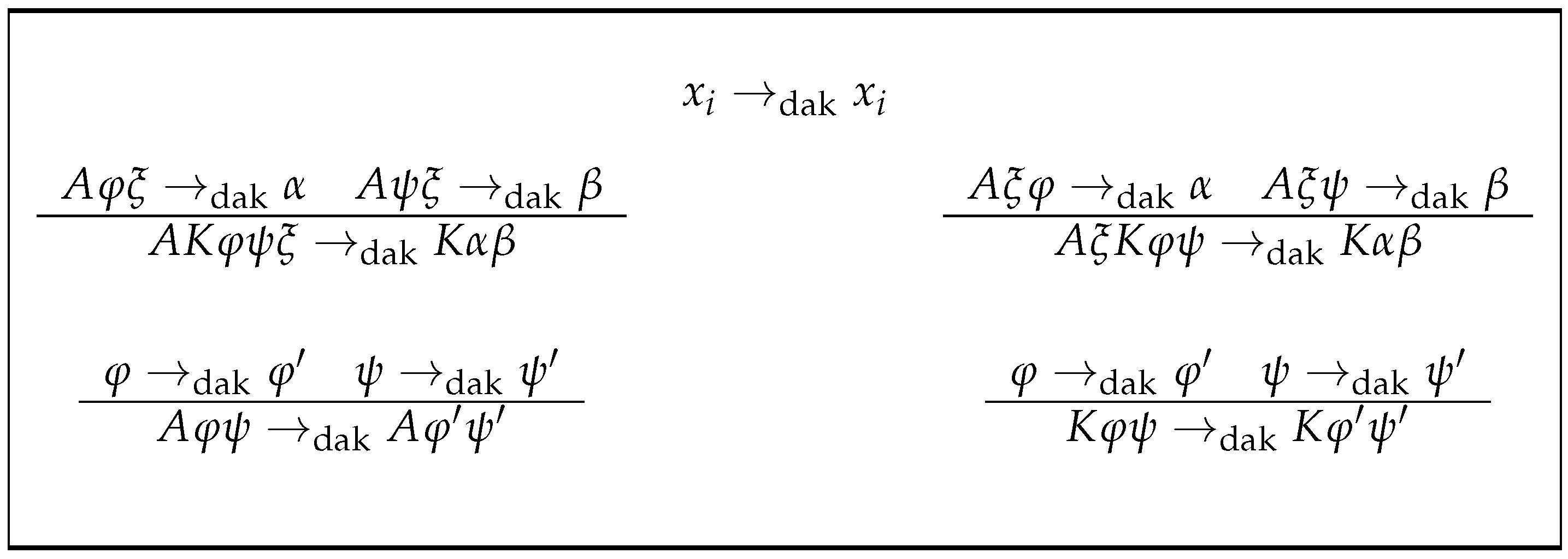1. Introduction
The conjunctive normal form (CNF) is famous in the history of thought because it organizes discourse by normalizing potentially chaotic statements through the conjunction of a series of statements in the form of disjunctions of other simple statements, namely atomic statements, or the negation of them.
CNF has proven to be essential in the treatment of the SAT problem (from “satisfiability”, usually abbreviated to SAT), which in turn is at the core of automated theorem proving, thanks to the effectiveness of the resolution rule and what is known about the treatment of Horn clauses (see [
1]).
The other great utility of CNF lies in the minimization of Boolean expressions under the condition of being expressed as a product of sums (POS) (see [
2,
3]). It is clear that the POS criterion is the dual concept of the sum of products (SOP) criterion.
In general, transforming a formula into CNF is the essence of Petrick’s method, an algorithm widely used in various fields: cybernetics, economics, linguistics, philosophy, psychology, etc. For an explanation of the algorithm and detailed applications, see [
2] (p. 157), plus extensive comments and applications of the CNF algorithm. In [
4] (pp. 69–71), we find a brilliant application of Petrick’s method to finite Boolean algebra.
