

Insights into Multi-Model Federated Learning: An Advanced Approach for Air Quality Index Forecasting

 ,
,  , , , , , , and
, , , , , , and
Abstract
1. Traditional Approaches in AQI Prediction
- Kind of models: statistical, artificial neural network (ANN), deep neural network (DNN), hybrid, and ensemble.
- Kind of data: temporal, spatial and spatiotemporal
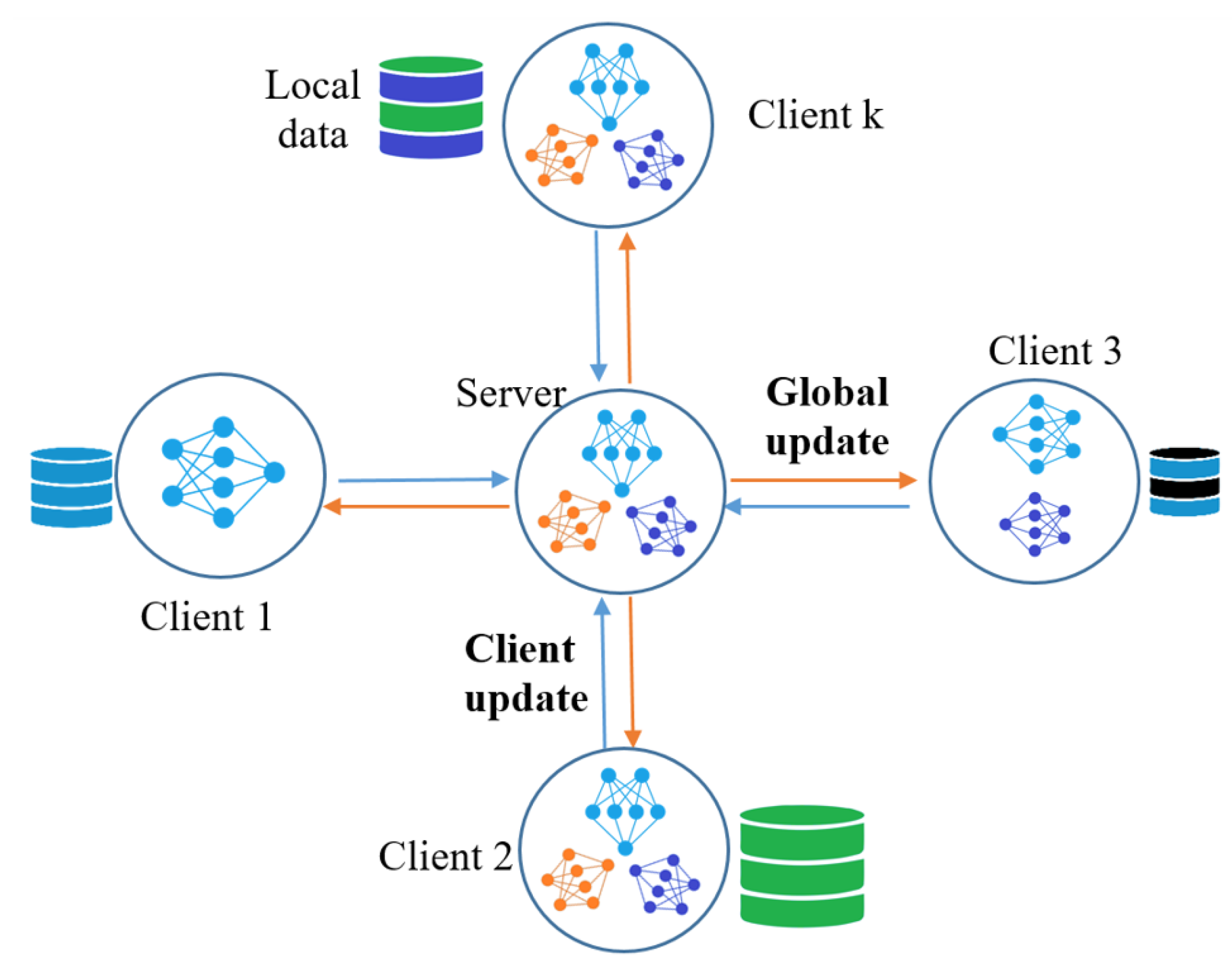
2. Federated Learning in AQI Prediction
- m: number of participants
- and
- : Local optimization function on participant k in Formula (2)
- : number of data samples
3. Insights into Federated Learning
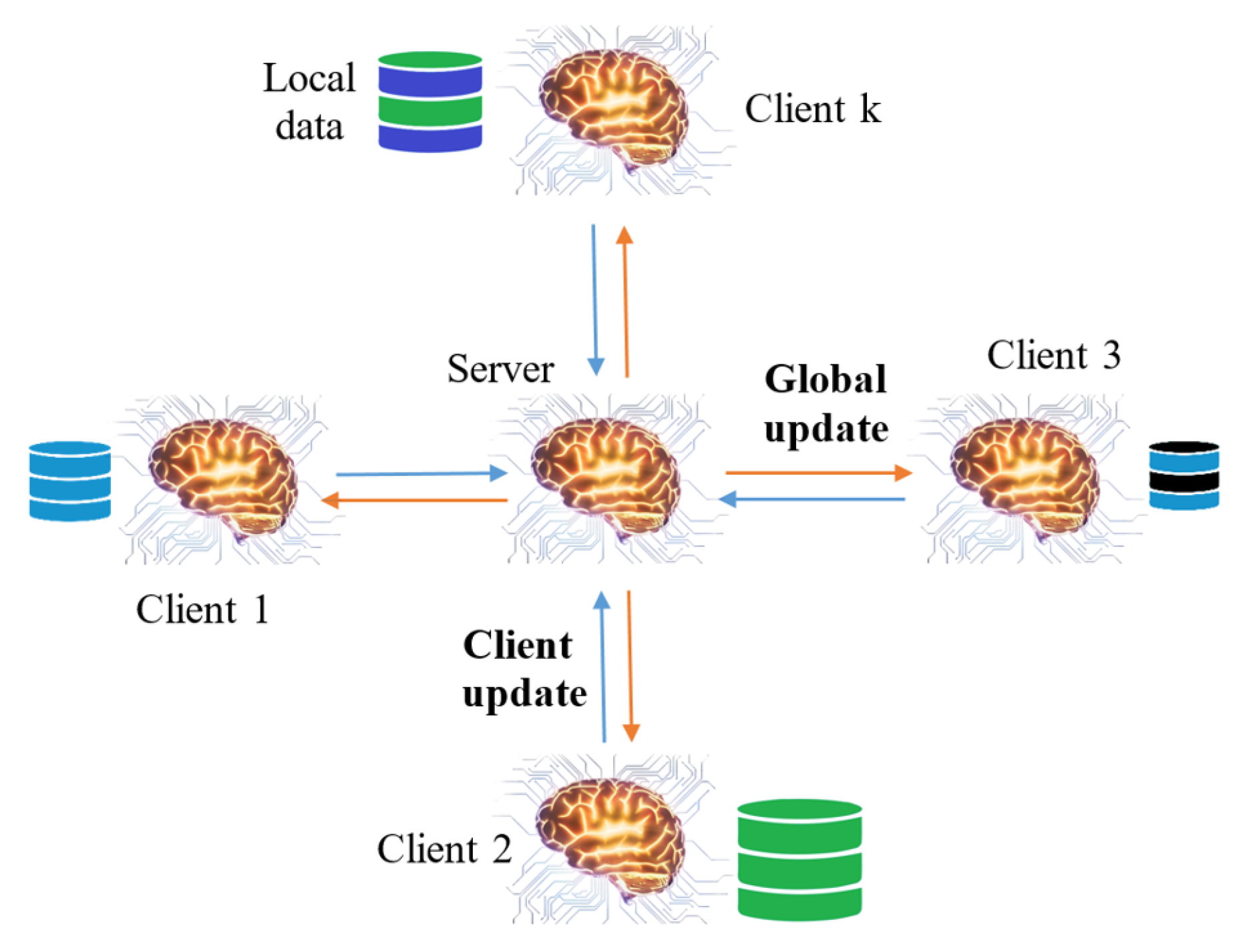
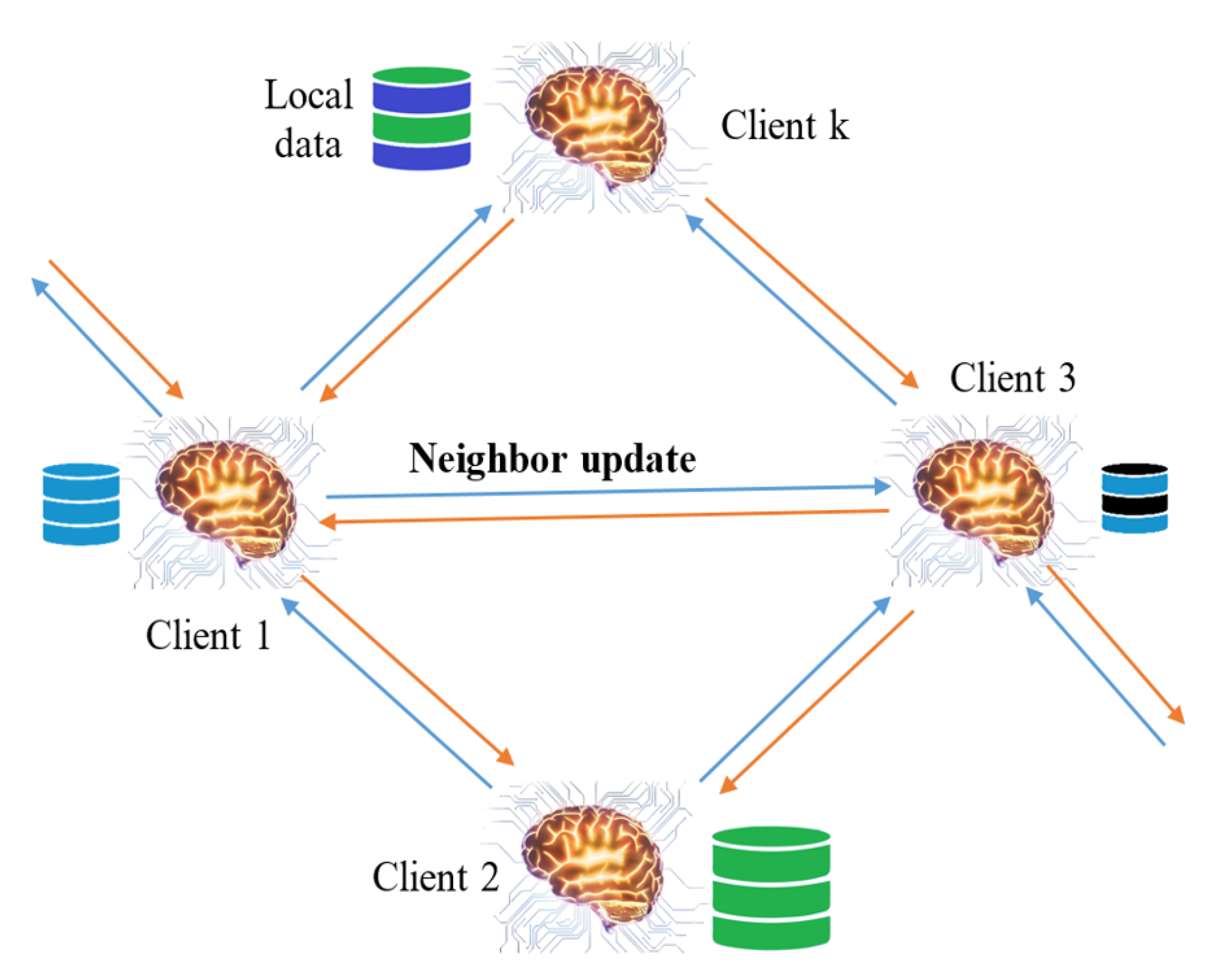
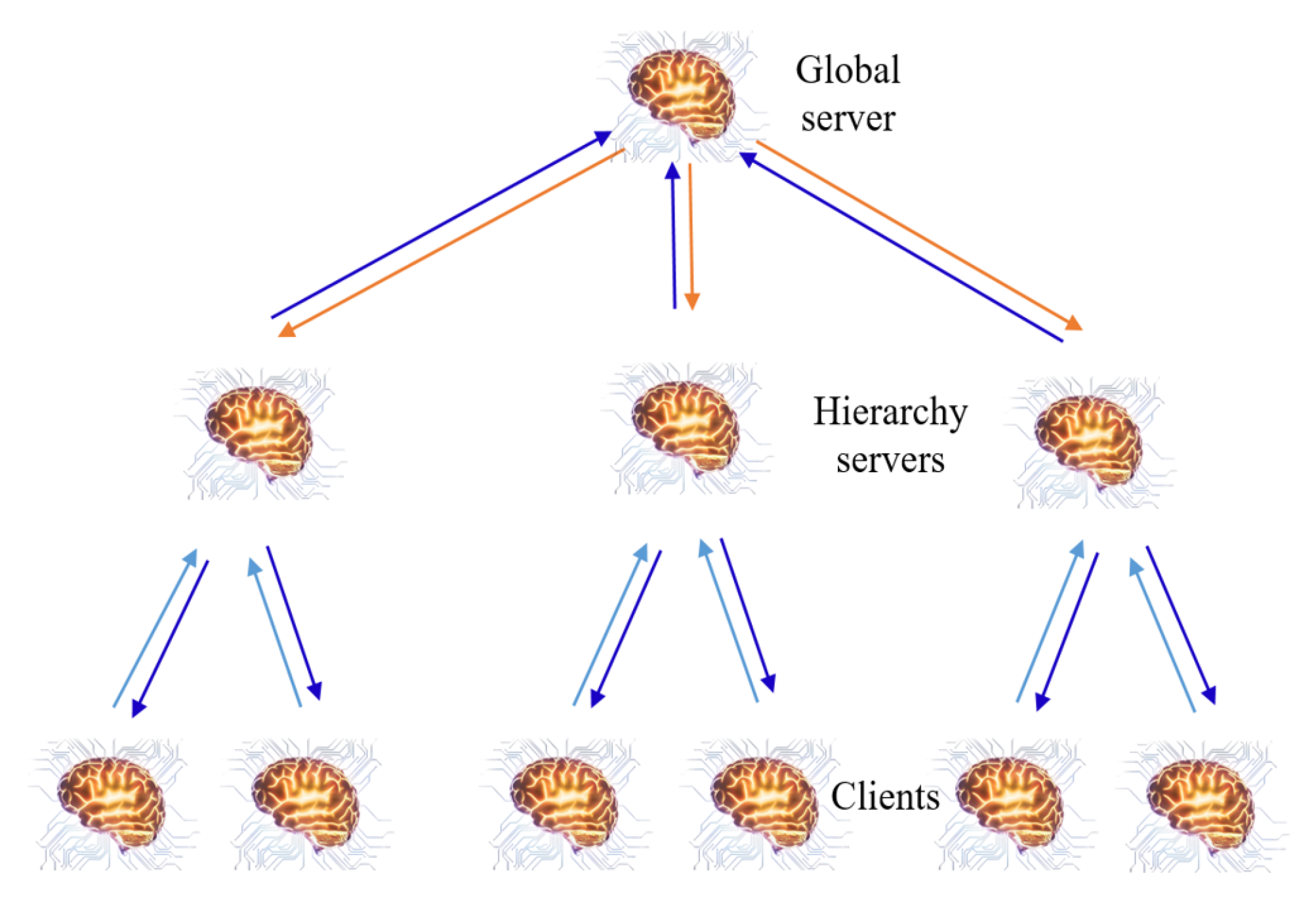
3.1. FL Architectures and Algorithms
| Algorithm 1 FedAvg centralized |
|
| Algorithm 2 FedAvg Decentralized |
|
| Algorithm 3 FedAvg Hierarchy |
|
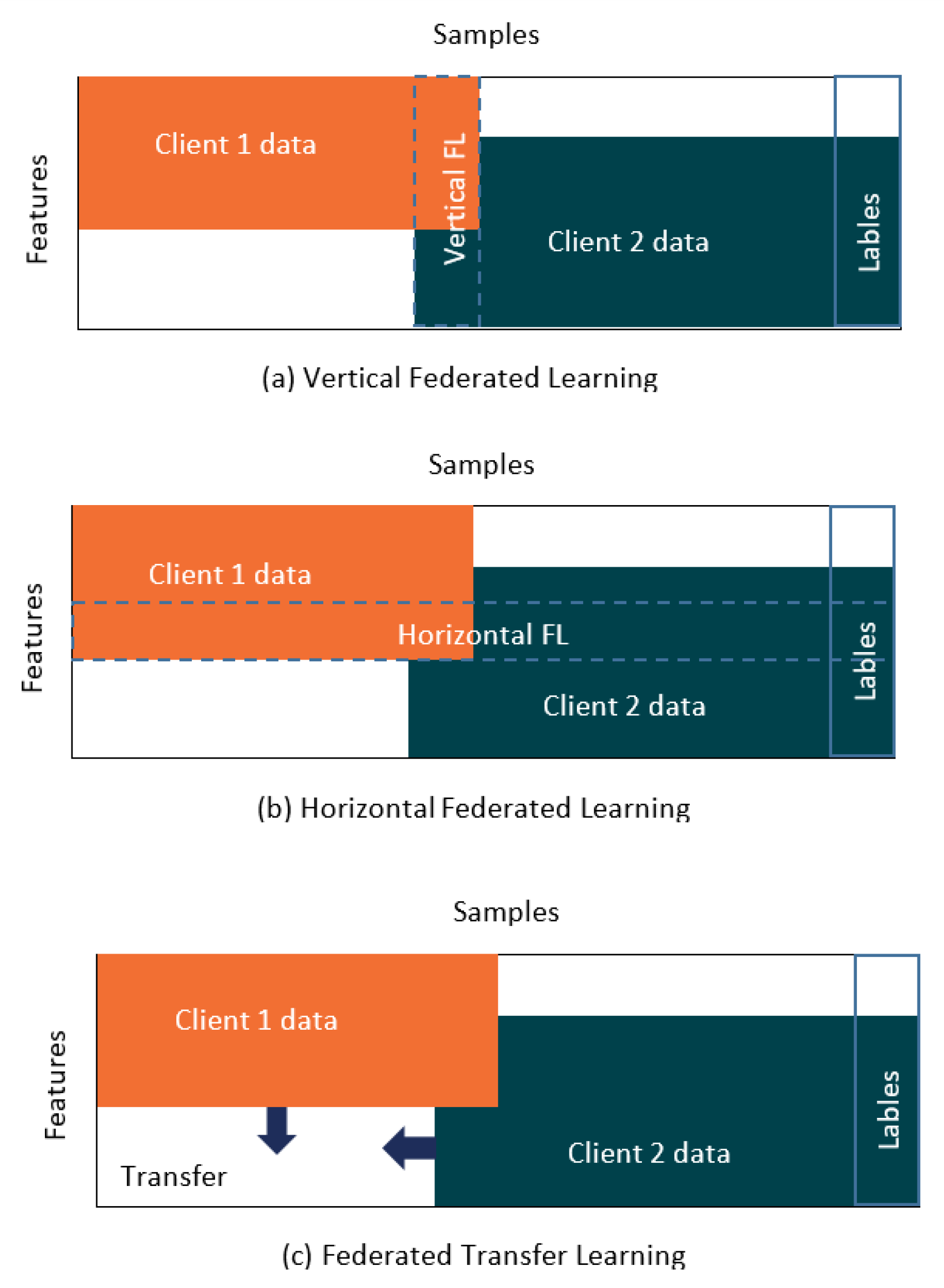
3.2. FL Categories
3.3. FL Domains
- FL in IoT: Nguyen, D.C., et al. [56] was inspired by the dearth of a thorough study on FL’s application in IoT. The authors first discuss current developments in FL and IoT to close this gap and offer thoughts on how they may be combined. FL is used in important IoT services, such as IoT data sharing, data offloading and caching, attack detection, localization, mobile crowdsensing, and IoT privacy and security. They also share the most recent advancements in integrated FL-IoT applications in several important use case areas, such as smart healthcare, smart transportation, UAVs, smart city, and smart industries, which have since caught the public interest.Jiang, J., et al. [60] made a survey to provide an outline of smart city sensing and its existing difficulties. They also discussed how FL could help to solve those difficulties. Both the state-of-the-art methods for FL and their use in smart city sensing are covered in detail; clear insights on unresolved problems, difficulties, and possibilities in this area are given as advice for the researchers looking into this topic.
