1. Introduction
Mapping and monitoring of impervious surfaces is required for a number of purposes, e.g., urban planning [
1], monitoring subtle urban changes (so-called subtle urban dynamics) [
2,
3,
4], as an essential component of effective stormwater management [
5], to assess the hydrologic condition of an area/catchment [
5], to evaluate water quality [
5,
6,
7], but also to facilitate rational stormwater management policies for specific lands/properties [
8], to improve environmental management and finally to promote sustainable urban development, including construction of appropriate facilities/infrastructure [
1]. Other important applications of impervious surface mapping/classification include developing appropriate standards for managing pollution from stormwater runoff [
9], implementing flood control measures [
5,
8] and supporting emergency management activities [
5]. Sobieraj et al. [
5] emphasize the need to map impervious surfaces in the context of so-called sustainable drainage technologies and small-scale architecture (sustainable urban drainage systems /SUDS/, water-sensitive urban design /WSUD/, low impact developments /LID/). According to Bauer et al. [
10], a measure of imperviousness can also be used as a proxy for assessing environmental quality. More specifically, impervious surface is an indicator of the ecological health of the areas in question [
9]. It indicates the degree of urbanization and has a direct impact on water balance [
9] and temperature cycles [
5] as well as water quality [
5,
6,
7,
8,
11,
12]. In this context, it is worth noting that the need for detailed estimates of impervious surfaces has increased [
1,
5,
7,
8]. Yang et al. [
13] state that accurate and up-to-date geospatial data on urban impervious surfaces serve a multi-level study of urban ecosystems. In most cases, an increase in impervious surfaces leads to insufficient groundwater recharge and an increase in storm runoff [
1,
14]. This, in turn, leads to an increase in the frequency of flooding and localized flooding [
5] and also affects water quality in the watersheds in which they are located. In addition, there are also studies that show that wherever the ratio of impervious to pervious surfaces increases, this leads to increased pollution (contamination) from nonpoint sources [
15]. This is due to increased transport of toxic pollutants, pathogens and various types of sediments.
Various approaches to characterizing and quantifying impervious surfaces can be found in the literature, with much attention paid to remote sensing and, in particular, some chronological context for the development of this method [
1]. One such approach to estimating impervious surfaces is the integration of remote sensing and various machine learning-based classification methods [
1]. In addition, although examples of studies dedicated to the use of AI in impervious surface classification can be found in the literature, e.g., using Support Vector Machines (SVM) [
16], Maximum Likelihood (ML) [
6,
17], or Random Trees/Forest (RT/F) [
18,
19], there is a lack of comparison of different machine learning methods (for impervious surface classification) in terms of their accuracy on high-resolution orthophoto maps. However, in general, there are examples of studies in the literature showing that SVM is superior to other classification methods in terms of performance, in particular it performs better than ML [
20,
21,
22,
23]. However, it is worth noting that in some cases the results of the ML method were only slightly worse (the study concerned land cover) [
21], while in another study SVM gave better results for SAR images (while ML proved to be the better classifier for TM images) [
20].
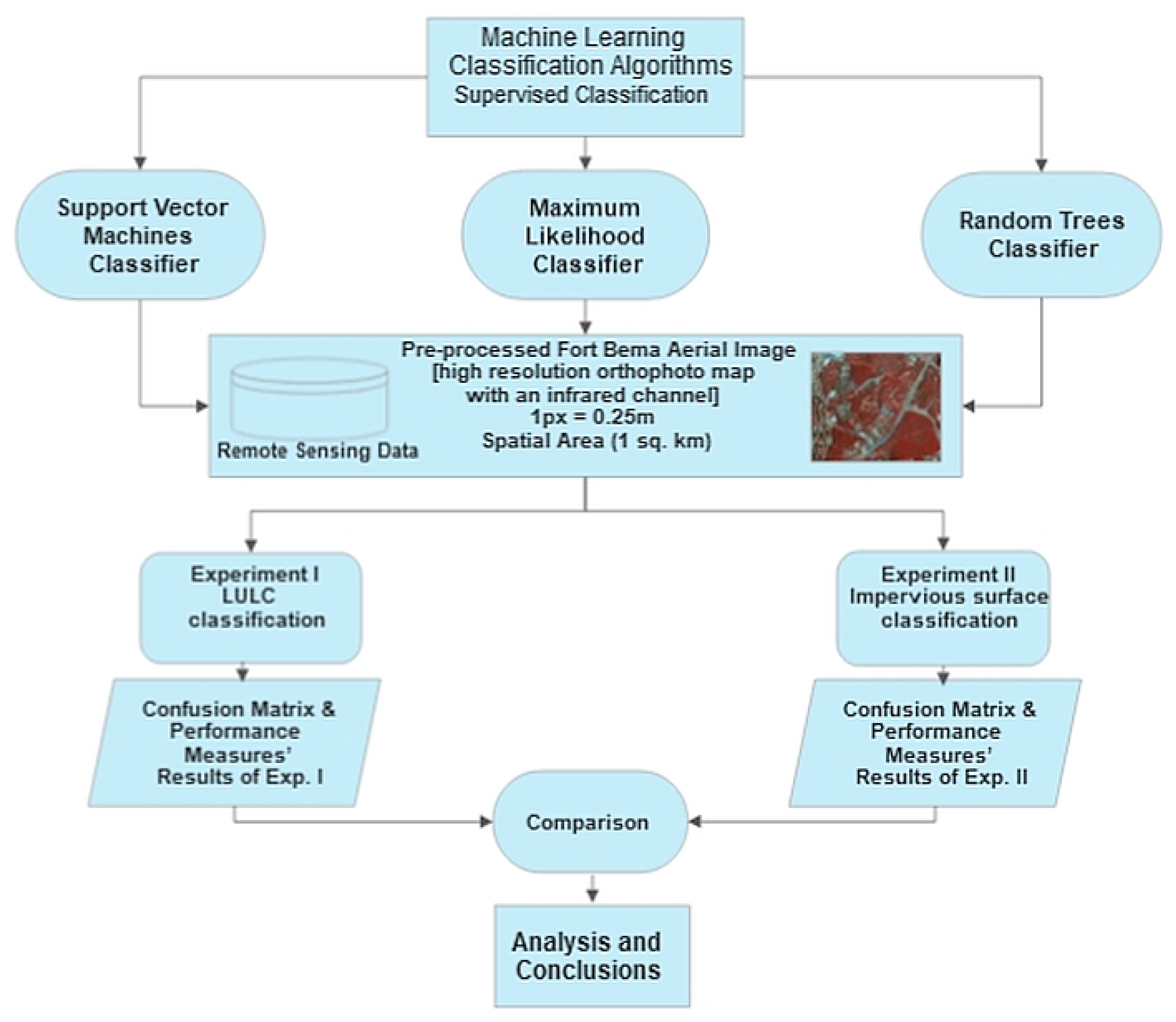
The aim of the article is to compare the performance of different machine learning algorithms in mapping impervious surfaces, using high-resolution orthophotos and evaluating the confusion matrix and other performance indicators. In this context, the article can be considered as original research (reporting a new work) that provides empirical sources and presents original evidence. In addition, the article also summarizes the existing literature on the topic under study and attempts to explain the current state of understanding on this topic. The essence of the review of several studies, on the other hand, is to highlight the importance of mapping and knowledge of impervious surfaces to solve various problems that are directly or indirectly applicable in civil engineering (e.g., for evaluating the stormwater bill of the site and determining the intensity of stormwater runoff). While there is an abundance of literature on impervious surface mapping, unlike other work, this study is original in that, in addition to practical experiments, knowledge of impervious surface classification was placed in the context of its usefulness for construction-related applications.
