1. Introduction
Remote sensing [
1] is a technology that obtains information about the earth by using sensors mounted on aircraft or spacecraft to receive electromagnetic signals from the earth. Among them, remote sensing images are an important product of remote sensing technology, which can provide rich geographic information and help people better understand and manage the earth. In recent years, with the rapid development of aerospace technology, remote sensing technology has also reached a new stage [
2]. It is mainly manifested in two aspects: One is that the use scenarios are more extensive, such as meteorology, agriculture, environment, disasters, etc. The second is that the data obtained are more abundant, such as multi-time and multi-band images. Faced with these massive data, how to analyze and extract semantic information from them has become an important research topic, which includes how to perform efficient and accurate object detection. Object detection is an important task in the field of computer vision, which aims to locate and identify the category of objects in an image. At present, a large number of studies [
3,
4,
5,
6,
7] have been proposed. Object detection has a wide range of applications in remote sensing images, such as military reconnaissance [
8], urban planning [
9], traffic monitoring [
10], etc. However, object detection in remote sensing images also faces some challenges.
The first challenge is how to efficiently fuse multimodal information. Remote sensing images acquired from a long distance are affected by multiple factors such as clouds, fog and lighting conditions. Using only a single band of sensor data will result in low detection accuracy, which will greatly limit the use scenarios of object detection algorithms. Most of the current [
3,
4,
5] object detection techniques are mainly oriented to single modalities, such as visible light images or infrared images. If multiple wavelengths of remote sensing images can be fused, the detection accuracy can be greatly improved by complementing the advantages of each modality. As shown in
Figure 1, in good lighting conditions during the day, visible light images can provide more color and texture information, while infrared images can show clearer object contours at night. Unfortunately, image data obtained from different sensors have problems such as different resolutions, different amounts of information carried and image misalignment [
11], so simply combining remote sensing images cannot improve detection performance.
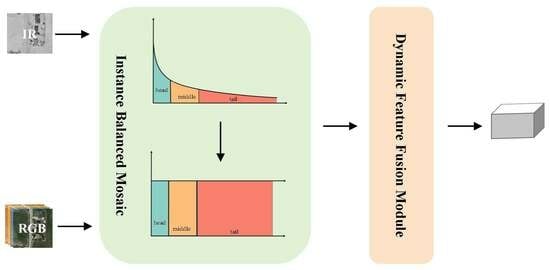
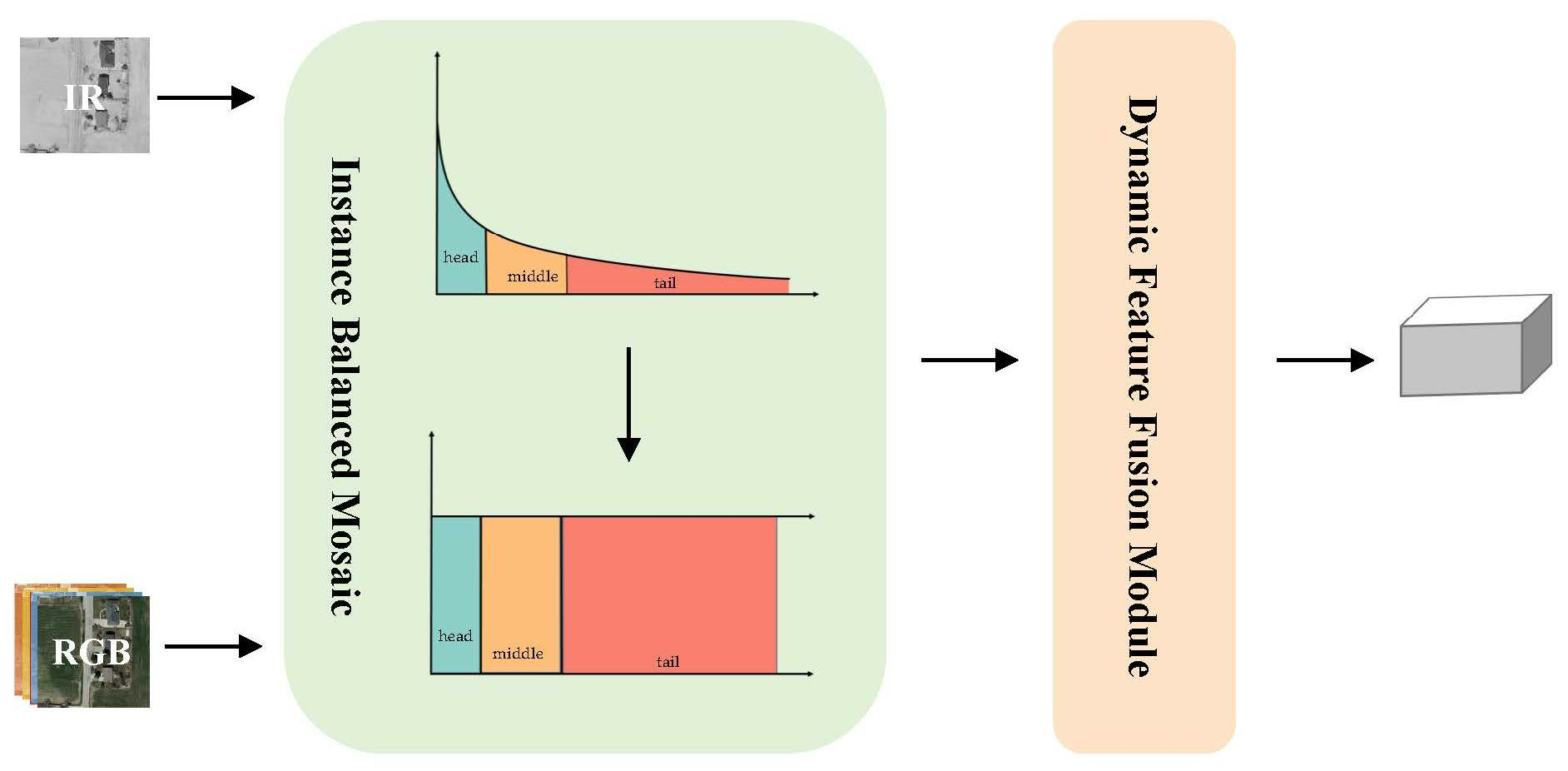
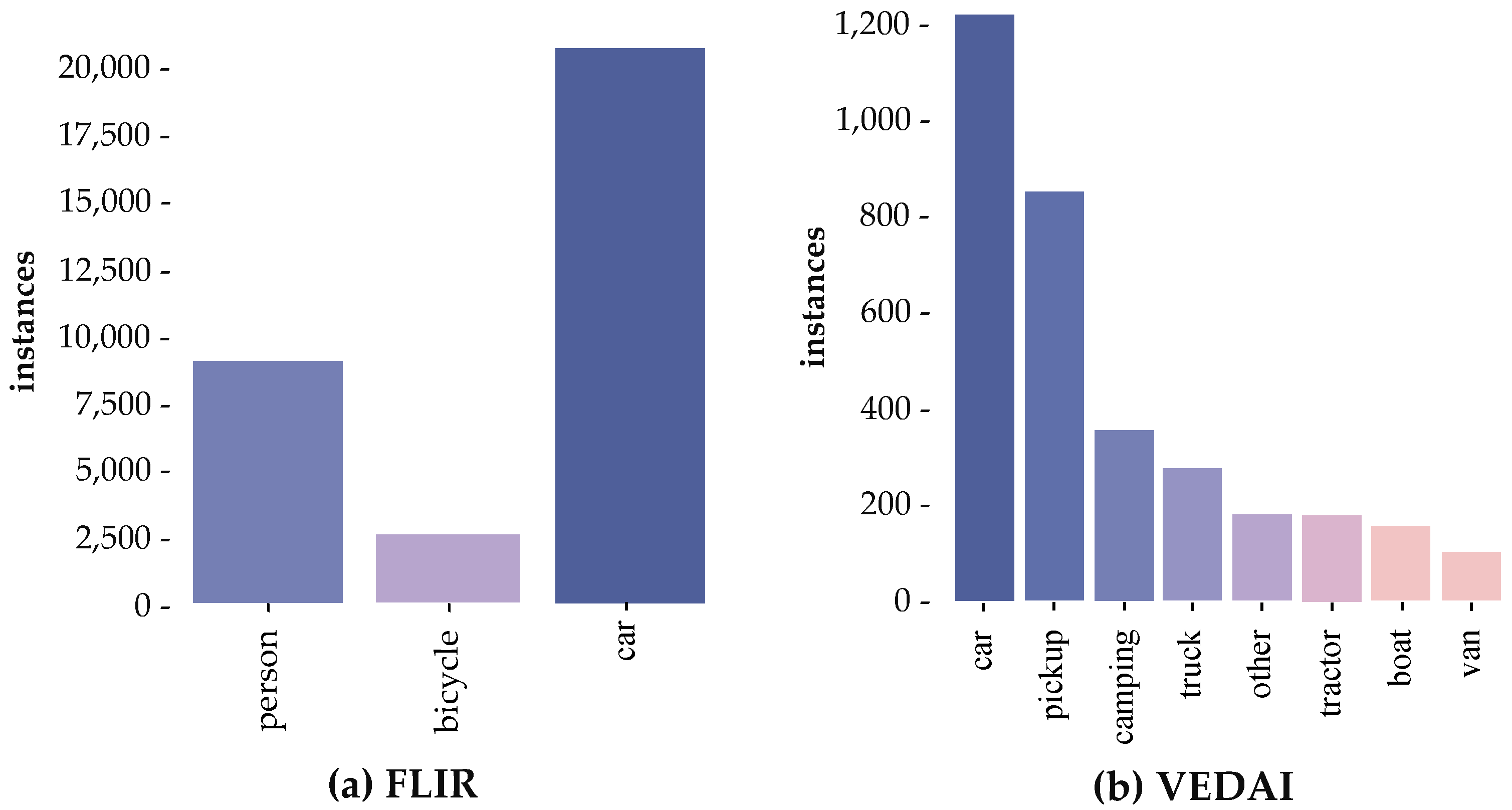
The second challenge is how to deal with long-tailed data with natural state distribution. Real-world data often show an open long-tailed distribution [
12], as shown in
Figure 2, where a small number of categories in the dataset have far more instances than other categories, resulting in a serious imbalance in data distribution. As more data are acquired, new category instances will appear, further exacerbating the long-tailed characteristics of the dataset. Although existing deep learning-based network models have begun to pay attention to the long-tailed problem [
13,
14,
15], most of the long-tailed research in the remote sensing field focuses on long-tailed recognition [
16,
17], and there is less research on the more complex long-tailed object detection task. We can see that the red line representing detection accuracy in
Figure 2 is positively correlated with instance number, which shows that the key to improving model detection accuracy is to improve the detection ability for tail classes.
