Anchor-free Convolutional Network with Dense Attention Feature Aggregation for Ship Detection in SAR Images




Abstract
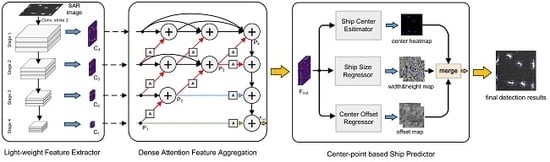
1. Introduction
2. Materials and Methods
2.1. Lightweight Feature Extractor Based on MobileNetV2
2.2. Dense Attention Feature Aggregation
2.2.1. Ideas of Dense Attention Feature Aggregation
2.2.2. Attention-Based Feature Fusion Block
2.3. Center-Point-Based Ship Predictor
3. Results
3.1. Data Set Description and Experimental Settings
3.2. Evaluation Metrics
3.3. Effectiveness of Dense Attention Feature Aggregation
3.4. Comparison with Other Ship Detection Methods
- Faster-RCNN [21]: Faster-RCNN is a classic deep learning detection algorithm, and is widely studied in the ship detection of SAR images [39,49]. Faster-RCNN employs the region proposal network (RPN) to extract target candidates for coarse detection. Then, the detection results are refined by further regression.
- RetinaNet [33]: RetinaNet is a deep learning algorithm based on the feature pyramid network (FPN) for multiscale target detection. The focal loss is proposed to improve the detection performance for hard samples.
- YOLOv3 [56]: YOLOv3 is a real-time detection algorithm, where the feature extraction network is carefully designed to realize the high-speed target detection.
- FCOS [36]: Among the above three deep learning detection algorithms, the predefined anchors are used to help predict targets in training and testing. FCOS is a recently proposed anchor-free detection algorithm. It achieves the anchor-free detection by regressing a 4D vector representing the location of the targets pixel by pixel.
- Reppoints [37]: Reppoints is also a newly proposed anchor-free detection algorithm, which locates a target by predicting a set of key points and transforming them into the predicted bounding box.
4. Discussion
4.1. Influence of the Network’s Width
4.2. Validating the Effectiveness of Feature Map Visualization
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Crisp, D. The State-of-the-Art in Ship Detection in Synthetic Aperture Radar Imagery; Australian Government, Department of Defense: Canberra, Australia, 2004; p. 115. [Google Scholar]
- Ao, W.; Xu, F.; Li, Y.; Wang, H. Detection and discrimination of ship targets in complex background from spaceborne alos-2 sar images. IEEE J. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 536–550. [Google Scholar] [CrossRef]
- Huo, W.; Huang, Y.; Pei, J.; Zhang, Q.; Gu, Q.; Yang, J. Ship detection from ocean sar image based on local contrast variance weighted information entropy. Sensors 2018, 18, 1196. [Google Scholar] [CrossRef] [PubMed]
- Schwegmann, C.P.; Kleynhans, W.; Salmon, B.P. Synthetic aperture radar ship detection using haar-like features. IEEE Geosci. Remote Sens. Lett. 2016, 14, 154–158. [Google Scholar] [CrossRef]
- Ai, J.; Qi, X.; Yu, W.; Deng, Y.; Liu, F.; Shi, L. A new cfar ship detection algorithm based on 2-d joint log-normal distribution in sar images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 806–810. [Google Scholar] [CrossRef]
- Liu, N.; Cao, Z.; Cui, Z.; Pi, Y.; Dang, S. Multi-scale proposal generation for ship detection in sar images. Remote Sens. 2019, 11, 526. [Google Scholar] [CrossRef]
- Zhang, F.; Wu, B. A scheme for ship detection in inhomogeneous regions based on segmentation of sar images. Int. J. Remote Sens. 2008, 29, 5733–5747. [Google Scholar] [CrossRef]
- Tello, M.; López-Martínez, C.; Mallorqui, J.J. A novel algorithm for ship detection in sar imagery based on the wavelet transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 201–205. [Google Scholar] [CrossRef]
- Tello, M.; Lopez-Martinez, C.; Mallorqui, J.J. Ship detection in sar imagery based on the wavelet transform. ESASP 2005, 584, 20. [Google Scholar]
- Leng, X.; Ji, K.; Zhou, S.; Xing, X.; Zou, H. An adaptive ship detection scheme for spaceborne sar imagery. Sensors 2016, 16, 1345. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, S.; Zhang, H.; Wu, F.; Zhang, B. Ship detection for high-resolution sar images based on feature analysis. IEEE Geosci. Remote Sens. Letters 2013, 11, 119–123. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Z.; Zhang, H.; Zhang, B.; Wu, F. A polsar ship detector based on a multi-polarimetric-feature combination using visual attention. Int. J. Remote Sens. 2014, 35, 7763–7774. [Google Scholar] [CrossRef]
- Ren, J. Ann vs. Svm: Which one performs better in classification of mccs in mammogram imaging. Knowl.-Based Syst. 2012, 26, 144–153. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. High-speed ship detection in sar images based on a grid convolutional neural network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef]