The use of remote sensing data and various machine learning algorithms to classify impervious surfaces shows how such surfaces can be mapped (that there are many different effective segmentation methods and GIS software to facilitate this) and how accurate and effective these methods are. In terms of contributions to the literature, the paper first provides a thorough overview of what is known about impervious surfaces, with particular attention to the context of remote sensing (due to its low cost) and various machine learning algorithms. Subsequently, the application of selected methods is demonstrated using a specific case study at the property level as an example. More specifically, the geographical area used and presented in the case study is one of the most prestigious housing estates in Warsaw (with an area of 1 square kilometre), which is ideal for this type of study, as the use of very high-resolution orthophotos (1 px = 0.25 m) allows precise segmentation at the parcel level (thus, the study area is neither too large nor too small to be suitable for the applied methods). At the same time, it is an area with a certain anthropological diversity (characterized by a high spectral heterogeneity) and therefore represents a certain challenge for mapping [
2,
4], so that the effectiveness and efficiency of the above methods can be tested in detail.
Indeed, Zhang et al. [
24] emphasize the need for further research in this context, i.e., research that compares different classification methods. Our study addresses this issue and, in a sense, fills a research gap. It is also worth noting that a similar study (but less detailed) was conducted by Martines et al. [
25], who also compared three image classification algorithms, namely SVM, ML and RT. However, in the case of this study, the AI classifiers were not used to estimate impervious surfaces, but to verify the discriminability of forest areas, forestry and other uses, for which these authors used geoprocessing and remote sensing techniques, as well as Sentinel satellite data, which have a relatively low resolution (although still higher than Landsat).
In the case of our study, however, orthophoto map data (rather than satellite data) were used because it would not have been possible to obtain such an accurate image from publicly available data and a pixel resolution of 10 m for Sentinel and 25 m for Landsat would not have provided satisfactory classification results at the scale of the settlement. More specifically, the data used in this study are aerial optical images (non-satellite and radar images) that have been orthorectified and therefore have a suitable coordinate system. The use of these data is therefore supported by the accuracy of the resulting product and the presence of the near-infrared channel.
The structure of this article is as follows. First, we introduce the materials and methods and outline the current state of academic knowledge on remote sensing, impervious surfaces and AI classification methods. Then, we present the methodology used and explain the differences between the three AI classification methods. Finally, we describe the obtained results, discuss them and draw conclusions from the conducted research.
2. Materials and Methods
As mentioned in the introduction, the objective of this paper is to investigate the classification of impervious surfaces using remote sensing data and various machine learning classifiers. There are several classification methods used in this type of engineering problems, namely Support Vector Machines (SVM), Maximum Likelihood (ML) and Random Forest/Trees (RT). More specifically, the study is based on the geographic information systems (GIS) that allow the integration and joint analysis of geospatial data (remote sensing imagery (orthophoto maps)) with AI classifiers. In other words, GIS is a system that creates, manages, analyses and links/integrates location data with a map (in the case of this article, these are data for the Fort Bema property in Warsaw-Bemowo with an area of about 1 km2) and provides useful descriptive information. As part of the GIS data types, orthophoto maps used for the purposes of this article are a powerful visual aid and serve as a source of derived information such as planimetry and classification schemes to provide knowledge details related to land use/land cover.
For example, Sobieraj et al. [
5,
8] point out that decisions about land use plans and development conditions should be coupled with a review of the hydrologic systems for the sites in question and a possible commitment to low-impact developments and SuDS facilities in places where the appropriate hydrologic systems are at risk. Modern technologies offer the ability to very easily verify the degree of urbanization of a given site relative to green space. One such technology is machine learning-based classifiers that can be used to calculate the ratio of urbanized to green space for specific sites. More specifically, methods such as SVM, ML or RT classification allow the extraction of features from multispectral images, and these classification results can then be used for further analysis. It is worth mentioning that the above-mentioned machine learning methods (of which there are many more) are increasingly used to solve many engineering problems [
8]. SVM, ML and RT are suitable for identifying impervious surfaces such as roads, roofs and sidewalks. Many local governments use impervious surfaces to calculate stormwater runoff for a property [
5,
8]. There is a technique consisting of an object-oriented feature extraction method and GIS-based platforms (e.g., the ArcGIS Pro Classification Wizard) to accomplish such a task. Using multispectral imagery (very high resolution orthophotos) containing a near-infrared band, it is possible to perform detailed feature extraction of impervious surfaces. In particular, it is possible to change the combination of image bands to highlight important features such as vegetation and roads. In
Figure 1, it can be seen that with the combination of colour and infrared bands, it is very easy to identify vegetation areas in the environment.
The combination of colour and infrared seems well suited for what is to be identified, as man-made features are clearly distinct from vegetation. The study provides a detailed GIS-based analysis with the use of three different AI impervious surface classification methods, which can be used, for example, to evaluate the stormwater bill of the property. Orthophoto maps are used for land cover classification. The next three subsections refer to: (
Section 2.1) the spatial area studied, (
Section 2.2) the remote sensing data used in the study and (
Section 2.3) a justification of why the study of impervious surfaces (using remote sensing and various classification methods) is so relevant and an interesting and important topic from a scientific perspective. A comprehensive overview of the many important studies of impervious surfaces and land cover combined with the various relevant classification methods can also be found in
Table A1 in
Appendix A, later in this article.
