
Deep LiDAR-Radar-Visual Fusion for Object Detection in Urban Environments



Abstract
:1. Introduction
- A novel framework LRVFNet is proposed to achieve accurate 2D object detection in urban environments exploiting spatial–temporal LiDAR, mmWave radar, and vision.
- A novel feature-level fusion module is proposed, which effectively integrates LiDAR and mmWave radar features into 2D object detection using self-attention and global attention mechanisms, showing significantly improved fusion performance compared to existing fusion schemes.
- Extensive experimental results on two public VoD and Flow datasets demonstrate that our LRVFNet outperforms the state-of-the-art model with large margins by 6.43% and 2.61% in terms of 2D object detection accuracy . Additionally, the ablation study validates the effectiveness of our network designs.
2. Materials
2.1. Single-Modality Methods
2.2. Fusion-Based Methods
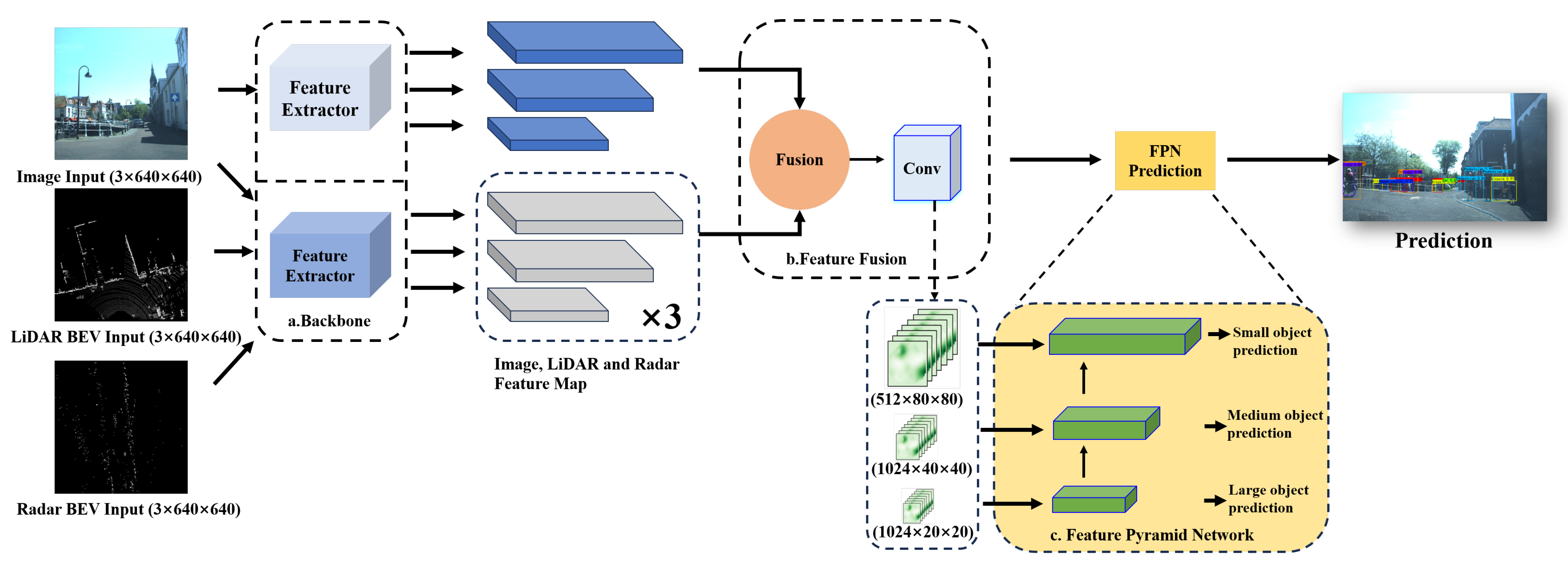
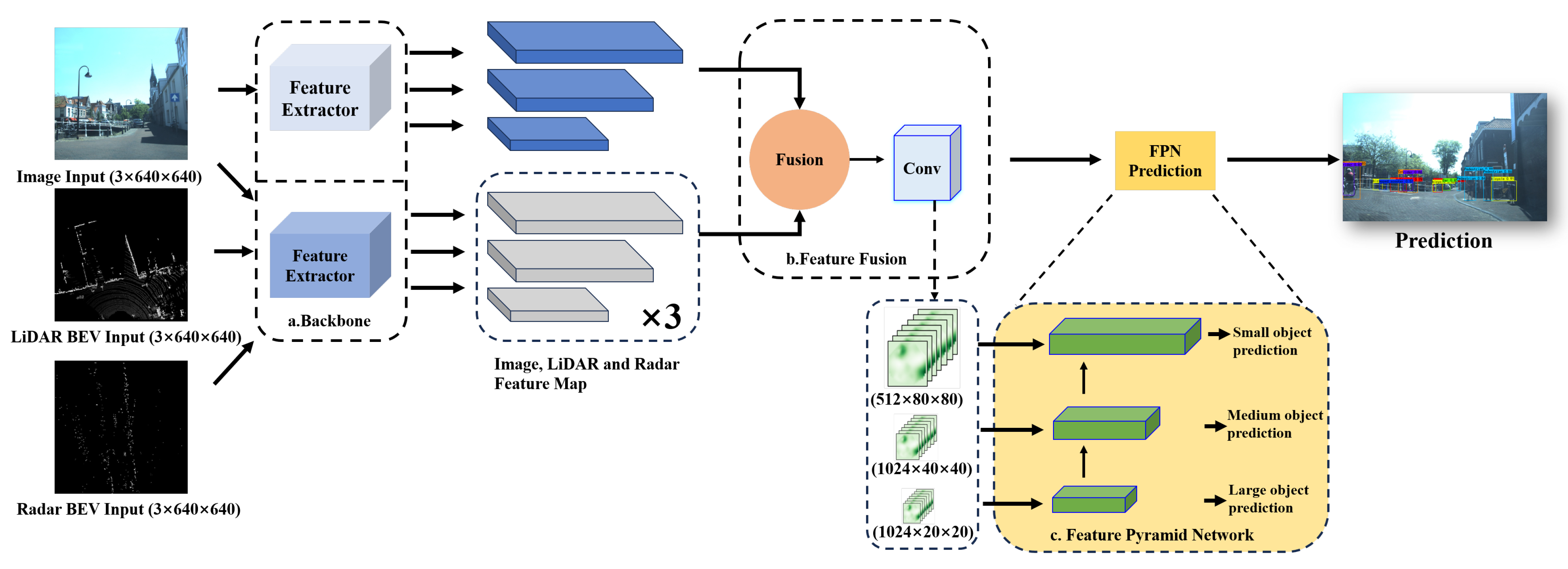
3. Methods
3.1. Representation of Different Modalities
3.2. Multi-Modal Fusion Network for Object Detection
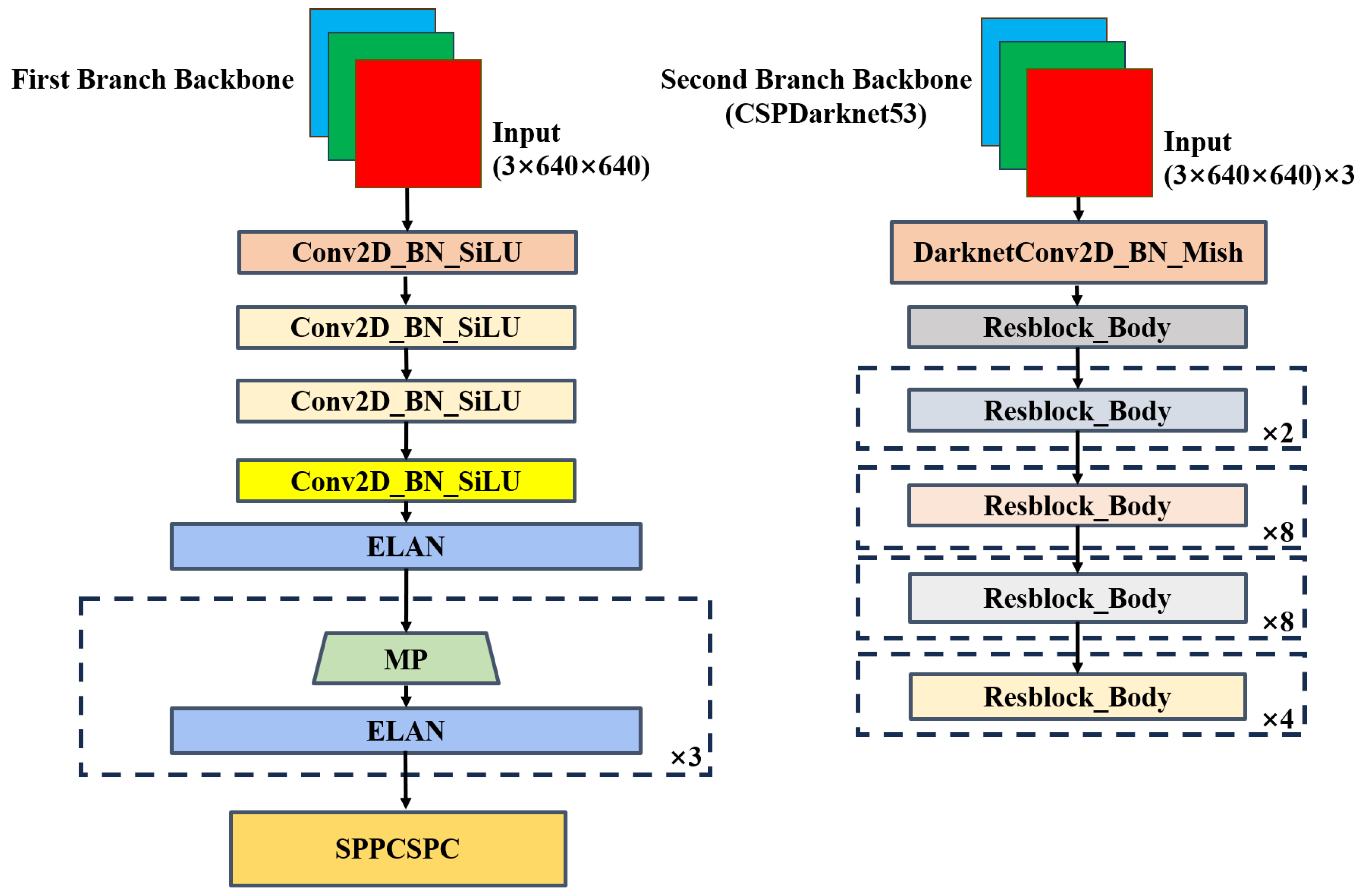
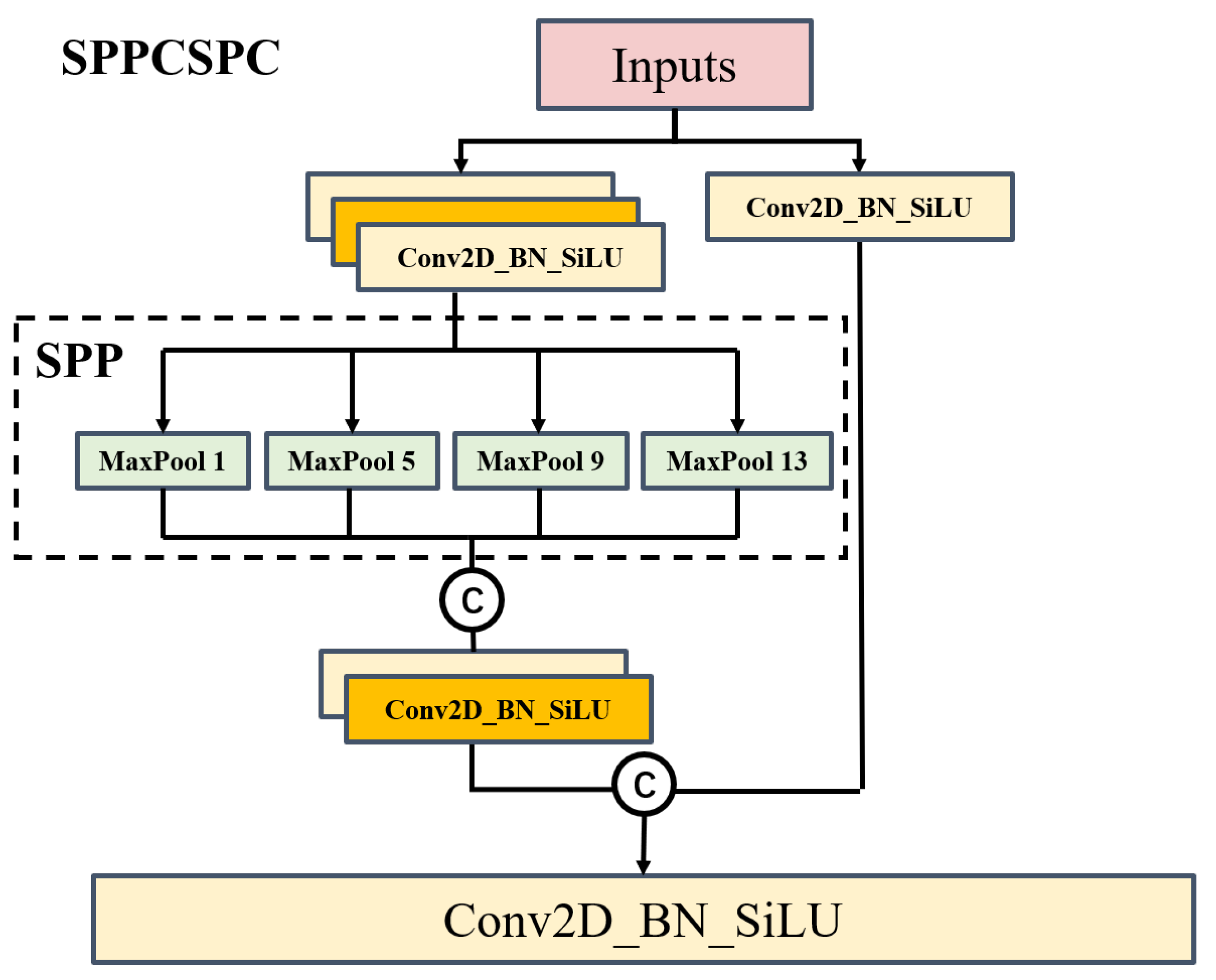
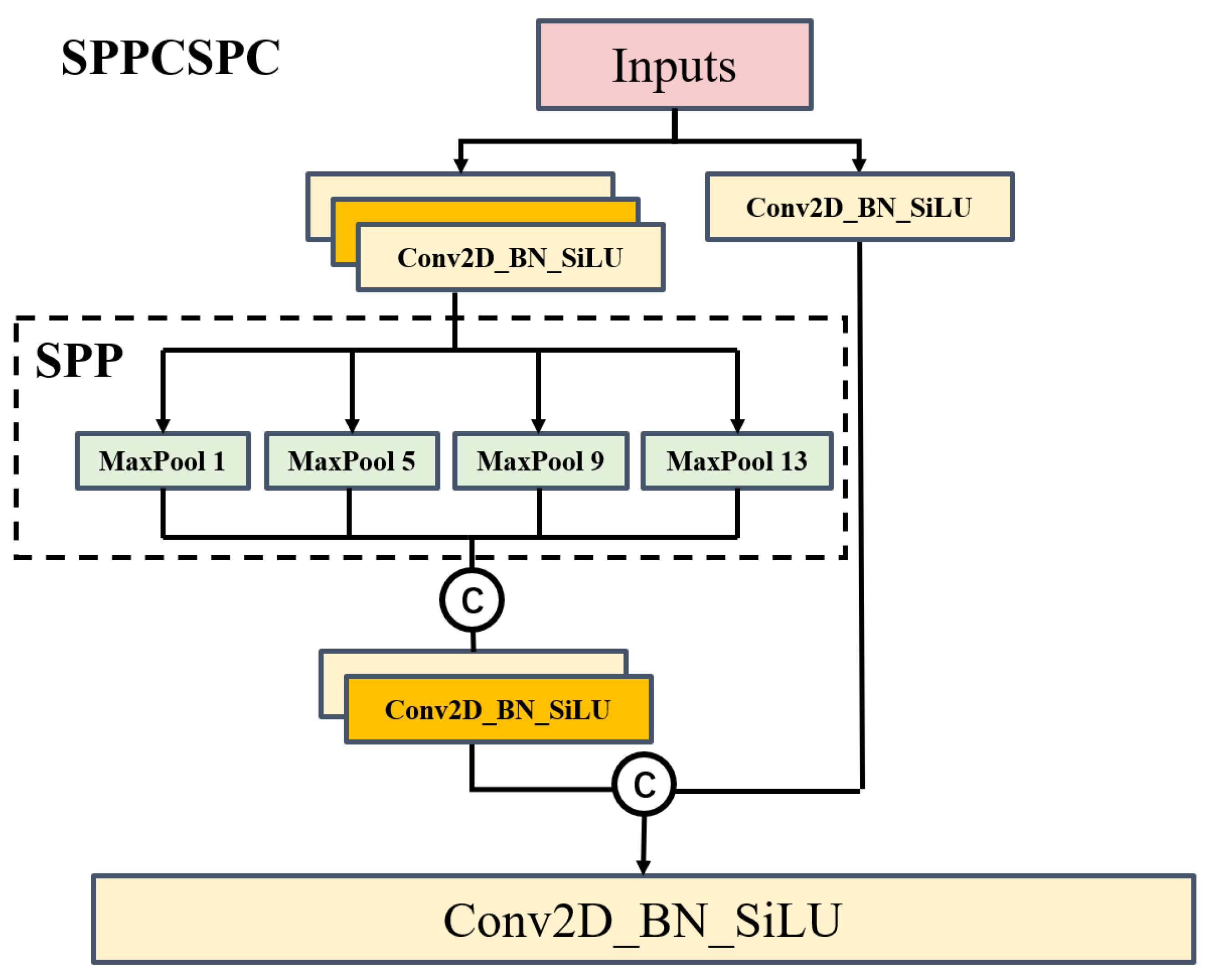
