Abstract
Natural disasters have a significant impact on urban areas, resulting in loss of lives and urban services. Using satellite and aerial imagery, the rapid and automatic assessment of at-risk located buildings from can improve the overall disaster management system of urban areas. To do this, the definition, and the implementation of models with strong generalization, is very important. Starting from these assumptions, the authors proposed a deep learning approach based on the U-Net model to map buildings that fall into mapped landslide risk areas. The U-Net model is trained and validated using the Dubai’s Satellite Imagery Dataset. The transferability of the model results are tested in three different urban areas within Calabria Region, Southern Italy, using natural color orthoimages and multi-source GIS data. The results show that the proposed methodology can detect and predict buildings that fall into landslide risk zones, with an appreciable transferability capability. During the prevention phase of emergency planning, this tool can support decision-makers and planners with the rapid identification of buildings located within risk areas, and during the post event phase, by assessing urban system conditions after a hazard occurs.
1. Introduction
Extracting buildings and infrastructure footprints automatically from high-resolution imagery is of great significance for urban planning applications, especially for disaster management planning [1]. The identification of buildings and infrastructures is essential for monitoring urban settlements and updating administration databases [2].
In recent literature research, developing reliable and accurate building extraction methods has become an important and challenging research issue receiving great attention [3]. Remote sensing provides valuable information to scientists and authorities with regards to this issue.
Over the past few years, many building and infrastructure extraction methods have been developed and used, such as parametric and non-parametric classifiers, the shadow-based method, the edge-based method, and the object-based method [4,5,6]. For example, Belgiu and Drǎgut [7] used and compared supervised and unsupervised multi-resolution segmentation methods with Random Forest (RF) classification to extract buildings from high-resolution satellite images. Chen et al. [8] identified buildings using three machine learning classifiers (AdaBoost, RF, and Support Vector Machine (SVM)) after a revised segmentation based on two new building features: Edge Regularity Indices (ERI); and Shadow Line Indices (SLI).
In many cases, these methods are influenced by unfair weather conditions and human perceptions. Due to this, they are area-specific, so transferability to other geographic areas is difficult to guarantee. Moreover, they are very time-consuming.
In recent years, deep learning technology has been widely used in remote sensing applications. It has the potential to overcome problems of traditional classification algorithms.
Among different deep learning technologies, Convolutional Neural Network (CNN) is mainly used for Computer Vision (CV) tasks. Since 2014, CNN-based semantic segmentation algorithms [9] have been applied to many pixel-wise remote sensing image analysis tasks, such as road extraction [10], building extraction [11], urban land use classification [12], vehicle detection [13], and building damage identification [14]. CNN is mostly used for structural image classification and change detection. Different CNN architectures have evolved, such as VGG16 [15], ResNet-50 [16], and U-Net [17,18,19,20], as well as EfficientNet [21]. All of these are valuable methods in the field of satellite image segmentation.
With reference to U-Net architecture, it was firstly used for biomedical image segmentation and then applied on object detection [22]. Later, it was also applied to pixel-wise classification of satellite images. So, few studies have been conducted to detect urban features from aerial images.
Li et al. [2] proposed a U-Net-based semantic segmentation method to extract building footprints from high-resolution multispectral satellite images of four cities (Las Vegas, Paris, Shanghai, and Khartoum) with the integration of GIS map datasets, such as OpenStreetMap, Google Maps, and MapWorld. Using the Massachusetts building dataset, Alsabhan and Alotaiby [23] compared the results of building extraction on high-resolution satellite images obtained with U-Net and Unet-ResNet50 models. Hussein and Ali [24] used the U-Net architecture to do a semantic segmentation of aerial images. Bouchard et al. [25] evaluated the applicability of CNN in detecting buildings and classifying their damage. Chen et al. [26] used a deep residual shrinkage U-Net (DRs-UNet), to automatically extract potential active landslides in InSAR imagery. Qi et al. [27] proposed a deep learning approach, the ResU-Net, to map regional landslides automatically from satellite images.
Many studies aim for automatic identification of buildings from satellite images in ordinary conditions. Few studies have been proposed aimed at using deep learning techniques for the automatic identification of buildings in emergency conditions. Remote sensing [28] and artificial intelligence [29] are a useful support for effective decision-making in disaster management planning. They can be used to analyze countless data and extract reliable information.
Disaster management planning is structured around the disaster management cycle, which consists of four stages: (1) reduction, (2) preparedness, (3) response, and (4) recovery. With reference to the reduction phase, remote sensing and deep learning are useful tools to automatically identify from aerial images buildings exposed to different hazards, such as landslides, earthquake, or flooding [30,31,32,33,34,35]. People in potentially at-risk locations can be rapidly evacuated and many lives can be saved. Moreover, remote sensing and deep learning techniques help agencies responding to emergencies, thanks to the rapid assessment of the impact rate of the disaster and the identification of disrupted and destroyed key buildings and infrastructures. After a hazard occurs, it is not possible to guide recovery interventions based on official cartography because it cannot be updated rapidly. Therefore, an instrument capable of acquiring aerial images from designed Unmanned Aerial Vehicles (UAV) flights, and quickly recognizing damaged buildings, assumes considerable importance in a post disaster scenario.
Given that few authors proposed remote sensing and deep learning methods for this purpose, to fill this gap, the authors present a method to identify, from satellite and aerial images, buildings potentially in at-risk locations in cases of natural disasters. To test the methodology’s level of capability to identify buildings subject to risk, this paper focuses on the application of a semantic segmentation-based method for the semi-automatic assessment, from satellite and aerial imagery, of buildings that fall into landslides risk zones. Once the level of statistical confidence of the model has been determined, it can be considered, on one side, as an early warning system capable of identifying the built-up areas that require periodic monitoring because they are potentially subject to a high risk of damage; on the other side, it could be employed for the estimation of damaged buildings in a post disaster phase.
