Novel Mode Adaptive Artificial Neural Network for Dynamic Learning: Application in Renewable Energy Sources Power Generation Prediction


Abstract
1. Introduction
1.1. Literature Review for Output Power Prediction of Solar Photovoltaic (PV) System
1.2. Literature Review for Output Power Prediction of Wind Turbine Energy System (WTES)
1.3. Research Gaps and Motivation for the Proposed Methodology
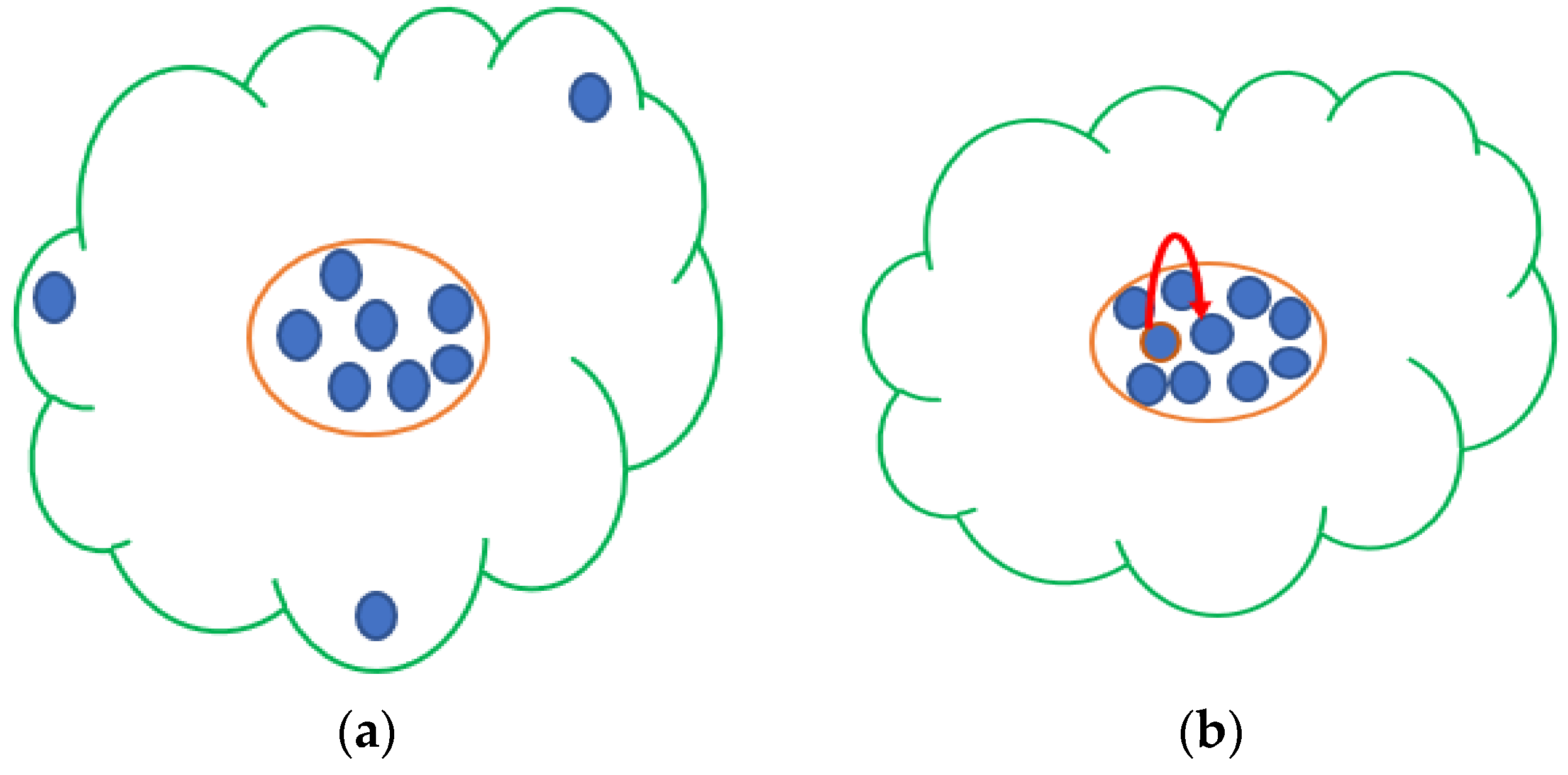
1.3.1. Necessity of Dynamic/Online Learning
1.3.2. Necessity of Correlation Coefficient (CC) Analysis among the Input and Output Variables
1.4. Contribution of This Research
- i.
- Determination of dominant input variables and data stability analysis using the dynamic application of Spearman’s rank-order correlation.
- ii.
- Application of recent population-based algorithms for better accuracy of the forecasting models compared to the conventional approach (fixed-sized dataset training with gradient descent and ARIMAX algorithm).
- iii.
- Algorithm validation by application on two different types of renewable sources of different locations, with different numbers of input variables and dataset size.
2. Related Theories for the Proposed Methodology
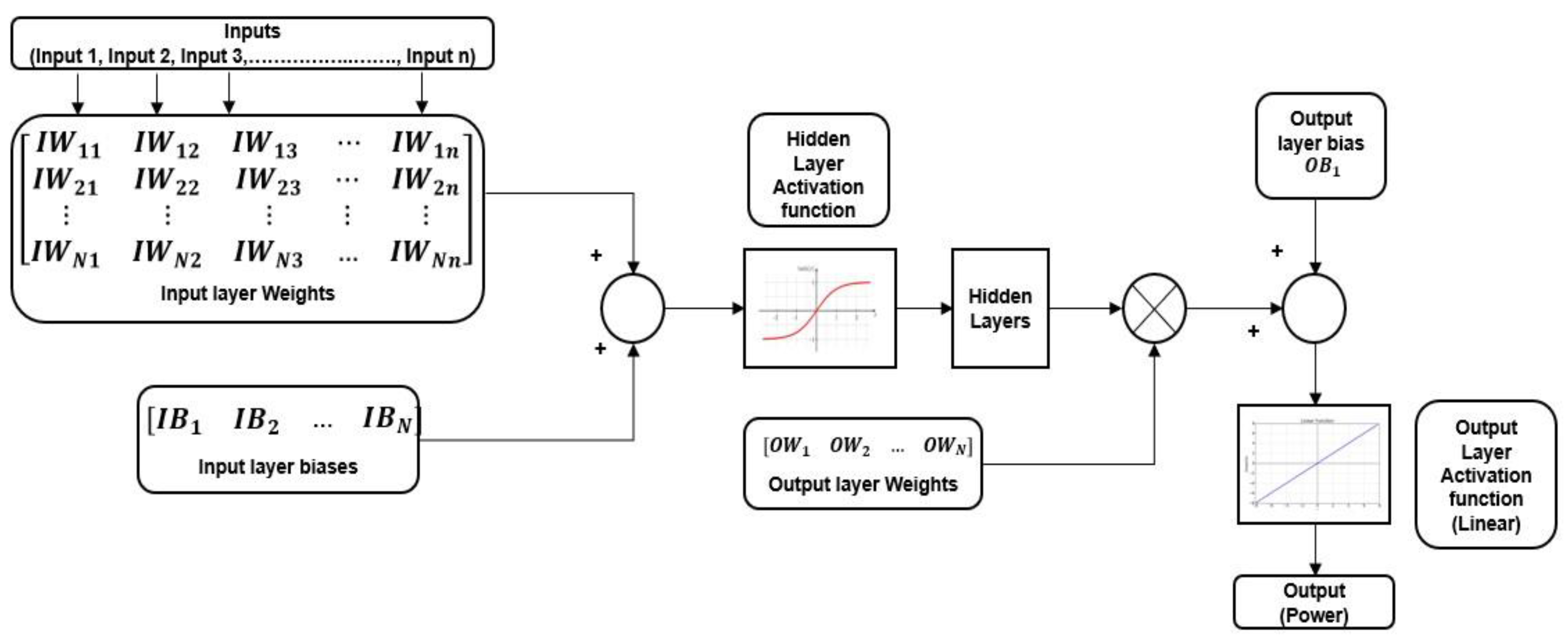
2.1. Artificial Neural Network (ANN)
2.2. Optimization Algorithms
2.2.1. Description of Jaya Algorithm
2.2.2. Description of APSO
2.2.3. Description of FTMA
2.2.4. Problem of Early Convergence and Solution
| Algorithm 1 Duplicate Solution Removal Algorithm. |
| 1: 2: 3: 4: 5: 6: 7: |
2.3. Spearman’s Rank-Order Correlation Analysis
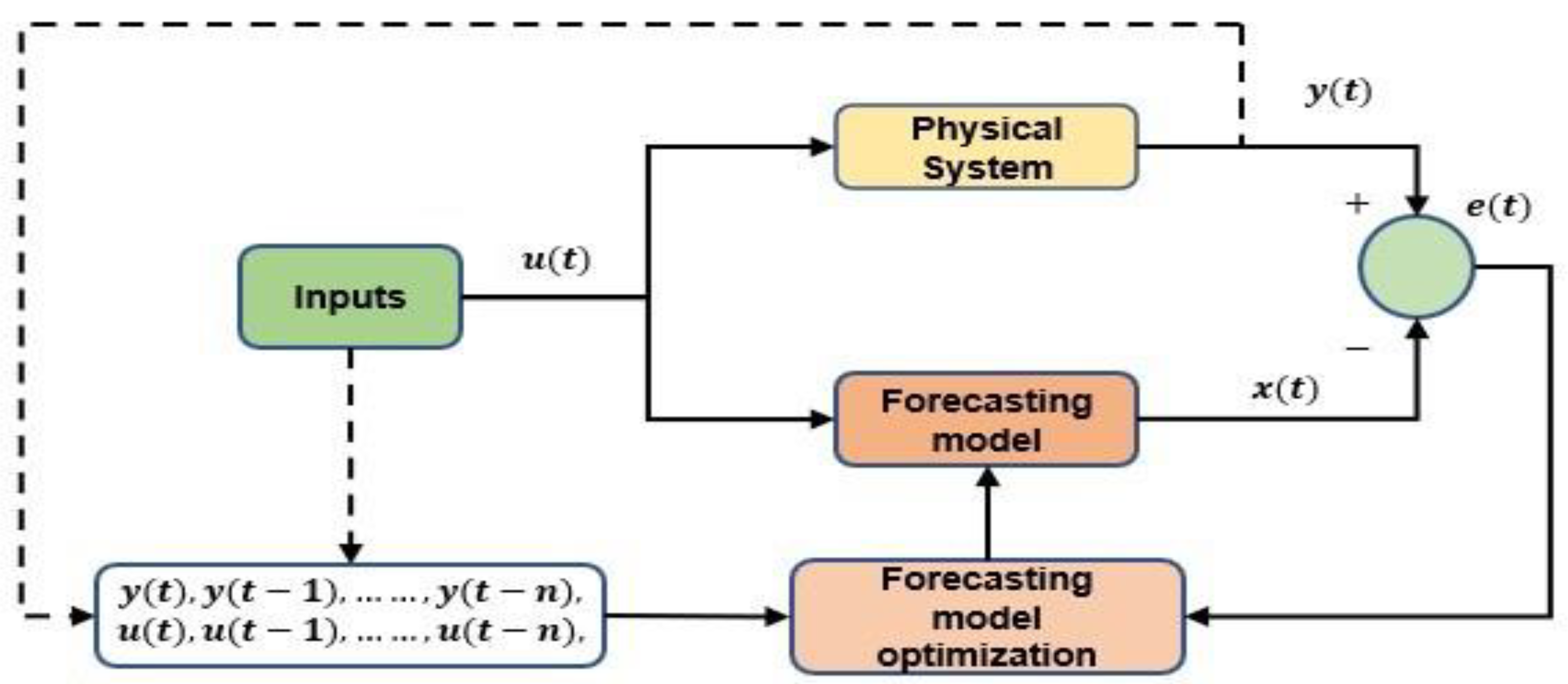
3. Proposed Algorithm for Dynamic Learning
3.1. Block 1 (System Initialization)
3.2. Blocks 2–6 (Data Collection and Sequential Entry, Feature Scaling and Correlation Analysis, Mode Consecutiveness Check)
3.3. Blocks 7–9 (Mode Occurrence Check, Solution Search Space Generation, and Evaluation of Model Performance)
3.4. Blocks 10–14 (Error Analysis, MAANN Optimization, Storing the Best Solution, Statistical Analysis, and Choosing the Best Algorithm)
4. Experimental Validations
4.1. Initialization of Experimental Setup
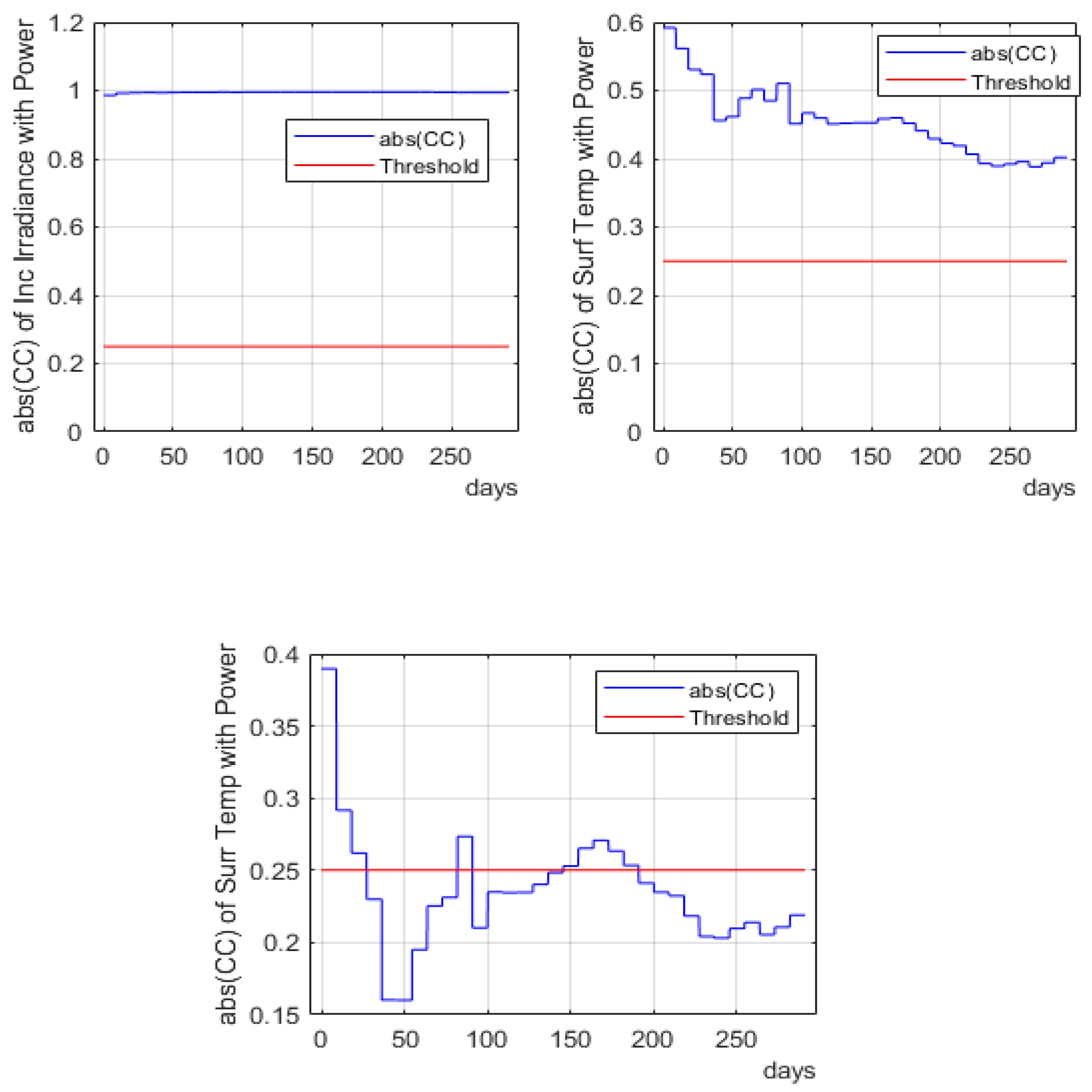
