
Machine Learning Techniques for Spatio-Temporal Air Pollution Prediction to Drive Sustainable Urban Development in the Era of Energy and Data Transformation



Abstract
1. Introduction
2. Materials and Methods
2.1. Urban Development and Energy Transition
2.2. Machine-Learning Data Pipeline
2.3. Machine Learning Forecasting
2.3.1. Models
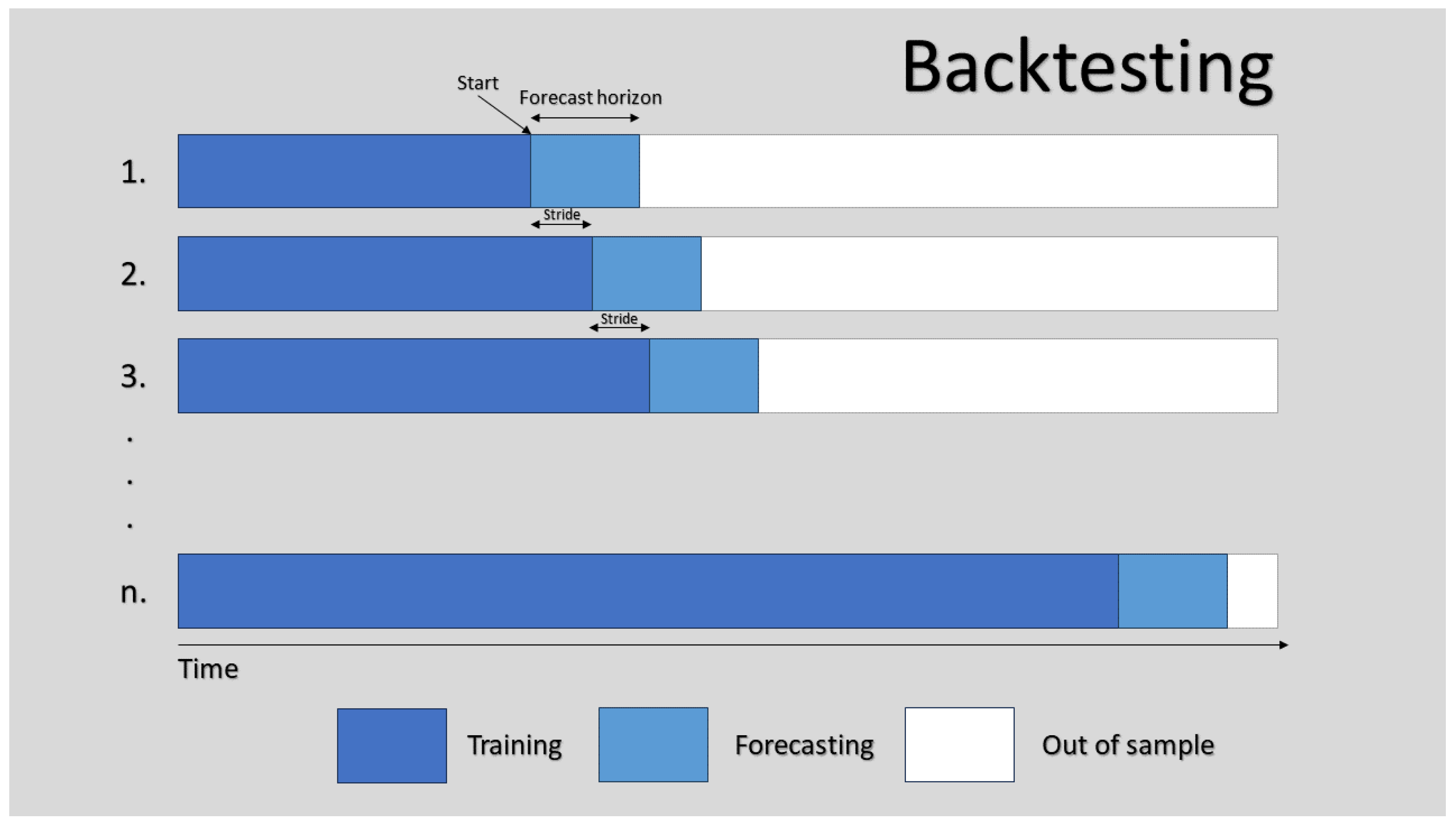
2.3.2. Evaluation
3. Results
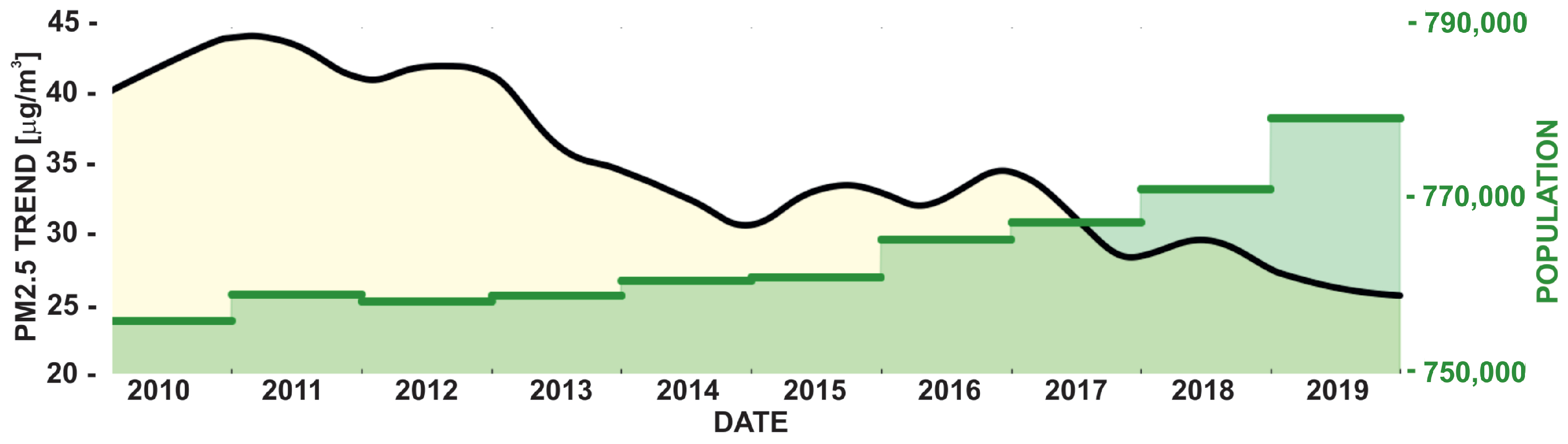
3.1. Urban Development
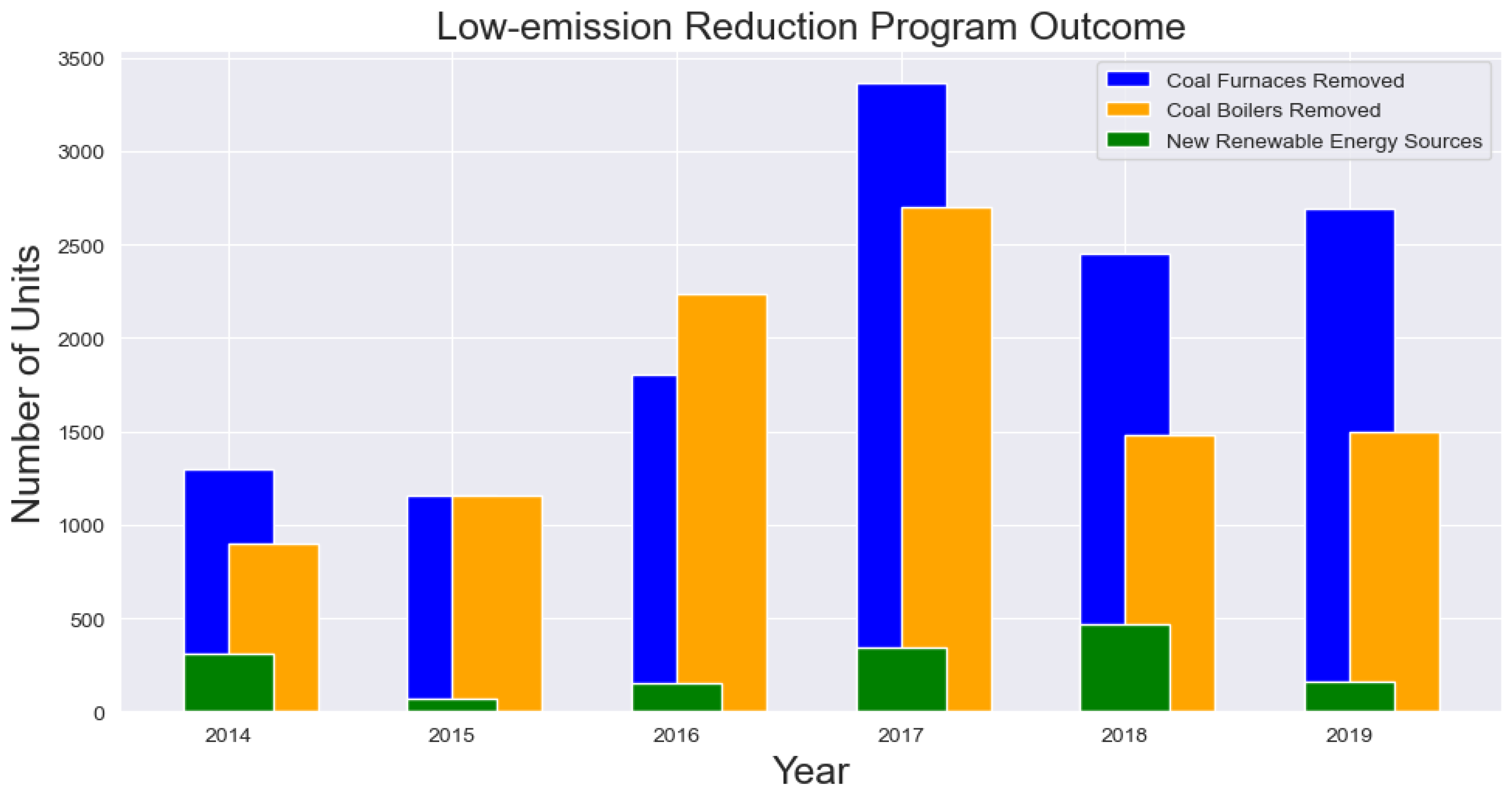
3.2. Energy Transition
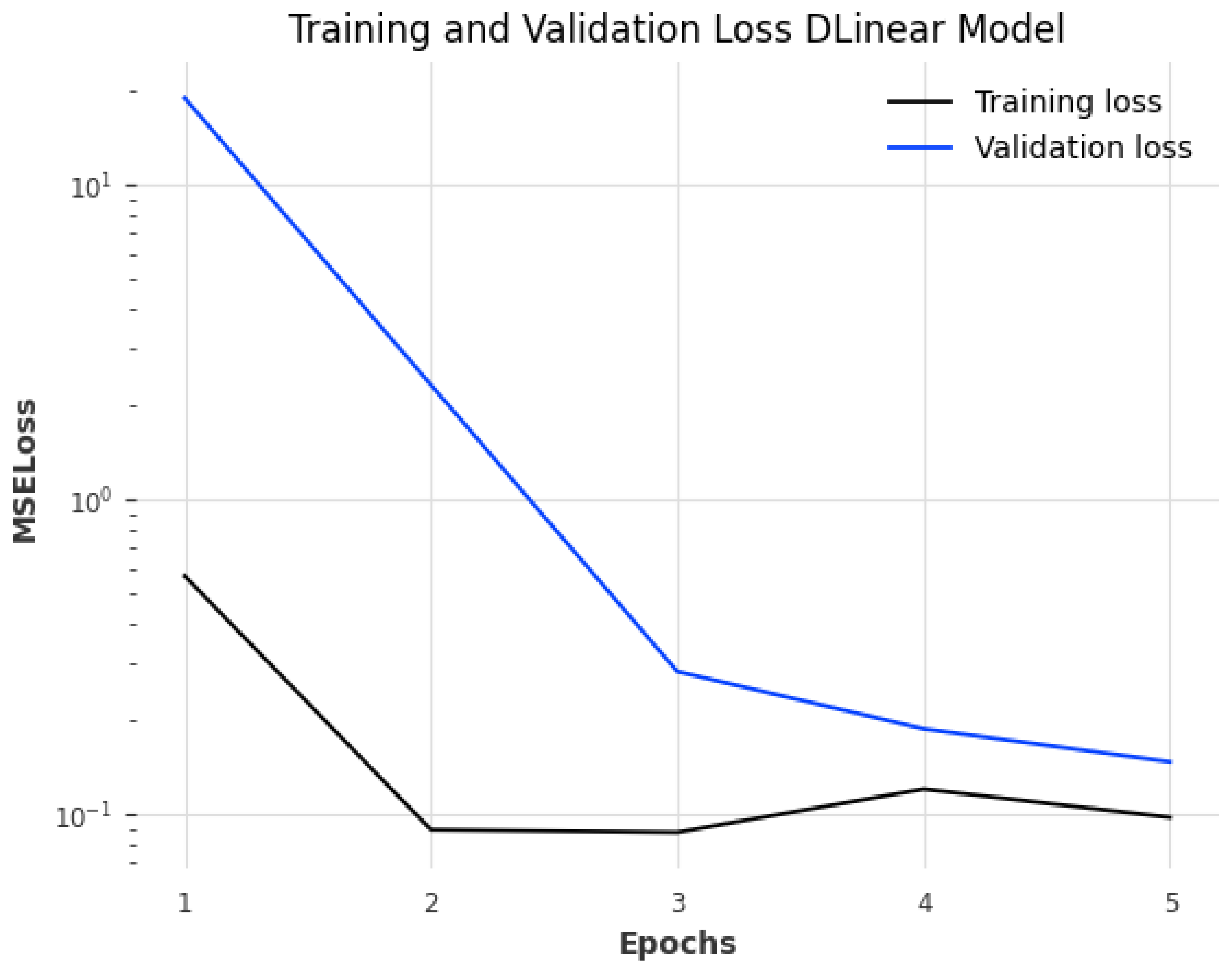
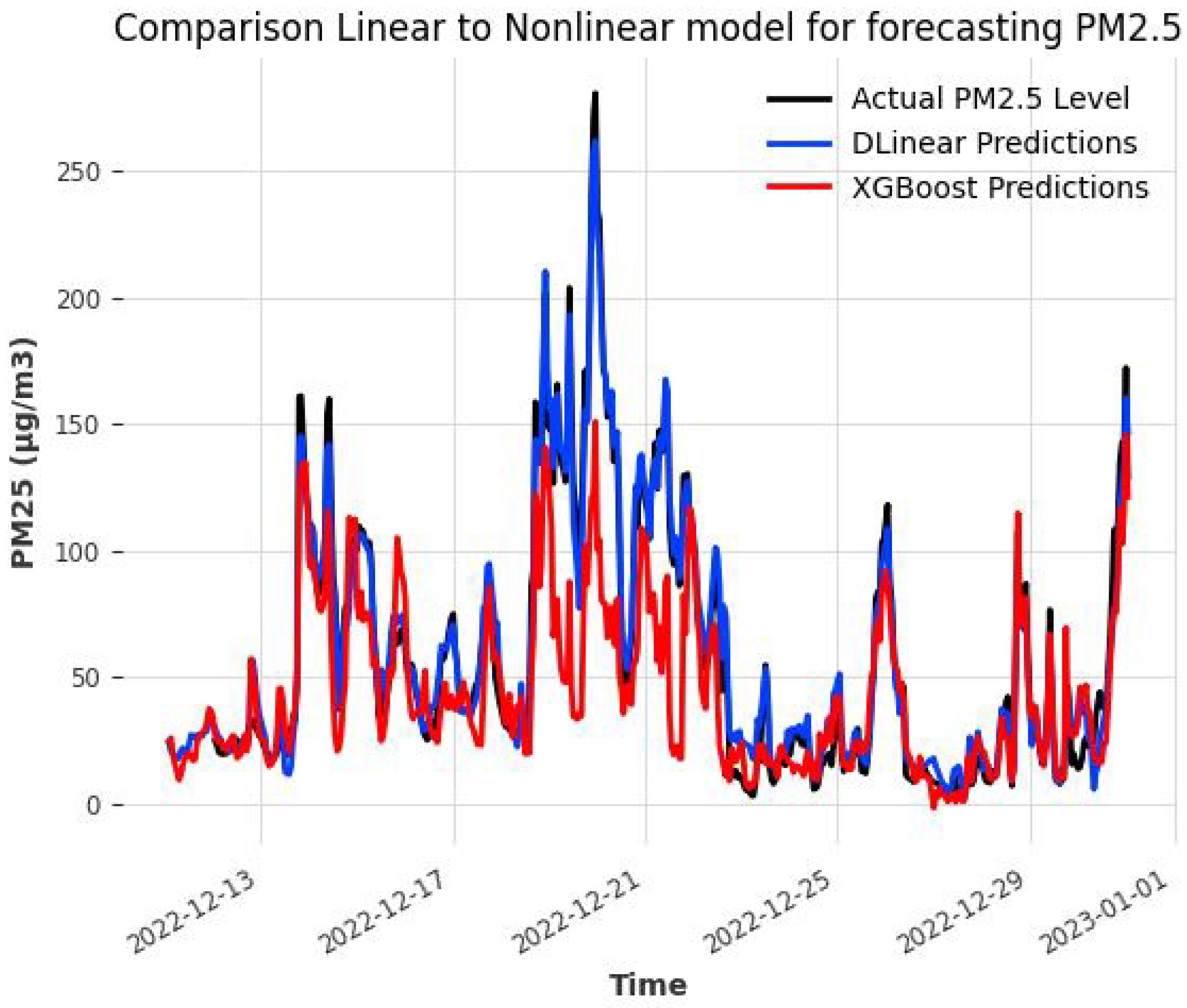
3.3. Machine Learning Forecasts
