
Sustainable Insights for Energy Big Data Governance in China: Full Life Cycle Curation from the Ecosystem Perspective

Abstract
:1. Introduction
2. Status Review and Trends of Energy Big Data in China
2.1. Status Review of Energy Big Data
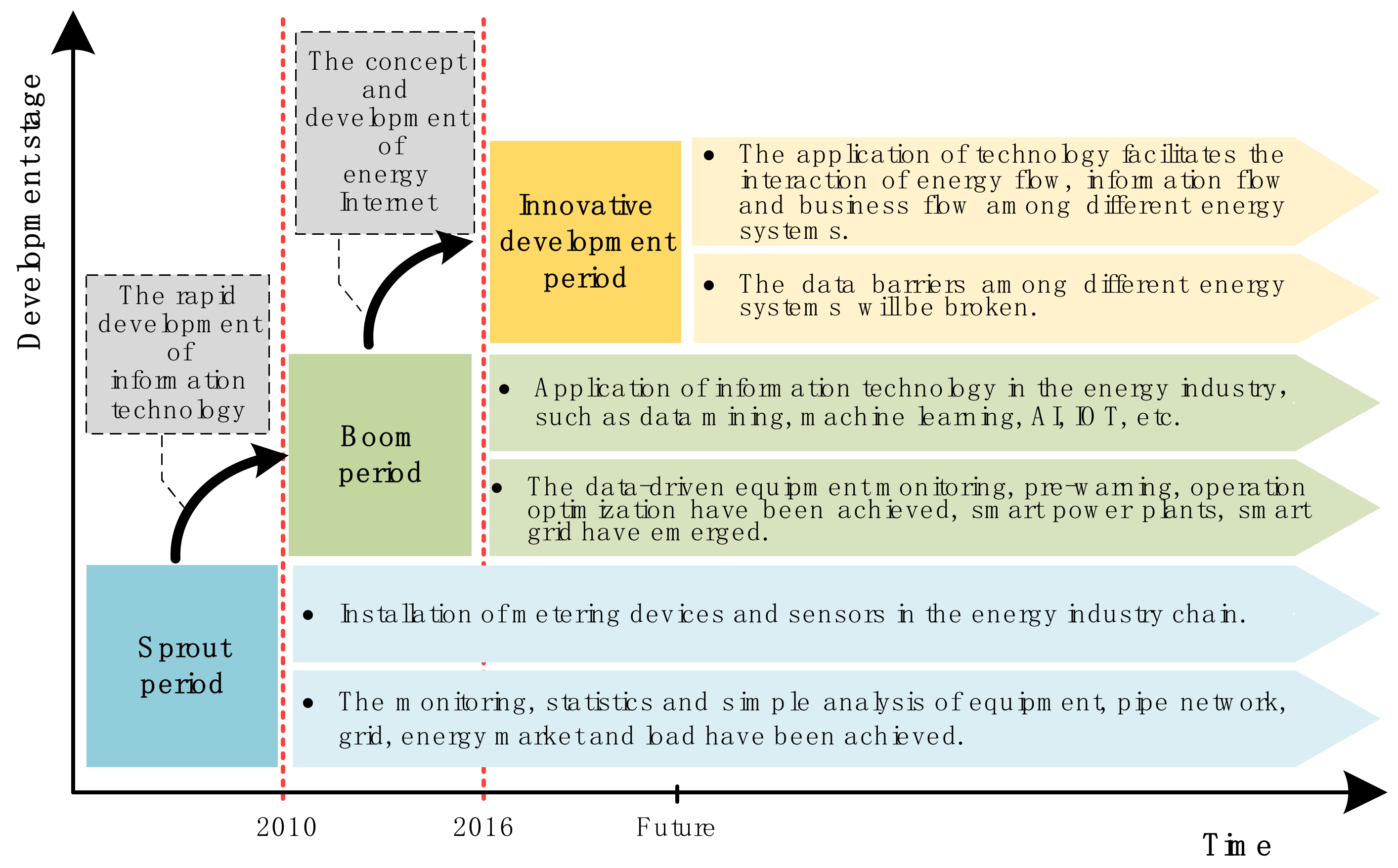
2.1.1. Development
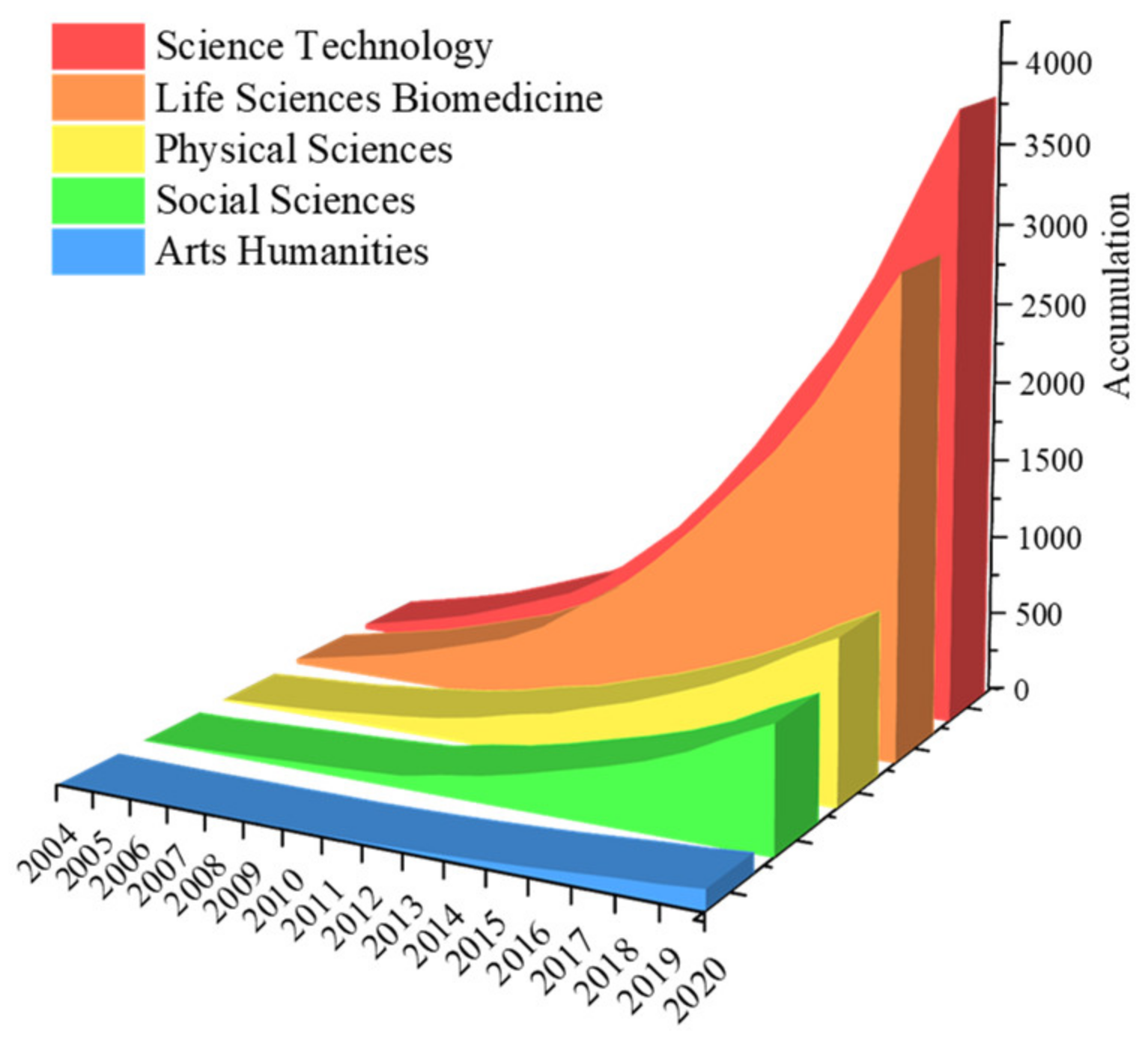
2.1.2. Research
- (1)
- Energy big data technology
- (2)
- Applications of energy big data
2.1.3. Policies
2.2. Evolutionary Trends of Energy Big Data—The Energy Big Data Ecosystem
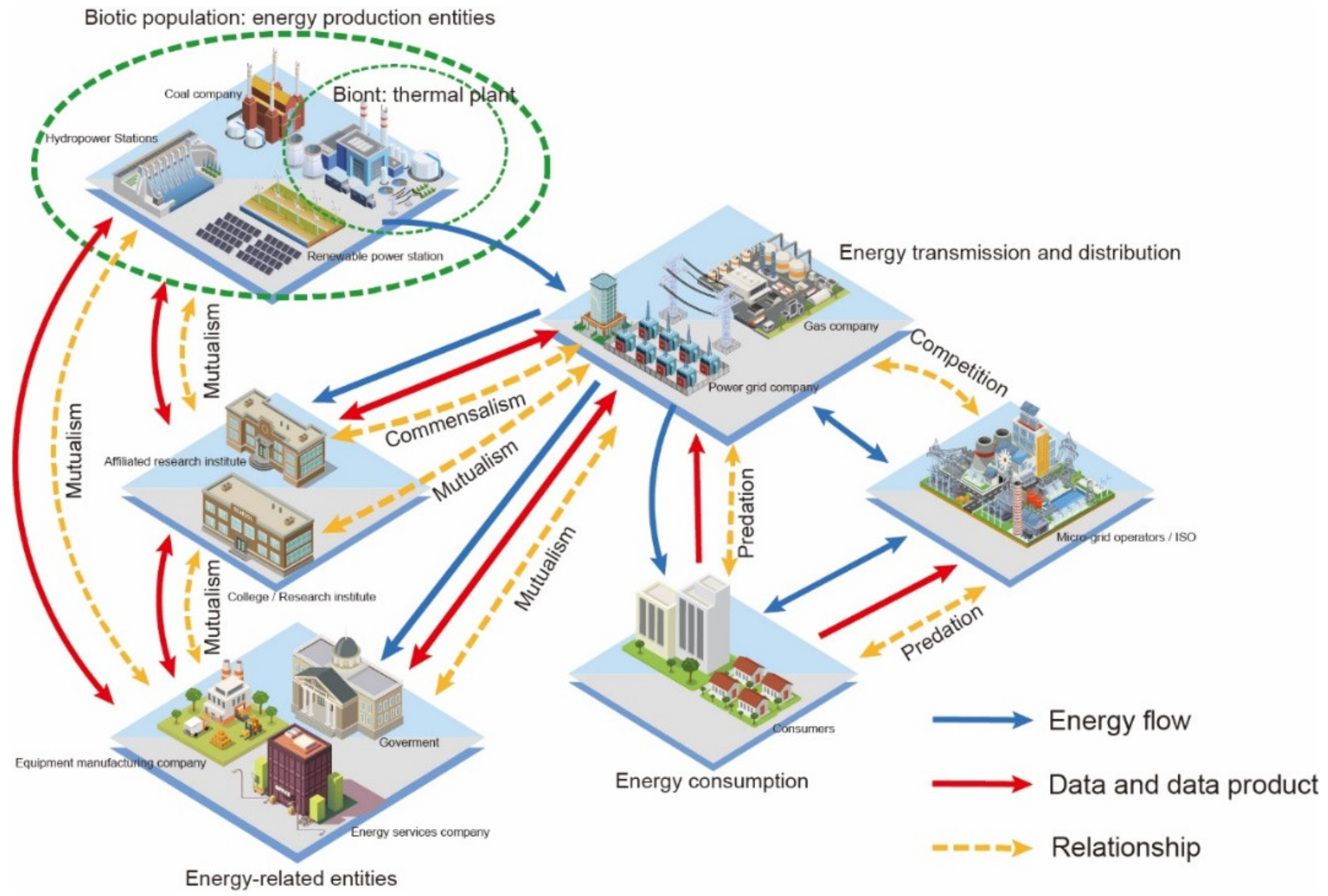
2.2.1. Elements of the Energy Big Data Ecosystem
2.2.2. Interaction between the Elements
2.2.3. Ecosystem Operation and Evolutionary Mechanism
2.3. Critical Challenges to the Sustainable Development of the Energy Big Data Ecosystem
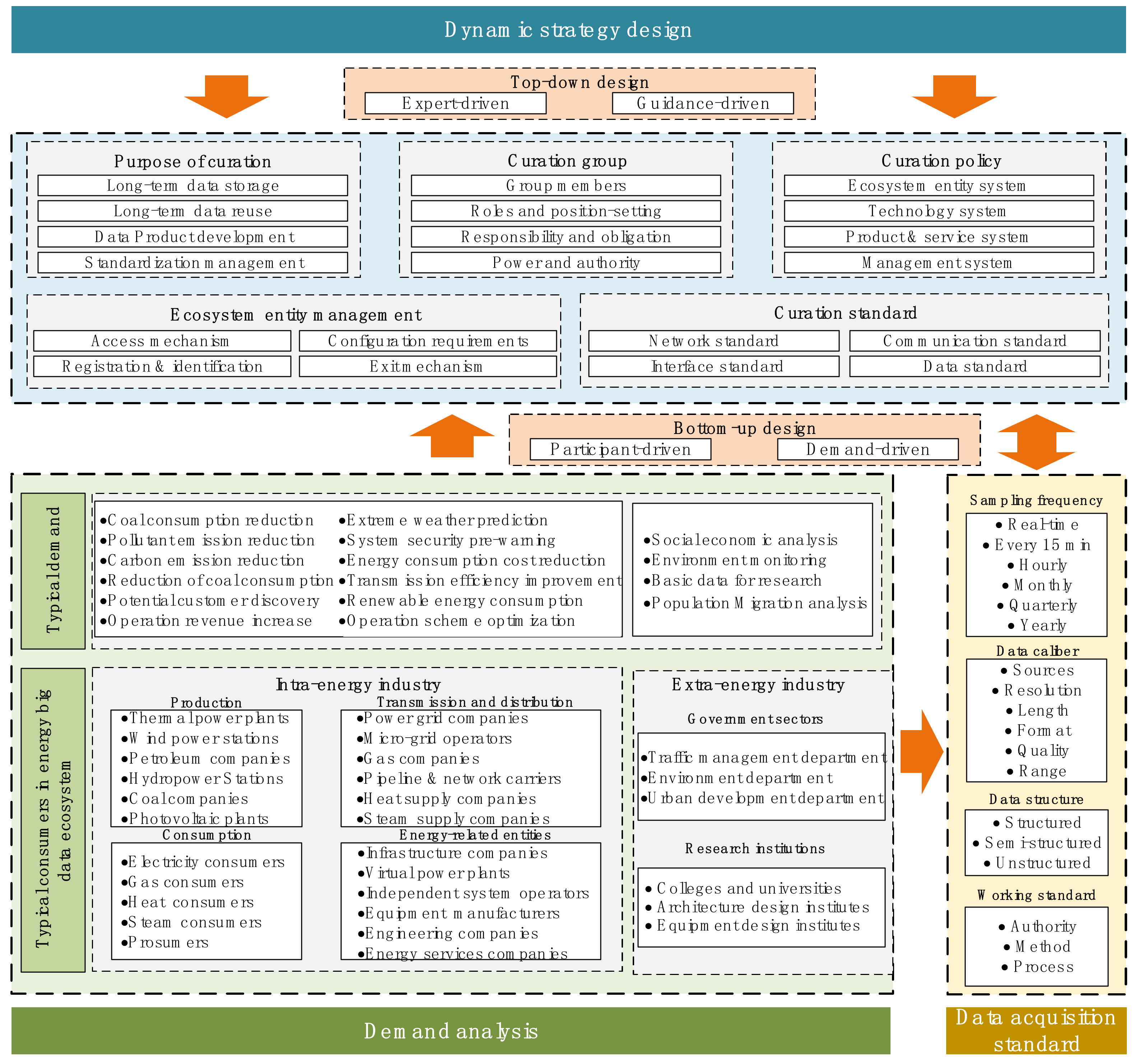
2.3.1. How to Conduct an Ecosystem-Oriented Top-Level Design of Data Governance
2.3.2. How to Define the Boundaries of Energy Big Data Governance
2.3.3. How to Balance the Relationship between Various Interests in the Ecosystem
3. Research Methodology
3.1. Data Curation Theory
3.2. Data Curation Methods
3.2.1. Functions and Effects of Data Curation
- (1)
- In accordance with certain principles and processes, data curation constructs a top-level design covering the period starting from data generation to extinction. Data curation defines the work that should be carried out at each stage to ensure the orderly development of data governance and provides a guiding paradigm for data governance. The correctness and timeliness of the data governance activities and decisions can be improved significantly.