- FL in Mobile: Some discussions on FL in mobile can be found in [43,57,58,59]. Lim, W.Y., et al. [58] provided a tutorial on FL and an in-depth analysis of the problems with FL implementation. The impetus for mobile edge computing is explained at the outset of the study, along with how FL may be used as an enabling technology for group model training at mobile edge networks. The fundamentals of DNN model training, FL, and system architecture for FL at scale are then discussed. The authors then offer thorough assessments, analyses, and comparisons of several implementation strategies for newly developing difficulties in FL. The cost of communication, resource distribution, data privacy, and data security are among the problems. Additionally, they discuss obstacles, future research prospects, and the use of FL for privacy-preserving mobile edge network optimization.
- FL in Healthcare: Rieke, N. et al. [45] foresee a federated for future digital health. The authors share their opinion with the community to provide context and detail about the advantages and impacts of FL for medical applications and highlight important considerations and challenges of implementing FL for future digital healthcare. There have been some lasted works in this scope, such as: a cloud-edge Network [66], a survey [67], and a survey in privacy preservation [68].
- Securing FL: Enthoven, D., et al. [61] examine FL’s current weaknesses and then conduct a literature assessment of potential attack strategies aimed at FL’s privacy protection features. A fundamental taxonomy is then used to characterize these assault strategies. They also offer a literature review of the most recent FL defense techniques and algorithms designed to counter these assaults. By the relevant fundamental defense concept, these defensive tactics are grouped. The use of a single defensive approach, according to the authors, is insufficient to offer sufficient defense against all known assault techniques.
4. Challenges of Federated Learning
