


Optical Remote Sensing Ship Recognition and Classification Based on Improved YOLOv5



Abstract
:1. Introduction
2. Related Work
2.1. Object Detection Algorithms
2.2. Ship Target Detection Algorithms
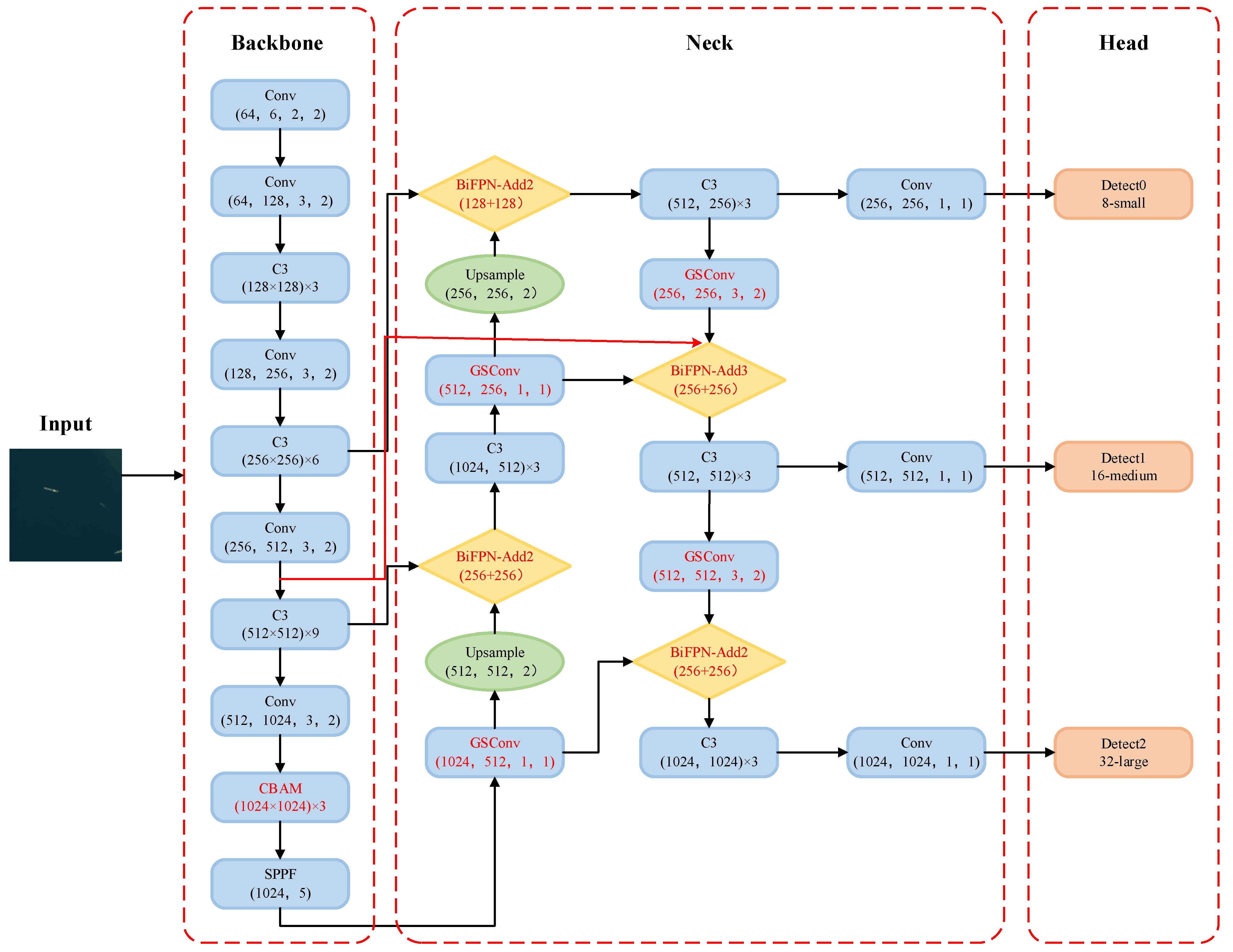
- Adding the Convolutional Block Attention Module (CBAM) [20] in the backbone network to focus on regions of interest, suppress useless information and improve the feature extraction capability;
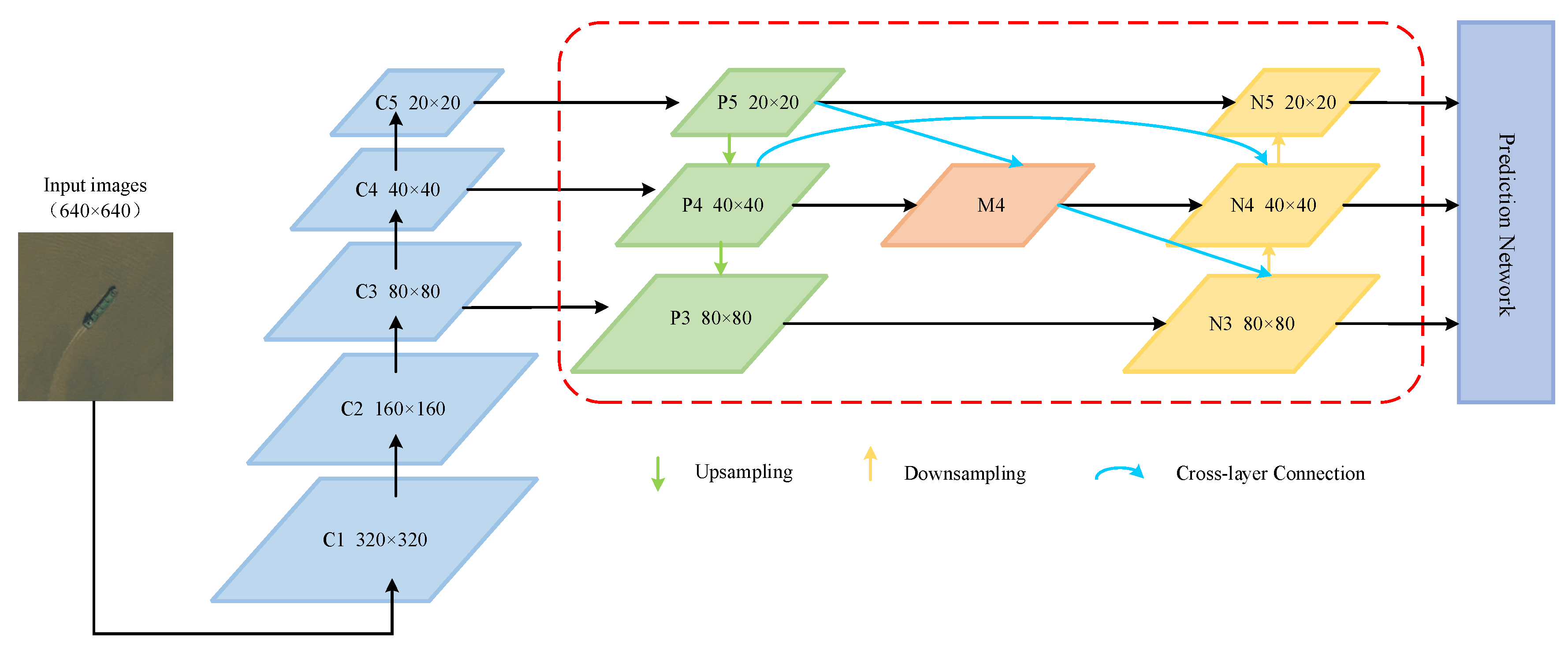
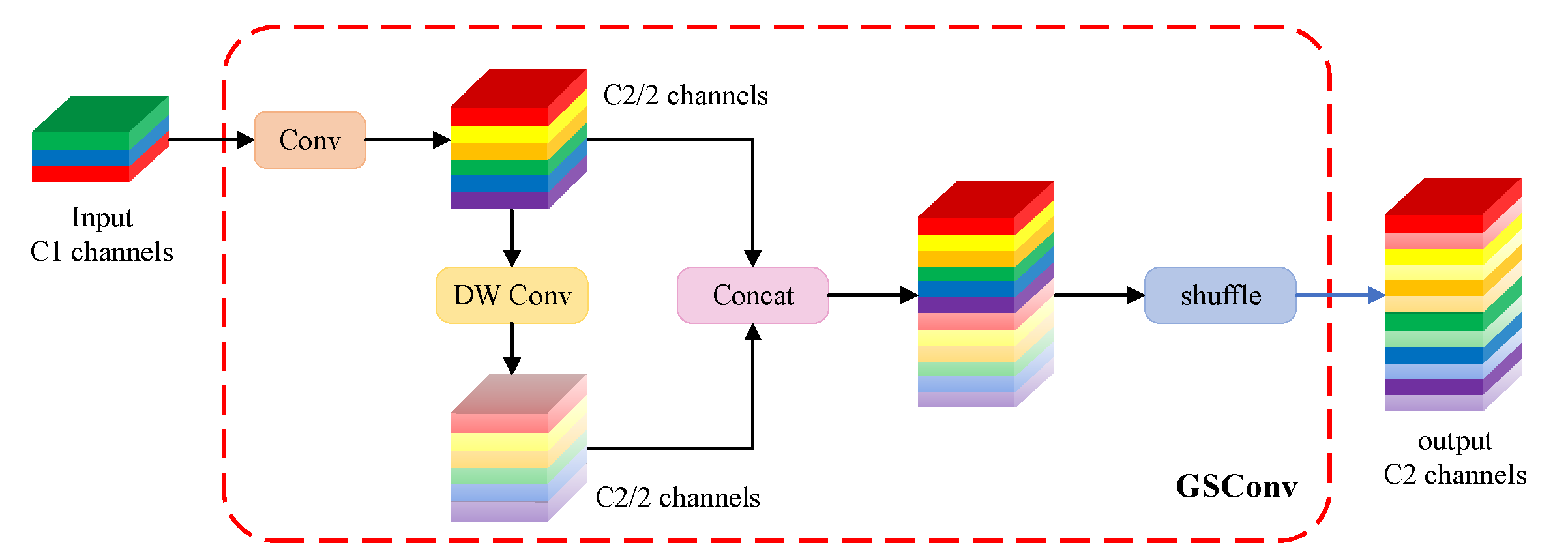
- Inspired by the Weighted Bi-directional Feature Pyramid Network (BiFPN) [21], adding an additional cross-layer connection channel in the Neck to enhance multi-scale feature fusion. Moreover, the lightweight GSConv structure [22] is introduced to replace conventional Conv, reducing the model parameters and accelerating convergence speed.
- The Wise-IoU loss function [23] is employed as the localization loss function at the Output to reduce the competitiveness of high-quality anchor boxes and mask the harmful gradients of low-quality examples.
- During the preprocessing stage of experimental data, a median+bilateral filter method is used to reduce noise, such as water ripples and waves, and to highlight the ship feature information.
