
A Generative Adversarial Network with Spatial Attention Mechanism for Building Structure Inference Based on Unmanned Aerial Vehicle Remote Sensing Images


Abstract
:1. Introduction
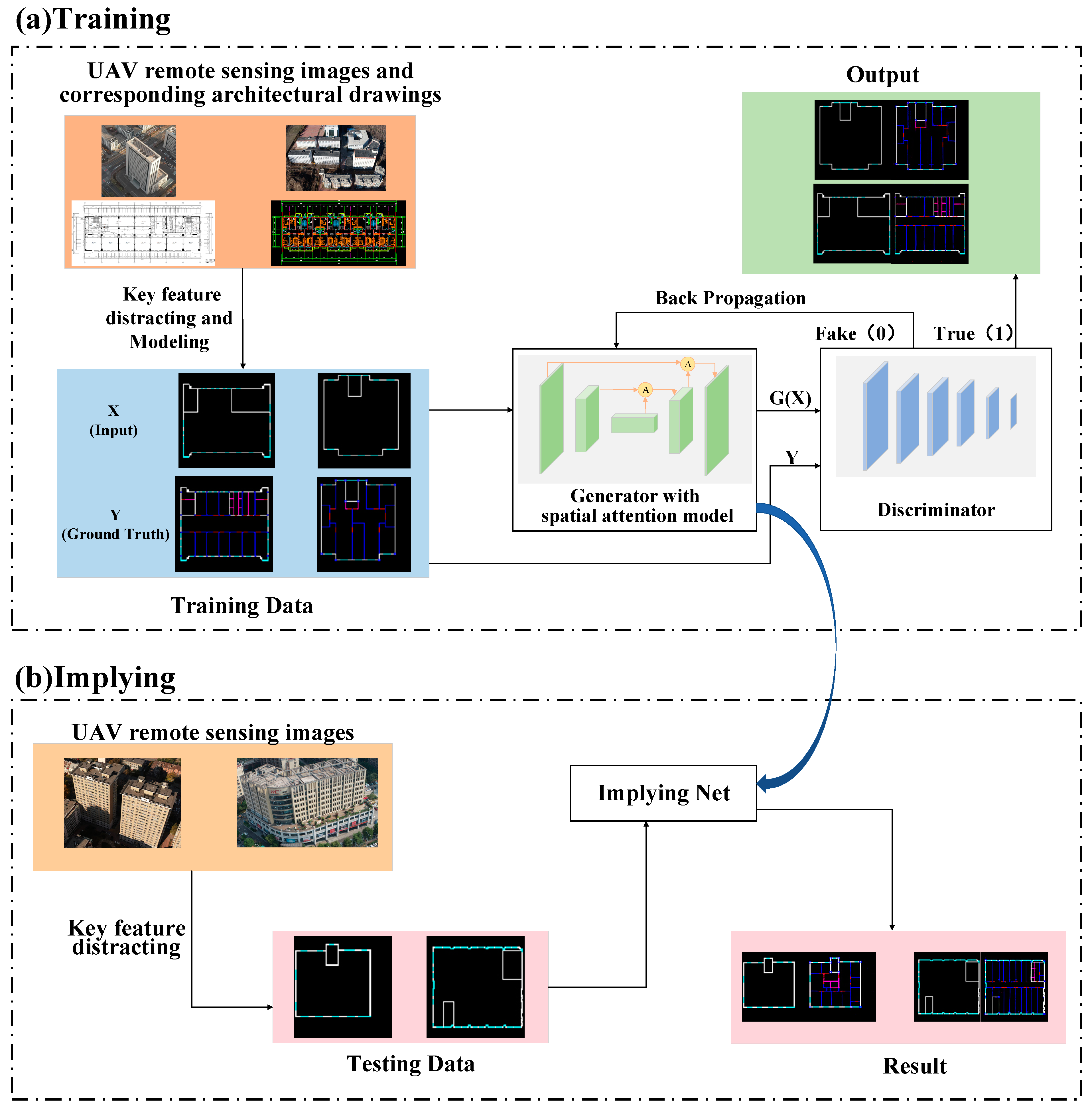
- In response to the limited research on inferring internal building floor structures using UAV remote sensing images, we propose an architecture inference network based on a PIX2PIX network backbone. The network takes the building appearance outline images as input and utilizes a trained generator for inference, achieving the specific task of inferring building structures.
