
Multi-Branch Deep Learning Framework for Land Scene Classification in Satellite Imagery



Abstract
1. Introduction
- The global streams of both the SKAL and GLDBS frameworks use feature maps of the last convolutional layer for classification. This strategy reduces the discriminating capability of the framework by ignoring the important information hidden in various layers of the network. Moreover, these frameworks have limitations in effectively aggregating global contextual information, which often results in misclassification of visually similar but distinct objects. In contrast, the proposed framework integrates the pyramid pooling module to incorporate more contextual information from various regions of the input feature maps.
- The local streams of both the SKAL and GLDBS frameworks utilize a convolutional neural network (CNN) to identify the coarse locations and scales of objects in the scene. Due to this strategy, the frameworks are unable to obtain fine-grained features from the local regions, and they lead to background noise. In contrast, the local branch of the proposed framework employs a two-stage model by exploiting a fully convolutional network (FCN). The model first generates multi-scale object proposals (corresponding to the local region of the image) and then extracts discriminating features from important local areas (object proposals) of the input image.
- 1.
- A multi-branch deep learning framework is proposed for land scene classification in satellite images.
- 2.
- Unlike previous methods, the first branch of the framework (global contextual module) effectively aggregates contextual information from various regions of the images by integrating the pyramid pooling module.
- 3.
- The local feature extraction module extracts multi-scale information and reduces background noise by learning discriminating features from the local regions of the image.
- 4.
- We gauged the performance on three publicly available challenging datasets. From the experiments results, we demonstrate the effectiveness of the proposed framework.
2. Related Work
2.1. Unsupervised Models
2.2. Supervised Models
2.2.1. Handcrafted Feature Representation Models
2.2.2. Deep Hierarchical Feature Models
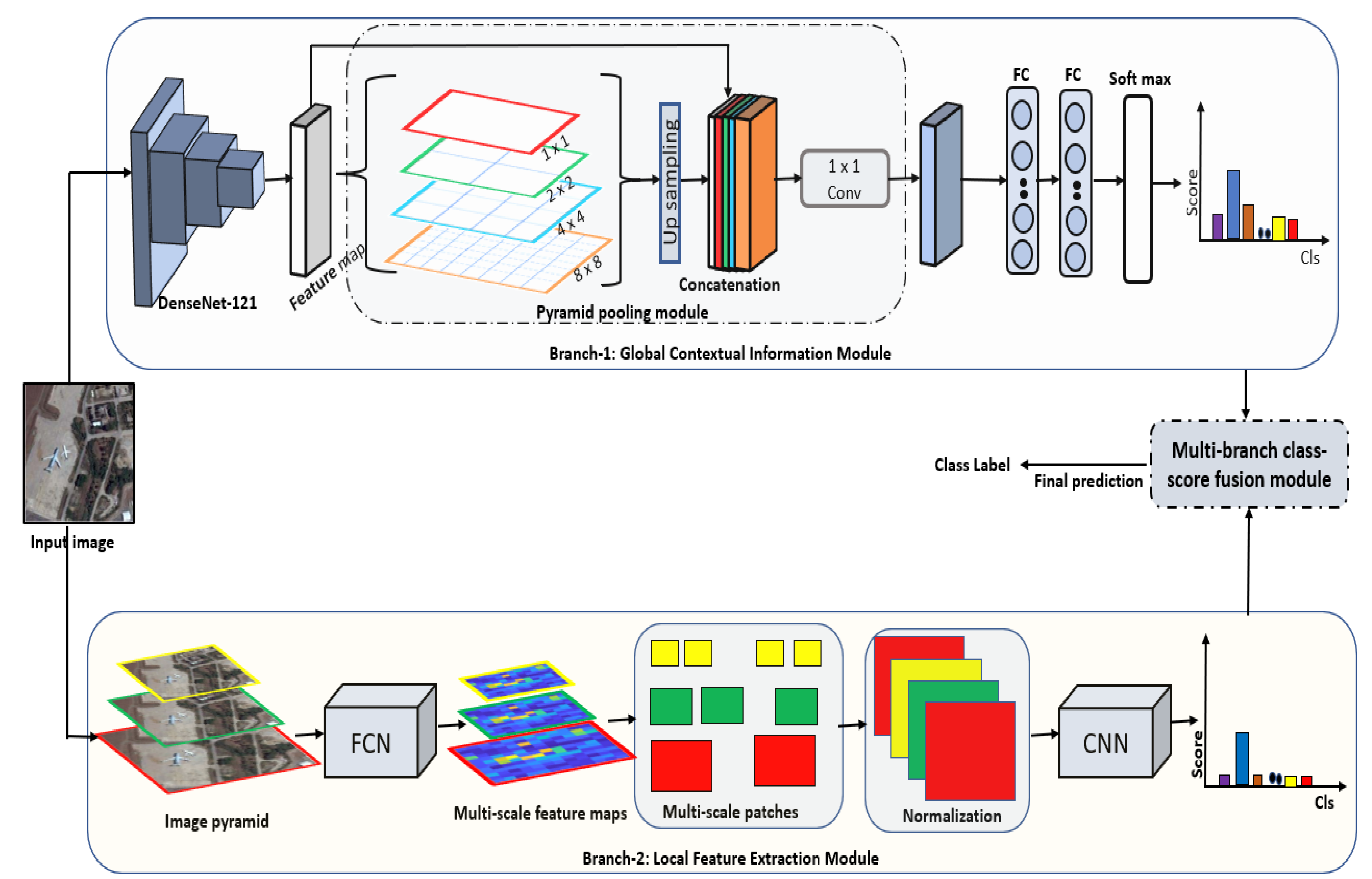
3. Methodology
3.1. Branch-1: Global Contextual Information Module
3.2. Branch-2: Local Feature Extraction Module
3.3. Multi-Branch Class Score Fusion Module
4. Experimental Results
4.1. Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | UC-Merced [38] | SIRI-WHU [72] | EuroSAT [73] |
|---|---|---|---|
| 1 | Agricultural | Agricultural | Annual Crop |
| 2 | Airplane | Commercial | Forest |
| 3 | Baseball diamond | Harbor | Herbaceous |
| 4 | Beach | Idle land | Highway |