The third challenge is how to reduce algorithm complexity for real-time detection. In scenarios such as disaster relief where timely detection and emergency handling are required, real-time performance will be a very important consideration factor. However, due to space limitations, detection models deployed on satellites or aircraft cannot increase performance by increasing complexity. Therefore, model complexity needs to be strictly controlled when fusing multimodal information and dealing with long-tailed problems.
In order to solve these challenges, based on the above analysis, we propose a multi-source fusion object detection method for natural long-tailed datasets, which uses infrared and visible light images to improve the detection accuracy of the model on natural long-tailed datasets. Considering that multimodal image fusion needs to be based on image sample features, we propose a dynamic feature fusion module based on image information entropy [
18]. By calculating the amount of information in the image, the model can dynamically allocate fusion coefficients during the training and inference stages, which enables the network to retain more key feature information and provide more accurate image features for subsequent object detection. In order to ensure that the model can meet the requirements of real-time detection and lightweight, we choose the small-sized YOLOv8s [
19] as our baseline model. Considering the characteristics of natural data long-tailed distribution, we propose an instance-balanced mosaic method by improving Mosaic [
20] to achieve balanced sampling, which provides more sample features for the model and alleviates the negative impact of data distribution imbalance. At the same time, in order to balance the gradient information during the training stage and reduce the impact of long-tailed distribution, we propose class-balanced BCE loss for object detection. This loss can dynamically adjust the loss weight according to the number of samples of different categories, thereby reducing the model’s overfitting on head categories and underfitting on tail categories.
Finally, in order to verify the performance of our proposed method, we conducted experimental verification on three public benchmark datasets and conducted ablation analysis. The experimental results proved that our proposed method achieves state-of-the-art performance; in particular, the optimization of the long-tailed problem enables the model to meet various application scenarios of remote sensing image detection.
In summary, our contributions can be summarized as follows:
We propose a dynamic feature fusion module based on image information entropy, which dynamically adjusts the fusion coefficient according to the different information entropy of images, enabling the model to capture more features. Compared with other similar methods, this module helps the model significantly improve detection accuracy without significantly increasing computational complexity, and this method is simple and can be easily inserted into other object detection networks to achieve feature fusion for remote sensing images.
We propose an instance-balanced mosaic data augmentation method based on instance number, which solves the long-tailed problem by providing rich tail-class features for the model through resampling during data augmentation.
We propose class-balanced BCE loss for long-tailed object detection. This loss provides more balanced loss information for the model according to sample number, improving the detection accuracy of tail instances.
Based on three public benchmark datasets, we constructed a large number of experiments to verify the performance of our method. Compared with baseline methods, our method can greatly improve the performance of baseline models. The experimental results and ablation analysis prove the effectiveness of our proposed method.
The rest of this paper is organized as follows:
Section 2 reviews related work.
Section 3 introduces the details of our proposed method. In
Section 4, we conduct experiments to verify the effectiveness of our method.
Section 5 deploys ablation experiments and gives corresponding performance analysis. In the final
Section 6, we summarize this paper and give possible future work.
3. Methodology
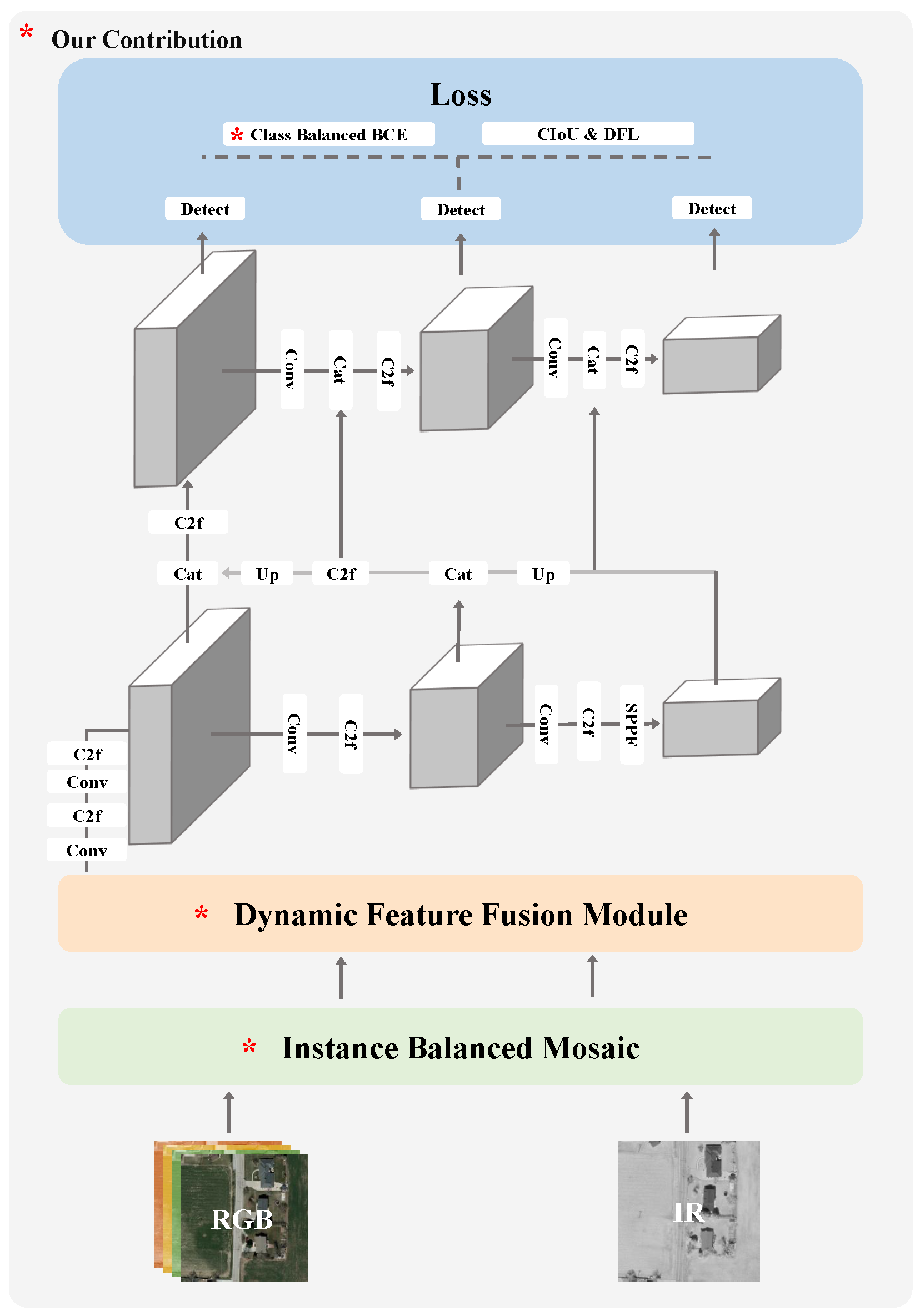
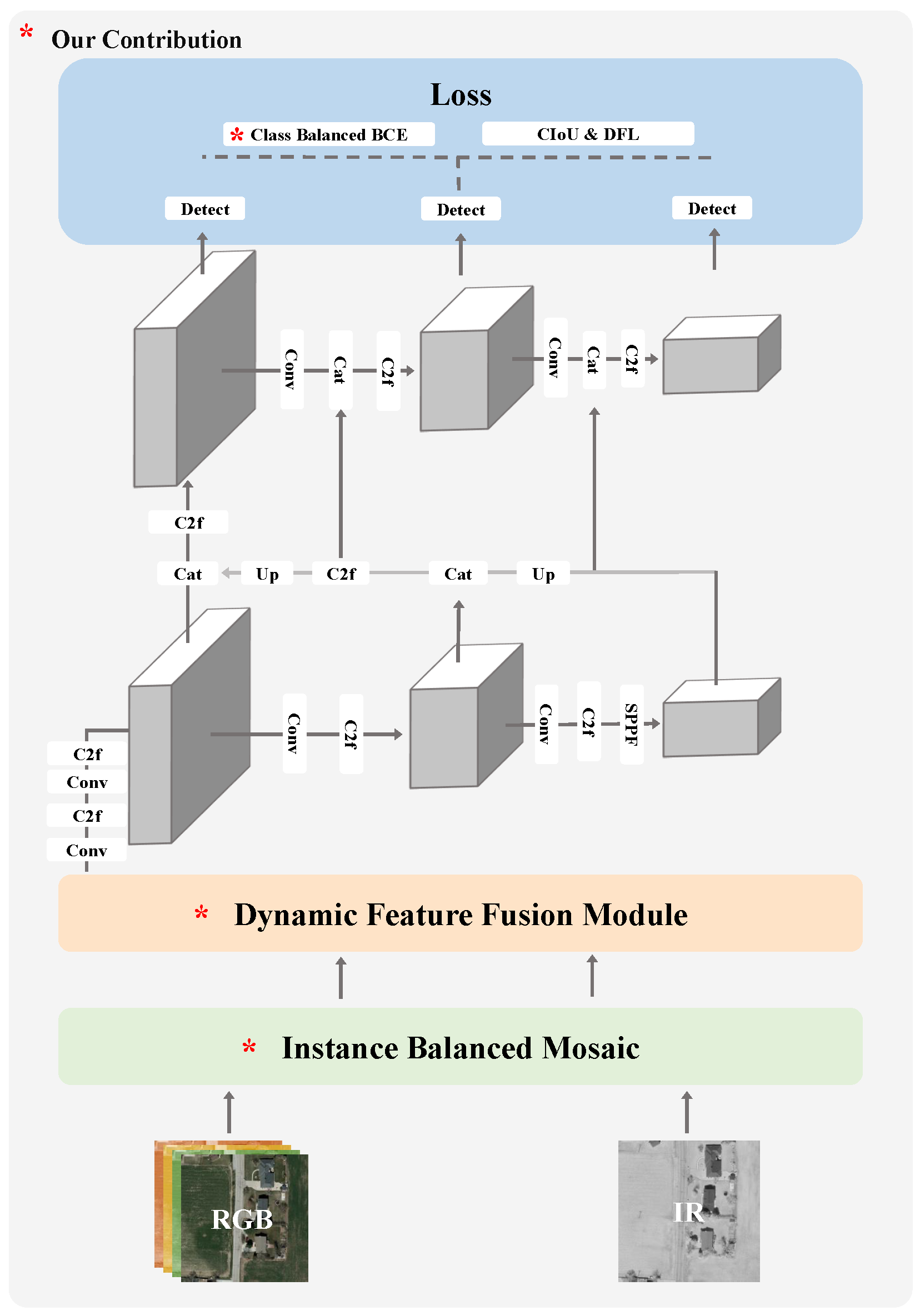
In this section, we first introduce the basic architecture of the method, and then describe the proposed modules in detail. The overall framework of our model is shown in
Figure 3, which mainly consists of three parts: the dynamic feature fusion module, instance-balanced mosaic and class-balanced BCE loss. Through the collaboration of these three modules, we achieve the detection of multimodal long-tailed datasets.
