

Optimizing Extreme Learning Machine for Drought Forecasting: Water Cycle vs. Bacterial Foraging

 ,
,  ,
,  ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. SPEI Calculation Using the Ground Truth Data
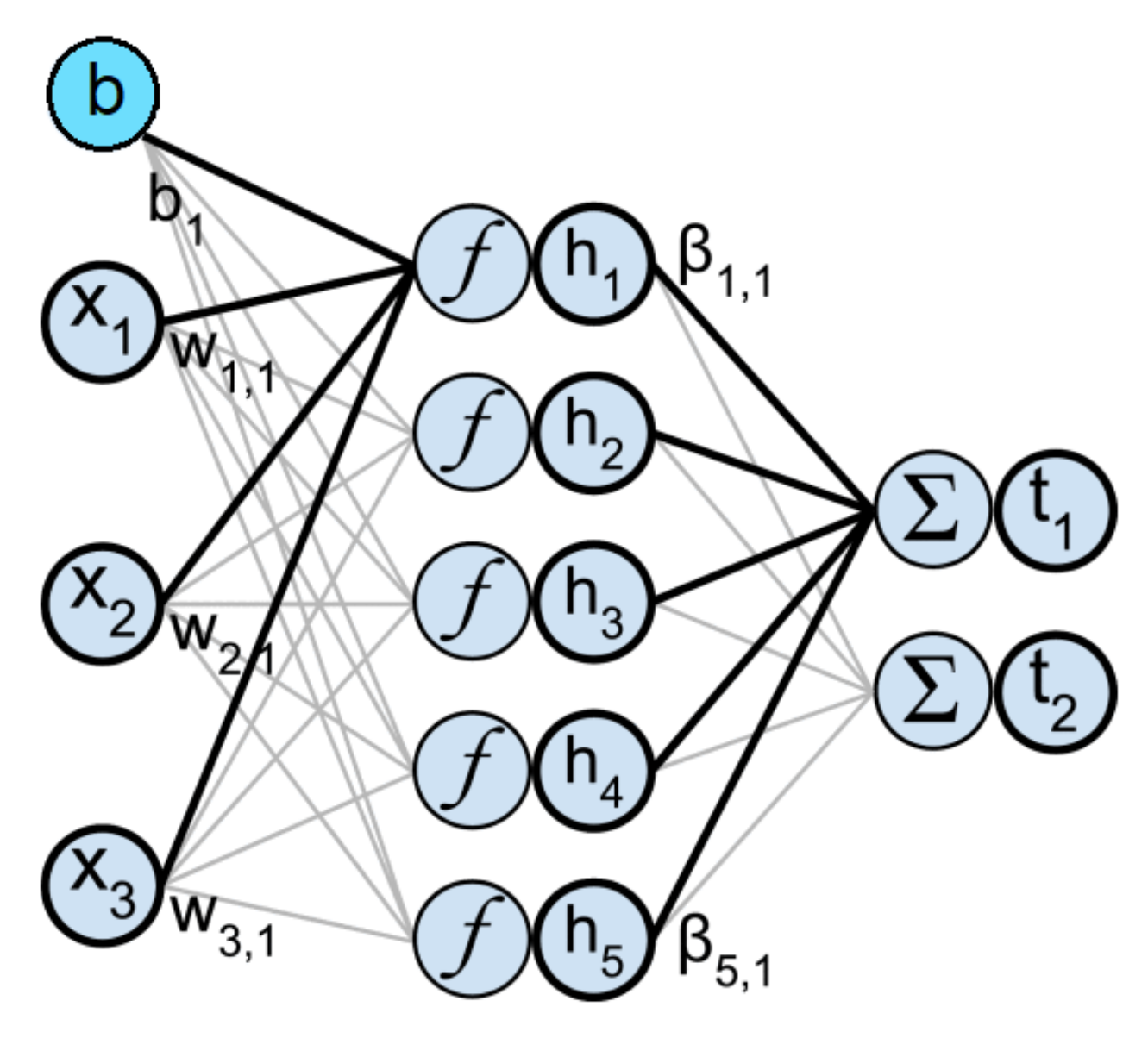
2.2. The Benchmark ELM Model
2.3. Water Cycle Algorithm
2.4. BFO Algorithm
- 1.
