
Multi-Scale Feature Aggregation Network for Water Area Segmentation




Abstract
:1. Introduction
- 1
- A Deep Feature Extraction module is proposed. In the last stage of down-sampling, context adjacent scales are integrated, and global and location information is extracted, so as to obtain more effective information and optimize context learning.
- 2
- A multi-branch aggregation network is proposed to enhance the communication abilities of the two channels through different-scale guidances. By capturing different scale feature representations, it can enhance the interconnection and merge the two types of element representations, which can provide more detailed information for image restoration.
- 3
- A Feature Fusion Upsample module is proposed to optimize the high-level features, enhance the pixel information and spatial position at the edge of the background, use the long-term dependence, eliminate useless information, guide the low-level features, obtain new features, and then guide the new features with the original high-level features.
- 4
- A high-resolution, remote-sensing image segmentation network is proposed, which uses the feature extraction network and three additional modules for segmentation tasks.
2. Method
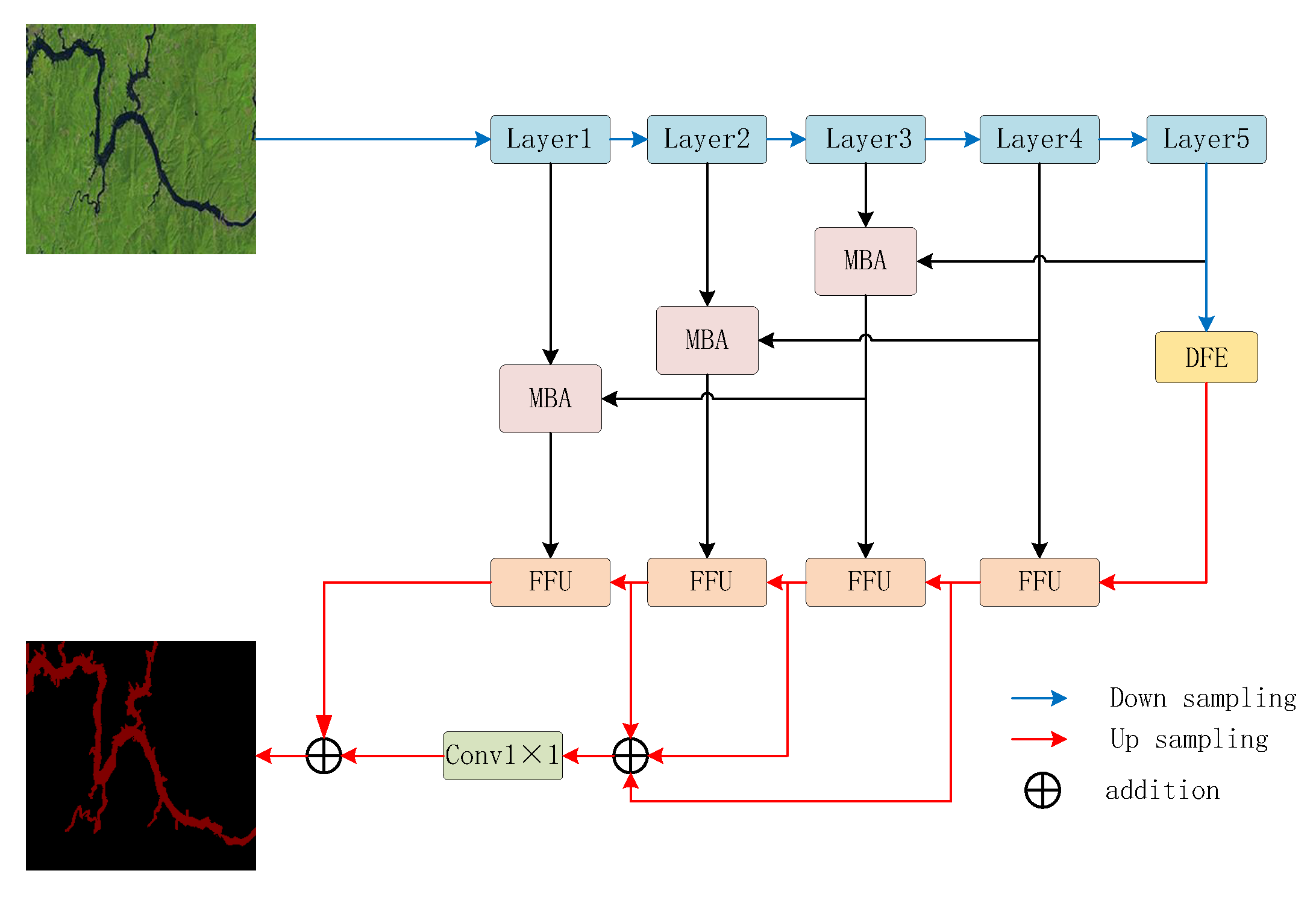
3. Network Structure
3.1. Backblone
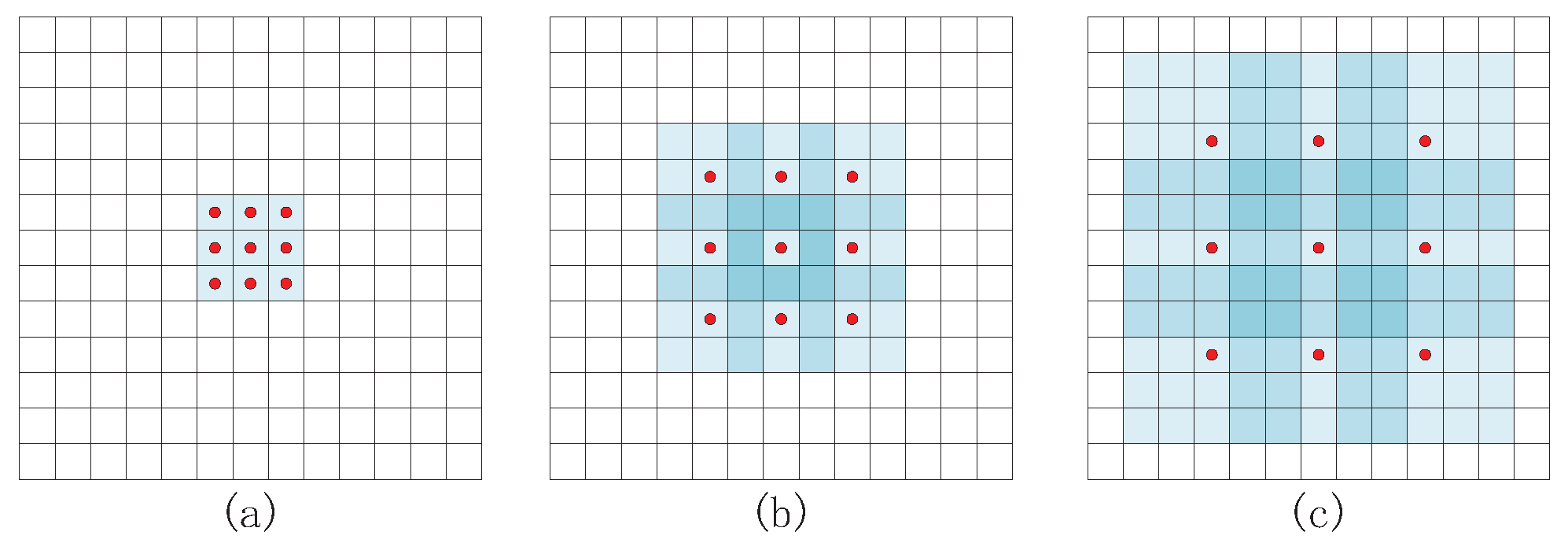
3.2. Deep Feature Extraction Module
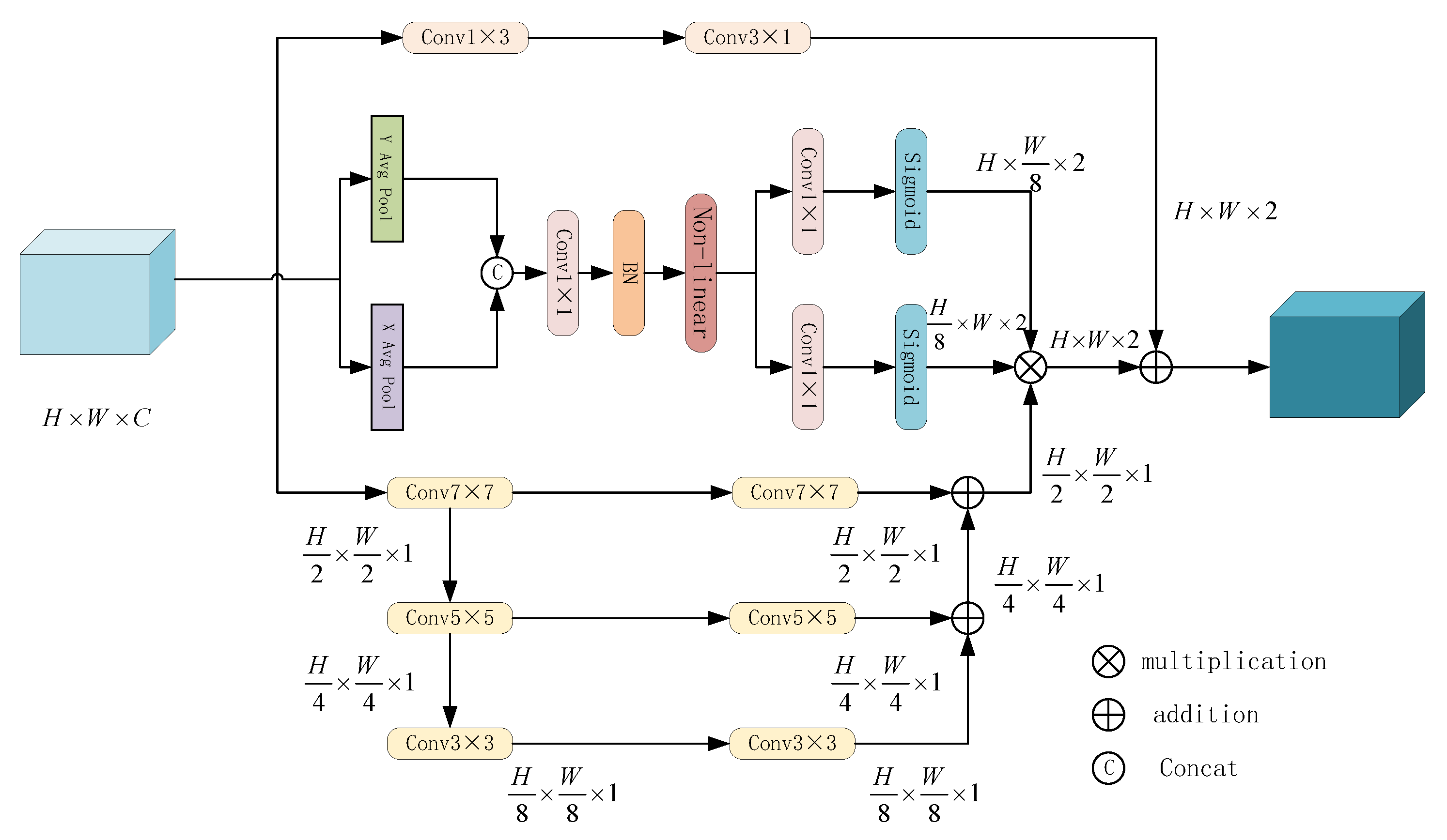
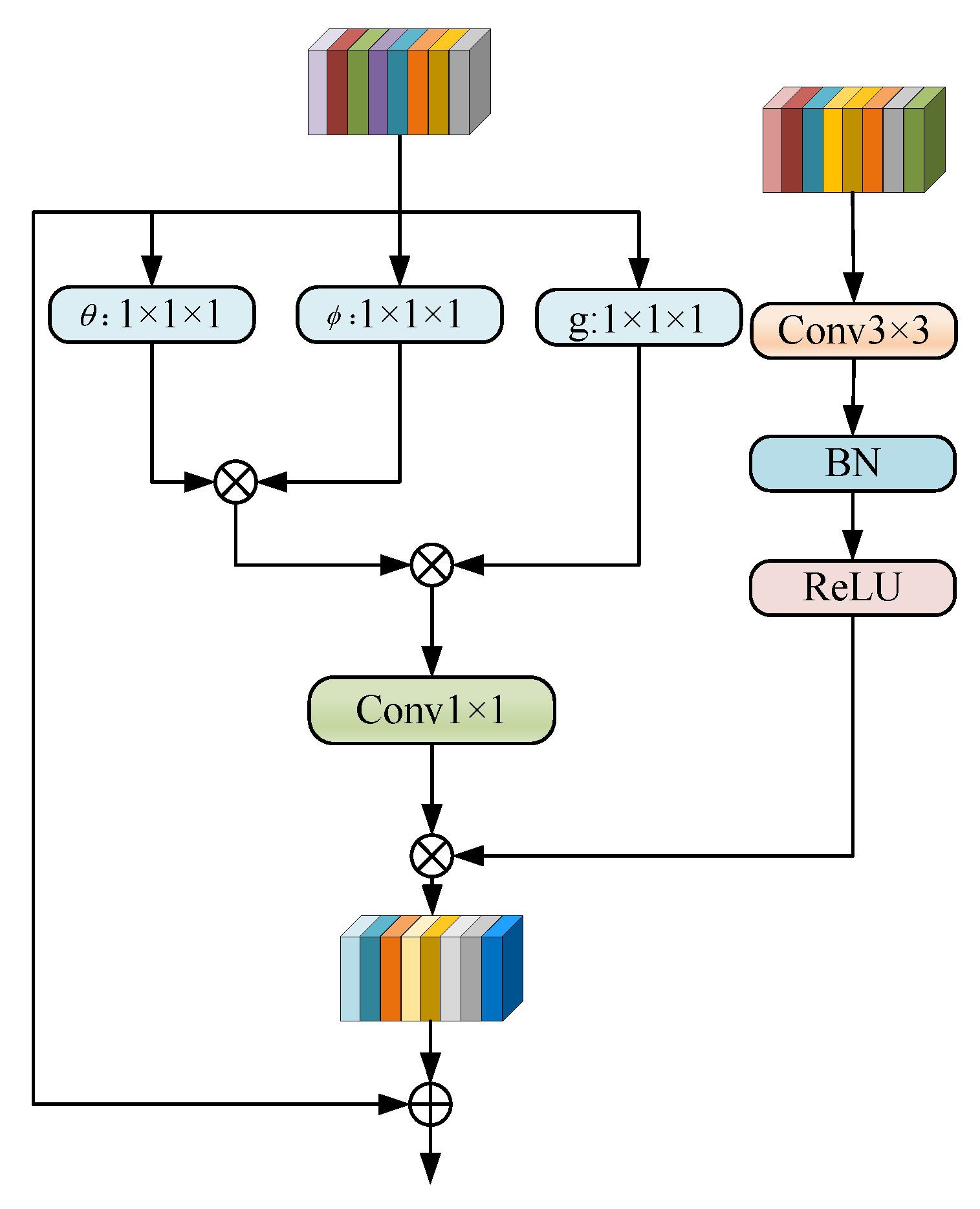
3.3. Multi-Branch Aggregation Module
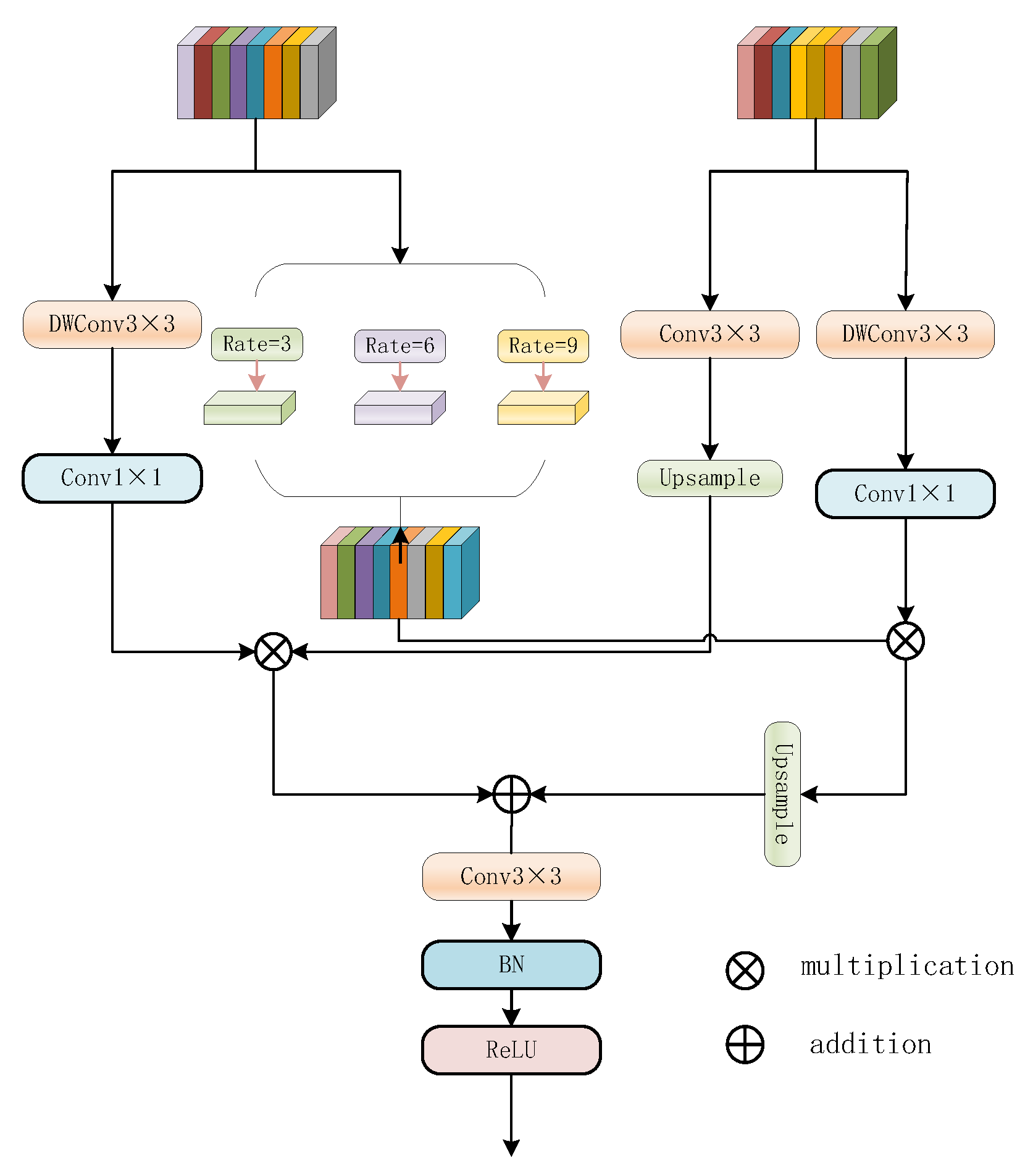
3.4. Feature Fusion Upsample Module
4. Experiment
4.1. Datasets
4.1.1. Water Segmentation Dataset
4.1.2. Cloud and Cloud Shadow Dataset
4.1.3. LandCover Dataset
4.2. Implementation Details
4.3. Ablation Experiment
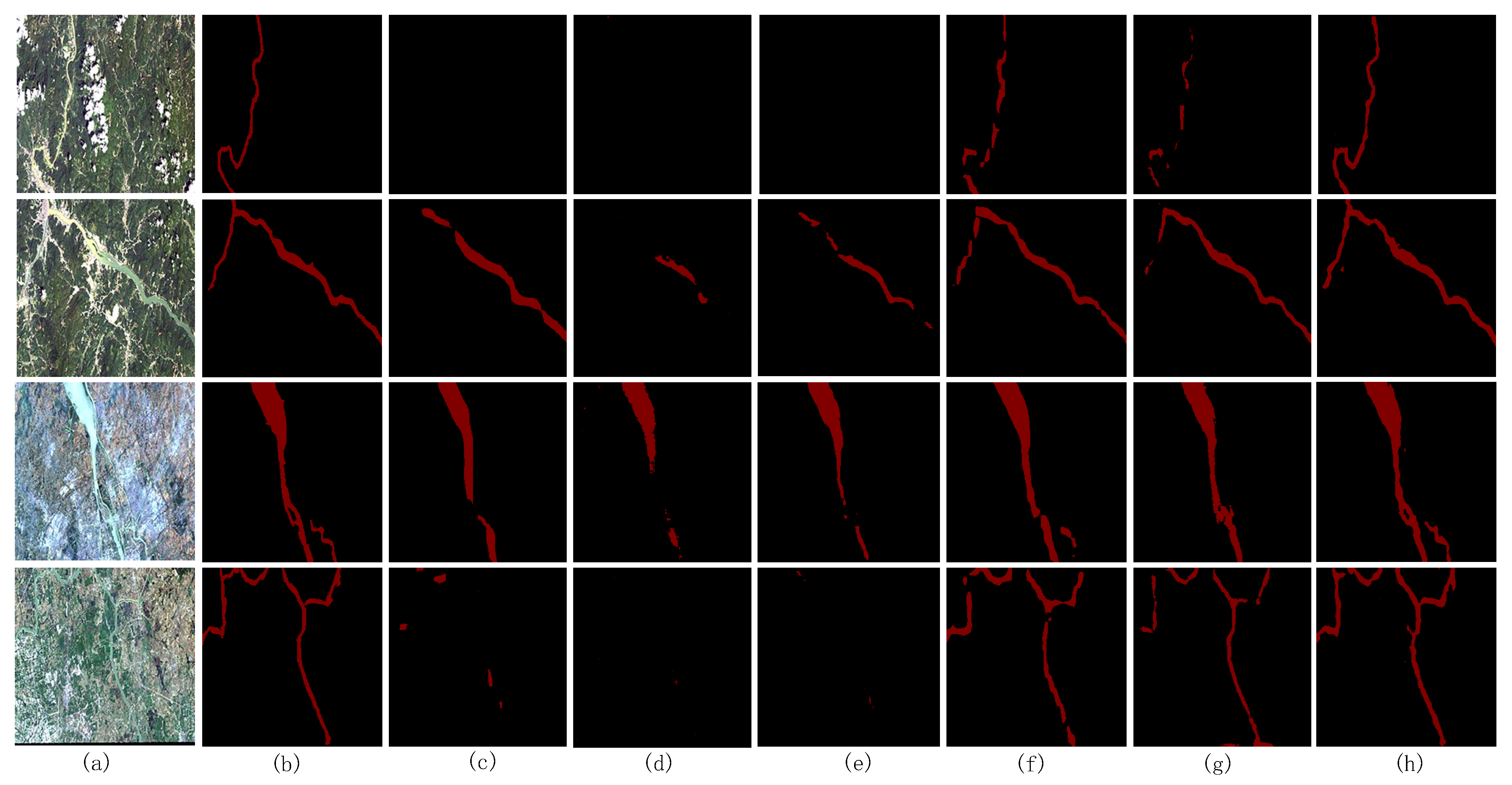
4.4. Comparative Experiment with Other Networks
4.5. Generalization Experiment
4.5.1. Cloud and Cloud Shadow Dataset
4.5.2. LandCover Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Verma, U.; Chauhan, A.; MM, M.P.; Pai, R. DeepRivWidth: Deep learning based semantic segmentation approach for river identification and width measurement in SAR images of Coastal Karnataka. Comput. Geosci. 2021, 154, 104805. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, J.Q.; Pa, L. River change detection based on remote sensing image and vector. In Proceedings of the First International Multi-Symposiums on Computer and Computational Sciences (IMSCCS’06), Hangzhou, China, 20–24 June 2006; pp. 188–191. [Google Scholar]
