
Deep Learning for Detecting Verticillium Fungus in Olive Trees: Using YOLO in UAV Imagery



Abstract
1. Introduction
2. Background
2.1. Verticillium Wilt
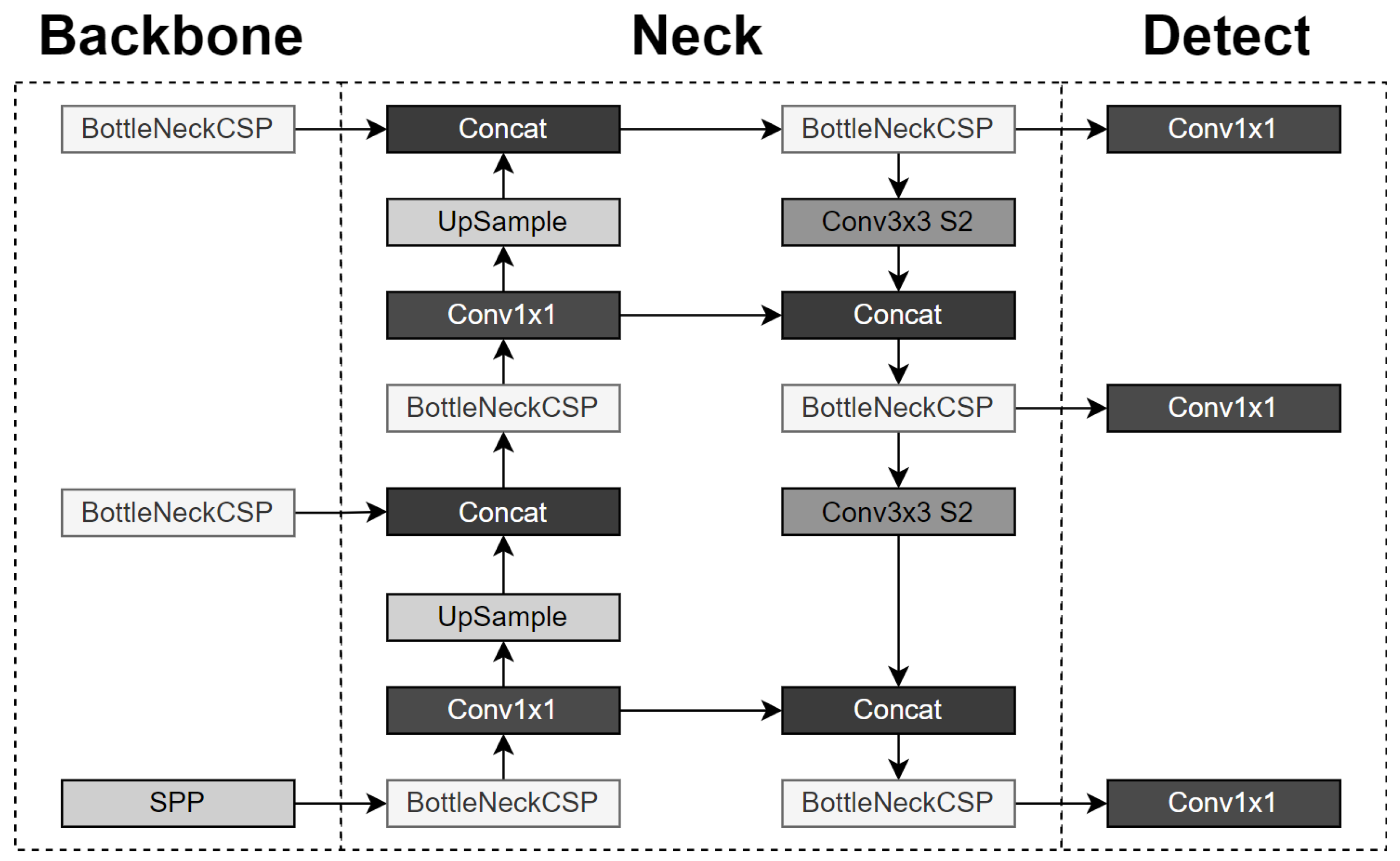
2.2. You Only Look Once (YOLO) Algorithm
3. Related Work
4. Materials and Methods
- Precision:
- Recall:where = true positives, = false positives, = false negatives.
