Random Forest Regression Model for Estimation of the Growing Stock Volumes in Georgia, USA, Using Dense Landsat Time Series and FIA Dataset





Abstract
1. Introduction
2. Materials and Methods
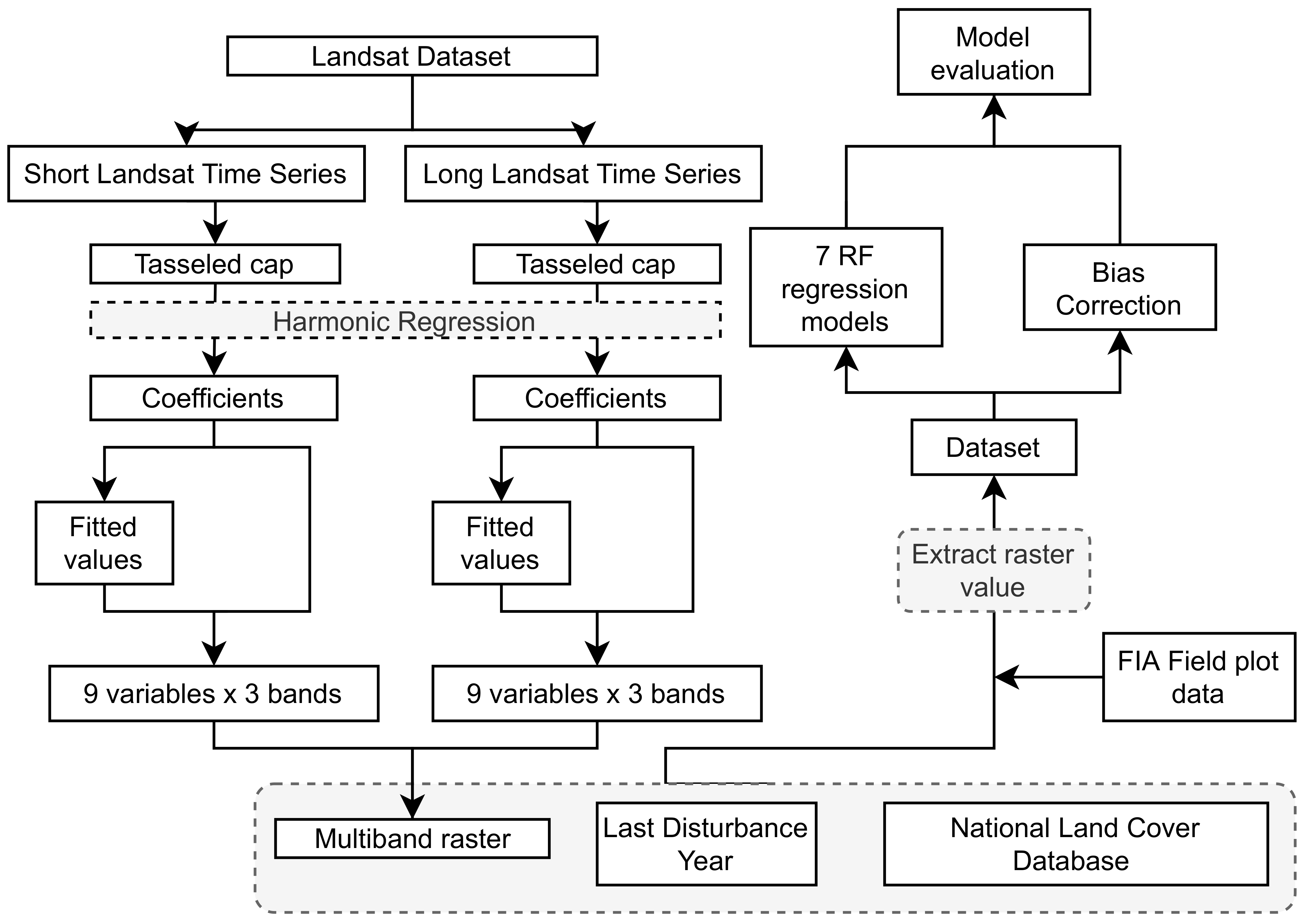