- Sun, J.Q.; Mao, S.Y. River detection algorithm in SAR images based on edge extraction and ridge tracing techniques. Int. J. Remote Sens. 2011, 32, 3485–3494. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Singh, P.K.; Sinha, N.; Sikka, K.; Mishra, A.K. Texture information-based hybrid methodology for the segmentation of SAR images. Int. J. Remote Sens. 2011, 32, 4155–4173. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, Q.G.; Xu, J. Coastline extraction using support vector machine from remote sensing image. J. Multim. 2013, 8, 175–182. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Ciecholewski, M. River channel segmentation in polarimetric SAR images: Watershed transform combined with average contrast maximisation. Expert Syst. Appl. 2017, 82, 196–215. [Google Scholar] [CrossRef]
- Sghaier, M.O.; Foucher, S.; Lepage, R. River extraction from high-resolution SAR images combining a structural feature set and mathematical morphology. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1025–1038. [Google Scholar] [CrossRef]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Shamsolmoali, P.; Chanussot, J.; Zareapoor, M.; Zhou, H.Y.; Yang, J. Multipatch Feature Pyramid Network for Weakly Supervised Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 1–13. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Chanussot, J.; Zhou, H.Y.; Yang, J. Rotation Equivariant Feature Image Pyramid Network for Object Detection in Optical Remote Sensing Imagery. arXiv 2021, arXiv:2106.00880. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.Y.; Wang, R.L.; Yang, J. Road Segmentation for Remote Sensing Images Using Adversarial Spatial Pyramid Networks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4673–4688. [Google Scholar] [CrossRef]
- Hoekstra, M.; Jiang, M.Z.; Clausi, D.A.; Duguay, C. Lake Ice-Water Classification of RADARSAT-2 Images by Integrating IRGS Segmentation with Pixel-Based Random Forest Labeling. Remote Sens. 2020, 12, 1425. [Google Scholar] [CrossRef]
- Weng, L.G.; Xu, Y.M.; Xia, M.; Zhang, Y.H.; Liu, J.; Xu, Y.Q. Water areas segmentation from remote sensing images using a separable residual segnet network. ISPRS Int. J. Geo-Inf. 2020, 9, 256. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Tsotsos, J.K. Analyzing vision at the complexity level. Behav. Brain Sci. 1990, 13, 423–445. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Zhu, M.L.; Chen, B.; Kalenichenko, D.; Wang, W.J.; Wey, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Wang, Z.W.; Xia, M.; Lu, M.; Pan, L.L.; Liu, J. Parameter Identification in Power Transmission Systems Based on Graph Convolution Network. IEEE Trans. Power Deliv. 2021. [Google Scholar] [CrossRef]
- Tsotsos, J.K. A Computational Perspective on Visual Attention; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3286–3295. [Google Scholar]
- Ge, S.; Wang, C.; Jiang, Z.W.; Hao, H.Z.; Gu, Q. Dual-input attention network for automatic identification of detritus from river sands. Comput. Geosci. 2021, 151, 104735. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Jin, J.; Qian, M.; Zhang, Y.H. SUACDNet: Attentional change detection network based on siamese U-shaped structure. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102597. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y.H. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wang, W.H.; Hu, X.L.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Xia, M.; Zhang, X.; Weng, L.; Xu, Y. Multi-stage feature constraints learning for age estimation. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2417–2428. [Google Scholar] [CrossRef]
- Xia, M.; Wang, K.; Song, W.Z.; Chen, C.L.; Li, Y.P. Non-intrusive load disaggregation based on composite deep long short-term memory network. Expert Syst. Appl. 2020, 160, 113669. [Google Scholar] [CrossRef]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Zambrzycka, A.; Dziedzic, T. Landcover. ai: Dataset for automatic mapping of buildings, woodlands and water from aerial imagery. arXiv 2020, arXiv:2005.02264. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Li, H.C.; Xiong, P.F.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Dang, B.; Li, Y.S. MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery. Remote Sens. 2021, 13, 3122. [Google Scholar] [CrossRef]
- Yu, C.Q.; Wang, J.B.; Peng, C.; Gao, C.X.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1857–1866. [Google Scholar]
- Yu, C.Q.; Wang, J.B.; Peng, C.; Gao, C.X.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.W.; Yang, K.Y. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Zhang, Z.L.; Lu, M.; Ji, S.P.; Yu, H.F.; Nie, C.H. Rich CNN Features for Water-Body Segmentation from Very High Resolution Aerial and Satellite Imager. Remote Sens. 2021, 13, 1912. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Imput | Kernel Size | Stride | Output |
|---|---|---|---|---|
| Layer1 | 2 | |||
| Layer2 | 2 | |||
| Layer3 | 2 | |||
