
Assessing the Impact of Features on Probabilistic Modeling of Photovoltaic Power Generation



Abstract
:1. Introduction
- (1)
- The effects of the 14 variables were evaluated by RF. Features were selected according to their gains, and PIs were generated by LUBE and QR.
- (2)
- When features with high gain were selected, there was an improvement in the accuracy of PIs in both QR and LUBE compared to when all features were used. However, features with low gain rarely contribute to or worsen the accuracy of PIs. According to Loss, the low gain features reduced the accuracy of PIs in LUBE, especially when PV output fluctuations were large.
2. Feature Selection Using Random Forest
- (i).
- From the training data consisting of n sets of P predictors and corresponding target variables, n sets are extracted, allowing for overlap. The extraction is repeated to generate K bootstrap samples. When generating bootstrap samples, approximately two-thirds of the training data are extracted at least once from the sample and about one-third are never extracted. The group of samples that are not extracted is referred to as out-of-bag (OOB).
- (ii).
- A decision tree is modeled for each of the K bootstrap samples and the mean square error (MSE) is obtained using OOB as test data. represents the MSE when is the test data. is the target variable and the hat symbol represents the predicted value.
- (iii).
- One arbitrary feature from the OOB features is selected, randomly permuted, and the MSE is obtained again. This is repeated for all features.
- (iv).
- The changes in MSE before and after permuting is obtained and the K results are averaged. Normalization is applied so that the sum of the importance of each feature is 1. If a feature is important to the accuracy of the forecast, permuting will significantly reduce the accuracy of the forecast. For unimportant features, the accuracy of the prediction is not affected.
3. Lower Upper Bound Estimation (LUBE)
3.1. Prediction Interval Coverage Probability (PICP)
3.2. Mean Prediction Interval Width (MPIW)
3.3. Loss
3.4. Continuous Ranked Probability Score (CRPS)
4. Case Study
4.1. Result of the Feature Selection by Random Forest
4.2. Prediction Intervals by Lower Upper Boundary Estimation and Quantile Regression
4.2.1. Evaluation of Prediction Intervals at 2-Week Average
4.2.2. Accuracy Evaluation by Forecast Target Date
4.2.3. Days of Maximum and Minimum Output Fluctuation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M.D. A Review and Evaluation of the State-of-the-Art in PV Solar Power Forecasting: Techniques and Optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Kodaira, D.; Jung, W.; Han, S. Optimal Energy Storage System Operation for Peak Reduction in a Distribution Network Using a Prediction Interval. IEEE Trans. Smart Grid 2020, 11, 2208–2217. [Google Scholar] [CrossRef]
