Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps

 , , ,
, , ,
Abstract
1. Introduction
1.1. Topographic Maps
1.2. Surface Mine Mapping
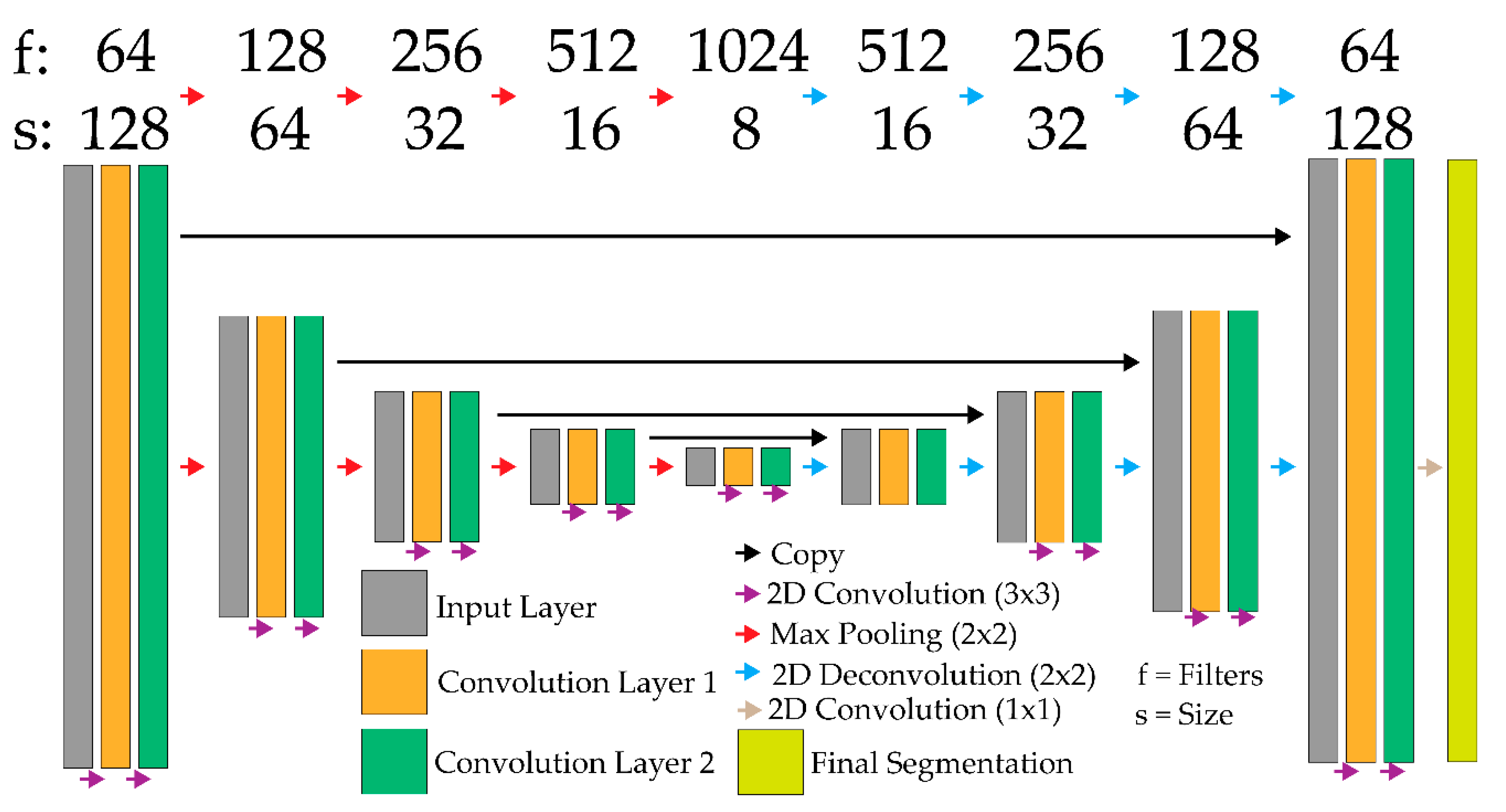
1.3. Deep Learning Semantic Segmentation
2. Materials and Methods
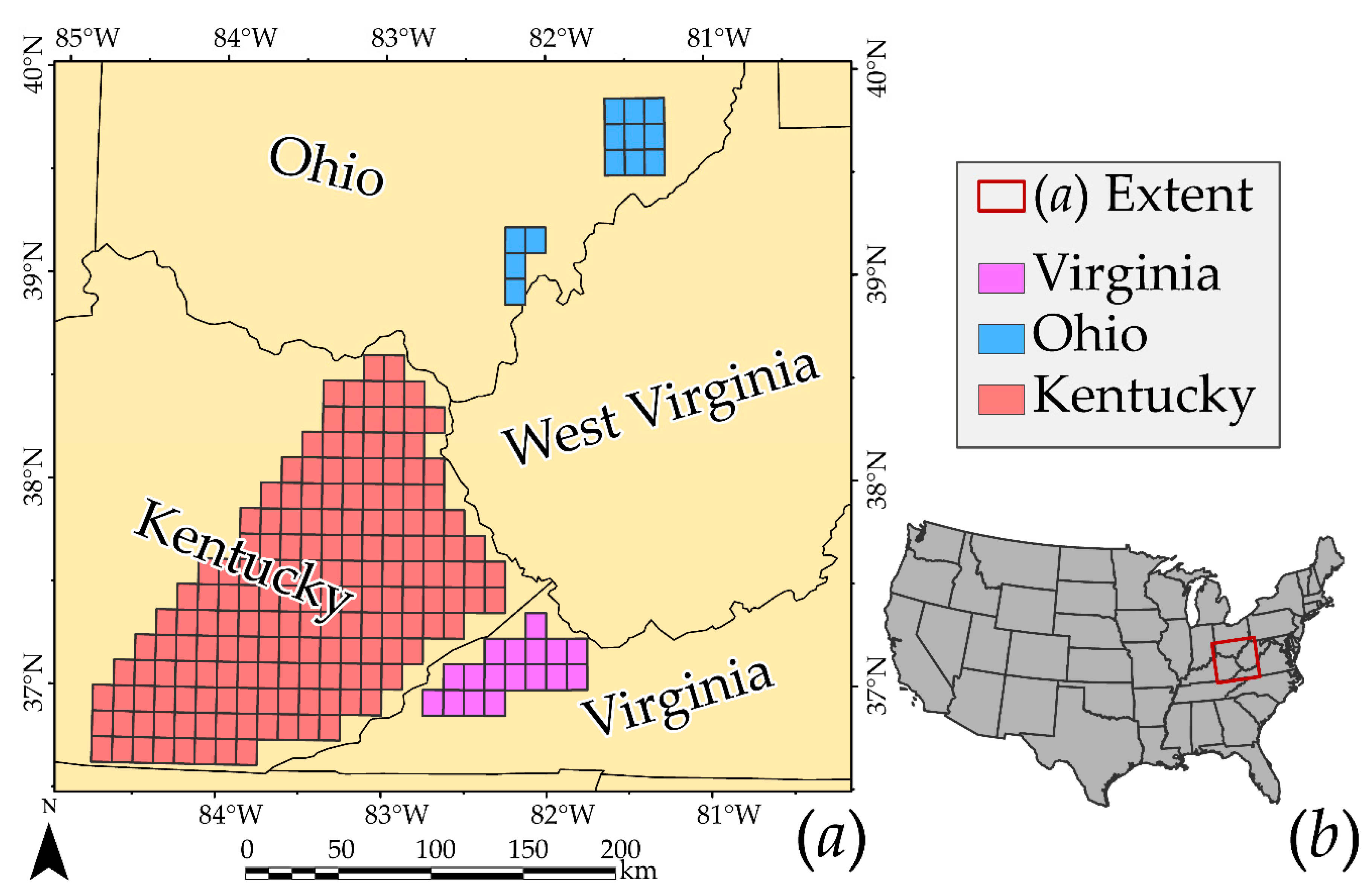
2.1. Study Areas and Input Data
2.2. Modeling Training
2.3. Prediction and Model Validation
2.4. Sample Size Comparisons
3. Results
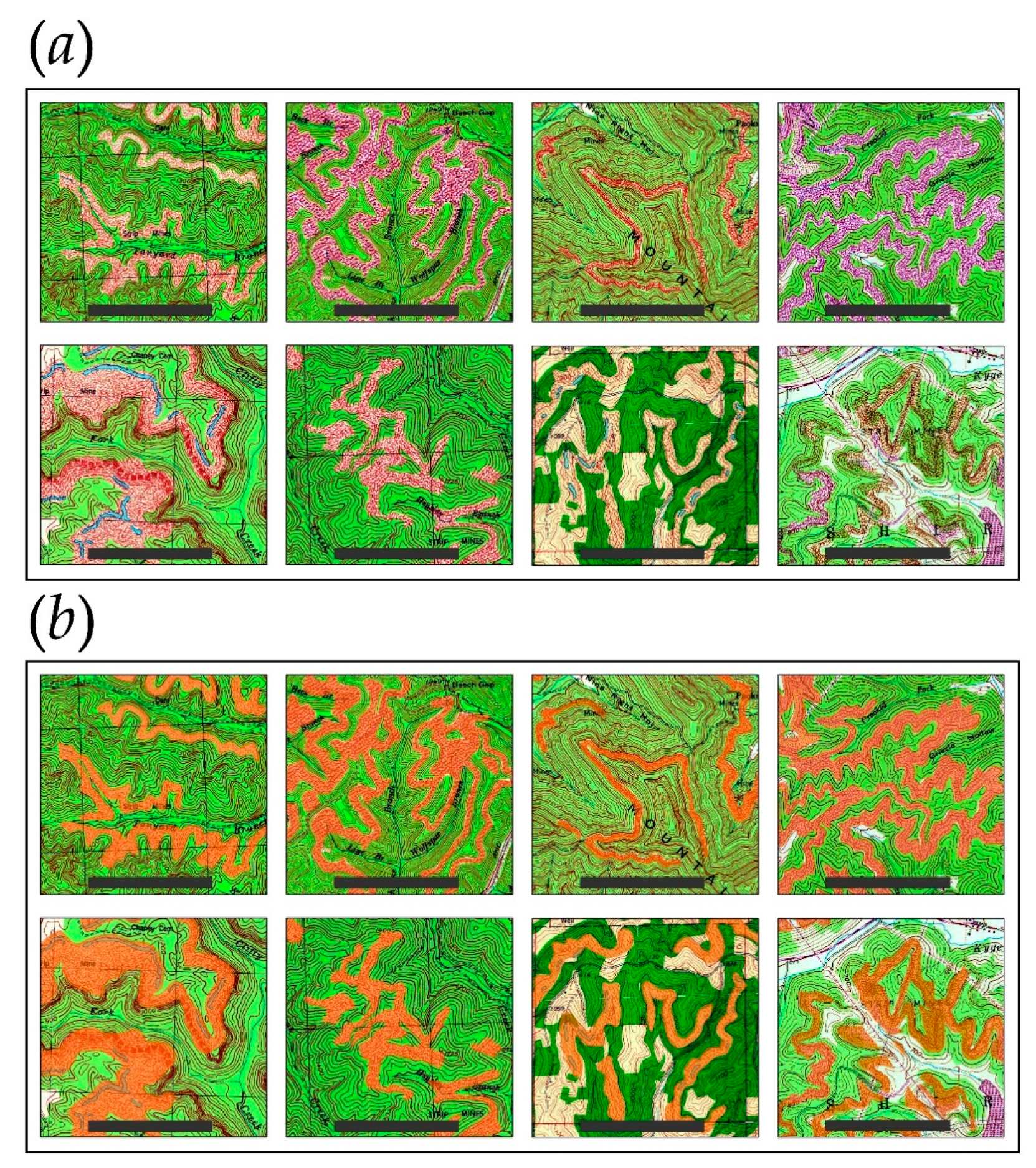
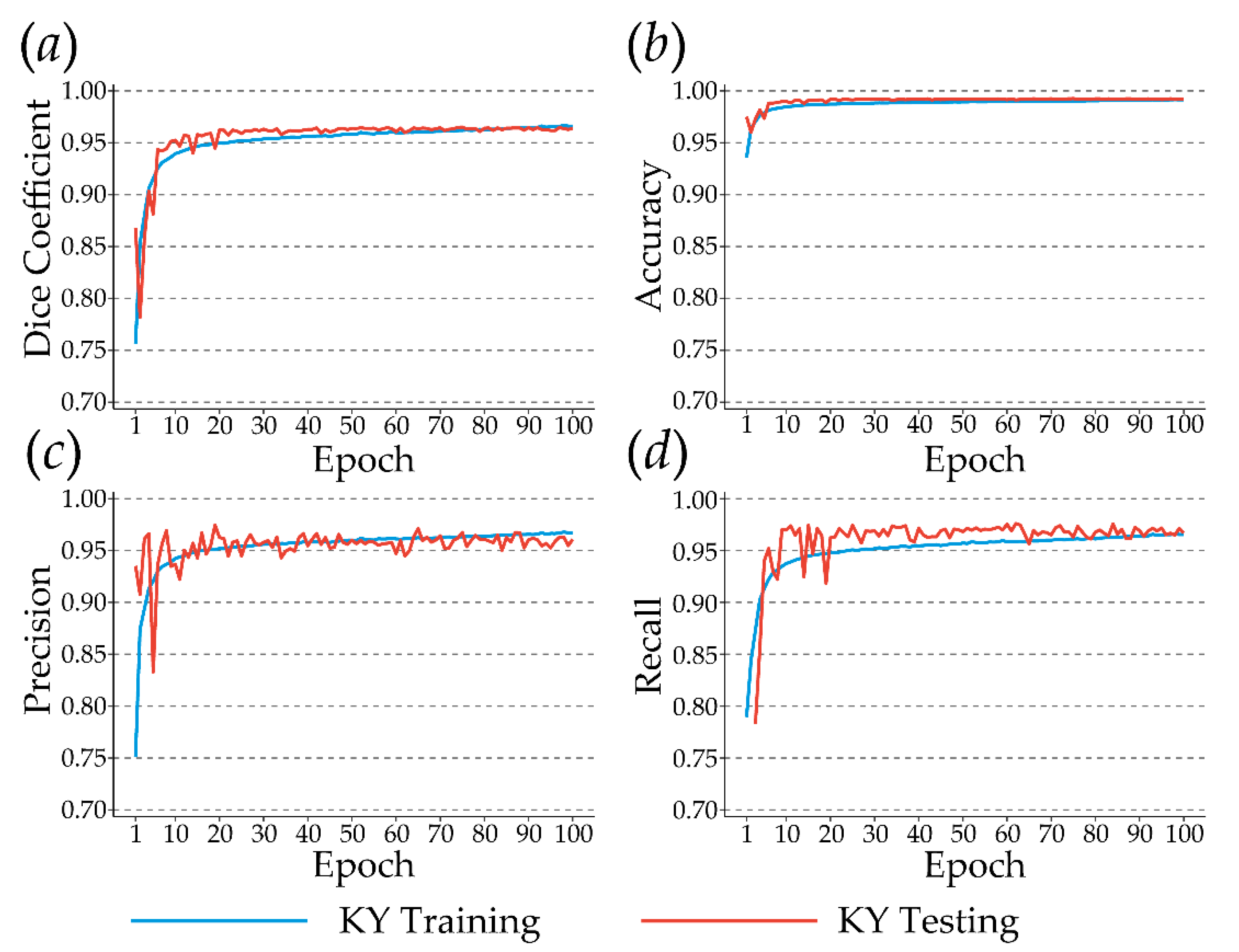
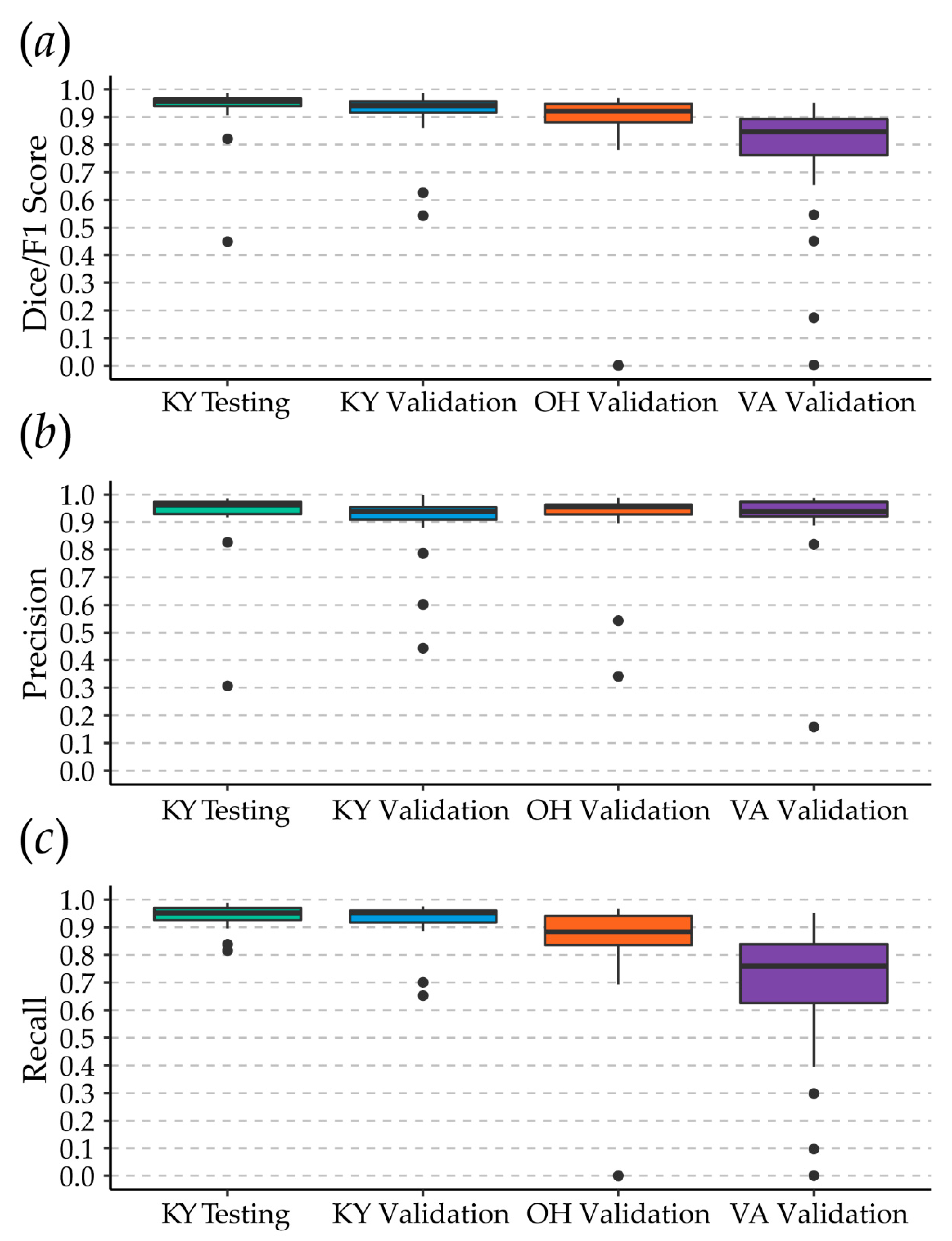
3.1. Chip-Based Assessment
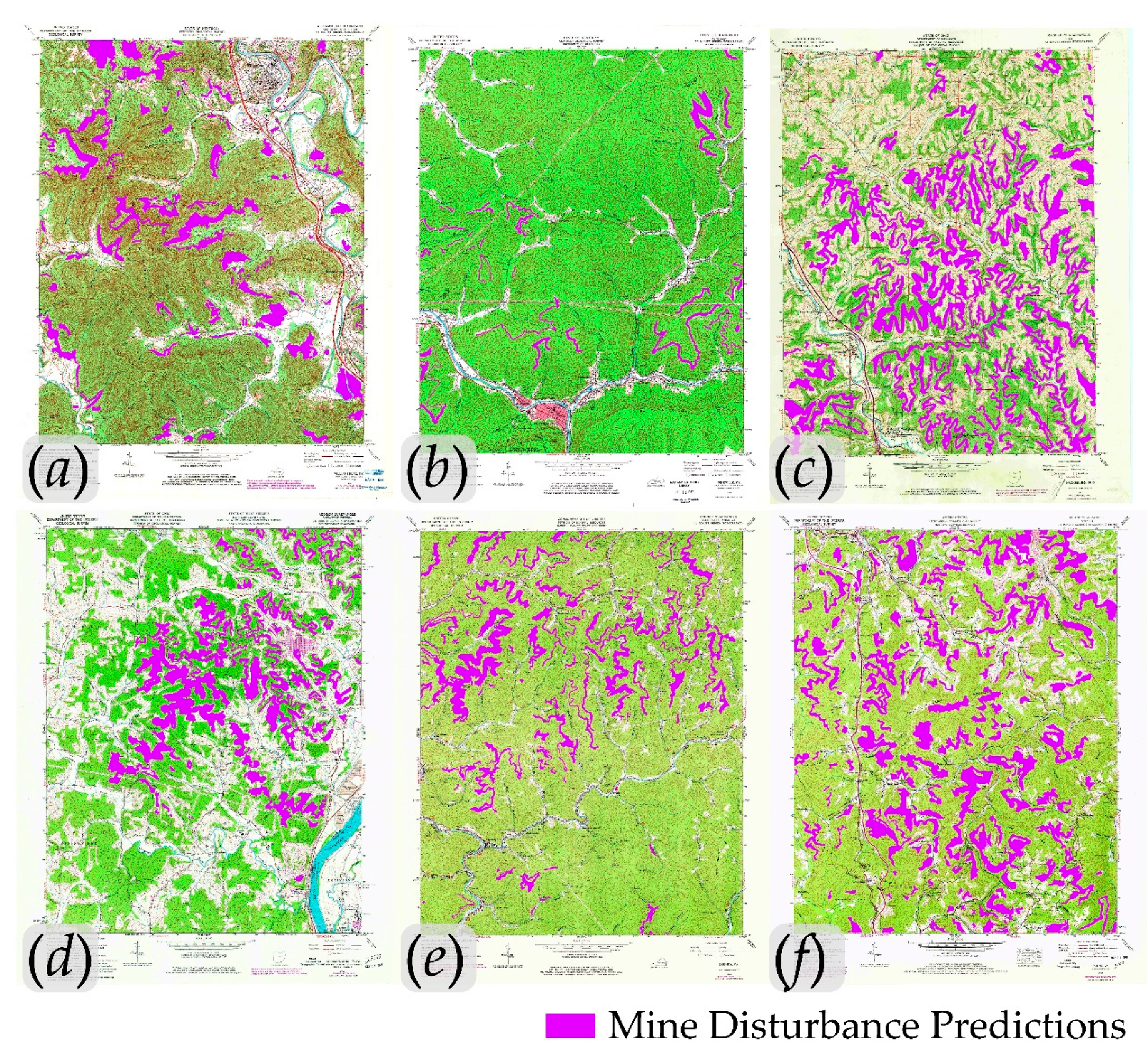
3.2. Topographic Map-Based Assessment
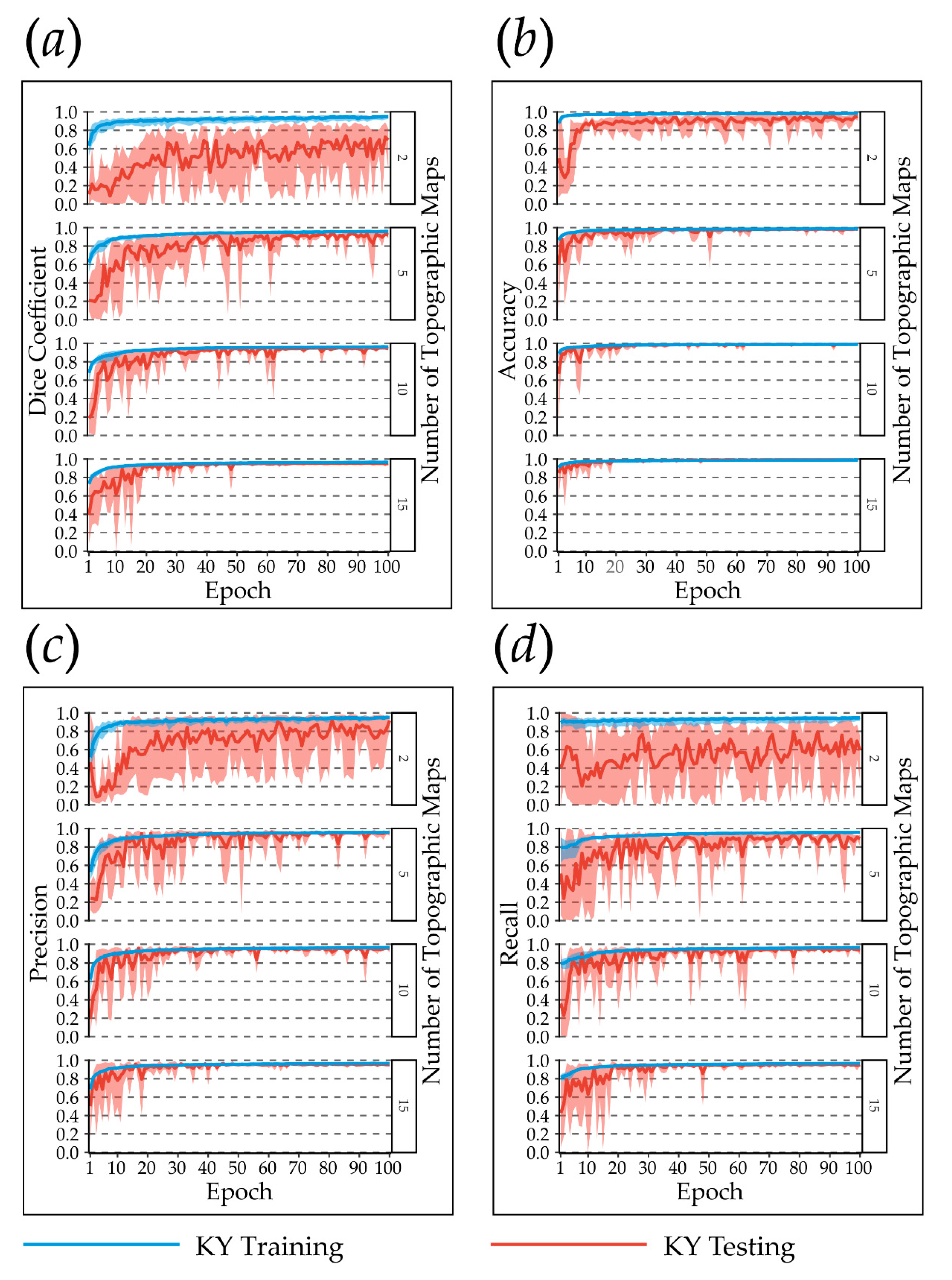
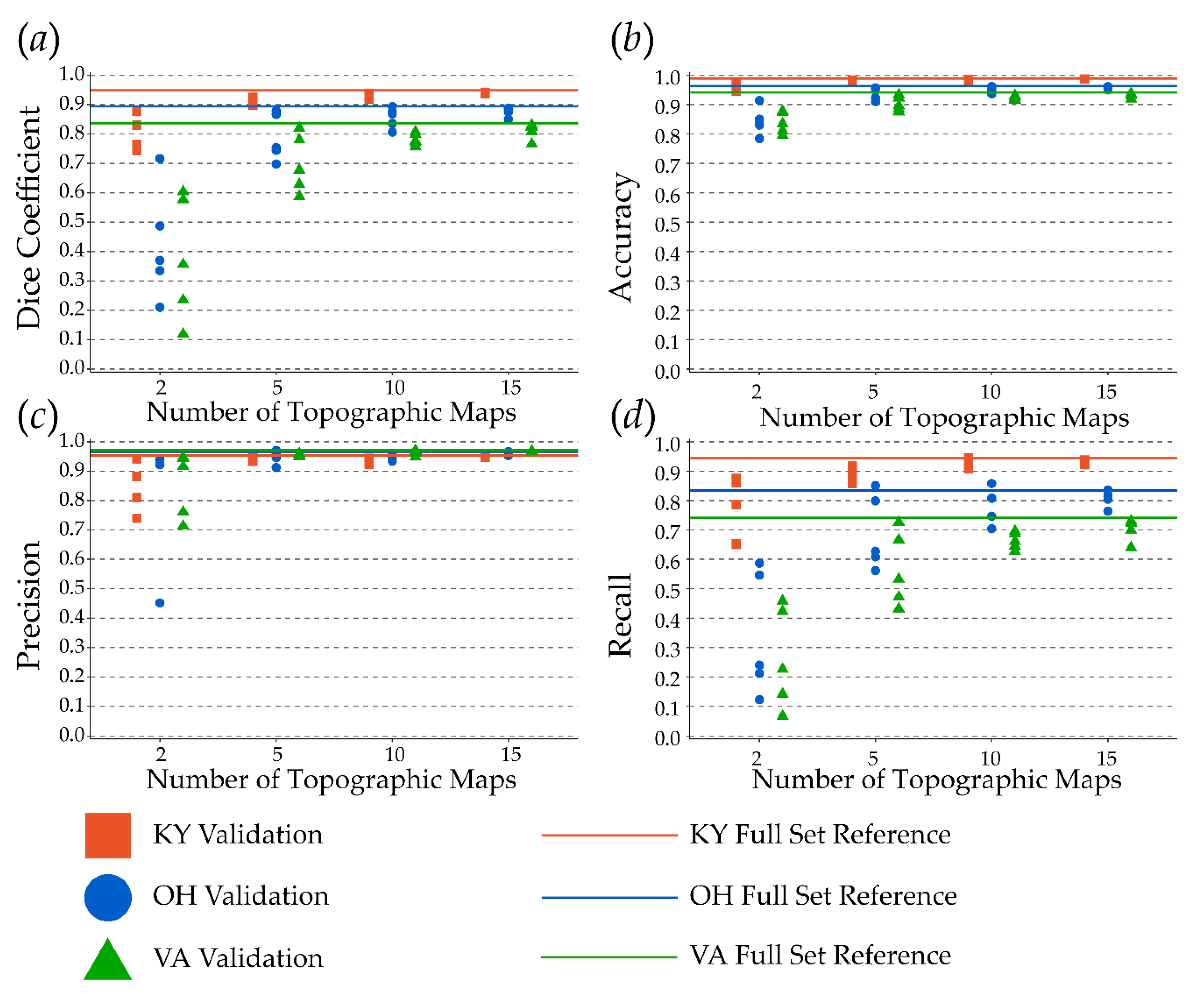
3.3. Sample Size Comparisons
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Acronyms
| Acronym | Meaning |
| Adam | Adaptive Momentum Estimation |
| ANNs | Artificial Neural Networks |
| API | Application Programming Interface |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| DRG | Digital Raster Graphic |