- Initializing parameters of elimination probability (P), swarm (population) size (S), number of chemotaxis steps (Ns; includes swimming and tumbling movements), number of reproduction step (Nre), number of elimination-dispersal step (Ned). The Ned denotes maximum number of iterations.
- 2.
- Performing elimination-dispersal step.
- 3.
- Performing reproduction step.
- 4.
- Performing chemotaxis step.
- 5.
- Computing health status (Jh) for each bacterium i and sort bacteria.
- 6.
- Selecting the healthiest E. coli group, splitting, and repeating steps II to V until k = Nre and l = Ns
2.5. Hybrid ELM-BFO and ELM-WCA Models
2.6. Identification of Optimum Predictors (Lagged SPEI Vectors)
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1. Pseudo-code of the WCO algorithm. |
| Initialization Stage |
|
| Procedure |
|
| for i = l:Npop |
| Stream flows to its corresponding rivers and sea. |
| Calculate the fitness function of the generated stream |
| Evaluate stream results |
| if F_new_stream < F_river |
| River = New_stream |
| if F_new_stream < F_sea |
| Sea = New_stream |
| end if |
| end if |
| River flows to its corresponding sea |
| Calculate the fitness function of the generated river |
| if F_new_river < F_sea |
| Sea = New_river |
| end if |
| end for |
| for i = l: Nsr |
| if (distance (Sea and river) < Dmax) or (rand < 0.1) |
| New streams are created. |
| end if |
| end for |
| Reduce Dmax |
| end while |
| Outputs |
|
| Algorithm A2. Pseudo-code of the BFO algorithm. |
| (1) Initialization: (a) Set parameters: S, Ns, Ci, Nre, Ned, Ped (b) Let j = k = l = 0 (three counters) (c) Initialize the bacterial population: randomly distribute each bacterium xi(0,0,0) across the domain of the optimization problem, and set xbest = x0(0,0,0). (2) Elimination and dispersal loop:l = l + 1 (3)Reproduction loop: k = k + 1 (4)Chemotaxis loop: j = j + 1 (5)For bacterium i = 1,2, ..., S, perform a chemotaxis operator. (a) Compute J (xi(j, k, l), let J(xi(j, k, 1)) = J(xi(j, k, 1))+ Jcc(xi(j, k, 1), P(j, k, l)) (b) Let Jlast = J (xi(j, k, 1)) to save this value since it is possible to find a better objective value via a run. (c) Tumble: randomly generate a n-dimensional vector Φ(i). (d) Move: Make a move according to Equation (14): J (xi(j + 1, k, l)) = J(xi (j + 1,k,l)) + Jcc(xi( j + 1, k, l), P( j + 1, k, l)) (e) Swim as follows: (i) Let m = 0 (The swimming counter). (ii) While m < Ns Let m = m +1. If J (xi(j + 1, k, l)) < Jlast, let Jlast = J(xi(j + 1, k, l)), keep on the move according to Equation (14), then use the new xi(j + 1, k, l) to compute the new J(xi) Else, let m = Ns (f) If J (xi(j + 1, k, l)) < J(xbest), then xbest = xi(j + 1, k, l). (g) Go to the next bacterium (i + 1) if i < S. (6) If j < Ci, go to step 4. (7) Reproduction (a) Compute the health value for each bacterium according to Equation (15). (b) Sort bacteria based on the health values in descending order. (c) Abandon Sr bacteria with higher health values and split each of another Sr bacteria into exactly same two ones. (8) If k < Nre, go to step 3. (9) Elimination and dispersal For each bacterium i = 1, 2, …, S may be dispersed into a new location (10) If l < Ned, go to step 2. Else return the optimal solution xbest |