| 5 | Buildings | Industrial | Industrial |
| 6 | Chaparral | Meadow | Pasture |
| 7 | Dense residential | Overpass | Permanent Crop |
| 8 | Forest | Park | Residential |
| 9 | Freeway | Pond | River |
| 10 | Golf course | Residential | Sea & Lake |
| 11 | Harbor | River | - |
| 12 | Intersection | Water | - |
| 13 | Medium-density residential | - | - |
| 14 | Mobile home park | - | - |
| 15 | Overpass | - | - |
| 16 | Parking lot | - | - |
| 17 | River | - | - |
| 18 | Runway | - | - |
| 19 | Sparse residential | - | - |
| 20 | Storage tanks | - | - |
| 21 | Tennis courts | - | - |
4.2. Evaluation Metrics
- Overall accuracy (OA) measures and provides general insight about the performance of the framework and is computed as the ratio of the number of samples correctly classified to the total number of samples in the test set.
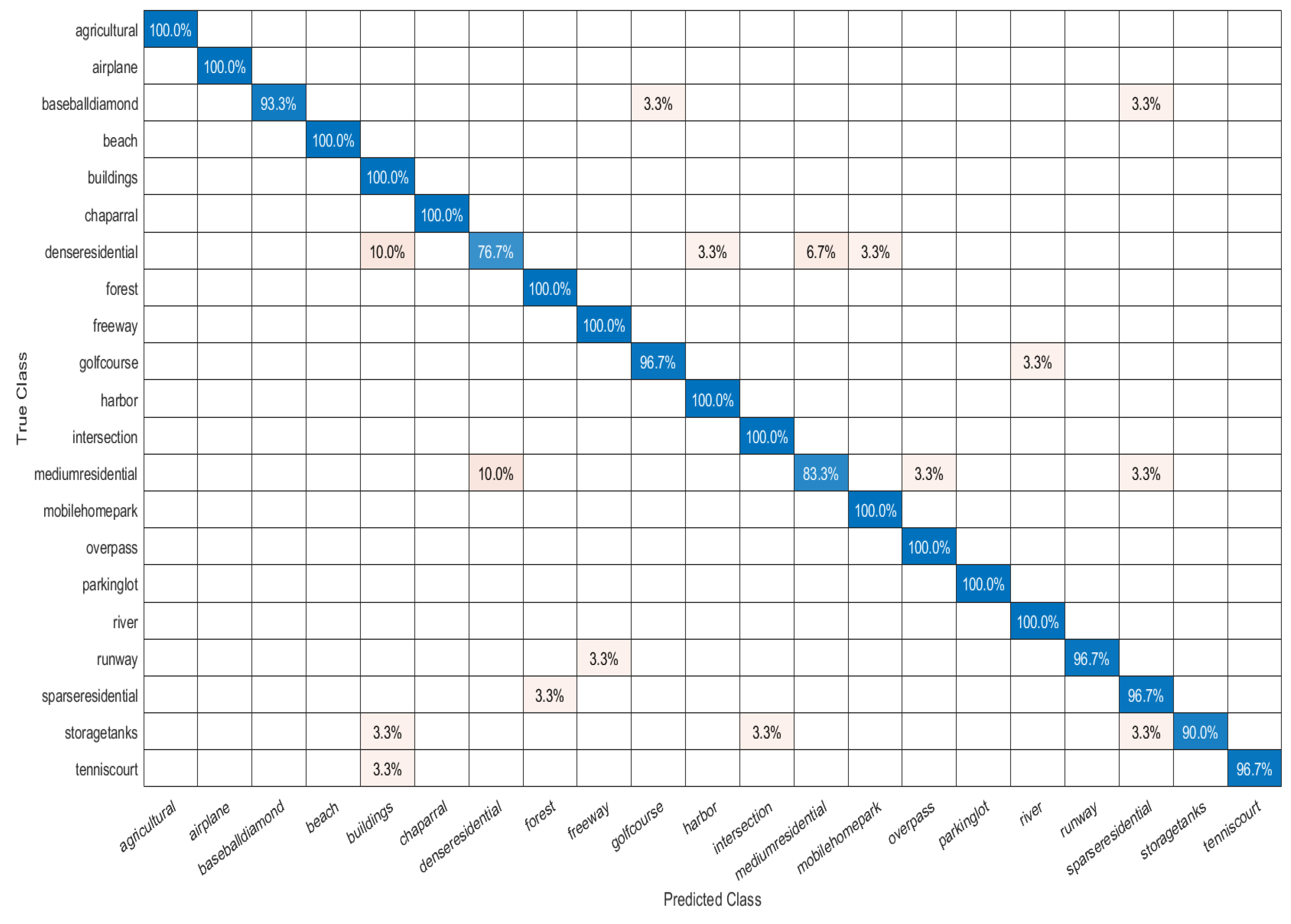
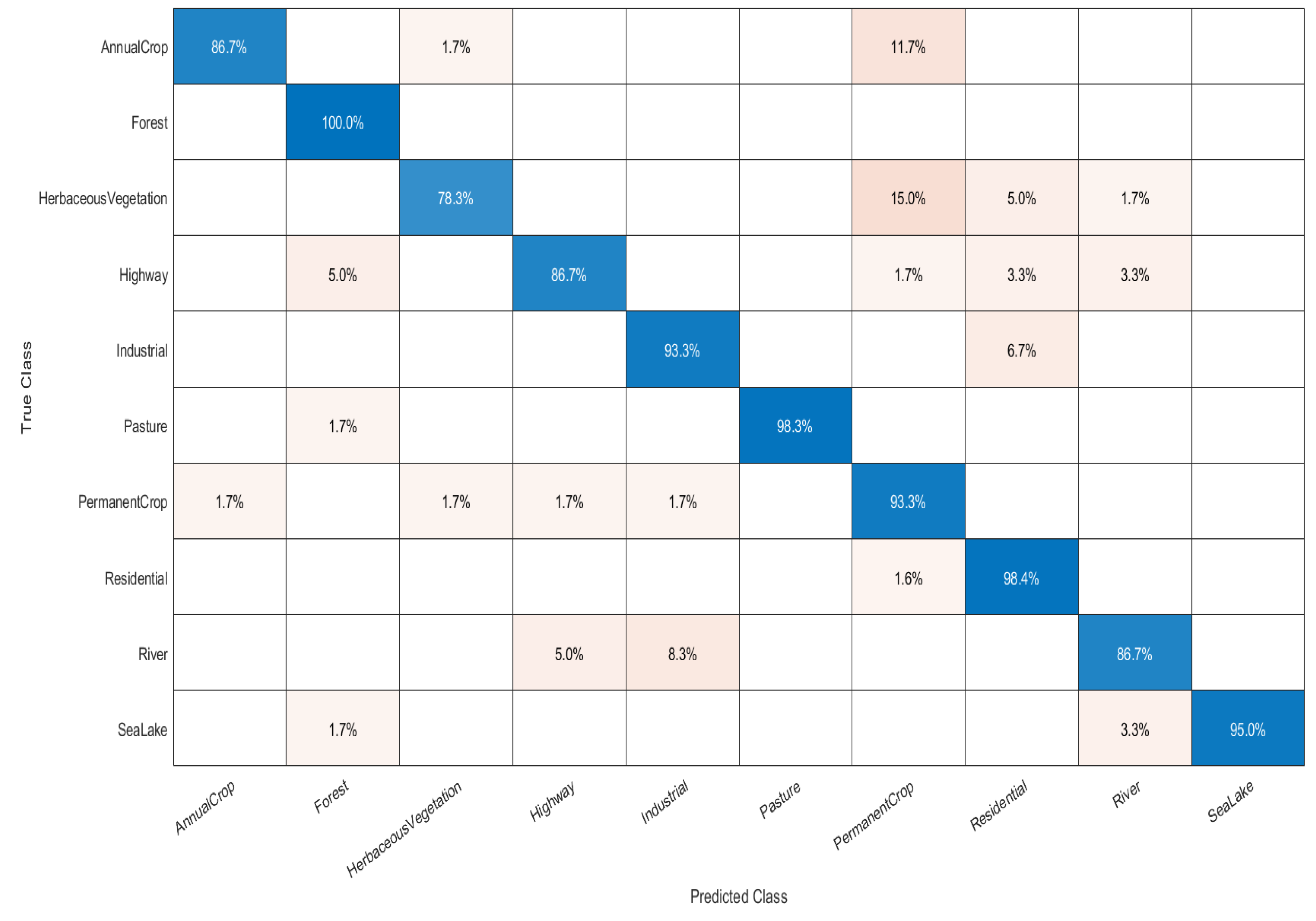
- The confusion matrix (CM) is a 2D matrix that gauges the detailed performance of classification models. The matrix measures the robustness of the models by computing inter-class and intra-class classification errors. Each row of the matrix represents the true class, while each column represents the predicted class. The value of each cell of the matrix gives insight into the degree of accuracy achieved by the classifier for a particular class.
