


Infrared Small Target Detection Based on a Temporally-Aware Fully Convolutional Neural Network

Abstract
:1. Introduction
2. Related Work
2.1. Single-Frame Image-Based Infrared Small Target Detection
2.2. Multi-Frame Image-Based Infrared Small Target Detection
3. Method
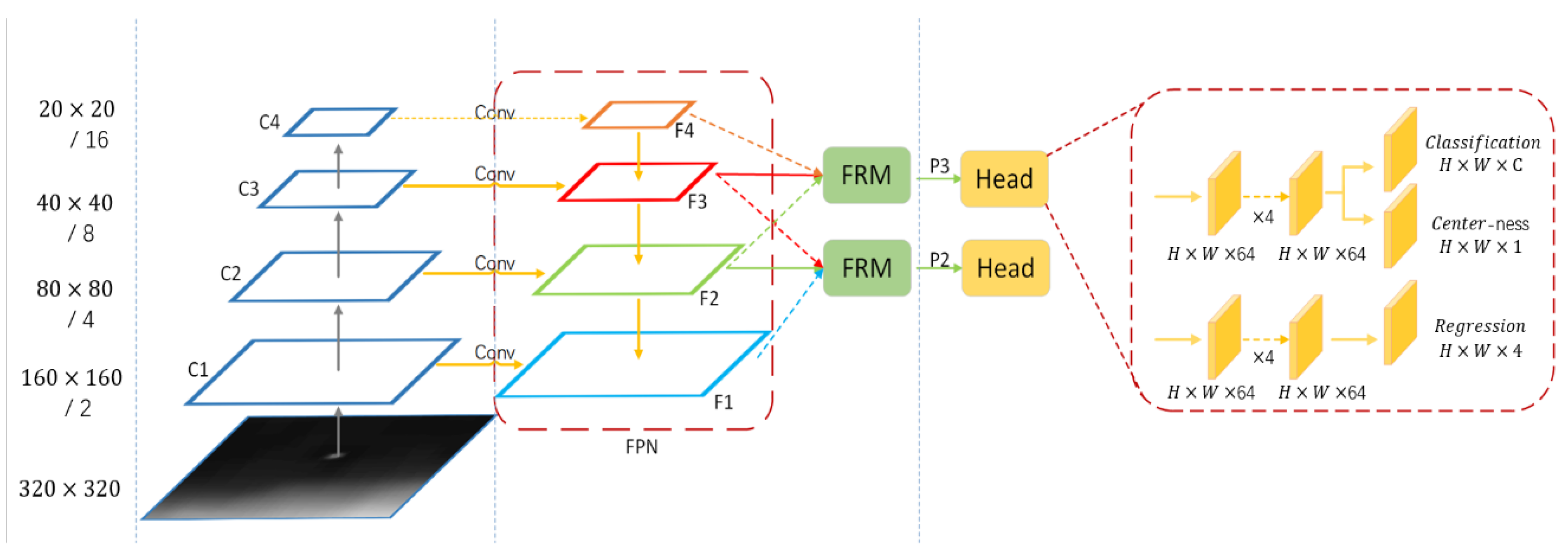
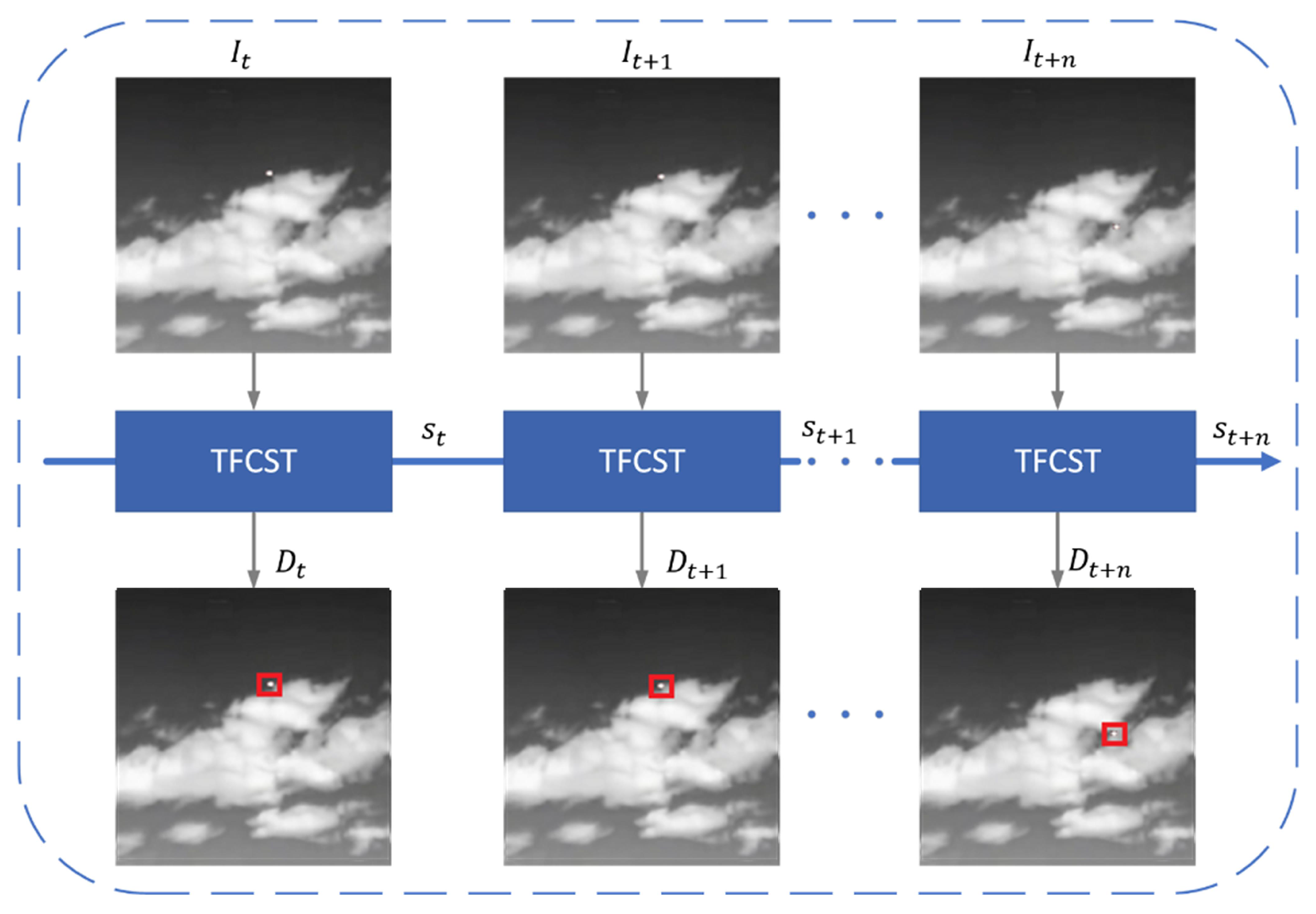
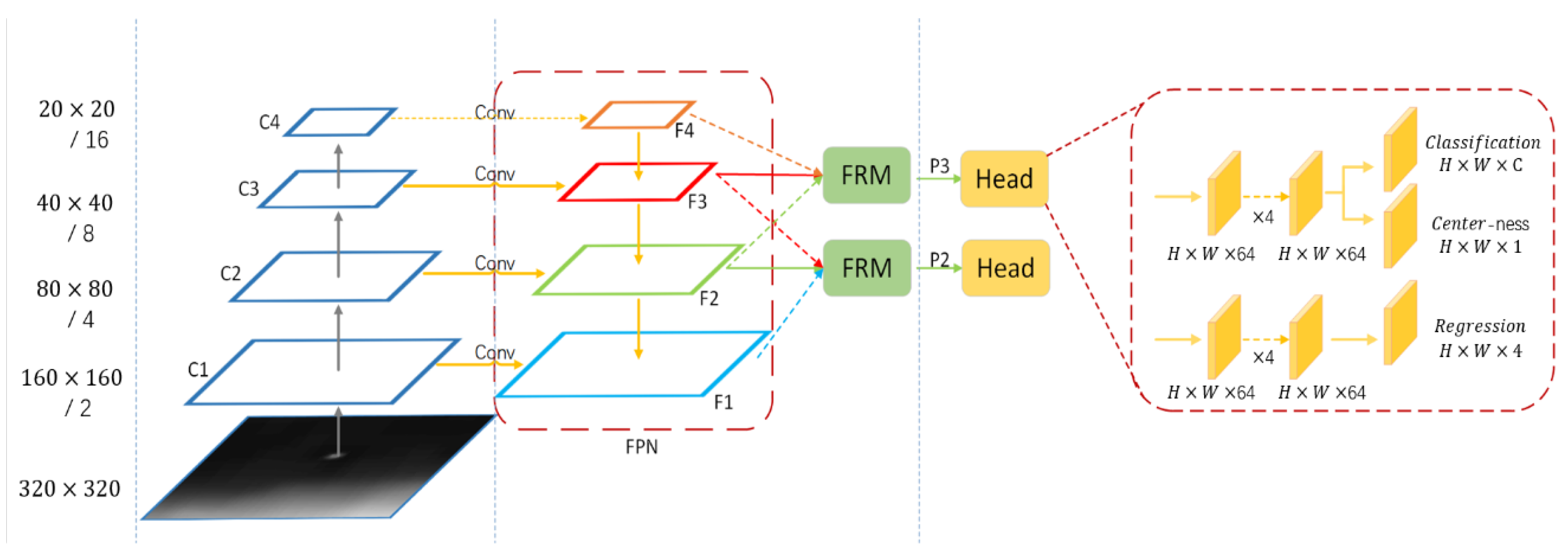
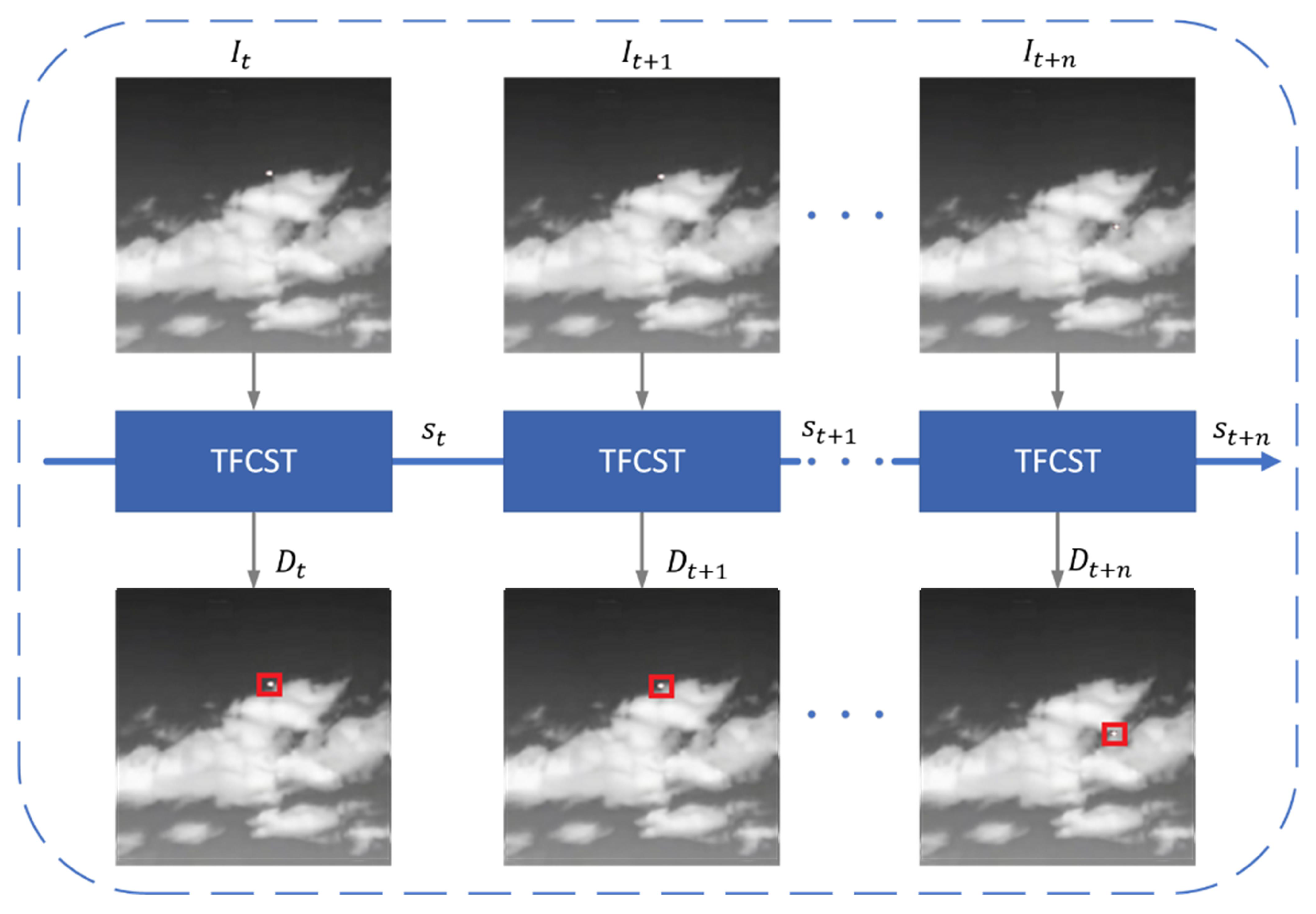
3.1. Overall Architecture
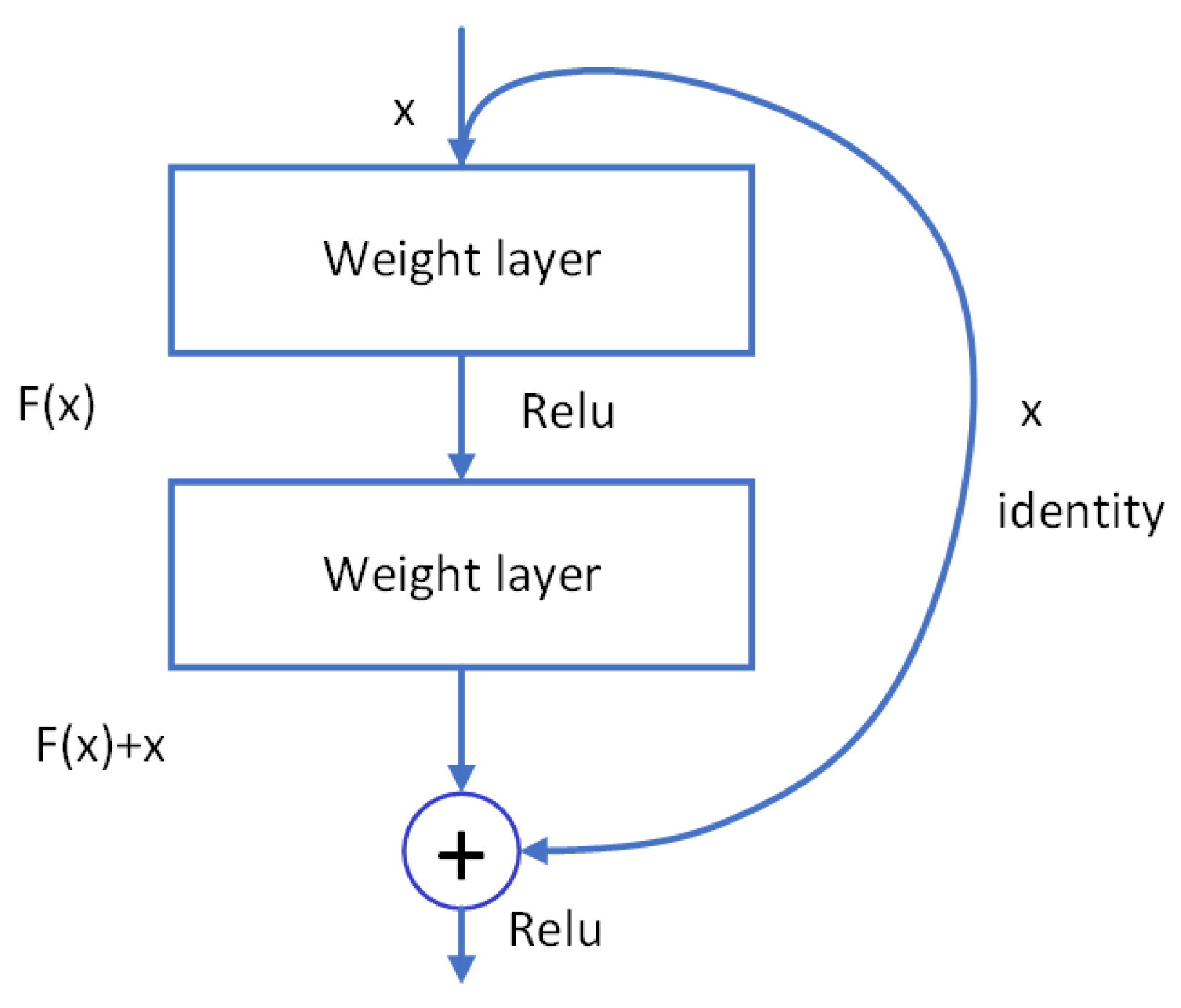
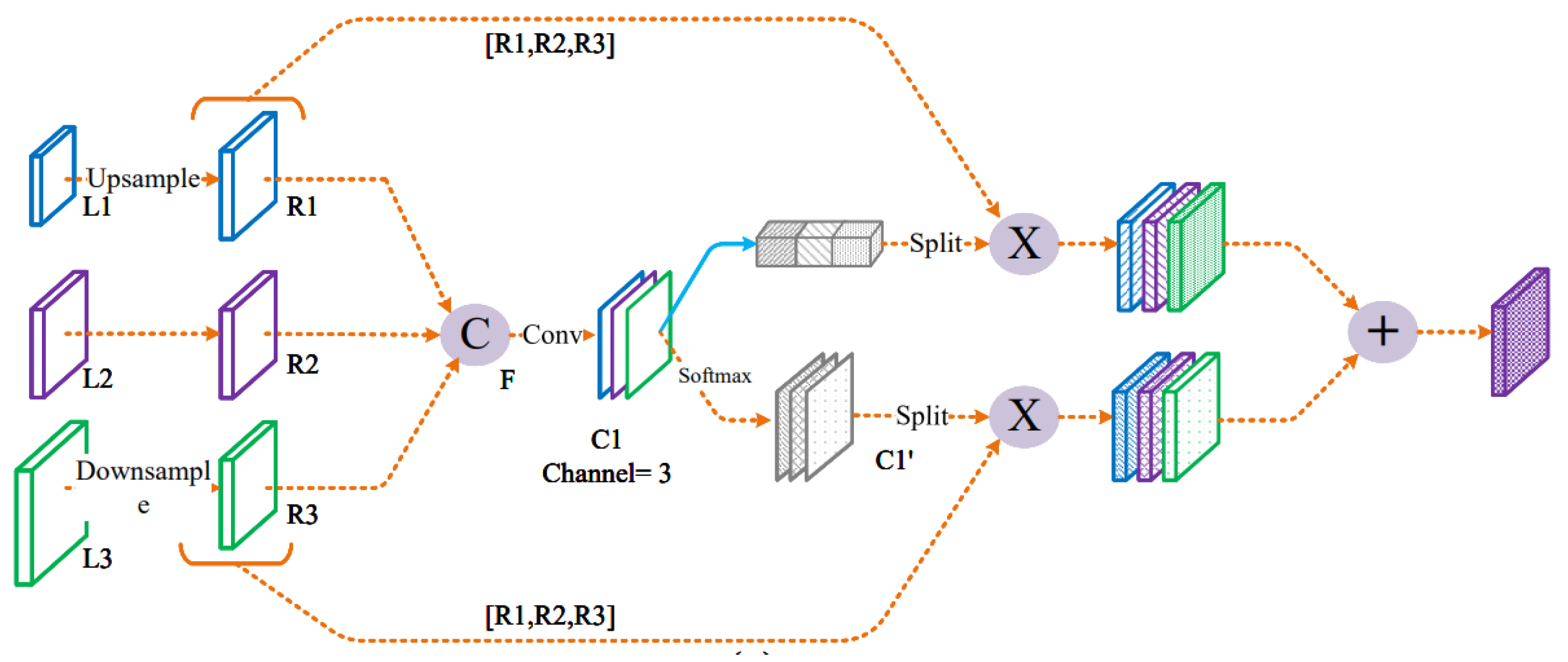
3.2. Fully Convolutional Neural Network for Infrared Small Target Detection
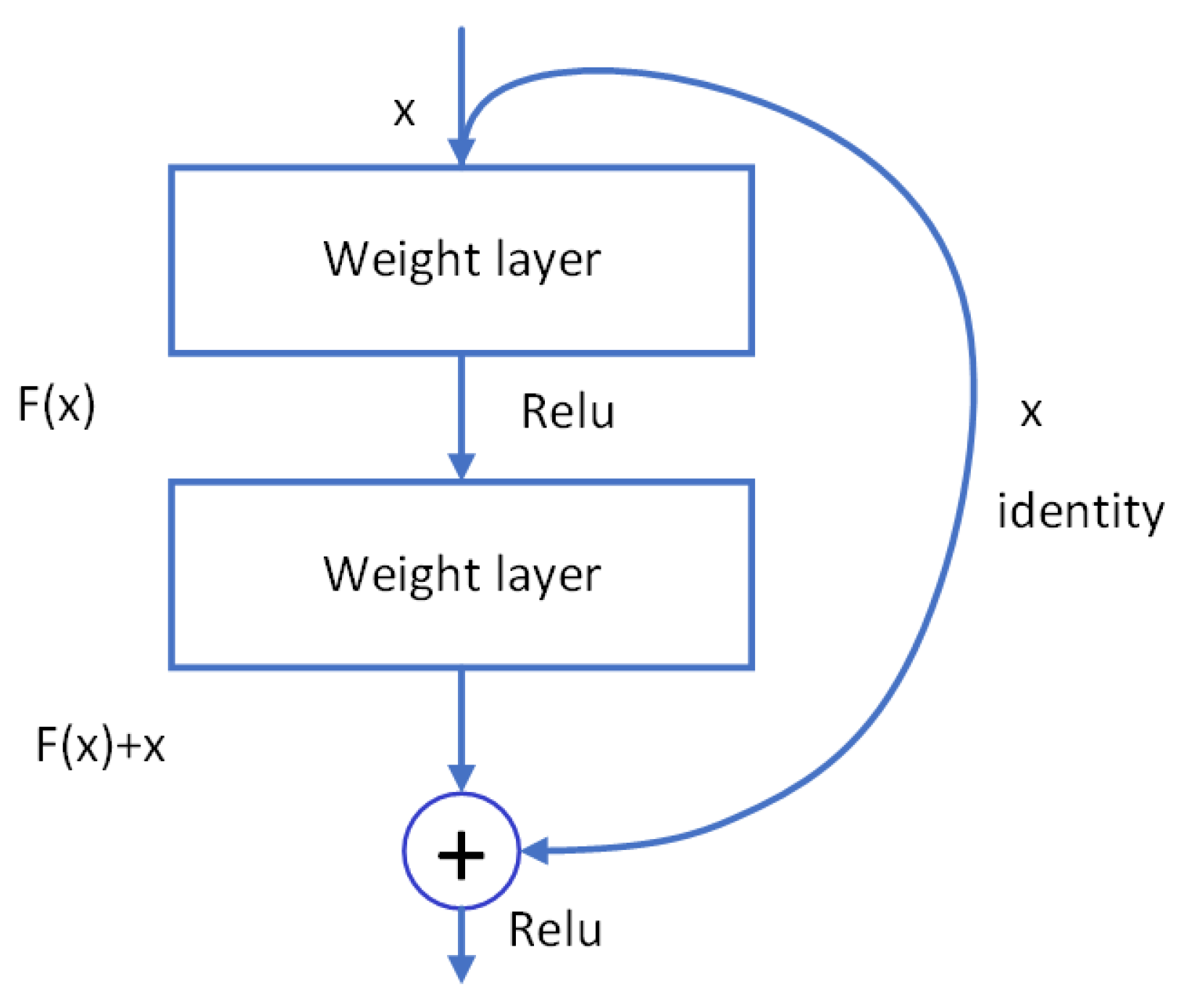
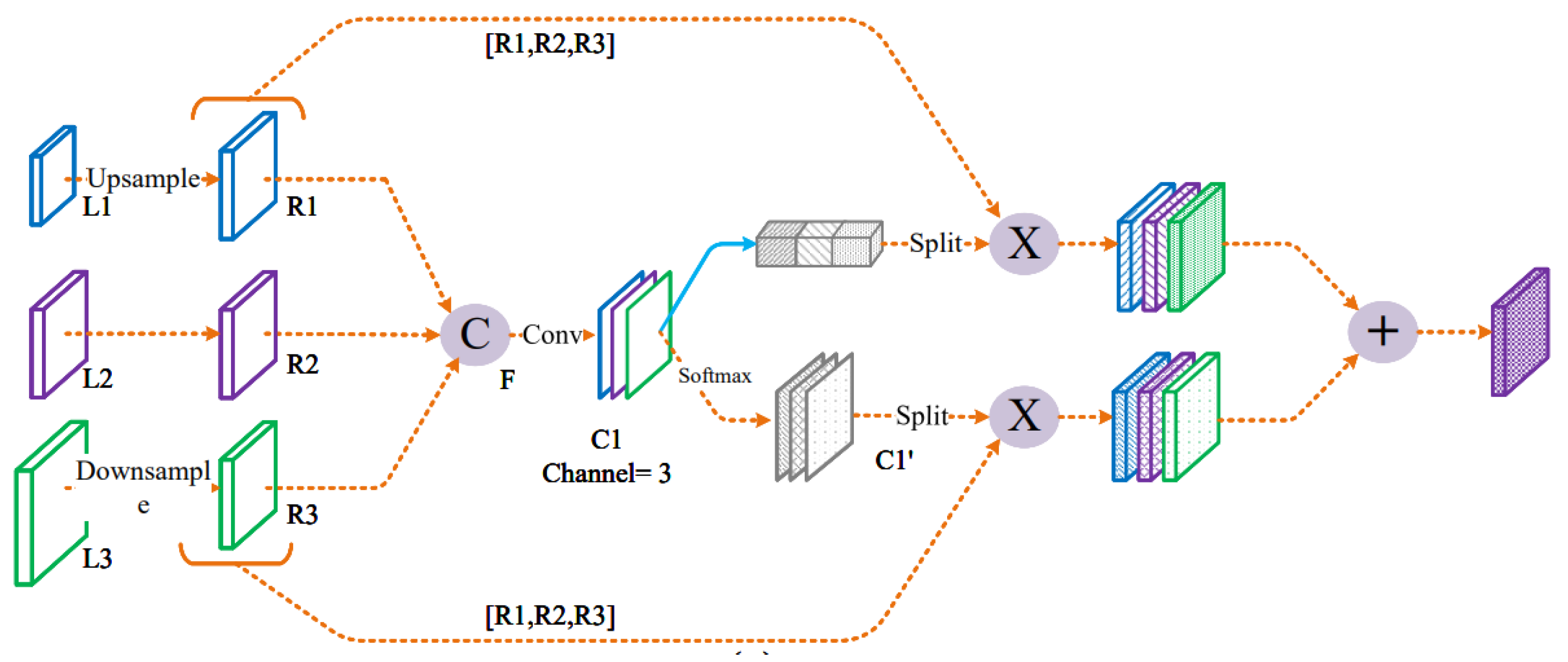
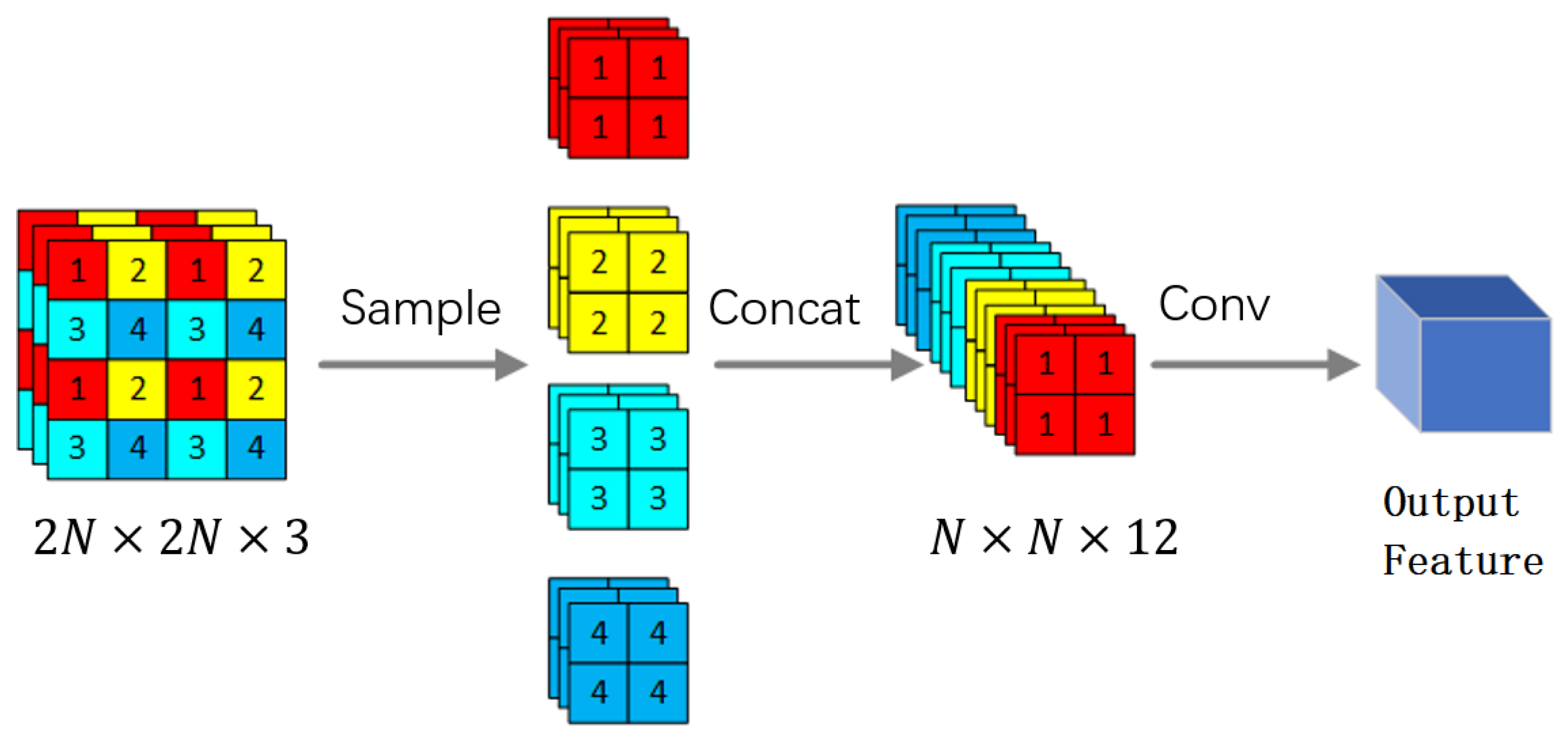
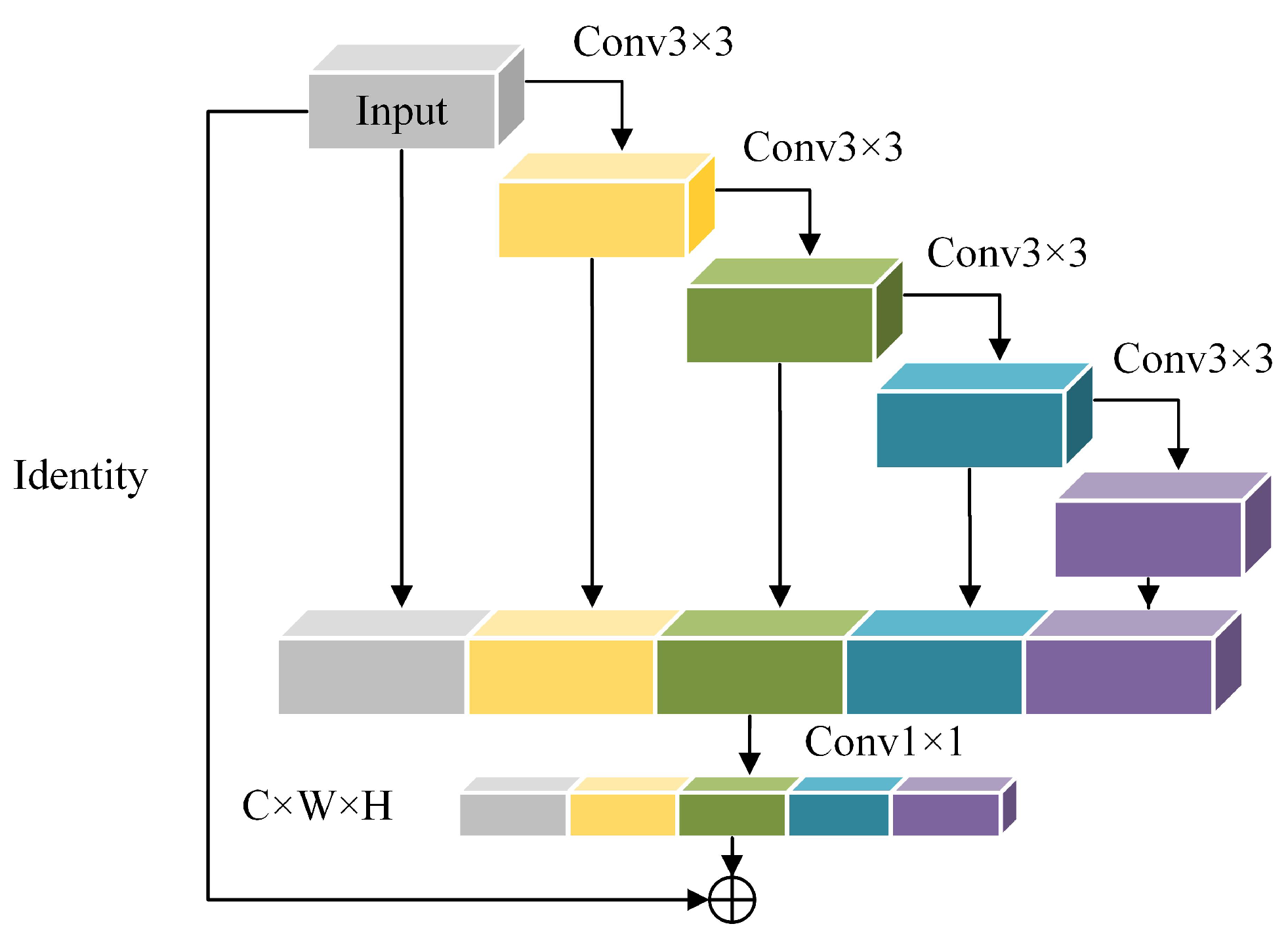
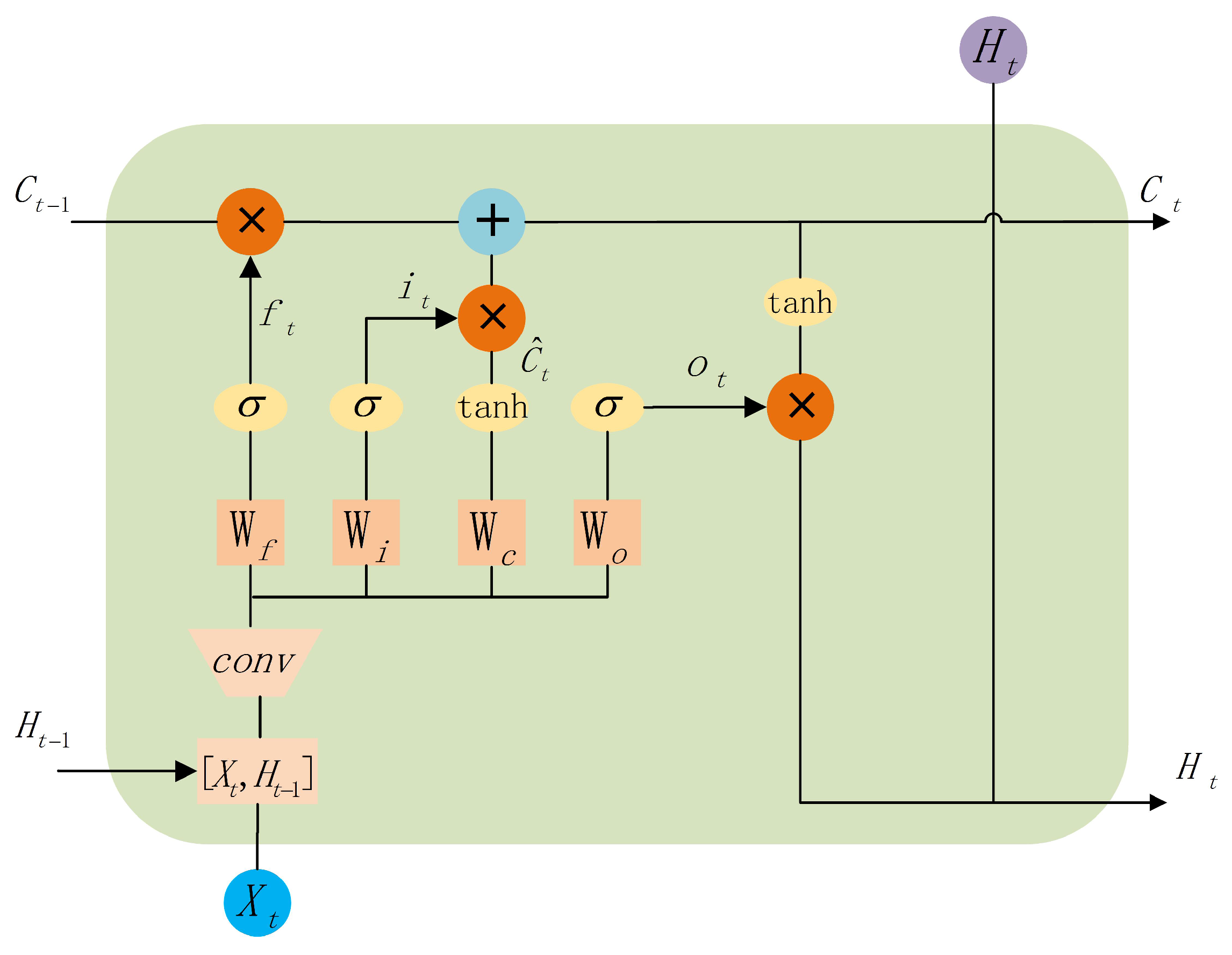
3.3. Temporally-Aware Fully Convolutional Neural Network
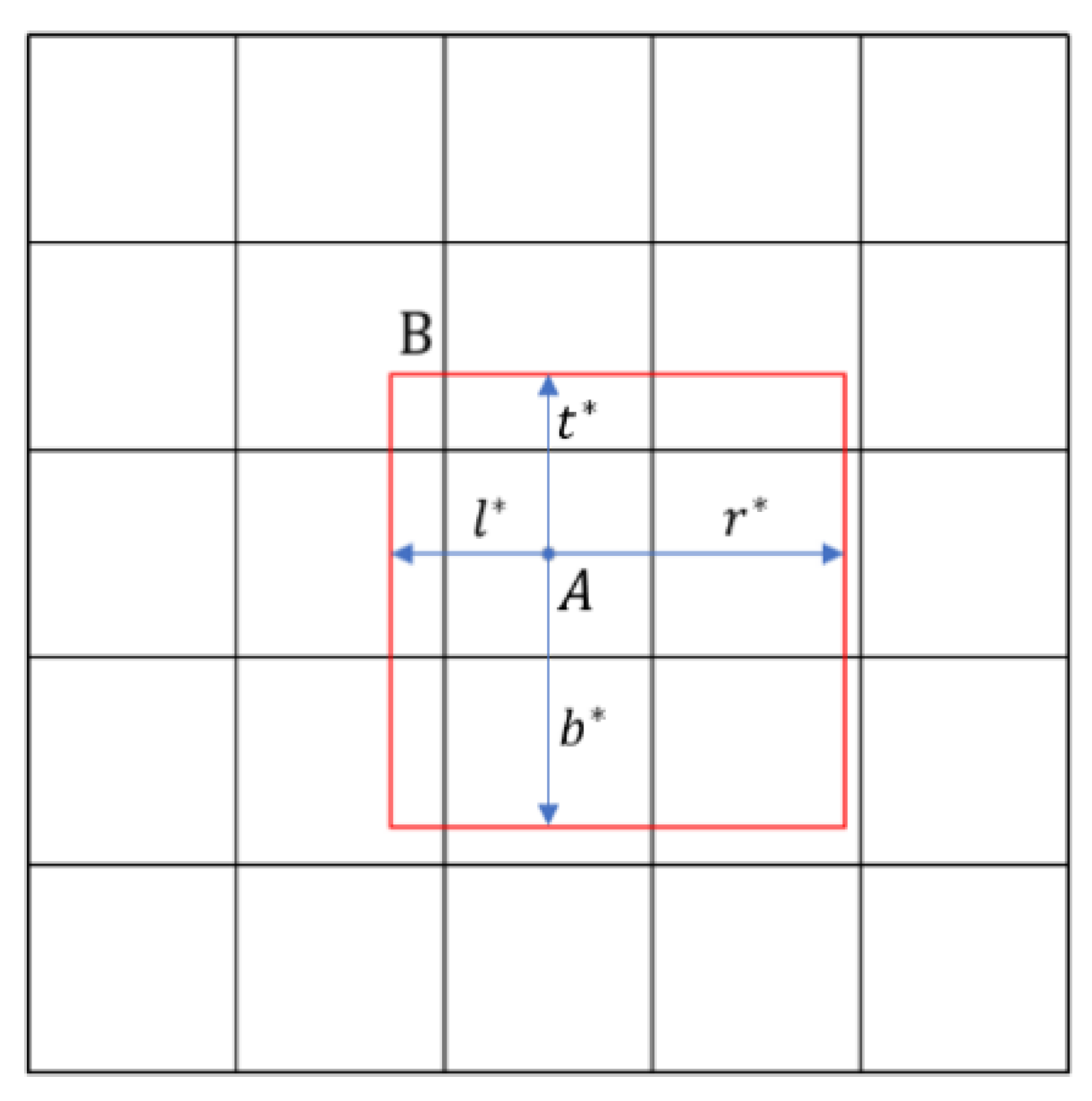
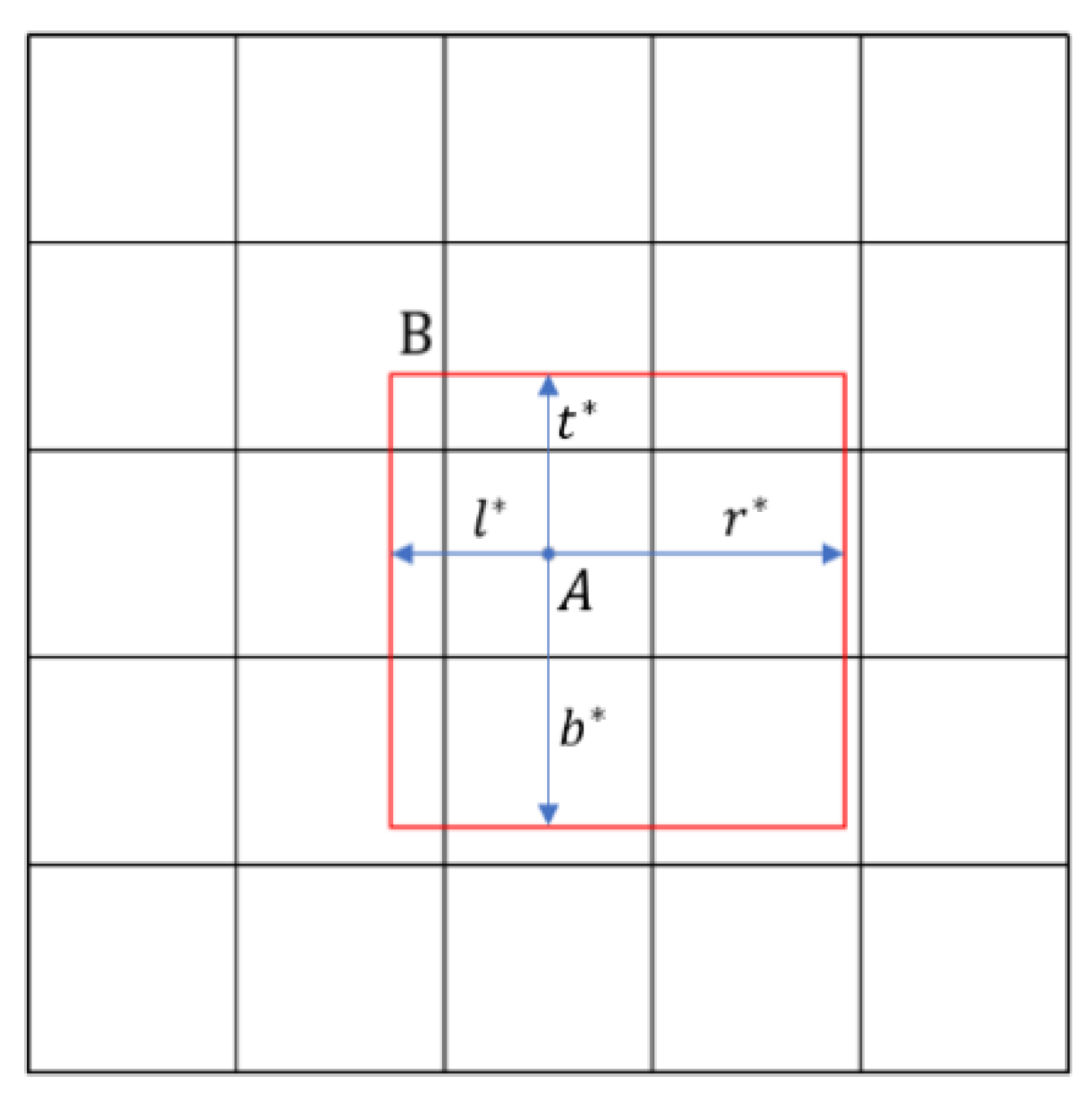
3.4. Loss Function
4. Experiments
4.1. Data Introduction
4.2. Training Parameter
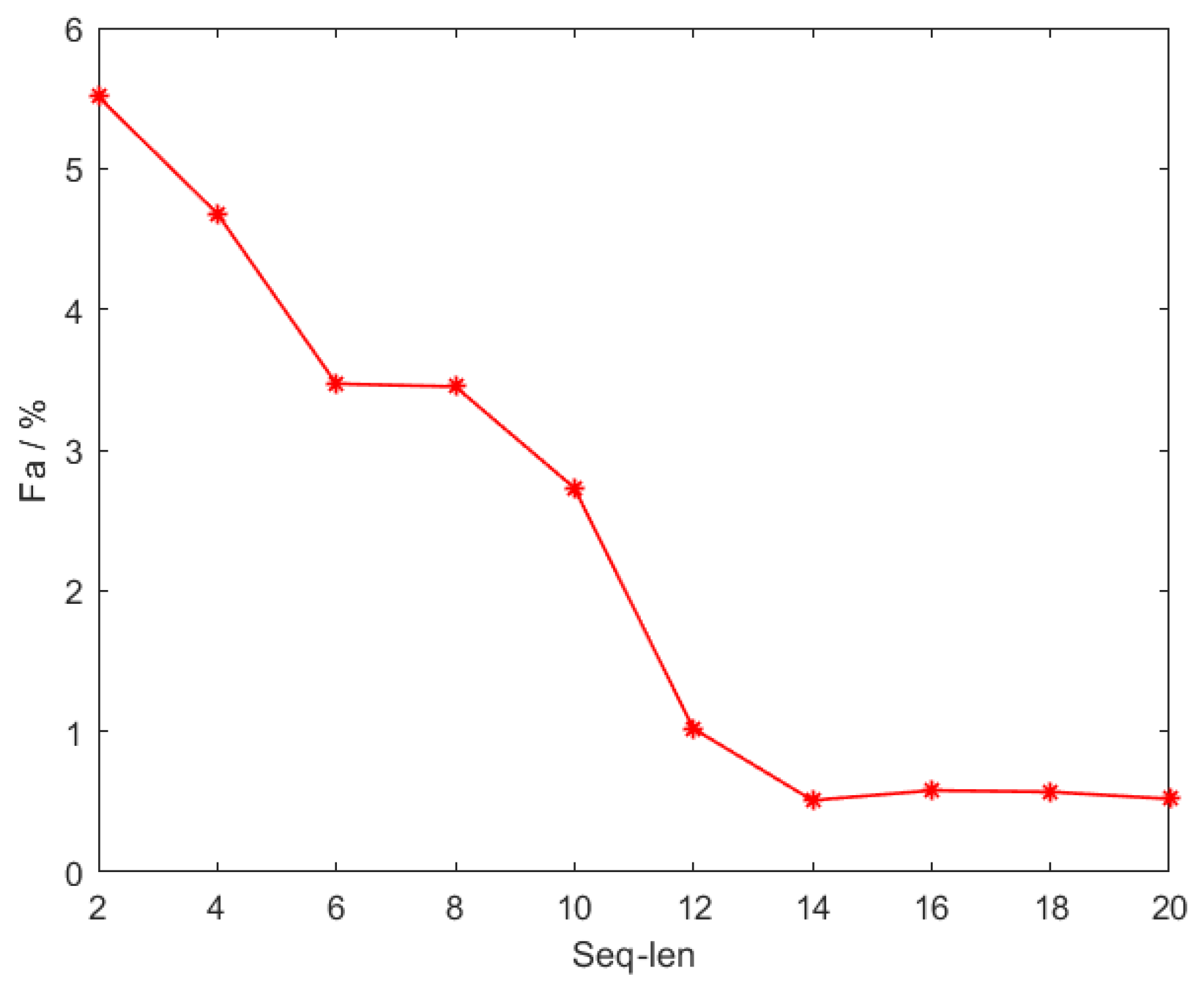
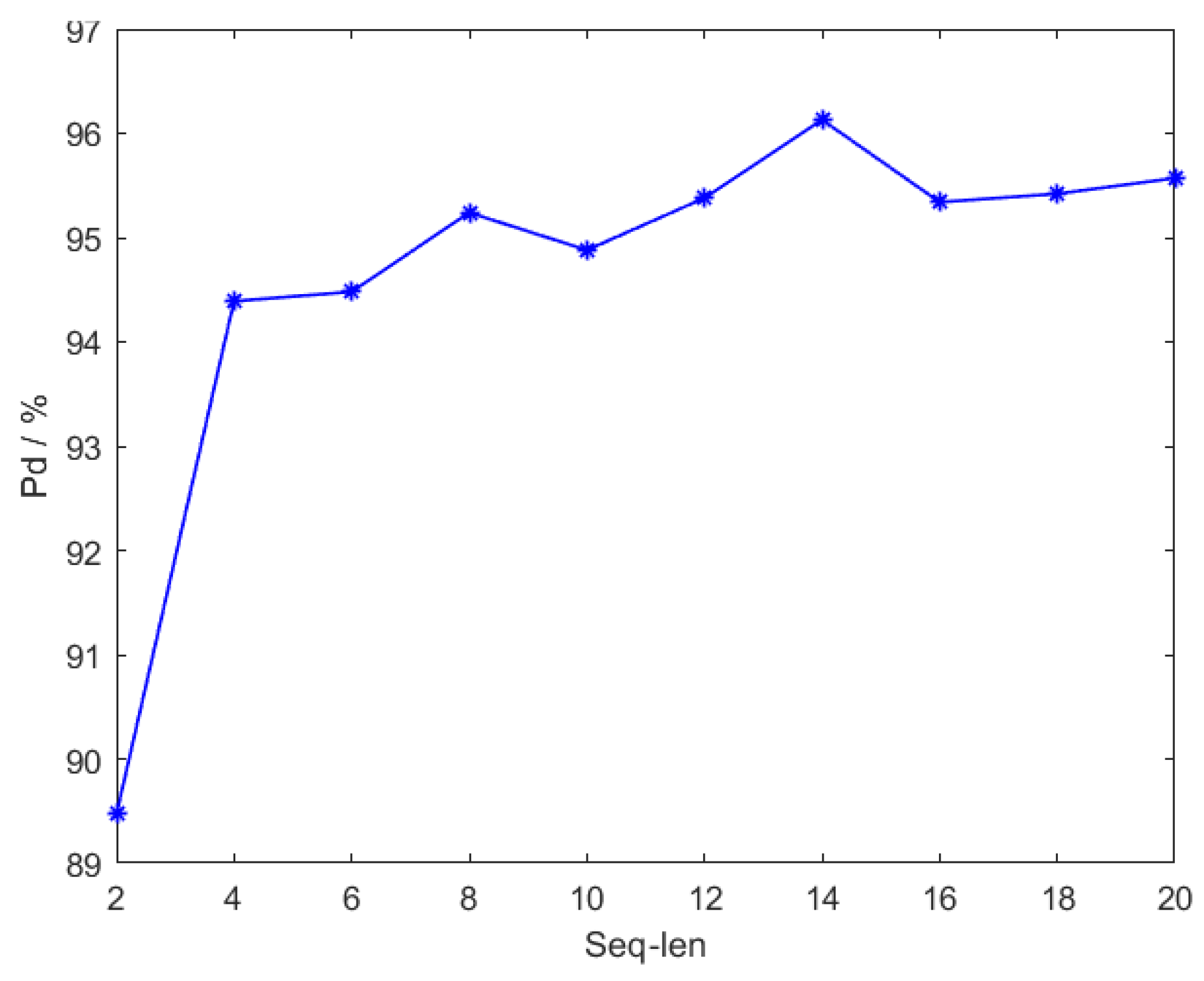
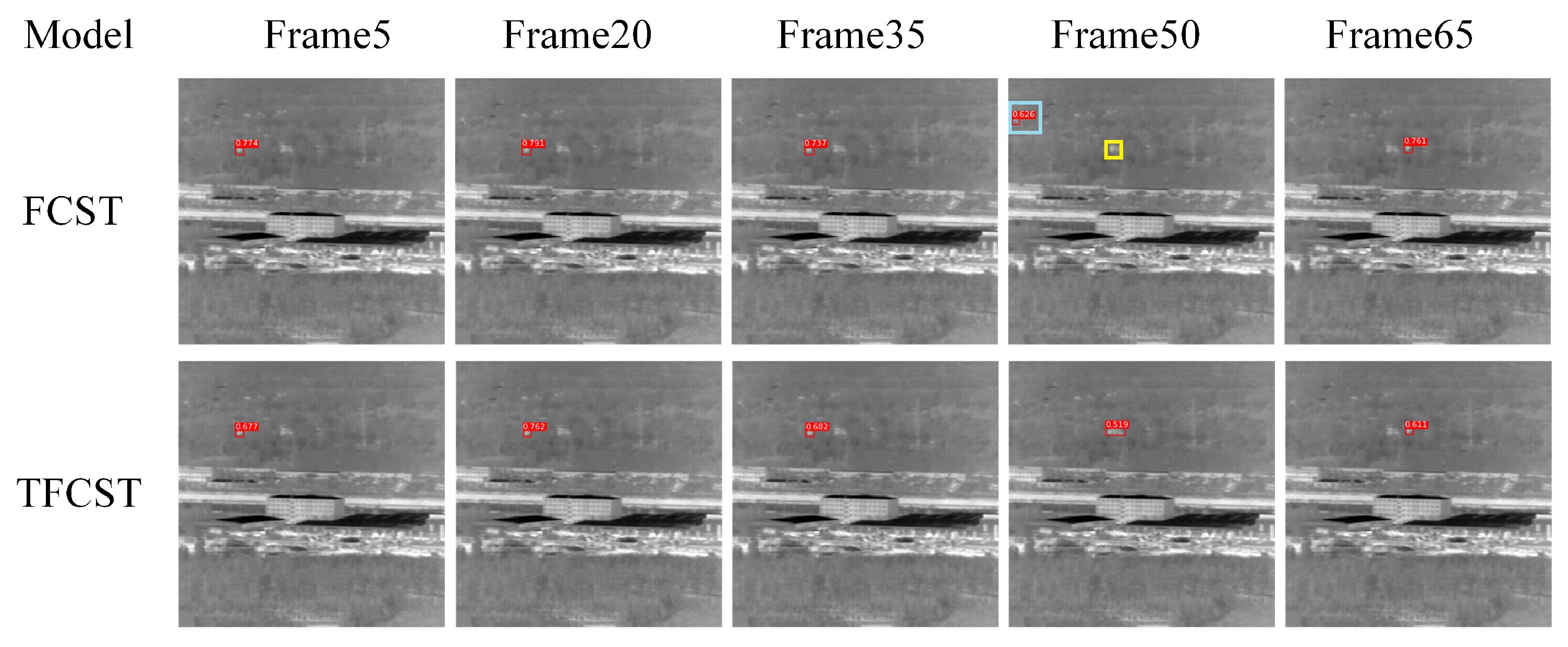
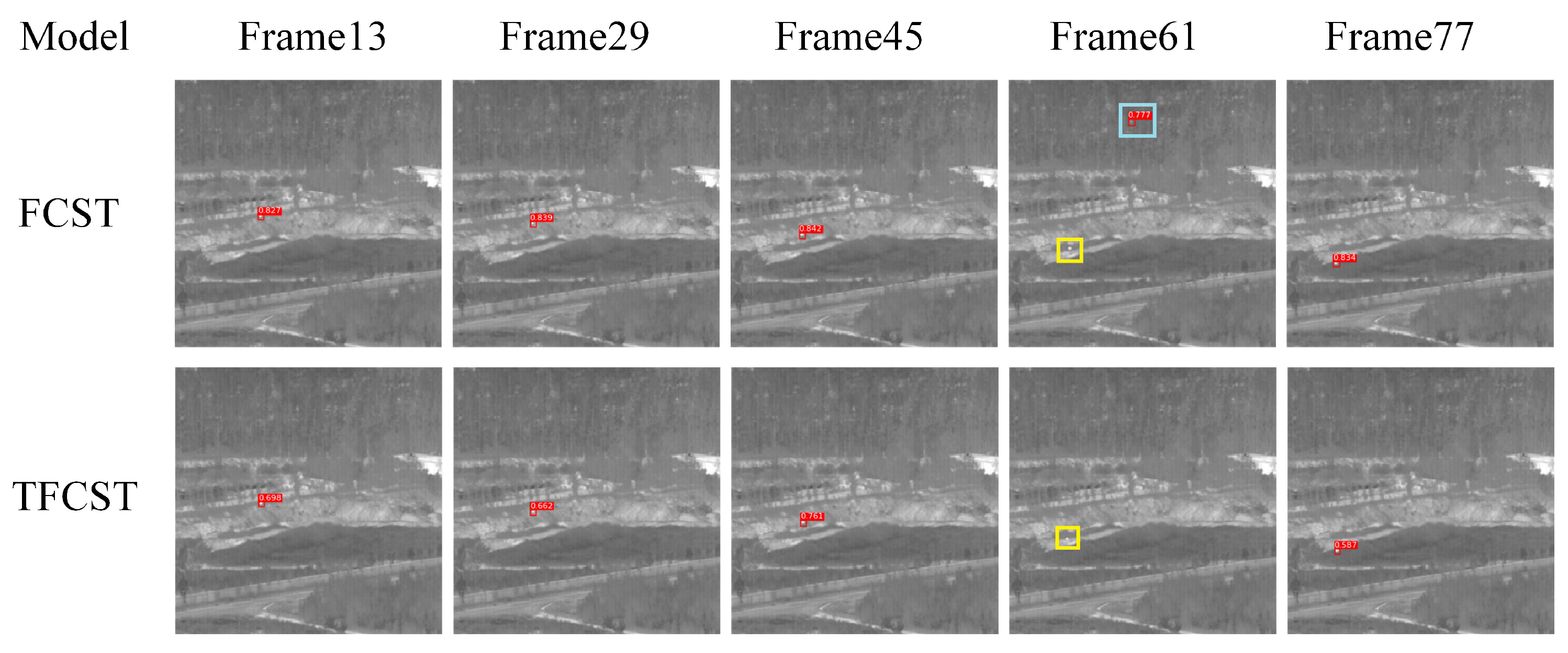
