
Denoising Diffusion Models on Model-Based Latent Space


Abstract
:1. Introduction
- We propose a shallow encoding for the perceptual compression stage which is of simple definition and predictable behavior (Section 3.1).
- We propose a simple strategy which allows training a continuous-space diffusion model on the discrete latent space. This is achieved by enforcing an originality property in the latent space through a sorting of the finite set of latent values along the direction of maximum covariance (Section 3.2.1).
- Finally, we propose to redefine the reverse diffusion process in a categorical framework by explicitly modeling the latent image representation as a set of categorical distributions over the discrete set of latent variables used for the lossy encoding (Section 3.2.2).
2. Related Works
2.1. Generative Models
Evaluation of Generative Models
2.2. Diffusion Models
2.3. Latent Diffusion Models
3. Proposed Method
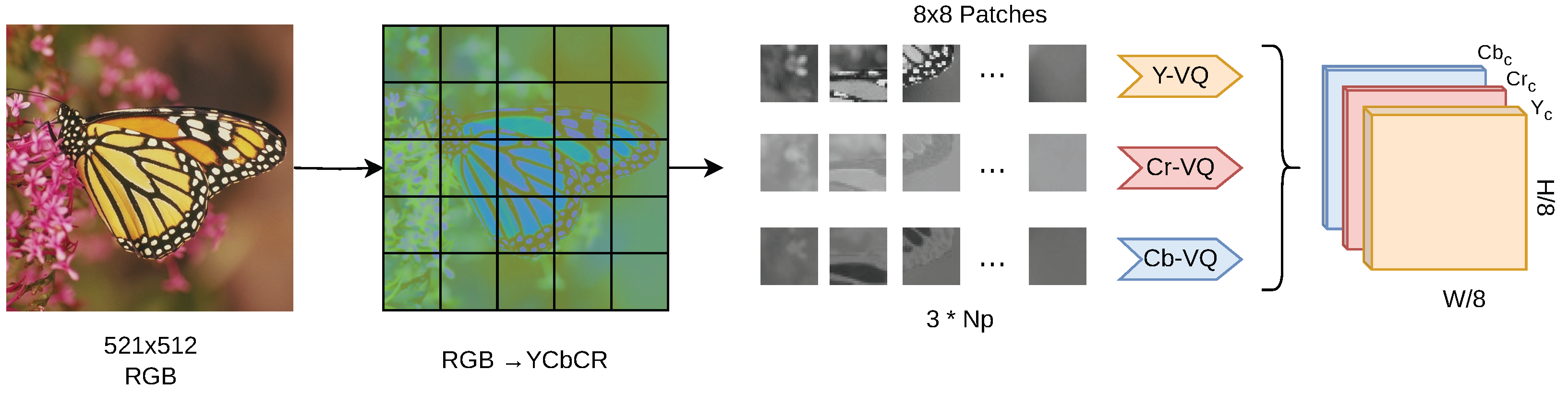
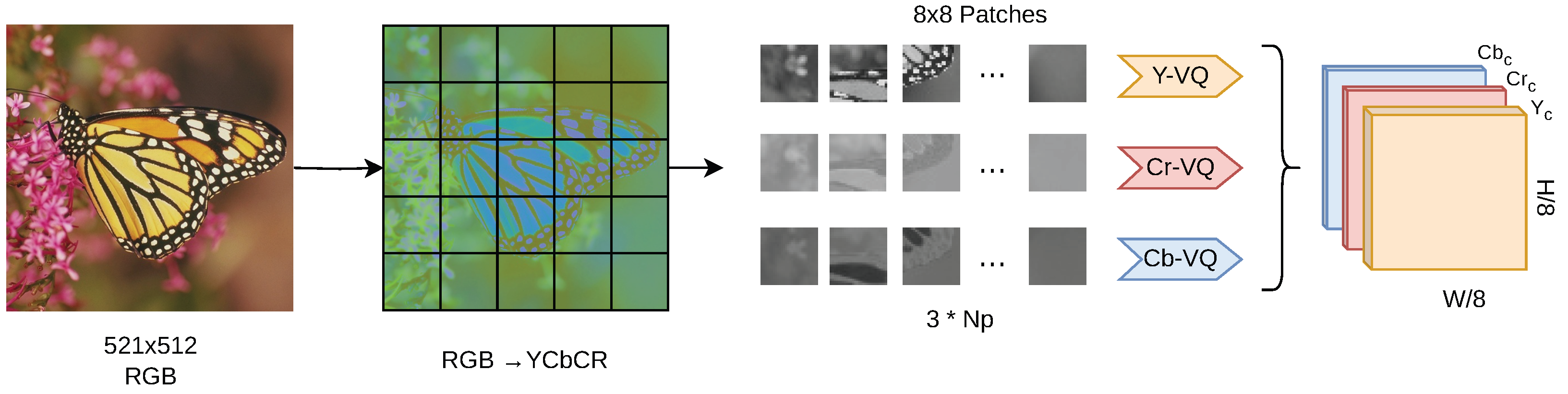
3.1. Latent-Space Encoding
3.1.1. Vector Quantization
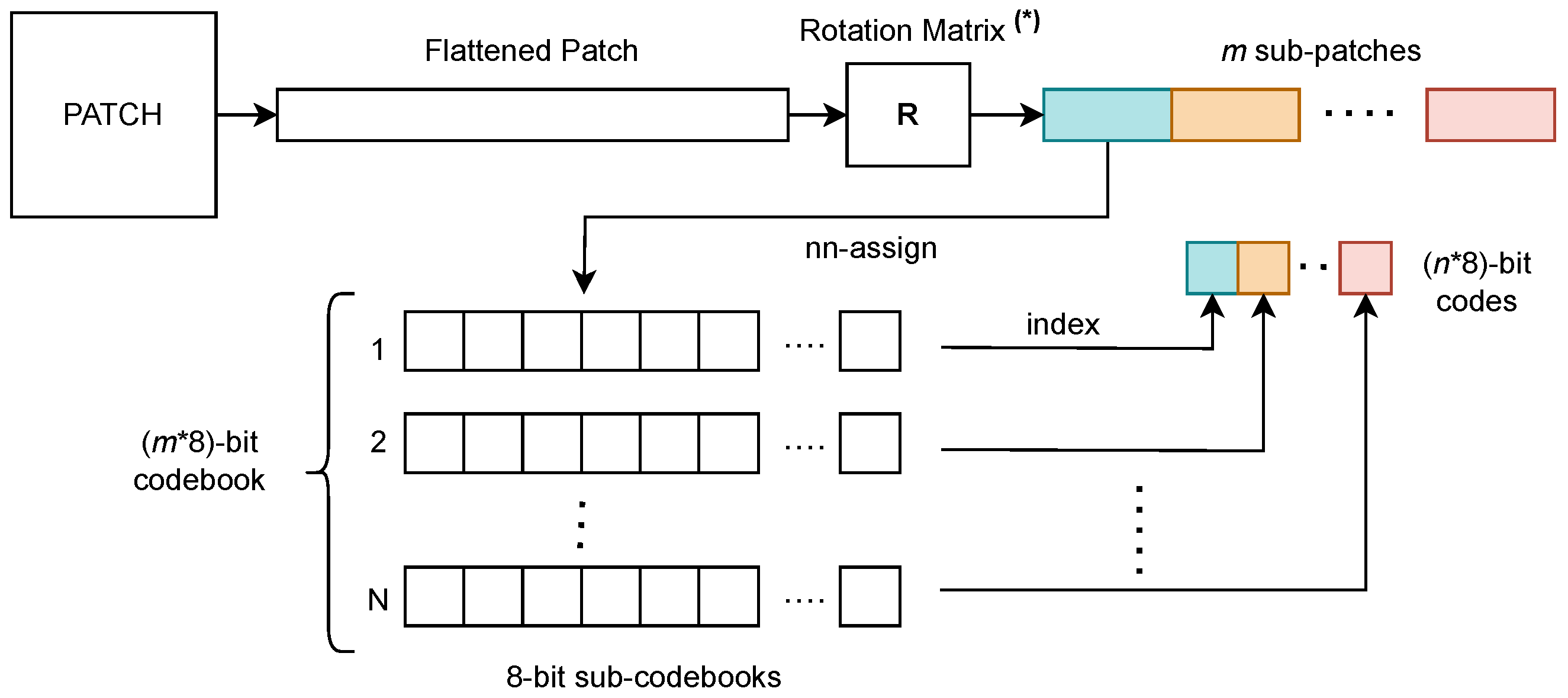
3.1.2. (Optimized) Product Quantization
3.1.3. Residual Quantization
3.2. Latent-Space Diffusion Models
3.2.1. Enforcing Pseudo-Ordinality
3.2.2. Categorical Posterior Distribution
| Algorithm 1 Differentiable decoding denoised sample |
| Require: noisy sample , time step t |
| Ensure: denoised sampled in image space |
| ▹ |
| for each channel do |
| for all i,j do |
| end for |
| end for |
| return |
| Algorithm 2 Sampling |
