
Guided Local Feature Matching with Transformer


Abstract
1. Introduction
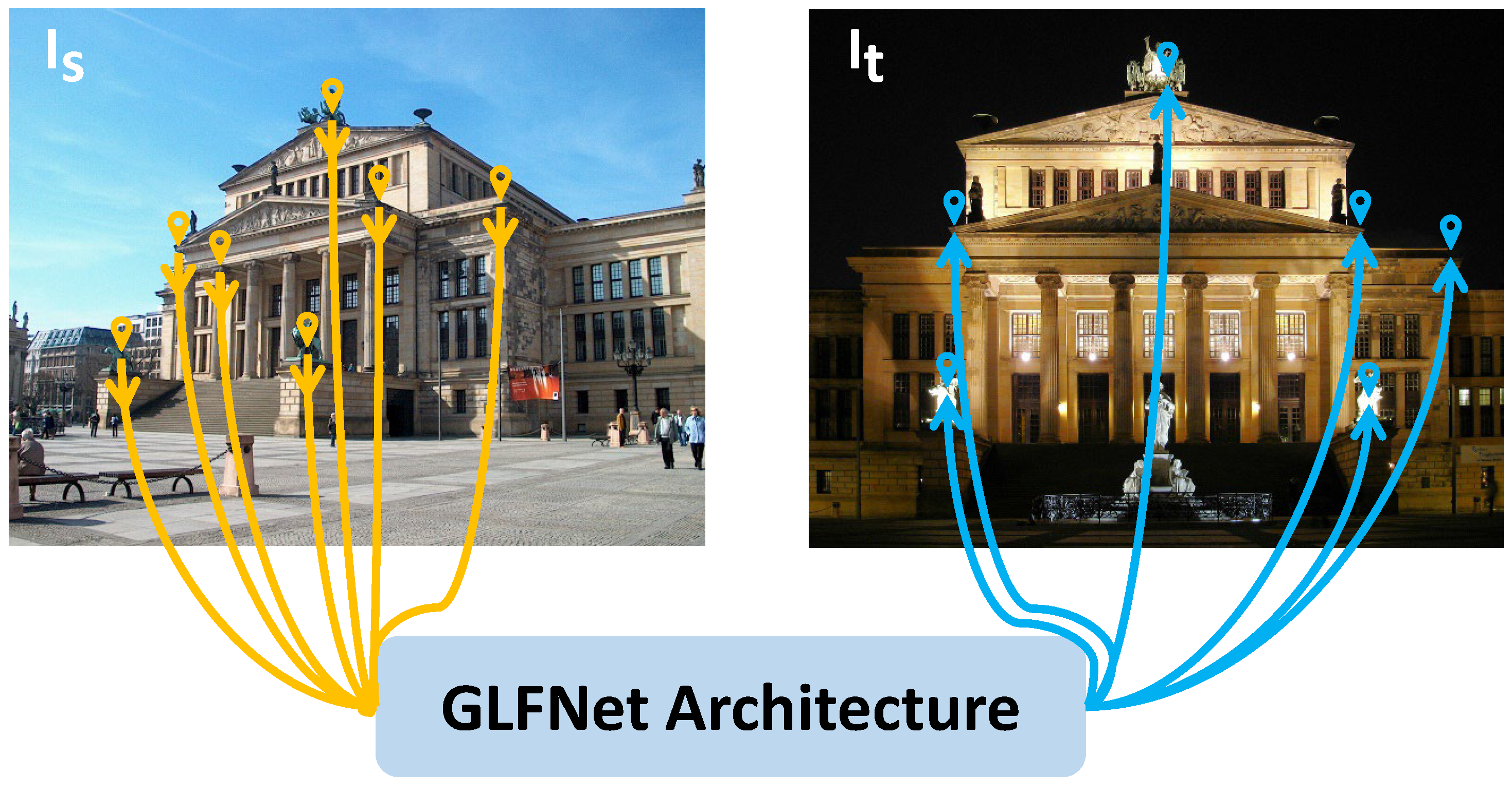
- The image-matching problem is reformulated by considering guided points as input.
- GLFNet is designed with a coarse-to-fine search network to efficiently and accurately detect and match corresponding points. Additionally, the guided point transformer is proposed to incorporate the guided points information during feature representation.
- The GLFNet significantly improves the standard image-matching task and benefits various applications.