- Precision, recall and F1 score are the popular metrics used to evaluate the performance of a classifier given the imbalanced data. Precision quantifies the ability of a model to precisely predict the class for the given samples that actually belong to the positive class. Precision can be measured as: , where C is the number of classes, and i represents the class. TP represents the true positive, and TN represents the true negative. The precision metric can be used to evaluate the performance of the model when the goal is to minimize the false positives.
- Recall, on the other hand, provides an indication to the missed positive prediction and can be mathematically expressed as: , where FN represents the false positive. The recall metric can be used as a performance measure where the goal of the model is to minimize the false negatives. The F1 score quantifies the performance of a model in a single metric by taking the harmonic mean of both precision and recall.
| Method | Overall Accuracy | ||
|---|---|---|---|
| UC Merced | Siri-WHU | Eurosat | |
| EfficientNet [77] | 88.00% | 83.88% | 85.23% |
| Wang et al. [78] | 94.81 % | - | - |
| MobileNet [75] | 93.00% | 92.63% | 87.52% |
| NSGA-II [79] | 79.17% | 72.14% | - |
| ResNet-50 [76] | 95.00% | 93.75% | 90.34% |
| MOEA [80] | 79.23% | 71.98% | - |
| ResNet-101 [76] | 95.00% | 93.14% | 90.51% |
| Yang et al. [81] | 93.67% | - | - |
| AR-MOEA [82] | 79.11% | 72.34% | - |
| ShuffleNet [83] | 91.00% | 92.08% | 88.68% |
| Basha et al. [84] | 88% | - | - |
| SMS-EMOA [85] | 78.45% | 73.02% | - |
| Shao et al. [86] | 92.38% | - | - |
| GoogleNet [70] | 94.00% | 91.11% | 88.51% |
| SKAL [22] | 97.95% | - | - |
| Proposed (Branch-1: DenseNet, Branch-2: VGG-16) | 96.00% | 94.16% | 91.68% |
| Proposed (Branch-1: DenseNet, Branch-2: DenseNet) | 99.52% | 96.37% | 94.75% |
5. Ablation Study
5.1. Ablation Study for Branch-1
- 1.
- Method M1: This method employs DenseNet in the Branch-1 network without a pyramid pooling module and VGG-16 in the Branch-2 network.
- 2.
- Method M2: This method utilizes DenseNet in the Branch-1 network with a pyramid module comprising a single max-pooling layer of size 1 × 1, while VGG-16 is employed in Branch-2 network.
- 3.
- Method M3: This method is similar to Method M2; however, instead of the max-pooling operation, the method employs an average pooling operation of size 1 × 1.
- 4.
- Method M4: This method employs DenseNet in the Branch-1 network and employs the pyramid pooling module with four different pooling sizes. The model employs 1 × 1, 2 × 2, 4 × 4, 8 × 8 pooling with max-pooling and uses VGG-16 as the backbone of the Branch-2 network.
- 5.
- Method M5 (proposed): This method is similar to Method M4; however, instead of using the max-pooling operation, it uses average pooling operations of sizes 1 × 1, 2 × 2, 4 × 4, 8 × 8.
- 6.
- Method M6 (proposed): This method is similar to Method M4; however, it uses DenseNet as the backbone in Branch-2.
- 7.
- Method M7 (proposed): This method is similar to Method M6; however, it employs average pooling operations instead of max-pooling.