References
- Schwabe, K.; Albiac, J.; Connor, J.D.; Hassan, R.M.; González, L.M. Drought in Arid and Semi-Arid Regions: A Multi-Disciplinary and Cross-Country Perspective; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Şen, Z. Applied Drought Modeling, Prediction, and Mitigation; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Crausbay, S.D.; Ramirez, A.R.; Carter, S.L.; Cross, M.S.; Hall, K.R.; Bathke, D.J.; Betancourt, J.L.; Colt, S.; Cravens, A.E.; Dalton, M.S.; et al. Defining ecological drought for the twenty-first century. Bull. Am. Meteorol. Soc. 2017, 98, 2543–2550. [Google Scholar] [CrossRef]
- Danandeh Mehr, A.; Fathollahzadeh Attar, N. A gradient boosting tree approach for SPEI classification and prediction in Turkey. Hydrol. Sci. J. 2021, 66, 1653–1663. [Google Scholar] [CrossRef]
- Pourraeisi, A.; Boorboori, M.R.; Sepehri, M. A Comparison of the Effects of Rhizophagus Intraradices, Serendipita Indica, and Pseudomonas Fluorescens on Soil and Zea maize L. Properties under Drought Stress Condition. Int. J. Sustain. Agric. Res. 2022, 9, 152–167. [Google Scholar] [CrossRef]
- Feng, K.; Su, X.; Zhang, G.; Javed, T.; Zhang, Z. Development of a new integrated hydrological drought index (SRGI) and its application in the Heihe River Basin, China. Theor. Appl. Climatol. 2020, 141, 43–59. [Google Scholar] [CrossRef]
- Kimwatu, D.M.; Mundia, C.N.; Makokha, G.O. Developing a new socio-economic drought index for monitoring drought proliferation: A case study of Upper Ewaso Ngiro River Basin in Kenya. Environ. Monit. Assess. 2021, 193, 213. [Google Scholar] [CrossRef] [PubMed]
- Jiang, T.; Su, X.; Singh, V.P.; Zhang, G. A novel index for ecological drought monitoring based on ecological water deficit. Ecol. Indic. 2021, 129, 107804. [Google Scholar] [CrossRef]
- Deo, R.C.; Tiwari, M.K.; Adamowski, J.F.; Quilty, J.M. Forecasting effective drought index using a wavelet extreme learning machine (W-ELM) model. Stoch. Environ. Res. Risk Assess. 2017, 31, 1211–1240. [Google Scholar] [CrossRef]
- Prodhan, F.A.; Zhang, J.; Hasan, S.S.; Pangali Sharma, T.P.; Mohana, H.P. A review of machine learning methods for drought hazard monitoring and forecasting: Current research trends, challenges, and future research directions. Environ. Model. Softw. 2022, 149, 105327. [Google Scholar] [CrossRef]
- Mishra, A.K.; Desai, V.R. Drought forecasting using stochastic models. Stochast. Environ. Res. Risk Assess. 2005, 19, 326–339. [Google Scholar] [CrossRef]
- Han, P.; Wang, P.X.; Zhang, S.Y. Drought forecasting based on the remote sensing data using ARIMA models. Math. Comput. Model. 2010, 51, 1398–1403. [Google Scholar] [CrossRef]
- Aghelpour, P.; Mohammadi, B.; Mehdizadeh, S.; Bahrami-Pichaghchi, H.; Duan, Z. A novel hybrid dragonfly optimization algorithm for agricultural drought prediction. Stoch. Environ. Res. Risk Assess. 2021, 35, 2459–2477. [Google Scholar] [CrossRef]
- Mehr, A.D.; Vaheddost, B.; Mohammadi, B. ENN-SA: A novel neuro-annealing model for multi-station drought prediction. Comput. Geosci. 2020, 145, 104622. [Google Scholar]