2. Related Work
2.1. Detector-Based Local Feature Matching
2.2. Detector-Free Local Feature Matching
2.3. Transformers in Vision
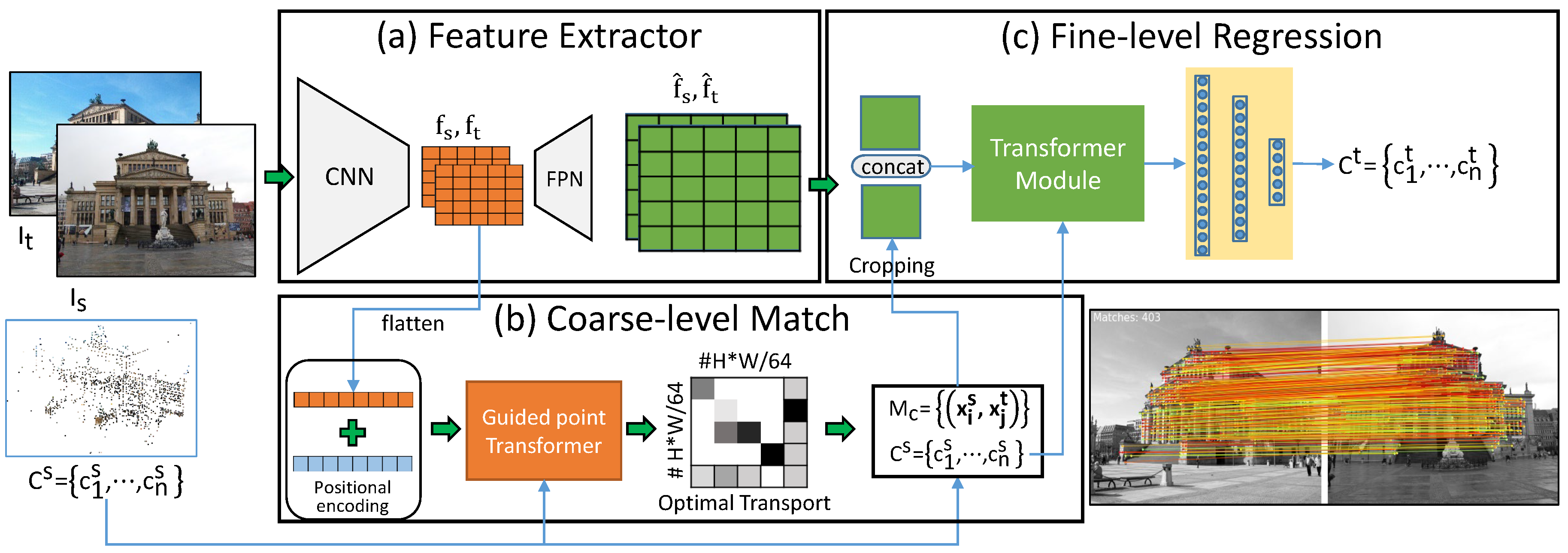
3. Method
3.1. Problem Definition
3.2. Feature Extraction Network
3.3. Coarse-Level Match Network
3.3.1. Positional Encoding
3.3.2. Guided Point Transformer
3.3.3. Coarse-Level Matching
3.4. Fine-Level Regression
3.5. The Implementation Details
4. Experiments
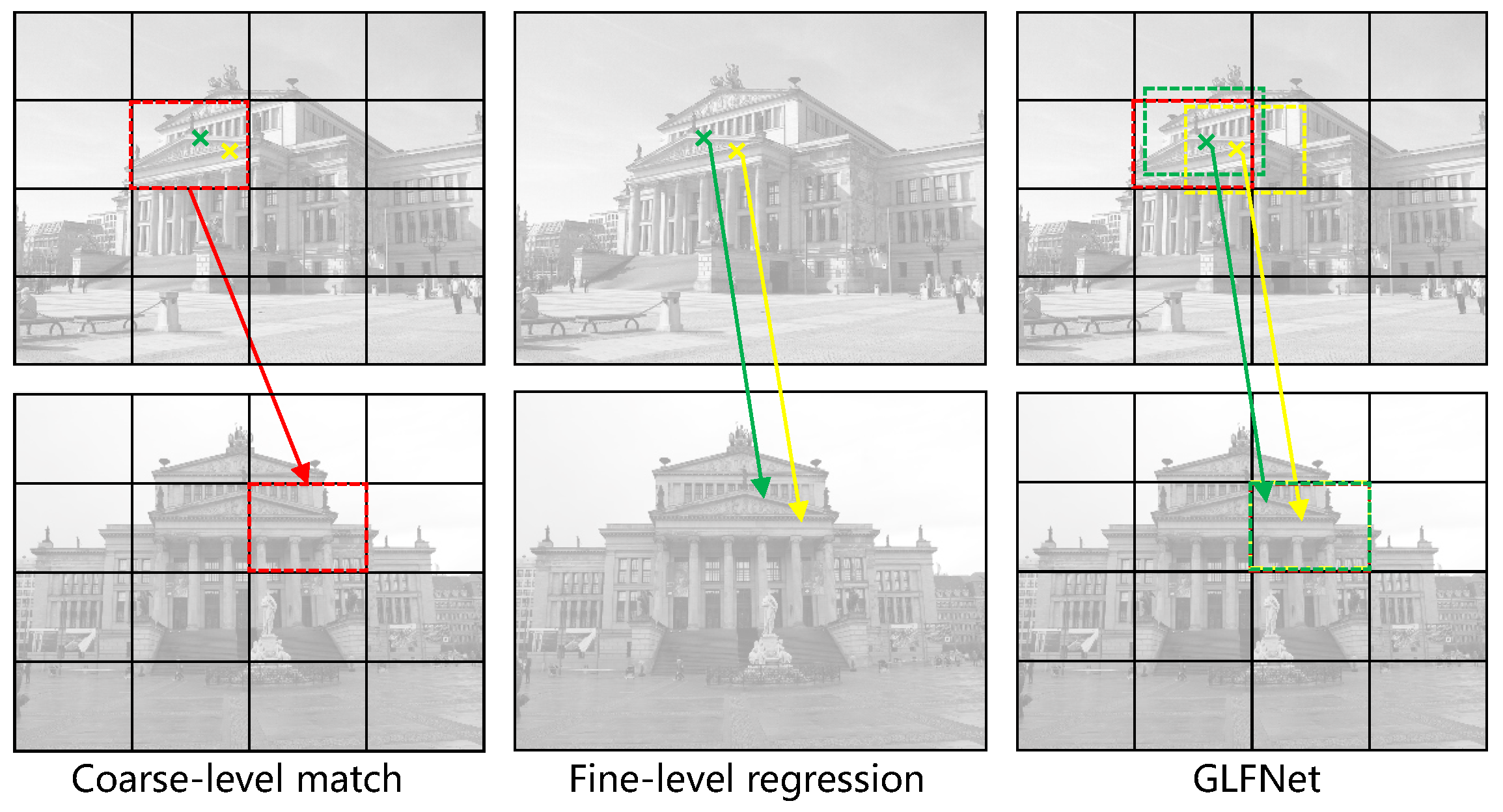
4.1. Ablation Study
4.1.1. Ablation Study
4.1.2. Parameter Sensitivity Analysis
4.2. Experimental Evaluations
4.2.1. The Contribution of Guided Points
4.2.2. Image Matching with Guided Points
4.3. Comparison
4.3.1. Remote-Sensing Image Registration
Datasets
Comparison
Results
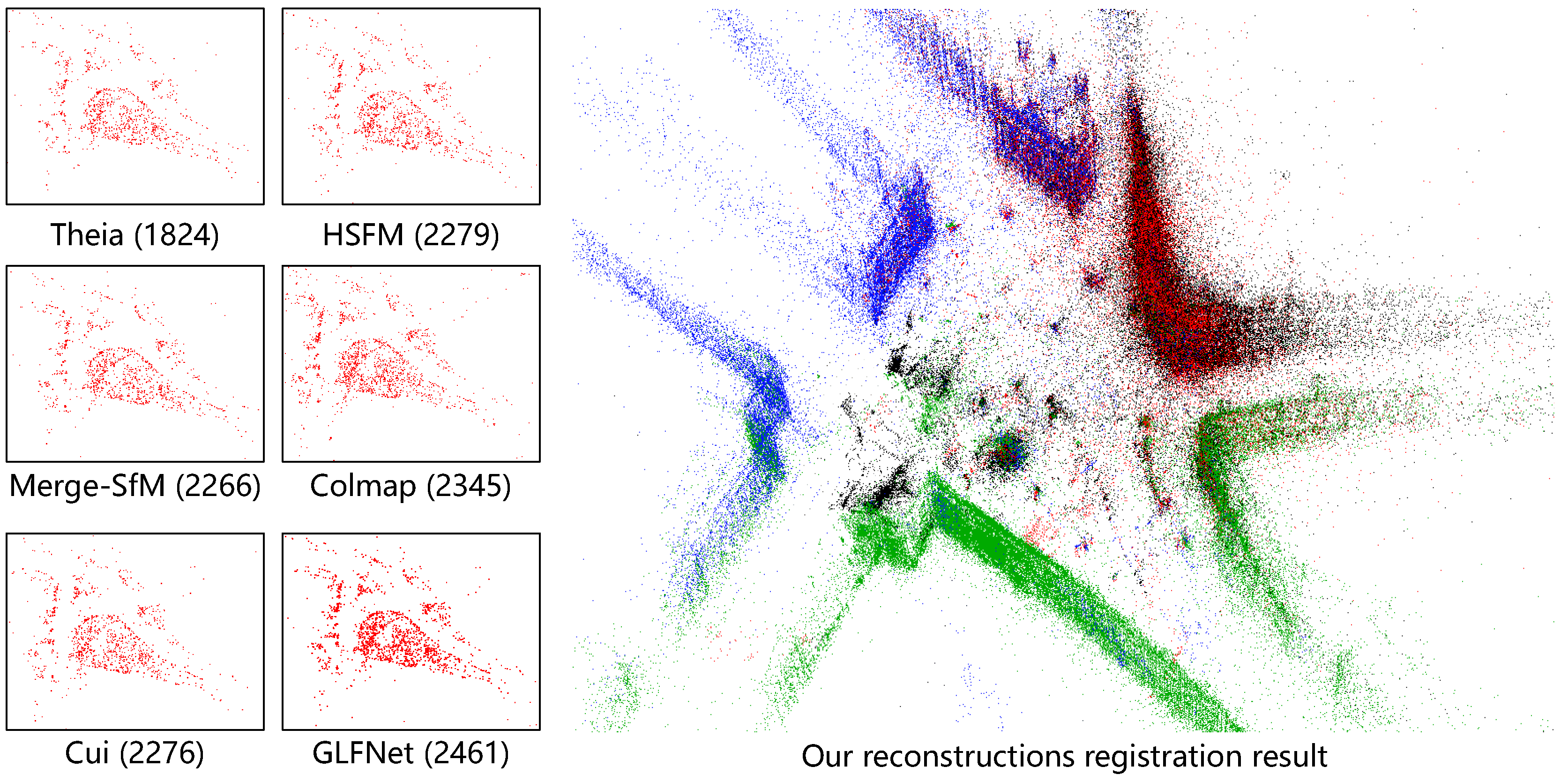
4.3.2. Reconstruction Registration
Datasets
Comparison
Results
4.3.3. Optical Flow Estimation
Datasets
Comparison
Results
4.3.4. Visual Localization
Datasets
Comparison
Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Huang, X.; Zhang, Z. Deep Lucas-Kanade Homography for Multimodal Image Alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Surrey, UK, 3–7 September 2012; pp. 15950–15959. [Google Scholar]
- Liang, C.; Dong, Y.; Zhao, C.; Sun, Z. A Coarse-to-Fine Feature Match Network Using Transformers for Remote Sensing Image Registration. Remote Sens. 2023, 15, 3243. [Google Scholar] [CrossRef]
- Cao, L.; Zhuang, S.; Tian, S.; Zhao, Z.; Fu, C.; Guo, Y.; Wang, D. A Global Structure and Adaptive Weight Aware ICP Algorithm for Image Registration. Remote Sens. 2023, 15, 3185. [Google Scholar] [CrossRef]
- Deng, X.; Mao, S.; Yang, J.; Lu, S.; Gou, S.; Zhou, Y.; Jiao, L. Multi-Class Double-Transformation Network for SAR Image Registration. Remote Sens. 2023, 15, 2927. [Google Scholar] [CrossRef]
- Qin, R.; Gruen, A. 3D change detection at street level using mobile laser scanning point clouds and terrestrial images. ISPRS J. Photogramm. Remote Sens. 2014, 90, 23–35. [Google Scholar] [CrossRef]
- Ardila, J.P.; Bijker, W.; Tolpekin, V.A.; Stein, A. Multitemporal change detection of urban trees using localized region-based active contours in VHR images. Remote Sens. Environ. 2012, 124, 413–426. [Google Scholar] [CrossRef]
