
Remote Sensing Based Yield Estimation of Rice (Oryza Sativa L.) Using Gradient Boosted Regression in India



Abstract
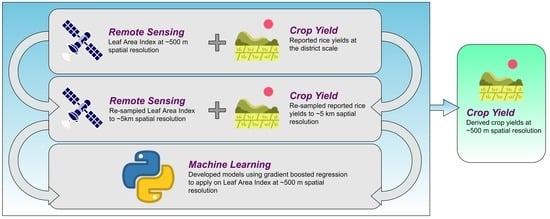
1. Introduction
2. Materials and Methods
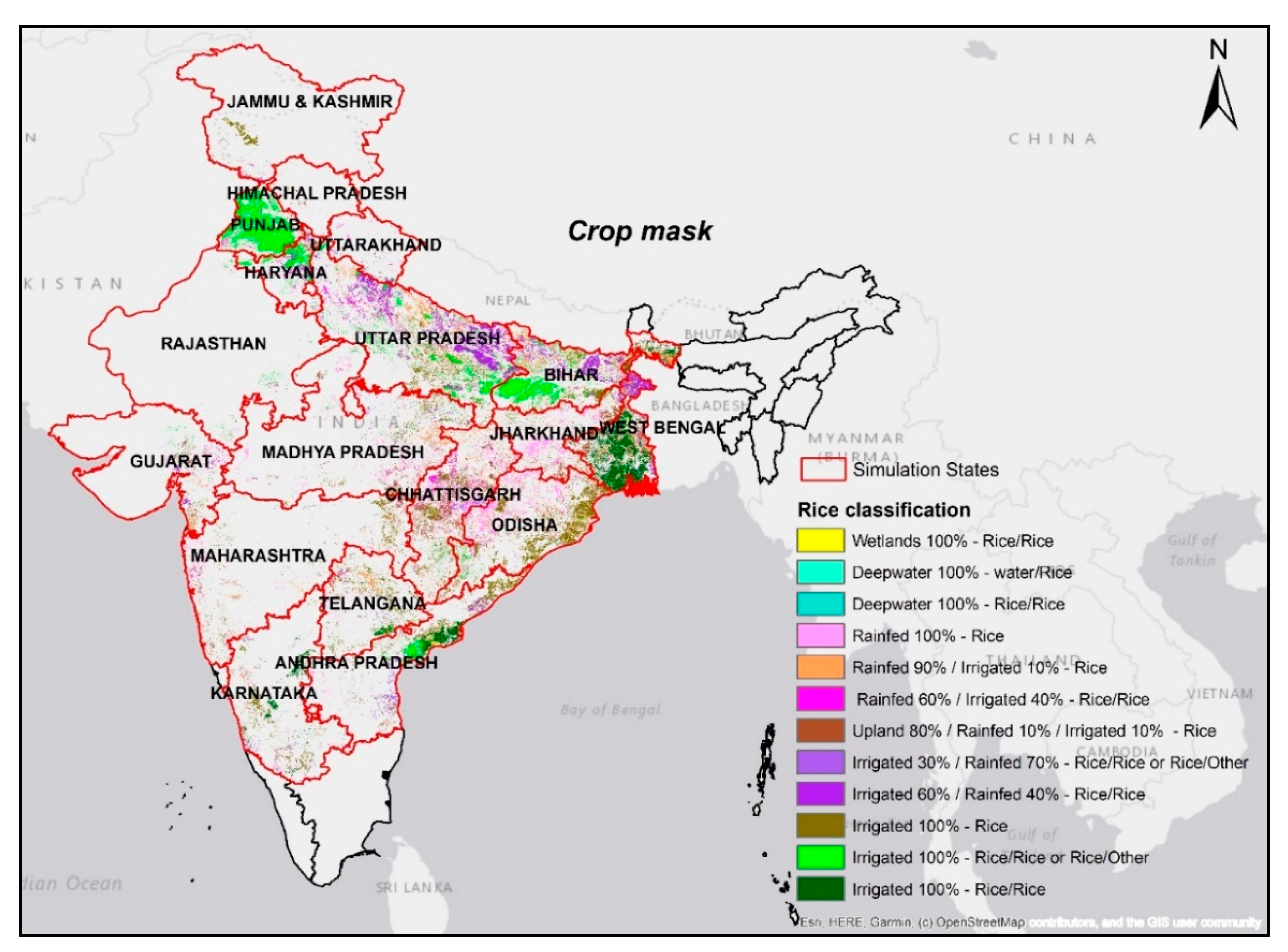
2.1. Study Area
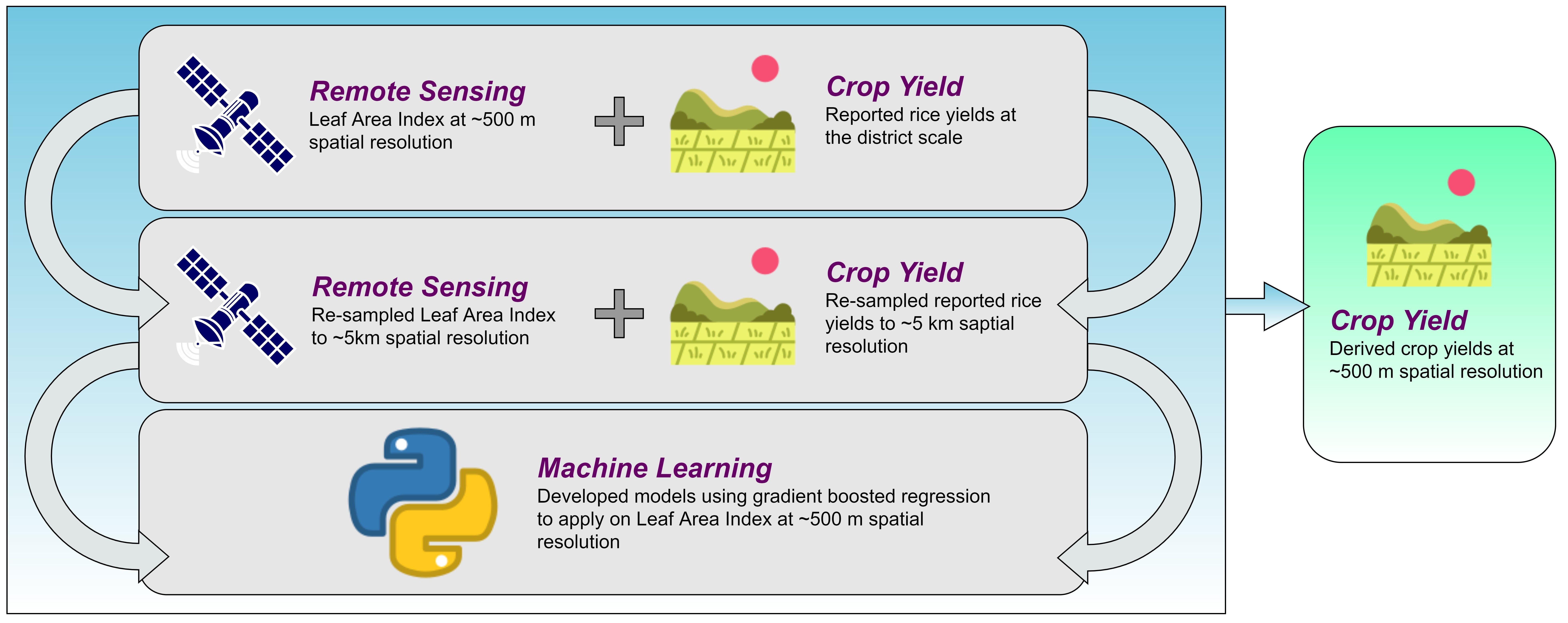
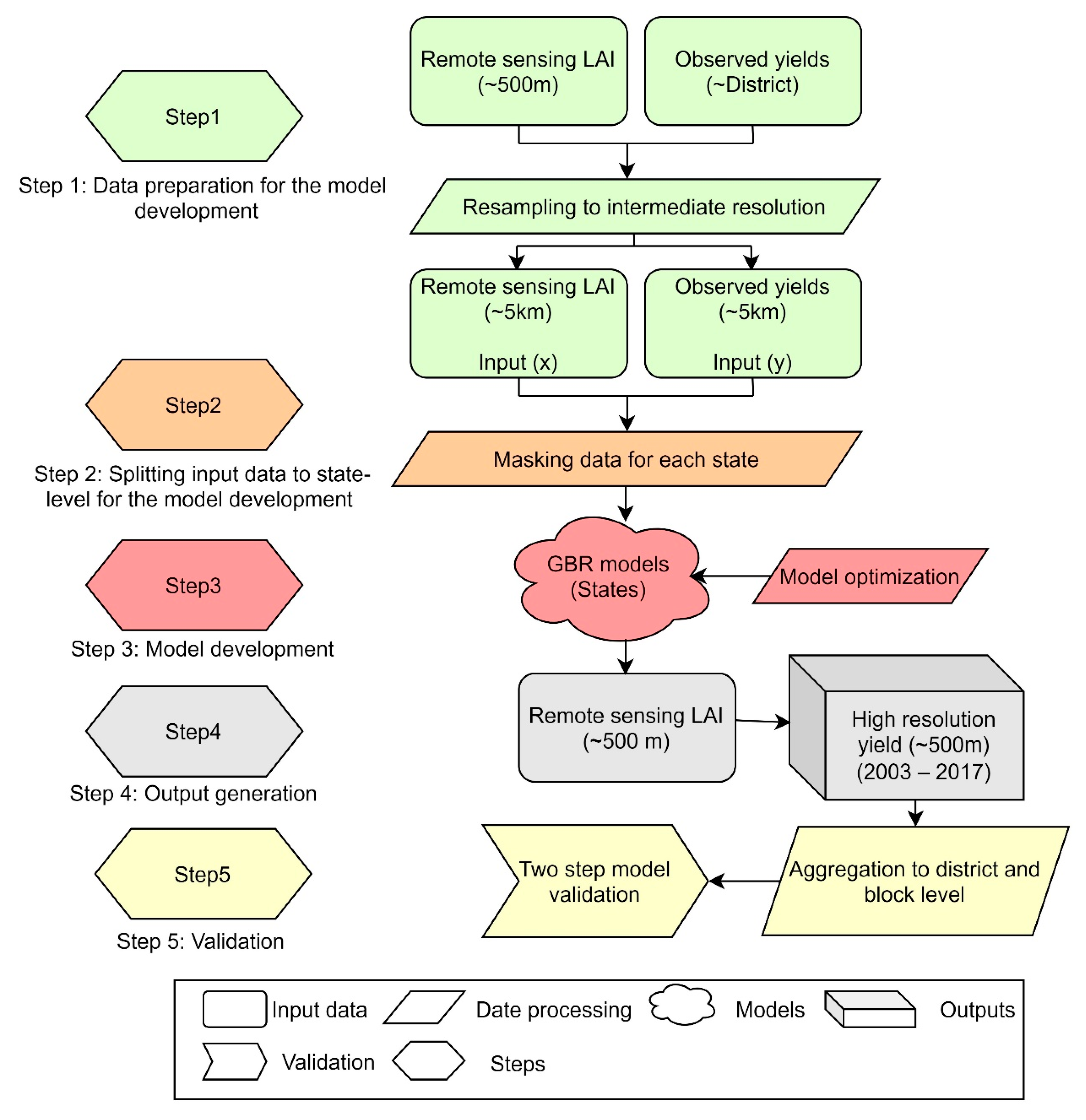
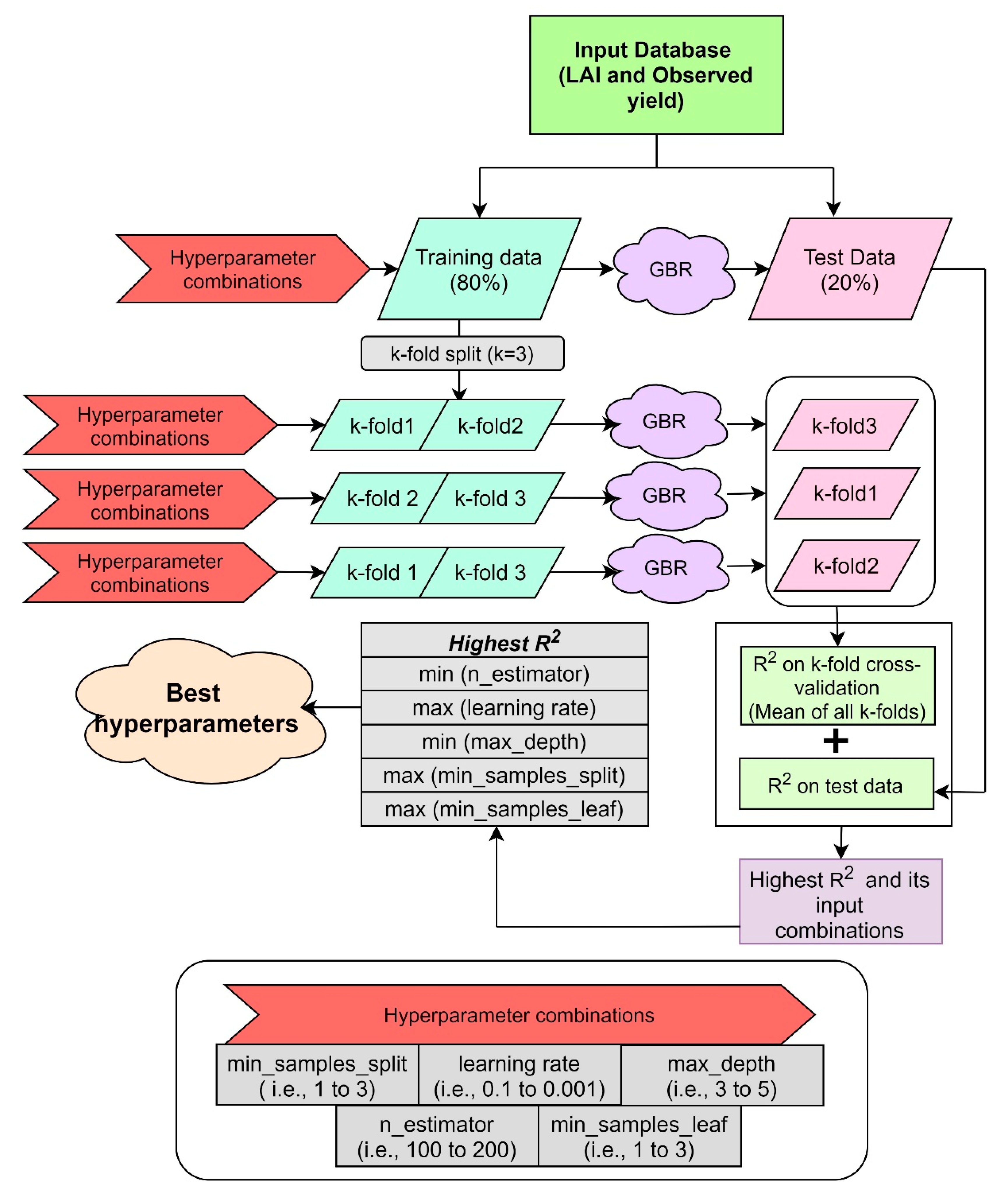
2.2. Methodology Overview
2.3. Observed Yields
2.4. Leaf Area Index (LAI)—Input (x)
2.5. Crop Mask
2.6. Quality Indicators for Model Optimization and Validation
2.7. Yield Modeling Approach
2.7.1. Gradient Boosted Regression (GBR) Trees
2.7.2. Model Parameters
2.7.3. Hyperparameter Tuning on the State Level
2.8. Two-Step Model Validation
3. Results
3.1. Relative Importance of Crop Growth Period
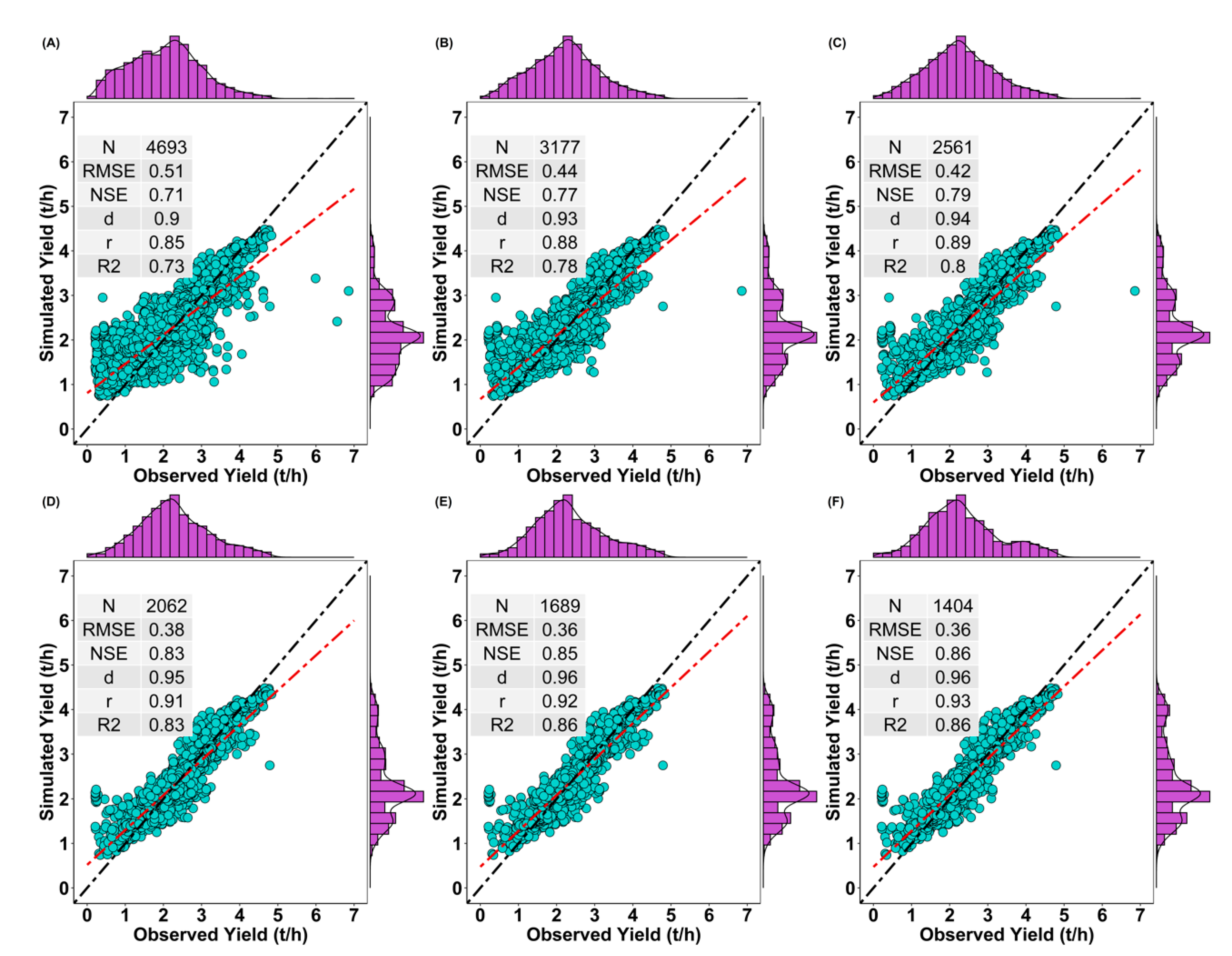
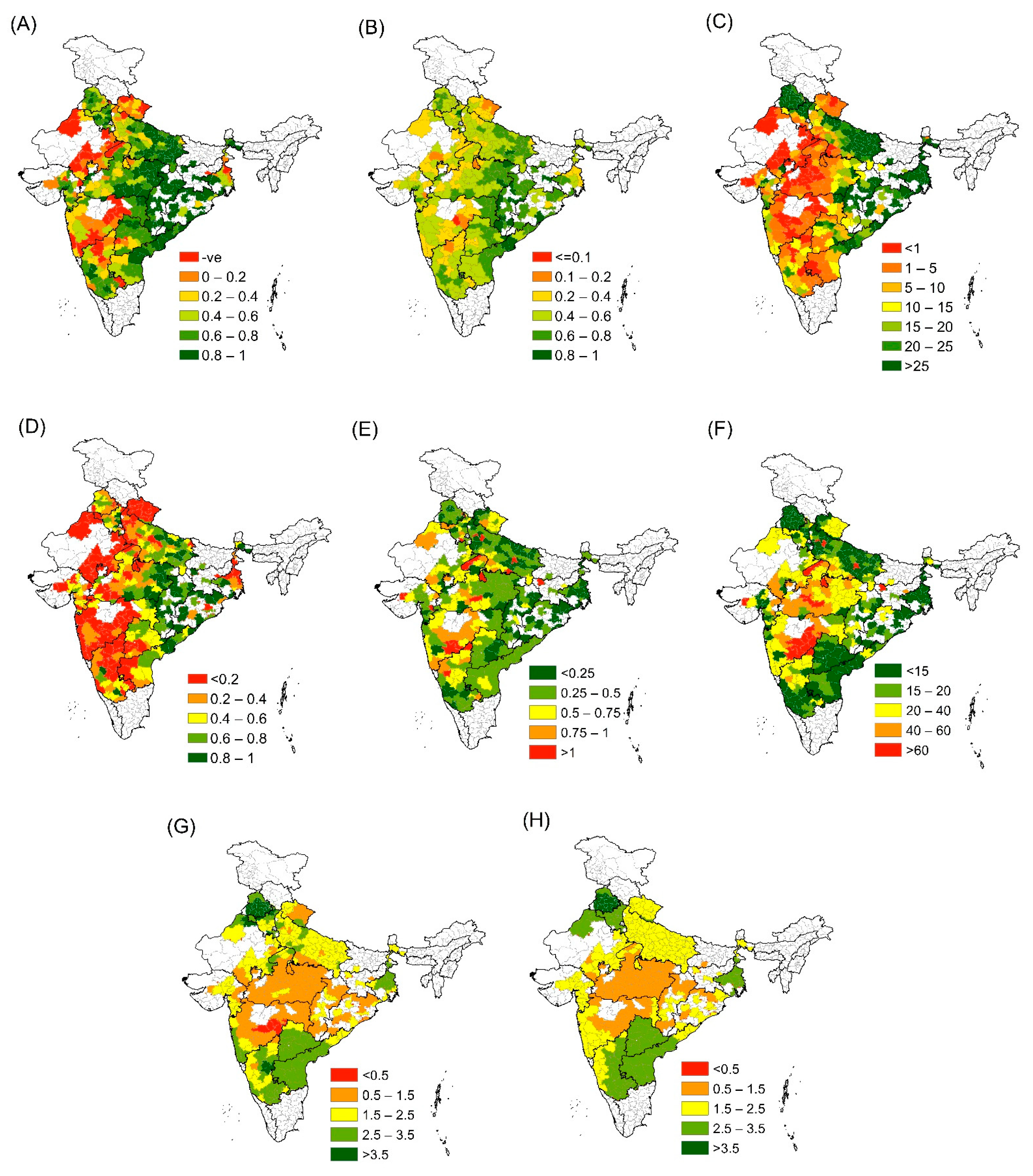
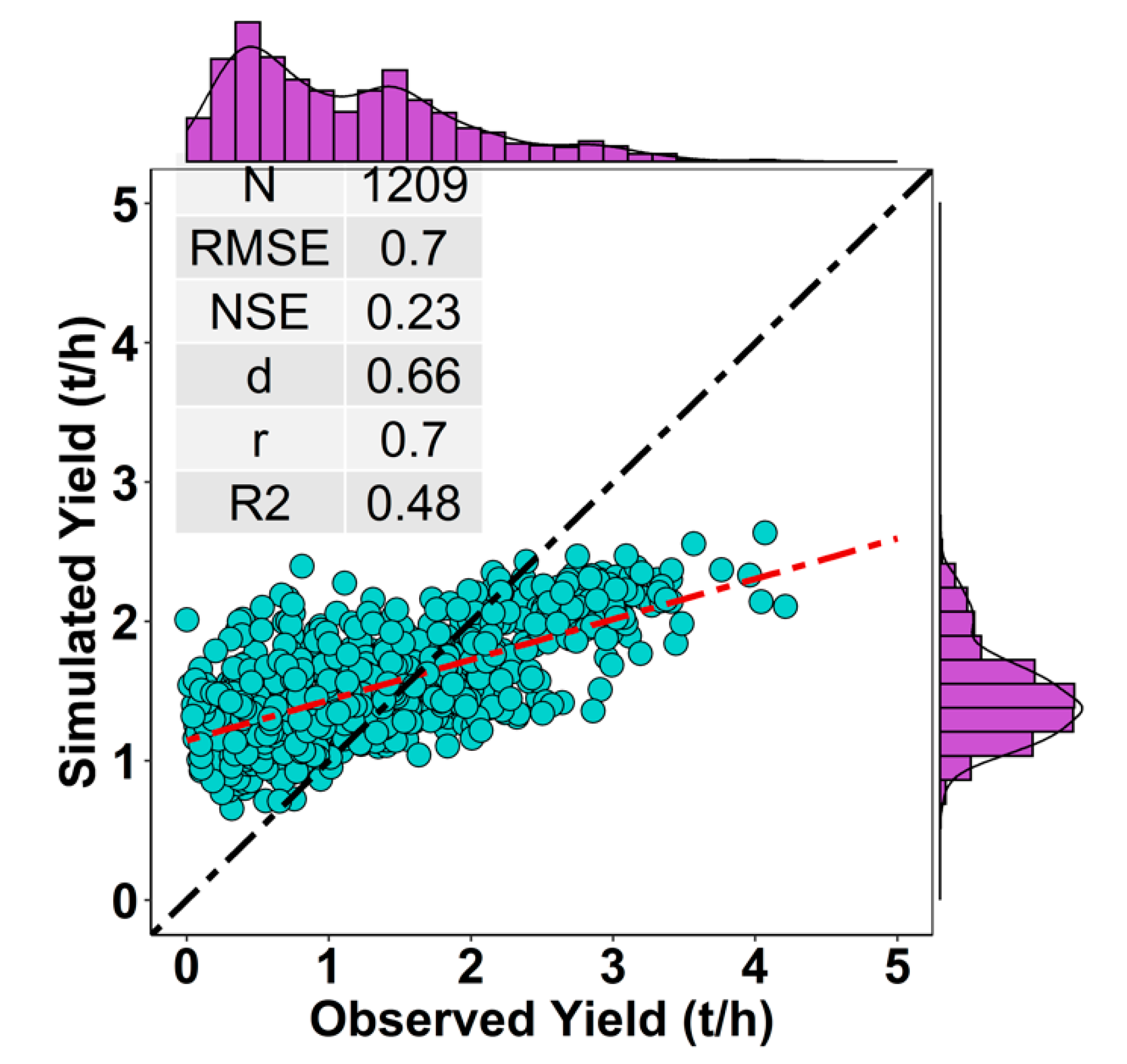
3.2. Spatio-Temporal Performance of Downscaling Approach (2003–2015)
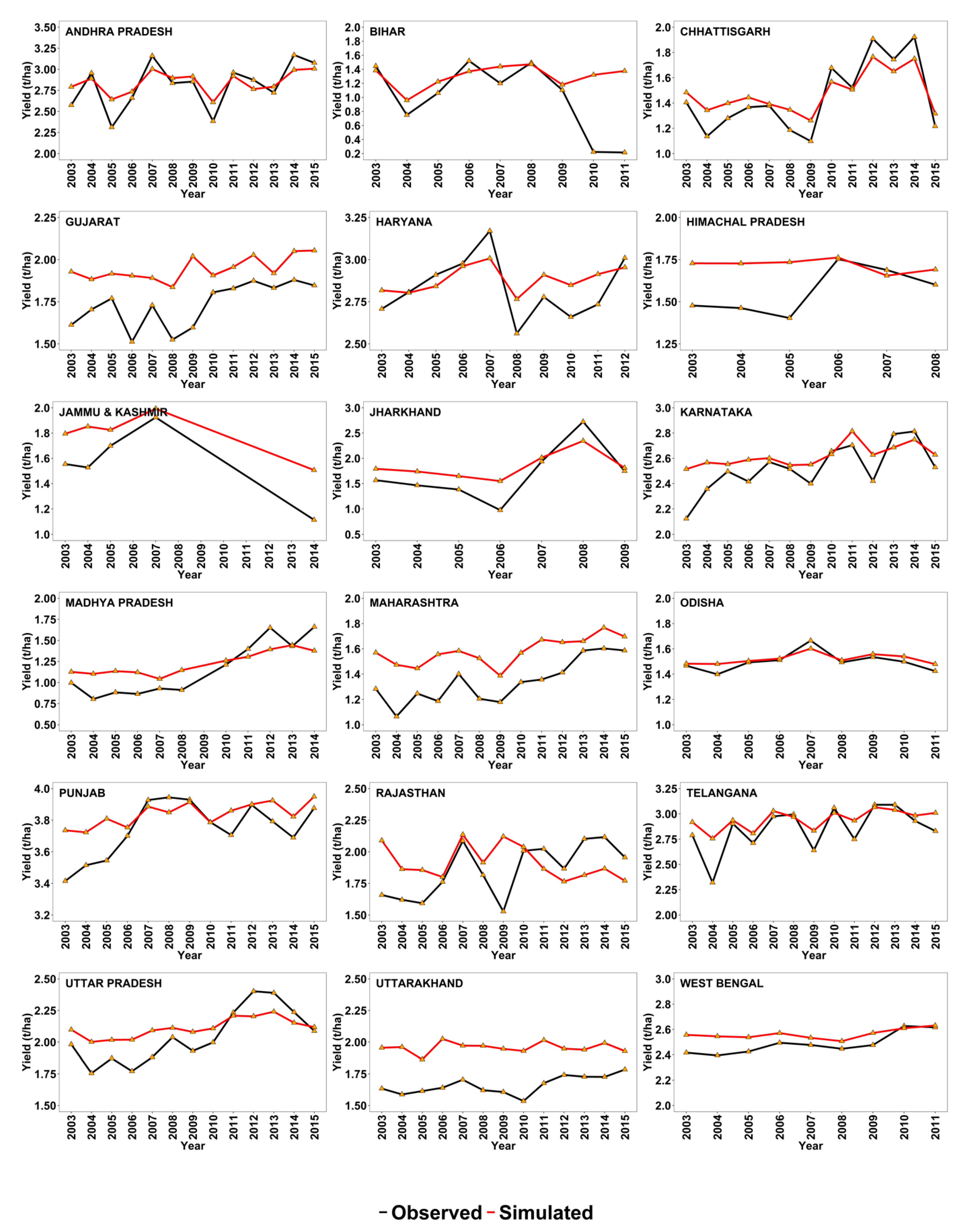
3.3. Inter-Annual Yield Variability
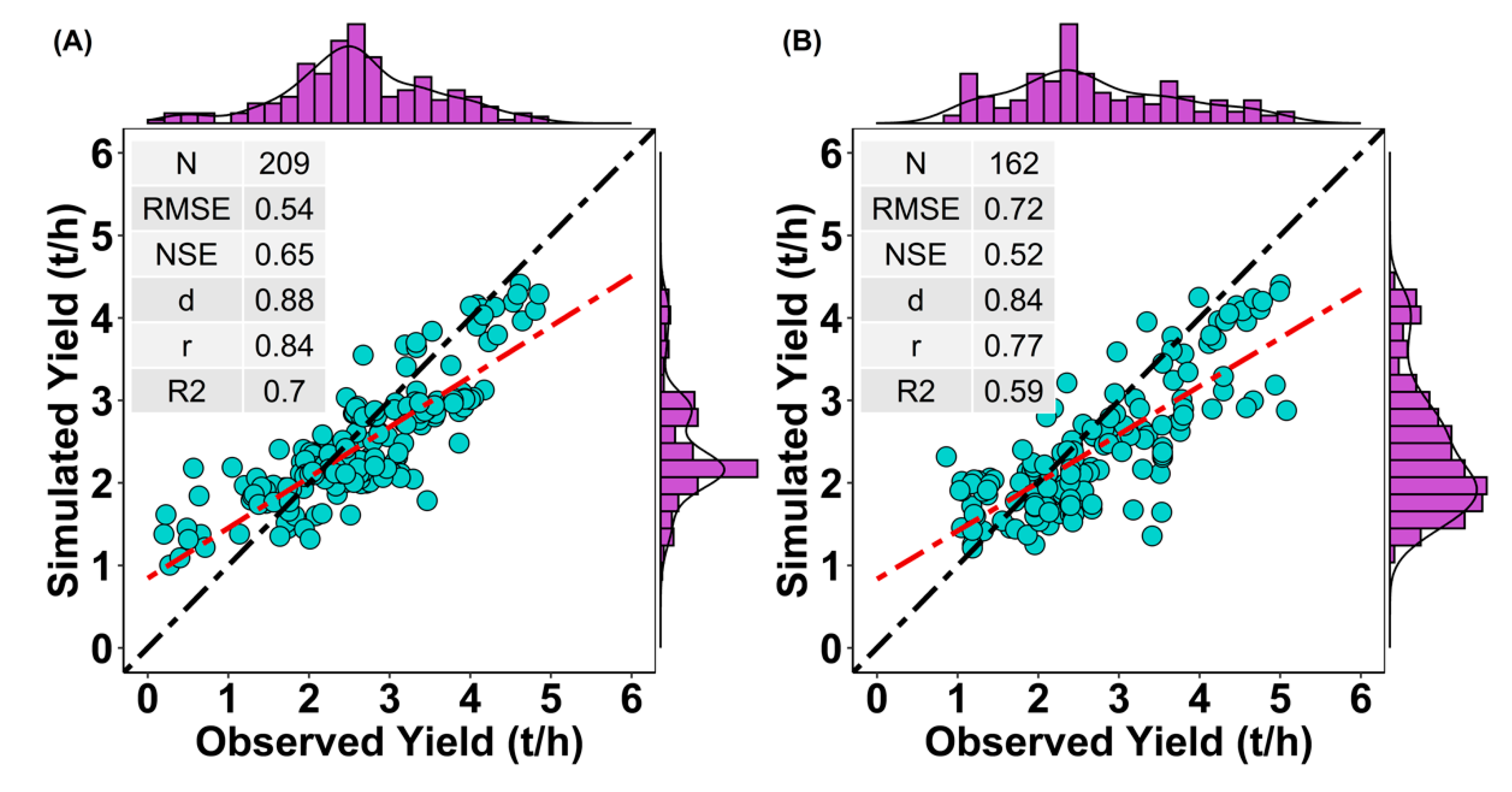
3.4. District-Wise Model Performance