- Mean Average Precision, or , which is the mean of Average Precision () values calculated for a certain threshold (e.g., [0.5]: for threshold value of 0.5) or range of thresholds (e.g., [0.5:0.95]: for threshold values of 0.5 up to 0.95 with a step of 0.05) for all classes:withwhere is the precision–recall curve, is the 101-point interpolated recall value and n is the class.
5. Results
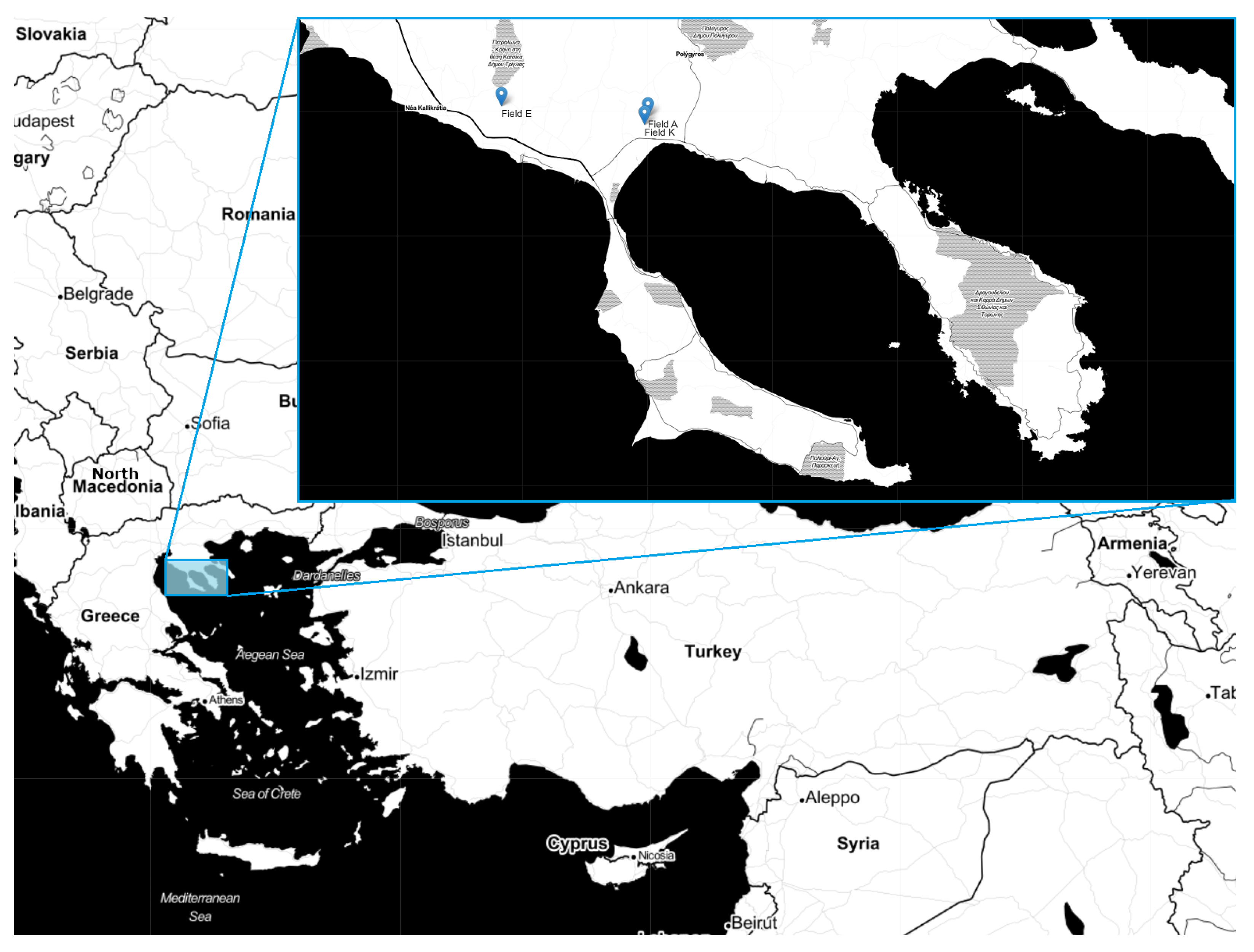
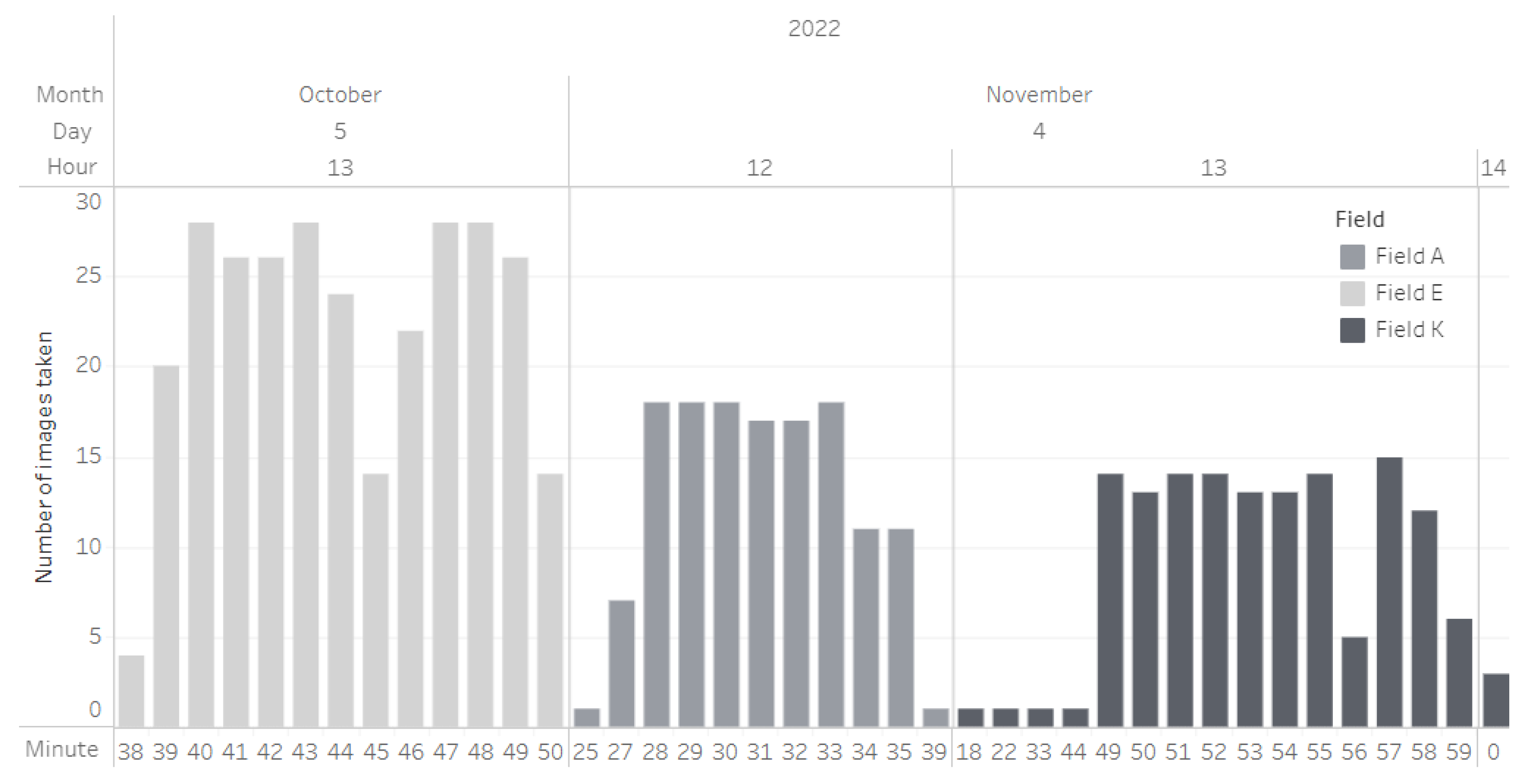
5.1. Data Collection and Dataset Processing
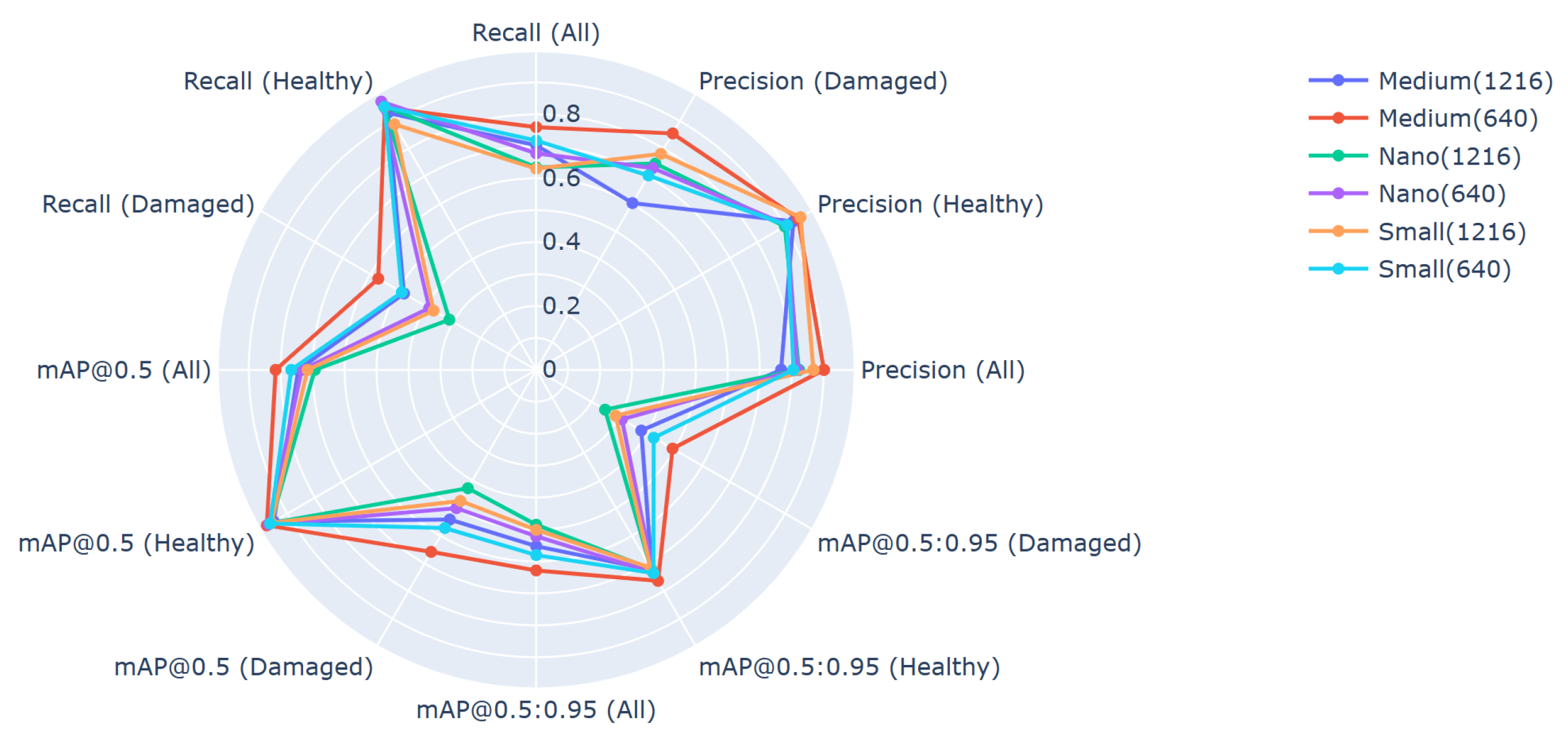
5.2. Application of the YOLOv5 Algorithm
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ruggieri, G. Una nuova malatia dell’olivo. L’Italia Agric. 1946, 83, 369–372. [Google Scholar]
- Pérez-Rodríguez, M.; Serrano, N.; Arquero, O.; Orgaz, F.; Moral, J.; López-Escudero, F.J. The Effect of Short Irrigation Frequencies on the Development of Verticillium Wilt in the Susceptible Olive Cultivar ‘Picual’ under Field Conditions. Plant Dis. 2016, 100, 1880–1888. [Google Scholar] [CrossRef]
- López-Escudero, F.J.; Mercado-Blanco, J. Verticillium wilt of olive: A case study to implement an integrated strategy to control a soil-borne pathogen. Plant Soil 2010, 344, 1–50. [Google Scholar] [CrossRef]
- Alstrom, S. Characteristics of Bacteria from Oilseed Rape in Relation to their Biocontrol Activity against Verticillium dahliae. J. Phytopathol. 2001, 149, 57–64. [Google Scholar] [CrossRef]
- Fichtel, L.; Frühwald, A.M.; Hösch, L.; Schreibmann, V.; Bachmeir, C.; Bohlander, F. Tree Localization and Monitoring on Autonomous Drones employing Deep Learning. In Proceedings of the 2021 29th Conference of Open Innovations Association (FRUCT), Tampere, Finland, 12–14 May 2021; pp. 132–140. [Google Scholar] [CrossRef]