| Layer4 | 2 | |||
| Layer5 | 2 |
| Method | mIOU (%) |
|---|---|
| ResNet50 | 90.94 |
| ResNet50 + FFU | 94.57 |
| ResNet50 + FFU + DFE | 95.01 |
| ResNet50 + FFU + DFE + MBA | 95.94 |
| Method | FLops (GMac) | T (s) | P (%) | R (%) | F1 (%) | MPA (%) | mIOU (%) |
|---|---|---|---|---|---|---|---|
| FCN8sAtOnce | 73.35 | 73 | 94.74 | 92.26 | 93.48 | 95.32 | 91.89 |
| Deeplabv3+ [41] | 64.92 | 76 | 96.28 | 92.75 | 94.48 | 95.81 | 93.09 |
| SegNet | 42.48 | 43 | 95.93 | 93.16 | 94.52 | 95.95 | 93.13 |
| PANnet [42] | 5.73 | 29 | 96.94 | 92.27 | 94.54 | 95.67 | 93.17 |
| MSResNet [43] | 31.94 | 53 | 94.91 | 94.54 | 94.73 | 97.46 | 93.35 |
| DFNnet [44] | 7.81 | 45 | 95.93 | 93.58 | 94.74 | 96.16 | 93.38 |
| BiSeNet [45] | 15.24 | 26 | 96.88 | 94.01 | 95.42 | 96.52 | 94.21 |
| PSPNet | 46.07 | 56 | 97.53 | 94.12 | 95.80 | 96.68 | 94.68 |
| UNet | 40 | 41 | 96.98 | 94.70 | 95.83 | 96.88 | 94.70 |
| DenseASPP [46] | 38.71 | 91 | 96.23 | 95.49 | 95.86 | 97.15 | 94.73 |
| MEcnet [47] | 46.04 | 105 | 97.67 | 94.64 | 95.45 | 96.13 | 95.01 |
| Ours | 29.43 | 56 | 98.07 | 95.62 | 96.83 | 97.51 | 95.94 |
| Method | PA (%) | MPA (%) | mIOU (%) |
|---|---|---|---|
| FCN8sAtOnce | 93.13 | 91.02 | 84.39 |
| SegNet | 93.30 | 91.53 | 84.70 |
