
Training a Disaster Victim Detection Network for UAV Search and Rescue Using Harmonious Composite Images





Abstract
:1. Introduction
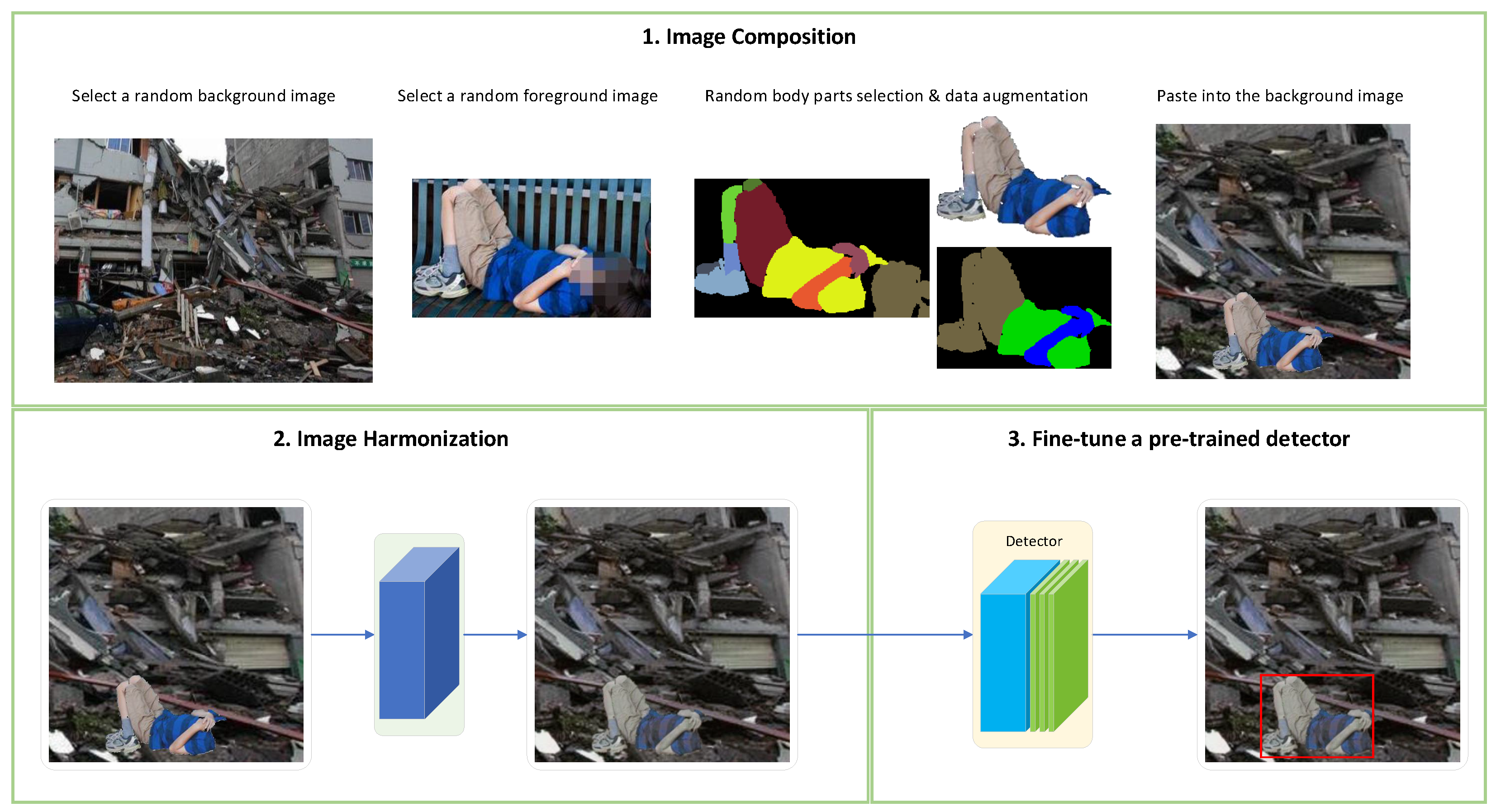
- We propose to generate composite images for training a visual victim detector. Specifically, we focus on the detection of human body parts in debris, which is useful for UAV search and rescue in post-disaster scenarios.
- We propose a deep harmonization network to make composite images more realistic and further improve the detection accuracy.