4.3. Ablation Experiment
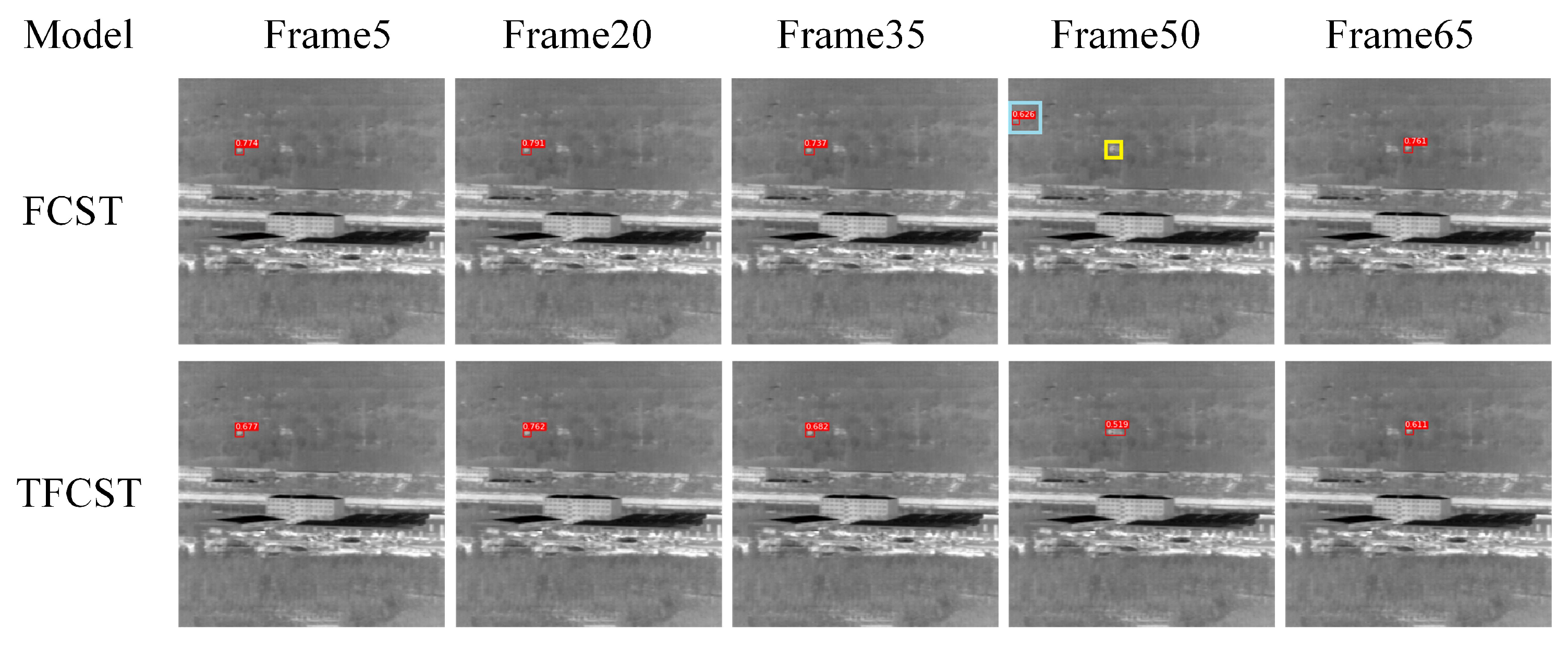
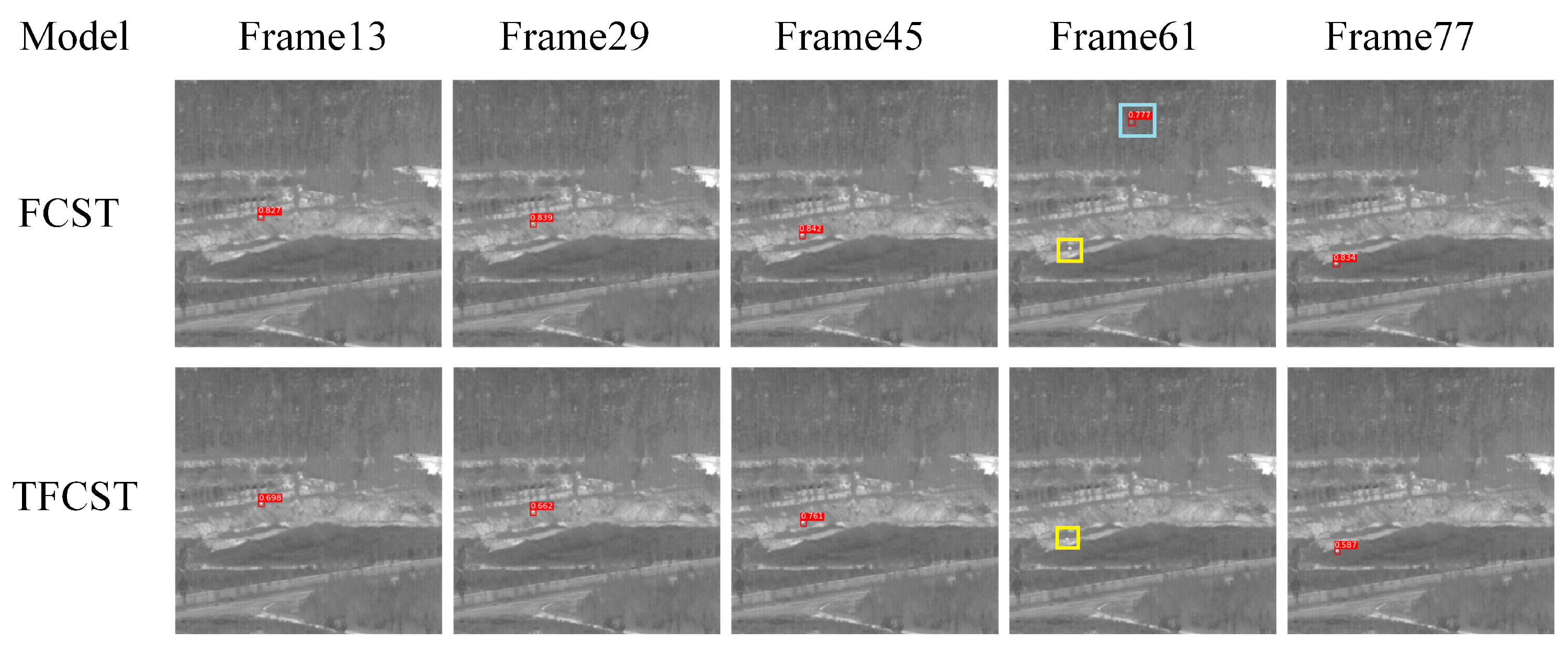
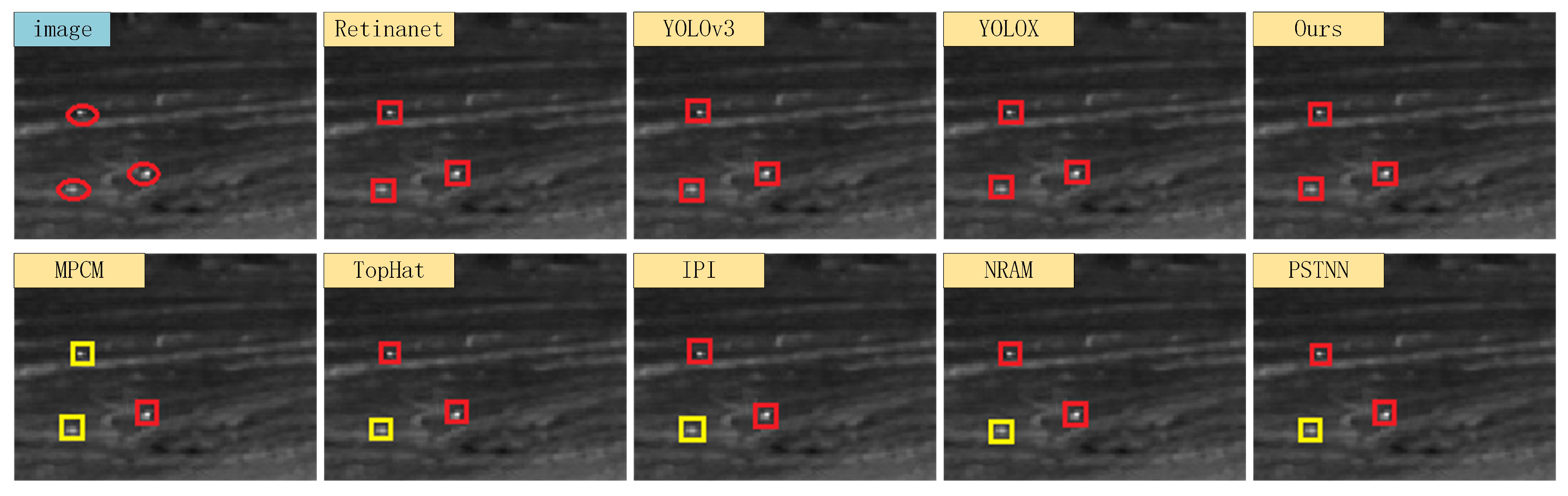
4.4. Contrast Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Lin, Y.; Yang, M.; Huang, J. Show, Match and Segment: Joint Weakly Supervised Learning of Semantic Matching and Object Co-Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3632–3647. [Google Scholar] [CrossRef] [PubMed]
- Izadinia, H.; Sadeghi, F.; Divvala, S.; Hajishirzi, H.; Choi, Y.; Farhadi, A. Segment-Phrase Table for Semantic Segmentation, Visual Entailment and Paraphrasing. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; p. 10. [Google Scholar]
- Huang, J.; Li, N.; Li, T.; Liu, S.; Li, G. Spatial-Temporal Context-Aware Online Action Detection and Prediction. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2650–2662. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, M.; Gu, Q. Class-wise boundary regression by uncertainty in temporal action detection. IET Image Process. 2022, 16, 3854–3862. [Google Scholar] [CrossRef]
- Chen, C.; Wei, J.; Peng, C.; Qin, H. Depth-Quality-Aware Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 2350–2363. [Google Scholar] [CrossRef] [PubMed]