The authors proposed a deep learning approach based on the U-Net model, a CNN that was originally employed for biomedical image segmentation. Its architecture allows for work with fewer training images, yielding more precise segmentation. The model is trained and validated using the “semantic segmentation of aerial imagery”, which contains 72 satellite images of Dubai, and, then, its transferability capability is tested by detecting and segmenting buildings that fall within landslide risk zones in three different urban regions of Calabria Region, Southern Italy. A platform that can be generally applied with a determined level of confidence to different geographical contexts is of fundamental importance; it avoids further training and validation operations, which subtract precious time from a rapid estimate of damaged buildings.
The rest of the paper is organized as follows. Section 2 contains the description of the study area and of the training, validation, and testing dataset. Section 3 introduces the proposed methodology, including data preparation and the semantic segmentation model for building footprint extraction. Section 4 describes the building extraction results of the proposed method, while Section 5 discusses and presents the results of the application of the proposed model to the case studies. Section 6 summarizes the conclusions of this research.
2. Datasets and Study Area
2.1. Training and Validation Dataset
For the proposed U-Net model training and validation stages, the employed dataset is “semantic segmentation of aerial imagery”, an open access dataset developed for a joint project with the Mohammed Bin Rashid Space Center in Dubai, the UAE [36]. The dataset contains 72 high resolution satellite images of Dubai with correspondent semantic segmentation masks. Each satellite image is segmented into six classes (Figure 1): water, land, road, building, vegetation, and unlabeled. The images were segmented by the trainees of the Roia Foundation in Syria. The training and validation sample are of 65 images and seven images, respectively.

Figure 1.
Sample of training and validation dataset.
2.2. Training and Validation Data Augmentation
The accuracy of deep learning models, especially in CV techniques, is directly connected to the quality, quantity, and contextual meaning of training data. One of the greatest problems in deep learning methods for image semantic segmentation applications is the scarce availability of data for training and validation tasks. Recently, in order to overcome this limitation, even greater attention has been paid to using data augmentation methods to generate qualified training and validation data. The main aim of data augmentation is to improve the sufficiency and diversity of training and validation data by generating a synthetic dataset [37]. It can be considered that the augmented dataset is extracted from a distribution that is close to the original one, allowing a more comprehensive configuration [38].
For this research, the authors used a variety of data augmentation strategies for both training and validation dataset. The data augmentation operations involved the input images and the respective semantic segmentation masks. A first strategy is represented by the under-sampling, in which an image is randomly cropped multiple times, and the crop size is 512 × 512. The multiple cropping operation considering the largest sum of pixel values is adopted to reduce the sampling frequency of non-buildings entities. In addition, in order to enhance the robustness of the model, the authors randomly flip, rotate, translate, side view, and zoom, the input images and the respective masks. Furthermore, all inputs are manipulated, adjusting their saturation, contrast, and brightness, converting the color space and band order, and adding Gaussian noise and filtering operations randomly.
2.3. Study Area and Testing Dataset
2.3.1. Study Area
The Calabria Region is located in Southern Italy. It includes five Provinces (Catanzaro (CZ), Cosenza (CS), Crotone (KR), Vibo Valentia (VV), and Reggio Calabria (RC)). In 2022, it counts a resident population of approximately 1,842,615 inhabitants, distributed in 404 municipalities, which, in many cases, do not exceed 3000 inhabitants (Figure 2). Because of its specific geological framework, tectonic history, and geomorphological landscape features, the whole region is highly exposed to different natural hazards, such as hydrogeological and seismic risks.
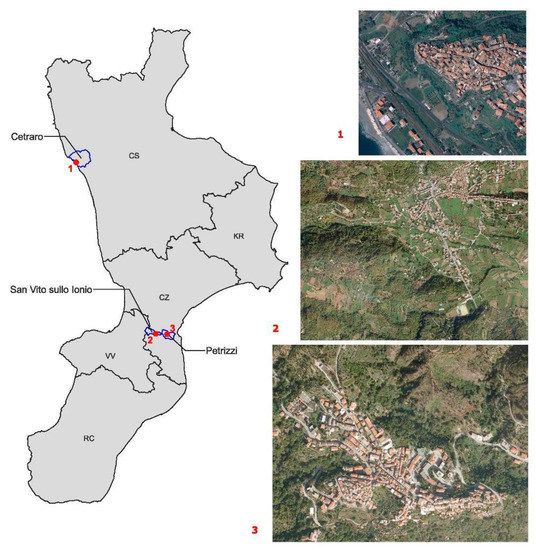
Figure 2.
Study area framework.
For this reason, the rapid and accurate buildings extraction within risk areas, from remote sensing images, is essential for emergency management applications.
The identification of buildings using deep learning methods is carried out considering landslide risk areas. The authors used the information related to landslide risk (location and level of risk) defined by the Hydrogeological Structure Plan [39]. This tool is used in Italy for basin planning, considering different types of risk (landslide, flood, and coastal erosion). For each risk, it divides the territorial context into different intensity levels.
The trained model is applied to three different urban areas of Calabria Region: Cetraro, Petrizzi, and San Vito sullo Ionio (Figure 2). These municipalities are characterized by different levels of landslide risk, as well as by different urban shapes. These differences helped the authors to test the model in different conditions concerning the automatic extraction of built-up areas, and the identification of buildings that fall into landslides.
Cetraro, located on the West Calabrian coast, is characterized by a low landslide risk level. The risk area is concentrated on the north-east side of the historical part of the built-up area. The urban shape is monocentric and compact.
Petrizzi is located in the middle part of the region, in the east side, and is about 13 km from the Ionian Sea. This urban center is characterized by a very high, as well as widespread landslide risk level. The urban shape of Petrizzi can be considered as polycentric and compact.
San Vito sullo Ionio is a municipality located near Petrizzi and, as with Cetraro, is characterized by a low landslide risk level. In this case, the urban shape is polycentric and very dispersed.