- Communication cost: Because federated networks may have a vast number of devices, the computation time of FL may take longer than local training. Even though there have been several studies addressing this issue, it is imperative to build communication-efficient approaches as a result of increasing clients. Some crucial factors to consider in this situation are reducing the total number of communication rounds, finding fast convergence algorithms, and making as small model updates as possible at each round. To address this issue, adding split learning to FL is one of the effective solutions. The following are the two examples of this direction.Pathak, R.,et al. [69] first examine various earlier methods for federated optimization and demonstrate that, even in straightforward convex settings with deterministic updates, their fixed points do not always have to coincide with the stationary points of the original optimization problem. They provide FedSplit, a set of methods for solving distributed convex minimization with an additive structure that is based on operator splitting processes, to address these problems. They demonstrate that these methods have the right fixed points, which correspond to the solutions of the initial optimization problem, and they describe the speeds at which these methods converge under various conditions. These techniques are resistant to the inaccurate calculation of intermediate local quantities, according to their theory. They support their argument with a few straightforward experiments that show how effective their plans are in action.In addition, Thapa, C., et al. proposed SplitFed [70], a novel distributed ML approach called splitfed learning (SFL) that combines (FL) and split learning (SL), eliminating the inherent drawbacks of each approach, as well as a refined architectural configuration incorporating differential privacy and PixelDP to improve data privacy and model robustness. According to their study and actual findings, SFL offers comparable test accuracy and communication effectiveness to SL while having a much shorter calculation time per global epoch for numerous clients. The effectiveness of its communication through FL also increases with the number of clients, just like in SL. Additionally, the effectiveness of SFL with privacy and resilience safeguards is assessed in more extensive experimental situations.
