
Hyperspectral Image Super-Resolution under the Guidance of Deep Gradient Information

Abstract
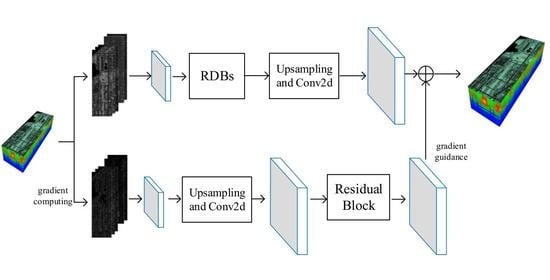
1. Introduction
1.1. Related Work
1.1.1. CNN-Based SR HSI Methods
1.1.2. ResNet and RDN
1.2. Main Contribution
- As far as we know, this is the first time that the gradient detail has been utilized to enhance the spatial information of the HSIs. Specifically, the gradient is learned via a ResNet and utilized to inject into the RDN, which ensures more information is imported in the SR process;
- The gradient loss and the mapping loss between the LR HSI and the desired HR HSI are combined to optimize both networks. This facilitates the joint optimization of the gradient ResNet and the mapping RDN by providing a feedback mechanism;
- Experiments were conducted on three datasets with both indoor scenes and outdoor scenes. Experimental results with different scaling factors and data analysis demonstrated the effectiveness of the proposed G-RDN.
2. Materials and Methods
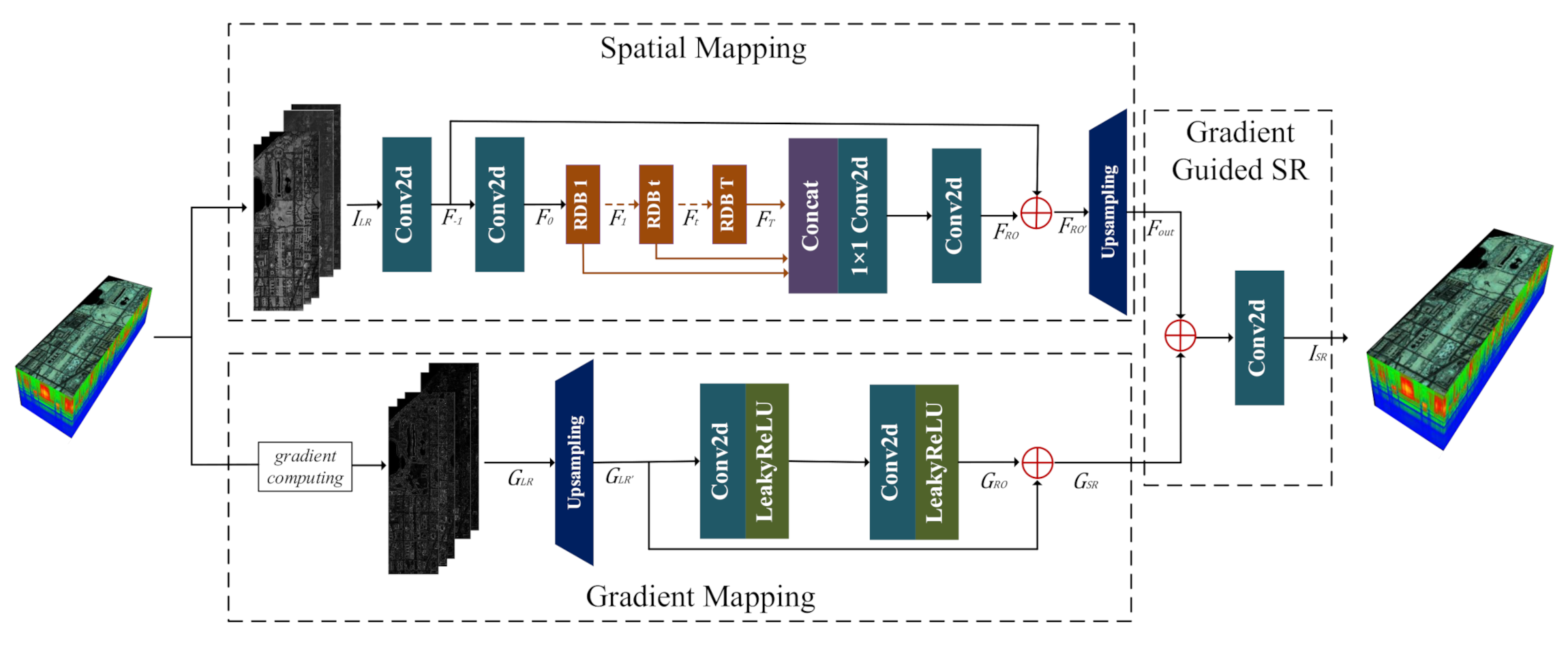
2.1. Framework Overview
2.2. Mapping between the LR HSI and the HR HSI
2.3. Learning Gradient Mapping by the ResNet
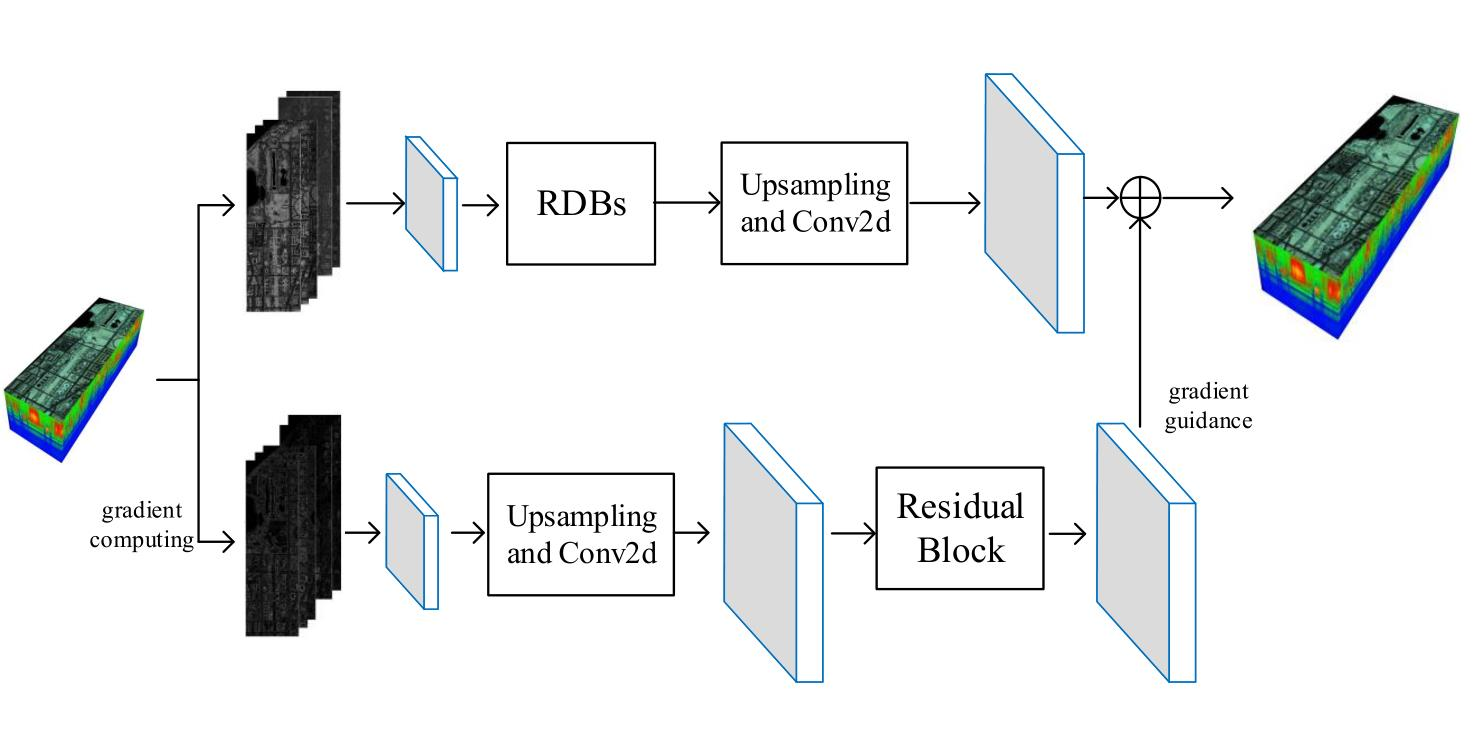
2.4. Combination of Gradient and the Spatial Information
3. Results
3.1. Implementation Details
3.1.1. Datasets and Evaluation Metrics
3.1.2. Training Details
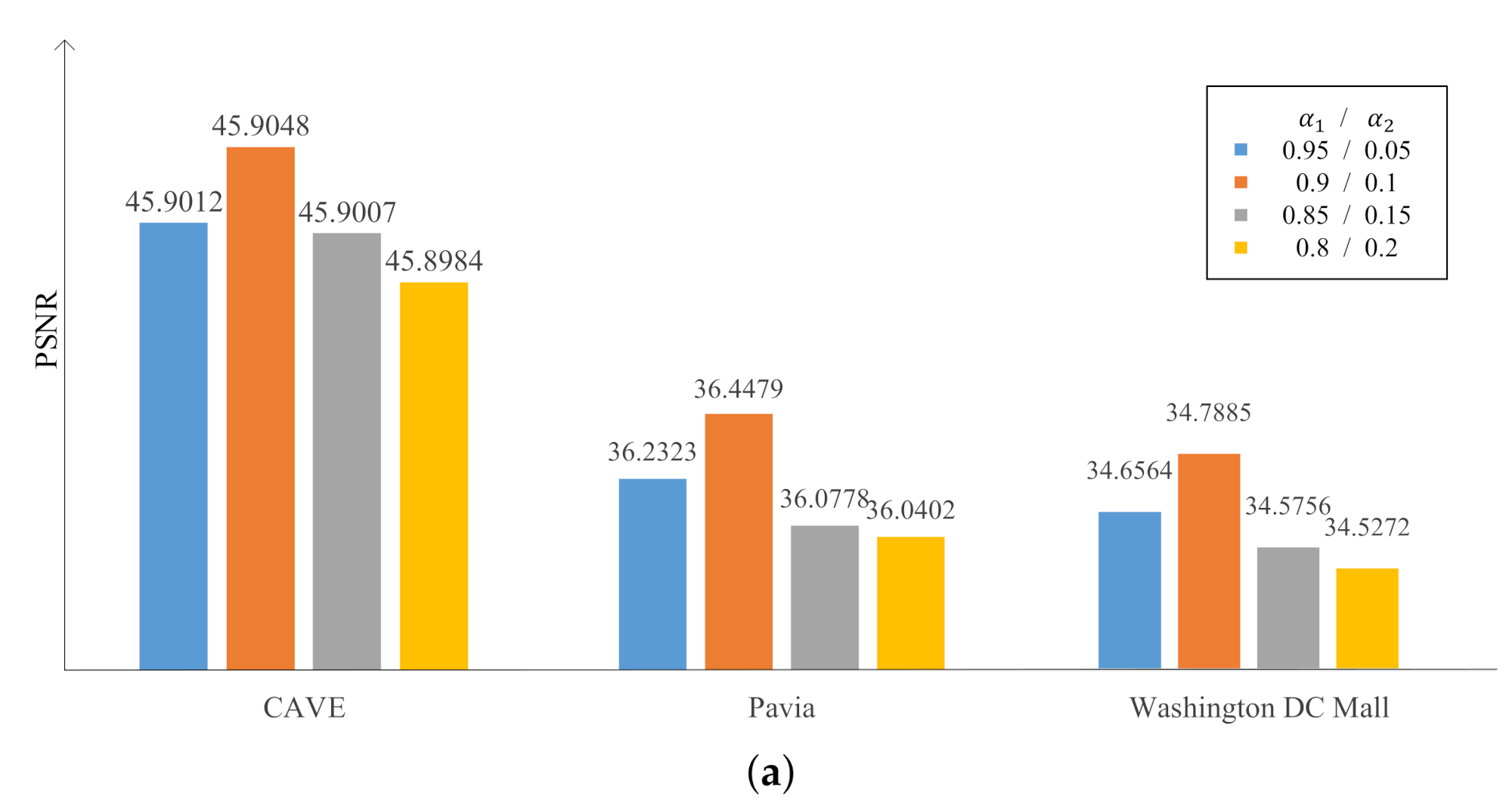
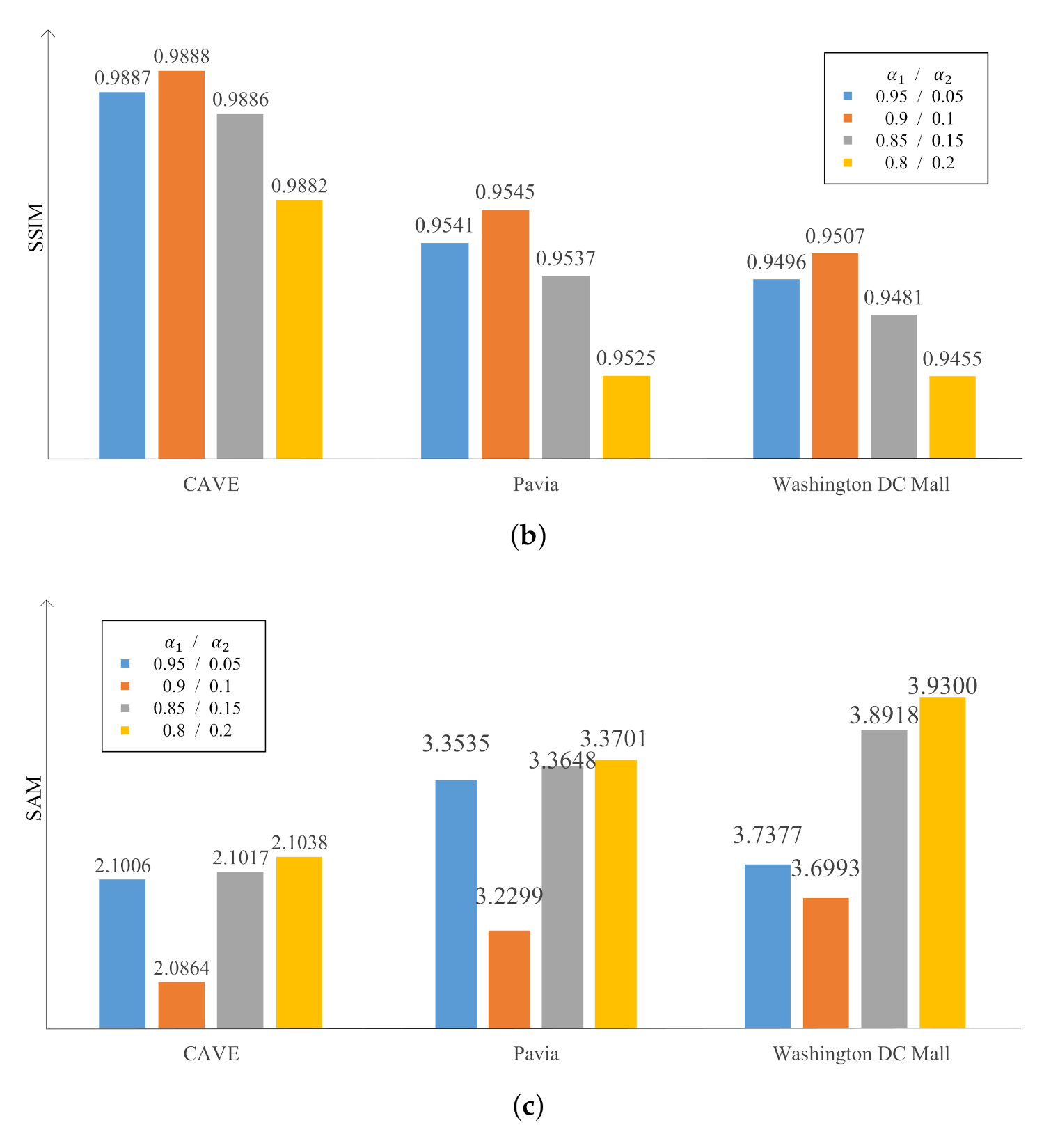
3.2. Parameters’ Sensitivity
4. Discussion
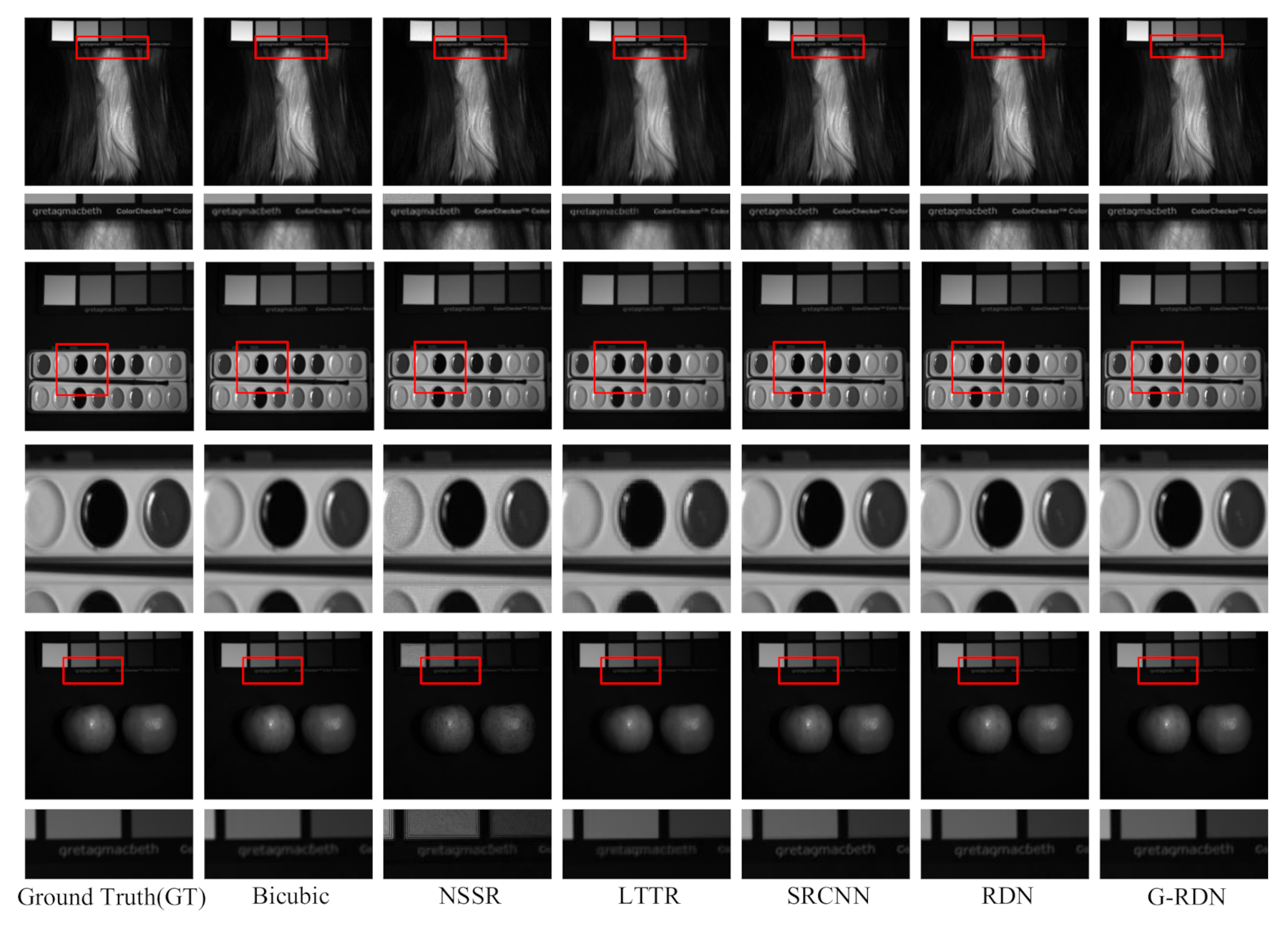
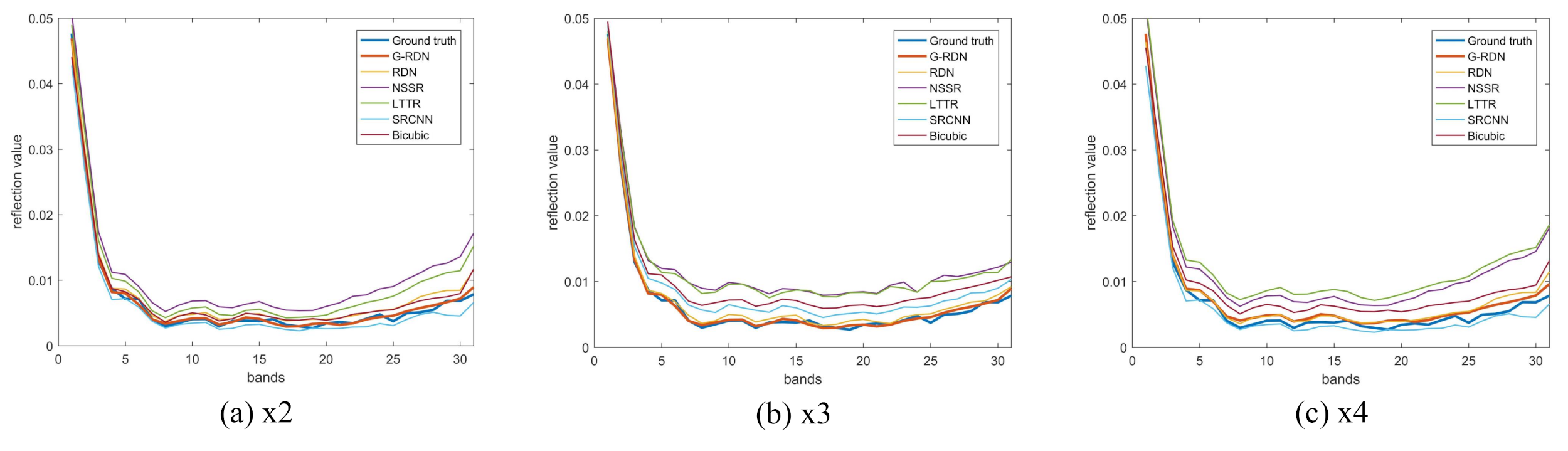
