1. Introduction
Land use information is critical for understanding complex human–environment relationships and promoting human socioeconomic development, such as environmental change [
1], ecosystem deterioration [
2], and urban planning [
3]. There is a tremendous demand for land use mapping for sustainable urban development in this era of rapid urbanization and population growth. However, land use, in contrast to land cover, is more difficult to distinguish. Land cover can be directly identified from images as it relates to the physical characteristics of the ground surface [
4], while land use reflects the socio-economic activities that take place on that surface. A land use unit may comprise a variety of diverse land cover types, resulting in dramatic differences in spatial arrangement and spectral characteristics, even in a homogeneous land use region [
5]. Thus, it is challenging to obtain reliable land use segmentation using low-level image features, such as spectral and textural features. Meanwhile, information about land use is implicitly provided as patterns or high-level semantic functions in very fine spatial resolution (VFSR) satellite images [
6]. Hence, it is essential to extract high-level semantic features from detailed images for accurate land use segmentation.
The topological relations among land cover elements are beneficial for narrowing the semantic gap between land cover and land use [
7,
8,
9]. Topological relations can describe the complicated spatial configuration of land cover objects, which are beneficial for land use identification. This assumption is built on the fact that land use parcels with similar structures tend to possess similar functional attributes [
5]. From another perspective, accurate land use segmentation necessitates a thorough understanding of complex urban structures. This structure is a global perception of urban areas, which is built on the long-range dependencies of land cover units. According to the perceptual organization theory, humans group visual objects together to recognize the visual as a whole, where topological relations play an important role in the grouping process.
The positive effects of topological relations can be illustrated by the application of urban park segmentation. Urban parks (hereinafter referred to as parks) are designated areas of natural, semi-natural, or planted space inside cities for human recreation. There are usually multiple land cover types inside a park unit, such as water, buildings, and forest. Thus, the spectral feature distribution of park pixels is irregular and difficult to distinguish. For instance, a building area in a park is easily recognized as non-park because most buildings do not appear in parks. Land cover data are advantageous for solving this problem, as topological relations can be better depicted. For example, a building surrounded by forests is more likely to belong to a park than one surrounded by buildings. As a result, land use segmentation can be further improved by the topological relation inference using land cover data. Meanwhile, land cover classification is one of the most fundamental tasks in remote sensing [
10]. There are many well-known public land cover products available, such as GlobeLand30 [
11], Finer Resolution Observation and Monitoring of Global Land Cover (FROM-GLC) [
12], and ESA’s Land Cover Climate Change Initiative (LC-CCI). Therefore, an appealing idea is to use land cover to support land use segmentation, and models capable of effectively extracting topological relationships are required.
In recent decades, many investigations have been conducted to improve the accuracy of land use segmentation. These approaches can be generally divided into two categories regarding the use of spatial information: grid-based and object-based. Grid-based algorithms learn image representation from regular regions, and the most basic strategy is to use only spectral characteristics for pixel-wise segmentation. Researchers have tried to increase the size of grids to get spatial context features since pixel-wise methods fail to describe the spatial structure of land use. The most successful design among them are deep CNNs, as CNNs provide a powerful framework for local pattern modeling by end-to-end and hierarchical learning. Many attempts have been made to better exploit spatial information. Dilated convolutions are exploited to enlarge receptive fields [
13]. Local features are enhanced with a global context vector obtained by global pooling [
14]. A pyramid pooling module was employed to collect semantic features [
15,
16], and on this basis, the atrous special pyramid pooling (ASPP) further incorporates the atrous algorithm [
17,
18,
19,
20]. It is worth mentioning that the use of spatial context boosts models’ performance and robustness. Thus, CNNs, such as fully convolutional network (FCN) [
21], U-net [
22], pyramid scene parsing network (PSPNet) [
15], and DeepLabv3 [
19] have achieved outstanding results in semantic segmentation. However, these models are highly inefficient in describing long-distance relationships because they are composed of the local operations of convolution and pooling [
23,
24].
It is preferable to depict relationships between objects rather than regular grids (the comparison can be seen in
Figure 1). On the one hand, interregional dependencies are of significantly longer range than those represented by local convolutions [
23]. On the other hand, objects and regions are of arbitrary shape in the real world, and object-based methods are more capable of describing the “reality” of human perception than pixel-level approaches [
25]. Furthermore, object-based techniques are more ideal for expressing topological relations among land cover objects inside a land use parcel, which, as mentioned before, is extremely beneficial for bridging the semantic gap between land cover and land use. As previous deep learning models are prepared for Euclidean data, complex topological relations among land cover objects are frequently neglected.
It is natural to consider graphs to explore relationships, because images can be easily converted into graphs with vertices and edges indicating image regions and their similarities. Graphs are a widely used data structure as well as a universal language for describing complex systems, and Euclidean data such as images (2D grids) can be regarded as instances of graphs. Graphs, which focus on relationships among objects rather than the attributes of individual objects [
26], have shown great expressive power in various domains, including social science [
27], protein–protein interaction networks [
28], and network biology [
29]. Subsequently, context modeling is typically postulated as an inference issue on graphs [
30]. In practice, the process of relation reasoning, i.e., context modeling, is realized by the aggregation of node information. The aggregation process depends on the graph structure, which is dominated by the topological relationships of geo-objects. Finally, a land use segmentation problem is converted into a node classification problem.
However, most current models are built on homogeneous graphs and fail to fully employ the rich semantic information of heterogeneous data. Recently, GCNs [
31] have received increasing attention for their ability to aggregate information by generalizing convolutions to graph-structure data. By employing GCNs on graphs transformed from images, relations among objects can be explicitly inferred along graph edges, and spatial structures can be better portrayed. For example, GCNs are used to model contextual structures in hyperspectral image classification problems [
32,
33,
34,
35]. In detail, GCNs are employed through graph reprojection [
23], in which vertex features are projected back to grid space based on region assignments. Then, the projected features are integrated (using operations such as addition) into the CNN feature maps. As mentioned above, it is suggested to accomplish land use segmentation with land cover data. However, these homogeneous graph-based approaches are severely limited in their ability to merge additional data. For instance, a co-occurrence matrix of node classes [
36] is employed in an implicit and inefficient way, and the use of coarse prediction maps [
37] ignores inter-class relationships and treats nodes of different classes equally.
Heterogeneous graphs [
38] are introduced to solve the aforementioned issues, which can appropriately infer land use from land cover. In a heterogeneous graph, the total number of node types and edge types is greater than two, whereas there is only one node type and one edge type in a homogeneous graph (see
Figure 1 for the difference).This work [
38] fully exploits the heterogeneity and rich semantic information embedded in the multiple node and edge types by using hierarchical attention, which consists of node-level and semantic-level attention. Specifically, the node and edge types are taken into consideration when aggregating features. Heterogeneous graphs are experts in portraying complex relationships among various classes of nodes. Thus, heterogeneous graph-based methods can better mine topological relations among different land cover nodes.
Our model is proposed based on heterogeneous graphs to bridge the semantic gap between land cover and land use. Specifically, in the case of park segmentation, there are
m node types and
edge types, where
m denotes the number of land cover types. Thus, we can build heterogeneous graphs with land cover data. It makes sense to define different edge calculation functions among the nodes of different land cover classes. For instance, reducing weights between road and forest objects is beneficial given that roads frequently appear outside parks. Moreover, the parameters of class-specific edge calculation functions are automatically learned, making the relation inference more adaptive. Similarly to the feature fusion framework [
32,
39], we integrate CNNs and our heterogeneous graph-based model to derive long-distance relationships among objects while preserving spatial details, since the shallow features of CNNs retain more spatial information. To this end, we propose the CNN-enhanced HEterogeneous Graph Convolutional Network(CHeGCN) for land use segmentation. The main distinction between CHeGCN and the existing models [
32,
39] is that CHeGCN is constructed on heterogeneous graphs, whereas these existing models are intended for homogeneous graphs and are thus unable to make use of extra data, such as land cover data. Furthermore, CHeGCN can also be easily degraded to situations without additional land cover data, which is detailed in ablation experiments.