2.1. Research Overview
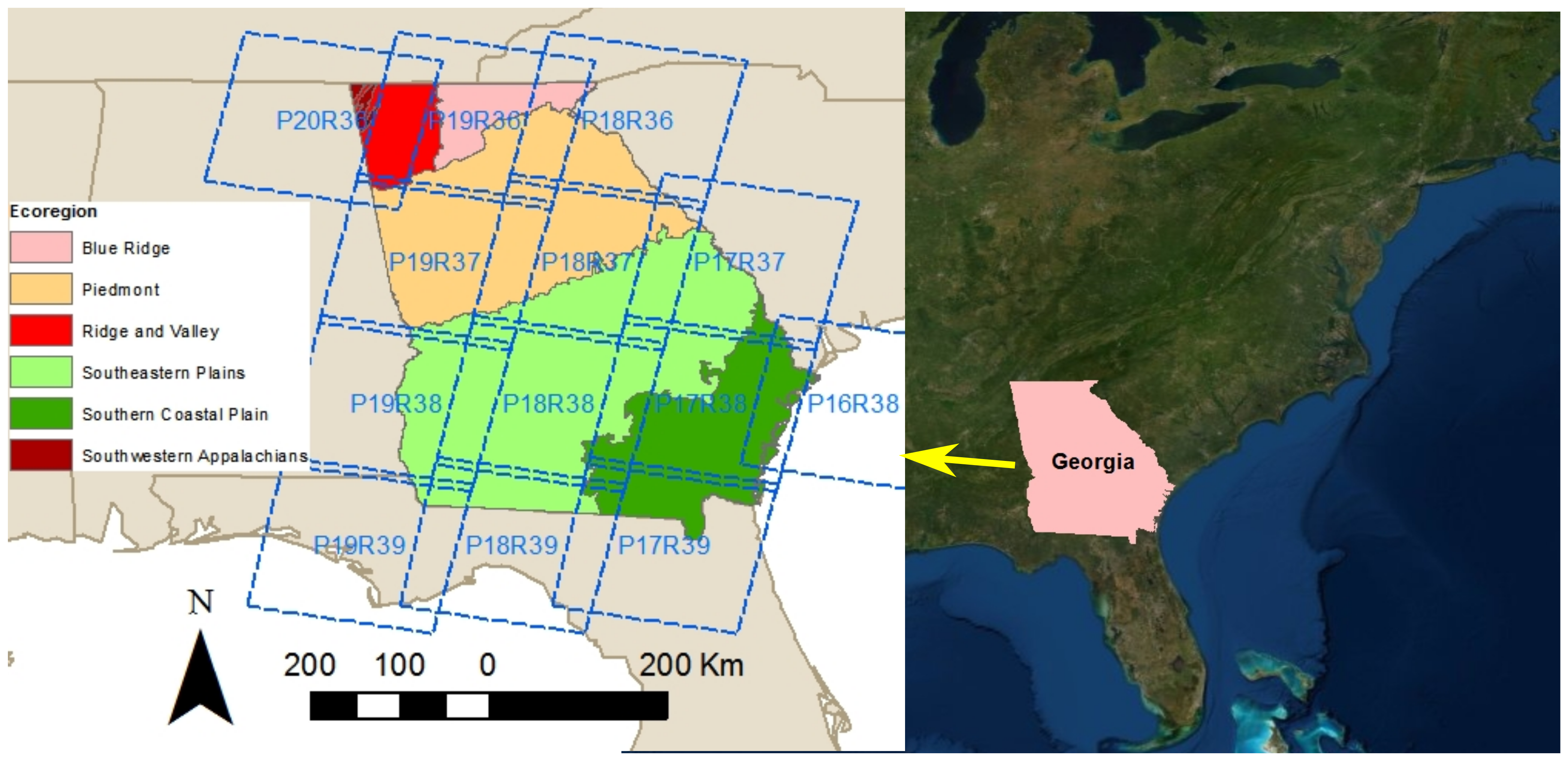
2.2. Study Area
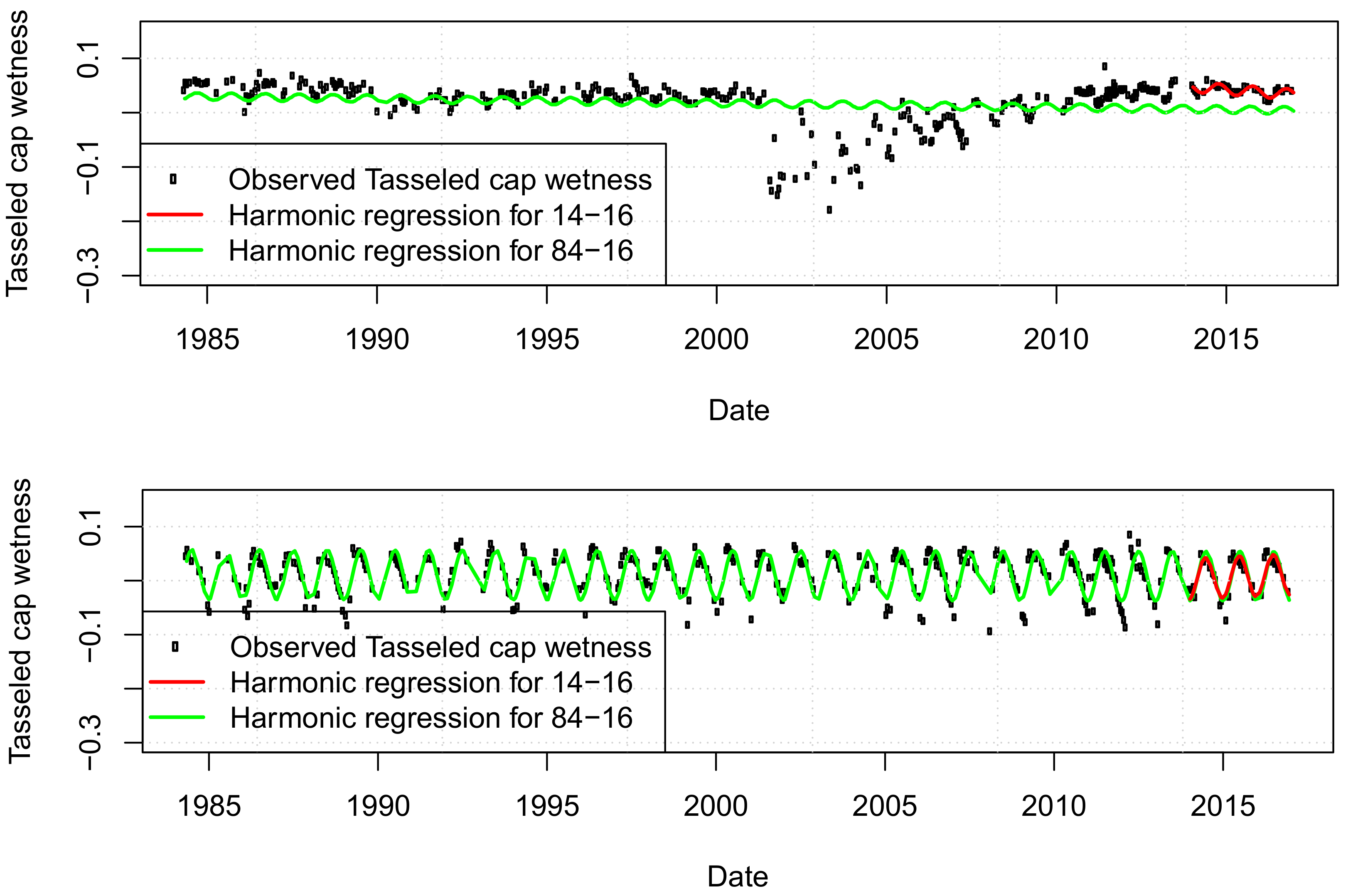
2.3. Satellite Data
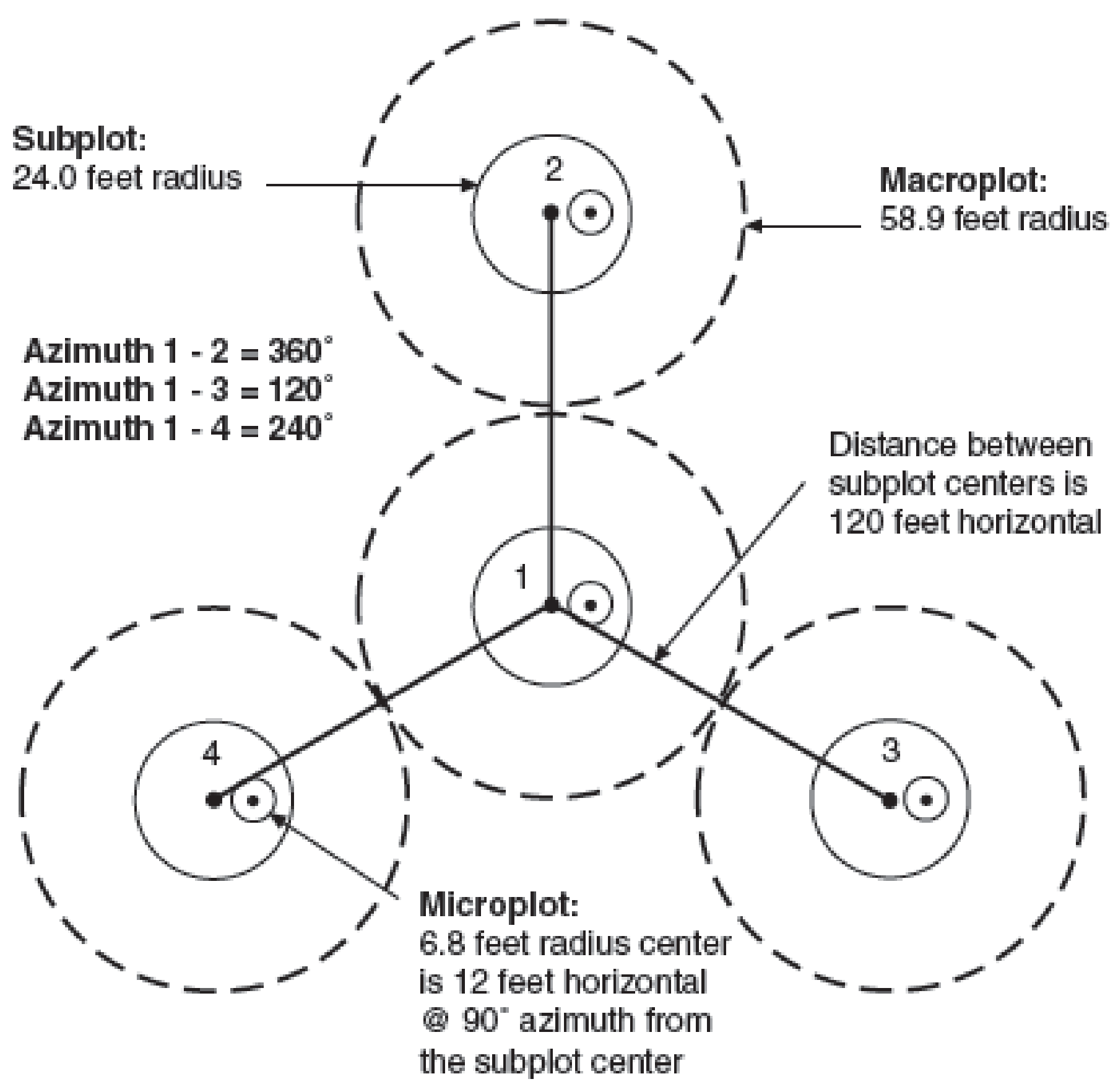
2.4. Ancillary Databases
