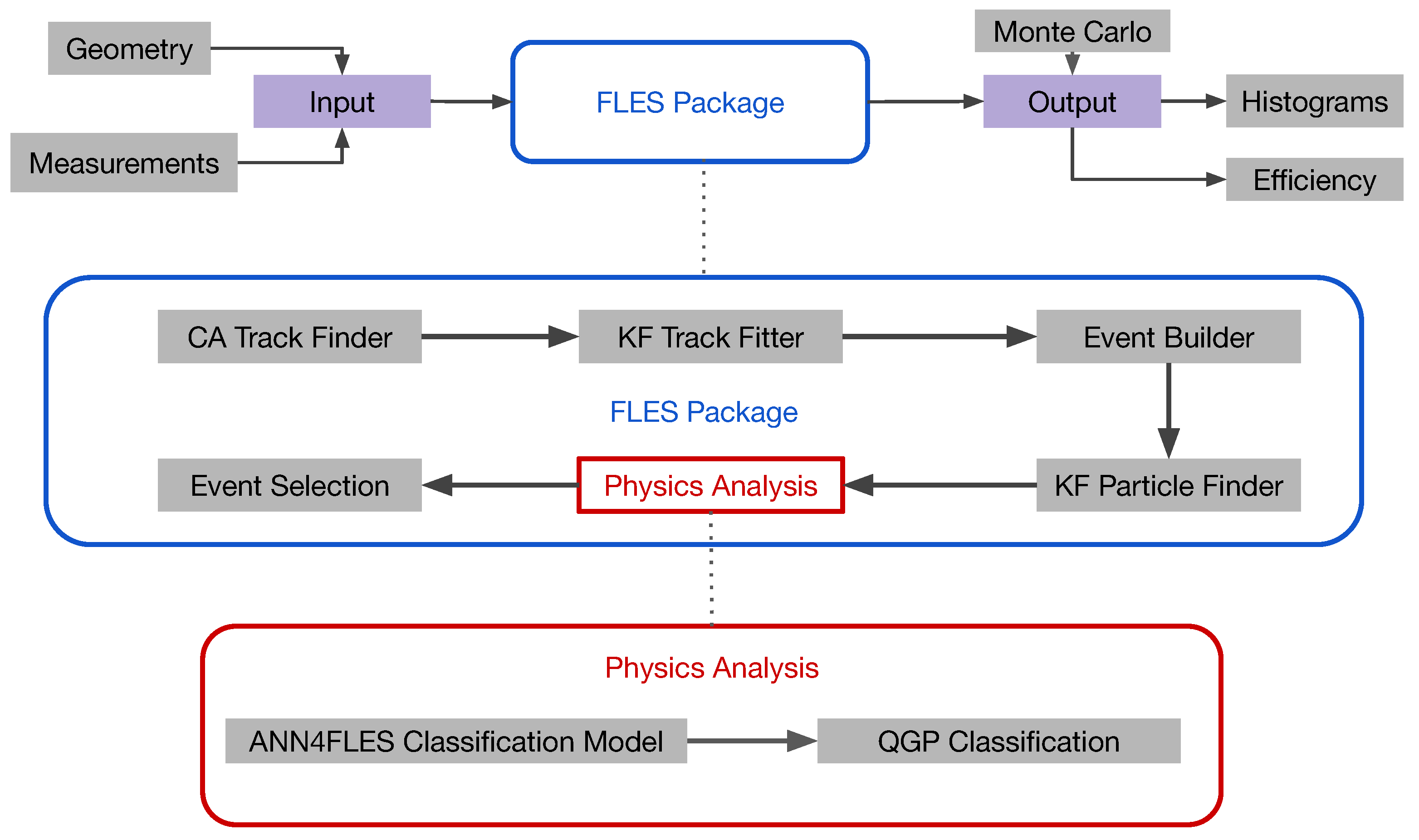
2.1. Input Data
The dataset created with the PHSD model consists of 10,000 events, half of which contain quark–gluon plasma information, referred to as () and the other half without quark–gluon plasma information, referred to as (). The data were simulated for central Au + Au collisions at a constant energy of 31.2 A GeV. This dataset is divided into 2 sets of 8000 and 2000 randomly selected events. The first set is used to train the neural network, and the second set is used for testing.