Experiments have been conducted to show the capability of CHeGCN in land use segmentation, and visualization results reveal that land cover information can significantly improve the graph inference. It can be observed that the contributions of objects with various land cover labels are different by visualizing the weights of graph edges, which is consistent with our knowledge. The main contributions of our work are summarized as follows:
We propose a novel CHeGCN that fully explores the relations between land cover and land use. CHeGCN is able to infer and extract high-level semantic features based on the heterogeneous graphs, which can significantly improve land use segmentation. Furthermore, our model provides a general framework that can be applied not only to land cover and land use segmentation, but also to land use segmentation with additional land cover data;
CHeGCN is an early attempt to investigate heterogeneous graph neural networks in the field of remote sensing. CHeGCN is a good example of successfully exploiting heterogeneous data, which further strengthened the inference ability of graphs with additional data. This work may encourage the integration of other Earth observation products;
CHeGCN outperforms CNNs and homogeneous graph-based models in our park segmentation datasets, mainly owing to the incorporation of local spectral-spatial features and long-distance topological relationships. In particular, class-specific calculation functions of edge weight boost the representation of the topology of land cover objects within land use parcels.
3. Results
In the experiments, our proposed CHeGCN model is evaluated on our two park segmentation datasets. Six state-of-the-art deep learning approaches are compared with our method: FCN [
21], U-net [
22], PSPNet [
15], DeepLabv3 [
19], CNN-enhanced graph convolutional network (CEGCN) [
32], and global reasoning unit (GloRe unit) [
24]. Three metrics, overall accuracy (OA), kappa coefficient (Kappa), and intersection over union (IoU), are adopted to measure the performance of models. Since the Kappa and IoU can better describe the segmentation results, we will focus on them more in the following analysis. The mean and standard deviation of these three indicators are presented after each experiment is repeated five times. Finally, ablation experiments and visualization results are conducted to demonstrate the benefits brought by heterogeneous graphs, which are constructed with land cover data.
3.1. Dataset
We created two new land use segmentation datasets with two categories: park and non-park. Parks that are too large or too small are excluded, because topological relationships among land cover objects in a park area cannot be well expressed by fixed-size image blocks at the current resolution. For a large park, an image block cannot reflect the overall spatial structure of it. For a small park, land cover data are not sufficiently refined to support the segmentation of tiny regions. In the Beijing dataset, we selected 157 parks of appropriate size in Beijing, China. In the Shenzhen dataset, we selected 99 parks in Shenzhen, Guangdong province, China. Due to the different shapes of these parks, we cropped them into image blocks of size 256 × 256 to facilitate the subsequent process. These samples are then randomly split into training, validation, and test sets in a 4:1:1 ratio using parks as units, which prevents data leakage. Samples in these sets are evenly distributed across districts (see
Figure 3). Each sample has three components obtained in 2015: a VFSR image, a park label, and a land cover label.
The VFSR images with RGB bands come from Google Earth imagery. These images are at a zoom level of 16, with a resolution of 1.8 m for the Beijing dataset and 2.2 m for the Shenzhen dataset. They are cloud free after careful selection, and most of them were taken between July and September of 2015. To expand the dataset, we realized dataset augmentation through adaptively sliding windows with the premise of preserving the park’s integrity as much as possible. The augmented training dataset is abbreviated as “training-aug”. The distribution of samples in these two datasets can be seen in
Table 1 and
Table 2.
Park labels are made by manual correction on the basis of the OpenStreetMap (OSM) project and area of interest (AOI) data collected from Baidu Map. After reprojection and rasterization, the corrected park vector data are then transformed into raster labels. The land cover product, with a spatial resolution of 2 m, is generated from GF-1 data and contains 13 categories. By visual interpretation, we label unknown regions with the other 12 categories. Afterwards, these 12 categories (except the unknown class) are merged into five classes: grass, forest, buildings, road, and water. The class distribution of the processed land cover data is shown in
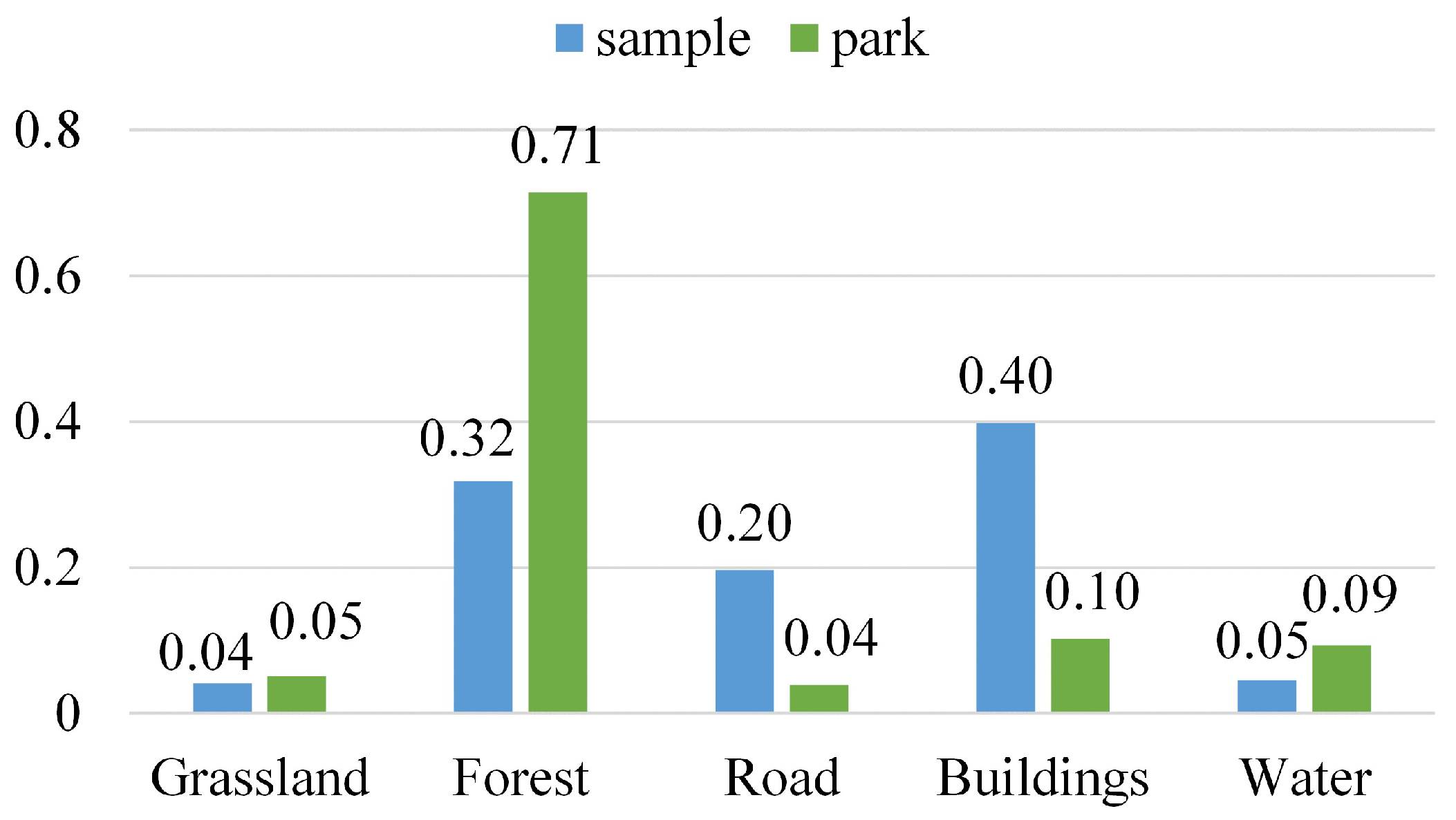
Figure 4. Blue bars indicate the distribution of samples in all areas, while green bars denote the distribution of park regions. It is worth noting that land cover labels are reprojected and resampled as the coordinate system and resolution of this product do not match images.