2.3.2. Testing and Ground Truth Dataset
For the testing stage of the model, the dataset employed consists of 0.423-m pixel resolution (approximately 1-foot), with natural color orthoimages covering the urban borders of the three considered municipalities. The building polygons output of the model are compared with the building polygons retrieved from the Regional Technical Cartography (CTR) [40]. This represents the ground truth dataset (Figure 3). As stated previously, landslide risk areas are localized considering the Hydrogeological Structure Plan [39].
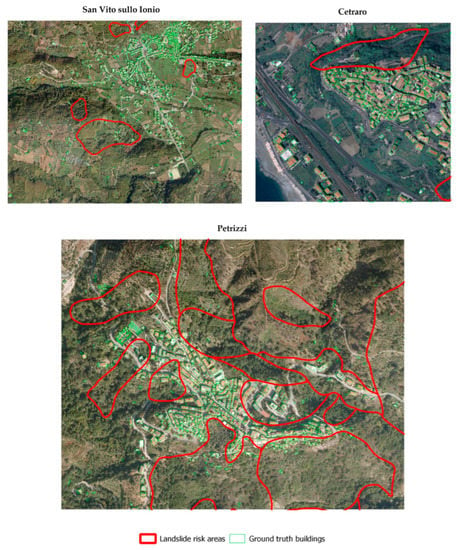
Figure 3.
Ground truth dataset.
3. Materials and Methods
3.1. Methodology Overview
The core part of the proposed methodology consists of a deep learning model based on a CNN specifically suited for the automatic segmentation of built-up areas, and then for the mapping of buildings characterized by landslide risk. The neural network is defined by a set of weights. For the evaluation of the quality of the mapping function, a training phase is developed. In the training phase, input tiles are propagated through the network and a loss function is calculated. The set of weights of the neural network is adjusted accordingly, to minimize the loss. A critical aspect that affects the network’s performance is the network architecture. The architecture employed for this research is based on a U-Net architecture [17]. The U-Net model is trained using the “semantic segmentation of aerial imagery”, applying two different loss functions.
To improve the sufficiency and diversity of training and validation data, the authors adopted several data augmentation operations, creating a new synthetic dataset [37]. The data augmentation operations involved the input images and the respective semantic segmentation masks. To evaluate its performance, Precision, Recall, and F1-Score metrics have been calculated.
The output of the trained model is a semantic segmentation mask, in which the segmented elements are classified into six classes: water, land, road, building, vegetation, and unlabeled. For this study, only buildings are considered. Then, considering the best model in terms of performance metrics, the transferability capability of the model is tested on three different urban areas within the Calabria region.
To test the accuracy of the model in correctly classifying and segmenting buildings exposed to natural hazards, the ability of the model to identify landslide risk buildings was considered. The case studies are characterized by different levels of landslide risk and urban shapes. This choice can lead to a better understanding of how the trained model responds in terms of accuracy, considering different contexts that the model had not experienced previously.
The semantic segmentation masks, and output of the model, are imported in a Geographic Information System (GIS) platform, and then vectorialized. For this research, the GIS platform considered is the open source QGIS Desktop software [41]. In order to evaluate the accuracy of the model applied to case studies, thanks to the GIS environment, the building polygons generated by the model are compared with building polygons of the Regional Technical Map, determining the F1-Score. In particular, the comparison between the model segmentation results and the ground truth dataset was made, considering both the entire built-up area and the buildings that fall into the landslide risk zones. The methodology workflow is presented in Figure 4.
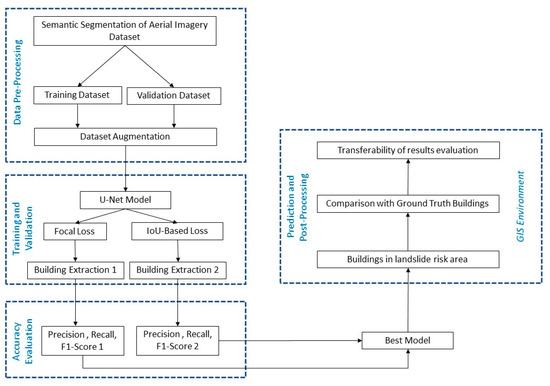
Figure 4.
Methodology flow chart.
3.2. The U-Net CNN Architecture
The U-Net model for building extraction tasks is based on a fully convolutional network, with encoder-decoder architecture capable of working with fewer training images, yielding more precise segmentation. Compared to conventional CNN, the contracting network (left side) is followed by an expanding network (right side) characterized by upsampling operators. This characteristic gives it the u-shaped architecture (Figure 5).
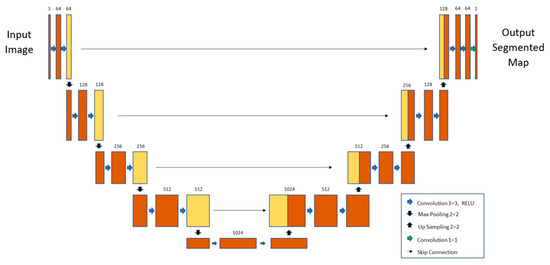
Figure 5.
U-net model structure [17].
The contracting path (encoder part) consists of repeated convolutions, each followed by a rectified linear unit (ReLU), and a max-pooling operation. In the contraction, the spatial information is reduced, while feature information is increased. Input data are elaborated by five convolutional blocks where features are extracted at different scales. Each convolutional block is composed of two 3 × 3 convolutions with ReLU activation.
The expanding part (decoder part) is characterized by a combination of the features and spatial information through a sequence of up-convolutions and concatenations with high-resolution features coming from the contracting path. In addition, an upsampling of the feature maps to the original image size is created by passing through five blocks.