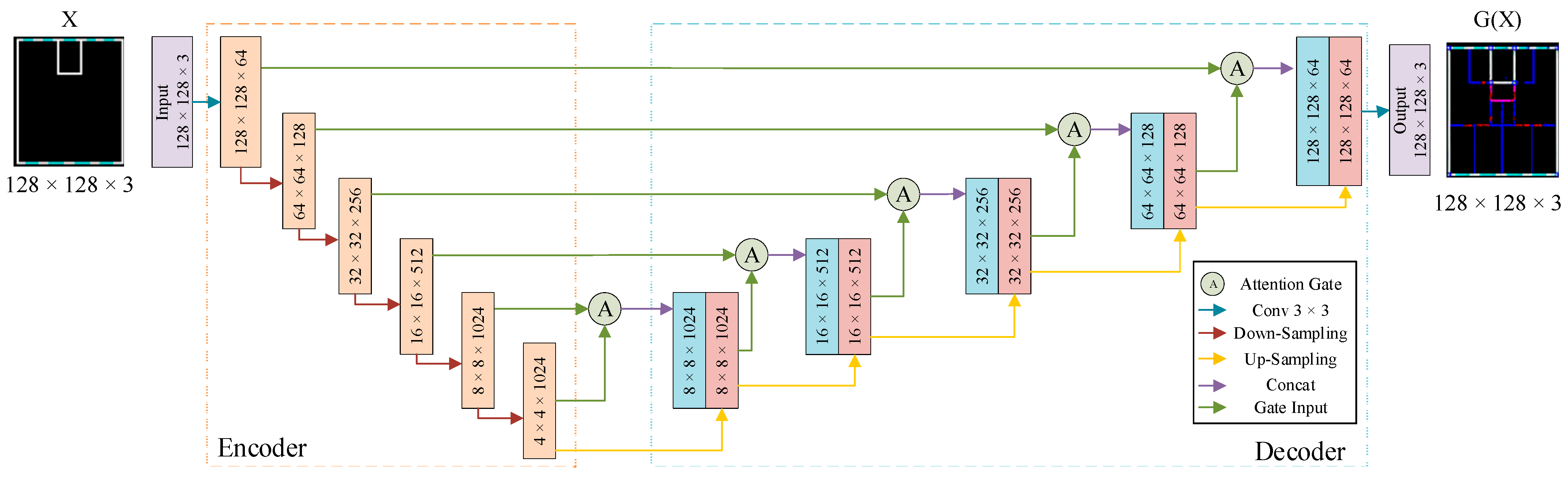
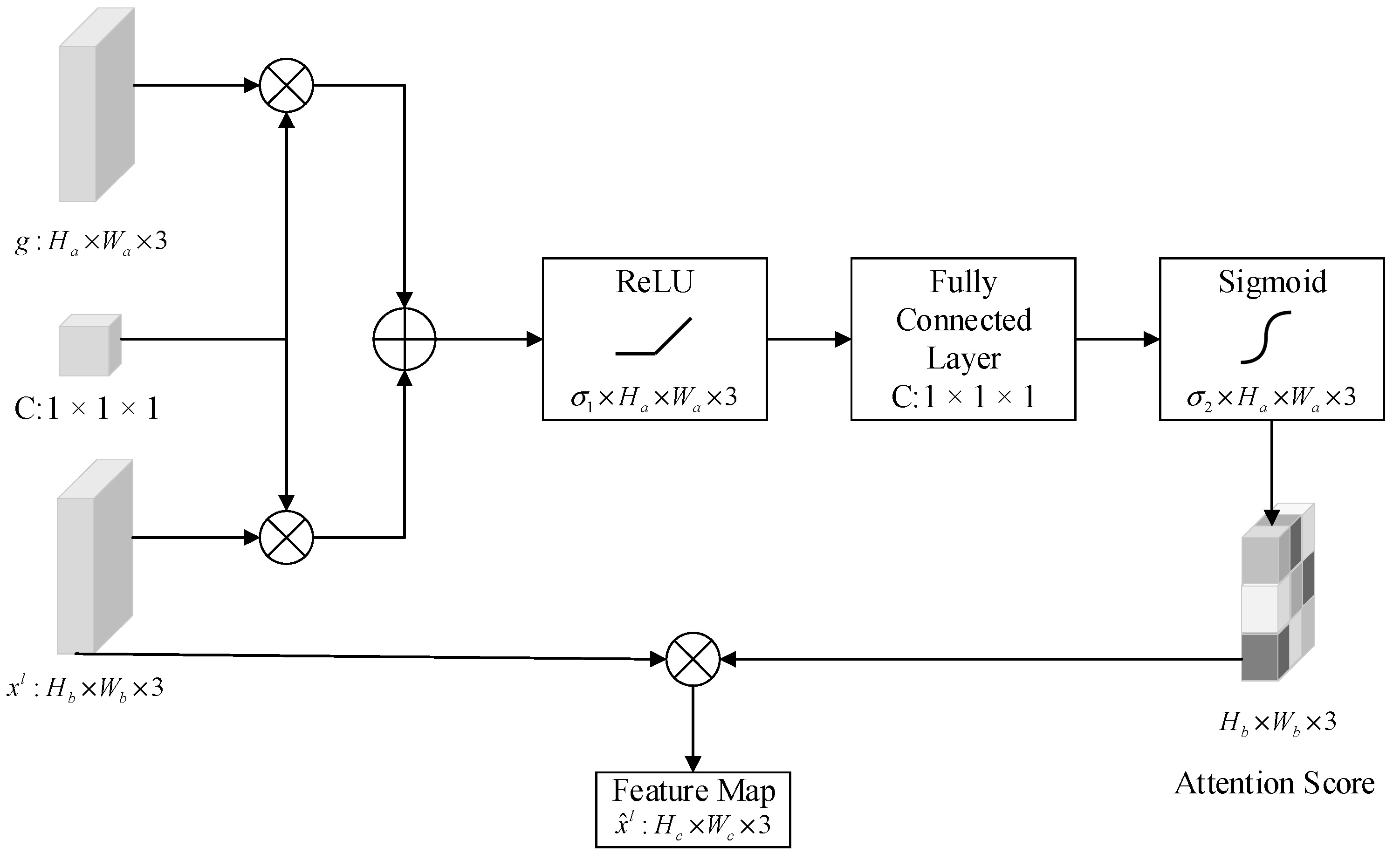
- In response to the characteristics of the dataset for this task, we introduce an adaptive attention module into the network. The inclusion of this module enhances feature extraction in the interested region, thereby avoiding the problem of global feature loss during downsampling to some extent and improving the accuracy of inference. At the same time, the introduction of the spatial attention mechanism improves computational efficiency and saves computing resources.