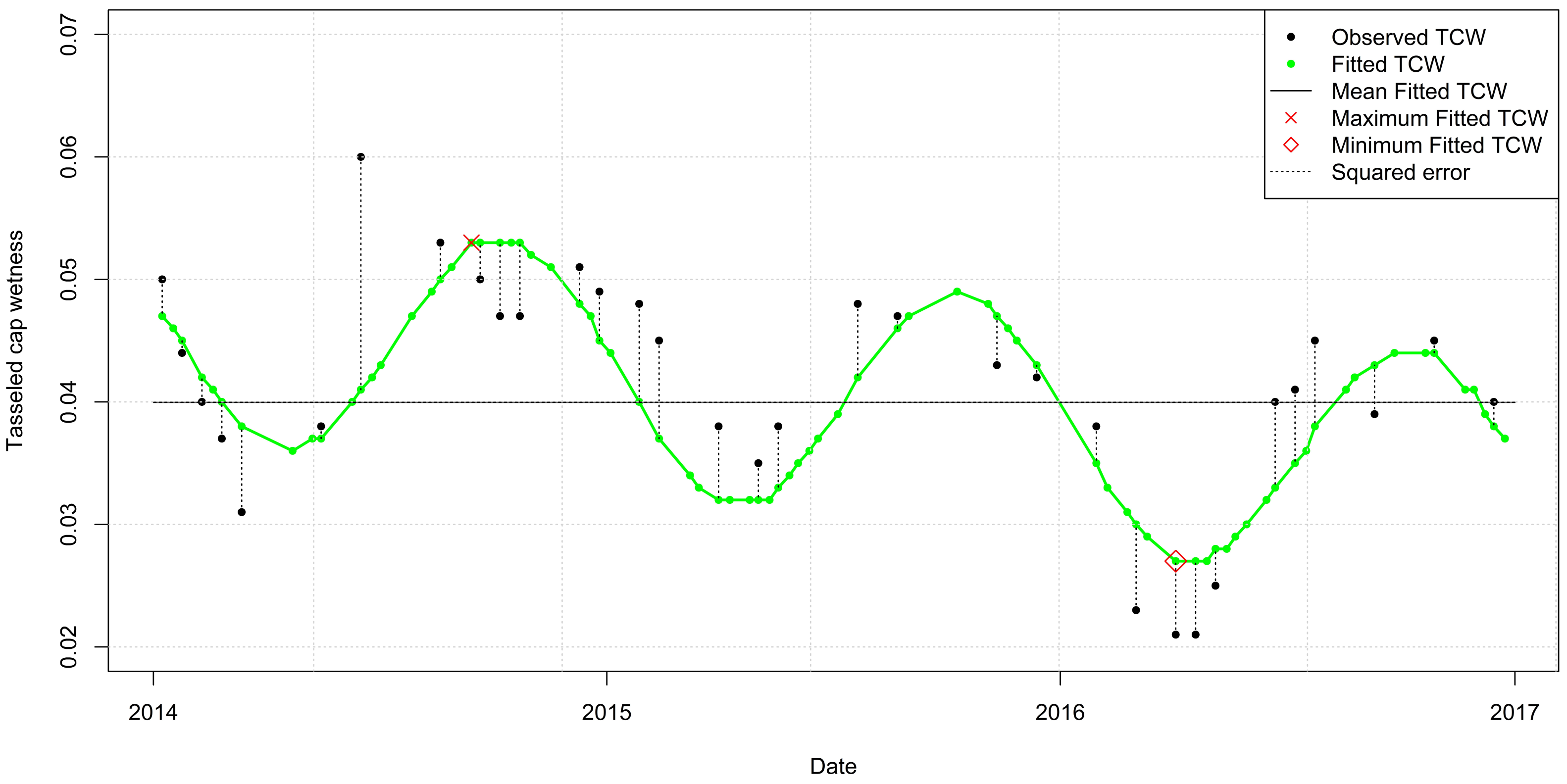
2.5. Growing Stock Estimation
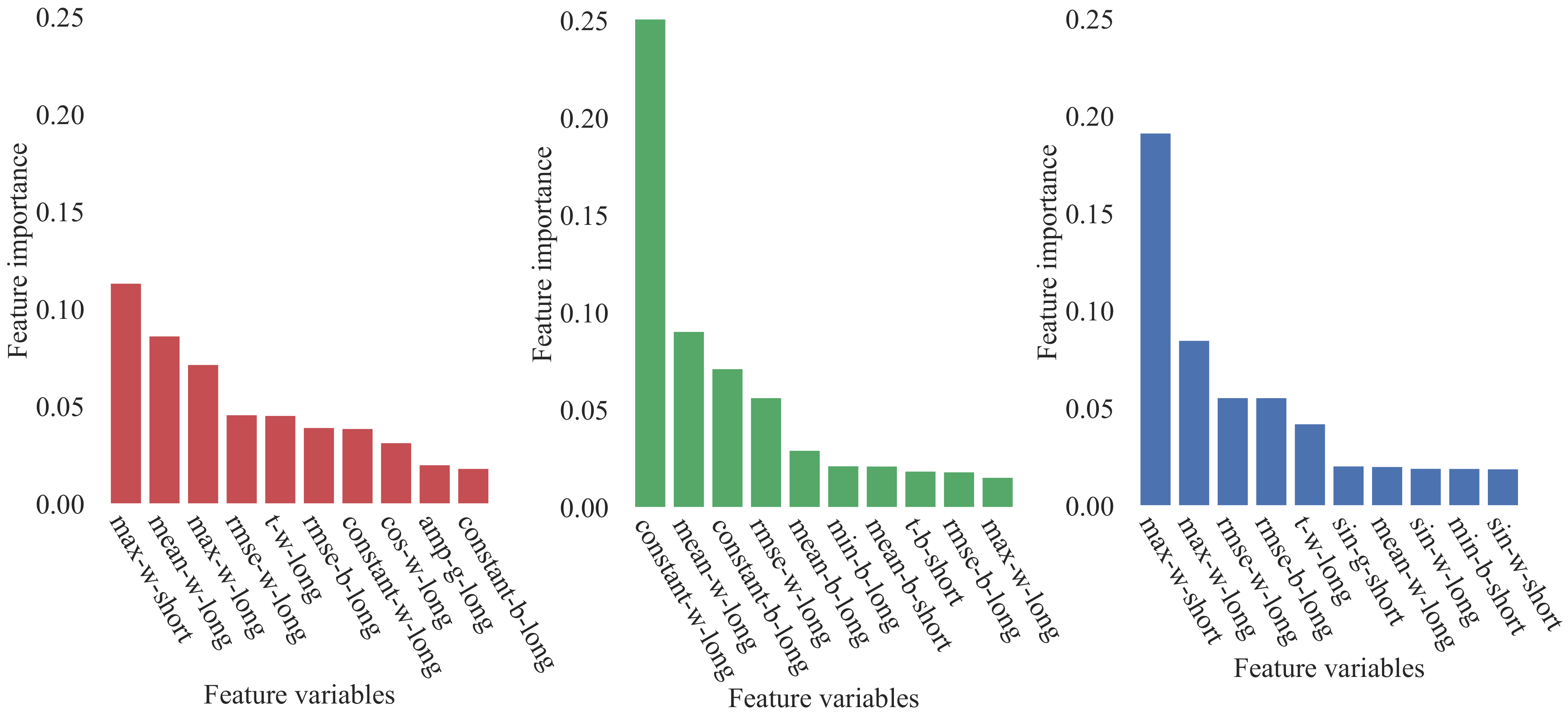
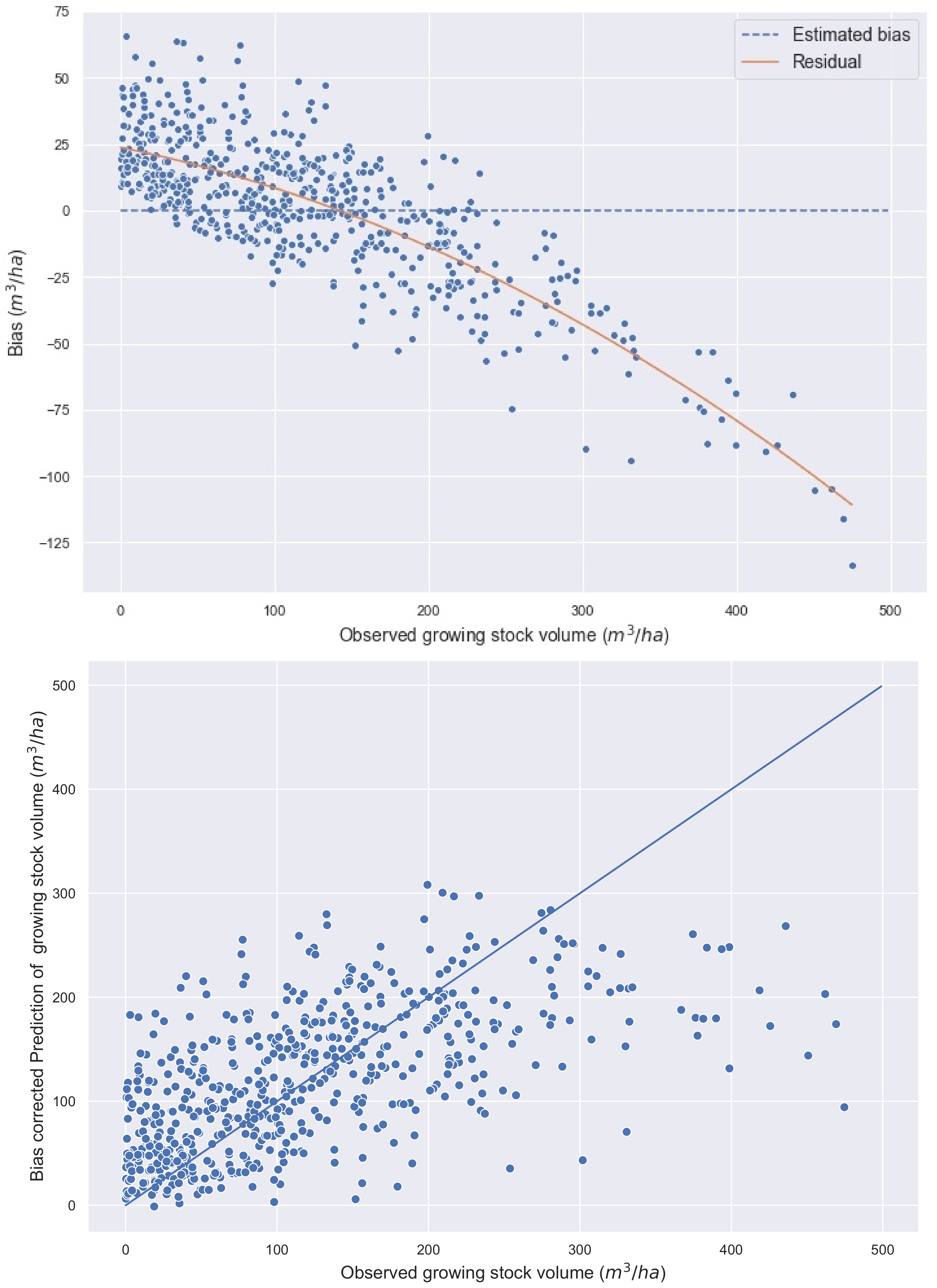
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- U.S. Department of the Interior, Fish and Wildlife Service. Recover Plan for the Red-Cockaded Woodpecker (Picoides borealis); Technical Report; U.S. Department of the Interior, Fish and Wildlife Service: Washington, DC, USA, 2003.
