1. Introduction
Hyperspectral images (HSIs) with high spectral resolution and fine spatial resolution are easily accessible on account of advanced sensor technology, which have been intensively studied and widely applied in many fields, such as environmental monitoring [
1], precision agriculture [
2], urban planning [
3], and Earth observation [
4]. HSIs contain a large number of consecutive narrow spectral bands, which provide rich information for classification [
5]. However, these bands have a strong correlation that results in massive redundant information in HSIs [
6]. In addition, the high dimensionality and limited training samples of HSIs lead to the Hughes phenomenon [
7]. Accordingly, dimensionality reduction (DR) plays an important role in addressing the aforementioned issue [
8,
9].
Many DR methods have been designed to transform the original features into a new low-dimensional space for HSI, most of which can be divided into supervised and unsupervised ones [
10,
11]. The supervised methods need the support of class labels to obtain the discriminant projection [
9]. For instance, linear discriminant analysis (LDA) [
12] utilizes the a priori class labels to separate the interclass samples and compact the intraclass samples. Nonparametric weighted feature extraction (NWFE) [
13] calculates the weighted means and constructs nonparametric between-class and within-class scatter matrices by setting different weights on each sample. Regularized local discriminant embedding (RLDE) [
14] constructs a similar graph of intraclass samples and a penalty graph of interclass samples, while adding two regularized terms to preserve the data diversity and address the singularity with limited training samples. To sum up, supervised methods usually aim to compact the homogeneity of intraclass samples and separate the heterogeneity of interclass samples by means of class labels, which is beneficial to improve the separability and classification performance of low-dimensional embedding. However, in practice, the collection of class labels of HSIs requires field exploration and verification by experts, which is expensive and time-consuming. This leads to the inability to obtain class labels in many cases, especially for HSIs covering land [
15]. Therefore, in view of the difficulty of obtaining class labels and their scarcity, a superior unsupervised DR (uDR) method with high separability possesses more practical value.
To explore the intrinsic structure, manifold learning (ML) has been widely applied for the uDR of HSIs, such as isometric mapping (ISOMP) [
16], local linear embedding (LLE) [
17] and Laplacian eigenmaps (LE) [
18]. ISOMP preserves the geodesic distances between points in low-dimensional space. LLE applies local neighbor reconstruction to preserve the local linear relationship. LE constructs a similarity graph for presenting the inherent nonlinear manifold structure. To address the out-of-sample problem of LE and LLE, locality preserving projection (LPP) [
19,
20] and neighborhood preserving embedding (NPE) [
21] are proposed. However, these classic unsupervised ML methods simply consider the spectral information but neglect the spatial information that has been shown to be of great importance for HSIs [
22,
23].
In recent years, many spectral-spatial DR methods have been proposed to fuse spatial correlation and spectral information for improving the classification performance [
24,
25]. Among them, two strategies for exploring spectral-spatial information can be summarized. One common strategy is preserving the spatial local pixel neighborhood structures, such as discriminative spectral-spatial margin (DSSM) [
26], spatial-domain local pixel NPE (LPNPE) [
14] and spatial-spectral local discriminant projection (SSLDP) [
27]. DSSM finds spatial-spectral neighbors and preserves the local spatial-spectral relationship of HSIs. LPNPE remains the original spatial neighborhood relationship via minimizing the local pixel neighborhood preserving scatter. SSLDP designs two weighted matrices within neighborhood scatter to reveal the similarity of spatial neighbors. Another widely used strategy is to replace the common spectral distance with spatial or spatial-spectral combined distance, such as image patches distance (IPD) [
28] and spatial coherence distance (SCD) [
29]. IPD maps the distances between two image patches in HSIs as the spatial-spectral similarity measure. SCD utilizes the spatial coherence to measure the pairwise similarity between two local spatial patches in HSI. More recently, Hong et al. [
24] proposed the spatial-spectral combined distance (SSCD) to fuse the spatial structure and spectral information for selecting effective spatial-spectral neighbors. Although these spectral-spatial methods use different ways to reveal the spatial intrinsic structure of HSIs, they still have two drawbacks: (1) the exploration of spatial information is merely based on the fixed spatial neighborhood window (or image patch), which may be constrained by the complex distribution of ground objects in HSIs; (2) they only consider the spectral information of local spatial neighborhood but ignore the importance of location coordinates.
In HSIs, rich information provided by high spectral resolution may increase the intraclass variation and decrease the interclass variation, while leading to lower interpretation accuracies. Moreover, different objects may share similar spectral properties (e.g., similar construction materials for both parking lots and roofs in the city area) which make it impossible to classify HSIs by only using spectral information [
22]. In this case, location information, as one of the attributes of pixels, can play an important role in classification. The closer the pixels are in location, the more probable it is that they come from the same class and vice versa, especially for HSIs covering land. The contribution of location coordinates to DR and classification has been demonstrated in several existing studies. Kim et al. [
30] directly combined the spatial proximity and the spectral similarity through a kernel PCA framework. Hou et al. [
31] constructed the joint spatial-pixel characteristics distance instead of the traditional Euclidean distance. Li et al. [
32] proposed a new distance metric by combining the spectral feature and spatial coordinate. However, these methods ignore the contribution of the spectral information in the local spatial neighborhood that can improve the robustness of the classifier against noise pixels, since pixels within a small spatial neighborhood usually present similar spectral characteristics.
In short, the methods mentioned above either neglect the location coordinates or the local spatial neighborhood characteristics and lack a comprehensive exploration of spectral-locational-spatial (SLS) information. To address this issue, two unsupervised SLS manifold learning (uSLSML) methods were proposed for uDR of HSIs, called SLS structure preserving projection (SLSSPP) and SLS reconstruction preserving embedding (SLSRPE). SLSSPP aims to preserve the SLS neighbor structure of data, while SLSRPE is designed to maintain the SLS manifold structure of HSIs.
The main contributions of this paper are listed below:
To facilitate the extraction of SLS information, a weighted spectral-locational (wSL) datum is generated with a parameter to balance the spectral and locational effects where the spectral information and location coordinates complement each other. Moreover, to discover SLS relationships among pixels. a new distance measurement, SLS distance (SLSD), which fuses the spectral-locational information and the local spatial neighborhood, is proposed for HSIs, which is excellent for finding the nearest neighbor of the same class.
In order to improve the separability of low-dimensional embeddings, SLSSPP constructs a new uDR model that compresses adjacent samples and separates cluster centroids to approximately compress intraclass samples and separate interclass samples without any class labels. The SLS adjacency graph is especially constructed based on SLSD instead of the original spectral distance and the cluster index in centroid adjacency graph is generated based on wSL data, which allows SLS information to be integrated into the projection and improves the identifiability of low-dimensional embeddings.
Conventional reconstruction weights are calculated only based on spectral information, which cannot truly reflect the relationship among samples because there is inevitable noise and high dimensionality in HSIs and even different objects may have similar spectral properties. To address this issue, SLSRPE redefines new reconstruction weights based on wSL data, which does not only consider the spectral-locational information but also the local spatial neighborhood, which allows SLS information to be integrated into the projection for achieving more efficient manifold reconstruction.
