1. Introduction
Advancements in technology and economics have increased the popularity of sensors with different characteristic features [
1]. The trade-offs in the characteristic features of different sensors have necessitated the use of fusion techniques to generate a robust and informative image from multi-sensor source images [
2]. The fused images have all the desired characteristics of the source images [
3]. Therefore, fusion techniques have been used in various applications such as medical diagnosis, monitoring, security, geological mapping, and agriculture monitoring [
4,
5,
6].
Image fusion has been successfully applied in various fields [
7]. However, the fusion sources have mostly been static images such as infrared and visible images, which do not provide dynamic information about the scene. This limitation can be overcome by fusing inverse synthetic aperture radar (ISAR) images with visible images. The fusion of ISAR and visible images yields informative images with detailed and dynamic information from the visible and ISAR images, respectively. The advantages of the fusion of the ISAR and visible images facilitate its application in security surveillance, air traffic control, wildlife conservation, and intelligent assistance [
8,
9,
10,
11].
In recent decades, numerous image fusion methods have emerged. The conventional image fusion methods can generally be grouped into three categories [
12], namely, spatial domain methods [
13,
14,
15], transform domain methods [
16,
17,
18] and deep-learning-based methods [
19]. The spatial domain methods directly operate on the pixel values of the input images and process the image on a pixel-by-pixel basis [
20]. These methods have a simple processing flow and strong interpretability, and are widely used in pixel-level image fusion [
21]. For example, Wan et al. [
22] merged the images using the most significant features of a sparse matrix, which were obtained through the robust principal component analysis. Mitianoudis et al. [
14] transformed the images using independent component analysis (ICA) and topographic independent component analysis. Fusion results were obtained in the transform domain using novel pixel-based or region-based rules. Yin et al. [
23] proposed a dual-kernel side window box filter decomposition method and a saliency-based fusion rule for image fusion. Smadi et al. [
24] adopted side window filtering employed on several filters to decompose and fuse the images. Yan et al. [
25] decomposed the images using an edge-preserving filter and refined the final fused image with a guided filter. Zou [
26] designed a multiscale decomposition method based on a guided filter and a side window box filter. The spatial-domain methods usually use a symmetric structure to design fusion strategies. However, in cases where there is a large difference in information intensity between the input images, weak signals are often overwhelmed by strong signals, resulting in the loss of some critical details.
The transform domain methods transform the images into another subspace where the features are classified and considered globally [
27]. These methods are usually established on some dictionaries or models and can retain more meaningful information [
17]. For instance, Liu et al. [
27] represented the different components in the original images using sparse coefficients. Zhang et al. [
28] represented the images through a multi-task robust sparse representation (MRSR) model, and were able to process the unregistered images. Liu et al. [
29] decomposed the images using nonsubsampled shearlet transform (NSST) for pre-fusion. Qu et al. [
30] represented the images in a nonsubsampled contour-let transform domain. Furthermore, a dual-pulse coupled neural network (PCNN) model was adopted to fuse the images. Panigrahy et al. [
31] transformed images into the NSST domain and fused the images with adaptive dual channel PCNN. Indhumathi et al. [
32] transformed the images with empirical mode decomposition (EMD) and then fused them with PCNN. Similarly to spatial-domain methods, transform-domain methods often use the same dictionary or model to extract feature information from images. These transformations use non-local or global information. However, this will lead to the loss of some important but globally less significant information, such as dim targets in infrared images.
Deep-learning-based methods have recently been introduced into the field of image fusion. These methods employ deep features to guide the fusion of two images [
7,
33]. Most of the deep-learning-based fusion strategies and generation methods report strong scene adaptability [
34,
35,
36]. However, due to down-sampling in the network, the fusion results of deep-learning-based methods are usually blurred.
Although most of the conventional approaches have achieved satisfactory results, these methods fuse the two different source images in the same way. In the ISAR and visible image fusion, objects in the captured scene are mostly stationary or move slowly relative to the radar. As a result, ISAR images have large black backgrounds and many weak signals, while visible images are information-rich. This significant information difference makes conventional symmetric approaches inadequate for processing these images. These approaches will result in the mismatching of feature layers and affect the final fusion performance. For example, in [
5], the same decomposition method is applied to both source images. Hence, significant information from these images may be lost during the fusion process. Similarly, in the sparse representation methods [
17,
27], the same over-complete dictionary is applied to different images, resulting in some features being ignored.
Hence, most conventional approaches cannot deal suitably with the fusion of different images containing quite different information content. Further research is needed on how to balance the differences in information between different source images to preserve as many details as possible. To the best of our knowledge, there are few studies considering the inequality information between two input images. This study aims to balance the information difference between different source images and preserve image details as much as possible in the fusion results. To achieve this objective, we analyzed heterogeneous image data, including ISAR, visible, and infrared data. We found that although the data acquisition methods are different, they describe different information about the same scene. There are some underlying connections between these pieces of information. Therefore, we hypothesized that these pieces of information can be guided and obtained through other source images. Under this assumption and motivated by the work of [
5,
25], we innovatively designed an asymmetric decomposition method, aiming to use strong signals to guide weak signals. Through the operation, we can obtain potential components from weak signals and enhance them, ensuring that weak signals can be fully preserved in the fusion result.