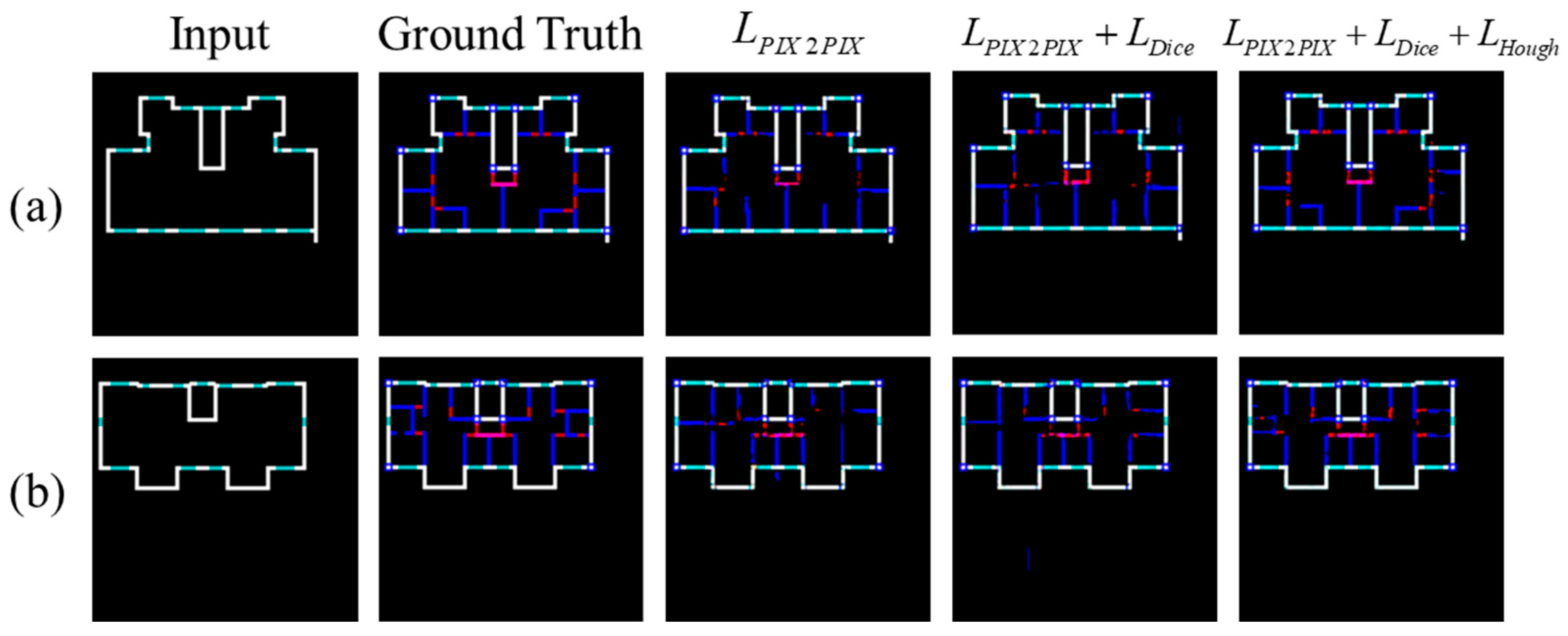
- In order to address the issue of the original loss function’s inability to effectively constrain the integrity of the results, we design a dedicated loss function that includes a penalty term for wall integrity in addition to the original loss function. Through measuring the number of intersection points after transformation in the Hough domain, this loss function can effectively constrain the results, giving sufficient attention to the integrity of the lines and walls, thereby improving the integrity of the walls in the results and increasing the accuracy of the inference.