- Heterogeneity: FL faces a considerable challenge when operating in various devices and data of the whole system [71,72,73]. Indeed, increasingly intelligent devices can connect to train the FL system. These devices have different hardware and software architectures (e.g., storage capacity, CPU topologies, power consumption level, operating system software, network bandwidth). In addition, each type of device is also designed to collect or generate different amounts and types of data, thus data nowadays is usually not independent and identically distributed (non IID data). To accommodate the heterogeneity of the system, it is necessary to develop clients’ selection solutions during the training process to ensure convergence of the whole system. Dealing with the diversity in statistical heterogeneity, multi-model FL should be considered [44].Yu, F., et al. [74] created a solid structure-information alignment across collaborative models. The authors offer a unique FL approach to address the heterogeneity of the FL system. To provide explicit feature information allocation in various neural network topologies, they specifically construct a feature-oriented regulation mechanism (Net). Matchable structures with similar feature information may be initialized at the very early training stage by using this regulating strategy on collaborative models. Dedicated cooperation methods further provide ordered information delivery with clear structure matching and full model alignment during the FL process in both IID and non-IID scenarios. In the end, this framework efficiently improves the applicability of FL to numerous heterogeneous contexts while offering good convergence speed, accuracy, and computation/communication efficiency.Moreover, to address the heterogeneity of computational capabilities of edge devices, Wang, C., et al. [75] suggested a novel heterogeneous FL framework built on multi-branch deep neural network models. This framework enables the client devices to choose the best sub-branch model for their computing capabilities. They also provide MFedAvg, a model training aggregation approach that uses branch-wise averaging-based aggregation. Extensive experiments on MNIST, FashionMNIST, MedMNIST, and CIFAR-10 demonstrate that their suggested approaches can achieve satisfactory performance with guaranteed convergence and efficiently use all the resources available for training across different devices with lower communication cost than its homogeneous counterpart.Abdelmoniem, A.M., and Canini, M. [73] also concentrate on reducing the degree of device heterogeneity by suggesting AQFL, a straightforward and useful method that uses adaptive model quantization to homogenize the customers’ computational resources. They assess AQFL using five standard FL metrics. The findings demonstrate that AQFL achieves roughly the same quality and fairness in diverse environments as the model trained in homogeneous conditions.
- Deep learning model architecture: DNN is proven to outperform other models in previous research, but its architecture in both traditional ML methods and FL was often pre-fixed [44,76]. Such a pre-defined setting carries many subjective factors that lead to the consequence that the models may fall into local optimal states. To address this challenge, [77] proposed a unified deep learning framework that suits data in multiple modalities and dimensions; the authors proved that using the proposed framework yields better performance than traditional ML approaches. In addition, [44] recommended using neural architecture search (NAS) to find the appropriate deep learning architecture for each task on each client.
- Securing FL system: Clients can learn a common global model cooperatively using FL without disclosing their training data to a cloud server. Malicious clients, however, can tamper with the global model and cause it to forecast inaccurate labels for test cases.Through ensemble, FL, Cao, X., et al. [78] close this gap. They utilize the technique to train numerous global models, each of which is learned using a randomly chosen subset of clients, given any basic FL algorithm. They use the global models’ majority vote when predicting a testing example’s label. They demonstrate that their ensemble FL is demonstrably safe against malicious clients using any FL base algorithm. In particular, a testing example’s label predicted by their ensemble global model is provably unaffected by a finite number of malevolent clients. They also demonstrate the tightness of their derived limit. On the MNIST and Human Activity Recognition datasets, they assess their methodology. For instance, when 20 out of 1000 clients are malicious, their technique may obtain a verified accuracy of 88% on MNIST.
5. Benchmarks for Federated Learning
- TensorFlow Federated (TFF) [79]: This is an open-source platform for FL and other decentralized data processing. It is led by Google and has grown in prominence in recent years. TFF allows developers to experiment with innovative algorithms by simulating the included FL algorithms on their models and data. Researchers will discover the beginning points and comprehensive examples for a wide range of studies.
- Leaf [80]: Leaf is an open-source framework for federated settings. It comprises a collection of federated datasets, a wide range of statistical and system metrics, and a collection of model implementations. Researchers and practitioners in fields such as FL, meta-learning, and multi-task learning will be able to evaluate novel solutions under more reasonable presumptions thanks to this platform.
- Flower [81]: A more smooth transition from an experimental study in simulation to system research on a large cohort of actual edge devices is made possible by Flower. It is a revolutionary end-to-end FL platform. Regarding simulation and real-world technology, Flower offers individual strength in both areas and allows experimental implementations to move between the two extremes as needed.
- PySyf: Ryffel, T., et al. [82] describe and explore a novel paradigm for privacy-preserving deep learning. The system prioritizes data ownership and secure processing, and it presents a useful representation based on command chains and tensors. This abstraction enables the implementation of complicated privacy-preserving structures such as FL, Secure Multiparty Computation, and Differential Privacy while providing a familiar deep learning API to the end user. They provide preliminary findings from the Boston Housing and Pima Indian Diabetes datasets. While privacy measures other than Differential Privacy do not affect prediction accuracy, the current implementation of the framework creates a large performance burden that will be addressed at a later stage of development. The authors feel that their work is a significant step toward developing the first dependable, universal framework for privacy-preserving deep learning.
- FedML: He, C., et al. [83] present FedML, an open research library and benchmark for FL algorithm development and fair performance comparison, in this paper. FedML offers three computing paradigms: edge device on-device training, distributed computing, and single-machine simulation. FedML also encourages various algorithmic research by the design of flexible and generic APIs and detailed reference baseline implementations (optimizer, models, and datasets). FedML, they think, will provide an efficient and reproducible method for building and assessing FL algorithms that will assist the FL research community.
- Sherpa.ai: Barroso, N.R., et al. [84] introduced the Sherpa.ai FL framework, which is based on a comprehensive understanding of FL and differential privacy. It is the outcome of research into how to adapt the ML paradigm to FL as well as the development of methodological recommendations for producing artificial intelligence services based on FL and differentiated privacy. Using classification and regression use cases, they also demonstrate how to adhere to the methodological principles with the Sherpa.ai FL framework.
- EMNIST: A benchmark database is presented by Cohen, G., et al. [85]. It is a derivative of the entire NIST dataset known as Extended MNIST (EMNIST), which uses the same conversion paradigm as the MNIST dataset. The end result is a collection of datasets that represent more difficult classification problems containing letters and digits, but which share the same picture structure and characteristics as the original MNIST job, allowing direct interoperability with all current classifiers and systems. Benchmark results are reported, along with validation of the conversion procedure by comparison of classification results on converted NIST and MNIST digits.
- FedEval: Di Chai, et al, [86] suggested a thorough approach to FL system evaluation in their works. Particularly, they first offer the ACTPR model, which identifies five metrics—accuracy, communication, time efficiency, privacy, and robustness—that cannot be disregarded in the FL assessment. Then, using FedEval, a benchmarking system they developed and put into use, it is possible to compare and evaluate previous works in a systematic manner while maintaining a constant experimental environment. The authors next present a thorough benchmarking analysis between FedSGD and FedAvg, the two most used FL methods. According to the benchmarking results, FedSGD and FedAvg both have benefits and drawbacks when using the ACTPR model. For instance, the non-IID data issue has little to no effect on FedSGD, while in their studies, FedAvg has an accuracy loss of up to 9%. However, when it comes to communication and time consumption, FedAvg outperforms FedSGD. Finally, they uncover a series of key findings that will be highly beneficial for researchers working in the FL region.
- OARF: An Open Application Repository for FL (OARF) is presented by Sixu Hu, et al, [87]. It is a benchmark set for federated ML systems. OARF simulates more realistic application situations. The benchmark suite is heterogeneous in terms of data quantity, dispersion, feature distribution, and learning task difficulty, as observed by their categorization. The thorough analyses with reference implementations highlight potential areas for future FL system development. The key components of FL, such as model correctness, communication cost, throughput, and convergence time, have been constructed as reference implementations and reviewed. They made several intriguing discoveries as a result of these tests, such as the fact that FL may significantly boost end-to-end throughput.