| FCNs | Fully Convolutional Neural Networks |
| FN | False Negative |
| FP | False Positive |
| GEOBIA | Geographic Object-Based Image Analysis |
| GGGSC | USGS Geology, Geophysics, and Geochemistry Science Center |
| GPU | Graphics Processing Unit |
| HTMC | Historic Topographic Map Collection |
| KY | Kentucky |
| LCLU | Land Cover and Land Use |
| LiDAR | Light Detection and Ranging |
| Mask R-CNN | Mask Regional-Convolutional Neural Networks |
| ML | Machine Learning |
| NLCD | National Land Cover Database |
| OLI | Operational Land Imager |
| ReLU | Rectified Linear Unit |
| RF | Random Forests |
| RMSProp | Root Mean Square Propagation |
| SMCRA | US Surface Mining Control and Reclamation Act |
| SVM | Support Vector Machines |
| TN | Tennessee |
| TN | True Negative |
| TP | True Positive |
| US | United States |
| USGS | United States Geological Survey |
| VA | Virginia |
| WV | West Virginia |
References
- Drummond, M.A.; Loveland, T.R. Land-use Pressure and a Transition to Forest-cover Loss in the Eastern United States. BioSscience 2010, 60, 286–298. [Google Scholar] [CrossRef]
- Midekisa, A.; Holl, F.; Savory, D.J.; Andrade-Pacheco, R.; Gething, P.W.; Bennett, A.; Sturrock, H.J.W. Mapping land cover change over continental Africa using Landsat and Google Earth Engine cloud computing. PLoS ONE 2017, 12, e0184926. [Google Scholar] [CrossRef] [PubMed]
- Potapov, P.; Hansen, M.C.; Kommareddy, I.; Kommareddy, A.; Turubanova, S.; Pickens, A.H.; Adusei, B.; Tyukavina, A.; Ying, Q. Kommareddy Landsat Analysis Ready Data for Global Land Cover and Land Cover Change Mapping. Remote Sens. 2020, 12, 426. [Google Scholar] [CrossRef]
- Brown, D.G.; Johnson, K.M.; Loveland, T.R.; Theobald, D.M. Rural land-use trends in the conterminous United States, 1950–2000. Ecol. Appl. 2005, 15, 1851–1863. [Google Scholar] [CrossRef]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 National Land Cover Database for the Conterminous United States—Representing a Decade of Land Cover Change Information. Photogramm. Eng. Remote Sens. 2015, 81, 346–354. [Google