- Rowe, M.; Yunusov, T.; Haben, S.; Singleton, C.; Holderbaum, W.; Potter, B. A Peak Reduction Scheduling Algorithm for Storage Devices on the Low Voltage Network. IEEE Trans. Smart Grid 2014, 5, 2115–2124. [Google Scholar] [CrossRef]
- Hafiz, F.; Awal, M.A.; De Queiroz, A.R.; Husain, I. Real-Time Stochastic Optimization of Energy Storage Management Using Deep Learning-Based Forecasts for Residential PV Applications. IEEE Trans. Ind. Appl. 2020, 56, 2216–2226. [Google Scholar] [CrossRef]
- Dolara, A.; Leva, S.; Manzolini, G. Comparison of Different Physical Models for PV Power Output Prediction. Sol. Energy 2015, 119, 83–99. [Google Scholar] [CrossRef] [Green Version]
- Miyazaki, Y.; Kameda, Y.; Kondoh, J. A Power-Forecasting Method for Geographically Distributed PV Power Systems Using Their Previous Datasets. Energies 2019, 12, 4815. [Google Scholar] [CrossRef] [Green Version]
- Saint-Drenan, Y.M.; Good, G.H.; Braun, M. A Probabilistic Approach to the Estimation of Regional Photovoltaic Power Production. Sol. Energy 2017, 147, 257–276. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Huang, T.; Gadh, R.; Li, N. Solar Generation Prediction Using the ARMA Model in a Laboratory-Level Micro-Grid. In Proceedings of the 2012 IEEE 3rd International Conference on Smart Grid Communications, SmartGridComm 2012, Tainan, Taiwan, 5–8 November 2012; pp. 528–533. [Google Scholar]
- Liu, J.; Fang, W.; Zhang, X.; Yang, C. An Improved Photovoltaic Power Forecasting Model with the Assistance of Aerosol Index Data. IEEE Trans. Sustain. Energy 2015, 6, 434–442. [Google Scholar] [CrossRef]
- Theocharides, S.; Theristis, M.; Makrides, G.; Kynigos, M.; Spanias, C.; Georghiou, G.E. Comparative Analysis of Machine Learning Models for Day-Ahead Photovoltaic Power Production Forecasting. Energies 2021, 14, 1081. [Google Scholar] [CrossRef]
- Jang, H.S.; Bae, K.Y.; Park, H.S.; Sung, D.K. Solar Power Prediction Based on Satellite Images and Support Vector Machine. IEEE Trans. Sustain. Energy 2016, 7, 1255–1263. [Google Scholar] [CrossRef]
- Tao, C.; Lu, J.; Lang, J.; Peng, X.; Cheng, K.; Duan, S. Short-Term Forecasting of Photovoltaic Power Generation Based on Feature Selection and Bias Compensation–Lstm Network. Energies 2021, 14, 3086. [Google Scholar] [CrossRef]
- Generations, P.; Kodaira, D.; Tsukazaki, K.; Kure, T.; Kondoh, J. Improving Forecast Reliability for Geographically Distributed. Energies 2021, 14, 7340. [Google Scholar]
- Yang, H.T.; Huang, C.M.; Huang, Y.C.; Pai, Y.S. A Weather-Based Hybrid Method for 1-Day Ahead Hourly Forecasting of PV Power Output. IEEE Trans. Sustain. Energy 2014, 5, 917–926. [Google Scholar] [CrossRef]