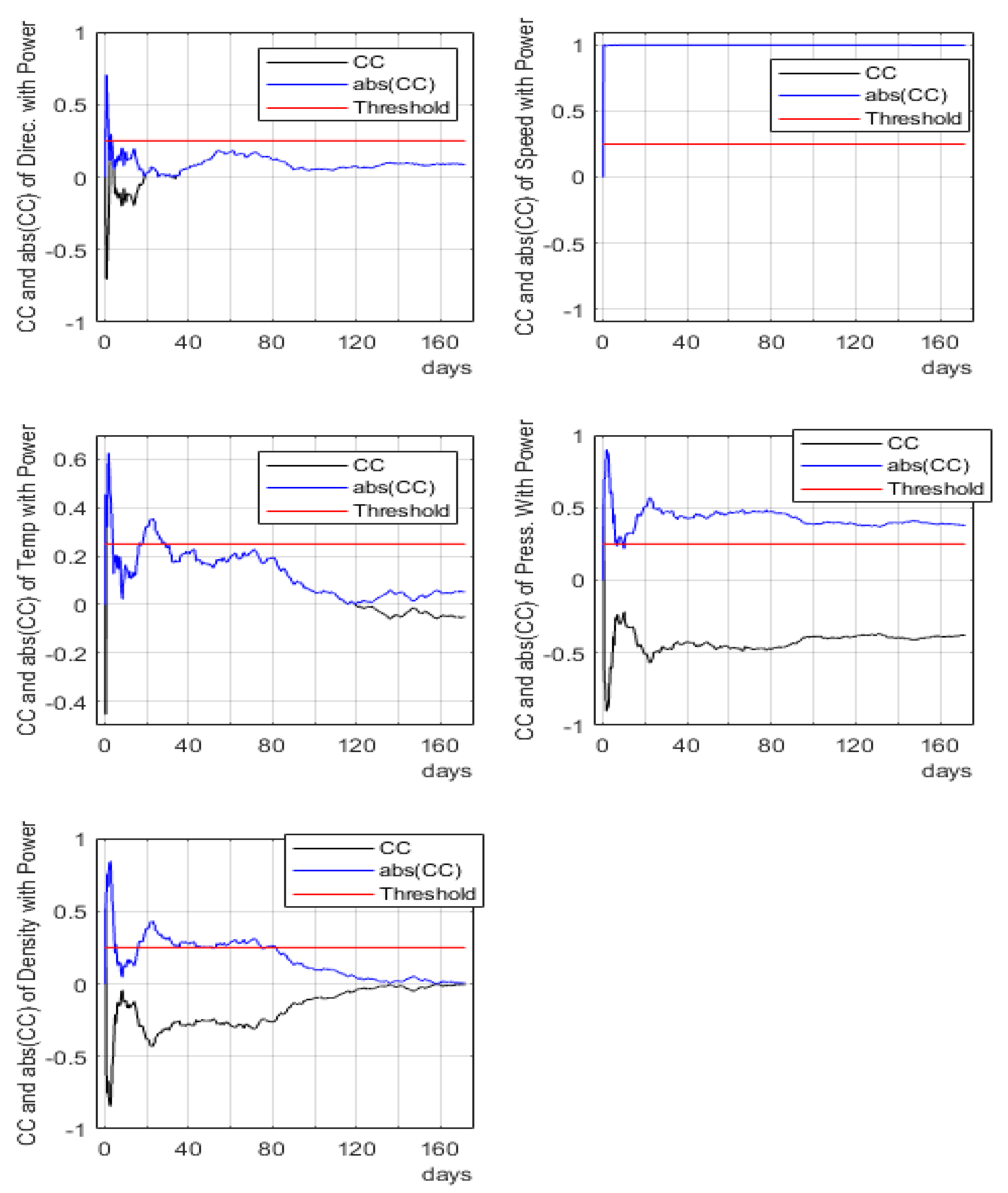
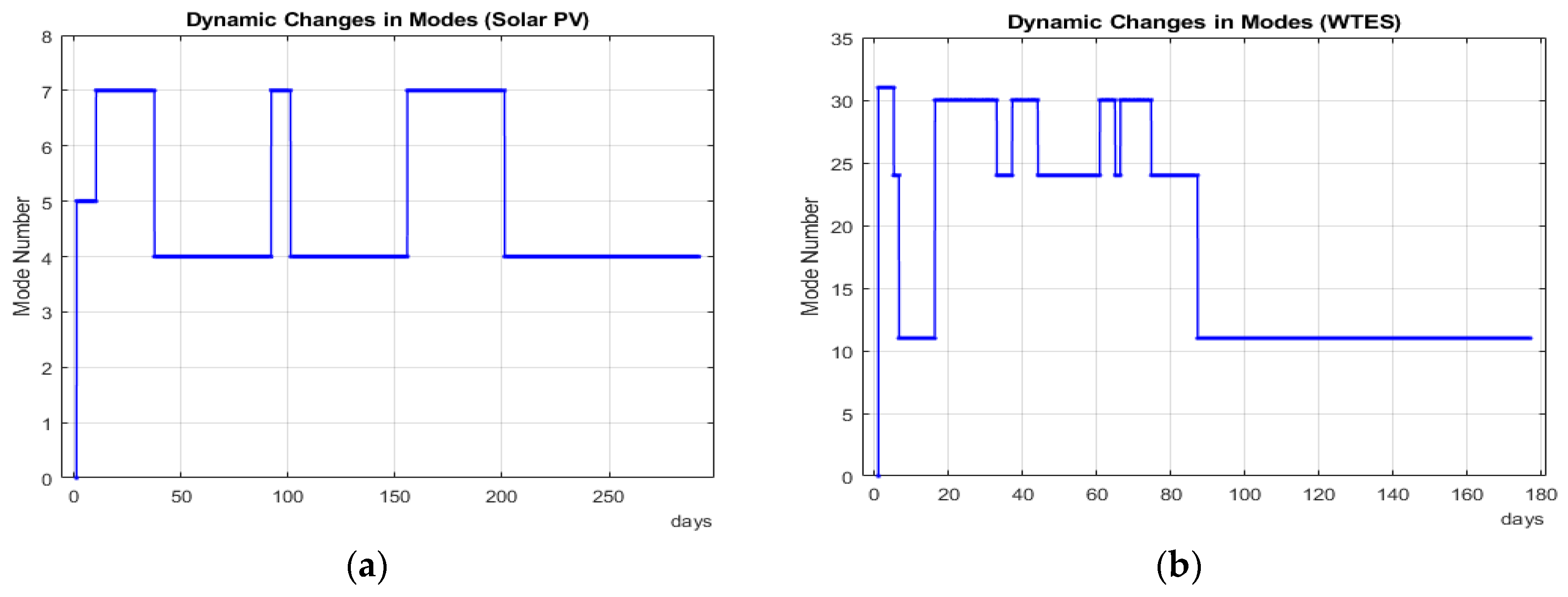
4.2. Dynamic Change in CC and Mode Analysis
4.3. Data Entry (Episode)-Wise Optimization Algorithms Performance Comparison
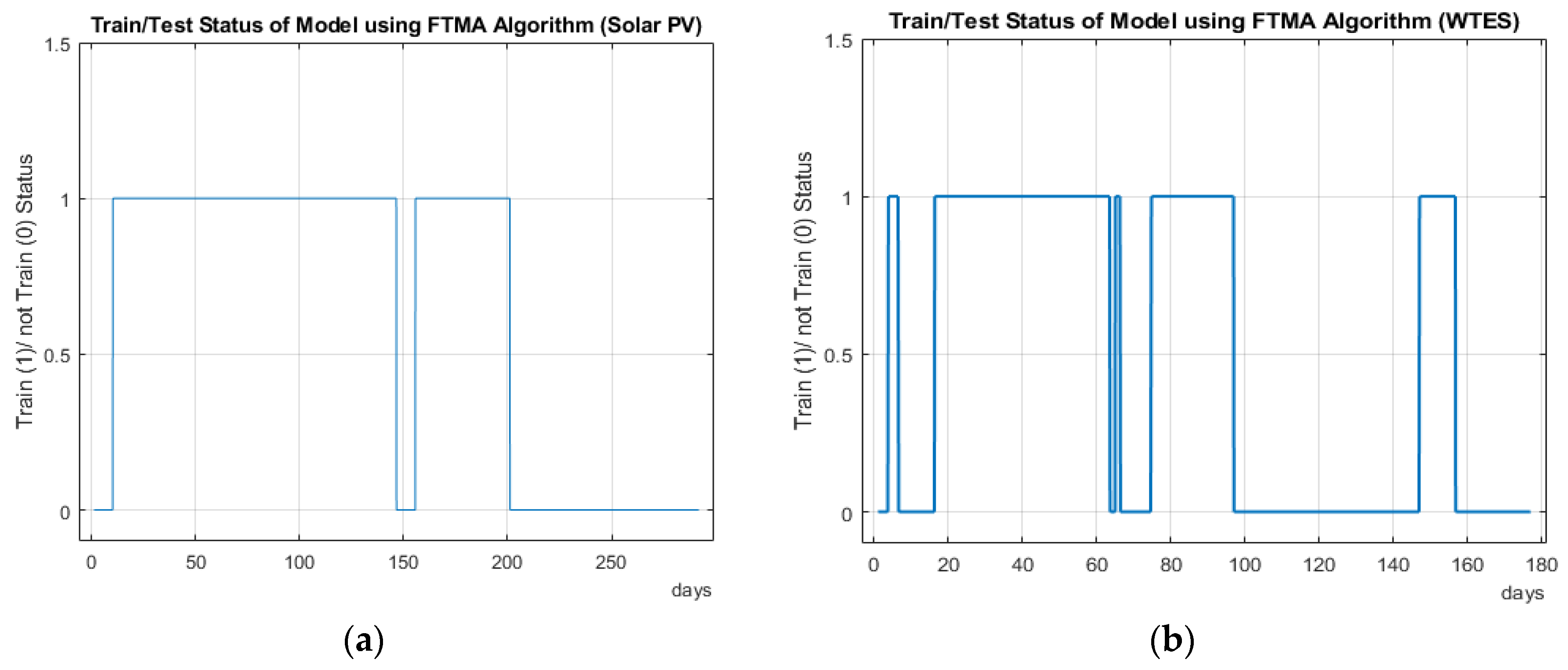
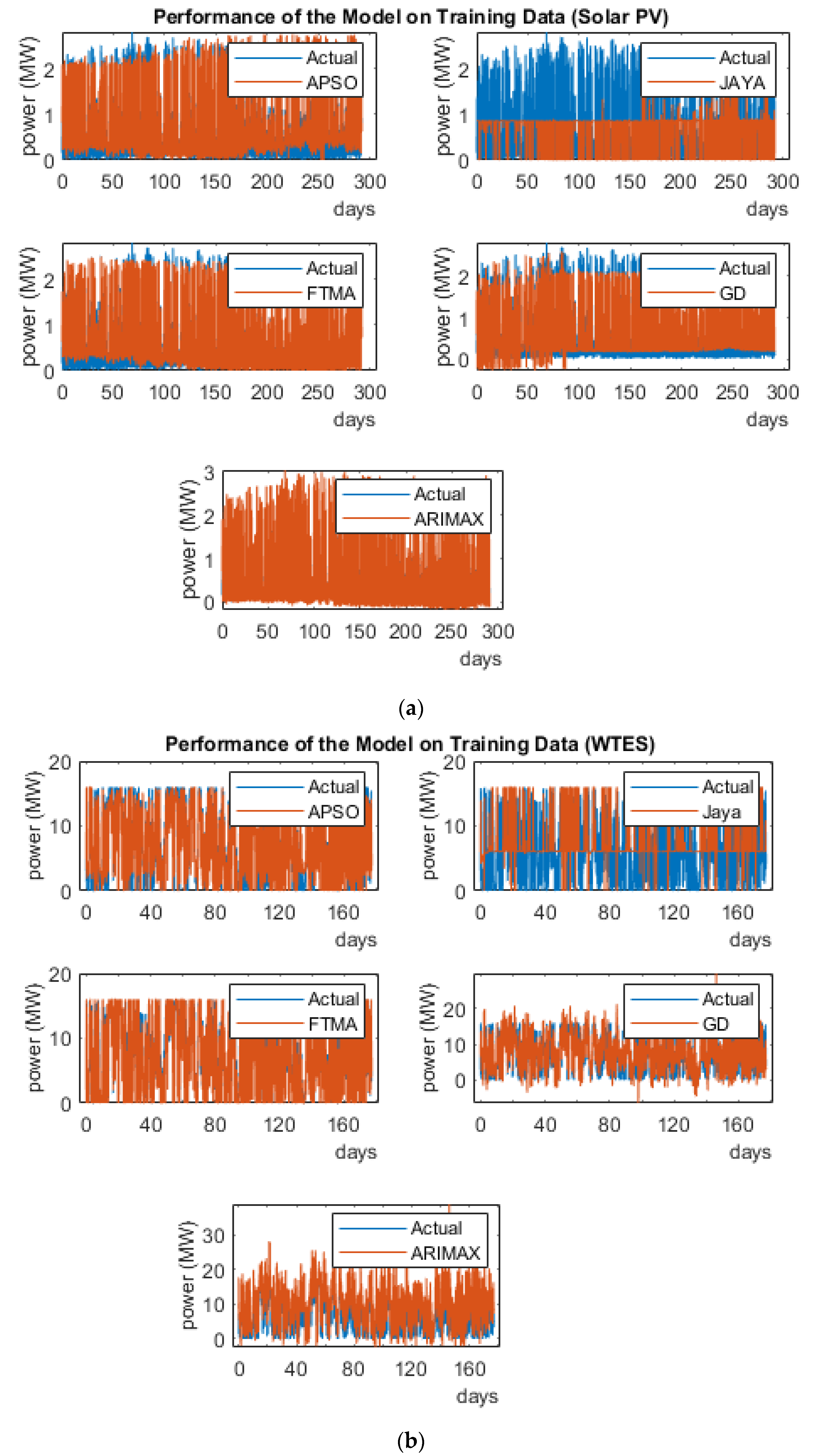
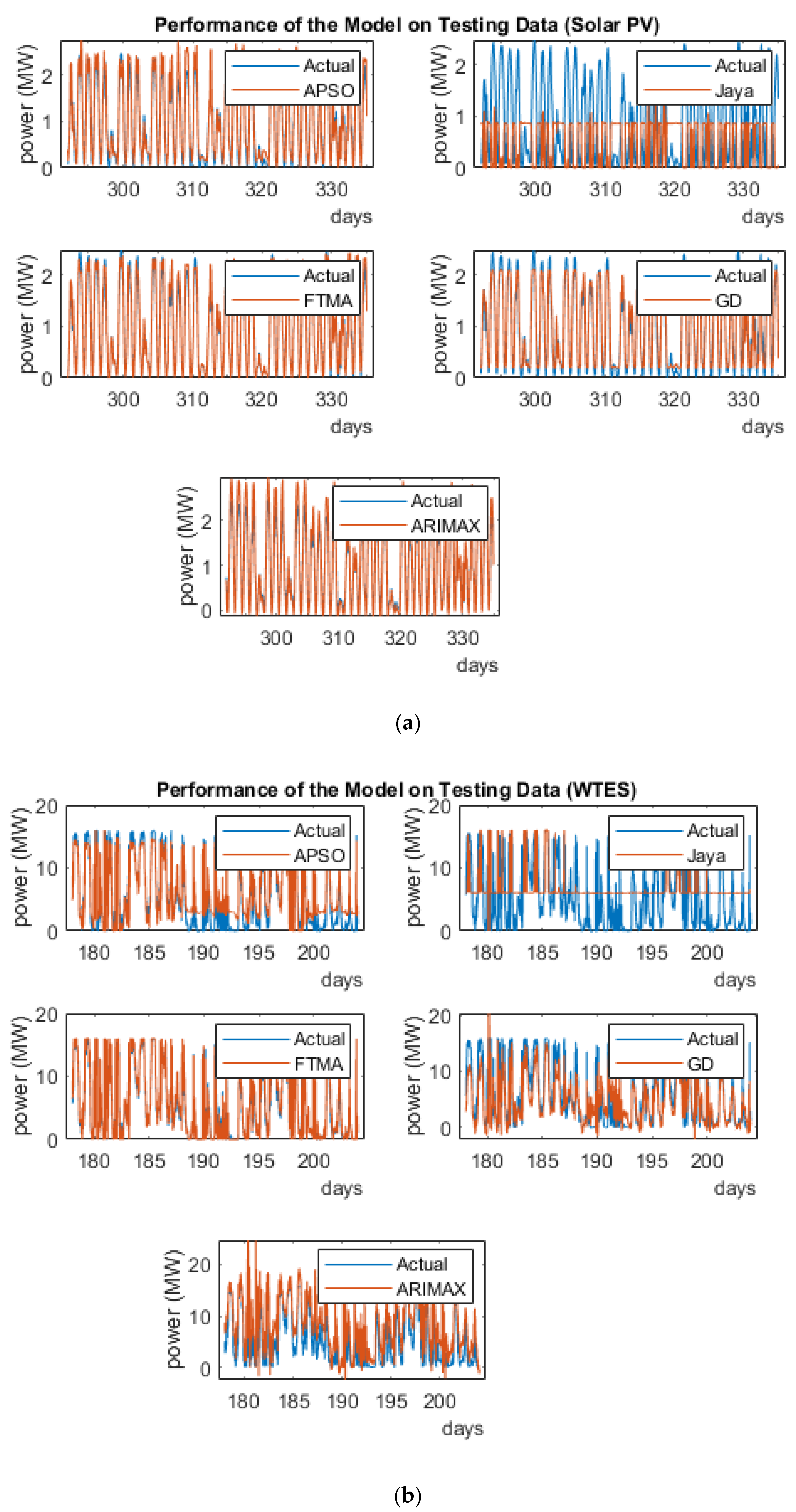
4.4. Train/Test Status of the Algorithm
4.5. Time Analysis of the FTMA
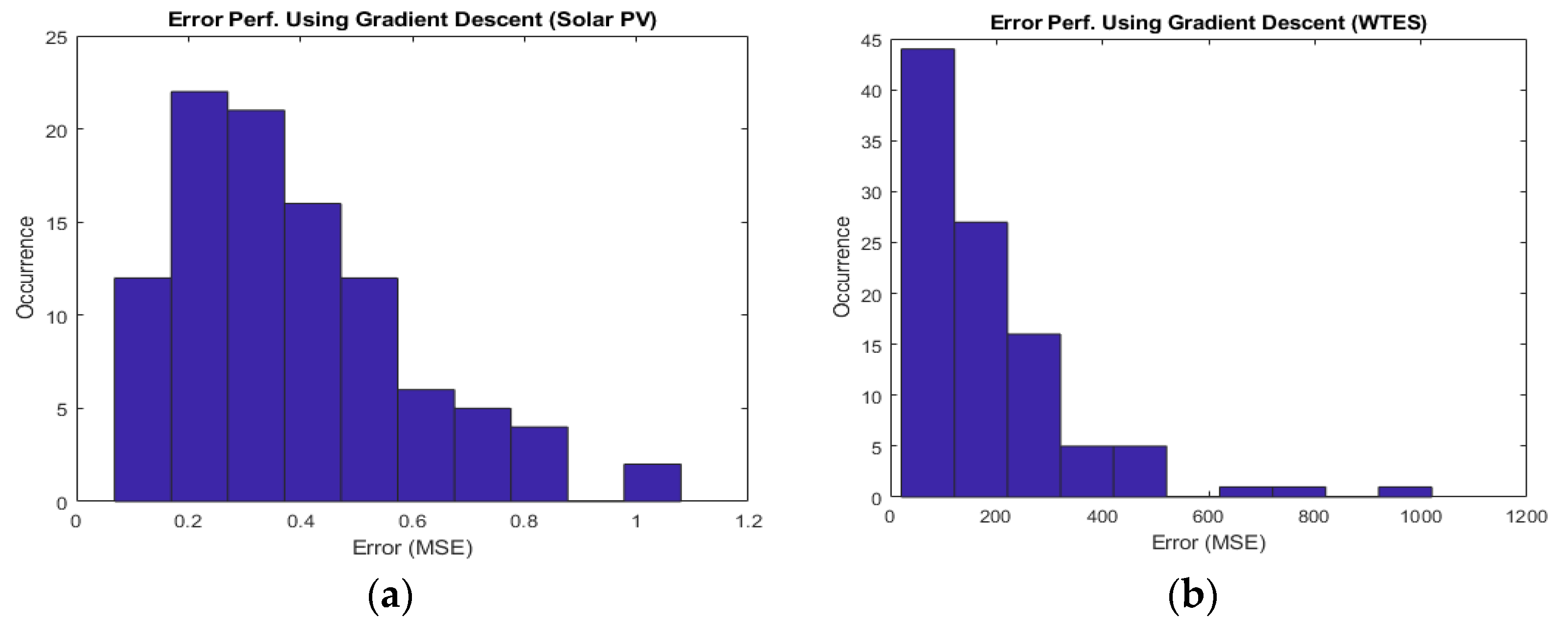
4.6. Solution Convergence Analysis of Different Optimization Algorithms
4.7. Comparison of Training and Test Dataset
4.8. Tabular Comparison
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode Number | Inputs | ||
|---|---|---|---|
| Inclined Irradiance | Surface Temperature | Surrounding Temperature | |
| 1 | ✔ | ✖ | ✖ |
| 2 | ✖ | ✔ | ✖ |
| 3 | ✖ | ✖ | ✔ |
| 4 | ✔ | ✔ | ✖ |
| 5 | ✔ | ✖ | ✔ |
| 6 | ✖ | ✔ | ✔ |
| 7 | ✔ | ✔ | ✔ |
| Mode Number | Inputs | ||||
|---|---|---|---|---|---|
| Direction | Speed | Temperature | Pressure | Density | |
| 1 | ✔ | ✖ | ✖ | ✖ | ✖ |
| 2 | ✖ | ✔ | ✖ | ✖ | ✖ |
| 3 | ✖ | ✖ | ✔ | ✖ | ✖ |
| 4 | ✖ | ✖ | ✖ | ✔ | ✖ |
| 5 | ✖ | ✖ | ✖ | ✖ | ✔ |
| 6 | ✔ | ✔ | ✖ | ✖ | ✖ |
| 7 | ✔ | ✖ | ✔ | ✖ | ✖ |
| 8 | ✔ | ✖ | ✖ | ✔ | ✖ |
| 9 | ✔ | ✖ | ✖ | ✖ | ✔ |
| 10 | ✖ | ✔ | ✔ | ✖ | ✖ |
| 11 | ✖ | ✔ | ✖ | ✔ | ✖ |
| 12 | ✖ | ✔ | ✖ | ✖ | ✔ |
| 13 | ✖ | ✖ | ✔ | ✔ | ✖ |
| 14 | ✖ | ✖ | ✔ | ✖ | ✔ |
| 15 | ✖ | ✖ | ✖ | ✔ | ✔ |
| 16 | ✔ | ✔ | ✔ | ✖ | ✖ |
| 17 | ✔ | ✔ | ✖ | ✔ | ✖ |
| 18 | ✔ | ✔ | ✖ | ✖ | ✔ |
| 19 | ✔ | ✖ | ✔ | ✔ | ✖ |
| 20 | ✔ | ✖ | ✔ | ✖ | ✔ |
| 21 | ✔ | ✖ | ✖ | ✔ | ✔ |
| 22 | ✖ | ✔ | ✔ | ✔ | ✖ |
| 23 | ✖ | ✔ | ✔ | ✖ | ✔ |
| 24 | ✖ | ✔ | ✖ | ✔ | ✔ |
| 25 | ✖ | ✖ | ✔ | ✔ | ✔ |
| 26 | ✔ | ✔ | ✔ | ✔ | ✖ |
| 27 | ✔ | ✔ | ✔ | ✖ | ✔ |
| 28 | ✔ | ✔ | ✖ | ✔ | ✔ |
| 29 | ✔ | ✖ | ✔ | ✔ | ✔ |
| 30 | ✖ | ✔ | ✔ | ✔ | ✔ |
| 31 | ✔ | ✔ | ✔ | ✔ | ✔ |
References
- Saberian, A.; Hizam, H.; Radzi, M.A.M.; Ab Kadir, M.Z.A.; Mirzaei, M. Modelling and Prediction of Photovoltaic Power Output Using Artificial Neural Networks. Int. J. Photoenergy 2014, 2014. [Google Scholar] [CrossRef]
