolutional network to learn the relationship between the labelled and unlabelled samples. In the case of a small number of samples, this method obtains better classification results than other methods. The spectral information of ground objects is crucial in this method, RGB images have more complex ground features than spectral images, and the method using a graph convolutional neural network needs to be optimised in the small sample data classification task, which only processes RGB images.
This type of method, from the perspective of weak sample expansion based on multi-source remote sensing data, can significantly improve the classification accuracy even with little annotated data, but the incorrectly annotated samples in the weak sample data will have an impact on the semantic segmentation model accuracy. How to improve the problem of incorrect samples in weak sample data in order to improve the classification accuracy of semantic segmentation models is still one of the directions to be investigated in semi-supervised classification methods.
Active learning (AL) [
29] in supervised learning methods can effectively deal with the small sample size problem. AL iteratively enhances the predictive performance of a classifier by actively increasing the size of training data for each training iteration by utilizing an unlabelled pool of samples. In each iteration, AL enhances the training dataset by actively selecting the most valuable instances from the pool of unlabelled data, and an oracle (human- or machine-based) assigns the true class labels to these instances. Finally, these useful instances are added to the existing training dataset, and the classifier is retrained on this new training dataset. The process continues until a stopping criterion (which may be the size of the training dataset), the number of iterations, or the desired accuracy score is achieved [
30]. AL is mainly applied to the processing of hyperspectral data. Due to the high dimensionality of hyperspectral data, AL can reduce the dimension and extract effective information from high-dimensional data. For example, Guo et al. [
31] proposed an AL framework that stitches together the spectral and spatial features of superpixels. Similarly, Xue et al. [
32] considered neighbourhood and superpixel information to enhance the uncertainty of query samples. Liu et al. [
33] proposed a feature-driven AL framework to define a well-constructed feature space for hyperspectral image classification (HSIC).
Semi-supervised learning (SSL) and AL’s main goal is to use limited sample tags to achieve good generalization performance, and combined with SSL, AL is reasonable. Zhang et al. [
34] proposed an RF-based semi-supervised AL method that exploits spectral–spatial features to define a query function to select the most informative samples as target candidates for the training set. Li et al. [
35] adopted multinomial logistic regression with AL to segment hyperspectral images (HSIs) in a semi-supervised manner. Munoz-Mari et al. [
36] utilized AL to improve the classification confidence of a hierarchical model by having it select the most informative samples. AL has also been adapted to a co-training framework in which the algorithm automatically selects new training samples from the abundant unlabelled samples. Wan et al. [
37] proposed collaborative active and semi-supervised learning (CASSL) for HSI classification. Wang et al. [
38] proposed a new semi-supervised active learning method that aims to discover representativeness and discriminativeness by semi-supervised active learning (DRDbSSAL). Zhang et al. [
39] proposed to combine AL and hierarchical segmentation method for the classification of HSIs, where the training set was enlarged by the self-learning-based semi-supervised method. Dópido et al. [
40] proposed a new framework for semi-supervised learning, which exploits active learning for unlabelled sample selection in hyperspectral data classification.
Weakly supervised refers to learning using high-level or noisy inputs from expert knowledge or crowdsourced data [
16] to obtain testing accuracy comparable to that of real samples as inputs. Wang et al. [
41] used image-level labels and labels consisting of individual geotagged points as weak sample sources to input into the model and converted the different classes of labels into pixel-level semantic segmentation results via a class activate map (CAM) [
42] and masks.
Weakly supervised learning is a research method to investigate how to make full use of the valid samples in weak sample data so as to improve the classification accuracy of semantic segmentation models. This method is an extension of semi-supervised learning in the direction of weak sample research. Weakly supervised learning requires not only acquiring weak sample data but also inputting unlabelled data, together with a small number of labelled samples, into the weakly supervised model to learn its deep features from a large amount of unlabelled data by means of specific loss functions [
43], generative adversarial networks (GANs) [
44], and other contrastive learning [
45] methods. This significantly reduces the need for a large number of accurately labelled samples. For example, Peng Rui et al. [
46] used a contrast learning model and label propagation method to generate a large number of high-confidence labels in multi-scale unlabelled data, and finally used the expanded samples in a weakly supervised network to obtain the classification results of scene images. Liang et al. [
47] constructed a weakly supervised semantic segmentation network based on conditional generative adversarial networks and used a self-training method to generate pseudo-labels of unlabelled data by a generator to achieve weakly supervised semantic segmentation. Weakly supervised learning was achieved by a self-training method in which the generator generated pseudo-labels of unlabelled data. The weakly supervised learning model obtains high-confidence labels from weak sample data with a contrast learning method, but contrast learning is a probability estimation method embedded inside the model and cannot explicitly analyse how to extract valid samples from weak sample data, and thus, improve the classification results of the weakly supervised model.