- Kang, M.; Leng, X.; Lin, Z.; Ji, K. A Modified Faster R-CNN Based on CFAR Algorithm for SAR Ship Detection. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Fei, G.; Aidong, L.; Kai, L.; Erfu, Y.; Hussain, A. A novel visual attention method for target detection from sar images. Chin. J. Aeronaut. 2019, 32, 1946–1958. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Tran. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Yue, Z.; Gao, F.; Xiong, Q.; Wang, J.; Huang, T.; Yang, E.; Zhou, H. A novel semi-supervised convolutional neural network method for synthetic aperture radar image recognition. Cogn. Comput. 2019, 1–12. [Google Scholar] [CrossRef]
- Gao, F.; Huang, T.; Sun, J.; Wang, J.; Hussain, A.; Yang, E. A new algorithm of sar image target recognition based on improved deep convolutional neural network. Cogn. Comput. 2019, 11, 809–824. [Google Scholar] [CrossRef]
- Zhang, W.; Li, Q.; Wu, Q.J.; Yang, Y.; Li, M. A novel ship target detection algorithm based on error self-adjustment extreme learning machine and cascade classifier. Cogn Comput. 2019, 11, 110–124. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; Morgan Kaufmann: San Mateo, CA, USA, 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision(ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, Y.; Zhang, M.-h.; Xu, P.; Guo, Z.-w. Sar ship detection using sea-land segmentation-based convolutional neural network. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Zhao, J.; Zhang, Z.; Yu, W.; Truong, T.-K. A cascade coupled convolutional neural network guided visual attention method for ship detection from sar images. IEEE Access 2018, 6, 50693–50708. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, W.; Zhang, Z.; Yu, W. A coupled convolutional neural network for small and densely clustered ship detection in sar images. Sci. China Inf. Sci. 2019, 62, 42301. [Google Scholar] [CrossRef]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for sar ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in sar images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Gao, F.; Shi, W.; Wang, J.; Yang, E.; Zhou, H. Enhanced feature extraction for ship detection from multi-resolution and multi-scene synthetic aperture radar (sar) images. Remote Sens. 2019, 11, 2694. [Google Scholar] [CrossRef]
- Chen, C.; He, C.; Hu, C.; Pei, H.; Jiao, L. A deep neural network based on an attention mechanism for sar ship detection in multiscale and complex scenarios. IEEE Access 2019, 7, 104848–104863. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise separable convolution neural network for high-speed sar ship detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.-Y.; Lee, W.-H. Ship detection based on yolov2 for sar imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision(ICCV), Seoul, Korea, 27 October–3 November 2019; pp. 9627–9636. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE International Conference on Computer Vision(ICCV), Seoul, Korea, 27 October–3 November 2019; pp. 9657–9666. [Google Scholar]
- Fan, Q.; Chen, F.; Cheng, M.; Lou, S.; Xiao, R.; Zhang, B.; Wang, C.; Li, J. Ship detection using a fully convolutional network with compact polarimetric sar images. Remote Sens. 2019, 11, 2171. [Google Scholar] [CrossRef]
- Mao, Y.; Yang, Y.; Ma, Z.; Li, M.; Su, H.; Zhang, J. Efficient low-cost ship detection for sar imagery based on simplified u-net. IEEE Access 2020, 8, 69742–69753. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Qingjun, Z. System design and key technologies of the gf-3 satellite. Acta Geod. Cartogr. Sin. 2017, 46, 269. [Google Scholar]
- Gao, F.; Ma, F.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. Visual saliency modeling for river detection in high-resolution sar imagery. IEEE Access 2017, 6, 1000–1014. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J. Learning deep ship detector in sar images from scratch. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4021–4039. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision(ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–499. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2403–2412. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 421–429. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Xian, S.; Zhirui, W.; Yuanrui, S.; Wenhui, D.; Yue, Z.; Kun, F. Air-sarship–1.0: High resolution sar ship detection dataset. J. Radars 2019, 8, 852–862. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems; Morgan Kaufmann: San Mateo, CA, USA, 2019; pp. 8026–8037. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Darknet: Open Source Neural Networks in C. Available online: http://pjreddie.com/darknet/ (accessed on 1 May 2020).