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ARIMA | AutoRegressive Integrated Moving Average |
| EDA | Exploratory Data Analysis |
| GRU | Gated Recurrent Unit |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| MARRE | Relative Risk Error |
| ML | Machine Learning |
| NBEATS | Neural Basis Expansion Analysis Time Series |
| PLN | Polish Zloty |
| PONE | Low-Emission Reduction Program in Krakow |
| R2 | R-squared (Coefficient of Determination) |
| RMSE | Root Mean Square Error |
| SHAP | SHapley Additive exPlanations |
| TFT | Temporal Fusion Transformer |
| XAI | Explainable AI |
References
- Zhang, L.; Su, D.; Guo, W.; Li, S. Empirical study on urban sustainable development model based on identification of advantages and disadvantages. Front. Sustain. Cities 2022, 4, 894658. [Google Scholar] [CrossRef]
- Wesz, J.G.B.; Miron, L.I.G.; Delsante, I.; Tzortzopoulos, P. Urban Quality of Life: A Systematic Literature Review. Urban Sci. 2023, 7, 56. [Google Scholar] [CrossRef]
- Keith, M.; Birch, E.; Buchoud, N.J.A.; Cardama, M.; Cobbett, W.; Cohen, M.; Elmqvist, T.; Espey, J.; Hajer, M.; Hartmann, G.; et al. A new urban narrative for sustainable development. Nat. Sustain. 2023, 6, 115–117. [Google Scholar] [CrossRef]
- Liang, L.; Gong, P. Urban and air pollution: A multi-city study of long-term effects of urban landscape patterns on air quality trends. Sci. Rep. 2020, 10, 18618. [Google Scholar] [CrossRef] [PubMed]