- Favalli, M.; Fornaciai, A.; Isola, I.; Tarquini, S.; Nannipieri, L. Multiview 3D reconstruction in geosciences. Comput. Geosci. 2012, 44, 168–176. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A Trainable CNN for Joint Description and Detection of Local Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bian, J.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. GMS: Grid-based Motion Statistics for Fast, Ultra-Robust Feature Correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching with Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Rocco, I.; Cimpoi, M.; Arandjelović, R.; Torii, A.; Pajdla, T.; Sivic, J. NCNet: Neighbourhood Consensus Networks for Estimating Image Correspondences. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1020–1034. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Han, K.; Li, S.; Prisacariu, V. Dual-Resolution Correspondence Networks. In The Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 17346–17357. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-Free Local Feature Matching with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual Conference, 19–25 June 2021; pp. 8922–8931. [Google Scholar]
- Jiang, W.; Trulls, E.; Hosang, J.; Tagliasacchi, A.; Yi, K.M. COTR: Correspondence Transformer for Matching Across Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 6207–6217. [Google Scholar]
- Luo, Z.; Zhou, L.; Bai, X.; Chen, H.; Zhang, J.; Yao, Y.; Li, S.; Fang, T.; Quan, L. ASLFeat: Learning Local Features of Accurate Shape and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Revaud, J.; Weinzaepfel, P.; de Souza, C.R.; Humenberger, M. R2D2: Repeatable and Reliable Detector and Descriptor. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Niessner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2564–2571. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Proceedings of the Computer Vision—ECCV 2006, Graz, Austria, 7–13 May 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the Computer Vision—ECCV 2010, Crete, Greece, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Melekhov, I.; Tiulpin, A.; Sattler, T.; Pollefeys, M.; Rahtu, E.; Kannala, J. DGC-Net: Dense geometric correspondence network. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar]