3.2.1. Two-Branch Backbone Module
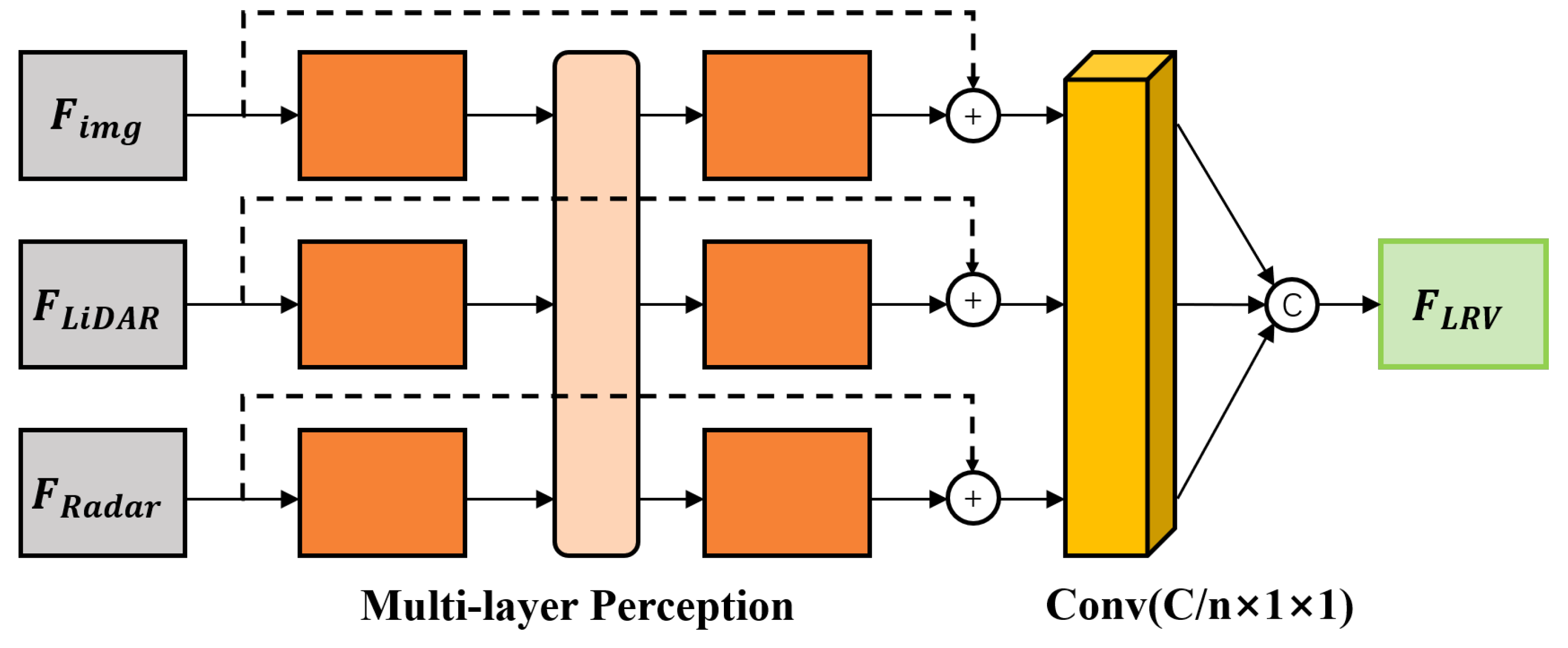
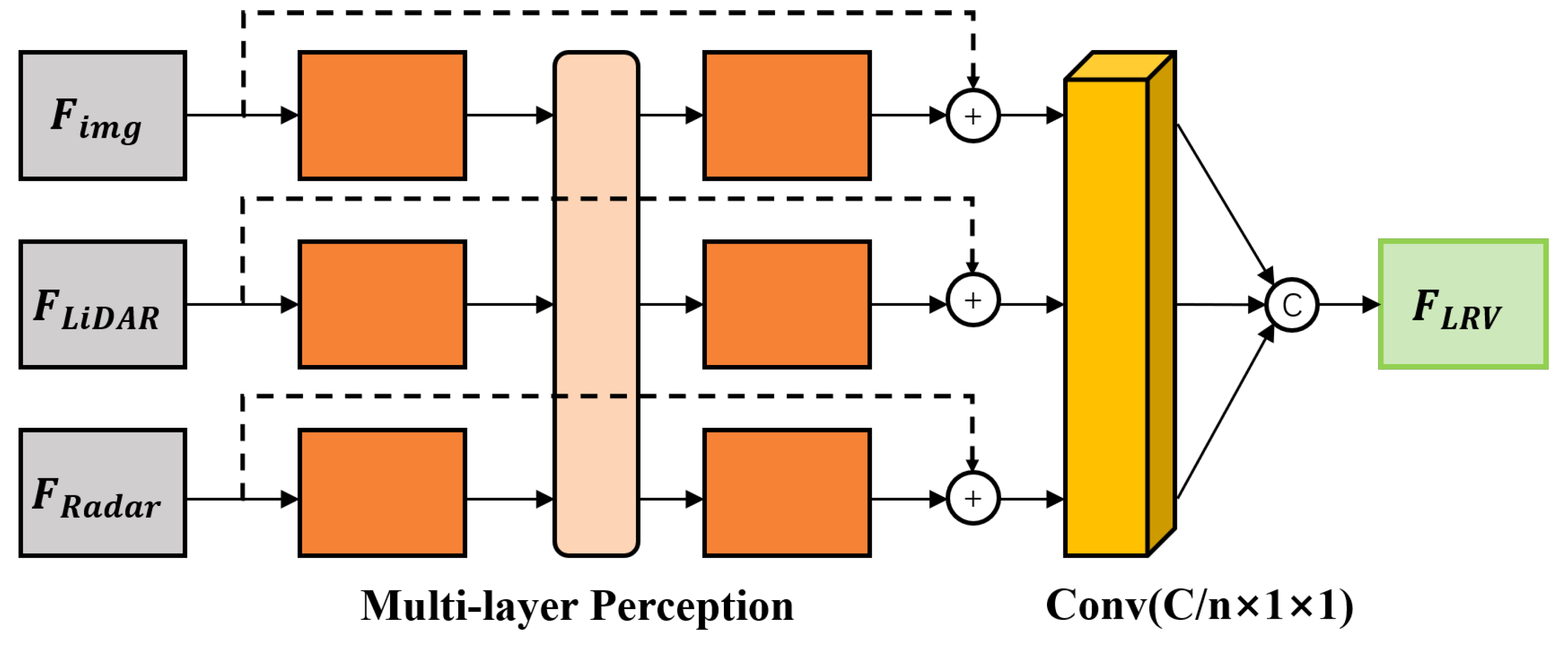
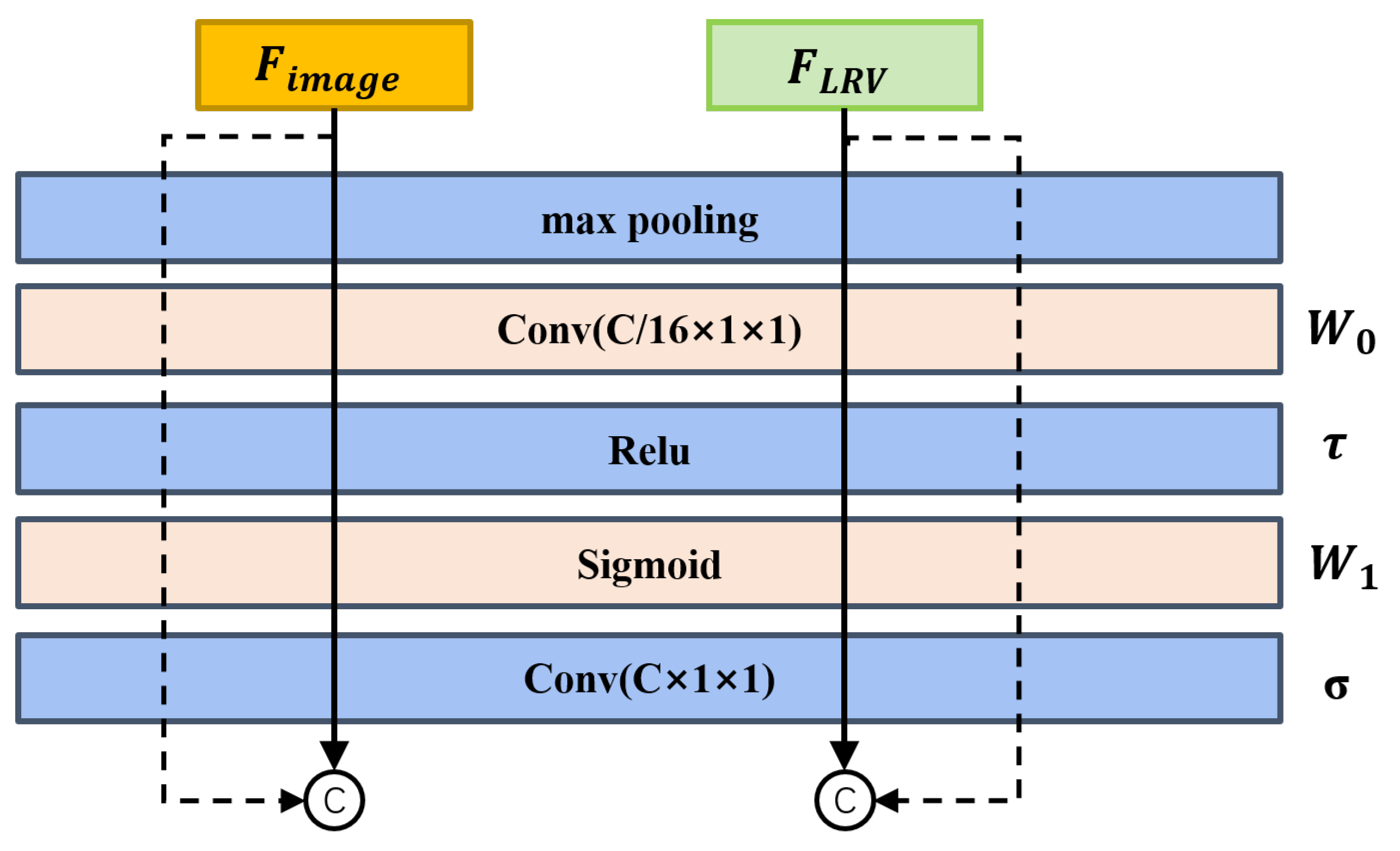
3.2.2. Feature Fusion Module
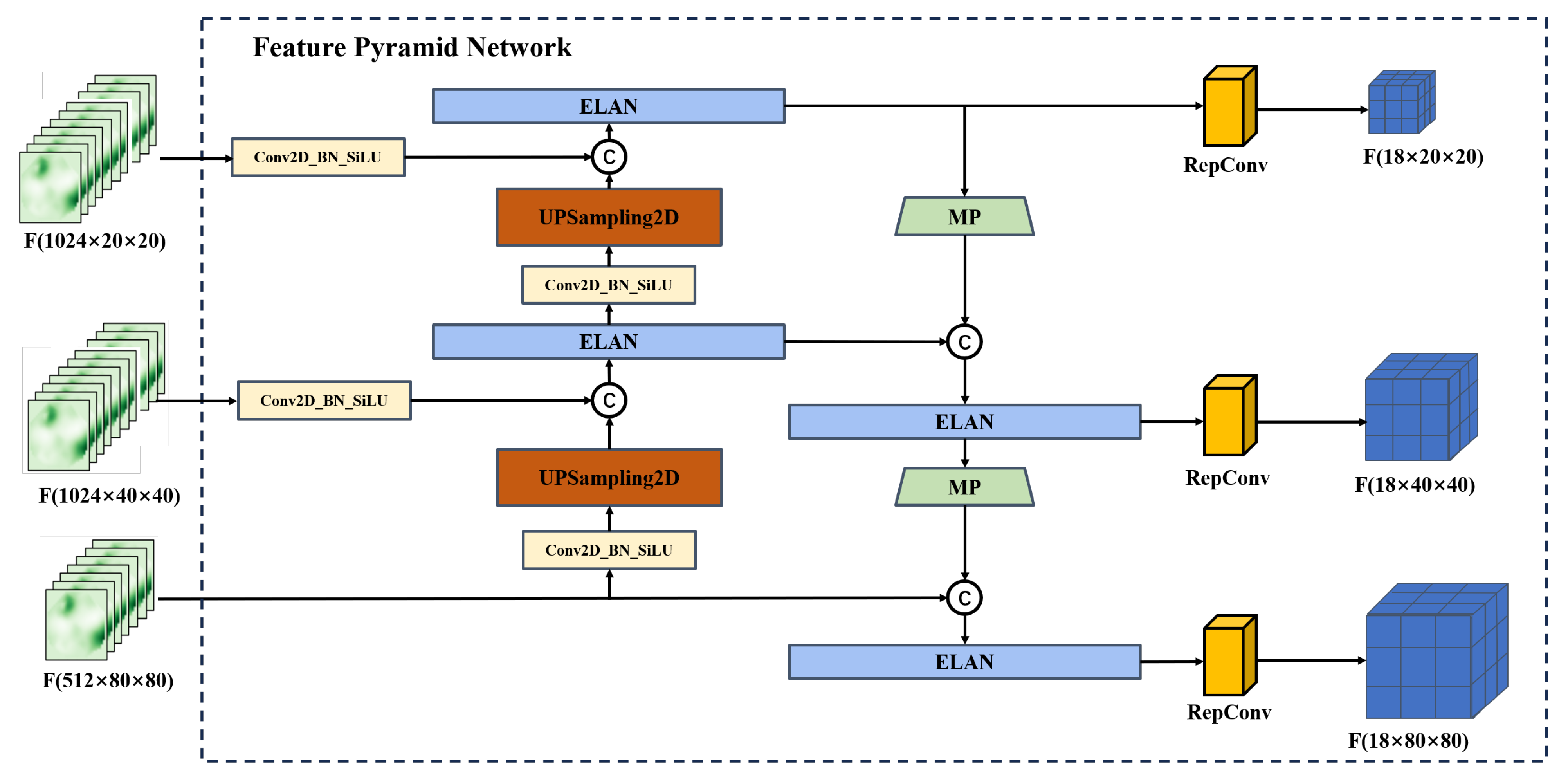
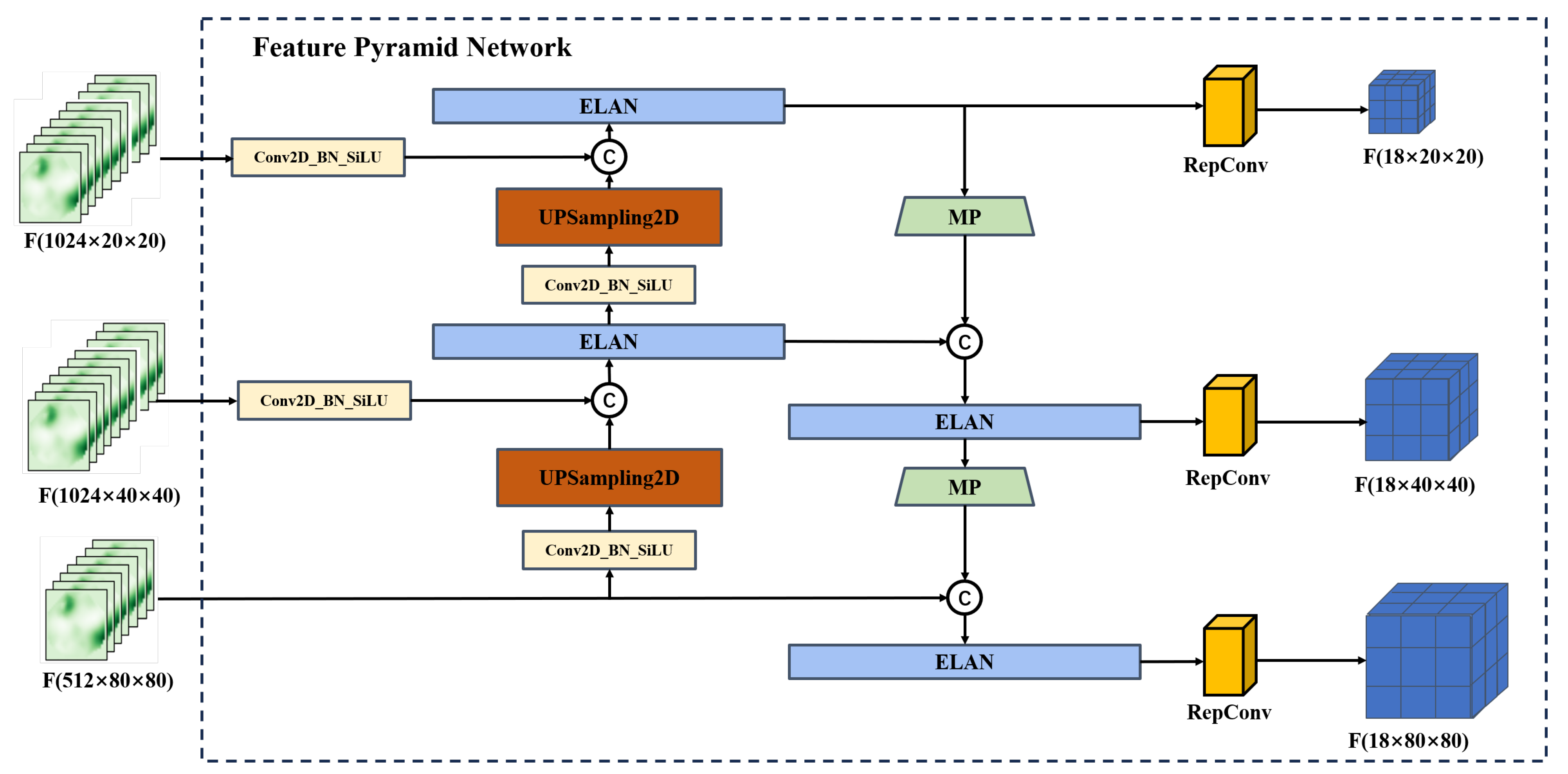
3.2.3. Feature Pyramid Network
3.3. Loss Functions
4. Results
4.1. Dataset
4.2. Implementation
4.3. Evaluation Metrics
4.4. Evaluation Results
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pastorino, M.; Montaldo, A.; Fronda, L. Multisensor and Multiresolution Remote Sensing Image Classification through a Causal Hierarchical Markov Framework and Decision Tree Ensembles. Remote Sens. 2021, 13, 849. [Google Scholar] [CrossRef]
- Huo, B.; Li, C.; Zhang, J.; Xue, Y.; Lin, Z. SAFF-SSD: Self-Attention Combined Feature Fusion-Based SSD for Small Object Detection in Remote Sensing. Int. J. Remote Sens. 2023, 15, 3027. [Google Scholar] [CrossRef]
- Yang, Z.; Zheng, N.; Wang, F. DSSFN: A Dual-Stream Self-Attention Fusion Network for Effective Hyperspectral Image Classification. Remote Sens. 2023, 15, 3701. [Google Scholar] [CrossRef]