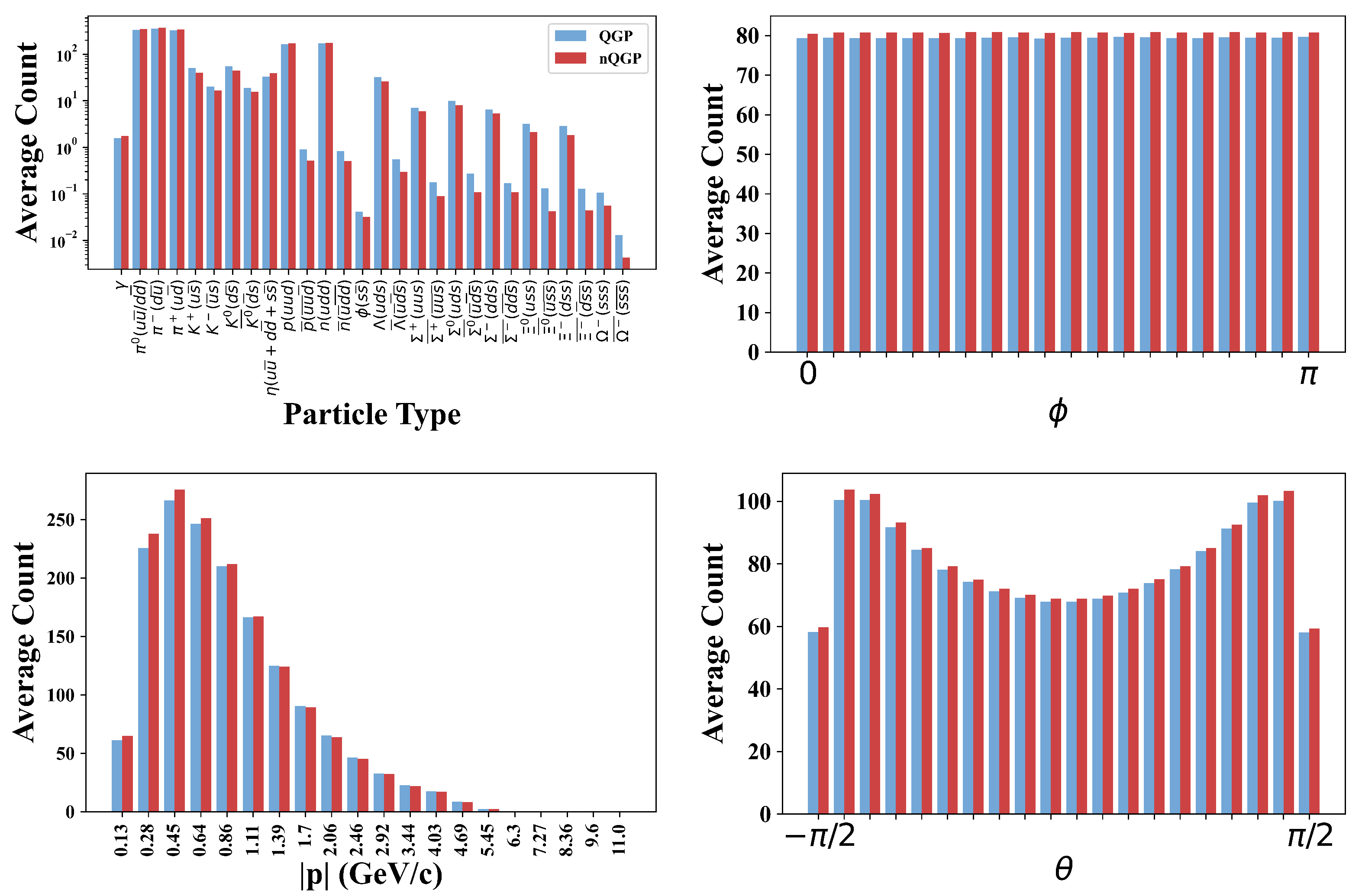
On average, each simulated collision produces around 1600 particles, most of which are quite rare. From all the particles recorded in the simulation, only 28 types of particles appear at least once in every 1000 events and were chosen as input features for the neural-network-based approaches. That way, it is possible to reduce the total size of the model as well as discard particles that are relatively less common and are assumed to have less impact on training. The remaining particles are produced too rarely to affect the trigger performance and might even be a hindrance in the training of the models. From the raw data for these 28 types of particles, the observables measured are the absolute value of momentum
, inclination angle or angle made by the momentum of the particle with respect to the positive direction of the beam axis
, and azimuthal angle
. This information is then entered into an array in such a way that the information for a single particle is split into 20 intervals for each of the observable, with the angle information divided into equal intervals and the absolute momentum value divided into 20 logarithmically spaced intervals. As most particles possess relatively small momentum, this enables the array to be more densely populated. So, the total length of the array comes out to be
for the complete 28 particles. Consequently, each event corresponds to a total of 22,400 input values or features which are the 28 different particles with each particle having a total of 8000 features from the 20 intervals for each of the
,
, and
bins. This flattened structure will be used as an input for the fully-connected networks. This can also be arranged as a 4D array, with dimensions
, and serves as the input for the convolutional neural networks. The distribution of input information for the average over simulated events is shown in
Figure 2.
On average, for the simulated dataset, nQGP collisions produce slightly more particles than QGP collisions. This can be seen clearly in the
distribution (top right) in
Figure 2. It should also be noted, from the top left panel of
Figure 2, that more heavy strange baryons are created in QGP collisions. This strange enhancement is a signature of QGP formation [
10].
2.2. Neural Networks
Feedforward Neural Networks or MultiLayer Perceptrons (MLPs) [
11] are among the architectures used for classification in this study. Using MLP enables the construction of models that are easy to implement as well as to train. MLPs are very popular models for supervised learning and are commonly used for classification and regression tasks [
12]. A supervised learning procedure means that the network builds a model based on labeled data.