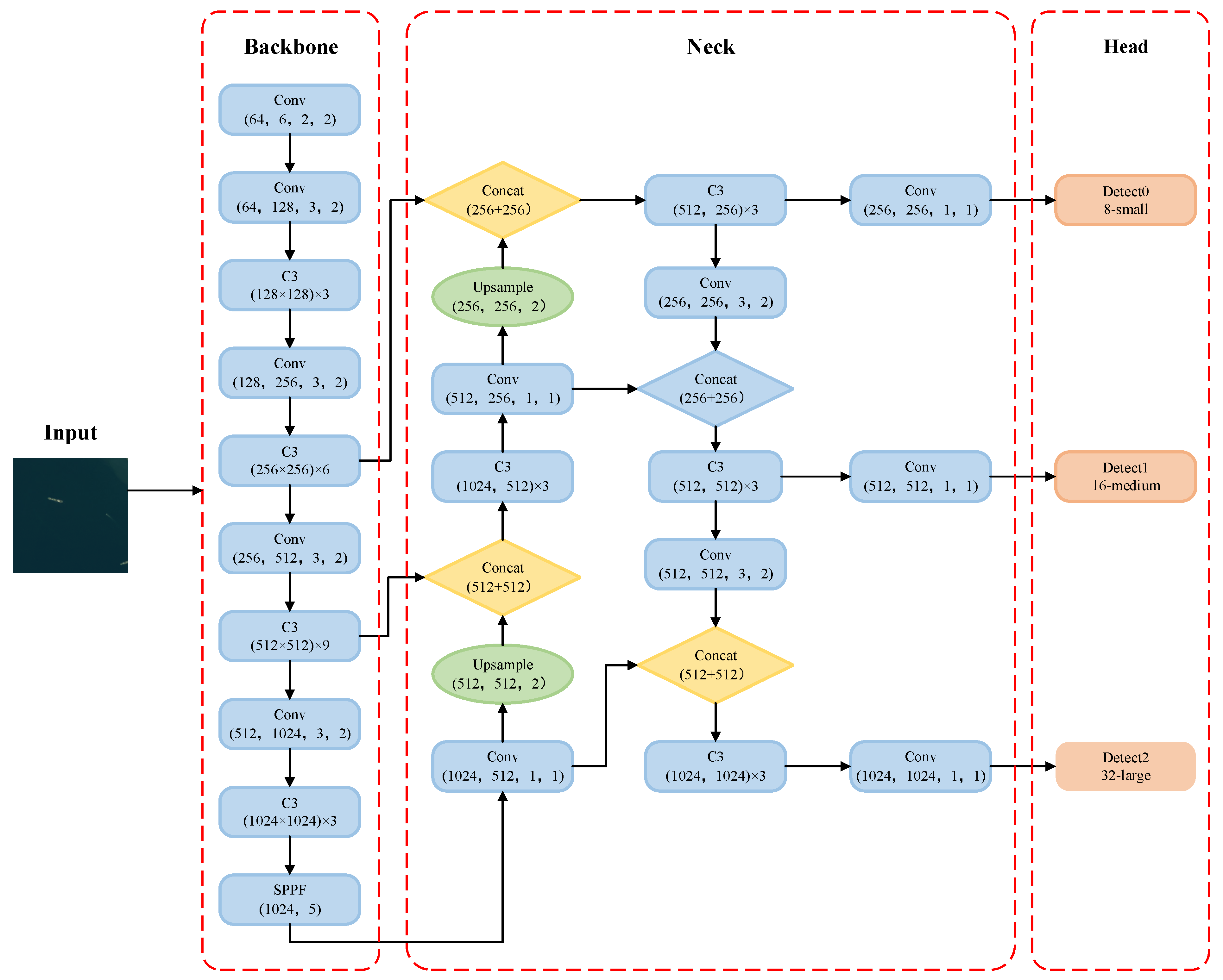
3. YOLOv5 Target Detection Algorithm
3.1. Network Structure
3.2. Loss Function
4. Improved-YOLOv5 Target Detection Algorithm
4.1. CBAM Attention Module
4.2. Multi-Scale Feature Fusion
4.2.1. BiFPN Network
4.2.2. GSConv Structure
4.3. Loss Function
5. Experimental Results and Analysis
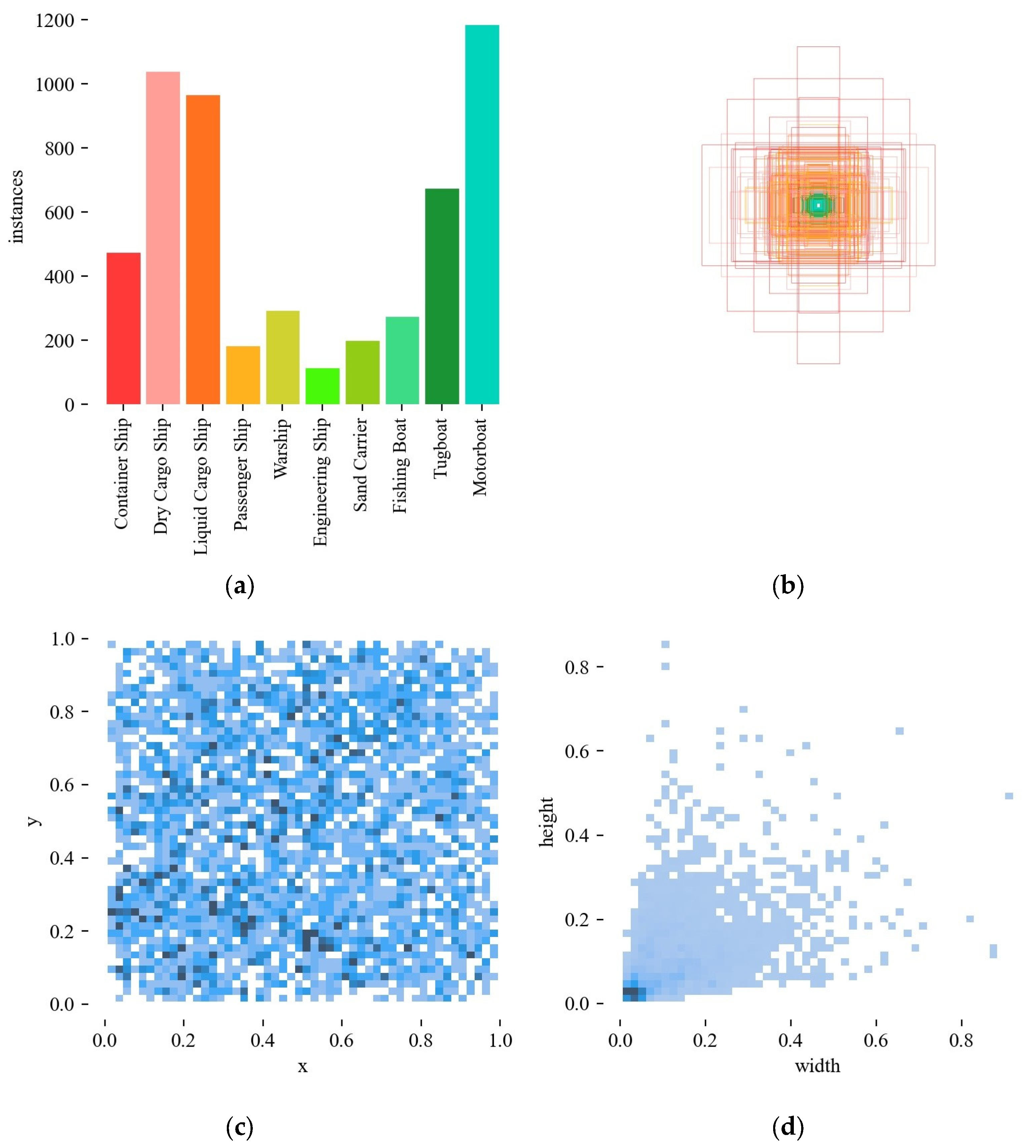
5.1. Experimental Dataset
5.2. Experimental Platform and Parameters Setting
5.3. Image Preprocessing
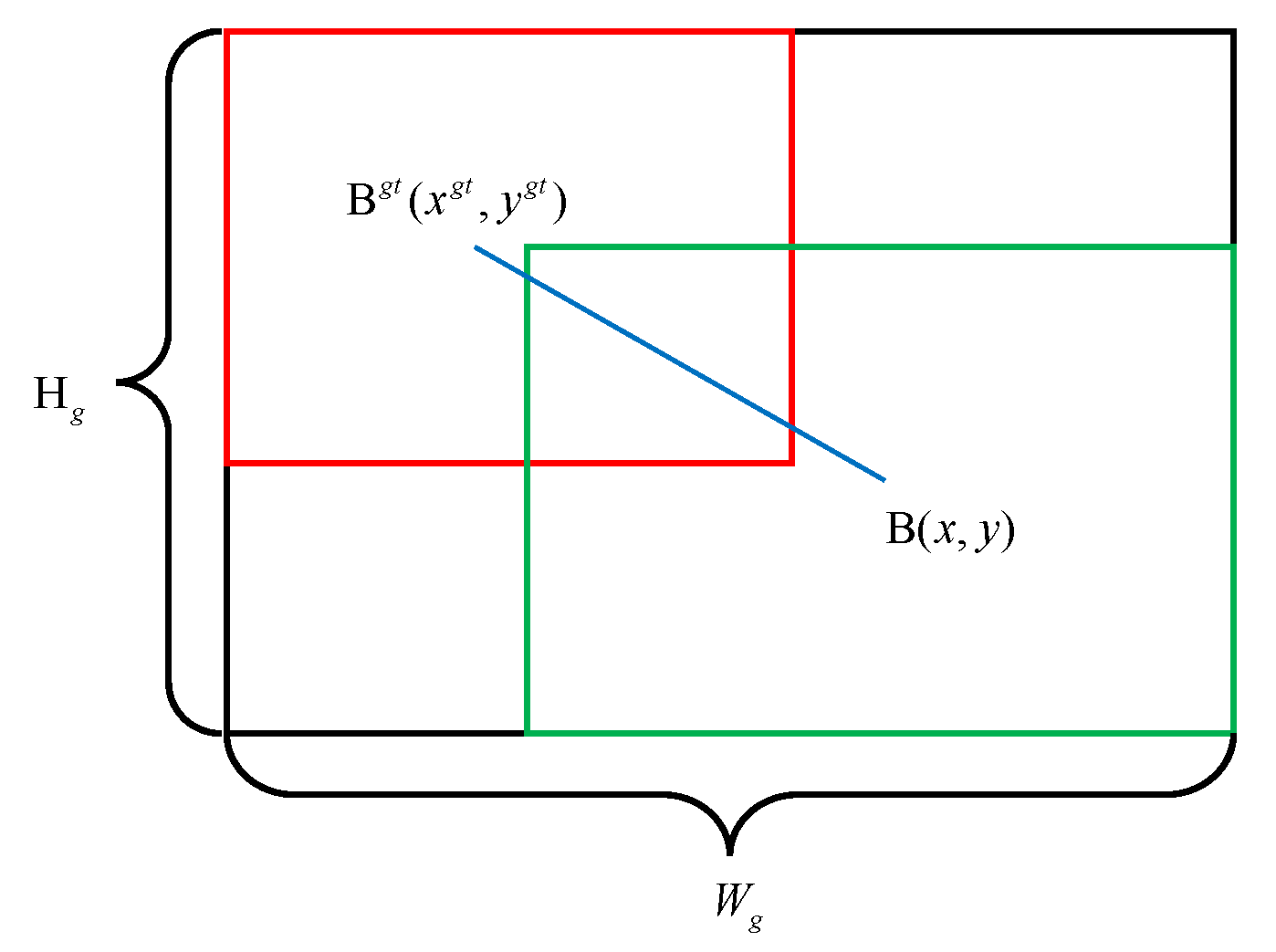
5.4. Evaluation Metrics
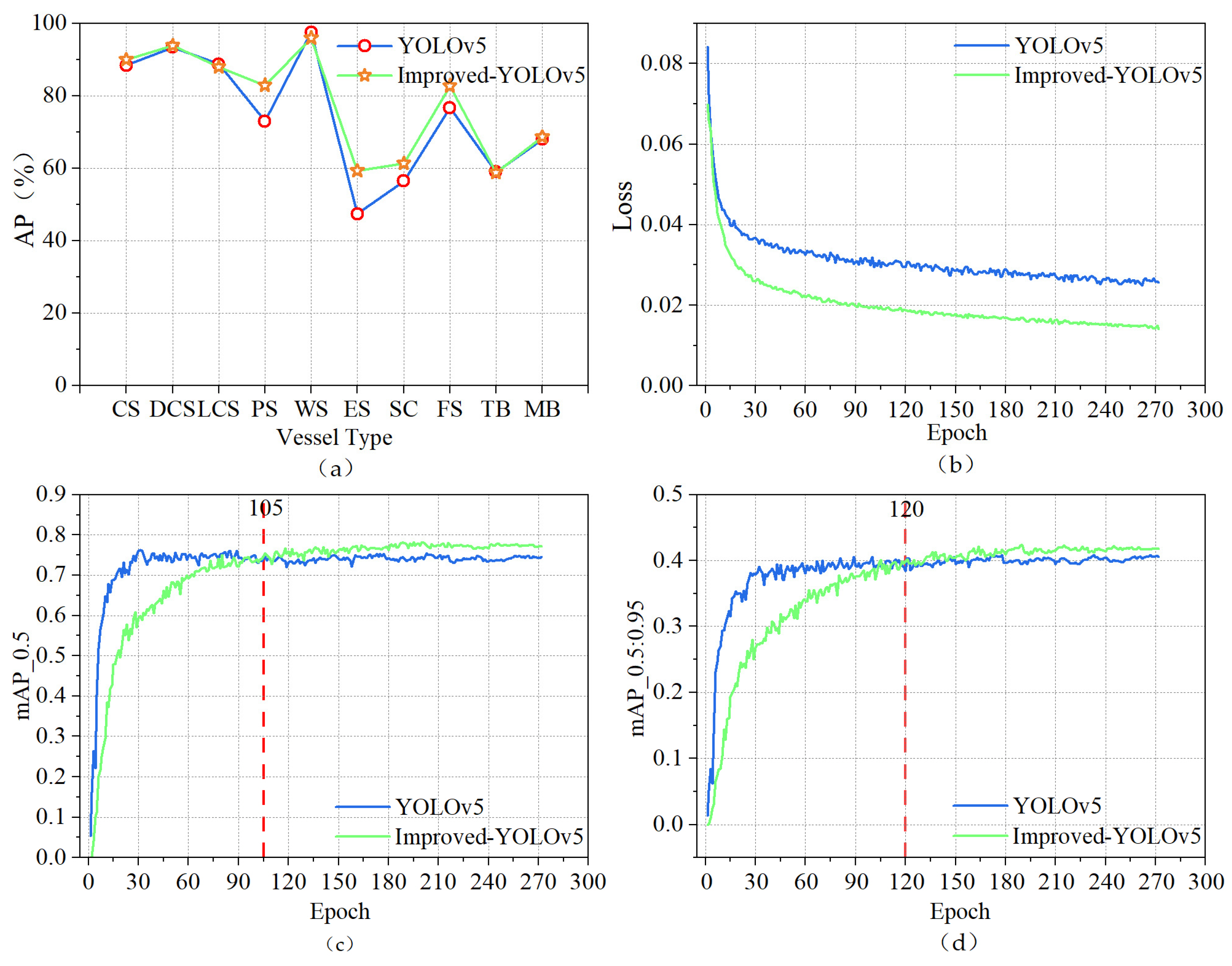
5.5. Ablation Experiment
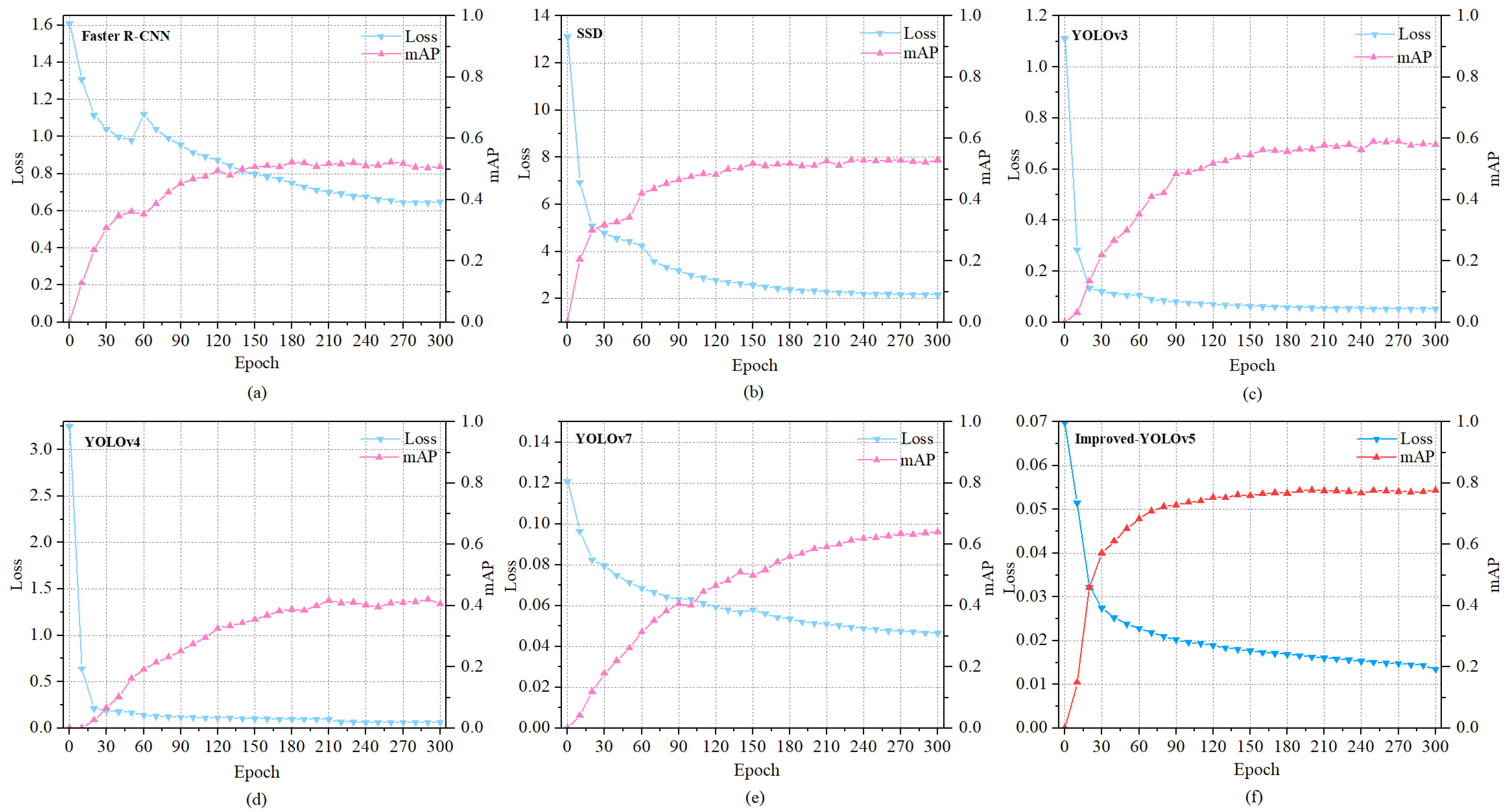
5.6. Performance Comparison of Various Target Detection Algorithms
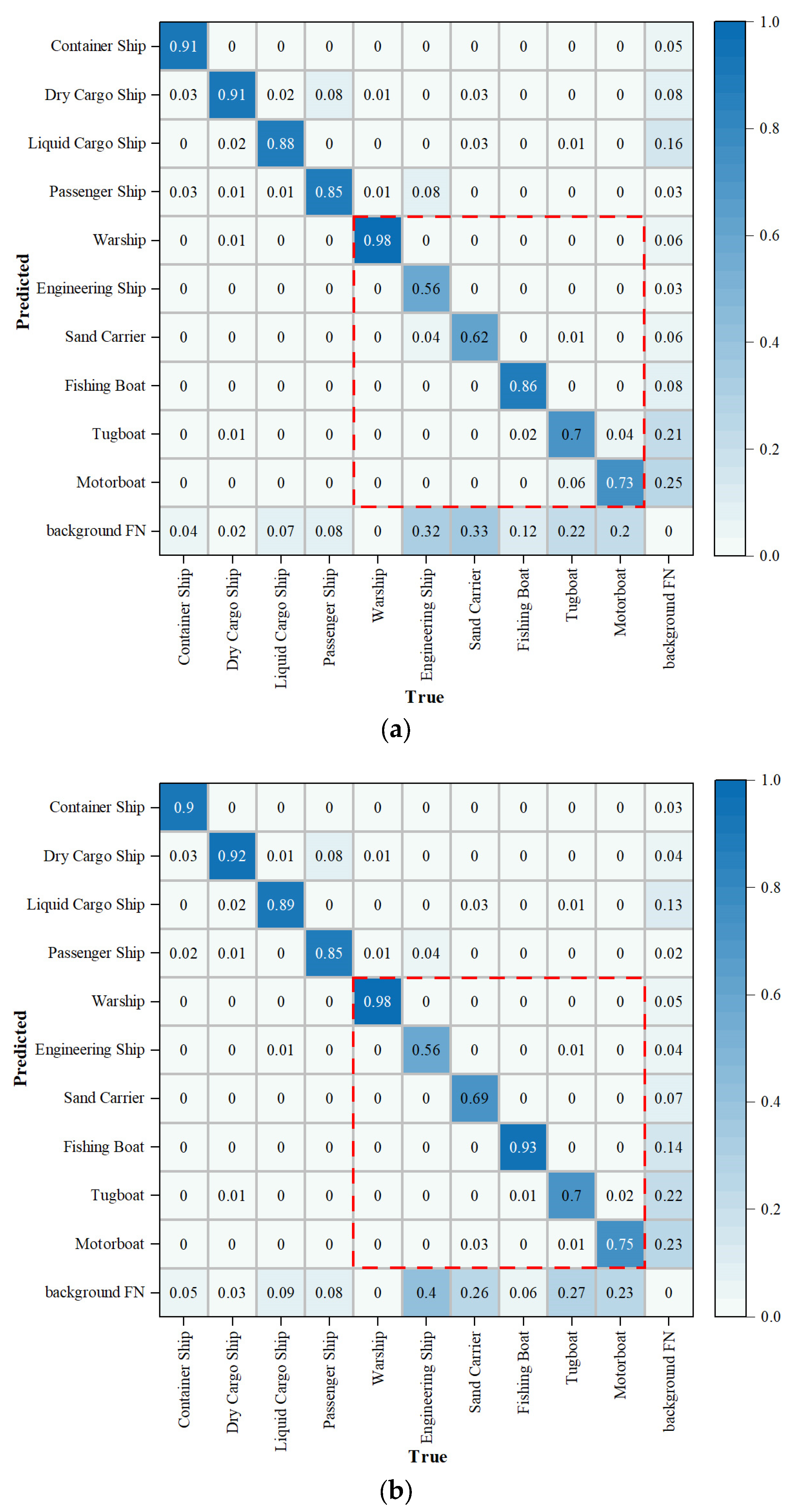
5.7. Comparison of Detection Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, B.; Dong, L.L.; Zhao, M.; Wu, H.D.; Ji, Y.Y.; Xu, W.H. An infrared maritime target detection algorithm applicable to heavy sea fog. Infrared Phys. Technol. 2015, 71, 56–62. [Google Scholar] [CrossRef]
- Zhao, E.Z.; Dong, L.L.; Dai, H. Infrared Maritime Small Target Detection Based on Multidirectional Uniformity and Sparse-Weight Similarity. Remote Sens. 2022, 14, 5492. [Google Scholar] [CrossRef]
- Yang, P.; Dong, L.; Xu, H.; Dai, H.; Xu, W. Robust Infrared Maritime Target Detection via Anti-Jitter Spatial–Temporal Trajectory Consistency. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Lang, H.T.; Wang, R.F.; Zheng, S.Y.; Wu, S.W.; Li, J.L. Ship Classification in SAR Imagery by Shallow CNN Pre-Trained on Task-Specific Dataset with Feature Refinement. Remote Sens. 2022, 14, 5986. [Google Scholar] [CrossRef]