In summary, there are still some shortcomings in the field of semi-supervised building classification from high-resolution remote sensing images that need to be explored, including:
The quality of weak samples generated based on multi-source remote sensing data needs to be improved;
The existing weakly supervised or semi-supervised classification methods lack explicit simulation and applicability analysis of the process of generating high-quality weak samples.
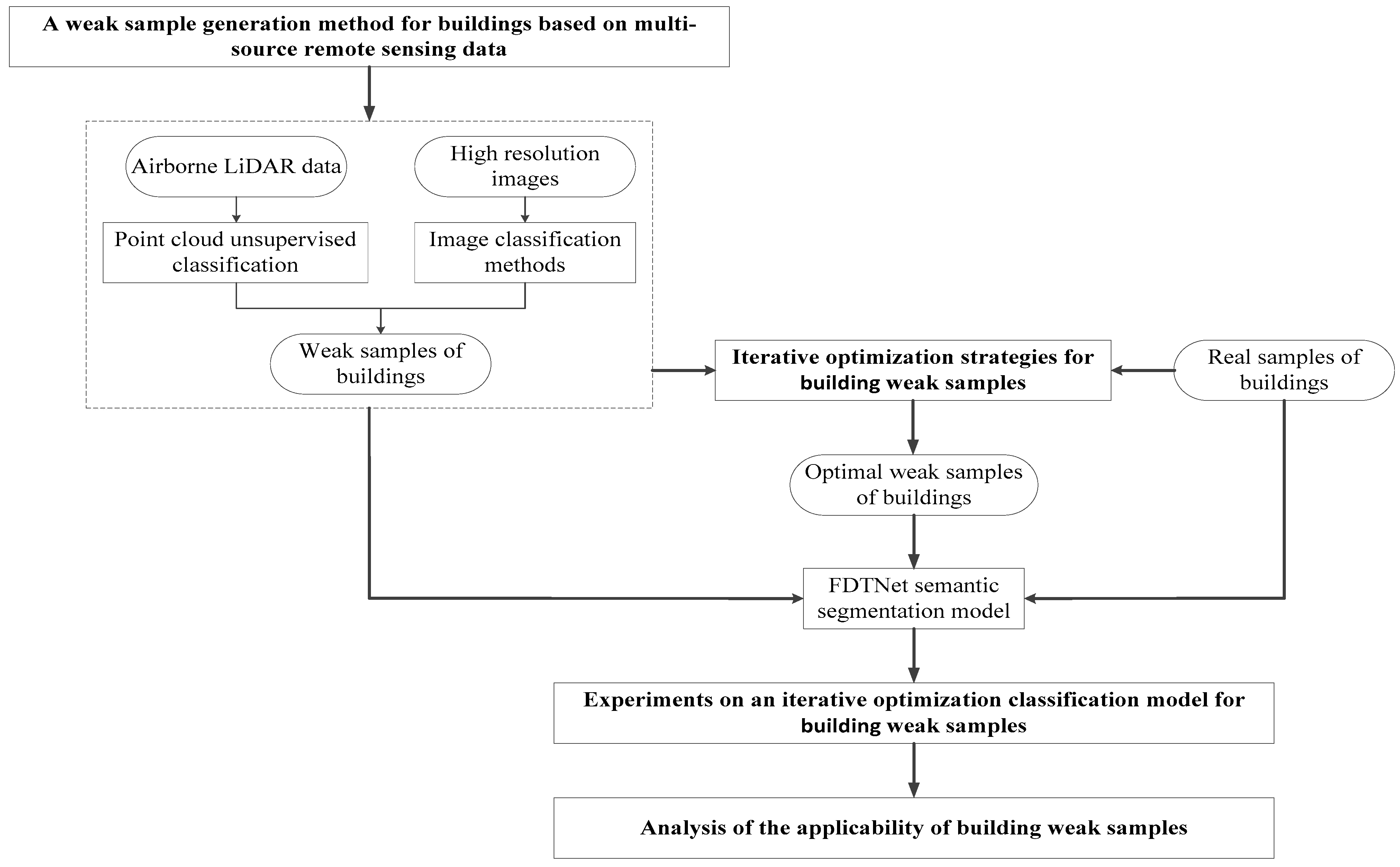
In view of the above problems, this paper proposes a semi-supervised building classification framework based on multi-source remote sensing data. It draws on the idea of active learning to automatically select the optimal sample feature information, and then applies the semi-supervised classification method and active learning strategy to the classification task with only a spatial domain (no spectral information). The proposed method focuses on the generation and quality optimization of weak building samples. The innovations of this paper are as follows:
From the perspective of constructing a weak sample generation strategy, this paper uses the unsupervised classification results of airborne LiDAR data and the test results of an image segmentation model to quickly generate initial image weak samples, thus reducing the need for the network to manually label the training samples;
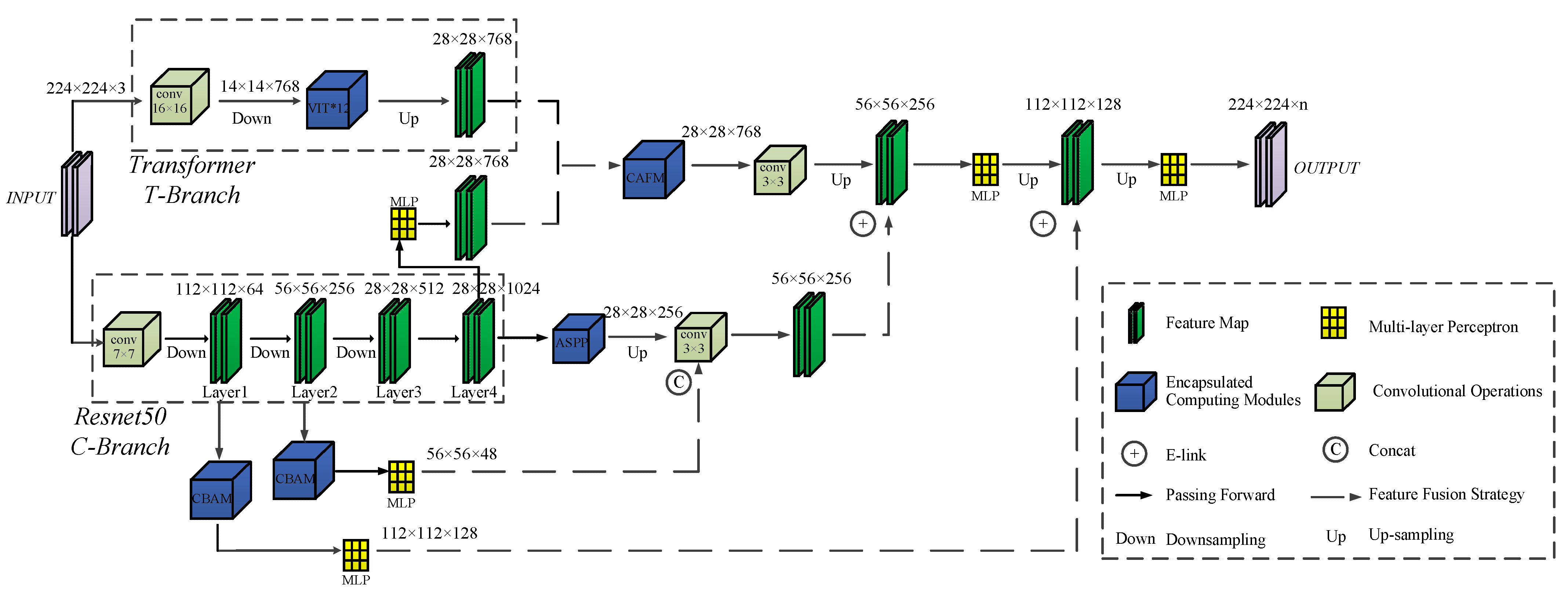
In this paper, a weak sample optimization strategy is proposed to improve the accuracy of the overall weak sample by iteratively comparing part of the weak sample with the real sample. Finally, the weak sample set with the highest iterative accuracy was sent to the high-resolution semantic segmentation network for training to improve the test accuracy of the weak samples;
A comparative analysis of the model testing accuracy of the real sample, the initial weak sample, and the optimised weak sample for each dataset was carried out on two datasets of different high resolutions and different building types, and we discuss the applicability of the proposed semi-supervised classification framework.