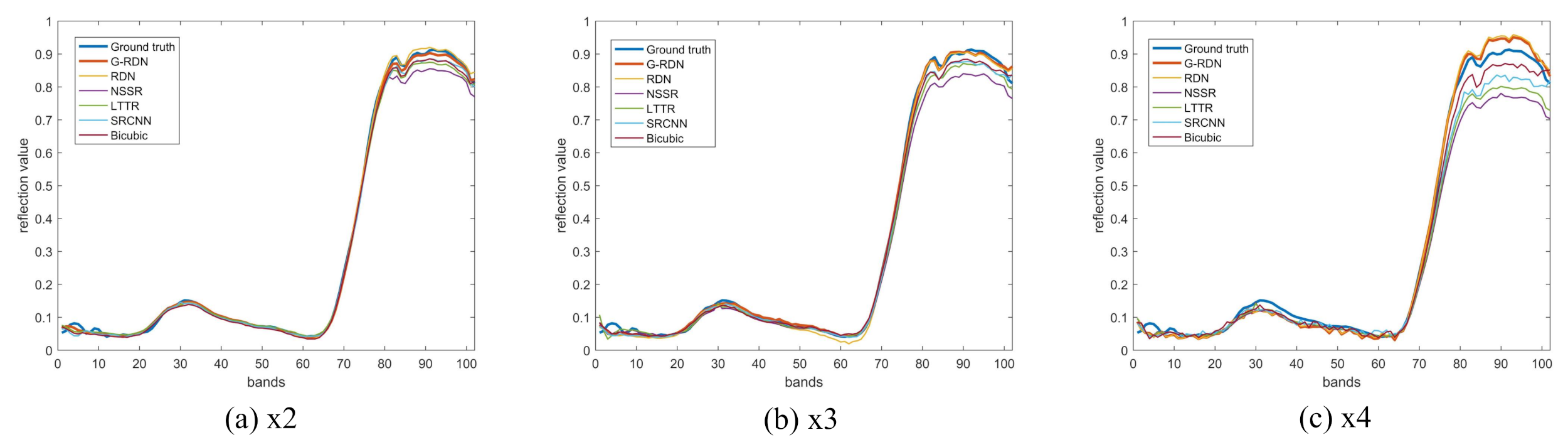
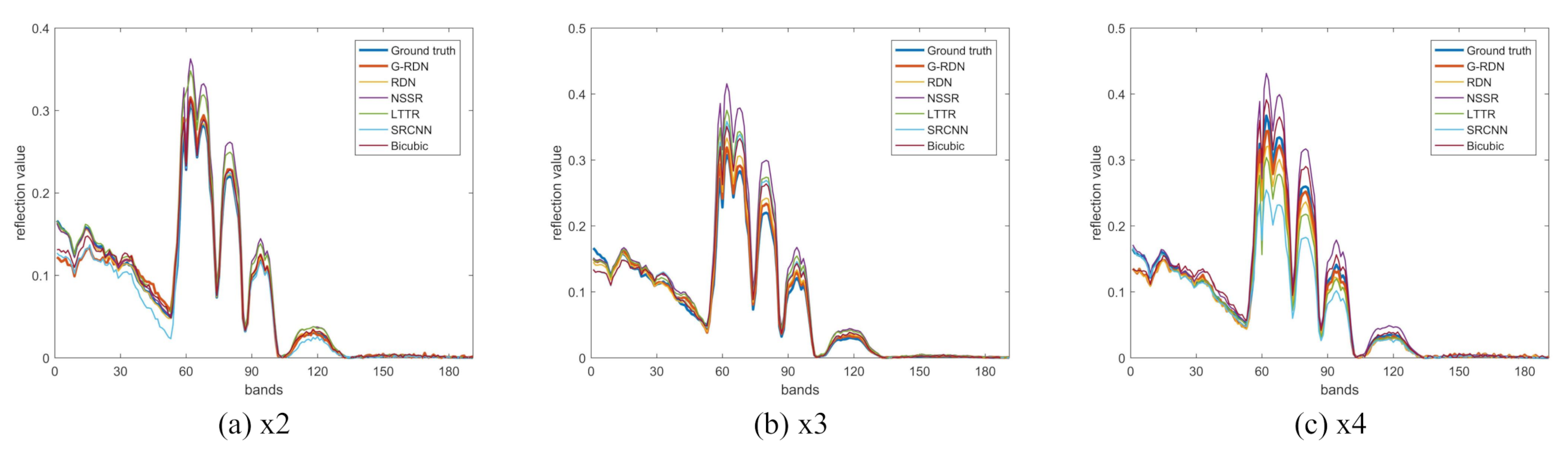
4.1. CAVE Dataset
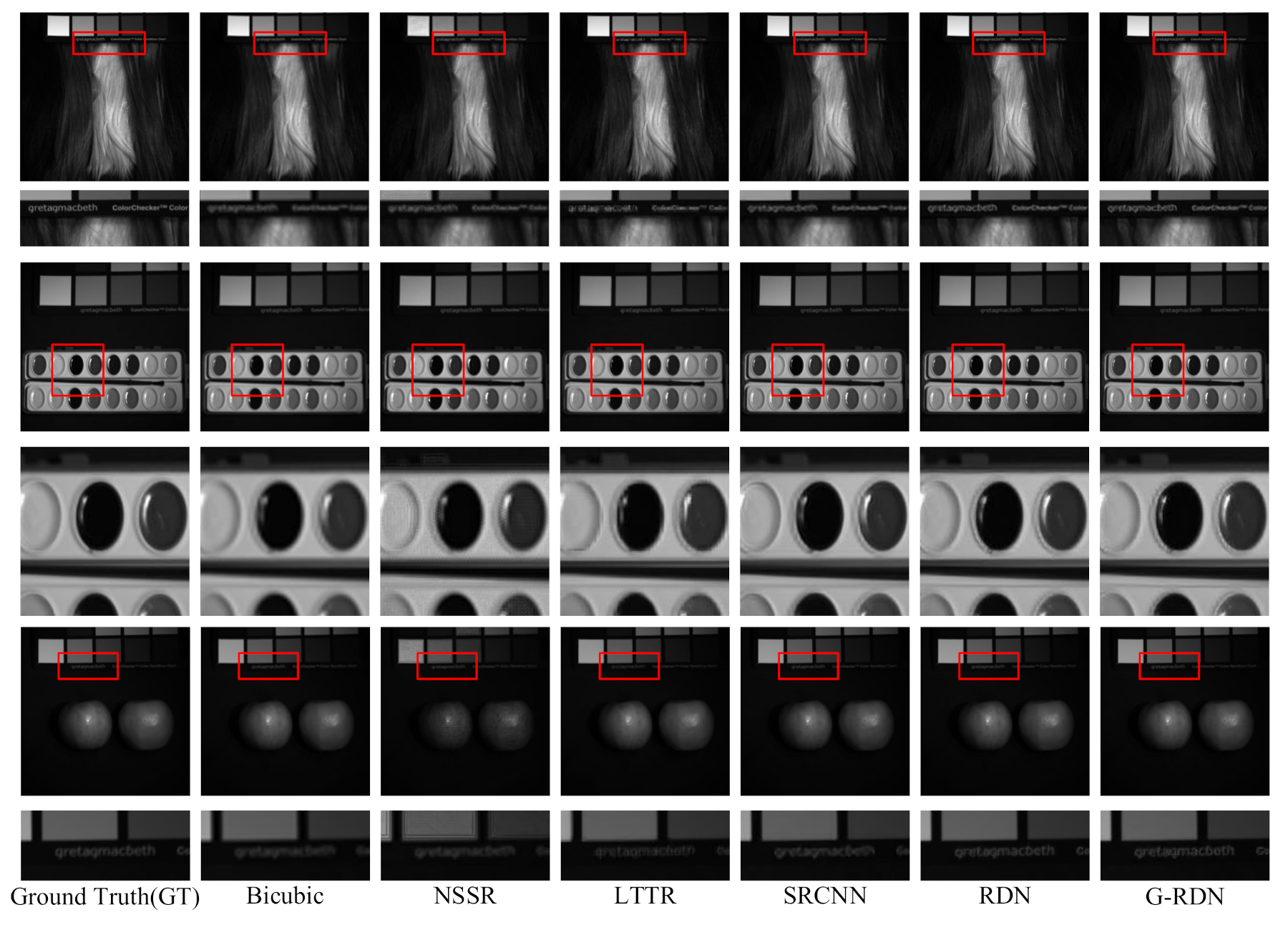
4.2. The Pavia Center Dataset
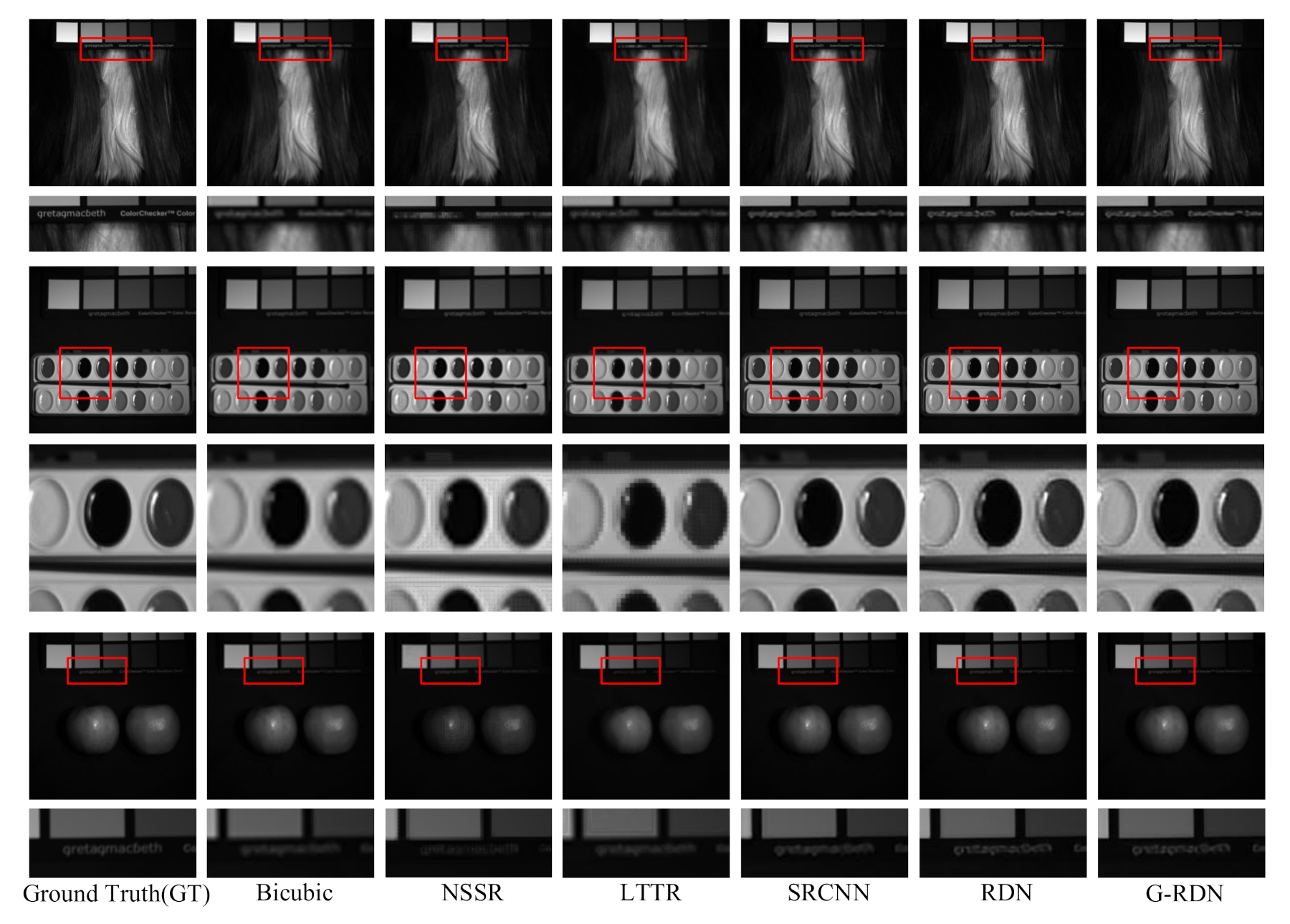
4.3. The Washington DC Mall Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Khan, M.J.; Khan, H.S.; Yousaf, A.; Khurshid, K.; Abbas, A. Modern Trends in Hyperspectral Image Analysis: A Review. IEEE Access 2018, 6, 14118–14129. [Google Scholar] [CrossRef]
- Tratt, D.M.; Buckland, K.N.; Keim, E.R.; Johnson, P.D. Urban-industrial emissions monitoring with airborne longwave-infrared hyperspectral imaging. In Proceedings of the 2016 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Los Angeles, CA, USA, 21–24 August 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.Q.; Chan, J.C.W.; Kong, S.G. Coupled Sparse Denoising and Unmixing With Low-Rank Constraint for Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1818–1833. [Google Scholar] [CrossRef]
- Yu, H.; Shang, X.; Song, M.; Hu, J.; Jiao, T.; Guo, Q.; Zhang, B. Union of Class-Dependent Collaborative Representation Based on Maximum Margin Projection for Hyperspectral Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 553–566. [Google Scholar] [CrossRef]
- Lei, J.; Fang, S.; Xie, W.; Li, Y.; Chang, C.I. Discriminative Reconstruction for Hyperspectral Anomaly Detection with Spectral Learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7406–7417. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Song, R.; Mei, S.; Du, Q. Local Spectral Similarity Preserving Regularized Robust Sparse Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7756–7769. [Google Scholar] [CrossRef]