- Safonova, A.; Hamad, Y.; Alekhina, A.; Kaplun, D. Detection of Norway Spruce Trees (Picea Abies) Infested by Bark Beetle in UAV Images Using YOLOs Architectures. IEEE Access 2022, 10, 10384–10392. [Google Scholar] [CrossRef]
- Puliti, S.; Astrup, R. Automatic detection of snow breakage at single tree level using YOLOv5 applied to UAV imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102946. [Google Scholar] [CrossRef]
- Snyder, W.C.; Hansen, H.N.; Wilhelm, S. New hosts of Verticillium alboatrum. Plant Dis. Report. 1950, 34, 26–27. [Google Scholar]
- Zachos, G.D. La verticilliose de l’olivier en Greece. Benaki Phytopathol. Inst. 1963, 5, 105–107. [Google Scholar]
- Geiger, J.; Bellahcene, M.; Fortas, Z.; Matallah-Boutiba, A.; Henni, D. Verticillium wilt in olive in Algeria: Geographical distribution and extent of the disease. Olivae 2000, 82, 41–43. [Google Scholar]
- Jiménez-Díaz, R.; Tjamos, E.; Cirulli, M. Verticillium wilt of major tree hosts: Olive. In A Compendium of Verticillium Wilts in Tree Species; CPRO: Wageningen, The Netherlands, 1998; pp. 13–16. [Google Scholar]
- Levin, A.; Lavee, S.; Tsror, L. Epidemiology of Verticillium dahliae on olive (cv. Picual) and its effect on yield under saline conditions. Plant Pathol. 2003, 52, 212–218. [Google Scholar] [CrossRef]
- Naser, Z.; Al-Raddad Al-Momany, A. Dissemination factors of Verticillium wilt of olive in Jordan. Dirasat. Agric. Sci. 1998, 25, 16–21. [Google Scholar]
- Porta-Puglia, A.; Mifsud, D. First record of Verticillium dahliae on olive in Malta. J. Plant Pathol. 2005, 87, 149. [Google Scholar]
- Sanei, S.; Okhoavat, S.; Hedjaroude, G.A.; Saremi, H.; Javan-Nikkhah, M. Olive verticillium wilt or dieback of olive in Iran. Commun. Agric. Appl. Biol. Sci. 2004, 69, 433–442. [Google Scholar] [PubMed]
- Saydam, C.; Copcu, M. Verticillium wilt of olives in Turkey. J. Turk. Phytopathol. 1972, 1, 45–49. [Google Scholar]