6. Multi-Models Federated Learning
| Algorithm 4 Multi-model FedAvg Centralized |
|
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bai, L.; Wang, J.; Ma, X.; Lu, H.H. Air Pollution Forecasts: An Overview. Int. J. Environ. Res. Public Health 2018, 15, 780. [Google Scholar] [CrossRef] [PubMed]
- Rahman, N.H.A.; Lee, M.H.; Latif, M.T. Artificial neural networks and fuzzy time series forecasting: An application to air quality. Qual. Quant. 2015, 49, 2633–2647. [Google Scholar] [CrossRef]
- Grivas, G.; Chaloulakou, A. Artificial neural network models for prediction of PM10 hourly concentrations, in the Greater Area of Athens, Greece. Atmos. Environ. 2006, 40, 1216–1229. [Google Scholar] [CrossRef]
- Elangasinghe, M.A.; Singhal, N.; Dirks, K.N.; Salmond, J.A. Development of an ANN–based air pollution forecasting system with explicit knowledge through sensitivity analysis. Atmos. Pollut. Res. 2014, 5, 696–708. [Google Scholar] [CrossRef]
- Bai, Y.; Li, Y.; Wang, X.; Xie, J.; Li, C. Air pollutants concentrations forecasting using back propagation neural network based on wavelet decomposition with meteorological conditions. Atmos. Pollut. Res. 2016, 7, 557–566. [Google Scholar] [CrossRef]
- Mishra, D.; Goyal, P. NO2 forecasting models Agra. Atmos. Pollut. Res. 2015, 6, 99–106. [Google Scholar] [CrossRef]
- Kurt, A.; Oktay, A.B. Forecasting air pollutant indicator levels with geographic models 3 days in advance using neural networks. Expert Syst. Appl. 2010, 37, 7986–7992. [Google Scholar] [CrossRef]
- Masood, A.; Ahmad, K. A review on emerging artificial intelligence (AI) techniques for air pollution forecasting: Fundamentals, application and performance. J. Clean. Prod. 2021, 322, 129072. [Google Scholar] [CrossRef]
- Navares, R.; Aznarte, J.L. Predicting air quality with deep learning LSTM: Towards comprehensive models. Ecol. Inf. 2020, 55, 101019. [Google Scholar] [CrossRef]
- Krishan, M.; Jha, S.; Das, J.; Singh, A.; Goyal, M.K.; Sekar, C. Air quality modelling using long short-term memory (LSTM) over NCT-Delhi, India. Air Qual. Health 2019, 12, 899–908. [Google Scholar] [CrossRef]
- Li, S.; Xie, G.; Ren, J.; Guo, L.; Yang, Y.; Xu, X. Urban PM2. 5 concentration prediction via attention-based CNN–LSTM. Appl. Sci. 2020, 10, 1953. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.J.; Chang, L.C.; Kao, I.F.; Wang, Y.S. Explore a deep learning multi-output neural network for regional multi-step-ahead air quality forecasts. J. Clean. Prod. 2019, 209, 134–145. [Google Scholar] [CrossRef]
- Xayasouk, T.; Lee, H. Air pollution prediction system using deep learning. WIT Trans. Ecol. Environ. 2018, 230, 71–79. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Freeman, B.S.; Taylor, G.; Gharabaghi, B.; The, J. Forecasting air quality time series using deep learning. J. Air Waste Manag. Assoc. 2018, 68, 866–886. [Google Scholar] [CrossRef]
- Ma, J.; Li, Z.; Cheng, J.C.; Ding, Y.; Lin, C.; Xu, Z. Air quality prediction at new stations using spatially transferred bi-directional long short-term memory network. Sci. Total Environ. 2020, 705, 135771. [Google Scholar] [CrossRef]
- Baklanov, A.; Zhang, Y. Advances in air quality modeling and forecasting. Glob. Transit. 2020, 2, 261–270. [Google Scholar] [CrossRef]
- Monache, L.D.; Deng, X.; Zhou, Y.; Stull, R. Ozone ensemble forecasts: 1. A new ensemble design. J. Geophys. Res. 2006, 111, D05307. [Google Scholar] [CrossRef]
- Pagowski, M.; Grell, G.A.; Devenyi, D.; Peckham, S.E.; McKeen, S.A.; Gong, W.; Monache, L.D.; McHenry, J.N.; McQueen, J.; Lee, P. Application of dynamic linear regression to improve the skill of ensemble-based deterministic ozone forecasts. Atmos. Environ. 2006, 40, 3240–3250. [Google Scholar] [CrossRef]
- Brasseur, G.P.; Xie, Y.; Petersen, A.K.; Bouarar, I.; Flemming, J.; Gauss, M.; Jiang, F.; Kouznetsov, R.; Kranenburg, R.; Mijling, B.; et al. Ensemble forecasts of air quality in eastern China—Part 1: Model description and implementation of the MarcoPolo–panda prediction system, version 1. Geosci. Model Dev. 2019, 12, 33–67. [Google Scholar] [CrossRef]
- McKeen, S.; Chung, S.H.; Wilczak, J.; Grell, G.; Djalalova, I.; Peckham, S.; Gong, W.; Bouchet, V.; Moffet, R.; Tang, Y.; et al. Evaluation of several PM2.5 forecast models using data collected during the ICARTT/NEAQS 2004 field study. J. Geophys. Res. 2007, 112, D10S20. [Google Scholar] [CrossRef]
- Masih, A. ML algorithms in air quality modeling. Glob. J. Environ. Sci. Manag. 2019, 5, 515–534. [Google Scholar]
- Liao, K.; Huang, X.H.; Dang, H.; Ren, Y.; Zuo, S.; Duan, C. Statistical Approaches for Forecasting Primary Air Pollutants: A Review. Atmosphere 2021, 12, 686. [Google Scholar] [CrossRef]
- Perez, P.; Trier, A.; Reyes, J. Prediction of PM2.5 concentrations several hours in advance using neural networks in Santiago, Chile. Atmos. Environ. 2000, 34, 1189–1196. [Google Scholar] [CrossRef]
- Ceylan, Z.; Bulkan, S. Forecasting PM10 levels using ANN and MLR: A case study for Sakarya City. Glob. Nest J. 2018, 20, 281–290. [Google Scholar]
- Belavadi, S.V.; Rajagopal, S.; Ranjani, R.; Mohan, R. Air Quality Forecasting using LSTM RNN and Wireless Sensor Networks. Procedia Comput. Sci. 2020, 170, 241–248. [Google Scholar] [CrossRef]
- Liao, Q.; Zhu, M.; Wu, L.; Pan, X.; Tang, X.; Wang, Z. Deep Learning for Air Quality Forecasts: A Review. Curr. Pollut. Rep. 2020, 6, 399–409. [Google Scholar] [CrossRef]
- Liu, H.; Yin, S.; Chen, C.; Duan, Z. Data multi-scale decomposition strategies for air pollution forecasting: A comprehensive review. J. Clean. Prod. 2020, 277, 124023. [Google Scholar] [CrossRef]
- Zhu, S.; Lian, X.; Liu, H.; Hu, J.; Wang, Y.; Che, J. Daily air quality index forecasting with hybrid models: A case in China. Environ. Pollut. 2017, 231, 1232–1244. [Google Scholar] [CrossRef]
- Patil, R.M.; Dinde, D.H.; Powar, S.K. A Literature Review on Prediction of Air Quality Index and Forecasting Ambient Air Pollutants using ML Algorithms. Int. J. Innov. Sci. Res. Technol. 2020, 5, 1148–1152. [Google Scholar] [CrossRef]
- Bui, T.C.; Le, V.D.; Cha, S.K. A Deep Learning Approach for Forecasting Air Pollution in South Korea Using LSTM. arXiv 2018, arXiv:1804.07891v3. [Google Scholar]
- Kim, S.; Lee, J.M.; Lee, J.; Seo, J. Deep-dust: Predicting concentrations of fine dust in Seoul using LSTM. arXiv 2019, arXiv:1901.10106. [Google Scholar]
- Huang, C.J.; Kuo, P.H. A deep CNN-LSTM model for particulate matter (PM2.5) forecasting in smart cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [PubMed]
- Soh, P.W.; Chang, J.W.; Huang, J.W. Adaptive deep learning-based air quality prediction model using the most relevant spatial-temporal relations. IEEE Access 2018, 6, 38186–38199. [Google Scholar] [CrossRef]
- Wang, H.; Zhuang, B.; Chen, Y.; Li, N.; Wei, D. Deep inferential spatial-temporal network for forecasting air pollution concentrations. arXiv 2018, arXiv:1809.03964v1. [Google Scholar]
- Govender, P.; Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019). Atmos. Pollut. Res. 2020, 11, 40–56. [Google Scholar] [CrossRef]