3.5. Block-Level Validation
3.6. Out of Sample Validation
4. Discussion
4.1. Data and Model Quality
4.2. Performance of the Downscaling Approach in Yield Estimation
4.3. Recommendations for Future Research
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gulati, A.; Terway, P.; Hussain, S. Crop Insurance in India: Key Issues and Way Forward; Working Paper 352; Econstor: Kiel, Germany, 2018. [Google Scholar]
- Rai, R. Pradhan Mantri Fasal Bima Yojana: An Assessment of India’s Crop Insurance Scheme. ORF Issue Brief 2019, 16, 296. [Google Scholar]
- GRiSP. A CGIAR Program on Rice-Based Production Systems; Global Rice Science Partnership (GRiSP): Cotonou, Benin, 2011. [Google Scholar]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine Learning Approaches for Crop Yield Prediction and Nitrogen Status Estimation in Precision Agriculture: A Review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Dubey, S.K.; Gavli, A.S.; Yadav, S.K.; Sehgal, S.; Ray, S.S. Remote Sensing-Based Yield Forecasting for Sugarcane (Saccharum officinarum L.) Crop in India. J. Indian Soc. Remote Sens. 2018, 46, 1823–1833. [Google Scholar] [CrossRef]
- Palakuru, M.; Yarrakula, K. Study on Paddy Phenomics Eco-System and Yield Estimation Using Multi-Temporal Remote Sensing Approach. Indian J. Ecol. 2019, 6, 293–297. [Google Scholar]
- Singh, R.; Semwal, D.P.; Rai, A.; Chhikara, R.S. Small Area Estimation of Crop Yield Using Remote Sensing Satellite Data. Int. J. Remote Sens. 2002, 23, 49–56. [Google Scholar] [CrossRef]
- Dolly; Saxena, S.; Dubey, S.K.; Choudhary, K.; Sehgal, S.; Neetu; Ray, S.S. An Analysis Of National-State-District Level Acreage And Production Estimates Of Rabi Sorghum Under FASAL Project. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-3/W6, 79–84. [Google Scholar] [CrossRef]
- Jain, V.; Saxena, S.; Dubey, S.; Choudhary, K.; Sehgal, S.; Neetu; Ray, S.S. Rice (Kharif) Production Estimation Using Sar Data Of Different Satellites And Yield Models: A Comparative Analysis Of The Estimates Generated Under FASAL Project. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-3/W6, 99–107. [Google Scholar] [CrossRef]
- Kumar, S.; Saxena, S.; Dubey, S.K.; Chaudhary, K.; Sehgal, S.; Ray, S.S. Analysis Of Wheat Crop Forecasts, In India, Generated Using Remote Sensing Data, Under FASAL Project. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-3/W6, 223–228. [Google Scholar] [CrossRef]