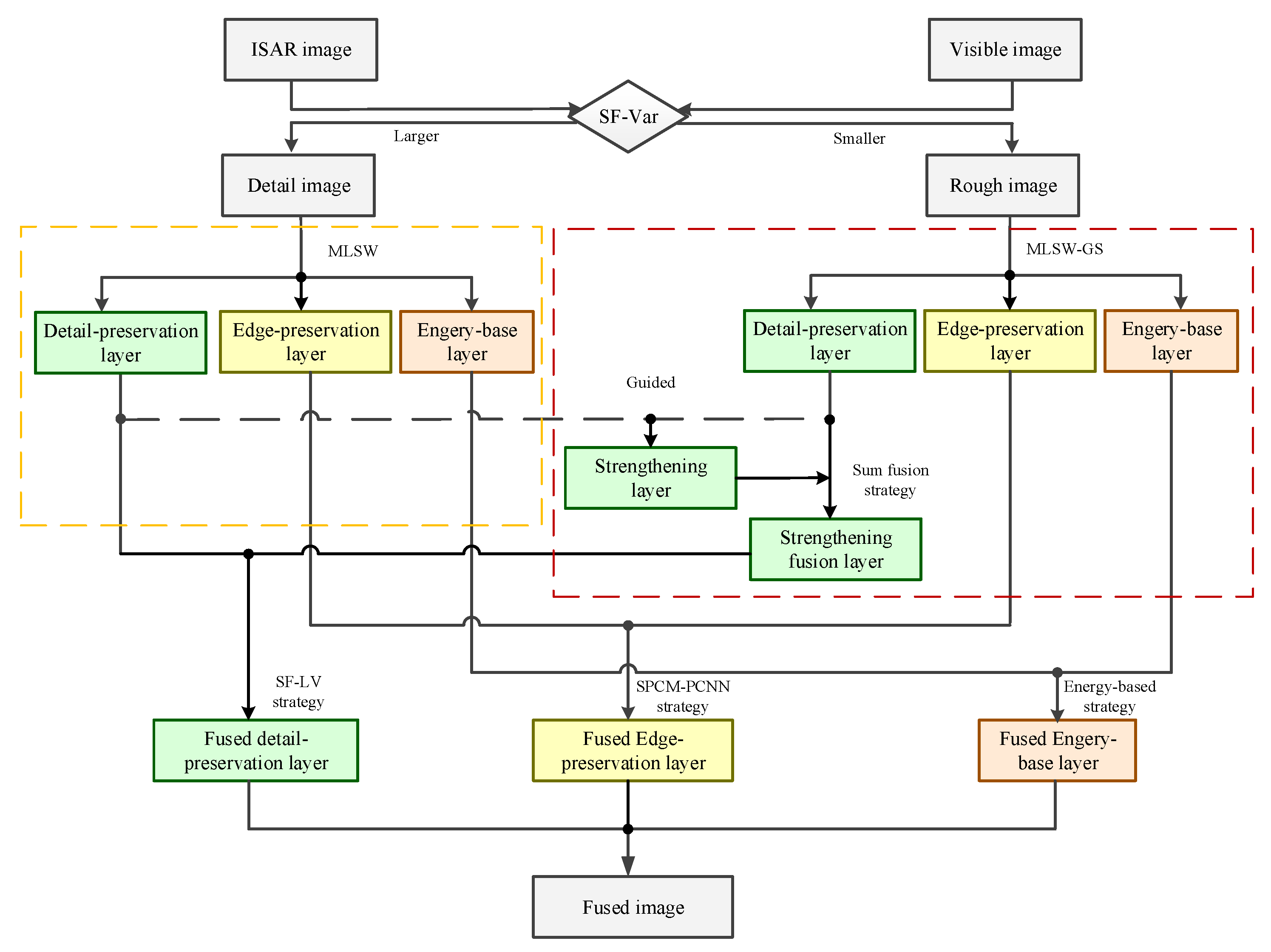
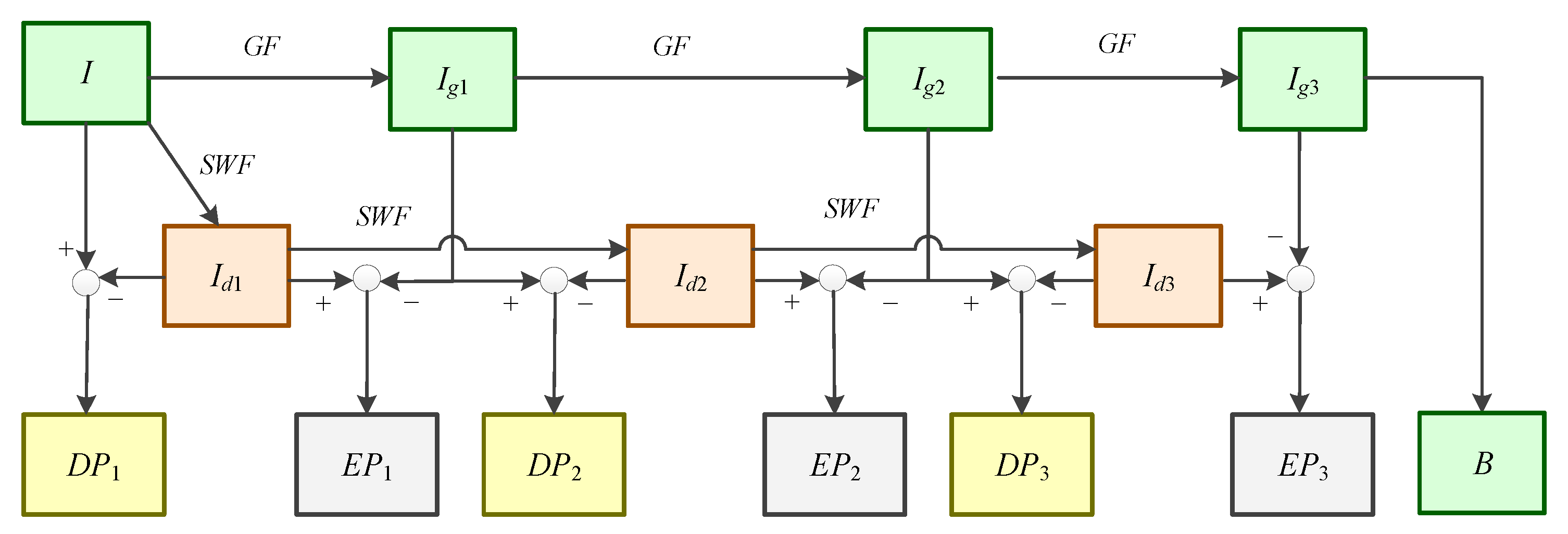
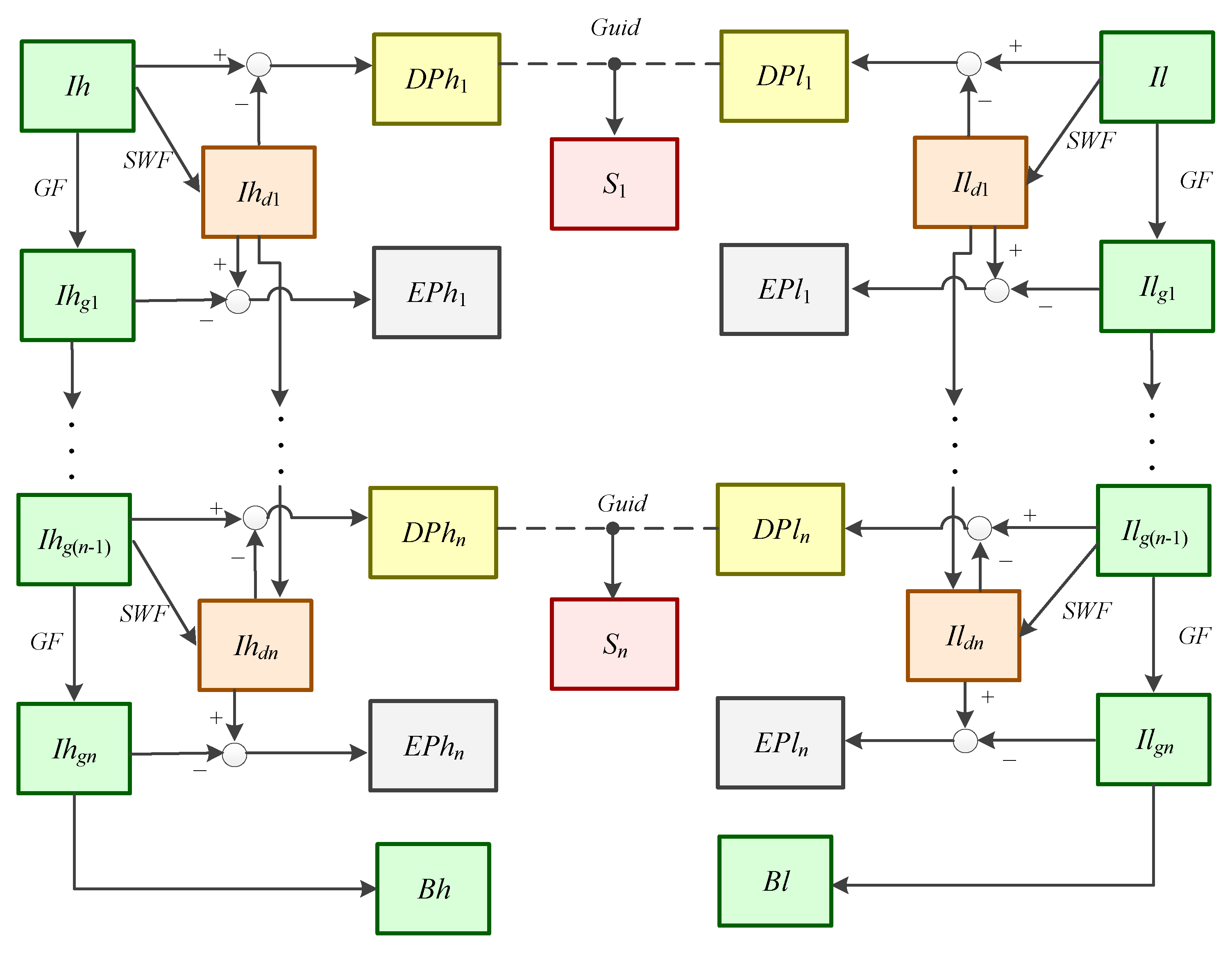
Based on the idea above, under the assumption that the images have been registered at the pixel level, the current research proposes a novel fusion method named the adaptive guided multi-layer side window box filter decomposition (AMLSW-GS) method. Firstly, an information abundance discrimination method is proposed to categorize the input images as detailed and coarse images. Secondly, a novel asymmetric decomposition framework is proposed to decompose the detailed and coarse images, respectively. The detailed image is decomposed into three layers constituting small details, long edges, and base energy. Similarly, the coarse image is used to yield an additional layer containing the strengthening information. Thirdly, a pre-fusion step is adopted to fuse the layers containing strengthening information and the layers containing the small details from the coarse image. Furthermore, three different fusion strategies are adopted to fuse the different layers, and the sub-fusion results are obtained. Finally, the fusion result is obtained as a summation of different sub-fusion results.
The main contributions of the current work are as follows:
- (1)
We innovatively propose an asymmetric decomposition method to avoid losing vital information and balance the features of input images.
- (2)
We design an information abundance measurement method to justify the amount of information in input images. This measurement estimates the information variance and edge details in the input images.