5.2. Ablation Study for Branch-2
6. Discussion
Time Complexity
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dong, Z.; Wang, M.; Wang, Y.; Zhu, Y.; Zhang, Z. Object detection in high resolution remote sensing imagery based on convolutional neural networks with suitable object scale features. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2104–2114. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. Roadtracer: Automatic extraction of road networks from aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4720–4728. [Google Scholar]
- Khan, S.D.; Alarabi, L.; Basalamah, S. Deep Hybrid Network for Land Cover Semantic Segmentation in High-Spatial Resolution Satellite Images. Information 2021, 12, 230. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Khan, S.D.; Alarabi, L.; Basalamah, S. An Encoder–Decoder Deep Learning Framework for Building Footprints Extraction from Aerial Imagery. Arab. J. Sci. Eng. 2022, 48, 1273–1284. [Google Scholar] [CrossRef]
- Chiu, M.T.; Xu, X.; Wei, Y.; Huang, Z.; Schwing, A.G.; Brunner, R.; Khachatrian, H.; Karapetyan, H.; Dozier, I.; Rose, G.; et al. Agriculture-vision: A large aerial image database for agricultural pattern analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2828–2838. [Google Scholar]
- Khan, S.D.; Alarabi, L.; Basalamah, S. A unified deep learning framework of multi-scale detectors for geo-spatial object detection in high-resolution satellite images. Arab. J. Sci. Eng. 2021, 47, 9489–9504. [Google Scholar] [CrossRef]
- Lin, L.; Di, L.; Zhang, C.; Guo, L.; Di, Y. Remote Sensing of Urban Poverty and Gentrification. Remote Sens. 2021, 13, 4022. [Google Scholar] [CrossRef]
- Kazemzadeh-Zow, A.; Darvishi Boloorani, A.; Samany, N.N.; Toomanian, A.; Pourahmad, A. Spatiotemporal modelling of urban quality of life (UQoL) using satellite images and GIS. Int. J. Remote Sens. 2018, 39, 6095–6116. [Google Scholar] [CrossRef]
- Hoque, M.A.A.; Phinn, S.; Roelfsema, C.; Childs, I. Tropical cyclone disaster management using remote sensing and spatial analysis: A review. Int. J. Disaster Risk Reduct. 2017, 22, 345–354. [Google Scholar] [CrossRef]
- Zhao, B.; Dai, Q.; Zhuo, L.; Zhu, S.; Shen, Q.; Han, D. Assessing the potential of different satellite soil moisture products in landslide hazard assessment. Remote Sens. Environ. 2021, 264, 112583. [Google Scholar] [CrossRef]
- Murray, N.J.; Keith, D.A.; Bland, L.M.; Ferrari, R.; Lyons, M.B.; Lucas, R.; Pettorelli, N.; Nicholson, E. The role of satellite remote sensing in structured ecosystem risk assessments. Sci. Total. Environ. 2018, 619, 249–257. [Google Scholar] [CrossRef]
- Mahato, S.; Pal, S. Groundwater potential mapping in a rural river basin by union (OR) and intersection (AND) of four multi-criteria decision-making models. Nat. Resour. Res. 2019, 28, 523–545. [Google Scholar] [CrossRef]
- Raeva, P.L.; Šedina, J.; Dlesk, A. Monitoring of crop fields using multispectral and thermal imagery from UAV. Eur. J. Remote Sens. 2019, 52, 192–201. [Google Scholar] [CrossRef]
- Yu, J.; Guo, P.; Chen, P.; Zhang, Z.; Ruan, W. Remote sensing image classification based on improved fuzzy c-means. Geo-Spat. Inf. Sci. 2008, 11, 90–94. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Hierarchical coding vectors for scene level land-use classification. Remote Sens. 2016, 8, 436. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Dalla Mura, M.; Rakotomamonjy, A.; Flamary, R. Automatic feature learning for spatio-spectral image classification with sparse SVM. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6062–6074. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Moustakidis, S.; Mallinis, G.; Koutsias, N.; Theocharis, J.B.; Petridis, V. SVM-based fuzzy decision trees for classification of high spatial resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2011, 50, 149–169. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; p. 25. [Google Scholar]
- Anwar, A.; Anwar, H.; Anwar, S. Towards Low-Cost Classification for Novel Fine-Grained Datasets. Electronics 2022, 11, 2701. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, W.; Xiong, Z.; Li, X. Looking closer at the scene: Multiscale representation learning for remote sensing image scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1414–1428. [Google Scholar] [CrossRef]