- Shivappriya, S.; Priyadarsini, M.; Stateczny, A.; Puttamadappa, C.; Parameshachari, B. Cascade Object Detection and Remote Sensing Object Detection Method Based on Trainable Activation Function. Remote Sens. 2021, 13, 200. [Google Scholar] [CrossRef]
- Zhao, K.; Zhao, K.; Kong, X. Discussion on the suppression and method of background noise of small target infrared image. Opt. Optoelectron. Technol. 2004, 2, 9–12. [Google Scholar]
- Deshpande, S.; Deshpande, S.; Er, M.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. Proc. SPIE 1999, 3809, 74–83. [Google Scholar]
- Hadhoud, M.; Hadhoud, M.; Thomas, D. The Two-Dimensional Adaptive LMS (TDLMS) Algorithm. IEEE Trans. Circuits Syst. 1988, 35, 485–494. [Google Scholar] [CrossRef]
- Bae, T.; Bae, T.; Sohng, K. Small Target Detection Using Bilateral Filter Based on Edge Component. J. Infrared Millim. Terahertz Waves 2010, 31, 735–743. [Google Scholar] [CrossRef]
- Zeng, M. The design of top-hat morphological filter and application to infrared target detection. Infrared Phys. Technol. 2006, 48, 67–76. [Google Scholar] [CrossRef]