- Deng, J.; Czarnecki, K. MLOD: A multi-view 3D object detection based on robust feature fusion method. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 279–284. [Google Scholar]
- Li, P.; Liu, S.; Shen, S. Multi-Sensor 3D Object Box Refinement for Autonomous Driving. arXiv 2019, arXiv:1909.04942. [Google Scholar]
- Nobis, F.; Geisslinger, M.; Weber, M.; Betz, J.; Lienkamp, M. A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection. In Proceedings of the 2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 15–17 October 2019. [Google Scholar]
- Chang, S.; Zhang, Y.; Zhang, F.; Zhao, X.; Huang, S.; Feng, Z.; Wei, Z. Spatial Attention Fusion for Obstacle Detection Using MmWave Radar and Vision Sensor. Sensors 2020, 20, 956. [Google Scholar] [CrossRef]
- Cheng, Y.; Xu, H.; Liu, Y. Robust Small Object Detection on the Water Surface through Fusion of Camera and Millimeter Wave Radar. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15243–15252. [Google Scholar]
- Palffy, A.; Pool, E.; Baratam, S.; Kooij, J.F.P.; Gavrila, D.M. Multi-Class Road User Detection With 3+1D Radar in the View-of-Delft Dataset. IEEE Robot. Autom. Lett. 2022, 7, 4961–4968. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhu, J.; Jiang, M.; Fu, J.; Pang, C.; Wang, P.; Sankaran, K.; Onabola, O.; Liu, Y.; Liu, D.; et al. FloW: A Dataset and Benchmark for Floating Waste Detection in Inland Waters. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10933–10942. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: London, UK; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Jin, X.; Yang, H.; He, X.; Liu, G.; Yan, Z.; Wang, Q. Robust LiDAR-Based Vehicle Detection for On-Road Autonomous Driving. Remote Sens. 2023, 15, 3160. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. arXiv 2017, arXiv:1711.06396. [Google Scholar]
- Zeng, Y.; Hu, Y.; Liu, S.; Ye, J.; Han, Y.; Li, X.; Sun, N. RT3D: Real-Time 3-D Vehicle Detection in LiDAR Point Cloud for Autonomous Driving. IEEE Robot. Autom. Lett. 2018, 3, 3434–3440. [Google Scholar] [CrossRef]
- Svenningsson, P.; Fioranelli, F.; Yarovoy, A. Radar-PointGNN: Graph Based Object Recognition for Unstructured Radar Point-cloud Data. In Proceedings of the 2021 IEEE Radar Conference (RadarConf21), Atlanta, GA, USA, 7–14 May 2021. [Google Scholar]
- Meyer, M.; Kuschk, G.; Tomforde, S. Graph Convolutional Networks for 3D Object Detection on Radar Data. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- González, A.; Vázquez, D.; Lpez, A.M.; Amores, J. On-Board Object Detection: Multicue, Multimodal, and Multiview Random Forest of Local Experts. IEEE Trans. Cybern. 2017, 47, 3980–3990. [Google Scholar] [CrossRef]
