

Indoor Scene Recognition: An Attention-Based Approach Using Feature Selection-Based Transfer Learning and Deep Liquid State Machine



Abstract
:1. Introduction
1.1. Challenges and Motivation
1.2. Contributions
- Implementation of fuzzy colour stacking for preprocessing improves the foreground quality of the images by filtering the background noise;
- Unlike outdoor scene recognition that utilises global spatial information, indoor scene recognition is possible using the objects in the scene. Therefore, for both local and global features, semantic information is needed. Hence, the segmentation provides an ROI (region of interest) to detect the objects;
- Pretrained DenseNet201 improves feature extraction due to a lack of vanishing gradient problems;
- An attention module to select the best features using the World Cup optimisation algorithm improves the robust nature of the model towards indoor scene recognition;
- Classification using the deep LSM model utilising the winner-take-all layer improves the overall accuracy of the indoor scene classification.
2. Related Works
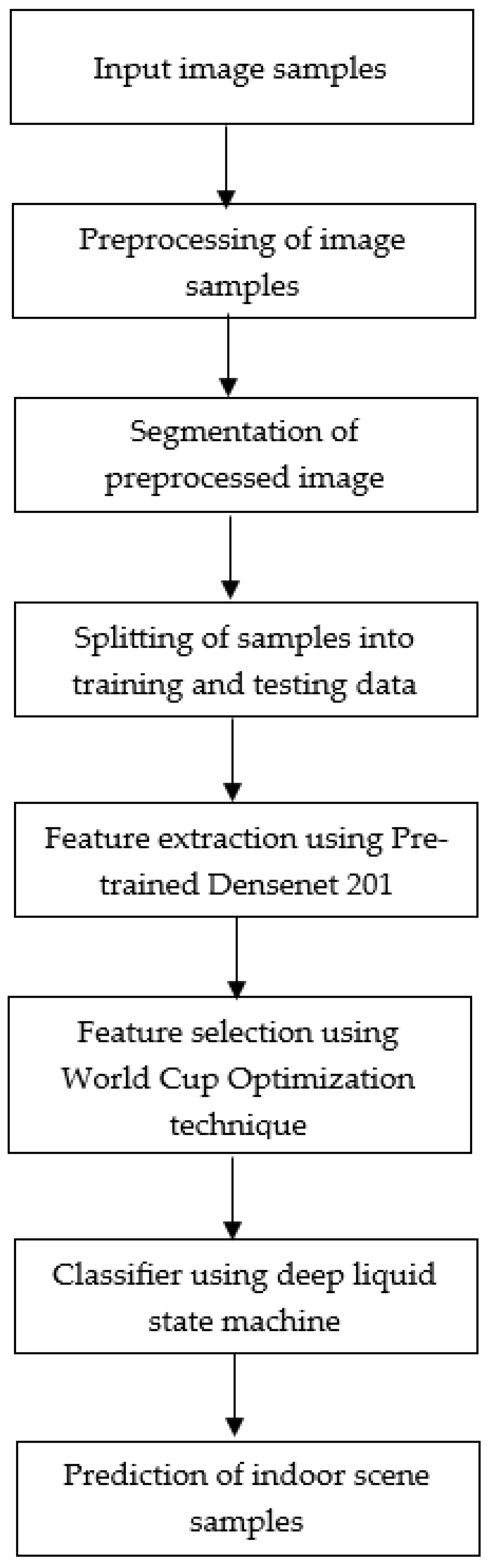
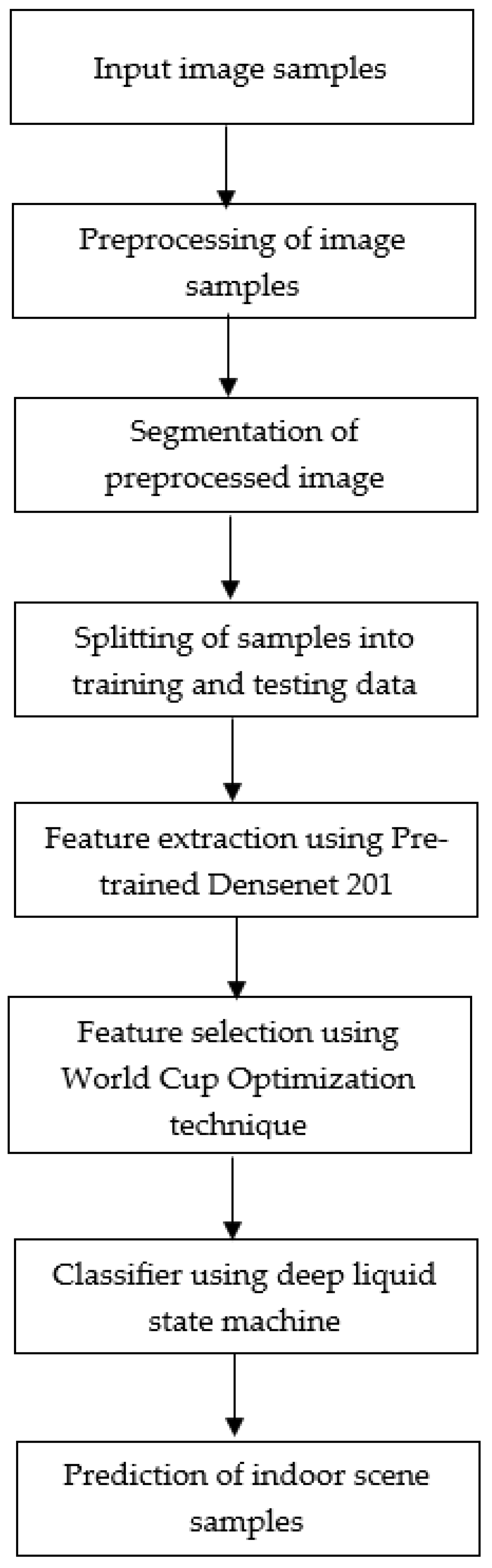
3. Proposed Approach
3.1. Preprocessing: Reconstructing Images Using Fuzzy Colour Technique