2. Related Work
2.1. Object Detection Based on Deep Learning
2.2. Object Detection in Emergency Scenarios
2.3. Using Unreal Data for Training
2.4. Image Harmonization
3. VictimDet: Training a Disaster Victim Detector Using Harmonious Composite Images
3.1. Victim Image Composition
3.2. Unsupervised Image Harmonization
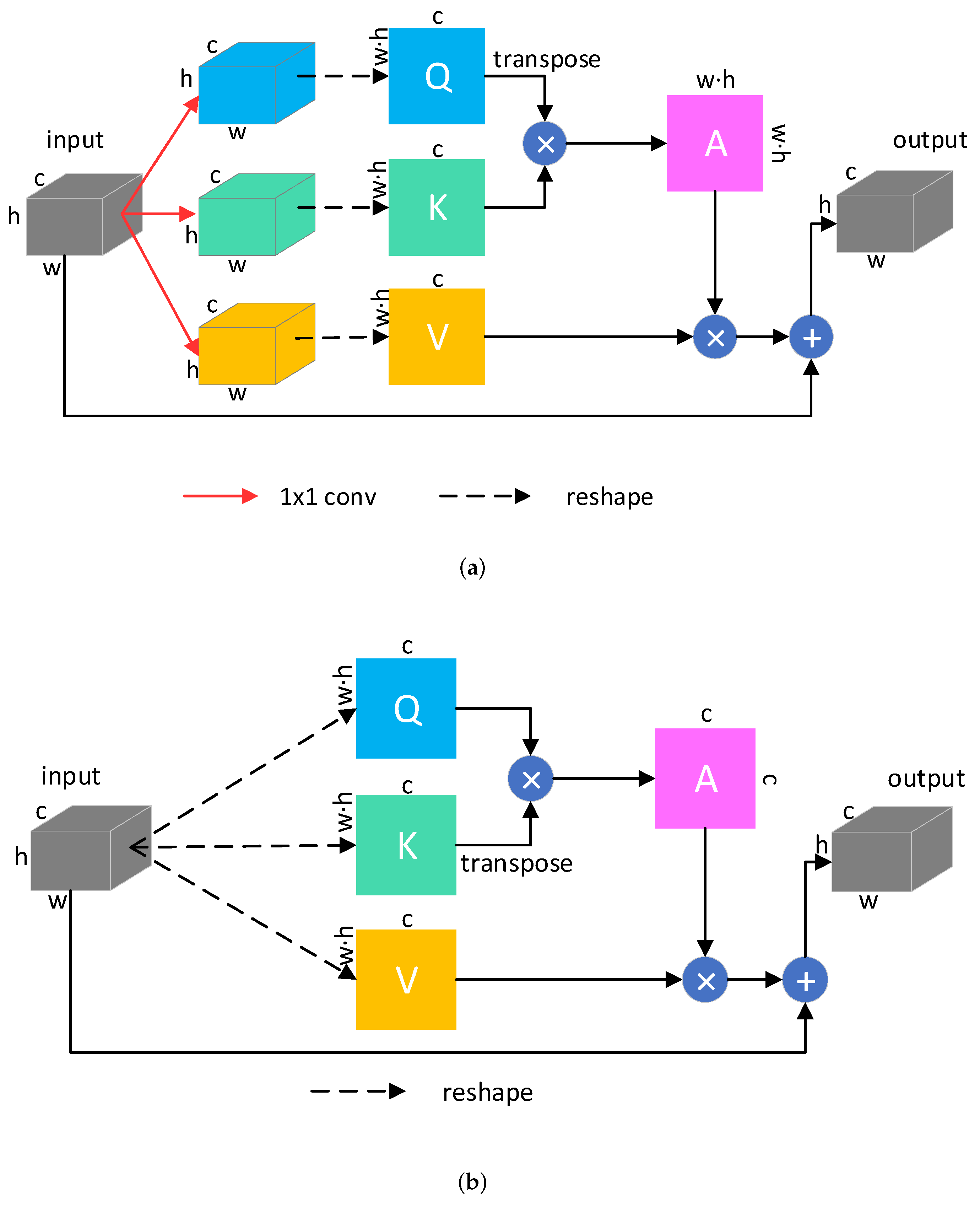
3.2.1. Self-Attention Enhanced Generator
3.2.2. Global and Local Discriminators
3.2.3. Loss Functions
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Qualitative Analysis of Harmonized Images
4.4. Quantitative Analysis of Victim Detection
4.5. Ablation Study
4.6. Study on Freezing Layers in Fine-Tuning
4.7. Discussion on Failure Cases
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sreenu, G.; Durai, M.S. Intelligent video surveillance: A review through deep learning techniques for crowd analysis. J. Big Data 2019, 6, 1–27. [Google Scholar] [CrossRef]
- Govil, K.; Welch, M.L.; Ball, J.T.; Pennypacker, C.R. Preliminary results from a wildfire detection system using deep learning on remote camera images. Remote Sens. 2020, 12, 166. [Google Scholar] [CrossRef] [Green Version]
- Loey, M.; ElSawy, A.; Afify, M. Deep learning in plant diseases detection for agricultural crops: A survey. Int. J. Serv. Sci. 2020, 11, 41–58. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, H.; Laszewski, M.; Kehtarnavaz, N. Deep learning-based person detection and classification for far field video surveillance. In Proceedings of the 2018 IEEE 13th Dallas Circuits and Systems Conference (DCAS), Dallas, TX, USA, 12 November 2018; pp. 1–4. [Google Scholar]
- Wei, H.; Kehtarnavaz, N. Semi-supervised faster RCNN-based person detection and load classification for far field video surveillance. Mach. Learn. Knowl. Extr. 2019, 1, 44. [Google Scholar] [CrossRef] [Green Version]
- Braun, M.; Krebs, S.; Flohr, F.; Gavrila, D.M. Eurocity persons: A novel benchmark for person detection in traffic scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1844–1861. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Xie, Y.; Wan, J.; Xia, H.; Li, S.Z.; Guo, G. Widerperson: A diverse dataset for dense pedestrian detection in the wild. IEEE Trans. Multimed. 2019, 22, 380–393. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Zhang, X.; Yang, Y.H.; Han, Z.; Wang, H.; Gao, C. Object class detection: A survey. ACM Comput. Surv. 2013, 46, 1–53. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. 2007. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 17 May 2022).
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Kwon, Y.; Michael, K.; Liu, C.; Fang, J.; Abhiram, V.; Skalski, S.P. Ultralytics/yolov5: V6. 0—YOLOv5n ‘Nano’models, Roboflow integration, TensorFlow export, OpenCV DNN support. Zenodo Tech. Rep. 2021. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Liu, Z.; Zheng, T.; Xu, G.; Yang, Z.; Liu, H.; Cai, D. Training-time-friendly network for real-time object detection. AAAI Conf. Artif. Intell. 2020, 34, 11685–11692. [Google Scholar] [CrossRef]
- Xin, Y.; Wang, G.; Mao, M.; Feng, Y.; Dang, Q.; Ma, Y.; Ding, E.; Han, S. Pafnet: An efficient anchor-free object detector guidance. arXiv 2021, arXiv:2104.13534. [Google Scholar]