Given a propositional formula or a Boolean expression, it is possible to obtain for it an equivalent formula or expression, as the case may be, in CNF by semantic means or by algebraic manipulations. Both procedures are described in [
5,
6,
7]; however, algebraic manipulation may be faster.
If we focus on the method of syntactic analysis for obtaining CNF, we will consider propositional logic formulas, without loss of generality, in the appropriate language. In this line of thought, the essence of the algorithm is quite simple: after internalizing negation and eliminating double negation, the main task is to replace subformulas of the form
by their equivalent
(distributivity). For the sake of efficiency, we will use Polish notation here as was introduced by Jan Łukasiewicz in [
8] (pp. 33–34). Łukasiewicz selected K (resp. A) to represent conjunction (resp. disjunction). Disjunction was originally called “alternation” by Łukasiewicz (in Polish “alternacja”, hence the symbol “A”). The word “disjunction” in Polish is “koniunkcja”, hence the symbol “K”. Our notation in this logical work, which is classical notation, is based on this Łukasiewicz guideline because it has the great advantage of avoiding parentheses and at the same time being univocal. Furthermore, Polish notation is ideal for transitioning to a functional implementation in the Haskell language given the peculiarities of its syntax (see [
9]). Since de functor A stands for disjunction and functor K for conjunction in standard Polish notation, what we are saying is that the application of distributivity translates
to
.
With regard to the CNF algorithm, the current state of the art can be found, for example, at [
5,
6]. To fix ideas, we will focus on [
5] (p. 26) and look at Algorithm 2.3, called
TREE-EQ-CNF. Its pseudocode contains the following snippet:
Therefore, we note that the basis of the algorithm is a
while loop with the sentinel condition
, where
is a copy of the value of the
at the start of the current round. Therefore, each round of the
while loop requires a comparison operation between the formula we are transforming in that round and the result of its transformation, stopping the process when there is a match. The basis of this work is to avoid all the comparisons we have just detected, the number of which will depend on the case, and instead to carry out a single inspection of the formula passed as a parameter initially to the coding of the algorithm; that single inspection, ultimately related to “distributivity”, will give us the minimum number of rounds for the correct operation of the loop. However, the expression of the resulting formula in the CNF algorithm is not satisfactory until we express it canonically with the functors K and A left-loaded. This has to do with “associativity” and will lead us a second time to the situation where we have to calculate the minimum number of rounds for another
while loop beforehand; that calculation will be carried out with the function akr defined below in
Section 3.
The basis of the classical algorithm, which is essentially the substitution of subformulas by equivalents, does not change in our work, but we will provide a very formal presentation of the substitution process in the algorithm. That presentation will be based on the specialized theory of recursive works, namely the lambda calculus.
Finally, as a result of the work, we provide a functional implementation (
https://github.com/ringstellung/CNF, accessed on 23 September 2023) of the algorithm in the Haskell programming language with these and other contributions.
In summary, the sections of this article contain the following. Since the aim of this paper is the manipulation of formulas over a language, in
Section 2, we suggest the rigorous definition of language and formula. Four subsets of formulas generated by a non-empty subset of formulas according to appropriate rules are then suggested; essentially they are the support for defining the concept of clause and formula in conjunctive normal forms. The section continues by giving several different concepts of the complexity of a formula. The rest of the section is devoted to defining the concept of semantic equivalence of formulas, according to classical propositional logic; some examples; and the statement of a classical result on distributivity. Negation is not mentioned because it is not relevant to the theoretical framework of the article.