- Truong, P.; Danelljan, M.; Timofte, R. GLU-Net: Global-Local Universal Network for dense flow and correspondences. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, H.; Luo, Z.; Zhou, L.; Tian, Y.; Zhen, M.; Fang, T.; McKinnon, D.; Tsin, Y.; Quan, L. ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 20–36. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient Transformer for Remote Sensing Image Segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Jmal, M.; Souidene Mseddi, W.; Attia, R. Wildfire Segmentation Using Deep Vision Transformers. Remote Sens. 2021, 13, 3527. [Google Scholar] [CrossRef]
- Li, Y.; Cheng, Z.; Wang, C.; Zhao, J.; Huang, L. RCCT-ASPPNet: Dual-Encoder Remote Image Segmentation Based on Transformer and ASPP. Remote Sens. 2023, 15, 379. [Google Scholar] [CrossRef]
- Zhong, B.; Wei, T.; Luo, X.; Du, B.; Hu, L.; Ao, K.; Yang, A.; Wu, J. Multi-Swin Mask Transformer for Instance Segmentation of Agricultural Field Extraction. Remote Sens. 2023, 15, 549. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Y.; Zeng, Y. Transformer with Transfer CNN for Remote-Sensing-Image Object Detection. Remote Sens. 2022, 14, 984. [Google Scholar] [CrossRef]
- Chen, G.; Mao, Z.; Wang, K.; Shen, J. HTDet: A Hybrid Transformer-Based Approach for Underwater Small Object Detection. Remote Sens. 2023, 15, 1076. [Google Scholar] [CrossRef]
- Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, B.; Lyu, S.; Wang, C.; Zhang, H. TPH-YOLOv5++: Boosting Object Detection on Drone-Captured Scenarios with Cross-Layer Asymmetric Transformer. Remote Sens. 2023, 15, 1687. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- He, X.; Chen, Y.; Lin, Z. Spatial-Spectral Transformer for Hyperspectral Image Classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Qing, Y.; Liu, W.; Feng, L.; Gao, W. Improved Transformer Net for Hyperspectral Image Classification. Remote Sens. 2021, 13, 2216. [Google Scholar] [CrossRef]
- Ali, A.M.; Benjdira, B.; Koubaa, A.; Boulila, W.; El-Shafai, W. TESR: Two-Stage Approach for Enhancement and Super-Resolution of Remote Sensing Images. Remote Sens. 2023, 15, 2346. [Google Scholar] [CrossRef]
- Zheng, X.; Bao, Z.; Yin, Q. Terrain Self-Similarity-Based Transformer for Generating Super Resolution DEMs. Remote Sens. 2023, 15, 1954. [Google Scholar] [CrossRef]
- Tang, S.; Zhang, J.; Zhu, S.; Tan, P. Quadtree Attention for Vision Transformers. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Cuturi, M. Sinkhorn Distances: Lightspeed Computation of Optimal Transport. In Proceedings of the Advances in Neural Information Processing Systems, New York, NY, USA, 5–10 December 2013; Burges, C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K., Eds.; Curran Associates, Inc.: New York, NY, USA, 2013; Volume 26. [Google Scholar]