- In each window, there is a membership degree associated with each image pixel;
- Based on the distance between the pixel and the window, we calculate the membership degrees;
- We sum up the weights of all the blurred windows, and we create the output image from the average value;
- Two images from a row are combined, and then they are divided into two parts, background and overlay, in order to eliminate the noise from the input image;
- The stacking technique eliminates the noise from the image by considering parameters such as contrast, brightness, opacity, and combining ratio;
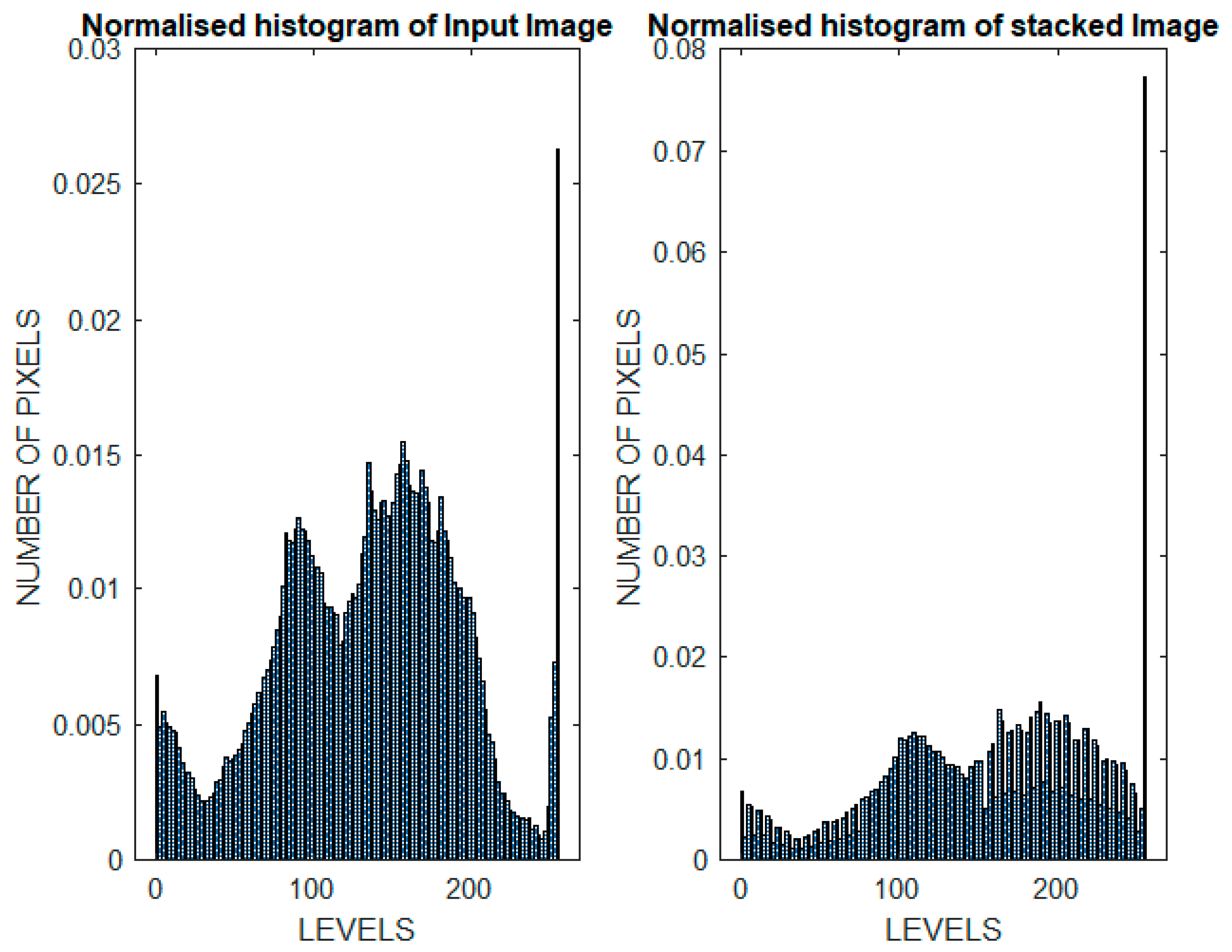
- Here, we have stacked our original dataset on the reconstructed dataset using the fuzzy colour technique.
3.2. Segmentation—Colour Based Approach Using K-Means Clustering
- Read the input image;
- Extract the red, green, and blue feature vectors;
- The image space is divided into four group centroids (k = 4);
- Classify the colour pixels using K-means clustering;
- Using the index from K-means clustering, every pixel in the image is labelled;
- Separation of objects in the image by using pixel labels;
- Separate the image by segmenting the cluster centroid.
