1. Introduction
Radar faces increasingly complex electronic countermeasures, with various new types of radar jamming patterns continuously emerging as challenges [
1,
2]. The accurate recognition of radar jamming is a precondition and key to implementing anti-jamming measures, and automatic recognition of radar jamming patterns can effectively improve the target detection and tracking performance of radar. Therefore, jamming pattern recognition has always been a research hotspot in anti-jamming technology [
3,
4]. Suppression jamming by emitting high-power noise signals is not only effective for linear frequency modulated (LFM) radar systems but also for other modulated radar systems, making it the most widely used [
5]. Therefore, this paper focuses on the recognition of suppression jamming. Its main patterns include amplitude modulation jamming (AMJ), frequency modulation jamming (FMJ), comb spectrum jamming (CJ), phase modulation jamming (PMJ), swept jamming (SJ), etc. Conventional jamming pattern detection and classification methods are generally based on feature engineering. Firstly, multi-dimensional features of signal in time domain, frequency domain, and transform domain are extracted, including features such as moment kurtosis, moment skewness, envelope fluctuation, noise factor [
6,
7,
8,
9], singular spectrum features [
10], bispectrum features [
11] and other signal features. Then, with the help of machine learning-based classifiers, such as support vector machine (SVM ) [
12], decision trees [
13], and back propagation (BP) neural networks [
12], classifications are accomplished. However, feature engineering-based classification methods are time-consuming and require expert experience, especially when the transform domain features are large, the classification performance has limited room for improvement, and the recognition rate is low in strong noise environment.
With the development of deep learning (DL) technology, the feature extraction capability of neural networks has been improving, and classification methods based on DL are emerging. In [
14], A novel hybrid framework of optimized deep learning models combined with multi-sensor fusion is developed for condition diagnosis of concrete arch beam, and the results demonstrate that the method can achieve the classification of structural damage with limited sensors and high levels of uncertainties.
Convolutional neural networks (CNNs), due to their network architecture which incorporates weight sharing and small local receptive fields, have significantly reduced the number of node connections compared to conventional neural networks. This simplification of network connections has made CNNs widely applied in deep learning models [
15,
16,
17]. CNNs can train their parameters using jamming signals, eliminating the need for manual feature extraction and the design of decision trees for classification criteria. As a result, CNNs have been extensively used in the research of classifying and recognizing radar jamming signals [
18].
In [
19], a jamming recognition algorithm based on improved LeNet·CNN network was designed which extracted one-dimensional radar received signals and adjusted the network structure parameters to achieve optimal performance for the recognition of jamming signals. Ref. [
20] obtained the time-frequency spectrogram of jamming signals by short-time Fourier transform, combined with the improved VGGNet·16 network model for feature learning and training, and the simulation verified that the algorithm is still effective for the identification of six kinds of mixed jamming. Ref. [
21] adopted an adaptive cropping algorithm to crop most of the redundant information of the time-frequency image and kept the complete information of the jamming in the CNN for training, and finally achieved the recognition of nine kinds of jamming signals with high accuracy and fast iteration. In [
22], a 1D CNN-based radar jamming signal classification model was proposed to achieve the classification of 12 typical jamming signals by putting the real and imaginary parts of jamming signals into the parallel network for training. In [
23], a CNN was constructed using the real and imaginary parts of the signal as inputs. With sufficient training samples, this method demonstrated excellent recognition capabilities. The mentioned papers primarily address the issue of recognizing jamming when there are sufficient labeled samples. However, [
6,
24,
25] considered the case of insufficient labeled samples. Ref. [
6] proposed a method based on a time-frequency self-attentive mechanism. The recognition rate for most of the patterns of jamming reaches 90% when the samples with labels account for 3%. In [
24], Tian et al. inputed features obtained through empirical mode decomposition and wavelet decomposition into the network. Simulations conducted on a dataset consisting of only 8400 samples showed that the recognition rates for four types of jamming were all above 90% when the JNR exceeded 6 dB. In [