- Cabaneros, S.M.; Calautit, J.K.; Hughes, B.R. A review of artificial neural network models for ambient air pollution prediction. Environ. Model. Softw. 2019, 119, 285–304. [Google Scholar] [CrossRef]
- Bekkar, A.; Hssina, B.; Douzi, S.; Douzi, K. Air-pollution prediction in smart city, deep learning approach. J. Big Data 2021, 8, 161. [Google Scholar] [CrossRef]
- Karroum, K.; Lin, Y.; Chiang, Y.; Ben Maissa, Y.; El haziti, M.; Sokolov, A.; Delbarre, H. A Review of Air Quality Modeling. MAPAN 2020, 35, 287–300. [Google Scholar] [CrossRef]
- Garaga, R.; Sahu, S.K.; Kota, S.H. A Review of Air Quality Modeling Studies in India: Local and Regional Scale. Curr. Pollut. Rep. 2018, 4, 59–73. [Google Scholar] [CrossRef]
- Wang, L.; Yang, J.; Zhang, P.; Zhao, X.; Wei, Z.; Zhang, F.; Su, J.; Meng, C. A Review of Air Pollution and Control in Hebei Province, China. Open J. Air Pollut. 2013, 2, 47. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; HAMFson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Li, T.; Sahu, A.; Talwalkar, A.S.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.B.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.; Landman, B.A.; Maier-Hein, K.H.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 119. [Google Scholar] [CrossRef]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated Learning on Non-IID Data: A Survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Chhikara, P.; Tekchandani, R.; Kumar, N.; Tanwar, S.; Rodrigues, J.J. Federated Learning for Air Quality Index Prediction using UAV Swarm Networks. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Chhikara, P.; Tekchandani, R.; Kumar, N.; Guizani, M.; Hassan, M.M. Federated Learning and Autonomous UAVs for Hazardous Zone Detection and AQI Prediction in IoT Environment. IEEE Internet Things J. 2021, 8, 15456–15467. [Google Scholar] [CrossRef]
- Liu, Y.; Nie, J.; Li, X.; Ahmed, S.H.; Lim, W.Y.; Miao, C. Federated Learning in the Sky: Aerial-Ground Air Quality Sensing Framework With UAV Swarms. IEEE Internet Things J. 2021, 8, 9827–9837. [Google Scholar] [CrossRef]
- Putra, K.T.; Chen, H.C.; Ogiela, M.R.; Chou, C.L.; Weng, C.E.; Shae, Z.Y. Federated Compressed Learning Edge Computing Framework with Ensuring Data Privacy for PM2.5 Prediction in Smart City Sensing Applications. Sensors 2021, 21, 4586. [Google Scholar] [CrossRef]
- Nguyen, D.V.; Zettsu, K. Spatially-distributed Federated Learning of Convolutional Recurrent Neural Networks for Air Pollution Prediction. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 3601–3608. [Google Scholar]
- Zhou, X.; Liu, X.; Lan, G.; Wu, J. Federated conditional generative adversarial nets imputation method for air quality missing data. Knowl. Based Syst. 2021, 228, 107261. [Google Scholar] [CrossRef]
- Huang, G.; Zhao, X.; Lu, Q. A new cross-domain prediction model of air pollutant concentration based on secure federated learning and optimized LSTM neural network. Environ. Sci. Pollut. Res. 2022, 1–23. [Google Scholar] [CrossRef]
- Chen, Y.; Ning, Y.; Slawski, M.; Rangwala, H. Asynchronous Online Federated Learning for Edge Devices with Non-IID Data. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 15–24. [Google Scholar]
- Neo, E.X.; Hasikin, K.; Mokhtar, M.I.; Lai, K.W.; Azizan, M.M.; Razak, S.A.; Hizaddin, H.F. Towards Integrated Air Pollution Monitoring and Health Impact Assessment Using Federated Learning: A Systematic Review. Front. Public Health 2022, 10, 851553. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.P.; Li, J.; Poor, H.V. Federated Learning for Internet of Things: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. arXiv 2021, arXiv:abs/1907.09693. [Google Scholar] [CrossRef]
- Lim, W.Y.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.; Yang, Q.; Niyato, D.T.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Ogundokun, R.O.; Misra, S.; Maskeliūnas, R.; Damaševičius, R. A Review on Federated Learning and ML Approaches: Categorization, Application Areas, and Blockchain Technology. Information 2022, 13, 263. [Google Scholar] [CrossRef]
- Jiang, J.; Kantarci, B.; Oktug, S.F.; Soyata, T. Federated Learning in Smart City Sensing: Challenges and Opportunities. Sensors 2020, 20, 6230. [Google Scholar] [CrossRef]
- Enthoven, D.; Al-Ars, Z. An Overview of Federated Deep Learning Privacy Attacks and Defensive Strategies. arXiv 2021, arXiv:abs/2004.04676. [Google Scholar]
- Huang, Y.; Wu, C.; Wu, F.; Lyu, L.; Qi, T.; Xie, X. A Federated Graph Neural Network Framework for Privacy-Preserving Personalization. Nat. Commun. 2022, 13, 3091. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.H.; Letaief, K.B. Edge-Assisted Hierarchical Federated Learning with Non-IID Data. arXiv 2019, arXiv:abs/1905.06641. [Google Scholar]
- Lin, T.; Stich, S.U.; Jaggi, M. Don’t Use Large Mini-Batches, Use Local SGD. arXiv 2020, arXiv:abs/1808.07217. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated ML: Concept and Applications. arXiv 2019, arXiv:1902.04885. [Google Scholar]
- Khoa, T.A.; Nguyen, D.-V.; Dao, M.-S.; Zettsu, K. Fed xData: A Federated Learning Framework for Enabling Contextual Health Monitoring in a Cloud-Edge Network. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 4979–4988. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pham, Q.; Pathirana, P.N.; Ding, M.; Seneviratne, A.P.; Lin, Z.; Dobre, O.A.; Hwang, W.J. Federated Learning for Smart Healthcare: A Survey. arXiv 2021, arXiv:abs/2111.08834. [Google Scholar] [CrossRef]
- Ali, M.; Naeem, F.; Tariq, M.A.; Kaddoum, G. Federated Learning for Privacy Preservation in Smart Healthcare Systems: A Comprehensive Survey. arXiv 2022, arXiv:2203.09702. [Google Scholar] [CrossRef] [PubMed]
- Pathak, R.; Wainwright, M.J. FedSplit: An algorithmic framework for fast federated optimization. arXiv 2020, arXiv:abs/2005.05238. [Google Scholar]
- Thapa, C.; Arachchige, P.C.M.; Camtepe, S.; Sun, L. SplitFed: When Federated Learning Meets Split Learning. arXiv 2022, arXiv:abs/2004.12088. [Google Scholar] [CrossRef]
- Abdelmoniem, A.M.; Ho, C.; Papageorgiou, P.; Canini, M. Empirical analysis of federated learning in heterogeneous environments. In Proceedings of the 2nd European Workshop on Machine Learning and Systems, Rennes, France, 5–8 April 2022. [Google Scholar]
- Yang, C.; Wang, Q.; Xu, M.; Chen, Z.; Bian, K.; Liu, Y.; Liu, X. Characterizing Impacts of Heterogeneity in Federated Learning upon Large-Scale Smartphone Data. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021. [Google Scholar]
- Abdelmoniem, A.M.; Canini, M. Towards Mitigating Device Heterogeneity in Federated Learning via Adaptive Model Quantization. In Proceedings of the 1st Workshop on Machine Learning and Systems, New York, NY, USA, 10 November 2019. [Google Scholar]
- Yu, F.; Zhang, W.; Qin, Z.; Xu, Z.; Wang, D.; Liu, C.; Tian, Z.; Chen, X. Heterogeneous federated learning. arXiv 2020, arXiv:2008.06767. [Google Scholar]
- Wang, C.; Huang, K.; Chen, J.; Shuai, H.; Cheng, W. Heterogeneous Federated Learning Through Multi-Branch Network. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July; pp. 1–6.