3.2. Hyperparameters Configuration
CHeGCN has four components: the CNN module, the heterogeneous graphs construction, the GCN module, and the classifier. The output dimensions of the CNN module are 32. The segment number
n and compactness
c of SLIC are set to 50 and 10, respectively. Parameter
n is the approximate number of segments, and
c balances the color proximity and space proximity. There are 3 layers each with 32 units in the GCN module. Each GCN layer is followed by a batch normalization [
49] layer and a ReLU activation layer. The fused feature maps are followed by a 1 × 1 convolutional layer, a softmax function, and the cross-entropy loss. We use the Adam optimizer [
50] to train CHeGCN for 130 epochs, with four examples per mini-batch. All hyperparameters are determined by the performance in the validation dataset, and the same hyperparameter configuration is used for both qualitative and quantitative results. Our code (Code is available at:
https://github.com/Liuzhizhiooo/CHeGCN-CNN_enhanced_Heterogeneous_Graph) is implemented with Python-3.6 and PyTorch-1.10.2 and is accessed on 6 October 2022.
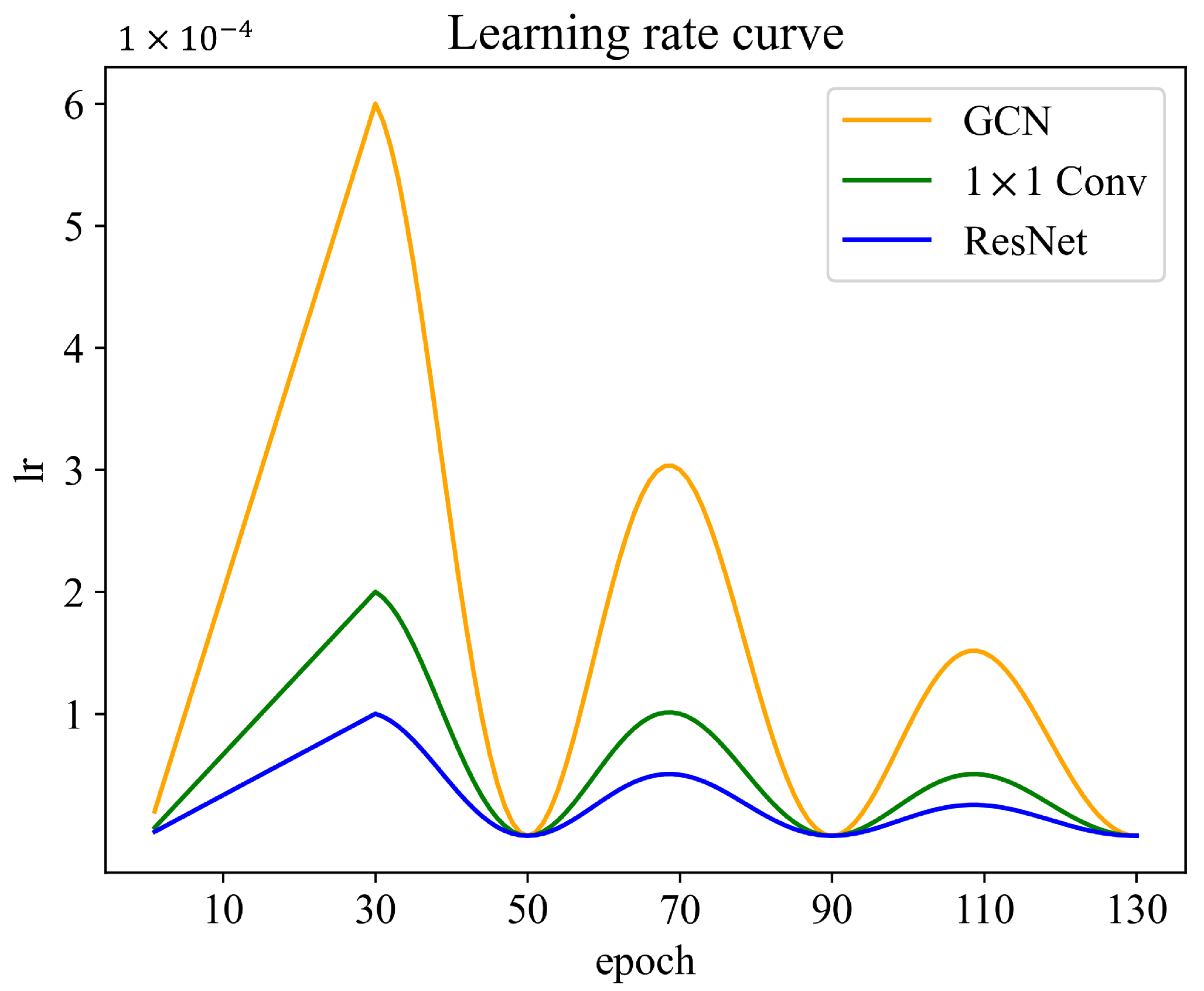
The learning rate (lr) parameters of modules should be different because the architectures of the CNN module and the GCN module are different. Meanwhile, the ResNet backbone is pretrained, thus the lr of it is set lower than convolutional layers that are used in dimension deduction and the classifier. Specifically, the maximum lr of the GCN module, the ResNet-18 backbone, and the 1 × 1 convolutional layers are
,
, and
, respectively. Furthermore, we adopt the warm-up strategy [
41], the cosine annealing warm restarts schedule [
51], and periodically decay the amplitude. The lr curves are shown in
Figure 5, and the lr schedule is formulated as Equation (
5):
where:
is the learning rate at current epoch t;
is the periodic decay factor and is set to ;
is the maximum learning rate of modules,
is a temporary variable and ;
is the number of epochs for warm-up and is set to 30;
T is the number of epochs between two warm restarts and is set to 20.
Figure 5.
Learning rate schedule, which combines the warm-up strategy, cosine annealing warm restarts schedule, and periodic decay. The maximum learning rates of different components in CHeGCN are different.
Figure 5.
Learning rate schedule, which combines the warm-up strategy, cosine annealing warm restarts schedule, and periodic decay. The maximum learning rates of different components in CHeGCN are different.
Moreover, the training details of these state-of-the-art models for comparison are as follows. The pretrained ResNet-18, with the last two down-sampling layers removed, serves as the backbone for FCN, PSPNet, DeepLabv3, and GloRe. All compared models adopt the learning rate schedule in Equation (
5) with
. We employ a heuristic strategy rather than grid search to determine the model structure and the hyperparameters because there are a lot of parameters in our model. Specifically, we first determine the model’s configuration, then the learning rate hyperparameters, and finally other parameters such as batch size and segmentation scale. All of these parameters are determined by the performance in the validation dataset. For some key parameters, such as model depth and segmentation scale, we conducted detailed experiments in the discussion section. It is worth noting that all quantitative metrics are obtained by the model with the maximum OA index on the validation dataset.
3.3. Comparison of Classification Performance
Table 3 and
Table 4 exhibit the segmentation scores (%) of CHeGCN and six state-of-the-art models in terms of OA, Kappa, and IoU in two datasets. Meanwhile, we show the qualitative segmentation results of all methods in
Figure 6.