- Li, Z.; Snavely, N. MegaDepth: Learning Single-View Depth Prediction From Internet Photos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-From-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Balntas, V.; Lenc, K.; Vedaldi, A.; Mikolajczyk, K. HPatches: A Benchmark and Evaluation of Handcrafted and Learned Local Descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chang, C.H.; Chou, C.N.; Chang, E.Y. CLKN: Cascaded Lucas-Kanade Networks for Image Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Deep Image Homography Estimation. arXiv 2016, arXiv:1606.03798. [Google Scholar]
- Le, H.; Liu, F.; Zhang, S.; Agarwala, A. Deep Homography Estimation for Dynamic Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Fang, M.; Pollok, T.; Qu, C. Merge-SfM: Merging Partial Reconstructions. In Proceedings of the BMVC, Wales, UK, 9–12 September 2019. [Google Scholar]
- Wilson, K.; Snavely, N. Robust Global Translations with 1DSfM. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 61–75. [Google Scholar]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Photo Tourism: Exploring Photo Collections in 3D. In The ACM SIGGRAPH 2006 Papers; Association for Computing Machinery: New York, NY, USA, 2006; pp. 835–846. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Ozyesil, O.; Singer, A. Robust Camera Location Estimation by Convex Programming. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Cui, Z.; Tan, P. Global Structure-From-Motion by Similarity Averaging. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Sweeney, C.; Sattler, T.; Hollerer, T.; Turk, M.; Pollefeys, M. Optimizing the Viewing Graph for Structure-From-Motion. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Cui, H.; Gao, X.; Shen, S.; Hu, Z. HSfM: Hybrid Structure-from-Motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sweeney, C.; Hollerer, T.; Turk, M. Theia: A Fast and Scalable Structure-from-Motion Library. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 693–696. [Google Scholar] [CrossRef]
- Schöps, T.; Schönberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A Multi-view Stereo Benchmark with High-Resolution Images and Multi-camera Videos. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2538–2547. [Google Scholar] [CrossRef]