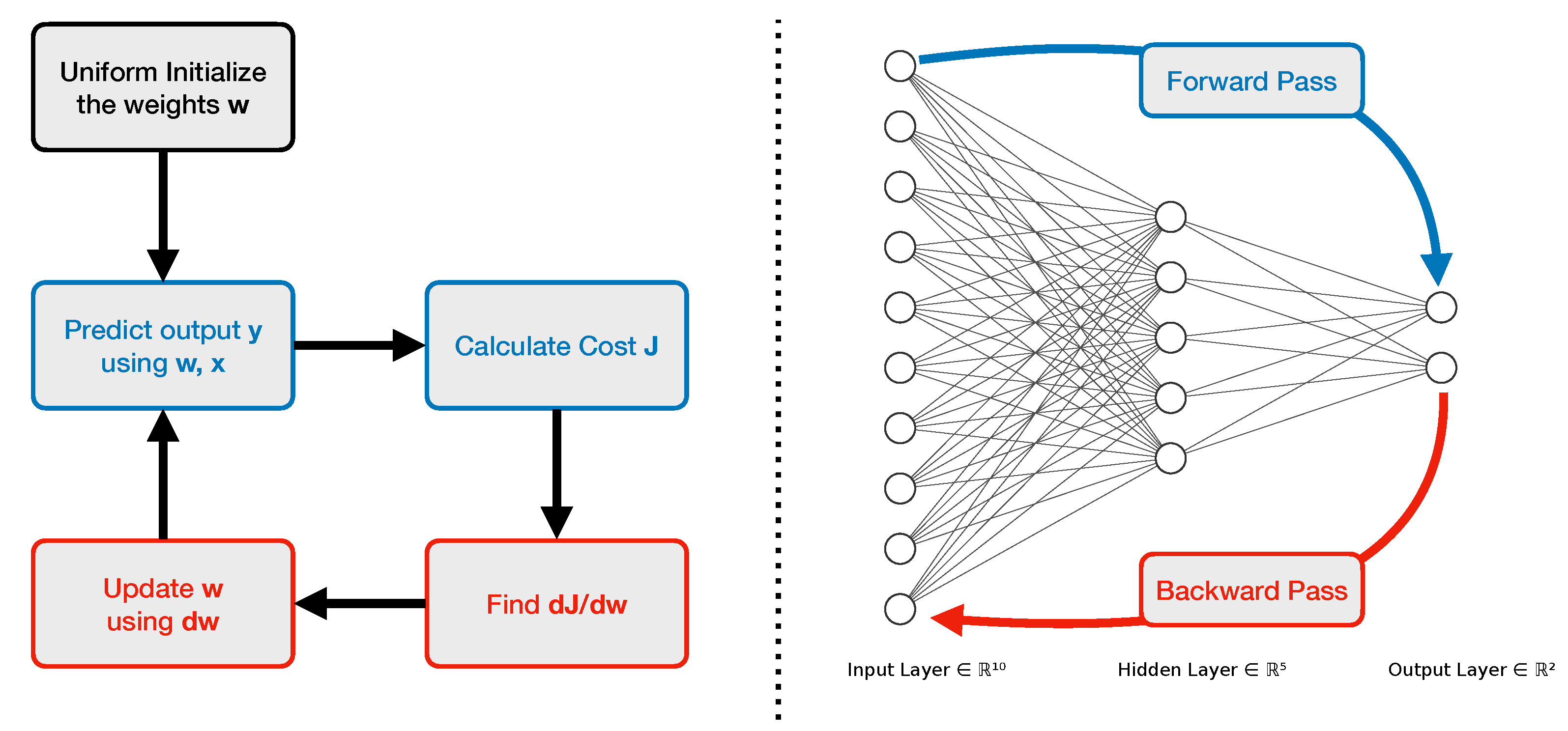
A MLP comprises three types of layers (input, hidden, and output) each with several nonlinear computational units (also called neurons). The information flows from the input layer to the output layer through the hidden layer(s) [
13]. Typically neurons from one layer are all connected to neurons in the adjacent fully-connected layers as shown in
Figure 3. The connection strengths are represented by weights in the computational process. The weights can be thought of as the parameters of the function the neural network is trying to approximate. The number of neurons in the input layer depends on the number of predictor variables in the examples of the dataset, whereas the number of neurons in the output layer is the same as the number of target or true value variables in the examples of the dataset. It can also be the number of variables required to produce the output for the required task. These multi-layer connections along with the activation function enable such networks to approximate a large class of functions with a high degree based on the number of hidden units [
14].