In the Beijing dataset, our model performs the best and outperforms the second one by nearly 3.5% on the IoU metric. All CNNs achieve a similar performance, except U-net. Under the condition of limited samples, U-net behaves worse than other CNNs because it is trained from scratch. Meanwhile, we observe that the performance of the graph-based model CEGCN is unsatisfactory. This could be due to insufficient local spatial feature extraction. CEGCN is developed for hyperspectral images with abundant spectral information, which extracts pixel-level features. GloRe has a marginal improvement over CNNs, which benefits from the constructed long-distance relationships. However, GloRe builds graphs by applying convolutions to images, resulting in mismatches between nodes in interaction space and land cover units. Therefore, the improvement is not significant. Compared to GloRe, CHeGCN builds graphs based on land cover elements and achieves better performance.
Similarly to the previous dataset, the Shenzhen dataset demonstrates CHeGCN’s advantages over other models. CHeGCN outperforms CNNs (e.g., DeepLabv3) and homogeneous GCNs (e.g., GloRe) by approximately 5% on the Kappa and IoU indices. GloRe, on the other hand, performs worse than PSPNet and U-net, demonstrating its instability. The topological relationships among land cover units cannot be properly established since GloRe builds graphs on virtual nodes. In contrast, CHeGCN achieves stable improvement over CNNs.
We further display the qualitative segmentation results of several test samples in
Figure 6. CNNs and CEGCN tend to classify all forest and water pixels as parks (see sample 1), regardless of the topological positions of these pixels. Meanwhile, CNNs, CEGCN, and GloRe fail to treat park regions as a whole. They classify buildings in the marked area of sample 2 as non-park. CNNs ignore the narrow park area in sample 3 as pooling operations of deep CNN severely destroy the spatial structure. In contrast, CHeGCN removes the last four convolutional layers of ResNet-18 to extract shallow CNN features, which are beneficial for small object recognition. The same goes for samples 4 and 5, where the predictions of CNNs tend to be over-smoothed and blurred. The noisy results of CEGCN indicate its lack of spatial features. Comparatively, CHeGCN yields more accurate results.
3.4. Ablation Experiments
The improvement in the performance of CHeGCN model can be attributed to two factors: the heterogeneous graph-based reasoning and the pretrained CNN module. We designed the following experiments on the Beijing dataset to demonstrate the effectiveness of these factors. It is worth noting that hyperparameters in ablation experiments remain unchanged unless otherwise specified.
First, we conduct experiments to demonstrate the effectiveness of graph reasoning. We build a CNN model with the same structure as CHeGCN, except that the CNN model substitutes the GCN module with three convolutional layers. These layers have the same hidden units as the GCN layers. As a result, rows 3 and 5 in
Table 5 show that the GCN module plays an important role, improving the accuracy by nearly 3.5%, 8.5%, and 8.5% in terms of OA, Kappa, and IoU, respectively.
Furthermore, considering the situation in which there are no land cover data available, CHeGCN cannot use meta-path parameters to refine edge weights and degenerates to the CNN-enhanced HOmogeneous Graph Convolutional Network (CHoGCN). The sole difference from CHeGCN is that nodes in CHoGCN do not have land cover labels. Therefore, CHoGCN calculates the edge weights by (
1). Compared with CHeGCN, there is a performance drop (nearly 2.5% in Kappa and IoU) in CHoGCN. This suggests that heterogeneous graphs have a stronger inference capability than homogeneous graphs. Meanwhile, CHoGCN outperforms the CNN model, demonstrating the effectiveness of graph reasoning once again.
Moreover, CNN features boost the performance of graph-based models. We report the accuracy metrics of the HOmogeneous Graph Convolutional Network (HoGCN) and HEterogeneous Graph Convolutional Network (HeGCN), neither of which employs a CNN module. The differences between HeGCN and CHeGCN are the initialization of node features and feature fusion. Node features in HeGCN are the average spectral features in superpixels of the input image, whereas CHeGCN takes the mean value of the CNN module’s feature maps as node features. Moreover, HeGCN only employs the GCN output to classify without using CNN feature maps. The same goes for the differences between HoGCN and CHoGCN. The CNN module significantly improves the Kappa of HoGCN and HeGCN, as shown in
Table 5. Meanwhile, HeGCN outperforms HoGCN, which is consistent with the previous conclusion that land cover data are beneficial.
3.5. Visualization Analysis
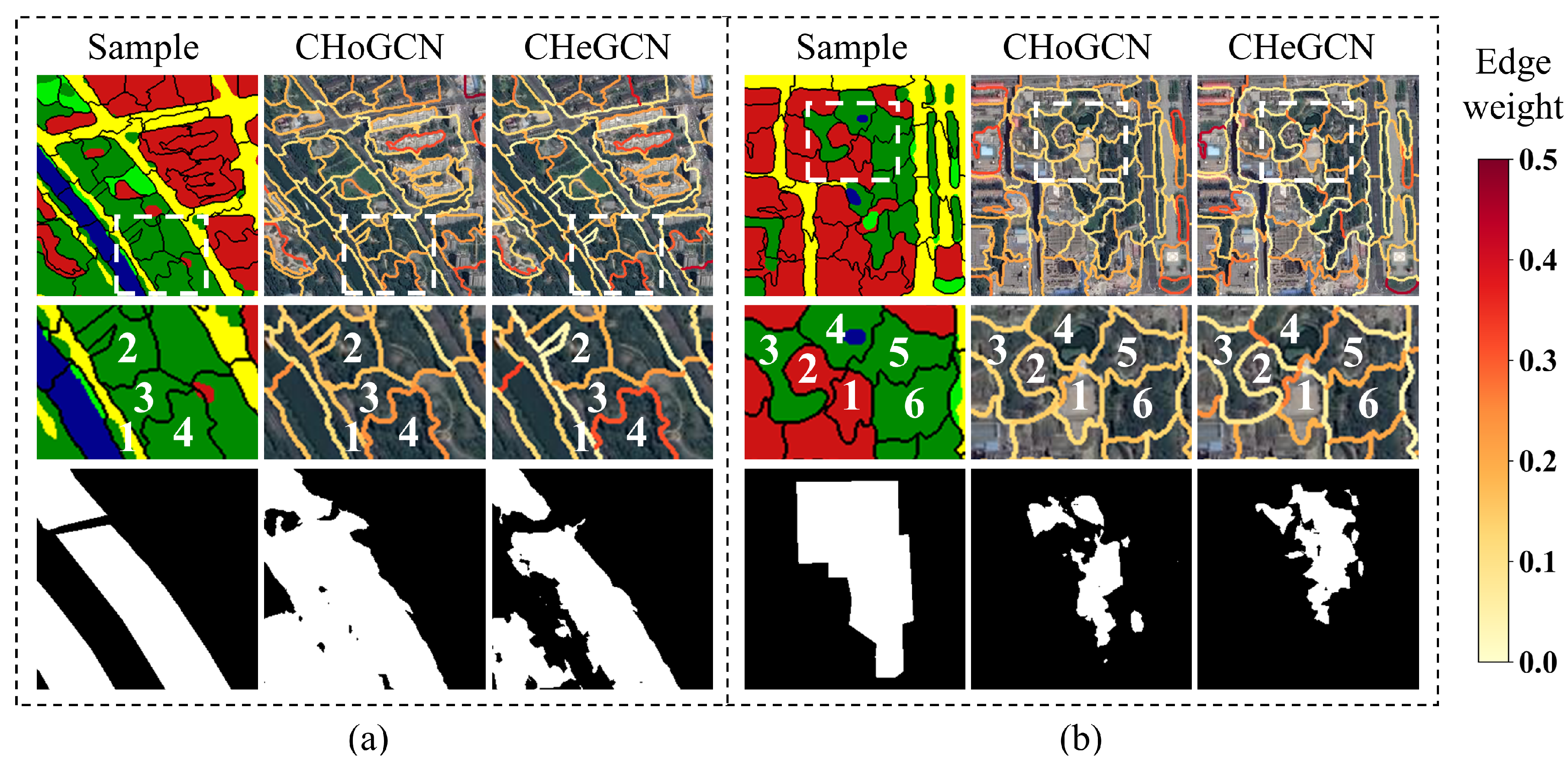
In this section, we analyze the underlying mechanism of CHeGCN. We visualize edge weights among adjacent land cover objects to observe topological relations among land cover objects in parks. CHoGCN is compared with the proposed CHeGCN to illustrate the advantages of heterogeneous graphs. Furthermore, we interpret segmentation results with meta-path parameters. We select two samples to show the edge weights and segmentation results of CHoGCN and CHeGCN in
Figure 7. The top row contains land cover data overlaid with superpixel boundaries, and the edge weights of models. The second row includes the zoomed-in views of the highlight boxes in the first row. The third row consists of the ground truth label, and the predictions of models.
