1. Introduction
Confirmatory factor analysis (CFA) and structural equation models (SEM) are among of the most important statistical approaches for analyzing multivariate data in the social sciences [
1,
2,
3,
4,
5,
6,
7]. In these models, a multivariate vector
of
I observed variables (also referred to as items) is modeled as a function of a vector of latent variables (i.e., factors)
. SEMs represent the mean vector
and the covariance matrix
of the random variable
as a function of an unknown parameter vector
. In this sense, they apply constrained estimation for the moment structure of the multivariate normal distribution [
8].
SEMs impose a measurement model that relates the observed variables
to latent variables
:
In addition, we denote the covariance matrix
, and
and
are multivariate normally distributed random vectors. Moreover,
and
are uncorrelated random vectors. The issue of model identification has to be evaluated on a case-by-case basis [
9,
10]. We now describe two different specifications: the CFA and the more general SEM approach.
In the CFA approach, the multivariate normal (MVN) distribution is represented as
and
. Hence, one can represent the mean vector
and the covariance matrix
in CFA as a function of an unknown parameter vector
as
The parameter vector
contains freely estimated elements of
,
,
,
, and
.
In the general SEM approach, a matrix
of regression coefficients is specified such that
Note that (
3) can be rewritten as
where
denotes the identity matrix. Hence, the mean vector and the covariance matrix are represented in SEM as
The estimation of SEM often follows an ideal measurement model. For example, a simple-structure factor loading matrix
is desired in a multidimensional CFA. In this case, an item loads on one and only factor
, meaning that the number of non-zero entries in a row of
is one. However, this assumption on the simple-structure loading matrix could be somewhat violated in practice. For this reason, some cross-loadings could be assumed to be different from zero. Such sparsity assumptions on SEM model parameters can be tackled with regularized SEM [
11]. Moreover, deviations in the entries of the observed and modeled mean vector (i.e.,
) can be quantified in non-zero entries of the vector of item intercepts
(see [
12]). Again, model errors could be sparsely distributed, which would allow for the application of regularized SEM. In a similar manner, model deviations
can be tackled by assuming sparsely distributed entries in the matrix of residual covariances
. Notably, regularized SEM estimation is now becoming more popular in the social sciences and is recognized as an important approach in the machine learning literature [
13].
In this article, we review several implementation aspects in estimating regularized SEMs with single and multiple groups. A recent article by Orzek et al. [
14] recommended avoiding differentiable approximations for the non-differentiable optimization function in regularized SEM. We critically evaluate the credibility of this statement. Furthermore, we compare the currently used regularization estimation approach in most software, such as the regsem R package [
15], with a recently proposed optimization function in the commercial SEM software package Mplus [
16]. Finally, we also investigate the performance of a clever replacement of the optimization function in regularized SEM with a smoothed differentiable approximation of the Bayesian information criterion [
17]. The findings were derived through two simulation studies. They are intended to provide guidance for the practical implementation of regularized SEM in future software pieces.
The remainder of the article is organized as follows. Different approaches of regularized maximum likelihood estimation methods of SEMs are reviewed in
Section 2. In
Section 3, research questions are formulated that are addressed in two subsequent simulation studies. In
Section 4, results from a simulation study involving a multiple-group CFA model with violations of measurement invariance in item intercepts are presented.
Section 5 reports findings from a simulation study of a single-group CFA in the presence of cross-loadings. In
Section 6, the findings of the two simulation studies are summarized, and the research questions from
Section 3 are answered. Finally, the article closes with a discussion in
Section 7.
2. Estimation of Regularized Structural Equation Models
We now describe regularized maximum likelihood (ML) estimation approach for multiple-group SEMs. Note that some identification constraints must be imposed to estimate the covariance structure model (
5) (see [
2]). For modeling multivariate normally distributed data without missing values, the empirical mean vector
and the empirical covariance matrix
are sufficient statistics for estimating
and
. Hence, they are also sufficient statistics for the parameter vector
.
Now, assume that there exist G groups with sample sizes and empirical means and covariance matrices (). The population mean vectors and covariance matrices are denoted by and , respectively. The model-implied mean vectors and covariance matrices are denoted by and , respectively. Note that the parameter vector does not have an index g to indicate that there can be common and unique parameters across groups. In a multiple-group CFA, equal factor loadings and item intercepts across groups are frequently imposed (i.e., measurement invariance holds).
Let
be the sufficient statistics of group
g. The combined vector containing all sufficient statistics for the multiple-group SEM is denoted by
. The negative log-likelihood function
l for the multiple-group SEM (see [
2,
4]) is given by
In empirical applications, the model-implied mean vectors covariance matrices will frequently be misspecified [
18,
19,
20], and
can be interpreted as a pseudo-true parameter defined as the maximizer of the fitting function
l in (
6).
In regularized SEM estimation, a penalty function is added to the log-likelihood function that imposes some sparsity assumption on a subset of model parameters [
11,
12,
21]. Frequently, the penalty function
is non-differentiable in order to impose sparsity. We define a known parameter
for all parameters
, where
indicates that for the
kth entry
in
, a penalty function is applied. The penalized log-likelihood function is given by
where
is a nonnegative regularization parameter, and
a scaling factor that frequently equals the total sample size
. The power
p in the penalty function usually takes values in
. Most of the literature on regularized SEMs employs the power
, but
has been recently suggested [
16] (but see also [
22]). The minimizer of
is denoted as the regularized (or penalized) ML estimate.
We now discuss typical choices of the penalty function
. For a scalar parameter
x, the least absolute shrinkage and selection operator (LASSO) penalty is a popular penalty function used in regularization [
23], and it is defined as
where
is a nonnegative regularization parameter that controls the extent of sparsity in the obtained parameter estimate. Note that the LASSO penalty function combined with
is equivalent to the alignment loss function (ALF [
16]):
It is known that the LASSO penalty introduces bias in estimated parameters. To circumvent this issue, the smoothly clipped absolute deviation (SCAD [
24]) penalty has been proposed.
In many studies, the recommended value of
(see [
24]) has been adopted (e.g., [
25,
26]). The SCAD penalty retains the penalization rate and the induced bias of the lasso for model parameters close to zero, but continuously relaxes the rate of penalization as the absolute value of the model parameters increases. Note that
has the property of the lasso penalty around zero, but has zero derivatives for
x values strongly differing from zero.
Note that the minimizer of
is a function of the fixed regularization parameter
; that is,
Hence, the parameter estimate
of
depends on a parameter that must be known. To circumvent this issue, the regularized SEM can be repeatedly estimated on a finite grid of regularization parameters
(e.g., on an equidistant grid between 0.01 and 1.00 with increments of 0.01). The Bayesian information criterion (BIC), defined by
, where
H denotes the number of parameters, can be used to select an optimal regularization parameter. Because the minimization of BIC is equivalent to the minimization of BIC/2, the final parameter estimate
is obtained as
where the function
as an indicator whether
is larger than
z for any
:
In particular, the quantity
in (
12) counts the number of parameter estimates
for
for which the penalty function is applied (i.e.,
) and which differ from 0.
Note that the minimization of the BIC depends on two components. First, the model fit can be improved by minimizing the negative log-likelihood function while freely estimating more parameters. Second, sparse models are preferred in BIC minimization because the second term in (
12) minimizes the number of estimated model parameters that are different from zero. Hence, there is always a trade-off between model fit improvement and parsimonious model estimation.