- (3)
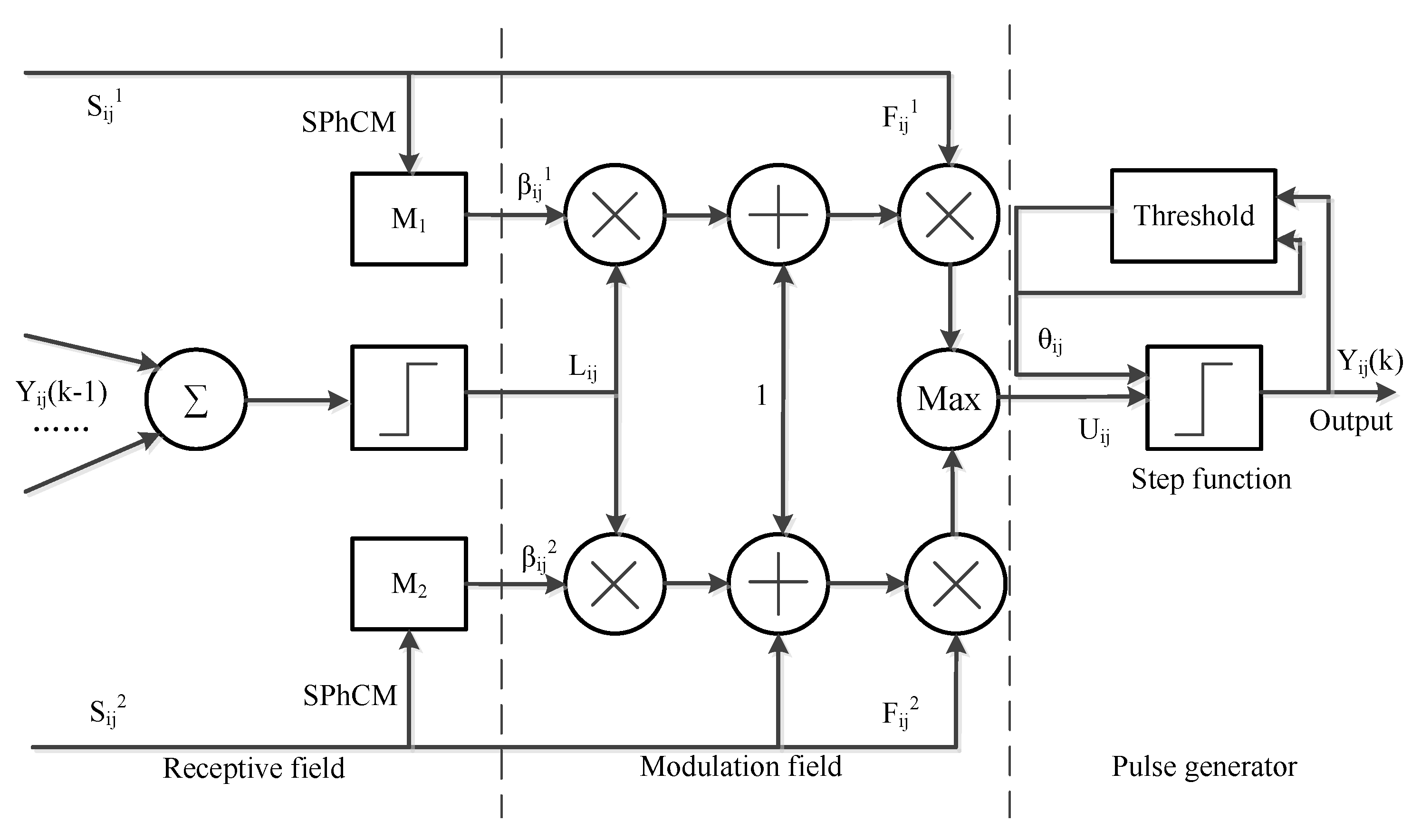
We propose three different fusion strategies to use different feature information for different layers. These strategies are designed according to the characteristics of different layers.
- (4)
We publicize a pixel-to-pixel co-registered dataset containing visible and ISAR images. To the best of our knowledge, this is the first dataset related to the fusion of visible and ISAR images.
In summary, to address the problem of weak signal loss due to uneven fusion information intensity, under the assumption that the images are already registered at the pixel level and information can be guided, this study proposes an asymmetric decomposition method to enhance the weak signal and ensure the completeness of information in the fusion result. This article is organized as follows. In
Section 2, the proposed method is presented in detail. In
Section 3, the dataset is introduced and the experimental results on ISAR and VIS images are presented. In
Section 4, some characteristics of the proposed method are discussed. In
Section 5, we conclude this paper.
4. Discussion
To further analyze the characteristics and applicability of the proposed method, some experiments were carried out in this section.
4.1. Parameter Analysis of the Proposed Method
In this section, we discuss the impact of parameters on the performance of the method. In the proposed method, many parameters need to be set: the number of decompositions s, the size of the guided filter k, the number of iterations in PCNN L, the number of scales in SPhC l, and the number of scales in morphological operation t. After conducting experiments, we found that the parameters that have a significant impact on the performance of the method are the number of decompositions s and the number of scales in morphological operation t. Hence, we mainly discuss the impact of these two parameters on the performance of the method.
In our experiments, we used the method of controlling the variables to explore. Except for the two parameters being explored, the values of the other parameters were set as follows: , , and . For convenience of analysis, we chose MI and as the metrics for evaluating the performance.