- Abuella, M.; Chowdhury, B. Solar power forecasting using artificial neural networks. In Proceedings of the 2015 North American Power Symposium (NAPS), Charlotte, NC, USA, 4–6 October 2015. [Google Scholar] [CrossRef]
- Qasrawi, I.; Awad, M. Prediction of the Power Output of Solar Cells Using Neural Networks: Solar Cells Energy Sector in Palestine. Int. J. Comput. Sci. Secur. 2015, 9, 280. [Google Scholar]
- Alomari, H.M.; Younis, O.; Hayajneh, M.A.S. A Predictive Model for Solar Photovoltaic Power using the Levenberg-Marquardt and Bayesian Regularization Algorithms and Real-Time Weather Data. Int. J. Adv. Comput. Sci. Appl. 2018, 9. [Google Scholar] [CrossRef]
- Theocharides, S.; Makrides, G.; Georghiou, E.G.; Kyprianou, A. Machine learning algorithms for photovoltaic system power output prediction. In Proceedings of the 2018 IEEE International Energy Conference (ENERGYCON), Limassol, Cyprus, 3–7 June 2018. [Google Scholar] [CrossRef]
- Al-Dahidi, S.; Ayadi, O.; Adeeb, J.; Louzazni, M. Assessment of Artificial Neural Networks Learning Algorithms and Training Datasets for Solar Photovoltaic Power Production Prediction. Front. Energy Res. 2019, 7. [Google Scholar] [CrossRef]
- Khandakar, A.; Chowdhury, E.H.M.; Khoda Kazi, M.; Benhmed, K.; Touati, F.; Al-Hitmi, M.; Gonzales, S.P.A., Jr. Machine Learning Based Photovoltaics (PV) Power Prediction Using Different Environmental Parameters of Qatar. Energies 2019, 12, 2782. [Google Scholar] [CrossRef]
- Su, D.; Batzelis, E.; Pal, B. Machine Learning Algorithms in Forecasting of Photovoltaic Power Generation. In Proceedings of the 2019 International Conference on Smart Energy Systems and Technologies (SEST), Porto, Portugal, 9–11 September 2019. [Google Scholar] [CrossRef]
- Velasco, N.J.; Ostia, F.C. Development of a Neural Network Based PV Power Output Prediction Application Using Reduced Features and Tansig Activation Function. In Proceedings of the 2020 6th International Conference on Control, Automation and Robotics (ICCAR), Singapore, 20–23 April 2020. [Google Scholar] [CrossRef]
- Gensler, A.; Henze, J.; Sick, B.; Raabe, N. Deep Learning for solar power forecasting—An approach using AutoEncoder and LSTM Neural Networks. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016. [Google Scholar] [CrossRef]