- Hu, J.; Jia, X.; Li, Y.; He, G.; Zhao, M. Hyperspectral Image Super-Resolution via Intrafusion Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7459–7471. [Google Scholar] [CrossRef]
- Li, S.; Dian, R.; Fang, L.; Bioucas-Dias, J.M. Fusing Hyperspectral and Multispectral Images via Coupled Sparse Tensor Factorization. IEEE Trans. Image Process. 2018, 27, 4118–4130. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Chanussot, J.; Wei, Z. Hyperspectral Images Super-Resolution via Learning High-Order Coupled Tensor Ring Representation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4747–4760. [Google Scholar] [CrossRef] [PubMed]
- Yi, C.; Zhao, Y.Q.; Chan, C.W. Hyperspectral Image Super-Resolution Based on Spatial and Spectral Correlation Fusion. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4165–4177. [Google Scholar] [CrossRef]
- Fang, L.; Zhuo, H.; Li, S. Super-Resolution of Hyperspectral Image via Superpixel-Based Sparse Representation. Neurocomputing 2017, 273, 171–177. [Google Scholar] [CrossRef]
- Fu, Y.; Zheng, Y.; Huang, H.; Sato, I.; Sato, Y. Hyperspectral Image Super-Resolution With a Mosaic RGB Image. IEEE Trans. Image Process. 2018, 27, 5539–5552. [Google Scholar] [CrossRef]
- Li, Y.; Hu, J.; Zhao, X.; Xie, W.; Li, J.J. Hyperspectral image super-resolution using deep convolutional neural network. Neurocomputing 2017, 266, 29–41. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, X.; Lu, X. Hyperspectral Image Superresolution by Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1963–1974. [Google Scholar] [CrossRef]