- Liu, P.F.; Wang, Q.; Zhang, H.; Mi, J.; Liu, Y.C. A Lightweight Object Detection Algorithm for Remote Sensing Images Based on Attention Mechanism and YOLOv5s. Remote Sens. 2023, 15, 2429. [Google Scholar] [CrossRef]
- Nie, G.T.; Huang, H. A Survey of Object Detection in Optical Remote Sensing Images. Acta Anat. Sin. 2021, 47, 1749–1768. [Google Scholar]
- Li, K.; Fan, Y. Research on Ship Image Recognition Based on Improved Convolution Neural Network. Ship Sci. Tech. 2021, 43, 187–189. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (ICCV), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE international Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 17 September 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Kumar, S.; Divvala, K.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, P.P.; Xie, G.K.; Zhang, J.S. Gaussian Function Fusing Fully Convolutional Network and Region Proposal-Based Network for Ship Target Detection in SAR Images. Int. J. Antenn. Propag. 2022, 2022, 3063965. [Google Scholar] [CrossRef]
- Wen, G.Q.; Cao, P.; Wang, H.N.; Chen, H.L.; Liu, X.L.; Xu, J.H.; Zaiane, O. MS-SSD: Multi-scale single shot detector for ship detection in remote sensing image. Appl. Intell. 2023, 53, 1586–1604. [Google Scholar] [CrossRef]
- Chen, L.Q.; Shi, W.X.; Deng, D.X. Improved YOLOv3 Based on Attention Mechanism for Fast and Accurate Ship Detection in Optical Remote Sensing Images. Remote Sens. 2021, 13, 660. [Google Scholar] [CrossRef]
- Huang, Z.X.; Jiang, X.N.; Wu, F.L.; Fu, Y.; Zhang, Y.; Fu, T.J.; Pei, J.Y. An Improved Method for Ship Target Detection Based on YOLOv4. Appl. Sci. 2023, 13, 1302. [Google Scholar] [CrossRef]