3.3. Training and Validation of the U-Net CNN
For the training task of the U-Net semantic segmentation model, the authors selected Adam as an optimization method, and two different loss functions. The loss function has an essential impact on the model accuracy and, usually, the most suitable loss function will depend on the data properties and the class definitions. In this work, the loss functions considered are the Focal Loss and the IoU-based Loss, named also as the Jaccard Index. Focal Loss can be viewed as a better solution to the unbalanced dataset problem. Its characteristics allow it to reduce the impact of correct predictions and focus on incorrect examples. Furthermore, the Focal Loss can improve segmentation results. The functional form Focal Loss is derived from Cross-Entropy Loss (CE), and to down-weight easy examples and focus training on hard negatives uses a modulating factor (1 − pt)γ as reported below:
Here, pt represents the estimated probability of class t, while γ is a hyperparameter greater than zero, which represents the level of reduction of the impact of correct predictions. Similarly, α is a coefficient ranging 0 to 1 and can be set by inverse class frequency or treated as a hyperparameter. In this research, α is treated as a hyperparameter.
IoU, also known as the Jaccard index, is a standard region-based performance metric for image segmentation problems. The IoU, generally, is adopted to measure similarity between the ground-truth region and the predicted region, according to the expression (2).
As defined by (2), it calculates the ratio of the intersection and the union between the prediction and the ground-truth object in an image. It is characterized by the properties of scale invariance, symmetricity, and nonnegativity. Its value is contained in a range from 0 to 1, where 0 represents no similarity and 1 represents the equivalence between the predictions and the ground truth labels. To incorporate the IoU measure as an objective optimization function, the IoU-based Loss function is calculated by (3). This Loss function in (3) was first incorporated into the objective function in [42]:
In the expression (2), TP represents True Positives, which correspond to the number of correctly predicted buildings; FP are the False Positives, that is, the number of non-building entities incorrectly identified as buildings; and FN are False Negative cases, which represent real buildings incorrectly classified as non-buildings.
The (Adam) optimization algorithm [43] was employed with an initial learning rate of 0.001 and default hyper-parameters β1 = 0.9 and β2 = 0.999. The validation task has been carried out during training and its loss was calculated and monitored. If validation loss did not improve within four epochs, the learning rate was reduced by factor 0.5. To prevent overfitting, training was stopped if validation loss had not improved within 100 epochs. At the end of the training process, the model associated with the lowest validation loss was saved. Training was carried out on Google Colaboratory pro plus environment, using 52 GB of RAM and the GPU NVIDIA Tesla P100. All the project was implemented in Python and the training was developed using Pytorch, with TensorFlow backend as the deep learning framework (Supplementary Materials: https://github.com/ingegnerevitale/U-Net-Semantic-Segmentation-Aerial-Images (accessed on 10 January 2022)).
3.4. U-Net Model Performance Assessment
In this study, Precision, Recall, and F1-Score [44] were selected to measure the performance of the U-Net model, with both loss functions considered. Precision refers to the proportion of the samples that are correctly classified within the samples predicted positive. Recall refers to the proportion of correct classifieds in all really true samples. The F1-Score represents the harmonic mean of Precision and Recall and can be considered as a very complete performance measure. As stated in the previous section of the paper, True Positive (TP) is the positive sample predicted by the model, True Negative (TN) is the negative sample predicted as negative by the model. False Positive (FP) is the negative sample predicted as positive by the model, and False Negative (FN) is the negative sample predicted as positive by the model. Equations (4)–(6) present the functional forms of the performance measures.
3.5. Geographic Transferability Assessment
After the training and validation tasks of the two U-Net models, carried out considering the Focal Loss and the IoU-based Loss functions, the best model is chosen considering the highest value of F1-Score. This model is applied to the three case studies, generating as output, the predicted masks of built-up areas and, specifically, of the buildings falling in the landslide risk zones. Then, these masks are imported into a QGIS desktop platform, converted into vectorial layers, and compared with the label masks belonging to the ground truth dataset.
The transferability of a deep learning model is assessed, applying the model to different geographic regions that are considerably spatially distant from regions employed to train and validate the model [45]. Testing geographic transferability is useful to remove patterns of spatial autocorrelation between training and testing data.
To measure the transferability performance of the proposed model, the authors considered the F1-Score (Equation (6)). It represents a performance measure of the model’s prediction transferability to geographic areas that the model had not experienced before.
4. Results
4.1. U-Net Model Training and Validation Results
The U-Net model, widely used in semantic segmentation tasks, as stated in Section 3.3, was trained, and validated, considering two different loss functions, which are the Focal Loss and the IoU-based Loss. Considering, initially, the U-Net model with the Focal Loss function, Figure 6 summarizes the training and validation loss curves of the model, and Figure 7 shows the F1-Score with the change of epochs. It can be seen that the loss and F1-Score curves of the model become smoother after about 50 epochs, and the model reaches convergence as the epochs continue to increase. The best model reached the convergence at epoch 70, as can be seen from figures, with, in the validation task, a loss function value of 0.485 and F1-Score value of 0.63.
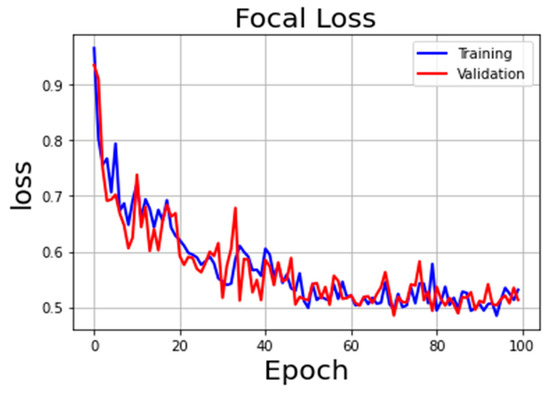
Figure 6.
Focal Loss curve during training and validation.
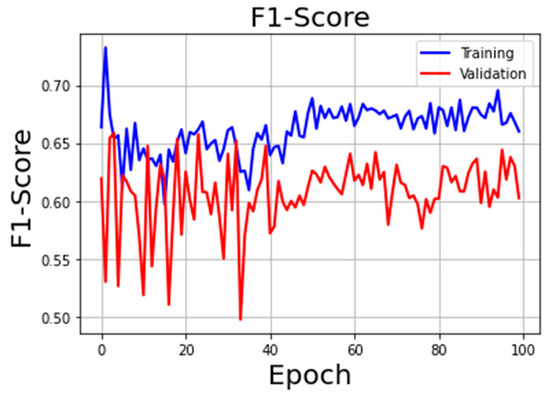
Figure 7.