- Xie, W.; Jia, X.; Li, Y.; Lei, J. Hyperspectral Image Super-Resolution Using Deep Feature Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6055–6067. [Google Scholar] [CrossRef]
- Mei, S.; Yuan, X.; Ji, J.; Zhang, Y.; Wan, S.; Du, Q. Hyperspectral Image Spatial Super-Resolution via 3D Full Convolutional Neural Network. Remote Sens. 2017, 9, 1139. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Li, X. Mixed 2D/3D Convolutional Network for Hyperspectral Image Super-Resolution. Remote Sens. 2020, 12, 1660. [Google Scholar] [CrossRef]
- Xu, X.; Zhong, Y.; Zhang, L.; Zhang, H. Sub-Pixel Mapping Based on a MAP Model With Multiple Shifted Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 580–593. [Google Scholar] [CrossRef]
- Wang, X.; Ma, J.; Jiang, J. Hyperspectral Image Super-Resolution via Recurrent Feedback Embedding and Spatial-Spectral Consistency Regularization. IEEE Trans. Geosci. Remote Sens. 2021, 1–13. [Google Scholar] [CrossRef]
- Mei, S.; Jiang, R.; Li, X.; Du, Q. Spatial and Spectral Joint Super-Resolution Using Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4590–4603. [Google Scholar] [CrossRef]
- Liu, D.; Li, J.; Yuan, Q. A Spectral Grouping and Attention-Driven Residual Dense Network for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2021, 1–15. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Q.; Li, X. Hyperspectral Image Super-Resolution Using Spectrum and Feature Context. IEEE Trans. Ind. Electron. 