2. Backgrounds
3. Proposed Method
3.1. Building Structure Inference Network
3.1.1. Generator
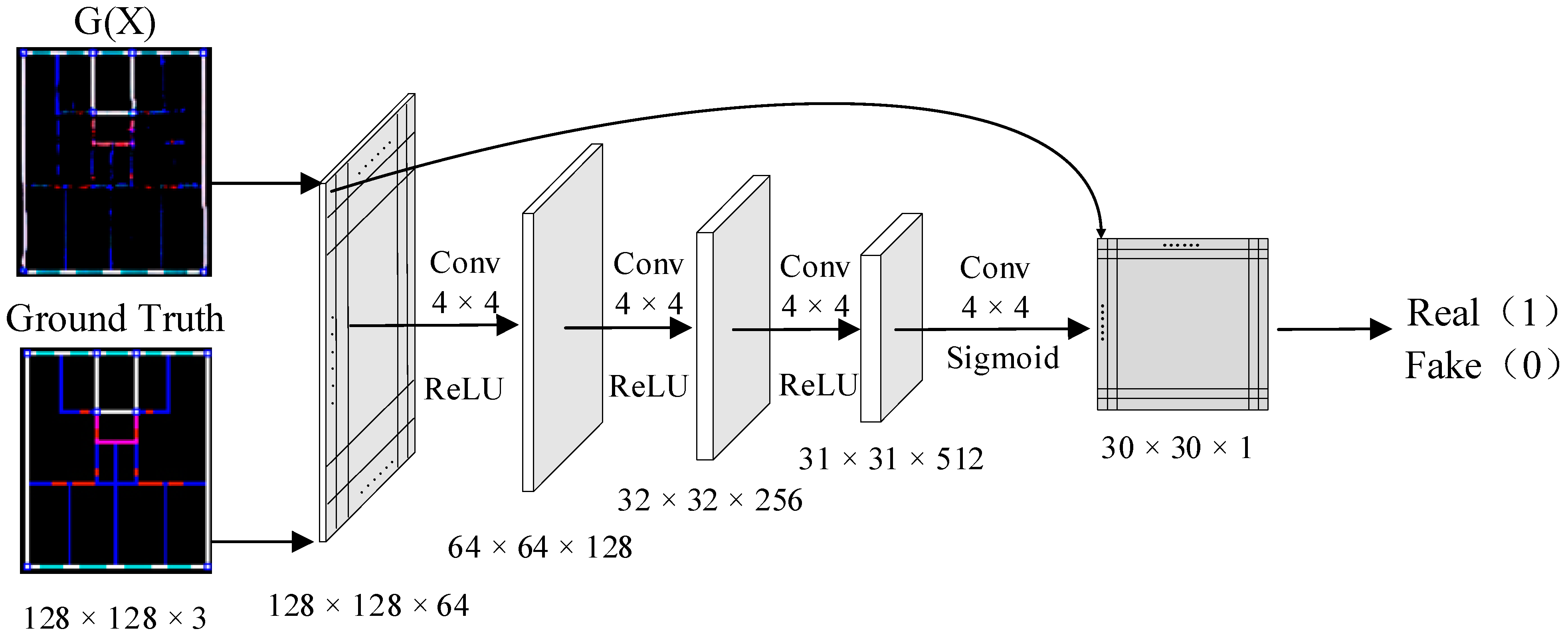
3.1.2. Discriminator
3.2. Loss Function
| Algorithm 1. Straight Lines Penalty Term |
| Input: Ground truth X and generator result Y Step 1. Converting X and Y into binary images and . Step 2. Transforming and into the Hough domain.
|
4. Experiments and Results
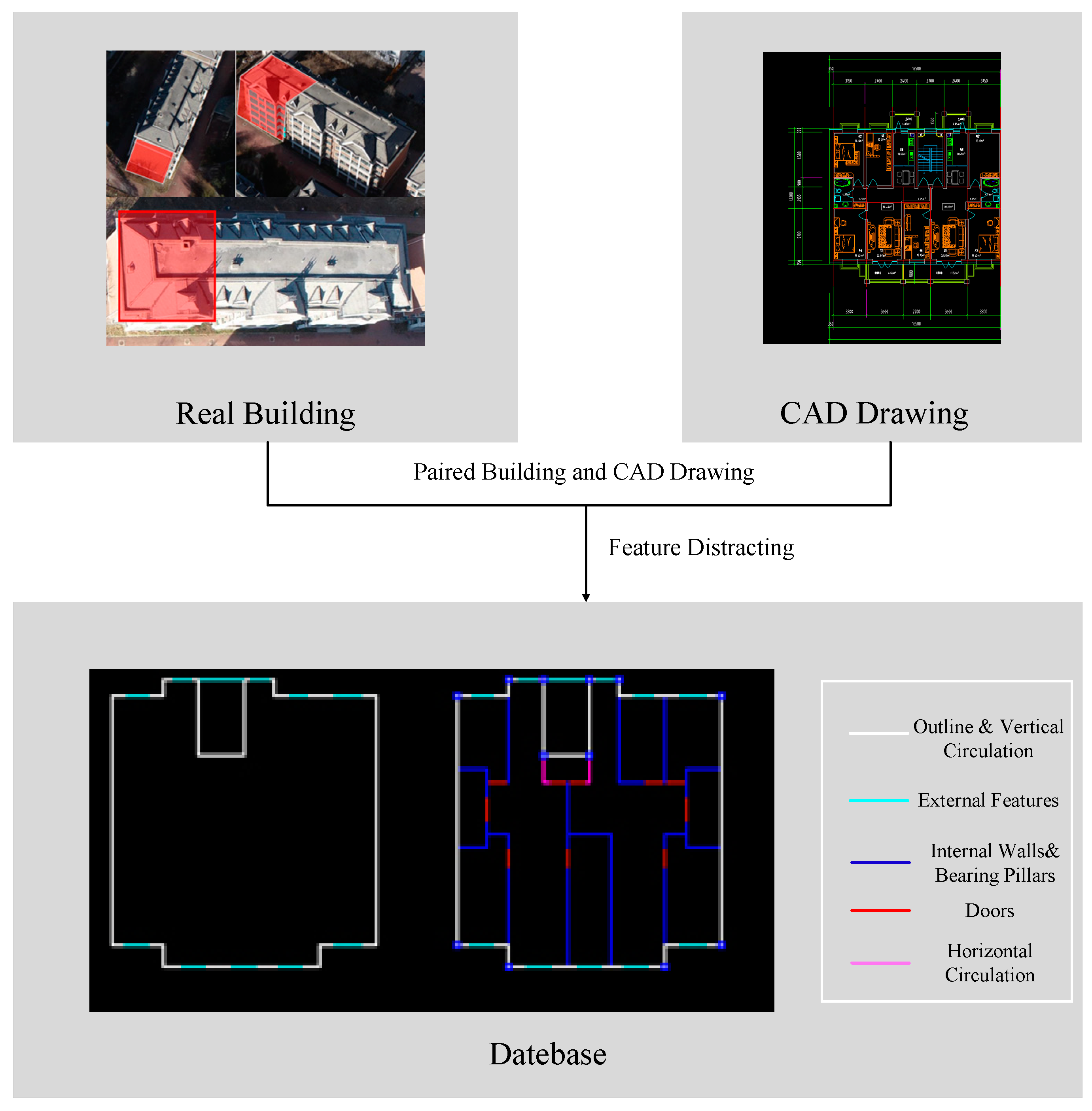
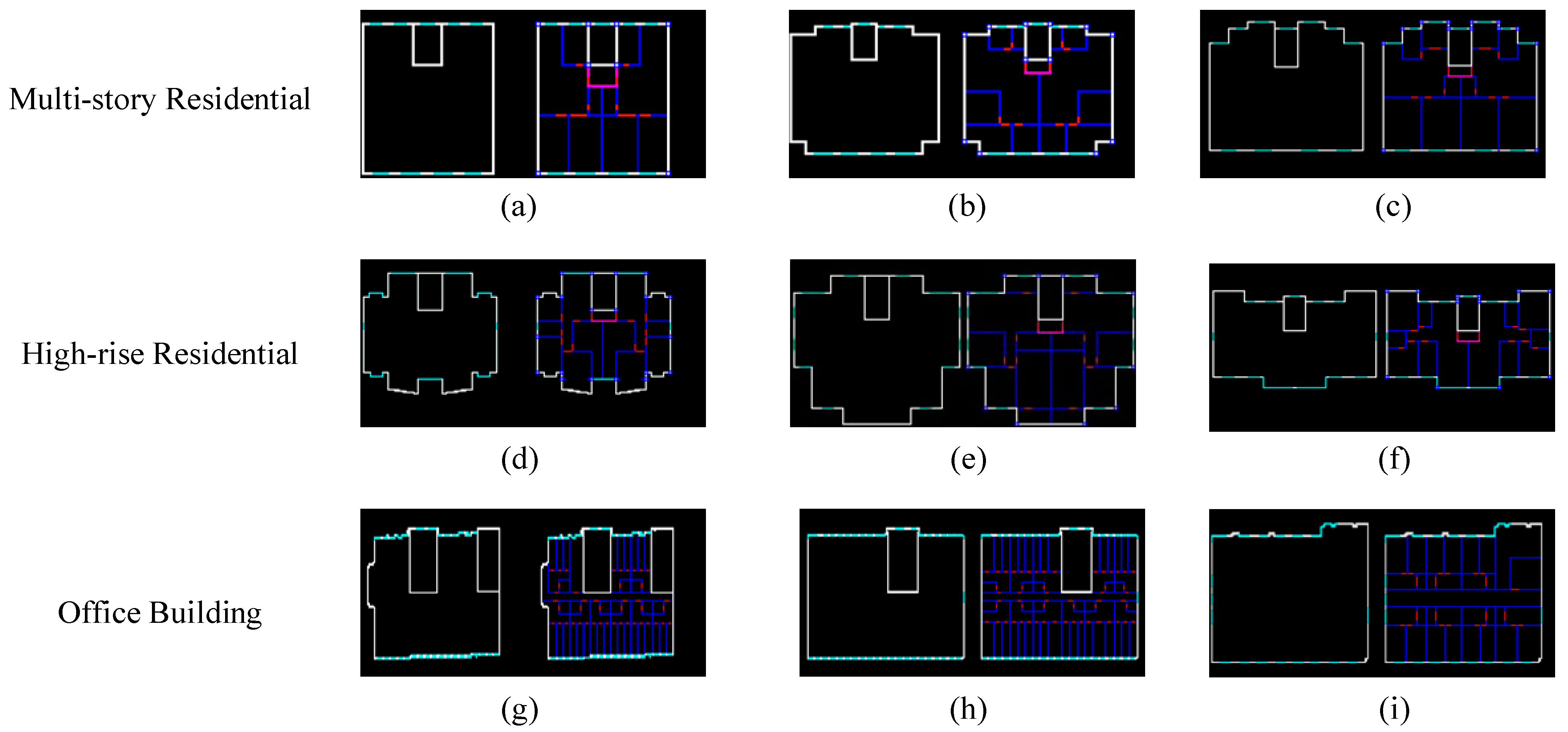
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experiment Settings
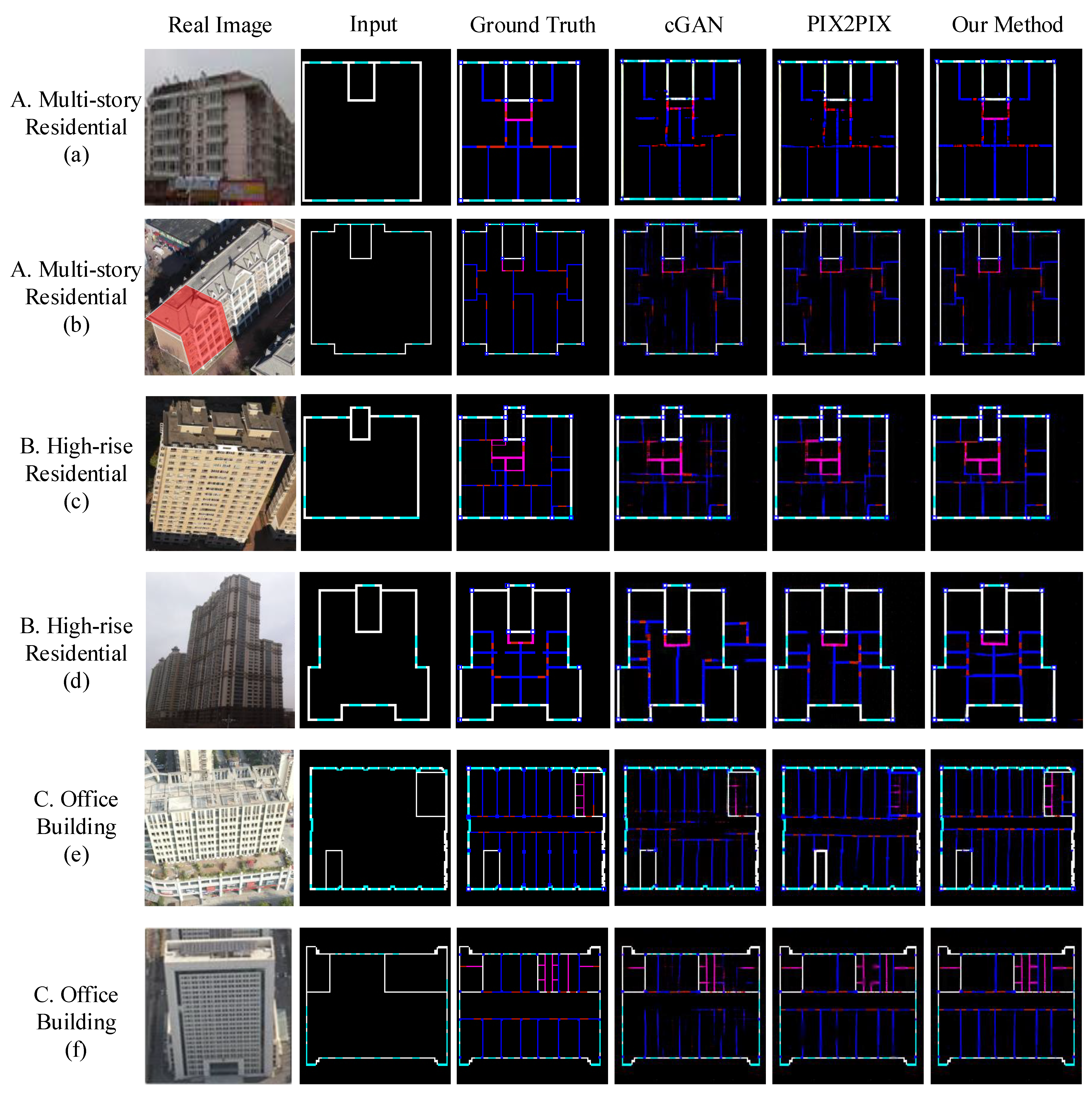
4.4. Results and Analysis
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jia, H.; Song, Y.; Chen, X.; Liu, S.; Zhang, B. Seismic Performance Evaluation of a High-Rise Building with Structural Irregularities. Buildings 2022, 12, 1484. [Google Scholar] [CrossRef]
- Akbas, B.; Shen, J.; Hao, H. Energy appproach in peformance-based seismic design of steel moment resisting frames for basic safety objective. Struct. Des. Tall Build. 2001, 10, 193–217. [Google Scholar] [CrossRef]
- Li, W.; Li, Q.-N.; Jiang, W.-S.; Jiang, L. Seismic performance of composite reinforced concrete and steel moment frame structures–state-of-the-art. Compos. B Eng. 2011, 42, 190–206. [Google Scholar] [CrossRef]
- De Domenico, D.; Messina, D.; Recupero, A. Seismic vulnerability assessment of reinforced concrete bridge piers with corroded bars. Struct. Concr. 2023, 24, 56–83. [Google Scholar] [CrossRef]
- Lott, G. Sourcing stone for the conservation and repair of historical buildings in Britain. Q. J. Eng. Geol. Hydrogeol. 2013, 46, 405–420. [Google Scholar] [CrossRef]
- Colomina, I.; Molina, P. Unmanned aerial systems for photogrammetry and remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2014, 92, 79–97. [Google Scholar] [CrossRef]