2.1. Spatial Area under Study and Data—Case Study of the Fort Bema Housing Complex
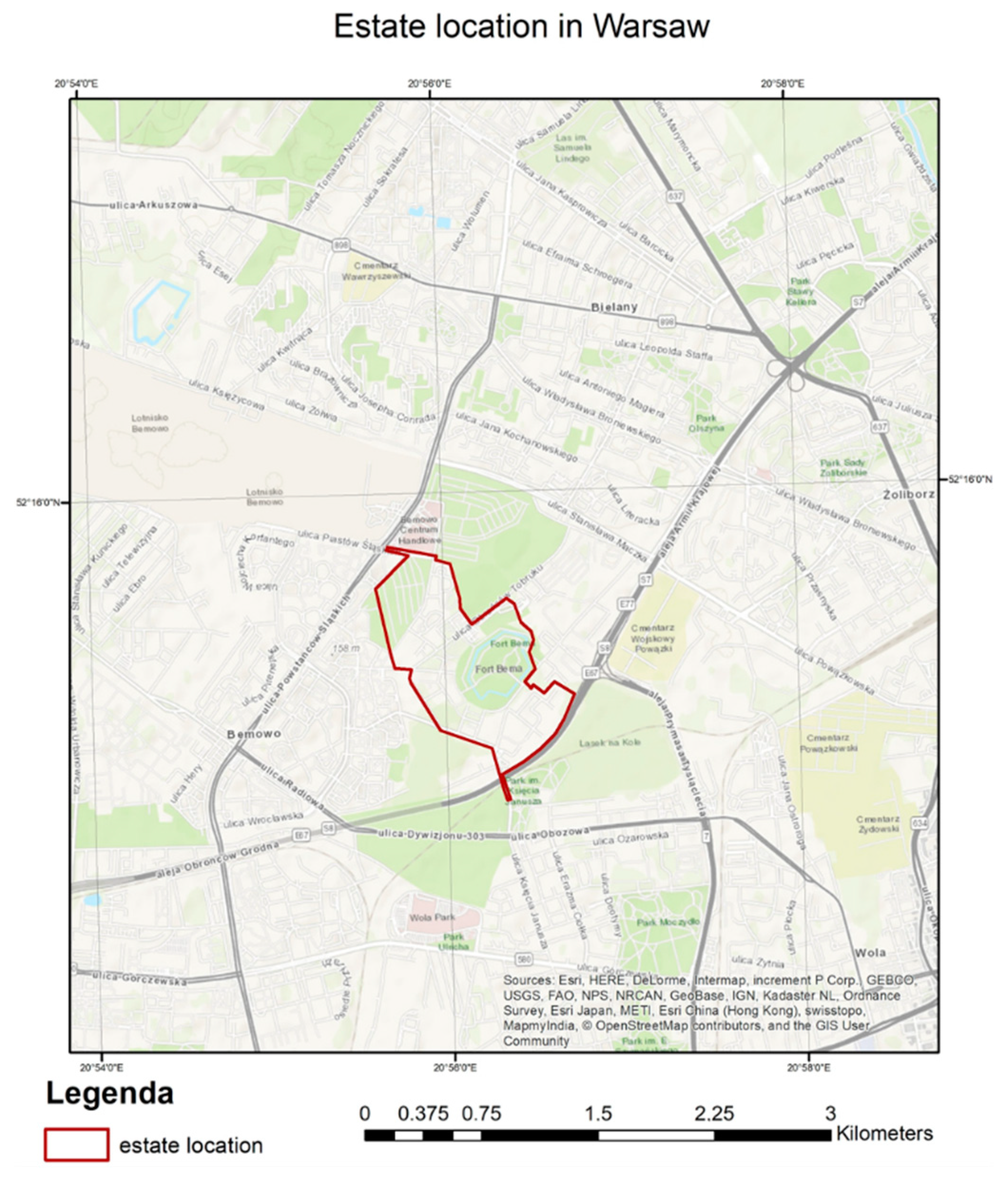
The area under study is located on the edge of the Vistula Basin (between 52°14′–52°16′ N and 20°55′–20°57′ E) and its spurs into the Bemowo Forest and further into the Kampinos Primeval Forest.
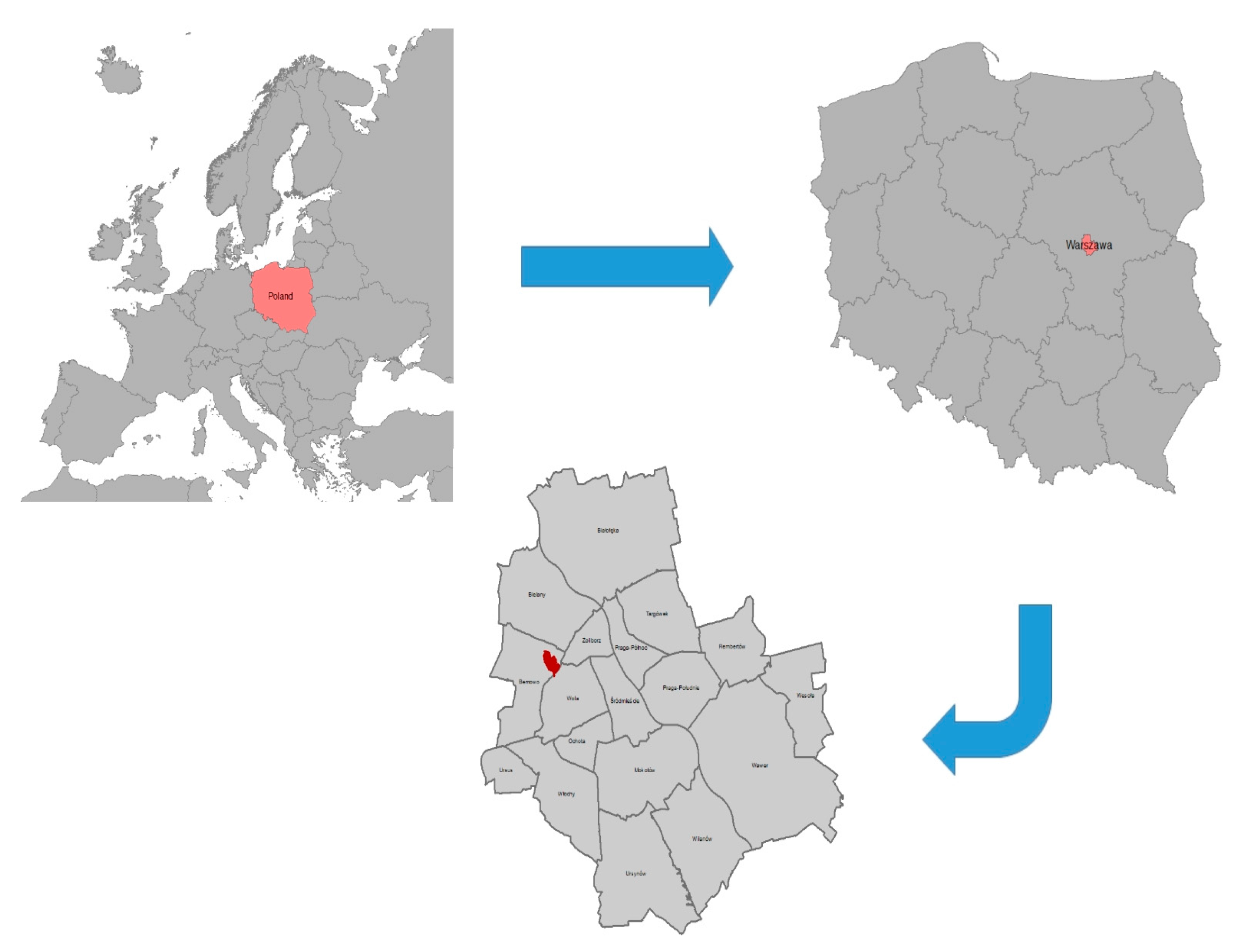
Figure 2 shows Poland against the background of Europe, then Warsaw (in relation to Poland) and finally the geographic area under study within Warsaw itself. Fort Bema, also known as Fort Parysów (after the name of the village), was built in 1886–1890 as part of the Inner Ring of Warsaw Fortifications—a complex of forts and other fortifications built around Warsaw by the authorities of the Russian Empire in the period from 1879 to 1913. Earlier it was an ammunition depot and later the site was used by various army units. Among others, the equestrian section of the military sports club “Legia” had its headquarters here. In 2002, the area was revitalized, the banks of the ditch were cleaned and new bridges were built over the ditch. In the summer season there is a water bike rental service. Fort Bema residential estate complex is one of the largest housing estates in Warsaw–Bemowo district [
5,
8]. It was built in 1999–2011, with a part of 1,480,000 (i.e., 148 hectares) earmarked for urban development and land use, and built with residential buildings (about 200,000 sqm of usable and residential space + services) [
5,
8,
26]. New housing estates are being built in the area, but the fortress still has many meadows and trees, which are a good source of food for dragonflies (see
Figure 3).