The primary operation in MLPs can be represented as:
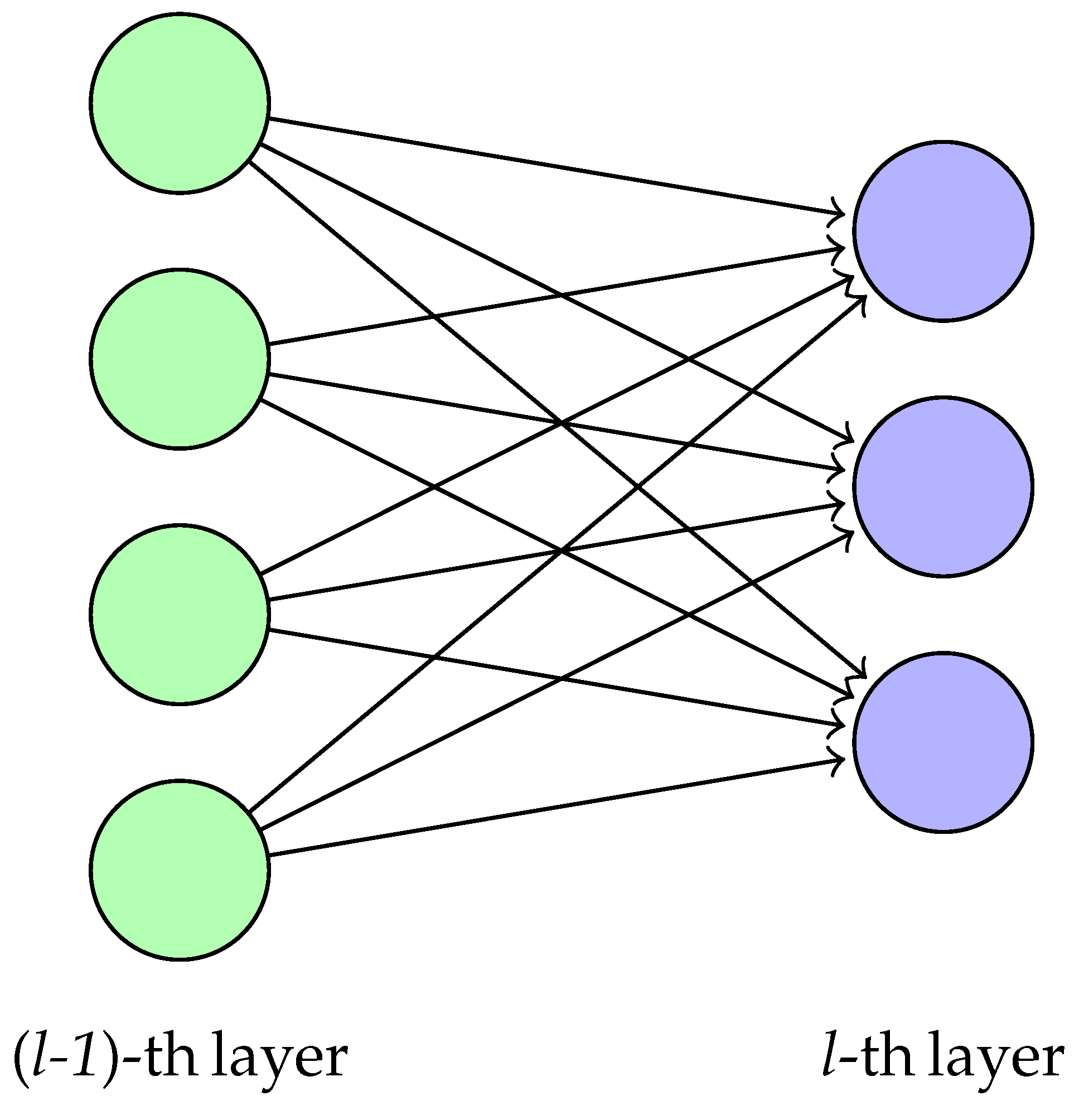
where neurons in the
n-th hidden layer are constructed from the neurons in the (
n − 1)-th, with 0-th layer being the input layer and the final layer being the output layer. Since every neuron in one layer is used to create a single neuron of the next layer, the corresponding weight matrix
would be
where
and
are the number of neurons in the (
n − 1)-th layer and
n-th layer, respectively, see
Figure 4. Here,
is the bias parameter for the
n-th layer, which helps in learning an overall shift for the output and would have the same size as the number of neurons in that layer.
is the activation function that usually serves the purpose of introducing non-linearity to the network and increasing its representative capacity.
and
are neurons in the
n-th and (
n − 1)-th layers, respectively.
The number of fully-connected hidden layers or network depth can be increased in an attempt to capture the optimal representational capacity of the network for this specific type of input and task that should be performed. A comparison of the performance of MLP models with different network depths for their architectures has been carried out by [
15].
The other type of network used is the Convolutional Neural Network (CNN) [
16]. As compared to the MLPs explained above, these types of networks are more capable of capturing position-dependent features of the data. CNNs are commonly used for grid-like data in multi-dimensional space. One of the popularly used examples of this is the object detection or image recognition models, which utilize the grid-like arrangement of pixels in 2D space with usually color information as the third dimension. A similar correspondence can be drawn to such image data with the input data used in this analysis. The dataset used in this study can be viewed as a grid-like arrangement of three observables, namely (
), (
), and (
), of the most common particles in QGP and non-QGP events. The structure of the convolutional neural network used for QGP detection is shown in
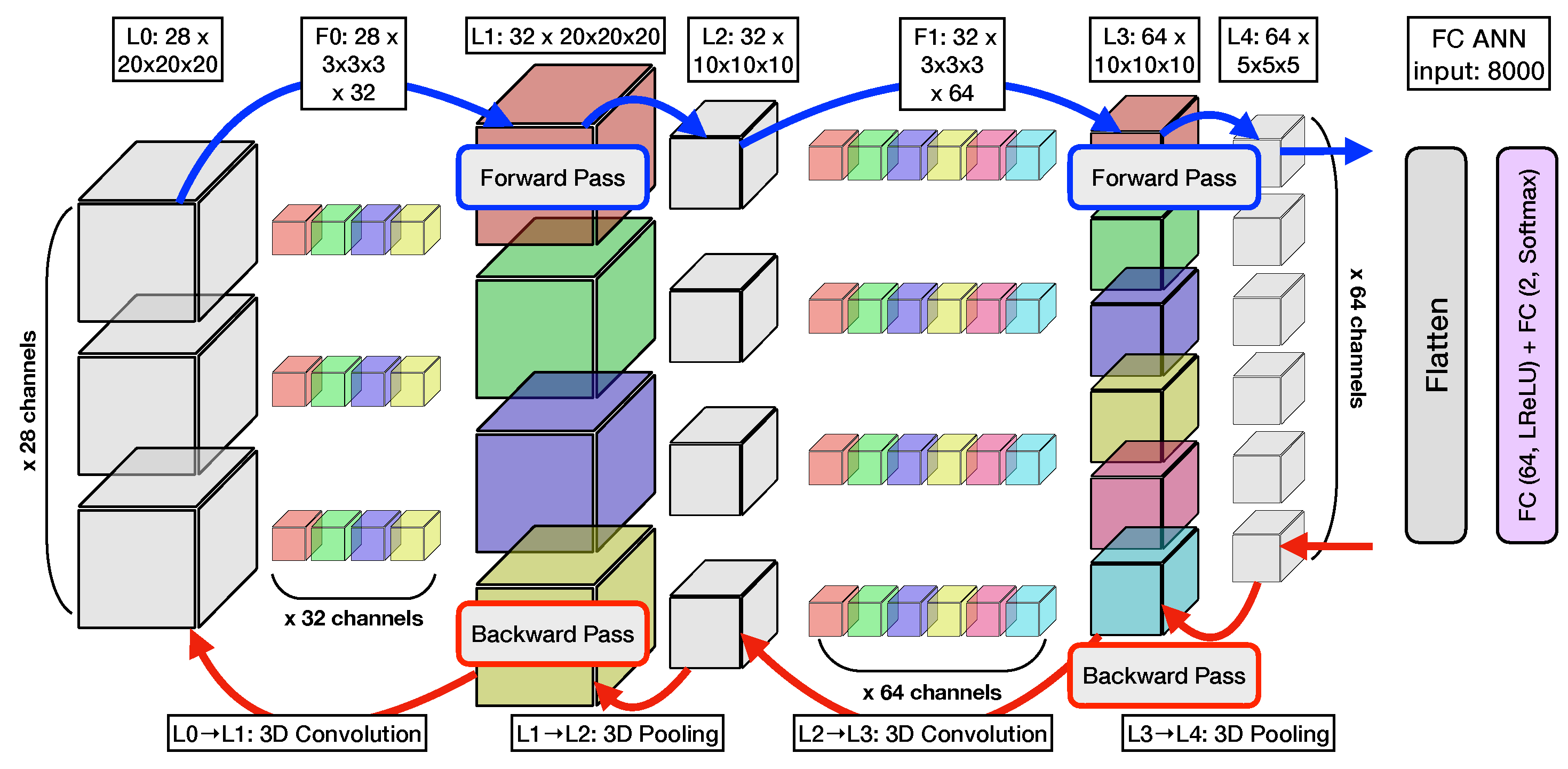
Figure 5.
CNNs are primarily based on the mathematical operation of the convolution [
17], denoted by the operator ∗ and are generally defined as follows:
where
and
are signals on the real line