Scholar] [CrossRef]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J.; et al. A new generation of the United States National Land Cover Database: Requirements, research priorities, design, and implementation strategies. ISPRS J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- Chance, C.M.; Hermosilla, T.; Coops, N.C.; Wulder, M.A.; White, J.C. Effect of topographic correction on forest change detection using spectral trend analysis of Landsat pixel-based composites. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 186–194. [Google Scholar] [CrossRef]
- Buchner, J.; Yin, H.; Frantz, D.; Kuemmerle, T.; Askerov, E.; Bakuradze, T.; Bleyhl, B.; Elizbarashvili, N.; Komarova, A.; Lewińska, K.E.; et al. Land-cover change in the Caucasus Mountains since 1987 based on the topographic correction of multi-temporal Landsat composites. Remote Sens. Environ. 2020, 248, 111967. [Google Scholar] [CrossRef]
- Batar, A.; Watanabe, T.; Kumar, A. Assessment of Land-Use/Land-Cover Change and Forest Fragmentation in the Garhwal Himalayan Region of India. Environments 2017, 4, 34. [Google Scholar] [CrossRef]
- Kassawmar, T.; Eckert, S.; Hurni, K.; Zeleke, G.; Hurni, H. Reducing landscape heterogeneity for improved land use and land cover (LULC) classification across the large and complex Ethiopian highlands. Geocarto Int. 2016, 33, 53–69. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; García-Haro, F.J.; Martínez, B.; Sánchez-Ruiz, S.; Gilabert, M.A.; Campos-Taberner, M.; Haro, G.-; Sanchez-Ruiz, S. A Copernicus Sentinel-1 and Sentinel-2 Classification Framework for the 2020+ European Common Agricultural Policy: A Case Study in València (Spain). Agronomy 2019, 9, 556. [Google Scholar] [CrossRef]
- Claverie, M.; Ju, J.; Masek, J.G.; Dungan, J.L.; Vermote, E.F.; Roger, J.-C.; Skakun, S.V.; Justice, C. The Harmonized Landsat and Sentinel-2 surface reflectance data set. Remote Sens. Environ. 2018, 219, 145–161. [Google Scholar] [CrossRef]
- WVGES Geology: History of West Virginia Coal Industry. Available online: http://www.wvgs.wvnet.edu/www/geology/geoldvco.htm (accessed on 5 October 2020).