- Jonek-Kowalska, I. Assessing the Effectiveness of Air Quality Improvements in Polish Cities Aspiring to Be Sustainably Smart. Smart Cities 2023, 6, 510–530. [Google Scholar] [CrossRef]
- Central Statistical Office of Poland. Energy Statistics—Energy Report 2023; Central Statistical Office of Poland: Warsaw, Poland, 2023.
- Bokwa, A. Environmental impacts of long-term air pollution changes in Krakow, Poland. Pol. J. Environ. Stud. 2008, 17, 673–686. [Google Scholar]
- Oleniacz, R.; Gorzelnik, T. Assessment of the variability of air pollutant concentrations at industrial, traffic and urban background stations in Krakow (Poland) using statistical methods. Sustainability 2021, 13, 5623. [Google Scholar] [CrossRef]
- Danek, T.; Zaręba, M. The Use of Public Data from Low-Cost Sensors for the Geospatial Analysis of Air Pollution from Solid Fuel Heating during the COVID-19 Pandemic Spring Period in Krakow, Poland. Sensors 2021, 21, 5208. [Google Scholar] [CrossRef] [PubMed]
- Wojewodzki Inspektorat Ochrony Srodowiska w Krakowie. Jakość powietrza w Krakowie. Podsumowanie wynikóW Badań. 2020. Available online: https://krakow.wios.gov.pl/2020/09/jakosc-powietrza-w-krakowie-podsumowanie-wynikow-badan/ (accessed on 12 April 2024).