- Dong, L.D.; Nguyen, V.T.; Le, D.T.; Tiep, M.V.; Hien, V.T.; Huy, P.P.; Trung, H.P. Modeling Transmission Rate of COVID-19 in Regional Countries to Forecast Newly Infected Cases in a Nation by the Deep Learning Method. In Proceedings of the 8th International Conference, FDSE 2021, Virtual Event, 24–26 November 2021. [Google Scholar]
- Xi, P.; Shu, C.; Goubran, R.A. A Unified Deep Learning Framework for Multi-Modal Multi-Dimensional Data. In Proceedings of the 2019 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Istanbul, Turkey, 26–28 June 2019; pp. 1–6. [Google Scholar]
- Cao, X.; Jia, J.; Gong, N.Z. Provably Secure Federated Learning against Malicious Clients. Proc. Aaai Conf. Artif. Intell. 2021, 35, 6885–6893. [Google Scholar] [CrossRef]
- Tensorflow Federated: ML on Decentralized Data. Available online: https://www.tensorflow.org/federated (accessed on 6 November 2022).
- Caldas, S.; Wu, P.; Li, T.; Koneˇcny, J.; McMahan, H.B.; Smith, V.; Talwalkar, A. Leaf: A benchmark for federated settings. arXiv 2018, arXiv:1812.01097. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Parcollet, T.; Gusmão, P.P.; Lane, N.D. Flower: A Friendly Federated Learning Framework. Available online: https://hal.archives-ouvertes.fr/hal-03601230/document (accessed on 6 November 2022).
- Ryffel, T.; Trask, A.; Dahl, M.; Wagner, B.; Mancuso, J.V.; Rueckert, D.; Passerat-Palmbach, J. A generic framework for privacy preserving deep learning. arXiv 2018, arXiv:abs/1811.04017. [Google Scholar]
- He, C.; Li, S.; So, J.; Zhang, M.; Wang, H.; Wang, X.; Vepakomma, P.; Singh, A.; Qiu, H.; Shen, L.; et al. FedML: A Research Library and Benchmark for Federated Machine Learning. arXiv 2020, arXiv:abs/2007.13518. [Google Scholar]
- Barroso, N.R.; Stipcich, G.; Jim’enez-L’opez, D.; Ruiz-Millán, J.A.; Martínez-Cámara, E.; González-Seco, G.; Luzón, M.V.; Veganzones, M.A.; Herrera, F. Federated Learning and Differential Privacy: Software tools analysis, the Sherpa.ai FL framework and methodological guidelines for preserving data privacy. Inf. Fusion 2020, 64, 270–292. [Google Scholar] [CrossRef]
- Cohen, G.; Afshar, S.; Tapson, J.C.; Schaik, A.V. EMNIST: An extension of MNIST to handwritten letters. arXiv 2017, arXiv:abs/1702.05373. [Google Scholar]
- Xie, M.; Long, G.; Shen, T.; Zhou, T.; Wang, X.; Jiang, J. Multi-Center Federated Learning. arXiv 2020, arXiv:abs/2108.08647. [Google Scholar]
- Hu, S.; Li, Y.; Liu, X.; Li, Q.; Wu, Z.; He, B. The oarf benchmark suite: Characterization and implications for federated learning systems. arXiv 2020, arXiv:2006.07856. [Google Scholar] [CrossRef]
- Seaton, M.D.; O’Neill, J.; Bien, B.; Hood, C.; Jackson, M.; Jackson, R.; Johnson, K.; Oades, M.; Stidworthy, A.; Stocker, J.; et al. A Multi-model Air Quality System for Health Research: Road model development and evaluation. Environ. Model. Softw. 2022, 155, 105455. [Google Scholar] [CrossRef]
- Qi, H.; Ma, S.; Chen, J.; Sun, J.; Wang, L.; Wang, N.; Wang, W.; Zhi, X.; Yang, H. Multi-model Evaluation and Bayesian Model Averaging in Quantitative Air Quality Forecasting in Central China. Aerosol Air Qual. Res. 2022, 22, 210247. [Google Scholar] [CrossRef]
- Zhang, J.; Li, S. Air quality index forecast in Beijing based on CNN-LSTM multi-model. Chemosphere 2022, 308, 136180. [Google Scholar] [CrossRef]
- Bhuyan, N.; Moharir, S. Multi-Model Federated Learning. In Proceedings of the 2022 14th International Conference on COMmunication Systems and NETworkS (COMSNETS), Bangalore, India, 4–8 January 2022; pp. 779–783. [Google Scholar]
- Zhao, Y.; Barnaghi, P.M.; Haddadi, H. Multimodal Federated Learning on IoT Data. In Proceedings of the 2022 IEEE/ACM Seventh International Conference on Internet-of-Things Design and Implementation (IoTDI), Milano, Italy, 4–6 May 2022. [Google Scholar]
- Xiong, B.; Yang, X.; Qi, F.; Xu, C. A unified framework for multi-modal federated learning. Neurocomputing 2022, 480, 110–118. [Google Scholar] [CrossRef]
- Smith, V.; Chiang, C.; Sanjabi, M.; Talwalkar, A.S. Federated Multi-Task Learning. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Muhammad, A.; Lin, K.; Gao, J.; Chen, B. Robust Multi-model Personalized Federated Learning via Model Distillation. In Proceedings of the 21st International Conference, ICA3PP 2021, Virtual Event, 3–5 December 2021. [Google Scholar]
- Bhuyan, N.; Moharir, S.; Joshi, G. Multi-Model Federated Learning with Provable Guarantees. arXiv 2022, arXiv:abs/2207.04330. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Methods | Model, Accuracy Data’s Features | Main Conclusions |
|---|---|---|---|
| [1] Bai, L., et al. (2018). | [2]: SARIMA, ANN, FTS [3]: FFMLP, MLP-GA, MLP [4]: MLP [5]: BPNN [6]: PCA–ANN [7]: GFM-NN | [2] ANN MAE: 2.70 MSE: 12.79 RMSE: 3.58 NO2 | - The most popular statistical method uses (AI) models. - The accuracy of ANNs is higher than other statistical models, but they are usually be local optima. - The accuracy of ANNs can be improved by adding data: meteorology, geographic, time-scale, emission pattern of sources. - Some hybrid models can improve the accuracy. |
| [8] Masood, A. and Ahmad, K. (2021). | ANN FUZZY SVM DNN | [9,10,11,12,13,14] DNN PM RMSE: 7.27 PM : 0.96 [10,14,15,16]: DNN RMSE: 3.51 : 0.92 [9,10]: DNN CO RMSE: 0.95 CO : 0.69 × The above RMSE and are mean values of the refs | - The most frequently applied input parameter is API - The best performing AI-based model is the DNN. - Fuzzy logic, DNN and SVM are the three commonly used AI-based techniques - DNN, SVM, and Fuzzy techniques showed better accuracy in forecasting PM concentrations - DNN outperformed the other AI techniques for this pollutant category. DNN improved spatial and temporal stability for a multi-step ahead forecasting of pollutants - Ability to exploit high-level features from raw air quality and meteorological data |
| [17] Baklanov, A., and Zhang, Y. (2020). | [18] Multi-models Ensemble forecasting: A new Ozone Ensemble Forecast System (OEFS), [19] Dynamic Linear Regression for ensemble (DLR), [20] MarcoPolo–Panda | [18] OEFS RMSE: 16.34 [19] DLR RMSE: 10.57 [20] MarcoPolo–Panda RMSE: 32.8 RMSE: 21.8 RMSE: 30.2 | - Ensemble forecasting has shown significant statistical improvements for both O3 and PM2.5 forecasts over any individual forecast [21]. - Multi-model ensemble air quality forecasting has been emerging for AQF on global and regional scales - Multi-model ensemble results provide a range and an indication of the robustness of the forecasts and help to improve the accuracy of chemical weather and air quality forecasting. |