3.3. Feature Extraction Using Pretrained DenseNet Model
3.4. World Cup Optimization-Based Feature Selection
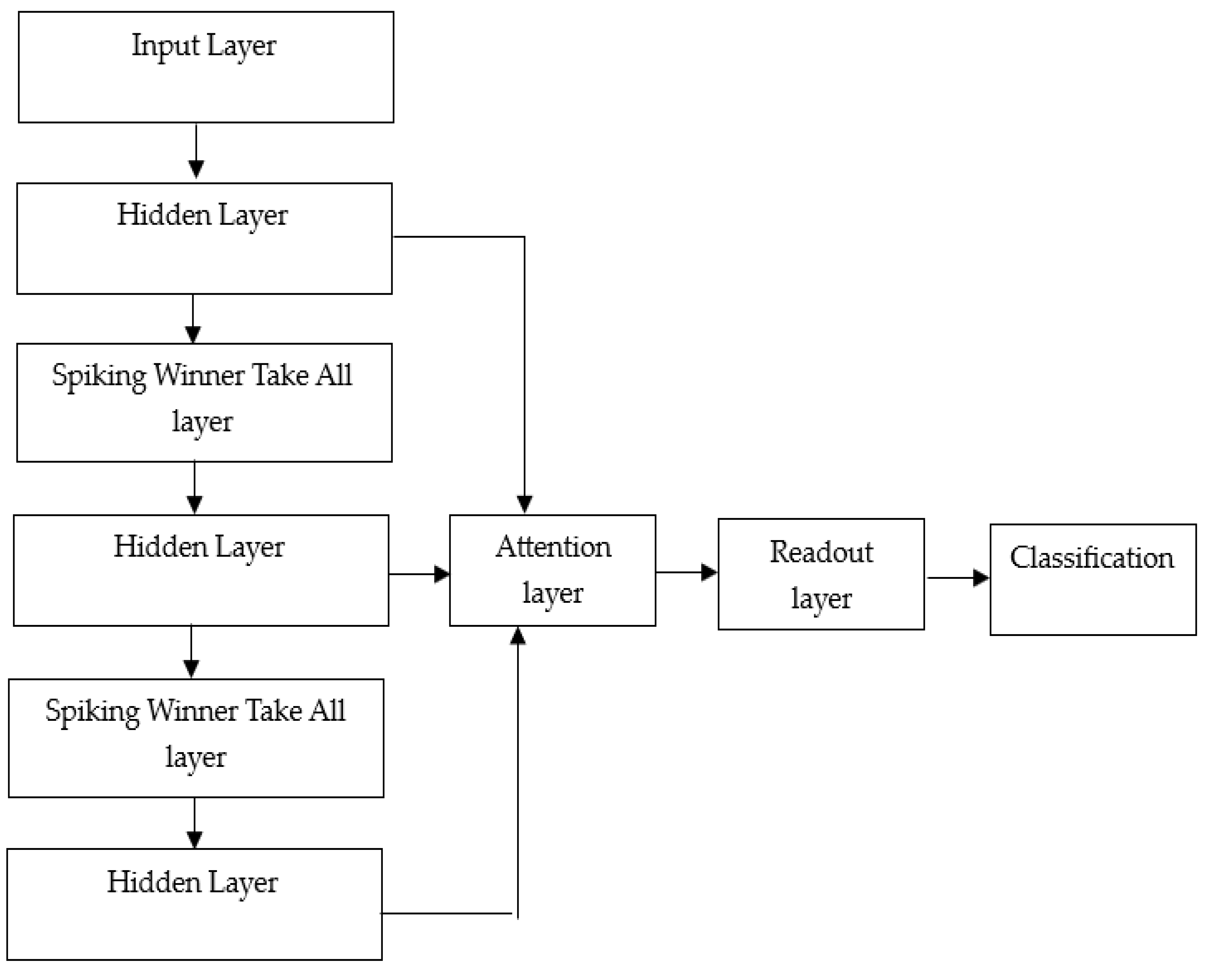
3.5. Deep Liquid State Machine Classifier
4. Dataset
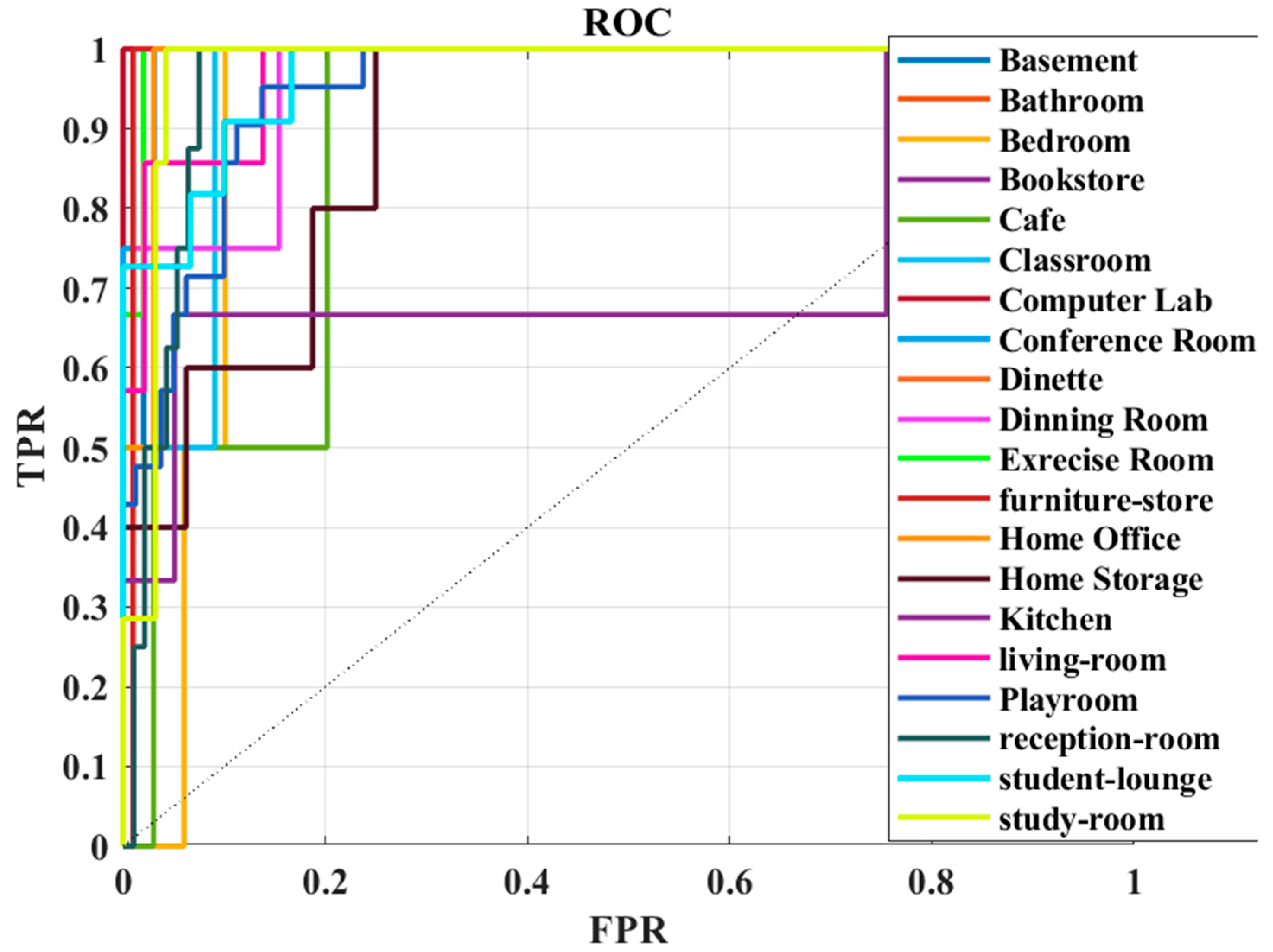
5. Experimental Results and Discussions
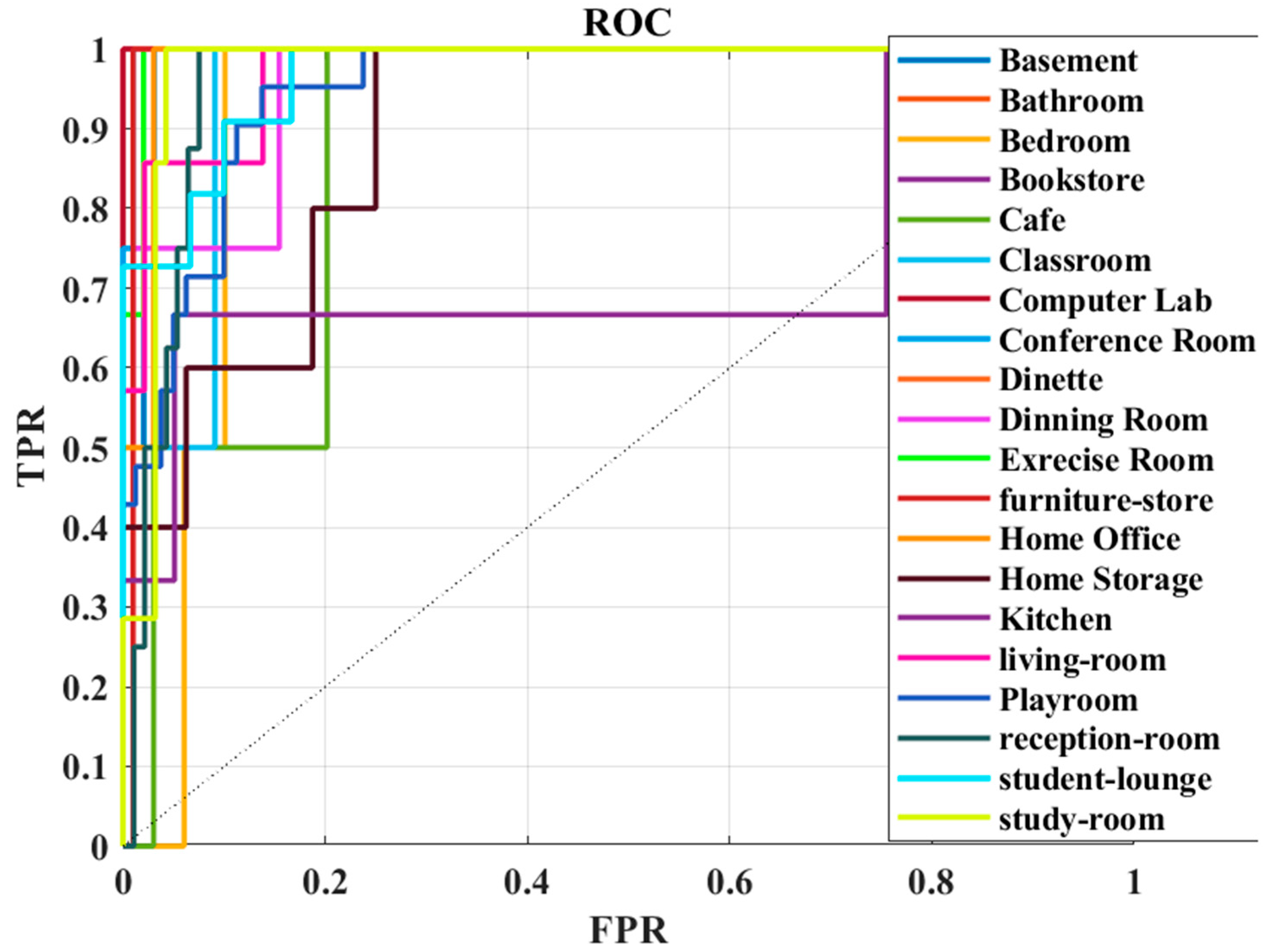
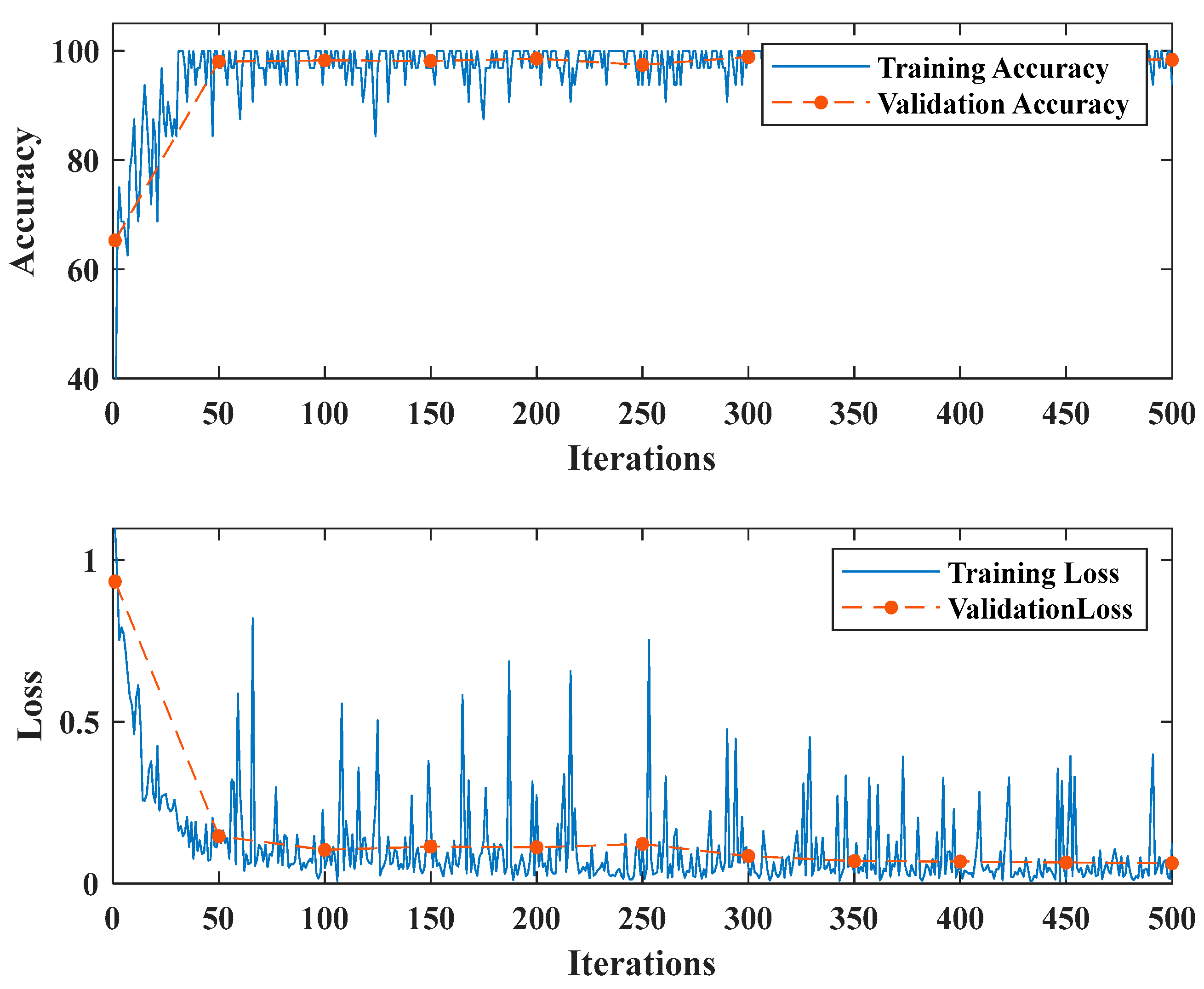
5.1. Results Analysis
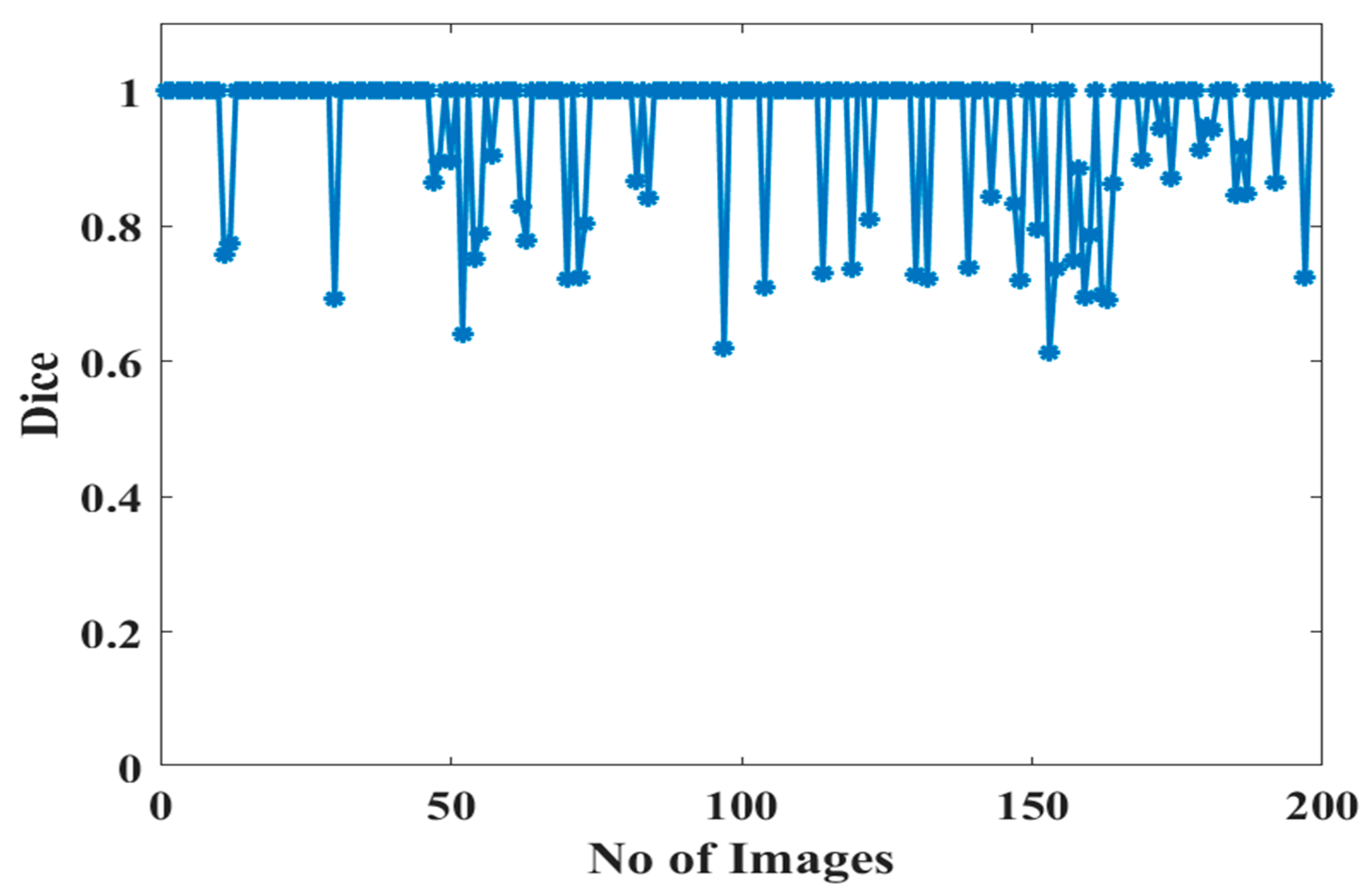
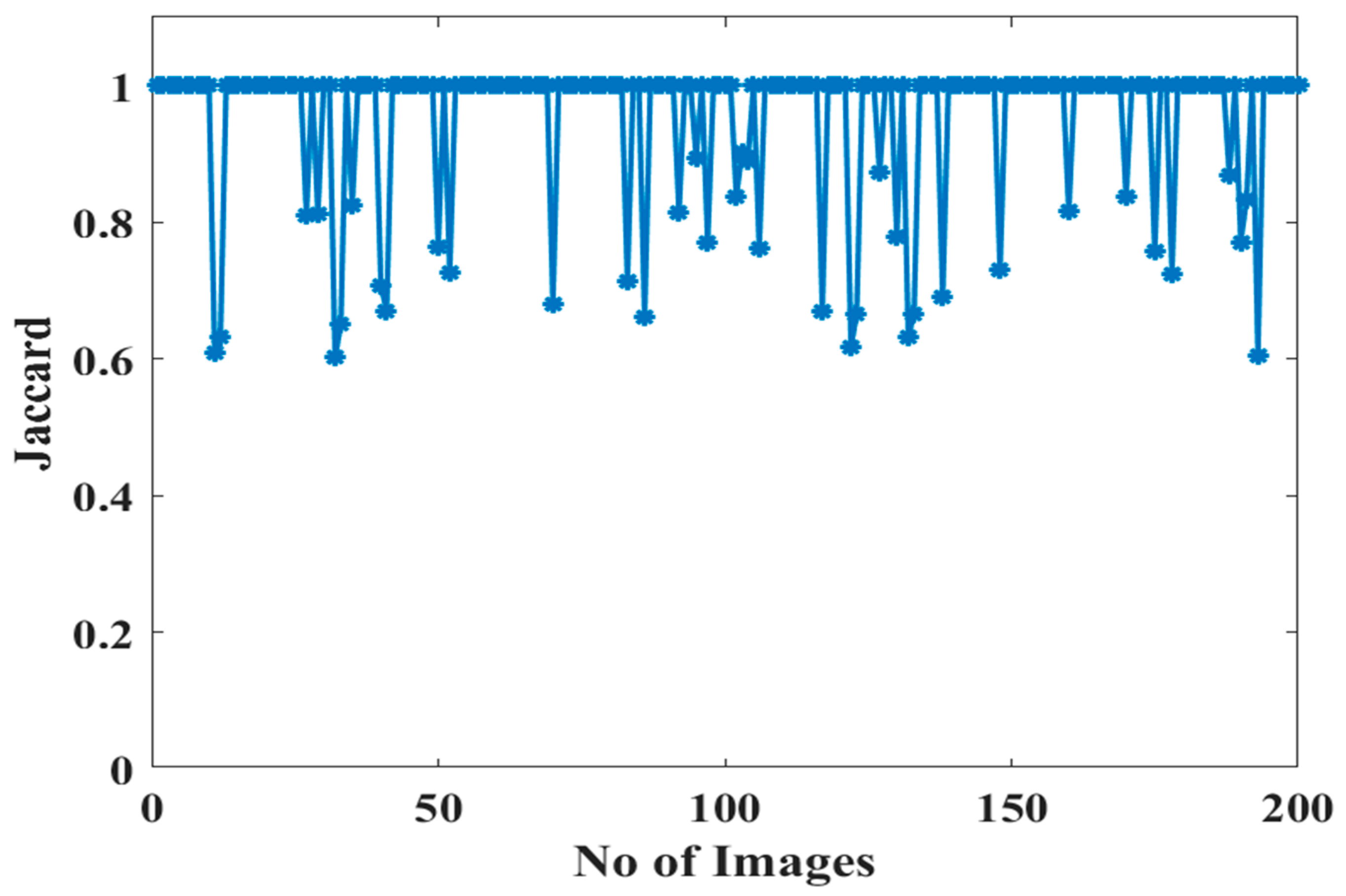
5.2. Classification Report–Performance Evaluation
5.3. Discussions
6. Comparison of Our Proposed Work to Existing Indoor Scene Recognition Research
7. Conclusions and Future Scope
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Herranz, L.; Jiang, S.; Li, X. Scene recognition with CNNs: Objects, scales and dataset bias. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 571–579. [Google Scholar]
- Surendran, R.; Anitha, J.; Hemanth, J.D. Recognition of human action for scene understanding using world cup optimization and transfer learning approach. PeerJ Comput. Sci. 2023, 9, e1396. [Google Scholar] [CrossRef] [PubMed]
- Hernandez, A.C.; Gomez, C.; Barber, R.; Mozos, O.M. Exploiting the confusions of semantic places to improve service robotic tasks in indoor environments. Robot. Auton. Syst. 2023, 159, 104290. [Google Scholar] [CrossRef]
- Guo, J.; Nie, X.; Ma, Y.; Shaheed, K.; Ullah, I.; Yin, Y. Attention based consistent semantic learning for micro-video scene recognition. Inf. Sci. 2021, 543, 504–516. [Google Scholar] [CrossRef]
- Bosch, A.; Muñoz, X.; Martí, R. Which is the best way to organize/classify images by content. Image Vis. Comput. 2007, 25, 778–791. [Google Scholar] [CrossRef]
- Brown, M.; Susstrun, S.K. Multi-spectral SIFT for scene category recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 177–184. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Yang, J.; Jiang, Y.G.; Hauptmann, A.; Ngo, C.W. Evaluating bag-of-visual-words representations in scene classification. In Proceedings of the International Workshop on Multimedia Information Retrieval, Bavaria, Germany, 24–29 September 2007; IEEE: Augsburg, Germany, 2007; pp. 197–206. [Google Scholar]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 7553. [Google Scholar] [CrossRef]