- (2)
- Data curation can establish standardized data governance norms through supervision, guidance, evaluation, and other tasks. Meanwhile, data curation can effectively encourage countries, industries, or companies to form a standard system that includes data access scope, data format, communication protocol standards, data naming, data update frequency, and other dimensions. Therefore, data quality can be improved from the dimensions of standardization, completeness, accuracy, timeliness, accessibility, and other dimensions, and large-scale multisource heterogeneous data from different institutions and industries can be integrated under the premise of effectively controlling governance costs.
- (3)
- Data curation can effectively clarify the roles of related individuals during the data governance and provide answers that allow individuals to take actions at specific stages, in specific situations, and for specific purposes. In this way, the interests of all the individuals can be balanced, cooperation can be organized effectively on the basis of protecting the rights of individuals, and access permissions can be guaranteed for individuals.
- (4)
- Data curation involves persistent work throughout the entire data life cycle. Through data product creation and data service innovation, data curation promotes the continuous development and maturation of data. Simultaneously, it provides broader, more reliable, and more valuable data and services to the individuals who are involved in data governance.
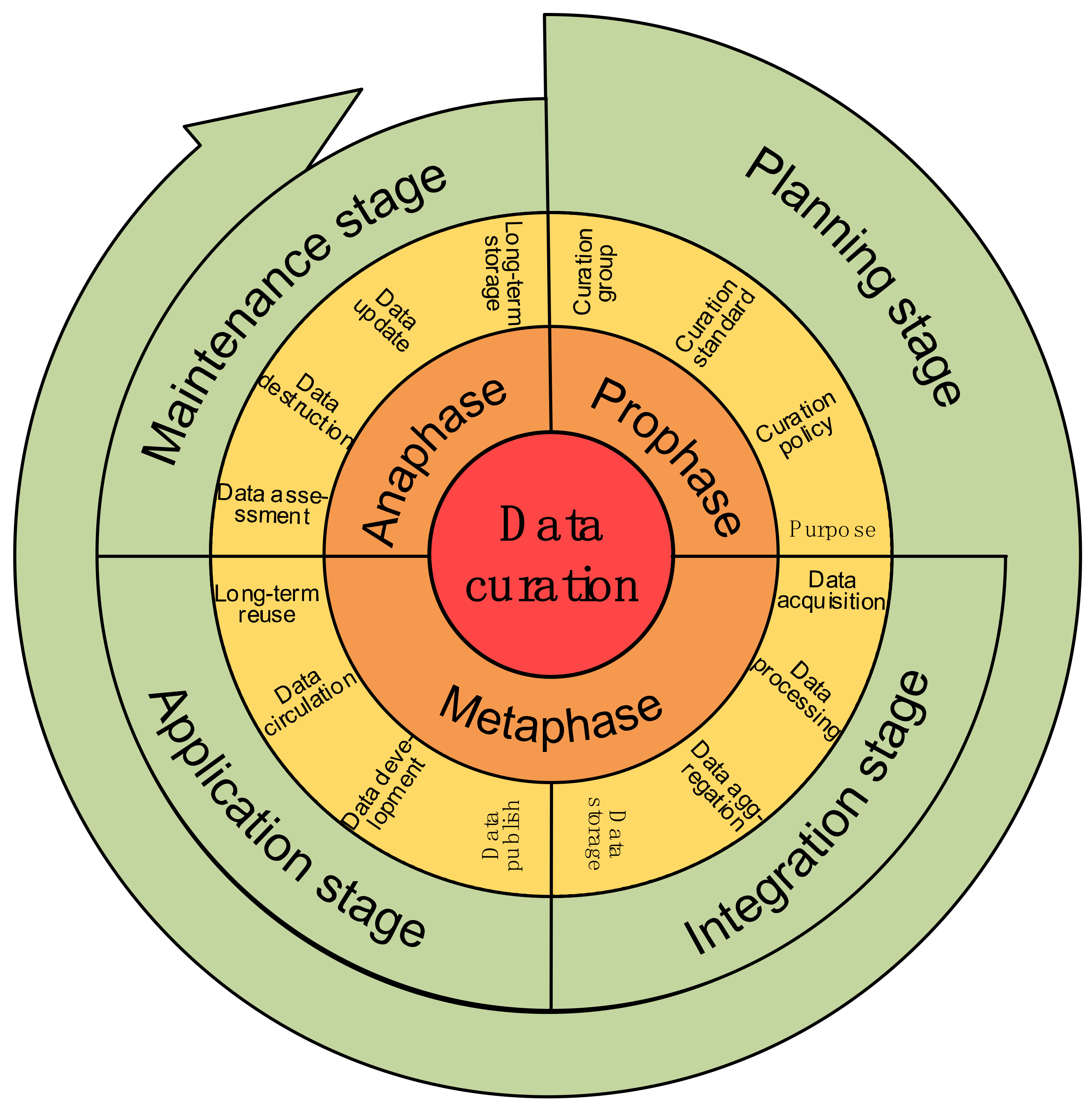
3.2.2. The Framework of Data Curation
4. A Paradigm for the Sustainable Full Life Cycle Curation of Energy Big Data
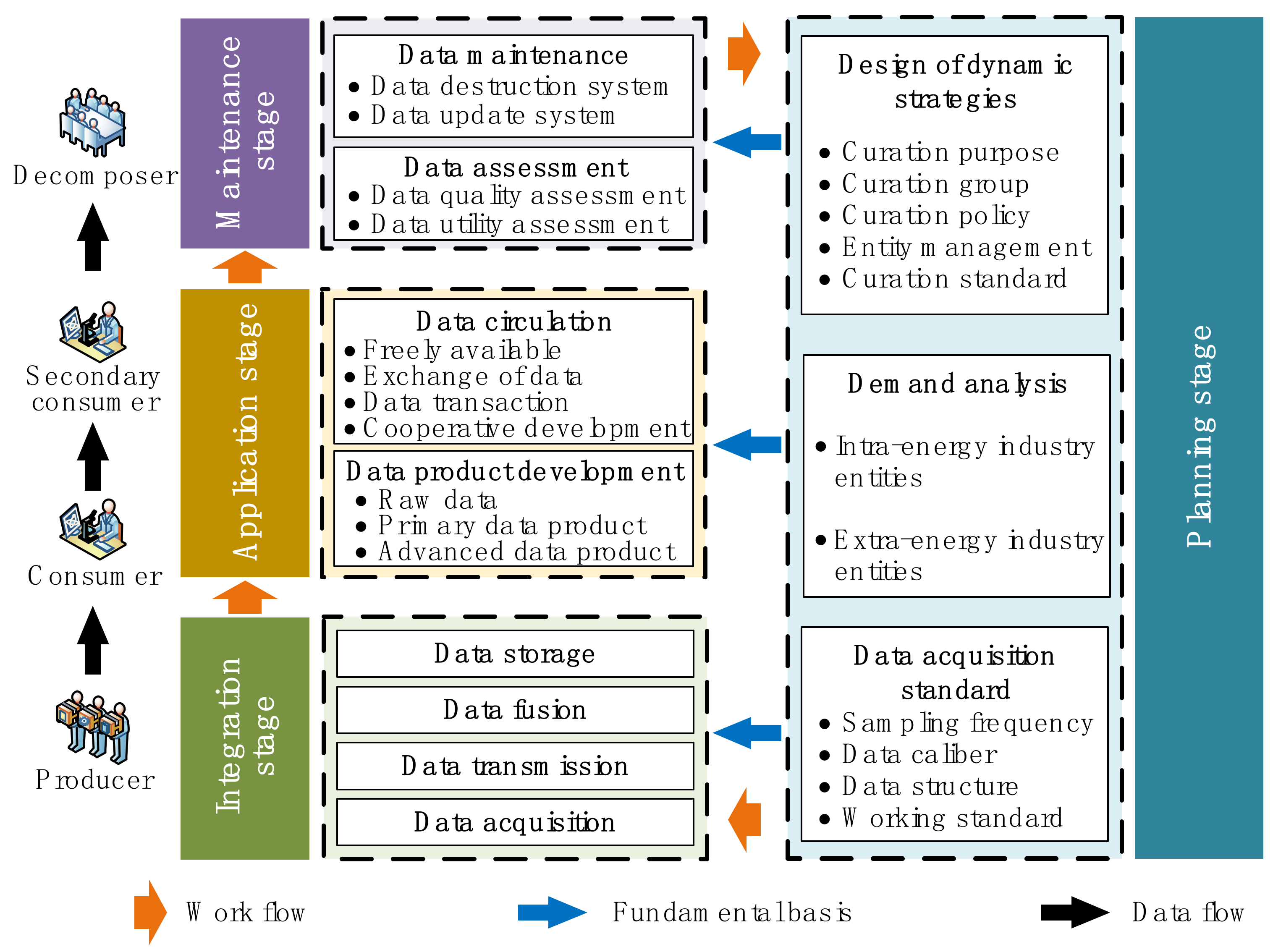
4.1. General Framework of the Full Life Cycle Curation Model for Energy Big Data
4.2. Implementing the Full Life Cycle Curation of Energy Big Data
4.2.1. Step 1: Planning Stage for the Full Life Cycle Curation of Energy Big Data
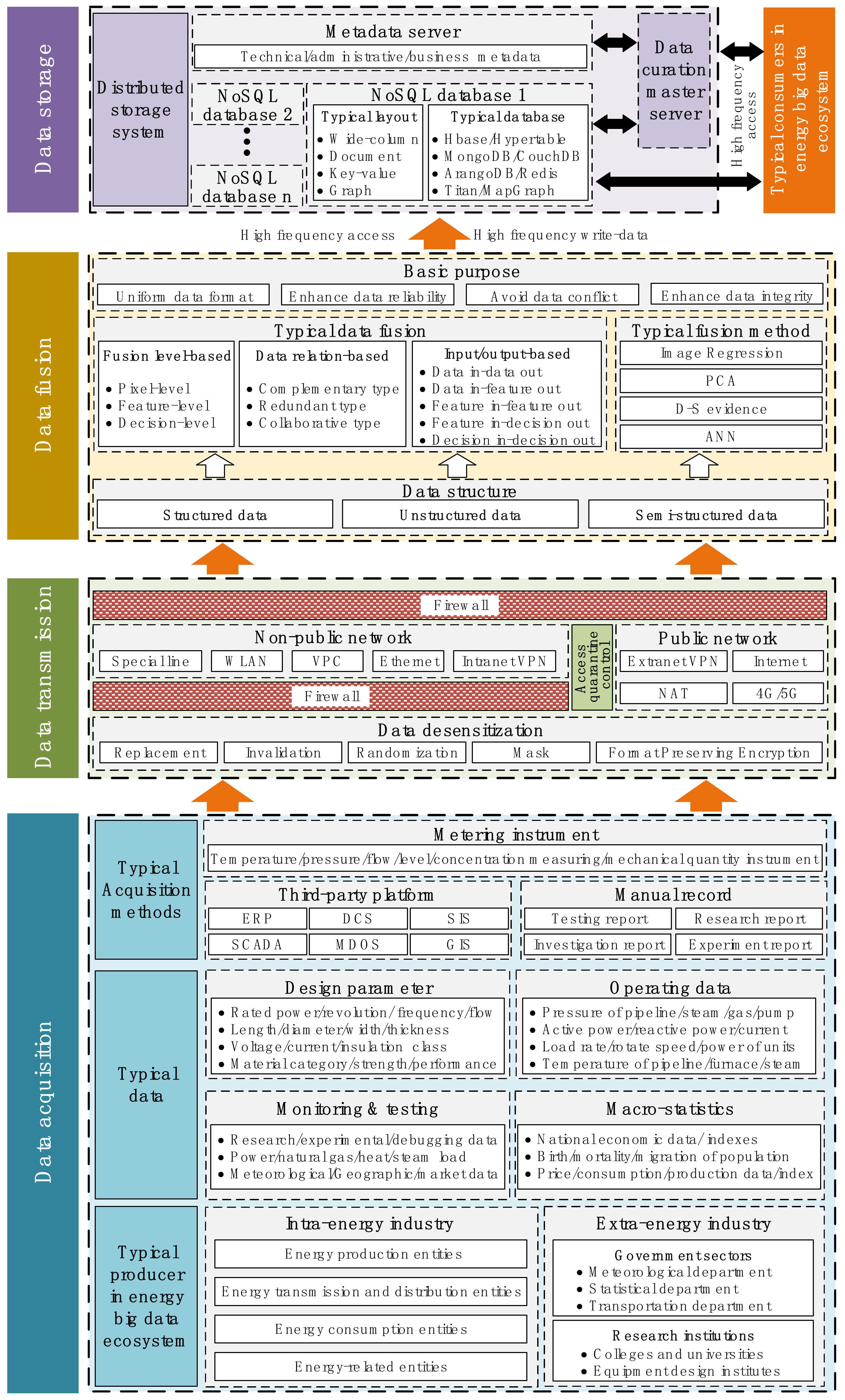
4.2.2. Step 2: Integration Stage of the Full Life Cycle Curation of Energy Big Data
4.2.3. Step 3: Application Stage of the Full Life Cycle Curation of Energy Big Data
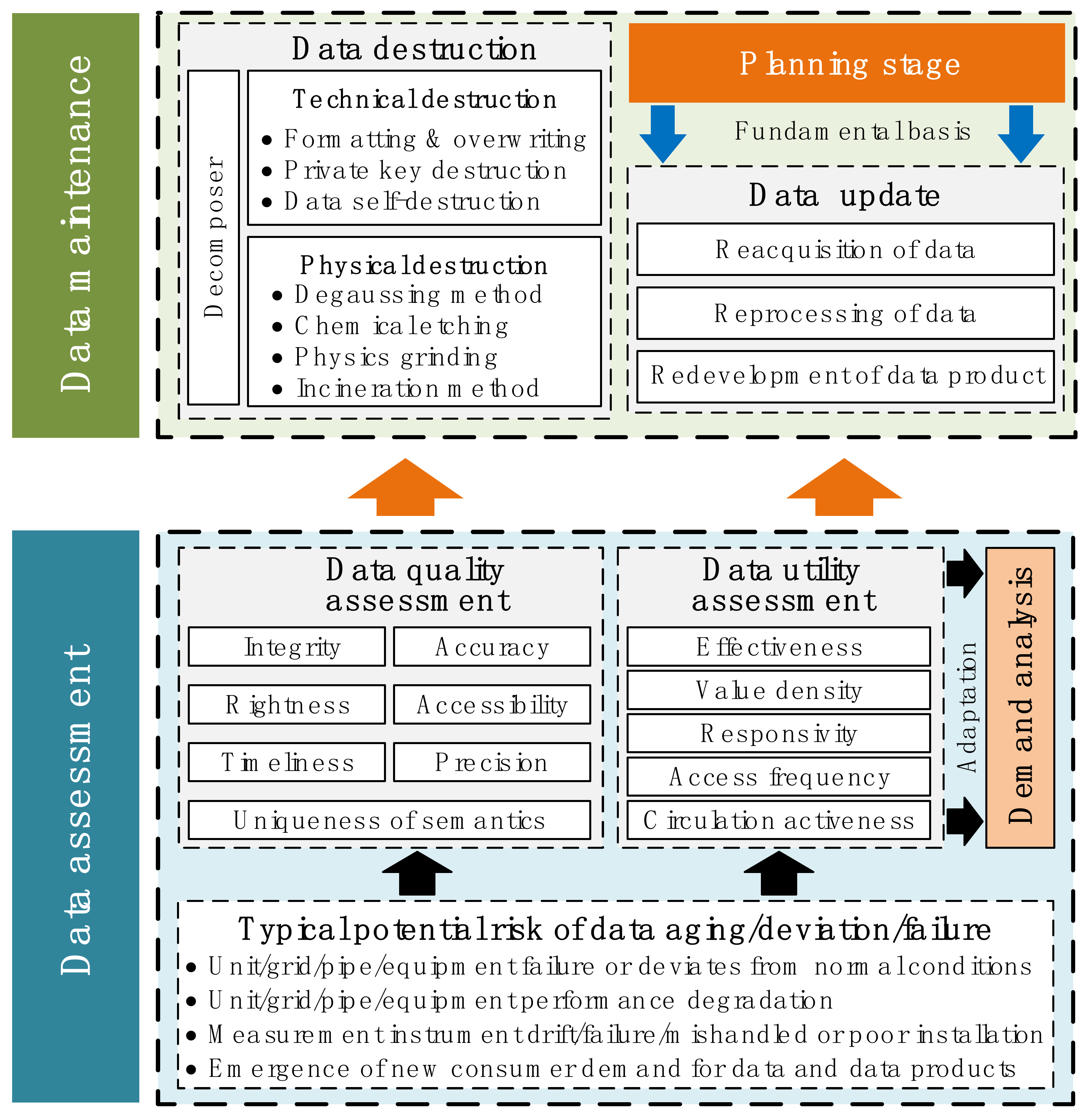
4.2.4. Step 4: Maintenance Stage of the Full Life Cycle Curation Model of Energy Big Data
5. Challenges and Key Issues in the Full Life Cycle Curation of Energy Big Data
5.1. Data Rights
5.1.1. Nonpublic Data Rights
5.1.2. Public Data Rights
5.2. Data Fusion
5.2.1. Inter-Source Data Fusion
5.2.2. Intra-Source Data Fusion
5.3. Data Security
5.3.1. Data Encryption
5.3.2. Access Permission Administration
5.4. Data Transaction
5.4.1. Data Valuation
5.4.2. Subject Matter
5.4.3. Pricing Mechanisms
6. Conclusions and Discussion
6.1. Conclusions
- (1)
- In terms of research, according to the data flow and life cycle, this paper shows that energy production enterprises, equipment manufacturers, and other entities constitute producers, consumers, secondary consumers, and decomposers in the energy big data ecosystem and that there are predation, competition, reciprocity, and other relationships among different entities around energy data. Different from ecology, a given entity in the energy big data ecosystem can switch between the roles of the producer and consumer in different situations. In contrast, previous research on energy big data governance is mainly oriented toward specific enterprises and industries. This paper provides a new perspective for energy big data governance research because it considers it from the macroscopic and systematic dimensions according to the ecosystem concept.
- (2)
- In terms of research methods, on the basis of analyzing applicability, this paper introduces curation theory, which originated from the fields of library science and information science, into energy big data governance. The model that was constructed in this paper based on curation theory can provide systematic and theoretical support for workflow organization, specification formulation, and interest coordination among different entities as well as full life cycle management in the process of energy big data governance, and this enriches the sustainable methods for energy big data governance.
- (3)
