
Can a Hierarchical Classification of Sentinel-2 Data Improve Land Cover Mapping?



Abstract
:1. Introduction
2. Materials and Methods
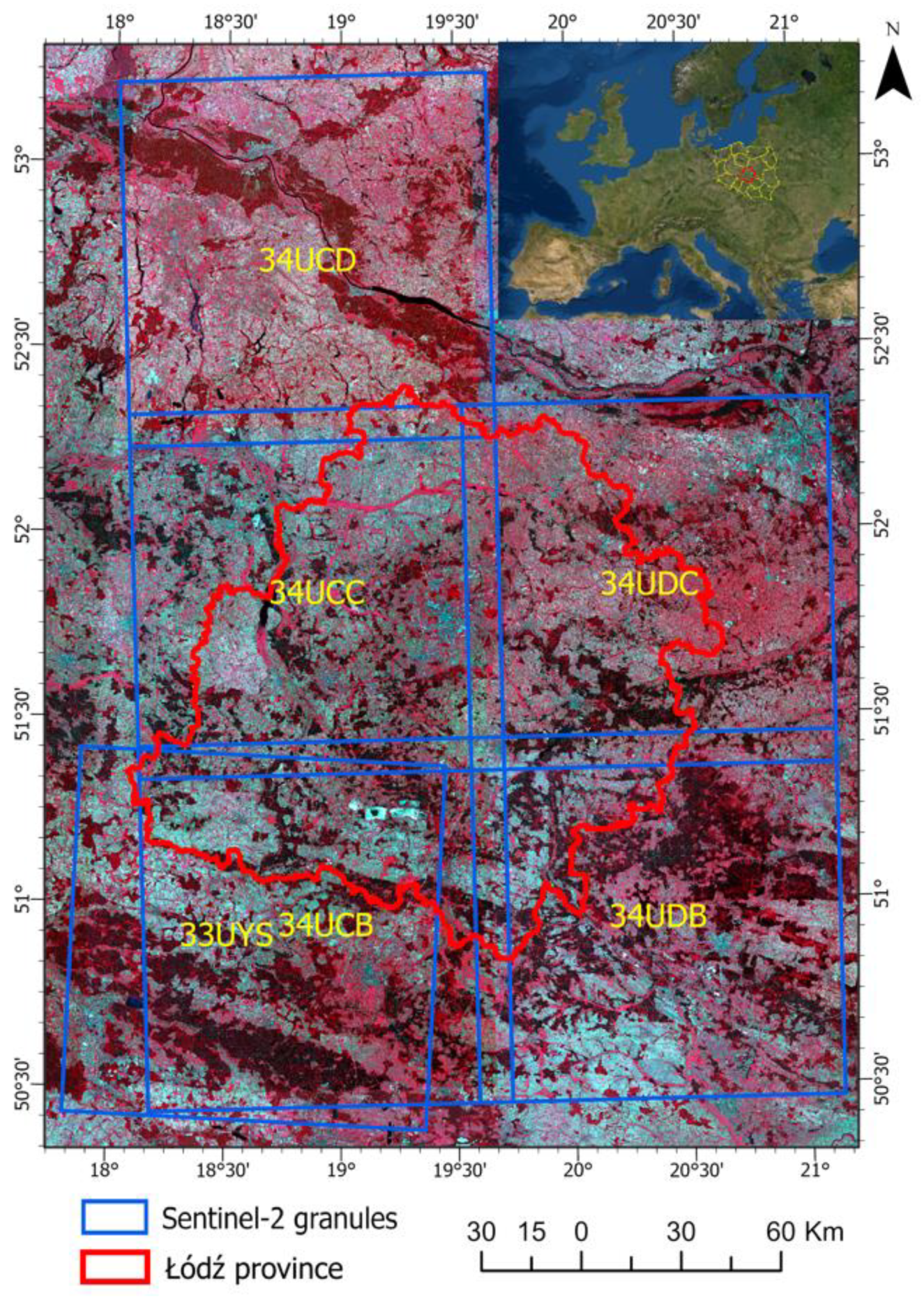
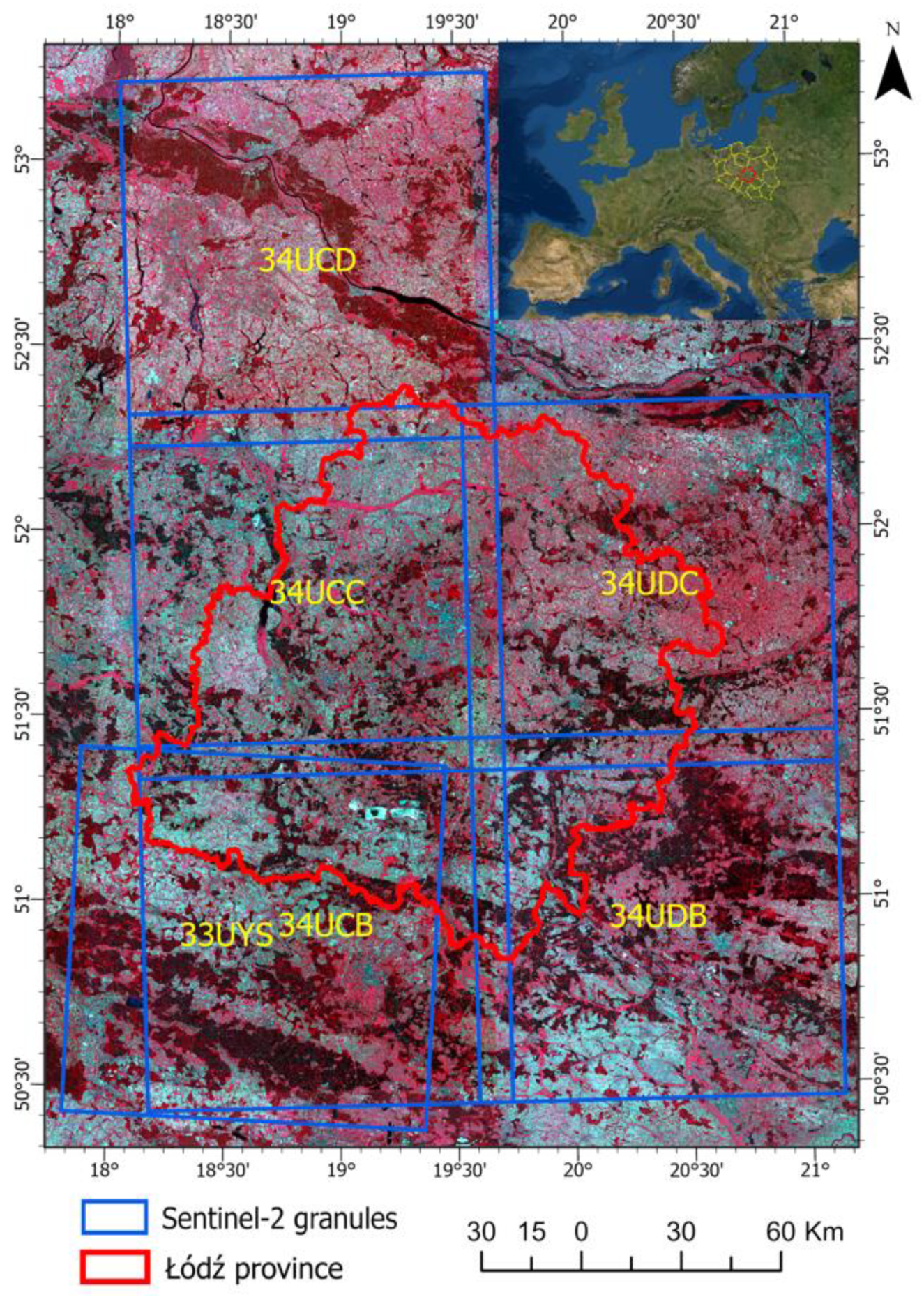
2.1. Study Area
2.2. Data
2.3. Reference Dataset
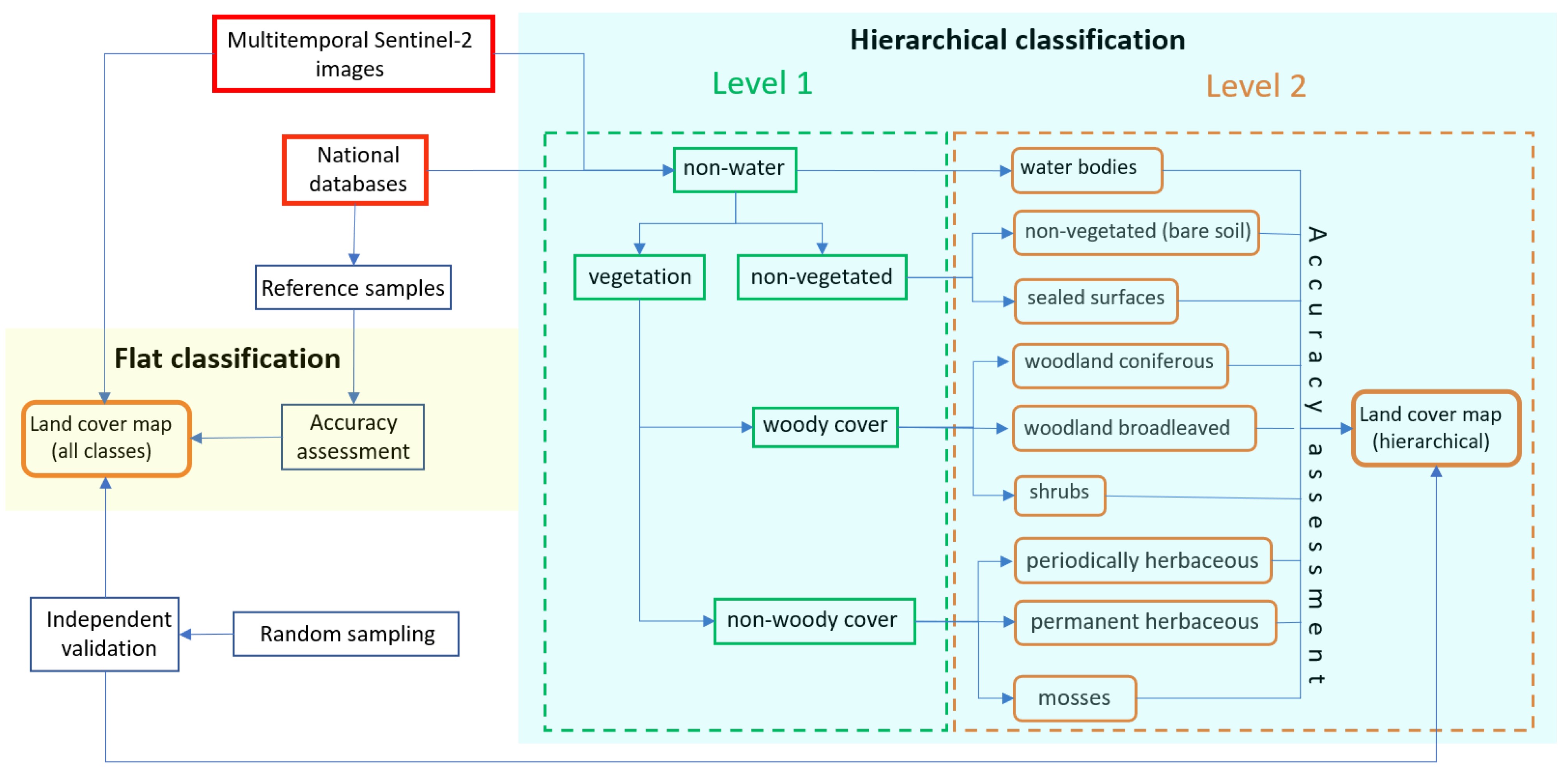
2.4. Methods
2.4.1. Random Forest (RF) Classification
2.4.2. Accuracy Assessment
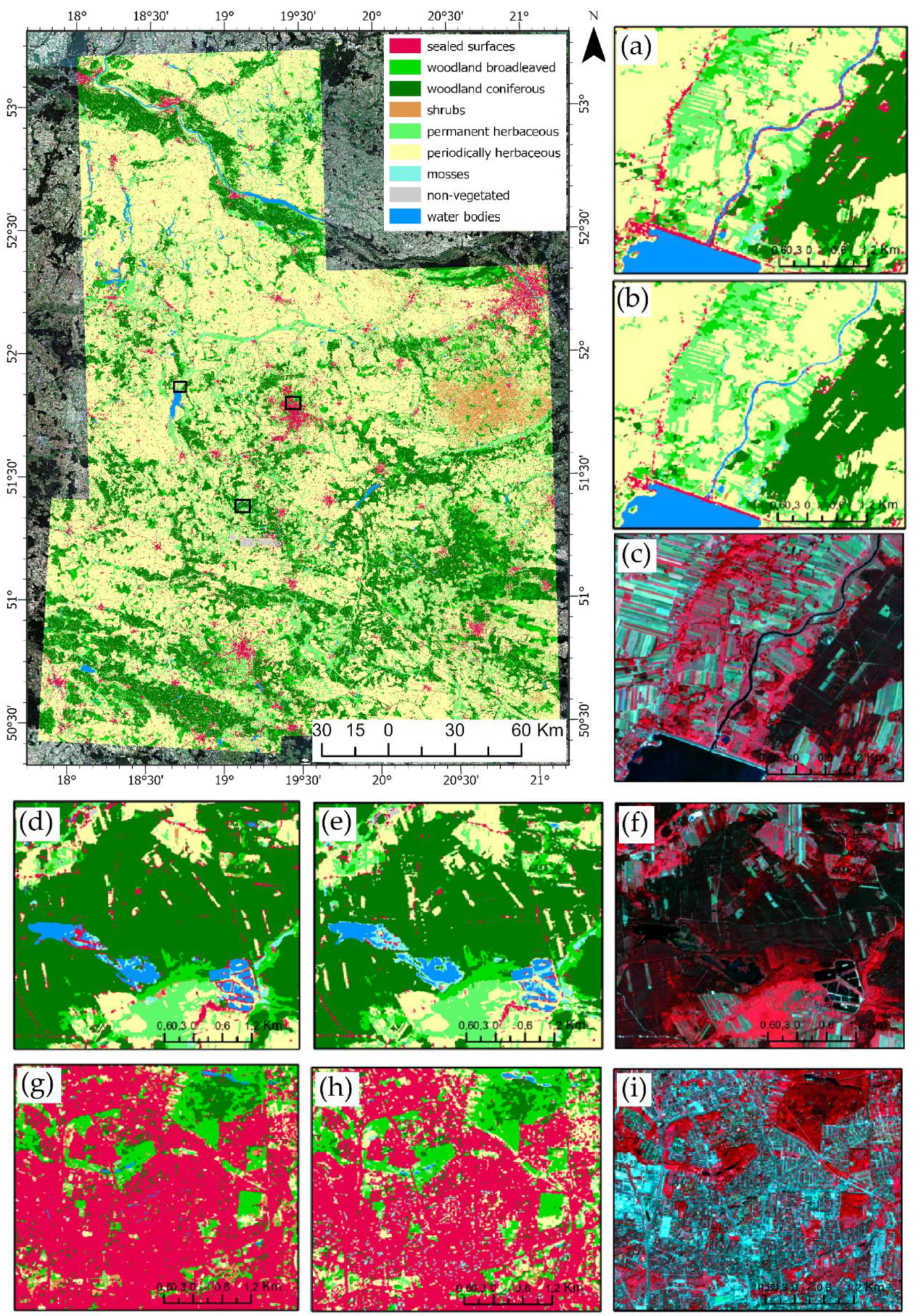
3. Results
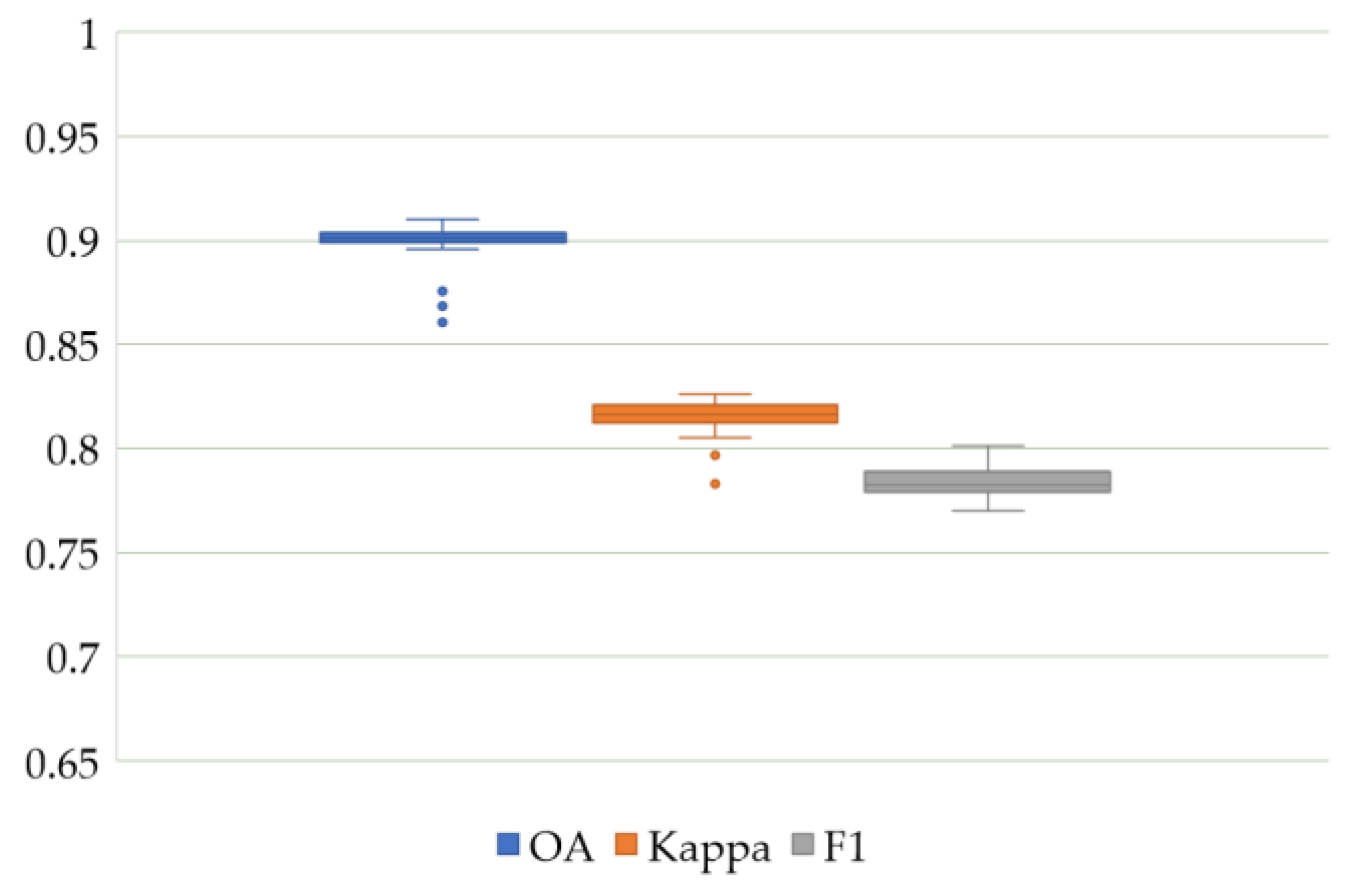
3.1. Flat Classification Accuracy
3.2. Hierarchical Classification Accuracy
3.3. Independent Verification of the Results of the Flat and Hierarchical Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohanrajan, S.N.; Loganathan, A.; Manoharan, P. Survey on Land Use/Land Cover (LU/LC) change analysis in remote sensing and GIS environment: Techniques and Challenges. Environ. Sci. Pollut. Res. 2020, 27, 29900–29926. [Google Scholar] [CrossRef] [PubMed]
- Mazzia, V.; Khaliq, A.; Chiaberge, M. Improvement in Land Cover and Crop Classification based on Temporal Features Learning from Sentinel-2 Data Using Recurrent-Convolutional Neural Network (R-CNN). Appl. Sci. 2020, 10, 238. [Google Scholar] [CrossRef] [Green Version]