| Require: noisy sample , time step t |
| Ensure: |
| for all i,j do |
| end for |
| ▹ implementation of the reverse process parametrized by |
| return |
4. Experiments and Evaluation
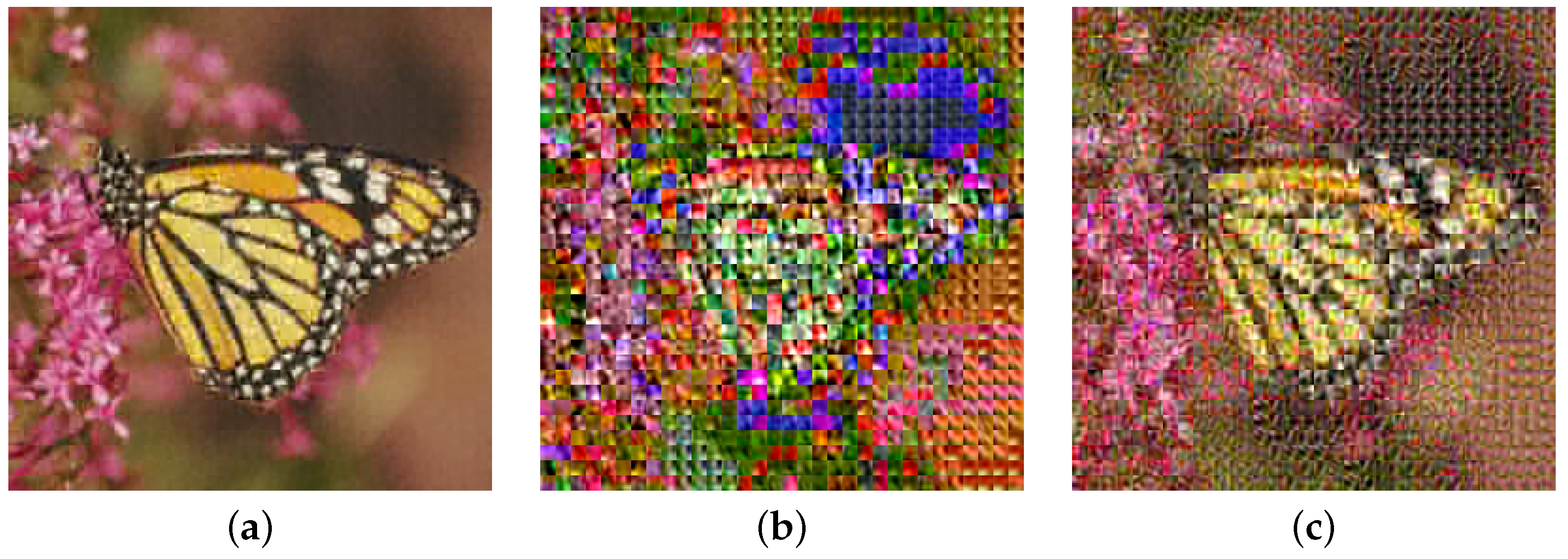
4.1. Image Compression
4.2. Image Generation
4.2.1. Experimental Setup
4.2.2. Continuous-Style Diffusion Model
4.2.3. Categorical Reverse Process
- is the derivation for the predicted noise in latent space, obtained from the prediction for the uncorrupted image sampled from using the Gumbel-Softmax trick;
- and are time-dependent constants values that are derived from the detailed definition of the diffusion process in [1], the details of which we omit for simplicity;
- The superscript is added to indicate values that are a function of model parameters.