- Sheng, H.; Xiao, J.; Cheng, Y.; Ni, Q.; Wang, S. Short-Term Solar Power Forecasting Based on Weighted Gaussian Process Regression. IEEE Trans. Ind. Electron. 2018, 65, 300–308. [Google Scholar] [CrossRef]
- Agoua, X.G.; Girard, R.; Kariniotakis, G. Probabilistic Models for Spatio-Temporal Photovoltaic Power Forecasting. IEEE Trans. Sustain. Energy 2019, 10, 780–789. [Google Scholar] [CrossRef] [Green Version]
- Almeida, M.P.; Muñoz, M.; de la Parra, I.; Perpiñán, O. Comparative Study of PV Power Forecast Using Parametric and Nonparametric PV Models. Sol. Energy 2017, 155, 854–866. [Google Scholar] [CrossRef] [Green Version]
- Mitrentsis, G.; Lens, H. An Interpretable Probabilistic Model for Short-Term Solar Power Forecasting Using Natural Gradient Boosting. Appl. Energy 2022, 309, 118473. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Lower Upper Bound Estimation Method for Construction of Neural Network-Based Prediction Intervals. IEEE Trans. Neural Netw. 2011, 22, 337–346. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D. Prediction Intervals for Short-Term Wind Farm Power Generation Forecasts. IEEE Trans. Sustain. Energy 2013, 4, 602–610. [Google Scholar] [CrossRef]
- Quan, H.; Srinivasan, D.; Khosravi, A. Uncertainty Handling Using Neural Network-Based Prediction Intervals for Electrical Load Forecasting. Energy 2014, 73, 916–925. [Google Scholar] [CrossRef]
- Ni, Q.; Zhuang, S.; Sheng, H.; Kang, G.; Xiao, J. An Ensemble Prediction Intervals Approach for Short-Term PV Power Forecasting. Sol. Energy 2017, 155, 1072–1083. [Google Scholar] [CrossRef]
- Raza, M.Q.; Nadarajah, M.; Ekanayake, C. On Recent Advances in PV Output Power Forecast. Sol. Energy 2016, 136, 125–144. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Congedo, P.M.; Malvoni, M. Photovoltaic Power Forecasting Using Statistical Methods: Impact of Weather Data. IET Sci. Meas. Technol. 2014, 8, 90–97. [Google Scholar] [CrossRef]
- Zhong, Y.J.; Wu, Y.K. Short-Term Solar Power Forecasts Considering Various Weather Variables. In Proceedings of the 2020 International Symposium on Computer, Consumer and Control, IS3C 2020, Taichung City, Taiwan, 13–16 November 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 432–435. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From Local Explanations to Global Understanding with Explainable AI for Trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Lauret, P.; David, M.; Pinson, P. Verification of Solar Irradiance Probabilistic Forecasts. Sol. Energy 2019, 194, 254–271. [Google Scholar] [CrossRef] [Green Version]