- Latwal, A.; Saxena, S.; Dubey, S.K.; Choudhary, K.; Sehgal, S.; Ray, S.S. Evaluation of pre-harvest production forecasting of mustard crop in major producing states of India, under FASAL project. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-3/W6, 115–122. [Google Scholar] [CrossRef]
- Ray, S.S.; Mamatha Neetu, S.; Gupta, S. Use of Remote Sensing in Crop Forecasting and Assessment of Impact of Natural Disasters: Operational Approaches in India. Crop Monit. Improv. Food Secur. 2014, 111–122. [Google Scholar]
- Aghighi, H.; Azadbakht, M.; Ashourloo, D.; Shahrabi, H.S.; Radiom, S. Machine Learning Regression Techniques for the Silage Maize Yield Prediction Using Time-Series Images of Landsat 8 OLI. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4563–4577. [Google Scholar] [CrossRef]
- Folberth, C.; Elliott, J.; Müller, C.; Balkovič, J.; Chryssanthacopoulos, J.; Izaurralde, R.C.; Jones, C.D.; Khabarov, N.; Liu, W.; Reddy, A.; et al. Parameterization-Induced Uncertainties and Impacts of Crop Management Harmonization in a Global Gridded Crop Model Ensemble. PLoS ONE 2019, 14, e0221862. [Google Scholar] [CrossRef] [PubMed]