2020. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Jia, J.; Ji, L.; Zhao, Y.; Geng, X. Hyperspectral image super-resolution with spectral–spatial network. Int. J. Remote Sens. 2018, 39, 7806–7829. [Google Scholar] [CrossRef]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled Nonnegative Matrix Factorization Unmixing for Hyperspectral and Multispectral Data Fusion. IEEE Trans. Geosci. Remote Sens. 2012, 50, 528–537. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Q.; Li, X. Spatial-Spectral Residual Network for Hyperspectral Image Super-Resolution. arXiv 2020, arXiv:2001.04609. [Google Scholar]
- Li, Q.; Wang, Q.; Li, X. Exploring the Relationship Between 2D/3D Convolution for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2021, 1–11. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. IEEE Comput. Soc. 2016. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Loncan, L.; de Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simões, M.; et al. Hyperspectral Pansharpening: A Review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 27–46. [Google Scholar] [CrossRef]
- Dong, W.; Fu, F.; Shi, G.; Cao, X.; Wu, J.; Li, G.; Li, X. Hyperspectral Image Super-Resolution via Non-Negative Structured Sparse Representation. IEEE Trans. Image Process. 2016, 25, 2337–2352. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Fang, L. Learning a Low Tensor-Train Rank Representation for Hyperspectral Image Super-Resolution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2672–2683. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scaling Factor | Bicubic | NSSR | LTTR | SRCNN | RDN | G-RDN | |