- Borges, J.; Higginbottom, T.P.; Symeonakis, E.; Jones, M. Sentinel-1 and Sentinel-2 Data for Savannah Land Cover Mapping: Optimising the Combination of Sensors and Seasons. Remote Sens. 2020, 12, 3862. [Google Scholar] [CrossRef]
- Brovelli, M.A.; Sun, Y.; Yordanov, V. Monitoring Forest Change in the Amazon Using Multi-Temporal Remote Sensing Data and Machine Learning Classification on Google Earth Engine. ISPRS Int. J. Geo-Inf. 2020, 9, 580. [Google Scholar] [CrossRef]
- Häme, T.; Sirro, L.; Kilpi, J.; Seitsonen, L.; Andersson, K.; Melkas, T. A Hierarchical Clustering Method for Land Cover Change Detection and Identification. Remote Sens. 2020, 12, 1751. [Google Scholar] [CrossRef]
- Topaloglu, H.R.; Sertel, E.; Musaoglu, N. Assessment of classification accuracies of SENTINEL-2 and LANDSAT-8 data for land cover/use mapping. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 1055–1059. [Google Scholar] [CrossRef] [Green Version]
- Rujoiu-Mare, M.-R.; Olariu, B.; Mihai, B.-A.; Nistor, C.; Săvulescu, I. Land cover classification in Romanian Carpathians and Subcarpathians using multi-date Sentinel-2 remote sensing imagery. Eur. J. Remote Sens. 2017, 50, 496–508. [Google Scholar] [CrossRef] [Green Version]