- Sergeeva, V.; Spooner-Hart, R. Olive diseases and disorders in Australia. Olive Dis. Disord. Aust. 2009, 59, 29–32. [Google Scholar]
- Báidez, A.G.; Gómez, P.; Río, J.A.D.; Ortuño, A. Dysfunctionality of the Xylem in Olea europaea L. Plants Associated with the Infection Process by Verticillium dahliae Kleb. Role of Phenolic Compounds in Plant Defense Mechanism. J. Agric. Food Chem. 2007, 55, 3373–3377. [Google Scholar] [CrossRef] [PubMed]
- Pegg, G.F.; Brady, B.L. Verticillium Wilts; CABI Publishing: Oxfordshire, UK, 2002. [Google Scholar]
- Blanco-López, M.A.; Jiménez-Díaz, R.M.; Caballero, J.M. Symptomatology, incidence and distribution of Verticillium wilt of Olive trees in Andalucía. Phytopathol. Mediterr. 1984, 23, 1–8. [Google Scholar]
- Thanassoulopoulos, C.C.; Biris, D.A.; Tjamos, E.C. Survey of verticillium wilt of olive trees in greece. Plant Dis. Report. 1979, 63, 936–940. [Google Scholar]
- Ayres, P. Water relations of diseased plants. In Water Deficits and Plant Growth; Kozlowski, T.T., Ed.; Academic Press: New York, NY, USA, 1978. [Google Scholar]
- Trapero, C.; Alcántara, E.; Jiménez, J.; Amaro-Ventura, M.C.; Romero, J.; Koopmann, B.; Karlovsky, P.; von Tiedemann, A.; Pérez-Rodríguez, M.; López-Escudero, F.J. Starch Hydrolysis and Vessel Occlusion Related to Wilt Symptoms in Olive Stems of Susceptible Cultivars Infected by Verticillium dahliae. Front. Plant Sci. 2018, 9, 72. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5 by Ultralytics. Zenodo 2020. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, J.; Yang, Y.; Liu, L.; Liu, F.; Kong, W. Rapid Target Detection of Fruit Trees Using UAV Imaging and Improved Light YOLOv4 Algorithm. Remote Sens. 2022, 14, 4324. [Google Scholar] [CrossRef]