|---|---|---|---|---|---|---|---|
| MPSNR | 43.6218 | 38.7055 | 40.4734 | 43.8789 | 45.8008 | 45.9048 | |
| MSSIM | 0.9851 | 0.9572 | 0.9664 | 0.9863 | 0.9888 | 0.9888 | |
| MSAM | 2.3093 | 3.5195 | 2.9955 | 2.5901 | 2.1038 | 2.0864 | |
| CC | 0.9978 | 0.9893 | 0.9907 | 0.9963 | 0.9989 | 0.9991 | |
| RMSE | 0.0105 | 0.0121 | 0.011 | 0.0096 | 0.0073 | 0.0067 | |
| ERGAS | 5.5374 | 5.9292 | 5.7933 | 4.2332 | 3.3101 | 3.2807 | |
| MPSNR | 38.1441 | 33.9825 | 38.8393 | 38.2535 | 39.8439 | 39.8535 | |
| MSSIM | 0.9667 | 0.9238 | 0.9663 | 0.9699 | 0.9756 | 0.9737 | |
| MSAM | 3.3536 | 4.7017 | 4.6334 | 3.7036 | 3.1577 | 3.1574 | |
| CC | 0.9943 | 0.9869 | 0.9895 | 0.9957 | 0.9971 | 0.9972 | |
| RMSE | 0.0175 | 0.019 | 0.0183 | 0.0161 | 0.0127 | 0.0122 | |
| ERGAS | 5.801 | 5.9397 | 5.8205 | 4.9949 | 3.8503 | 3.8494 | |
| MPSNR | 33.833 | 30.5175 | 33.531 | 34.2023 | 36.4958 | 36.5326 | |
| MSSIM | 0.9381 | 0.8859 | 0.9137 | 0.9418 | 0.9508 | 0.9523 | |
| MSAM | 3.9615 | 5.0025 | 4.1639 | 4.0125 | 3.8109 | 3.7993 | |
| CC | 0.9904 | 0.9818 | 0.9842 | 0.9925 | 0.9940 | 0.9943 | |
| RMSE | 0.0228 | 0.0231 | 0.0229 | 0.0207 | 0.0181 | 0.0177 | |
| ERGAS | 5.6172 | 5.7003 | 5.6639 | 4.8337 | 4.1010 | 4.0494 |
| Scaling Factor | Bicubic | NSSR | LTTR | SRCNN | RDN | G-RDN | |
|---|---|---|---|---|---|---|---|
| MPSNR | 33.6862 | 34.0858 | 34.3149 | 35.8849 | 36.0463 | 36.4479 | |
| MSSIM | 0.9269 | 0.9248 | 0.9297 | 0.9487 | 0.9542 | 0.9545 | |
| MSAM | 3.5016 | 3.6888 | 3.6018 | 3.4889 | 3.365 | 3.2299 | |