This paper is organized as follows. In
Section 2, we briefly introduce the related works. The proposed SLSD, SLSSPP and SLSRPE are described in detail in
Section 3.
Section 4 presents the experimental results on three datasets that demonstrate the superiority of the proposed DR methods. The conclusion is presented in
Section 5.
2. Related Works
In this section, we briefly review the related works, LPP and NPE. Suppose that an HSI dataset consists of D bands and m pixels, it can be defined as . denotes the class label of , where c is the number of land cover types. The low-dimensional embedding dataset is defined as , in which d denotes the number of embedding dimensionality and . For the linear DR methods, is replaced by with the projection matrix .
2.1. Locality Preserving Projection
Locality preserving projection (LPP) is a linear approximation of the nonlinear Laplacian eigenmaps [
33]. LPP [
19] expects that the low-dimensional representation can preserve the local geometric construction of original high dimensional space. The first step in LPP is to construct an adjacency graph. It aims to make nodes related to each other (nodes connected to adjacency graphs) as close as possible in low-dimensional space. It puts an edge between nodes
i and
j in adjacency graphs if
and
are close. Then, LPP weights the edges and the weight is defined as
where
is the k nearest neighbors of
and
t is the parameter. The optimization problem of LPP is defined as
where
is the Laplacian matrix.
is a diagonal matrix whose entries are column (or row, since
is symmetric) sums of
,
. The optimization problem Equation (
2) can be solved by solving the following generalized eigenvalue problem:
2.2. Neighborhood Preserving Embedding
Neighborhood preserving embedding is a linear approximation to locally linear embedding (LLE) [
34] and aims to preserving the local manifold structure [
21]. Similar to LPP, the first step in NPE is to construct an adjacency graph. Then, it computes the weight matrix
. If there is no edge between the nodes
i and
j, the weight
. Otherwise,
can be calculated by minimizing the following reconstruction error function:
To preserve the local manifold structure on high-dimensional data, NPE assumes that the low-dimensional embedding
can be approximated by the linear combination of its corresponding neighbors. The optimization problem of NPE is defined as
where
and
. The optimization problem Equation (
5) can be solved by solving the following generalized eigenvalue problem:
3. Methodology
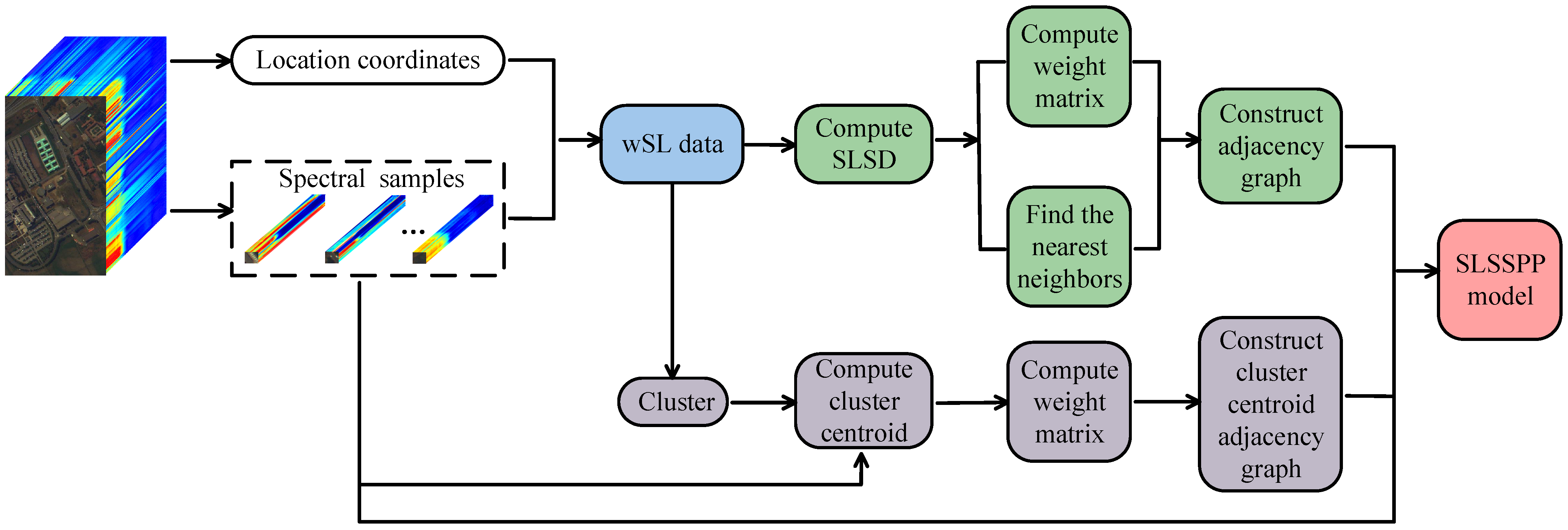
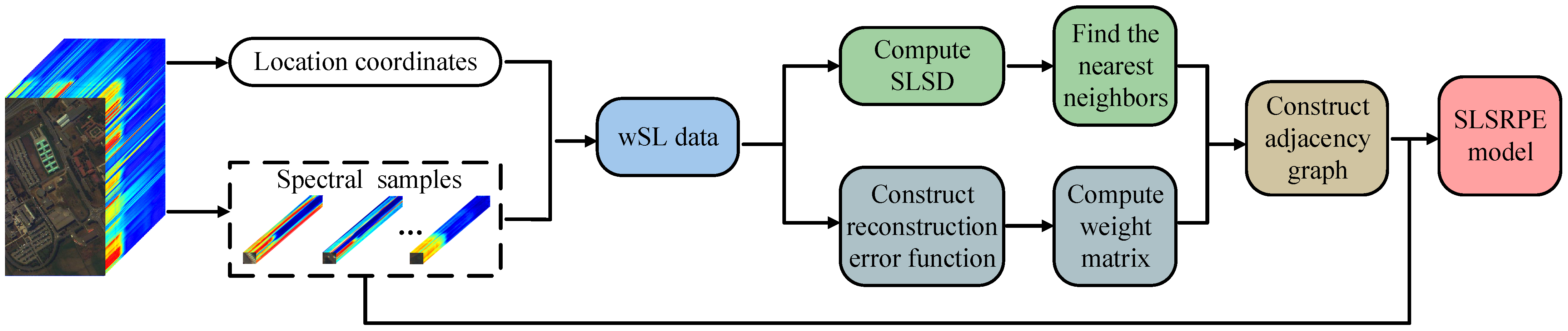
In this section, we introduce the proposed SLSD and two uSLSML methods, SLSSPP and SLSRPE, in detail. Their flowcharts are shown in
Figure 1 and
Figure 2.
Figure 1 shows the calculation process of SLSSPP, where the first step is to generate wSL data with the location coordinates and spectral band of each pixels, which is the key to break the locality of spatial information extraction. Then, SLSD is computed based on wSL data which are also clustered to generate a clustering index. Then, based on the SLSD, SLSSPP finds
k nearest neighbors and computes the weight matrix to construct the SLS adjacency graph. Meanwhile, according to the clustering index, the cluster centroid is computed based on the raw spectral data. On the basis of the cluster centroid, the weight matrix is calculated to construct the cluster centroid adjacency graph. Eventually, on account of the SLS adjacency graph and the cluster centroid adjacency graph, the SLSSPP model was built to obtain an optimal projection matrix based on the raw spectral data.