- Lecun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, I.; Sutskever, G.E. Hinton. Imagenet classification with deep convolutional neural networks. Proc. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. 2016 SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Simonyan, K.; Zisserman, A. 2015 Very deep convolutional networks for large-scale image recognition, ICLR. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Der Maaten, L.V.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGB-D images. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Quattoni, A.; Torralba, A. Recognizing indoor scenes. In Proceedings of the IEEE Conference on Computer and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 413–420. [Google Scholar]
- Vailaya, A.; Figueiredo, M.A.T.; Jain, A.K.; Zhang, H.-J. Image classification for content-based indexing. IEEE Trans. Image Process. 2001, 10, 117–130. [Google Scholar] [CrossRef] [PubMed]
- Li, L.J.; Su, H.; Lim, Y.; Fei-Fei, L. Objects as attributes for scene classification. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany; pp. 57–69. [Google Scholar]
- Espinace, P.; Kollar, T.; Soto, A.; Roy, N. Indoor scene recognition through object detection. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, Alaska, 3–8 May 2010. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 487–495. [Google Scholar]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Togneri, R.; Sohel, F.A. A discriminative representation of convolutional features for indoor scene recognition. IEEE Trans. Image Process. 2016, 25, 3372–3383. [Google Scholar] [CrossRef] [PubMed]
- Hayat, M.; Khan, S.H.; Bennamoun, M.; An, S. A spatial layout and scale invariant feature representation for indoor scene classification. IEEE Trans. Image Process. 2016, 25, 4829–4841. [Google Scholar] [CrossRef]
- Glavan, A.; Talavera, E. InstaIndoor and multi-modal deep learning for indoor scene recognition. Neural Comput. Appl. 2022, 34, 6861–6877. [Google Scholar] [CrossRef]