Section 3 is devoted to the treatment of the distributivity that, in a broad sense of the term, classical propositional logic contains between disjunction and conjunction. In that section, the function dak is defined (see
Figure 1), which, when applied to formulas, manages to reduce the alternation in them of the connector K over A in a unit; this alternation is measured in each formula by the function alt. The section concludes by showing that the alternation of each formula is precisely the minimum number of applications of dak to it, in order to obtain another equivalent formula in conjunctive normal form. Practical laboratory experience in the field of logical deduction indicates that the associativity of the connectives K and A must be taken into account in order to obtain a canonical form, which, in Polish notation, accumulates these connectives at the beginning of the formula. The rigorous treatment of this matter is the aim of
Section 4. In writing it, we were inspired by the structure of
Section 3; however, the intrinsic theory is appreciably more complex. It is all based on two “measures” on formulas that essentially express how far the formula is from that canonical form; the maximum of these two values is also important. In that section, we justify the expressive capacity of the aforementioned measures to characterise the membership of the subsets of formulas defined in
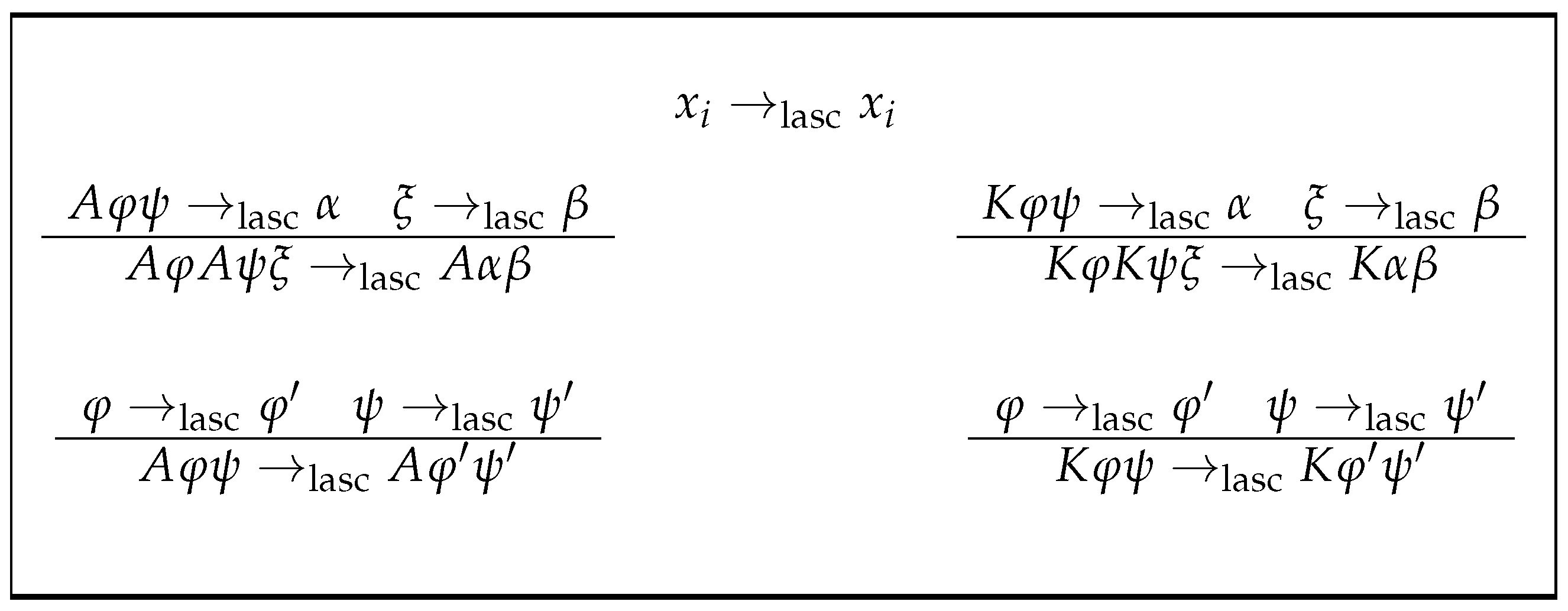
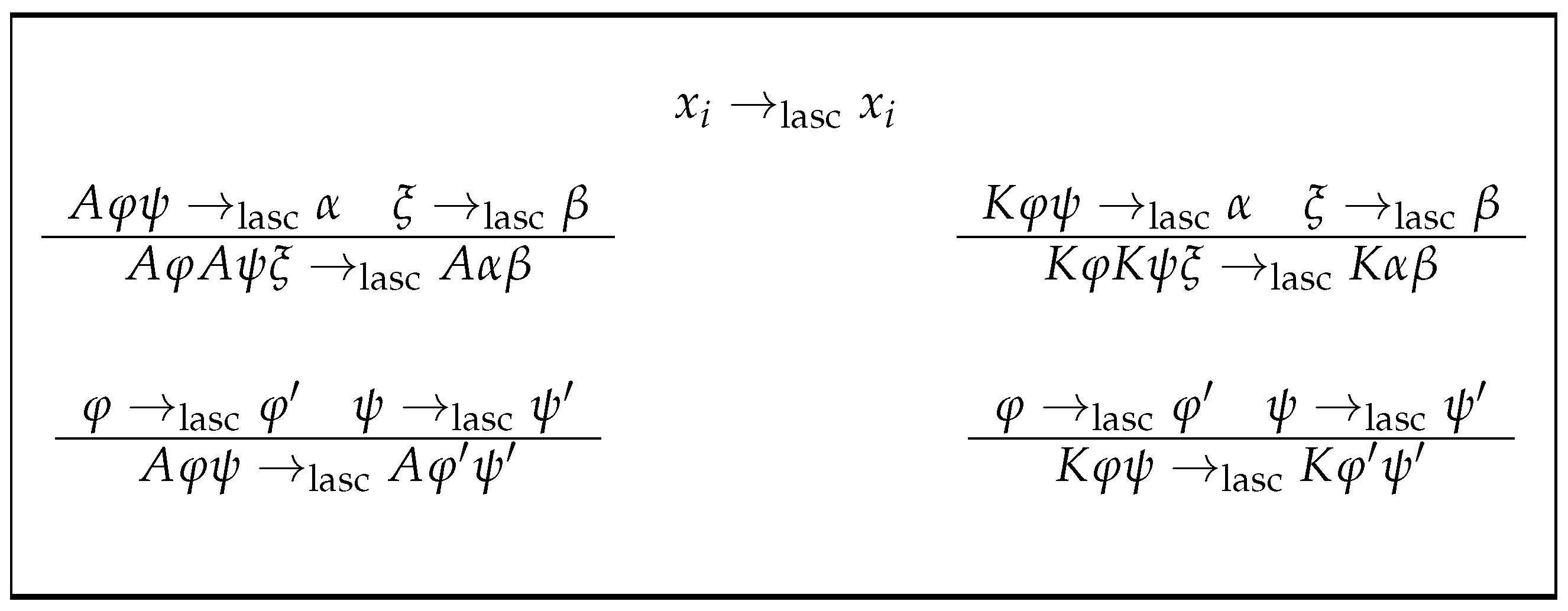
Section 2. The counterpart for the associativity of the dak function is defined, namely the lasc function (see