- Tian, H.; Fang, X.; Lan, Y.; Ma, C.; Huang, H.; Lu, X.; Zhao, D.; Liu, H.; Zhang, Y. Extraction of Citrus Trees from UAV Remote Sensing Imagery Using YOLOv5s and Coordinate Transformation. Remote Sens. 2022, 14, 4208. [Google Scholar] [CrossRef]
- Özer, T.; Akdoğan, C.; Cengız, E.; Kelek, M.M.; Yildirim, K.; Oğuz, Y.; Akkoç, H. Cherry Tree Detection with Deep Learning. In Proceedings of the 2022 Innovations in Intelligent Systems and Applications Conference (ASYU), Antalya, Turkey, 7–9 September 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Jintasuttisak, T.; Edirisinghe, E.; Elbattay, A. Deep neural network based date palm tree detection in drone imagery. Comput. Electron. Agric. 2022, 192, 106560. [Google Scholar] [CrossRef]
- Aburasain, R.Y.; Edirisinghe, E.A.; Albatay, A. Palm Tree Detection in Drone Images Using Deep Convolutional Neural Networks: Investigating the Effective Use of YOLO V3. In Digital Interaction and Machine Intelligence; Biele, C., Kacprzyk, J., Owsiński, J.W., Romanowski, A., Sikorski, M., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 21–36. [Google Scholar]
- Chowdhury, P.N.; Shivakumara, P.; Nandanwar, L.; Samiron, F.; Pal, U.; Lu, T. Oil palm tree counting in drone images. Pattern Recognit. Lett. 2022, 153, 1–9. [Google Scholar] [CrossRef]
- Wibowo, H.; Sitanggang, I.; Mushthofa, M.; Adrianto, H. Large-Scale Oil Palm Trees Detection from High-Resolution Remote Sensing Images Using Deep Learning. Big Data Cogn. Comput. 2022, 6, 89. [Google Scholar] [CrossRef]
- Sun, Z.; Ibrayim, M.; Hamdulla, A. Detection of Pine Wilt Nematode from Drone Images Using UAV. Sensors 2022, 22, 4704. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5375–5384. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; Van Der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 181–196. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 1. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Learning to model the tail. Adv. Neural Inf. Process. Syst. 2017, 30, 1. [Google Scholar]