- Nagarajan, A.; Gopinath, M.P. Hybrid Optimization-Enabled Deep Learning for Indoor Object Detection and Distance Estimation to Assist Visually Impaired Persons. Adv. Eng. Softw. 2023, 176, 103362. [Google Scholar] [CrossRef]
- Song, C.; Ma, X. SRRM: Semantic Region Relation Model for Indoor Scene Recognition. arXiv 2023, arXiv:2305.08540. [Google Scholar]
- Lin, C.; Lee, F.; Xie, L.; Cai, J.; Chen, H.; Liu, L.; Chen, Q. Scene recognition using multiple representation network. Appl. Soft Comput. 2022, 118, 108530. [Google Scholar] [CrossRef]
- Xie, T.; Dai, K.; Wang, K.; Li, R.; Zhao, L. Deepmatcher: A deep transformer-based network for robust and accurate local feature matching. arXiv 2023, arXiv:2301.02993. [Google Scholar] [CrossRef]
- Dai, K.; Xie, T.; Wang, K.; Jiang, Z.; Li, R.; Zhao, L. OAMatcher: An Overlapping Areas-based Network for Accurate Local Feature Matching. arXiv 2023, arXiv:2302.05846. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Xie, T.; Wang, L.; Li, R.; Zhang, X.; Zhang, H.; Yang, L.; Liu, H.; Li, J. FARP-Net: Local-Global Feature Aggregation and Relation-Aware Proposals for 3D Object Detection. IEEE Trans. Multimed. 2023, 1–15. [Google Scholar] [CrossRef]
- Sitaula, C.; KC, S.; Aryal, J. Enhanced Multi-Level Features for Very High-Resolution Remote Sensing Scene Classification. arXiv 2023, arXiv:2305.00679. [Google Scholar]
- Rafique, A.A.; Ghadi, Y.Y.; Alsuhibany, S.A.; Chelloug, S.A.; Jalal, A.; Park, J. CNN Based Multi-Object Segmentation and Feature Fusion for Scene Recognition. In Proceedings of the Conference on Membrane Computing, Chandler, AZ, USA, 27–29 April 2022. [Google Scholar]
- Yee, P.S.; Lim, K.M.; Lee, C.P. DeepScene: Scene classification via convolutional neural network with spatial pyramid pooling. Expert Syst. Appl. 2022, 193, 116382. [Google Scholar] [CrossRef]
- Du, D.; Wang, L.; Li, Z.; Wu, G. Cross-modal pyramid translation for RGB-D scene recognition. Int. J. Comput. Vis. 2021, 129, 2309–2327. [Google Scholar] [CrossRef]
- Ahmed, A.; Jalal, A.; Kim, K. A Novel Statistical Method for Scene Classification Based on Multi-Object Categorization and Logistic Regression. Sensors 2020, 20, 3871. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Tian, G. An Indoor Scene Classification Method for Service Robot Based on CNN Feature. J. Robot. 2019, 2019, 8591035. [Google Scholar] [CrossRef]