- Gholizadeh, R.; Yılmaz, H.; Danandeh Mehr, A. Multitemporal meteorological drought forecasting using Bat-ELM. Acta Geophys. 2022, 70, 917–927. [Google Scholar] [CrossRef]
- Mouatadid, S.; Raj, N.; Deo, R.C.; Adamowski, J.F. Input selection and data-driven model performance optimization to predict the Standardized Precipitation and Evaporation Index in a drought-prone region. Atmos. Res. 2018, 212, 130–149. [Google Scholar] [CrossRef]
- Madadgar, S.; AghaKouchak, A.; Shukla, S.; Wood, A.W.; Cheng, L.; Hsu, K.L.; Svoboda, M. A hybrid statistical-dynamical framework for meteorological drought prediction: Application to the southwestern United States. Water Resour. Res. 2016, 52, 5095–5110. [Google Scholar] [CrossRef]
- AghaKouchak, A.; Pan, B.; Mazdiyasni, O.; Sadegh, M.; Jiwa, S.; Zhang, W.; Love, C.A.; Madadgar, S.; Papalexiou, S.M.; Davis, S.J.; et al. Status and prospects for drought forecasting: Opportunities in artificial intelligence and hybrid physical–statistical forecasting. Phil. Trans. R. Soc. A 2022, 380, 20210288. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.; Babovic, V. Analysis of variability and trends of precipitation extremes in Singapore during 1980–2013. Int. J. Climatol. 2018, 38, 125–141. [Google Scholar] [CrossRef]
- Morid, S.; Smakhtin, V.; Bagherzadeh, K. Drought forecasting using artificial neural networks and time series of drought indices. Int. J. Climatol. 2007, 27, 2103–2111. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Z.Y.; Xu, L.J.; Ou, C.Q. Meteorological drought forecasting based on a statistical model with machine learning techniques in Shaanxi province, China. Sci. Total Environ. 2019, 665, 338–346. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z.; Wu, X.; Xu, C.Y.; Guo, S.; Chen, X.; Zhang, Z. Robust Meteorological Drought Prediction Using Antecedent SST Fluctuations and Machine Learning. Water Resour. Res. 2021, 57, e2020WR029413. [Google Scholar] [CrossRef]
- Warsito, B.; Yasin, H.; Prahutama, A. Particle swarm optimization versus gradient based methods in optimizing neural network. J. Phys. Conf. Ser. 2019, 1217, 012101. [Google Scholar] [CrossRef]
- Bacanin, N.; Bezdan, T.; Zivkovic, M.; Chhabra, A. Weight Optimization in Artificial Neural Network Training by Improved Monarch Butterfly Algorithm. In Lecture Notes on Data Engineering and Communications Technologies; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar] [CrossRef]
- Kisi, O.; Docheshmeh Gorgij, A.; Zounemat-Kermani, M.; Mahdavi-Meymand, A.; Kim, S. Drought forecasting using novel heuristic methods in a semi-arid environment. J. Hydrol. 2019, 578, 124053. [Google Scholar] [CrossRef]
- Dwijendra, N.; Sharma, S.; Asary, A.; Majdi, A.; Muda, I.; Mutlak, D.; Parra, R.; Hammid, A. Economic Performance of a Hybrid Renewable Energy System with Optimal Design of Resources. Environ. Clim. Technol. 2022, 26, 441–453. [Google Scholar] [CrossRef]
- Ahmadi, F.; Mehdizadeh, S.; Mohammadi, B. Development of Bio-Inspired- and Wavelet-Based Hybrid Models for Reconnaissance Drought Index Modeling. Water Resour. Manag. 2021, 35, 4127–4147. [Google Scholar] [CrossRef]
