Application of Support Vector Machine Modeling for the Rapid Seismic Hazard Safety Evaluation of Existing Buildings





Abstract
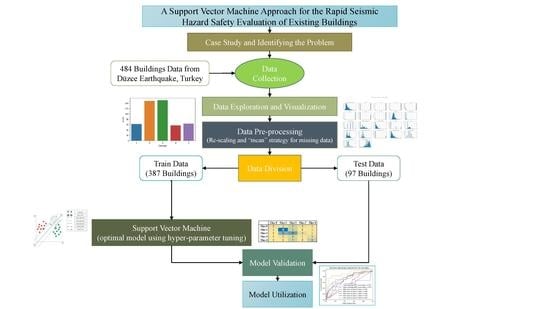
:
1. Introduction
2. Choice of Building’s Damage Inducing Parameters
2.1. System Type
2.1.1. Reinforced Concrete Frame
2.1.2. Reinforced Concrete Frame with Shear Walls
2.2. Year of Construction
2.3. Number of Stories (NS)
2.4. Ground Floor
2.5. Total Floor Area
2.6. Overhang Area
2.7. Ground and Normal Story Height
2.8. Irregularities
2.8.1. Horizontal Plan Irregularity
- A1: Torsional irregularity,
- A2: Floor irregularity,
- A3: Discontinuity in plan,
- A4: Non-parallel axes of structural elements.
2.8.2. Vertical Irregularity
- B1: Strength irregularity (weak story),
- B2: Stiffness irregularity (soft story),
- B3: Discontinuity of vertical structural elements.
2.9. Number of Continuous Frames in X-direction and Y-direction
2.10. Normalized Redundancy Score (NRS)
2.11. Soft Story Index (SSI)
2.12. Overhang Ratio (OR)
2.13. Minimum Normalized Lateral Strength Index (MNLSI)
2.14. Minimum Normalized Lateral Stiffness Index (MNLSTFI)
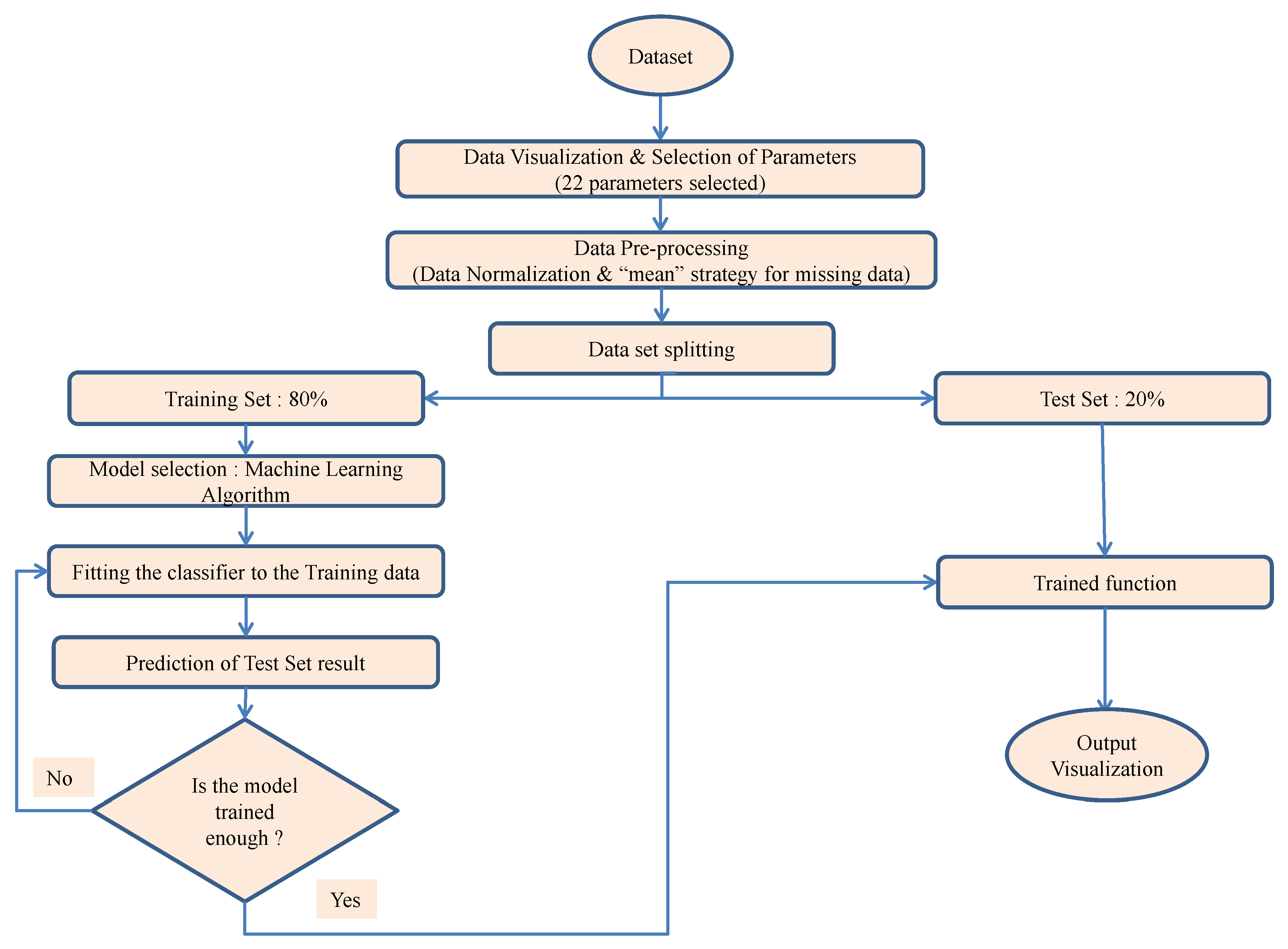
3. ML Modelling Approach
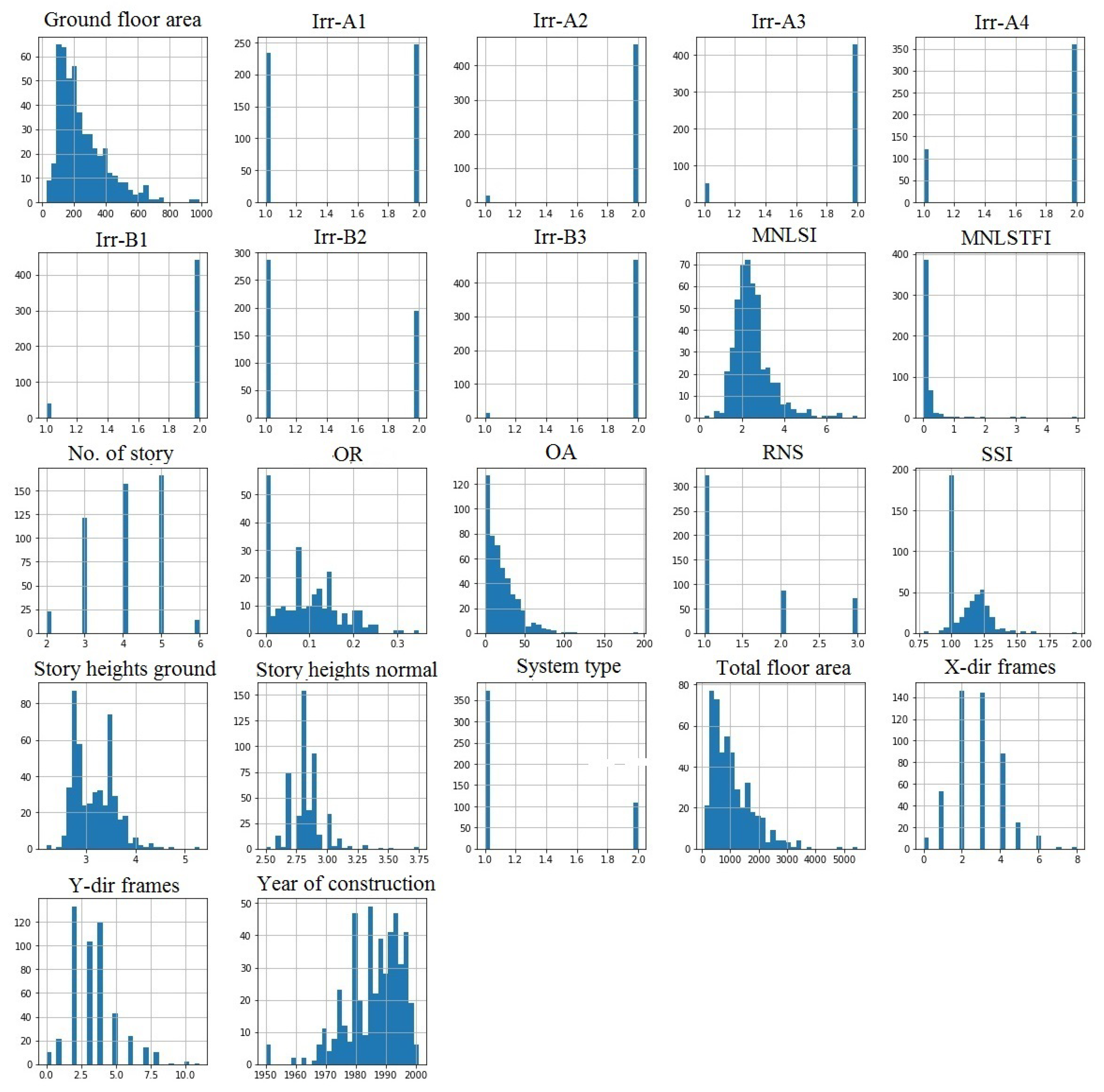
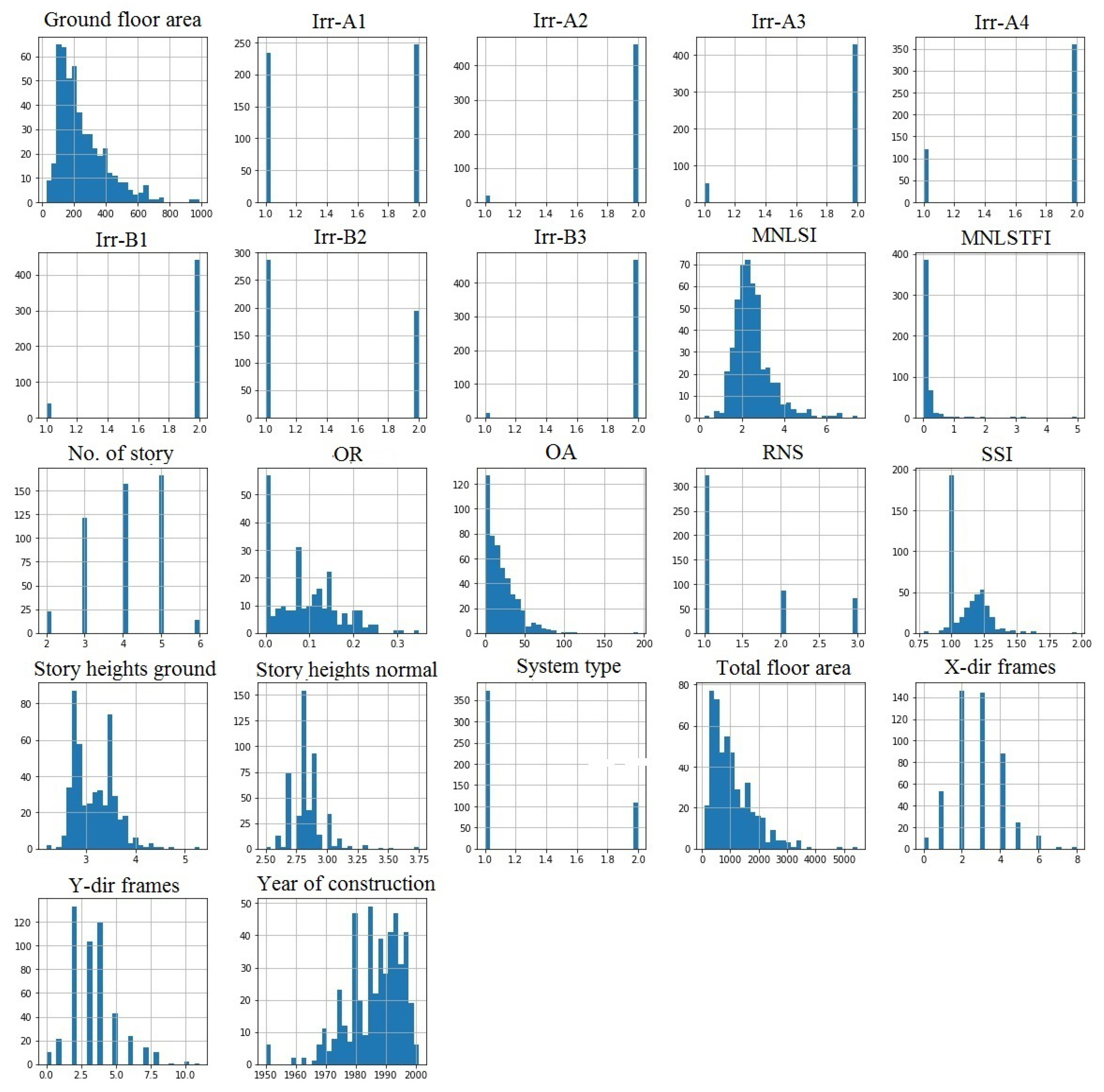
3.1. Input Dataset
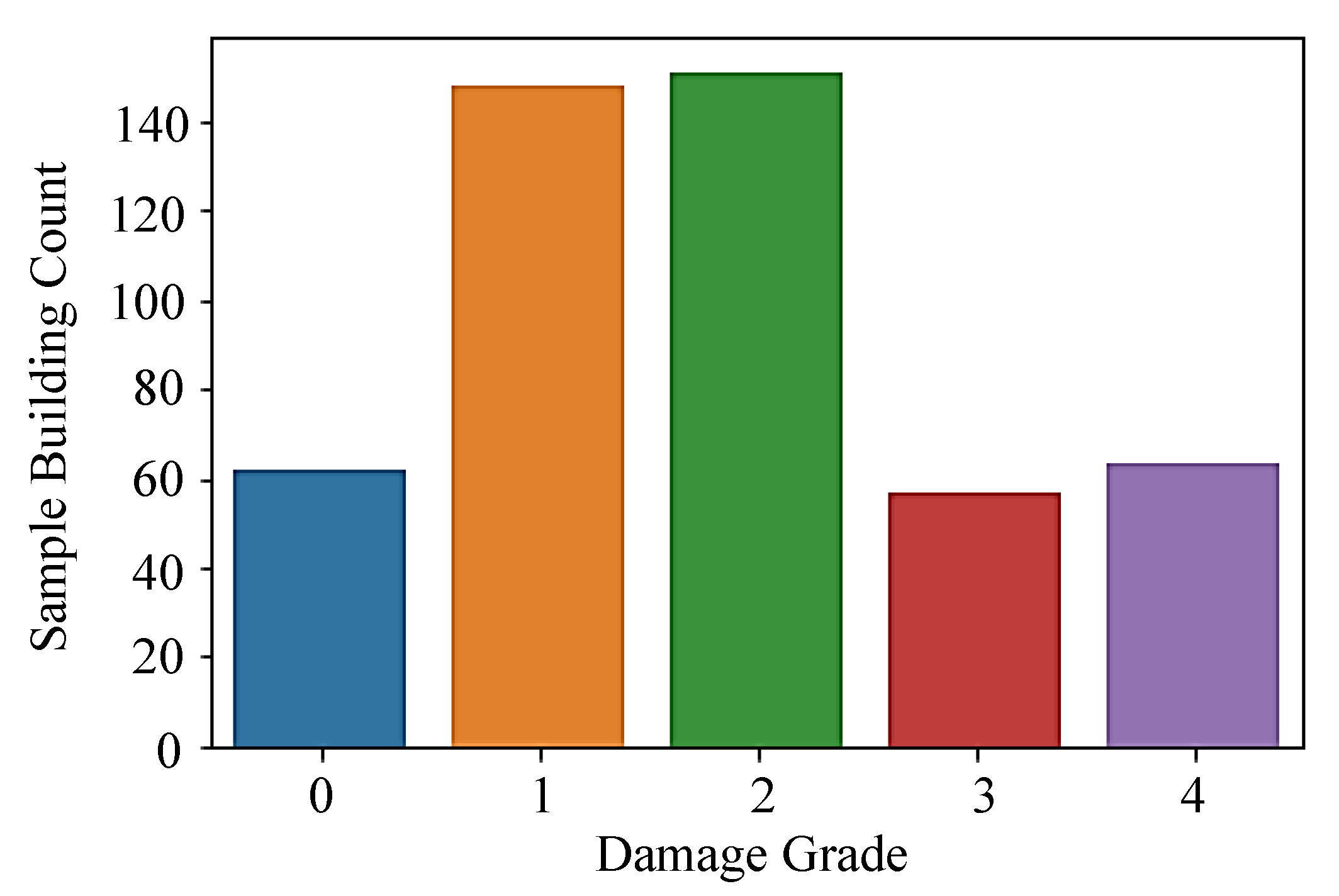
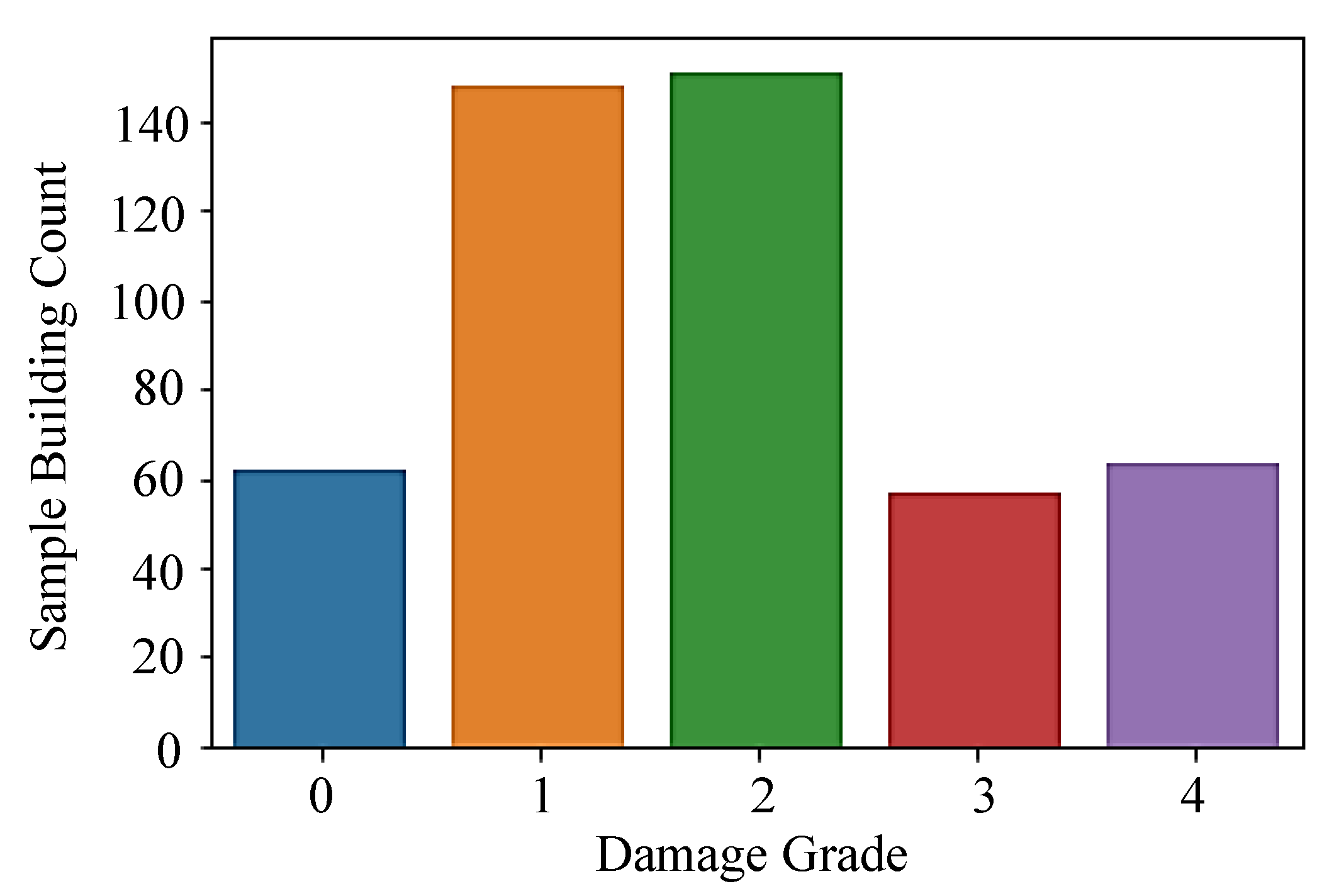
3.2. Classification of Damage Data
3.3. Data Pre-Processing
3.4. Selection of Input Parameters
3.5. Splitting of Dataset
3.6. Model Selection
