
3D Point Cloud Semantic Augmentation: Instance Segmentation of 360° Panoramas by Deep Learning Techniques



Abstract
:
1. Introduction
2. State of the Art/Overview
2.1. Panoramic Image and Projections
2.1.1. Rectilinear Projection
2.1.2. Curved or Tiled Projection
2.1.3. Special Projection
2.2. Segmentation for the Extraction of Semantics
2.2.1. Object Detection
2.2.2. Semantic Segmentation
2.2.3. Instance Segmentation
2.2.4. Previous Work: Tabkha’s Thesis 2019
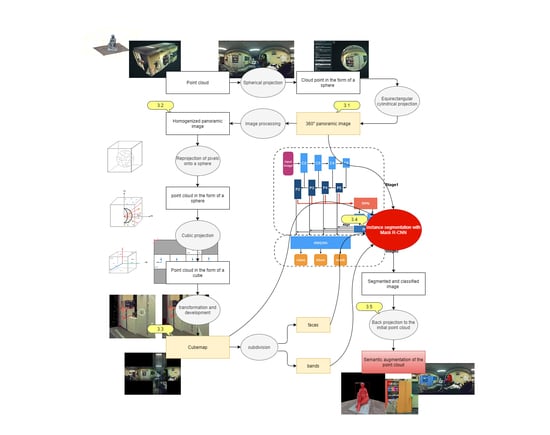
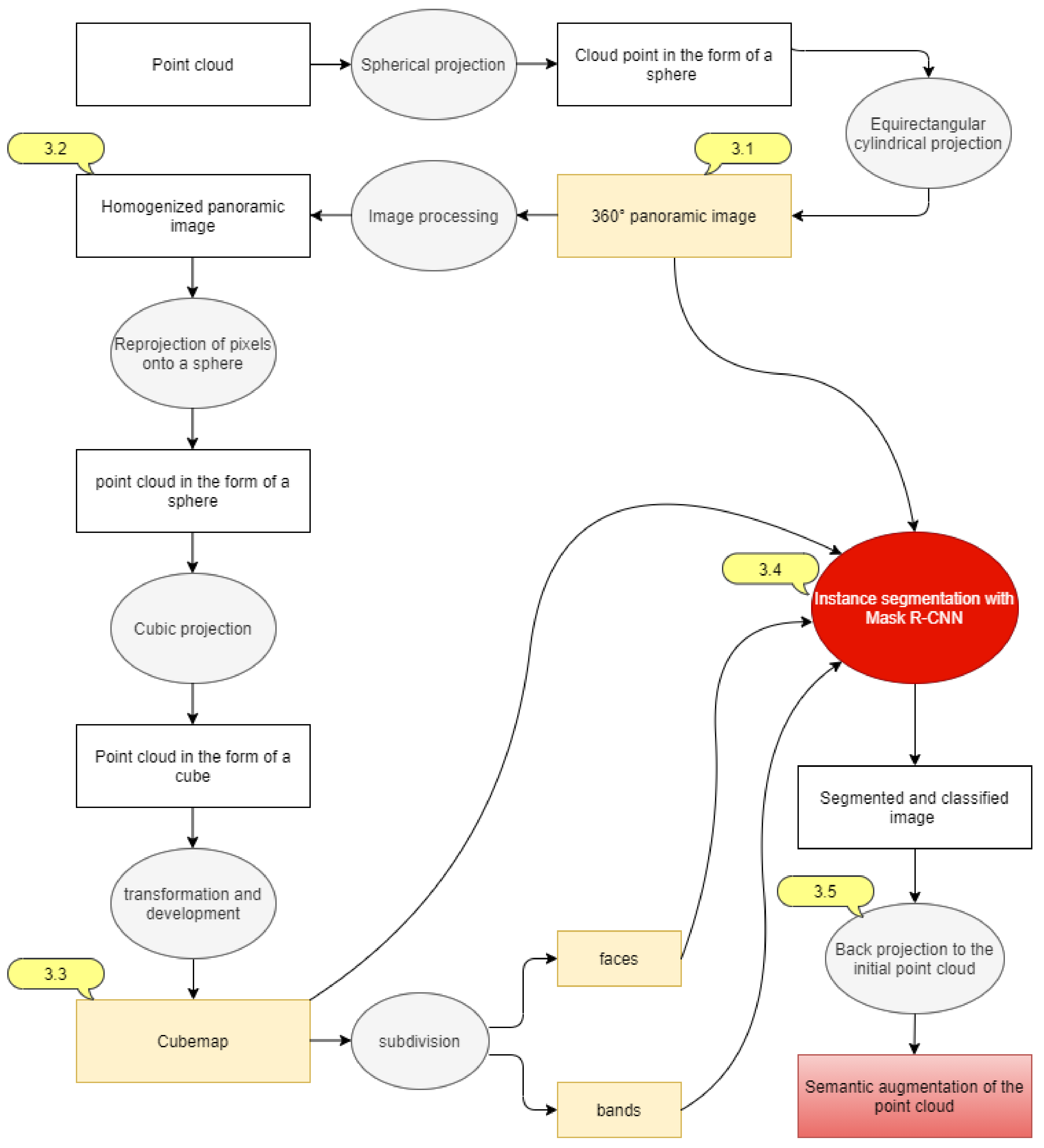
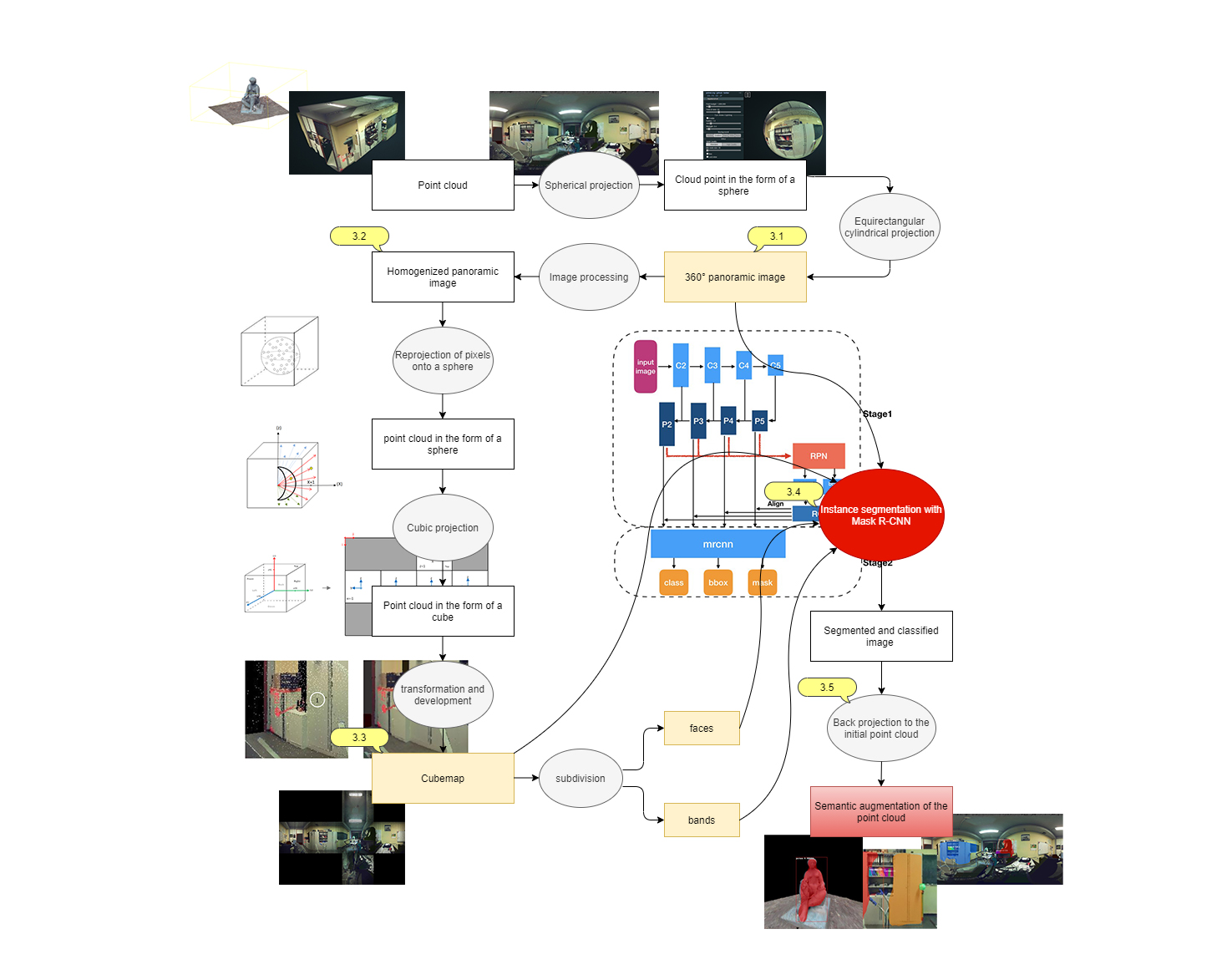
3. Methods
3.1. 360° Panoramic Image
3.1.1. Spherical Projection
3.1.2. Equirectangular Cylindrical Projection
3.2. Homogenisation of the Panoramic Image