- In terms of research content, this paper presents three energy big data curation challenges, namely how to carry out the ecosystem-oriented top-level design for data governance; how to determine the boundaries of energy big data governance; and how to balance the relationships among various interests in the ecosystem. In view of the above problems, this paper proposes a governance paradigm that covers the entire energy big data life cycle according to the planning, integration, application, and maintenance stages; furthermore, this research analyzes four key issues of full life cycle curation, including data rights, fusion, security, and transactions: (1) in contrast, non-public data rights emphasize personality and real rights, and public data rights emphasize sovereignty. (2) In order to improve data quality and accuracy, inter-source data fusion should be processed from the time dimension; in order to alleviate the “isolated island of information”, intra-source data fusion should be processed from the spatial dimension at the pixel layer, feature layer, and decision layer. (3) The encryption of the data itself, the data address, and the secret key can be achieved by using the blockchain to create smart contracts. The application of this technology can reduce the risk of unauthorized access and tampering, effectively enhancing data security. (4) The valuation and confirmation of the subject matter are the premise of data transaction. The three value evaluation methods, the comprehensive evaluation-based, cost-based, and comprehensive utility-based methods, can effectively reflect the objectivity and dynamics of data value; the essence of data transactions is the paid transfer of data rights. According to different transaction scenarios, the subject matter can be a combination of ownership rights, use rights, and usufruct rights. Based on this, diversified pricing mechanisms can be used for data pricing, including bilateral negotiations, public auctions, expected revenue-based pricing methods, etc. These pricing methods can effectively overcome the difficulties in formulating price mechanisms due to the complexity of the data value and subject matter.
6.2. Discussion
- (1)
- In terms of laws and regulations, in addition to the “invisible hand” of the market, the development of energy big data in the digital economy era also needs the support of the “visible hand” of the government. In the future, relevant laws and regulations on data curation should be studied and formulated from the perspectives of rights protection, access authority, market mechanisms, arbitration methods, and risk control.
- (2)
- In terms of organizational mechanisms, considering the complex role positioning of the various entities in the energy big data ecosystem, the diverse governance goals, and the potential conflicts of interest, in the early stages, a joint curation working group should be set up by energy industry companies under government supervision and gradually promote the development of energy big data curation at the regional (provincial), industrial, and national levels.
- (3)
- In terms of professional talent cultivation, energy big data curation requires professionals. Unlike traditional data administrators, data curators need to assume more complex roles, including those of planners, policy makers, information technology specialists, and researchers [86]. In addition to the ability for data archiving and preservation, database management and maintenance, etc., energy big data curation requires considerable knowledge of the law and the energy industry. Such knowledge includes intellectual property law, integrated energy system planning and operation optimization theory, energy demand-side management theory, etc. As interdisciplinary integration becomes a more prominent trend, it is necessary to establish and improve the education and cultivation for energy big data curation talents in the future.
- (4)