25], a large number of unlabeled samples were first used to train an jamming recognition network to extract valuable features. Then, a small number of labeled samples were used to improve the classification accuracy.
Although the application of deep learning technology in radar jamming recognition is rapidly developing, the current methods still suffer from the closed-set assumption, i.e., the existing methods assume that the jamming patterns are included in the training set. However, in the actual battlefield environment, the enemy may invent new jamming patterns, making it challenging to collect data for all patterns in the training set, so the actual radar jamming environment is an open set scenario, i.e., the test environment is likely to have jamming patterns that do not exist in the training jamming library. In the actual open set jamming scenario, when a jamming pattern that does not exist in the training jamming library appears in the test environment, the existing radar jamming identification methods will incorrectly identify this unknown jamming as one of the known jamming patterns. In [
26], Zhou et al. first investigated the open set recognition problem for radar jamming; however, the method can only detect or reject the unknown patterns, but cannot effectively identify the unknown patterns. How to further classify these unknown pattern signals remains a challenging task, and it falls under the research domain of open world recognition (OWR).
Currently, OWR techniques have been applied in target recognition of synthetic aperture radar (SAR) images. In [
27], a hierarchical embedding and incremental evolutionary network (HEIEN) was designed for when there are fewer unknown target training sets in open scenarios, which requires only a small number of unknown target samples for effective model training. A more stable feature space was built in [
28], which has better interpretability. In testing, experiments on a dataset containing seven known targets and one unknown target show that the method improves the reliability of recognizing unknown targets. In [
29], Song et al. used physical EM simulation images of targets at different azimuths as training data in order to learn the features of unknown targets. An accuracy of 91.93% can be achieved in a recognition task with a dataset containing nine known targets and one unknown target.
Nevertheless, OWR is just starting in radar jamming pattern recognition. Zero-shot learning (ZSL) [
30,
31] is an effective approach to address the challenge of open world recognition. The most typical implementation of ZSL is based on feature mapping. The goal of this approach is to learn the mapping relationship between the original signal space and the semantic feature space using the known jamming patterns. This learned relationship is then generalized to the unknown pattern dataset, enabling recognition and classification of unknown patterns using the semantic features. ZSL can be classified into two types: traditional zero-shot learning (TZSL) and generalized zero-shot learning (GZSL) [
32]. TZSL assumes that the training patterns are known, while the testing patterns are unknown, and there is mutual exclusion between the training and testing patterns. GZSL assumes that the training patterns include both known and unknown patterns in the testing phase. GZSL has a more relaxed experimental setting, which better reflects real-world scenarios. Therefore, in this paper, we consider the GZSL scenario.
To address the challenge of existing methods being unable to classify unknown jamming patterns specifically, this paper adopts the idea of ZSL and conducts research on jamming patterns recognition in an open world scenario. We propose a residual convolutional autoencoder-based radar jamming open world recognition algorithm, abbreviated as RCAE-OWR.
In summary, the main contributions of this paper are as follows:
In order to address the limitations of existing radar jamming pattern recognition methods, which are mostly closed-set recognition or simply rejecting unknown patterns, we propose a zero-shot learning approach based on residual conventional autoencoders. This method does not require prior information about the patterns of jamming and can classify both known and unknown patterns using distance-based recognition methods.
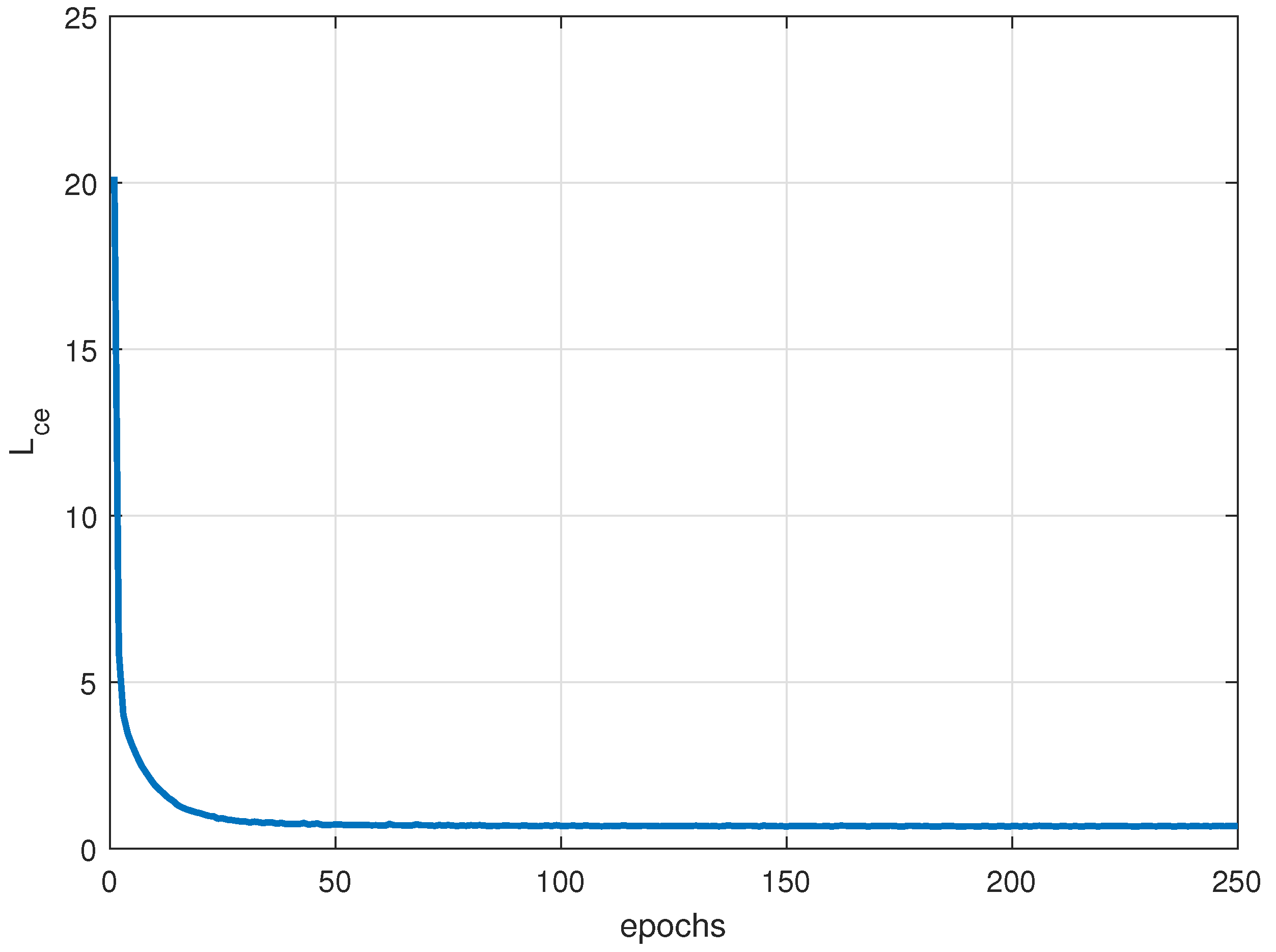
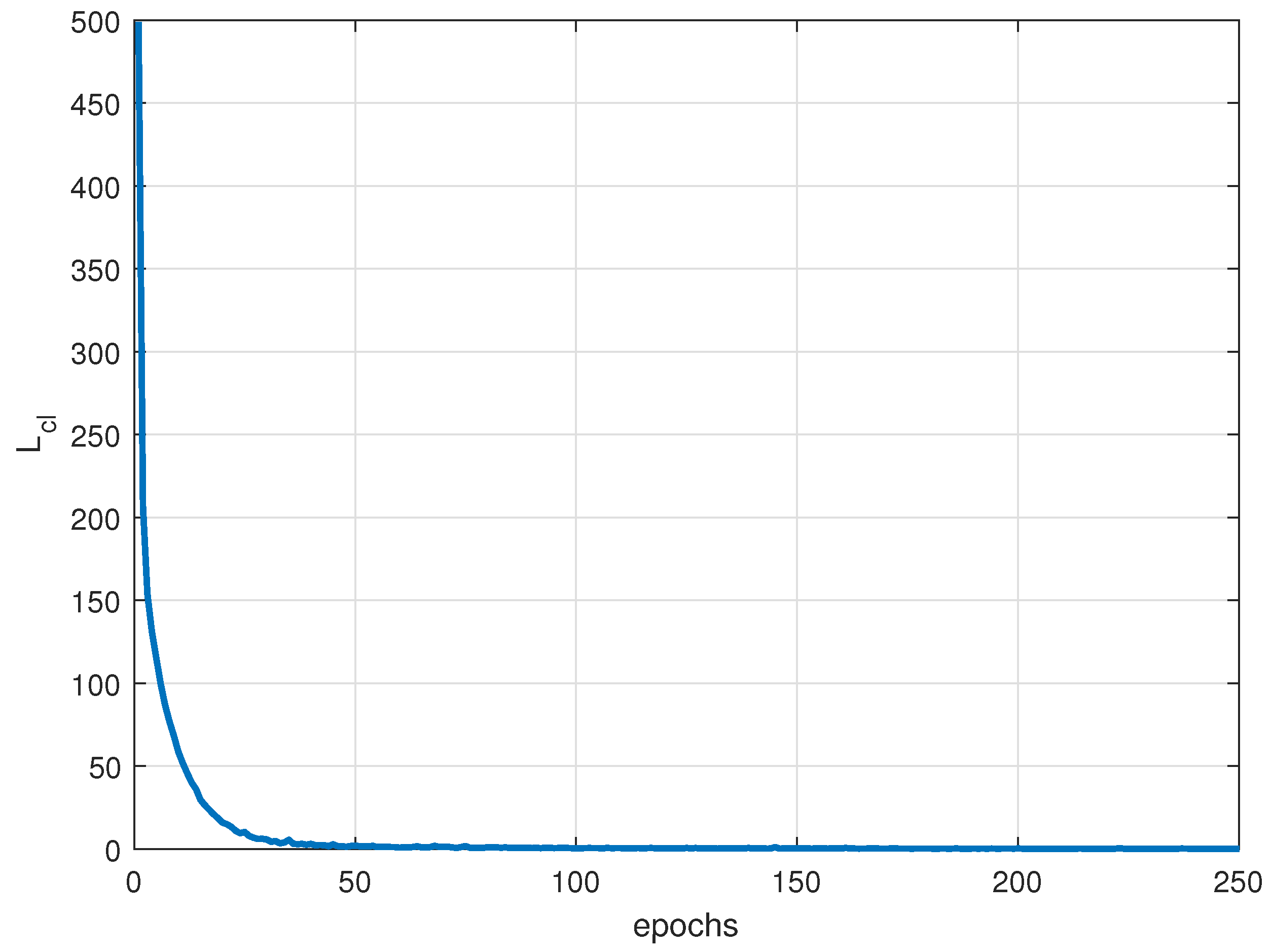
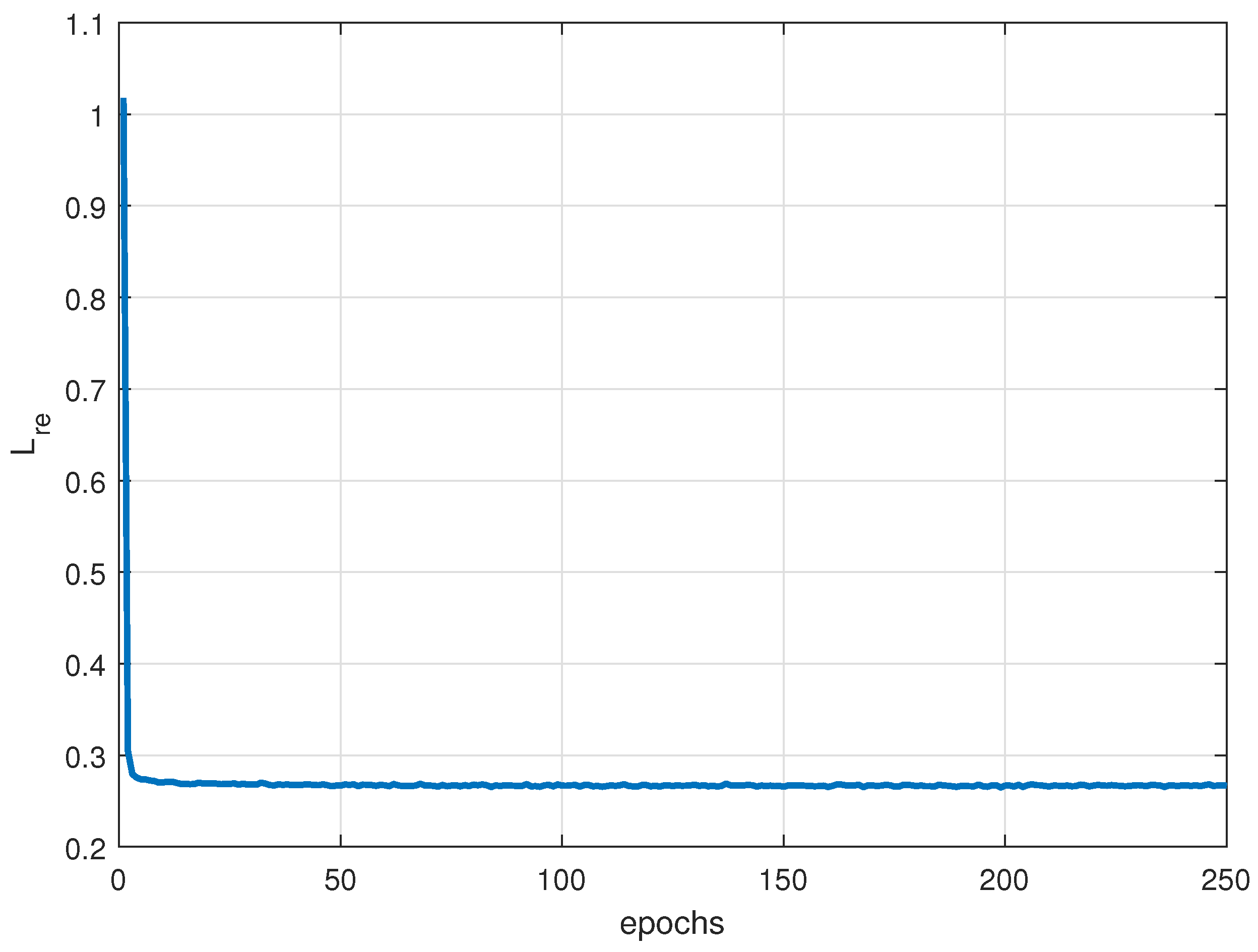
A hybrid loss function consisting of cross-entropy loss, center loss and reconstruction loss is introduced to recognize different patterns of jamming signals. Where the cross-entropy loss makes the features obtained from the mapping network divisible, and to some extent widens the distance among different patterns, the center loss makes it easier to delineate the boundaries of the various patterns, and the reconstruction loss ensures that the most essential characterization of the pattern features is learned from the known patterns dataset.
