
Online Distribution Network Scheduling via Provably Robust Learning Approach




Abstract
1. Introduction
2. Parametric Distribution Network Scheduling Formulation
2.1. DNS Model
2.2. P-DNS Model
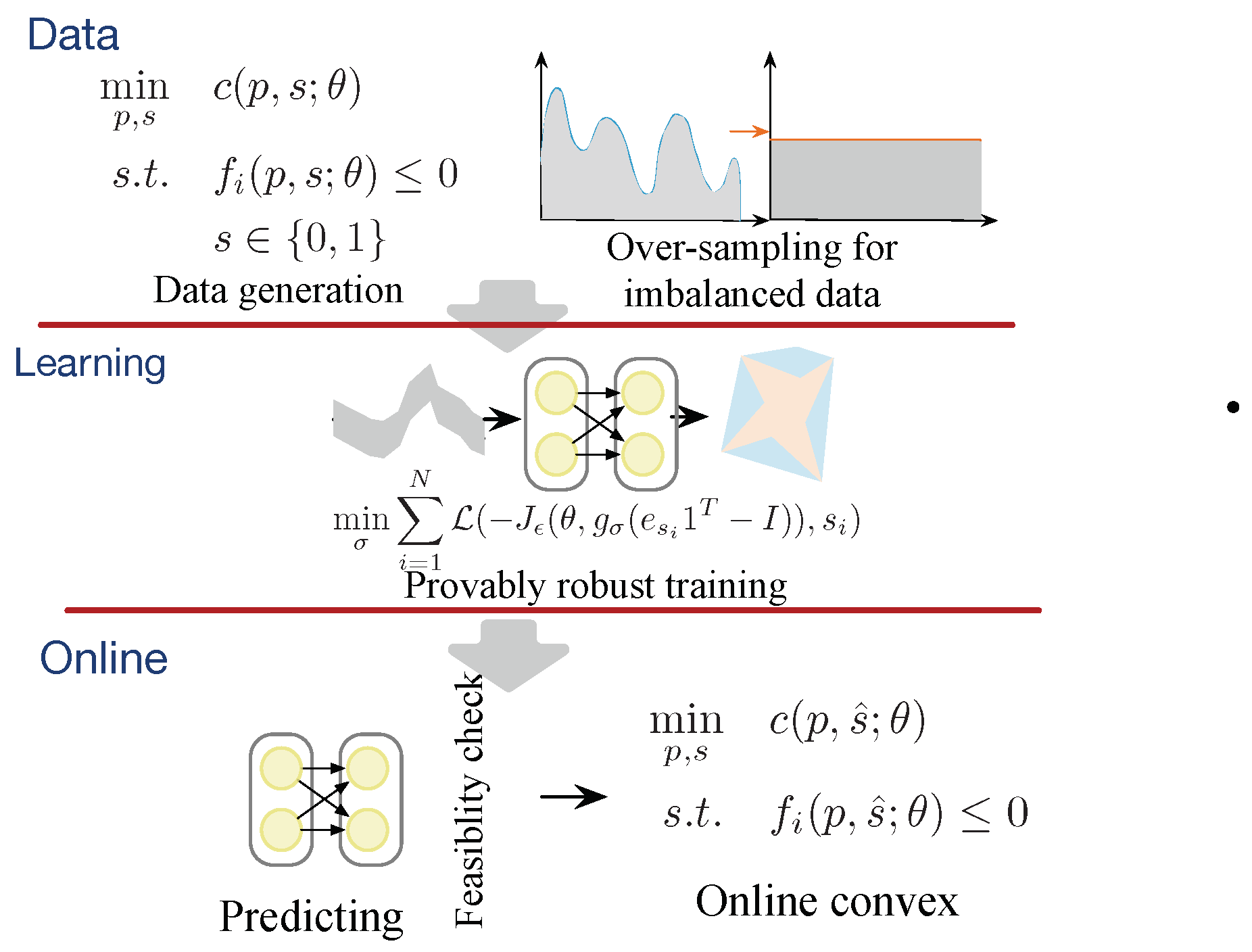
3. Provably Robust Distribution Network Scheduling
3.1. Provably Robust Learning Approach for Online DNS
3.1.1. Motivation
3.1.2. Neural Networks for Online DNS
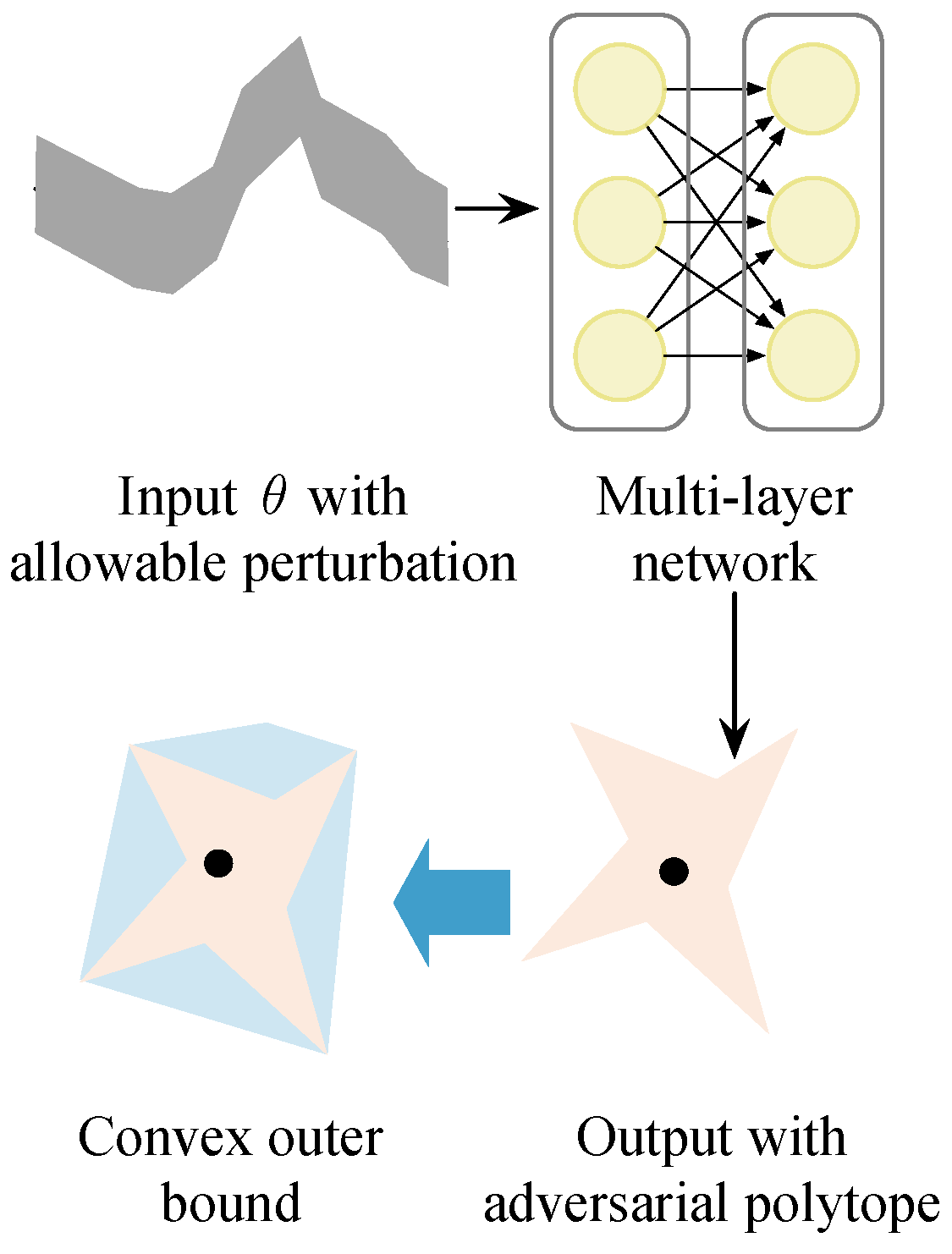
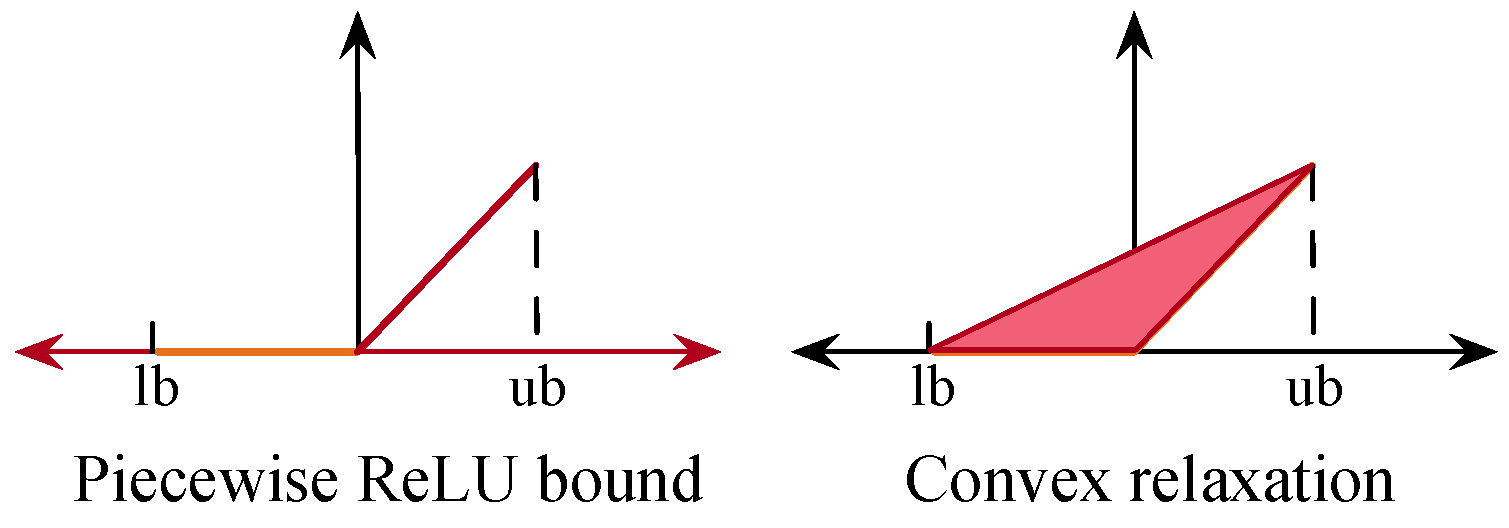
3.1.3. Convex Outer Bound Formulation of the Neural Network
3.1.4. Robust Optimization in Online DNS via Dual Neural Network
3.1.5. Provably Robust Training of Learning Models for Online DNS
4. Case Study
4.1. Data Sampling
4.2. Experiment Results
4.2.1. Training Analysis
4.2.2. Online DNS Performance Analysis
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| A. Abbreviation | |
| DNS | Distribution network scheduling; |
| MIP | Mixed-integer programming; |
| P-DNS | Parametric distribution network scheduling; |
| LP | Linear programming; |
| ACOPF | Alternate current optimal power flow; |
| PR-L2O | Provably robust learn-to-optimize; |
| L2O | Learn-to-optimize; |
| MICP | Mixed-integer convex program; |
| B. Sets | |
| Set of the time periods; | |
| Set of the system branches; | |
| Set of the system PV; | |
| Set of the system CB; | |
| Set of the system SVR; | |
| Set of the parent buses of bus i; | |
| Set of the child buses of bus i. | |
| C. Parameters | |
| PV i capacity; | |
| , | Resistance/reactance of branch ; |
| Base voltage at the substation; | |