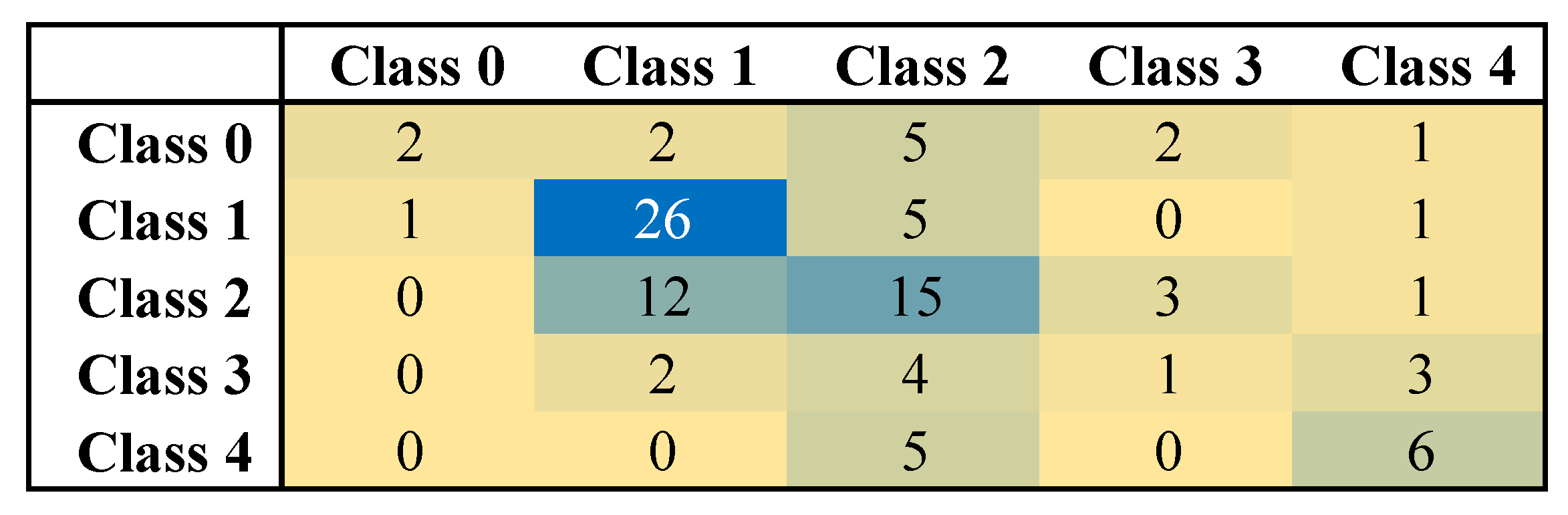
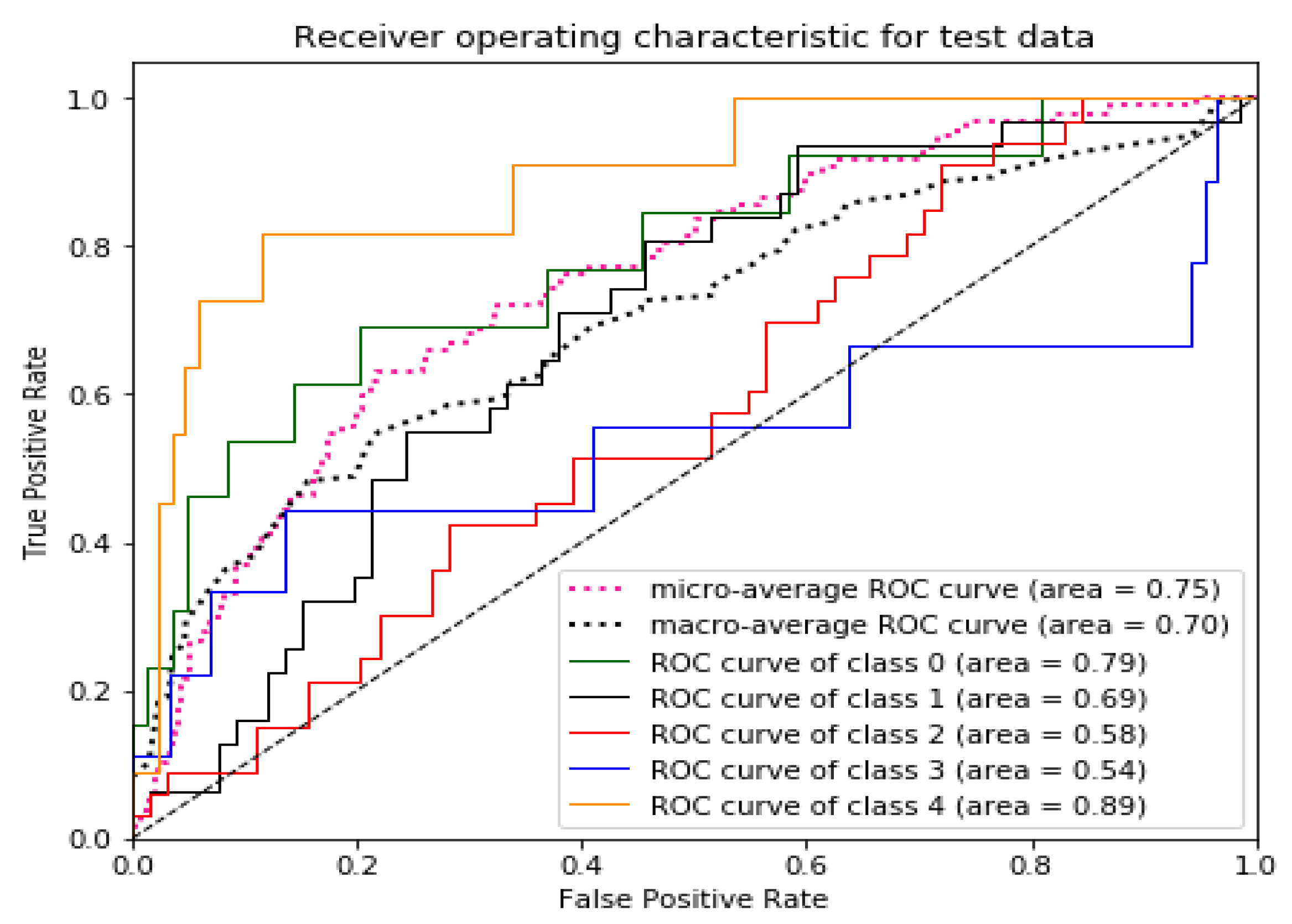
3.7. Evaluating the Performance of Predicted Model
3.8. Model Utilization
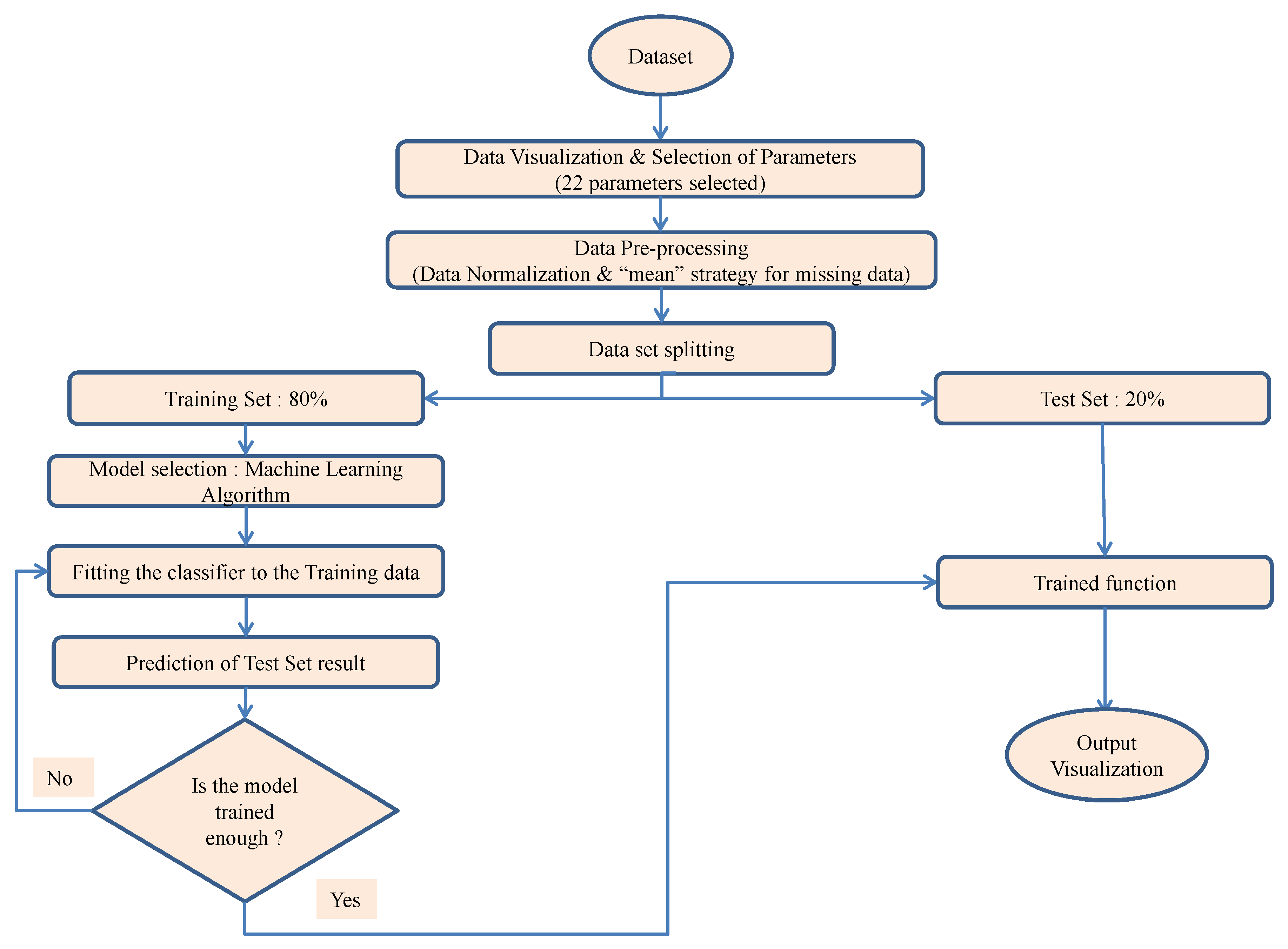
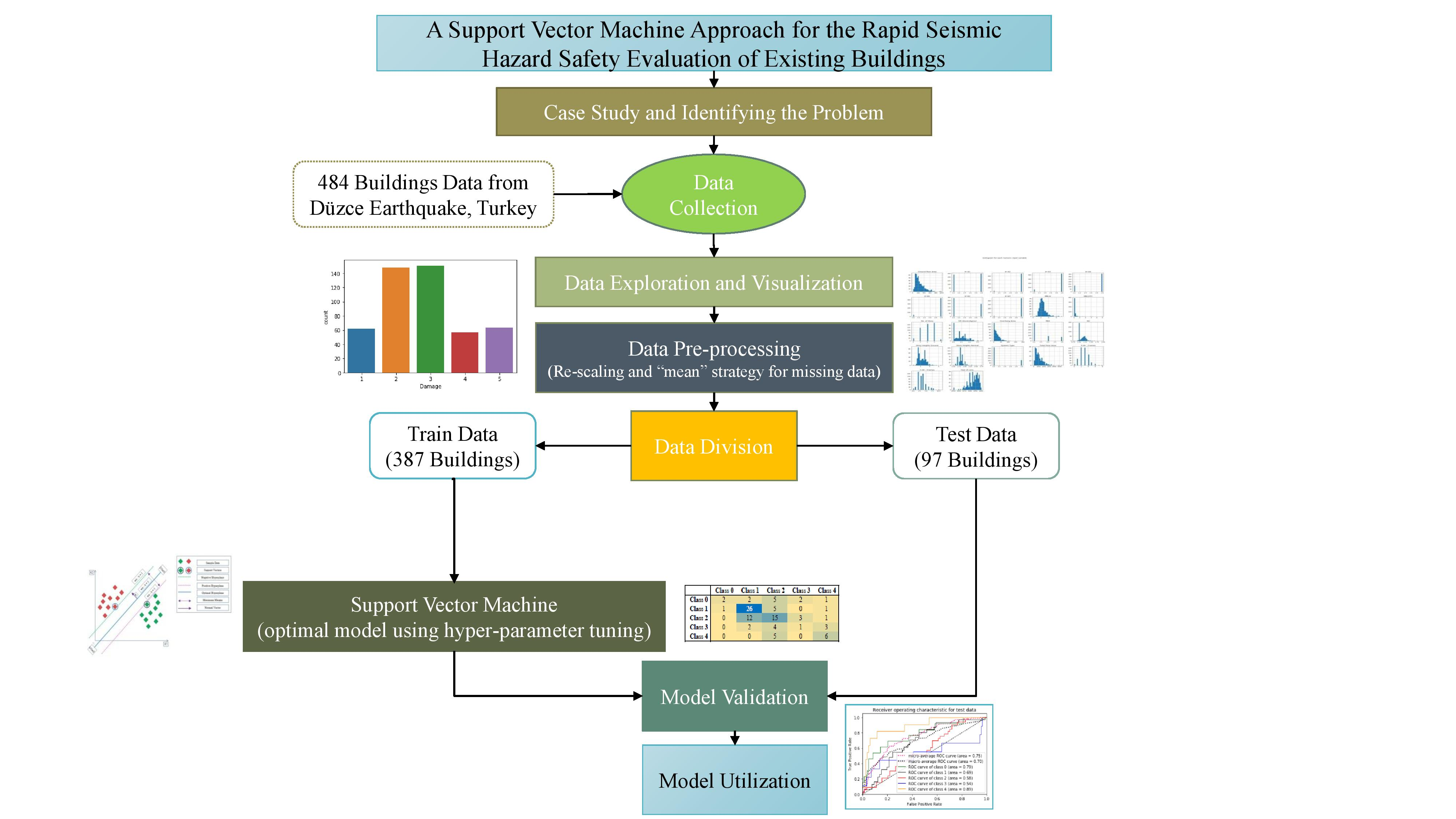
4. Methodology and Database
4.1. Data Pre-Processing
4.2. Splitting of Dataset
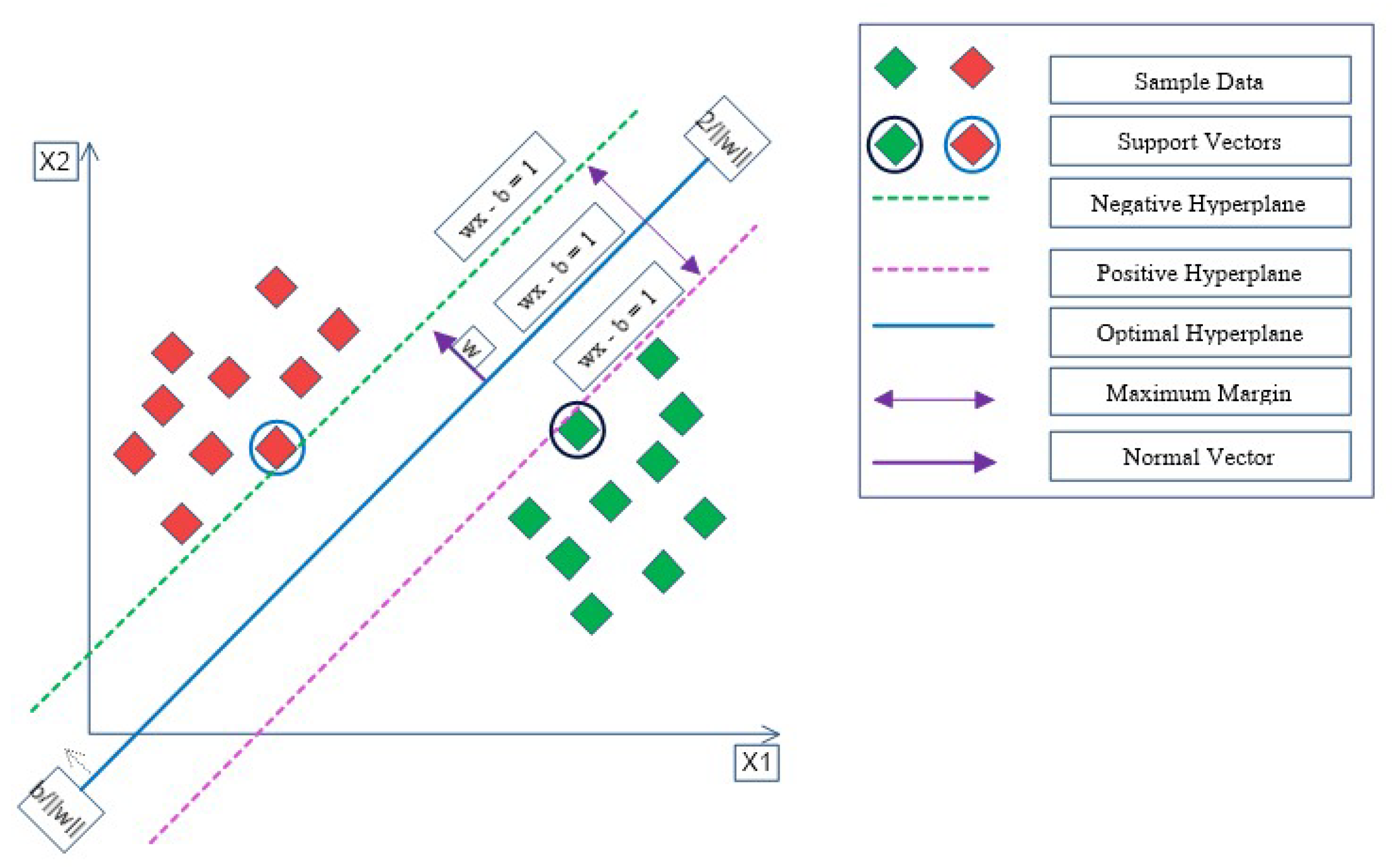
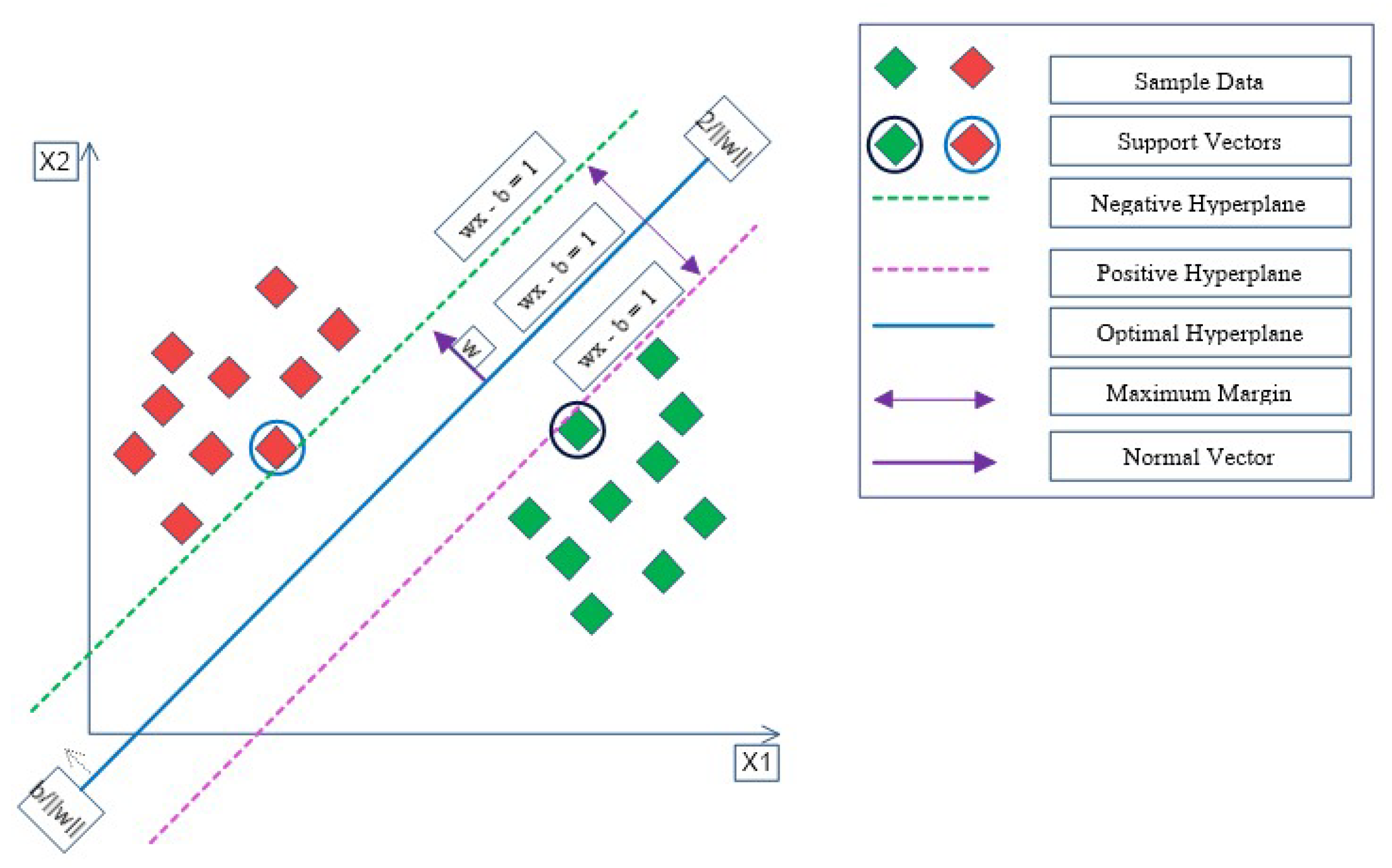
4.3. SVM: Feature Selection and Kernels
- Kernels: Kernels are a combination of mathematical functions. They are designed to collect the input data and alter them into the necessary form. Various SVM mechanisms employ the various form of kernel functions. The kernel functions may vary in types like linear, nonlinear, polynomial, radial basis function (RBF), and sigmoid.
- C (Regularization): C acts as a penalty parameter, which adds an upper bound to the bias of each support vector and manipulates the proximity of fit to the training samples, and kernel value. The misclassification or error term tells the SVM optimization of how much error is bearable. When C is high, it classifies all the data points correctly, but often there is a chance of over-fitting. In counter, when C is low, the optimizer looks for a larger-margin to separate the hyperplane, though the hyperplane misinterprets more points.
- Gamma: Gamma is specific to the RBF kernel, not for the linear or polynomial kernel. The gamma parameter characterizes the effect of a single training sample attainment, where lower gamma means “far”, and higher gamma means “close-by”. Gamma decides the curvature in a decision boundary.