- Mu, H.; Zhou, L.; Dang, X.; Yuan, B. Winter Wheat Yield Estimation from Multitemporal Remote Sensing Images Based on Convolutional Neural Networks. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar]
- Channe, H.; Kothari, S.; Kadam, D. Multidisciplinary Model for Smart Agriculture Using Internet-of-Things (IoT), Sensors, Cloud-Computing, Mobile-Computing & Big-Data Analysis. Int J Comput. Technol. Appl. 2015, 6, 374–382. [Google Scholar]
- Si, S.; Zhang, H.; Keerthi, S.S.; Mahajan, D.; Dhillon, I.S.; Hsieh, C.-J. Gradient Boosted Decision Trees for High Dimensional Sparse Output. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 3182–3190. [Google Scholar]
- Huang, J.; Sedano, F.; Huang, Y.; Ma, H.; Li, X.; Liang, S.; Tian, L.; Zhang, X.; Fan, J.; Wu, W. Assimilating a Synthetic Kalman Filter Leaf Area Index Series into the WOFOST Model to Improve Regional Winter Wheat Yield Estimation. Agric. For. Meteorol. 2016, 216, 188–202. [Google Scholar] [CrossRef]
- Mokhtari, A.; Noory, H.; Vazifedoust, M. Improving Crop Yield Estimation by Assimilating LAI and Inputting Satellite-Based Surface Incoming Solar Radiation into SWAP Model. Agric. For. Meteorol. 2018, 250–251, 159–170. [Google Scholar] [CrossRef]
- Trombetta, A.; Iacobellis, V.; Tarantino, E.; Gentile, F. Calibration of the AquaCrop Model for Winter Wheat Using MODIS LAI Images. Agric. Water Manag. 2016, 164, 304–316. [Google Scholar] [CrossRef]
- Paliwal, A.; Laborte, A.; Nelson, A.; Singh, R.K. Salinity Stress Detection in Rice Crops Using Time Series MODIS VI Data. Int. J. Remote Sens. 2019, 40, 8186–8202. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, R.K.P.; Singh, K.M.; Bharati, R.C.; Jee, S.; Bhatt, B.P. Agricultural Transformationin VDSA Villages in Jharkhand; International Crops Research Institute for the Semi-Arid Tropics (ICRISAT): Hyderabad, India, 2015. [Google Scholar]
- Department of Agriculture, Government of Maharashtra Crop Statistics (Area, Production, Productivity) of Maharashtra. Crop Stat. Area Prod. Product. 2014. Available online: http://krishi.maharashtra.gov.in/1250/Taluka-Level (accessed on 26 April 2021).