- Chen, C.; Chen, C.; Li, H.; Wei, Y.; Xia, T.; Tang, Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2013, 52, 574–581. [Google Scholar] [CrossRef]
- Han, J.; Han, J.; Yong, M.; Bo, Z. A Robust Infrared Small Target Detection Algorithm Based on Human Visual System. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2168–2172. [Google Scholar]
- Wang, H.; Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8508–8517. [Google Scholar]
- Shi, M.; Shi, M.; Wang, H. Infrared Dim and Small Target Detection Based on Denoising Autoencoder Network. Mob. Netw. Appl. 2020, 25, 1469–1483. [Google Scholar] [CrossRef]
- Zhao, B.; Zhao, B.; Wang, C.; Fu, Q.; Han, Z. A Novel Pattern for Infrared Small Target Detection With Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2020, 99, 1–12. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, R.; Xu, L.; Yu, Z.; Shi, Y.; Xu, M. Deep-IRTarget: An automatic target detector in infrared imagery using dual-domain feature extraction and allocation. IEEE Trans. Multimed. 2022, 24, 1735–1749. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, R.; Yang, S.; Zhang, Q.; Xu, L.; He, Y.; Zhang, F. Graph-based few-shot learning with transformed feature propagation and optimal class allocation. Neurocomputing 2022, 470, 247–256. [Google Scholar] [CrossRef]