3.1. Basic Architecture
As shown in
Figure 3, the baseline architecture YOLOv8 [
19] network used by our method consists of two main components: a backbone network and a head module. The backbone network is used to extract multi-scale feature maps, including low-level texture features and high-level semantic features. Then, these feature maps are fed into the head for object detection and classification. Compared with YOLOv5 [
32], YOLOv8 replaces C3 with a C2f module for lighter weight, and uses split instead of conv to layer the features. It also uses a decoupled head in the head module, which aligns the classification and regression tasks by introducing task-alignment learning, making the model design more reasonable and efficient.
YOLOv8, as the latest SOTA model, has strong performance in object detection, but it still has some limitations.
Limitation 1: YOLOv8 cannot perform multimodal fusion object detection, resulting in low detection accuracy. Because there are differences between different modal images, simply fusing them cannot fully utilize the complementary information between them. For example, in good lighting conditions, visible light images contain more information such as texture, color, etc., than infrared images. Conversely, in low-visibility environments, especially when there is slight occlusion, infrared images can capture the outline of the target and other information significantly. These problems affect the accuracy and robustness of object detection, so it is necessary to design a more effective multimodal fusion method to transform the YOLO network, to extract the complementary information between different modalities and eliminate the differences and noise between different modalities.
Limitation 2: The mosaic data augmentation method used by YOLOv8 is not suitable for remote sensing object detection; because remote sensing target samples are small and scattered, cropping and stitching will lead to loss of tail-class samples, resulting in a decrease in the overall detection accuracy of the model. The mosaic data augmentation method can increase the diversity of data without increasing the size of the dataset, thereby improving the generalization ability of deep network models. The specific method is to randomly crop four images and then combine and stitch them into a new image input network. However, this method is not suitable for remote sensing object detection; because the targets in remote sensing images are usually small and sparse, random cropping will cause many targets to be cut off or only retain a part, thus affecting the model’s detection and localization of targets. Especially for tail class targets, since they are rare in themselves, if they are cropped off, it will cause the model to lack enough training samples, thereby reducing the model’s detection accuracy for tail classes.
Limitation 3: The loss function of YOLOv8 only considers hard samples, not tail class samples learning, resulting in low detection accuracy for tail-class instances. YOLOv8 network uses the CIoU loss function [
33] to optimize the regression of target boxes. It is a loss function based on IoU (intersection over union), which can consider factors such as overlap degree, center distance, aspect ratio, etc. between target boxes, and improves the localization accuracy of target boxes. However, this loss function only focuses on hard samples, i.e., prediction boxes with low overlap with ground truth boxes, and ignores the detection difficulty difference between classes. For tail-class targets, since they are rare and difficult to detect in themselves, if only hard samples are considered and tail-class samples are ignored, this will cause the model to calculate inaccurate losses, thereby reducing the model’s detection accuracy for tail classes. Therefore, it is necessary to design a loss function that can consider both hard samples and tail-class samples at the same time to improve the model’s detection performance for tail classes.
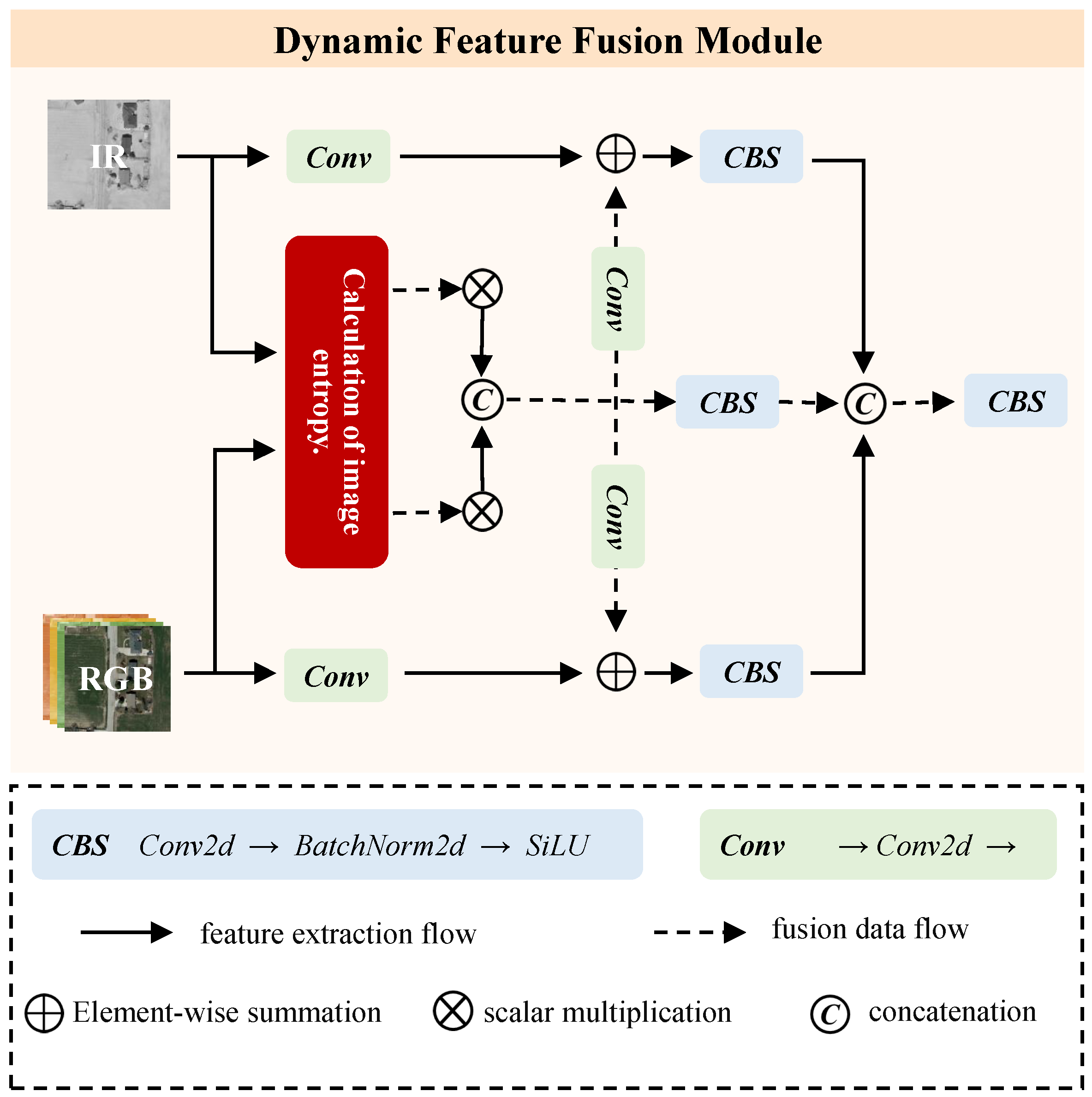
3.2. Dynamic Feature Fusion Module
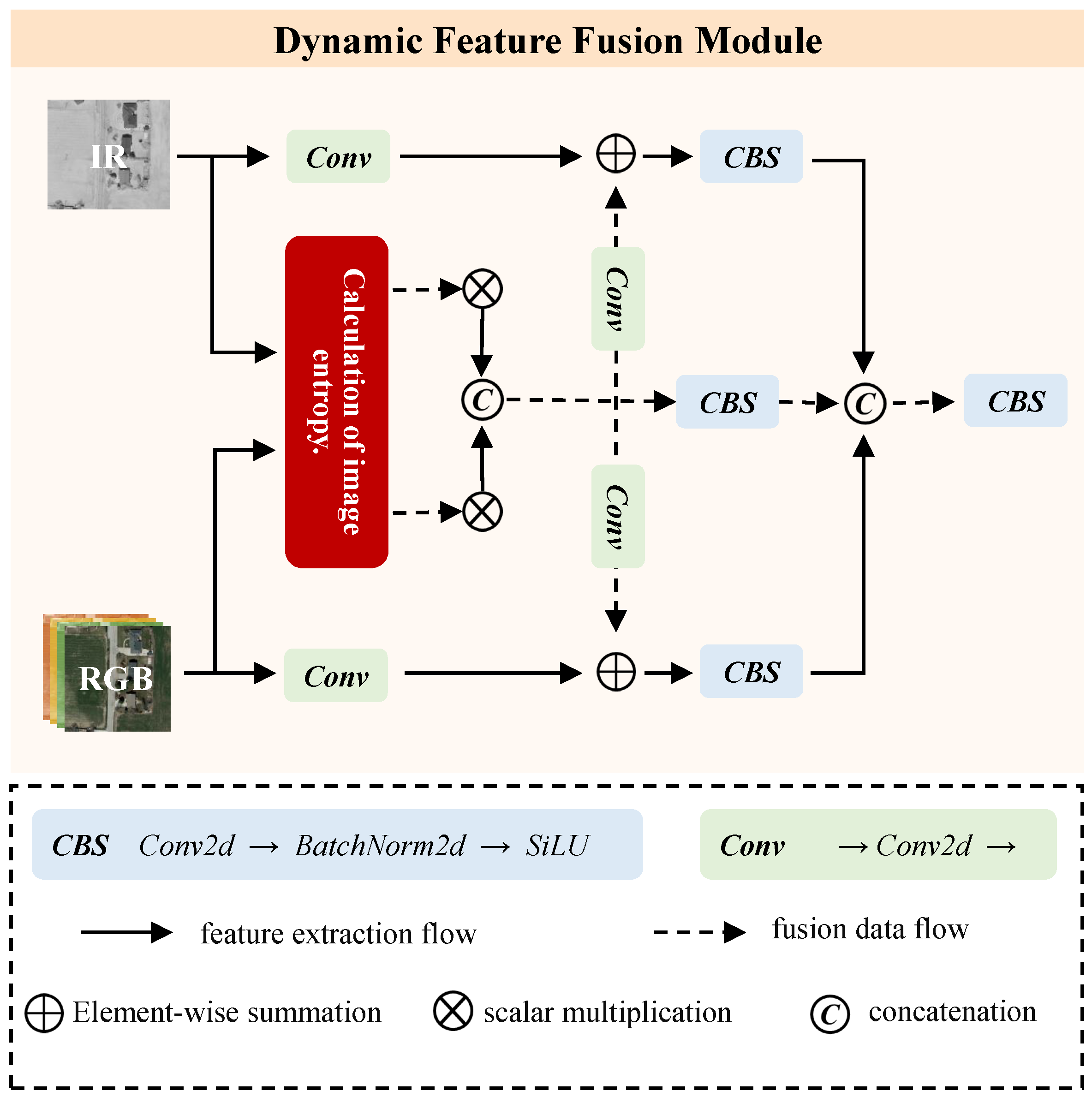
To efficiently utilize multi-source information for object detection, we propose the dynamic feature fusion module. As shown in
Figure 4, the module consists of two parts, namely the calculation of image entropy module and the multimodal feature fusion module. The image information quantity calculation module can accurately perceive the target scene by calculating the image entropy and dynamically assigning fusion coefficients for the images. The feature fusion module then fuses the images according to the information quantity, providing more salient features for subsequent object detection.