| Maximal OLTC/CB taps; | |
| Allowed maximum switching changing time for the OLTC/CB during the operation period; | |
| Reactive power supply of per unit CB; | |
| , | Upper/lower bounds of SVR reactive power supply; |
| , | Upper/lower bounds of bus voltage. |
| D. Variables | |
| Power loss of branch in time t; | |
| Power and var of branch in time t; | |
| , , | Active PV/load active power/load reactive power; |
| Bus voltage magnitude; | |
| Reactive load/power supply of PV/CB/SVR; | |
| , | Auxiliary binary variables of OLTC/CB. |
References
- Sang, L.; Xu, Y.; Long, H.; Wu, W. Safety-Aware Semi-End-to-End Coordinated Decision Model for Voltage Regulation in Active Distribution Network. IEEE Trans. Smart Grid 2023, 14, 1814–1826. [Google Scholar] [CrossRef]
- Gao, H.; Ma, W.; He, S.; Wang, L.; Liu, J. Time-Segmented Multi-Level Reconfiguration in Distribution Network: A Novel Cloud-Edge Collaboration Framework. IEEE Trans. Smart Grid 2022, 13, 3319–3322. [Google Scholar] [CrossRef]
- Xie, L.; Zheng, X.; Sun, Y.; Huang, T.; Bruton, T. Massively Digitized Power Grid: Opportunities and Challenges of Use-Inspired AI. Proc. IEEE 2023, 111, 762–787. [Google Scholar] [CrossRef]
- Sarma, D.S.; Cupelli, L.; Ponci, F.; Monti, A. Distributed Optimal Power Flow with Data-Driven Sensitivity Computation. In Proceedings of the 2021 IEEE Madrid PowerTech, Madrid, Spain, 28 June–2 July 2021; pp. 1–6. [Google Scholar]
- Xavier, Á.S.; Qiu, F.; Wang, F.; Thimmapuram, P.R. Transmission constraint filtering in large-scale distribution network scheduling. IEEE Trans. Power Syst. 2019, 34, 2457–2460. [Google Scholar] [CrossRef]