- In terms of information platform development, as an important physical carrier for the curation of energy big data, information platforms should realize the functions of access subject management, cross-system data transmission and integration, and data transaction aggregation on the premise of guaranteed security and privacy. How to design and develop a platform suitable for regional, industrial, national, and international levels in terms of communication protocols, interfaces and ports, model algorithms, etc., is one of the key issues for future research and practices.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guo, L.; Dong, J.; Chen, Z.; Bao, N.; Wang, Y.; Wu, C.; Wu, Y.; Xue, G. Business Model Evaluation of Energy Big Data Value-added Services Based on Entropy Weight-Topsis-Grey Correlation Method. Sci. Technol. Manag. Res. 2022, 42, 73–80. [Google Scholar]
- Wang, X.; Chen, A.; Li, J.; Zheng, C.; Pan, X.; Yang, Z. Research on Data Business Operation Mode Based on Energy Big Data Center. Distrib. Util. 2021, 38, 37–42. [Google Scholar]
- Chen, Q.; Liu, D.; Lin, J.; He, J.; Wang, Y. Business Models and Market Mechanisms of Energy Internet. Power Syst. Technol. 2015, 39, 3050–3056. [Google Scholar]
- Chen, R.; Li, H.; Peng, X.; Yang, J.; Dong, X.; Liu, S.; Li, X. Study on Evaluation Method for New Energy Big Data Service Project Applying Improved TOPSIS. Electr. Power Constr. 2021, 42, 126–134. [Google Scholar]
- Zhao, Y.; Yuan, S.; Chen, Y.; Qian, C.; Xu, H. Design of Internet power information management system for energy in the park based on big data analysis. Autom. Instrum. 2021, 10, 169–173. [Google Scholar]
- Zhang, X.; Tang, C. Study on the construction of the framework of metadata standards for government information in China. J. Inf. Resour. Manag. 2018, 8, 25–36. [Google Scholar]
- Han, W.; Wang, T.; Peng, J.; Wu, G.; Zhang, X.; Zhang, M.; Cao, N.; Ma, H. Research on Standard System Framework of Power Transmission and Distribution Project Data Management Technology. Sci. Technol. Manag. Res. 2018, 38, 224–229. [Google Scholar]
- Xu, Z.; Wang, Z.; Chi, R.; Hong, Y.; Chi, M.; Yi, W. Equalization Treatment Technique for Inverted Secondary Index Cluster of Quasi-real-time Data in Distribution Network. Proc. CSEE 2020, 40, 6494–6506. [Google Scholar]
- Sun, C.; Xiao, W.; Zeng, L.; Bai, J. Design and Implementation of Massive Surveillance Data Cloud Storage Sevice Model. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1099–1106. [Google Scholar]
- Mu, L.; Cu, L.; An, N. Research and Practice of Cloud Computing Center for Power System. Power Syst. Technol. 2011, 35, 171–175. [Google Scholar]
- Gong, Y.; Lv, J. Application of Big Data Mining Analysis in Power Equipment State Assessment. South. Power Syst. Technol. 2014, 8, 74–77. [Google Scholar]
- Qu, H.; Pang, X.; You, M.; Xu, Z. Application value of power big data and analysis and design of sharing platform. Manag. Adm. 2017, 7, 104–108. [Google Scholar]
- Zeng, M.; Yang, Y.; Li, Y.; Zeng, B.; Cheng, J.; Bai, X. The Preliminary Research for Key Operation Mode and Technologies of Electrical Power System with Renewable Energy Sources Under Energy Internet. Proc. CSEE 2016, 36, 681–691. [Google Scholar]
- Xue, S.; Lai, Y. Integration of Macro Energy Thinking and Big Data Thinking Part Two Applications and Exploration. Autom. Electr. Power Syst. 2016, 40, 1–13. [Google Scholar]
- Xue, S.; Lai, Y. Integration of Macro Energy Thinking and Big Data Thinking Part One Big Data and Power Big Data. Autom. Electr. Power Syst. 2016, 40, 1–8. [Google Scholar]
- Feng, D.; Zhang, M.; Li, H. Big Data Security and Privacy Protevtion. Chin. J. Comput. 2014, 37, 246–258. [Google Scholar]
- Yu, X.; Xu, X.; Chen, S.; Wu, J.; Jia, H. A Brief Review to Integrated Energy System and Energy Internet. Trans. China Electrotech. Soc. 2016, 31, 1–13. [Google Scholar]
- Wang, J.; Li, C.; Zheng, Y.; Chen, L. Design of power grid clean energy three base construction system based on big data platform. Autom. Instrum. 2019, 5, 44–47. [Google Scholar]
- Li, L.; Xu, Z.; You, M. Power big data trading for the future smart grid. Manag. Adm. 2018, 2, 121–124. [Google Scholar]
- Zhang, D.; Miao, X.; Liu, L.; Zhang, Y.; Liu, K. Research on Development Strategy for Smart Grid Big Data. Proc. CSEE 2015, 35, 2–12. [Google Scholar]
- Sun, L.-L. Knowledge innovation-oriented knowledge ecosystem model construction for e-commerce enterprises. Intell. Sci. 2016, 34, 143–146. [Google Scholar]