It should be emphasized that BIC is frequently preferred over the Akaike information criterion (AIC) in regularized estimation [
11,
27]. In typical sample sizes, BIC imposes stronger penalization of the number of estimated parameters than AIC. In fact, alternative information criteria with even stronger penalization are discussed in regularization [
25,
28,
29].
Regularized estimation of single-group and multiple-group SEMs are widespread in the methodological literature [
11,
21,
30,
31,
32,
33,
34]. In these applications, cross-loadings, entries in the covariance matrix of residuals, or the vector of item intercepts are regularized. Applying regularized estimation in SEMs allows for flexible yet parsimonious model specifications.
2.1. Regularized SEM Estimation Approaches
Regularized estimation of (
11) typically involves a non-differentiable optimization function because the penalty function is non-differentiable. In [
14], exact and approximate solutions are distinguished for minimizing the penalized log-likelihood function
in (
11).
Exact estimation operates on the non-differentiable penalized log-likelihood function. In coordinate descent (CD), the penalized log-likelihood function is cyclically minimized across all entries of the parameter vector
(see [
23]). If the function
is minimized in the
kth coordinate
of
, the remaining entries in
are fixed to the estimate from the previous iteration. This coordinate-wise estimation can be repeated for all parameters and iterated until convergence is reached. The advantage of CD when using the LASSO or the SCAD penalty is that regularized parameters are exactly zero, while nonregularized parameters differ from zero. Hence, a sparse estimate
is obtained. However, CD can be computationally demanding [
14]. In addition, it can also not be generally ensured that a global minimum (instead of a local minimum) is found with CD estimation.
Alternatively, the non-differentiable optimization function can be replaced by a differentiable one [
12,
35,
36,
37,
38]. The penalty function involves the non-differentiable absolute value function that can be replaced by
for a sufficiently small
, such as
or
. Fortunately, general-purpose optimizers that rely on derivatives can be relied on when using differentiable approximations based on the penalized log-likelihood function. These optimizers are widely available in software and are reliable if good starting values are available. The disadvantage of the differentiable approximation (DA) approach is that there are no estimated parameters that are exactly zero. To determine a parameter estimate
, a threshold
[
14] must be specified that defines which small parameter entries should be set to zero. Hence, the final parameter estimate in DA is given by
Note that the threshold
is typically a function of
[
14], and
should be (much) larger than
. In general, the penalized ML estimate based on DA defined in (
15) relies on two tuning parameters,
and
, that must be properly chosen. Orzek et al. [
14] argue that there is typically not enough knowledge on how to choose these tuning parameters in practical applications. Therefore, they generally prefer CD over DA.
2.2. Direct BIC Minimization Approach of O’Neill and Burke
The estimation approaches described in
Section 2.1 require repeatedly fitting a SEM on a grid of regularization parameters
. Such an approach is computationally demanding, in particular for SEMs with a large number of parameters. The final parameter estimate is obtained by minimizing the BIC across all estimated regularized SEMs. A naïve idea might be directly minimizing the BIC to avoid introducing the penalty function and the unknown regularization parameter
in the optimization. Only a subset of parameters for which sparsity should be imposed is relevant in the BIC computation. Hence, a parameter estimate by minimizing the BIC is given by
The optimization function in (
16) employs a
penalty function [
39,
40,
41] with a fixed regularization parameter
. This optimization function contains the non-differentiable indicator function
. However, like in the DA of the non-differentiable penalty function, the function
could also be replaced by a differentiable approximation. O’Neill and Burke [
17] had the brilliant idea of approximating the indicator function
by
for a sufficiently small
. Hence, the minimization problem (
16) can be replaced by
The estimation approach from (
18) is referred to as the smoothed direct BIC minimization (DIR) approach. This estimation approach has been applied to distributional regression models [
17].
2.3. Standard Error Estimation
We now describe the computation of the variance matrix of parameter estimates
from penalized ML estimation for a fixed regularized parameter
or the direct BIC minimization approach. Both estimation approaches minimize a differentiable (or differentiable approximation) function
with respect to
as a function of sufficient statistics
(see also [
6]). The vector of sufficient statistics
is approximately normally distributed (see [
3]); that is,
for a true population parameter
of sufficient statistics. We denote by
the vector of partial derivatives with respect to
. The parameter estimate
is given as the root of the non-linear equation
General M-estimation theory (i.e., the delta method [
18]) can be applied to derive the variance matrix of
. Assume that there exists a (pseudo-)true parameter
such that
We now derive the covariance matrix of
by utilizing a Taylor expansion of
. We denote by
and
the matrices of second-order partial derivatives of
with respect to
and
, respectively. We obtain
As the parameter estimate
is a non-linear function of
, the Taylor expansion (
22) provides the approximation
By defining
, we get by using the multivariate delta formula [
18]:
An estimate of
is obtained as
. This approach is ordinarily used for differentiable discrepancy functions in the SEM literature [
3,
7,
42]. Standard errors for entries in
can be obtained by taking the square root of diagonal elements of
computed from (
24).
3. Research Questions
In the following two simulation studies, several implementation and algorithmic aspects of regularized SEM estimation are investigated. Five research questions (RQ) are imposed in this section that will be answered by means of the simulation studies.
The research questions are tackled through two simulation studies. The first, Simulation Study 1, considers the case of regularized multiple-group SEM estimation with noninvariant item intercept. In the second, Simulation Study 2, regularized SEM estimation is applied for data simulated from a two-factor model in the presence of cross-loadings.
3.1. RQ1: Fixed or Estimated Regularization Parameter ?
In the first research question, RQ1, we consider the choice of the regularization parameter regarding statistically efficient parameter estimation if structural parameters, such as factor means or factor correlations, are the primary analytical focus. We study whether an optimal regularization parameter is obtained by information criteria or a pre-chosen regularization parameter. Using only a fixed value of the regularization parameter instead of estimating the regularized SEM on a sequence of regularization parameters would decrease the computational burden of the estimation.
3.2. RQ2: Exact Optimization or Differentiable Approximation?
In the second research question, RQ2, we compare exact optimization and approximate optimization approaches based on differentiable approximations for regularized SEMs. Previous work argued that the exact approach should be generally preferred. We thoroughly investigate whether this preference is justified. Notably, approximate optimization with differentiable optimization functions is easier to implement because general-purpose optimizers are widely available and provide reliable convergence guarantees if adequate starting values are used in the estimation.
3.3. RQ3: Direct BIC Minimization or Minimizing BIC Using a Grid of Values?
The third research question, RQ3, investigates whether the direct one-step BIC minimization approach provides comparable results to the indirect estimation approach that requires the estimation of the regularized SEM on a grid of regularization parameters. If the one-step BIC minimization approach provides similar findings to the indirect approach, substantial computational gains would be achieved, which eases the application of regularized SEM.
3.4. RQ4: Always Choosing the Power in the Penalty Function?
In the fourth research question, RQ4, we investigate whether there are considerable differences in the choice of the power p in the penalty. While the majority of regularization approaches employ the absolute value function , a recent implementation in the popular Mplus software utilizes . The outcome of this comparison gives hints on how future regularized SEM software should be implemented.