F1-Score during training and validation using Focal Loss.
Figure 8 summarizes the training and validation loss curves of the U-Net model with IoU-based loss, and Figure 9 shows the F1-Score with the change of epochs. The best model reached the convergence at epoch 91 with, in the validation task, a loss function value of 0.634 and F1-Score value of 0.72.
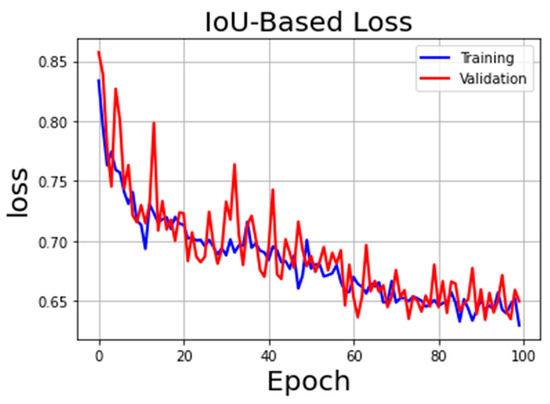
Figure 8.
IoU-based Loss curve during training and validation.
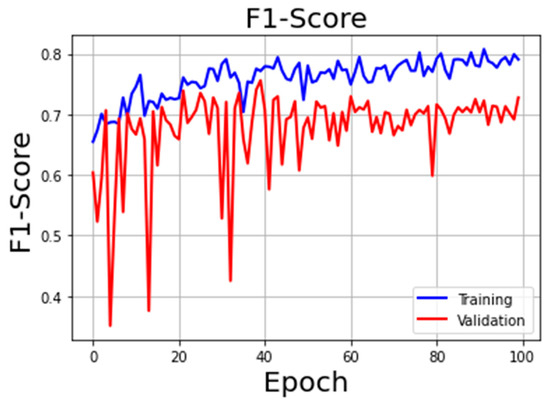
Figure 9.
F1-Score during training and validation using IoU-based Loss.
Table 1 highlights how U-Net model with IoU-based Loss has better results in terms of Precision, Recall, and F1-Score. Precision, using IoU-based Loss, improved significantly (0.14 higher), while Recall decreased slightly (0.03). Furthermore, the IoU-based Loss function allowed the model to increase F1-Score significantly (0.14), raising the value to 0.72.

Table 1.
U-Net model performance metrics considering different loss functions.
Therefore, the model applied to the three different case studies is the U-Net model with IoU-based Loss function, which ensures a better accuracy level.
4.2. Geographic Transferability of the U-Net Model
The U-Net model with IoU-based Loss function, which provides a better performance, is selected to explore its applicability in geographic areas that the model had not seen before. In particular, the trained and validated model is applied to three different urban areas of the Calabria region: Cetraro, Petrizzi, and San Vito sullo Ionio, as described in Section 2. For all of the case studies, the representation of the various elements of the aerial image is developed using the QGIS platform. The level of geographic transferability of the U-Net model results is calculated evaluating the F1-Score value, according to real and predicted buildings’ footprint area. In Figure 10, Figure 11 and Figure 12, for all case studies, the predicted buildings’ mask from the U-Net model are in green, the landslide risk zones from official Basin Authority dataset are in red, and the predicted buildings’ shape falling into landslide risk zones are in orange.

Figure 10.
Predicted buildings’ mask and landslide risk zones delimitation in Cetraro, represented in QGIS environment.
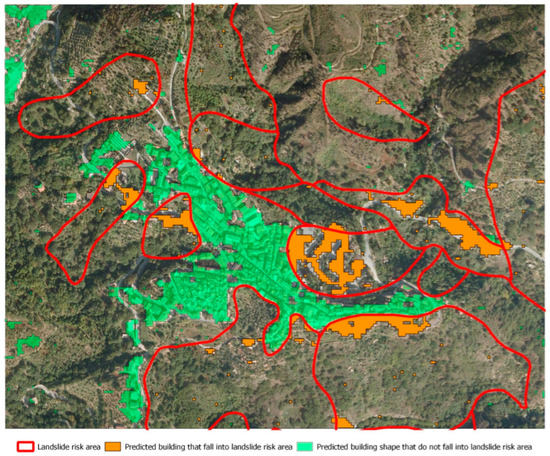
Figure 11.
Predicted buildings’ mask and landslide risk zones delimitation in Petrizzi, represented in QGIS environment.
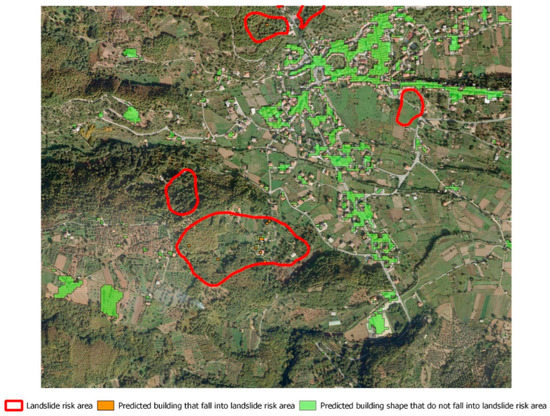
Figure 12.
Predicted buildings’ mask and landslide risk zones delimitation in San Vito sullo Ionio, represented in QGIS environment.
As stated in Section 2, Cetraro is characterized by a monocentric and compact urban shape. Considering the overall built-up area, it is composed of 162 buildings and from Figure 10 it is possible to appreciate a very good level of correspondence between real and predicted labels. However, it can be noted that there are some voids not detected as buildings inside the main inhabited nucleus. Even in the peripheral area, it is possible to view few False Negatives, and few areas with the presence of False Positives. Considering the totality of the buildings in Cetraro, the F1-Score reached a value of 0.93 (Table 2). This transferability measure indicates a great degree of matching between real and predicted values.