- Zhang, P.; Li, Q.; Zhang, J. A collaborative knowledge evolution model of supply chain enterprises based on ecological population perspective. Intell. Sci. 2016, 34, 150–153. [Google Scholar]
- Wang, G. Digital scholarly journal knowledge ecosystem and its evolutionary motives. Mod. Intell. 2012, 32, 28–31, 43. [Google Scholar]
- Li, T. Research on the mechanism of micro knowledge ecosystem operation in smart libraries. Intell. Sci. 2019, 37, 133–137. [Google Scholar]
- Zhang, M.; Huo, C.; Wu, Y. A study on the evolution of knowledge ecosystem in international digital libraries. Library 2015, 10, 88–93. [Google Scholar]
- Yang, H. UK data guardianship research results and their application in university libraries—A review of DCC construction. Libr. J. 2014, 33, 84–90. [Google Scholar]
- Beagrie, N.; Pothen-Ariadne, P. The Digital Curation: Digital Archives, Libraries and e-Science Seminar. 2001. Available online: http://www.ariadne.ac.uk/issue/30/digital-curation/ (accessed on 20 October 2021).
- DCC. What Is Digital Curation? Available online: https://www.dcc.ac.uk/guidance/briefing-papers/introduction-curation/what-digital-curation/ (accessed on 2 October 2021).
- Laughton, P. OAIS functional model conformance test: A proposed measurement. Program Electron. Libr. Inf. Syst. 2012, 46, 308–320. [Google Scholar] [CrossRef]
- Wallis, J.C. Moving archival practices upstream: An exploration of the life cycle of ecological sensing data in collaborative field research. Int. J. Digit. Curation 2008, 3, 114–126. [Google Scholar] [CrossRef]
- DAMA International. The DAMA Guide to the Data Management Body of Knowledge; Technics Publications: New York, NY, USA, 2009; Volume 37. [Google Scholar]
- Bao, D.; Fan, Y.; Li, M. Data governance and its framework in higher education libraries. Libr. Intell. Work. 2015, 59, 134–141. [Google Scholar]
- Data Governance Framework. Available online: https://datagovernance.com/data-governance-framework-components/ (accessed on 20 October 2021).
- Xiao, J.; Feng, G. A comparative analysis of domestic and foreign data governance models. J. Lit. Data 2020, 2, 14–25. [Google Scholar]
- Chu, J.; Wang, M. The strategy of open sharing of scientific data in the United States and the inspiration for China. Intell. Theory Pract. 2019, 42, 153–158. [Google Scholar]
- Zhang, X.; Ming, X.; Yin, D. Application of industrial big data for smart manufacturing in product service system based on system engineering using fuzzy DEMATEL. J. Clean. Prod. 2020, 8, 121863. [Google Scholar] [CrossRef]
- Wang, S.; Peng, Y.; Lan, H.; Luo, Q.; Peng, Z. Survey and Prospect: Data Integration Techniques. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.13328/j.cnki.jos.005911 (accessed on 9 September 2021).
- Liu, Y.; Cao, X. Research on performance optimization of distributed storage of massive video data. Appl. Res. Comput. 2021, 38, 1734–1738. [Google Scholar]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR guiding principles for scientific data management and stewardship. Sci. Data 2016, 3, 167–172. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Darch, P.T.; Sands Ashley, E.; Borgman Christine, L.; Golshan Milena, S. Library Cultures of Data Curation: Adventures in Astronomy. J. Assoc. Inf. Sci. Technol. 2020, 71, 1470–1483. [Google Scholar] [CrossRef]
- Yang, C.; Puthal, D.; Mohanty, S.P.; Kougianos, E. Big-Sensing-Data Curation for the Cloud is Coming: A Promise of Scalable Cloud-Data-Center Mitigation for Next- Generation IoT and Wireless Sensor Networks. IEEE Consum. Electron. Mag. 2017, 6, 48–56. [Google Scholar] [CrossRef]
- Vasily, B.; Brian, M. Data Curation Framework for Facilities Science. In Proceedings of the International Conference on Data Management Technologies and Applications, Reykjavík, Iceland, 29–31 July 2013; pp. 211–216. [Google Scholar]
- Xing, H.Q. Mechanisms for Distribution and Realization of Personal Information Property Rights Under Background of Big Data Transactions. Law Rev. 2019, 37, 98–110. [Google Scholar]
- Chen, Y.Y.; Wang, Y.Y. The Research on Stakeholder Interaction Relationship of Open Sharing of Scientific Research Data, Library Tribune. 2020. Available online: http://kns.cnki.net/kcms/detail/44.1306.G2.20191218.1413.004.html (accessed on 9 October 2021).