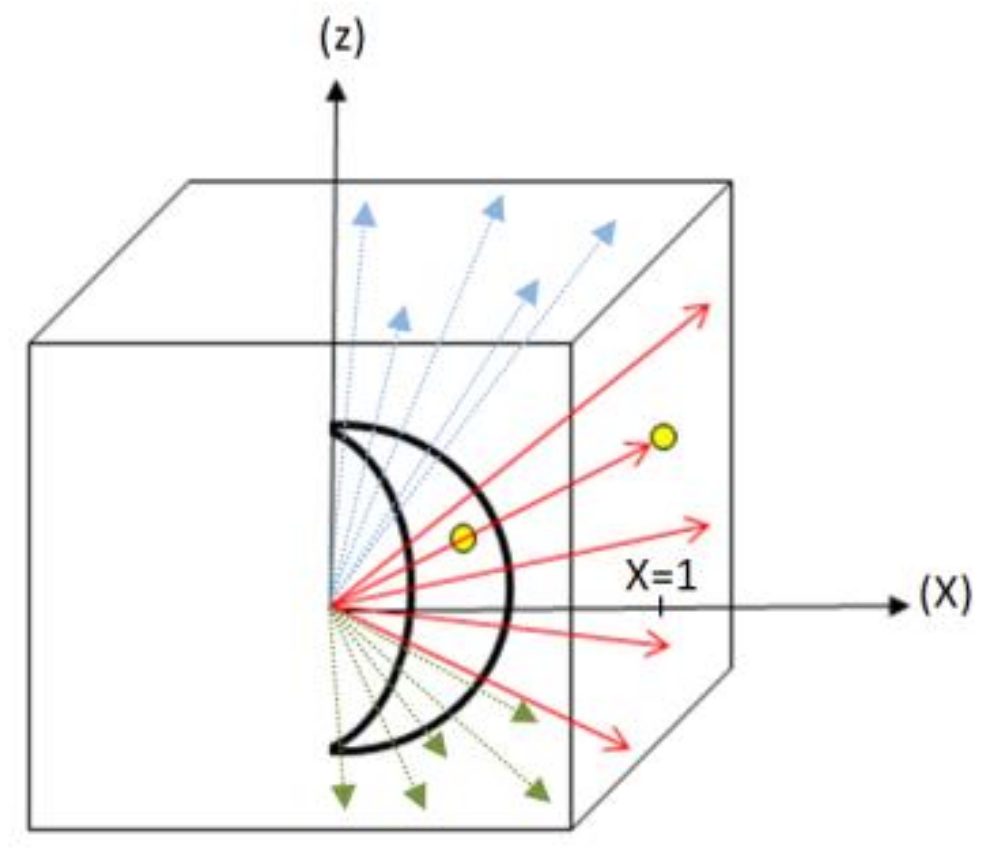
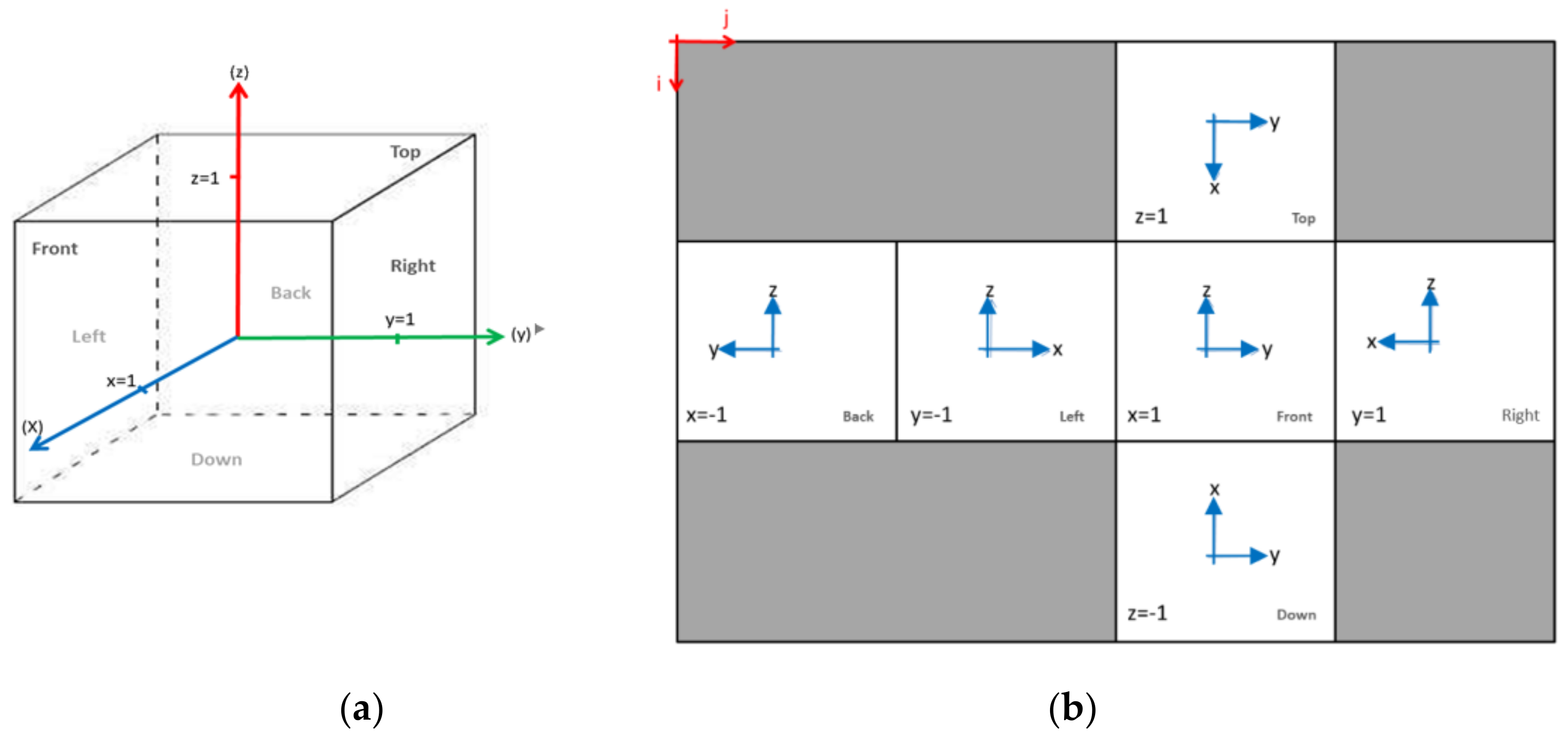
3.3. Cubemap Generation Using Cubic Projection
- If , the points are on the 1st facet, otherwise;
- If , these points are not considered and should rather be projected on the plane z = 1 (the top facet);
- Otherwise, if , these points should be projected on the plane z = −1.