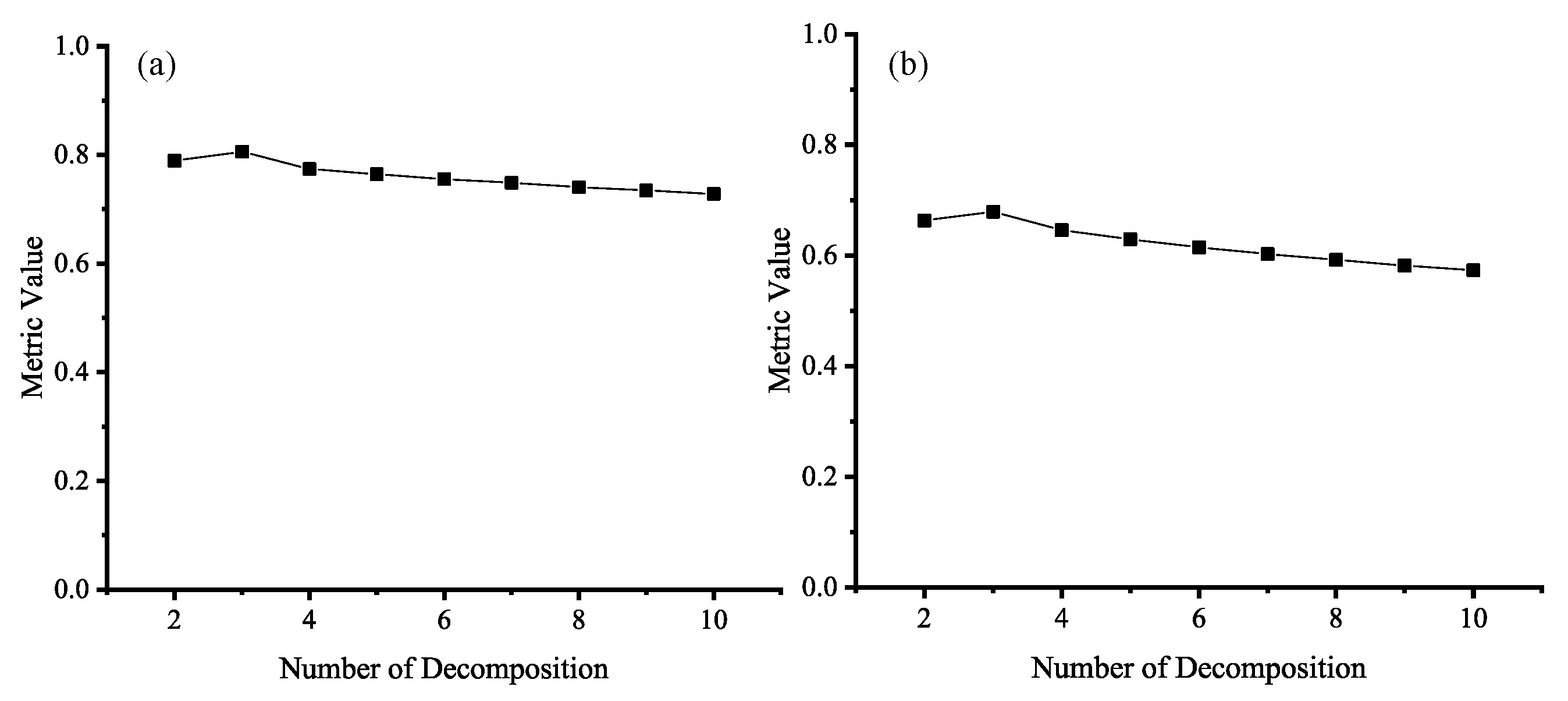
As shown in
Figure 11, as the number of decompositions increases, both MI and
show an increase followed by a decrease. The best number of decompositions is 3. This is mainly due to the fact that at lower decomposition levels, details can be better distinguished to improve the performance of the fusion result with the increase in the number of decompositions. However, when the number of decompositions is too large, weak details are overly enhanced, resulting in a decrease in the structural similarity of the final fusion result with the input images. The enhancement operations can lead to information imbalance.
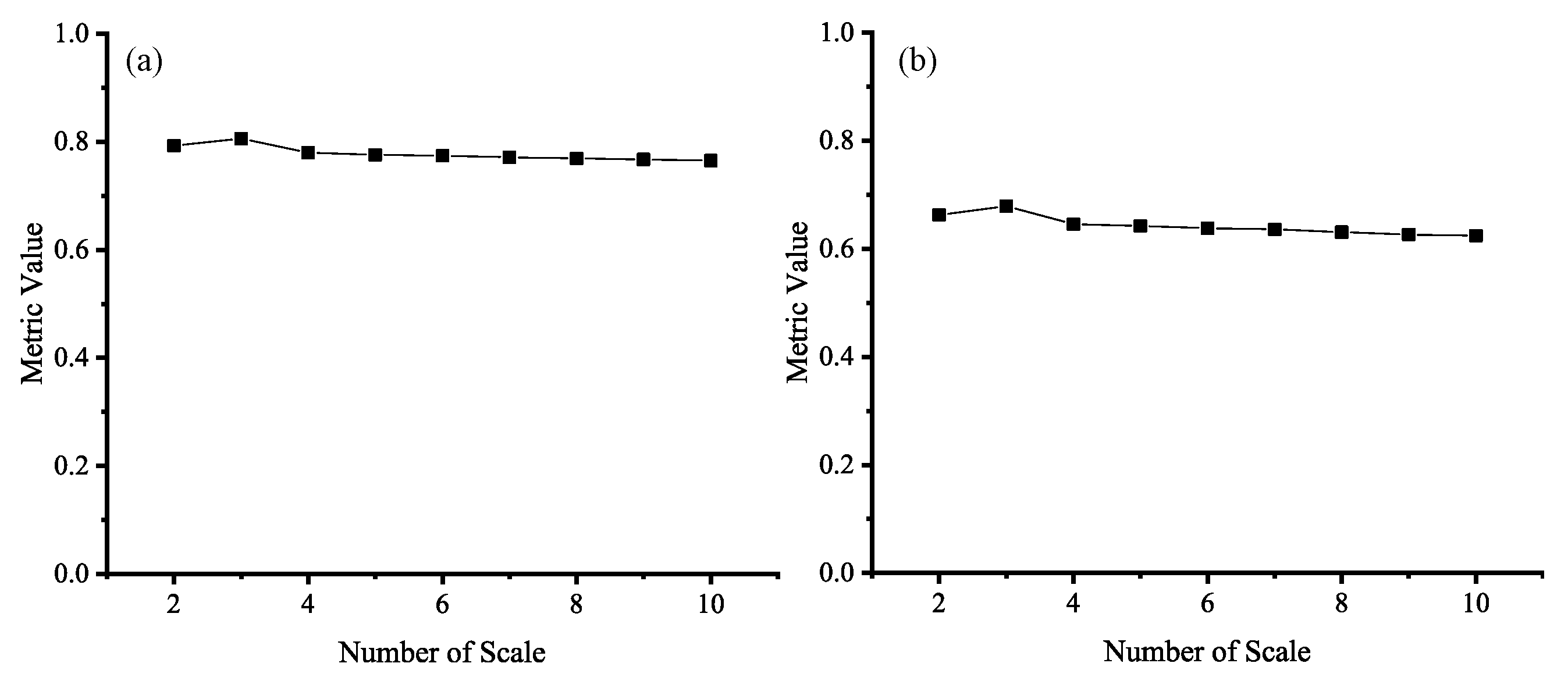
As shown in
Figure 12, while the number of scales increases, both MI and
also show an increase followed by a decrease. The best number on the scale is 3. This is due to the fact that when the number of scales is small, the multi-scale morphological operation can well locate the position of the object compared to the edge, which improves the final fusion performance. However, when the number of scales is large, due to the characteristics of the morphological operators, there will be more artifacts in the fusion weights, leading to incorrect weight allocation in the areas around the edges, resulting in poorer fusion results.