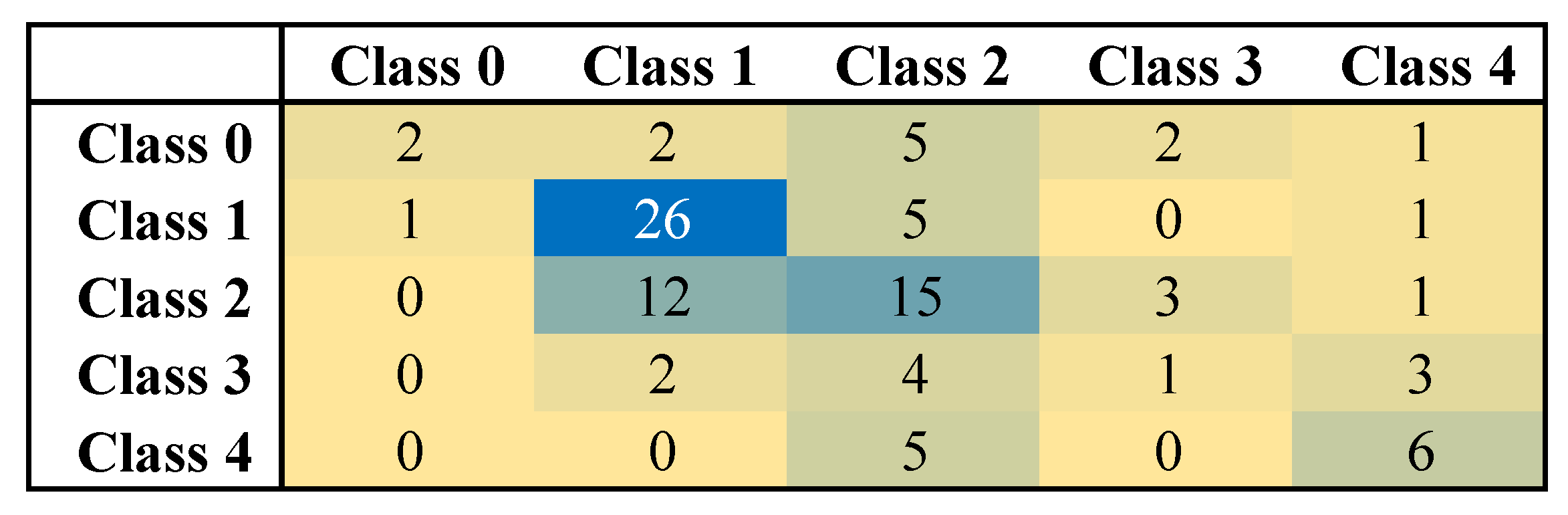
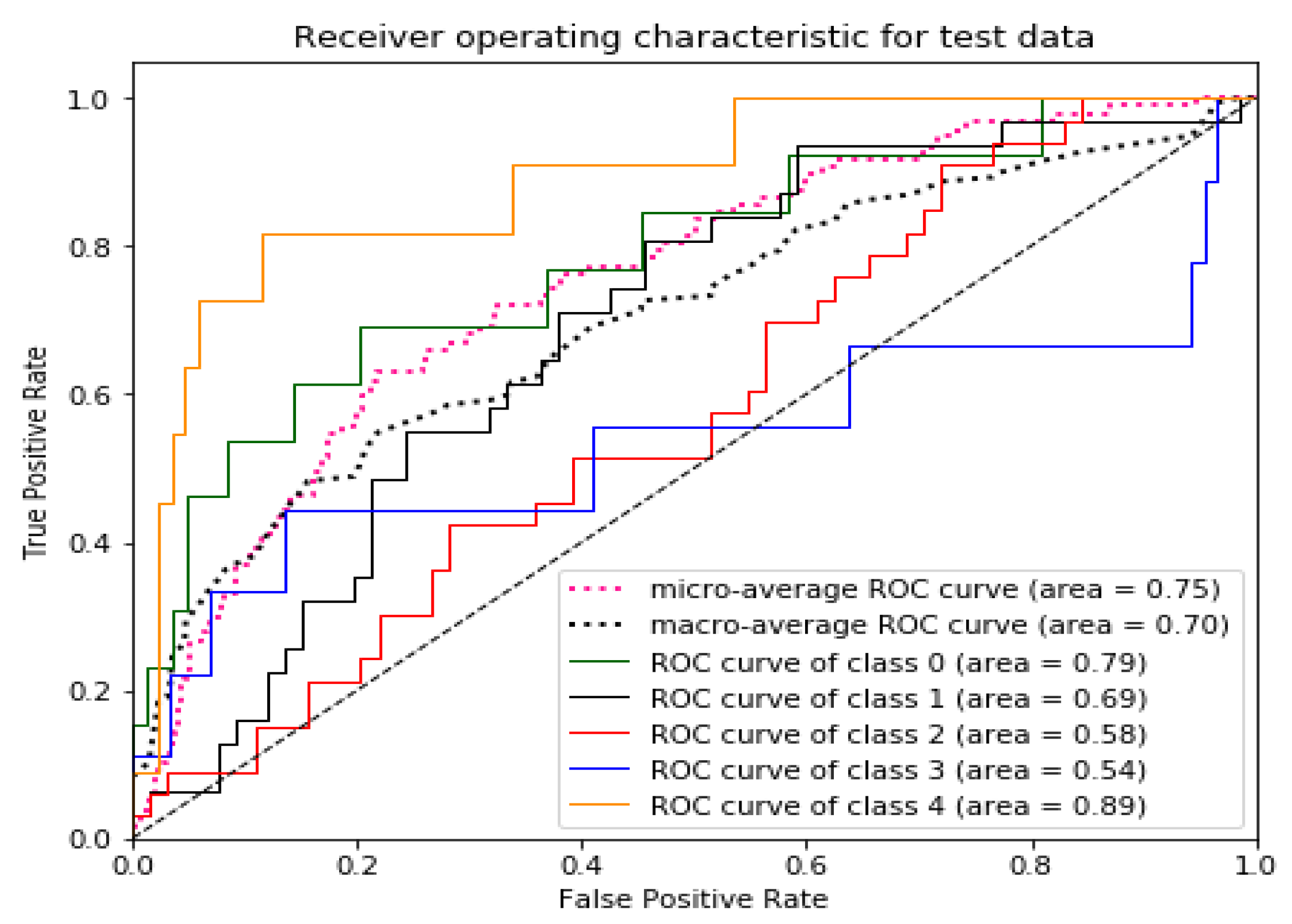
5. Result and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| AUC | Area under the Curve |
| C | Cost of constraints violation |
| FEMA | Federal Emergency Management Agency |
| ML | Machine Learning |
| MNLSI | Minimum Normalized Lateral Strength Index |
| MNLSTFI | Minimum Normalized Lateral Stiffness Index |
| N | Number of Stories |
| NRS | Normalized Redundancy Score |
| OR | Overhang Ratio |
| RBF | Radial Basis Function |
| RC | Reinforced Concrete |
| ROC | Receiver Operating Characteristics |
| RVS | Rapid Visual Screening |
| SSI | Soft story Index |
| SVM | Support Vector Machine |
References
- Jain, S.; Mitra, K.; Kumar, M.; Shah, M. A proposed rapid visual screening procedure for seismic evaluation of RC-frame buildings in India. Earthq. Spectra 2010, 26. [Google Scholar] [CrossRef]
- Chanu, N.; Nanda, R. A Proposed Rapid Visual Screening Procedure for Developing Countries. Int. J. Geotech. Earthq. Eng. 2018, 9, 38–45. [Google Scholar] [CrossRef]
- Sinha, R.; Goyal, A.A. A national policy for seismic vulnerability assessment of buildings and procedure for rapid visual screening of buildings for potential seismic vulnerability. In Report to Disaster Management Division; Ministry of Home Affairs, Government of India: New Delhi, India, 2004. [Google Scholar]