| DFNnet | 93.99 | 92.60 | 86.20 |
| UNet | 94.18 | 92.84 | 86.43 |
| PSPNet | 94.19 | 92.18 | 86.76 |
| Ours | 94.46 | 93.13 | 87.28 |
| Method | PA (%) | MPA (%) | mIOU (%) |
|---|---|---|---|
| SegNet | 94.93 | 94.38 | 89.97 |
| BiSeNet | 95.64 | 95.38 | 91.35 |
| PAN | 96.07 | 95.69 | 92.15 |
| DenseASPP | 96.11 | 95.85 | 92.24 |
| UNet | 96.17 | 95.58 | 92.35 |
| MSResNet | 96.20 | 96.04 | 92.43 |
| Deeplabv3+ | 96.23 | 95.84 | 92.45 |
| Ours | 96.45 | 96.12 | 92.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, K.; Li, M.; Xia, M.; Lin, H. Multi-Scale Feature Aggregation Network for Water Area Segmentation. Remote Sens. 2022, 14, 206. https://doi.org/10.3390/rs14010206
Hu K, Li M, Xia M, Lin H. Multi-Scale Feature Aggregation Network for Water Area Segmentation. Remote Sensing. 2022; 14(1):206. https://doi.org/10.3390/rs14010206
Chicago/Turabian StyleHu, Kai, Meng Li, Min Xia, and Haifeng Lin. 2022. "Multi-Scale Feature Aggregation Network for Water Area Segmentation" Remote Sensing 14, no. 1: 206. https://doi.org/10.3390/rs14010206
APA StyleHu, K., Li, M., Xia, M., & Lin, H. (2022). Multi-Scale Feature Aggregation Network for Water Area Segmentation. Remote Sensing, 14(1), 206. https://doi.org/10.3390/rs14010206