- Pearce, T.; Zaki, M.; Brintrup, A.; Neely, A. High-Quality Prediction Intervals for Deep Learning: A Distribution-Free, Ensembled Approach. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 9, pp. 6473–6482. [Google Scholar]
- Breiman, L. Random Forests; Springer: Berlin/Heidelberg, Germany, 2001; Volume 45. [Google Scholar]
- Kim, S.G.; Jung, J.Y.; Sim, M.K. A Two-Step Approach to Solar Power Generation Prediction Based on Weather Data Using Machine Learning. Sustainability 2019, 11, 1501. [Google Scholar] [CrossRef] [Green Version]
- Lahouar, A.; Ben Hadj Slama, J. Hour-Ahead Wind Power Forecast Based on Random Forests. Renew. Energy 2017, 109, 529–541. [Google Scholar] [CrossRef]
- Grömping, U. Variable Importance Assessment in Regression: Linear Regression versus Random Forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Svetnik, V.; Liaw, A.; Tong, C.; Christopher Culberson, J.; Sheridan, R.P.; Feuston, B.P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Comprehensive Review of Neural Network-Based Prediction Intervals and New Advances. IEEE Trans. Neural Netw. 2011, 22, 1341–1356. [Google Scholar] [CrossRef]
- Panamtash, H.; Zhou, Q.; Hong, T.; Qu, Z.; Davis, K.O. A Copula-Based Bayesian Method for Probabilistic Solar Power Forecasting. Sol. Energy 2020, 196, 336–345. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E.; Westveld, A.H.; Goldman, T. Calibrated Probabilistic Forecasting Using Ensemble Model Output Statistics and Minimum CRPS Estimation. Mon. Weather. Rev. 2005, 133, 1098–1118. [Google Scholar] [CrossRef]
- Stephan Hoyer Properscoring. Available online: https://github.com/TheClimateCorporation/properscoring.git (accessed on 17 May 2022).
- Massidda, L.; Marrocu, M. Quantile Regression Post-Processing Ofweather Forecast for Short-Term Solar Power Probabilistic Forecasting. Energies 2018, 11, 1763. [Google Scholar] [CrossRef] [Green Version]
- Markovics, D.; Mayer, M.J. Comparison of Machine Learning Methods for Photovoltaic Power Forecasting Based on Numerical Weather Prediction. Renew. Sustain. Energy Rev. 2022, 161, 112364. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameter | Search Values | Selected Value |
|---|---|---|---|
| LUBE | nλ | 3, 5, 7 | 5 |
| learning rate | 0.01, 0.001, 0.0001 | 0.001 | |
| epochs | 100, 500, 1000, 3000 | 3000 | |
| QR | learning rate | 0.05, 0.02, 0.01 | 0.05 |
| maximum depth of trees | 3, 4, 5 | 3 | |
| minimum number of samples in leaf | 3, 5, 7 | 7 | |
| number of estimates | 100, 200, 500 | 500 |
| Feature | Gain | Feature | Gain |
|---|---|---|---|
| solar radiation | 0.7644 | atmospheric temperature | 0.0065 |
| hour sine | 0.0961 | monthly cosine | 0.0062 |
| hour cosine | 0.0757 | wind speed | 0.0057 |
| annual cosine | 0.0130 | daily sine | 0.0038 |