- Rapid Visual Screening of Buildings for Potential Seismic Hazards: A Handbook, 3rd ed.; FEMA P-154; Homeland Security Dept, Federal Emergency Management Agency: Washington, DC, USA, 2015.
- Harirchian, E.; Lahmer, T.; Buddhiraju, S.; Mohammad, K.; Mosavi, A. Earthquake Safety Assessment of Buildings through Rapid Visual Screening. Buildings 2020, 10, 51. [Google Scholar] [CrossRef] [Green Version]
- Rai, D.C. Seismic Evaluation and Strengthening of Existing Buildings; IIT Kanpur and Gujarat State Disaster Mitigation Authority: Gandhinagar, India, 2005; pp. 1–120. [Google Scholar]
- Vallejo, C.B. Rapid Visual Screening of Buildings in the City of Manila, Philippines. In Proceedings of the 5th Civil Engineering Conference in the Asian Region and Australasian Structural Engineering Conference 2010; Engineers Australia: Sydney, Australia, 2010; pp. 513–518. [Google Scholar]
- Mishra, S. Guide Book for Integrated Rapid Visual Screening of Buildings for Seismic Hazard; TARU Leading Edge Private Ltd.: Guragon, India, 2014. [Google Scholar]
- Luca, F.; Verderame, G. Seismic Vulnerability Assessment: Reinforced Concrete Structures; Springer: Berlin/Heidelberg, Germany, 2015; pp. 1–31. [Google Scholar] [CrossRef]
- Chanu, N.; Nanda, R. Rapid Visual Screening Procedure of Existing Building Based on Statistical Analysis. Int. J. Disast. Risk Reduc. 2018, 28. [Google Scholar] [CrossRef]
- Özhendekci, N.; Özhendekci, D. Rapid Seismic Vulnerability Assessment of Low- to Mid-Rise Reinforced Concrete Buildings Using Bingöl’s Regional Data. Earthq. Spectra 2012, 28, 1165–1187. [Google Scholar] [CrossRef]