2.2. Remote Sensing Data Used in the Study
Publicly available satellite imagery has at best a pixel resolution of 10 m (Sentinel) or 25 m (Landsat). It should be noted that the quality in such a case is rather poor and insufficient when it comes to surveying the area of a housing estate in the order of 1 square kilometre (for use with the expected accuracy of classification). In the case of the study of the residential area of Fort Bema, we needed high-resolution data, as such images provide much better results. Therefore, the survey conducted for this article used orthophotos with an infrared channel and a pixel size of 0.25 m, which provide much more accurate results. The data are from 2017 (or more precisely, 27 May 2017). The data were used for classification by the different methods presented in this article, i.e., SVM, ML and RT. ArcGIS software was used for the classification. The orthophoto map is provided free of charge on Geoportal (
https://www.geoportal.gov.pl/, accessed on 3 November 2022). Unfortunately, 2017 was the last year it was acquired with an infrared channel, and no more recent data are available. For the NDVI, we used data from SENTINEL—10 m resolution, the satellite imagery is from 9 May 2022, and the data were downloaded from Earth Explorer (
https://earthexplorer.usgs.gov, accessed on 2 November 2022). In addition, we would not obtain sufficiently accurate imagery from Landsat or even Sentinel and expect satisfactory classification results at the settlement/ neighbourhood level of one square kilometre. The orthophotos used for the purposes of this article, on the other hand, are optical aerial photographs (and thus non-satellite and non-radar) that have been orthorectified, i.e., they have been given an appropriate coordinate system. The use of these data is therefore supported by the accuracy of the resulting product and the presence of the near-infrared channel.
Figure 4 shows the visual composition with the housing estate and the NIR band. The blue colour indicates the boundaries of the FORT-BEMA housing estate, which is located in the western-northern part of Warsaw.
2.3. Impervious Surfaces
Impervious surfaces are man-made associated structures such as roads, sidewalks, parking lots, roofs and other outdoor facilities of an anthropogenic nature [
1,
7,
27]. They are an important determinant of the degree of urbanization and have a direct impact on water and temperature cycles and water quality—and thus on the ecological health of the areas they affect [
5,
6,
7,
8,
11,
12]. In this context, Weng [
1] and Yu et al. [
7] point out the increasing need for detailed maps showing impervious surfaces. Since the size of impervious surfaces is variable, it would be good if such maps were as reliable as possible while being up-to-date and reflecting the latest state of affairs. Therefore, cost-effective methods are even more important in this context. Weng [
1] has reviewed various surveying methods with particular emphasis on remote sensing, which has been practiced for more than half a century [
28].
Deng et al. [
9] emphasize that the knowledge of impervious surface is used as an important indicator and also as an input parameter for the simulation of water management, hydrological cycle and pollution assessment of the studied area. In this context, it can be used to evaluate the environmental changes in the studied areas [
9,
29]. Wu and Murray [
29] emphasize that the analysis of impervious surface changes is particularly important for a better understanding of the urban environment and human activities. Yang et al. [
13] state that accurate and up-to-date geospatial data on urban impervious surfaces are used for multilevel studies of urban ecosystems and, in particular, to study land use planning issues, resource management, urban hydrology and local climate. Weng [
1] highlights various approaches to characterizing and quantifying impervious surfaces and devotes much space to remote sensing, in particular providing some chronological context for the development of this method. The author emphasizes that although remote sensing data have been used since the 1970s, it is only since the beginning of the first decade of the current century that they have really been used extensively. Furthermore, Weng [
1] points out the different approaches and techniques used to process remote sensing data in terms of space, spectrum, texture and the actual context of these data.
The use of high-resolution remote sensing data plays an important role in monitoring subtle urban changes (referred to as subtle urban dynamics) [
2,
3,
4]. In addition to the remote sensing data themselves, appropriate methods are still needed to extract impervious surfaces with sufficient efficiency, especially when dealing with the problem of spectral heterogeneity—which is particularly important when extracting impervious surfaces in a diverse environment, especially with high-resolution data [
2,
3,
4,
30]. Lu et al. [
30] point out that mapping and monitoring the dynamic changes in impervious surfaces in a complex urban–rural interface is particularly challenging due to the spectral confusion of impervious surfaces with other non-vegetated land covers (the so-called mixed pixel problem), and the use of very high spatial resolution satellite imagery is required to address this problem. It is worth mentioning that the multidimensional heterogeneity of the data leads, among other things, to spatial misregistration manifested by the parallax effect, i.e., the incompatibility of different images of the same object observed from different directions (considering different viewpoints)—which is particularly relevant for high object structures [
4]. Huang et al. [
4] emphasize that there are few studies that use high-resolution data to detect changes on large geographic scales. According to Bauer et al. [
10], Landsat TM data are well suited to quantify the degree of surface imperviousness (over large areas and over a long period of time, at moderate cost); the measure of imperviousness can also be used as a proxy for assessing environmental quality.
As Arnold and Gibbons [
31], Weng [
1] and Yu et al. [
7] have noted, impervious surfaces are anthropogenic objects that promote infiltration into the soil and are good indicators of the degree of urbanization and environmental quality [
2,
29]. Wu and Murray [
29] and Liu et al. [
2] emphasize that impervious surfaces are an important indicator to observe and analyse changes in urban land cover and draw some conclusions about human–environment interactions. Schueler [
12] notes that the specificity of impervious surfaces due to their large impact on watershed hydrology, means that their analysis at different scales brings together specialists from different disciplines, from various activists, planners, officials, architects, engineers to scientists and social scientists. Weng [
1] emphasizes that hydrology is influenced by both the size and spatial pattern (including geometry and location) of impervious surfaces. Size, of course, refers to the ratio of impervious to pervious surfaces. An increase in the latter ratio in turn determines the intensity of water runoff, more specifically its volume and duration [
5,
32].
Moreover, it is widely recognized in land use planning that the negative impacts of impervious surfaces associated with transportation infrastructure are more harmful compared to those of rooftops [
1,
32]. In most cases, an increase in impervious surfaces leads to insufficient groundwater recharge and an increase in runoff during storm events [
1,
14]. This, in turn, leads to an increase in the frequency of flooding and localized inundation [
5,
8] and also affects water quality in the watercourses of the watershed in which they are located. In addition, there are also studies that show that wherever the ratio of impervious to pervious surfaces increases, pollution (contamination) from nonpoint sources also increases [
15]. This is due to increased transport of toxic pollutants, pathogens and various types of sediments. In turn, the disturbance associated with the hydrological cycle in an area (manifested, among other things, in water pollution, but also in runoff rates and an increase in runoff volume) in turn leads to a disturbance of the natural ecosystem as a whole (i.e., the biota) and, in particular, can lead to an impairment of aquatic habits, such as a disturbance of riparian areas and habitats [
1,
14]. This is perfectly illustrated by a study conducted by Gillies et al. [
14], who used remote sensing data to examine the effects of urbanization on aquatic fauna in the Line Creek watershed in Atlanta. In the study, the authors presented impervious surfaces as an ecological indicator to explain the impact of water resources on mussel populations in three watersheds. The study shows that the extent of impervious surfaces increases habitat degradation for mussels. In other words, the loss of species (in the order of 50–70%) could be attributed primarily to the areas where the expansion of impervious surfaces was observed. Hence the great importance of this issue.