- Hui, T.W.; Tang, X.; Loy, C.C. LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8981–8989. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Teed, Z.; Deng, J. RAFT: Recurrent All-Pairs Field Transforms for Optical Flow. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2020; pp. 402–419. [Google Scholar] [CrossRef]
- Sattler, T.; Weyand, T.; Leibe, B.; Kobbelt, L. Image Retrieval for Image-Based Localization Revisited. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; pp. 76.1–76.12. [Google Scholar] [CrossRef]
- Zhang, Z.; Sattler, T.; Scaramuzza, D. Reference Pose Generation for Long-term Visual Localization via Learned Features and View Synthesis. Int. J. Comput. Vis. 2021, 129, 821–844. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Homography Est.AUC | Time Cost | ||
|---|---|---|---|---|
| @3 px | @5 px | @10 px | ||
| Coarse-level match network (conventional transformer [15]) | 14.9 | 31.7 | 56.4 | 1 min 3 s |
| Coarse-level match network (guided point transformer) | 18.7 | 36.0 | 61.2 | 52 s |
| Fine-level regression | 54.0 | 68.2 | 77.4 | 1 h 12 min |
| GLFNet | 68.2 | 77.9 | 86.5 | 1 min 24 s |
| Parameter | Homography Est.AUC | Time Cost | ||
|---|---|---|---|---|
| Window Size of Fine-Level Regression | @3 px | @5 px | @10 px | |
| 5 × 5 | 67.3 | 76.9 | 84.7 | 1 min 3 s |
| 7 × 7 | 67.9 | 77.5 | 86.3 | 1 min 11 s |
| 9 × 9 | 68.2 | 77.9 | 86.5 | 1 min 24 s |
| 11 × 11 | 68.0 | 78.1 | 85.6 | 2 min 06 s |
| of coarse-level matching | @3px | @5px | @10px | |
| 0.1 | 67.6 | 77.2 | 85.9 | 1 min 26 s |
| 0.2 | 68.2 | 77.9 | 86.5 | 1 min 24 s |
| 0.3 | 67.7 | 77.1 | 85.7 | 1 min 24 s |
| 0.4 | 67.4 | 76.8 | 85.5 | 1 min 22 s |
| 0.5 | 67.0 | 76.2 | 84.9 | 1 min 21 s |
| Category | Method | Homography Est.AUC | Time Cost | #Matches | ||
|---|---|---|---|---|---|---|
| @3 px | @5 px | @10 px | ||||
| Detector-based | SIFT + NN [8] | 49.8 | 61.0 | 73.9 | 47 s | 0.4K |
| D2Net + NN [9] | 23.2 | 35.9 | 53.6 | 8 min 57 s | 0.2 K | |
| R2D2 + NN [18] | 50.6 | 63.9 | 76.8 | 4 min 22 s | 0.5 K | |
| SuperPoint + SuperGlue [12] | 53.9 | 68.3 | 81.7 | 1 min 11 s | 0.6 K | |
| Detector-free | LoFTR [15] | 65.9 | 75.6 | 84.6 | 5 min 2 s | 1.0 K |
| ASpanFormer [25] | 67.4 | 76.9 | 85.6 | 6 min 1 s | 1.0 K | |