- Ren, X.; Ren, X.; Wang, J.; Ma, T.; Bai, K.; Wang, Y. Infrared dim and small target detection based on three-dimensional collaborative filtering and spatial inversion modeling. Infrared Phys. Technol. 2019, 101, 13–24. [Google Scholar] [CrossRef]
- Irsoy, O.; Cardie, C. Opinion mining with deep recurrent neural networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing 2014, Doha, Qatar, 26–28 October 2014; pp. 720–728. [Google Scholar]
- Xiao, F.; Xiao, F.; Lee, Y. Video Object Detection with an Aligned Spatial-Temporal Memory. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 485–501. [Google Scholar]
- Lu, Y.; Lu, Y.; Lu, C.; Tang, C. Online video object detection using association LSTM. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2344–2352. [Google Scholar]
- Shi, X.; Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning apporach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Infromation Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Liu, W.; Liu, W.; Anguelov, D.; Erhan, D. SSD: Single Shot MultiBox Detector; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Wei, K.; Wei, K.; Fu, Y.; Huang, H. 3-d quasi-recurrent neural network for hyperspectral image denoising. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 363–375. [Google Scholar] [CrossRef]
- Tian, Z.; Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- He, K.; He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Huang, G.; Liu, Z.; Laurens, V. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lee, Y.; Lee, Y.; Hwang, J.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Lin, T.; Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision & Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Lin, T.; Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 2999–3007. [Google Scholar]
- Rezatofighi, H.; Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Ballas, N.; Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving Deeper into Convolutional Networks for Learning Video Representations. Comput. Sci. 2015. [CrossRef]
- Liu, M.; Zhu, M. Mobile Video Object Detection with Temporally-Aware Feature Maps. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Cho, K.; Cho, K.; Van Merrienboer, B.; Gulcehre, C. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. Comput. Sci. 2014. [Google Scholar] [CrossRef]