3.5. RQ5: Does the Delta Method Work for Standard Error Estimation?
Finally, in the fifth research question, RQ5, the quality of standard error estimation in terms of coverage rates (see
Section 2.3) is studied. It is interesting whether the standard errors based on the delta method are reliable if they are applied for differentiable approximations of the optimization function in regularized SEM.
5. Simulation Study 2: Two-Dimensional Factor Model with Cross-Loadings
In Simulation Study 1, regularized ML estimation of a two-dimensional factor model with cross-loadings was investigated.
5.1. Method
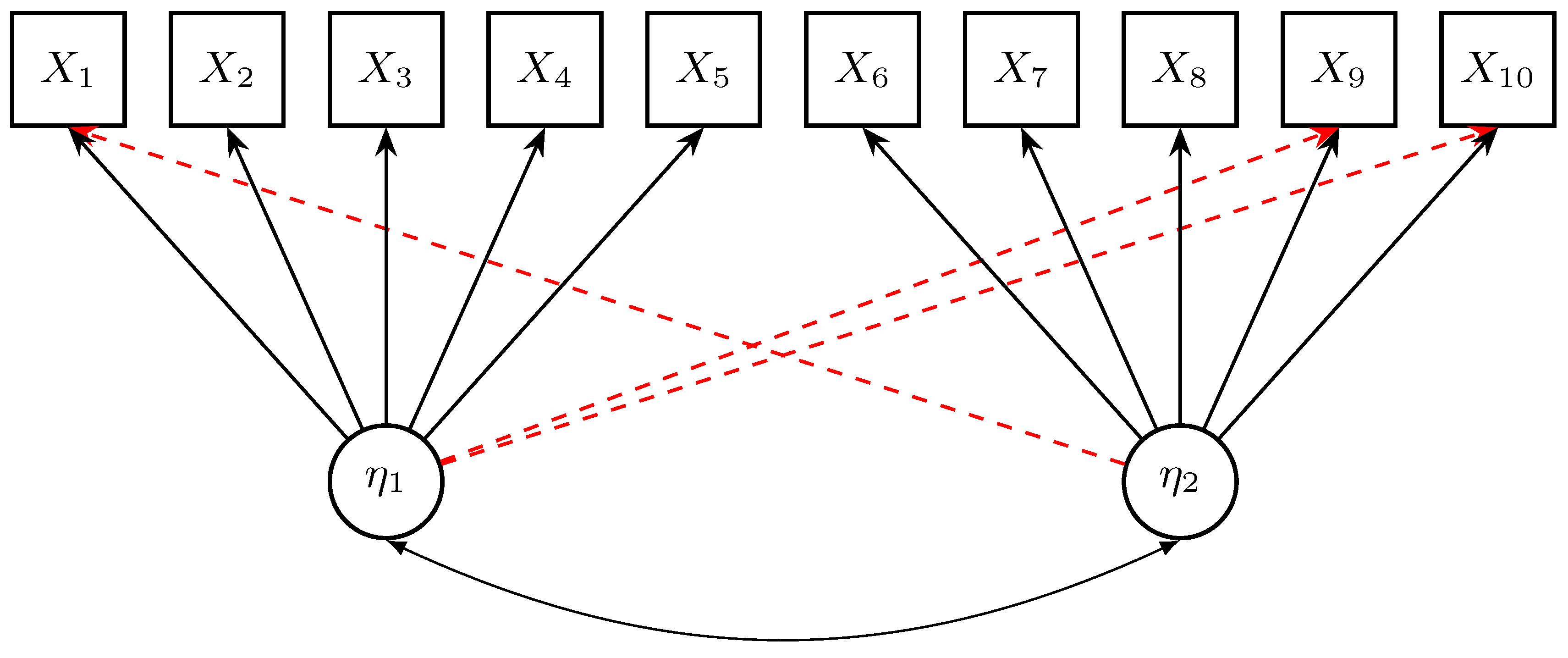
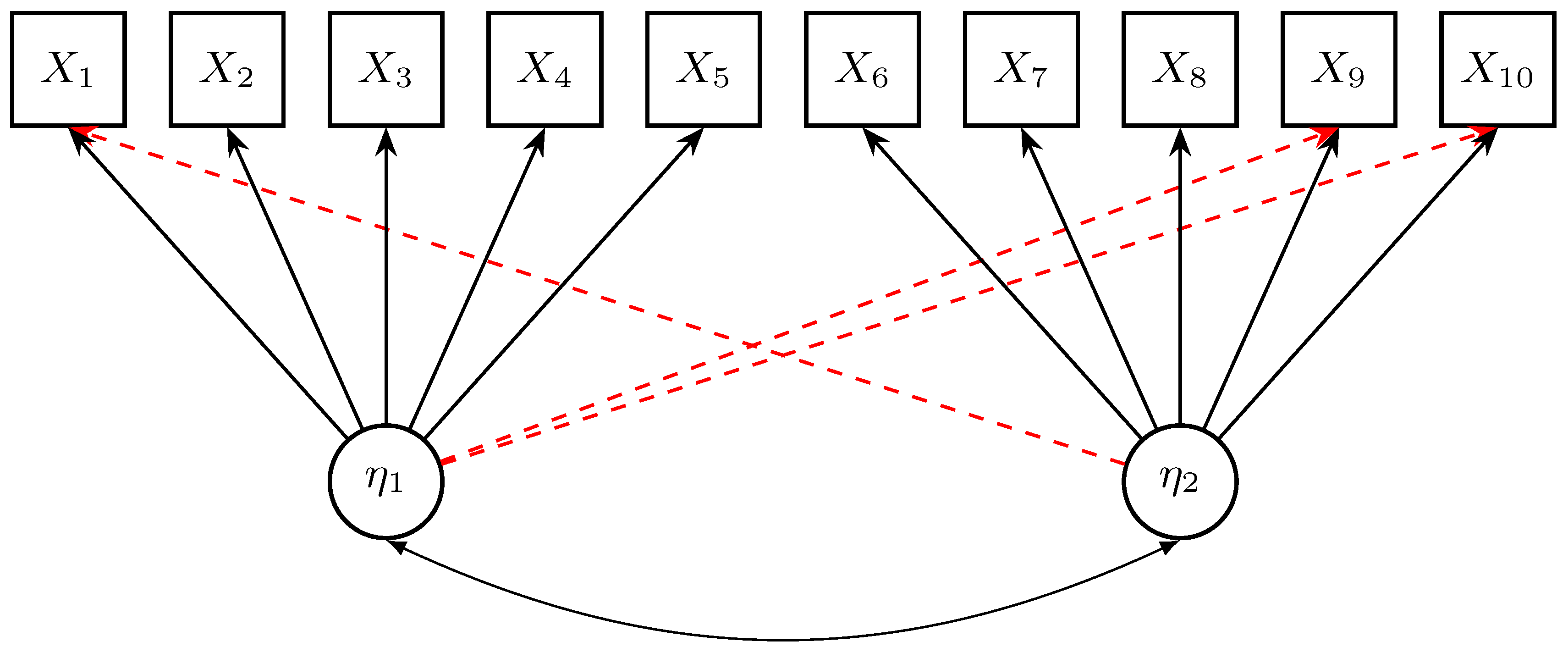
The data-generating method involves a two-dimensional factor model involving ten manifest variables
(i.e., items), and two latent (factor) variables
and
. The data-generating model is graphically presented in
Figure 3. The first five items load on the first factor, while the last five items load on the second factor. Three cross-loadings for items
,
, and
were introduced.