3.4. Instance Segmentation with Mask-RCNN
- The main reason is the fact that this model allows for a pixel level classification by outputting for each object of the input image a different colour mask, which is perfectly adapted to the logic of the developed program based on the back projection of the new pixel values after the semantic segmentation of the panoramic images. Models that only allow object detection, such as the R-CNN, fast R-CNN, or YOLO neural networks, are not suitable for this study since they only generate bounding boxes around the objects but not a dense classification at the pixel level;
- This model is pretrained on the Microsoft COCO (Common Objects in Context) dataset and available under an open-source license on Github;
- Published in 2017, it is one of the most popular models for instance segmentation today.
- The resulting image contains in addition to object recognition masks: bounding boxes, prediction values, and object class names.
- As an output, the code does not allow for the downloading of the segmented image but only its visualisation as a graph on the development environment used.
- The choice of the prediction threshold.
- The choice of the object classes to detect, allowing the user to filter the classes displayed in the network output.
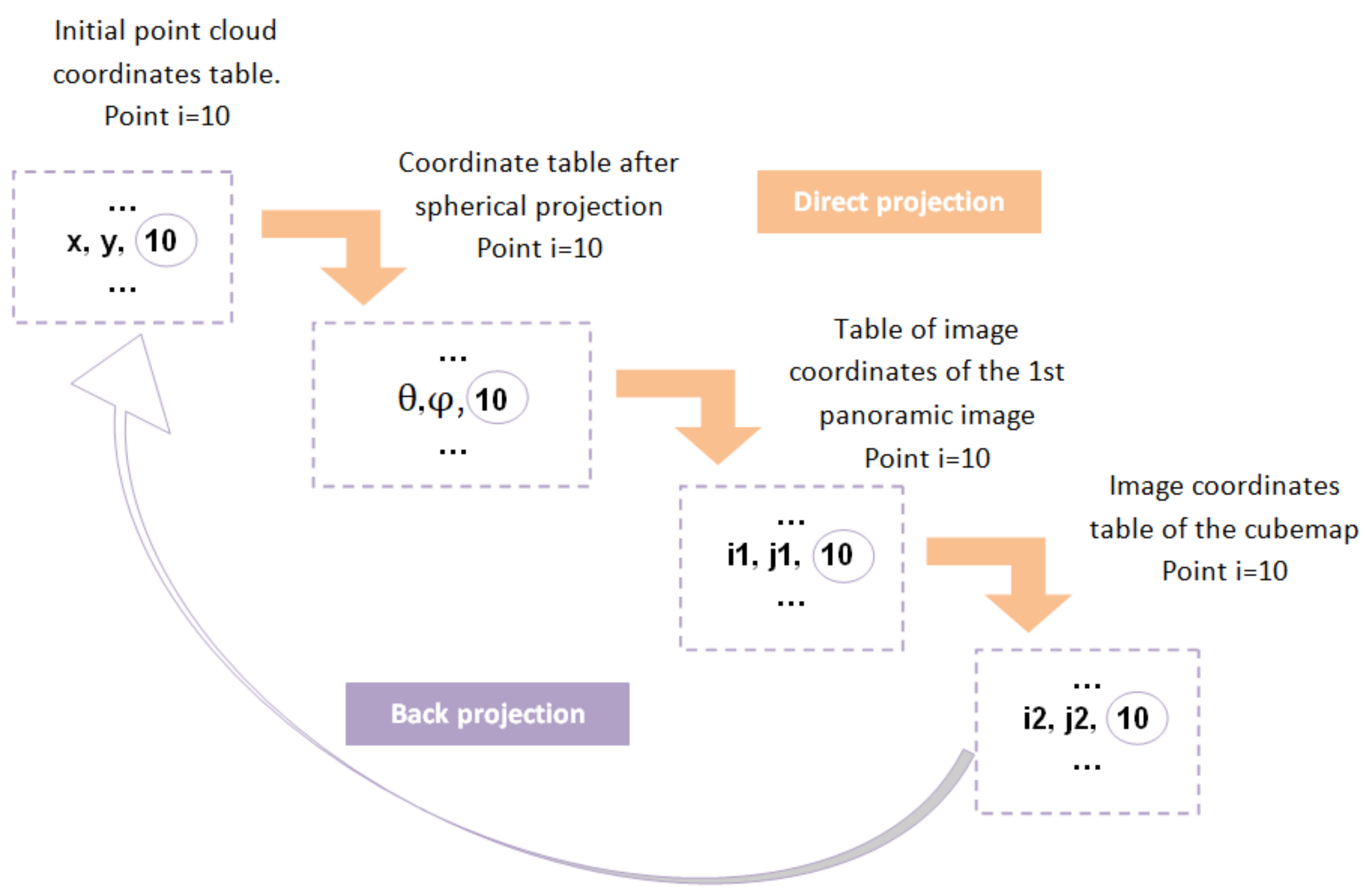
3.5. Back Projection of Class Instances Predictions to the Point Cloud
4. Results
4.1. Datasets
4.2. The Optimal Resolution for the First Panoramic Image