3.2.1. Calculation of Image Entropy
Preliminaries. The model input in the image multimodal object detection task is multimodal images, where we use to represent the corresponding visible light image and infrared image. For convenience of calculating the image information quantity, we separate the visible light image into , where .
First, calculate the gradient magnitude and direction of the input images. The gradient magnitude is the change amplitude in the direction of maximum gray level change, and the gradient direction is the direction of maximum gray level change. Previous researchers have proposed many operators to calculate the gradient magnitude and direction, such as Sobel operator [
34], Prewitt operator [
35], Roberts operator [
36], etc., which are all based on the difference between adjacent pixels in the image to estimate the gradient. In order to maintain the stability of model detection, we choose Sobel operator to calculate the image gradient.
where
I is the image matrix,
,
is convolution operation,
and
are gradients in horizontal and vertical directions, respectively. Then, the image gradient magnitude and direction can be obtained by the following formulas:
where
G is gradient magnitude,
is gradient direction. After obtaining the gradient magnitude and direction of each pixel, calculate the two-dimensional joint histogram
n of gradient magnitude and direction. Each element
can be calculated by
where
W and
H are the width and height of the image,
,
,
,
is an indicator function that obtains the gradient distribution map by judging each pixel one by one, i.e.,
Further, the pixel probability
can be obtained. Then, the probability of gradient magnitude being
i and direction value being
j is
Based on the probability map
r, the final two-dimensional gradient entropy
[
37] of the image can be calculated.
Using the above method, we can obtain the image entropy of the images , respectively.
3.2.2. Multimodal Feature Fusion
To fuse multimodal information for object detection, we propose multimodal feature fusion. As shown in
Figure 4, we extract the shallow features of the visible light and infrared images
input to the model using 1 × 1 convolution module while sending them to the image entropy calculation module.
Then, we fuse each channel of the image according to the calculated information quantity, and the obtained features can be expressed as
In the formula,
represents the concatenation operation along the channel axis; ∗ is the multiplication of image entropy and image. Further, we use 1 × 1 convolution module to extract global features and fuse different modal features,
On the basis of preliminary fusion of shallow features, in order to extract more spatial information, we use
module to extract global features and fusion features of different modalities.
Finally, we use a CBS module to fuse all the features calculated by the above formula and pass them to the subsequent backbone network for high-level semantic information extraction.
The final output of this module is f that fuses visible light and infrared images.
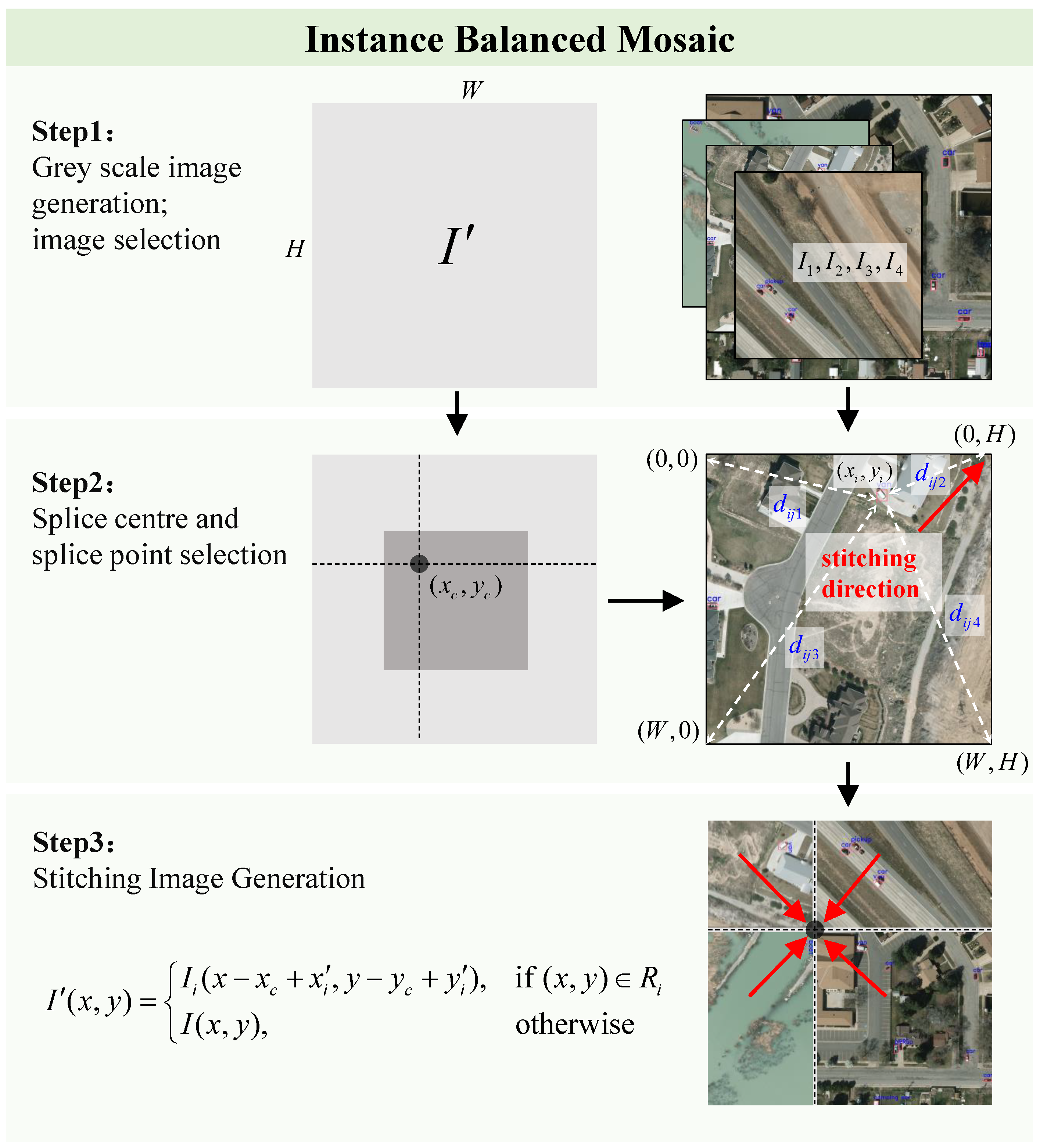
3.3. Instance-Balanced Mosaic
As mentioned in
Section 3.1, the default data augmentation module of YOLOv8 network is not suitable for remote sensing object detection. Because the targets in remote sensing images are small and sparse, especially when the instances present a long-tailed distribution, the tail-class instances with fewer numbers will be discarded, resulting in low detection accuracy of the model for these classes.
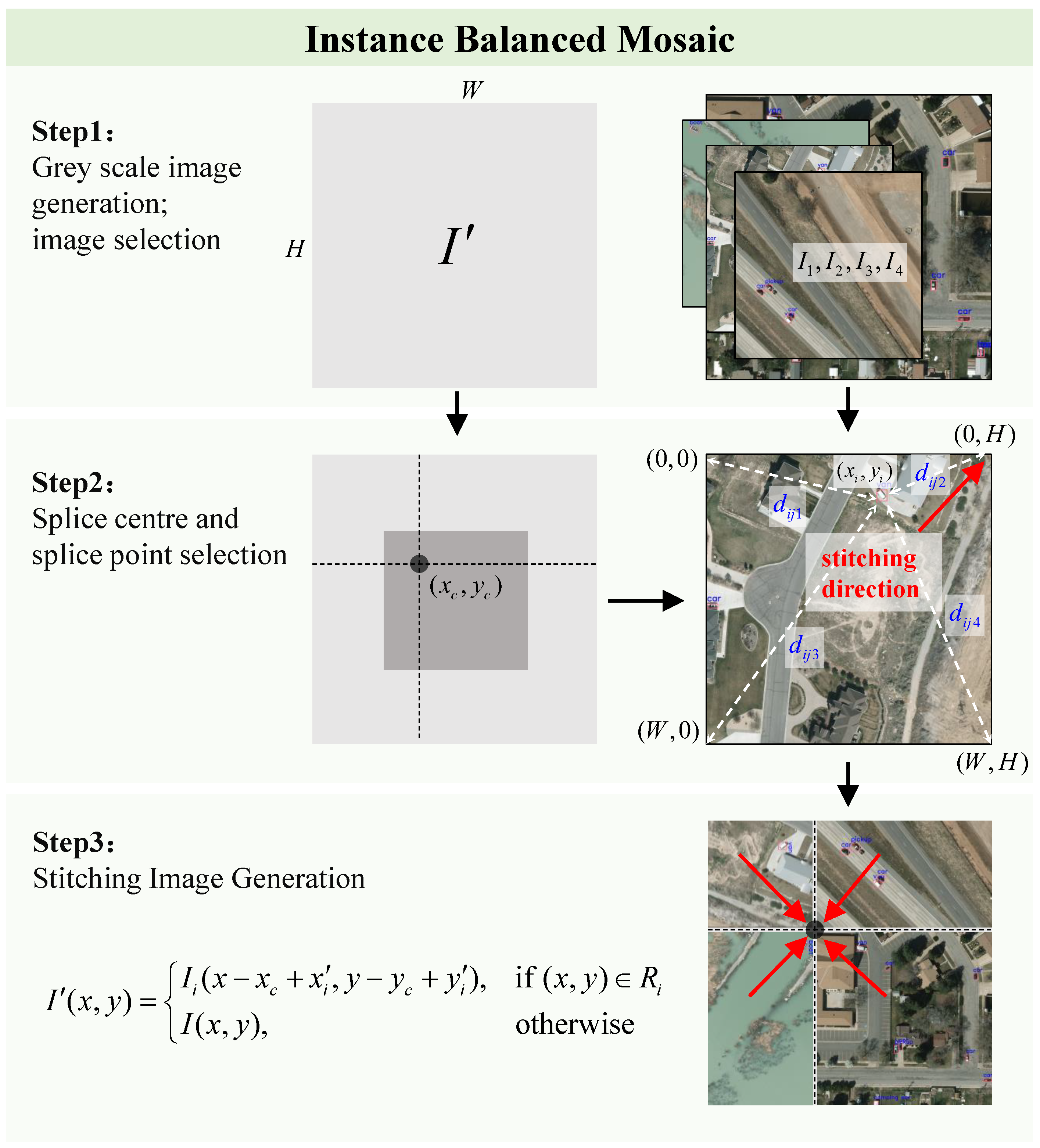
In order to improve the model’s detection accuracy for tail classes, we propose the instance-balanced mosaic module, which considers the long-tailed problem of data and tries to preserve tail-class instances as much as possible during data augmentation. By stitching part of the content and annotation information of four original images onto a gray image to increase the diversity of the training set, this method enhances the model’s detection performance for remote sensing images. As shown in
Figure 5, the process can be divided into three steps.