| degree of cloudiness | 0.0076 | daily cosine | 0.0037 |
| annual sine | 0.0069 | monthly sine | 0.0025 |
| humidity | 0.0069 | precipitation | 0.0003 |
| Number of Features | Min | Max | Mean | Median | Standard Deviation |
|---|---|---|---|---|---|
| LUBE(1) | 2.28 | 2.37 | 2.32 | 2.32 | 0.0193 |
| LUBE(4) | 1.95 | 2.30 | 2.13 | 2.13 | 0.0861 |
| LUBE(14) | 2.65 | 6.03 | 3.74 | 3.70 | 0.5967 |
| Number of Features | Min | Max | Mean | Median | Standard Deviation |
|---|---|---|---|---|---|
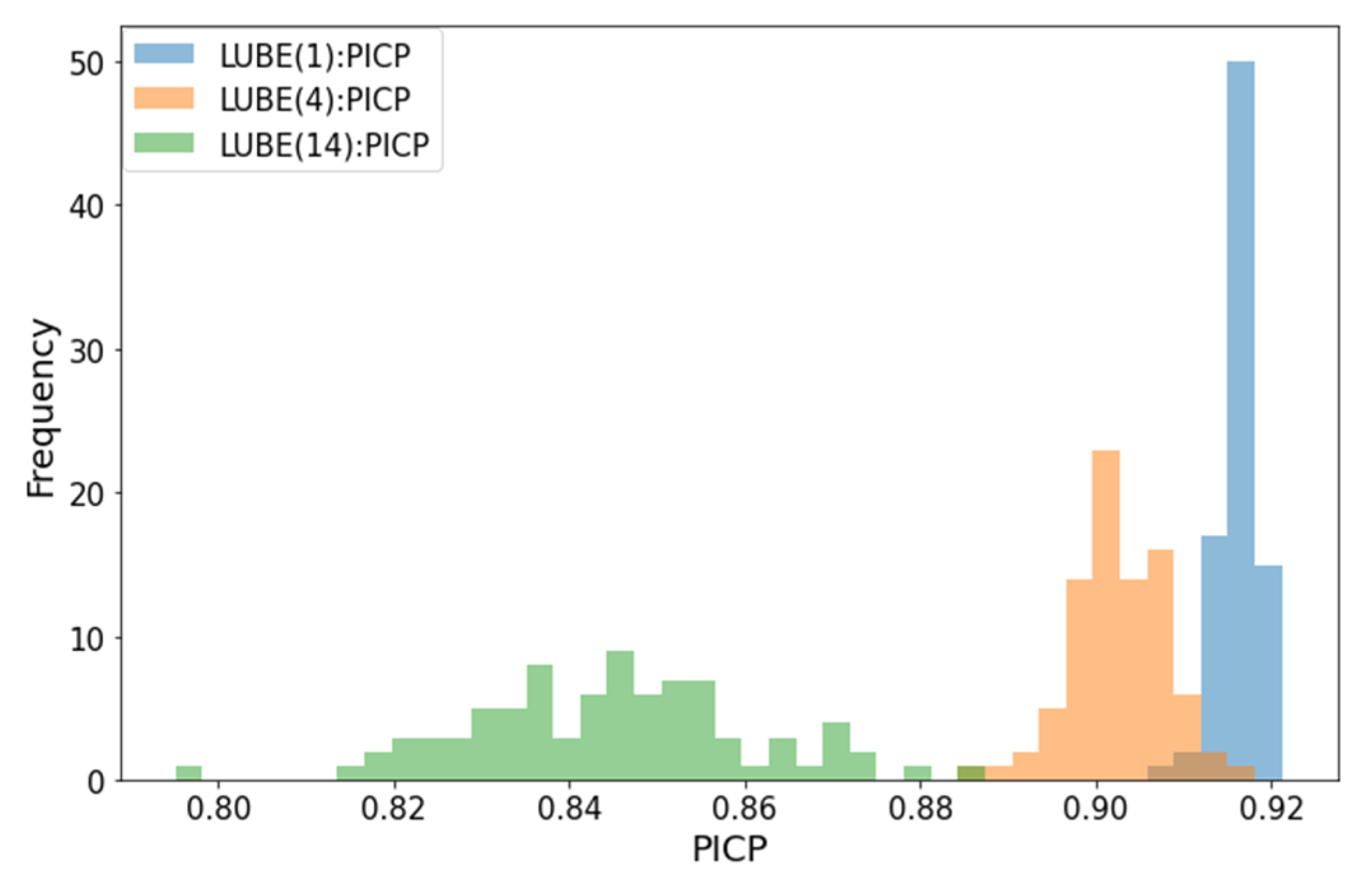
| LUBE(1) | 0.907 | 0.921 | 0.916 | 0.917 | 0.00231 |
| LUBE(4) | 0.886 | 0.916 | 0.903 | 0.902 | 0.00537 |
| LUBE(14) | 0.795 | 0.886 | 0.845 | 0.845 | 0.0160 |
| QR(2) | - | - | - | 0.942 | - |
| Number of Features | Min | Max | Mean | Median | Standard Deviation |
|---|---|---|---|---|---|
| LUBE(1) | 2.02 | 2.13 | 2.07 | 2.07 | 0.0151 |
| LUBE(4) | 1.47 | 1.66 | 1.53 | 1.53 | 0.0340 |
| LUBE(14) | 1.53 | 1.78 | 1.64 | 1.65 | 0.0536 |
| QR(2) | - | - | - | 2.51 | - |
| Number of Features | Min | Max | Mean | Median | Standard Deviation |
|---|---|---|---|---|---|
| LUBE(1) | 0.53 | 0.54 | 0.53 | 0.53 | 0.0024 |
| LUBE(4) | 0.39 | 0.43 | 0.41 | 0.41 | 0.0056 |
| LUBE(14) | 0.42 | 0.46 | 0.44 | 0.44 | 0.0064 |
| QR(2) | - | - | - | 0.51 | - |
| PICP | MPIW [kW] | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Day | Fluctuation [kW] | LUBE(1) | LUBE(4) | LUBE(14) | QR(2) | LUBE(1) | LUBE(4) | LUBE(14) | QR(2) |
| 1 | 0.489 | 0.958 | 0.979 | 0.979 | 0.938 | 2.45 | 1.55 | 2.02 | 2.91 |
| 2 | 0.582 | 0.896 | 0.864 | 0.791 | 0.958 | 2.50 | 1.52 | 1.40 | 3.01 |
| 3 | 0.505 | 0.916 | 0.875 | 0.831 | 1.000 | 2.50 | 1.61 | 1.58 | 2.88 |
| 4 | 0.522 | 0.895 | 0.853 | 0.834 | 0.938 | 2.41 | 1.49 | 1.59 | 2.86 |
| 5 | 0.350 | 0.979 | 0.979 | 0.979 | 1.000 | 1.74 | 1.66 | 2.03 | 2.13 |
| 6 | 0.193 | 0.916 | 0.984 | 0.911 | 1.000 | 0.85 | 1.44 | 1.61 | 1.48 |
| 7 | 0.233 | 0.937 | 0.984 | 1.000 | 1.000 | 1.25 | 1.46 | 1.92 | 1.86 |
| 8 | 0.412 | 0.894 | 0.917 | 0.875 | 0.896 | 1.64 | 1.65 | 1.50 | 2.25 |
| 9 | 0.968 | 0.874 | 0.833 | 0.765 | 0.875 | 2.73 | 1.63 | 1.47 | 2.90 |
| 10 | 0.909 | 0.835 | 0.849 | 0.815 | 0.938 | 2.53 | 1.63 | 1.66 | 2.86 |
| 11 | 0.308 | 0.957 | 0.879 | 0.876 | 0.875 | 1.43 | 1.10 | 1.44 | 1.69 |
| 12 | 0.271 | 0.937 | 0.956 | 0.958 | 0.958 | 1.92 | 1.58 | 1.76 | 2.34 |
| 13 | 0.807 | 0.894 | 0.808 | 0.739 | 0.896 | 2.56 | 1.36 | 1.53 | 3.03 |
| 14 | 0.513 | 0.937 | 0.974 | 0.937 | 0.917 | 2.43 | 1.60 | 1.68 | 2.90 |
| Average (Fluctuation > 0.5 kW) | 0.687 | 0.892 | 0.865 | 0.816 | 0.932 | 2.52 | 1.55 | 1.56 | 2.92 |
| Average (Fluctuation < 0.5 kW) | 0.322 | 0.940 | 0.954 | 0.940 | 0.952 | 1.61 | 1.49 | 1.75 | 2.09 |