- Jucker, T.; Caspersen, J.; Chave, J.; Antin, C.; Barbier, N.; Bongers, F.; Dalponte, M.; Van Ewijk, K.Y.; Forrester, D.I.; Haeni, M.; et al. Allometric equations for integrating remote sensing imagery into forest monitoring programmes. Glob. Chang. Biol. 2017, 23, 177–190. [Google Scholar] [CrossRef] [Green Version]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Randazzo, G.; Cascio, M.; Fontana, M.; Gregorio, F.; Lanza, S.; Muzirafuti, A. Mapping of Sicilian Pocket Beaches Land Use/Land Cover with Sentinel-2 Imagery: A Case Study of Messina Province. Land 2021, 10, 678. [Google Scholar] [CrossRef]
- Ye, J.; Hu, Y.; Zhen, L.; Wang, H.; Zhang, Y. Analysis on Land-Use Change and Its Driving Mechanism in Xilingol, China, during 2000–2020 Using the Google Earth Engine. Remote Sens. 2021, 13, 5134. [Google Scholar] [CrossRef]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing; Guilford Press: New York, NY, USA, 2011; Volume 5. [Google Scholar]
- Phiri, D.; Morgenroth, J. Developments in Landsat Land Cover Classification Methods: A Review. Remote Sens. 2017, 9, 967. [Google Scholar] [CrossRef] [Green Version]
- Da Ponte, E.; Mack, B.; Wohlfart, C.; Rodas, O.; Fleckenstein, M.; Oppelt, N.; Dech, S.; Kuenzer, C. Assessing Forest Cover Dynamics and Forest Perception in the Atlantic Forest of Paraguay, Combining Remote Sensing and Household Level Data. Forests 2017, 8, 389. [Google Scholar] [CrossRef] [Green Version]