- Simic Milas, A.; Cracknell, A.P.; Warner, T.A. Drones–the third generation source of remote sensing data. Int. J. Remote Sens. 2018, 39, 7125–7137. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Sam, L.; Martín-Torres, F.J.; Kumar, R. UAVs as remote sensing platform in glaciology: Present applications and future prospects. Remote Sens. Environ. 2016, 175, 196–204. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y.; Chen, W. UAV Aerial Image Generation of Crucial Components of High-Voltage Transmission Lines Based on Multi-Level Generative Adversarial Network. Remote Sens. 2023, 15, 1412. [Google Scholar] [CrossRef]
- Macé, S.; Locteau, H.; Valveny, E.; Tabbone, S. A system to detect rooms in architectural floor plan images. In Proceedings of the 9th IAPR International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010; pp. 167–174. [Google Scholar]
- Ahmed, S.; Liwicki, M.; Weber, M.; Dengel, A. Improved automatic analysis of architectural floor plans. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 864–869. [Google Scholar]
- De Las Heras, L.-P.; Fernández, D.; Valveny, E.; Lladós, J.; Sánchez, G. Unsupervised wall detector in architectural floor plans. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1245–1249. [Google Scholar]
- Gimenez, L.; Robert, S.; Suard, F.; Zreik, K. Automatic reconstruction of 3D building models from scanned 2D floor plans. Autom. Constr. 2016, 63, 48–56. [Google Scholar] [CrossRef]
- Jang, H.; Yang, J.H.; Kiyun, Y. Automatic wall detection and building topology and property of 2D floor plan (short paper). In Proceedings of the 10th International Conference on Geographic Information Science (GIScience 2018), Melbourne, Australia, 28–31 August 2018. [Google Scholar]
- Dalal, A.-A.; Al-qaness, M.A.; Cai, Z.; Alawamy, E.A. IDA: Improving distribution analysis for reducing data complexity and dimensionality in hyperspectral images. Pattern Recognit. 2023, 134, 109096. [Google Scholar]