- Romero-González, C.; Martínez-Gómez, J.; García-Varea, I.; Rodriguez-Ruiz, L. On robot indoor scene classification based on descriptor quality and efficiency. Expert Syst. Appl. 2017, 79, 181–193. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B.; Cömert, Z. COVID-19 detection using deep learning models to exploit Social Mimic Optimization and structured chest X-ray images using fuzzy color and stacking approaches. Comput. Biol. Med. 2020, 121, 103805. [Google Scholar] [CrossRef]
- Oladipupo, G.G. Research on the Concept of Liquid State Machine. arXiv 2019, arXiv:1910.03354. [Google Scholar]
- Chitade, A.Z.; Katiyar, S.K. Colour based image segmentation using k-means clustering. Int. J. Eng. Sci. Technol. 2010, 2, 5319–5325. [Google Scholar]
- Razmjooy, N.; Khalilpour, M.; Ramezani, M. A New Meta-Heuristic Optimization Algorithm Inspired by FIFA World Cup Competitions: Theory and Its Application in PID Designing for AVR System. J. Control. Autom. Electr. Syst. 2016, 27, 419–440. [Google Scholar] [CrossRef]
- Pereira, R.; Barros, T.; Garrote, L.; Lopes, A.; Nunes, U.J. A Deep Learning-based Global and Segmentation-based Semantic Feature Fusion Approach for Indoor Scene Classification. arXiv 2023, arXiv:2302.06432. [Google Scholar]
- Heikel, E.; Espinosa-Leal, L. Indoor Scene Recognition via Object Detection and TF-IDF. J. Imaging 2022, 8, 209. [Google Scholar] [CrossRef] [PubMed]
- Mosella-Montoro, A.; Ruiz-Hidalgo, J. 2d–3d geometric fusion network using multi-neighbourhood graph convolution for rgb-d indoor scene classification. Inf. Fusion 2021, 76, 46–54. [Google Scholar] [CrossRef]
- Afif, M.; Ayachi, R.; Said, Y.; Atri, M. Deep learning-based application for indoor scene recognition. Neural Process. Lett. 2020, 51, 2827–2837. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Z.; Cheng, Y.; Wang, L.; Tan, T. MAPNet: Multi-modal attentive pooling network for RGB-D indoor scene classification. Pattern Recognit. 2019, 90, 436–449. [Google Scholar] [CrossRef]