Table 2.
Geographic transferability performance of U-Net model considering the entire built-up area.
From Figure 10, it can be seen that the landslide risk zones are quite small and circumscribed near the main urban nucleus. The number of real buildings that fall within the landslide risk areas is very small and is equal to seven. The model seems to predict well the footprint of such buildings, except for the cases where the roofs are manufactured with materials having an RGB spectrum that can be easily confused with other elements in the aerial image. Also in this case, the number of False Positives and of False Negatives is the same as for the overall built-up area. The F1-Score for this category of buildings is equal to 0.80 (Table 3).
Table 3.
Geographic transferability performance of U-Net model considering only buildings falling in landslide risk zones.
As stated in Section 2, Petrizzi, differently from Cetraro, is characterized by a polycentric and compact urban shape. Considering the overall built-up area of the principal urban nucleus, it is composed of 488 buildings. From Figure 11, it is possible to appreciate a good level of correspondence between real and predicted labels. Considering the totality of the buildings, the peripheral areas of Petrizzi are characterized by a greater number of False Positives than Cetraro. The False Negatives in this case are lower than the False Positives. This situation is reflected in a F1-Score value of 0.81, lower than Cetraro.
As can be seen from Figure 11, landslide risk zones are located with a uniform distribution in the whole built-up area. The number of real buildings that fall within the landslide risk areas is equal to 180, which represents a value 25 times higher than Cetraro. Considering this scenario, the model seems to predict with a very good level of accuracy the footprint of such buildings. The False Negative cases are higher than the False Positive ones. The F1-Score value for this category of buildings is equal to 0.91 (Table 3).
San Vito sullo Ionio is the last case study and, differently from Cetraro and Petrizzi, is characterized by a polycentric and dispersed urban shape. Considering the overall built-up area, it is composed of a total of 932 buildings, a number greater than the other case studies. Figure 12 highlights a good level of correspondence between real and predicted labels, considering the high territorial dispersion of the buildings. The model seems to predict with a good level of accuracy the single buildings dispersed into the urban area. However, also for this case study, the peripheral areas are characterized by a number of False Positives and False Negatives equally distributed. This situation is reflected in a F1-Score value of 0.82, which is lower than Cetraro and higher than Petrizzi.
As can be seen from Figure 12, there is not a great level of landslide risk and the number of real buildings that fall within the landslide risk areas is very low and is equal to 25. This value is greater than Cetraro but about seven times lower with respect to Petrizzi. The model seems to predict with a quite good level of accuracy the footprint of such buildings. The F1-Score is 0.75, which is lower than Cetraro and Petrizzi (Table 3).
5. Discussion
The results described in Section 4 demonstrate an appreciable capability of the proposed methodology to automatically classify and segment buildings in built-up areas and, above all, those that fall into landslide risk zones. Starting with the training and validation operations, the applied methodology allowed the proposed U-Net model with the IoU-based Loss function to reach Precision, Recall, and F1-Score values of 0.63, 0.84, and 0.72, respectively.
The great challenge of the present research is to apply the model to geographic areas that it has never experienced, with very different geomorphological and territorial characteristics from those of the training and validation dataset. Despite this, the model showed a good level of geographical transferability of the results, although with differences from one case study to another. It implies that there are low patterns of spatial autocorrelation between training and testing data. This is very important for the generalization of the model, especially during emergency conditions. Then, in the presence of calamitous events, the model allows to quickly obtain an estimation, with a good level of accuracy, of the buildings to be monitored, or damaged, as a result of the catastrophic event. Therefore, there is no need to spend as much time on additional training and validation tasks for each case study.
Considering the classification and segmentation of the entire inhabited center, the best result in terms of geographic transferability was obtained for the urban area of Cetraro, with a high F1-Score metric (0.93). This result probably depends on the very compact and localized nature of the urban shape, which facilitates the segmentation task of the model.
From this point of view, it would seem that, considering the entire inhabited center, a greater degree of urban shape dispersion corresponds to a lower accuracy of the model. In fact, for the urban areas of Petrizzi and San Vito sullo Ionio, the F1-Scores decreases to 0.81 and 0.82, respectively.
This assumption also seems to be valid for the estimation of the footprint area of buildings falling within landslide risk zones, even if it also depends on the distribution, the localization, and the extension of the areas characterized by landslide risk. In fact, although the overall built-up area in Cetraro is very compact, the number of buildings falling within landslide risk zones is lower than the other urban areas. Consequently, the probability that the method generates False Positive and False Negative cases is higher. This is confirmed by the results obtained, that led to a F1-Score equal to 0.80.
Petrizzi, even though it is characterized by a polycentric and compact urban shape, as the opposite of Cetraro, is characterized by a widespread landslide risk. This condition implies that the capacity of the model to predict the footprint of the buildings located inside the landslide risk areas is higher than the previous case. In fact, in this case, the F1-Score reaches the value of 0.91.
Among the three case studies, the F1-Score of built-up area in landslide is lower for San Vito sullo Ionio (0.75), because the buildings in the landslide zones are fewer than Petrizzi, and very scattered.
Other elements that probably influenced the level of geographic transferability of the model are the different typology of land use, the different geomorphology of the territories, and the different constructive characteristics of the buildings, which led to different RGB spectrum values for the same classes of objects.
The proposed deep learning platform, and its future developments, based on an innovative and powerful methodology, can be employed as an early warning system capable of identifying vulnerable built-up areas that require periodic monitoring, becoming a very important tool for emergency management. It could also be employed for a rapid reconnaissance and a rough estimation of damaged buildings in a post hazard scenario. The platform can work receiving as input satellite images or, alternatively, aerial images coming from ad-hoc designed UAV flights in areas which, due to the occurrence of calamitous events, are not accessible. However, there are some issues to be highlighted.