- Miksys, V.; Varnagiryte-Kabasinskiene, I.; Stupak, I.; Armolaitis, K.; Kukkola, M.; Wojcik, J. Above-ground biomass functions for Scots pine in Lithuania. Biomass Bioenergy 2007, 31, 685–692. [Google Scholar] [CrossRef]
- Cieszewski, C.J.; Zasada, M.; Borders, B.E.; Lowe, R.C.; Zawadzki, J.; Clutter, M.L.; Daniels, R.F. Spatially explicit sustainability analysis of long-term fiber supply in Georgia, USA. For. Ecol. Manag. 2004, 187, 349–359. [Google Scholar] [CrossRef]
- Brandeis, T.J.; Hartsell, A.J.; Bentley, J.W.; Brandeis, C. Economic Dynamics of Forests and Forest Industries in the Southern United States; Technical Report SRS-152; U.S. Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2012.
- Bechtold, W.A.; Patterson, P.L. The Enhanced Forest Inventory and Analysis Program: National Sampling Design and Estimation Procedures; Technical Report SRS-GTR-80; U.S. Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2015. [CrossRef]
- Tomppo, E. Designing a Satellite Image-Aided National Forest Survey in Finland; Swedish University of Agricultural Sciences: Umea, Sweden, 1990; pp. 43–47. [Google Scholar]
- Reese, H.; Nilsson, M.; Sandström, P.; Olsson, H. Applications using estimates of forest parameters derived from satellite and forest inventory data. Comput. Electron. Agric. 2002, 37, 37–55. [Google Scholar] [CrossRef]
- Reese, H.; Nilsson, M.; Pahén, T.G.; Hagner, O.; Joyce, S.; Tingelöf, U.; Egberth, M.; Olsson, H. Countrywide estimates of forest variables using satellite data and field data from the National Forest Inventory. J. Hum. Environ. 2003, 32, 542–548. [Google Scholar] [CrossRef] [PubMed]
- Franco-Lopez, H.; Ek, A.R.; Bauer, M.E. Estimation and mapping of forest stand density, volume, and cover type using the k-nearest neighbors method. Remote Sens. Environ. 2001, 77, 251–274. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Nelson, M.D.; Wendt, D.G. Stratified estimation of forest area using satellite imagery, inventory data, and the k-Nearest Neighbors technique. Remote Sens. Environ. 2002, 82, 457–468. [Google Scholar] [CrossRef]
- Maselli, F.; Chirici, G.; Bottai, L.; Corona, P.; Marchetti, M. Estimation of Mediterranean forest attributes by the application of k-NN procedures to multitemporal Landsat ETM+ images. Int. J. Remote Sens. 2005, 26, 3781–3796. [Google Scholar] [CrossRef]
- Tanaka, S.; Takahashi, T.; Nishizono, T.; Kitahara, F.; Saito, H.; Iehara, T.; Kodani, E.; Awaya, Y. Stand volume estimation using the k-NN technique combined with forest inventory data, satellite Image data and additional feature variables. Remote Sens. 2014, 7, 378–394. [Google Scholar] [CrossRef]
- Barrett, F.; McRoberts, R.E.; Tomppo, E.; Cienciala, E.; Waser, L.T. A questionnaire-based review of the operational use of remotely sensed data by national forest inventories. Remote Sens. Environ. 2016, 174, 279–289. [Google Scholar] [CrossRef]
- Moody, A.; Johnson, D.M. Land-surface phenologies from AVHRR using the discrete fourier transform. Remote Sens. Environ. 2001, 75, 305–323. [Google Scholar] [CrossRef]
- Hird, J.N.; McDermid, G.J. Noise reduction of NDVI time series: An empirical comparison of selected techniques. Remote Sens. Environ. 2009, 113, 248–258. [Google Scholar] [CrossRef]
- Woodcock, C.E.; Allen, R.; Anderson, M.; Belward, A.; Bindschadler, R.; Cohen, W.; Gao, F.; Goward, S.N.; Helder, D.; Helmer, E.; et al. Free access to Landsat imagery. Science 2008, 320, 1011. [Google Scholar] [CrossRef] [PubMed]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B.; Pfaff, E.; Braaten, J.; Nelson, P. Spatial and temporal patterns of forest disturbance and regrowth within the area of the Northwest Forest Plan. Remote Sens. Environ. 2012, 122, 117–133. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef]
- Brooks, E.B.; Wynne, R.H.; Thomas, V.A.; Blinn, C.E.; Coulston, J.W. On-the-fly massively multitemporal change detection using statistical quality control charts and Landsat data. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3316–3332. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Jones, S.; Soto-Berelov, M.; Haywood, A.; Hislop, S. Landsat time-series for estimating forest aboveground biomass and Its dynamics across space and time: A review. Remote Sens. 2020, 12, 98. [Google Scholar] [CrossRef]
- Pflugmacher, D.; Cohen, W.B.; Kennedy, R.E. Using Landsat-derived disturbance history (1972–2010) to predict current forest structure. Remote Sens. Environ. 2012, 122, 146–165. [Google Scholar] [CrossRef]