- Zhou, J.C.; Jiang, P.; Zou, A.; Chen, X.L.; Hu, W.W. Ship Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2021, 9, 908. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Filaretov, V.F.; Yukhimets, D.A. Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images. Remote Sens. 2023, 15, 2071. [Google Scholar] [CrossRef]
- Dong, Z.; Lin, B.J. Learning a robust CNN-based rotation insensitive model for ship detection in VHR remote sensing images. Int. J. Remote Sens. 2020, 41, 3614–3626. [Google Scholar] [CrossRef]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), New York, NY, USA, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Tan, M.; Pnag, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Li, H.L.; Li, J.; Wei, H.B.; Liu, Z.; Zhan, Z.F.; Ren, Q.L. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Tong, Z.J.; Chen, Y.H.; Xu, Z.W.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. In Proceedings of the IEEE Transactions on Circuits and Systems for Video Technology, February 2023; Available online: https://arxiv.org/abs/2301.10051 (accessed on 31 May 2023).
- Wang, Z.; Wu, L.; Li, T.; Shi, P.B. A Smoke Detection Model Based on Improved YOLOv5. Mathematics 2022, 10, 1190. [Google Scholar] [CrossRef]
- Malta, A.; Mendes, M.; Farinha, T. Augmented Reality Maintenance Assistant Using YOLOv5. Appl. Sci. 2021, 11, 4758. [Google Scholar] [CrossRef]
- Wang, C.Y.; Markliao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.P.; Jia, J.Y. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhang, X.P.; Xu, Z.Y.; Qu, J.; Qiu, W.X.; Zhai, Z.Y. Maritime Ship Recognition Based on Improved YOLOv5 Deep Learning Algorithm. J. Dalian Ocean Univ. 2022, 37, 866–872. [Google Scholar]