Figure 2 also shows the calculation process of SLSRPE, whose first step is also to generate wSL data with the location coordinates and spectral band of each pixel. Based on the wSL data, the second step of SLSRPE is constructing the redefined reconstruction error function to compute the redefined reconstruction weight matrix while computing SLSD to find
k nearest neighbors. Then, according to the redefined reconstruction weight matrix and
k nearest neighbors, the adjacency graph is constructed. Finally, the SLSRPE model is built to obtain an optimal projection matrix which is harvested to transform the original high-dimensional data into low-dimensional space. In the end, the low-dimensional features are classified by classifiers.
3.1. Spectral-Locational-Spatial Distance
In fact, SLSSPP and SLSRPE are two graph embedding methods. For an HSI dataset with m pixels, its adjacency graph have m nodes. In general, we put an edge between nodes i and j in if and are close (that is is the nearest neighbor of , or is the nearest neighbor of .). As a rule, we expect that the samples of the same class are connected and put edges when constructing since the connected samples are usually required to gather or maintain a manifold structure. However, if there is a mass of connected samples belonging to different classes, the classification performance of low-dimensional features will inevitably be reduced. Accordingly, how to explore the relationship among samples and find the nearest neighbor of the same class is the key to unsupervised manifold learning. In this subsection, we propose a distance calculation method, SLSD, to measure the similarity among samples.
With the recognition of the importance of spatial information in HSI, many spectral-spatial DR methods design different spectral-spatial distance to replace the raw spectral distance but ignore the location information of pixels.
Figure 3 shows the comparison of spectral bands of pixels with different locational relationships. A and B display the spectral curves of pixels that are in the same class and close to each other in location, while their spectral bands are quite different. At the same time, although the two pixels in C or D are of different kinds and located far away, their spectral curves are almost identical. In both cases, it is difficult to determine the correct pixel relationship between them based on spectral information alone. In fact, location information can alleviate this problem well since pixels that are closer to each other in location are more likely to belong to the same class, especially for HSIs covering land.
In this paper, we regard the location information as one of the attributes of pixels and utilize it to break the locality of spatial information extraction and capture more spatial information. For an HSI dataset
, the location information can be denoted as
where
is the coordinate of the pixel
. To fuse the spectral and locational information of pixels in HSIs, a spectral-locational dataset is constructed as follows:
However, due to the difference of image size and the complexity of homogeneous domain distribution in HSIs, this simple combination of spectrum and location is not reasonable. In order to balance the effect of location and spectrum on the relationships among samples, the weighted spectral-locational (wSL) data
are redefined as
and
.
is a spectral-locational trade-off parameter. It needs to be emphasized that
is only used to calculate the relationship among pixels, not the DR data. There is therefore no need to discuss the rationality of the physical meaning of
. In addition,
with location also breaks the locality of spatial information extraction.
We assume the local neighborhood space of
is
with
in a
spatial window, which is formulated as
Actually, the primary responsibility of SLSD is to find the effective nearest neighbors. To search for highly credible neighbors, SLSD uses a local neighborhood space instead of a central sample. Accordingly, the SLSD of the sample
and
is defined as
where
is one of the neighbors of the target sample
.
is the distance between
and
and defined as follows:
in which
is calculated by
is a constant which is empirically set to 0.2 in the experiments. The window parameter
s is the size of the local spatial neighborhood
.
is a pixel in
surrounding
.
is the weight of
. The more similar
is to
, the larger the value of
, and the more important the distance between
and
is. The spectral-locational trade-off parameter
can adjust the influence of location information on distance. When
, SLSD is the spectral-spatial distance only based on spectral domain. When
, SLSD is the locational-spatial distance only based on coordinate. By choosing the appropriate
value, we can excavate the more realistic relationships among the samples as much as possible. Furthermore, this allows the neighbor samples to be more likely to fall into the same class as the target sample. To sum up, SLSD not only extracts local spatial neighborhood information, but also explores global spatial relations in HSIs based on location information.
To illustrate the effectiveness of SLSD, we compared it with the SD and SSCD proposed in [
24]. SD is the simple spectral distance and SSCD is a spectral-spatial distance without location information.
Table 1 shows the number of samples with different classes in the top 10 nearest neighbors of samples, which includes all samples in the three datasets. For a fair comparison, SSCD and SLSD has the same spatial window parameters for the three datasets. From
Table 1, the number of samples are presented as: SLSD < SSCD < SD. This means that not only the local spatial neighborhood but also the location information are both quite valuable for the exploration of the relationship among the samples. In addition,
Table 1 also shows that SLSD rarely has different classes of samples in the top 10 nearest neighbors. This means that the neighbors obtained by SLSD mostly belong to the same class as the target sample, which indicates that SLSD is excellent for correctly determining the pixel relationship in HSIs.
3.2. Spectral-Locational-Spatial Structure Preserving Projection
The core of many supervised DR algorithms to obtain discriminant projections is to shorten the intraclass distance and expand the interclass distance in low-dimensional space [
14,
27]. In the case of sufficient class labels, this way can indeed achieve excellent DR for classification. However, it is quite difficult to obtain class labels for HSIs covering land. In this paper, SLSSPP was proposed to approach this concept without any class labels. On account of SLSD, SLSSPP can achieve the goal of shortening the intra-class distance in an unsupervised manner, since most of the nearest neighbors belong to the same class as the target sample. Meanwhile, in SLSSPP, expanding the interclass distance is simulated by maximizing the distance among the cluster centroids based on wSL data.
With SLSD, the SLS adjacency graph
can be constructed, where
is the vertex of the graph and
is the weight matrix. In graph
, if
belongs to the
k nearest neighbors
of
based on SLSD, an edge should be connected between them. In this paper, if
or
, the weight of each edge is defined as
where:
Otherwise, . is the SLSD between and . Due to the superior performance of SLSD in representing the relationship among samples in HSIs, based on SLSD can make the low-dimensional space keep the more real structure of the raw space. Actually, , therefore is a sparse matrix.
In order to shorten the distance among each sample and its
k nearest neighbors in embedding space, the optimization problem is defined as
in which
is a symmetric matrix and
is a diagonal matrix whose entries are column or row sums of
,
.
is the Laplacian matrix. In addition, it can be further evolved to:
To indirectly expand the interclass distance, we maximize the distance among cluster centroids.