- Poudel, P.; Jang, B. Solar Power Prediction Using Deep Learning Technique. Adv. Future Gener. Commun. Netw. 2017, 146, 148–151. [Google Scholar]
- Hua, C.; Zhu, E.; Kuang, L.; Pi, D. Short-term power prediction of photovoltaic power station based on long short-term memory-back-propagation. Int. J. Distrib. Sens. Netw. 2019. [Google Scholar] [CrossRef]
- Dawan, P.; Sriprapha, K.; Kittisontirak, S.; Boonraksa, T.; Junhuathon, N.; Titiroongruang, W.; Niemcharoen, S. Comparison of Power Output Forecasting on the Photovoltaic System Using Adaptive Neuro-Fuzzy Inference Systems and Particle Swarm Optimization-Artificial Neural Network Model. Energies 2020, 13, 351. [Google Scholar] [CrossRef]
- Zhu, H.; Lian, W.; Lu, L.; Dai, S.; Hu, Y. An Improved Forecasting Method for Photovoltaic Power Based on Adaptive BP Neural Network with a Scrolling Time Window. Energies 2017, 10, 1542. [Google Scholar] [CrossRef]
- Le Cadre, H.; Aravena, I.; Papavasiliou, A. Solar PV Power Forecasting Using Extreme Learning Machine and Information Fusion. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–24 April 2015; Available online: https://hal.archives-ouvertes.fr/hal-01145680 (accessed on 15 August 2020).
- Varanasi, J.; Tripathi, M.M. K-means clustering based photo voltaic power forecasting using artificial neural network, particle swarm optimization and support vector regression. J. Inf. Optim. Sci. 2019, 40, 309–328. [Google Scholar] [CrossRef]
- Chiang, P.; Prasad Varma Chiluvuri, S.; Dey, S.; Nguyen, Q.T. Forecasting of Solar Photovoltaic System Power Generation Using Wavelet Decomposition and Bias-Compensated Random Forest. In Proceedings of the 2017 Ninth Annual IEEE Green Technologies Conference (GreenTech), Denver, CO, USA, 29–31 March 2017. [Google Scholar] [CrossRef]
- O’Leary, D.; Kubby, J. Feature Selection and ANN Solar Power Prediction. J. Renew. Energy 2017, 2017. [Google Scholar] [CrossRef]
- AlKandari, M.; Ahmad, I. Solar power generation forecasting using ensemble approach based on deep learning and statistical methods. Appl. Comput. Inform. 2019. [Google Scholar] [CrossRef]