| CC | 0.9821 | 0.9826 | 0.9837 | 0.9866 | 0.9889 | 0.9894 | |
| RMSE | 0.0207 | 0.0199 | 0.0187 | 0.0172 | 0.0162 | 0.0151 | |
| ERGAS | 6.9033 | 6.8302 | 6.6229 | 5.8707 | 5.1004 | 5.0744 | |
| MPSNR | 30.3553 | 30.6463 | 30.6624 | 31.0216 | 31.4001 | 31.4287 | |
| MSSIM | 0.8561 | 0.8504 | 0.8594 | 0.8782 | 0.8860 | 0.8866 | |
| MSAM | 4.2437 | 5.5145 | 5.5125 | 4.8702 | 4.1229 | 4.114 | |
| CC | 0.9646 | 0.9687 | 0.9693 | 0.9712 | 0.9727 | 0.9731 | |
| RMSE | 0.0304 | 0.0299 | 0.0295 | 0.0289 | 0.0272 | 0.0268 | |
| ERGAS | 6.5948 | 6.5777 | 6.4981 | 6.0287 | 5.6505 | 5.6418 | |
| MPSNR | 28.4842 | 28.6269 | 28.971 | 29.4192 | 29.7698 | 29.8027 | |
| MSSIM | 0.7917 | 0.7727 | 0.7761 | 0.8294 | 0.8379 | 0.8378 | |
| MSAM | 4.7936 | 6.8398 | 6.3484 | 4.8281 | 4.7765 | 4.764 | |
| CC | 0.9473 | 0.9488 | 0.9502 | 0.9545 | 0.9593 | 0.9602 | |
| RMSE | 0.0377 | 0.0371 | 0.036 | 0.0346 | 0.0331 | 0.0327 | |
| ERGAS | 6.0684 | 5.9553 | 5.7378 | 5.4939 | 5.2201 | 5.1964 |
| Scaling Factor | Bicubic | NSSR | LTTR | SRCNN | RDN | G-RDN | |
|---|---|---|---|---|---|---|---|
| MPSNR | 33.7651 | 31.2735 | 32.1645 | 34.1544 | 34.5633 | 34.7885 | |
| MSSIM | 0.9334 | 0.8931 | 0.9213 | 0.9464 | 0.9488 | 0.9507 | |
| MSAM | 3.774 | 5.5977 | 3.947 | 4.7756 | 3.9052 | 3.6993 | |
| CC | 0.9699 | 0.9613 | 0.9678 | 0.9765 | 0.9794 | 0.9795 | |
| RMSE | 0.0205 | 0.0258 | 0.0213 | 0.0196 | 0.0189 | 0.0182 | |
| ERGAS | 11.1844 | 12.3789 | 11.9301 | 10.9491 | 10.8581 | 10.8572 | |
| MPSNR | 31.0348 | 27.5924 | 28.3509 | 31.1778 | 32.6729 | 32.7584 | |