Table 2 shows the number of heterogeneous samples in the same cluster when three datasets are divided into 35 clusters. Compared with the raw spectral datum
, the wSL datum
has better clustering performance. This means that
should be used to compute the cluster index that guide the low-dimensional features. To facilitate the implementation and calculation, we adopt K-means algorithm to cluster
. Assuming
is divided into
clusters, the index
of
clusters can be obtained as follows:
where
is the K-means algorithm and
is the sample index belonging to the
i-th cluster. According to the index
F, the cluster centroid
of
is calculated as
The optimization problem of cluster centroid distance maximization is defined as
Here,
is the weight matrix of the cluster centroid, which is defined as
is the Euclidean distance function. The definition of
means that the greater the distance between cluster centroid
and
, the greater the weight
, and thus the greater the degree of separation between cluster
i and
j in low-dimensional space, and vice versa.
is a symmetric matrix and
. This optimization problem can be further evolved to:
Aiming to simultaneously minimize the distance among each sample and its
k nearest neighbors and maximize the distance among cluster centroids to obtain the discriminant low-dimensional representations, the DR model of SLSSPP is defined as
As a general rule, this equals to the following optimization program:
where
is a non-zero constant matrix. Based on the Lagrangian multipliers, the optimization solution can be obtained through the following generalized eigenvalue problem:
where
is the eigenvalue of Equation (
24). With the eigenvectors
corresponding to the
d largest eigenvalues, the optimal projection matrix can be represented as
Finally, the low-dimensional embedding dataset can be given by .
The detailed procedure of SLSSPP is given in Algorithm 1. In general, SLSSPP has two contributions: (1) it takes advantage of SLSD to search the nearest neighbor and construct an adjacency graph; and (2) a cluster centroid adjacency graph based on wSL data is constructed. In order to demonstrate their superiority in dimensionality reduction, the comparative experiments based on three datasets are carried out and the classification overall accuracies (OAs) are shown in
Table 3 where
is the number of training samples per class used for the classifiers. The LPP_Cluster represents the combination of LPP and the cluster centroid adjacency graph, while LPP_SLSD represents that traditional LPP uses SLSD to explore the nearest neighbor and construct adjacency graph. From
Table 3, both LPP_Cluster and LPP_SLSD outperform traditional LPP under different training conditions of the two classifiers, which means that both designs in SLSSPP are valid. In fact, based on these two designs, the SLSSPP model in Equation (
22) can indirectly reduce the intraclass distance and increase the interclass distance in an unsupervised manner, which not only preserves the neighborhood structure of HSIs, but also effectively enhances the separability of low-dimensional embeddings.
Table 3 also shows that SLSSPP has better classification performance than LPP_Cluster and LPP_SLSD, which indicates that the proposed SLSSPP is quite meaningful.
| Algorithm 1 SLSSPP |
Input: A D-dimensional HSI dataset , nearest neighbors number , spatial window size , embedding dimension d and trade-off parameter .
- 1:
Obtain location information and generate wSL data as Equation ( 8). - 2:
Compute the SLSD among samples by Equations ( 10)–( 12). - 3:
Find the k nearest neighbors of each samples based on SLSD. - 4:
Compute the weight matrix in adjacency graph by Equations ( 13) and ( 14). - 5:
Compute the cluster centroid index F by Equation ( 17) and the cluster centroid by Equation ( 18). - 6:
Compute the weight matrix of the cluster centroid by Equation ( 20). - 7:
Construct the DR model as Equation ( 22) and solve the generalized eigenvalue problem as Equation ( 24). - 8:
Obtain the projection matrix with the d largest eigenvalues corresponding eigenvectors: .
Output: |
3.3. Spectral-Locational-Spatial Reconstruction Preserving Embedding
From
Section 2.2, NPE constructs the reconstruction error function simply based on the spectral information, which is unreliable not only due to the spectral redundancy and noise in HSIs, but also because different objects may share the same spectral properties. To address this problem, SLSRPE redefines an SLS reconstruction error function to compute the SLS reconstruction weights, which is based on the wSL data instead of the raw spectral data. In addition, the SLS reconstruction weights also consider the contribution of local spatial neighborhood.
Based on SLSD, the adjacency graph
is constructed.
is the reconstruction weight matrix. The superiority of SLSD in finding the nearest neighbor proves that SLS information is quite beneficial to characterize the relationship among samples. As a result, SLS information should be used to construct the reconstruction error function and calculate the reconstruction weight. In fact, the closer the SLS relationship is, the more probable it is that the selected neighbor has the same class as the target sample, and the greater its reconstruction weight will be. In this way, the reconstruction error function for the optimal weights is redefined as follows:
in which
is the local spatial neighbor of
and
.
is the SLSD between
and
. The more similar
is to
, the greater the contribution
makes to the relationship between
and
, which improves the robustness of reconstructed weights to noisy samples. By solving the reconstruction error function, we obtain the reconstructed weight matrix
.
Supposing that
is the
jth nearest neighbor of
based on SLSD,
k is the number of the selected nearest neighbors,
is the
rth local spatial neighbor of
. For the sake of explanation:
indicates the SLS combined measure between
and
. The reconstruction error function can be simplified to:
where
and
. Then, the reconstruction error function can be expressed as the following optimization problem:
with the Lagrange multiplier method,
is given as follows:
where
and
.
is the reconstruction coefficient of
to
. In fact,
, so the reconstruction matrix
is a sparse matrix. According to
, SLSRPE maintains the reconstructed relationship between the target sample and the nearest neighbors in a low-dimensional space. The DR model of SLSRPE is defined as
which can be reduced as
where
and
. Equation (
32) can be solved by the Lagrange multiplier, and it can be transformed into the following form:
where
is the eigenvalue of Equation (
33). With the eigenvectors
corresponding to the
d smallest eigenvalues, the optimal projection matrix can be represented by
. Finally, the low-dimensional embeddings can be given by
.
The detailed procedure of the presented SLSRPE approach is given in Algorithm 2. In contrast to traditional NPE, SLSRPE also has two contributions: (1) it takes advantage of SLSD to search the nearest neighbor, (2) it redefines the reconstruction error function to calculate the reconstruction weight matrix. Both of these include an integrated exploration of spectral-locational-spatial information. To demonstrate their effectiveness separately, we conducted experiments on three datasets, and the experimental results are shown in
Table 4. NPE_SLS is used to test our proposed reconstruction weights that contain SLS information, while NPE_SLSD indicates that traditional NPE uses SLSD to search the nearest neighbors. From
Table 4, both NPE_SLS and NPE_SLSD are superior to traditional NPE. Even more, NPE_SLS has advantages over NPE_SLSD. This means that the two points proposed in SLSRPE are meaningful, and that the reconstruction weights we redefine to include the SLS information are valuable. Accordingly, SLSRPE explores reconstruction relationships among samples not only in spectral domain, but also based on the location and local spatial neighborhood. SLSRPE makes full use of spectral-locational-spatial information of HSIs to obtain discriminating features to improve the classification performance. In fact,
Table 4 also shows that SLSRPE is superior to NPE_SLS and NPE_SLSD.
| Algorithm 2 SLSRPE |
Input: A D-dimensional HSI dataset , nearest neighbors number , spatial window size , embedding dimension d and trade-off parameter .
- 1:
Obtain location information and generate wSL data as Equation ( 8). - 2:
Compute the SLSD by Equations ( 10)–( 12). - 3:
Find the k nearest neighbors of each samples based on SLSD. - 4:
Construct the reconstruction error function as Equation ( 26). - 5:
Compute the reconstruction weight by Equation ( 30). - 6:
Solve the generalized eigenvalue problem as Equation ( 33). - 7:
Obtain the projection matrix with the d smallest eigenvalues corresponding eigenvectors: .