All variables had zero means and were normally distributed. Furthermore, the latent variables and were standardized (i.e., they had a true variance of 1). The true factor correlation of the two factor variables was set to 0.5. The primary factor loadings of the ten items were 1.000, 0.858, 0.782, 0.877, 0.888, 1.000, 0.815, 0.721, 0.880, and 0.749. The variances of the normally distributed residual error variables were chosen as 0.115, 0.464, 0.572, 0.345, 0.411, 0.122, 0.536, 0.680, 0.383, and 0.627.
All cross-loadings were simulated with the size . In the simulation, was chosen as 0.2 or 0.4. Furthermore, the sample size N was chosen to be either 500 or 1000.
The two-dimensional factor model with the SCAD penalty function on the cross-loadings was specified as the analysis model. For identification reasons, the variances of the factor variables were fixed to 1. The estimation method followed those used in Simulation Study 1. Again, was employed in the differentiable approximation method (DA) utilizing thresholds , 0.02, and 0.04 in the BIC minimization. The smoothed direct BIC minimization approach (DIR) was again conducted with .
In total, 1000 replications were conducted for all 2 (size of cross-loadings ) × 2 (sample size N) = 4 conditions of the simulation study. We analyzed the estimation quality of model parameter estimates through bias, RMSE, and coverage rates.