- Balazinska, M.; Howe, B.; Suciu, D. Data Markets in the Cloud: An Opportunity for the Database Community. Proc. VLDB Endow. 2011, 4, 1482–1485. [Google Scholar] [CrossRef]
- Stvilia, B.; Hinnant, C.C.; Wu, S.; Worrall, A.; Lee, D.J.; Burnett, K.; Kazmer, M.M.; Marty, P.F. Research project tasks, data, and perceptions of data quality in a condensed matter physics community. J. Assoc. Inf. Sci. Technol. 2015, 66, 246–263. [Google Scholar] [CrossRef]
- Sun, L.L.; Yuan, Q.J. Research on Evaluation Index System of E-commerce Data Quality from the Perspective of Data Asset Management. J. Mod. Inf. 2019, 39, 90–97. [Google Scholar]
- Chang, P. Simulation Research on Automatic Destruction Method of Life Cycle Controllable Data. Comput. Simul. 2019, 36, 371–375. [Google Scholar]
- Xiang, F. I am the Alpha—On the ethics of human-machine. Cult. Column 2017, 6, 128–139. [Google Scholar]
- Hsu, Y.C.; Hong, J.R. Caution on Urban “Public-Private Partnerships” and Private Control of Public Data: A Review of “Smart Cities in a Digital World”. Int. J. 2020, 42, 159–176. [Google Scholar]
- Wiebe, A. Protection of Industrial Data—A New Property Right for the Digital Economy? J. Intellect. Prop. Law Prot. 2017, 12, 62–71. [Google Scholar] [CrossRef]
- Wei, F.; Chang, Y. Review of domestic and foreign research on data tenure and analysis of development dynamics. Mod. Intell. 2017, 37, 159–165. [Google Scholar]
- Shen, W. On data usufruct rights. China Soc. Sci. 2020, 11, 110–131, 207. [Google Scholar]
- Artyushina, A. The EU is Launching a Market for Personal Data: Here’s What That Means for Privacy. MIT Technology Review. 2020. Available online: https://www.researchgate.net/publication/343640324_The_EU_is_launching_a_market_for_personal_data_Here%27s_what_that_means_for_privacy (accessed on 9 September 2021).
- Václav, J. Ownership of Personal Data in the Internet of Things. Comput. Law Secur. Rev. 2018, 34, 1039–1052. [Google Scholar]
- Jansen, L. Private law protection of data property rights and interests. Gansu Soc. Sci. 2020, 6, 132–138. [Google Scholar]
- Duch-Brown, N.; Martens, B.; Mueller-Langer, F. The Economics of Ownership, Access and Trade in Digital Data; Digital Economy Working Paper; 2017. Available online: https://ssrn.com/abstract=2914144 (accessed on 9 September 2021).
- Van Asbroeck, B.; Debussche, J.; César, J. Building the European Data Economy: Data Ownership. White Paper, Bird and Bird. 2017. Available online: https://sites-twobirds.vuture.net/1/773/uploads/white-paper-ownership-of-data-(final) (accessed on 12 October 2021).
- Banterle, F.; Data Ownership in the Digital Economy: An European Dilemma. EU Internet Law in the Digital Era. 2020. Available online: https://link.springer.com/chapter/10.1007/978-3-030-25579-4_9 (accessed on 20 October 2021).
- Feng, G.; Xue, Y. From the rights regulation model to the behavior control model of data trust—An alternative way of thinking about the construction of data subject rights protection mechanism. Law Rev. 2020, 38, 70–82. [Google Scholar]
- Yu, P.K. Data Producer’s Right and the Protection of Machine-Generated Data. Tulane Law Rev. 2019, 93, 859–929. [Google Scholar]
- Cui, G.B. The theory underlying the limited exclusivity of big data. Jurisprud. Res. 2019, 41, 3–24. [Google Scholar]
- Du, Y. Research on national data sovereignty in the era of big data. Int. Obs. 2016, 3, 1–14. [Google Scholar]
- Feng, S. The data game and legal response in Tik Tok’s ban. Orient. Law 2021, 74–89. [Google Scholar]
- Zhang, X. Patterns and lessons learned from the rule building of data sovereignty and the rule building of data sovereignty in China. Mod. Jurisprud. 2020, 42, 136–149. [Google Scholar]
- Pang, B.; Xuan, L.; Bai, Y.; Li, G. Status and characteristics of the EU’s construction of a data space governance rule system in the context of global data sovereignty game. J. Inf. Resour. Manag. 2021. Available online: http://kns.cnki.net/kcms/detail/42.1812.G2.20201125.1513.002.html (accessed on 22 October 2021).
- Li, W. Digital sovereignty in Europe in the framework of strategic autonomy in 2020: A comprehensive acceleration. Inf. Secur. Commun. Priv. 2021, 3, 31–37. [Google Scholar]
- Dong, W.; Tian, K.; Chen, Y.; Xu, Y.; Lan, M.; Zeng, M. Research on the evaluation method of integrated energy system based on game and evidence theory under energy internet. Smart Power 2020, 48, 73–80. [Google Scholar]
- Zhang, Y.; Xie, H.; Mao, J.; Li, G. Research on multi-source data requirements and fusion methods for urban data portrait construction. Intell. Theory Pract. 2020, 43, 88–96. [Google Scholar]
- Franks, P.C. Implications of Blockchain Distributed Ledger Technology for Records Management and Information Governance Programs. Rec. Manag. J. 2020, 30, 287–299. [Google Scholar] [CrossRef]
- Wang, P.; Li, M.; Liu, X. The construction of credible ecology of document archive management from the perspective of blockchain. Arch. Res. 2020, 4, 115–121. [Google Scholar]
- She, W.; Chen, J.S.; Liu, Q.; Hu, Y.; Gu, Z.; Tian, Z.; Liu, W. New blockchain technology for medical big data security sharing. J. Chin. Comput. Syst. 2019, 40, 1449–1454. [Google Scholar]
- Wang, R.; Yu, S.; Li, Y.; Tang, Y.; Zhang, F. Medical blockchain of privacy data sharing model based on ring signature. J. Univ. Electron. Sci. Technol. China 2019, 48, 886–892. (In Chinese) [Google Scholar]
- Ge, J.; Shen, T. Blockchain-Based Access Control Method for Energy Data. Computer Applications. Available online: http://kns.cnki.net/kcms/detail/51.1307.TP.20210304.1108.004.html (accessed on 12 October 2021).
- Zuo, W.J.; Liu, L.J. Research on big data asset valuation method based on user perceived value. Intell. Theory Pract. 2021, 44, 71–77+88. [Google Scholar]
- Shannon, C.; Yang, L.; Song, J. A CIME model design and implementation for data asset evaluation. Comput. Appl. Softw. 2020, 37, 27–34. [Google Scholar]
- Li, C.; Wen, T. Research on the profitability model of big data trading in China. J. Intell. 2020, 39, 179–186. [Google Scholar]
- Xiong, Q.; Tang, K. Advances in research on the boundary rights, transactions and pricing of data elements. Dyn. Econ. 2021, 2, 143–158. [Google Scholar]
- Gkatzelis, V.; Aperjis, C.; Huberman, B.A. Pricing Private Data. SSRN Electron. J. 2012, 25, 1–15. [Google Scholar] [CrossRef]
- Bocken, N.M.; Mugge, R.; Bom, C.A.; Lemstra, H.J. Pay-per-use business models as a driver for sustainable consumption: Evidence from the case of HOMIE. J. Clean. Prod. 2018, 198, 498–510. [Google Scholar] [CrossRef]
- Bakos, Y.; Brynjolfsson, E. Bundling Information Goods: Pricing, Profits, and Efficiency. Manag. Sci. 1999, 45, 1613–1630. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Huang, Z.H.; Liang, Y.; Zhu, Y.Y. A review of data pricing research. Comput. Sci. Explor. 2021, 15, 1595–1606. [Google Scholar]
- Li, X.; Yao, J.; Liu, X.; Guan, H. A First Look at Information Entropy-based Data Pricing. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 2053–2060. [Google Scholar]
- Koutris, P.; Upadhyaya, P.; Balazinska, M.; Howe, B.; Suciu, D. Query-based Data Pricing. J. ACM 2015, 62, 1–44. [Google Scholar] [CrossRef]
- Cai, L.; Huang, Z.H.; Liang, Y.; Zhu, Y.Y. Research on Data Transaction Pricing Based on Information Entropy; Shanghai Jiaotong University: Shanghai, China, 2018. [Google Scholar]
- Wang, F.; Shen, J. Progress of foreign data stewardship (Data Curation) research and practice. Chin. J. Libr. Sci. 2014, 40, 116–128. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Companies | Associated Development Strategies |
|---|---|
| State Grid Corporation of China (SGCC) (Beijing, China) | Build a world-leading energy internet company and enhance company momentum by improving the digitalization of grid operations and company business operations. |
| China Energy Investment Corporation (China Energy) (Beijing, China) | Actively carry out big data applications and governance to achieve goals related to “platform development, digital operations, ecological collaboration, industry chain collaboration and intelligent production”. |
| China Petroleum & Chemical Corporation (Sinopec Corp.) (Beijing, China) | Access internal and external data widely, create a “data + platform + application” development model, expand to a new space for digital economic growth, and create a new engine for the company’s high-quality development. |
| China Huaneng Group Co., Ltd. (Beijing, China) | Build a unified intelligent energy data center covering all of the industrial sectors of the company to achieve both the up- and the downstream data penetration of the industrial chain as well as energy production and consumption. |
| China Southern Power Grid Company (Guangzhou, China) | Accelerate digital transformation and digital grid construction to achieve interconnection patterns for a digital government, national industrial internet, and the energy industry chain. |
| Implementation Time | Departments | Strategies | Related Content |
|---|---|---|---|
| 2015 | The State Council | Outline of Action to Promote the Development of Big Data | Propose the planning and construction of an information resource base and security protection systems in important fields, including the energy field; accelerate data collection, analysis, and open sharing; and promote the integration of data resources |