Output: |
4. Experiments
4.1. Description of Datasets
The first dataset covers the University of Pavia, Northern Italy, which was acquired by ROSIS sensor and called the PaviaU Dataset. Its spectral range is 0.4–0.82
m. After removing 12 noise bands from the original dataset with 115 spectral bands, 103 bands were employed in this paper. The spatial resolution is 1.3 m and each band has
pixels. This dataset consists of nine ground-truth classes with 42,776 pixels and a background with 164,624 pixels.
Figure 4a,b show the color image and the labeled image with nine classes.
The second dataset, Salinas Dataset, covering Salinas Vally, CA, was acquired by AVIRIS sensor in 1998, whose spatial resolution is 3.7 m. There are 224 original bands with spectral ranging from 0.4 to 2.45
m. Each band has
pixels including 16 ground-truth classes with 56,975 pixels and a background with 54,129 pixels. The color image and the labeled image with 16 classes are shown in
Figure 4c,d.
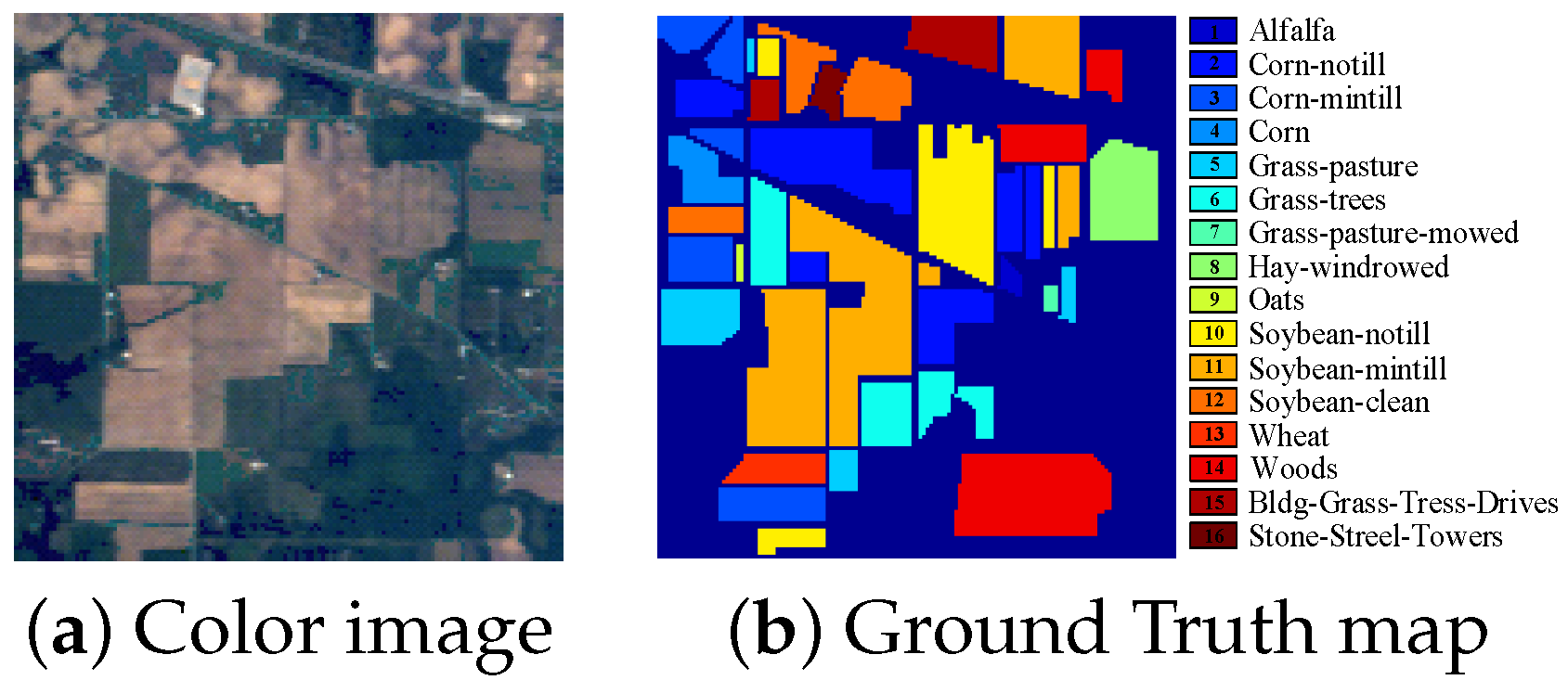
The third dataset, Indian Pines Dataset, covering the Indian Pines region, northwest Indiana, USA, was acquired by AVIRIS sensor in 1992. The spatial resolution of this image is 20 m. It has 220 original spectral bands in the 0.4–2.5
m spectral region and each band contains
pixels. Owing to the noise and water absorption, 104–108, 150–163 and 220 spectral bands were abandoned and the remaining 200 bands are used in this dataset. This dataset contains background with 10,776 pixels and 16 ground-truth classes with 10,249 pixels. The number of pixels in each class ranges from 20 to 2455. The color image and the labeled image with 16 classes are shown in
Figure 5.
4.2. Experimental Setup
In order to verify the superiority of two uSLSML methods, seven state-of-art DR algorithms were selected for comparison, including NPE [
21], LPP [
20], regularized local discriminant embedding (RLDE) [
14], LPNPE [
14], spatial and spectral RLDE (SSRLDE) [
14], SSMRPE [
24], and SSLDP [
27]. The former three methods are spectral-based DR methods, while the latter four approaches make use of both spatial and spectral information for the DR of HSIs. In addition, the raw spectral feature of HSIs is also used for comparison. SSRLDE has single-scale and multi-scale versions, and we select its single-scale version because SLSSPP and SLSRPE are two single-scale models. SSMRPE [
24] proposes a new SSCD to construct the spatial-spectral adjacency graph to reveal the intrinsic manifold structure of HSIs. Among them, RLDE, SSRLDE [
14], and SSLDP [
27] are three supervised methods and require class labels to implement DR, while others are unsupervised.
Two classifiers, support vector machines (SVMs) and k nearest neighbors (KNNs), are applied to the classification of low-dimensional features. In this paper, we utilized the one nearest neighbor and LibSVM toolbox with a radial basis function. In all experiments, we randomly divided each HSI dataset into training and test sets. It should be emphasized that the training set used for training the DR model and classifier in supervised algorithm was only used to train the classifier in unsupervised algorithm. For unsupervised methods in all experiments, all samples in an HSI dataset are utilized to train the DR model. The test set was projected into the low-dimensional space for classification. The classification overall accuracy (OA), the average accuracy (AA), and the Kappa coefficient are used to evaluate classification performance.