- Wei, Y.; Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Gao, C.; Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared Small Target Detection via Non-Convex Rank Approximation Minimization Joint l2,1 Norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Peng, Z. Infrared small target detection based on partial sum of the tensor nuclear norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Redmon, J.; Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ge, Z.; Ge, Z.; Liu, S.; Wang, F.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RNN | Pd | Fa | FPS | #Param(M) |
|---|---|---|---|---|
| ConvGRU | 95.14% | 3.56% | 63.5 | 2.50 |
| Bottleneck-LSTM | 93.84% | 2.52% | 65.3 | 2.37 |
| ConvLSTM | 95.25% | 0.58% | 66.7 | 2.65 |
| RNN | Pd | Fa | FPS |
|---|---|---|---|
| MPCM | 79.23% | 26.74% | 16.2 |
| TopHat | 87.36% | 57.45% | 82.9 |
| IPI | 84.81% | 18.57% | 0.21 |
| NRAM | 80.62% | 24.27% | 0.47 |
| PSTNN | 82.60% | 26.31% | 5.3 |
| Retinanet | 87.85% | 9.1% | 38.9 |
| YOLOv3 | 92.35% | 7.65% | 54.2 |
| YOLOX | 91.99% | 5.43% | 48.6 |
| FCOS | 91.62% | 4.80% | 68.3 |
| FCST | 94.85% | 2.32% | 66.4 |
| Input | Frame | Image Size | Target Size | Background Description |
|---|---|---|---|---|