- Gumma, M.K.; Nelson, A.; Yamano, T. Mapping Drought-Induced Changes in Rice Area in India. Int. J. Remote Sens. 2019, 29, 8146–8173. [Google Scholar] [CrossRef]
- Vadrevu, K.P.; Dadhwal, V.K.; Gutman, G.; Justice, C. Remote Sensing of Agriculture—South/Southeast Asia Research Initiative Special Issue. Int. J. Remote Sens. 2019, 40, 8071–8075. [Google Scholar] [CrossRef]
- Myneni, R.; Knyazikhin, Y.; Park, T. MCD15A2H MODIS/Terra+ Aqua Leaf Area Index/FPAR 8-Day L4 Global 500m SIN Grid V006; NASA EOSDIS Land Processes DAAC: Sioux Falls, SD, USA, 2015. [Google Scholar]
- Choudhury, B.U.; Singh, A.K.; Bouman, B.A.M.; Prasad, J. System of Rice Intensification and Irrigated Transplanted Rice: Effect on Crop Water Productivity. J. -Indian Soc. Soil Sci. 2007, 8, 464. [Google Scholar]
- Singh, S.S.; Mukherjee, J.; Kumar, S.; Idris, M. Effect of Elevated CO2 on Growth and Yield of Rice Crop in Open Top Chamber in Sub Humid Climate of Eastern India. J. Agrometeorol. 2013, 15, 11. [Google Scholar]
- Gumma, M.K. Mapping Rice Areas of South Asia Using MODIS Multitemporal Data. J. Appl. Remote Sens. 2011, 5, 053547. [Google Scholar] [CrossRef]
- The World Bank Group. Agricultural Land (% of Land Area); Food and Agriculture Organization: Rome, Italy, 2019. [Google Scholar]
- Elith, J.; Leathwick, J.R.; Hastie, T. A Working Guide to Boosted Regression Trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Biau, G.; Cadre, B.; Rouvìère, L. Accelerated Gradient Boosting. Mach. Learn. 2019, 108, 971–992. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Fransisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Parr, T.; Howard, J. How to Explain Gradient Boosting. Section 2.3. Explain. Ai 2018. Available online: https://explained.ai/gradient-boosting/ (accessed on 26 April 2021).
- Grover, P. Gradient Boosting from Scratch. Retrieved Medium 2017. Available online: https://blog.mlreview.com/ (accessed on 26 April 2021).
- Ridgeway, G. Generalized Boosted Models: A Guide to the Gbm Package. Update 2007, 1, 2007. [Google Scholar]
- Prettenhofer, P.; Louppe, G. Gradient Boosted Regression in Scikit-Learn. 2014. Available online: http://hdl.handle.net/2268/163521 (accessed on 26 April 2021).
- Van Rossum, G. Python Programming Language. In Proceedings of the USENIX Annual Technical Conference, Santa Clara, CA, USA, 17–22 June 2007; Volume 41, p. 36. [Google Scholar]
- Kramer, O. Scikit-Learn, Machine Learning for Evolution Strategies; Springer: Cham, Switzerland, 2016; pp. 45–53. [Google Scholar]
- OECD. Agricultural Policies in India; OECD Food and Agricultural Reviews; OECD: Paris, France, 2018; ISBN 978-92-64-30232-7. [Google Scholar]
- Doraiswamy, P.C.; Sinclair, T.R.; Hollinger, S.; Akhmedov, B.; Stern, A.; Prueger, J. Application of MODIS Derived Parameters for Regional Crop Yield Assessment. Remote Sens. Environ. 2005, 97, 192–202. [Google Scholar] [CrossRef]
- Nawar, S.; Mouazen, A.M. Comparison between Random Forests, Artificial Neural Networks and Gradient Boosted Machines Methods of on-Line Vis-NIR Spectroscopy Measurements of Soil Total Nitrogen and Total Carbon. Sensors 2017, 17, 2428. [Google Scholar] [CrossRef]
- Khanal, S.; Fulton, J.; Klopfenstein, A.; Douridas, N.; Shearer, S. Integration of High Resolution Remotely Sensed Data and Machine Learning Techniques for Spatial Prediction of Soil Properties and Corn Yield. Comput. Electron. Agric. 2018, 153, 213–225. [Google Scholar] [CrossRef]
- Zhang, L.; Traore, S.; Ge, J.; Li, Y.; Wang, S.; Zhu, G.; Cui, Y.; Fipps, G. Using Boosted Tree Regression and Artificial Neural Networks to Forecast Upland Rice Yield under Climate Change in Sahel. Comput. Electron. Agric. 2019, 166, 105031. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting machine. Ann. Stat. 2001, 44, 1189–1232. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984; ISBN 0-412-04841-8. [Google Scholar]
- Shahhosseini, M.; Martinez-Feria, R.A.; Hu, G.; Archontoulis, S.V. Maize Yield and Nitrate Loss Prediction with Machine Learning Algorithms. Environ. Res. Lett. 2019, 14, 124026. [Google Scholar] [CrossRef]
- Gilad-Bachrach, R.; Rashmi, K. DART: Dropouts Meet Multiple Additive Regression Trees; Cornell University: Cornell, Ithaca, NY, USA, 2015. [Google Scholar]
- Thomas, J. Gradient Boosting in Automatic Machine Learning: Feature Selection and Hyperparameter Optimization. Ph.D. Dissertation, an der Fakultät für Mathematik, Informatik und Statistik der Ludwig-Maximilians-Universität München, München, Germany, 2019. [Google Scholar]
- Obsie, E.Y.; Qu, H.; Drummond, F. Wild Blueberry Yield Prediction Using a Combination of Computer Simulation and Machine Learning Algorithms. Comput. Electron. Agric. 2020, 178, 105778. [Google Scholar] [CrossRef]
- Panigrahi, B.; Panda, S.N.; Mull, R. Simulation of Water Harvesting Potential in Rainfed Ricelands Using Water Balance Model. Agric. Syst. 2001, 69, 165–182. [Google Scholar] [CrossRef]
- Widawsky, D.A.; O’Toole, J.C. Prioritizing the Rice Biotechnology Research Agenda for Eastern India; The Rockefeller Foundation: New York, NY, USA, 1990; ISBN 81-85514-00-3.