- Lawrance, A.; Lewis, P. An exponential moving-average sequence and point process (EMA1). J. Appl. Probab. 1977, 14, 98–113. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6023–6032. [Google Scholar]
- Nex, F.; Duarte, D.; Tonolo, F.G.; Kerle, N. Structural building damage detection with deep learning: Assessment of a state-of-the-art cnn in operational conditions. Remote Sens. 2019, 11, 2765. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Hu, W.; Dong, H.; Zhang, X. Building damage detection from post-event aerial imagery using single shot multibox detector. Appl. Sci. 2019, 9, 1128. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Xu, J.; Xu, L.; Guo, H. Deep convolutional neural networks for forest fire detection. In 2016 International Forum on Management, Education and Information Technology Application; Atlantis Press: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Sharma, J.; Granmo, O.C.; Goodwin, M.; Fidje, J.T. Deep convolutional neural networks for fire detection in images. In International Conference on Engineering Applications of Neural Networks; Springer: Cham, Switzerland, 2017; pp. 183–193. [Google Scholar]
- Jadon, A.; Omama, M.; Varshney, A.; Ansari, M.S.; Sharma, R. FireNet: A specialized lightweight fire & smoke detection model for real-time IoT applications. arXiv 2019, arXiv:1905.11922. [Google Scholar]
- Toulouse, T.; Rossi, L.; Campana, A.; Celik, T.; Akhloufi, M.A. Computer vision for wildfire research: An evolving image dataset for processing and analysis. Fire Saf. J. 2017, 92, 188–194. [Google Scholar] [CrossRef] [Green Version]
- Sulistijono, I.A.; Risnumawan, A. From concrete to abstract: Multilayer neural networks for disaster victims detection. In Proceedings of the 2016 International Electronics Symposium, Denpasar, Indonesia, 29–30 September 2016; pp. 93–98. [Google Scholar]
- Andriluka, M.; Schnitzspan, P.; Meyer, J.; Kohlbrecher, S.; Petersen, K.; Von Stryk, O.; Roth, S.; Schiele, B. Vision based victim detection from unmanned aerial vehicles. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 1740–1747. [Google Scholar]
- Hartawan, D.R.; Purboyo, T.W.; Setianingsih, C. Disaster victims detection system using convolutional neural network (CNN) method. In Proceedings of the 2019 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology, Bali, Indonesia, 1–3 July 2019; pp. 105–111. [Google Scholar]
- Hoshino, W.; Seo, J.; Yamazaki, Y. A study for detecting disaster victims using multi-copter drone with a thermographic camera and image object recognition by SSD. In Proceedings of the 2021 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Delft, The Netherlands, 12–16 July 2021; pp. 162–167. [Google Scholar]
- Sulistijono, I.A.; Imansyah, T.; Muhajir, M.; Sutoyo, E.; Anwar, M.K.; Satriyanto, E.; Basuki, A.; Risnumawan, A. Implementation of Victims Detection Framework on Post Disaster Scenario. In Proceedings of the 2018 International Electronics Symposium on Engineering Technology and Applications (IES-ETA), Bali, Indonesia, 29–30 October 2018; pp. 253–259. [Google Scholar]
- Dalal, N.; Triggs, B. INRIA Person Dataset. 2005. Available online: http://pascal.inrialpes.fr/data/human (accessed on 17 May 2022).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. 2012. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 17 May 2022).