Figure 2). This time, the application of the lasc function decreases the separation measure of the formula to the canonical form by half; in that sense, it serves to make big steps. A certain natural value based on the logarithm in base two gives the minimum number of applications of lasc to the formula to obtain its desired canonical form. The last section,
Section 5, is for the conclusions.
2. Basic Definitions and Preliminary Results
In this section, we list the main definitions of the basic concepts that will be used in the development of this work, as well as the essential results needed in it.
Here, the concept of sentencial or propositional language is that of J.D. Monk in [
10] (see also [
11,
12]), but our functors (in the sense of Jan Łukasiewicz in [
8]) will be A and K. Moreover, it is necessary to impose that
X, the set of atomic or propositional variables, be a nonfinite numerable set; its elements are notated by the last lower–case letters of the latin alphabet:
x,
y,
z, etc., subindicating them if necessary. We will call
the above propopositional language and
, or simply
, the set of its formulas or sentences. The reader should be thoroughly familiar with the principle of induction for sentences, the construction sequence for sentences, and the unique readability principle. We will also assume the knowledge of the principle of finite induction in its different formulations, as it is exposed, for example, in [
6].
The statements of some particular results (lemmas and theorems), in this and subsequent sections, will be given without complete proofs, because some of them are quite evident, and the rest could be carried out using the principle of finite induction, taking into account, in a meticulous and orderly manner, all the possible cases that can occur, in a similar way as it is carried out in the selected proofs included in this paper.