- Waśniewski, A.; Hościło, A.; Zagajewski, B.; Moukétou-Tarazewicz, D. Assessment of Sentinel-2 Satellite Images and Random Forest Classifier for Rainforest Mapping in Gabon. Forests 2020, 11, 941. [Google Scholar] [CrossRef]
- Hościło, A.; Lewandowska, A. Mapping Forest Type and Tree Species on a Regional Scale Using Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 929. [Google Scholar] [CrossRef] [Green Version]
- Fagan, M.; Defries, R.; Sesnie, S.; Arroyo-Mora, J.; Soto, C.; Singh, A.; Townsend, P.; Chazdon, R. Mapping Species Composition of Forests and Tree Plantations in Northeastern Costa Rica with an Integration of Hyperspectral and Multitemporal Landsat Imagery. Remote Sens. 2015, 7, 5660–5696. [Google Scholar] [CrossRef] [Green Version]
- Robertson, L.D.; King, D. Comparison of pixel- and object-based classification in land cover change mapping. Int. J. Remote Sens. 2013, 32, 1505–1529. [Google Scholar] [CrossRef]
- ESA. Sentinel-2 Missions-Sentinel Online; ESA: Paris, France. Available online: https://sentinel.esa.int/web/sentinel/missions/sentinel-2 (accessed on 9 January 2022).
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Forkuor, G.; Dimobe, K.; Serme, I.; Tondoh, J.E. Landsat-8 vs. Sentinel-2: Examining the added value of sentinel-2’s red-edge bands to land-use and land-cover mapping in Burkina Faso. GIScience Remote Sens. 2018, 55, 331–354. [Google Scholar] [CrossRef]