Step 1: We generate a gray image , where W and H represent the width and height of the target image, respectively. We randomly select four images from the training set, denoted as .
Step 2: In the rectangular area on the gray image that satisfies , , we randomly select a point as the stitching center point , and split the gray image from this point along horizontal and vertical directions to form stitching areas.
For each selected image
, we traverse each instance’s class
and count the number of that class in the training set
. Then, we randomly select an instance
of the class with the least number
, and calculate the Euclidean distance
between its center point
and the four vertices
of the image, and select the closest vertex as the stitching point
. This distance can be calculated by
where
are the coordinates of the
k-th vertex,
.
Step 3: For each image
, according to the stitching point and direction, we stitch it onto the gray image so that the stitching point
is aligned with the stitching center point
. If the two points are not aligned, we need to rotate, flip or perform other transformations on the original image; the coordinates of the aligned stitching point
can be expressed as
. The stitching transformation can be expressed by
where
is the stitched image,
is the
i-th quadrant of stitching area on the gray image. For each image
, we also copy its target instance annotation information (such as bounding box, class etc.) to the gray image and adjust it according to stitching position. This way, we obtain a new data-augmented image that contains part of content and annotation information from four original images.
3.4. Class-Balanced BCE Loss
The overall loss function of our network is consistent with the baseline network, which consists of three parts: box loss
, classification loss
, and regression loss
[
38], which can be expressed as
where
are the balance coefficients set at the beginning of training. In the calculation of classification loss, compared with the original YOLOv5 network, YOLOv8 learns from TOOD [
39] and introduces dynamic positive and negative sample allocation tasks, which aligns the classification and regression tasks. Unfortunately, the calculation of classification loss still does not consider the impact of long-tailed distribution of datasets. The datasets with long-tailed distribution have extremely unbalanced sample numbers among different classes, with a few minority classes having many samples, while most classes have few samples. This will cause the model to pay more attention to majority-class samples during training, and ignore minority-class samples. In order to better recognize tail class samples, and thus improve the model’s detection accuracy on long-tailed datasets, we adjust the loss to class-balanced BCE loss based on the original BCE loss.
In order to assign reasonable weights to classes based on the number of instances per class, we first need to establish a formula that assigns higher weights to classes with fewer samples. Suppose we have
N samples, the weight of class
c can be
where
is the number of samples belonging to class
c. Based on the calculated weight
, we calculate the target score. The calculation of positive and negative samples is consistent with the original method [
39], which first calculates the alignment degree between candidate anchor points and objects
where
and
are two hyperparameters that control the weights of classification and localization.
represents the score of class
c for anchor point
j of sample
i.
represents the predicted box corresponding to anchor point
j of sample
i.
represents the ground truth box corresponding to anchor point
j of sample
i. IoU is the intersection over union calculated by CIoU method [
33] between two boxes.
Then, we obtain the target score related to alignment degree
, where
l is the corresponding sample class label. By weighting, we obtain the final target score
where
is a hyperparameter that controls the weighted strength of a class, and
is the normalized weight of
for more stable balancing of importance between classes.
The weighted classification loss assigns larger weights to minority classes and smaller weights to majority classes according to the distribution of different classes in the dataset, which makes the model pay more attention to minority-class samples. The final classification loss continues to use cross-entropy loss function
where
is the predicted probability that sample
i belongs to class
c.
4. Experiment and Results
4.1. Dataset
We conducted relevant experiments on three common datasets to test the effectiveness of our method.
(1) VEDAI dataset. VEDAI (vehicle detection in aerial imagery) dataset is a dataset designed specifically for vehicle detection in aerial images, released by the University of Caen in 2015. The images in this dataset contain various types of vehicles, which have differences in illumination, occlusion and orientation. In addition, each image contains two bands of visible light and infrared, and two resolutions of 512 × 512 and 1024 × 1024. In order to better reproduce the experimental results and compare with other experiments, it provides a unified division of training set and test set data, which makes this dataset have the ability to verify whether the model has complex multimodal object detection ability. The VEDAI dataset contains a total of 1246 images, including eight different types of vehicles, such as cars, pickups, trucks, etc., and each image has corresponding annotation information such as location.
(2) LLVIP dataset. LLVIP dataset is a dataset created specifically for low-light vision tasks, collecting a large number of visible light and infrared images taken under low-illumination conditions. These images are captured by a dual-spectral camera with a bird’s-eye-view monitoring angle, containing a lot of pedestrians and cyclists on the street, and each pair of infrared and visible light images is spatially and temporally aligned. Therefore, this dataset can be used to study visual tasks such as image fusion, pedestrian detection and image-to-image translation. Since most of the images are taken at night with poor lighting conditions, it can well reflect the complementarity between visible light and infrared images, thus testing the model’s fusion detection ability for multimodal images. All pedestrians in this dataset have accurate annotation files, recording their categories and locations. According to statistics, it contains 33,672 images, that is, 16,836 pairs of images; each image has a pixel size of 640 × 512.
(3) FLIR dataset. FLIR dataset is a visible light and infrared dataset for training neural network object detection, mainly containing daytime and nighttime scenes on the highway, aiming to test the model’s fusion ability of complementary information from multispectral images. However, with regard to the original version released by Teledyne FLIR company with 26,442 fully annotated images, although annotated with various types such as people, cars, traffic lights, etc., there are a lot of unaligned images in time and space, which makes the model training too complicated and unable to reasonably test the model’s performance. Therefore, ref. [
40] released an “aligned” version, which contains 5142 pairs of strictly aligned infrared and visible light images, excluding other categories besides people, cars and bicycles. In our experiments, we also choose to use this “aligned” version of the dataset to test and verify our model.
Table 1 summarizes the details of the datasets used in our experiments.
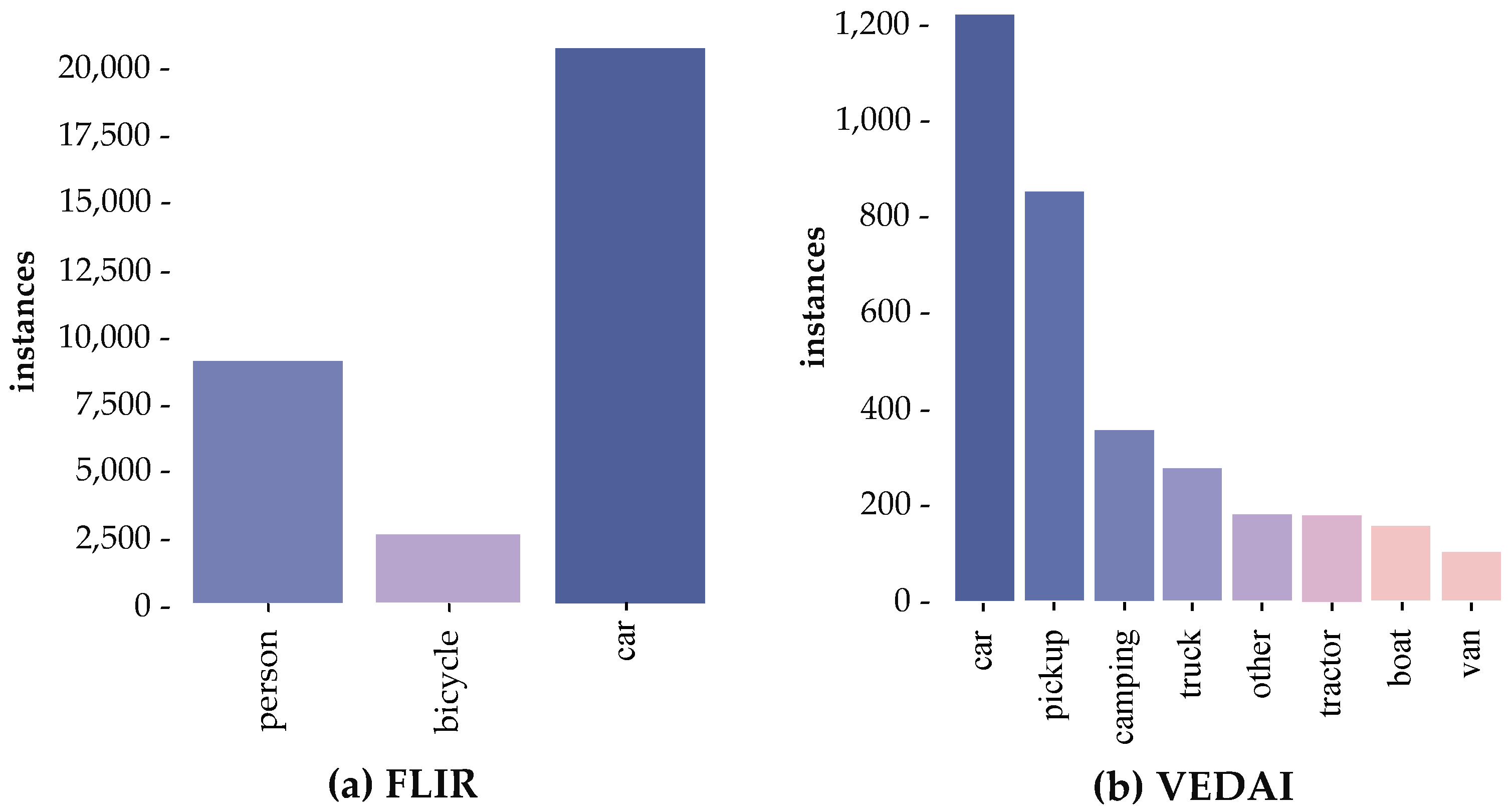
Figure 6 shows the class imbalance distribution of FLIR and VEDAI datasets.