Given a set of formulas of the language , consider the smallest set of formulas that, containing it, is at the same time closed for the functors A (resp. K); it will be represented by (resp. ). Thus, the elements of are exactly the set of formulas in conjunctive normal form. Clauses are exactly the formulas of the smallest set, , containing X and being closed for the functor A whenever it operates on an element of X to its right. The set (resp. ) is the smallest set containing X (resp. ) and being closed for the functor K whenever it operates on an element of X () to its right.
Remark 1. Note that and that .
Definition 1. For all let (complexity), the natural value defined as follows: and (complexity in K
) defined by If necessary, consider as the dual concept of .
Consider the semantic consequence ⊧ in the classical sense, as in, for example, Ref. [
5]. The formula
and
are
equivalent, in symbols
, iff by definition
and
. In the following, we will use the symbol = to indicate equivalence and the symbol ≡ to indicate syntactic equality (verbatim equal). It is well known that if
and
, then
.
Remark 2. It is well know as a basic theorem of classical logic that if (resp. ), then (resp. ).
3. Distributivity
The aim now is, given a formula in , to find in such that both are equivalent. This will be the basis of the algorithm, and the first thing to do is to determine how far is from . As we shall see shortly, the expected measure is given by the function , which indicates the alternation in its formula argument of the symbols K and A from the inner to the outside formula.
Definition 2. Let α be any formula in . The alternation of α, in symbols , is defined by In Lemma 1, we characterise the meaning of “belong to the set ” by means of the map alt. As we shall see, the formulas for which are exactly those of the set .
Lemma 1. Let . The following statements are equivalent:
- 1.
.
- 2.
.
Definition 3 (distributivity). Consider the following compound rules on binary relationships between formulas of :
where (2)–(4) are applied with the precedence indicated by the order in which they are given. This being so, we define the following application:by Remark 3. dak is an application, because a clear and univocal precedence has been established in the rules on which its definition is based. For example, note that by Rule (2), ; dak is a recursive process with stop in propositional variables due to Rule (1). Moreover, it is clear from Remark 2 that for all , (semantical equality). By Lemma 2, is a sufficient condition for , but it is not a necessary condition. Lemma 3, which is a consequence of Lemma 2, gives the necessary and sufficient condition, although this will be fully concluded in Corollary 1. The proof of Lemma 2 is straighforward.
Lemma 2. Let α be a formula in . If , then .
Lemma 3. Let . If then .
Proof. Let us assume that and . Reasoning by induction on we will show that . As an induction hypothesis, suppose that the implication is true for any formula such that . If , then two situations are possible:
□
As for Theorem 1, in essence its meaning is that in applying dak to a given formula not in , say , according to the “measure” alt, the result is closer to than .
Proof. The proof is by induction on the complexity of the formula
. Let
be a formula in
such that
. Suppose, as an induction hypothesis, that (
6) holds for any formula
such that
. Several cases are possible:
- 1.
; in this case, and since , we deduce according to Lemma 1 that , which proves the result in this case.
- 2.
; therefore,
and
On the other hand,
so that
For short, we will call to and to . Let us bear in mind the following:
- (a)
; then
and
. Since
, the induction hypothesis allows us to establish that:
- (b)
; then
. According to Lemma 2, then
and, according to Lemma 1,
We will now analyse equality (
8) on a case-by-case basis:
- (a)
- (b)
- (c)
and ; this situation is treated as the case in paragraph 2b.
- (d)
and ; in this case and . By what Lemma 3 states, and, as Lemma 1 states, ; so .
- 3.
; this situation is treated as the case in paragraph 2.
- 4.
; neither
nor
begin with
K but
; without loss of generality, suppose that
, whence
and
begins with
A, i.e.,
. Then
and
- 5.
; without loss of generality, suppose that
. If
, then
,
and so
(see Lemma 1). If
, i.e.,
, then
. Thus,
□
As a consequence of Theorem 1, it follows that the sufficient condition of Lemma 3 is also a necessary condition.