The models were again estimated using the
sirt::mgsem() function in the R [
45] package sirt [
46]. Replication material and the data-generating parameters can be found in the directory “
Simulation Study 2” located at
https://osf.io/7kzgb (accessed on 21 August 2023).
5.2. Results
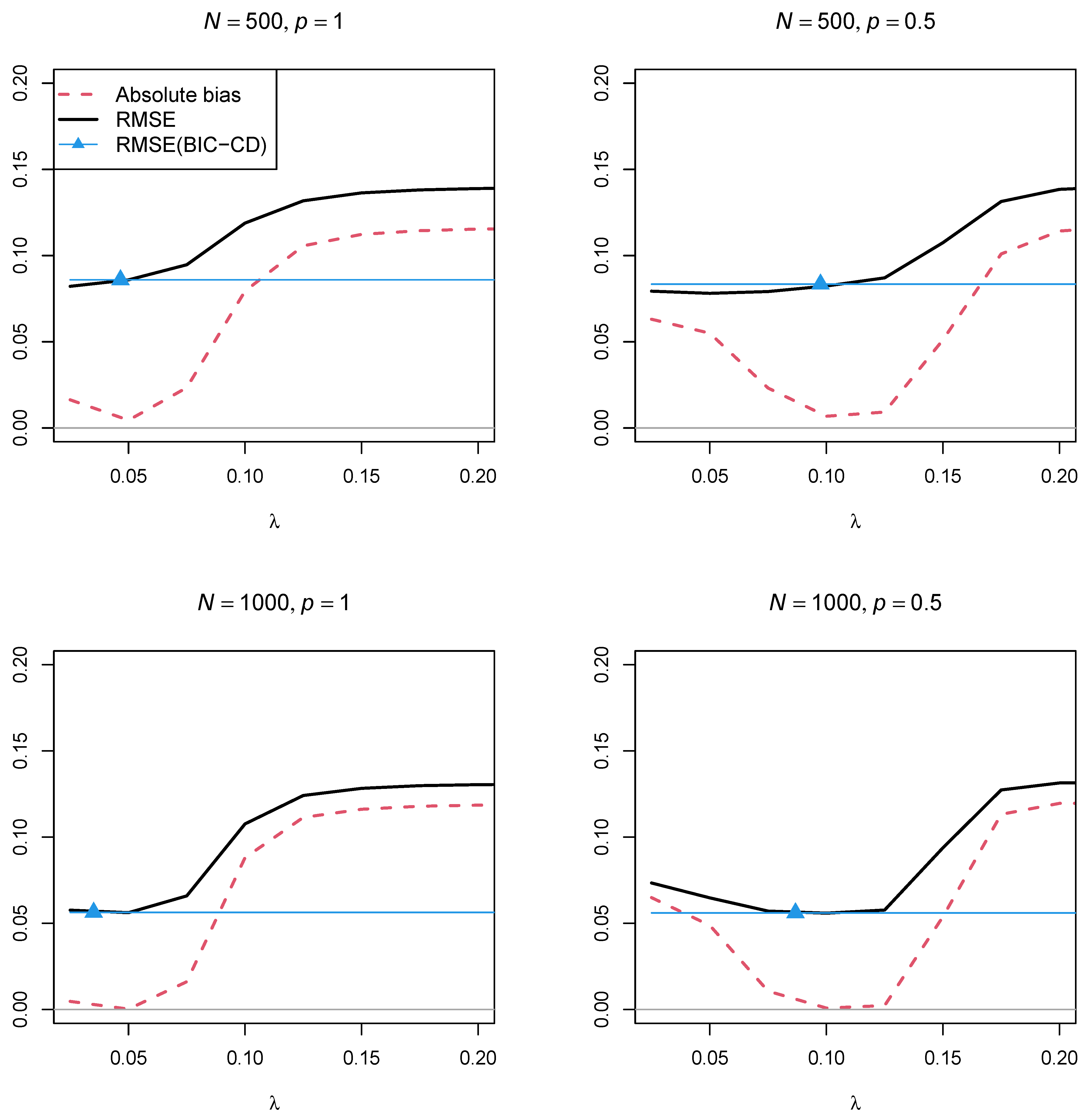
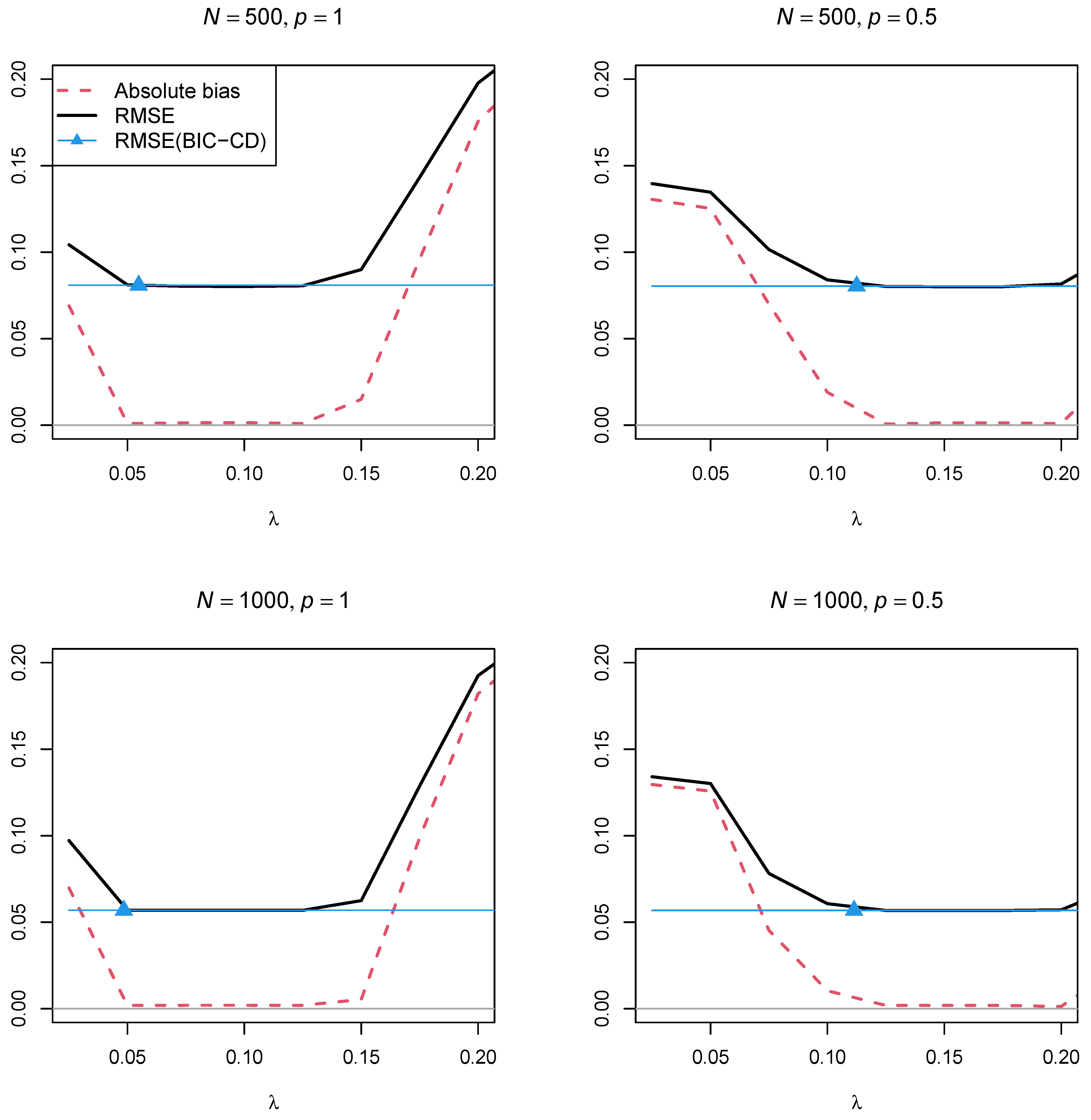
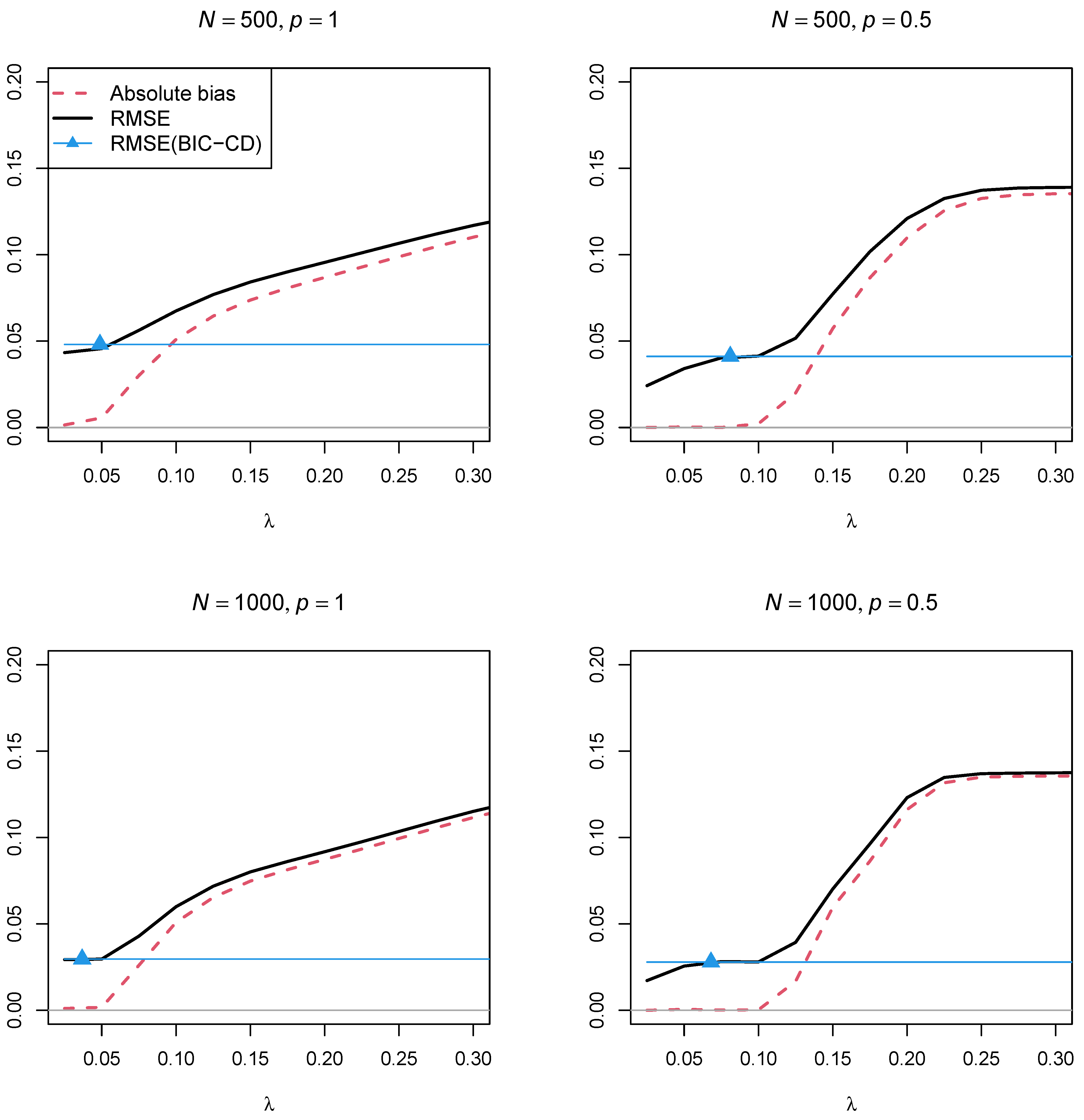
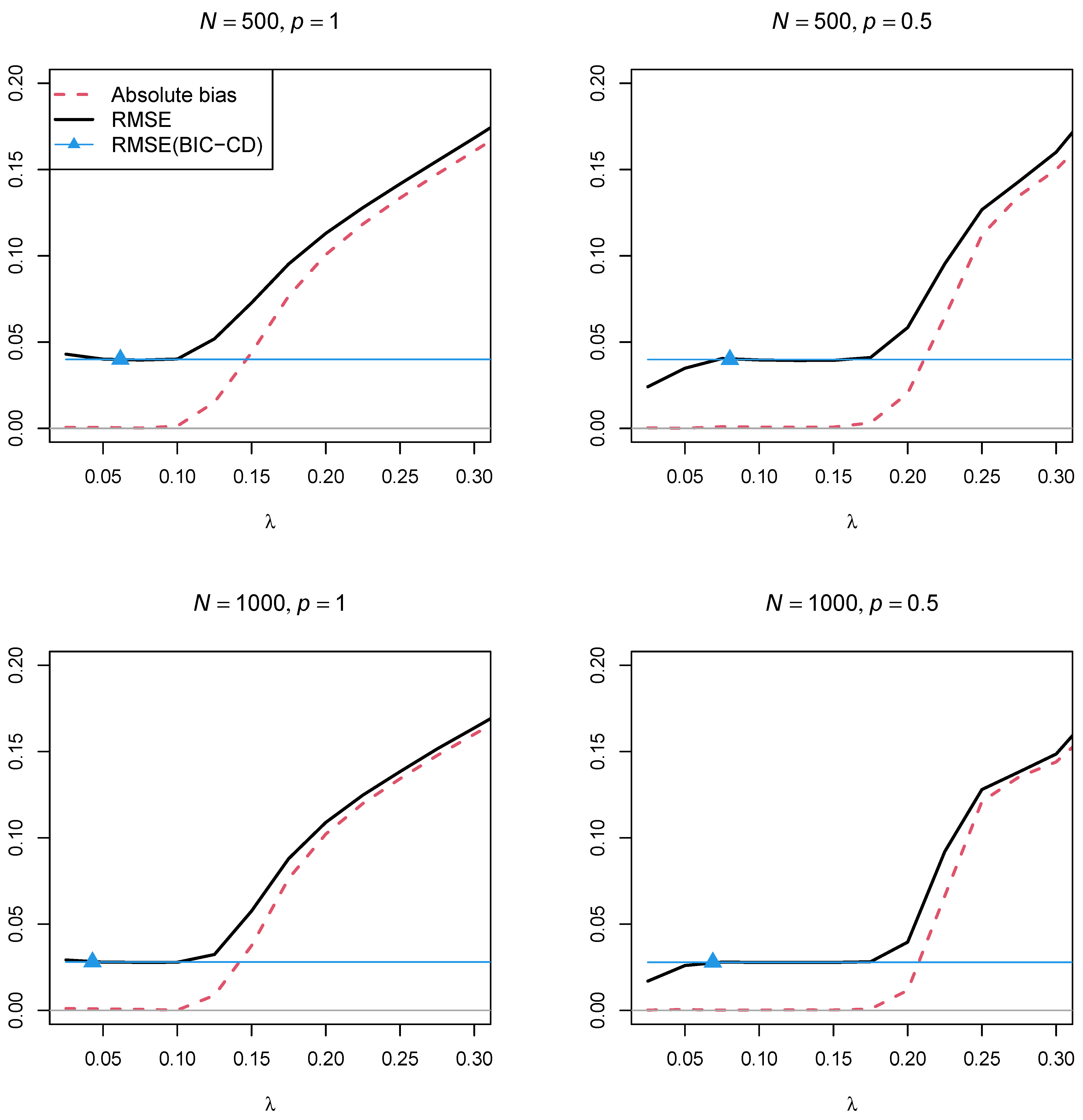
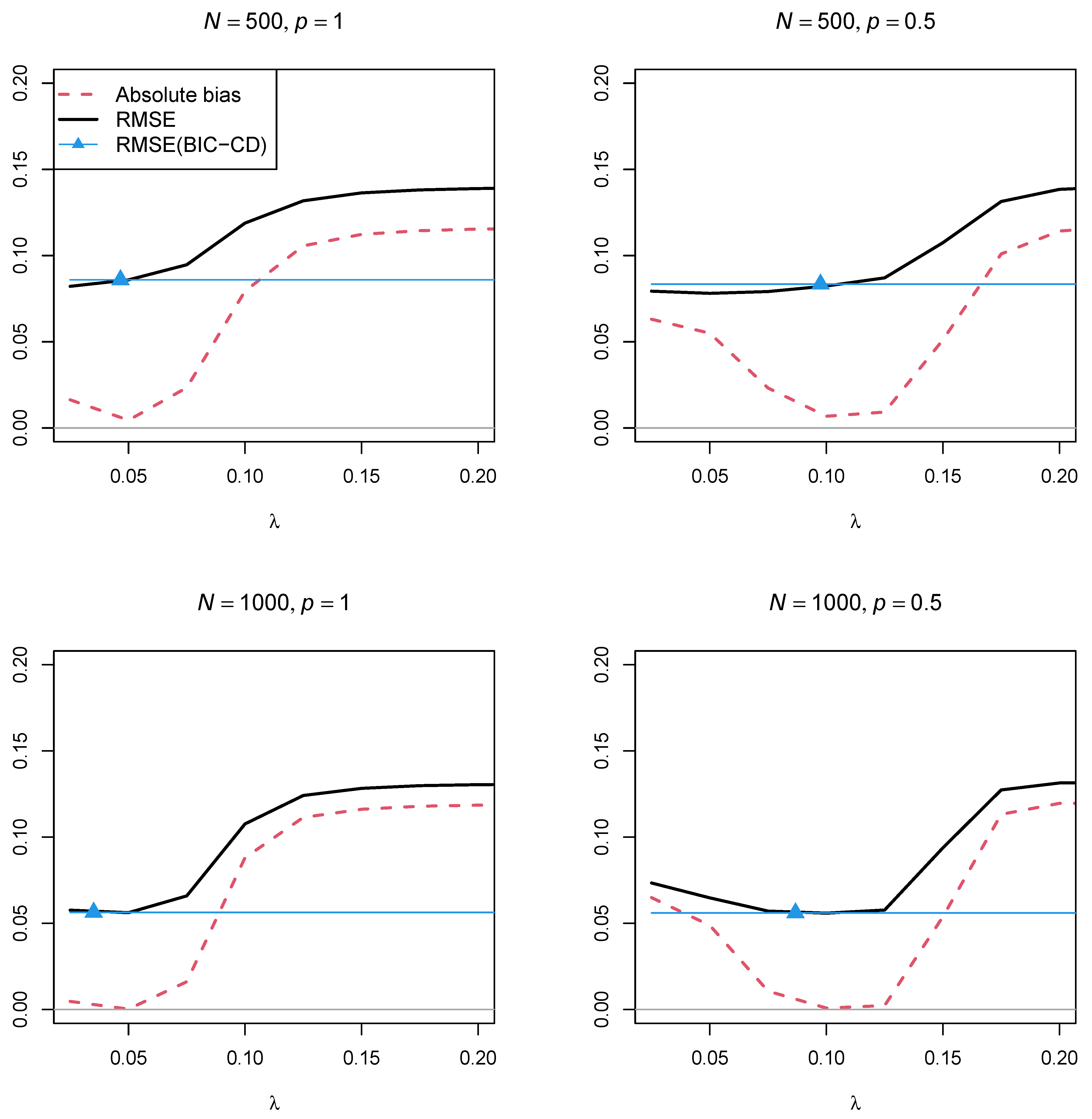
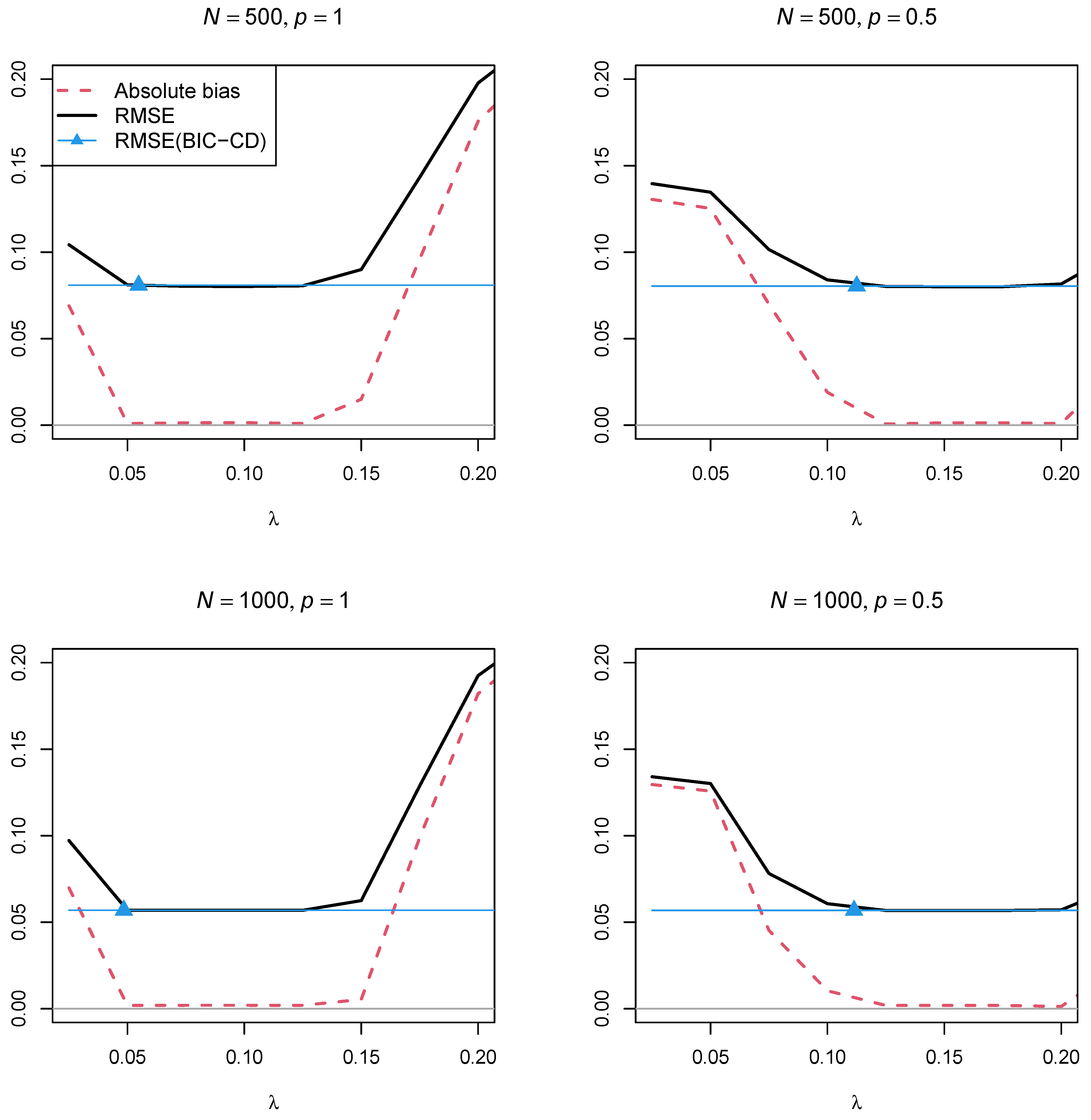
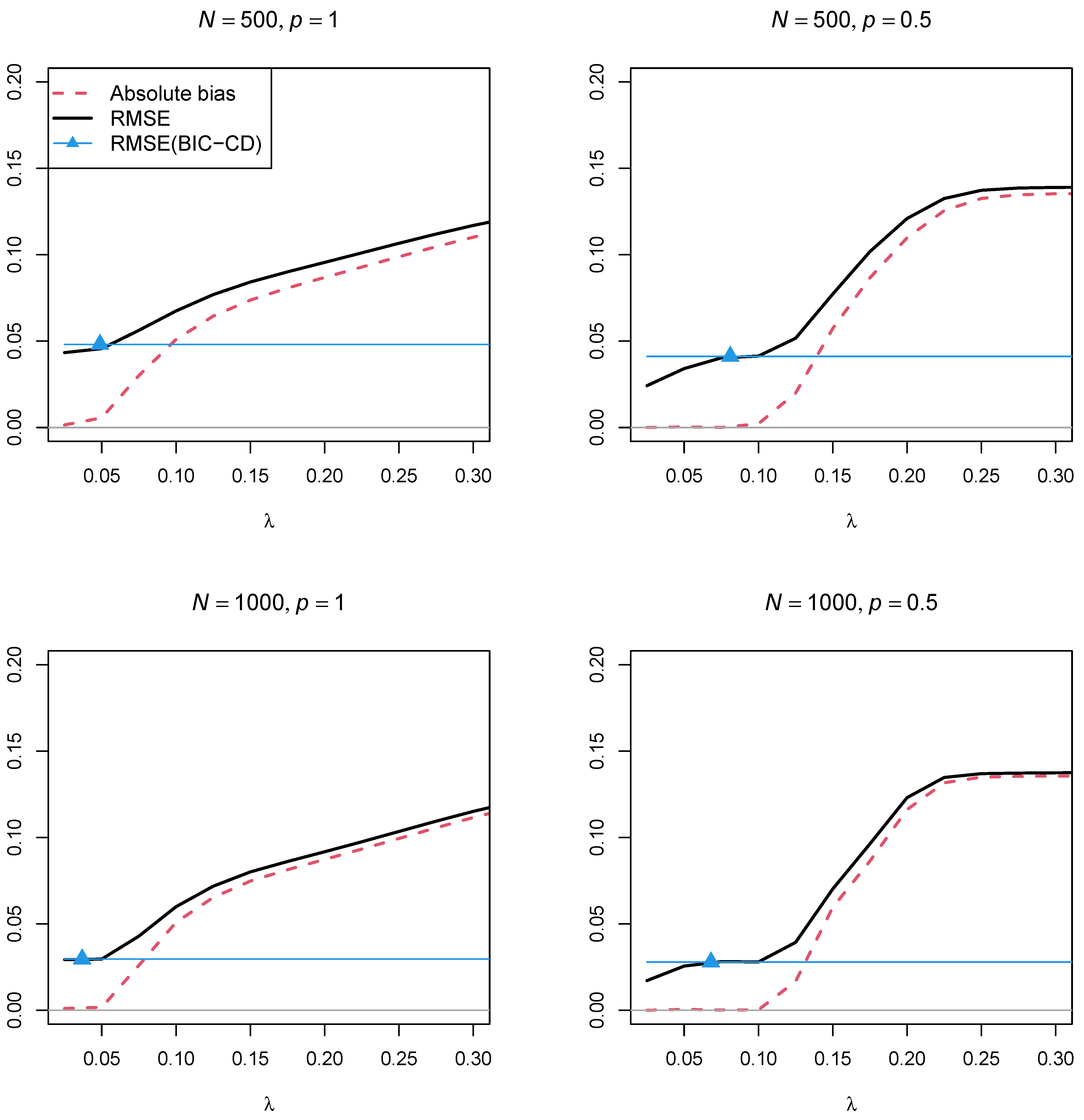
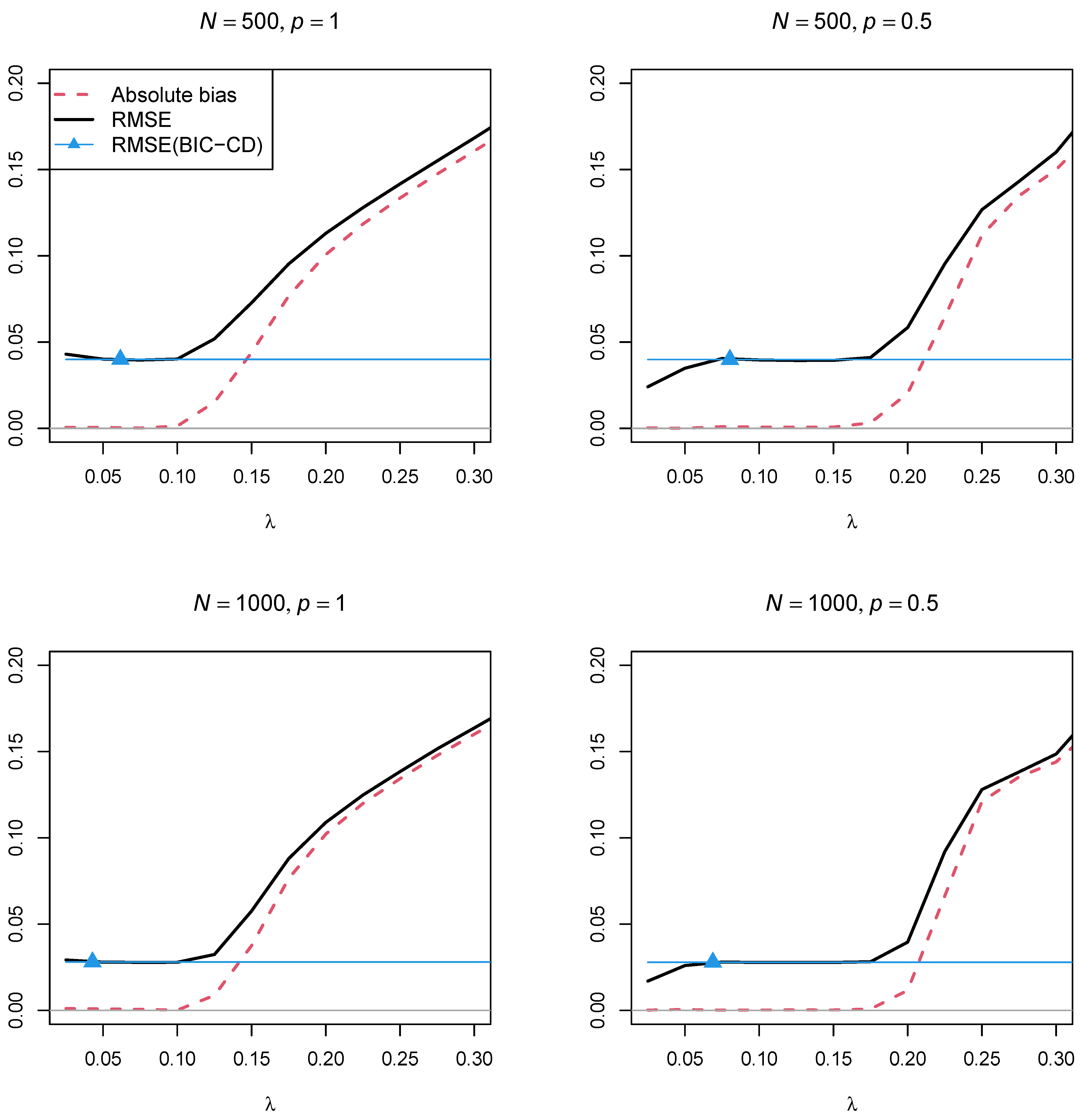
Figure 4 and
Figure 5 display the absolute bias and the RMSE of the factor correlation
of the two factors as a function of the regularization parameter
for the two sample sizes,
and
, and the two powers of the penalty function
and
, respectively. In contrast to Simulation Study 1, the two figures showed that using a regularization parameter
that is smaller than the optimal
selected by BIC resulted in parameter estimates with a smaller RMSE. This property somehow questions the standard procedure of searching for a parsimonious model according to the BIC if a structural parameter should be estimated with low variance. Furthermore, parameter estimates with the power
in the penalty function resulted in a lower RMSE than using the power
.