- Pflugmacher, D.; Cohen, W.B.; Kennedy, R.E.; Yang, Z. Using Landsat-derived disturbance and recovery history and lidar to map forest biomass dynamics. Remote Sens. Environ. 2014, 151, 124–137. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Ohmann, J.; Gregory, M.; Roberts, H.; Yang, Z.; Bell, D.M.; Kane, V.; Hughes, M.J.; Cohen, W.B.; Powell, S.; et al. An empirical, integrated forest biomass monitoring system. Environ. Res. Lett. 2018, 13, 025004. [Google Scholar] [CrossRef]
- Liu, L.; Peng, D.; Wang, Z.; Hu, Y. Improving artificial forest biomass estimates using afforestation age information from time series Landsat stacks. Environ. Monit. Assess. 2014, 186, 7293–7306. [Google Scholar] [CrossRef] [PubMed]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W. An integrated Landsat time series protocol for change detection and generation of annual gap-free surface reflectance composites. Remote Sens. Environ. 2015, 158, 220–234. [Google Scholar] [CrossRef]
- Matasci, G.; Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W.; Zald, H.S.J. Large-area mapping of Canadian boreal forest cover, height, biomass and other structural attributes using Landsat composites and lidar plots. Remote Sens. Environ. 2018, 209, 90–106. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Jung, J.; Lee, J.; Choi, S.U.; Hong, S.Y.; Heo, J. Optimal atmospheric correction for above-ground forest biomass estimation with the ETM+ remote sensor. Sensors 2015, 15, 18865–18886. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Jones, S.; Soto-Berelov, M.; Haywood, A.; Hislop, S. A Comparison of imputation approaches for estimating forest biomass using Landsat time-series and inventory data. Remote Sens. 2018, 10, 1825. [Google Scholar] [CrossRef]
- Zhu, X.; Liu, D. Improving forest aboveground biomass estimation using seasonal Landsat NDVI time-series. ISPRS J. Photogramm. Remote Sens. 2015, 102, 222–231. [Google Scholar] [CrossRef]
- Wilson, B.T.; Knight, J.F.; McRoberts, R.E. Harmonic regression of Landsat time series for modeling attributes from national forest inventory data. ISPRS J. Photogramm. Remote Sens. 2018, 137, 29–46. [Google Scholar] [CrossRef]
- Fox, T.R.; Jokela, E.J.; Allen, H.L. The development of pine plantation silviculture in the Southern United States. J. For. 2007, 105, 337–347. [Google Scholar] [CrossRef]
- D’Amato, A.W.; Jokela, E.J.; O’Hara, K.L.; Long, J.N. Silviculture in the United States: An amazing period of change over the past 30 years. J. For. 2017, 116, 55–67. [Google Scholar] [CrossRef]
- Obata, S.; Cieszewski, C.J.; Bettinger, P.; Lowe, R.C., III; Bernardes, S. Preliminary analysis of forest stand disturbances in Coastal Georgia (USA) using Landsat time series stacked imagery. Formath 2019, 18, 1–11. [Google Scholar] [CrossRef]
- U.S. Geological Survey. Landsat Levels of Processing. 2020. Available online: https://www.usgs.gov/land-resources/nli/landsat/landsat-levels-processing (accessed on 9 February 2020).
- Masek, J.; Vermonte, E.; Saleous, N.; Wolfe, R.; Hall, F.; Huemmrich, F.; Gao, F.; Kulter, J.; Lim, T. A Landsat surface reflectance data set for North America, 1990–2000. Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Hughes, M.J.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef]
- Crist, E.P. A TM Tasseled Cap equivalent transformation for reflectance factor data. Remote Sens. Environ. 1985, 17, 301–306. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. Spectral analysis and filtering. In Time Series Analysis and Its Applications: With R Examples, 4th ed.; Springer Texts in Statistics; Springer Science + Business Media: New York, NY, USA, 2017; pp. 165–172. [Google Scholar]
- Zhu, Z.; Fu, Y.; Woodcock, C.E.; Olofsson, P.; Vogelmann, J.E.; Holden, C.; Wang, M.; Dai, S.; Yu, Y. Including land cover change in analysis of greenness trends using all available Landsat 5, 7, and 8 images: A case study from Guangzhou, China (2000–2014). Remote Sens. Environ. 2016, 185, 243–257. [Google Scholar] [CrossRef]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J.; et al. A new generation of the United States national land cover database: Requirements, research priorities, design, and implementation strategies. ISPRS J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- Obata, S.; Bettinger, P.; Cieszewski, C.J.; Lowe, R.C., III. Mapping forest disturbances between 1987–2016 using all available time series Landsat TM/ETM+ Iimagery: Developing a reliable methodology for Georgia, United States. Forests 2020, 11, 335. [Google Scholar] [CrossRef]
- Smith, W. Forest inventory and analysis: A national inventory and monitoring program. Environ. Pollut. 2002, 116, 233–242. [Google Scholar] [CrossRef]
- Burrill, E.A.; Wilson, A.M.; Turner, J.A.; Pugh, S.A.; Menlove, J.; Christensen, G.; Conkling, B.L.; David, W. The Forest Inventory and Analysis Database: Database Description and User Guide for Phase 2 (Version 7.2); Technical Report; U.S. Forest Service: Washington, DC, USA, 2018.