for a 1D dataset. In general, as input data are usually discrete signals/data in real-world applications, it is more suitable to use the discrete version of the above equation:
It is important to note that in CNNs, although the operation is termed as convolution, it is actually cross-correlation. Basically, in a CNN or for the cross-correlation operation, there will not be a flip of the filter as is required in typical convolutions. However, except for this flip, both operations are identical.
CNNs have a local connection between specific regions in the input data and the corresponding units in the subsequent layer. In general, multiple filters can be applied to create a set of feature maps. Through the learning process, the filters are trained to capture abstract structural features of the data that help to match the desired output and reduce the corresponding cost function [
18]. This makes them very suitable for classification tasks, as is the case for this analysis, but their applications extend to regression tasks as well.
With regards to practical implementation, there are also the benefits of parameter sharing, which increase its efficiency, reduce the overall complexity of the network, and help with overfitting issues. Some examples of possible applications of CNN in the field of particle physics include regression tasks such as Pileup Mitigation in
reconstruction [
19] and classification tasks include quark–gluon jet discrimination [
20].
In general, there can be three different types of convolution such as valid, same, and full convolutions. It depends on the size of the output feature map compared to the input feature map, such as if the output map is smaller (valid), same (same), or bigger (full) than the input map.
An example of forward pass in convolutional layers is shown below, which shows the application of valid convolution with
kernel and
input map.
It is very common to see a max-pooling layer either right after a convolution layer or after multiple ones. The main objective here is to extract the sharpest features of the input data. It also helps with reducing the dimension of the output feature map and computations. In the max-pooling layer, instead of matrix calculations in the convolution operation above, the maximum element from the group of elements coinciding with the elements of the filter size is selected.