- Danek, T.; Weglinska, E.; Zareba, M. The influence of meteorological factors and terrain on air pollution concentration and migration: A geostatistical case study from Krakow, Poland. Sci. Rep. 2022, 12, 11050. [Google Scholar] [CrossRef]
- Zaręba, M.; Danek, T.; Zając, J. On Including Near-surface Zone Anisotropy for Static Corrections Computation—Polish Carpathians 3D Seismic Processing Case Study. Geosciences 2020, 10, 66. [Google Scholar] [CrossRef]
- Government of Poland. A Sustainable Tourism Policy for Kraków in the Years 2021–2028; Government of Poland: Warsaw, Poland, 2022.
- European Commission, Directorate-General for Research and Innovation. EU Missions—100 Climate-Neutral and Smart Cities; European Commission: Brussels, Belgium, 2024. [Google Scholar]
- Government of Poland. mObywatel 2.0; Government of Poland: Warsaw, Poland, 2024.
- Zareba, M.; Danek, T.; Stefaniuk, M. Unsupervised Machine Learning Techniques for Improving Reservoir Interpretation Using Walkaway VSP and Sonic Log Data. Energies 2023, 16, 493. [Google Scholar] [CrossRef]
- Rana, R.; Kalia, A.; Boora, A.; Alfaisal, F.M.; Alharbi, R.S.; Berwal, P.; Alam, S.; Khan, M.A.; Qamar, O. Artificial Intelligence for Surface Water Quality Evaluation, Monitoring and Assessment. Water 2023, 15, 3919. [Google Scholar] [CrossRef]
- Zaresefat, M.; Derakhshani, R. Revolutionizing Groundwater Management with Hybrid AI Models: A Practical Review. Water 2023, 15, 1750. [Google Scholar] [CrossRef]
- Uriarte-Gallastegi, N.; Arana-Landín, G.; Landeta-Manzano, B.; Laskurain-Iturbe, I. The Role of AI in Improving Environmental Sustainability: A Focus on Energy Management. Energies 2024, 17, 649. [Google Scholar] [CrossRef]
- Zareba, M.; Dlugosz, H.; Danek, T.; Weglinska, E. Big-Data-Driven Machine Learning for Enhancing Spatiotemporal Air Pollution Pattern Analysis. Atmosphere 2023, 14, 760. [Google Scholar] [CrossRef]
- Biuletyn Informacji Publicznej. Kraków w Liczbach. 2011–2019. Available online: https://www.bip.krakow.pl/?mmi=6353 (accessed on 13 May 2024).
- Kraków, M.P.K.M. Program Ograniczania Niskiej Emisji. 2019. Available online: https://www.krakow.pl/aktualnosci/209034,29,komunikat,mobi_short,program_ograniczania_niskiej_emisji_w_pigulce.html (accessed on 13 May 2024).
- QuantumBlack, M. Kedro Documentation. Available online: https://docs.kedro.org/en/stable/ (accessed on 10 May 2024).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Cleveland, R.B. STL: A Seasonal-Trend Decomposition Procedure Based on Loess. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Herzen, J.; Lässig, F.; Piazzetta, S.G.; Neuer, T.; Tafti, L.; Raille, G.; Pottelbergh, T.V.; Pasieka, M.; Skrodzki, A.; Huguenin, N.; et al. Darts: User-Friendly Modern Machine Learning for Time Series. J. Mach. Learn. Res. 2022, 23, 1–6. [Google Scholar]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Amat Rodrigo, J.; Escobar Ortiz, J. Skforecast; Zenodo: Geneva, Switzerland, 2023. [Google Scholar] [CrossRef]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are Transformers Effective for Time Series Forecasting? Proc. AAAI Conf. Artif. Intell. 2022, 37, 11121–11128. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice, 2nd ed.; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Lim, B.; Arik, S.O.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. arXiv 2020, arXiv:1912.09363. [Google Scholar] [CrossRef]
- Yang, R. Omphalos, Uber’s Parallel and Language-Extensible Time Series Backtesting Tool. 2018. Available online: https://www.uber.com/en-PL/blog/omphalos/ (accessed on 10 May 2024).
- Elektrycznych, P.S. Licznik Elektromobilności: Wzrost Liczby Samochodów Elektrycznych na Polskich Drogach o Prawie 90% r/r (Sierpień 2019). Available online: https://psnm.org/2019/informacja/licznik-elektromobilnosci-wzrost-liczby-samochodow-elektrycznych-na-polskich-drogach-o-prawie-90-r-r-sierpien-2019 (accessed on 27 April 2024).