4.2. Implementation Details
In this experiment, we deployed our model using the PyTorch framework based on Python 3.8. The model training used a server with two NVIDIA GeForce 3090 GPUs, with a CPU of inter 13,900 k and a memory of 128 G. During the training process, we set momentum to 0.9 and weight_decay to 5 × . We chose the optimizer corresponding to the dataset according to the dataset, and chose AdamW for FLIR and VEDAI datasets, and SGD for LLVIP dataset. Because the LLVIP dataset has large image size and many samples in the training set, the model has more iterations during training, and SGD can better escape local optimal solutions. On the contrary, although the AdamW optimizer may fall into local optimal solutions, it can dynamically adjust the learning rate according to the gradient size of parameters, and converge faster on small datasets. The initial learning rate was set to 1 × and the final learning rate was 1 × . The batch size was fixed at 16 and the total epoch was 100.
4.3. Accuracy Metrics
In the model evaluation, we chose to use the evaluation metric mean average precision (mAP) created by the MS-COCO dataset to evaluate the performance of the model, which represents the average value of average precision (AP), and is used to measure the performance of detection models. The higher the mAP, the stronger the detection ability, that is, the higher the better. It can be calculated by
where
is precision and
r is recall, and they are calculated as follows:
where TP stands for true positive, which is the number of positive-class samples that are correctly predicted by the model under a certain IoU threshold; FP stands for false positive, which is the number of negative-class samples that are misreported by the model under this IoU threshold; FN stands for false negative, which is the number of positive-class samples that are missed by the model. As the most widely used evaluation metric in object detection field, mAP has various different IoU threshold standards such as mAP50 and mAP50:95. mAP50 means the average value of AP values of all classes at IoU = 0.50, and mAP50:95 means the average value when IoU = 0.50:0.05:0.95. We choose these metrics to evaluate our proposed model.
4.4. Comparisons with Previous Methods
4.4.1. Experiment Results of the VEDAI Dataset
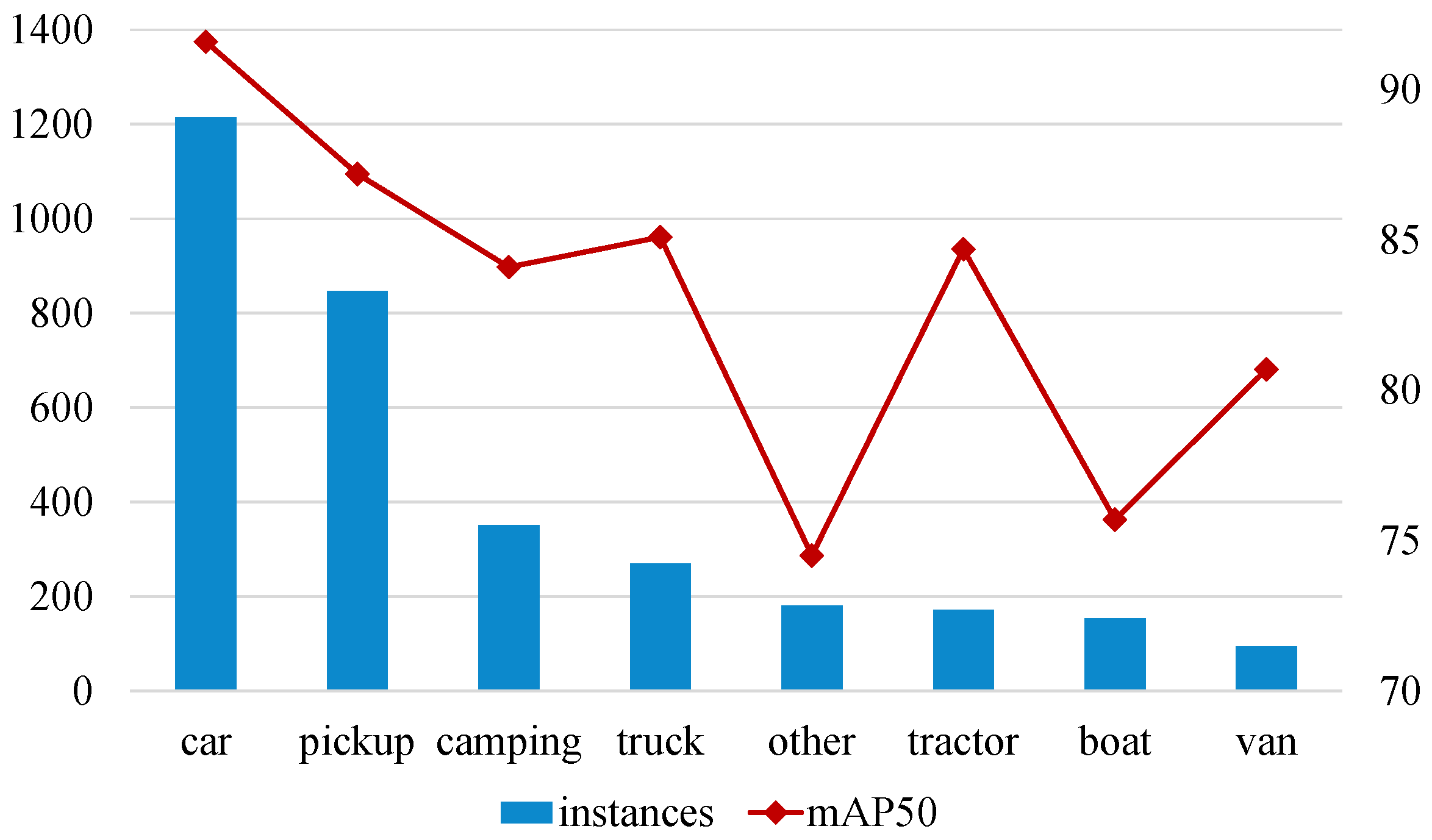
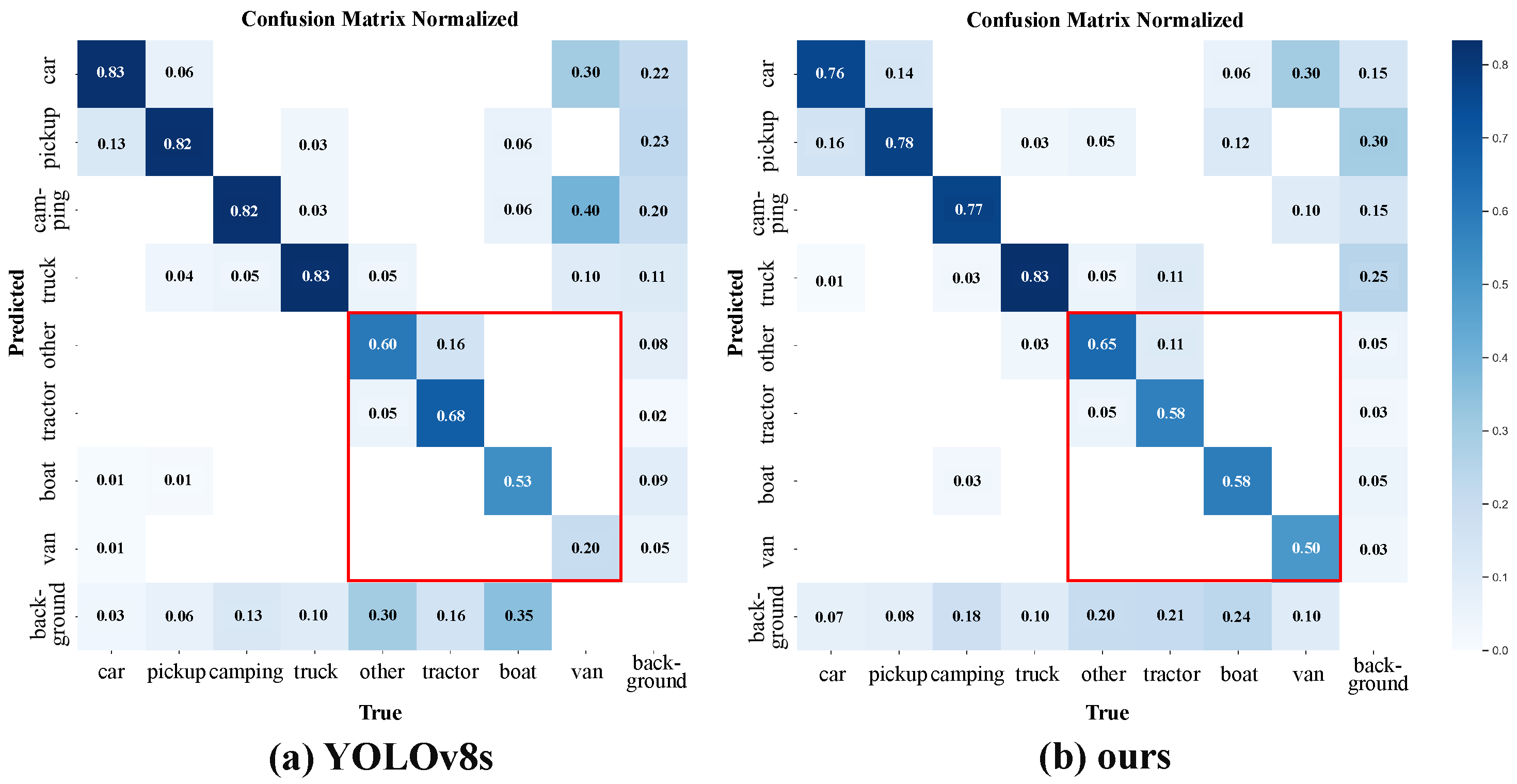
The VEDAI dataset is a long-tailed remote sensing image dataset composed of eight classes; as shown in
Figure 6, the car class has a large number of samples, while tail classes such as vans have very few samples. In this paper, we conducted extensive comparative experiments on this dataset to verify the effectiveness of our method for remote sensing object detection data with long-tailed instance distribution.