- Jiang, B.R.; Luo, R.X.; Mao, J.Y.; Xiao, T.; Jiang, Y.N. Acquisition of localization confidence for accurate objection. In Computer Vision-ECCV 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 816–832. [Google Scholar]
- Merugu, S.; Tiwari, A.; Sharma, S.K. Spatial–Spectral Image Classification with Edge Preserving Method. J. Indian Soc. Remote Sens. 2021, 49, 703–711. [Google Scholar] [CrossRef]
- Fu, G.D.; Huang, J.; Yang, T.; Zheng, S.Y. Improved Lightweight Attention Model Based on CBAM. Comput. Eng. Appl. 2021, 57, 150–156. [Google Scholar]
- Zhao, W.Q.; Kang, Y.J.; Zhao, Z.B.; Zhai, Y.J. A Remote Sensing Image Object Detection Algorithm with Improved YOLOv5s. CAAI Trans. Int. Sys. 2023, 18, 86–95. [Google Scholar]
- Sun, X.; Wang, P.J.; Yan, Z.Y.; Xu, F.; Wang, R.P.; Diao, W.h.; Chen, J.; Li, J.H.; Feng, Y.C.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Lei, F.; Tang, F.F.; Li, S.H. Underwater Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- Kumar, S.; Raja, R.; Mahmood, M.R.; Choudhary, S. A Hybrid Method for the Removal of RVIN Using Self Organizing Migration with Adaptive Dual Threshold Median Filter. Sens. Imaging 2023, 24, 9. [Google Scholar] [CrossRef]
- Wu, L.S.; Fang, L.Y.; Yue, J.; Zhang, B.; Ghamisi, P.; He, M. Deep Bilateral Filtering Network for Point-Supervised Semantic Segmentation in Remote Sensing Images. IEEE Tran. Image Process. 2022, 31, 7419–7434. [Google Scholar] [CrossRef] [PubMed]
- Gong, H.; Mu, T.K.; Li, Q.X.; Dai, H.S.; Li, C.L.; He, Z.P.; Wang, W.J.; Han, F.; Tuniyani, A.; Li, H.Y.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Liu, K.Y.; Sun, Q.; Sun, D.M.; Peng, L.; Yang, M.D.; Wang, N.Z. Underwater Target Detection Based on Improved YOLOv7. J. Mar. Sci. Eng. 2023, 11, 667. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Configuration |