- City of Krakow. Program Ograniczania Niskiej Emisji w Pigułce. City of Krakow Website. 2024. Available online: https://www.krakow.pl/aktualnosci/209034,29,komunikat,mobi_short,program_ograniczania_niskiej_emisji_w_pigulce.html (accessed on 27 April 2024).
- Marshal’s Office of the Małopolska Region. Uchwała Nr XVIII/243/16 Sejmiku Województwa Małopolskiego z Dnia 15 Stycznia 2016 r. w Sprawie Wprowadzenia Na Obszarze Gminy Miejskiej Kraków Ograniczeń w Zakresie Eksploatacji Instalacji, w Których Następuje Spalanie Paliw; Marshal’s Office of the Małopolska Region: Kraków, Poland, 2016. [Google Scholar]
- Krakowski Alarm Smogowy. Krakowski Alarm Smogowy z Tytułem Człowieka Roku Polskiej Ekologi. 2016. Available online: https://www.gramwzielone.pl/walka-ze-smogiem/21385/krakowski-alarm-smogowy-z-tytulem-czlowieka-roku-polskiej-ekologi (accessed on 13 May 2024).
- Zareba, M.; Danek, T. Analysis of Air Pollution Migration during COVID-19 Lockdown in Krakow, Poland. Aerosol Air Qual. Res. 2022, 22, 210275. [Google Scholar] [CrossRef]
- Wielgosiński, G.; Czerwińska, J. Smog Episodes in Poland. Atmosphere 2020, 11, 277. [Google Scholar] [CrossRef]
- Zareba, M.; Weglinska, E.; Danek, T. Air pollution seasons in urban moderate climate areas through big data analytics. Sci. Rep. 2024, 14, 3058. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Performance for 24 h Prediction | |||||
|---|---|---|---|---|---|
| Model | MAE | RMSE | R2 | MAPE | MARRE |
| Ridge | 2.666 | 3.867 | 0.956 | 15.621 | 1.859 |
| ARIMA | 6.688 | 9.282 | 0.755 | 36.417 | 4.622 |
| XGBoost | 4.104 | 6.763 | 0.879 | 19.234 | 2.747 |
| CatBoost | 3.839 | 6.236 | 0.897 | 18.463 | 2.569 |
| LGBM | 4.863 | 7.445 | 0.850 | 27.175 | 3.340 |
| GRU | 5.170 | 7.790 | 0.831 | 25.855 | 3.582 |
| LTSM | 5.258 | 7.704 | 0.830 | 27.206 | 3.682 |
| NBEATS | 12.000 | 17.915 | 0.079 | 76.314 | 8.547 |
| TCN | 13.276 | 19.651 | −0.108 | 68.585 | 9.448 |
| TFT | 3.915 | 5.971 | 0.900 | 17.675 | 2.710 |
| NLinear | 3.356 | 4.695 | 0.932 | 20.706 | 2.418 |
| DLinear | 2.947 | 3.888 | 0.947 | 20.354 | 2.210 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zareba, M.; Cogiel, S.; Danek, T.; Weglinska, E. Machine Learning Techniques for Spatio-Temporal Air Pollution Prediction to Drive Sustainable Urban Development in the Era of Energy and Data Transformation. Energies 2024, 17, 2738. https://doi.org/10.3390/en17112738
Zareba M, Cogiel S, Danek T, Weglinska E. Machine Learning Techniques for Spatio-Temporal Air Pollution Prediction to Drive Sustainable Urban Development in the Era of Energy and Data Transformation. Energies. 2024; 17(11):2738. https://doi.org/10.3390/en17112738
Chicago/Turabian StyleZareba, Mateusz, Szymon Cogiel, Tomasz Danek, and Elzbieta Weglinska. 2024. "Machine Learning Techniques for Spatio-Temporal Air Pollution Prediction to Drive Sustainable Urban Development in the Era of Energy and Data Transformation" Energies 17, no. 11: 2738. https://doi.org/10.3390/en17112738
APA StyleZareba, M., Cogiel, S., Danek, T., & Weglinska, E. (2024). Machine Learning Techniques for Spatio-Temporal Air Pollution Prediction to Drive Sustainable Urban Development in the Era of Energy and Data Transformation. Energies, 17(11), 2738. https://doi.org/10.3390/en17112738