The results in
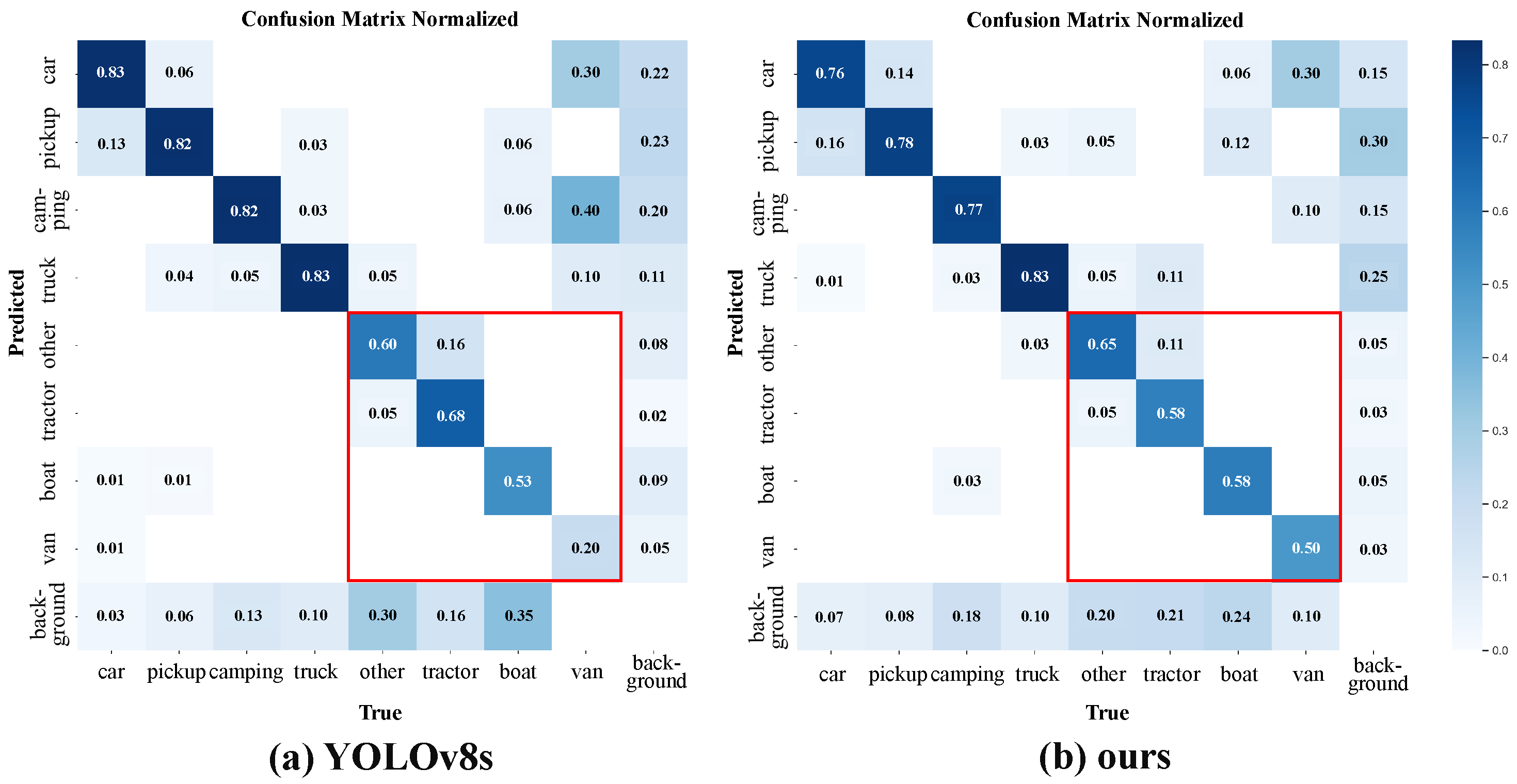
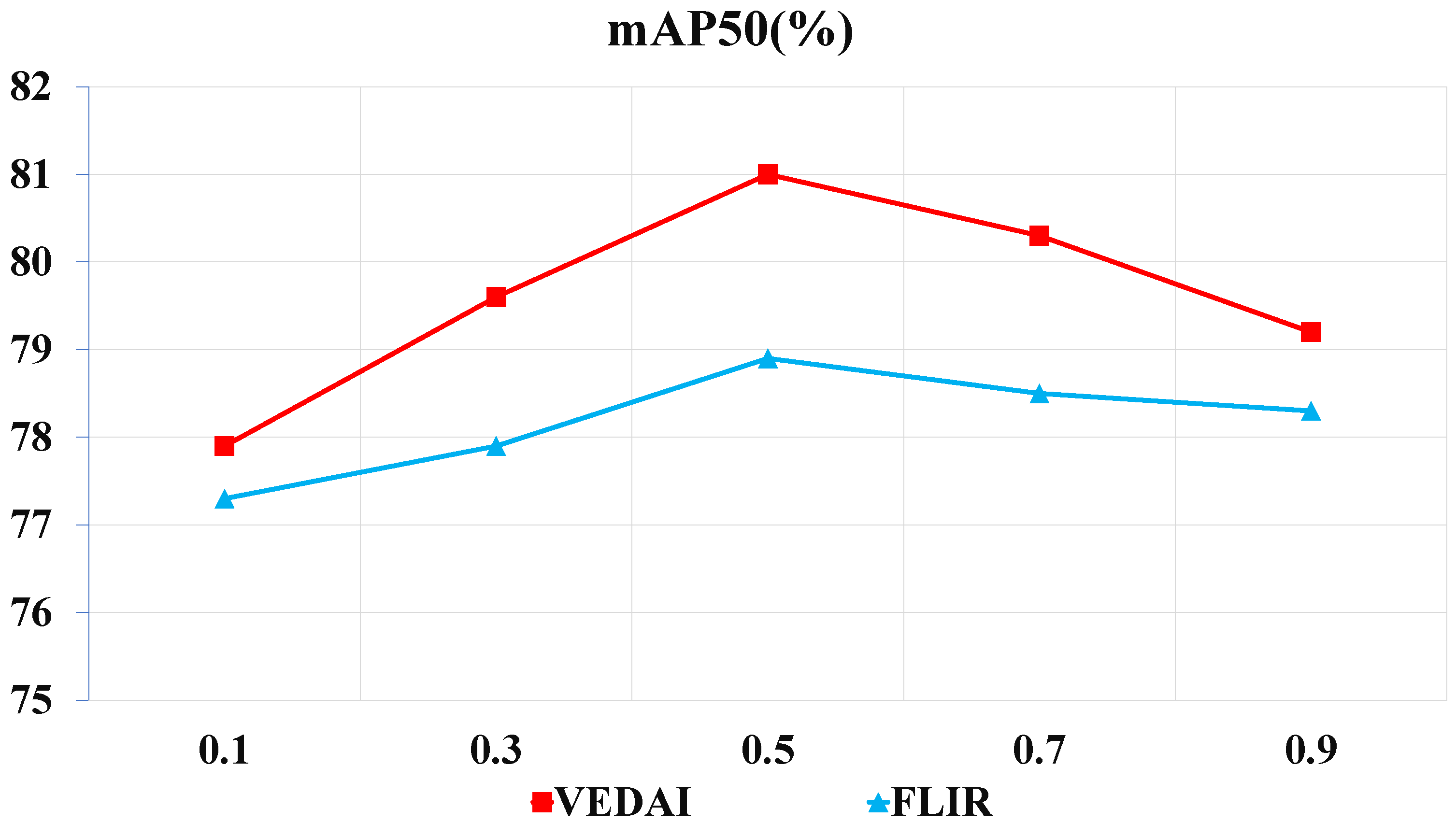
Table 2 show that our proposed method achieves the highest detection accuracy on VEDAI dataset. This fully verifies the effectiveness of our proposed method for long-tailed remote sensing object detection data. Specifically, our method can achieve superior performance over other methods for two main reasons. One is that the DFF module fuses complementary information from infrared and visible light images, and obtains an mAP50 of 81% after fusion, which is much higher than 76.6% using only infrared images and 72.7% using only visible light images. These data further illustrate the performance of our proposed DFF module. The other is that by balancing classes between instances, we reduce the model’s overconfidence for head instances. As shown in
Figure 7, our method has the highest performance compared to other methods on tail instances such as boats, thereby improving the overall performance of the model.