- Das, P.; Naganna, S.R.; Deka, P.C.; Pushparaj, J. Hybrid wavelet packet machine learning approaches for drought modeling. Environ. Earth Sci. 2020, 79, 221. [Google Scholar] [CrossRef]
- Passino, K.M. Biomimicry of Bacterial Foraging for Distributed Optimization and Control. IEEE Control Syst. 2002, 22, 52–67. [Google Scholar] [CrossRef]
- Eskandar, H.; Sadollah, A.; Bahreininejad, A.; Hamdi, M. Water cycle algorithm—A novel metaheuristic optimization method for solving constrained engineering optimization problems. Comput. Struct. 2012, 110–111, 151–166. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, Q.; Luo, J.; Xu, Y.; Zhang, X. An enhanced Bacterial Foraging Optimization and its application for training kernel extreme learning machine. Appl. Soft Comput. 2020, 86, 105884. [Google Scholar] [CrossRef]
- Qaderi, K.; Akbarifard, S.; Madadi, M.R.; Bakhtiari, B. Optimal operation of multi-reservoirs by water cycle algorithm. Proc. Inst. Civ. Eng. Water Manag. 2018, 171, 179–190. [Google Scholar] [CrossRef]
- Yavari, H.R.; Robati, A. Developing Water Cycle Algorithm for Optimal Operation in Multi-reservoirs Hydrologic System. Water Resour. Manag. 2021, 35, 2281–2303. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I. A multiscalar drought index sensitive to global warming: The standardized precipitation evapotranspiration index. J. Clim. 2010, 23, 1696–1718. [Google Scholar] [CrossRef]
- Dikici, M. Drought analysis with different indices for the Asi Basin (Turkey). Sci. Rep. 2020, 10, 20739. [Google Scholar] [CrossRef] [PubMed]
- Danandeh Mehr, A.; Vaheddoost, B. Identification of the trends associated with the SPI and SPEI indices across Ankara, Turkey. Theor. Appl. Climatol. 2020, 139, 1531–1542. [Google Scholar] [CrossRef]
- Mishra, A.K.; Desai, V.R. Drought forecasting using feed-forward recursive neural network. Ecol. Modell. 2006, 198, 127–138. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Chen, C.; Li, K.; Duan, M.; Li, K. Extreme Learning Machine and Its Applications in Big Data Processing. Big Data Anal. Sens.—Netw. Collect. Intell. 2017, 117–150. [Google Scholar] [CrossRef]
- Khalilpourazari, S.; Khalilpourazary, S. An efficient hybrid algorithm based on Water Cycle and Moth-Flame Optimization algorithms for solving numerical and constrained engineering optimization problems. Soft Comput. 2019, 23, 1699–1722. [Google Scholar] [CrossRef]
- Sadollah, A.; Eskandar, H.; Lee, H.M.; Yoo, D.G.; Kim, J.H. Water cycle algorithm: A detailed standard code. SoftwareX 2016, 5, 37–43. [Google Scholar] [CrossRef]
- Adnan, R.M.; Mostafa, R.; Islam, A.R.M.T.; Kisi, O.; Kuriqi, A.; Heddam, S. Estimating reference evapotranspiration using hybrid adaptive fuzzy inferencing coupled with heuristic algorithms. Comput. Electron. Agric. 2021, 191, 106541. [Google Scholar] [CrossRef]
- Chadalawada, J.; Babovic, V. Review and comparison of performance indices for automatic model induction. J. Hydroinform. 2019, 21, 13–31. [Google Scholar] [CrossRef]