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Gigović, L.; Pourghasemi, H.R.; Drobnjak, S.; Bai, S. Testing a new ensemble model based on SVM and random forest in forest fire susceptibility assessment and its mapping in Serbia’s Tara National Park. Forests 2019, 10, 408. [Google Scholar] [CrossRef]
- Tompalski, P.; White, J.C.; Coops, N.C.; Wulder, M.A. Demonstrating the transferability of forest inventory attribute models derived using airborne laser scanning data. Remote Sens. Environ. 2019, 227, 110–124. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, Y. Bias-corrected random forests in regression. J. Appl. Stat. 2012, 39, 151–160. [Google Scholar] [CrossRef]
- Chen, C.; Liaw, A.; Breiman, L. Using Random Forest to Learn Imbalanced Data; Technical Report 666; Department of Statistics, University of California Berkeley: Berkley, CA, USA, 2004. [Google Scholar]
- Chirici, G.; Mura, M.; McInerney, D.; Py, N.; Tomppo, E.O.; Waser, L.T.; Travaglini, D.; McRoberts, R.E. A meta-analysis and review of the literature on the k-Nearest Neighbors technique for forestry applications that use remotely sensed data. Remote Sens. Environ. 2016, 176, 282–294. [Google Scholar] [CrossRef]
- McRoberts, R.E. Diagnostic tools for nearest neighbors techniques when used with satellite imagery. Remote Sens. Environ. 2009, 113, 489–499. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bolton, D.K.; White, J.C.; Wulder, M.A.; Coops, N.C.; Hermosilla, T.; Yuan, X. Updating stand-level forest inventories using airborne laser scanning and Landsat time series data. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 174–183. [Google Scholar] [CrossRef]
- Foody, G.M.; Boyd, D.S.; Cutler, M.E.J. Predictive relations of tropical forest biomass from Landsat TM data and their transferability between regions. Remote Sens. Environ. 2003, 85, 463–474. [Google Scholar] [CrossRef]
- Lu, D.; Chen, Q.; Wang, G.; Liu, L.; Li, G.; Moran, E. A survey of remote sensing-based aboveground biomass estimation methods in forest ecosystems. Int. J. Digit. Earth 2016, 9, 63–105. [Google Scholar] [CrossRef]
- Tinkham, W.T.; Mahoney, P.R.; Hudak, A.T.; Domke, G.M.; Falkowski, M.J.; Woodall, C.W.; Smith, A.M. Applications of the United States Forest Inventory and Analysis dataset: A review and future directions. Can. J. For. Res. 2018, 48, 1251–1268. [Google Scholar] [CrossRef]
- Deo, R.K.; Russell, M.B.; Domke, G.M.; Woodall, C.W.; Falkowski, M.J.; Cohen, W.B. Using Landsat time-series and LiDAR to inform aboveground forest biomass baselines in Northern Minnesota, USA. Can. J. Remote Sens. 2017, 43, 28–47. [Google Scholar] [CrossRef]
- Matasci, G.; Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W.; Bolton, D.K.; Tompalski, P.; Bater, C.W. Three decades of forest structural dynamics over Canada’s forested ecosystems using Landsat time-series and lidar plots. Remote Sens. Environ. 2018, 216, 697–714. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Jones, S.D.; Soto-Berelov, M.; Haywood, A.; Hislop, S. Monitoring aboveground forest biomass dynamics over three decades using Landsat time-series and single-date inventory data. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101952. [Google Scholar] [CrossRef]
- Deo, R.K.; Russell, M.B.; Domke, G.M.; Andersen, H.E.; Cohen, W.B.; Woodall, C.W. Evaluating site-specific and generic spatial models of aboveground forest biomass based on Landsat time-series and LiDAR strip samples in the Eastern USA. Remote Sens. 2017, 9, 598. [Google Scholar] [CrossRef]
- U.S. Geological Survey. 3D Elevation Program. 2020. Available online: https://www.usgs.gov/core-science-systems/ngp/3dep (accessed on 19 February 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
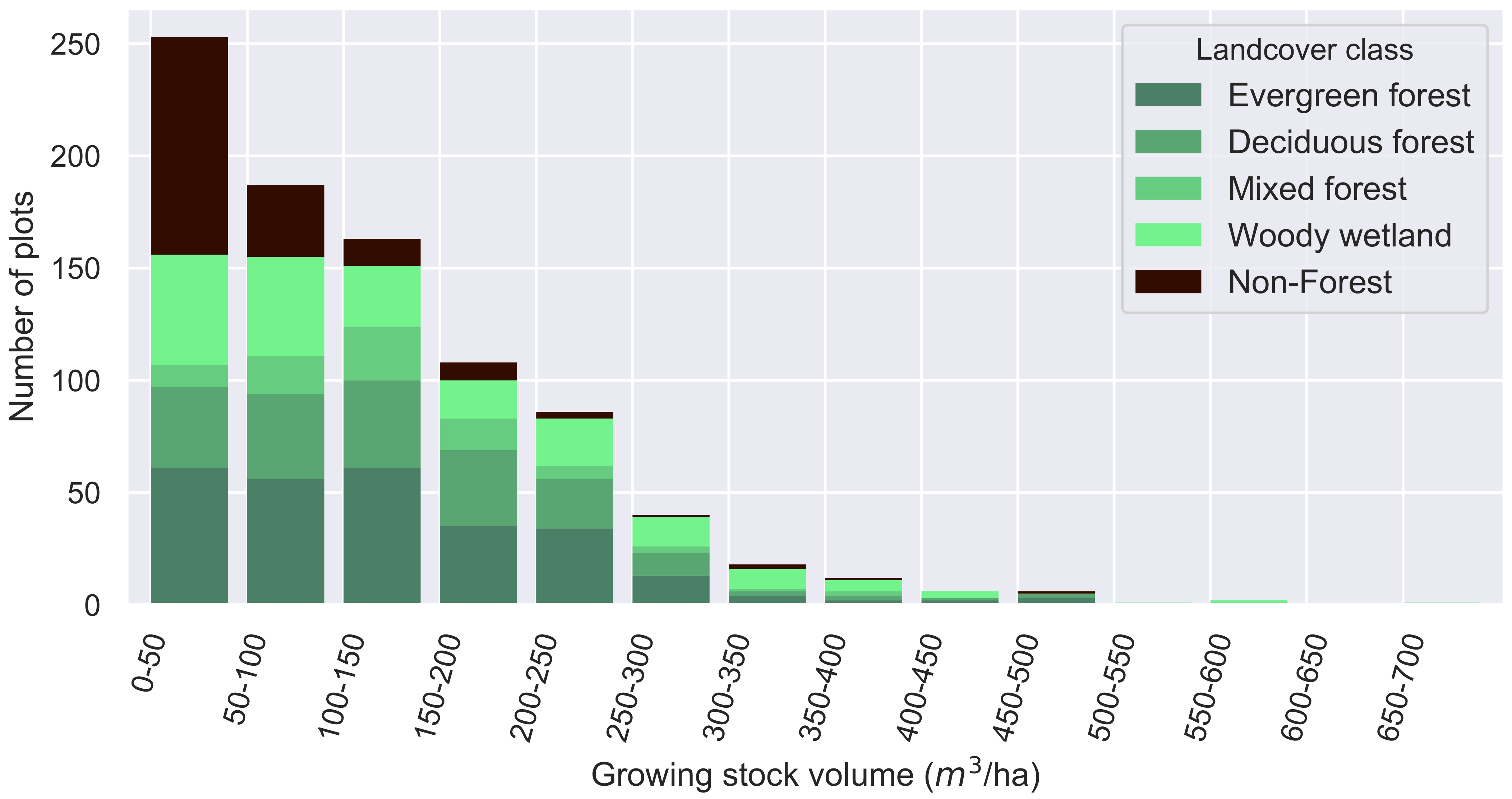
| Land Cover Class | Class | # of Plots | Mean Volume (m/ha) | # of Plots Disturbed |
|---|---|---|---|---|
| Water | 0 | 4 | 220.61 | 2 |
| Developed | 0 | 43 | 330.14 | 6 |
| Barren land | 0 | 2 | 146.99 | 1 |
| Deciduous forest | 2 | 191 | 433.5 | 21 |
| Evergreen forest | 1 | 274 | 431.61 | 80 |
| Mixed forest | 2 | 75 | 416.8 | 10 |