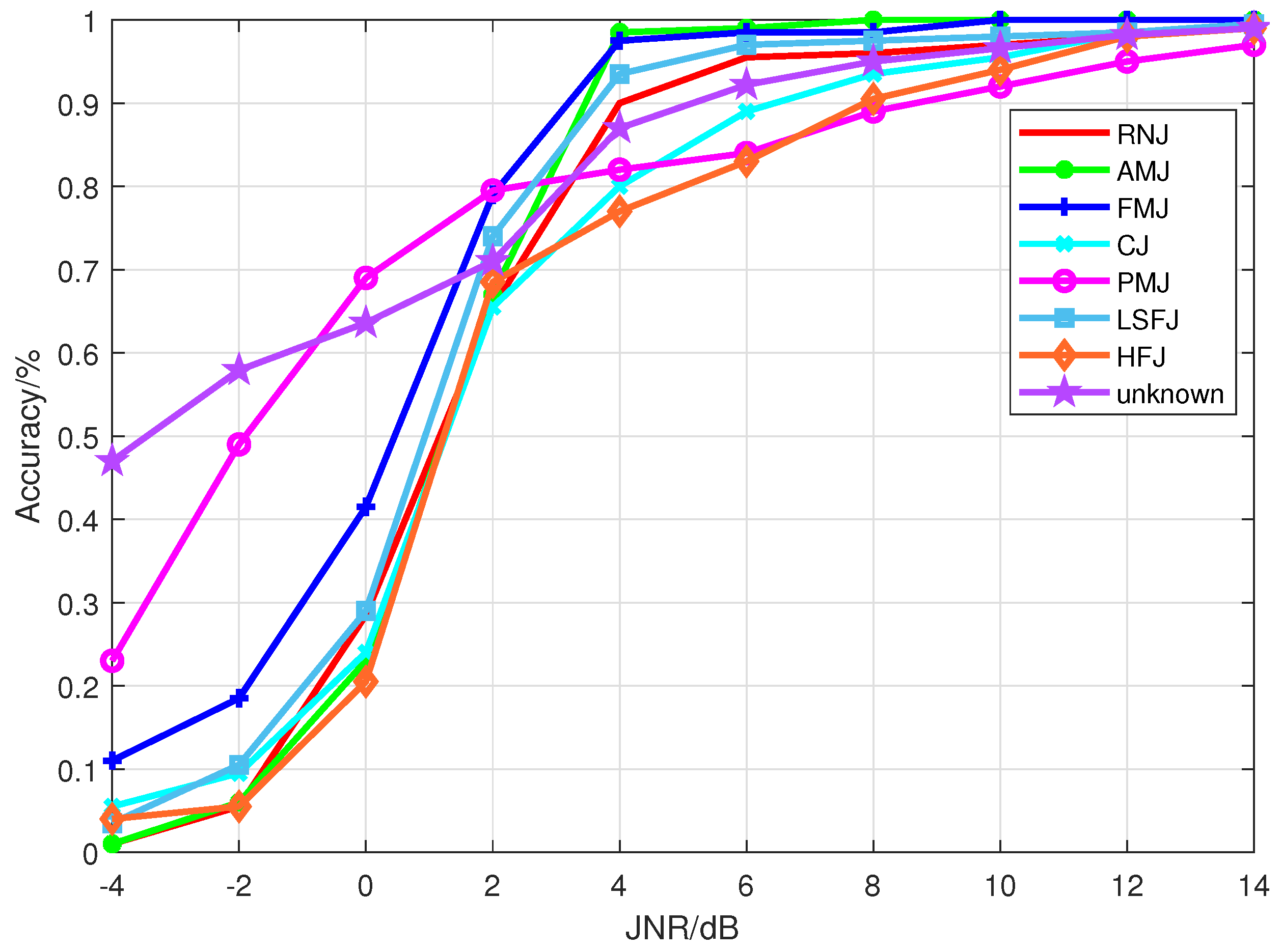
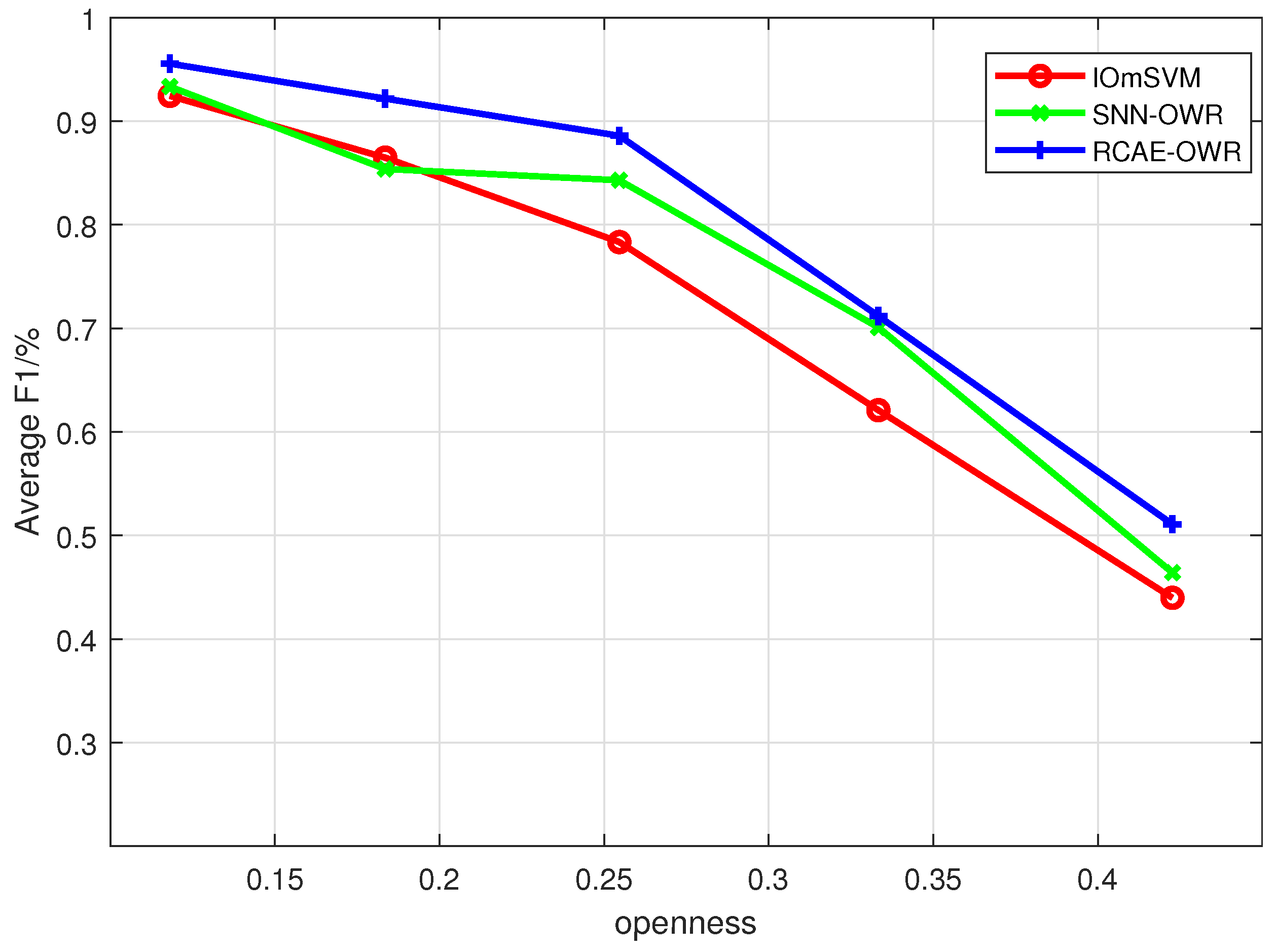
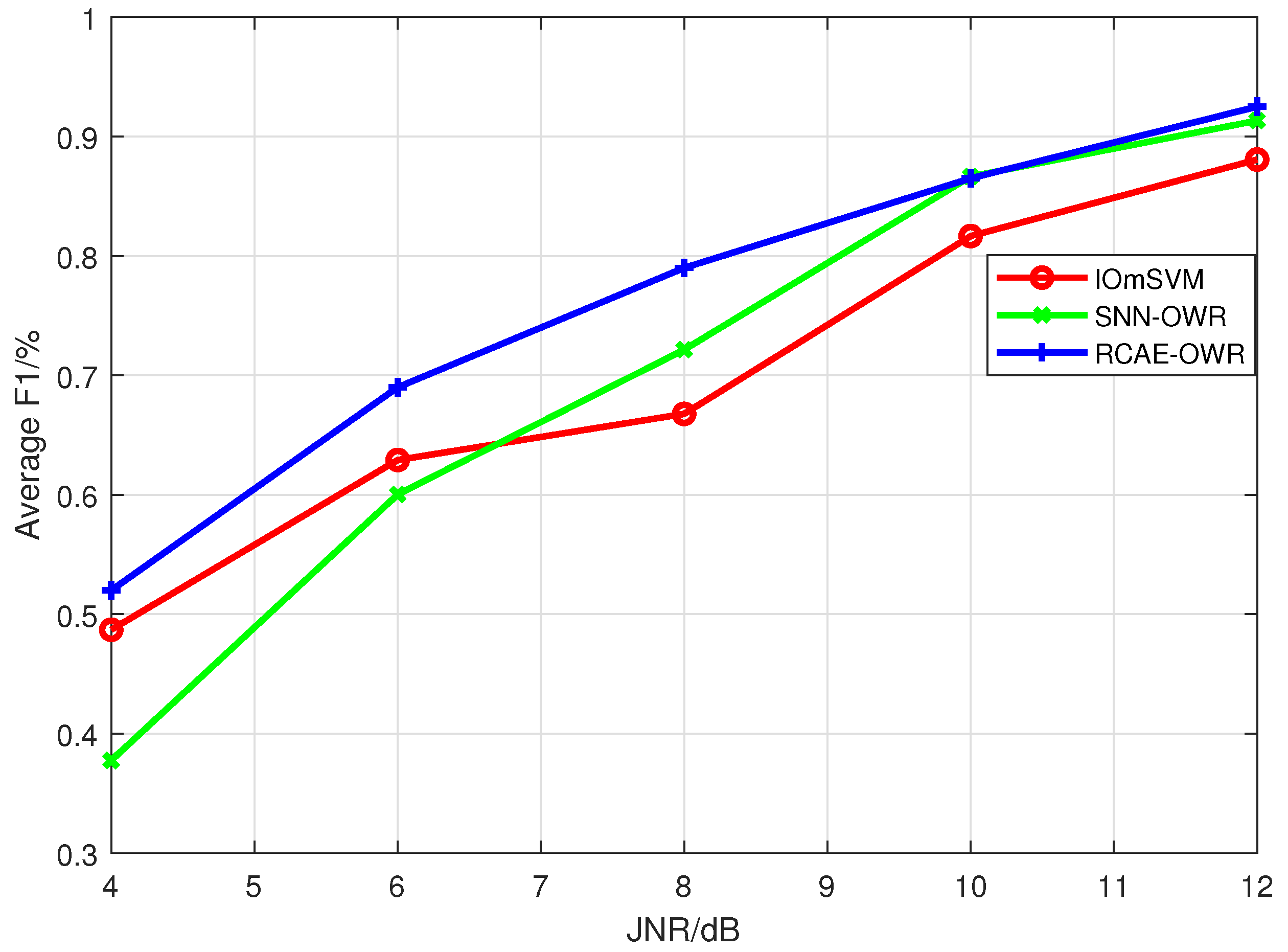
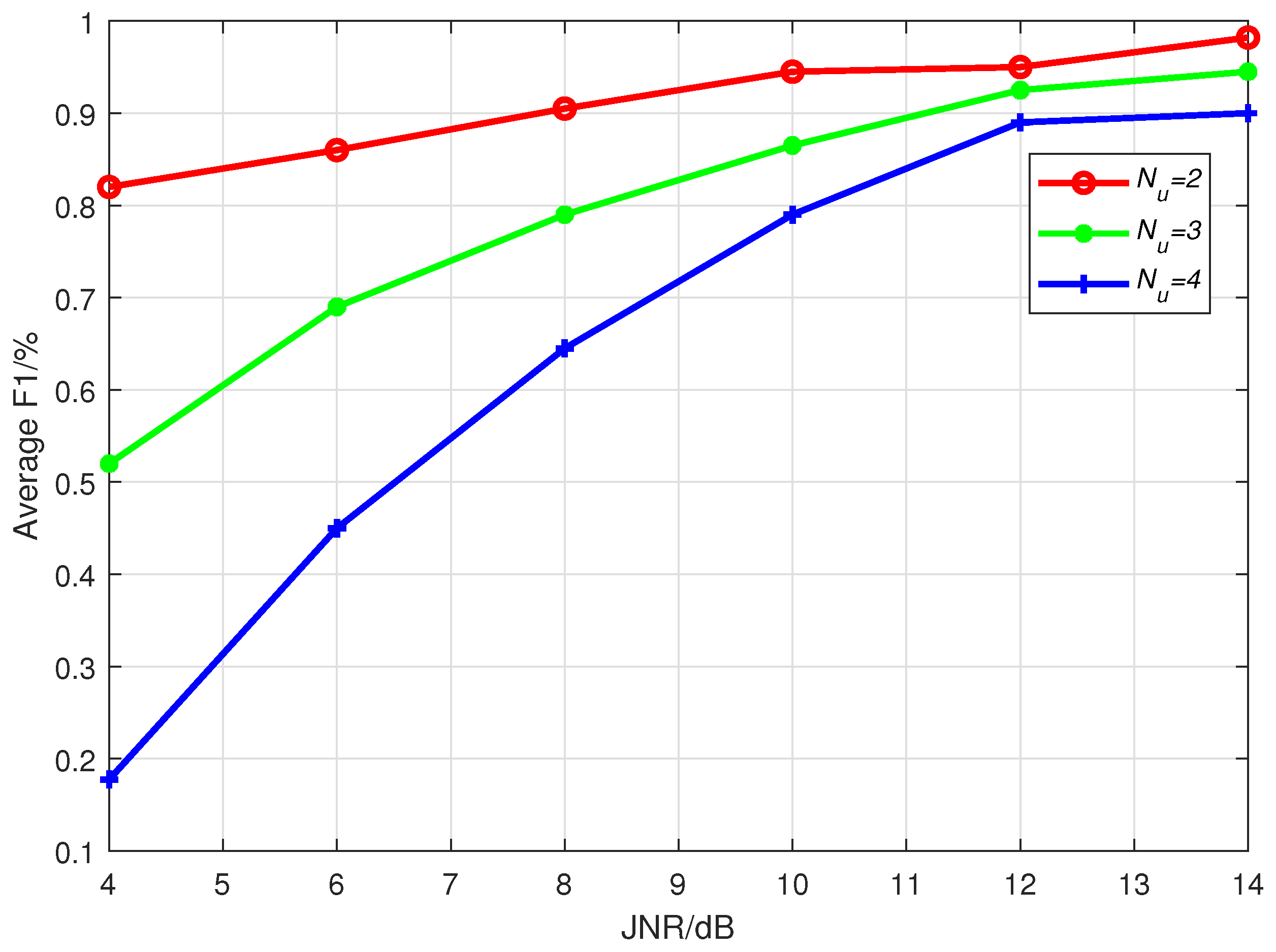
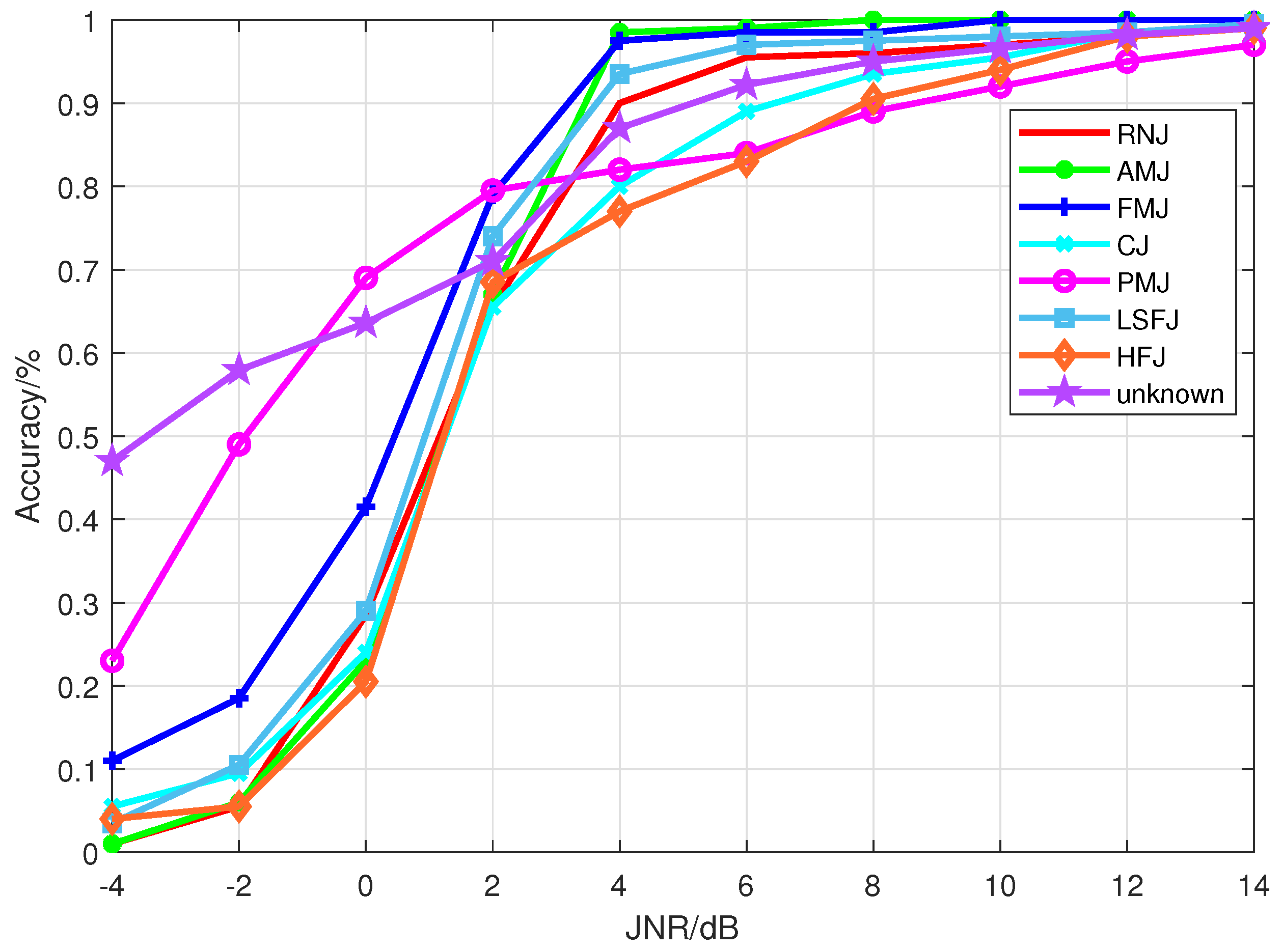
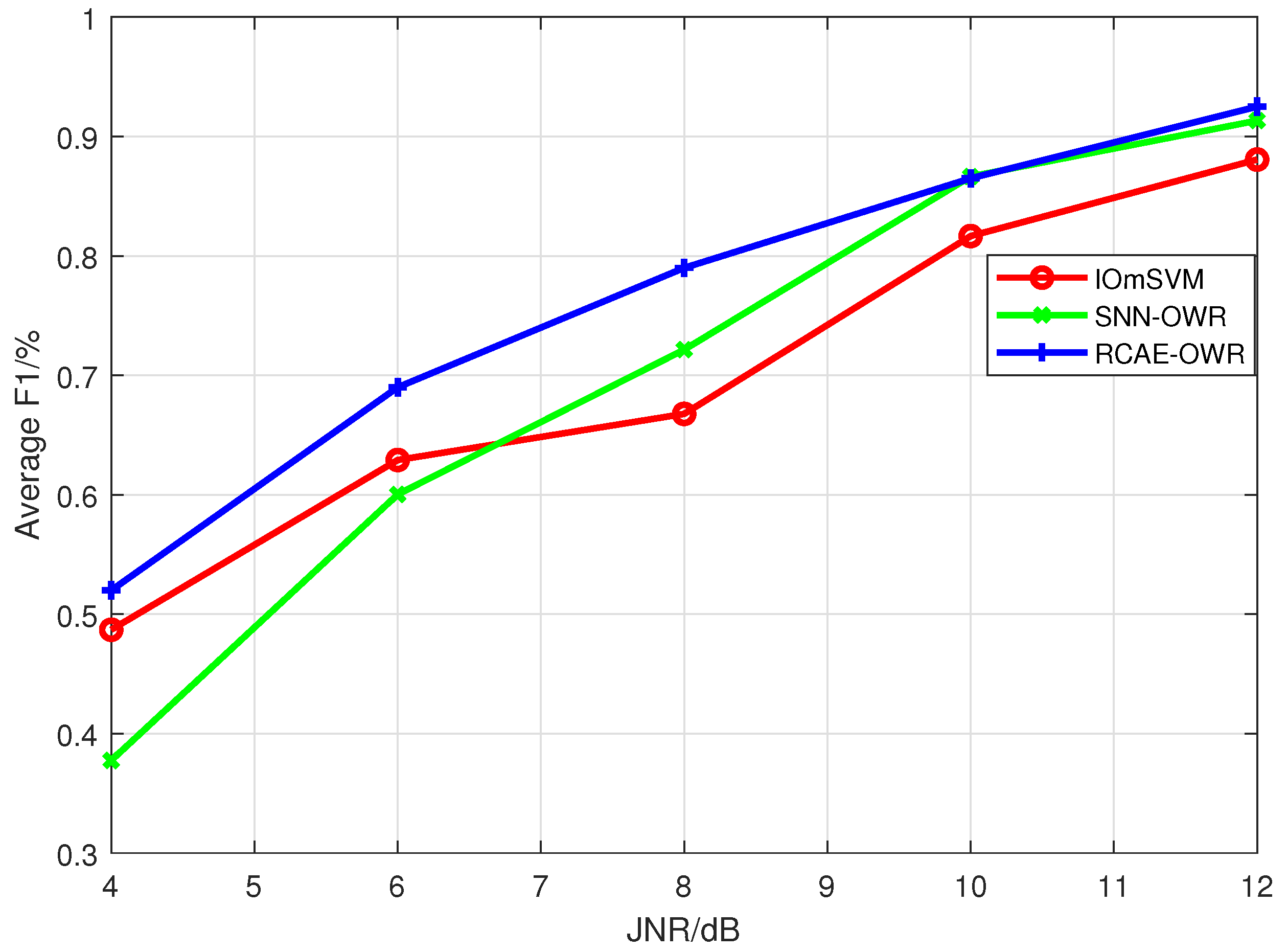
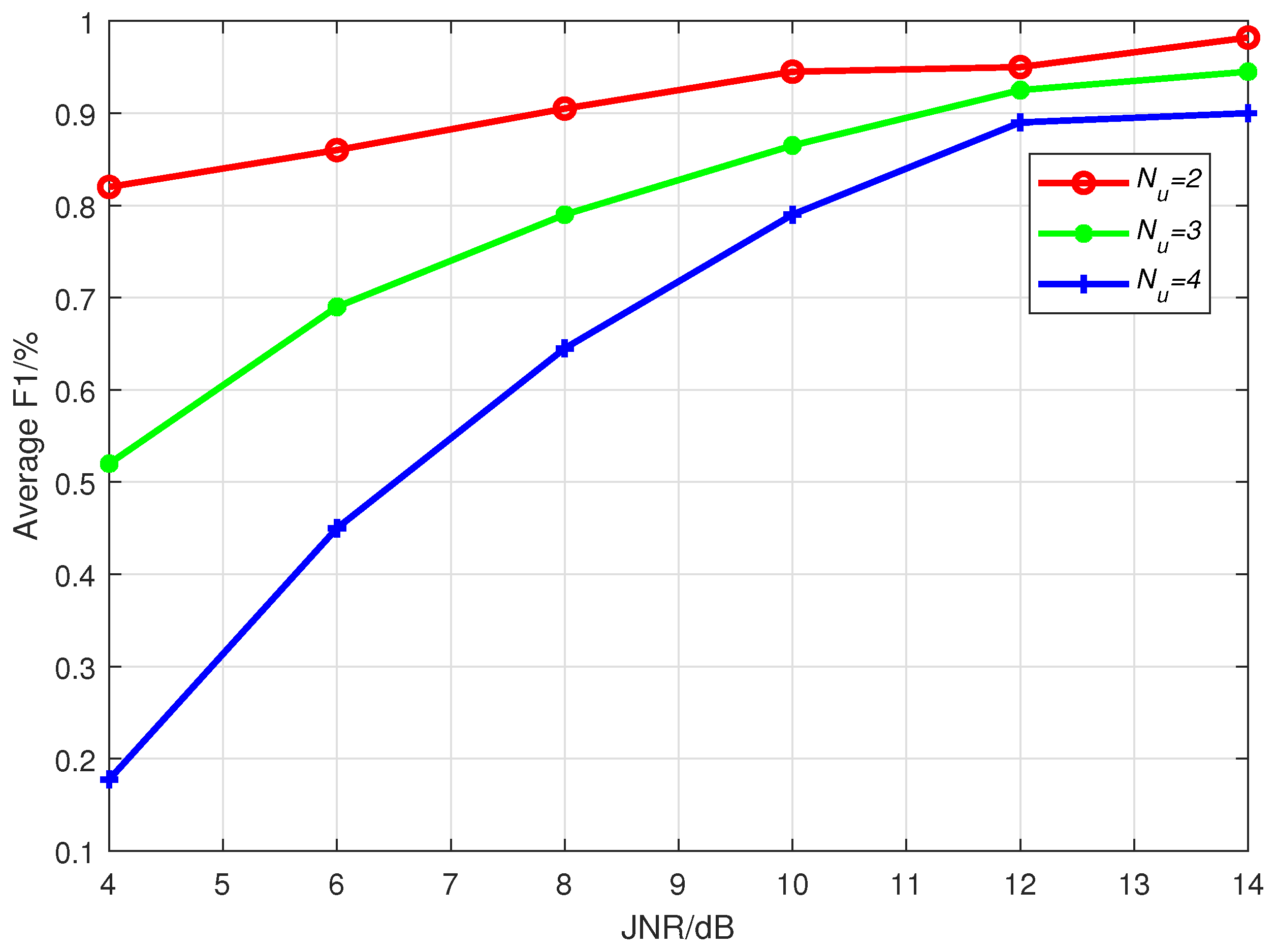
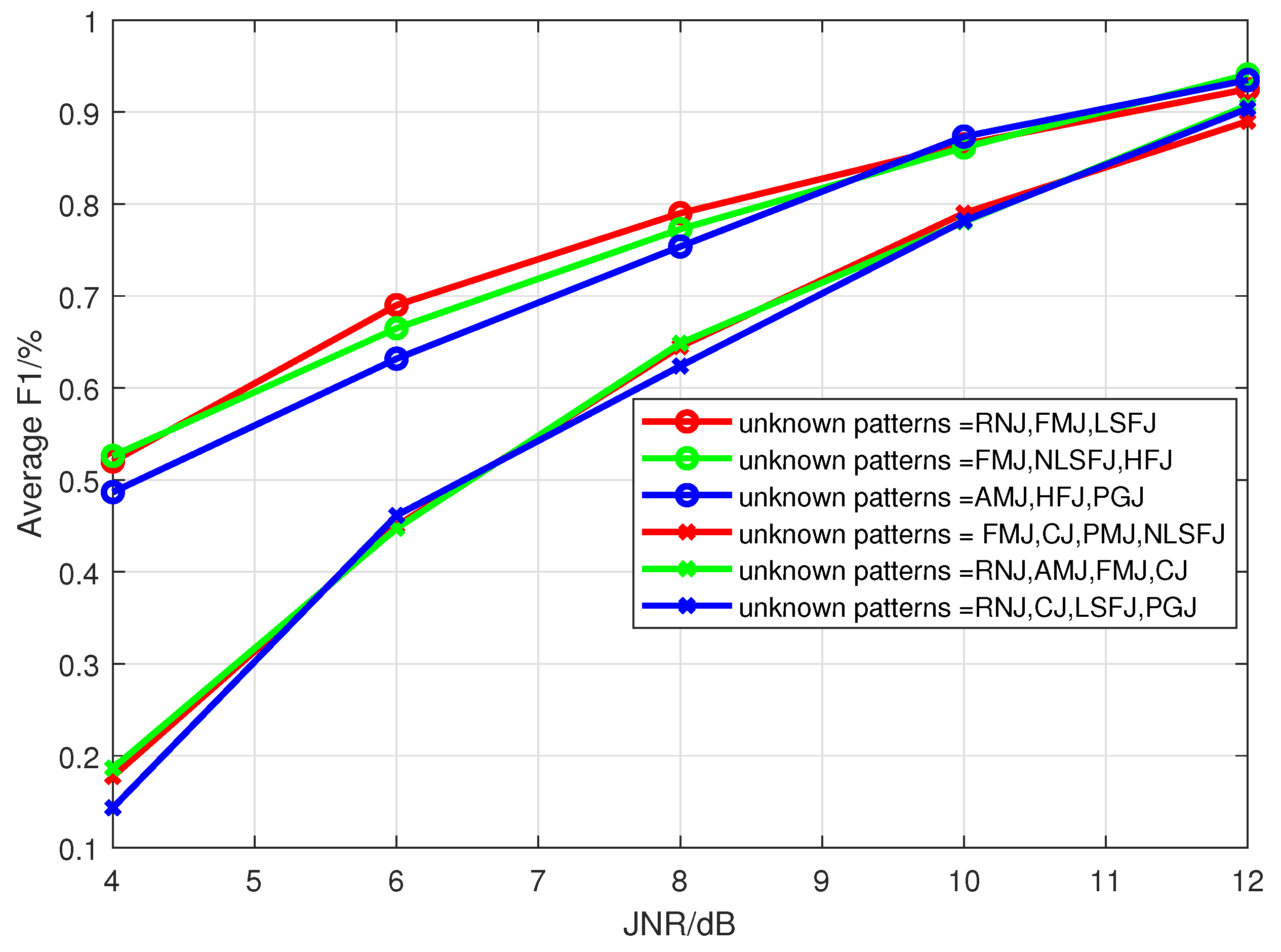
Through extensive experimental simulations, we evaluate the open world recognition performance of the proposed algorithm and investigate the influence of JNR and the number of unknown patterns on the algorithm’s performance. The simulation results demonstrate that the proposed algorithm achieves effective recognition of both known and unknown patterns, especially in high-JNR environments.
3. Proposed Method
Assuming that the dataset of jamming signals received by the radar is , it consists of kinds of patterns of jamming. The subset is composed of samples of kinds of known patterns, while the subset is composed of samples of kinds of unknown patterns. The two subsets are complementary, meaning and . For the known patterns set containing samples of kinds of patterns, where represents a -dimensional vector of the i-th sample, is the label of the sample, and denotes the -dimensional semantic vector describing the features of the sample’s corresponding pattern to be obtained by supervised learning. Similarly, for the unknown patterns dataset consisting of samples of kinds of patterns, , where is the -dimensional feature vector of the i-th sample, represents the label of the sample, and denotes the -dimensional semantic information of the sample’s corresponding pattern.
For the generalized zero-shot learning classification task considered in this paper, the supervised training phase only allows the utilization of dataset of known patterns . However, the objective is to ensure that the model trained in the supervised training phase can accurately classify into the -dimensional space during the unsupervised classification phase.