As shown in
Figure 7a, CHoGCN misclassifies the road and water regions in the lower left of the image. Due to the improper selection of edge weights, the topological relationships are insufficiently constructed. As mentioned previously, roads generally form the boundaries of parks. This is consistent with land cover distribution statistics in
Figure 4, where the number of road pixels in parks is much less than that in all regions. However, the edge weight of CHoGCN between a road object and a forest object is high. Specifically, the edges between a road node (1) and forest nodes (2, 3, 4) in CHoGCN are high, which are orange-colored. This will reduce the interclass variance in the feature aggregation, leading to the false positive classification. CHeGCN decreases the edge weights (rendered in yellow) between road and forest objects, making these nodes further apart in the feature space.
Figure 7b shows another example. Because of inadequate use of neighboring information, CHoGCN incorrectly labels the building area in the park as non-park. CHeGCN reduces intraclass variance during feature aggregation to smooth local variations, which finally achieves global perception. In detail, the forest superpixels (nodes 3, 4, 5, 6) surrounding the building are more closely connected than those of CHoGCN, and the corresponding edges in CHeGCN tend to be red. As a result, the features of the building regions (nodes 1, 2) tend to be similar to those of their neighbors, making them easier to recognize as parks.
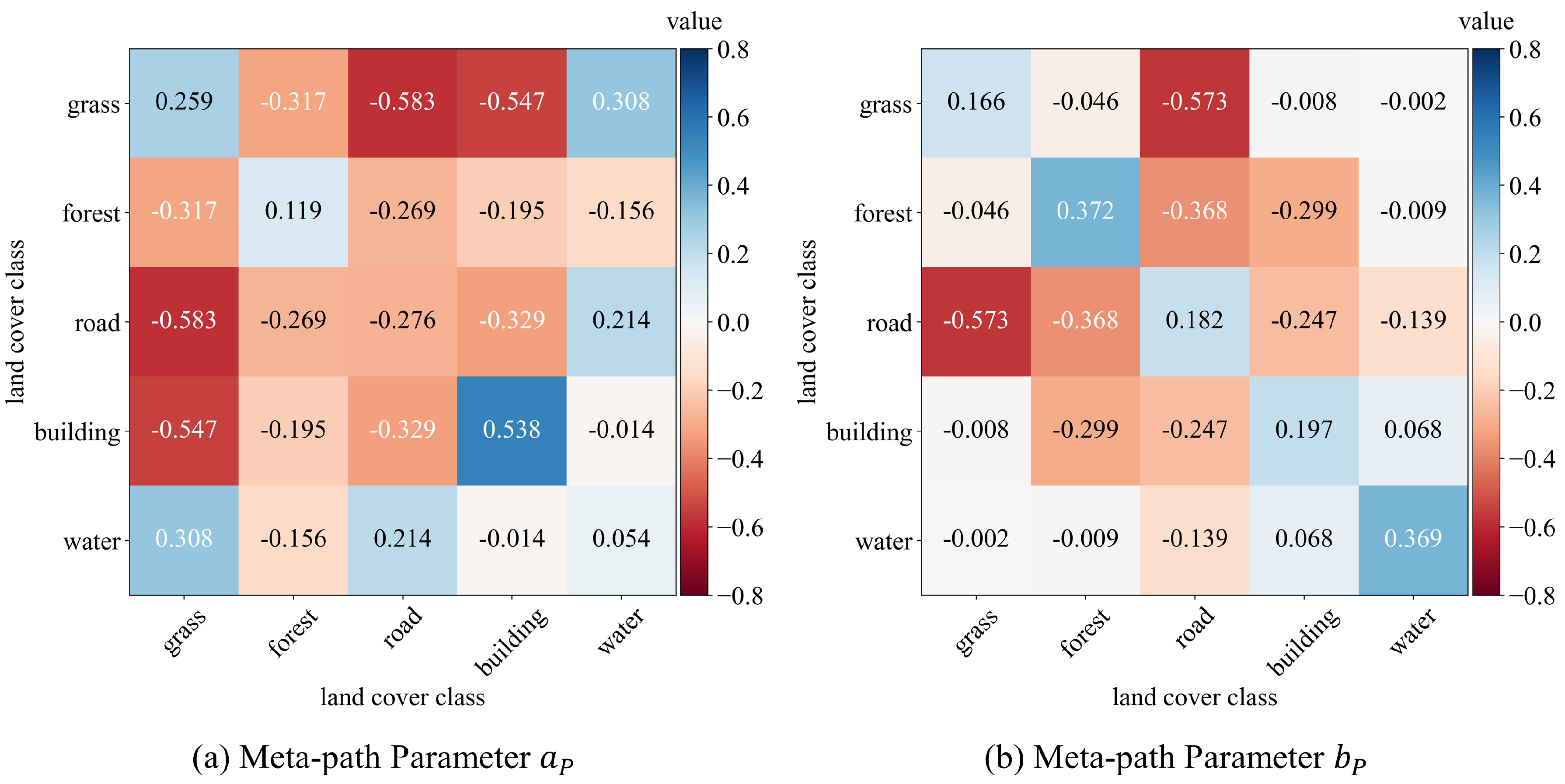
We visualize meta-path parameters
,
in
Figure 8 because they play a critical role in heterogeneous graph construction (the calculation equation is seen in Equation (
2)). Combined with the above cases, we find these parameters interpretable. Almost all parameters of the self-connection meta-path are positive, which is profitable for decreasing the intraclass variance. Most of the values related to roads are negative, especially the parameters of meta-path “road-grass” and “road-forest”. As such, meta-path parameters are advantageous for the segmentation of the scene in
Figure 7a. Meanwhile, despite being negative, the absolute values of the parameters of the meta-path “buildings-forest” are relatively small. These behaviors make it possible to realize global recognition for segmentation, such as the case in
Figure 7b. From the above analysis, we find that meta-path-based adjacency matrix calculation in Equation (
2) greatly enhances graph reasoning capability.
To summarize, the mechanism of the heterogeneous graph-based model is to adaptively adjust interclass and intraclass variance based on topological relations. We take the sample in
Figure 7a to show the difference in feature distribution before and after the GCN module, where the feature dimension is reduced to two by principal component analysis (PCA) [
52]. As shown in
Figure 9a, the CNN features of water nodes are close to those of park nodes since the water regions are located in the middle of two parks. After the GCN module, the interclass variance between the forest and water nodes are increased (see
Figure 9b), which is consistent with the analysis of the edge weights in
Figure 7a. Moreover, the intraclass variance of buildings is increased after the node feature aggregation. This makes it possible to distinguish building nodes inside parks from those outside parks. The building nodes outside parks are gathered together and move away from the park cluster because the
of the meta-path “buildings-buildings” is high. Finally, park nodes form a pure cluster.