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Input | Operation | t | c | n | s | Output Name |
|---|---|---|---|---|---|---|---|
| 1 | 512 × 512 × 3 | Conv2d | - | 32 | 1 | 2 | - |
| 256 × 256 × 32 | IRB | 1 | 16 | 1 | 1 | - | |
| 256 × 256 × 16 | IRB | 6 | 24 | 2 | 2 | C4 | |
| 2 | 128 × 128 × 24 | IRB | 6 | 32 | 3 | 2 | C3 |
| 3 | 64 × 64 × 32 | IRB | 6 | 64 | 4 | 2 | - |
| 32 × 32 × 64 | IRB | 6 | 96 | 3 | 2 | - | |
| 32 × 32 × 96 | IRB | 6 | 160 | 3 | 1 | C2 | |
| 4 | 16 × 16 × 160 | IRB | 6 | 320 | 1 | 2 | C1 |
| Methods | Precision (%) | Recall (%) | f1-Score (%) | AP (%) |
|---|---|---|---|---|
| LSC | 77.86 | 75.17 | 76.49 | 77.13 |
| IDA | 79.70 | 77.93 | 78.81 | 80.49 |
| DIA (ours) | 82.98 | 80.69 | 81.82 | 82.96 |
| DHA (ours) | 82.07 | 84.26 | 83.15 | 85.34 |
| DAFA (ours) | 85.03 | 86.21 | 85.62 | 86.99 |
| Methods | Precision (%) | Recall (%) | f1-Score (%) | AP (%) |
|---|---|---|---|---|
| YOLOv3 | 63.87 | 68.28 | 66.00 | 64.65 |
| FCOS | 67.07 | 77.24 | 71.79 | 68.84 |
| Reppoints | 65.24 | 84.07 | 73.47 | 73.98 |
| RetinaNet | 72.12 | 82.07 | 76.77 | 79.00 |
| Faster-RCNN | 73.49 | 84.14 | 78.46 | 78.43 |
| Ours | 85.03 | 86.21 | 85.62 | 86.99 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, F.; He, Y.; Wang, J.; Hussain, A.; Zhou, H. Anchor-free Convolutional Network with Dense Attention Feature Aggregation for Ship Detection in SAR Images. Remote Sens. 2020, 12, 2619. https://doi.org/10.3390/rs12162619
Gao F, He Y, Wang J, Hussain A, Zhou H. Anchor-free Convolutional Network with Dense Attention Feature Aggregation for Ship Detection in SAR Images. Remote Sensing. 2020; 12(16):2619. https://doi.org/10.3390/rs12162619
Chicago/Turabian StyleGao, Fei, Yishan He, Jun Wang, Amir Hussain, and Huiyu Zhou. 2020. "Anchor-free Convolutional Network with Dense Attention Feature Aggregation for Ship Detection in SAR Images" Remote Sensing 12, no. 16: 2619. https://doi.org/10.3390/rs12162619
APA StyleGao, F., He, Y., Wang, J., Hussain, A., & Zhou, H. (2020). Anchor-free Convolutional Network with Dense Attention Feature Aggregation for Ship Detection in SAR Images. Remote Sensing, 12(16), 2619. https://doi.org/10.3390/rs12162619