- Harirchian, E.; Lahmer, T.; Rasulzade, S. Earthquake Hazard Safety Assessment of Existing Buildings Using Optimized Multi-Layer Perceptron Neural Network. Energies 2020, 13, 2060. [Google Scholar] [CrossRef] [Green Version]
- Arslan, M.; Ceylan, M.; Koyuncu, T. An ANN approaches on estimating earthquake performances of existing RC buildings. Neural Netw. World 2012, 22, 443–458. [Google Scholar] [CrossRef] [Green Version]
- Tesfamariam, S.; Liu, Z. Earthquake induced damage classification for reinforced concrete buildings. Struct. Saf. 2010, 32, 154–164. [Google Scholar] [CrossRef]
- Harirchian, E.; Harirchian, A. Earthquake Hazard Safety Assessment of Buildings via Smartphone App: An Introduction to the Prototype Features- 30. Forum Bauinformatik: von jungen Forschenden für junge Forschende: September 2018, Informatik im Bauwesen; Professur Informatik im Bauwesen, Bauhaus-Universität Weimar: Weimar, Germany, 2018; pp. 289–297. [Google Scholar] [CrossRef]
- Ketsap, A.; Hansapinyo, C.; Kronprasert, N.; Limkatanyu, S. Uncertainty and fuzzy decisions in earthquake risk evaluation of buildings. Eng. J. 2019, 23, 89–105. [Google Scholar] [CrossRef]
- Mandas, A.; Dritsos, S. Vulnerability assessment of RC structures using fuzzy logic. WIT Trans. Ecol. Environ. 2004, 77. [Google Scholar] [CrossRef]
- Tesfamariam, S.; Saatcioglu, M. Seismic vulnerability assessment of reinforced concrete buildings using hierarchical fuzzy rule base modeling. Earthq. Spectra 2010, 26, 235–256. [Google Scholar] [CrossRef]