- Delegido, J.; Verrelst, J.; Alonso, L.; Moreno, J. Evaluation of Sentinel-2 Red-Edge Bands for Empirical Estimation of Green LAI and Chlorophyll Content. Sensors 2011, 11, 7063–7081. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.; Murayama, Y.; Ranagalage, M. Sentinel-2 Data for Land Cover/Use Mapping: A Review. Remote Sens. 2020, 12, 2291. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10 m 2020 v100; European Space Agency: Brussels, Belgium, 2021. [Google Scholar]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar] [CrossRef]
- Malinowski, R.; Lewiński, S.; Rybicki, M.; Gromny, E.; Jenerowicz, M.; Krupiński, M.; Nowakowski, A.; Wojtkowski, C.; Krupiński, M.; Krätzschmar, E.; et al. Automated Production of a Land Cover/Use Map of Europe Based on Sentinel-2 Imagery. Remote Sens. 2020, 12, 3523. [Google Scholar] [CrossRef]
- Olsen, J.B. Technical Specifications for Implementation of a New Land-Monitoring Concept Based on EAGLE. Public Consultation Document for CLC+ Core; European Environment Agency: Copenhagen, Denmark, 2020. [Google Scholar]
- Europe’s Eyes on Earth; Land Monitoring Service. CLC+. Available online: https://land.copernicus.eu/pan-european/clc-plus (accessed on 7 November 2021).