Table 4 presents the bias and the RMSE of the estimated factor correlation and the four factor loadings for the first two items. According to the findings in
Figure 4 and
Figure 5, we also display the parameter estimates for the fixed regularization parameter
. The estimated parameters were unbiased. Hence, we focus on differences between the estimation approaches regarding the RMSE. Like in Simulation Study 1, the exact estimation approach (CD) performed similarly to the differentiable estimation approach (DA). The only exception was the case of
and the fixed regularization parameter
. In this case, the DA approach resulted in fewer variables estimated than the CD approach for the factor correlation
. Moreover, the direct BIC minimization approach (DIR) was similar or superior to the CD and DA estimation approaches based on BIC. This is an interesting finding because repeatedly fitting the regularized SEM on a grid of regularization parameters is not required in DIR.
Table 5 displays the average number of regularized cross-loadings. It turned out that the choice of the threshold parameter
was less critical for
than for
. Furthermore, using
in the DA approach resulted in a similar average number of regularized parameters to the exact approach (CD).
Finally,
Table 6 displays the coverage rates and bias of the estimated factor correlation and the factor loading of the first item. Coverage rates were satisfactory for the DIR approach as well as for the DA approach with fixed regularization parameters. There was a tendency of overcoverage for the power
for a small regularization parameter
.
7. Discussion and Conclusions
In this article, implementation aspects of regularized maximum likelihood estimation of SEMs were investigated. We obtained some insights into how regularized SEMs could be efficiently implemented in practice. In contrast to statements in the literature, differentiable approximations of the non-differentiable penalty functions in regularized SEM perform comparably well to specialized estimation methods if tuning parameters in these approximations are thoughtfully chosen.
Our preliminary conclusion for regularized SEM estimation from our simulation studies is that the direct BIC minimization approach or the fixed regularization parameter approach should deserve more attention in future research. By focusing on these approaches, the computational burden of regularized SEM is noticeably reduced. Future research might investigate whether the findings obtained for SEMs transfer to other models involving latent variables such as item response models [
47,
48,
49,
50,
51,
52], latent class models [
28,
53,
54,
55], or mixture models [
56,
57].
In this article, we focused on a differentiable approximation of the BIC. However, the same approximation technique could be applied to estimating regularized SEMs that minimize the AIC. However, we have preliminary simulation evidence that convergence issues appeared more frequently when minimizing the differentiable approximation of the AIC compared to BIC.
Hopefully, the availability of the direct BIC minimization approach could lead to more widespread use of regularized estimation. Nevertheless, the regularization approaches discussed in this paper still hinge on the assumption that there is sparsity with respect to regularized model parameters. Such sparse models or parameter deviations might not always be appropriate for modeling real-world datasets.
The simulation studies showed that the optimal regularization parameter
regarding the bias and RMSE of the model parameters of interest does not necessarily coincide with the optimal
obtained by minimizing the BIC. Determining the optimal regularization parameter
for particular regularized SEMs is, therefore, difficult for researchers. Maybe only simulation studies that involve a similarly complex model and a similar sample size could help to determine an appropriate
. If the researcher’s interest lies in the interpretation of model parameters in a regularized SEM, it is uncertain as to why model fitting is aimed at minimizing a prediction error, as in BIC, because such a criterion can only be weakly related to estimating optimal model parameters (see [
58]).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}