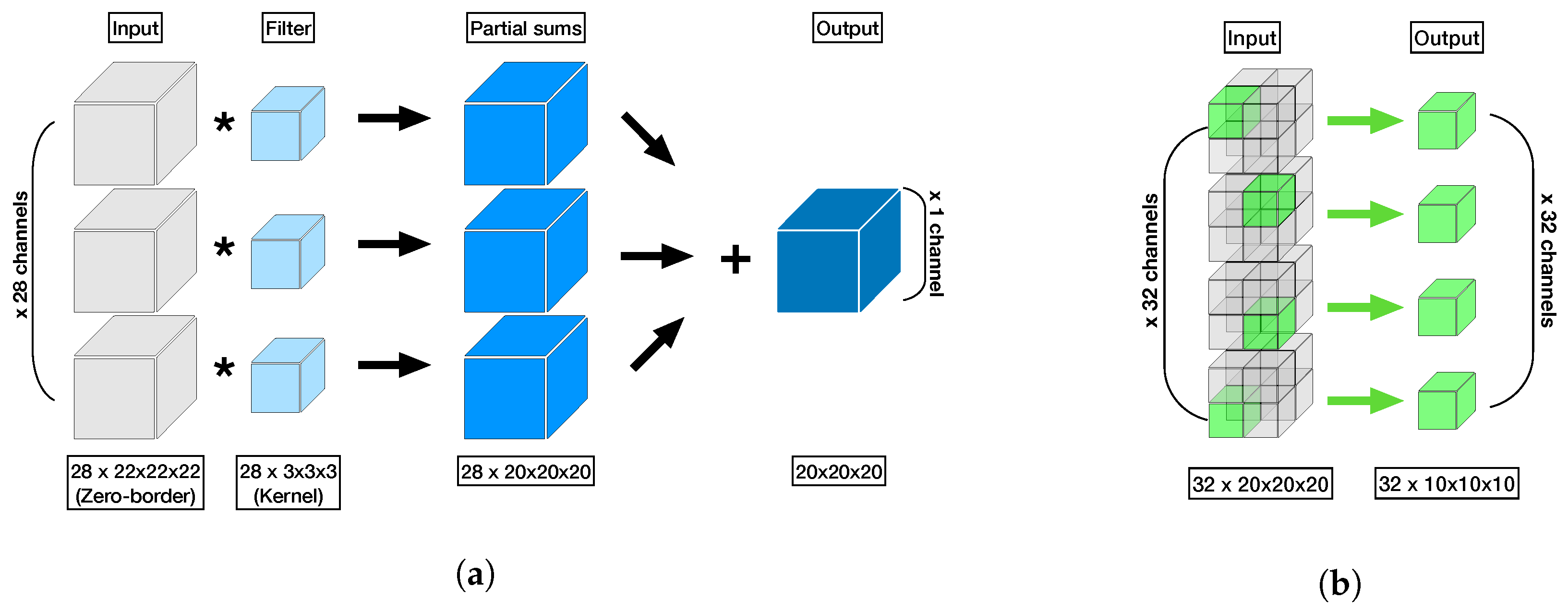
In the case of 3D convolution, there will also be analogous calculations in the third dimension for both the kernel and input feature map such as shown in
Figure 6a. This also applies to max-pooling in 3D as shown in
Figure 6b. In the case of same convolution, as applied in this study, the input feature map will be padded with zeroes, called zero-padding, before applying the convolution in order to obtain an output feature map of the same dimension as the input feature map. Taking the above 2D convolution as an example again, the corresponding convolution operation in matrix multiplication can be expressed as follows:
In the above convolution, a zero-padding of width 1 is used to achieve a same convolution output. The backpropagation for such a convolution operation can be found using a similar convolution operation but changing the kernel and input depending on whether the gradient with respect to the weight matrix or the input gradient is required. The gradient with respect to the weight parameters is given as
which can be translated to the matrix form, when taking the 2D convolution without padding for the sake of matrix size, as (here it is a valid convolution because the output feature map is smaller than the input one):
and that for the input gradient the convolution in matrix form can be represented if the kernel is rotated and zero-padding is added to the output so that there is proper matching of the kernel elements and output elements in the order where it appeared in the forward pass convolution.
These equations involve computations of the gradients of the loss function
with respect to the output feature map
, the kernel
, and the input feature map
in the backward pass of 2D convolution using explicit matrix multiplication. See
Figure 5 for 3D cube-like representation of the
,
, and
matrices and the corresponding convolution operations for the model used in this analysis.