- Nair, V.; Bartunov, S.; Gimeno, F.; von Glehn, I.; Lichocki, P.; Lobov, I.; O’Donoghue, B.; Sonnerat, N.; Tjandraatmadja, C.; Wan, P.G.; et al. Solving mixed integer programs using neural networks. arXiv 2021, arXiv:2012.13349. [Google Scholar]
- Park, S.; Chen, W.; Han, D.; Tanneau, M.; Hentenryck, P.V. Confidence-Aware Graph Neural Networks for Learning Reliability Assessment Commitments. IEEE Trans. Power Syst. 2023, 39, 3839–3850. [Google Scholar] [CrossRef]
- Chen, W.; Park, S.; Tanneau, M.; Hentenryck, P.V. Learning optimization proxies for large-scale Security-Constrained Economic Dispatch. Electr. Power Syst. Res. 2021, 213, 108566. [Google Scholar] [CrossRef]
- Sang, L.; Xu, Y.; Wu, W.; Long, H. Online Voltage Regulation of Active Distribution Networks: A Deep Neural Encoding-Decoding Approach. IEEE Trans. Power Syst. 2024, 39, 4574–4586. [Google Scholar] [CrossRef]
- Sang, L.; Xu, Y.; Sun, H. Ensemble Provably Robust Learn-to-Optimize Approach for Security-Constrained Unit Commitment. IEEE Trans. Power Syst. 2023, 38, 5073–5087. [Google Scholar] [CrossRef]
- Wong, E.; Kolter, J.Z. Provable defenses against adversarial examples via the convex outer adversarial polytope. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Wong, E.; Schmidt, F.R.; Metzen, J.H.; Kolter, J.Z. Scaling Provable Adversarial Defenses. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 3–8 December 2018; pp. 8410–8419. [Google Scholar]