- Steinhausen, M.J.; Wagner, P.D.; Narasimhan, B.; Waske, B. Combining Sentinel-1 and Sentinel-2 data for improved land use and land cover mapping of monsoon regions. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 595–604. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Aghdam, H.H.; Heravi, E.J. Guide to Convolutional Neural Networks: A Practical Application to Traffic-Sign Detection and Classification; Springer Publishing Company, Incorporated: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Jamali, A. Evaluation and comparison of eight machine learning models in land use/land cover mapping using Landsat 8 OLI: A case study of the northern region of Iran. SN Appl. Sci. 2019, 1, 1448. [Google Scholar] [CrossRef] [Green Version]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Amani, M.; Brisco, B.; Afshar, M.; Mirmazloumi, S.M.; Mahdavi, S.; Mirzadeh, S.M.J.; Huang, W.; Granger, J. A generalized supervised classification scheme to produce provincial wetland inventory maps: An application of Google Earth Engine for big geo data processing. Big Earth Data 2019, 3, 378–394. [Google Scholar] [CrossRef]
- Dabija, A.; Kluczek, M.; Zagajewski, B.; Raczko, E.; Kycko, M.; Al-Sulttani, A.H.; Tardà, A.; Pineda, L.; Corbera, J. Comparison of Support Vector Machines and Random Forests for Corine Land Cover Mapping. Remote Sens. 2021, 13, 777. [Google Scholar] [CrossRef]
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an Operational System for Crop Type Map Production Using High Temporal and Spatial Resolution Satellite Optical Imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef] [Green Version]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-use/cover classification in a heterogeneous coastal landscape using RapidEye imagery: Evaluating the performance of random forest and support vector machines classifiers. Int. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar] [CrossRef]
- Nguyen, H.T.T.; Doan, T.M.; Tomppo, E.; McRoberts, R.E. Land Use/Land Cover Mapping Using Multitemporal Sentinel-2 Imagery and Four Classification Methods—A Case Study from Dak Nong, Vietnam. Remote Sens. 2020, 12, 1367. [Google Scholar] [CrossRef]
- Woznicki, S.A.; Baynes, J.; Panlasigui, S.; Mehaffey, M.; Neale, A. Development of a spatially complete floodplain map of the conterminous United States using random forest. Sci. Total Environ. 2019, 647, 942–953. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Clark, M.L. Comparison of simulated hyperspectral HyspIRI and multispectral Landsat 8 and Sentinel-2 imagery for multi-seasonal, regional land-cover mapping. Remote Sens. Environ. 2017, 200, 311–325. [Google Scholar] [CrossRef]
- Ghorbanian, A.; Kakooei, M.; Amani, M.; Mahdavi, S.; Mohammadzadeh, A.; Hasanlou, M. Improved land cover map of Iran using Sentinel imagery within Google Earth Engine and a novel automatic workflow for land cover classification using migrated training samples. ISPRS J. Photogramm. Remote Sens. 2020, 167, 276–288. [Google Scholar] [CrossRef]
- Whyte, A.; Ferentinos, K.P.; Petropoulos, G.P. A new synergistic approach for monitoring wetlands using Sentinels -1 and 2 data with object-based machine learning algorithms. Environ. Model. Softw. 2018, 104, 40–54. [Google Scholar] [CrossRef] [Green Version]
- Bobáľová, H.; Benová, A.; Kožuch, M. Hierarchical Object-Based Mapping of Urban Land Cover Using Sentinel-2 Data: A Case Study of Six Cities in Central Europe. PFG–J. Photogramm. Remote Sens. Geoinf. Sci. 2021, 89, 15–31. [Google Scholar] [CrossRef]
- Rahdari, V.; Soffianian, A.; Pourmanafi, S.; Mosadeghi, R.; Mohammadi, G.H. A hierarchical approach of hybrid image classification for land use and land cover mapping. Geogr. Pannonica 2018, 22, 30–39. [Google Scholar] [CrossRef] [Green Version]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image Classification with the Fisher Vector: Theory and Practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Avci, M. A Hierarchical classification of Landsat TM Imagery For Landcover Mapping. Int. Soc. Photogramm. Remote Sens. 2004, IV. [Google Scholar]