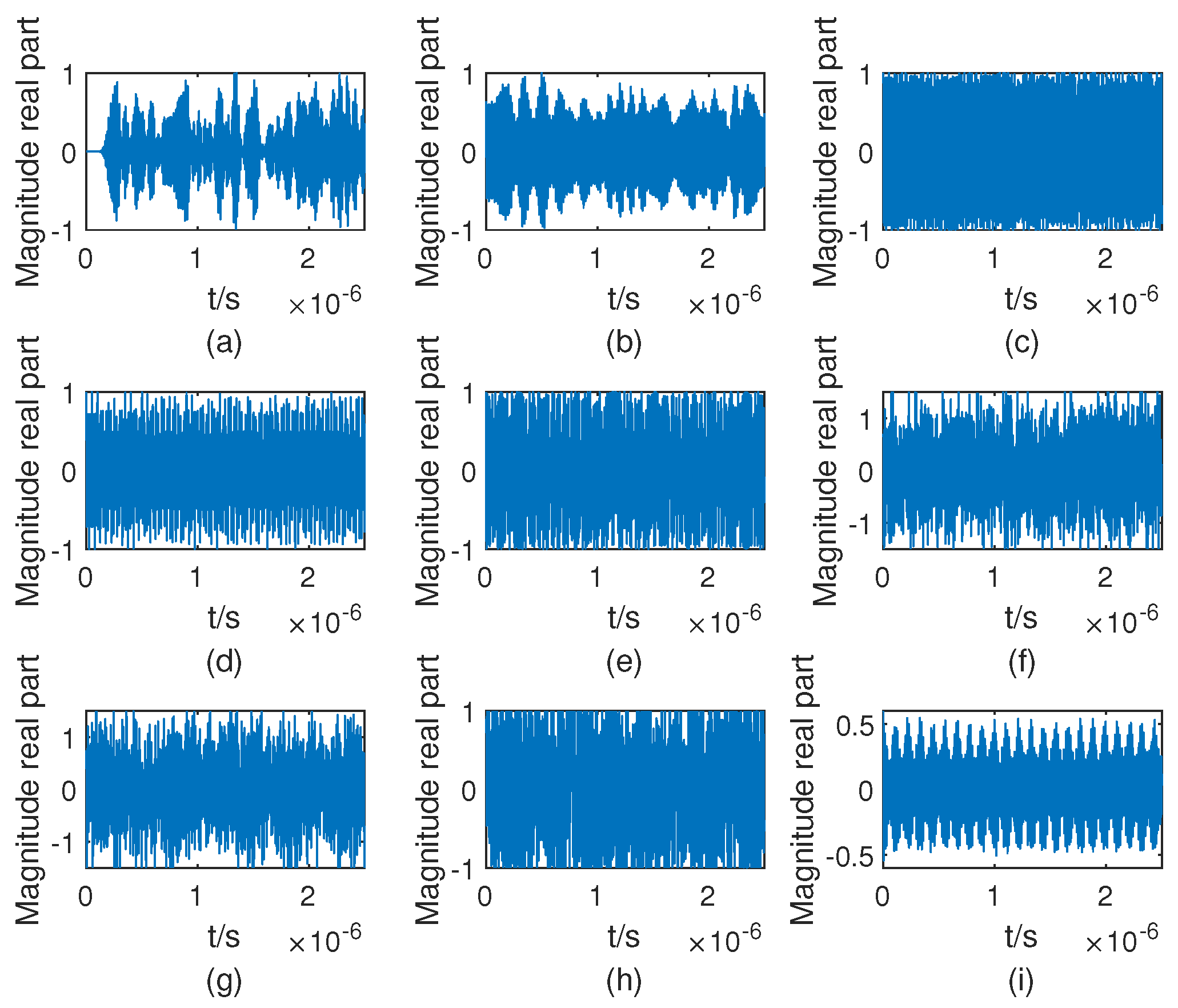
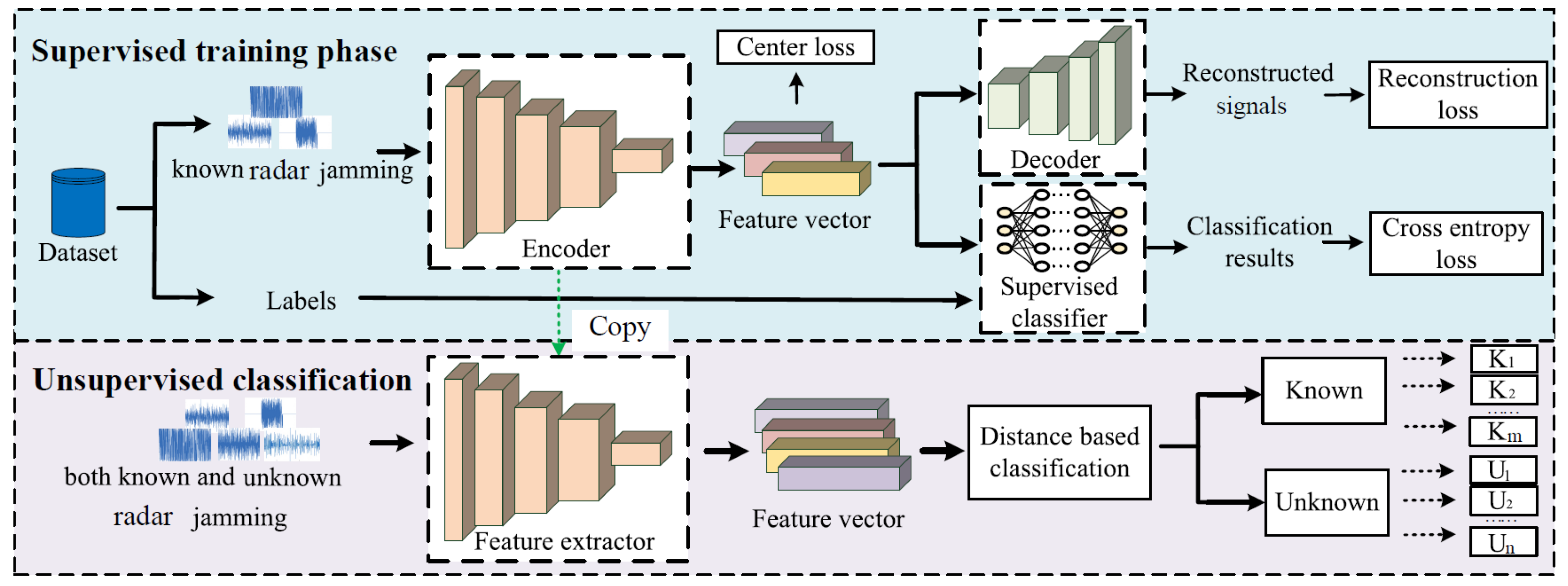
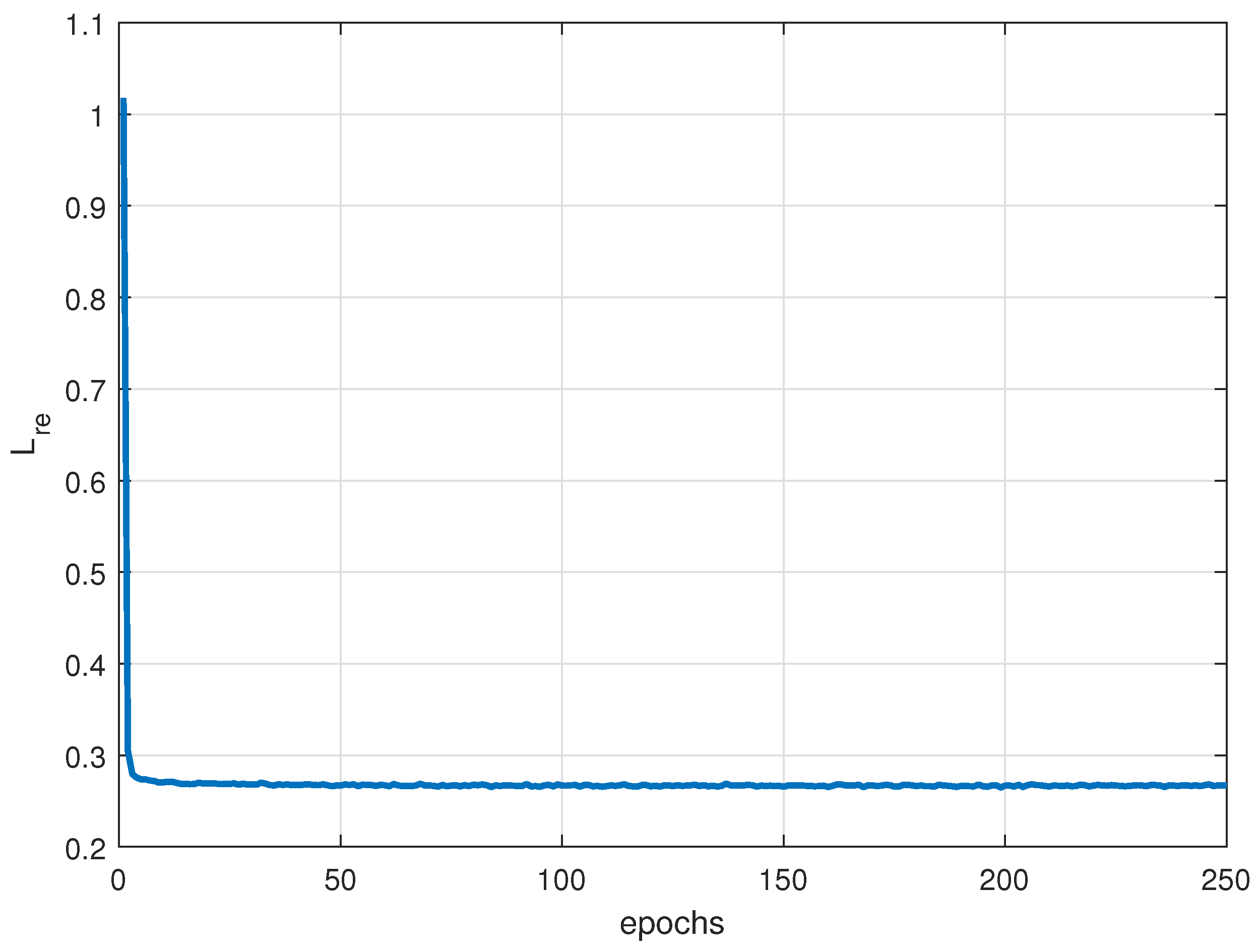
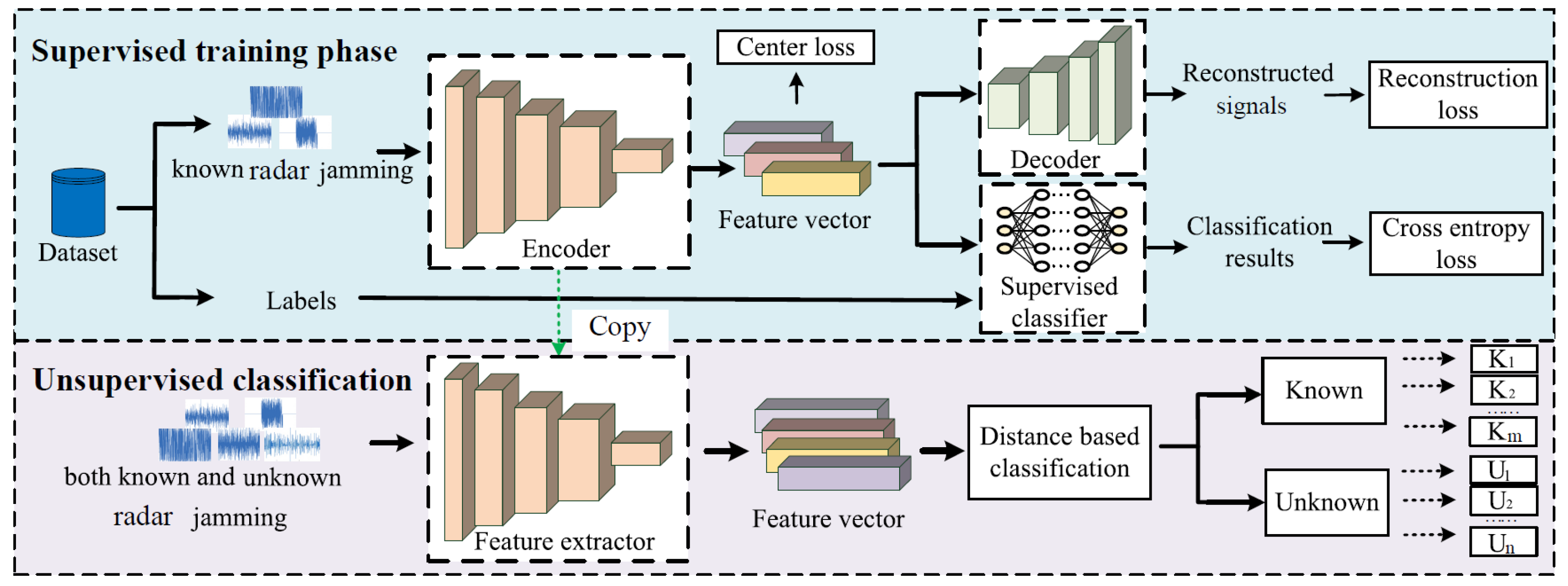
Figure 2 illustrates the network framework of the RCAE-OWR algorithm, which consists of a supervised training phase and an unsupervised classification phase. In the supervised training phase, the residual convolutional autoencoder (RCAE) network is used to extract semantic features of known jamming patterns. Meanwhile, the network is trained using center loss, cross-entropy loss, and reconstruction loss. In [
22,
37], time-domain signals are directly used as inputs to the network to extract the deep features of different signals, and the simulation results prove that the direct time-domain signal-based recognition methods obtain good recognition performance in terms of accuracy and speed, demonstrating a huge potential for radar signal processing. Motivated by [
22,
37], in this paper, we also directly feed the IQ data of the jamming signals into the model. Then, after the supervised training, the unsupervised classification phase was entered. At this phase, the parameters of encoder of the RCAE are kept fixed, and both known and unknown jamming samples are input to the encoder to obtain their semantic features. Then, a distance-based discriminative method is employed to achieve open world recognition of radar jamming signals.