- Handa, A.; Patraucean, V.; Badrinarayanan, V.; Stent, S.; Cipolla, R. Understanding real world indoor scenes with synthetic data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4077–4085. [Google Scholar]
- McCormac, J.; Handa, A.; Leutenegger, S.; Davison, A.J. Scenenet rgb-d: Can 5 m synthetic images beat generic imagenet pre-training on indoor segmentation? In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2678–2687. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Zhang, N.; Nex, F.; Kerle, N.; Vosselman, G. Towards Learning Low-Light Indoor Semantic Segmentation with Illumination-Invariant Features. Int. Arch. Photogramm. Remote Sens. 2021, 43, 427–432. [Google Scholar] [CrossRef]
- Zhang, N.; Nex, F.; Kerle, N.; Vosselman, G. LISU: Low-light indoor scene understanding with joint learning of reflectance restoration. ISPRS J. Photogramm. Remote Sens. 2022, 183, 470–481. [Google Scholar] [CrossRef]
- Rozantsev, A.; Lepetit, V.; Fua, P. On rendering synthetic images for training an object detector. Comput. Vis. Image Underst. 2015, 137, 24–37. [Google Scholar] [CrossRef] [Green Version]
- Peng, X.; Sun, B.; Ali, K.; Saenko, K. Learning deep object detectors from 3d models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1278–1286. [Google Scholar]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, paste and learn: Surprisingly easy synthesis for instance detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1301–1310. [Google Scholar]
- Madaan, R.; Maturana, D.; Scherer, S. Wire detection using synthetic data and dilated convolutional networks for unmanned aerial vehicles. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3487–3494. [Google Scholar]
- Tremblay, J.; To, T.; Birchfield, S. Falling things: A synthetic dataset for 3d object detection and pose estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2038–2041. [Google Scholar]
- Zhang, Q.X.; Lin, G.H.; Zhang, Y.M.; Xu, G.; Wang, J.J. Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images. Procedia Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Han, J.; Karaoglu, S.; Le, H.A.; Gevers, T. Object features and face detection performance: Analyses with 3D-rendered synthetic data. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 9959–9966. [Google Scholar]
- Tsai, Y.H.; Shen, X.; Lin, Z.; Sunkavalli, K.; Lu, X.; Yang, M.H. Deep image harmonization. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3789–3797. [Google Scholar]
- Luan, F.; Paris, S.; Shechtman, E.; Bala, K. Deep painterly harmonization. In Computer Graphics Forum; Wiley: Hoboken, NJ, USA, 2018; Volume 37, pp. 95–106. [Google Scholar]
- Zhang, L.; Wen, T.; Shi, J. Deep image blending. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 231–240. [Google Scholar]
- Cong, W.; Zhang, J.; Niu, L.; Liu, L.; Ling, Z.; Li, W.; Zhang, L. Dovenet: Deep image harmonization via domain verification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8394–8403. [Google Scholar]
- Cun, X.; Pun, C.M. Improving the harmony of the composite image by spatial-separated attention module. IEEE Trans. Image Process. 2020, 29, 4759–4771. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, Y.; Zhang, H.; Zhang, J.; Wang, Y.; Lin, Z.; Sunkavalli, K.; Chen, S.; Amirghodsi, S.; Kong, S.; Wang, Z. SSH: A Self-Supervised Framework for Image Harmonization. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 4832–4841. [Google Scholar]
- Gong, K.; Liang, X.; Zhang, D.; Shen, X.; Lin, L. Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 932–940. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- PaddlePaddle. PaddleDetection: Object Detection and Instance Segmentation Toolkit Based on PaddlePaddle. 2019. Available online: https://github.com/PaddlePaddle/PaddleDetection (accessed on 17 May 2022).