- Guo, W.; Wu, R.; Chen, Y.; Zhu, X. Deep learning scene recognition method based on localization enhancement. Sensors 2018, 18, 3376. [Google Scholar] [CrossRef]
- Tang, P.; Wang, H.; Kwong, S. G-MS2F: GoogLeNet based multi-stage feature fusion of deep CNN for scene recognition. Neurocomputing 2017, 225, 188–197. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Author | Methodology Used and Results | Merits | Demerits |
|---|---|---|---|---|
| 1 | Sitaula et al. [41] | Enhanced VHR attention module (EAM) + atrous spatial pyramid pooling+ global average pooling. Accuracy of 95.39% on AID and 93.04% on NwPU dataset. | Rich discriminative salient features are achieved. | Performance could be improved by using various pretrained models to classify new data. |
| 2 | Rafique et al. [42] | Segmentation + feature extraction (Using SegNet, VGG, DCT, DWT) + feature selection using genetic algorithm + neuro fuzzy classifier. Accuracy of 96.13% on Cityscapes, 63.1% for SUN RGB D, and 72.8% on NYU datasets. | Multi-object recognition against any varying environment. | Approach performs well for outdoor scenes when compared to indoor scenes. |
| 3 | Yee et al. [43] | CNN + spatial pyramid pooling. Accuracies of 71%, 95.6%, and 98.1% on Event-8, Scene-15, and MIT-67 datasets. | Ensemble learning improves the overall performance. | Data augmentation is employed. |
| 4 | Du et al. [44] | TrecgNet and feature selection. Accuracy of 71.8% on NYU depth datasets. | Model performs well with aligned colour and depth information. | Only single modality scene recognition is possible. |
| 5 | Ahmed et al. [45] | Fuzzy c-mean, mean shift algorithm + logistic regression classifier. Accuracies of 88.75%, 85.75%, and 80.02% on MSRC, COREL 10K, and CVPR 67 datasets. | Classification of a complex scene is possible, | Performance could be increased by using deep CNN models. |
| 6 | Shaopeng et al. [46] | Pretrained ResNet CNN with feature-matching algorithm. Accuracies of 96.49% and 81.69% on scene-15 and MIT 67 datasets. | Eliminates the problem of over fitting. | Performance reduces for images having varying illumination, scale, etc. |