2.3. Neural Network Models
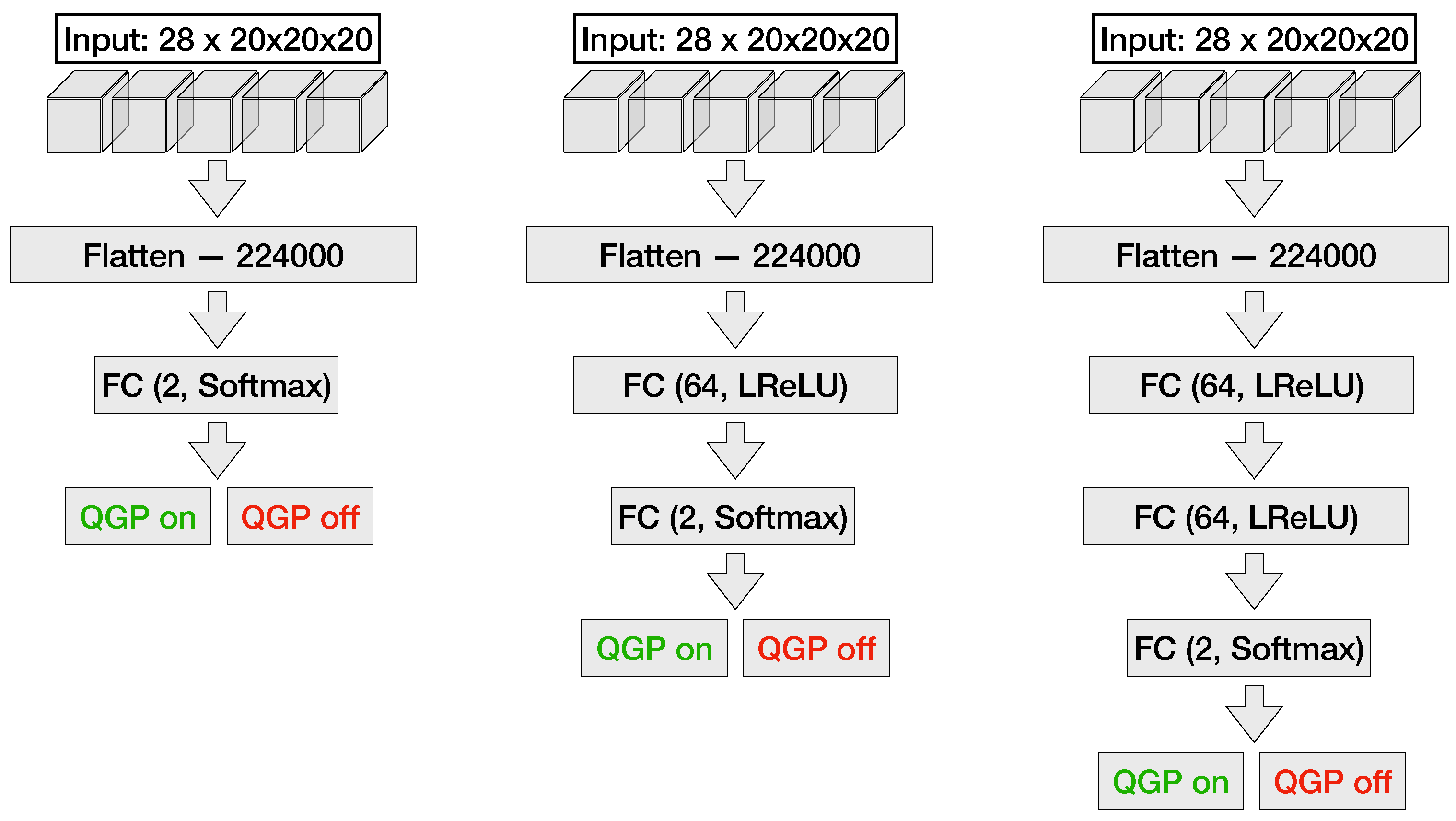
For MLP networks (shown in
Figure 7), a hidden layer with 64 fully-connected neurons complemented by Leaky Rectified Linear Unit (LReLU) [
21] activation function is implemented. The number of neurons is determined empirically and remains constant to allow comparison of FC neural networks with varying numbers of layers. LReLU is chosen for its performance, which is akin to the widely used Rectified Linear Unit (ReLU) activation function, but it circumvents issues related to dead neurons [
22]. For the learning process, the adaptive moment estimation (ADAM) [
23] algorithm is used to optimize the network parameters after each step. The ADAM algorithm updates exponential moving averages of the gradient (
) and the squared gradient (
), which themselves are estimates of the 1st moment (the mean) and the 2nd raw moment (the uncentered variance) of the gradient with the hyper-parameters
,
, which control the exponential decay rates of these moving averages with respective values 0.9 and 0.999. The values for
and
are 0.001 and