- Şen, Z. Rapid visual earthquake hazard evaluation of existing buildings by fuzzy logic modeling. Expert Syst. Appl. 2010, 37, 5653–5660. [Google Scholar] [CrossRef]
- Harirchian, E.; Lahmer, T. Improved Rapid Visual Earthquake Hazard Safety Evaluation of Existing Buildings Using a Type-2 Fuzzy Logic Model. Appl. Sci. 2020, 10, 2375. [Google Scholar] [CrossRef] [Green Version]
- Cerovecki, A.; Gharahjeh, S.; Harirchian, E.; Ilin, D.; Okhotnikova, K.; Kersten, J. Evaluation of Change Detection Techniques using Very High Resolution Optical Satellite Imagery. In Preface 2 Summer Course 2015; Bauhaus-Universitätsverlag: Weimar, Germany, 2018; p. 20. [Google Scholar]
- Ezquerro, P.; Del Soldato, M.; Solari, L.; Tomás, R.; Raspini, F.; Ceccatelli, M.; Fernández-Merodo, J.A.; Casagli, N.; Herrera, G. Vulnerability Assessment of Buildings due to Land Subsidence Using InSAR Data in the Ancient Historical City of Pistoia (Italy). Sensors 2020, 20, 2749. [Google Scholar] [CrossRef]
- Harirchian, E. Constructability Comparison between IBS and Conventional Construction. Ph.D. Thesis, Universiti Teknologi Malaysia, Kuala Lumpur, Malaysia, 2015. [Google Scholar]
- Kegyes-Brassai, O. Vulnerability Assessment of Buildings Based on Rapid Visual Screening and Pushover: Case Study of Gyor, Hungary. In Computational Methods and Experimental Measurements XIX & Earthquake Resistant Engineering Structures XII; WIT Press: Southampton, UK, 2019; Volume 185, pp. 63–74. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Seismic parameters’ combinations for the optimum prediction of the damage state of R/C buildings using neural networks. Adv. Eng. Softw. 2017, 106, 1–16. [Google Scholar] [CrossRef]