Buildings are characterized by roofs built with different types of materials, having a different RGB spectrum. Every country is characterized by different construction characteristics and the materials employed. Often, deep learning models do not consider these differences, and they have poor performances in detecting buildings with singular architectural shapes. Nevertheless, although the authors trained and validated the proposed model with aerial images of Dubai, and applied it to different geographic areas, it distinguished buildings well from other elements, and also for those within a landslide risk area.
The “semantic segmentation of aerial imagery”, provided by Mohammed Bin Rashid Space Center in Dubai, has a spatial resolution of 1 m-pixel. With higher spatial resolution DEM in training and validation tasks, the model could probably better detect and segment the buildings. Nevertheless, the U-Net model, applied to aerial images with 0.423-m pixel resolution, is able to classify and segment buildings with a good level of accuracy, as demonstrated in Section 4.
Building extraction using deep learning models requires large amounts of label data and raw images. The number of images with the respective segmentation masks employed in training and validation tasks is quite low. To overcome this limitation, starting with the original dataset, the authors employed a data augmentation process, creating an augmented and more consistent artificial dataset.
The authors will improve this research project, considering a larger amount of label data for training and validation tasks. Further development of this study will also be aimed at testing and evaluating other deep learning architectures that are more suitable, and more accurate, for the purposes of the proposed methodology to reach a better performance in building extraction, and to make a comparison between them. This task implies greater computational costs; therefore, it is necessary to have local or remote dedicated servers with a large RAM performance (up to 50 GB).
6. Conclusions
Using satellite and aerial images, this paper presents an innovative methodology based on a deep learning approach to semi-automatically identify built-up areas potentially at risk of damage in the case of a natural disaster. The deep learning model used in the proposed methodology is the U-Net model, trained using the “semantic segmentation of aerial imagery”. To improve the sufficiency and diversity of training and validation data, the authors applied several data augmentation operations to input images, and the respective semantic segmentation masks. Two different loss functions have been considered. Between them, the best result was reached with the IoU-based Loss function, which allowed building extraction results close to the ground truth.
To avoid spatial autocorrelation patterns, the authors tested the level of geographic transferability of the model, considering the assessment of the overall built-up areas and the vulnerable or damaged buildings that fall into landslides risk zones in geographic areas that the model had never experienced. Although with some differences from one case study to another, the results demonstrate a good level of geographical transferability of the model.
The results obtained from the geographic transferability assessment demonstrate that geographic transferability could depend on different elements, such as: the different urban shapes of the analyzed contexts; the distribution, localization, and extension of the landslide risk zones; the different typology of land use (residential, commercial, industrial land use, etc.); the geomorphological characteristics of the territories; the different constructive typologies of the buildings; and the different material used, which led to different RGB spectrum values for the same classes of objects.
The proposed methodology can be viewed as a Decision Support System that, in the presence of calamitous events, allows to quickly obtain an estimation of the built-up areas to be monitored, or damaged. It can be considered a very useful tool for disaster management planning, becoming an early warning system capable of identifying critical built-up areas that require periodic monitoring. It can also be employed to assess damaged buildings and disrupted infrastructures when a hazardous event occurs, using satellite and aerial images, or ad-hoc designed UAV flights in less accessible urban areas. Due to the good geographic transferability demonstrated by the proposed model, this tool can help decision-makers in defining rapid solutions and in finding opportune countermeasures in disaster response.
Supplementary Materials
Python code, input image data, and output predicted buildings’ masks can be accessed at: https://github.com/ingegnerevitale/U-Net-Semantic-Segmentation-Aerial-Images.
Author Contributions
Conceptualization, M.F., C.S. and A.V. (Alessandro Vitale); methodology, A.V. (Alessandro Vitale); software, A.V. (Alessandro Vitale); validation, M.F., C.S., A.V. (Antonio Viscomi) and A.V. (Alessandro Vitale); formal analysis, C.S. and A.V. (Alessandro Vitale); data curation, A.V. (Antonio Viscomi) and A.V. (Alessandro Vitale); writing—original draft preparation, C.S. and A.V. (Alessandro Vitale); writing—review and editing, M.F., C.S., A.V. (Antonio Viscomi) and A.V. (Alessandro Vitale); supervision, M.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received funding from the Department of Civil Engineering of University of Calabria.
Data Availability Statement
The “semantic segmentation dataset” employed in training and validation tasks is available, registering at https://humansintheloop.org/semantic-segmentation-dataset/ (accessed on 10 January 2022).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gupta, A.; Watson, S.; Yin, H. Deep learning-based aerial image segmentation with open data for disaster impact assessment. Neurocomputing 2021, 439, 22–33. [Google Scholar] [CrossRef]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic Segmentation-Based Building Footprint Extraction Using Very High-Resolution Satellite Images and Multi-Source GIS Data. Remote Sens. 2019, 11, 403. [Google Scholar] [CrossRef]
- Ivanovsky, L.; Khryashchev, V.; Pavlov, V.; Ostrovskaya, A. Building detection on aerial images using U-NET neural networks. In Proceedings of the 24th Conference of Open Innovations Association (FRUCT), Moscow, Russia, 8–12 April 2019. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Ziaei, Z.; Pradhan, B.; Mansor, S.B. A rule-based parameter aided with object-based classification approach for extraction of building and roads fromWorldView-2 images. Geocarto Int. 2014, 29, 554–569. [Google Scholar] [CrossRef]