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Params (M) | Speed (FPS) | Trained on COCO | Harmonized Images | ||
|---|---|---|---|---|---|---|
| AP | AP | |||||
| FCOS-R50-FPN | 32.2 | 14 | 17.0 | 28.1 | (+13.1) 30.1 | (+20.5) 48.6 |
| FCOS-DCN-R50-FPN | 33.7 | 11 | 18.3 | 30.1 | (+18.6) 36.9 | (+26.6) 56.7 |
| TTFNet-darknet53 | 45.8 | 23 | 16.5 | 26.0 | (+9.2) 25.7 | (+13.1) 39.1 |
| PAFNet | 33.8 | 21 | 23.1 | 36.8 | (+22.5) 45.6 | (+28.2) 65.0 |
| YOLOv5s | 7.2 | 212 | 9.2 | 14.5 | (+15.5) 24.7 | (+28.4) 42.9 |
| YOLOv5m | 21.2 | 123 | 11.8 | 17.4 | (+27.9) 39.7 | (+42.6) 60.0 |
| YOLOv5l | 46.5 | 89 | 15.3 | 21.4 | (+29.6) 44.9 | (+44.0) 65.4 |
| Exp. | Method | YOLOv5s | YOLOv5m | YOLOv5l | |||
|---|---|---|---|---|---|---|---|
| AP | AP | AP | |||||
| A | w/o Fine-Tuning | 9.2 | 14.5 | 11.8 | 17.4 | 15.3 | 21.4 |
| B | Composite Images | (+12.4) 21.6 | (+23.8) 38.3 | (+19.6) 31.4 | (+33.2) 50.6 | (+19.4) 34.7 | (+32.1) 53.5 |
| C | B + | (+0.5) 22.1 | (+1.8) 40.1 | (+2.8) 34.2 | (+2.6) 53.2 | (+3.1) 37.8 | (+5.4) 58.9 |
| D | C + Attention | (+1.3) 22.9 | (+1.6) 39.9 | (+3.8) 35.2 | (+5.8) 56.4 | (+3.5) 38.2 | (+7.0) 60.5 |
| E | C + | (+0.9) 22.5 | (+1.9) 40.2 | (+6.2) 37.6 | (+6.7) 57.3 | (+6.1) 40.8 | (+9.6) 63.1 |
| F | D + | (+3.1) 24.7 | (+4.6) 42.9 | (+8.3) 39.7 | (+9.4) 60.0 | (+10.2) 44.9 | (+11.9) 65.4 |
| G | B + Blending [48] | (−0.5) 21.1 | (+0.1) 38.4 | (+1.4) 32.8 | (+2.3) 52.9 | (+1.2) 35.9 | (+3.1) 56.6 |
| Frozen Layers | YOLOv5s | YOLOv5m | YOLOv5l | |||
|---|---|---|---|---|---|---|
| AP | AP | AP | ||||
| Backbone | 24.7 | 42.9 | 39.7 | 60.0 | 44.9 | 65.4 |
| Backbone + Neck | (−12.3) 11.8 | (−20.2) 22.7 | (−20.8) 18.9 | (−25.9) 34.1 | (−22.4) 22.5 | (−24.6) 40.8 |
| No Frozen Layer | (−6.4) 18.3 | (−3.5) 39.4 | (−15.5) 24.2 | (−14.3) 45.7 | (−15.7) 29.2 | (−9.9) 55.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, N.; Nex, F.; Vosselman, G.; Kerle, N. Training a Disaster Victim Detection Network for UAV Search and Rescue Using Harmonious Composite Images. Remote Sens. 2022, 14, 2977. https://doi.org/10.3390/rs14132977
Zhang N, Nex F, Vosselman G, Kerle N. Training a Disaster Victim Detection Network for UAV Search and Rescue Using Harmonious Composite Images. Remote Sensing. 2022; 14(13):2977. https://doi.org/10.3390/rs14132977
Chicago/Turabian StyleZhang, Ning, Francesco Nex, George Vosselman, and Norman Kerle. 2022. "Training a Disaster Victim Detection Network for UAV Search and Rescue Using Harmonious Composite Images" Remote Sensing 14, no. 13: 2977. https://doi.org/10.3390/rs14132977
APA StyleZhang, N., Nex, F., Vosselman, G., & Kerle, N. (2022). Training a Disaster Victim Detection Network for UAV Search and Rescue Using Harmonious Composite Images. Remote Sensing, 14(13), 2977. https://doi.org/10.3390/rs14132977