- Dodge, S.; Xu, J.; Stenger, B. Parsing floor plan images. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 358–361. [Google Scholar]
- Liu, C.; Wu, J.; Kohli, P.; Furukawa, Y. Raster-to-vector: Revisiting floorplan transformation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2195–2203. [Google Scholar]
- Lee, C.-Y.; Badrinarayanan, V.; Malisiewicz, T.; Rabinovich, A. Roomnet: End-to-end room layout estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4865–4874. [Google Scholar]
- Huang, W.; Zheng, H. Architectural drawings recognition and generation through machine learning. In Proceedings of the 38th Annual Conference of the Association for Computer Aided Design in Architecture, Mexico City, Mexico, 18–20 October 2018; pp. 18–20. [Google Scholar]
- Yamasaki, T.; Zhang, J.; Takada, Y. Apartment structure estimation using fully convolutional networks and graph model. In Proceedings of the 2018 ACM Workshop on Multimedia for Real Estate Tech, Yokohama, Japan, 11 June 2018; pp. 1–6. [Google Scholar]
- Friedman, G.M.; Gebelein, C.D.; Sanders, J.E. Micritic envelopes of carbonate grains are not exclusively of photosynthetic algal origin. Sedimentology 1971, 16, 89–96. [Google Scholar] [CrossRef]
- Stiny, G. Introduction to shape and shape grammars. Environ. Plann. B Plann. Des. 1980, 7, 343–351. [Google Scholar] [CrossRef]
- Schwarz, M.; Müller, P. Advanced procedural modeling of architecture. ACM Trans. Graph. 2015, 34, 107. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Nauata, N.; Chang, K.-H.; Cheng, C.-Y.; Mori, G.; Furukawa, Y. House-gan: Relational generative adversarial networks for graph-constrained house layout generation. In Computer Vision—ECCV 2020 Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part I 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 162–177. [Google Scholar]