|---|---|
| Operating Environment | Windows 11 |
| GPU | GeForce RTX 3050 |
| Programming Language | Python 3.7 |
| Programming Platform | Pycharm |
| Deep Learning Framework | Pytorch 1.13.0 |
| CUDA | 11.0 |
| CuDNN | 8.0 |
| Parameter | Number |
|---|---|
| Img-size | 640 × 640 |
| Batch-size | 8 |
| Epochs | 300 |
| Learning rate | 0.01 |
| Momentum | 0.937 |
| Weight-decay | 0.0005 |
| Improvement Strategy | AP (%) | mAP_0.5 (%) | FPS (f/s) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Large-Size | Medium-Size | Small-Size | ||||||||||||
| CBAM | BiFPN+GSConv | W-IoU | CS | DCS | LCS | PS | WS | ES | SC | FB | TB | MB | ||
| × | × | × | 88.4 | 93.4 | 88.7 | 73 | 97.6 | 47.4 | 56.5 | 76.7 | 59 | 68 | 74.9 | 69 |
| √ | × | × | 91.3 | 93.2 | 89.5 | 78.7 | 97 | 52.7 | 58 | 85.2 | 57.4 | 67.7 | 77.1 | 67 |
| × | √ | × | 88.1 | 94.5 | 87.6 | 79.6 | 98.3 | 53.7 | 65.4 | 81.9 | 53.3 | 67.5 | 77 | 69 |
| × | × | √ | 89.8 | 94 | 87.8 | 80.5 | 96.6 | 55.7 | 60.4 | 83.7 | 56.8 | 67.5 | 77.3 | 71 |
| √ | √ | × | 91.2 | 93.9 | 90.4 | 81.9 | 95.4 | 55.2 | 55.9 | 84.9 | 53.5 | 66.5 | 76.9 | 76 |
| √ | × | √ | 89.3 | 92.9 | 87.6 | 77.8 | 97.4 | 56.2 | 58.1 | 79 | 47.5 | 63.8 | 75 | 76 |
| × | √ | √ | 89.2 | 94.7 | 88.9 | 78 | 97.7 | 61.7 | 47.4 | 81.7 | 54 | 64.7 | 75.8 | 76 |
| √ | √ | √ | 89.9 | 93.9 | 87.9 | 82.9 | 96 | 59.3 | 61.3 | 82.7 | 58.8 | 68.6 | 78.1 | 75 |
| Modeling Algorithm | AP (%) | mAP (%) | FPS (f/s) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Large-Size | Medium-Size | Small-Size | ||||||||||