| 2016 | Ministry of Industry and Information Technology | The Big Data Industry Development Plan (2016–2020) | Promote big data applications in energy and other industries; ensure data information security in energy and other industries as a key project |
| 2016 | National Development and Reform Commission, National Energy Administration | Guiding Opinions on Promoting the Development of “Internet+” Smart Energy | Propose the development of the energy big data service industry; improve energy big data business and supervision systems; encourage cooperation between internet companies and energy companies to explore the commercial value of energy big data; and promote innovation in energy big data applications |
| 2017 | Drafting committee directly led by the Political Bureau of the CPC Central Committee | Reports of the 19th National Congress of the Communist Party of China | Propose promoting the deep integration of the big data, energy, and other real economy sectors; strengthen the construction of power grids and other infrastructure networks; and support the optimization and upgrade of traditional industries |
| 2020 | Ministry of Industry and Information Technology | Guidance on the development of industrial big data | Propose promoting the digital transformation of energy and other important industries while considering data aggregation, data sharing, data applications, data governance, and data industry development as key tasks |
| Economies | Relevant Policies | Related Content |
|---|---|---|
| The United States | Digital government Strategy, Grid 2030, Federal Big Data Research and Development Strategic Plan, Federal Data Strategy, Critical and Emerging Technologies National Strategies, etc. | In the early 2010s, the United States proposed exploring the potential value of data by building an open and shared digital platform. In the mid-2010s, the United States further enhanced investment and guidance on big data-related projects in various fields, including the energy industry. These projects included the development and application of big data technology, the establishment of data sharing and protection mechanisms, etc. In the early 2020s, the United States proposed standardizing the big data governance model, technical standards, resource library construction, and ethical framework in various fields. The positioning of big data begins to change from “technology” to an “asset”. |
| European Union | European Digital Agenda, Digitising European Industry, Shaping Europe’s digital future, 2030 Digital Compass, Action Plan on the Digitalisation of the Energy Sector, etc. | In the early 2010s, the EU proposed that all of society should enjoy the benefits brought by the digital era. Data market construction, the development of digital technology standards, and data security enhancement were identified as the critical directions for development directions in the future. In the mid-2010s, the EU proposed speeding up the process of digital infrastructure construction and increasing the digital innovation capacity of various industries by relying on Digital Innovation Hubs, thereby accelerating the process of European industrial digitalization. In the early 2020s, the EU proposed accelerating the digitalization process from the industry level rather than at the enterprise level. |
| The United Kingdom | Data Capability Development Strategic Plan, UK Digital Strategy, Industrial Strategy: building a Britain fit for the future, National Data Strategy, etc. | In the early 2010s, the UK proposed attaching importance to the cultivation of talents in the field of big data technology and improving the legal and institutional system to ensure that data could be shared securely. In the mid-2010s, the UK proposed strengthening the development and protection of big data in the industrial field and further improving digital infrastructure in the energy sector. In the early 2020s, the UK proposed fully exploring the economic value of big data and promoting the cross-border flow of data under the premise of ensuring security. |
| Japan | Basic Law on the Promotion of Public and Private Data Utilization, Manifesto to Create the World’s Most Advanced Information Technology Nation, Strategic Implementation Framework for Japan’s Industrial Internet Value chains, Science and Technology Basic Plan Sixth Edition, etc. | In the mid-2010s, Japan proposed accelerating the application of big data technology in agriculture, industry, and other fields. In addition, Japan proposed promoting the reasonable opening and circulation of public and private data through the formulation of laws and standards. In the early 2020s, Japan proposed a top-level framework for the development of the industrial internet in the digital era and promoting technological research and innovation in big data. Additionally, Japan proposed accelerating industrial transformation and upgrading by promoting the application of big data technology in energy industries. |
| Russia | 2017~2030 Russian Federation Information Society Development Strategy, Russian Federation digital economy planning, Development goals and strategic tasks of the Russian Federation until 2024, Decree on the Development Goals of the Russian Federation up to 2030, etc. | In the mid-2010s, Russia proposed positioning the digital economy as one of 12 priority areas for development by 2024 and analyzing and managing big data as a key production factor; Russia also proposed promoting a revolution in production methods, technology, and equipment in various fields through digital infrastructure construction and big data technology talent training and application. In the early 2020s, Russia proposed positioning digital transformation as one of the five national development goals and increasing investment in big data technology. |
| Conceptual Model | Characteristics | Model Elements |
|---|---|---|
| DCC model | Mainly applicable to the governance of research data. | Mainly includes creation or reception, appraisal and selection, ingestion, preservation, action, storage, access, reuse, and transformation. |
| OAIS model | Primarily applied for the long-term preservation, retrieval, and reading of digital resources in information systems. | Consists of five main modules, including ingestion, archival storage, data management, access administration, and preservation planning. |
| CENS model | Primarily applied to the governance of experimental data. | Includes nine main elements: experimental design, instrument calibration, data collection, data cleaning, calculation and derivation, data integration, data analysis, results publication, and data preservation. |
| DAMA model | The impact of functional and environmental elements on data governance is fully considered. | Primarily consists of a functional framework and environmental framework. The functional framework includes strategy, organization, roles, and standards. The environmental framework includes culture, practices and methods, technology, and principles. |
| CALib model | Mainly applied for data governance in university libraries. | Consists of three main submodels: enabler, scope, and implementation and evaluation. The enabler includes strategic objectives, roles and functions, technology, and other elements. The scope includes three elements: a value creation layer, a value guarantee layer, and a basic data layer. Implementation and evaluation include the implementation method, maturity evaluation, and auditing. |
| DGI model | This model is largely used for data governance in business operations. It provides auxiliary support for decision-making tasks such as enterprise management and business expansion. | Consists of three main submodels: rules, people and organization, and processes. Specific elements include mission and vision, objectives, stakeholders, data managers, data rules and definitions, and ten other elements. |
| Gartner 6 phases model | This model has process management characteristics and is mostly used for data governance in business operations. | The model is divided into four parts: specification, planning, construction, and operation. The main elements of these parts include demand analysis, data architecture design, data quality monitoring, and data access auditing. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, M.; Xu, Y.; Wu, H.; Ma, J.; Gao, J. Sustainable Insights for Energy Big Data Governance in China: Full Life Cycle Curation from the Ecosystem Perspective. Sustainability 2022, 14, 6013. https://doi.org/10.3390/su14106013
Zeng M, Xu Y, Wu H, Ma J, Gao J. Sustainable Insights for Energy Big Data Governance in China: Full Life Cycle Curation from the Ecosystem Perspective. Sustainability. 2022; 14(10):6013. https://doi.org/10.3390/su14106013
Chicago/Turabian StyleZeng, Ming, Yanbin Xu, Haoyu Wu, Jiaxin Ma, and Jianwei Gao. 2022. "Sustainable Insights for Energy Big Data Governance in China: Full Life Cycle Curation from the Ecosystem Perspective" Sustainability 14, no. 10: 6013. https://doi.org/10.3390/su14106013
APA StyleZeng, M., Xu, Y., Wu, H., Ma, J., & Gao, J. (2022). Sustainable Insights for Energy Big Data Governance in China: Full Life Cycle Curation from the Ecosystem Perspective. Sustainability, 14(10), 6013. https://doi.org/10.3390/su14106013