To achieve good classification results, we optimized the parameters of various algorithms. For LPP [
20] and NPE [
21], the number of nearest neighbors
k was set to 7 on Indian Pines dataset, 25 on PaviaU and Salinas datasets. We chose the optimal parameters of their source literature for other comparison algorithms. For RLDE, LPNPE and SSRLDE [
14], the number of intraclass and interclass neighbors are both 5, the heat kernel parameter is 0.5, the parameters
,
and neighborhood scale are set to 0.1, 0.1, 11 on the Indian Pines and Salinas datasets, and 0.2, 0.3, 7 on the PaviaU dataset. For SSMRPE [
24], the spatial window size and neighbor number are set to 7, 10 on Indian Pines dataset, 13, 20 on PaviaU dataset, 15, 15 on Salinas dataset. For SSLDP [
27], the intraclass and interclass neighbor number, spatial neighborhood scale and trade-off parameter are set to 7, 63, 15, 0.6 on the Indian Pines and Salinas datasets, and 6, 66, 19, 0.4 on the PaviaU dataset. To reduce the influence of noise in HSIs, the weighted mean filtering with the
window is used to preprocess the pixels. In addition, each experiment in this paper is repeated 10 times in each condition for reducing the experimental random error.
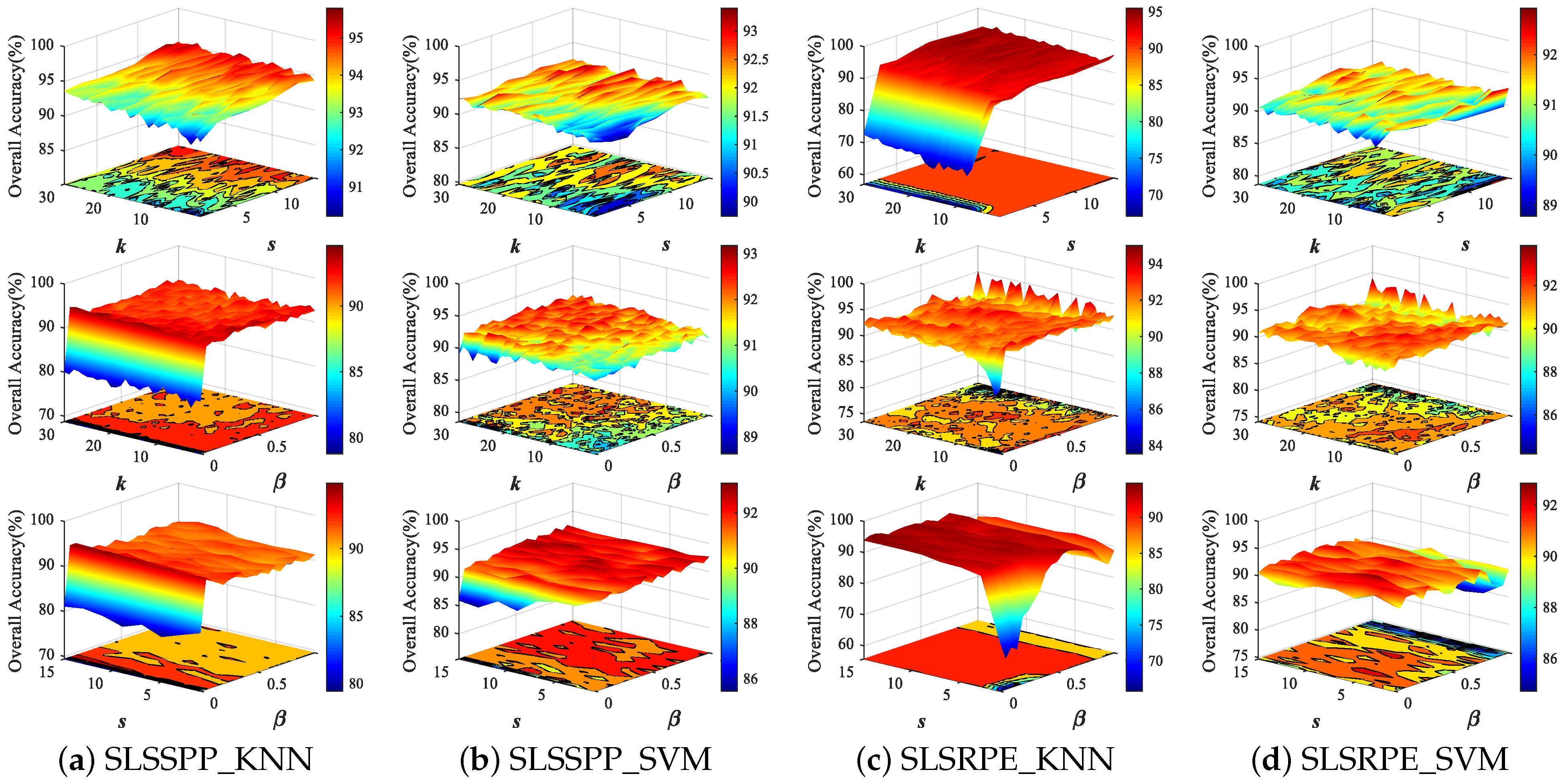
4.3. Parameters Analysis
The two proposed uSLSML methods both have three parameters: nearest neighbor number
k, spatial window size
s and spectral-locational trade-off parameter
. In order to analyze the influence of three parameters on the DR results, we conduct parameter tuning experiments on three HSI datasets. Thirty samples in each class are randomly selected as the training set and the remaining samples are the testing set for two classifiers. For ease of analysis,
Figure 6 and
Figure 7 show the classification OAs with different parameters on Indian Pines and PaviaU datasets. In experiments, the parameter values are set to:
,
,
. The fixed parameters of SLSSPP and SLSRPE are set to
,
,
on Indian Pines dataset,
,
,
on PaviaU dataset to analyze the other two parameters.
We first analyzed the effect of SLSSPP parameters on classification. From
Figure 6 and
Figure 7, the classification OA increases slightly with the increase in
k and
s when
is fixed, while the OA significantly increases with the increase in
when
k and
s are fixed, respectively, on two datasets. In particular, the change in
developing from nothing brings a significant improvement to the classification. This proves that the location information is quite beneficial for DR for classification. However, the OAs have not changed much as
continues to grow, because the value of location information is much larger than that of spectral information due to the normalization of spectral bands.
For the proposed SLSRPE method, the OAs increase as s increases on two datasets when or k is fixed, especially for KNN classifiers, since the large spatial neighborhood is beneficial to characterize the spatial relationship between samples. This means that the spatial neighborhood added in reconstruction weights of SLSRPE is helpful for DR for classification. At the same time, the OAs are improved with the increase in on two datasets on account of the importance of location information to DR for classification. It is worth noting that compared with KNN, SVM has stronger robustness to parameters in view of the advantages of SVM model training.
In fact, when k is greater than 15, the influence of k on uSLSML tends to be stable. For a new HSI datum, k can be valued between 15 and 30. The setting of s depends on the smoothness of the image. If the homogeneous pixels of the HSI image are relatively clustered, s can take a larger value and vice versa. Actually, the further increase in s after increasing to 5 does not significantly improve uSLSML. Therefore, in order to ensure the low computational complexity and the effectiveness of dimension reduction, s can be set to . The value of is obviously influenced by the size of the image. If the image size is large, the value of should be small, and vice versa. usually ranges from 0.01 to 1. In the following experiment, the parameters of SLSSPP are set as , , for the Indian Pines dataset, , , for the PaviaU dataset, , , for the Salinas dataset. The parameters of SLSRPE are set as , , for the Indian Pines dataset, , , for the PaviaU dataset, and , , for the Salinas dataset.