| MSSIM | 0.8717 | 0.8195 | 0.8288 | 0.8703 | 0.8776 | 0.8774 | |
| MSAM | 5.4422 | 7.3769 | 6.4613 | 5.6762 | 5.3778 | 5.3676 | |
| CC | 0.9414 | 0.9337 | 0.9369 | 0.9498 | 0.9568 | 0.9572 | |
| RMSE | 0.0361 | 0.0443 | 0.0401 | 0.0318 | 0.0294 | 0.0290 | |
| ERGAS | 8.3716 | 10.0755 | 9.7328 | 8.1876 | 7.9231 | 7.8387 | |
| MPSNR | 29.5499 | 25.7901 | 26.4819 | 29.3781 | 30.5434 | 30.5691 | |
| MSSIM | 0.8212 | 0.7642 | 0.7645 | 0.8342 | 0.8408 | 0.8408 | |
| MSAM | 6.5745 | 8.1343 | 8.0897 | 7.8393 | 6.4336 | 6.291 | |
| CC | 0.9264 | 0.9197 | 0.921 | 0.9318 | 0.9339 | 0.9341 | |
| RMSE | 0.0362 | 0.0409 | 0.0387 | 0.0351 | 0.0337 | 0.0333 | |
| ERGAS | 7.3201 | 8.9878 | 8.2713 | 6.9525 | 6.4718 | 6.4647 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, M.; Ning, J.; Hu, J.; Li, T. Hyperspectral Image Super-Resolution under the Guidance of Deep Gradient Information. Remote Sens. 2021, 13, 2382. https://doi.org/10.3390/rs13122382
Zhao M, Ning J, Hu J, Li T. Hyperspectral Image Super-Resolution under the Guidance of Deep Gradient Information. Remote Sensing. 2021; 13(12):2382. https://doi.org/10.3390/rs13122382
Chicago/Turabian StyleZhao, Minghua, Jiawei Ning, Jing Hu, and Tingting Li. 2021. "Hyperspectral Image Super-Resolution under the Guidance of Deep Gradient Information" Remote Sensing 13, no. 12: 2382. https://doi.org/10.3390/rs13122382
APA StyleZhao, M., Ning, J., Hu, J., & Li, T. (2021). Hyperspectral Image Super-Resolution under the Guidance of Deep Gradient Information. Remote Sensing, 13(12), 2382. https://doi.org/10.3390/rs13122382