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Belgiu, M.; Drǎguţ, L. Comparing supervised and unsupervised multiresolution segmentation approaches for extracting buildings from very high resolution imagery. ISPRS J. Photogramm. Remote Sens. 2014, 96, 67–75. [Google Scholar] [CrossRef]
- Chen, R.; Li, X.; Li, J. Object-Based Features for House Detection from RGB High-Resolution Images. Remote Sens. 2018, 10, 451. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Li, W.; He, C.; Fang, J.; Fu, H. Semantic Segmentation based Building Extraction Method using Multi-source GIS Map Datasets and Satellite Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Cao, R.; Zhu, J.; Tu, W.; Li, Q.; Cao, J.; Liu, B.; Zhang, Q.; Qiu, G. Integrating Aerial and Street View Images for Urban Land Use Classification. Remote Sens. 2018, 10, 1553. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-Detect: Vehicle Detection and Classification through Semantic Segmentation of Aerial Images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.; Zhang, X.; Luo, P. Transferability of Convolutional Neural Network Models for Identifying Damaged Buildings Due to Earthquake. Remote Sens. 2021, 13, 504. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Ghorbanzadeh, O.; Crivellari, A.; Ghamisi, P.; Shahabi, H.; Blaschke, T. A comprehensive transferability evaluation of U-Net and ResU-Net for landslide detection from Sentinel-2 data (case study areas from Taiwan, China, and Japan). Sci. Rep. 2021, 11, 14629. [Google Scholar] [CrossRef] [PubMed]
- John, D.; Zhang, C. An attention-based U-Net for detecting deforestation within satellite sensor imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102685. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, B.; Zhang, A. Building segmentation from satellite imagery using U-Net with ResNet encoder. In Proceedings of the 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICLM), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Miao, H.; Zhao, Z.; Su, C.; Li, B.; Yan, R. A U-Net-Based Approach for Tool Wear Area Detection and Identification. IEEE Trans. Instrum. Meas. 2020, 70, 5004110. [Google Scholar] [CrossRef]
- Alsabhan, W.; Alotaiby, T. Automatic Building Extraction on Satellite Images Using Unet and ResNet50. Comput. Intell. Neurosci. 2022, 2022, 5008854. [Google Scholar] [CrossRef]
- Hussein, S.K.; Ali, K.H. Semantic Segmentation of Aerial Images Using U-Net Architecture. Iraqi J. Electr. Electron. Eng. 2021, 18, 58–63. [Google Scholar] [CrossRef]
- Bouchard, I.; Rancourt, M.-È.; Aloise, D.; Kalaitzis, F. On Transfer Learning for Building Damage Assessment from Satellite Imagery in Emergency Contexts. Remote Sens. 2022, 14, 2532. [Google Scholar] [CrossRef]
- Chen, X.; Yao, X.; Zhou, Z.; Liu, Y.; Yao, C.; Ren, K. DRs-UNet: A Deep Semantic Segmentation Network for the Recognition of Active Landslides from InSAR Imagery in the Three Rivers Region of the Qinghai–Tibet Plateau. Remote Sens. 2022, 14, 1848. [Google Scholar] [CrossRef]
- Qi, W.; Wei, M.; Yang, W.; Xu, C.; Ma, C. Automatic Mapping of Landslides by the ResU-Net. Remote Sens. 2020, 12, 2487. [Google Scholar] [CrossRef]
- Joyce, K.E.; Belliss, S.E.; Samsonov, S.V.; McNeill, S.J.; Glassey, P.J. A review of the status of satellite remote sensing and image processing techniques for mapping natural hazards and disasters. Prog. Phys. Geogr. 2009, 33, 183–207. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Bocchini, P.; Davison, B.D. Applications of Artificial Intelligence for Disaster Management. Nat. Hazards 2020, 103, 2631–2689. [Google Scholar] [CrossRef]
- Bragagnolo, L.; Rezende, L.R.; da Silva, R.V.; Grzybowski, J.M.V. Convolutional neural networks applied to semantic segmentation of landslide scars. Catena 2021, 201, 105189. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, C. Building damage evaluation from satellite imagery using deep learning. In Proceedings of the 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020. [Google Scholar]
- Amit, S.N.K.B.; Aoki, Y. Disaster detection from aerial imagery with convolutional neural network. In Proceedings of the 2017 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC), Surabaya, Indonesia, 26–27 September 2017. [Google Scholar]
- Knopp, L.; Wieland, M.; Rättich, M.; Martinis, S. A Deep Learning Approach for Burned Area Segmentation with Sentinel-2 Data. Remote Sens. 2020, 12, 2422. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, F.; Xia, J.; Xu, Y.; Li, G.; Xie, J.; Du, Z.; Liu, R. Building Damage Detection Using U-Net with Attention Mechanism from Pre- and Post-Disaster Remote Sensing Datasets. Remote Sens. 2021, 13, 905. [Google Scholar] [CrossRef]
- You, D.; Wang, S.; Wang, F.; Zhou, Y.; Wang, Z.; Wang, J.; Xiong, Y. EfficientUNet+: A Building Extraction Method for Emergency Shelters Based on Deep Learning. Remote Sens. 2022, 14, 2207. [Google Scholar] [CrossRef]
- Semantic Segmentation Dataset. Available online: https://humansintheloop.org/semantic-segmentation-dataset/ (accessed on 10 January 2022).
- Yang, S.; Xiao, W.; Zhang, M.; Guo, S.; Zhao, J.; Shen, F. Image Data Augmentation for Deep Learning: A Survey. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), New Orleans, LO, USA, 19–24 June 2022. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef]
- Autorità di Bacino della Regione Calabria. Available online: https://www.regione.calabria.it/website/ugsp/autoritadibacino/ (accessed on 10 January 2022).
- Geoportale della Regione Calabria. Available online: http://geoportale.regione.calabria.it/ (accessed on 10 January 2022).
- QGIS. 2022 QGIS User Guide. Available online: https://docs.qgis.org/3.22/it/docs/user_manual/ (accessed on 10 January 2022).
- Boughorbel, S.; Jarray, F.; El-Anbari, M. Optimal classifier for imbalanced data using matthews correlation coefficient metric. PLoS ONE 2017, 12, e0177678. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chinchor, N.; Sundheim, B.M. MUC-5 evaluation metrics. In Proceedings of the Fifth Message Understanding Conference (MUC-5), Baltimore, MD, USA, 25–27 August 1993. [Google Scholar]
- Spasov, A.; Petrova-Antonova, D. Transferability assessment of open-source deep learning model for building detection on satellite data. In Proceedings of the 16th GeoInfo Conference 2021, New York, NY, USA, 11–14 October 2021. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).