3.1. Supervised Training
The supervised training phase mainly consists of an autoencoder network (AE) and a supervised classification network classifier. The autoencoder is divided into two parts: the encoder and the decoder. In the supervised training phase, the focus is on constructing the mapping relationship between the time-domain signal and the semantic features.
3.1.1. Residual Convolutional Autoencoder
Due to the simplicity of the traditional AE structure, this study primarily considers the Residual Convolutional Autoencoder (RCAE). It replaces the fully connected layers in AE with convolutional layers and pooling layers, inheriting the characteristics of an autoencoder. This enables better feature learning and improves the efficiency of feature learning in AE. To prevent degradation in recognition performance, a residual network structure is employed. The input signals are IQ dual-channel data with a length of 512, resulting in a dimension of 2 × 512. Additionally, to maintain the vector dimensions after convolution, we have set the convolution kernel size to 3 × 3, padding = 1 and stride = 1. RCAE is based on the semantic autoencoder (SAE) architecture [
31], and SAE enables mapping functions learned from known patterns to be better generalized to unknown patterns, which can effectively resist the domain shift problem [
38]. In the encoding process, convolutional operations are used to extract features from input samples and obtain semantic vectors. Then, the decoder utilizes transpose convolution to reconstruct the semantic vectors and restore them to the original inputs.
The basic components of RCAE include the input layer, convolutional layers, semantic layer, deconvolutional layers, and output layer.
The RCAE designed in this paper is illustrated in
Figure 3. It replaces the fully connected layers (FC) in the AE with convolutional layers and pooling layers, inheriting the characteristics of the AE for better feature learning. In addition, to prevent degradation of recognition performance, a residual structure is employed. The encoder uses convolutional operations to extract features from the input samples to obtain the semantic vector; the decoder utilizes transposed convolution to reconstruct the semantic vector and reduce it to the original signal.
The basic components of RCAE include: input layer, convolutional layer, semantic layer, deconvolutional layer and output layer.
In the encoding part, the input layer receives the input data and passes it to the encoder. The encoder gradually extracts the semantic features of the input data through multiple convolutional layers and their residual structures, denoted as , where denotes the mapping function of the encoder.
The convolutional layers extract features from the input data
using convolutional operations. The data processing can be described as follows:
where
is the
i-th convolutional kernel matrix,
denotes the convolution operation,
represents the
i-th bias term,
represents the activation function. The feature layer integrates the diverse features extracted by the convolutional layers and outputs the semantic vector
.
In the decoding part, the semantic feature
is up-sampled through transpose convolutional operations, aiming to reconstruct the original signal
based on the semantic features. This process is denoted as
, where
denotes the mapping function of the decoder. Finally, the reconstructed results are outputted through the output layer. The data processing can be described as follows:
where
represents the
-th convolutional kernel matrix, deconv
denotes the transpose convolution operation,
represents the
i-th bias term.
The training process of
aims to minimize the reconstruction error, ensuring the effectiveness of feature extraction. It can be expressed as:
where
M represents the number of samples in a batch,
is the signal reconstructed by
through the RCAE network.
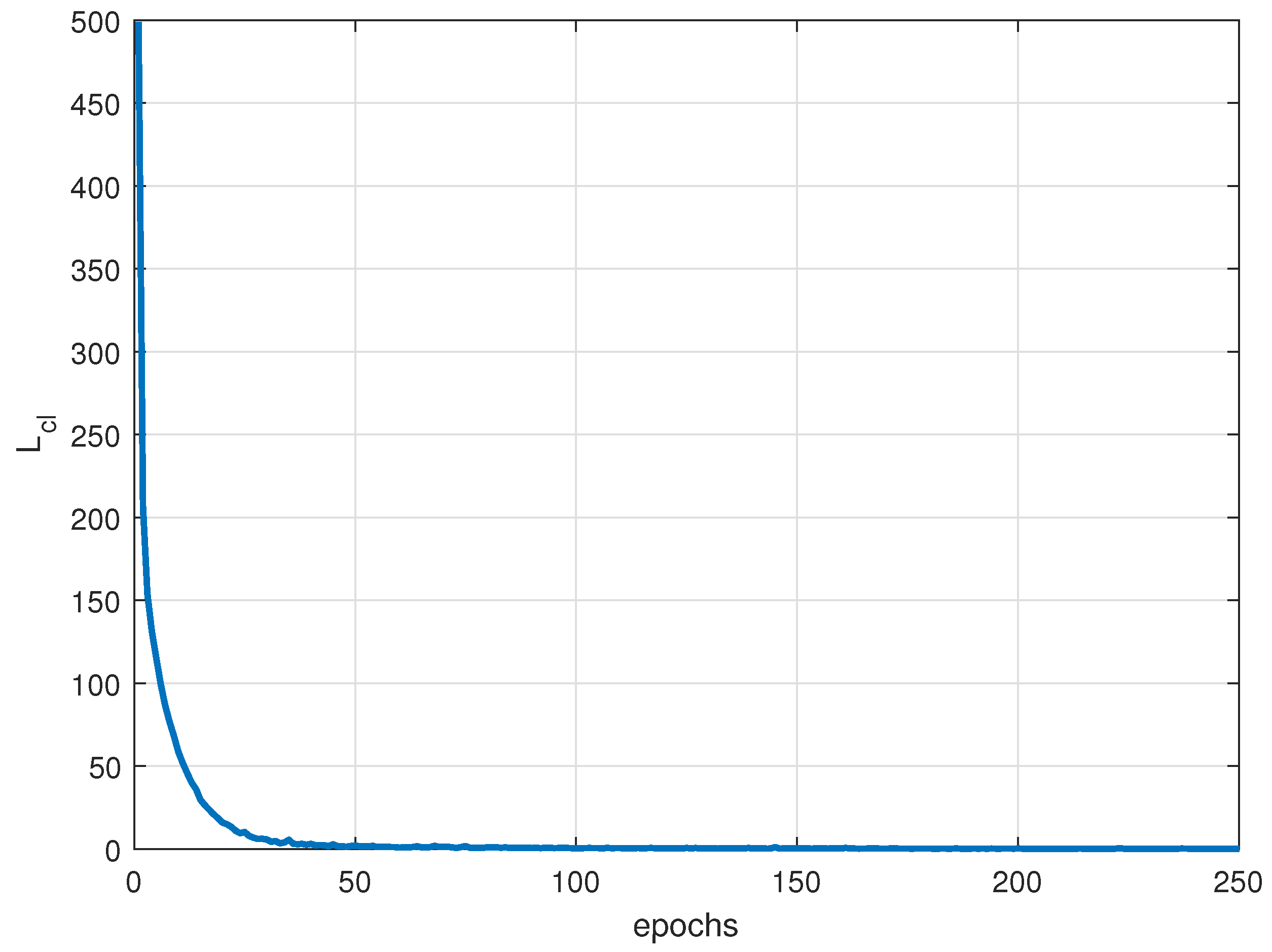
To encourage the feature vectors of the same patterns to be close to their corresponding pattern centers and far from centers of different patterns, a center loss is introduced. During model training, the center loss assigns a center for each jamming pattern. Assuming the input sample is
with label
, and the center for pattern
is denoted as
. The center loss can be defined as: 0
During the model iteration process, the selection of pattern center
is an important issue. Theoretically, the optimal center for pattern
would be the mean of all the feature vectors in that pattern. However, calculating the mean for all samples in each iteration would impose additional computational cost and reduce the efficiency of the model. To address this, the pattern center are initialized randomly, and then updated separately for each batch. The update process is as follows:
where
when
; otherwise, it is 0.
is the semantic center of
at the
t-th epoch,
is the learning rate.