The size of impervious surfaces affects not only water management but also climate by causing, among other things, changes in warm air movement. Williams et al. [
33] and Sobieraj et al. [
5,
8] point out that rapid urbanization due to the increase in impervious surfaces and climate change makes urban communities more vulnerable to natural hazards and weakens urban resilience [
5,
33]. Sabine et al. [
34] and Sobieraj et al. [
5] highlight that increased urbanisation and the associated increase in impervious surfaces pose an increased risk to climate change, including by altering carbon cycling and other biogeochemical processes, and by disrupting heat fluxes within urban canopies and boundary layers [
13]. Sobieraj et al. [
5,
8] note that the so-called precipitation peaks are also becoming more frequent, which in the case of large cities turn them into heat islands (partly due to soil properties and the degree of urbanization). This is due to the pressure of the heated air masses on the city, and this additional energy is released at the periphery of the cities [
5]. An insufficient ratio of impervious to pervious surfaces leads to a decrease in vegetation production (decrease in vegetation cover, changes in cover within the watershed and thus in vegetation production). Depending on the type of land use (the particular land use category), the percentage of land covered by impervious surfaces may vary [
1]. Weng [
1] points out that mapping impervious surfaces is therefore particularly important, especially in the context of their central role in monitoring human–environment interactions and environmental change [
2]. Similarly, Sobieraj et al. [
8] emphasized the need to map impervious surfaces in the context of a range of sustainable drainage technologies and small-scale architecture (SUDS, WUDS, LIDs).
There are a number of reasons that justify the need to map and estimate impervious surfaces, such as urban planning issues, hydrological condition assessment, water quality assessment, but also to facilitate the handling of stormwater taxation issues, and finally this would allow better environmental management, facilitate the concern of sustainable urban development, including the construction of adequate facilities and urban infrastructure [
1]. Impervious surfaces can be estimated based on ground measurements (field measurements with GPS) and remote sensing data [
1]. The former are accurate and reliable, but also very time consuming and expensive [
1]. Other methods include digitizing paper maps, using aerial imagery, scanning and feature extraction using appropriate algorithms [
1]. Satellite imagery and aerial photography have been used for environmental studies since the 1970s [
27]. Slonecker et al. [
27] mention imperviousness modelling as one of the applications of these images, in addition to interpretive or spectral applications, etc. The mapping and measurement of the impervious surface is well described in the work of Brabec et al. [
11]. In their work, these authors refer to the use of various methods, including the use of aerial photography and the measurement of impervious surface either based on a planimeter or by overlaying a special grid and counting the intersections on this grid; other methods include image classification and estimation of the percentage of urbanization in a given area. Weng [
1] points out that the use of remote sensing to estimate impervious surfaces was rare in practice until the end of the last century because there were no suitable remote sensing sensors for analysing and estimating such surfaces, computational power was inadequate at the time (standards were not satisfactory in this regard), and finally, suitable techniques for digital processing of such images (with resolution less than 5 m) had not yet been developed. The increasing interest in the application of remote sensing to the measurement of impervious surfaces (with the beginning of the 21st century) was also accompanied by a corresponding increase in the number of scientific studies on this topic. Against the background of all studies dealing with remote sensing, the estimation of impervious surfaces (using remote sensing) had one of the highest citation rates, indicating that this particular area of knowledge is rapidly growing and gaining popularity [
1]. In the context of growing awareness of environmental threats (e.g., climate change and problems in hydrological systems), research on estimation of impervious surfaces (using remote sensing and various methods) is increasingly being conducted by various government agencies and non-governmental organizations with the intention of mapping and collecting information about these surfaces for various civil and environmental objectives.
4. Results
Figure 6 and
Figure 7 and
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 show the respective results.
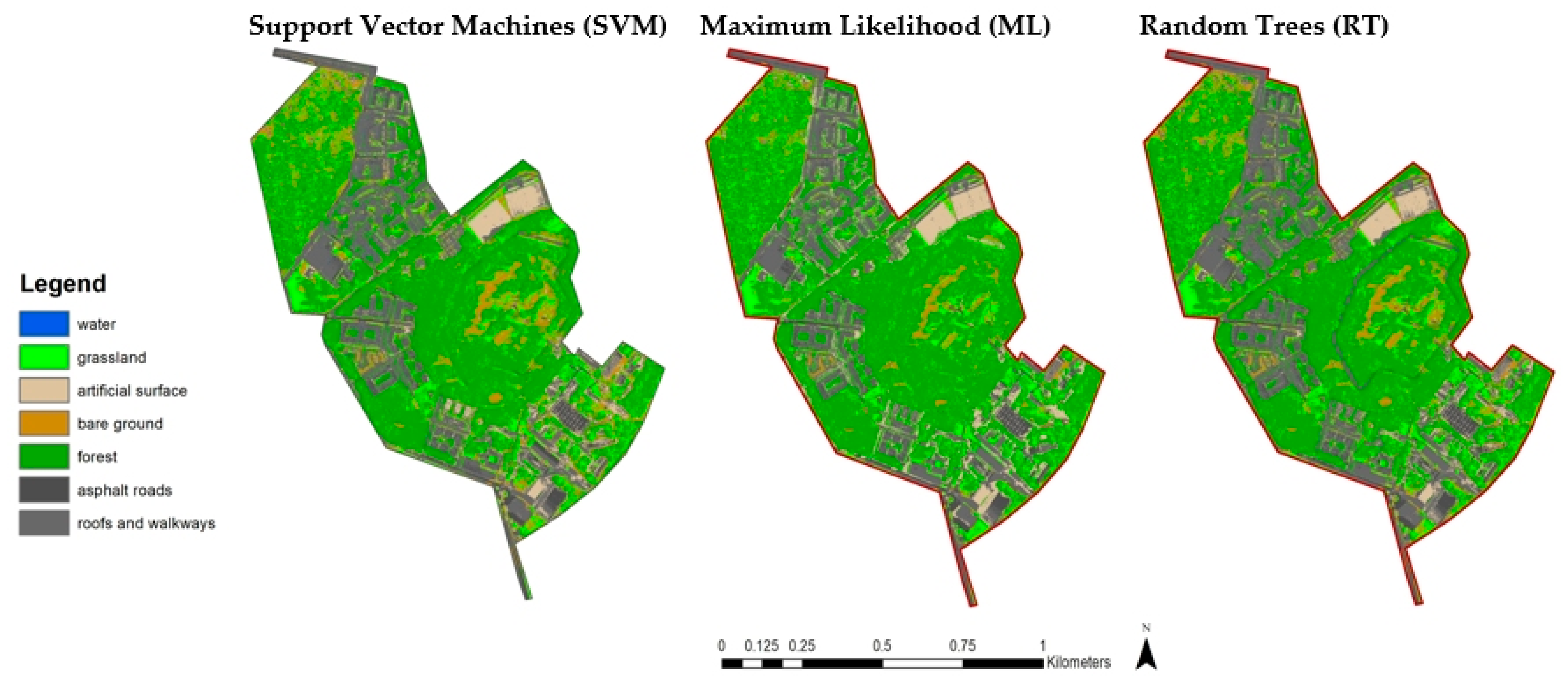
Figure 6 compares the land use and land cover (LULC) classification for the Fort-Bema housing estate (an area of approximately one square kilometre), which was conducted using three different methods, SVM, ML and RT. From the comparison shown in
Figure 6, it is evident that the LULC classification performed with the SVM method reflects much more of the fine details that are not visible with either the ML or RT methods.