- Gasse, M.; Chételat, D.; Ferroni, N.; Charlin, L.; Lodi, A. Exact combinatorial optimization with graph convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kargarian, A.; Fu, Y.; Li, Z. Distributed distribution network scheduling for large-scale power systems. IEEE Trans. Power Syst. 2015, 30, 1925–1936. [Google Scholar] [CrossRef]
- Cauligi, A.; Culbertson, P.; Stellato, B.; Bertsimas, D.; Schwager, M.; Pavone, M. Learning mixed-integer convex optimization strategies for robot planning and control. In Proceedings of the 2020 59th IEEE Conference on Decision and Control (CDC), Jeju, Republic of Korea, 14–18 December 2020; pp. 1698–1705. [Google Scholar]
- Ding, J.Y.; Zhang, C.; Shen, L.; Li, S.; Wang, B.; Xu, Y.; Song, L. Accelerating primal solution findings for mixed integer programs based on solution prediction. Proc. AAAI Conf. Artif. Intell. 2020, 34, 1452–1459. [Google Scholar] [CrossRef]
- Wang, J.; Botterud, A.; Bessa, R.; Keko, H.; Carvalho, L.; Issicaba, D.; Sumaili, J.; Miranda, V. Wind power forecasting uncertainty and integer commitment. Appl. Energy 2011, 88, 4014–4023. [Google Scholar] [CrossRef]
- Chen, Y.; Casto, A.; Wang, F.; Wang, Q.; Wang, X.; Wan, J. Improving large scale day-ahead security constrained integer commitment performance. IEEE Trans. Power Syst. 2016, 31, 4732–4743. [Google Scholar] [CrossRef]
- Palmintier, B.S.; Webster, M.D. Heterogeneous integer clustering for efficient operational flexibility modeling. IEEE Trans. Power Syst. 2014, 29, 1089–1098. [Google Scholar] [CrossRef]