Our method alleviates the problem of deep learning models requiring a large number of manually annotated samples, while the weak sample optimisation strategy improves the model testing accuracy when using weak samples as training data in semi-supervised classification studies.
The remainder of this paper is organized as follows:
Section 2 illustrates the data sources used in this study,
Section 3 illustrates the methodology, and
Section 4 reports the results and the discussion. Finally,
Section 5 presents the conclusions of this work.
5. Discussion
In the LiDAR point cloud weak sample iterative optimization experiments, although the iterative optimization strategy improved the test accuracy of the building semantic segmentation model, when using exclusively LiDAR weak samples as training region, but the final optimised test accuracy still falls short of the test accuracy of the real samples. This section discusses the main reason, why the test accuracy of the LiDAR weak samples is much lower than that of the real samples in the building classification experiments for the Yuhu Urban dataset.
The first factor considered in this paper is, the uncertainty of weak samples in the during each iteration, which affects the final optimization accuracy.
So, we added the
area’s real samples to the optimisation iteration process, i.e., the weak samples from the two training region datasets were simultaneously optimised with their real samples. And the test accuracy evaluation results obtained are shown in
Table 8, where the “FDTNet (after optimization+)+” in the table represents the addition of the real samples from
to the comparison iteration. As can be seen from
Table 8, the
of all kinds of buildings are dropped. Overall, whether or not the real samples of the were added did not have an impact on the classification of the
.
After excluding the influence of the weak sample iterative optimisation strategy and the semantic segmentation model used on the applicability of the weak samples, the main influence is that the LiDAR weak sample data lacks the key feature samples that can identify and distinguish between classes of buildings compared to the real samples.
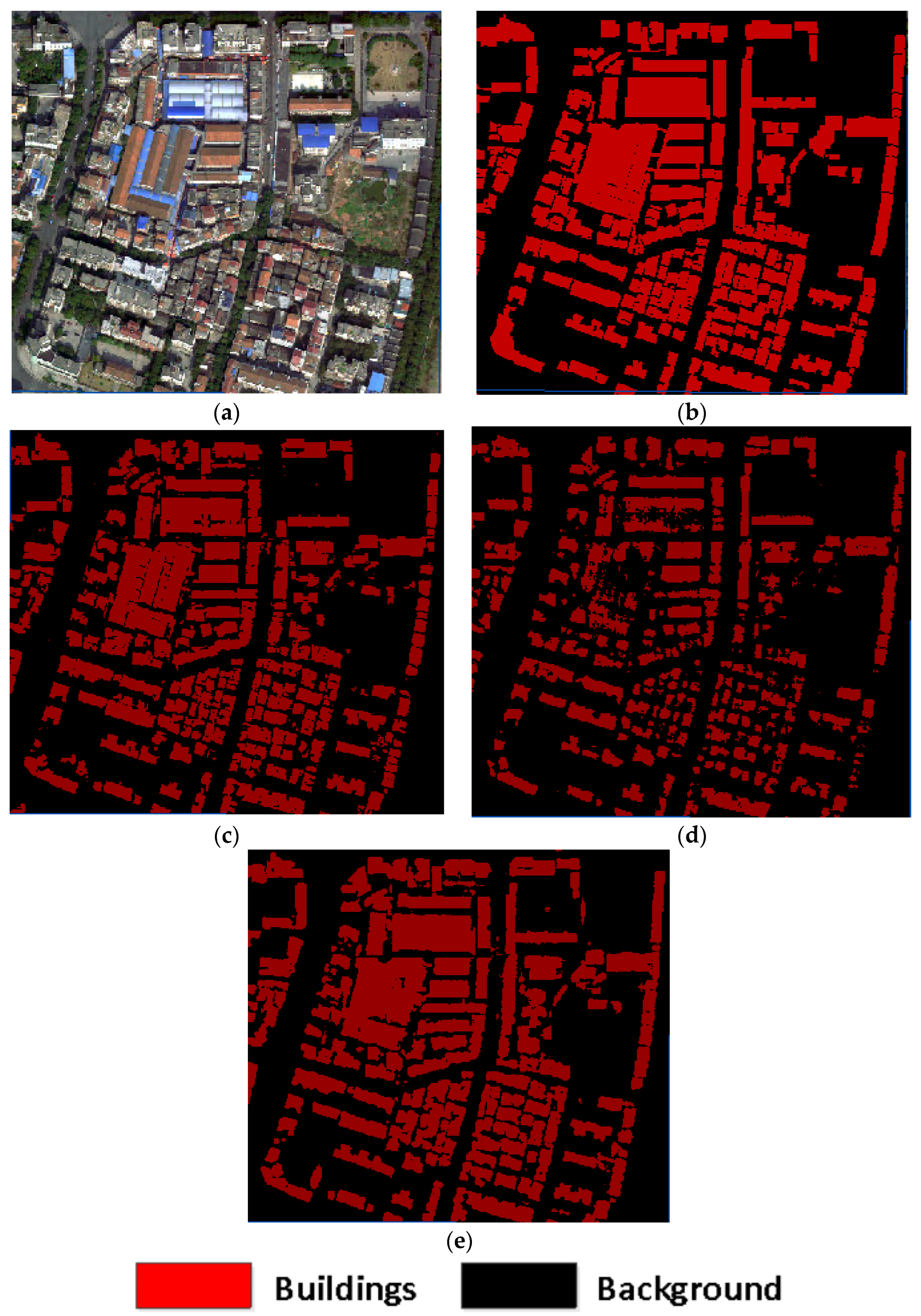
The classification
mIoU for LiDAR buildings (roof point cloud) in
Section 3.3.1 was only 59.9%. As shown in
Figure 15, the roof of the high-rise building in the lower left region of the image was never correctly classified throughout the weak sample optimisation method process.
Due to the lack of building samples and their features in the figure, so that the subsequent model cannot learn the features of such high-rise buildings. And the wide distribution of such buildings in the test area, the model cannot learn their features when training, thus resulting in the low classification accuracy of high-rise buildings in the test area. Therefore, the accuracy and completeness of the LiDAR weak sample labels are the main reasons affecting the accuracy of the iterative optimization algorithm. When the LiDAR weak samples of typical features are insufficient, the semantic segmentation accuracy of the model decreases significantly, and the test accuracy of the model cannot approach the test accuracy of the real samples, regardless of whether the subsequent iterative optimization strategy is used.