Table 1,
Table 2 and
Table 3 show the confusion matrices for all three methods (SVM, ML and RT) for LULC classification of 7 classes (C1—water; C2—forest; C3—asphalt roads; C4—artificial surfaces; C5—roofs and sidewalks; C6—grassland; C7—bare soil). The RT method has the lowest accuracy (0.75), while approximately similar values (0.83–0.84) were obtained for SVM and ML. When comparing SVM and ML, the SVM method proved to be slightly better (kappa = 0.8416). The RT method, on the other hand, shows the greatest detail in subdividing permeable and impermeable surfaces, but as it turns out (as confirmed by the confusion matrices) is not always correct, because in many cases water/shade features are misclassified as impermeable surfaces (hence kappa = 0.7469).
Table 1 shows the confusion matrix for the classification performed with the SVM method.
The confusion matrix for the classification performed with the method ML is shown below in
Table 2.
The confusion matrix for LULC classification (7 classes) using the RT method is shown in
Table 3.
Table 4, in turn, shows the respective RMSE values, which are a measure of accuracy. It can be considered as a useful measure to understand the performance of classification [
7,
29]. This study shows that SVM classification (3.31) has the lowest error, followed by ML (3.50) and RT (4.50), further confirming the higher classification accuracy of the SVM classifier.
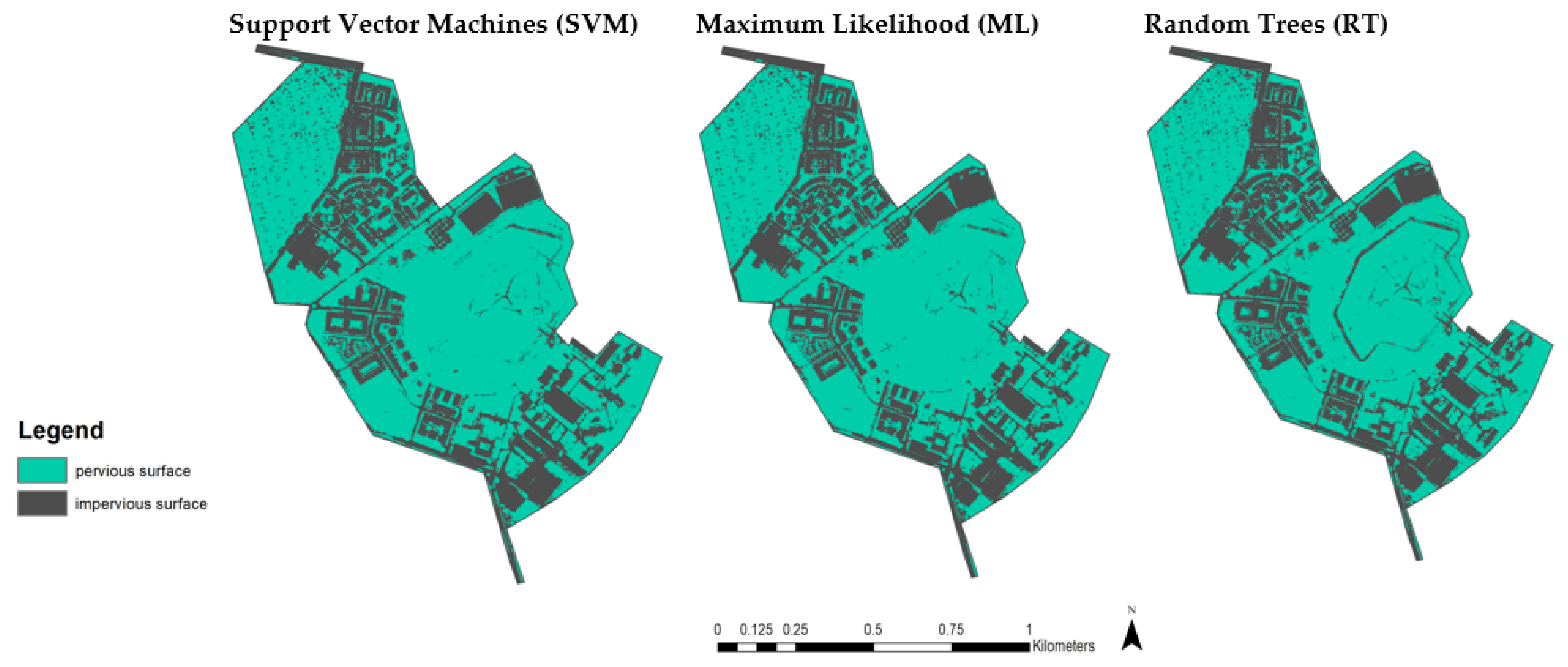
Below is a classification of impervious surfaces (i.e., a binary classification) (see
Figure 7). It is worth noting that with this type of classification using a binary classifier, the classification accuracy is much higher than with the LULC classification presented above.
When classified into 2 classes (impervious-pervious), the results showed that SVM again achieved the highest percentage of overall accuracy. However, the classification results of ML were only slightly worse (the difference was almost nonexistent, i.e., 91.51% vs. 91.35%), and again RT had the worst accuracy (see
Table 5,
Table 6 and
Table 7).
In addition, the RMSE was lowest for the ML classification (see
Table 8). Considering both the kappa index and the RMSE, we can conclude that when classifying orthophoto map data with a very high resolution (0.25 m per pixel), both the SVM and ML classifiers give very similar results.
In addition, the SVM classification method was also used to accurately quantify the character of the area in the Fort Bema housing estate complex: (1) pervious—630,117.2948 m2 = 0.64 km2—67.42%; (2) impervious—304,538.23 m2 = 0.30 km2—32.58%.