- Liang, G.; Hong, H.; Xie, W.; Zheng, L. Combining convolutional neural network with recursive neural network for blood cell image classification. IEEE Access 2018, 6, 36188–36197. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yu, C.; Yang, N.; Cai, W. Multi-feature fusion: Graph neural network and CNN combining for hyperspectral image classification. Neurocomputing 2022, 501, 246–257. [Google Scholar] [CrossRef]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Nanni, L.; De Luca, E.; Facin, M.L.; Maguolo, G. Deep learning and handcrafted features for virus image classification. J. Imaging 2020, 6, 143. [Google Scholar] [CrossRef] [PubMed]
- Sandoval, C.; Pirogova, E.; Lech, M. Two-stage deep learning approach to the classification of fine-art paintings. IEEE Access 2019, 7, 41770–41781. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Deng, P. Remote sensing image scene classification based on global–local dual-branch structure model. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2013, 52, 439–451. [Google Scholar] [CrossRef]
- Dai, D.; Yang, W. Satellite image classification via two-layer sparse coding with biased image representation. IEEE Geosci. Remote Sens. Lett. 2010, 8, 173–176. [Google Scholar] [CrossRef]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Tao, C.; Zhu, H. Content-based high-resolution remote sensing image retrieval via unsupervised feature learning and collaborative affinity metric fusion. Remote Sens. 2016, 8, 709. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Risojević, V.; Babić, Z. Unsupervised quaternion feature learning for remote sensing image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1521–1531. [Google Scholar] [CrossRef]
- Li, Y.; Tao, C.; Tan, Y.; Shang, K.; Tian, J. Unsupervised multilayer feature learning for satellite image scene classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 157–161. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2175–2184. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J.; Guo, L.; Han, J. Auto-encoder-based shared mid-level visual dictionary learning for scene classification using very high resolution remote sensing images. IET Comput. Vis. 2015, 9, 639–647. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Li, H.; Gu, H.; Han, Y.; Yang, J. Object-oriented classification of high-resolution remote sensing imagery based on an improved colour structure code and a support vector machine. Int. J. Remote Sens. 2010, 31, 1453–1470. [Google Scholar] [CrossRef]
- Ren, J.; Jiang, X.; Yuan, J. Learning LBP structure by maximizing the conditional mutual information. Pattern Recognit. 2015, 48, 3180–3190. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2016, 10, 745–752. [Google Scholar] [CrossRef]
- Li, Z.; Itti, L. Saliency and gist features for target detection in satellite images. IEEE Trans. Image Process. 2010, 20, 2017–2029. [Google Scholar] [PubMed]
- Risojević, V.; Momić, S.; Babić, Z. Gabor descriptors for aerial image classification. In Proceedings of the International Conference on Adaptive and Natural Computing Algorithms, Ljubljana, Slovenia, 14–16 April 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 51–60. [Google Scholar]
- Zhao, L.; Tang, P.; Huo, L. A 2-D wavelet decomposition-based bag of visual words model for land-use scene classification. Int. J. Remote Sens. 2014, 35, 2296–2310. [Google Scholar] [CrossRef]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing local and global features for high-resolution scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Zhang, P.; Ke, Y.; Zhang, Z.; Wang, M.; Li, P.; Zhang, S. Urban land use and land cover classification using novel deep learning models based on high spatial resolution satellite imagery. Sensors 2018, 18, 3717. [Google Scholar] [CrossRef]
- Lv, Q.; Dou, Y.; Niu, X.; Xu, J.; Xu, J.; Xia, F. Urban land use and land cover classification using remotely sensed SAR data through deep belief networks. J. Sensors 2015, 2015, 1–10. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Scene classification using multi-scale deeply described visual words. Int. J. Remote Sens. 2016, 37, 4119–4131. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.; Dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Li, Y.; Shi, G. Multilayer feature fusion network for scene classification in remote sensing. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1894–1898. [Google Scholar] [CrossRef]