4. Discussion
In this section, we further investigated some critical hyperparameters on the Beijing dataset. Meanwhile, we analyze the reasons behind these phenomena in combination with previous findings.
4.1. Influence of Segmentation Scale
Graph size is determined by the segmentation scale. The larger
n is, the more nodes there are in the graph. Large objects are easily over-smoothed, whereas small objects are noisy.
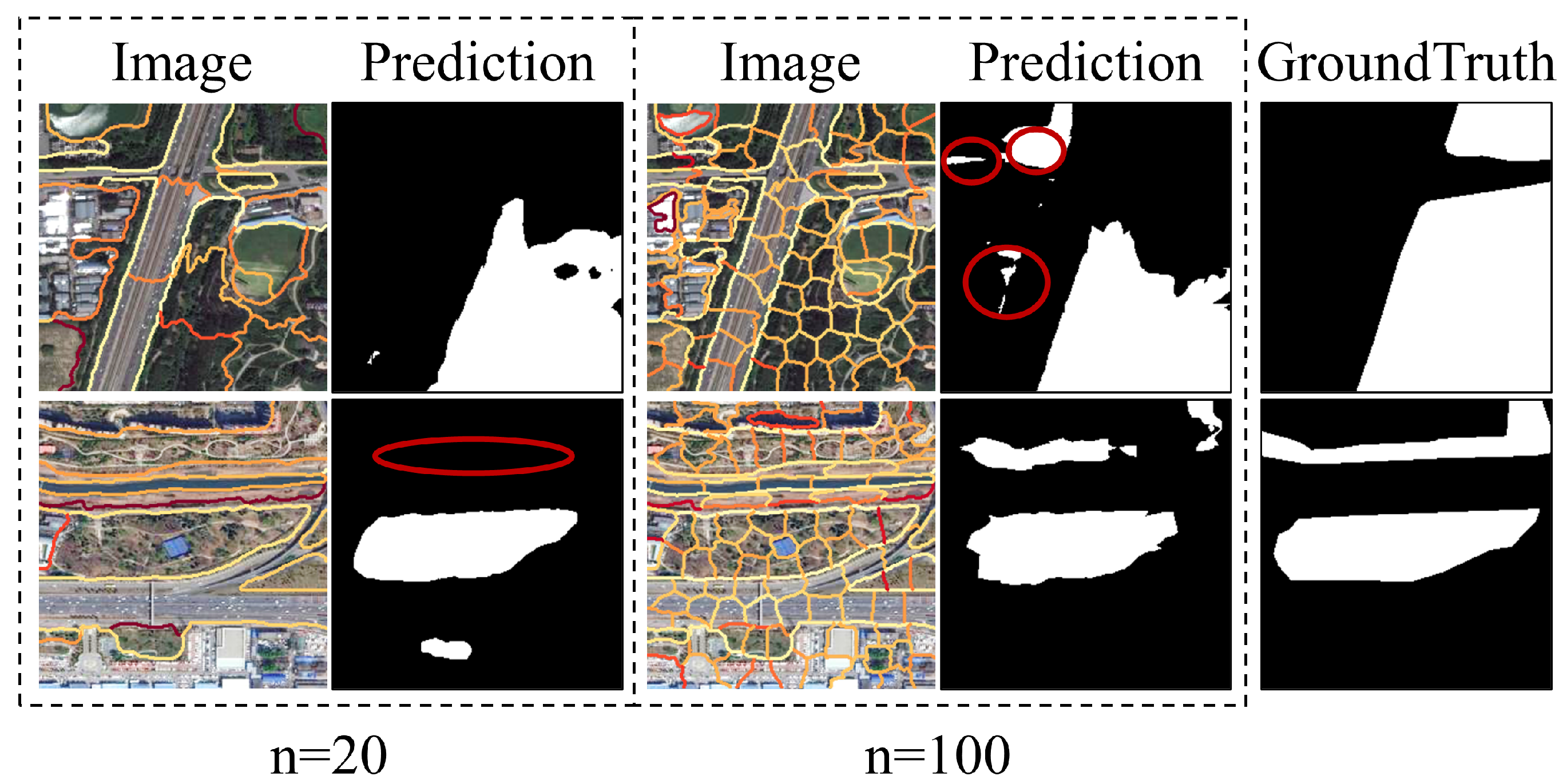
Figure 10 shows that, on the first sample, the model performs better with a smaller
n = 20, which filters out the noisy regions. When
n = 100, however, the long and narrow park can be better identified.
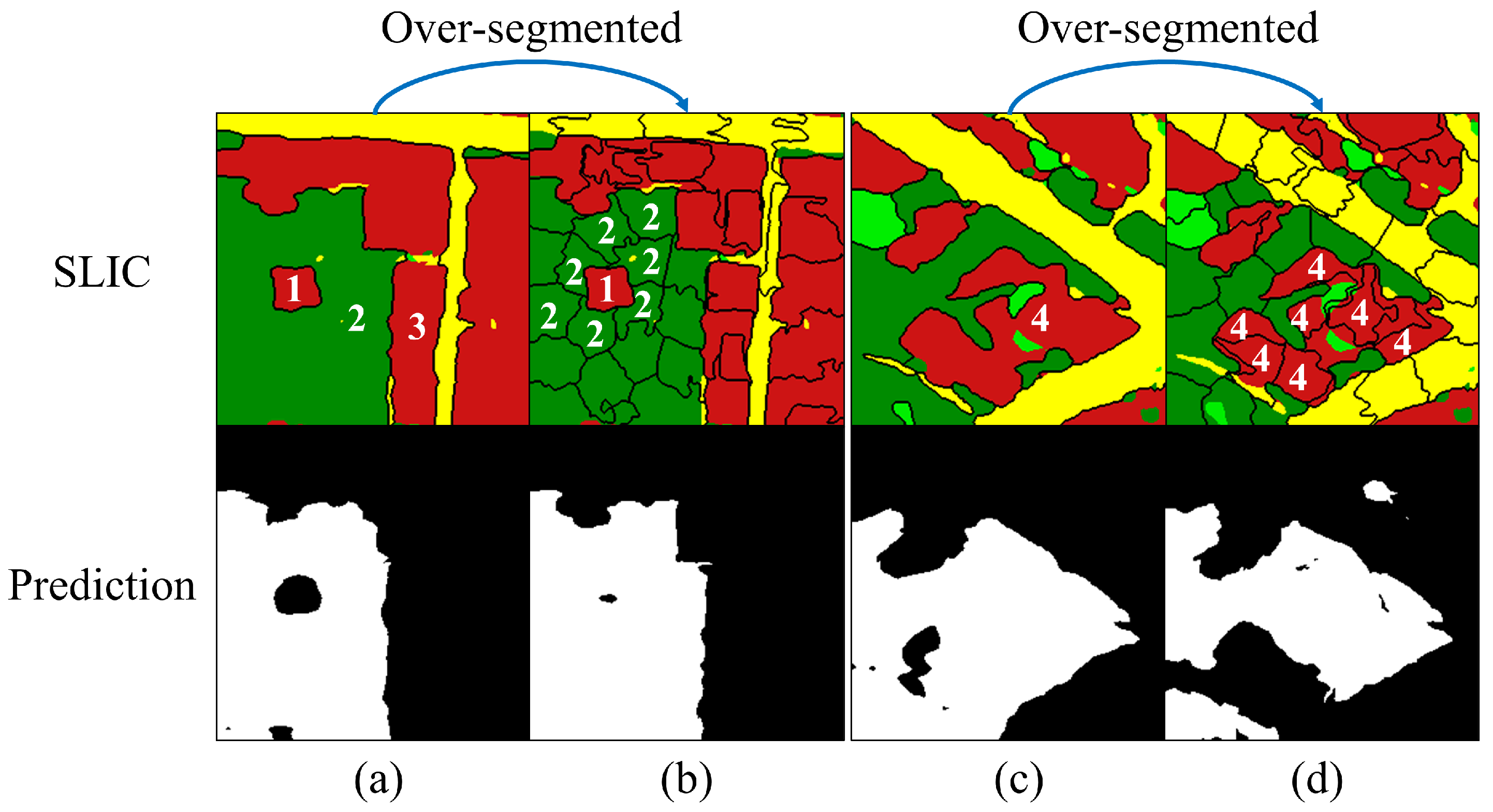
Generally, we prefer appropriate over-segmentation, which ensures that the segmented regions are homogeneous and preserves more spatial details. Furthermore, we believe that proper over-segmentation can better establish topological relationships. When relations are described by large objects in
Figure 11a, the “surrounded” relation is the same as the “adjacent” relation because there is only a single edge between node 2 and node 1, and the same thing between node 2 and node 3. By contrast, there are more edges between node 1 and its surrounding nodes in