- Chang, K.-H.; Cheng, C.-Y.; Luo, J.; Murata, S.; Nourbakhsh, M.; Tsuji, Y. Building-GAN: Graph-conditioned architectural volumetric design generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 11956–11965. [Google Scholar]
- Nauata, N.; Hosseini, S.; Chang, K.-H.; Chu, H.; Cheng, C.-Y.; Furukawa, Y. House-gan++: Generative adversarial layout refinement network towards intelligent computational agent for professional architects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13632–13641. [Google Scholar]
- Jiang, F.; Ma, J.; Webster, C.J.; Li, X.; Gan, V.J. Building layout generation using site-embedded GAN model. Autom. Constr. 2023, 151, 104888. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784 2014. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 8th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part III 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 702–716. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Wu, W.; Fu, X.-M.; Tang, R.; Wang, Y.; Qi, Y.-H.; Liu, L. Data-driven interior plan generation for residential buildings. ACM Trans. Graph. 2019, 38, 234. [Google Scholar] [CrossRef]
- Peters, N. Enabling Alternative Architectures: Collaborative Frameworks for Participatory Design. Harvard University Graduate School of Design: Cambridge, MA, USA, 2018. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Multi-Story Residential | High-Rise Residential | Office Building | ||||
|---|---|---|---|---|---|---|
| RMSE (Pixel) | IoU | RMSE (Pixel) | IoU | RMSE (Pixel) | IoU | |
| cGAN | 2.093 ± 0.214 | 0.525 ± 0.066 | 2.017 ± 0.196 | 0.549 ± 0.062 | 1.708 ± 0.202 | 0.408 ± 0.059 |
| PIX2PIX | 1.461 ± 0.158 | 0.682 ± 0.054 | 1.433 ± 0.147 | 0.677 ± 0.058 | 1.115 ± 0.136 | 0.495 ± 0.050 |