- Lasson, K. A History of Appalachian Coal Mines. In Legal Problems of Coal Mine Reclamation: A Study in Maryland, Ohio, Pennsylvania and West Virginia; U.S. Government Printing Office: Washington, DC, USA, 1972; 20p. [Google Scholar]
- Höök, M.; Aleklett, K. Historical trends in American coal production and a possible future outlook. Int. J. Coal Geol. 2009, 78, 201–216. [Google Scholar] [CrossRef]
- Bernhardt, E.S.; Palmer, M. The environmental costs of mountaintop mining valley fill operations for aquatic ecosystems of the Central Appalachians: Mountaintop mining impacts on aquatic ecosystems. Annals of the New York Academy of Sciences. Ann. N. Y. Acad. Sci. 2011, 1223, 39–57. [Google Scholar] [CrossRef]
- Palmer, M.; Bernhardt, E.S.; Schlesinger, W.H.; Eshleman, K.N.; Foufoula-Georgiou, E.; Hendryx, M.S.; Lemly, A.D.; Likens, G.E.; Loucks, O.L.; Power, M.E.; et al. Mountaintop Mining Consequences. Science 2010, 327, 148–149. [Google Scholar] [CrossRef]
- US EPA. Basic Information about Surface Coal Mining in Appalachia. Available online: https://www.epa.gov/sc-mining/basic-information-about-surface-coal-mining-appalachia (accessed on 22 September 2020).
- Henrich, C. Acid Mine Drainage: Common Law, SMCRA, and the Clean Water Act. J. Nat. Resour. Environ. Law 1994, 10, 235–260. [Google Scholar]
- Zipper, C.E.; Barnhisel, R.I.; Darmody, R.G.; Daniels, W.L. Coal Mine Reclamation, Acid Mine Drainage, and the Clean Water Act. In Reclamation of Drastically Disturbed Lands; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2015; pp. 169–191. ISBN 978-0-89118-233-7. [Google Scholar]
- Topographic Maps. Available online: https://www.usgs.gov/core-science-systems/national-geospatial-program/topographic-maps (accessed on 22 September 2020).
- Horacio, J.; Dunesme, S.; Piégay, H. Can we characterize river corridor evolution at a continental scale from historical topographic maps? A first assessment from the comparison of four countries. River Res. Appl. 2019, 36, 934–946. [Google Scholar] [CrossRef]
- Horton, J.D.; San Juan, C.A. Prospect- and Mine-Related Features from U.S. Geological Survey 7.5- and 15-Minute Topographic Quadrangle Maps of the United States; U.S. Geological Survey: Reston, VA, USA, 2017.
- Li, H.; Liu, J.; Zhou, X. Intelligent Map Reader: A Framework for Topographic Map Understanding with Deep Learning and Gazetteer. IEEE Access 2018, 6, 25363–25376. [Google Scholar] [CrossRef]
- Uhl, J.; Leyk, S.; Chiang, Y.-Y.; Duan, W.; Knoblock, C. Extracting Human Settlement Footprint from Historical Topographic Map Series Using Context-Based Machine Learning. In Proceedings of the 8th International Conference of Pattern Recognition Systems (ICPRS 2017), Madrid, Spain, 11–13 July 2017. [Google Scholar]
- Davis, L.R.; Fishburn, K.A.; Lestinsky, H.; Moore, L.R.; Walter, J.L. US Topo Product Standard (Ver. 2.0, February 2019): U.S. Geological Survey Techniques and Methods Book 11, Chap. B2, 20p, 3 Plates, Scales 1:24,000, 1:25,000, and 1:20,000. Available online: https://doi.org/10.3133/tm11b2 (accessed on 11 December 2020).
- Topographic Mapping Booklet. Available online: https://pubs.usgs.gov/gip/topomapping/topo.html (accessed on 6 October 2020).
- Fishburn, K.A.; Allord, G.J. Historical Topographic Map Collection Bookmark; General Information Product; U.S. Geological Survey: Reston, VA, USA, 2017.
- Fishburn, K.A.; Davis, L.R.; Allord, G.J. Scanning and Georeferencing Historical USGS Quadrangles; Fact Sheet; U.S. Geological Survey: Reston, VA, USA, 2017; p. 2.
- Allord, G.J.; Fishburn, K.A.; Walter, J.L. Standard for the U.S. Geological Survey Historical Topographic Map Collection; Techniques and Methods; Version 1, 2011; Version 2, July 2014; U.S. Geological Survey: Reston, VA, USA, 2014; p. 20. Available online: https://pubs.er.usgs.gov/publication/tm11B03 (accessed on 11 December 2020).
- Allord, G.J.; Walter, J.L.; Fishburn, K.A.; Shea, G.A. Specification for the U.S. Geological Survey Historical Topographic Map Collection; Techniques and Methods; U.S. Geological Survey: Reston, VA, USA, 2014; p. 78. Available online: https://pubs.usgs.gov/tm/11b6/ (accessed on 11 December 2020).
- topoView. USGS. Available online: https://ngmdb.usgs.gov/maps/topoview/ (accessed on 6 October 2020).