- Enzweiler, M.; Gavrila, D.M. A multilevel mixture-of-experts framework for pedestrian classification. IEEE Trans. Image Process. 2011, 20, 2967–2979. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Ma, H.M.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar]
- Chadwick, S.; Maddetn, W.; Newman, P. Distant Vehicle Detection Using Radar and Vision. In Proceedings of the IEEE International Conference on Robotics & Automation, Montreal, BC, Canada, 20–24 May 2019. [Google Scholar]
- John, V.; Mita, S. RVNet: Deep Sensor Fusion of Monocular Camera and Radar for Image-Based Obstacle Detection in Challenging Environments. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Cham, Switzerland, 2019; pp. 351–364. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Li, L.q.; Xie, Y.l. A Feature Pyramid Fusion Detection Algorithm Based on Radar and Camera Sensor. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 18–22 October 2020; Volume 1, pp. 366–370. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. MVX-Net: Multimodal VoxelNet for 3D Object Detection. In Proceedings of the IEEE International Conference on Robotics & Automation, Montreal, BC, Canada, 20–24 May 2019; pp. 7276–7282. [Google Scholar]
- Dong, H.; Zhang, X.; Xu, J.; Ai, R.; Gu, W.; Lu, H.; Kannala, J.; Chen, X. SuperFusion: Multilevel LiDAR-Camera Fusion for Long-Range HD Map Generation. arXiv 2021, arXiv:2211.15656. [Google Scholar]
- Chen, X.; Zhang, H.; Lu, H.; Xiao, J.; Qiu, Q.; Li, Y. Robust SLAM system based on monocular vision and LiDAR for robotic urban search and rescue. In Proceedings of the IEEE International Conference on Safety, Security and Rescue Robotics (SSRR), Shanghai, China, 11–13 October 2017. [Google Scholar]
- Meyer, G.P.; Charland, J.; Hegde, D.; Laddha, A.; Vallespi-Gonzalez, C. Sensor Fusion for Joint 3D Object Detection and Semantic Segmentation. arXiv 2019, arXiv:1904.11466. [Google Scholar]
- Zhao, X.; Liu, Z.; Hu, R.; Huang, K. 3D Object Detection Using Scale Invariant and Feature Reweighting Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9267–9274. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3Deep: Fast object detection in 3D point clouds using efficient convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics & Automation, Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3D lidar using fully convolutional network. arXiv 2016, arXiv:1608.07916. [Google Scholar]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Dou, Z.Y.; Tu, Z.; Wang, X.; Wang, L.; Zhang, S.S. Dynamic Layer Aggregation for Neural Machine Translation with Routing-by-Agreement. arXiv 2019, arXiv:1902.05770. [Google Scholar] [CrossRef]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-Aware Global Attention for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.M. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vision 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Method | ||
|---|---|---|---|
| Image | Yolov4 [45] | 31.06 | 29.78 |
| Yolov7 [20] | 83.74 | 80.65 | |
| Image + Radar | RISFNet [8] | 66.78 | 45.55 |
| LRVFNet (Ours) | 88.30 | 85.03 | |
| Image+LiDAR+Radar | RISFNet + LiDAR | 76.72 | 54.23 |
| LRVFNet (Ours) | 89.37 | 86.50 |
| Modality | Method | ||
|---|---|---|---|
| Image | Faster-RCNN [13] | 77.35 | 57.58 |
| Yolov4 [45] | 78.46 | 57.04 | |
| EfficientDet [15] | 78.62 | 58.52 | |
| FCOS [49] | 68.71 | 58.56 | |
| Image + Radar | CRF-Net [6] | 79.63 | 57.74 |
| Li et al. [35] | 85.28 | 64.64 | |