- Liu, Z.N.; Li, Q.F.; Nguyen, L.B.; Xu, G.H. Comparing machine-learning models for drought forecasting in Vietnam’s cai river basin. Pol. J. Environ. Stud. 2018, 27, 2633–2646. [Google Scholar] [CrossRef]
- Zhang, X.; Yuan, J.; Chen, X.; Zhang, X.; Zhan, C.; Fathollahi-Fard, A.M.; Wang, C.; Liu, Z.; Wu, J. Development of an Improved Water Cycle Algorithm for Solving an Energy-Efficient Disassembly-Line Balancing Problem. Processes 2022, 10, 1908. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Sum of rivers and sea (NSr) | 4 |
| Evaporation condition constant (dmax) | 1 × 10−5 |
| Maximum iteration (Itmax) | 100 |
| Population (Npop) | 5 |
| Number of design variables (Nvar) | 2 |
| Search range | [−1, 1] |
| Parameter | Value |
|---|---|
| Population size (S) | 20 |
| Step size (Ci) | 0.01 |
| Number of chemotaxis steps (Ns) | 2 |
| Number of reproduction step (Nre) | 2 |
| Number of elimination-dispersal step (Ned) | 1000 |
| Elimination Probability (Ped) | 0.9 |
| Model (Structure) | Beypazari | Nallihan | ||
|---|---|---|---|---|
| RMSE | NSE | RMSE | NSE | |
| Training stage of SPEI-3 | ||||
| ELM | 0.650 | 0.540 | 0.597 | 0.590 |
| ELM-WCA | 0.405 | 0.821 | 0.363 | 0.848 |
| ELM-BFO | 0.503 | 0.695 | 0.526 | 0.681 |
| Testing stage of SPEI-3 | ||||
| ELM | 0.825 | 0.481 | 0.801 | 0.438 |
| ELM-WCA | 0.436 | 0.829 | 0.463 | 0.812 |
| ELM-BFO | 0.618 | 0.652 | 0.663 | 0.615 |
| Training stage of SPEI-6 | ||||
| ELM | 0.494 | 0.736 | 0.434 | 0.780 |
| ELM-WCA | 0.219 | 0.948 | 0.205 | 0.951 |
| ELM-BFO | 0.0.38 | 0.854 | 0.306 | 0.891 |
| Testing stage of SPEI-6 | ||||
| ELM | 0.641 | 0.605 | 0.564 | 0.712 |
| ELM-WCA | 0.235 | 0.947 | 0.249 | 0.944 |
| ELM-BFO | 0.343 | 0.887 | 0.446 | 0.820 |
| Station | Models | SPEI-3 | SPEI-6 | ||
|---|---|---|---|---|---|
| RMSE (%) | NSE (%) | RMSE (%) | NSE (%) | ||
| Beypazari | ELM-WCA vs. ELM | 47.1 | 72.0 | 63.3 | 56.2 |
| ELM-BFO vs. ELM | 25.0 | 35.0 | 46.5 | 46.6 | |
| Nallihan | ELM-WCA vs. ELM | 42.2 | 85.0 | 55.8 | 32.6 |
| ELM-BFO vs. ELM | 17.2 | 40.0 | 21.0 | 15.2 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Danandeh Mehr, A.; Tur, R.; Alee, M.M.; Gul, E.; Nourani, V.; Shoaei, S.; Mohammadi, B. Optimizing Extreme Learning Machine for Drought Forecasting: Water Cycle vs. Bacterial Foraging. Sustainability 2023, 15, 3923. https://doi.org/10.3390/su15053923
Danandeh Mehr A, Tur R, Alee MM, Gul E, Nourani V, Shoaei S, Mohammadi B. Optimizing Extreme Learning Machine for Drought Forecasting: Water Cycle vs. Bacterial Foraging. Sustainability. 2023; 15(5):3923. https://doi.org/10.3390/su15053923
Chicago/Turabian StyleDanandeh Mehr, Ali, Rifat Tur, Mohammed Mustafa Alee, Enes Gul, Vahid Nourani, Shahrokh Shoaei, and Babak Mohammadi. 2023. "Optimizing Extreme Learning Machine for Drought Forecasting: Water Cycle vs. Bacterial Foraging" Sustainability 15, no. 5: 3923. https://doi.org/10.3390/su15053923
APA StyleDanandeh Mehr, A., Tur, R., Alee, M. M., Gul, E., Nourani, V., Shoaei, S., & Mohammadi, B. (2023). Optimizing Extreme Learning Machine for Drought Forecasting: Water Cycle vs. Bacterial Foraging. Sustainability, 15(5), 3923. https://doi.org/10.3390/su15053923