- Chen, S.; Yang, D.; Liu, J.; Tian, Q.; Zhou, F. Automatic weld type classification, tacked spot recognition and weld ROI determination for robotic welding based on modified YOLOv5. Robot. Comput.-Integr. Manuf. 2023, 81, 102490. [Google Scholar] [CrossRef]
- Bjerge, K.; Alison, J.; Dyrmann, M.; Frigaard, C.E.; Mann, H.M.R.; Høye, T.T. Accurate detection and identification of insects from camera trap images with deep learning. PLoS Sustain. Transform. 2023, 2, e0000051. [Google Scholar] [CrossRef]
- Kubera, E.; Kubik-Komar, A.; Kurasiński, P.; Piotrowska-Weryszko, K.; Skrzypiec, M. Detection and Recognition of Pollen Grains in Multilabel Microscopic Images. Sensors 2022, 22, 2690. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Jin, Y.; Ruan, Z.; Ma, Z.; Gao, R.; Su, Z. Real-Time Detection of Seedling Maize Weeds in Sustainable Agriculture. Sustainability 2022, 14, 15088. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv5 Architecture | Depth_Multiple | Width_Multiple | ResNet in CSPNet | Convolution Kernel |
|---|---|---|---|---|
| Medium | 0.67 | 0.75 | 24 | 768 |
| Small | 0.33 | 0.50 | 12 | 512 |
| Nano | 0.33 | 0.25 | 12 | 256 |
| Reference | YOLO Version Tested | Number of Images | UAV Flight Altitude |
|---|---|---|---|
| [28] | YOLOv5 | - | 50 m |
| [29] | YOLOv5 (s, m, x) | 889 | - |
| [30] | YOLOv5 | 125 | 122 m |
| [31] | YOLOv3 | 221 | - |
| [32] | Improved version of YOLOv5 | 1558 | - |
| [33] | YOLOv3, v4, v5m | 17,343 | 200 m |
| Field A | Field E | Field K | |
|---|---|---|---|
| Number and percentage of healthy instances | 804 (92.94%) | 927 (98.82%) | 1102 (89.23%) |
| Number and percentage of damaged instances | 61 (7.05%) | 11 (1.17%) | 133 (10.76%) |
| Train | Validation | Test | |