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Glossary of Mathematical Notation
| w, h | Width and height of the image |
| c | Number of channels |
| Image encoding function to latent space | |
| Decoding function from latent space | |
| z | Encoded image in latent space |
| Generated image, generated latent representation. | |
| Number of channels of the latent representation | |
| s | Patch size |
| q | quantizer |
| E | VQ Encoder |
| D | VQ Decoder |
| n | Length of the vector to be encoded |
| m | Number of subquantizers in PQ and RQ |
| R | OPQ Rotation matrix |
| Generic VQ Codebook | |
| c | Generic codebook element |
| i | Index of the codebook entry |
| Set of the indices i | |
| Principal component on the i-th codebook entry | |
| X | Set of vectors to be approximated by q |
| Number of bits used to encode a vector with (bitrate). |
References
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming Transformers for High-Resolution Image Synthesis. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning. PMLR, Online, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. CogView: Mastering Text-to-Image Generation via Transformers. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 19822–19835. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6626–6637. [Google Scholar]
- Parmar, G.; Zhang, R.; Zhu, J.Y. On Aliased Resizing and Surprising Subtleties in GAN Evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Van Den Oord, A.; Vinyals, O. Neural discrete representation learning. Adv. Neural Inf. Process. Syst. 2017, 30, 6306–6315. [Google Scholar]
- Goldberg, M.; Boucher, P.; Shlien, S. Image Compression Using Adaptive Vector Quantization. IEEE Trans. Commun. 1986, 34, 180–187. [Google Scholar] [CrossRef]
- Nasrabadi, N.; King, R. Image coding using vector quantization: A review. IEEE Trans. Commun. 1988, 36, 957–971. [Google Scholar] [CrossRef]
- Scribano, C.; Franchini, G.; Prato, M.; Bertogna, M. DCT-Former: Efficient Self-Attention with Discrete Cosine Transform. J. Sci. Comput. 2023, 94, 67. [Google Scholar] [CrossRef]
- Garg, I.; Chowdhury, S.S.; Roy, K. DCT-SNN: Using DCT To Distribute Spatial Information Over Time for Low-Latency Spiking Neural Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 4671–4680. [Google Scholar]
- Gray, R. Vector quantization. IEEE Assp Mag. 1984, 1, 4–29. [Google Scholar] [CrossRef]
- Gray, R.; Neuhoff, D. Quantization. IEEE Trans. Inf. Theory 1998, 44, 2325–2383. [Google Scholar] [CrossRef]
- Jegou, H.; Douze, M.; Schmid, C. Product quantization for nearest neighbor search. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 117–128. [Google Scholar] [CrossRef] [PubMed]
- Ge, T.; He, K.; Ke, Q.; Sun, J. Optimized Product Quantization. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 744–755. [Google Scholar] [CrossRef] [PubMed]
- Schönemann, P.H. A generalized solution of the orthogonal procrustes problem. Psychometrika 1966, 31, 1–10. [Google Scholar] [CrossRef]
- Babenko, A.; Lempitsky, V. Additive quantization for extreme vector compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 931–938. [Google Scholar]
- Chen, Y.; Guan, T.; Wang, C. Approximate Nearest Neighbor Search by Residual Vector Quantization. Sensors 2010, 10, 11259–11273. [Google Scholar] [CrossRef]