4.3. Homogenisation of the 360° Panoramic Image
4.4. Back Projection on the Point Cloud Analysis
4.4.1. Influence of the Projection Centre Position (Depth of the Cloud Points)
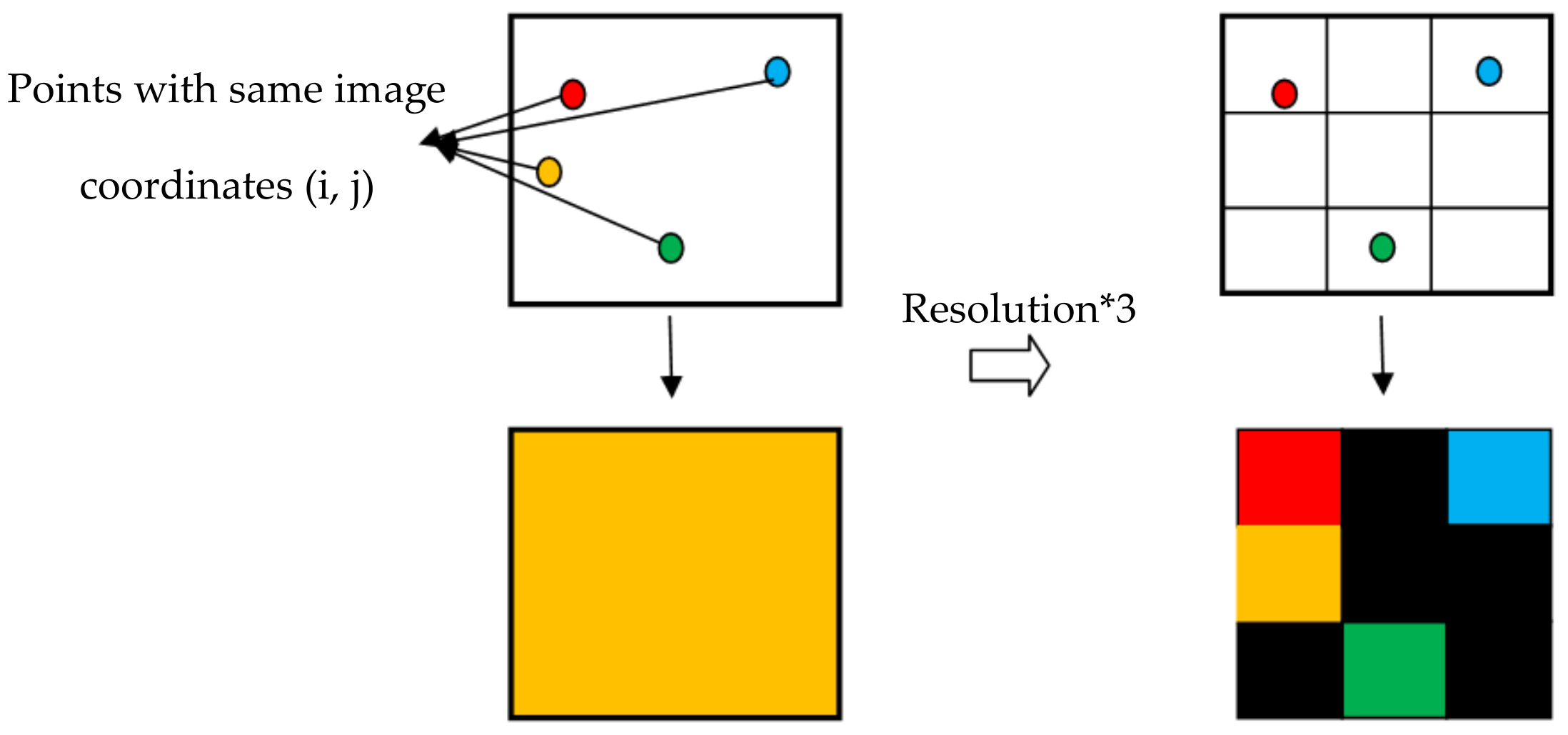
4.4.2. Influence of Panoramic Image Resolution on Cloud Segmentation
4.4.3. Influence of the Scattered Structure of the Point Cloud
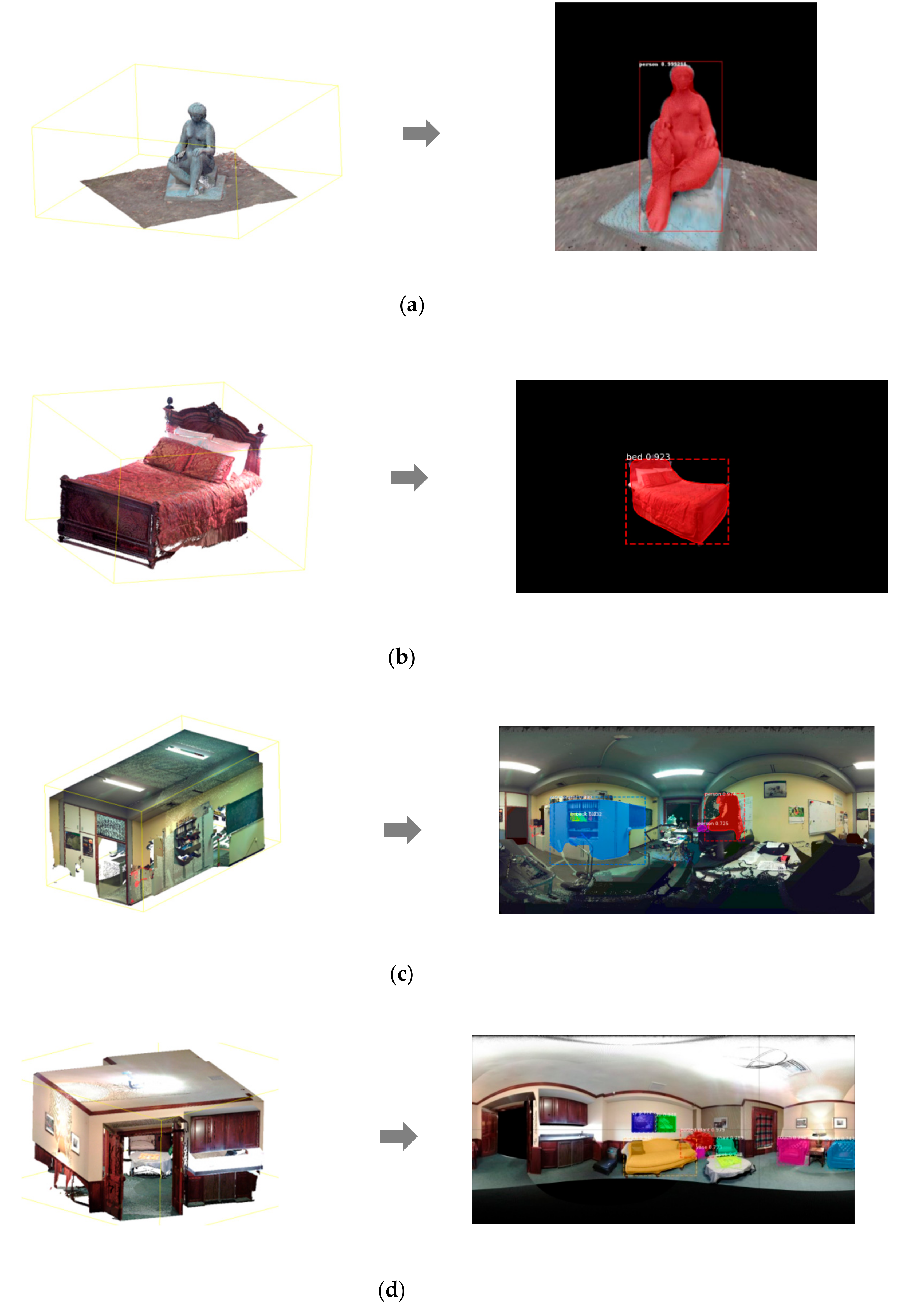
4.5. Analysis of Instance Segmentation by Mask R-CNN
4.6. Comparison with the Approach Developed by Tabkha in 2019
5. Discussion
- The projection of all the points of the cloud on the panoramic image by adopting a spherical projection followed by another cylindrical one, which cannot be achieved if only by a cylindrical projection.
- The addition of the cubic projection first allowed to get rid of the alterations caused by tiled projections (spherical and cylindrical projections). Secondly, the cubemap has allowed more input image options that we can use as a basis for instance segmentation (cubemap itself, strips, and individual facets).
- The influence of the projection centre position choice on the results of the instance segmentation.
- The need to multiply the projections from several positions to allow the segmentation of a point cloud composed of many “subspaces”. A single projection from a single virtual camera position is not enough to segment the entire cloud, given the depth condition (only points in the foreground view of the camera can be segmented).