| 7 | Romero et al. [47] | Dense SIFT + BoW model + spatial pyramid pooling + binary classifier. Accuracy of 92.64% on ImageCLEF 2012 robot vision dataset. | Could classify scenes of different illumination and scaling. | Slow in execution. |
| Proposed Model | Specificity | Sensitivity | Precision | F1-Score |
|---|---|---|---|---|
| DenseNet201 (Feature extraction) + LSM classifier | 0.96 | 1 | 0.94 | 0.95 |
| Accuracy | 0.96% |
| S. No. | Author | Methodology Used | Accuracy |
|---|---|---|---|
| 1 | Proposed Model | Segmentation + DenseNet201 + World Cup Optimization + LSM Classifier | 96% |
| 2 | Pereira et al. [52] | Semantic Segmentation + VGG16, ResNet18-50-101, DenseNet and MobileNetV2+ Feature fusion | 75.8% |
| 3 | Heikel et al. [53] | YOLO + TF + IDF | 83.63% |
| 4 | Mosella et al. [54] | 2D–3D geometric feature fusion + Graph convolutional neural network | 75% |
| 5 | Afif et al. [55] | EfficientNet CNN model + Scaling | 95.6% |
| 6 | Li et al. [56] | MAPNet + Attentive pooling | 67.7% |
| 7 | Guo et al. [57] | GoogleNet + Inception V3 + Feature fusion | 96% |
| 8 | Tang et al. [58] | GoogleNet + Multi feature fusion | 92.92% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Surendran, R.; Chihi, I.; Anitha, J.; Hemanth, D.J. Indoor Scene Recognition: An Attention-Based Approach Using Feature Selection-Based Transfer Learning and Deep Liquid State Machine. Algorithms 2023, 16, 430. https://doi.org/10.3390/a16090430
Surendran R, Chihi I, Anitha J, Hemanth DJ. Indoor Scene Recognition: An Attention-Based Approach Using Feature Selection-Based Transfer Learning and Deep Liquid State Machine. Algorithms. 2023; 16(9):430. https://doi.org/10.3390/a16090430
Chicago/Turabian StyleSurendran, Ranjini, Ines Chihi, J. Anitha, and D. Jude Hemanth. 2023. "Indoor Scene Recognition: An Attention-Based Approach Using Feature Selection-Based Transfer Learning and Deep Liquid State Machine" Algorithms 16, no. 9: 430. https://doi.org/10.3390/a16090430
APA StyleSurendran, R., Chihi, I., Anitha, J., & Hemanth, D. J. (2023). Indoor Scene Recognition: An Attention-Based Approach Using Feature Selection-Based Transfer Learning and Deep Liquid State Machine. Algorithms, 16(9), 430. https://doi.org/10.3390/a16090430