Corollary 1. Let α be any formula in . The following statements are equivalent:
- 1.
.
- 2.
.
- 3.
.
Given any formula in , we now know that it is possible to obtain from it another in conjunctive normal form by iterated application of the dak function. Moreover, the minimum number or iterations required is exactly . By Remark 3, we know that this other formula in conjunctive normal form is logically equivalent to , the input formula.
Corollary 2. For all , the natural number is the smallest natural number m satisfying .
Proof. The proof is by induction on n according to the predicate of the literal content:
The reasoning is as follows:
; if and , then by Corollary 1, we know that , i.e., , since is the identity map. Since 0 is the smallest natural number, the set of natural numbers smaller than it is empty, from which we conclude the assertion.
Suppose that
, that
is true, and that
is fixed but arbitrary under the condition that
. As we know from Theorem 1 and Corollary 1, it holds that
By (
14) and the induction hypothesis, we have, in particular, that
On the other hand, let m be a natural number, such that . Three cases can occur:
- *
; then:
so (see Corollary 1)
.
- *
; by Theorem 1, we know that
, and since
, by the induction hypothesis, we have
- *
; , and since , we deduce that .
By the principle of finite induction, we deduce that is true for any natural number n. Since the function alt can be applied to any formula, the result is true. □
4. Associativity
By iterating dak from any formula, we obtain, as we have seen, a formula equivalent to it that is in conjunctive normal form. However, for certain formulas in conjunctive normal form, there are several others also in conjunctive normal form that are equivalent to it, but such that they are all distinct from each other. In this section, we intend to provide an algorithm to select among all those formulas, one of which we will consider in canonical form. For practical reasons, we will consider the set , the set of formulas in conjunctive left normal form, as the one that gathers exactly all the formulas in canonical form.
Definition 4. Let be defined as follows:
and let be defined as follows: Also let be defined as follows: Remark 4. The maps ar and kr have the properties given in Lemma 4. This Lemma characterises the elements of , , and X. The particular assignation in both functions of the value to the elements of X is just in order to adjust the final computations accordingly.
Lemma 4. For all :
- 1.
if, and only if, .
- 2.
if, and only if, .
- 3.
if, and only if, .
- 4.
.
Proof. Let us prove statement 1. First we will reason by induction according to the complexity of and according to the predicate of the literal content:
Suppose, as an induction hypothesis, that n is a natural number and that for any natural number k such that , holds. We have the following cases:
By the second principle of finite induction, for any natural number n is true and hence the implication. Reciprocally, let us now consider the predicate :
Suppose, as an induction hypothesis, that n is a natural number and that for any natural number k, such that , holds. We have the following cases:
; then let —as the only case of interest— . Since it follows that is true.
; let such that and . In principle, the following are possible:
- -
there exist
, such that
; then
- -
there exist
, such that
; then
so that is true.
By the
second principle of finite induction, for any natural number
n,
holds and hence the implication. Statement 2 can be proved with the same scheme as above. Suppose now that
. Since
, we have that
and if there exist
, such that
, then one would have
which is absurd, so
. The reciprocal statement is obviously true and it follows that
. □
The proof of Lemma 5 is straightforward from Lemma 4.
Lemma 5. For all :
- 1.
If then .
- 2.
If then .
- 3.
and if, and only if, .
Remark 5. The respective reciprocal statements of the first two sentences of Lemma 5 are not true. Indeed, (resp. ), and yet (resp. ).
Lemma 6 characterises the elements of and . Its proof can be carried out by induction by making a careful distinction of cases.
Lemma 6. For all ,
- 1.
and if, and only if, .
- 2.
and if, and only if, .
Lemma 7. For all , the following statements are equivalent:
- 1.
and .
- 2.
.
Remark 6. The formula satisfies , but ; hence the need for the restriction in the statement of Lemma 7.
By means of akr, the above technical lemmas make it possible to characterise in Theorem 2 the set of formulas in left conjunctive normal form. Note how ≤ appears in the statement, again highlighting the subtle role played by in the definition of akr.