In summary, the adaptability and the stability of the parameters in the proposed method are weak. Our method performs better with fewer decomposition layers and morphological scales. This is because an increase in the number of layers results in the excessive enhancement of weak signals, and increasing the number of morphological scales results in the inaccurate location of the edges. Both factors will lead to decreased performance. Hence, to further improve the stability of the parameters, we need to further study the internal mechanism of the enhancement, and design a more effective enhancement method to achieve better performance.
As analyzed above, we chose and under consideration of the effectiveness and efficiency of the method.
4.2. Ablation Analysis of the Structure
To verify the effectiveness of the proposed asymmetric method, we conducted some experimental studies in this section.
Based on the analysis of the proposed method, we believe that the factors that mainly affect the fusion performance are concentrated in two aspects: the asymmetric decomposition framework and the selection of fusion strategies. Hence, we analyzed these aspects in this section. The fusion strategy for the energy layer is a classic weighted fusion, so we do not intend to discuss this fusion strategy in this section.
In the experiments, three different structures are discussed and four metrics including MI, NCIE,
, and SSIM are adopted. The proposed method is denoted as AMLSW + SP + SL, where AMLSW represents the asymmetric decomposition framework we proposed, SP represents the SPhCM-PCNN fusion strategy, and SL represents the SF-LV fusion strategy. Meanwhile, we use MLSW to represent the symmetric decomposition strategy, which replaces MLSW-GS in AMLSW with MLSW. AMLSW + SP represents the decomposition method being AMLSW, and the fusion strategies for detail preservation layers and edge preservation layers are SPhCM-PCNN. AMLSW + SL represents the decomposition method being AMLSW, and the fusion strategies for detail preservation layers and edge preservation layers are SF-LV. The experimental results are shown in
Figure 13.
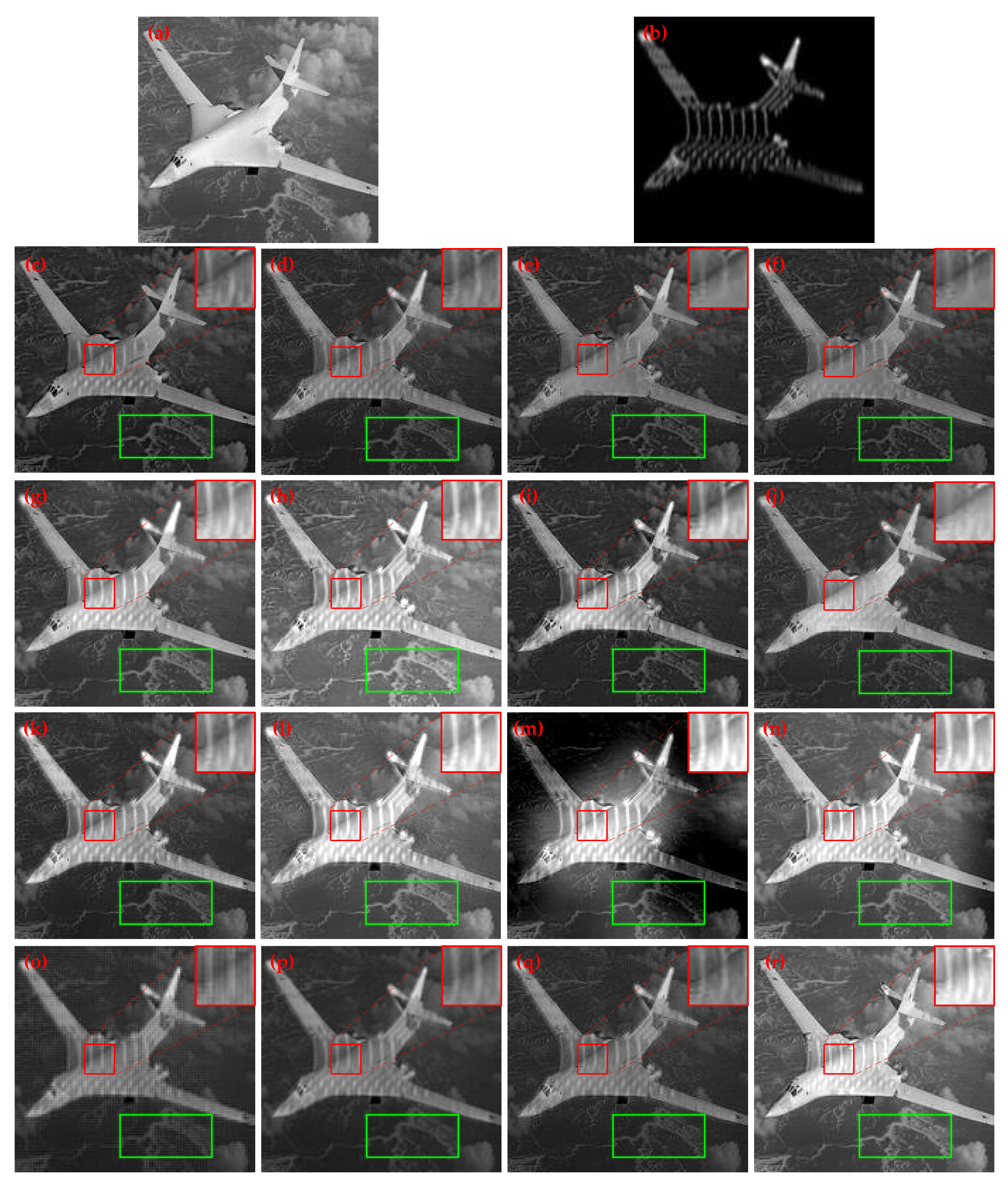
Through
Figure 13, we can find that by replacing the decomposition method with a symmetric one, which is shown in
Figure 13d,h, some potential information about detail is lost, causing signal distortion in certain areas. This indicates that our asymmetric decomposition structure has the ability to preserve weak signals compared to the symmetric structure. By replacing the detail preservation fusion strategy with SPhCM-PCNN, which is shown in
Figure 13e,i, we can find that some small structures and details are lost. This indicates that SF-LV has a better fusion performance on small structures and details, and can better preserve the details of small structures compared to SPhCM-PCNN. By replacing the edge preservation fusion strategy with SF-LV, which is shown in
Figure 13f,j, we can find that some long edges are blurred. This indicates that SPhCM-PCNN has a better fusion performance for long edge preservation due to its high precision in edge localization, and that SPhCM-PCNN can better preserve the details of long edges compared to SF-LV.