Figure 11b if over-segmented. Thus, node 1 is more likely to be identified as a park node. However, when there is a large building in a park, such as node 4 in
Figure 11c, the prediction result will be unsatisfactory if over-segmented. As aforementioned, CHeGCN can reduce intraclass variation, causing node 4 in
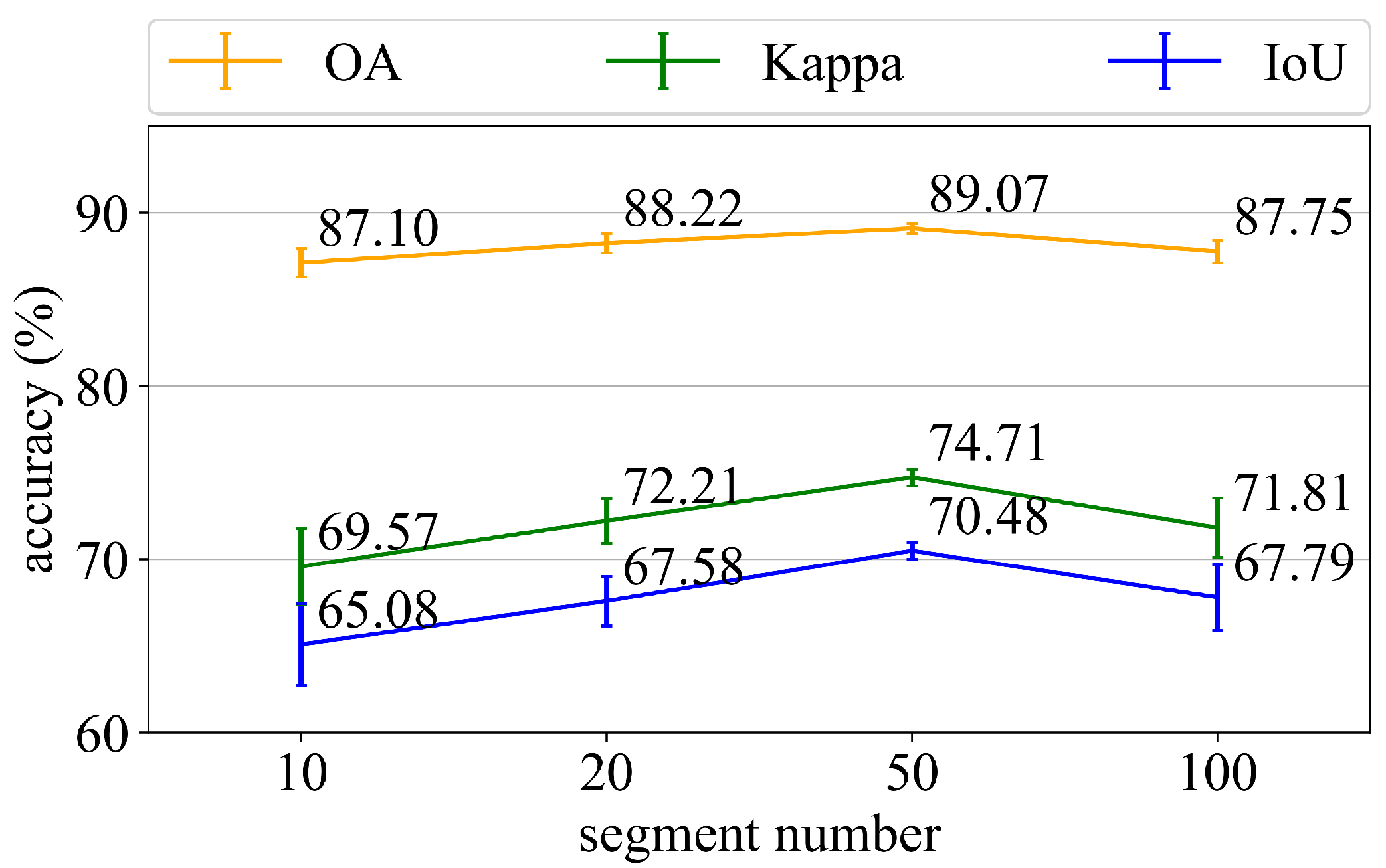
Figure 11d to move away from the park cluster after over-segmentation. As a result, the accuracy of CHeGCN rises at first, and then falls as
n increases in
Figure 12. Meanwhile, the standard deviation is high when
n is too high or too low, indicating that using an appropriate segmentation scale can produce more stable results. The determination of the segment number is data-dependent and heuristic.
4.2. Influence of Network Depth
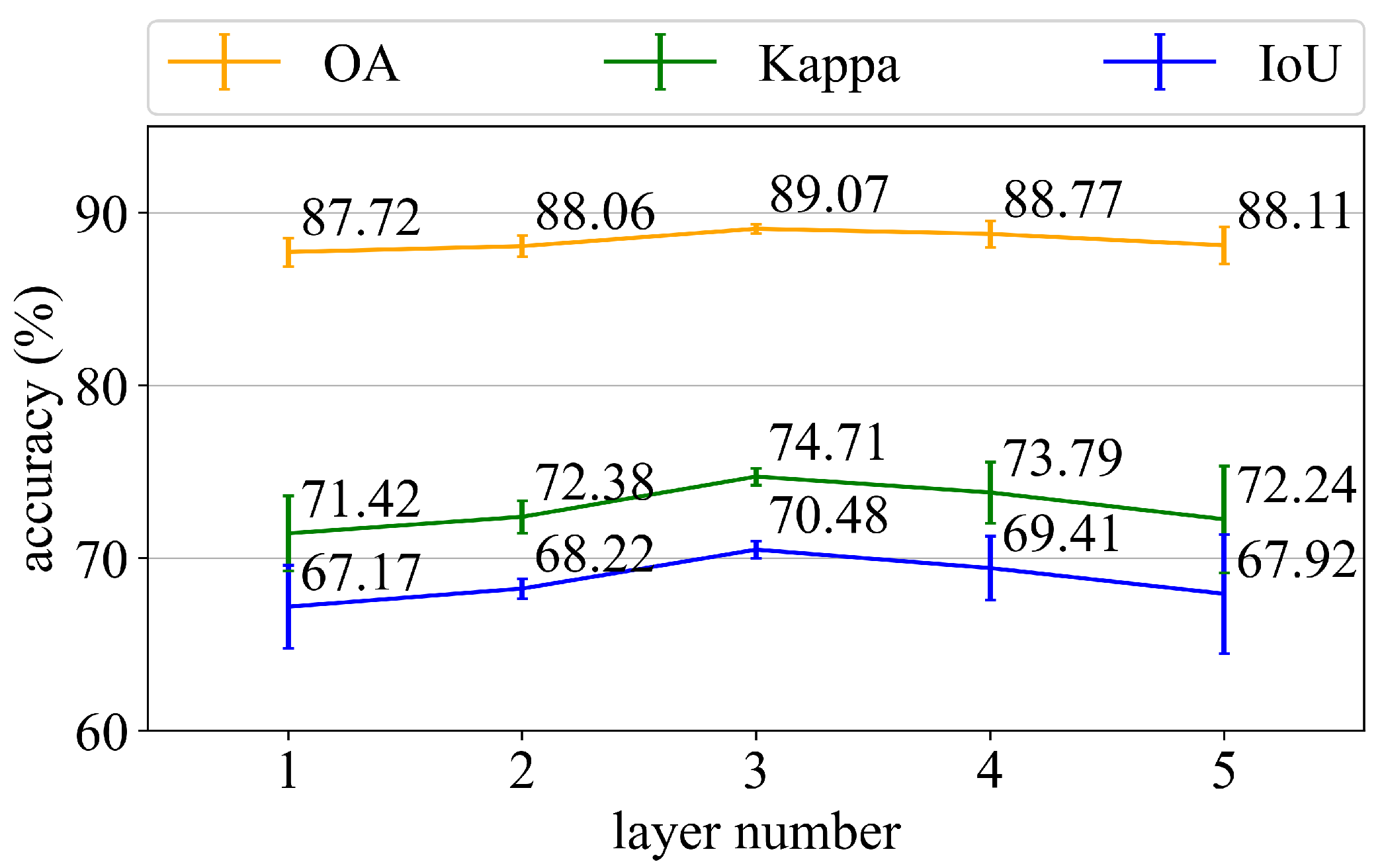
Although GCNs have shown promise, their architectures are much shallower than those of CNNs. Because of the vanishing gradient problem, most current GCNs generally contain 2–4 layers. The variation of model depth will greatly influence the performance of the model as the layer number is limited. We investigate the impact of CHeGCN depth in the following experiments. In more detail, we evaluate the performance of CHeGCN with 1–5 layers, where the number of hidden units in each layer is 32. Other hyperparameters are unchanged from previously.