- The difficulty of choosing a good panoramic image resolution that allows one to have a balance between preserving the richness of the initial point cloud without generating a great number of empty pixels. Therefore, it is necessary to carry out several projection tests to find the optimal resolution.
- The scattered structure of the cloud’s points decreases the accuracy of object segmentation (example of the segmentation of the ‘computer’ object in the previous chapter).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Poux, F. The Future of 3D Point Clouds: A New Perspective, Towards Data Science. Available online: https://towardsdatascience.com/the-future-of-3d-point-clouds-a-new-perspective-125b35b558b9 (accessed on 29 May 2021).
- Poux, F.; Billen, R. Voxel-based 3D Point Cloud Semantic Segmentation: Unsupervised geometric and relationship featuring vs deep learning methods. ISPRS Int. J. Geo-Inf. 2019, 8, 213. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Yu, H.; Liu, X.; Yang, Z.; Sun, W.; Wang, Y.; Fu, Q.; Zou, Y.; Mian, A. Deep Learning based 3D Segmentation: A Survey; Deep Learning based 3D Segmentation: A Survey. arXiv 2021, arXiv:2103.05423. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale Point Cloud Semantic Segmentation with SuperpointGraphs. arXiv 2017, arXiv:1711.09869. [Google Scholar]
- Topiwala, A. Spherical Projection for Point Clouds, Towards Data Science. Available online: https://towardsdatascience.com/spherical-projection-for-point-clouds-56a2fc258e6c (accessed on 31 May 2021).