4.4.2. Experiment Results of the FLIR Dataset
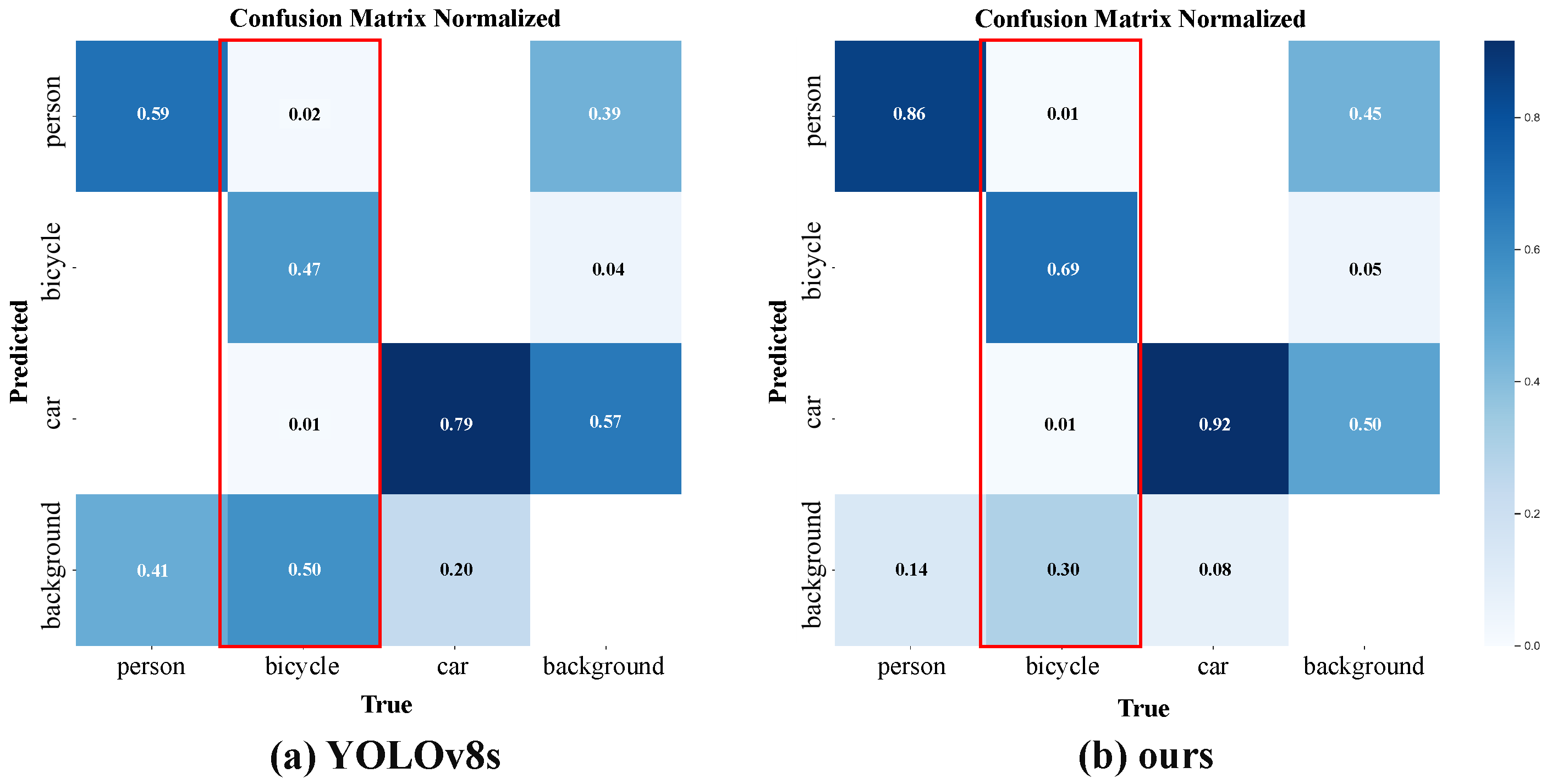
As shown in
Figure 6a, FLIR is a remote sensing object detection dataset that contains three categories. We conducted extensive comparative experiments on this dataset with the current state-of-the-art methods to verify the effectiveness of our proposed method for long-tailed remote sensing object detection datasets. The experimental results are shown in
Figure 8 and
Table 3.
The results in
Table 3 show that our proposed method achieves the highest average detection accuracy on the FLIR dataset. It can be observed that compared to single-modality methods, multi-source fusion methods generally have higher performance. Our method can surpass other multi-source fusion methods, mainly due to the solution of the long-tailed problem. From
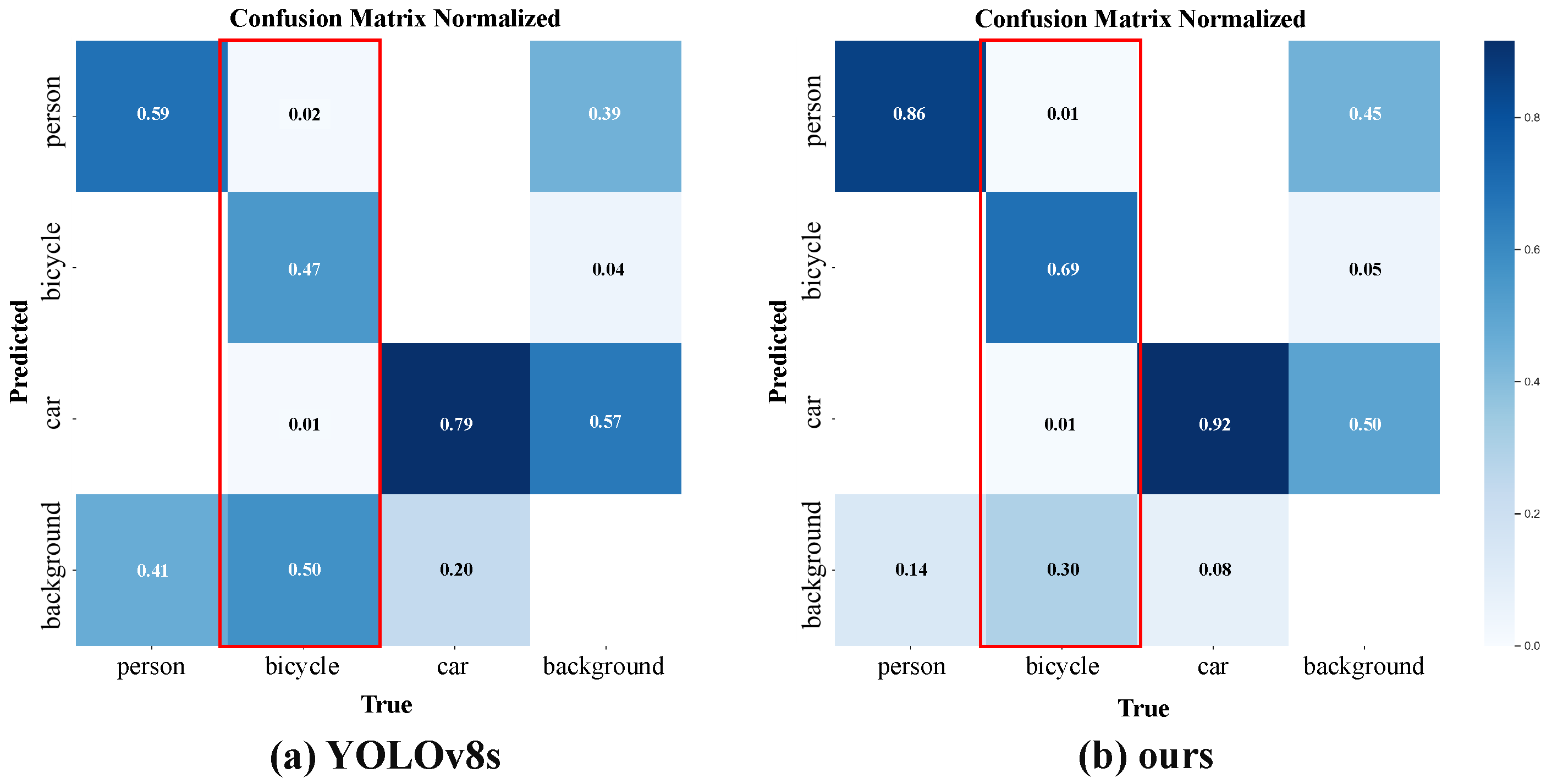
Figure 8, it can also be seen that our proposed method can solve the long-tailed distribution problem in remote sensing object detection by significantly improving the detection accuracy of tail-category instances, while maintaining or slightly improving the detection accuracy of head-category instances. Since the data obtained by remote sensing usually show a long-tailed distribution, our proposed method is more consistent with the real-world situation and has broad application value. The experimental data on the FLIR dataset fully demonstrate that our proposed method has very good detection performance on long-tailed remote sensing detection data, especially for better detection of tail-category instances.
The visual detection results of the baseline method YOLOv8s and our method in five randomly selected scenes are shown in
Figure 9, where the yellow ellipses represent the targets missed by the model in detection, and the purple ellipses indicate the targets falsely detected by the model. We can observe that our method is significantly better than the baseline method in tail-class samples and complex scenes. In
Figure 9a, our model detects two tail-class samples of bicycles that are missed by the baseline model, and moreover, the confidence of the only bicycle detected by the baseline model is also lower than that of our model. As marked by the purple ellipses in scenes
Figure 9c,e, the baseline model also erroneously detects cars and bicycles, further demonstrating the advantage of our method.
4.4.3. Experiment Results of the LLVIP Dataset
The LLVIP dataset is a single-target remote sensing dataset that contains multiple scene categories. Although this dataset only has one target of pedestrians and does not have a long-tailed distribution, the scenes in this dataset are mostly under dark light conditions, which can well test the performance of the DFF module in our method. Therefore, we conducted extensive comparative experiments on this dataset with current advanced similar methods to verify the effectiveness of our proposed method for multi-source data fusion. The experimental results are shown in
Table 4.
The results in
Table 4 show that our proposed method achieves the highest average detection accuracy on this dataset. At the same time, other similar algorithms such as YOLOFusion [
44] also have very good performance, which indicates that multimodal fusion methods are very effective remote sensing object detection methods. In contrast, the detection accuracy of methods based on single modality is generally not high. This fully illustrates the powerful performance of the DDF module in our proposed method.
6. Conclusions
In this paper, we propose a new method for long-tailed object detection in multimodal remote sensing images, which can effectively fuse the complementary information of visible light and infrared images, and adapt to the imbalance between positive and negative samples of different classes. The main contributions of this paper are as follows: (1) Based on image entropy, the dynamic feature fusion module can dynamically adjust the fusion coefficient according to the information content of different source images, and retain more key feature information for subsequent object detection. (2) The instance-balanced mosaic data augmentation method can balance the sampling of instances in the data augmentation stage, provide more sample features for the model, and reduce the negative impact of data distribution imbalance. (3) Class-balanced BCE loss can consider both instance learning difficulty and class learning difficulty, and improve the model’s detection accuracy for tail instances. The experimental results on three public benchmark datasets show that proposed method achieves state-of-the-art performance.
In summary, we propose a new method for long-tailed object detection in multimodal remote sensing images, which can effectively fuse the complementary information of visible light and infrared images, and adapt to the imbalance between positive and negative samples of different classes. Our method can improve detection accuracy and robustness of remote sensing objects, especially for tail classes. However, our method is not robust to multi-source images that are not geometrically aligned. In future, we plan to extend our method to other modalities such as radar and hyperspectral images, and explore more effective methods to deal with long-tailed data distribution.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}