- Sucuoglu, H.; Yazgan, U.; Yakut, A. A Screening Procedure for Seismic Risk Assessment in Urban Building Stocks. Earthq. Spectra 2007, 23. [Google Scholar] [CrossRef]
- Aldemir, A.; Sahmaran, M. Rapid screening method for the determination of seismic vulnerability assessment of RC building stocks. Bull. Earthq. Eng. 2019. [Google Scholar] [CrossRef]
- Askan, A.; Yucemen, M. Probabilistic methods for the estimation of potential seismic damage: Application to reinforced concrete buildings in Turkey. Struct. Saf. 2010, 32, 262–271. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Use of Artificial Neural Networks in the R/C Buildings’ Seismic Vulnerabilty Assessment: The Practical Point of View. In Proceedings of the 7th ECCOMAS Thematic Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Crete, Greece, 24–26 June 2019; Aristotle University of Thessaloniki: Thessaloniki, Greece, 2019; Volume 18969, No. IKEECONF-2019-411. pp. 5435–5455. [Google Scholar] [CrossRef] [Green Version]
- Dritsos, S.; Moseley, V. A fuzzy logic rapid visual screening procedure to identify buildings at seismic risk. Beton- und Stahlbetonbau 2013, 136–143. Available online: https://www.researchgate.net/publication/295594396_A_fuzzy_logic_rapid_visual_screening_procedure_to_identify_buildings_at_seismic_risk (accessed on 30 June 2020).