- Amarasinghe, P.A.G.M.; Abeygunawardana, N.S.; Jayasekara, T.N.; Edirisinghe, E.A.J.P.; Abeygunawardane, S.K. Ensemble models for solar power forecasting—A weather classification approach. AIMS Energy 2020, 8, 252–271. [Google Scholar] [CrossRef]
- Pattanaik, D.; Mishra, S.; Prasad Khuntia, G.; Dash, R.; Chandra Swain, S. An innovative learning approach for solar power forecasting using genetic algorithm and artificial neural network. Open Eng. 2020, 10, 630–641. [Google Scholar] [CrossRef]
- Chen, B.; Lin, P.; Lai, Y.; Cheng, S.; Chen, Z.; Wu, L. Very-Short-Term Power Prediction for PV Power Plants Using a Simple and Effective RCC-LSTM Model Based on Short Term Multivariate Historical Datasets. Electronics 2020, 9, 289. [Google Scholar] [CrossRef]
- Liu, Z.; Gao, W.; Wan, Y.; Muljadi, E. Wind power plant prediction by using neural networks. In Proceedings of the 2012 IEEE Energy Conversion Congress and Exposition (ECCE), Raleigh, NC, USA, 15–20 September 2012. [Google Scholar] [CrossRef]
- Tao, Y.; Chen, H.; Qiu, C. Wind power prediction and pattern feature based on deep learning method. In Proceedings of the 2014 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Hong Kong, China, 7–10 December 2014. [Google Scholar] [CrossRef]
- Li, T.; Li, Y.; Liao, M.; Wang, W.; Zeng, C. A New Wind Power Forecasting Approach Based on Conjugated Gradient Neural Network. Math. Probl. Eng. 2016, 2016. [Google Scholar] [CrossRef]
- Shao, H.; Deng, X.; Jiang, Y. A novel deep learning approach for short-term wind power forecasting based on infinite feature selection and recurrent neural network. J. Renew. Sustain. Energy 2018, 10. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Yuan, X.; Kisi, O.; Akhlaq, M.; Li, B. Comparison of LSSVR, M5RT, NF-GP, and NF-SC Models for Predictions of Hourly Wind Speed and Wind Power Based on Cross-Validation. Energies 2019, 12, 329. [Google Scholar] [CrossRef]
- Zameer, A.; Khan, A.; Javed, S.G. Machine Learning based short term wind power prediction using a hybrid learning model. Comput. Electr. Eng. 2015, 45, 122–133. [Google Scholar] [CrossRef]