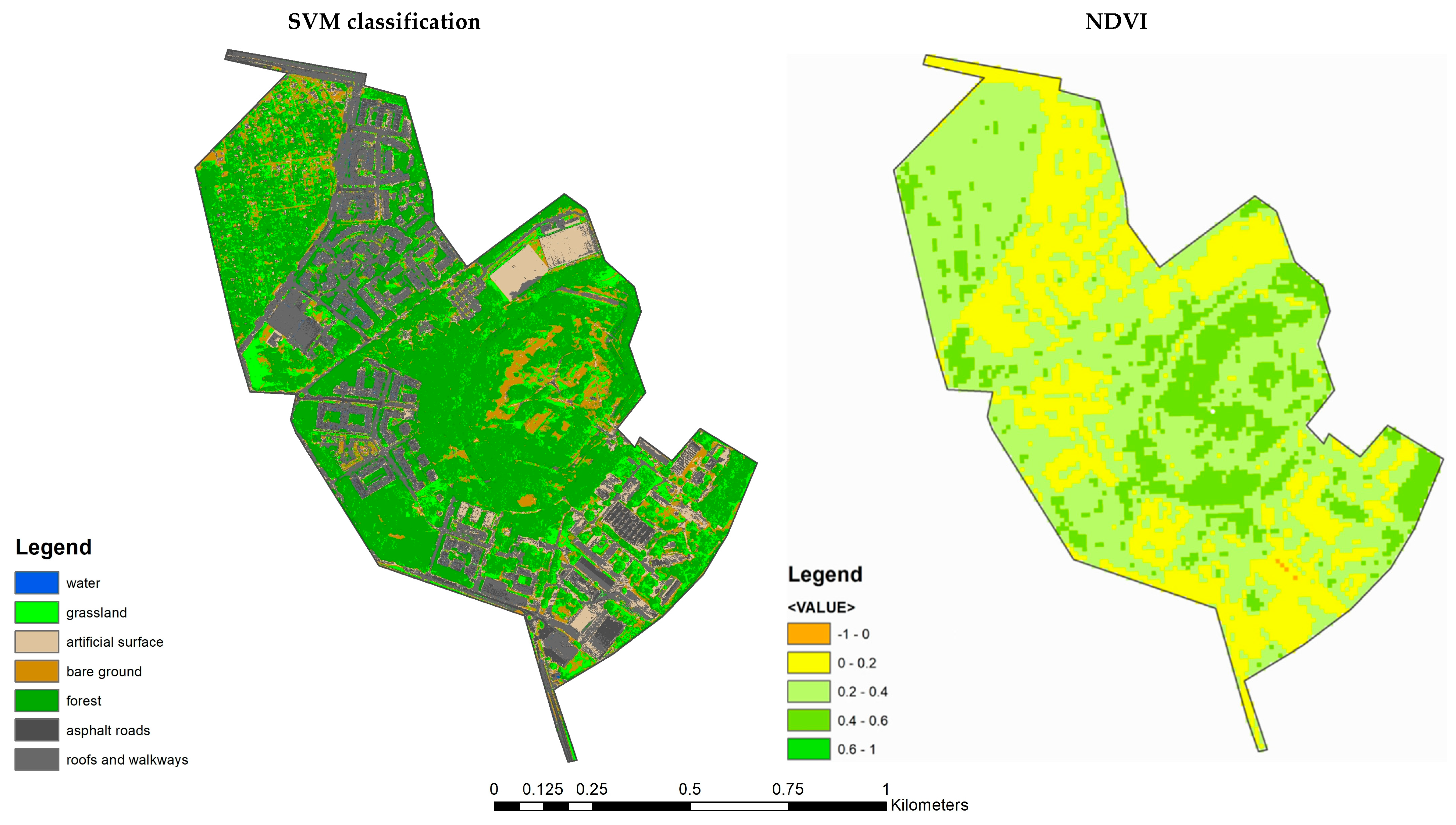
High-resolution orthophotos covering the near-infrared range are also a good method to estimate sealed areas in an urban area (such as the residential complex that is the spatial study area of this paper). Vegetation production in near-infrared images has a relatively high reflectance, which in turn can be very well represented by the Normalized Difference Vegetation Index (NDVI) [
50]. This index represents the ratio between visible light and near-infrared light. Briefly, the NDVI index can be expressed as follows:
where R represents the red band and NIR represents the near infrared band.
When the NDVI index has a high value, it is clear that vegetation production is present. More specifically, vegetation is characterized by a high index, while sealed surfaces, such as built-up areas such as roads and sidewalks, are characterized by low values of this index (see
Figure 8).
5. Discussion
SVM, ML and RT are different classification methods used in machine learning. While ML is a parametric method—built as a probabilistic model whose parameters are determined based on Bayes theory (which amounts to knowing/estimating the parameters of the model before classification), SVM and RT are non-parametric methods. The former is an optimization-based non-parametric method and the latter is an ensemble method that belongs to the special category of bagging methods. There are a number of studies that confirm the effectiveness of the ML method in solving classification and signal identification problems from very different fields of knowledge: in quadrature-linked classification, which combines the two simplest digital modulations: Amplitude (ASK) and Phase (PSK) [
51], in speech recognition [
52], in bioengineering and in particular in gene selection [
53] or finally in remote sensing [
54]. Similarly, the application of the SVM method is ubiquitous in almost all fields that involve the classification and prediction of data to solve very different problems from different walks of life. For example, to solve problems in engineering [
55,
56,
57,
58,
59,
60] and construction [
61,
62]. Similarly, there are many application examples for RT classification [
63,
64,
65,
66].
When comparing the three methods, the performance of each method is different [
20,
21,
22,
23]. In particular, with respect to the application in remote sensing, there are many studies in the literature showing that SVM is superior to other classification methods in terms of performance, especially it performs better than ML [
20,
21,
22,
23]. However, it is worth noting that in some cases the ML method performed only slightly worse (e.g., in the land cover classification study) [
21], and in another study, SVM provided better results only for SAR images, while ML proved to be the better classifier for TM images [
20]. Indeed, Zhang et al. [
24] emphasize the need for further research in this context, i.e., research that compares different machine learning classification methods [
24].
ML classifiers are quite complex models because they involve a large number of data points in their calculations (this should sound familiar to anyone who has ever studied regression analysis). However, ML also has some drawbacks. For example, ML classifiers can be slow compared to SVM and may even produce misleading results in certain situations. On the other hand, RT can be extremely fast. Sometimes the speed can even be too fast, since the model itself does not try to consider more than one branching scenario whenever possible. SVM is a more complex classifier (but at the same time gives better results) and does not require any preprocessing of the input data. SVM and ML algorithms can be trained much faster than RT and can handle a large number of features (SVMs even use the absence of a given feature as a positive feature). Among the algorithms of the same classifiers, SVM has the best generalization capabilities. The disadvantage of SVMs is their complexity and lack of interpretability.
Moreover, it is worth mentioning that the SVM classifier not only works well on standard images, but also performs well on segmented raster data. It performs pixel-based classification based on a predefined sample of training attributes. Multiband images with arbitrary bit depth are well suited for classification using the SVM method. The advantages of the SVM classifier compared to the ML method are: (a) requiring fewer samples, which, unlike ML, do not have to be normally distributed; (b) being more robust to noise, correlated bands and unbalanced number or size of training sites in each class. Unlike the SVM classifier, the ML classifier assumes that the statistics for each class in each band are normally distributed and computes the probability that a given pixel belongs to a given class. Nevertheless, the results of this study show that the SVM and ML methods give very similar results for the binary classification of high-resolution orophotomaps (0.25 m per pixel), with Cohen’s kappa coefficients of over 0.9 indicating very high classification precision (near perfect level of agreement). The kappa coefficient tests interrater reliability, which indicates the extent to which the data collected in the study accurately reflect the variables measured [
67].
When we compare the results presented in
Table 5,
Table 6 and
Table 7 with the interpretation of Coehan’s kappa value (see
Table 9) in terms of the percentage reliability of the data (measured by Cohen’s kappa), we find that the percentage reliability of the data is in the range of 82–100% when classified by the SVM and ML methods. The test performed by the method RT is slightly worse, but even in this case the level of agreement can be considered strong, as the percentage reliability of the data is in the range of 64–81%.
This study is a testament to the growing importance of remote sensing. It analyses different methods and compares them with each other. It also identifies the current state of research and prevailing trends (in the form of
Table A1 in
Appendix A). The study addresses the current standards for remote sensing data used to estimate impervious surfaces. In this context, it is worth considering how the characteristics of the remote sensing data (i.e., spatial, spectral and temporal resolution) affect the results. In this study, we evaluate different methods for estimating impervious surfaces and compare classification accuracy as a function of method (for high-resolution orthophoto map data). It is also worth noting that there are increasingly powerful and readily available (also for cost reasons) GIS platforms that use digital image processing algorithms and integrate various machine learning methods for classification. These platforms make the field of remote sensing very popular and allow easy estimation and mapping of impervious surfaces, especially very fast visualization of these surfaces and estimation of their size.