| CS | DCS | LCS | PS | WS | ES | SC | FB | TB | MB | |||
| Faster R-CNN | 95.7 | 76.3 | 81.6 | 72 | 94.6 | 48.2 | 16.4 | 25.9 | 10.1 | 16.9 | 53.8 | 7 |
| SSD | 92.3 | 73.9 | 82.3 | 77.3 | 88.3 | 37.1 | 16.3 | 73.8 | 19.5 | 19.3 | 57.9 | 45 |
| YOLOv3 | 93.9 | 72.7 | 84.6 | 85 | 92 | 26.2 | 10.2 | 55.7 | 38.7 | 50.8 | 60.9 | 33 |
| YOLOv4 | 78.2 | 69.5 | 79.1 | 72.3 | 77.4 | 0 | 0 | 0 | 12.9 | 42.5 | 43.2 | 41 |
| YOLOv5 | 88.4 | 93.4 | 88.7 | 73 | 97.6 | 47.4 | 56.5 | 76.7 | 59 | 68 | 74.9 | 69 |
| YOLOv7 | 84.3 | 89.9 | 73.9 | 76.8 | 96.4 | 34 | 26.5 | 79.1 | 27 | 54..6 | 64.3 | 35 |
| YOLOv8 | 86.6 | 93.8 | 88.1 | 80.7 | 96.9 | 54.3 | 61.6 | 79.9 | 60.2 | 68.7 | 77.3 | 46 |
| Improved-YOLOv5 | 89.9 | 93.9 | 87.9 | 82.9 | 96 | 59.3 | 61.3 | 82.7 | 58.8 | 68.6 | 78.1 | 75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jian, J.; Liu, L.; Zhang, Y.; Xu, K.; Yang, J. Optical Remote Sensing Ship Recognition and Classification Based on Improved YOLOv5. Remote Sens. 2023, 15, 4319. https://doi.org/10.3390/rs15174319
Jian J, Liu L, Zhang Y, Xu K, Yang J. Optical Remote Sensing Ship Recognition and Classification Based on Improved YOLOv5. Remote Sensing. 2023; 15(17):4319. https://doi.org/10.3390/rs15174319
Chicago/Turabian StyleJian, Jun, Long Liu, Yingxiang Zhang, Ke Xu, and Jiaxuan Yang. 2023. "Optical Remote Sensing Ship Recognition and Classification Based on Improved YOLOv5" Remote Sensing 15, no. 17: 4319. https://doi.org/10.3390/rs15174319
APA StyleJian, J., Liu, L., Zhang, Y., Xu, K., & Yang, J. (2023). Optical Remote Sensing Ship Recognition and Classification Based on Improved YOLOv5. Remote Sensing, 15(17), 4319. https://doi.org/10.3390/rs15174319