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating multilayer features of convolutional neural networks for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote sensing image scene classification using bag of convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Deng, P.; Li, Y. Deep feature aggregation framework driven by graph convolutional network for scene classification in remote sensing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 5751–5765. [Google Scholar] [CrossRef] [PubMed]
- Pradhan, B.; Al-Najjar, H.A.; Sameen, M.I.; Tsang, I.; Alamri, A.M. Unseen land cover classification from high-resolution orthophotos using integration of zero-shot learning and convolutional neural networks. Remote Sens. 2020, 12, 1676. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B. Integrated technique of segmentation and classification methods with connected components analysis for road extraction from orthophoto images. Expert Syst. Appl. 2021, 176, 114908. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A.M. An ensemble architecture of deep convolutional Segnet and Unet networks for building semantic segmentation from high-resolution aerial images. Geocarto Int. 2022, 37, 3355–3370. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Gite, S.; Alamri, A. Building footprint extraction from high resolution aerial images using generative adversarial network (GAN) architecture. IEEE Access 2020, 8, 209517–209527. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; p. 27. [Google Scholar]
- Nneji, G.U.; Cai, J.; Deng, J.; Monday, H.N.; Hossin, M.A.; Nahar, S. Identification of diabetic retinopathy using weighted fusion deep learning based on dual-channel fundus scans. Diagnostics 2022, 12, 540. [Google Scholar] [CrossRef]
- Atitallah, S.B.; Driss, M.; Almomani, I. A novel detection and multi-classification approach for IoT-malware using random forest voting of fine-tuning convolutional neural networks. Sensors 2022, 22, 4302. [Google Scholar] [CrossRef]
- Noreen, N.; Palaniappan, S.; Qayyum, A.; Ahmad, I.; Imran, M.; Shoaib, M. A deep learning model based on concatenation approach for the diagnosis of brain tumor. IEEE Access 2020, 8, 55135–55144. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Xia, G.S.; Zhang, L. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 54, 2108–2123. [Google Scholar] [CrossRef]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Zhao, J.; Yao, R.; Liu, B.; Ma, D.; Zheng, Y. Multiobjective ResNet pruning by means of EMOAs for remote sensing scene classification. Neurocomputing 2020, 381, 298–305. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Wang, E.K.; Li, Y.; Nie, Z.; Yu, J.; Liang, Z.; Zhang, X.; Yiu, S.M. Deep fusion feature based object detection method for high resolution optical remote sensing images. Appl. Sci. 2019, 9, 1130. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Li, K.; Deb, K.; Zhang, Q.; Kwong, S. An evolutionary many-objective optimization algorithm based on dominance and decomposition. IEEE Trans. Evol. Comput. 2014, 19, 694–716. [Google Scholar] [CrossRef]
- Yang, M.Y.; Al-Shaikhli, S.; Jiang, T.; Cao, Y.; Rosenhahn, B. Bi-layer dictionary learning for remote sensing image classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3059–3062. [Google Scholar]
- Tian, Y.; Cheng, R.; Zhang, X.; Cheng, F.; Jin, Y. An indicator-based multiobjective evolutionary algorithm with reference point adaptation for better versatility. IEEE Trans. Evol. Comput. 2017, 22, 609–622. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Basha, S.; Vinakota, S.K.; Dubey, S.R.; Pulabaigari, V.; Mukherjee, S. Autofcl: Automatically tuning fully connected layers for handling small dataset. Neural Comput. Appl. 2021, 33, 8055–8065. [Google Scholar] [CrossRef]
- Beume, N.; Naujoks, B.; Emmerich, M. SMS-EMOA: Multiobjective selection based on dominated hypervolume. Eur. J. Oper. Res. 2007, 181, 1653–1669. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.S.; Liu, G. A hierarchical scheme of multiple feature fusion for high-resolution satellite scene categorization. In Proceedings of the International Conference on Computer Vision Systems, St. Petersburg, Russia, 16–18 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 324–333. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2147–2154. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]









| Dataset | UC Merced [38] | SIRI-WHU [38] | EuroSAT [73] |
|---|---|---|---|
| No. of categories | 21 | 12 | 10 |
| Images per category | 100 | 200 | 2000∼3000 |