It should also be emphasized that the delineation of sealed surfaces (i.e., impervious surfaces) and the temporal and spatial analysis of these surfaces are important and relevant from a policy, environmental and land use management perspective [
9].
Choosing one of these methods is usually not easy, as each has its own advantages and disadvantages. In summary, all three algorithms are efficient and provide either near-perfect (for SVM and ML classification) or strong (for RT classification) results. Much also depends on what data are tested (i.e., what types of images), but also on how the training set is chosen, which can also affect the results accordingly. It is good to have some knowledge in this area, and highlighting some of the important elements of the comparison between the three methods is also one of the goals of this article.
The advantage of the SVM method can be seen in another context. Pai et al. [
68] state that the SVM is based on the assumption of minimizing structural risk and an upper bound on generalization error, rather than minimizing training error. In this respect, the SVM method provides better results than, for example, most conventional neural network models based on the principle of empirical risk minimization. Therefore, empirical results for SVMs provide better classification and problem-solving results, which has been confirmed in various studies on different knowledge domains. Ustuner et al. [
60] state that the selection of appropriate classification algorithms (e.g., SVMs) and the accuracy of remote sensing data lead to classification results that are crucial from the perspective of the spatial data community, as they provide a basis for other models and various applications.
Finally, Zhang et al. [
24] suggest that classification improvement can still be achieved by combining both classification methods, i.e., ML (based on Bayesian theory) with SVM. Elements of Bayesian decision theory can be used in the SVM method to optimize parameters [
69], improve performance in optimizing certain features [
70], reduce optimality error (in visualizing SVM outputs) [
71], reduce posterior probability of class membership [
72], or finally speed up the training process itself (to estimate certain hyperparameters), among others [
73]. A broader and more comprehensive investigation of the possibility of integrating both classification methods (i.e., SVM and ML) to further improve performance can therefore be identified as a future research direction.
It should be noted that the methods presented in this study may be useful, for example, for urban environment assessment, calculation of percent sealed area (%ISA), or land use/land cover (LULC) classification. Mapping of impervious surfaces and knowledge of NDVI can also be used for quantitative analysis LST in urban heat island studies using infrared remote sensing in urban environments [
6]. Knowledge of impervious surfaces can be useful in determining runoff intensity and pollution levels in a given area [
5]. It is worth mentioning that researchers are interested in calculating the percentage of sealed area for a given catchment. In the case of Warsaw, the subject of such a study is the Służewiecki [
5,
8] stream catchment in the southern part of Warsaw. One of the methods of estimating impervious surfaces of large-scale projects can be high-resolution remote sensing aerial photographs covering the near-infrared range and mapping the NDVI [
74]. This is because vegetation in near-infrared imagery has a relatively high reflectance, which in turn can be very well represented by the NDVI index. This index represents the ratio of visible light to near-infrared light. So, if it has a high value, it is clear that we are dealing with the production of vegetation. More specifically, vegetation is characterized by a high NDVI index, while impervious surfaces, such as built-up areas such as roads and sidewalks, are characterized by low values of this index. The NDVI scale ranges from −1.0 to +1.0, and a value just above 0 is considered a threshold for this index, separating vegetation production from any non-vegetation (this is well illustrated in
Figure 7).
The quality of the NIR images is also important for proper classification. In other words, an image showing the area may give different results depending on the quality. Thus, the more accurate the images are, the better. Classifying the areas according to the different NDVI indices allows the study area to be represented in terms of vegetation and non-vegetation. In order to determine the impervious areas, it is necessary to take into account that there is a strong correlation between the areas covered with vegetation production and the pervious areas. Thus, when determining the areas covered with vegetation, one is actually indicating permeable areas and vice versa when it comes to NDVI from the lower end of the range of values of this indicator (they are indicative of impermeable areas). It should also be pointed out that this method is not without drawbacks. First of all, the method based on NIR band images underestimates the actual results in some very specific cases. Examples of such situations are shading of some areas by tall objects. Such shaded areas, e.g., by trees, are treated as opaque because they hinder the propagation of light. Another example is soils and surfaces where no vegetation grows. In this case, too, the surface may be incorrectly classified as opaque when in fact it is permeable. Therefore, the classification of vegetation surfaces should be performed in a supervised manner and any doubt about the classification must be corrected manually. However, these drawbacks do not diminish the great value of the method for knowledge building.
Finally, in the literature review in
Table A1 in
Appendix A, we show that the first methods for classifying urban coverage (based on remote sensing) were developed in the early 1990s. At that time, a linear segmentation model was used that included texture, contextual information and reflectance properties [
75]. For the time, this model provided satisfactory results. However, it was not until the early 2000s, with advances in sensors and computing power, that studies of impervious surfaces were conducted on a larger scale. At that time, traditional estimation methods were used, including a linear spectral mixture model to model heterogeneous urban land cover [
29], a regression model relating the percentage of impervious surface to the green area of the urban fringe [
10] and a regression tree model [
13]. With the growing interest in urban land use classification, more complex methods have been developed over time, often combining different approaches, such as the decision tree method using a linear spectral mixture analysis model (simultaneously combining impervious surface classifications with population density knowledge) [
76]. Increasingly available high-resolution imagery facilitates the mapping of impervious surfaces. One such study used a hierarchical image segmentation method combining a multichannel watershed transformation and watershed contour dynamics [
77]. Another study sought tools to extract spatial features from remote sensing imagery using morphological attribute profiles (MAPs) [
78]. High-resolution imagery has also made it possible to analyse normalized multitemporal portions of impervious surfaces [
30]. Later, impervious surfaces also began to be estimated using multisensory and cross-source data [
9]. The second decade of the 2000s brought entirely new challenges. New opportunities emerged with the increasing availability of various location data acquisition technologies for geospatial research and the massive analysis of location data and discovery of patterns in location data [
79]. In addition, machine learning algorithms were used, for example, in the classification of point-of-interest data (POI) [
80]. At a later stage, different data sources also began to be integrated, which led to the creation of a modified normalized difference index of impervious surface (MNDISI) in one such study [
2]. Over time, social knowledge became an important element in the integration of various data sources. Several of these studies combined remote sensing features with social knowledge (VGI, OSM data, POI, social sensorimotor data, etc.) [
7,
81,
82,
83,
84,
85]. It is also worth noting that there is considerable interest in studying the so-called subtle dynamics of urban change, based on a multi-level approach (pixel, grid and city block) [
4], a multi-object approach to monitor surface changes over several years [
3]. In terms of outlook and suggestions from the review, it is natural to expect further progress in integrating different types of methods, including of course social knowledge, as advances in technology facilitate this type of research. Nonetheless, there is also a need for studies such as this one, which combines different methods and compares the results, embedding knowledge about impervious surface segmentation and urban land use classification in the context of their usefulness. In this study, we show, among other things, what the integration of different methods (remote sensing, machine learning algorithms, NDVI) can be useful from the point of view of civil engineering theorists and practitioners, especially in the construction sector in its broadest sense, highlighting, for example, issues of urban planning and hydrology).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}