Theorem 2. For all , the following statements are equivalent:
- 1.
.
- 2.
.
Proof. Let us first show that statement 1 is a sufficient condition for 2. to be fulfilled. The following cases are possible:
- 1.
; as stated in Lemma 5, .
- 2.
and ; as stated in Lemma 6, .
- 3.
and ; as stated in Lemma 6, .
- 4.
and ; as stated in Lemma 7, .
and hence, . However, 1 is a necessary condition for 2, which follows as a consequence of the aforementioned lemmas. □
Now everything is ready to carry out the accumulation of the functors A and K on the left side of the formula without changing its logical meaning. This task will be carried out by the function lasc, defined in Definition 5, by means of convenient iterations. The lasc function is the classical one, but formulated here univocally in a novel recursive way via rules.
Definition 5 (left associativity). Consider the following rules:
where (16)–(19) shall be applied with the priority from highest to lowest according to the order given. Les us now define the map by if, and only if, . It is clear that for any formula , is equivalent to (see Remark 2); therefore, lasc does not alter the logical meaning of the formulas by acting on them, although it does eventually alter their syntax. What is stated in Lemma 8 is obviously true.
Lemma 8. For all ,
- 1.
If then .
- 2.
If then .
Proof. The proof is by induction on the complexity of . □
Remark 7. It is also evident that for all As we can see, the reductive role of lasc on is very powerful when applying lasc to the formula ; as we can see, it is such that divides the “complexity of the situation” by 2, which inevitably invokes the logarithm in base 2. The information provided by Theorem 3 is crucial in this section, so we will give a detailed demonstration of it.
Theorem 3. For all :
- 1.
- 2.
- 3.
Proof. To prove 1, we will reason by induction about the complexity of using the predicate of the literal content:
Suppose, as an induction hypothesis, that n is a natural number and that for any natural number k such that holds. We have the following cases:
; must be , the formula for which is , as set out in Lemma 9.
; let —as the only case of interest— for certain . Let us distinguish the following cases:
- -
- -
; then
for certain
. In this case,
By the second principle of finite induction, for every natural number n, holds, hence the validity of statement 1. To prove 2, let us reason by induction about the complexity of according to the predicate of the literal content:
Suppose, as an induction hypothesis, that n is a natural number and that for any natural number k such that , holds. We have the following cases:
; must be , the formula for which is , as set out in Remark 7.
; let —as the only case of interest— for certain . Let us distinguish the following cases:
- -
- -
; then
for certain
. In this case,
By the
second principle of finite induction, for every natural number
n,
holds, hence the validity of statement 2. Statement 3 is immediate from statements 1 and 2, given that
□
Lemma 10. Let . The following statements are equivalent:
- 1.
- 2.
- 3.
Proof. To show that statement 1 implies statement 2, we will reason by induction about the complexity of according to the predicate of the literal content:
Suppose, as an induction hypothesis, that n is a natural number and that for any natural number k such that , holds. We distinguish the following cases:
By the
second principle of finite induction, for every natural number
n holds, hence the validity of statement 2. Let us now suppose that statement 2 is true, i.e., that
and that
; then, one has
from which we deduce that
, i.e., that statement 3 holds. Finally, suppose that
and that
. The following cases are possible (note that, according to statement 2 of Lemma 4, necessarily
):
This proves that under the assumption of statement 3. the fact is satisfied, as we sought to prove. □
In Theorem 4, the effects of alt and lasc are finally combined to characterise the formulas in .
Theorem 4. For all , the following statements are equivalent:
- 1.
.
- 2.
and .
- 3.
and .