3.1.2. Supervised Classifier
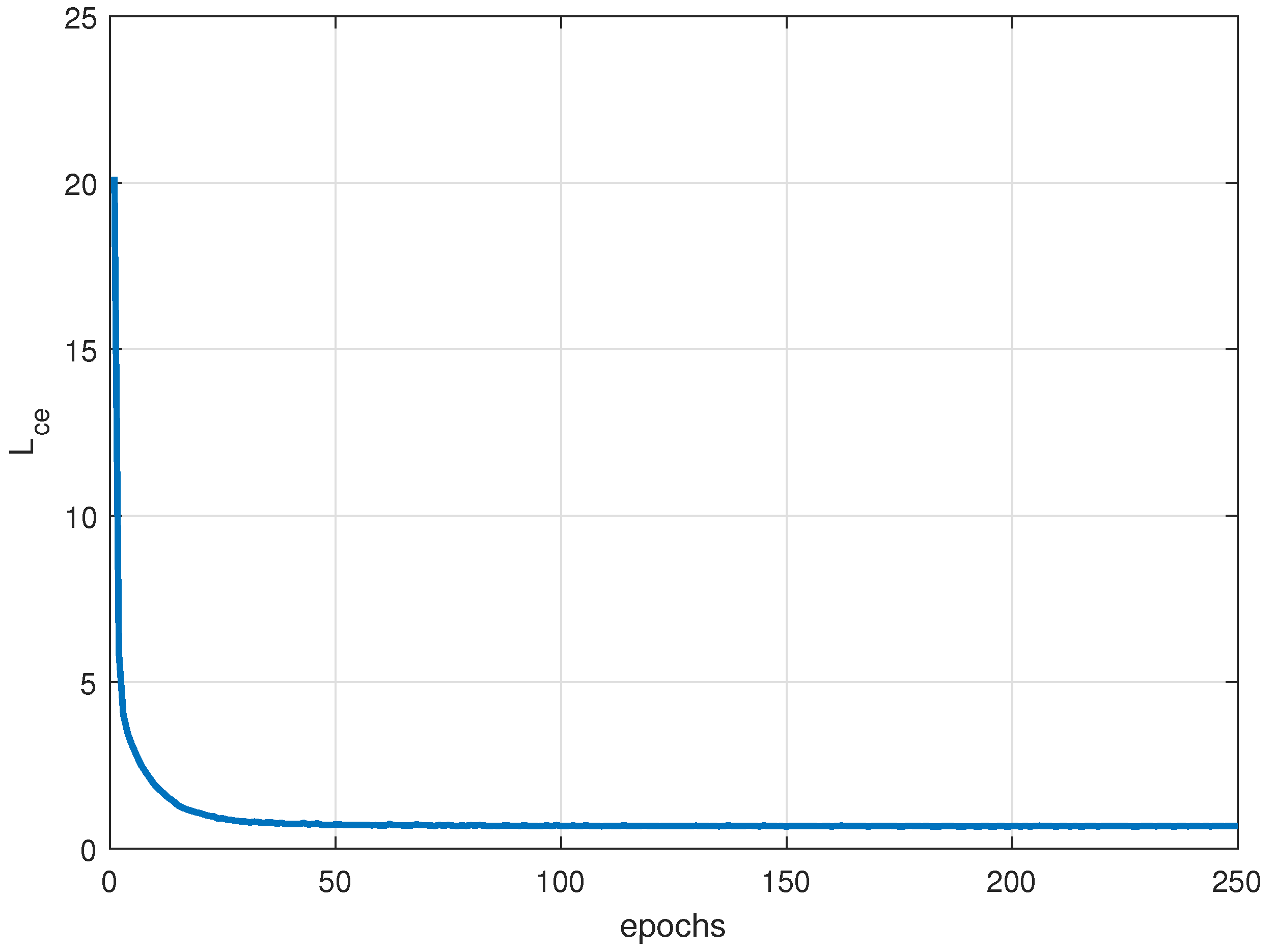
The encoder, acting as a feature extractor, takes the encoded features and feeds them into a fully connected layer followed by a softmax classifier, which outputs the predicted label. The loss function for this process utilizes cross-entropy between the predicted label and the true label.
where
represents the true label
in one-hot format, and
represents the predicted probability vector.
The reconstruction loss
ensures that the reduced-dimensional semantic features are representative, the central loss
promotes cohesion among feature vectors of the same jamming pattern, and the cross-entropy loss
enhances the discriminative ability of feature vectors among different jamming patterns. To achieve both increased inter-class distance and reduced intra-class distance, a joint loss function is proposed:
where
and
are constants used to balance the weights of the three loss functions. The detailed gradient
of
L is shown in
Appendix A.
The network parameters during the supervised training phase are updated as shown in Algorithm 1.
| Algorithm 1 Pseudocode for supervised training of RCAE-OWR |
Input: known jamming patterns dataset and hyperparameter.
Output:
Optimal parameters .
- 1:
while do - 2:
for each batch with size M do - 3:
Feed in a batch . - 4:
Calculate via Equation ( 16). - 5:
Calculate via Equation ( 17). - 6:
Calculate via Equation ( 18). - 7:
Calculate via Equation ( 15). - 8:
Calculate via Equation ( 14). - 9:
Calculate L via Equation ( 19). - 10:
Update . - 11:
end for - 12:
end while
|
3.2. Unsupervised Classification
After learning the mapping relationship between the original time-domain signals and the semantic feature space in the supervised training phase, this learned relationship can be generalized to the unknown jamming patterns dataset. Finally, the unknown patterns can be recognized and classified using the semantic features. Inspired by [
39], a distance-based classification rule is proposed.
3.2.1. Known Jamming Patterns Classification
Sequentially, the
known jamming samples from the training set are inputted into the trained RCAE-OWR model to extract semantic features. The semantic center vector
corresponding to the
k-th known jamming pattern is defined as:
where
denotes the semantic feature extracted from the
i-th input sample
. When a test sample
is input, its semantic features
are extracted by the encoder, and its Mahalanobis distance to the center vectors of each known jamming pattern is calculated as:
where
is the diagonal covariance matrix corresponding to
, and
is its inverse matrix.
Let
. If
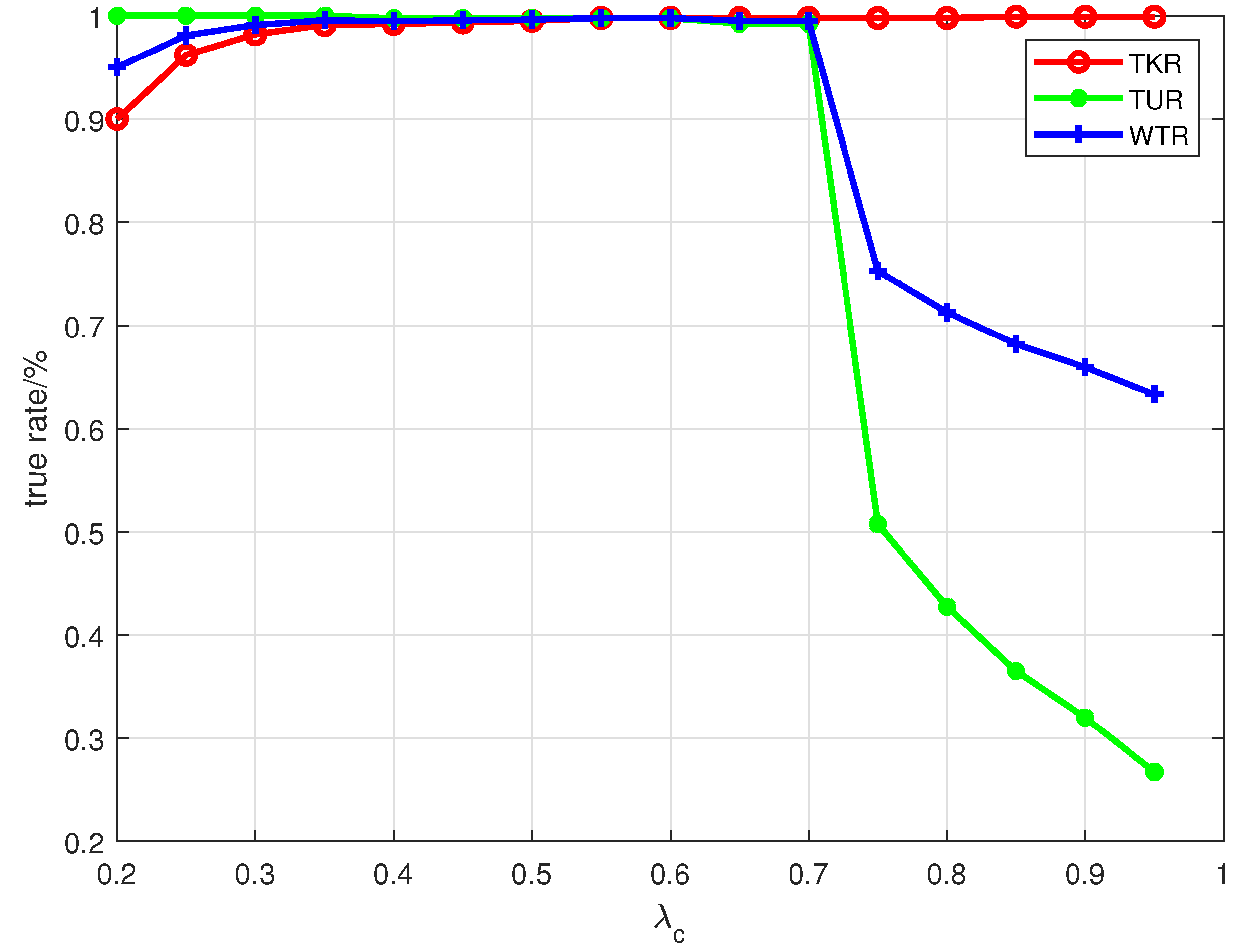
, then
belongs to the known jamming patterns. Here,
is a given threshold determined by the
criterion [
34], where
is a coefficient and
is the dimension of
. In this case, the label
of
can be determined as follows:
when
belongs to the unknown jamming patterns, and its label
in this case is described in
Section 3.2.2.
3.2.2. Unknown Jamming Patterns Classification
Let
represent the dataset of unknown jamming patterns. If
, then
belongs to the first sample of a new unknown jamming pattern, and its label is
. The sample
is then recorded in the
. If
, the following rules are applied to determine whether
belongs to a previously recorded unknown jamming pattern or a new unknown jamming pattern. First, let
represent the semantic center vector of pattern
in the
:
where
N is the number of patterns that already exist in
.
denotes the semantics extracted from the
j-th unknown pattern sample
. Let
. If
, then
belongs to an existing unknown jamming pattern. Here,
is a given threshold, where
is a coefficient,
and
are defined as follows:
In this case, the label
of
can be determined as follows:
Otherwise, belongs to a new unknown jamming pattern, and its label is . The test sample is then recorded in the .
In summary, the recognition rules for the unsupervised classification phase are presented in Algorithm 2.
| Algorithm 2 Pseudocode for unsupervised classification of RCAE-OWR |
Input: test sample and well-trained weight of Encoder, .
Output: Jamming pattern .
- 1:
for do - 2:
Calculate semantic vector of - 3:
- 4:
- 5:
- 6:
- 7:
- 8:
if then - 9:
- 10:
else if and then - 11:
add to - 12:
- 13:
else if and then - 14:
- 15:
else - 16:
- 17:
add t to . - 18:
end if - 19:
end for
|








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}