| SIFT + COTR [16] | 34.5 | 49.8 | 67.2 | 4 h 1 min | 1.0 K | |
| R2D2 + COTR [16] | 34.9 | 50.2 | 68.7 | 4 h 3 min | 1.0 K | |
| SuperPoint + COTR [16] | 56.1 | 69.4 | 81.3 | 4 h 2 min | 1.0 K | |
| SIFT + GLFNet | 62.4 | 73.1 | 83.7 | 1 min 10 s | 1.0 K | |
| R2D2 + GLFNet | 63.8 | 74.7 | 84.2 | 1 min 30 s | 1.0K | |
| SuperPoint + GLFNet | 68.2 | 77.9 | 86.5 | 1 min 24 s | 1.0 K | |
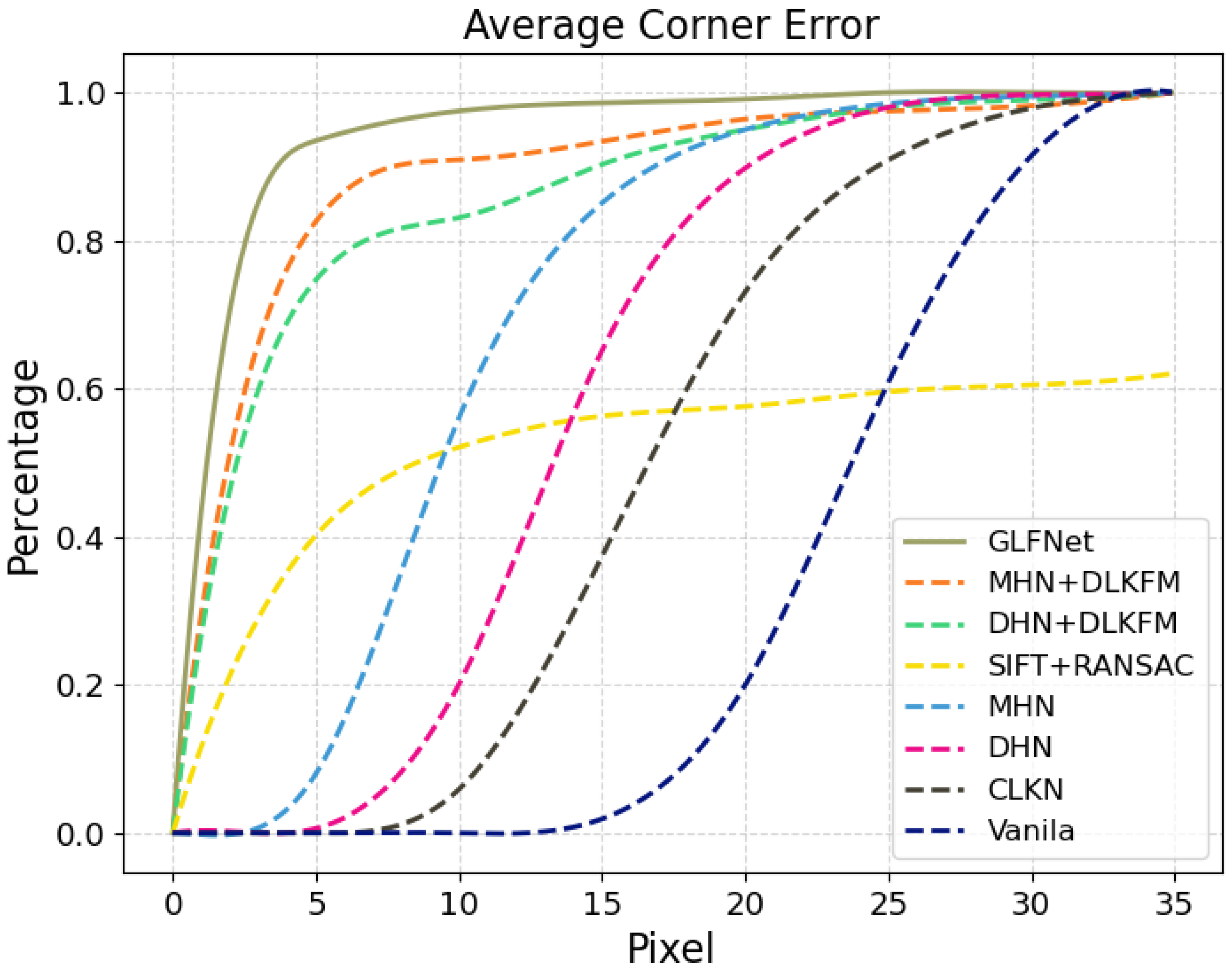
| Method | Average Corner Error | ||
|---|---|---|---|
| <3 Pixel | <5 Pixel | <10 Pixel | |
| Vanila | 0 | 0 | 0 |
| CLKN [48] | 0 | 0 | 5.9 |
| DHN [49] | 0 | 1 | 20.1 |
| MHN [50] | 1.0 | 8.0 | 56.1 |
| SIFT + RANSAC [8] | 29.1 | 40.2 | 52.1 |
| DHN + DLKFM [1] | 60.0 | 74.7 | 83.1 |
| MHN + DLKFM [1] | 66.3 | 82.6 | 90.9 |
| GLFNet | 85.3 | 93.5 | 97.5 |
| Dataset | 1DSfM [52] | LUD [55] | Cui [56] | Swe [57] | HSfM [58] | Theia [59] | Merge-SfM [51] | GLFNet | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | N | |||||||||||||||||||||||||
| Alamo | 4 | 627 | 529 | 0.3 | 2 | 547 | 0.3 | 2 | 574 | 0.5 | 3.1 | 533 | 0.4 | - | 566 | 0.3 | 1.5 | 520 | 0.4 | 1.8 | 582 | 0.5 | 2.6 | 599 | 0.3 | 1.9 |
| EllisIsland | 3 | 247 | 214 | 0.3 | 3 | - | - | - | 233 | 0.7 | 4.2 | 203 | 0.5 | - | 233 | 2 | 4.8 | 210 | 1.7 | 2.8 | 232 | 0.8 | 4.4 | 238 | 0.8 | 3.3 |
| Metropolis | 2 | 394 | 291 | 0.5 | 70 | 288 | 1.5 | 4 | 317 | 3.1 | 16.6 | 272 | 0.4 | - | 344 | 1 | 3.4 | 301 | 1 | 2.1 | 328 | 1.6 | 5.3 | 335 | 1.5 | 5.3 |
| MontrealND | 2 | 474 | 427 | 0.4 | 1 | 435 | 0.4 | 1 | 452 | 0.3 | 1.1 | 416 | 0.3 | - | 461 | 0.3 | 0.6 | 422 | 0.4 | 0.6 | 374 | 0.3 | 0.8 | 453 | 0.2 | 0.8 |
| NYCLibrary | 3 | 376 | 295 | 0.4 | 1 | 320 | 1.4 | 7 | 338 | 0.3 | 1.6 | 294 | 0.4 | - | 344 | 0.3 | 1.5 | 291 | 0.4 | 1 | 336 | 0.3 | 1.3 | 351 | 0.3 | 3 |
| PiazzadelPopolo | 3 | 354 | 308 | 2.2 | 200 | 305 | 1 | 4 | 340 | 1.6 | 2.5 | 302 | 1.8 | - | 344 | 0.8 | 2.9 | 290 | 0.8 | 1.5 | 344 | 0.5 | 1.1 | 346 | 0.5 | 1.1 |
| RomanForum | 4 | 1134 | 989 | 0.2 | 3 | - | - | - | 1077 | 2.5 | 10.1 | 966 | 0.7 | - | 1087 | 0.9 | 8.4 | 942 | 0.6 | 2.6 | 1109 | 0.8 | 6.4 | 1093 | 0.4 | 1.7 |
| TowerofLondon | 4 | 508 | 414 | 1 | 40 | 425 | 3.3 | 10 | 465 | 1 | 12.5 | 409 | 0.9 | - | 481 | 0.7 | 6.4 | 439 | 1 | 1.9 | 469 | 0.7 | 5.4 | 481 | 0.6 | 5.5 |
| UnionSquare | 4 | 930 | 710 | 3.4 | 90 | - | - | - | 570 | 3.2 | 11.7 | 701 | 2.1 | - | 827 | 2.8 | 3.4 | 626 | 1.9 | 3.7 | 724 | 2.3 | 5.5 | 927 | 1.4 | 5.8 |