Proof. Let be any formula in . Assume what statement 1 states, i.e., that . We will reason by induction about the complexity of according to the predicate of the literal content:
Suppose, as an induction hypothesis, that n is a natural number and that for any natural number k such that , holds. We distinguish the following cases:
By the
second principle of finite induction, for every natural number
n is true
, hence the validity of assertion 2. If we now assume that 2 is true, that
and that
is ensured by the Corollary 1. In particular, as a consequence of Theorem 3, we have
and therefore,
and
; thus, we have proved 3. Let us finally assume 3 to be true and show that
. Since
and again using Corollary 1, we know that
. According to Theorem 2, since
,
must necessarily hold and this is what statement 1 establishes. □
Definition 6. For all , is the natural number defined by the equality: Remark 8. Understanding the evaluation of the expressions from a “lazy” point of view, the following equality should be accepted:where, of course, is the characteristic function on the set . Let it also be noted that in the case where for the formula α one has , then is the number of digits in the (single) binary expression of when it is greater than 0, and 0 otherwise. Finally, the next corollary, Corollary 3, informs us that for any formula in , is a formula in left conjunctive normal form (equivalent to , of course) and that per iteration of lasc, the number of iterations is the smallest number of those that achieve it. It is based on how many times the function must be iterated to obtain zero, in order to express x in binary form. This gives us an estimate of the complexity of our algorithm: it is logarithmic, which is fantastic news. The corresponding result, with its complete proof, is given just below. The demonstration of the corollary is simple if we rely on this observation, and it can be carried out by inductive reasoning based on a careful distinction of cases.
Corollary 3. For all , is the smallest of the natural numbers m satisfying .






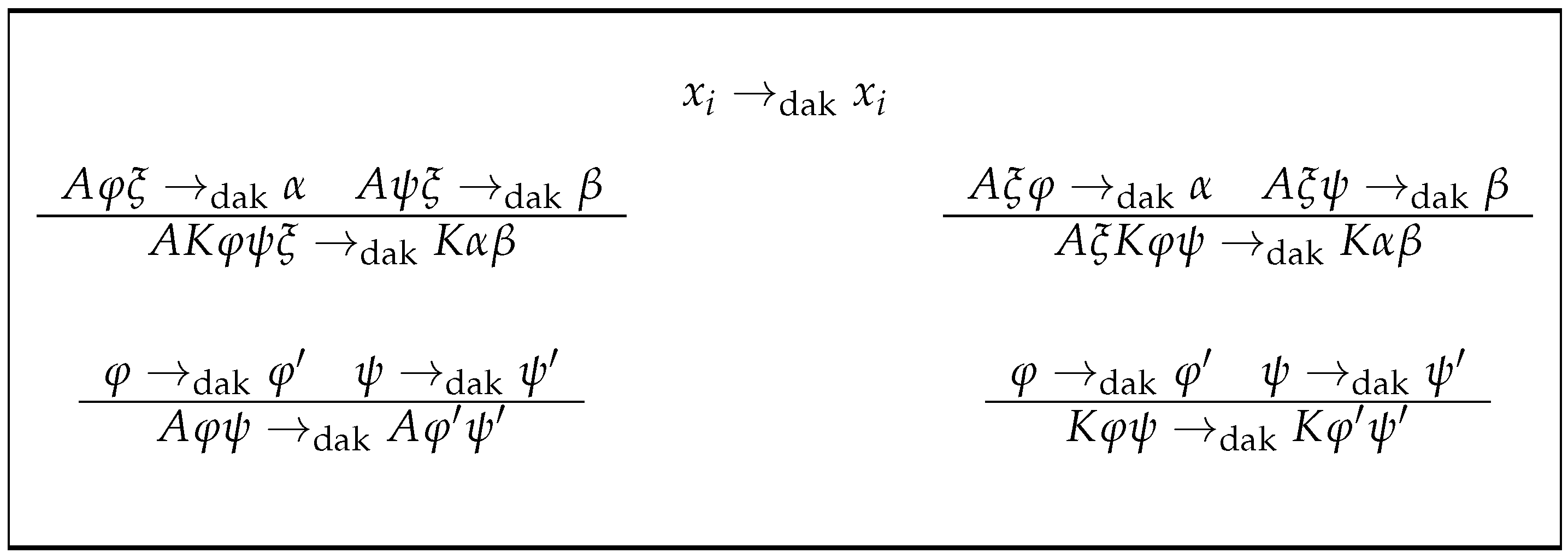{kind=link}
{kind=link}