- Austin, J.; Johnson, D.D.; Ho, J.; Tarlow, D.; Van Den Berg, R. Structured denoising diffusion models in discrete state-spaces. Adv. Neural Inf. Process. Syst. 2021, 34, 17981–17993. [Google Scholar]
- Hoogeboom, E.; Nielsen, D.; Jaini, P.; Forré, P.; Welling, M. Argmax flows and multinomial diffusion: Learning categorical distributions. Adv. Neural Inf. Process. Syst. 2021, 34, 12454–12465. [Google Scholar]
- Campbell, A.; Benton, J.; De Bortoli, V.; Rainforth, T.; Deligiannidis, G.; Doucet, A. A continuous time framework for discrete denoising models. Adv. Neural Inf. Process. Syst. 2022, 35, 28266–28279. [Google Scholar]
- Vahdat, A.; Kreis, K.; Kautz, J. Score-based generative modeling in latent space. arXiv 2021, arXiv:2106.05931. [Google Scholar]
- Tang, Z.; Gu, S.; Bao, J.; Chen, D.; Wen, F. Improved vector quantized diffusion models. arXiv 2022, arXiv:2205.16007. [Google Scholar]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Zhang, L.; Wu, X.; Buades, A.; Li, X. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding. J. Electron. Imaging 2011, 20, 023016. [Google Scholar]
- Johnson, J.; Douze, M.; Jégou, H. Billion-scale similarity search with GPUs. IEEE Trans. Big Data 2019, 7, 535–547. [Google Scholar] [CrossRef]
- Roberts, L. Picture coding using pseudo-random noise. IRE Trans. Inf. Theory 1962, 8, 145–154. [Google Scholar] [CrossRef]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Hang, T.; Gu, S.; Li, C.; Bao, J.; Chen, D.; Hu, H.; Geng, X.; Guo, B. Efficient diffusion training via min-snr weighting strategy. arXiv 2023, arXiv:2303.09556. [Google Scholar]
- Chen, T.; Zhang, R.; Hinton, G. Analog bits: Generating discrete data using diffusion models with self-conditioning. arXiv 2022, arXiv:2208.04202. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoding | C.R | Baboon | Peppers | Lenna | |||
|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| VQ-{8-8-8} | 1:64 | 28.83 | 0.40 | 30.75 | 0.63 | 31.23 | 0.67 |
| PQ-{32-8-8} | 1:32 | 29.07 | 0.60 | 31.28 | 0.69 | 31.80 | 0.74 |
| OPQ-{32-8-8} | 1:32 | 29.12 | 0.62 | 31.56 | 0.72 | 32.35 | 0.78 |
| RQ-{32-8-8} | 1:23 | 29.22 | 0.64 | 31.97 | 0.75 | 32.81 | 0.81 |
| VQ-f4 [6] | n.d | 21.43 | 0.66 | 29.17 | 0.77 | 31.33 | 0.83 |
| VQ-f8 [6] | n.d | 18.31 | 0.37 | 26.66 | 0.68 | 27.16 | 0.73 |
| Model | FID Score (↓) | |
|---|---|---|
| LSUN-Cat | LSUN-Church | |
| Continuous | 14.01 | 12.46 |
| Continuous + Refiner | 11.92 | 10.05 |
| Categorical Rev. () | 13.97 | 12.06 |
| Categorical Rev. () | 13.75 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Scribano, C.; Pezzi, D.; Franchini, G.; Prato, M. Denoising Diffusion Models on Model-Based Latent Space. Algorithms 2023, 16, 501. https://doi.org/10.3390/a16110501
Scribano C, Pezzi D, Franchini G, Prato M. Denoising Diffusion Models on Model-Based Latent Space. Algorithms. 2023; 16(11):501. https://doi.org/10.3390/a16110501
Chicago/Turabian StyleScribano, Carmelo, Danilo Pezzi, Giorgia Franchini, and Marco Prato. 2023. "Denoising Diffusion Models on Model-Based Latent Space" Algorithms 16, no. 11: 501. https://doi.org/10.3390/a16110501
APA StyleScribano, C., Pezzi, D., Franchini, G., & Prato, M. (2023). Denoising Diffusion Models on Model-Based Latent Space. Algorithms, 16(11), 501. https://doi.org/10.3390/a16110501