| RISFNet [8] | 90.05 | 75.09 | |
| LRVFNet (Ours) | 91.12 | 78.46 |
| Ablation Ways | ||
|---|---|---|
| only use one backbone | 82.28 | 79.15 |
| no use self attention | 87.17 | 82.32 |
| no use global attention | 86.74 | 80.07 |
| 1 scans Radar | 89.28 | 85.79 |
| 3 scans Radar | 89.37 | 86.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Y.; Liu, Y.; Luan, K.; Cheng, Y.; Chen, X.; Lu, H. Deep LiDAR-Radar-Visual Fusion for Object Detection in Urban Environments. Remote Sens. 2023, 15, 4433. https://doi.org/10.3390/rs15184433
Xiao Y, Liu Y, Luan K, Cheng Y, Chen X, Lu H. Deep LiDAR-Radar-Visual Fusion for Object Detection in Urban Environments. Remote Sensing. 2023; 15(18):4433. https://doi.org/10.3390/rs15184433
Chicago/Turabian StyleXiao, Yuhan, Yufei Liu, Kai Luan, Yuwei Cheng, Xieyuanli Chen, and Huimin Lu. 2023. "Deep LiDAR-Radar-Visual Fusion for Object Detection in Urban Environments" Remote Sensing 15, no. 18: 4433. https://doi.org/10.3390/rs15184433
APA StyleXiao, Y., Liu, Y., Luan, K., Cheng, Y., Chen, X., & Lu, H. (2023). Deep LiDAR-Radar-Visual Fusion for Object Detection in Urban Environments. Remote Sensing, 15(18), 4433. https://doi.org/10.3390/rs15184433