To further demonstrate the effectiveness of each part of the algorithm, we selected four metrics to assess the final fusion results. These metrics are MI, NCIE,
, and SSIM. The experimental results are shown in
Table 5, where the best metric values have been bolded.
In
Table 5, we can draw the same conclusion as above: (1) The asymmetric decomposition structure has better fusion performance compared with the symmetric decomposition structure by comparing the metrics of MLSW + SP + SL and AMLSW + SP + SL. (2) The SF-LV fusion strategy has a better performance in detail preservation by comparing the metrics of AMLSW + SP and AMLSW + SP + SL. (3) The SPhCM-PCNN fusion strategy has a better performance in edge preservation by comparing the metrics of AMLSW + SL and AMLSW + SP + SL. We can find that all of the structures are necessary for good fusion performance.
As analyzed above, both in the objective and subjective evaluations, the asymmetric structure proposed in this method performs better than the symmetric one. This is because the asymmetric structure extracts more weak signals and effectively enhances them. The fusion strategies can also effectively preserve the details according to the characteristics of the corresponding layers. The main structures proposed in this study are both necessary and effective. The proposed method can inspire researchers to consider a new asymmetric fusion framework that can adapt to the differences in information richness of the images, and promote the development of fusion technology.
4.3. Generalization Analysis of the Method
To validate the adaptability and applicability of our proposed method on real-world data, we discuss the applicability of the proposed method in this section. We use publicly available infrared and visible fusion datasets to validate the proposed method. The infrared and visible fusion datasets that are widely used by many researchers include TNO [
64], RoadScene [
33], Multi-Spectral Road Scenarios(MSRS) [
65], etc.
For the evaluation carried out in this study, we used the TNO datasets for infrared and visible image fusion. The TNO dataset contains images captured in various bands, including visual (390–700 nm), near-infrared (700–1000 nm), and longwave-infrared (8–12 m). The scenarios were captured at nighttime so that the advantage of infrared could be exploited. All of the images are registered at the pixel level with different multi-band camera systems.
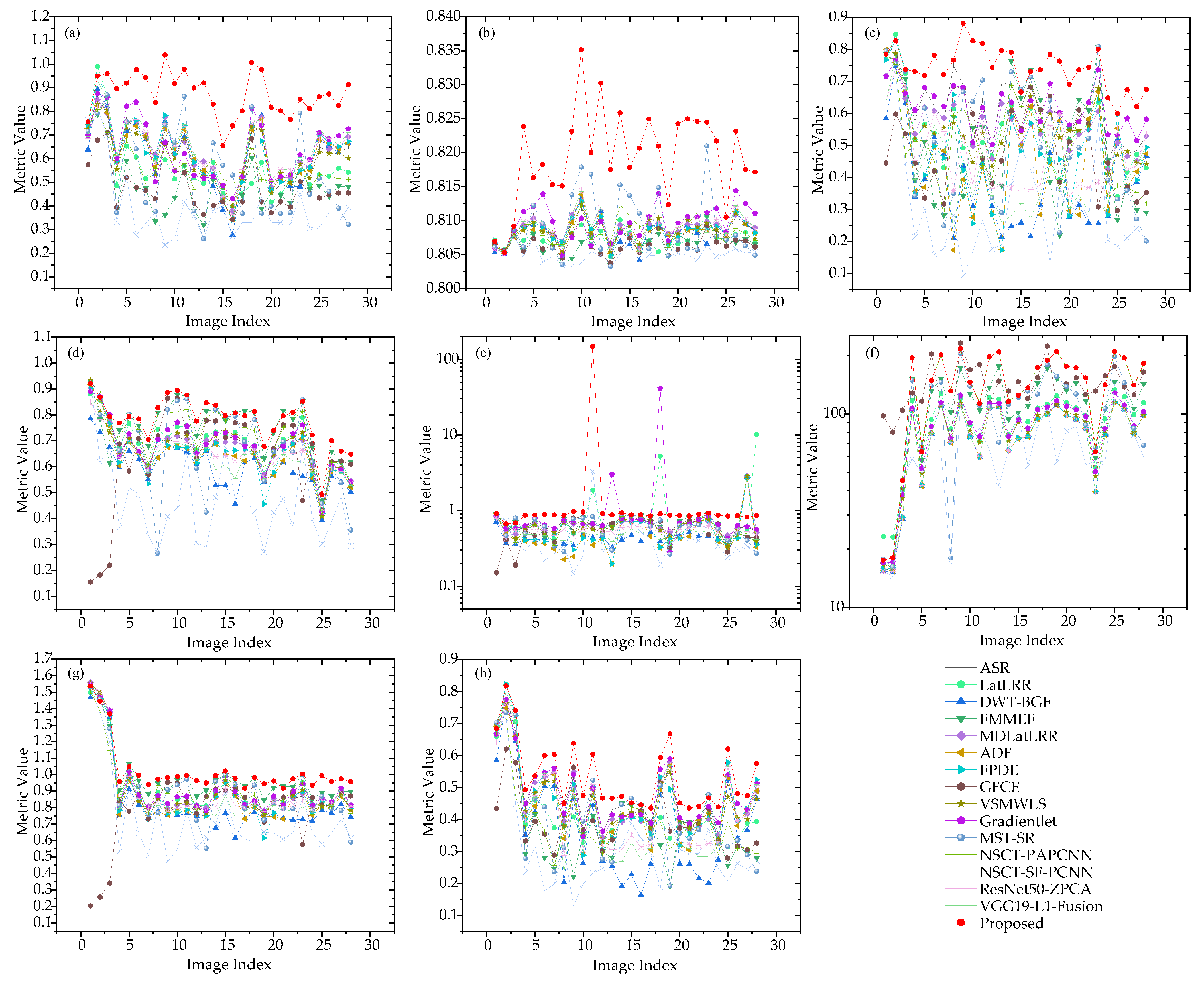
To illustrate the performance of our method, we compared it with three other infrared and visible image fusion methods: MDLatLRR, NSCT-SF-PCNN and ResNet50-ZPCA. The fusion results are shown in
Figure 14.