- Frieler, K.; Schauberger, B.; Arneth, A.; Balkovič, J.; Chryssanthacopoulos, J.; Deryng, D.; Elliott, J.; Folberth, C.; Khabarov, N.; Müller, C. Understanding the Weather Signal in National Crop-yield Variability. Earths Future 2017, 5, 605–616. [Google Scholar] [CrossRef] [PubMed]
- Raudys, S.J.; Jain, A.K. Small Sample Size Effects in Statistical Pattern Recognition: Recommendations for Practitioners. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 252–264. [Google Scholar] [CrossRef]
- Singh, V.P.; Khedikar, S.; Verma, I.J. Improved Yield Estimation Technique for Rice and Wheat in Uttar Pradesh, Madhya Pradesh and Maharashtra States in India. MAUSAM 2019, 70, 541–550. [Google Scholar]
- Chandra Paul, G.; Saha, S.; Hembram, T.K. Application of Phenology-Based Algorithm and Linear Regression Model for Estimating Rice Cultivated Areas and Yield Using Remote Sensing Data in Bansloi River Basin, Eastern India. Remote Sens. Appl. Soc. Environ. 2020, 19, 100367. [Google Scholar] [CrossRef]
- Ranjan, A.K.; Parida, B.R. Paddy Acreage Mapping and Yield Prediction Using Sentinel-Based Optical and SAR Data in Sahibganj District, Jharkhand (India). Spat. Inf. Res. 2019, 27, 399–410. [Google Scholar] [CrossRef]
- Setiyono, T.D.; Quicho, E.D.; Holecz, F.H.; Khan, N.I.; Romuga, G.; Maunahan, A.; Garcia, C.; Rala, A.; Raviz, J.; Collivignarelli, F. Rice Yield Estimation Using Synthetic Aperture Radar (SAR) and the ORYZA Crop Growth Model: Development and Application of the System in South and South-East Asian Countries. Int. J. Remote Sens. 2019, 40, 8093–8124. [Google Scholar] [CrossRef]
- Shetty, S.A.; Padmashree, T.; Sagar, B.M.; Cauvery, N.K. Performance Analysis on Machine Learning Algorithms with Deep Learning Model for Crop Yield Prediction. In Data Intelligence and Cognitive Informatics; Springer: Singapore, 2021; pp. 739–750. [Google Scholar]
- Arumugam, P.; Chemura, A.; Schauberger, B.; Gornott, C. Near Real-Time Biophysical Rice (Oryza sativa L.) Yield Estimation to Support Crop Insurance Implementation in India. Agronomy 2020, 10, 1674. [Google Scholar] [CrossRef]
- Priya, S.; Shibasaki, R. National Spatial Crop Yield Simulation Using GIS-Based Crop Production Model. Ecol. Model. 2001, 136, 113–129. [Google Scholar] [CrossRef]
- Lobell, D.B.; Thau, D.; Seifert, C.; Engle, E.; Little, B. A Scalable Satellite-Based Crop Yield Mapper. Remote Sens. Environ. 2015, 164, 324–333. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Observations | r | R2 | MAE (t/ha) | RMSE (t/ha) |
|---|---|---|---|---|---|
| Andhra Pradesh | 13 | 0.94 | 0.88 | 0.13 | 0.15 |
| Bihar | 9 | 0.28 | 0.08 | 0.35 | 0.55 |
| Chhattisgarh | 13 | 0.99 | 0.97 | 0.11 | 0.12 |
| Gujarat | 13 | 0.54 | 0.29 | 0.21 | 0.24 |
| Haryana | 10 | 0.82 | 0.67 | 0.11 | 0.13 |
| Himachal Pradesh | 6 | −0.19 | 0.04 | 0.16 | 0.21 |
| Jammu & Kashmir | 5 | 0.96 | 0.93 | 0.23 | 0.26 |
| Jharkhand | 7 | 0.99 | 0.97 | 0.27 | 0.31 |
| Karnataka | 13 | 0.79 | 0.62 | 0.13 | 0.16 |
| Madhya Pradesh | 11 | 0.93 | 0.86 | 0.18 | 0.2 |
| Maharashtra | 13 | 0.85 | 0.72 | 0.24 | 0.26 |
| Odisha | 9 | 0.94 | 0.88 | 0.04 | 0.04 |
| Punjab | 13 | 0.78 | 0.6 | 0.12 | 0.15 |
| Rajasthan | 13 | −0.16 | 0.03 | 0.21 | 0.26 |
| Telangana | 13 | 0.91 | 0.83 | 0.12 | 0.16 |
| Uttar Pradesh | 13 | 0.96 | 0.92 | 0.14 | 0.15 |
| Uttarakhand | 13 | 0.13 | 0.02 | 0.3 | 0.31 |
| West Bengal | 9 | 0.83 | 0.69 | 0.08 | 0.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arumugam, P.; Chemura, A.; Schauberger, B.; Gornott, C. Remote Sensing Based Yield Estimation of Rice (Oryza Sativa L.) Using Gradient Boosted Regression in India. Remote Sens. 2021, 13, 2379. https://doi.org/10.3390/rs13122379
Arumugam P, Chemura A, Schauberger B, Gornott C. Remote Sensing Based Yield Estimation of Rice (Oryza Sativa L.) Using Gradient Boosted Regression in India. Remote Sensing. 2021; 13(12):2379. https://doi.org/10.3390/rs13122379
Chicago/Turabian StyleArumugam, Ponraj, Abel Chemura, Bernhard Schauberger, and Christoph Gornott. 2021. "Remote Sensing Based Yield Estimation of Rice (Oryza Sativa L.) Using Gradient Boosted Regression in India" Remote Sensing 13, no. 12: 2379. https://doi.org/10.3390/rs13122379
APA StyleArumugam, P., Chemura, A., Schauberger, B., & Gornott, C. (2021). Remote Sensing Based Yield Estimation of Rice (Oryza Sativa L.) Using Gradient Boosted Regression in India. Remote Sensing, 13(12), 2379. https://doi.org/10.3390/rs13122379