| [22] Masih, A., et al. (2019). | Ensemble learning (EL) Classical Regression (CR) NN SVM Lazy | : EL:0.79 CR: 0.74 SVM :0.67 NN: 0.6 | - The high accuracies achieved with ML algorithms explains it all why these algorithms are appropriate and should be preferred over traditional approaches - Should use critical pollutants ( and ) ensemble learning techniques to improve model accuracy |
| [23] Liao, K., et al. (2021). | Multi-layer neural network (NN) Land use regression (LUR) Multiple linear regression (MLR) Hybrid methods | [24] NN error: 30%–60% [25] Variety of NN algorithms RMSE: 15.700 MAE: 9.047 : 0.840 [26] DNN MAPE: 11.93% | - ANN methods were preferred in studies of PM and - LUR were more widely used in studies of - Multi-method hybrid techniques gradually became the most widely used approach between 2010 and 2018 - The most difficult element of research on air pollution prediction is likely to be the interaction between pollutants, which will be based on a mixed technique to forecast numerous contaminants concurrently in the future. |
| [27] Liao, Q., et al. (2020). | Artificial Neural Network (ANN) Linear and Logistic Regression | SVR shows better performance in prediction of AQI while RFR gives the better performance in predicting the NOx concentration | - Linear and Logistic Regression are the choices of many researchers for the prediction of AQI and air pollutants concentration - The future scope may include consideration of all parameters that is meteorological parameters, air pollutants while predicting AQI or forecasting the future concentration level of different pollutants. |
| Authors | Methods | Data Processing | Evaluation Metrics | Main Conclusions |
|---|---|---|---|---|
| [47] P. Chhikara, et al. | Centralized FL (FedAvg) with LSTM in each UAVs. Compare with other traditional training ML: SVM, KNN, Decision tree, ANN | - AQI from Dehli Inida (2015 to 2020) with 2009 timesteps - Train: 0.75 - Test: 0.25 | - RMSE: 56.222 - MAE: 41.219 - MAPE: 24.184 | - Traditional ML models miss the temporal dependencies between the data - The proposed model predicts the future AQI value with a minor error compared to other ML models. - The outcomes illustrate the efficacy of the proposed scheme to predict the AQI of a given area |
| [48] P. Chhikara, et al. | - FedAvg with CNN-LSTM in each UAVs. Compare with: RNN, GRU, Vanilla LSTM, Stacked LSTM, Bidi LSTM. - POS to find hazardous zone | Same as [47] Link to data | - RMSE:221.682 - MAE: 200.668 - MAPE: 1217.897 | - The proposed model is better than the others in term of the given erea - Model compression should be applied to reduce it’s size - Need to find communication efficient FL frameworks for long term UAV monitoring. |
| [49] Yi Liu, et al. | - Air: Light-weight FL-based UAV (FedAvg) - Ground: graph convolution neural network combines spatio-temporal model (LSTM) - Compare with 2D CNN, 3D CNN, AQNet, SVM | Air: 5298 haze images: - Train: 0.8 - Test: 0.2 Ground: 6 months 2019 AQI from China - Train: 5/6 - Test: 1/6 Link to data | RMSE: - Real-time: 3.212 - After 2 h: 4.589 - After 4 h: 6.357 - After 6 h: 9.145 | - The proposed method not only realizes high-precision AQI monitoring, but also reduces UAV energy consumption. - Need to design some novel model compression techniques to deploy large-scale and complex DNN to UAVs - Need to solve the expensive communication cost for UAV to achieve long term monitoring |
| [50] Karisma Trinanda Putra | Federated Compressed Learning (FCL): - Compressed Sensing - FedAvg with LSTMCompare with Centralized Learning (CL) | During 9/2020 by 1000 sensors across Taiwan, and 4 sensors of the prototype with 5 features: PM1.0, PM2.5, PM10, temperature, and humidity | RMSE: - FCL: 5.044 - CL: 4.480 | - The data consumption is reduced by more than 95%, error rate below 5% - The FCL will generates slightly lower accuracy compared with centralized training - The data could be heavily compacted and securely transmitted in WSNs |
| [51] Do-Van Nguyen, et al. | - FL CRNN Model, compare with Auxiliary CNN - Proposed spatial averaging aggregation function of federated learning paradigm | Kanto region, Japan, from 2018 to 2021, 15 dimentions Link to data | See Figure 8–13 in [51] | - FL CRNN models can capture spatial-temporal local information and be able to share knowledge among participating cities - Can transfer knowledge to newly added participants - Epochs should be large enough to fully capture knowledge from each local side |
| [53] Huang, G., et al. | A new cross-domain prediction model FL: SSA-LSTM, FL-DPLA-SSA-LSTM. | Hourly air pollutants and meteorological data from 12 cities in the Fenhe River and Weihe River Plains in China in 2020 | The prediction performance of the proposed model is significantly better than all comparison models | |
| [54] Chen, Y., et al. | Asynchronous Online FL (ASO-Fed). | Air pollutants collected from multiple weather sensor devices distributed in 9 locations of Beijing with features such as thermometer and barometer | MAE: 36.71 SMAPE: 0.42 | ASO-Fed has lower SMAPE errors than all other models as the dropout rate increases and the performance of ASO-Fed is relatively stable. However, as expected, if one of the nodes never sends updates to the central server, the model does not generalize. This explains the poor performance as the dropout rate increases. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, D.-D.; Tran, A.-K.; Dao, M.-S.; Nguyen-Ly, K.-C.; Le, H.-S.; Nguyen-Thi, X.-D.; Pham, T.-Q.; Nguyen, V.-L.; Nguyen-Thi, B.-Y. Insights into Multi-Model Federated Learning: An Advanced Approach for Air Quality Index Forecasting. Algorithms 2022, 15, 434. https://doi.org/10.3390/a15110434
Le D-D, Tran A-K, Dao M-S, Nguyen-Ly K-C, Le H-S, Nguyen-Thi X-D, Pham T-Q, Nguyen V-L, Nguyen-Thi B-Y. Insights into Multi-Model Federated Learning: An Advanced Approach for Air Quality Index Forecasting. Algorithms. 2022; 15(11):434. https://doi.org/10.3390/a15110434
Chicago/Turabian StyleLe, Duy-Dong, Anh-Khoa Tran, Minh-Son Dao, Kieu-Chinh Nguyen-Ly, Hoang-Son Le, Xuan-Dao Nguyen-Thi, Thanh-Qui Pham, Van-Luong Nguyen, and Bach-Yen Nguyen-Thi. 2022. "Insights into Multi-Model Federated Learning: An Advanced Approach for Air Quality Index Forecasting" Algorithms 15, no. 11: 434. https://doi.org/10.3390/a15110434
APA StyleLe, D.-D., Tran, A.-K., Dao, M.-S., Nguyen-Ly, K.-C., Le, H.-S., Nguyen-Thi, X.-D., Pham, T.-Q., Nguyen, V.-L., & Nguyen-Thi, B.-Y. (2022). Insights into Multi-Model Federated Learning: An Advanced Approach for Air Quality Index Forecasting. Algorithms, 15(11), 434. https://doi.org/10.3390/a15110434