| Our method | 1.281 ± 0.135 | 0.832 ± 0.051 | 1.238 ± 0.129 | 0.814 ± 0.049 | 1.030 ± 0.095 | 0.682 ± 0.051 |
| Method | Params | Training Time (min) |
|---|---|---|
| cGAN | 25.7 M | 19.3 |
| PIX2PIX | 44.6 M | 44.1 |
| Our method | 101.1 M | 129.6 |
| Multi-Story Residential | High-Rise Residential | Office Building | ||||
|---|---|---|---|---|---|---|
| RMSE (Pixel) | IoU | RMSE (Pixel) | IoU | RMSE (Pixel) | IoU | |
| 1.426 ± 0.145 | 0.707 ± 0.069 | 1.415 ± 0.139 | 0.692 ± 0.065 | 1.096 ± 0.098 | 0.513 ± 0.050 | |
| 1.403 ± 0.143 | 0.749 ± 0.072 | 1.392 ± 0.136 | 0.755 ± 0.068 | 0.986 ± 0.090 | 0.641 ± 0.061 | |
| 1.281 ± 0.135 | 0.832 ± 0.051 | 1.218 ± 0.129 | 0.814 ± 0.049 | 1.030 ± 0.095 | 0.682 ± 0.051 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Guo, Z.; Meng, X.; He, F. A Generative Adversarial Network with Spatial Attention Mechanism for Building Structure Inference Based on Unmanned Aerial Vehicle Remote Sensing Images. Remote Sens. 2023, 15, 4390. https://doi.org/10.3390/rs15184390
Chen H, Guo Z, Meng X, He F. A Generative Adversarial Network with Spatial Attention Mechanism for Building Structure Inference Based on Unmanned Aerial Vehicle Remote Sensing Images. Remote Sensing. 2023; 15(18):4390. https://doi.org/10.3390/rs15184390
Chicago/Turabian StyleChen, Hao, Zhixiang Guo, Xing Meng, and Fachuan He. 2023. "A Generative Adversarial Network with Spatial Attention Mechanism for Building Structure Inference Based on Unmanned Aerial Vehicle Remote Sensing Images" Remote Sensing 15, no. 18: 4390. https://doi.org/10.3390/rs15184390
APA StyleChen, H., Guo, Z., Meng, X., & He, F. (2023). A Generative Adversarial Network with Spatial Attention Mechanism for Building Structure Inference Based on Unmanned Aerial Vehicle Remote Sensing Images. Remote Sensing, 15(18), 4390. https://doi.org/10.3390/rs15184390