- Demirkan, D.; Koz, A.; Düzgün, H. Hierarchical classification of Sentinel 2-a images for land use and land cover mapping and its use for the Corine system. J. App. Remote Sens. 2020, 14, 026524. [Google Scholar] [CrossRef]
- Peña, J.; Gutiérrez, P.; Hervás-Martínez, C.; Six, J.; Plant, R.; López-Granados, F. Object-Based Image Classification of Summer Crops with Machine Learning Methods. Remote Sens. 2014, 6, 5019–5041. [Google Scholar] [CrossRef] [Green Version]
- Haest, B.; Vanden Borre, J.; Spanhove, T.; Thoonen, G.; Delalieux, S.; Kooistra, L.; Mücher, C.; Paelinckx, D.; Scheunders, P.; Kempeneers, P. Habitat Mapping and Quality Assessment of NATURA 2000 Heathland Using Airborne Imaging Spectroscopy. Remote Sens. 2017, 9, 266. [Google Scholar] [CrossRef] [Green Version]
- Freeman, E.A.; Moisen, G.G.; Coulston, J.W.; Wilson, B.T. Random forests and stochastic gradient boosting for predicting tree canopy cover: Comparing tuning processes and model performance. Can. J. For. Res. 2016, 46, 323–339. [Google Scholar] [CrossRef] [Green Version]
- Kleeschulte, S.; Banko, G.; Smith, G.; Arnold, S.; Scholz, J.; Kosztra, B.; Maucha, G. Maucha Technical Specifications for Implementation of a New Land-Monitoring Concept Based on EAGLE. D3: Draft Design Concept and CLC-Backbone, CLC-Core Technical Specifications, Including Requirements Review; European Environment Agency: Copenhagen, Denmark, 2017; p. 79. [Google Scholar]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Lesiv, M.; Li, L.; Tsendbazar, N.E. ESA WorldCover 10 m 2020 v1. Product User Manual; European Space Agency: Brussels, Belgium, 2020. [Google Scholar]
- BDL. Bank Danych o Lasach. Available online: https://www.bdl.lasy.gov.pl/portal/opis-bdl (accessed on 3 September 2021).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Jiao, L.; Sun, W.; Yang, G.; Ren, G.; Liu, Y. A Hierarchical Classification Framework of Satellite Multispectral/Hyperspectral Images for Mapping Coastal Wetlands. Remote Sens. 2019, 11, 2238. [Google Scholar] [CrossRef] [Green Version]
- Europe’s Eyes on Earth. High Resolution Layers. Available online: https://land.copernicus.eu/pan-european/high-resolution-layers (accessed on 13 December 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Granule ID | 33UYS | 34UCB | 34UCC | 34UCD | 34UDB | 34UDC |
|---|---|---|---|---|---|---|
| Acquisition data | 2020-04-12 | 2020-04-12 | 2020-04-12 | 2020-04-05 | 2020-04-09 | 2020-04-07 |
| 2020-07-01 | 2020-07-01 | 2020-06-01 | 2020-05-15 | 2020-05-09 | 2020-05-09 | |
| 2020-07-31 | 2020-07-31 | 2020-07-01 | 2020-06-01 | 2020-07-01 | 2020-06-01 | |
| 2020-09-14 | 2020-09-09 | 2020-08-05 | 2020-08-05 | 2020-08-12 | 2020-07-01 | |
| 2020-09-14 | 2020-08-20 | 2020-09-14 | 2020-08-12 | |||
| 2020-09-22 | 2020-09-14 |
| Land Cover Class | Definition |
|---|---|
| Sealed surfaces | Land covered by buildings, roads and other human-made structures such as railroads. Buildings include both residential and industrial built-up areas. |
| Woodland broadleaved | Land cover dominated by trees with cover of 10% or more; 80% or more tree species should be broadleaved. |
| Woodland coniferous | Land cover dominated by trees with cover of 10% or more; 80% or more tree species should be coniferous. |
| Shrubs | Land cover includes area dominated by natural shrubs with cover of 10% or more. Shrubs are defined as woody perennial plants with persistent and woody stems. This class also includes orchards. |
| Permanent herbaceous | This class includes any geographic area dominated by natural herbaceous plants such as grasslands, pastures, any grassy covered areas. |
| Periodically herbaceous | Land covered with annual cropland that is sowed/planted and harvestable at least once within the 12 months after the sowing/planting date. |
| Mosses | Wetlands, peat bogs covered by mosses, lichens that are permanently or regularly flooded. |