, respectively [
23].
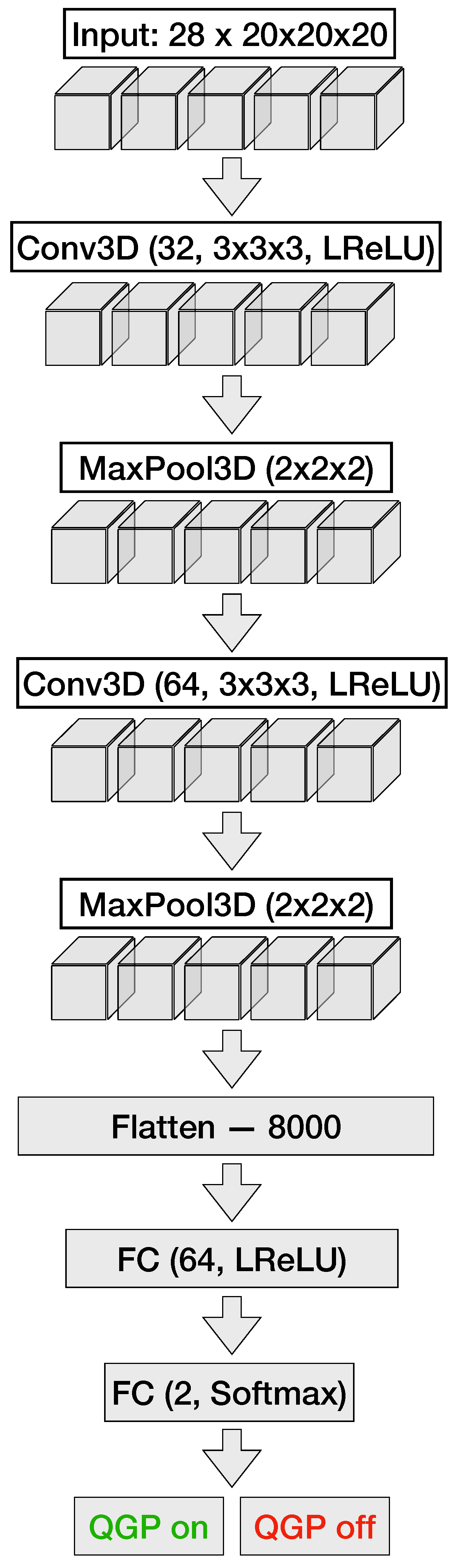
The architecture of the CNN (shown in
Figure 8) is composed of two three-dimensional convolutional layers, each succeeded by a max-pooling layer, and two sequentially arranged fully-connected layers. The initial convolutional layer contains 32 filters of size
, with a zero-padding of
and a stride of
, thus preserving the spatial dimensions of the input. The convolution is then followed by a max-pooling operation with a filter size of
and stride of
, leading to a halving of the spatial dimensions. The second convolutional layer consists of 64 filters of identical size and employs the same padding and stride length as the preceding convolutional layer. It is subsequently followed by a max-pooling layer with an identical filter size and stride length to the previous pooling layer. The resulting
matrix is then flattened and fed into the fully-connected layers with parameters mirroring those utilized in the MLP architectures.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
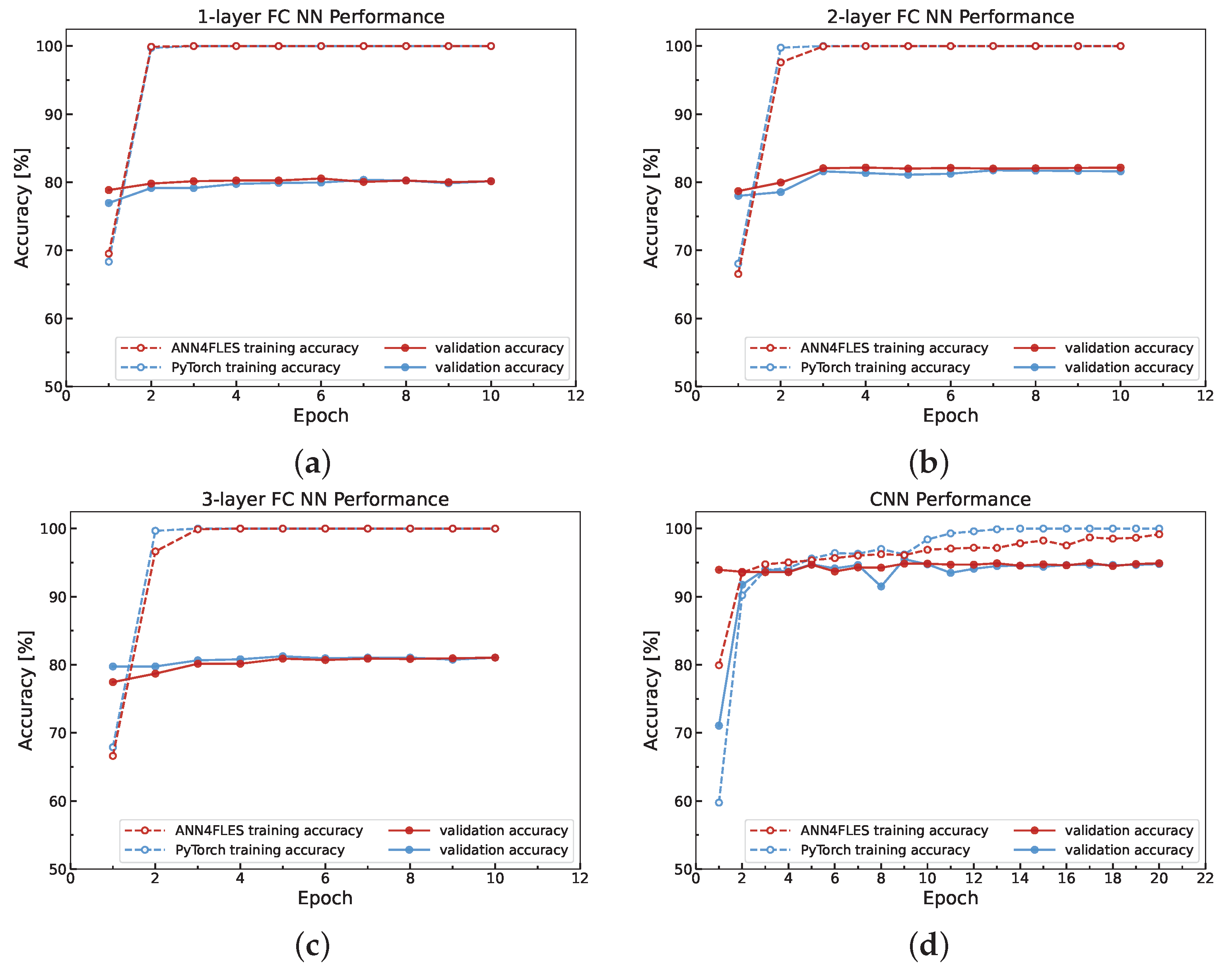{kind=link}