- Jabi, M.; Pedersoli, M.; Mitiche, A.; Ayed, I.B. Deep clustering: On the link between discriminative models and K-Means. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1887–1896. [Google Scholar] [CrossRef] [PubMed]
- Renewables. 2023. Available online: https://www.renewables.ninja/ (accessed on 20 September 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | B&B | L2O | PR-L2O |
|---|---|---|---|
| Mean | 1.207 s | 0.0149 s | 0.0110 s |
| Maximum time | 1.383 s | 0.0182 s | 0.0179 s |
| B&B | L2O | PR-L2O | |
|---|---|---|---|
| Mean gap | 0% | 0.141% | 0.110% |
| Maximum gap | 0% | 1.87% | 0.72% |
| Operation cost | $225.610 | $224.675 | $224.352 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, N.; Cai, X.; Sang, L.; Zhang, T.; Yi, Z.; Xu, Y. Online Distribution Network Scheduling via Provably Robust Learning Approach. Energies 2024, 17, 1361. https://doi.org/10.3390/en17061361
Wang N, Cai X, Sang L, Zhang T, Yi Z, Xu Y. Online Distribution Network Scheduling via Provably Robust Learning Approach. Energies. 2024; 17(6):1361. https://doi.org/10.3390/en17061361
Chicago/Turabian StyleWang, Naixiao, Xinlei Cai, Linwei Sang, Tingxiang Zhang, Zhongkai Yi, and Ying Xu. 2024. "Online Distribution Network Scheduling via Provably Robust Learning Approach" Energies 17, no. 6: 1361. https://doi.org/10.3390/en17061361
APA StyleWang, N., Cai, X., Sang, L., Zhang, T., Yi, Z., & Xu, Y. (2024). Online Distribution Network Scheduling via Provably Robust Learning Approach. Energies, 17(6), 1361. https://doi.org/10.3390/en17061361