| Image size (pixels) | 256 × 256 | 200 × 200 | 64 × 64 |
| Spatial resolution (meters) | 0.3 | 2 | 10 |
| Total images | 2100 | 2400 | 27,000 |
| Train percentage | 80 | 70 | 80 |
| Test percentage | 20 | 30 | 20 |
| Class Name | Precision | Recall | F1 Score |
|---|---|---|---|
| Agricultural | 100.00% | 100.00% | 100.00% |
| Airplane | 100.00% | 100.00% | 100.00% |
| Baseball Diamond | 100.00% | 93.33% | 96.55% |
| Beach | 100.00% | 100.00% | 100.00% |
| Buildings | 85.71% | 100.00% | 92.31% |
| Chaparral | 100.00% | 100.00% | 100.00% |
| Dense Residential | 88.46% | 76.67% | 82.14% |
| Forest | 96.77% | 100.00% | 98.36% |
| Freeway | 96.77% | 100.00% | 98.36% |
| Golf Course | 96.67% | 96.67% | 96.67% |
| Harbor | 96.77% | 100.00% | 98.36% |
| Intersection | 96.77% | 100.00% | 98.36% |
| Medium Residential | 92.59% | 83.33% | 87.72% |
| Mobile Home Park | 96.77% | 100.00% | 98.36% |
| Overpass | 96.77% | 100.00% | 98.36% |
| Parking Lot | 100.00% | 100.00% | 100.00% |
| River | 96.77% | 100.00% | 98.36% |
| Runway | 100.00% | 96.67% | 98.31% |
| Sparse Residential | 90.63% | 96.67% | 93.55% |
| Storage Tanks | 100.00% | 90.00% | 94.74% |
| Tennis Court | 100.00% | 96.67% | 98.31% |
| Class Name | Precision | Recall | F1 Score |
|---|---|---|---|
| Agriculture | 100.00% | 100.00% | 100.00% |
| Commercial | 93.65% | 98.33% | 95.93% |
| Harbor | 92.31% | 100.00% | 96.00% |
| Idle Land | 93.10% | 90.00% | 91.53% |
| Industrial | 98.33% | 98.33% | 98.33% |
| Meadow | 91.23% | 86.67% | 88.89% |
| Overpass | 100.00% | 100.00% | 100.00% |
| Park | 88.71% | 91.67% | 90.16% |
| Pond | 90.32% | 93.33% | 91.80% |
| Residential | 92.06% | 96.67% | 94.31% |
| River | 90.57% | 80.00% | 84.96% |
| Water | 100.00% | 95.00% | 97.44% |
| Class Name | Precision | Recall | F1-Score |
|---|---|---|---|
| Annual Crop | 98.11% | 86.67% | 92.04% |
| Forest | 92.31% | 100.00% | 96.00% |
| Herbaceous Vegetation | 95.92% | 78.33% | 86.24% |
| Highway | 92.86% | 86.67% | 89.66% |
| Industrial | 90.32% | 93.33% | 91.80% |
| Pasture | 100.00% | 98.33% | 99.16% |
| Permanent Crop | 75.68% | 93.33% | 83.58% |
| Residential | 86.96% | 98.36% | 92.31% |
| River | 91.23% | 86.67% | 88.89% |
| Sea Lake | 100.00% | 95.00% | 97.44% |
| Method | Branch-1 Network | Branch-2 Network | Pooling Size | Pooling Type | OA |
|---|---|---|---|---|---|
| M1 | DenseNet [62] | VGG-16 [68] | - | - | 89.95% |
| M2 | 1 × 1 | Max pooling | 91.64% | ||
| M3 | 1 × 1 | Avg pooling | 92.74% | ||
| M4 | [1 × 1, 2 × 2, 4 × 4, 8 × 8] | Max pooling | 95.28% | ||
| M5 (proposed) | [1 × 1, 2 × 2, 4 × 4, 8 × 8] | Avg pooling | 96.00% | ||
| M6 (proposed) | DenseNet [62] | [1 × 1, 2 × 2, 4 × 4, 8 × 8] | Max pooling | 97.89% | |
| M7 (proposed) | [1 × 1, 2 × 2, 4 × 4, 8 × 8] | Avg pooling | 99.52% |
| Region Proposal Strategy | Branch-2 Network | Overall Accuracy |
|---|---|---|
| RPN [88] | VGG16 | 93.45% |
| ZF | 92.98% | |
| AlexNet | 87.63% | |
| Selective Search [89] | VGG16 | 86.85% |
| ZF | 83.92% | |
| AlexNet | 79.24% | |
| Multibox [90] | VGG16 | 92.71% |
| ZF | 87.22% | |
| AlexNet | 84.26% | |
| Multiscale (Proposed) | VGG16 | 96.00% |
| DenseNet (Avg pooling) | 99.52% | |
| ZF | 94.75% | |
| AlexNet | 88.95% |
| Methods | Training Time (Hours) | Testing Time (Seconds) |
|---|---|---|
| DenseNet-baseline | 10.20 | 3.35 |
| ResNet-101 | 8.40 | 3.22 |
| MobileNet | 4.35 | 0.33 |
| EfficientNet | 12.50 | 3.15 |
| GoogleNet | 5.30 | 1.33 |
| Proposed (Branch-1: DenseNet, Branch-2: VGG-16) | 14.37 | 4.15 |
| Proposed (Branch-1: DenseNet, Branch-2: DenseNet) | 19.40 | 5.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, S.D.; Basalamah, S. Multi-Branch Deep Learning Framework for Land Scene Classification in Satellite Imagery. Remote Sens. 2023, 15, 3408. https://doi.org/10.3390/rs15133408
Khan SD, Basalamah S. Multi-Branch Deep Learning Framework for Land Scene Classification in Satellite Imagery. Remote Sensing. 2023; 15(13):3408. https://doi.org/10.3390/rs15133408
Chicago/Turabian StyleKhan, Sultan Daud, and Saleh Basalamah. 2023. "Multi-Branch Deep Learning Framework for Land Scene Classification in Satellite Imagery" Remote Sensing 15, no. 13: 3408. https://doi.org/10.3390/rs15133408
APA StyleKhan, S. D., & Basalamah, S. (2023). Multi-Branch Deep Learning Framework for Land Scene Classification in Satellite Imagery. Remote Sensing, 15(13), 3408. https://doi.org/10.3390/rs15133408