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Guirado, E.; Tabik, S.; Alcaraz-Segura, D.; Cabello, J.; Herrera, F. Deep-learning Versus OBIA for scattered shrub detection with Google Earth imagery: Ziziphus lotus as case study. Remote Sens. 2017, 9, 1220. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Shao, G. Object-based land-cover mapping with high resolution aerial photography at a county scale in midwestern USA. Remote Sens. 2014, 6, 11372–11390. [Google Scholar] [CrossRef] [Green Version]
- Pierce, K. Accuracy optimization for high resolution object-based change detection: An example mapping regional urbanization with 1-m aerial imagery. Remote Sens. 2015, 7, 12654–12679. [Google Scholar] [CrossRef] [Green Version]
- Tiede, D.; Krafft, P.; Füreder, P.; Lang, S. Stratified template matching to support refugee camp analysis in OBIA workflows. Remote Sens. 2017, 9, 326. [Google Scholar] [CrossRef] [Green Version]
- Laliberte, A.S.; Rango, A.; Havstad, K.M.; Paris, J.F.; Beck, R.F.; McNeely, R.; Gonzalez, A.L. Object-oriented image analysis for mapping shrub encroachment from 1937 to 2003 in southern New Mexico. Remote Sens. Environ. 2004, 93, 198–210. [Google Scholar] [CrossRef]
- Hellesen, T.; Matikainen, L. An object-based approach for mapping shrub and tree cover on grassland habitats by use of LiDAR and CIR orthoimages. Remote Sens. 2013, 5, 558–583. [Google Scholar] [CrossRef] [Green Version]
- Stow, D.; Hamada, Y.; Coulter, L.; Anguelova, Z. Monitoring shrubland habitat changes through object-based change identification with airborne multispectral imagery. Remote Sens. Environ. 2008, 112, 1051–1061. [Google Scholar] [CrossRef]
- Tabkha, A.; Hajji, R.; Billen, R.; Poux, F. Semantic enrichment of point cloud by automatic extraction and enhancement of 360° panoramas. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, 42, 355–362. [Google Scholar] [CrossRef] [Green Version]
- Frich, A. What Is a Panoramic Photography? 2019. Available online: https://www.panoramic-photo-guide.com/panoramic-photography.html (accessed on 31 May 2021).
- Labracherie, R.; Numérique, F.; Thomas, M. La Photographie Panoramique #1: Les Prérequis—Les Numériques. Available online: https://www.lesnumeriques.com/photo/la-photographie-panoramique-1-les-prerequis-pu100641.html (accessed on 31 May 2021).
- La Perspective Conique. Available online: http://dam.archi.free.fr/1A1S/Descriptive/Cours5.pdf (accessed on 31 May 2021).
- Britannica. Mercator Projection. Definition, Uses, & Limitations. Available online: https://www.britannica.com/science/Mercator-projection (accessed on 31 May 2021).
- Mercator Projection—An Overview, ScienceDirect Topics. Available online: https://www.sciencedirect.com/topics/earth-and-planetary-sciences/mercator-projection (accessed on 12 July 2021).
- Houshiar, H.; Elseberg, J.; Borrmann, D.; Nüchter, A. A study of projections for key point based registration of panoramic terrestrial 3D laser scan. Geo-Spat. Inf. Sci. 2015, 18, 11–31. [Google Scholar] [CrossRef]
- Equirectangular Projection—Wikipedia. Available online: https://en.wikipedia.org/wiki/Equirectangular_projection (accessed on 31 May 2021).
- Sharpless, T.K.; Postle, B.; German, D.M. Pannini: A new projection for rendering wide angle perspective images. In Computational Aesthetics in Graphics, Visualization, and Imaging; Jepp, P., Deussen, O., Eds.; The Eurographics Association: Geneva, Switzerland, 2010. [Google Scholar]
- Brown, M. Content-Aware Projection for Tiny Planets; Short Papers; Eurographics: Geneva, Switzerland, 2015. [Google Scholar]
- Mirror Ball, Angular Map and Spherical. Available online: https://horo.ch/docs/mine/pdf/Mb-Am-Sph.pdf (accessed on 31 May 2021).
- Bello, S.A.; Yu, S.; Wang, C. Review: Deep learning on 3D point clouds. arXiv 2020, arXiv:2001.06280. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Oster, M.; Douglas, R.; Liu, S.C. Computation with spikes in a winner-take-all network. Neural Comput. 2009, 21, 2437–2465. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 2017, 5100–5109. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Longbeach, CA, USA, 16–20 June 2019; pp. 11105–11114. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6410–6419. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2018, 38, 13. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, L.; Wang, G.; et al. Recent Advances in Convolutional Neural Networks. arXiv 2015, arXiv:1512.07108. [Google Scholar] [CrossRef] [Green Version]
- Basha, S.H.S.; Dubey, S.R.; Pulabaigari, V.; Mukherjee, S. Impact of fully connected layers on performance of convolutional neural networks for image classification. Neurocomputing 2019, 378, 112–119. [Google Scholar] [CrossRef] [Green Version]
- Coursera. Convolutional Neural Networks. Available online: https://www.coursera.org/learn/convolutional-neural-networks (accessed on 31 May 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. Lect. Notes Comput. Sci. 2014, 8691, 346–361. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. Lect. Notes Comput. Sci. 2015, 9905, 21–37. [Google Scholar] [CrossRef] [Green Version]
- Schütz, M.; Ohrhallinger, S.; Wimmer, M. Fast out-of-core octree generation for massive point clouds. Comput. Graph. Forum 2020, 39, 155–167. [Google Scholar] [CrossRef]
- Bergounioux, M. Quelques Méthodes de Filtrage en Traitement d’Image. ffhal-00512280v2. 2011. Available online: https://hal.archives-ouvertes.fr/file/index/docid/569384/filename/CoursFiltrage.pdf (accessed on 20 July 2021).