| Average (All days) | 0.504 | 0.916 | 0.910 | 0.878 | 0.942 | 2.07 | 1.52 | 1.66 | 2.51 |
| Loss [kW] | CRPS [kW] | |||||||
|---|---|---|---|---|---|---|---|---|
| Day | Fluctuation [kW] | LUBE(1) | LUBE(4) | LUBE(14) | LUBE(1) | LUBE(4) | LUBE(14) | QR(2) |
| 1 | 0.489 | 2.45 | 1.55 | 2.02 | 0.62 | 0.26 | 0.27 | 0.63 |
| 2 | 0.582 | 2.81 | 2.30 | 4.05 | 0.75 | 0.48 | 0.49 | 0.55 |
| 3 | 0.505 | 2.62 | 2.21 | 3.07 | 0.58 | 0.48 | 0.53 | 0.43 |
| 4 | 0.522 | 2.73 | 2.49 | 3.00 | 0.61 | 0.45 | 0.47 | 0.38 |
| 5 | 0.350 | 1.74 | 1.66 | 2.03 | 0.26 | 0.26 | 0.31 | 0.31 |
| 6 | 0.193 | 0.97 | 1.44 | 1.77 | 0.20 | 0.20 | 0.22 | 0.28 |
| 7 | 0.233 | 1.27 | 1.46 | 1.92 | 0.20 | 0.15 | 0.22 | 0.30 |
| 8 | 0.412 | 1.96 | 1.76 | 2.09 | 0.38 | 0.35 | 0.41 | 0.40 |
| 9 | 0.968 | 3.33 | 3.08 | 5.07 | 0.87 | 0.64 | 0.70 | 0.70 |
| 10 | 0.909 | 3.93 | 2.70 | 3.57 | 0.91 | 0.69 | 0.72 | 0.73 |
| 11 | 0.308 | 1.43 | 1.64 | 2.01 | 0.29 | 0.42 | 0.44 | 0.51 |
| 12 | 0.271 | 1.93 | 1.58 | 1.76 | 0.31 | 0.24 | 0.24 | 0.36 |
| 13 | 0.807 | 2.89 | 3.50 | 6.22 | 0.87 | 0.73 | 0.76 | 0.89 |
| 14 | 0.513 | 2.45 | 1.60 | 1.69 | 0.62 | 0.28 | 0.29 | 0.73 |
| Average (Fluctuation > 0.5 kW) | 0.687 | 2.97 | 2.55 | 3.81 | 0.74 | 0.54 | 0.57 | 0.63 |
| Average (Fluctuation < 0.5 kW) | 0.322 | 1.68 | 1.58 | 1.94 | 0.32 | 0.27 | 0.30 | 0.40 |
| Average (All days) | 0.504 | 2.32 | 2.07 | 2.88 | 0.53 | 0.40 | 0.43 | 0.51 |
| Metric | PICP | MPIW | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | LUBE(1) | LUBE(4) | LUBE(14) | QR(2) | LUBE(1) | LUBE (4) | LUBE(14) | QR(2) |
| Correlation coefficient | −0.726 | −0.758 | −0.762 | −0.51 | 0.818 | 0.258 | −0.355 | 0.862 |
| Metric | Loss | CRPS | ||||||
| Method | LUBE(2) | LUBE(4) | LUBE(14) | QR(2) | LUBE(1) | LUBE(4) | LUBE(14) | QR(2) |
| Correlation coefficient | 0.932 | 0.879 | 0.821 | - | 0.949 | 0.894 | 0.891 | 0.807 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamamoto, H.; Kondoh, J.; Kodaira, D. Assessing the Impact of Features on Probabilistic Modeling of Photovoltaic Power Generation. Energies 2022, 15, 5337. https://doi.org/10.3390/en15155337
Yamamoto H, Kondoh J, Kodaira D. Assessing the Impact of Features on Probabilistic Modeling of Photovoltaic Power Generation. Energies. 2022; 15(15):5337. https://doi.org/10.3390/en15155337
Chicago/Turabian StyleYamamoto, Hiroki, Junji Kondoh, and Daisuke Kodaira. 2022. "Assessing the Impact of Features on Probabilistic Modeling of Photovoltaic Power Generation" Energies 15, no. 15: 5337. https://doi.org/10.3390/en15155337
APA StyleYamamoto, H., Kondoh, J., & Kodaira, D. (2022). Assessing the Impact of Features on Probabilistic Modeling of Photovoltaic Power Generation. Energies, 15(15), 5337. https://doi.org/10.3390/en15155337