- Qureshi, A.S.; Khan, A.; Zameer, A.; Usman, A. Wind power prediction using deep neural network based meta regression and transfer learning. Appl. Soft Comput. 2017, 58, 742–755. [Google Scholar] [CrossRef]
- Khan, M.; Liu, T.; Ullah, F. A New Hybrid Approach to Forecast Wind Power for Large Scale Wind Turbine Data Using Deep Learning with TensorFlow Framework and Principal Component Analysis. Energies 2019, 12, 2229. [Google Scholar] [CrossRef]
- Son, N.; Yang, S.; Na, J. Hybrid Forecasting Model for Short-Term Wind Power Prediction Using Modified Long Short-Term Memory. Energies 2019, 12, 3901. [Google Scholar] [CrossRef]
- Cali, U.; Sharma, V. Short-term wind power forecasting using long-short term memory based recurrent neural network model and variable selection. Int. J. Smart Grid Clean Energy 2019, 103–110. [Google Scholar] [CrossRef]
- Fischer, A.; Montuelle, L.; Mougeot, M.; Picard, D. Statistical learning for wind power: A modeling and stability study towards forecasting. Wind Energy 2017, 20, 2037–2047. [Google Scholar] [CrossRef]
- Barque, M.; Martin, S.; Etienne Norbert Vianin, J.; Genoud, D.; Wannier, D. Improving wind power prediction with retraining machine learning algorithms. In Proceedings of the 2018 International Workshop on Big Data and Information Security (IWBIS), Jakarta, Indonesia, 12–13 May 2018. [Google Scholar] [CrossRef]
- Demolli, H.; Sakir Dokuz, A.; Ecemis, A.; Gokcek, M. Wind power forecasting based on daily wind speed data using machine learning algorithms. Energy Convers. Manag. 2019, 198, 111823. [Google Scholar] [CrossRef]
- Kosovic, B.; Haupt, S.E.; Adriaansen, D.; Alessandrini, S.; Wiener, G.; Delle Monache, L.; Liu, Y.; Linden, S.; Jensen, T.; Cheng, W.; et al. A Comprehensive Wind Power Forecasting System Integrating Artificial Intelligence and Numerical Weather Prediction. Energies 2020, 13, 1372. [Google Scholar] [CrossRef]
- Chaudhary, A.; Sharma, A.; Kumar, A.; Dikshit, K.; Kumar, N. Short term wind power forecasting using machine learning techniques. J. Stat. Manag. Syst. 2020, 23, 145–156. [Google Scholar] [CrossRef]
- Pearson Correlation Coefficient, Wikipedia. Available online: https://en.wikipedia.org/wiki/Pearson_correlation_coefficient (accessed on 15 March 2020).