|---|---|---|---|
| Number and percentage of healthy instances | 1610 (92.36%) | 591 (93.95%) | 631 (94.74%) |
| Number and percentage of damaged instances | 133 (7.63%) | 38 (6.04%) | 35 (5.25%) |
| Architecture | Model Input Size | Max Fitness Epoch | Max Model Fitness Reached |
|---|---|---|---|
| Nano | 640 × 640 | 282 | 0.577714 |
| Nano | 1216 × 1216 | 300 | 0.569750 |
| Small | 640 × 640 | 208 | 0.587946 |
| Small | 1216 × 1216 | 269 | 0.616960 |
| Medium | 640 × 640 | 263 | 0.640254 |
| Medium | 1216 × 1216 | 262 | 0.652587 |
| Architecture | Model Input Size | Preprocessing Speed | Inference Speed | NMS Speed |
|---|---|---|---|---|
| Nano | 640 × 640 | 1.0 | 94.7 | 5.9 |
| Nano | 1216 × 1216 | 1.0 | 77.5 | 2.5 |
| Small | 640 × 640 | 1.0 | 178.9 | 2.4 |
| Small | 1216 × 1216 | 1.0 | 168.0 | 1.5 |
| Medium | 640 × 640 | 1.3 | 328.8 | 1.5 |
| Medium | 1216 × 1216 | 1.0 | 318.0 | 2.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mamalis, M.; Kalampokis, E.; Kalfas, I.; Tarabanis, K. Deep Learning for Detecting Verticillium Fungus in Olive Trees: Using YOLO in UAV Imagery. Algorithms 2023, 16, 343. https://doi.org/10.3390/a16070343
Mamalis M, Kalampokis E, Kalfas I, Tarabanis K. Deep Learning for Detecting Verticillium Fungus in Olive Trees: Using YOLO in UAV Imagery. Algorithms. 2023; 16(7):343. https://doi.org/10.3390/a16070343
Chicago/Turabian StyleMamalis, Marios, Evangelos Kalampokis, Ilias Kalfas, and Konstantinos Tarabanis. 2023. "Deep Learning for Detecting Verticillium Fungus in Olive Trees: Using YOLO in UAV Imagery" Algorithms 16, no. 7: 343. https://doi.org/10.3390/a16070343
APA StyleMamalis, M., Kalampokis, E., Kalfas, I., & Tarabanis, K. (2023). Deep Learning for Detecting Verticillium Fungus in Olive Trees: Using YOLO in UAV Imagery. Algorithms, 16(7), 343. https://doi.org/10.3390/a16070343