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2014; Volume 8693 LNCS, pp. 740–755. [Google Scholar]
- Indoor Lidar-RGBD Scan Dataset. Available online: http://redwood-data.org/indoor_lidar_rgbd/ (accessed on 6 June 2021).
- Zhang, L.; Sun, J.; Zheng, Q. 3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network. Sensors 2018, 18, 3681. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bai, S.; Bai, X.; Zhou, Z.; Zhang, Z.; Latecki, L.J. GIFT: A Real-time and Scalable 3D Shape Search Engine. arXiv 2016, arXiv:1604.01879. [Google Scholar]
- Kalogerakis, E.; Averkiou, M.; Maji, S.; Chaudhuri, S. 3D Shape Segmentation with Projective Convolutional Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6630–6639. [Google Scholar]
- Qi, C.R.; Su, H.; Niessner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and Multi-View CNNs for Object Classification on 3D Data. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Facet | Coordinate i | Coordinate j |
|---|---|---|
| front | ||
| back | ||
| left | ||
| right | ||
| top | ||
| bottom |
| Point Cloud | Nb of Pts | Source | Attributes |
|---|---|---|---|
| Office | 6,971,911 | Canon EOS 70D (Photogrammetry) | XYZ-RGB |
| Female Statue | 3,525,792 | Leica P30 | XYZ-RGB-I |
| Bed | 3,876,880 | FARO Focus 3D X330 HDR | XYZ-RGB-D |
| Boardroom | 30,876,388 | FARO Focus 3D X330 HDR | XYZ-RGB-D |
| Point Cloud | Object | Precision | Recall | F1 Score |
|---|---|---|---|---|
| 1 | #1 | 0.787 | 0.971 | 0.869 |
| 2 | #1 | 0.989 | 0.948 | 0.968 |
| #1 | 0.952 | 0.899 | 0.925 | |
| #2 | 0.94 | 0.869 | 0.903 | |
| #3 | 0.864 | 0.986 | 0.921 | |
| 4 | #4 | 0.969 | 0.945 | 0.957 |
| #5 | 0.744 | 0.86 | 0.798 | |
| #6 | 0.874 | 0.895 | 0.884 | |
| #7 | 1 | 0.768 | 0.869 | |
| #8 | 0.999 | 0.748 | 0.855 | |
| Average | 0.917 | 0.871 | 0.889 | |
| Min | 0.744 | 0.748 | 0.798 | |
| Max | 1 | 0.986 | 0.957 |
| Class | Prediction (%) |
|---|---|
| Interior | 41 |
| Room | 27 |
| Modern | 25 |
| Architecture | 24 |
| Building | 22 |
| Device | 21 |
| Hall | 20 |
| Seat | 19.9 |
| Wall | 19.2 |
| Light | 18 |
| Class | Prediction (%) |
|---|---|
| Room | 80.28 |
| Interior | 53.94 |
| furniture | 50.33 |
| Bedroom | 48.21 |
| House | 42.60 |
| Home | 42.26 |
| Modern | 29.43 |
| Table | 28 |
| Design | 27.56 |
| Floor | 26.95 |
| Living | 26.53 |
| Wall | 26.07 |
| Decor | 25.63 |
| Chair | 25.46 |
| Lamp | 24.97 |
| Sofa | 23.20 |
| Indoors | 21.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karara, G.; Hajji, R.; Poux, F. 3D Point Cloud Semantic Augmentation: Instance Segmentation of 360° Panoramas by Deep Learning Techniques. Remote Sens. 2021, 13, 3647. https://doi.org/10.3390/rs13183647
Karara G, Hajji R, Poux F. 3D Point Cloud Semantic Augmentation: Instance Segmentation of 360° Panoramas by Deep Learning Techniques. Remote Sensing. 2021; 13(18):3647. https://doi.org/10.3390/rs13183647
Chicago/Turabian StyleKarara, Ghizlane, Rafika Hajji, and Florent Poux. 2021. "3D Point Cloud Semantic Augmentation: Instance Segmentation of 360° Panoramas by Deep Learning Techniques" Remote Sensing 13, no. 18: 3647. https://doi.org/10.3390/rs13183647
APA StyleKarara, G., Hajji, R., & Poux, F. (2021). 3D Point Cloud Semantic Augmentation: Instance Segmentation of 360° Panoramas by Deep Learning Techniques. Remote Sensing, 13(18), 3647. https://doi.org/10.3390/rs13183647