- Corizzo, R.; Ceci, M.; Fanaee, T.H.; Gama, J. Multi-aspect renewable energy forecasting. Inf. Sci. 2021, 546, 701–722. [Google Scholar] [CrossRef]
- Cavalcante, L.; Bessa, R.J.; Reis, M.; Browell, J. LASSO vector autoregression structures for very short-term wind power forecasting. Wind Energy 2017, 20. [Google Scholar] [CrossRef]
- Ceci, M.; Corizzo, R.; Japkowicz, N.; Mignone, P.; Pio, G. ECHAD: Embedding-Based Change Detection From Multivariate Time Series in Smart Grids. IEEE Access 2020, 8, 156053–156066. [Google Scholar] [CrossRef]
- Spearman’s Rank Correlation Coefficient, Wikipedia. Available online: https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient (accessed on 3 March 2020).
- Activation Functions in Neural Networks. Available online: https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6 (accessed on 4 November 2020).
- Fundamentals of Learning: The Exploration-Exploitation Trade-Off. Available online: http://tomstafford.staff.shef.ac.uk/?p=48 (accessed on 3 September 2020).
- Kumar Ojha, V.; Abraham, A.; Snášel, V. Metaheuristic Design of Feedforward Neural Networks: A Review of Two Decades of Research. Eng. Appl. Artif. Intell. 2017, 60, 97–116. [Google Scholar] [CrossRef]
- Venkata Rao, R. Jaya: A simple and new optimization algorithm for solving constrained and unconstrained optimization problems. Int. J. Ind. Eng. Comput. 2015, 7, 19–34. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995. [Google Scholar] [CrossRef]
- Ali Khan, T.; Ho Ling, S.; Sanagavarapu Mohan, A. Advanced Particle Swarm Optimization Algorithm with Improved Velocity Update Strategy. In Proceedings of the 2018 IEEE International Conference on Systems, Man and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018. [Google Scholar] [CrossRef]
- Allawi, Z.T.; Ibraheem, I.K.; Humaidi, A.J. Fine-Tuning Meta-Heuristic Algorithm for Global Optimization. Processes 2019, 7, 657. [Google Scholar] [CrossRef]
- Spearman’s Rank-Order Correlation, Laerd Statistics. Available online: https://statistics.laerd.com/statistical-guides/spearmans-rank-order-correlation-statistical-guide.php (accessed on 4 November 2020).
- Normalization (Statistics), Wikipedia. Available online: https://en.wikipedia.org/wiki/Normalization_(statistics) (accessed on 15 March 2020).
- Statistics How, To. Available online: https://www.statisticshowto.datasciencecentral.com/uniform-distribution/ (accessed on 3 September 2020).
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- NREL Wind Prospector. Available online: https://maps.nrel.gov/wind-prospector/?aL=sgVvMX%255Bv%255D%3Dt&bL=groad&cE=0&lR=0&mC=41.983994270935625%2C-98.173828125&zL=5 (accessed on 15 March 2020).
- DATA.GO.KR. Available online: https://www.data.go.kr/ (accessed on 2 February 2020).
- Chegg Study. Available online: https://www.chegg.com/homework-help/definitions/pearson-correlation-coefficient-pcc-31 (accessed on 3 September 2020).

















| Full-Form | Abbreviation | Full-Form | Abbreviation |
|---|---|---|---|
| Mode Adaptive Artificial Neural Network | MAANN | Stationary Wavelet Transform | SWT |
| Artificial Neural Network | ANN | Random Forest | RF |
| Advanced Particle Swarm Optimization | APSO | Machine Learning and Statistical Hybrid Model | MLSHM |
| Fine-Tuning Metaheuristic Algorithm | FTMA | Auto-Gate Recurrent Unit | Auto-GRU |
| Photovoltaic | PV | Deep Learning | DL |
| Wind Turbine Energy System | WTES | Genetic Algorithm-based ANN | GA-ANN |
| Machine Learning | ML | Radiation Classification Coordinate | RCC |
| Feedforward Backpropagation | FFBP | Recurrent Neural Network | RNN |
| Feedforward Neural Network | FFNN | Conjugated Gradient Neural Network | CGNN |
| Multilayer Feed-Forward with Backpropagation Neural Networks | MFFNNBP | Neuro-Fuzzy System with Grid Partition | NF-GP |
| Nonlinear Autoregressive Network with Exogenous Inputs-based Neural Network | NARXNN | Enhanced PSO | EPSO |
| Bayesian Regularization | BR | Deep Neural Network-based Meta-Regression and Transfer learning | DNN-MRT |
| Levenberg-Marquardt | LM | Principal Component Analysis | PCA |
| Deep Belief Network | DBN | Gradient Boosting Tree | GBT |
| Long Short-Term Memory | LSTM | Least Absolute Shrinkage Selector Operator | LASSO |
| Adaptive Neuro-Fuzzy Inference System | ANFIS | k Nearest Neighbor | kNN |
| Adaptive Backpropagation | ABP | Extreme Gradient Boost | xGBoost |
| General Regression Neural Network | GRNN | Artificial Intelligence and Numerical Weather Prediction | AI-NWP |
| Backpropagation Neural Network | BPNN | Multiple Linear Regression | MLR |
| Elman Neural Network | ENN | Neuro-Fuzzy system with Subtractive Clustering | NF-SC |
| Multi-Layer Perceptron | MLP | Least-Square Support Vector Regression | LSSVR |
| Particle Swarm Optimization | PSO | M5 Regression Tree | M5RT |
| Particle Swarm Optimization-based Artificial Neural Network | PSO-ANN | Support Vector Machine | SVM |
| Broyden-Fletcher-Goldfarb-Shanno Quasi-Newton | BFGSQN | Correlation Coefficient | CC |
| Resilient Backpropagation | RB | Autoregressive Integrated Moving Average with Explanatory Variable | ARIMAX |
| Linear Regression | LR | Mean Squared Error | MSE |
| Support Vector Regression | SVR | Bayesian Information Criterion | BIC |
| Random Tree | RT | Mean Absolute Error | MAE |
| M5P Decision Tree | M5PDT | Standard Deviation of the Errors | SDE |
| Gaussian Process Regression | GPR | Sum of Squared Errors | SSE |
| Physical Photovoltaic Forecasting Model | P-PVFM | Gradient Descent | GD |
| Distributed Extreme Learning Machine | DELM | Decision Tree | DT |
| Solar PV | ||||
| Category | Proposed Methodology | Compared Methodologies | Correlation Analysis | Dynamic Learning |
| Variants of neural network | ANN (FFBP/FFNN/MFFNNBP/NARXNN) [1,2,3,4,5,6,7,8,9] DBN [10], Autoencoder [11], LSTM [10,11,12], ANFIS [13], ABP [14] | GRNN [1], LR [2,7], persistent [2], LM [4,6], SVR, RT [5], BR, BFGSQN, RB etc. [6], M5PDT, GPR [7], BPNN, BPNN-GA, ENN, etc. [8], MLP [8,10], P-PVFM [10], SVM [12], PSO-ANN [13] | Yes [2,6] | Yes [14] |
| Hybrid Models | ANN-PSO with K-mean clustering [16], DELM and information fusion rule combined [15], SWT and RF combined [17], ML, Image Processing, and acoustic classification-based technique [18], MLSHM and Auto-GRU [19], General ensemble model with DL technique [20], GA-ANN [21], RCC-LSTM [22] | SVR [16], LSTM [22] | Yes [16,20,22] | Yes [17] |
| Wind Turbine Energy Systems | ||||
| Category | Proposed Methodology | Compared Methodologies | Correlation Analysis | Dynamic Learning |
| Variants of neural network | Probabilistic neural network with RNN [23], DBN [24], CGNN [25], RNN [26], NF-GP [27] | NF-SC, LSSVR, M5RT [27] | Not found | Not found |