| Shrubland | 0 | 32 | 138.43 | 16 |
| Herbaceous | 0 | 28 | 148.46 | 19 |
| Planted/Cultivated | 0 | 51 | 132.47 | 2 |
| Woody wetlands | 2 | 185 | 462.28 | 32 |
| Vegetation Index /Data Source | Time Range | # of Variables | Values | RF Models | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Features | Landsat TCB | 1984–2016 | 4 | Regression coefficients | ✓ | ✓ | ✓ | ✓ | |||
| 1984–2016 | 5 | Fitted values | ✓ | ✓ | ✓ | ✓ | |||||
| 2014–2016 | 4 | Regression coefficients | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| 2014–2016 | 5 | Fitted values | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Landsat TCG | 1984–2016 | 4 | Regression coefficients | ✓ | ✓ | ✓ | ✓ | ||||
| 1984–2016 | 5 | Fitted values | ✓ | ✓ | ✓ | ✓ | |||||
| 2014–2016 | 4 | Regression coefficients | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| 2014–2016 | 5 | Fitted values | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Landsat TCW | 1984–2016 | 4 | Regression coefficients | ✓ | ✓ | ✓ | ✓ | ||||
| 1984–2016 | 5 | Fitted values | ✓ | ✓ | ✓ | ✓ | |||||
| 2014–2016 | 4 | Regression coefficients | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| 2014–2016 | 5 | Fitted values | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| NLCD | 2016 | 1 | Land use class | ✓ | ✓ | ||||||
| Last disturbance | 1984–2016 | 1 | Disturbance year | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Response | FIA dataset | 2016 | 1 | Growing stock volume | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 57 variables | 14 | 26 | 17 | 32 | 56 | 57 | 57 | ||||
| + NE | ||||||||
|---|---|---|---|---|---|---|---|---|
| Observation Mean | 121.21 | 121.21 | 121.21 | 121.21 | 121.21 | 113.39 | 128.16 | - |
| rRMSE | 68.93 | 67.38 | 71.48 | 65.09 | 64.42 | 59.66 | 70.50 | 65.67 |
| rB | 4.19 | 3.48 | 3.72 | 2.66 | 3.79 | 3.09 | 4.82 | - |
| OOB_score | 34.8 | 35.87 | 23.39 | 35.63 | 36.11 | 46.52 | 34 | 39.15 |
| Species | all | all | all | all | all | Evergreen | non-Evergreen | all |
| Length | Model | Max | Mean | Min | RMSE | Sin | Slope | Intercept | Total |
|---|---|---|---|---|---|---|---|---|---|
| SLTS | 1 | - | - | 2 | - | - | - | 3 | |
| - | 1 | - | - | - | 1 | - | 2 | ||
| 1 | - | 1 | - | 2 | - | - | 4 | ||
| LLTS | 1 | 1 | - | 2 | 1 | 1 | 1 | 7 | |
| 1 | 2 | 1 | 2 | - | - | 2 | 8 | ||
| 1 | 1 | - | 2 | 1 | 1 | - | 6 |
| rB | 4.19 | 3.48 | 3.72 | 2.66 | 3.79 | 3.09 | 4.82 |
| rB_corr | −2.73 | −1.98 | −1.48 | −0.69 | −1.47 | −1.26 | −2.86 |
| middle80 | −16.63 | −15.42 | −16.19 | −11.94 | −14.1 | −15.17 | −15.857 |
| middle80_corr | −14.41 | −13.08 | −13.6 | −9.01 | −10.91 | −12.61 | −13.23 |
| bottom10 | −69.16 | −65.42 | −71.37 | −71.51 | −69.89 | −53.39 | −71.03 |
| bottom10_corr | −56.43 | −52.74 | −58.14 | −60.13 | −57.43 | −42.03 | −56.31 |
| top10 | 151.93 | 146.08 | 159.81 | 138.88 | 140.93 | 141.87 | 142.24 |
| top10_corr | 139.55 | 132.90 | 152.97 | 127.93 | 131.01 | 128.26 | 128.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Obata, S.; Cieszewski, C.J.; Lowe, R.C., III; Bettinger, P. Random Forest Regression Model for Estimation of the Growing Stock Volumes in Georgia, USA, Using Dense Landsat Time Series and FIA Dataset. Remote Sens. 2021, 13, 218. https://doi.org/10.3390/rs13020218
Obata S, Cieszewski CJ, Lowe RC III, Bettinger P. Random Forest Regression Model for Estimation of the Growing Stock Volumes in Georgia, USA, Using Dense Landsat Time Series and FIA Dataset. Remote Sensing. 2021; 13(2):218. https://doi.org/10.3390/rs13020218
Chicago/Turabian StyleObata, Shingo, Chris J. Cieszewski, Roger C. Lowe, III, and Pete Bettinger. 2021. "Random Forest Regression Model for Estimation of the Growing Stock Volumes in Georgia, USA, Using Dense Landsat Time Series and FIA Dataset" Remote Sensing 13, no. 2: 218. https://doi.org/10.3390/rs13020218
APA StyleObata, S., Cieszewski, C. J., Lowe, R. C., III, & Bettinger, P. (2021). Random Forest Regression Model for Estimation of the Growing Stock Volumes in Georgia, USA, Using Dense Landsat Time Series and FIA Dataset. Remote Sensing, 13(2), 218. https://doi.org/10.3390/rs13020218