- Townsend, P.A.; Helmers, D.P.; Kingdon, C.C.; McNeil, B.E.; De Beurs, K.M.; Eshleman, K.N. Changes in the extent of surface mining and reclamation in the Central Appalachians detected using a 1976–2006 Landsat time series. Remote Sens. Environ. 2009, 113, 62–72. [Google Scholar] [CrossRef]
- Pericak, A.A.; Thomas, C.J.; Kroodsma, D.A.; Wasson, M.F.; Ross, M.R.V.; Clinton, N.E.; Campagna, D.J.; Franklin, Y.; Bernhardt, E.S.; Amos, J.F. Mapping the yearly extent of surface coal mining in Central Appalachia using Landsat and Google Earth Engine. PLoS ONE 2018, 13, e0197758. [Google Scholar] [CrossRef]
- Xiao, W.; Deng, X.; He, T.; Chen, W. Mapping Annual Land Disturbance and Reclamation in a Surface Coal Mining Region Using Google Earth Engine and the LandTrendr Algorithm: A Case Study of the Shengli Coalfield in Inner Mongolia, China. Remote Sens. 2020, 12, 1612. [Google Scholar] [CrossRef]
- Sen, S.; Zipper, C.E.; Wynne, R.H.; Donovan, P.F. Identifying Revegetated Mines as Disturbance/Recovery Trajectories Using an Interannual Landsat Chronosequence. Photogramm. Eng. Remote Sens. 2012, 78, 223–235. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Zégre, N.P.; Yuill, C.B. Comparison of NAIP orthophotography and RapidEye satellite imagery for mapping of mining and mine reclamation. GISci. Remote Sens. 2014, 51, 301–320. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Strager, M.P.; Conley, J.F.; Sharp, A.L. Assessing machine-learning algorithms and image- and lidar-derived variables for GEOBIA classification of mining and mine reclamation. Int. J. Remote Sens. 2015, 36, 954–978. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A. Differentiating mine-reclaimed grasslands from spectrally similar land cover using terrain variables and object-based machine learning classification. Int. J. Remote Sens. 2015, 36, 4384–4410. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Strager, M.P.; Pal, M. Combining RapidEye Satellite Imagery and Lidar for Mapping of Mining and Mine Reclamation. Photogramm. Eng. Remote Sens. 2014, 80, 179–189. [Google Scholar] [CrossRef]
- Liu, T.; Miao, Q.; Xu, P.; Zhang, S. Superpixel-Based Shallow Convolutional Neural Network (SSCNN) for Scanned Topographic Map Segmentation. Remote Sens. 2020, 12, 3421. [Google Scholar] [CrossRef]
- Behrens, T.; Schmidt, K.; Macmillan, R.A.; Viscarra Rossel, R.A. Multi-scale digital soil mapping with deep learning. Sci. Rep. 2018, 8, 15244. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Cowley, D.C.; Waldeland, A.U. Using deep neural networks on airborne laser scanning data: Results from a case study of semi-automatic mapping of archaeological topography on Arran, Scotland. Archaeol. Prospect. 2019, 26, 165–175. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Pourmohammadi, P.; Poyner, J.D. Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data. Remote Sens. 2020, 12, 547. [Google Scholar] [CrossRef]
- Warner, T.A.; Nellis, M.D.; Foody, G.M. The SAGE Handbook of Remote Sensing; SAGE: Newcastle upon Tyne, UK, 2009; ISBN 978-1-4462-0676-8. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; Van Der Meer, F.; Van Der Werff, H.; Van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef]
- Warner, T. Kernel-Based Texture in Remote Sensing Image Classification. Geogr. Compass 2011, 5, 781–798. [Google Scholar] [CrossRef]
- Chen, G.; Weng, Q.; Hay, G.J.; He, Y. Geographic object-based image analysis (GEOBIA): Emerging trends and future opportunities. GISci. Remote Sens. 2018, 55, 159–182. [Google Scholar] [CrossRef]
- Kucharczyk, M.; Hay, G.J.; Ghaffarian, S.; Hugenholtz, C.H. Geographic Object-Based Image Analysis: A Primer and Future Directions. Remote Sens. 2020, 12, 2012. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Tatnall, A.R.L. Introduction Neural networks in remote sensing. Int. J. Remote Sens. 1997, 18, 699–709. [Google Scholar] [CrossRef]
- Mas, J.; Flores, J.J. The application of artificial neural networks to the analysis of remotely sensed data. Int. J. Remote Sens. 2007, 29, 617–663. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv 2016, arXiv:1511.00561. [Google Scholar] [CrossRef]
- Christ, P.F.; Elshaer, M.E.A.; Ettlinger, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; Rempfler, M.; Armbruster, M.; Hofmann, F.; D’Anastasi, M.; et al. Automatic Liver and Lesion Segmentation in CT Using Cascaded Fully Convolutional Neural Networks and 3D Conditional Random Fields. Lect. Notes Comput. Sci. 2016, 9901, 415–423. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.-A. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Cui, B.; Zhang, Y.; Li, X.; Wu, J.; Lu, Y. WetlandNet: Semantic Segmentation for Remote Sensing Images of Coastal Wetlands via Improved UNet with Deconvolution. In Genetic and Evolutionary Computing; Pan, J.-S., Lin, J.C.-W., Liang, Y., Chu, S.-C., Eds.; Springer: Singapore, 2020; pp. 281–292. [Google Scholar]
- Freudenberg, M.; Nölke, N.; Agostini, A.; Urban, K.; Wörgötter, F.; Kleinn, C. Large Scale Palm Tree Detection in High Resolution Satellite Images Using U-Net. Remote Sens. 2019, 11, 312. [Google Scholar] [CrossRef]
- Jiao, L.; Huo, L.; Hu, C.; Tang, P. Refined UNet: UNet-Based Refinement Network for Cloud and Shadow Precise Segmentation. Remote Sens. 2020, 12, 2001. [Google Scholar] [CrossRef]
- Li, L.; Wang, C.; Zhang, H.; Zhang, B.; Wu, F. Urban Building Change Detection in SAR Images Using Combined Differential Image and Residual U-Net Network. Remote Sens. 2019, 11, 1091. [Google Scholar] [CrossRef]
- Wagner, F.H.; Dalagnol, R.; Tarabalka, Y.; Segantine, T.Y.F.; Thomé, R.; Hirye, M.C.M. U-Net-Id, an Instance Segmentation Model for Building Extraction from Satellite Images—Case Study in the Joanópolis City, Brazil. Remote Sens. 2020, 12, 1544. [Google Scholar] [CrossRef]
- Wang, C.; Li, L. Multi-Scale Residual Deep Network for Semantic Segmentation of Buildings with Regularizer of Shape Representation. Remote Sens. 2020, 12, 2932. [Google Scholar] [CrossRef]
- Ren, Y.; Yu, Y.; Guan, H. DA-CapsUNet: A Dual-Attention Capsule U-Net for Road Extraction from Remote Sensing Imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Qi, W.; Wei, M.; Yang, W.; Xu, C.; Ma, C. Automatic Mapping of Landslides by the ResU-Net. Remote Sens. 2020, 12, 2487. [Google Scholar] [CrossRef]
- ArcGIS. Pro Help—ArcGIS Pro. Documentation. Available online: https://pro.arcgis.com/en/pro-app/help/main/welcome-to-the-arcgis-pro-app-help.htm (accessed on 7 October 2020).
- Export Training Data for Deep Learning (Image Analyst)—ArcGIS Pro. Documentation. Available online: https://pro.arcgis.com/en/pro-app/tool-reference/image-analyst/export-training-data-for-deep-learning.htm (accessed on 7 October 2020).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Allaire, J.J.; Chollet, F. Keras: R Interface to “Keras”. 2020. Available online: https://cran.r-project.org/web/packages/keras/index.html (accessed on 11 December 2020).
- Allaire, J.J.; Tang, Y. Tensorflow: R Interface to “TensorFlow”. 2020. Available online: https://cran.r-project.org/web/packages/tensorflow/index.html (accessed on 11 December 2020).
- Team, K. Keras Documentation: Keras API Reference. Available online: https://keras.io/api/ (accessed on 7 October 2020).
- Welcome to Python.org. Available online: https://www.python.org/doc/ (accessed on 7 October 2020).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 7 October 2020).
- Ushey, K.; Allaire, J.J.; Tang, Y. Reticulate: Interface to “Python”. 2020. Available online: https://cran.r-project.org/web/packages/reticulate/index.html (accessed on 11 December 2020).
- Ooms, J. Magick: Advanced Graphics and Image-Processing in R. 2020. Available online: https://cran.r-project.org/web/packages/magick/index.html (accessed on 11 December 2020).
- Rstudio/Keras. Available online: https://github.com/rstudio/keras (accessed on 7 October 2020).