As seen in
Figure 13, the best choice of model depth is three. Excessively shallow or excessively deep networks have larger deviation values. The model with fewer layers captures an insufficient global context, resulting in a large variation in the extracted features. The model with more layers, on the other hand, is prone to over-smoothing, which ultimately makes nodes of different types indistinguishable in the feature space.
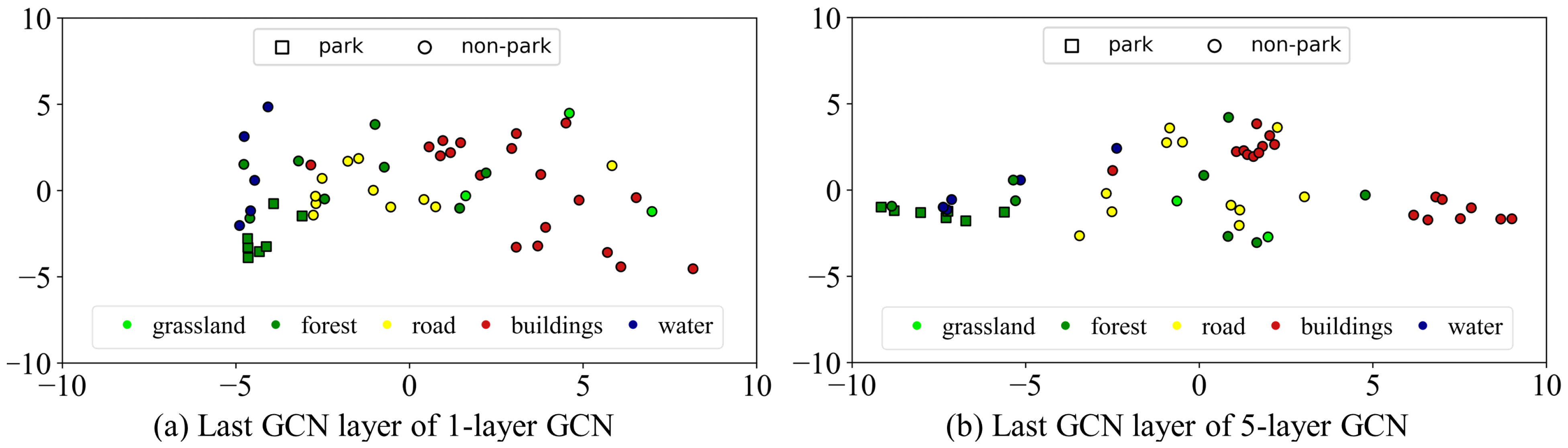
Figure 14 depicts the feature distributions of the last GCN layer in the single-layer CHeGCN and the five-layer CHeGCN. The intraclass variance of the shallow GCN is high, where the building nodes are discretely distributed. Meanwhile, the interclass variance of the deeper GCN is minor. The water and forest nodes are mixed together, and it is difficult to distinguish. As a result, building an extremely shallow or deep GCN is not recommended. In all of the other experiments, the layer number is fixed to three.
4.3. Spatially Adjacent vs. Global Adjacent
As mentioned above, land use segmentation requires global context information. CHeGCN stacks
k GCN layers to aggregate features from
k-hop neighborhoods based on topological relations. Another solution is to connect a pixel to all pixels [
43,
53]. Inspired by it, we propose a non-local CHoGCN and a non-local CHeGCN, which calculate the response at a given superpixel as a weighted sum of all superpixels. We compare the results between non-local models and the local connected models. Each experiment is repeated five times, with the average of the indices (OA, Kappa, and IoU) recorded in
Table 6.
We observe that both non-local CHoGCN and non-local CHeGCN models perform worse than CHoGCN and CHeGCN, respectively, as model depth is three. Considering that fully connected non-local models are prone to overfitting, we compare these models in a single-layer structure. However, these single-layer non-local networks still fail to compete with the single-layer local connected models. On the one hand, it is difficult to train a fully connected network with limited samples. On the other hand, park segmentation relies heavily on topological relations, where non-local models fail to extract dependencies among heterogeneous regions and cannot capture local spatial structures. Furthermore, we discover that a non-local structure has far more negative effects on CHeGCN than on CHoGCN. When adopting the non-local strategy, IoU drops (ΔIoU) by 4.55% and 6.89% for 3-layer CHoGCN and 3-layer CHeGCN, respectively. This demonstrates that the performance of heterogeneous graph-based models will suffer greatly when meta-path parameters are not appropriately selected.
4.4. Other Types of Land Use
Based on the aforementioned experiments and analysis, we demonstrated the great improvements in park segmentation with land cover data. Furthermore, we believe that, in addition to parks, there are other types of land use that can benefit from the land cover information. Some land use categories are combinations of multiple land cover components, and different land use categories have distinct combination patterns. For example, wetlands typically consist of water and grass regions while urban parks may also contain buildings. In addition, the location of land use units is closely tied to the land cover distribution. For instance, commercial areas regularly emerge in the center of building areas, and fields are rarely seen among buildings. However, several land use categories, such as forest, grass, and water, may obtain slight improvements given that they share similar definitions with land cover.
4.5. Imagery with Multiple Spectral Bands
In this article, the images in our datasets only contain RGB bands, while most of VFSR images contain four spectral bands (RGB + near-infrared). The simple method to generalize our model to VFSR images with four bands is to take the RGB bands. On the one hand, the primary information for land use segmentation is included in RGB bands. On the other hand, as the short-wave infrared spectrum predominantly provides relevant information for vegetation recognition, the additional land cover information provides supplemental information for vegetation. In addition, we could modify the CNN module to better exploit the multi-spectral data. For example, we can substitute the ResNet-18 backbone with U-net, which does not restrict the band number at 3. Meanwhile, the U-net trained from scratch may require more data to obtain comparable results.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}