Through the results shown in
Figure 14, we find that our proposed method can also be applied to infrared and visible image fusion. Due to the fact that infrared and visible light images are obtained from different types of signal sources, there is a relatively large information difference. The proposed method can deal with two different images with large information differences. Therefore, our method is also suitable for fusing infrared and visible images. The image data used for fusion are all from real scenes, which indicates that our method is capable of processing the image information of real scenes with information differences.
To further demonstrate the applicability of our method, we used four fusion metrics to evaluate the fusion performance: MI, NCIE,
, and
. The metric values of different fusion methods in different scenes are shown in
Table 6, where the best values have been bolded.
As is evident in
Table 6, the proposed method achieves the best values for these four metrics. Hence, in view of objective metrics, the proposed method is applicable to the task of infrared and visible image fusion. Our proposed method exhibits good adaptability.
4.4. Analysis of Time Complexity
Because the proposed fusion method has a relatively complex structure, it is necessary to conduct a time complexity analysis of the method. In this part, we analyze the time consumption for the proposed method.
The time complexity analysis can be performed by analyzing the number of operations required to complete the method as a function of the input size. The time complexity of the method is typically denoted as , where n represents the input size.
In our study, the entire processing procedure can be divided into four stages: image complexity assessment, image decomposition, multi-level image fusion, and the aggregation process. Suppose that the size of the input image is . For the image complexity assessment stage, the SF and the variance are calculated. Both the SF and the variance have an complexity. Thus, the time complexity of this stage is . For the image decomposition stage, the MLSW and MLSW-GS are adopted. MLSW-GS has a higher complexity than MLSW. The complexity of MLSW-GS is determined by the number of decomposition layers s, filter operation, and guided operation. The complexity of the filter operation is determined by the kernel size k. It has an complexity, and so is the guided operation. So in this stage, the time complexity is . For the multi-level image fusion stage, SPhCM-PCNN, SF-LV and Energy based fusion strategies are adopted. Both SF-LV and Energy-based method have complexity. The time complexity of SPhCM-PCNN is , where the l is the scale parameter in SPhC method. The 4 represents the four orientations in SPhC. . t is the number of scales in SPhCM. L is the iteration number in PCNN. So in this stage, the time complexity is . For the aggregating process stage, a sum operation is adopted. Sum operation has an complexity. So in this stage, the complexity is determined by the number of decomposition layers s. The time complexity of this stage is . Hence, the time complexity of the entire proposed method is . As we analyzed, the second and third stages account for the main part of the time consumption of the proposed method.
To demonstrate the run-time of the proposed method more specifically, we separately timed each stage of the method. The results are shown in
Table 7. It should be noted that the input image size is
.
The results in
Table 7 indicate that the time consumption of the proposed method is mainly concentrated in the image decomposition and multi-level image fusion stages, which is consistent with our previous analysis of time complexity.
To compare the time consumption with other state-of-the-art methods, we selected four of the methods mentioned above as references, timed them, and compared the results. The experimental results are shown in
Table 8.
Compared with other methods, our method has a higher time complexity and longer processing time. It can not meet the real-time processing requirement. This needs further improvement to help our proposed method enter engineering practice. One feasible solution is to design a parallel structure for the method because the main structures of the method process the images in the local area, which is more amenable to parallel computation. Furthermore, simplification methods for some structures can also be used to improve the time performance.
5. Conclusions
In this work, a novel fusion method named adaptive guided multi-layer side window box filter decomposition (AMLSW-GS) is proposed to mitigate detail loss in the fusion process of ISAR and visible images. Firstly, a new information abundance discrimination method based on spatial frequency and variance is proposed to sort the input images into detailed and coarse images. Secondly, the MLSW decomposition and MLSW-GS decomposition methods are proposed to decompose the detailed image and the coarse image into different scales, respectively. Thirdly, four fusion strategies—sum fusion, SF-LV, SPhCM-PCNN, and energy-based methods—are adopted to fuse different scale features to retain more detail. Finally, the fusion result is obtained by accumulating different sub-fusion results. In this way, the proposed method can make full use of the latent features from different types of images and retain more detail in the fusion result. On the synthetic ISAR-VIS dataset and the real-world IR-VIS dataset, compared with other state-of-the-art fusion methods, the experimental results show that the proposed method has the best performance in both subjective and objective fusion quality evaluations. This demonstrates the superiority and effectiveness of the proposed asymmetric decomposition methods.
Additionally, the unstable parameters limit the overall performance of the method, and further optimization is needed for the weak signal enhancement method. Simultaneously, the fusion time is in the order of seconds, which cannot meet the real-time requirements of engineering. In the future, we will mainly research more effective methods of enhancing weak signals to better preserve information. Furthermore, we will consider the execution efficiency of the methods while designing fusion strategies to make them applicable in engineering practices.






 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}