| Hybrid Models | SVR and Hybrid SVR with EPSO-ANN [28], DNN-MRT [29], PCA and DL [30], Hybrid LSTM [31], LSTM-RNN [32] | MLR [28], Four multivariate model [31] | Yes [32] | Not found |
| Non-neural network ML | CART-Bagging [33], GBT [34], ML [35], AI-NWP [36], DT, and RF [37] | Persistence approach [34], LASSO, kNN, xGBoost, RF and SVR [35], SVM [37] | Not found | Yes [34] |
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| Number of input variables | Best remembered swarm positions | ||
| Number of hidden layer nodes | and | Maximum and Minimum value of inertia | |
| Output function of the single-layer feedforward neural network | Maximum number of generations | ||
| Output layer weight vector | Size of the population for the metaheuristic optimizations | ||
| Hidden layer activation function | and | Random variables associated with the FTMA exploitation and randomization stage | |
| Input layer weight matrix | Spearman’s rank-order correlation | ||
| Arbitrary input variable | Rank wise distance between two variables | ||
| Bias of the output layer | Correlation coefficient Threshold value | ||
| Input variable sample number | z | Predefined number of sample entry when ANN training can be stopped | |
| Number of observations/lengths of the input variables | Error threshold limit for training | ||
| and | predicted and actual output of the ANN | Min–Max feature scaling variable | |
| solution particle | , | Minimum and Maximum value of the input variable | |
| Location/position of any arbitrary solution from the set of the solution vector | Minimum and Maximum value of the output variable | ||
| any parameter (weights/biases) within the neural network which needs to be optimized | Arbitrary occurrence number of a specific Mode | ||
| Generation number | M | Mode number | |
| Random number (ranges within 0–1) | Number of parameters to be estimated | ||
| Velocity of the solution particle | Maximized value of the likelihood function of the Model | ||
| Inertia (ranges within 0–1) | P | Number of parameters (weights and biases) in ANN in case of BIC | |
| and | Cognitive and social parameters(range between 0 and 2) | Standard deviation | |
| Best remembered individual position | Mean of the population |
| Mode No | Inputs | ||||
|---|---|---|---|---|---|
| Variable 1 | Variable 2 | Variable 3 | ….. | Variable N | |
| 1 | ✔ | ✖ | ✖ | ✖ | ✖ |
| 2 | ✖ | ✔ | ✖ | ✖ | ✖ |
 | | | | | |
| M | ✔ | ✔ | ✔ | ✔ | ✔ |
| WTES (New Kirk-Site ID: 19287) | PV (Yeongam F1 Stadium 1 Electrical Room) | ||
|---|---|---|---|
| Parameters | Numerical values | Parameters | Numerical Values |
| Plant Maximum Output | 16 MW | Plant Maximum Output | 2610 kW |
| Maximum Wind Speed | 23.0352 | Plant Capacity | 3026 kW |
| Maximum Wind Direction | 359.3794 degrees | Maximum Inclined Irradiance | 999.96 |
| Maximum Temperature | 35.9660 degrees Celsius | ||
| Maximum air Pressure | 8.5927 × 104 Pa | Maximum Surface Temperature | 49.78 |
| Maximum air density | 1.0980 Kg/m3 | ||
| Longitude | −104.258 | Maximum Surrounding Temperature | 125.60 |
| Latitude | 35.00168 | ||
| Duration | (1 Year) 2012 | Duration | 3 years, 10 months (2015 to 2018) |
| Time Interval | 5 min | Time interval | 1 h |
| No of datapoints | 105,116 | Data points | 17,252 |
| Parameters | Initial Solution Search Space | Number of Input Layer Weights (n, Number of Inputs) | Number of Input Layer Biases | Number of Output Layer Weights | Number of Output Layer Biases | Number of Hidden Layers |
|---|---|---|---|---|---|---|
| Values | (−5, 5) | × 10 | 10 | 10 | 1 | 1 |
| Algorithm | Parameter | Values | Population Size | Max Generation |
|---|---|---|---|---|
| APSO | 1.5, 1.5, 0.9 | 20 | 10 | |
| Jaya | - | |||
| FTMA | 0.7, 0.7 |
| Algorithms | MSE (MW2) | RMSE (MW) | BIC(−1 × 104) | MAE (MW) | |||
| Training | Testing | Training | Testing | Training | Testing | Training | |
| APSO | 0.0684 | 0.0714 | 0.2615 | 0.2672 | 0.8007 | 0.0819 | 0.1941 |
| JAYA | 1.1204 | 1.5149 | 1.0584 | 1.2308 | −0.0938 | −0.0635 | 0.8639 |
| FTMA | 0.0196 | 0.0207 | 0.14 | 0.1438 | 1.2008 | 0.1399 | 0.1034 |
| Gradient Descent | 0.0682 | 0.0256 | 0.2611 | 0.16 | −0.1704 | 0.1273 | 0.8405 |
| ARIMAX | 0.0230 | 0.0660 | 0.1516 | 0.2569 | 0.8357 | 0.1347 | 0.9362 |
| Standard Deviation | R-Value | Episode Winner | SDE (MW) | MAE (MW) | |||
| Training | Testing | Training | Testing | Testing | |||
| APSO | 13.0717 | 0.9519 | 0.9565 | 45 | 14.7976 | 5.7798 | 0.1950 |
| JAYA | 3.3917 | 0.2128 | 0.0764 | 0 | 59.8978 | 26.8282 | 1.0277 |
| FTMA | 0.0075 | 0.9863 | 0.9874 | 245 | 7.9161 | 3.1352 | 0.1005 |
| Gradient Descent | - | 0.9669 | 0.9871 | - | 59.4784 | 3.5814 | 0.1363 |
| ARIMAX | - | 0.9838 | 0.9659 | - | 66.6497 | 27.5989 | 1.0272 |
| Algorithms | MSE (MW2) | RMSE (MW) | BIC(1 × 104) | MAE (MW) | |||
| Training | Testing | Training | Testing | Training | Testing | Training | |
| APSO | 1.4439 | 2.3080 | 1.2 | 1.5192 | 1.9352 | 0.6071 | 0.9574 |
| JAYA | 22.5438 | 22.1656 | 4.7480 | 4.7080 | 1.5825 | 2.3591 | 3.9185 |
| FTMA | 1.21 | 0.4944 | 1.1 | 0.7031 | 1.056 | −0.4996 | 0.7283 |
| Gradient Descent | 6.2096 | 8.1727 | 2.4919 | 2.858 | 22.694 | 1.3718 | 6.7104 |
| ARIMAX | 9.3338 | 7.7290 | 3.055 | 2.780 | −31.955 | −4.5964 | 7.4354 |
| Standard Deviation | R-Value | Episode Winner | SDE (MW) | MAE (MW) | |||
| Training | Testing | Training | Testing | Testing | |||
| APSO | 1.4439 × 103 | 0.9835 | 0.9616 | 66 | 271.1004 | 131.8828 | 1.2750 |
| JAYA | 12.9087 | 0.7424 | 0.6317 | 0 | 1.0712 × 103 | 409.1466 | 4.1227 |
| FTMA | 65.0949 | 0.9861 | 0.9918 | 109 | 248.5482 | 60.6081 | 0.4939 |
| Gradient Descent | - | 0.9221 | 0.9122 | - | 708.6053 | 210.9264 | 1.9018 |
| ARIMAX | - | 0.8934 | 0.9170 | - | 799.3252 | 667.8077 | 6.2505 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zamee, M.A.; Won, D. Novel Mode Adaptive Artificial Neural Network for Dynamic Learning: Application in Renewable Energy Sources Power Generation Prediction. Energies 2020, 13, 6405. https://doi.org/10.3390/en13236405
Zamee MA, Won D. Novel Mode Adaptive Artificial Neural Network for Dynamic Learning: Application in Renewable Energy Sources Power Generation Prediction. Energies. 2020; 13(23):6405. https://doi.org/10.3390/en13236405
Chicago/Turabian StyleZamee, Muhammad Ahsan, and Dongjun Won. 2020. "Novel Mode Adaptive Artificial Neural Network for Dynamic Learning: Application in Renewable Energy Sources Power Generation Prediction" Energies 13, no. 23: 6405. https://doi.org/10.3390/en13236405
APA StyleZamee, M. A., & Won, D. (2020). Novel Mode Adaptive Artificial Neural Network for Dynamic Learning: Application in Renewable Energy Sources Power Generation Prediction. Energies, 13(23), 6405. https://doi.org/10.3390/en13236405