- Unet. Available online: https://keras.rstudio.com/articles/examples/unet.html (accessed on 7 October 2020).
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Dubey, A.K.; Jain, V. Comparative Study of Convolution Neural Network’s ReLu and Leaky-ReLu Activation Functions. In Applications of Computing, Automation and Wireless Systems in Electrical Engineering; Springer: Berlin/Heidelberg, Germany, 2019; pp. 873–880. [Google Scholar]
- Zeng, X.; Zhang, Z.; Wang, D. AdaMax Online Training for Speech Recognition. 2016, pp. 1–8. Available online: http://cslt.riit.tsinghua.edu.cn/mediawiki/images/d/df/Adamax_Online_Training_for_Speech_Recognition.pdf (accessed on 17 December 2020).
- Shamir, R.R.; Duchin, Y.; Kim, J.; Sapiro, G.; Harel, N. Continuous Dice Coefficient: A Method for Evaluating Probabilistic Segmentations. arXiv 2019, arXiv:1906.11031. [Google Scholar]
- Tustison, N.; Gee, J. Introducing Dice, Jaccard, and Other Label Overlap Measures to ITK. Insight J. 2009, 707. Available online: http://hdl.handle.net/10380/3141 (accessed on 11 December 2020).
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A. Thematic Classification Accuracy Assessment with Inherently Uncertain Boundaries: An Argument for Center-Weighted Accuracy Assessment Metrics. Remote Sens. 2020, 12, 1905. [Google Scholar] [CrossRef]
- How U-Net Works? ArcGIS for Developers. Available online: https://developers.arcgis.com/python/guide/how-unet-works/ (accessed on 8 October 2020).
- De Albuquerque, A.O.; Júnior, O.A.D.C.; De Carvalho, O.L.F.; De Bem, P.P.; Ferreira, P.G.; Moura, R.D.S.D.; Silva, C.R.; Gomes, R.A.T.; Guimarães, R.F.; De Bem, P.P. Deep Semantic Segmentation of Center Pivot Irrigation Systems from Remotely Sensed Data. Remote Sens. 2020, 12, 2159. [Google Scholar] [CrossRef]
- Schuegraf, P.; Bittner, K. Automatic Building Footprint Extraction from Multi-Resolution Remote Sensing Images Using a Hybrid FCN. ISPRS Int. J. Geo-Inf. 2019, 8, 191. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Wang, F.; Piao, S.; Xie, J. CSE-HRNet: A Context and Semantic Enhanced High-Resolution Network for Semantic Segmentation of Aerial Imagery. IEEE Access 2020, 8, 182475–182489. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-Scale Context Aggregation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef]
- Francis, N.S.; Francis, N.J.; Xu, Y.; Saqib, M.; Aljasar, S.A. Identify Cancer in Affected Bronchopulmonary Lung Segments Using Gated-SCNN Modelled with RPN. In Proceedings of the 2020 IEEE 6th International Conference on Control Science and Systems Engineering (ICCSSE), Beijing, China, 17–19 July 2020; pp. 5–9. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. arXiv 2019, arXiv:1907.05740. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Unique Maps (SCANID) | Unique Quads (Name) | Mining and Absence Chips | Absence Only Chips | Total Chips | Oldest Year | Newest Year |
|---|---|---|---|---|---|---|---|
| KY Training | 84 | 70 | 17,792 | 12,600 | 30,392 | 1949 | 1980 |
| KY Testing | 18 | 15 | 2588 | 2700 | 5288 | 1953 | 1992 |
| KY Validation | 20 | 15 | 3849 | 3000 | 6849 | 1951 | 1992 |
| OH Validation | 23 | 10 | 6849 | 3450 | 10,299 | 1960 | 2002 |
| VA Validation | 25 | 12 | 12,140 | 3750 | 15,890 | 1957 | 1968 |
| Parameter | Value |
|---|---|
| Trainable Number of Parameters | 34,527,041 |
| Non-Trainable Number of Parameters | 13,696 |
| Input Image Size (Height × Width × Channels) | 128 × 128 × 3 |
| Kernel Size | 3 × 3 |
| Padding | “Same” |
| Max Pooling | 2 × 2 |
| Max Pooling Stride | 2 × 2 |
| Number of Downsampling Blocks | 4 |
| Number of Upsampling Blocks | 4 |
| Convolutional Layers per Block (Downsampling) | 2 |
| Convolutional Layers per Block (Upsampling) | 3 |
| Number of Filters | 64, 128, 256, 512, 1024 |
| CNN Activation | Leaky ReLU |
| Classification Activation | Sigmoid |
| Loss Metric | Dice Coefficient Loss |
| Optimizer | AdaMax |
| Reference Data | |||
|---|---|---|---|
| True | False | ||
| Classification Result | True | TP | FP |
| False | FN | TN | |
| Dataset | Dice/F1 Score | Precision | Recall | Accuracy | N |
|---|---|---|---|---|---|
| KY Training | 0.959 | 0.967 | 0.951 | 0.990 | 30,392 |
| KY Testing | 0.965 | 0.967 | 0.963 | 0.993 | 5288 |
| KY Validation | 0.949 | 0.954 | 0.944 | 0.989 | 6849 |
| OH Validation | 0.894 | 0.966 | 0.835 | 0.963 | 10,299 |
| VA Validation | 0.837 | 0.971 | 0.741 | 0.942 | 15,890 |
| Dataset | Dice/F1 Score | Precision | Recall | Specificity | Accuracy | N |
|---|---|---|---|---|---|---|
| KY Testing | 0.920 | 0.914 | 0.939 | 0.999 | 0.999 | 18 |
| KY Validation | 0.902 | 0.891 | 0.917 | 0.999 | 0.998 | 20 |
| OH Validation | 0.837 | 0.905 | 0.811 | 0.998 | 0.992 | 23 |
| VA Validation | 0.763 | 0.910 | 0.686 | 0.998 | 0.983 | 25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maxwell, A.E.; Bester, M.S.; Guillen, L.A.; Ramezan, C.A.; Carpinello, D.J.; Fan, Y.; Hartley, F.M.; Maynard, S.M.; Pyron, J.L. Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps. Remote Sens. 2020, 12, 4145. https://doi.org/10.3390/rs12244145
Maxwell AE, Bester MS, Guillen LA, Ramezan CA, Carpinello DJ, Fan Y, Hartley FM, Maynard SM, Pyron JL. Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps. Remote Sensing. 2020; 12(24):4145. https://doi.org/10.3390/rs12244145
Chicago/Turabian StyleMaxwell, Aaron E., Michelle S. Bester, Luis A. Guillen, Christopher A. Ramezan, Dennis J. Carpinello, Yiting Fan, Faith M. Hartley, Shannon M. Maynard, and Jaimee L. Pyron. 2020. "Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps" Remote Sensing 12, no. 24: 4145. https://doi.org/10.3390/rs12244145
APA StyleMaxwell, A. E., Bester, M. S., Guillen, L. A., Ramezan, C. A., Carpinello, D. J., Fan, Y., Hartley, F. M., Maynard, S. M., & Pyron, J. L. (2020). Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps. Remote Sensing, 12(24), 4145. https://doi.org/10.3390/rs12244145