| Non-vegetated | Lands with exposed bare soil, sand or rocks with less than 10% vegetation. |
| Water | This class includes area covered by water for most of the year such as: lakes, ponds, and rivers. |
| 33UYS | 34UCB | 34UCC | 34UCD | 34UDB | 34UDC | |
|---|---|---|---|---|---|---|
| Sealed surfaces | 1084 | 934 | 923 | 670 | 665 | 1089 |
| Woodland broadleaved | 830 | 609 | 426 | 672 | 630 | 553 |
| Woodland coniferous | 3682 | 2738 | 2997 | 2462 | 3447 | 2925 |
| Shrubs | 200 | 239 | 474 | 702 | 652 | 1962 |
| Permanent herbaceous | 1587 | 1766 | 1736 | 2767 | 1379 | 1426 |
| Periodically herbaceous | 11,665 | 10,998 | 13,119 | 11,811 | 10,320 | 11,584 |
| Mosses | 200 | 200 | 205 | 357 | 200 | 200 |
| Non-vegetated | 754 | 649 | 218 | 265 | 211 | 231 |
| Water | 449 | 231 | 675 | 1058 | 380 | 713 |
| Sum | 20,451 | 18,364 | 20,773 | 20,764 | 17,884 | 20,683 |
| Land Cover Classes | UA | PA | F1 |
|---|---|---|---|
| sealed surfaces | 0.63–0.82 | 0.79–0.82 | 0.72–0.83 |
| woodland broadleaved | 0.77–0.89 | 0.76–0.83 | 0.77–0.84 |
| woodland coniferous | 0.94–0.99 | 0.92–0.98 | 0.94–0.98 |
| shrubs | 0.15–0.74 | 0.38–0.77 | 0.25–0.76 |
| permanent herbaceous | 0.65–0. 80 | 0.73–0.81 | 0.69–0.80 |
| periodically herbaceous | 0.94–0.96 | 0.90–0.94 | 0.92–0.95 |
| mosses | 0.32–0.67 | 0.55–0.79 | 0.40–0.73 |
| non-vegetated (bare soil) | 0.18–0.76 | 0.50–0.89 | 0.26–0.80 |
| water bodies | 0.90–0.99 | 0.92–0.99 | 0.92–0.99 |
| OA | Kappa | F1 | ||
|---|---|---|---|---|
| Level 1 | non-water/water bodies | 0.99–1.00 | 0.93–0.99 | 0.96–1.00 |
| vegetation/non-vegetated | 0.97–0.98 | 0.70–0.79 | 0.85–0.90 | |
| woody cover/non-woody cover | 0.95–0.99 | 0.86–0.97 | 0.92–0.99 | |
| Level 2 | sealed surfaces, non-vegetated (bare soil) | 0.92–0.97 | 0.56–0.85 | 0.78–0.92 |
| woodland coniferous, woodland broadleaved, shrubs | 0.94–0.99 | 0.86–0.97 | 0.88–0.99 | |
| permanent herbaceous, periodically herbaceous, mosses | 0.93–0.99 | 0.68–0.79 | 0.77–0.87 |
| Land Cover Class | Sealed Surfaces | Woodland Broadleaved | Woodland Coniferous | Shrubs | Permanent Herbaceous | Periodically Herbaceous | Mosses | Non-Vegetated (Bare Soil) | Water Bodies | PA |
|---|---|---|---|---|---|---|---|---|---|---|
| Sealed surfaces | 37|46 | 1|1 | 3|0 | 1|0 | 5|2 | 1|0 | 1|0 | 0|1 | 1|0 | 0.74|0.92 |
| Woodland broadleaved | 0|0 | 37|44 | 8|3 | 4|3 | 0|0 | 0|0 | 1|0 | 0|0 | 0|0 | 0.74|0.88 |
| Woodland coniferous | 0|0 | 1|0 | 44|50 | 3|0 | 0|0 | 1|0 | 0|0 | 1|0 | 0|0 | 0.88|1.00 |
| Shrubs | 0|0 | 6|10 | 1|0 | 35|39 | 2|1 | 3|0 | 3|0 | 0|0 | 0|0 | 0.70|0.78 |
| Permanent herbaceous | 0|1 | 0|1 | 0|0 | 3|4 | 46|42 | 0|2 | 1|0 | 0|0 | 0|0 | 0.92|0.84 |
| Periodically herbaceous | 0|1 | 0|4 | 1|1 | 0|4 | 9|4 | 40|35 | 0|0 | 0|1 | 0|0 | 0.80|0.70 |
| Mosses | 0|0 | 0|2 | 1|1 | 6|5 | 7|1 | 2|2 | 32|37 | 0|0 | 1|2 | 0.64|0.74 |
| Non-vegetated (bare soil) | 10|12 | 0|0 | 0|0 | 2|0 | 1|0 | 4|4 | 0|0 | 33|34 | 0|0 | 0.66|0.68 |
| Water bodies | 0|0 | 0|0 | 0|0 | 0|0 | 0|0 | 0|0 | 1|0 | 0|1 | 49|49 | 0.98|0.98 |
| UA | 0.79|0.77 | 0.80|0.71 | 0.76|0.91 | 0.65|0.71 | 0.66|0.84 | 0.78|0.81 | 0.82|1.00 | 0.97|0.92 | 0.96|0.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waśniewski, A.; Hościło, A.; Chmielewska, M. Can a Hierarchical Classification of Sentinel-2 Data Improve Land Cover Mapping? Remote Sens. 2022, 14, 989. https://doi.org/10.3390/rs14040989
Waśniewski A, Hościło A, Chmielewska M. Can a Hierarchical Classification of Sentinel-2 Data Improve Land Cover Mapping? Remote Sensing. 2022; 14(4):989. https://doi.org/10.3390/rs14040989
Chicago/Turabian StyleWaśniewski, Adam, Agata Hościło, and Milena Chmielewska. 2022. "Can a Hierarchical Classification of Sentinel-2 Data Improve Land Cover Mapping?" Remote Sensing 14, no. 4: 989. https://doi.org/10.3390/rs14040989
APA StyleWaśniewski, A., Hościło, A., & Chmielewska, M. (2022). Can a Hierarchical Classification of Sentinel-2 Data Improve Land Cover Mapping? Remote Sensing, 14(4), 989. https://doi.org/10.3390/rs14040989