4.4. Dimension Analysis
In order to analyze the impact of the embedding dimension
d of each DR algorithm on classification performance, thirty samples from each class are randomly selected as the training set, and the rest as the test set. If the number of samples in a class is less than 60, half of the samples in this class are used as the training set.
Figure 8 gives the OAs with a different embedding dimension for various DR algorithms on three datasets. The embedding dimension
d is tuned from 2 to 40 with an interval of 2.
As can be seen from
Figure 8, the OAs in the low-dimensional space are mostly higher than those in the raw space. This proves that DR is necessary for classification. Meanwhile, the OAs of each algorithm gradually increases with the increase in embedding dimension, because the higher-dimensional embedding features contain more discriminative information that is helpful for classification. However, as the dimension continues to grow, the OAs tends to be stable or even slightly decreased. The reason is that the discriminative information of the embedding space is gradually approaching saturation and the Hughes phenomenon occurs due to fewer training samples for classifiers. In addition, it is obvious that the classification performance of the DR algorithm fusing spatial and spectral information, LPNPE, SSRLDE [
14], SSMRPE [
24], SSLDP [
27], SLSSPP and SLSRPE, is generally higher than that of the spectral-based algorithm, LPP [
20], NPE [
21] and RLDE [
14], which effectively testifies that spatial information is beneficial to DR for classification. It is worth noting that compared with other DR algorithms, in this experiment, SLSSPP and SLSRPE achieve the best classification performance in almost all embedding dimensions of the three datasets, because SLSSPP and SLSRPE take full advantage of spectral-locational-spatial information in HSIs for DR. In order to ensure each algorithm achieves optimal performance, we set the embedding dimension
on three datasets in the following experiments.
4.5. Classification Result
In practical applications, the classification accuracy of the DR algorithm is sensitive to the size of training set. To explore the classification performance of DR algorithms under different training conditions, we randomly selected
(
) samples from each class for training, and the others for testing. If the number of samples in a class is less than
, half of samples in this class are randomly selected for training.
Table 5 shows the classification OAs of the embedding features of different DR algorithms on three datasets using KNN and SVM classifiers under different training conditions.
As shown in
Table 5, for three datasets, the larger the number of training samples is, the higher the OA value is, since a large number of training samples with class labels can enable a supervised DR algorithm and classifier to obtain more discriminative information. In the comparison algorithms, the spectral-spatial algorithms, LPNPE, SSRLDE [
14], SSMRPE [
24], and SSLDP [
27] are superior to the spectral-based algorithms, including LPP [
20], NPE [
21], and RLDE [
14]. The supervised spectral-spatial algorithms, SSRLDE [
14] and SSLDP [
27], are better than the unsupervised spectral-spatial algorithms, including LPNPE [
14]. These demonstrate once again that label and spatial information are advantageous to DR for classification.
As mentioned in
Section 1, obtaining class labels is time-consuming, expensive, and difficult. Thus, the sensitivity of the classification performance of the DR algorithm to the number of training samples with class labels can also be used to evaluate the DR algorithm. Without doubt, we expected that the classification of a DR algorithm can achieve good performance with fewer training samples with class labels. From
Table 5, it is as expected that when
, SLSRPE on Indian Pines and PaviaU datasets, and SLSSPP on the Salinas dataset achieve the best and satisfactory classification performance in this experiment. In addition, the proposed uSLSML achieved better classification results than other algorithms under almost all training conditions of this experiment. Because uSLSML presents a new SLSD to extract SLS information to choose the effective neighbor and constructs an SLS adjacency graph and a cluster centroid adjacency graph for SLSSPP to enhance the separability of embedded features, it also redefines the reconstruction weights for SLSRPE to mine the SLS reconstruction relationships among samples to discover the intrinsic manifold structure of HSIs.
In order to explore the classification accuracy of different DR algorithms on each class, we classified the embedding features of different DR algorithms with the KNN and SVM classifier on three datasets.
Table 6,
Table 7 and
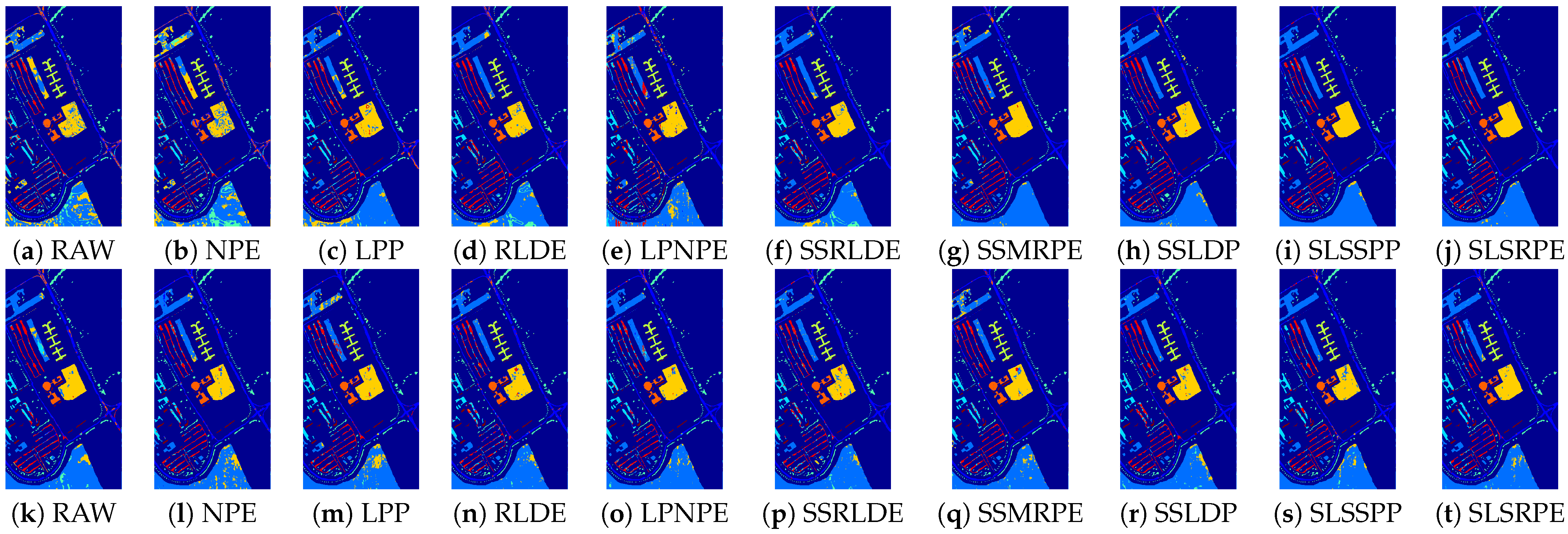
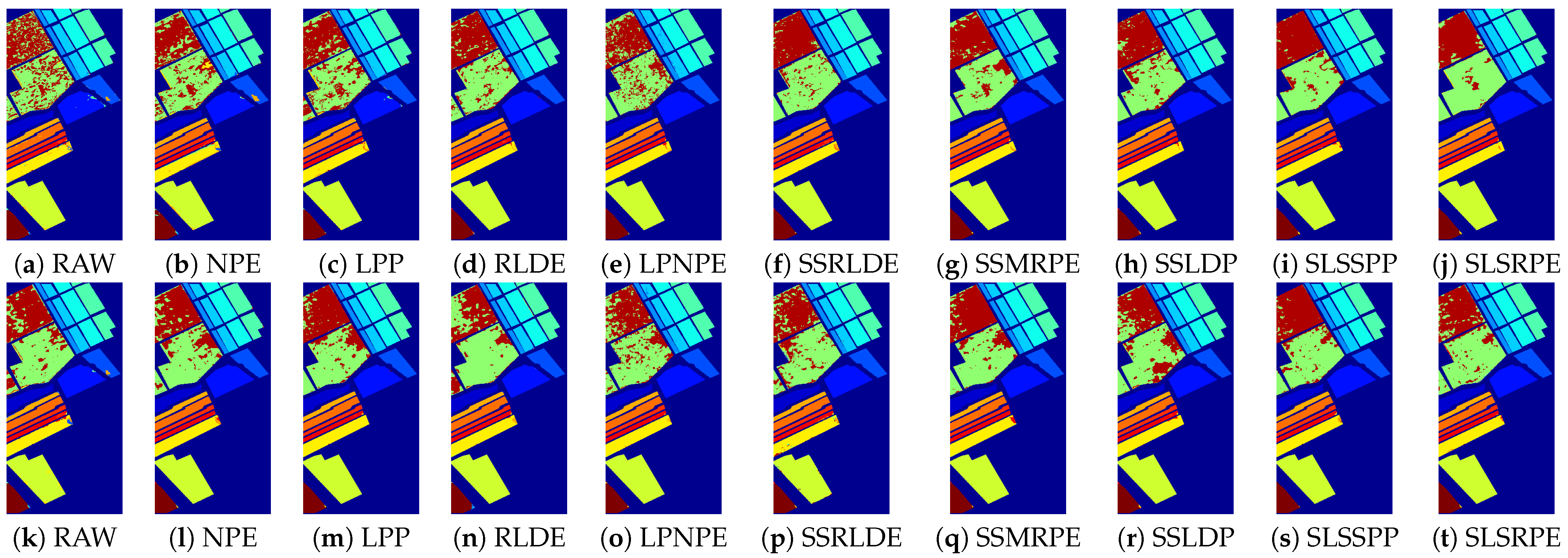
Table 8 listed the classification accuracy of each class, OA, AA, and Kappa coefficient. The visualized classification maps of different approaches on three datasets are displayed in