| ViennaCathedral | 4 | 918 | 770 | 0.4 | 2e4 | 750 | 4.4 | 10 | 842 | 1.7 | 4.9 | 771 | 0.6 | - | 849 | 1.4 | 3.3 | 738 | 1.8 | 3.6 | 823 | 0.7 | 3.5 | 906 | 0.7 | 2.6 |
| Yorkminster | 2 | 458 | 401 | 0.1 | 500 | 404 | 1.3 | 4 | 417 | 0.6 | 14.2 | 409 | 0.3 | - | 421 | 1.2 | 1.7 | 370 | 1.2 | 1.8 | 431 | 1.2 | 4.2 | 438 | 0.4 | 3.8 |
| Gendarmenmarkt | 4 | 742 | - | - | - | - | - | - | 609 | 4.2 | 27.3 | - | - | - | 611 | 2.8 | 26.3 | 597 | 2.9 | 28 | 704 | 2.4 | 38 | 729 | 2.4 | 19.3 |
| Piccadilly | 6 | 2508 | 1956 | 0.7 | 700 | - | - | - | 2276 | 0.4 | 2.2 | 1928 | 1 | - | 2279 | 0.7 | 2 | 1824 | 0.6 | 1.1 | 2266 | 0.7 | 9 | 2461 | 0.3 | 1.6 |
| Method | AEPE | ||||||
|---|---|---|---|---|---|---|---|
| Rate = 3 | Rate = 5 | Rate = 7 | Rate = 9 | Rate = 11 | Rate = 13 | Rate = 15 | |
| LiteFlowNet [61] | 1.66 | 2.58 | 6.05 | 12.95 | 29.67 | 52.41 | 74.96 |
| PWC-Net [62] | 1.75 | 2.10 | 3.21 | 5.59 | 14.35 | 27.49 | 43.41 |
| DGC-Net [23] | 2.49 | 3.28 | 4.18 | 5.35 | 6.78 | 9.02 | 12.23 |
| GLU-Net [24] | 1.98 | 2.54 | 3.49 | 4.24 | 5.61 | 7.55 | 10.78 |
| RAFT [63] | 1.92 | 2.12 | 2.33 | 2.58 | 3.90 | 8.63 | 13.74 |
| COTR [16] | 1.66 | 1.82 | 1.97 | 2.13 | 2.27 | 2.41 | 2.61 |
| GLFNet | 1.49 | 1.61 | 1.78 | 1.90 | 2.07 | 2.34 | 2.65 |
| Matching Method | Day | Night |
|---|---|---|
| (0.25 m, 2°)/(0.5 m, 5°)/(5 m, 10°) | ||
| SIFT + NN [8] | 84.5/92.7/97.5 | 66.3/75.5/87.8 |
| SIFT + COTR [8,16] | 82.4/91.9/96.8 | 75.5/90.8/99.0 |
| SIFT + SuperGlue [8,12] | 85.3/93.9/98.2 | 72.4/88.8/96.9 |
| SIFT + GLFNet | 88.2/95.4/98.2 | 84.7/92.9/99.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, S.; Xiao, Y.; Huang, J.; Sun, M.; Liu, M. Guided Local Feature Matching with Transformer. Remote Sens. 2023, 15, 3989. https://doi.org/10.3390/rs15163989
Du S, Xiao Y, Huang J, Sun M, Liu M. Guided Local Feature Matching with Transformer. Remote Sensing. 2023; 15(16):3989. https://doi.org/10.3390/rs15163989
Chicago/Turabian StyleDu, Siliang, Yilin Xiao, Jingwei Huang, Mingwei Sun, and Mingzhong Liu. 2023. "Guided Local Feature Matching with Transformer" Remote Sensing 15, no. 16: 3989. https://doi.org/10.3390/rs15163989
APA StyleDu, S., Xiao, Y., Huang, J., Sun, M., & Liu, M. (2023). Guided Local Feature Matching with Transformer. Remote Sensing, 15(16), 3989. https://doi.org/10.3390/rs15163989