- Zhang, Z.; Hsu, T.Y.; Wei, H.H.; Chen, J.H. Development of a Data-Mining Technique for Regional-Scale Evaluation of Building Seismic Vulnerability. Appl. Sci. 2019, 9, 1502. [Google Scholar] [CrossRef] [Green Version]
- Stone, H. Exposure and Vulnerability for Seismic Risk Evaluations. Ph.D. Thesis, UCL (University College London), London, UK, 2018. [Google Scholar]
- Harirchian, E.; Lahmer, T. Earthquake Hazard Safety Assessment of Buildings via Smartphone App: A Comparative Study. IOP Conf. Ser. Mater. Sci. Eng. 2019, 652, 012069. [Google Scholar] [CrossRef]
- Yakut, A.; Aydogan, V.; Ozcebe, G.; Yucemen, M. Preliminary Seismic Vulnerability Assessment of Existing Reinforced Concrete Buildings in Turkey. In Seismic Assessment and Rehabilitation of Existing Buildings; Springer: Berlin/Heidelberg, Germany, 2003; pp. 43–58. [Google Scholar]
- Yücemen, M.; Özcebe, G.; Pay, A. Prediction of potential damage due to severe earthquakes. Struct. Saf. 2004, 26, 349–366. [Google Scholar] [CrossRef]
- Yakut, A.; Ozcebe, G.; Yucemen, M.S. Seismic vulnerability assessment using regional empirical data. Earthq. Eng. Struct. Dyn. 2006, 35, 1187–1202. [Google Scholar] [CrossRef]
- Achs, G.; Adam, C. A Rapid-Visual-Screening Methodology for the Seismic Vulnerability Assessment of Historic Brick-Masonry Buildings in Vienna. In Proceedings of the 15th World Conference on Earthquake Engineering (15 WCEE), Lisbon, Portugal, 24–28 September 2012; pp. 1833–1856. [Google Scholar]
- Yakut, A. Reinforced Concrete Frame Construction; Summary Publication; Middle East Technical University: Ankara, Turkey, 2004; pp. 1–9. [Google Scholar]
- Kathir. Construction of Reinforced Concrete Shear Walls, Civil Snapshot. Available online: https://civilsnapshot.com/shear-wall/ (accessed on 20 December 2019).
- Yakut, A.; Ozcebe, G.; Yucemen, M.S. A statistical procedure for the assessment of seismic performance of existing reinforced concrete buildings in Turkey. In Proceedings of the 13th World Conference on Earthquake Engineering, Vancouver, BC, Canada, 1–6 August 2004; Volume 13. [Google Scholar]
- Law Insider. Available online: https://www.lawinsider.com/dictionary/ground-floor-area (accessed on 10 February 2020).
- Tesfamariam, S.; Saatcioglu, M. Risk-based seismic evaluation of reinforced concrete buildings. Earthq. Spectra 2008, 24, 795–821. [Google Scholar] [CrossRef]
- Ozcebe, G.; Sucuoglu, H.; Yucemen, M.S.; Yakut, A.; Kubin, J. Seismic Risk Assessment of Existing Building Stock in Istanbul a Pilot Application in Zeytinburnu District. In Proceedings of the 8th US National Conference on Earthquake Engineering, San Fransisco, CA, USA, 18–22 April 2006. [Google Scholar]
- Wasti, S.T.; Özcebe, G. Seismic Assessment and Rehabilitation of Existing Buildings; Springer Science & Business Media: Dordrecht, The Netherlands, 2003; Volume 29, pp. 31–34. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw Hill: Burr Ridge, IL, USA, 1997; Volume 45, pp. 870–877. [Google Scholar]
- Cortes, C.; Vapnik, V.N. Support Vector Networks. Mach. Learn. 1995, 20, 273–295. [Google Scholar] [CrossRef]
- Kia, A.; Sensoy, S. Classification of earthquake-induced damage for R/C slab column frames using multiclass SVM and its combination with MLP neural network. Math. Probl. Eng. 2014, 2014, 734072. [Google Scholar] [CrossRef]
- Knerr, S.; Personnaz, L.; Dreyfus, G. Single-layer learning revisited: A stepwise procedure for building and training a neural network. In Neurocomputing; Springer: Berlin/Heidelberg, Germany, 1990; Volume 68, pp. 41–50. [Google Scholar]
- SERU. Middle East Technical University, Ankara, Turkey. Archival Material from Düzce Database Located at Website. Available online: http://www.seru.metu.edu.tr (accessed on 19 April 2020).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Damage State | Damage Grade |
|---|---|
| None | 0 |
| Light | 1 |
| Moderate | 2 |
| Severe | 3 |
| Collapse | 4 |
| Kernel | Accuracy (in %) |
|---|---|
| RBF | 45 |
| Sigmoid | 45 |
| Linear | 45 |
| Polynomial | 26 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harirchian, E.; Lahmer, T.; Kumari, V.; Jadhav, K. Application of Support Vector Machine Modeling for the Rapid Seismic Hazard Safety Evaluation of Existing Buildings. Energies 2020, 13, 3340. https://doi.org/10.3390/en13133340
Harirchian E, Lahmer T, Kumari V, Jadhav K. Application of Support Vector Machine Modeling for the Rapid Seismic Hazard Safety Evaluation of Existing Buildings. Energies. 2020; 13(13):3340. https://doi.org/10.3390/en13133340
Chicago/Turabian StyleHarirchian, Ehsan, Tom Lahmer, Vandana Kumari, and Kirti Jadhav. 2020. "Application of Support Vector Machine Modeling for the Rapid Seismic Hazard Safety Evaluation of Existing Buildings" Energies 13, no. 13: 3340. https://doi.org/10.3390/en13133340
APA StyleHarirchian, E., Lahmer, T., Kumari, V., & Jadhav, K. (2020). Application of Support Vector Machine Modeling for the Rapid Seismic Hazard Safety Evaluation of Existing Buildings. Energies, 13(13), 3340. https://doi.org/10.3390/en13133340