Figure 9,
Figure 10 and
Figure 11.
From
Table 6,
Table 7 and
Table 8, the spatial-spectral combined methods are completely superior to spectral-based methods and supervised spatial-spectral algorithms slightly outperform unsupervised spatial-spectral algorithms. This means that compared with the label information, the spatial information is more conducive to improving the representation of embedded features in this experiment. SLSRPE and SSMRPE [
24] are two improved versions of NPE [
21], both of which are dedicated to maintaining the local manifold structure of the data.
Table 6,
Table 7 and
Table 8 show that their improvement is effective, and SLSRPE is more outstanding than SSMRPE [
24]. The proposed SLSD can find more neighbor samples from the same class than the SSCD of the SSMRPE [
24], and more importantly, SLSRPE adds the SLS information to the reconstruction weights to reveal the intrinsic manifold structure of HSIs. This experiment also testifies that SLSSPP is far superior to LPP, which is attributed to the proposed SLSD and the new DR model with an SLS adjacency graph and a cluster centroid adjacency graph.
It is worth mentioning that SLSRPE and SLSSPP are even more outstanding than the supervised spectral-spatial algorithms, SSRLDE [
14] and SSLDP [
27], which are two graph-based methods. For supervised graph-based methods, the supervised information is usually placed in the adjacency graph. The above implicitly proves the excellence of the extracted SLS information stored in the adjacency graph of uSLSML.
Specifically, SLSSPP achieves the best classification results in 9 and 10 classes on the Indian Pines dataset, 5 and 3 classes on the PaviaU dataset, 8 and 10 classes on the Salinas dataset for KNN and SVM classifiers, respectively. SLSRPE achieves the best classification results in 9 and 7 classes on the Indian Pines dataset, 4 and 3 classes on the PaviaU dataset, and 9 and 6 classes on the Salinas dataset for KNN and SVM classifiers, respectively. From the numerical value of OA, SLSSPP and SLSRPE are more suitable for the KNN classifier because these two algorithms are based on distance. In general, SLSSPP and SLSRPE are more outstanding than other comparison algorithms in this experiment, due to the full exploration of the spectral-locational-spatial information of HSIs.
According to the classification maps in
Figure 9,
Figure 10 and
Figure 11, SLSSPP and SLSRPE produce smoother classification maps and less misclassification pixels compared with other DR methods, especially in the classes that
Corn-notill,
Soybean-mintill for the Indian Pines dataset,
Asphalt,
Meadows,
Gravel for the Pavia University dataset,
Grapes-untrained,
Vinyard-untrained for the Salinas dataset. These maps illustrate that the comprehensive exploration of SLS information ignored by other comparison algorithms is very helpful for the low-dimensional representation of HSIs and it is absorbed by SLSSPP and SLSRPE.
5. Concluding Remarks
In this paper, we propose two unsupervised DR algorithms, SLSSPP and SLSRPE, to learn the low-dimensional embeddings for HSI classification based on the spectral-locational-spatial information and manifold learning theory. A wSL datum is generated to facilitate the extraction of SLS information. A new SLSD is designed to search the proper nearest neighbors most probably belonging to the class of target samples. Then, SLSSPP constructs a DR model with an SLS adjacency graph based on SLSD and a cluster centroid adjacency graph based on wSL data to preserve SLS structure in HSIs, which compresses the nearest neighbor distance and expands the distance among clustering centroids to enhance the separability of embedding features. SLSRPE constructs an adjacency graph based on the redefined reconstruction weights with SLS information, which maintains the intrinsic manifold structure to extract the discriminant projection. As a result, two uSLSML methods can extract two discriminative low-dimensional features which can effectively improve the classification performance.
Extensive experiments on the Indian Pines, PaviaU and Salinas datasets demonstrated that the points we proposed are effective and the proposed uSLSML algorithms perform much better than some state-of-the-art DR methods in classification. Compared with LPP, the average improvements of OA are about 3.50%, 2.44%, 2.05% by the cluster centroid adjacency graph, 8.24%, 6.55%, 3.09% by SLSD, and 9.04%, 8.67%, 3.26% by SLSSPP on three datasets, while compared with NPE, the improvements are about 5.31%, 12.25%, and 5.05% by redefined reconstruction weights with SLS information, 4.38%, 3.75%, 1.75% by SLSD, 9.66%, 13.27%, 5.72% by SLSRPE.
This work just considers the neighbor samples and ignores the target samples in exploring the local spatial neighborhood information. Thus, our future work will focus on solving this problem while reducing the computational complexity.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}