| Sequence_1 | 80 | Less cluster of Building | ||
| Sequence_2 | 60 | Heavy cluster of Ground and Building | ||
| Sequence_3 | 260 | Heavy cluster of Cloud | ||
| Sequence_4 | 125 | Heavy cluster of Ground |
| Model | Pd | Fa | FPS |
|---|---|---|---|
| FCST | 93.40% | 8.64% | 66.4 |
| TFCST | 96.13% | 0.51% | 65.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Han, P.; Xi, J.; Zuo, Z. Infrared Small Target Detection Based on a Temporally-Aware Fully Convolutional Neural Network. Remote Sens. 2023, 15, 4198. https://doi.org/10.3390/rs15174198
Zhang L, Han P, Xi J, Zuo Z. Infrared Small Target Detection Based on a Temporally-Aware Fully Convolutional Neural Network. Remote Sensing. 2023; 15(17):4198. https://doi.org/10.3390/rs15174198
Chicago/Turabian StyleZhang, Lei, Peng Han, Jiahua Xi, and Zhengrong Zuo. 2023. "Infrared Small Target Detection Based on a Temporally-Aware Fully Convolutional Neural Network" Remote Sensing 15, no. 17: 4198. https://doi.org/10.3390/rs15174198
APA StyleZhang, L., Han, P., Xi, J., & Zuo, Z. (2023). Infrared Small Target Detection Based on a Temporally-Aware Fully Convolutional Neural Network. Remote Sensing, 15(17), 4198. https://doi.org/10.3390/rs15174198