In contrast, the classification accuracy of the weak sample in the XXURB dataset reached 80%, and the weak training sample size was sufficient, so the difference between the weak sample test accuracy of the model and that of the real sample was less than 1%. This result demonstrates that when there are sufficient key features in the weak samples, the test accuracy of the optimised weak samples can be iterated to be close to that of the real samples, and further demonstrates the applicability of the weak sample iterative optimisation strategy proposed in this paper.
6. Conclusions
In this paper, a semi-supervised learning model framework is proposed to alleviate the problem that, building semantic segmentation models require a large number of real samples to achieve good classification accuracy. Firstly, the method of generating weak samples based on airborne LiDAR point cloud data and image data can effectively reduce the time cost of manually annotating samples; Secondly, the weak sample iterative optimisation strategy proposed in this paper can improve the testing accuracy of the semantic segmentation model, when weak samples are selected as training samples, with 1.9% and 0.6% improvement on two building datasets respectively; Finally, the paper discusses the impact of the quality of the weak samples on the accuracy of the model tests. It is concluded that when the initial accuracy of the weak sample is good and there are sufficient key features in the weak sample, the gap between the test accuracy of the weak sample, i.e., the test accuracy of the weak samples after using the iterative optimization strategy is close to the real samples. In this paper, we propose a building weak sample generation and optimization strategy that reduces the time cost of a large number of manually labelled samples, under the condition that the amount of weak sample data is sufficient and of good quality, and at the expense of a small amount of classification accuracy. The method in this paper can be used instead of a fully supervised learning method with real samples for semantic segmentation and extraction of buildings in high resolution remote sensing images.
The weak sample generation and optimization strategy proposed in this study is mainly used to simulate the implementation process of weakly supervised learning model. However, the real weakly supervised model does not need to deal with the weak samples separately. Instead, the labelled samples and unlabelled samples are directly input into the weakly supervised model, and the optimized weak sample classification results are automatically obtained through the generator, discriminator, discriminant loss function and so on. Therefore, the next step is to design an end-to-end weakly supervised learning model to automatically obtain weak samples of unlabelled data and output test classification results. At the same time, multi-modal remote sensing data is introduced for weak sample generation and multiple weak sample feature learning, which can further propose the applicability of weak/semi-supervised classification models.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}