

A CNN-Transformer Hybrid Framework for Multi-Label Predator–Prey Detection in Agricultural Fields

Abstract
1. Introduction
- Forward-looking problem formulation: The deficiency in co-occurrence relationship modeling within current insect recognition methods is systematically identified, and for the first time, the integrated modeling of multi-label recognition and semantic pairing for “natural enemy–pest” relationships is explicitly proposed.
- Architecture integrating perception and relational modeling: A CNN-Transformer hybrid structure is designed to combine local feature extraction with global relationship modeling, significantly enhancing object recognition and pairing performance in complex imagery.
- Construction of an ecological multi-label dataset: The first publicly available multi-label “natural enemy–pest” pairing dataset based on natural field scenes is developed, featuring high ecological fidelity and strong task relevance, providing a solid foundation for future research.
- Application-oriented methodology: The proposed method exhibits strong precision, adaptability, and interpretability, offering technical support for intelligent biological control systems and contributing to the implementation of precision agriculture and green pest management.
2. Related Work
2.1. Agricultural Pest and Disease Image Recognition Research Status
2.2. Multi-Object Detection and Co-Occurrence Modeling Methods
2.3. Biological Control of Pests and Intelligent Matching Research
3. Materials and Method
3.1. Data Collection
3.2. Data Preprocessing and Augmentation
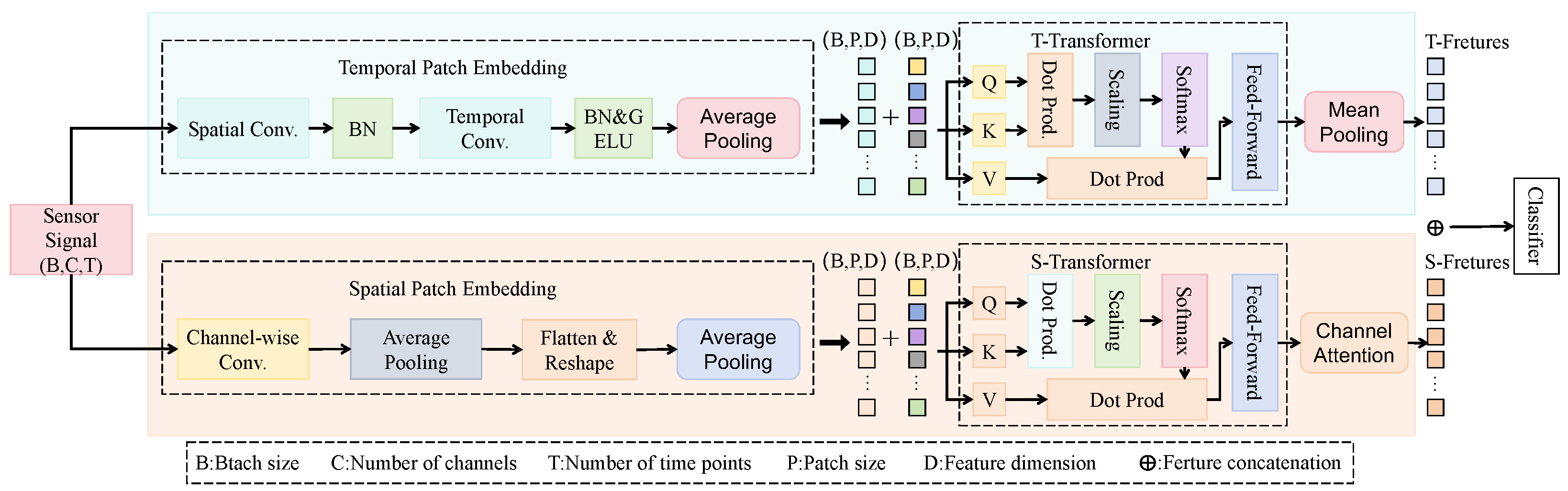
3.3. Proposed Method
3.3.1. Overall
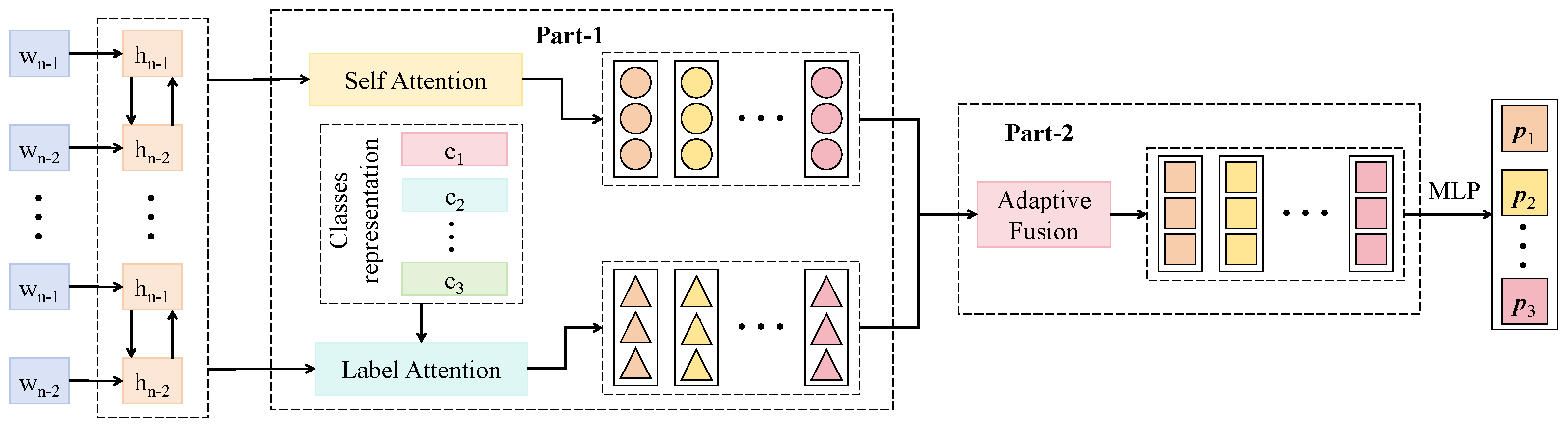
3.3.2. Multi-Label Co-Attention Module
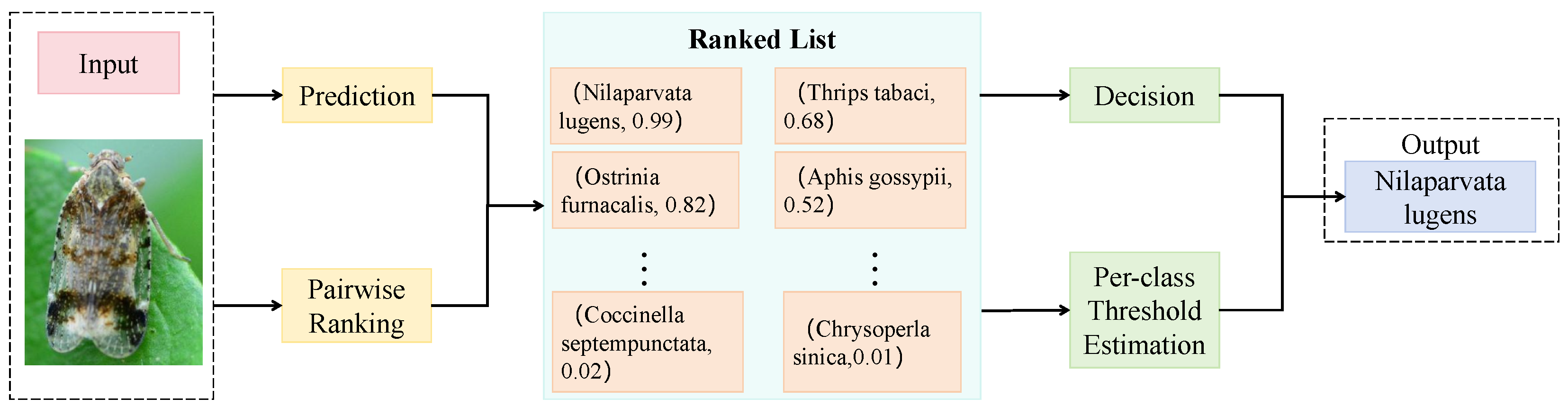
3.3.3. Pairwise Label Matching Loss
3.4. Experimental Design
3.4.1. Evaluation Metrics
3.4.2. Baseline Methods
3.4.3. Platform and Environment
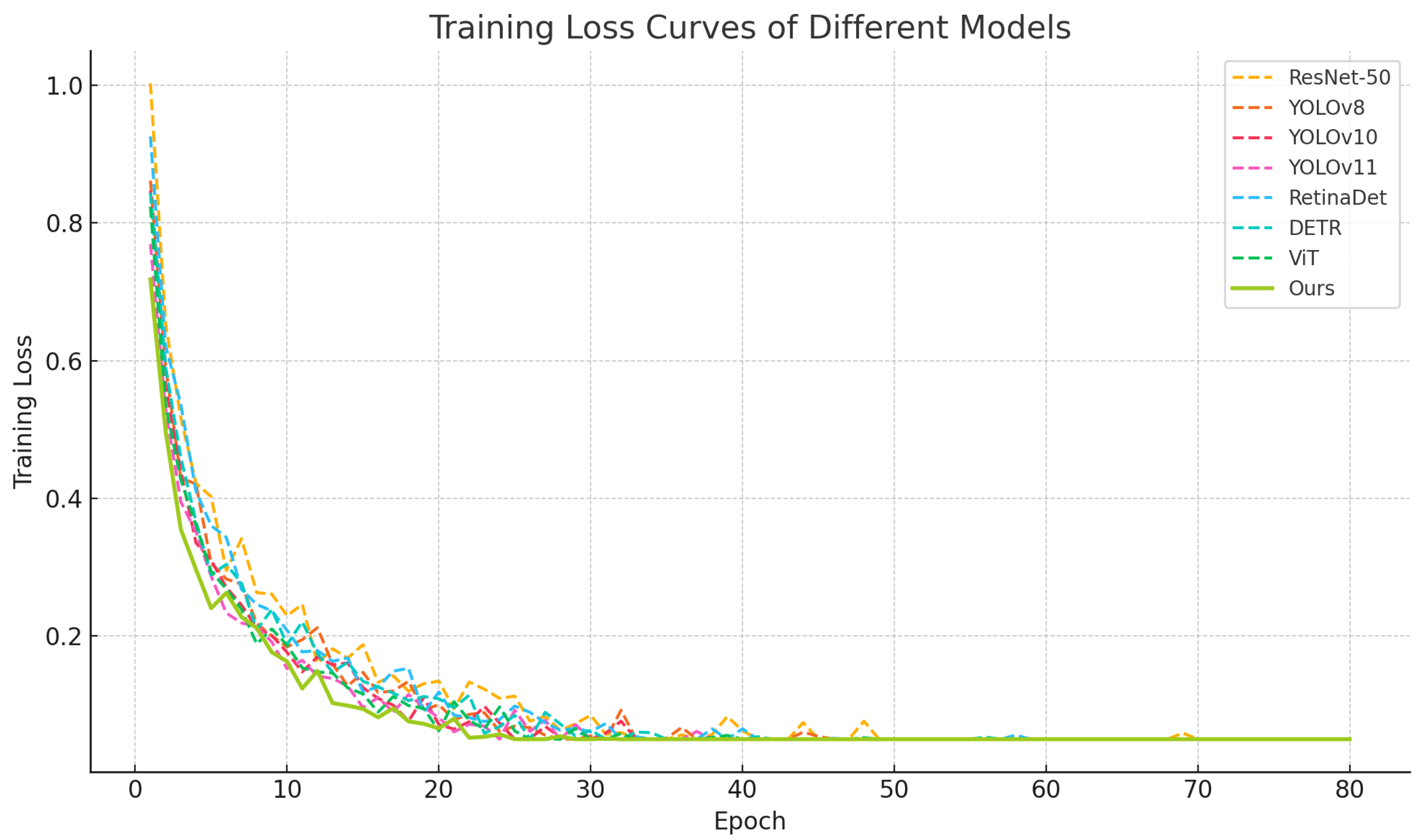
4. Results
4.1. Performance Comparison with Baseline Methods on the Test Set
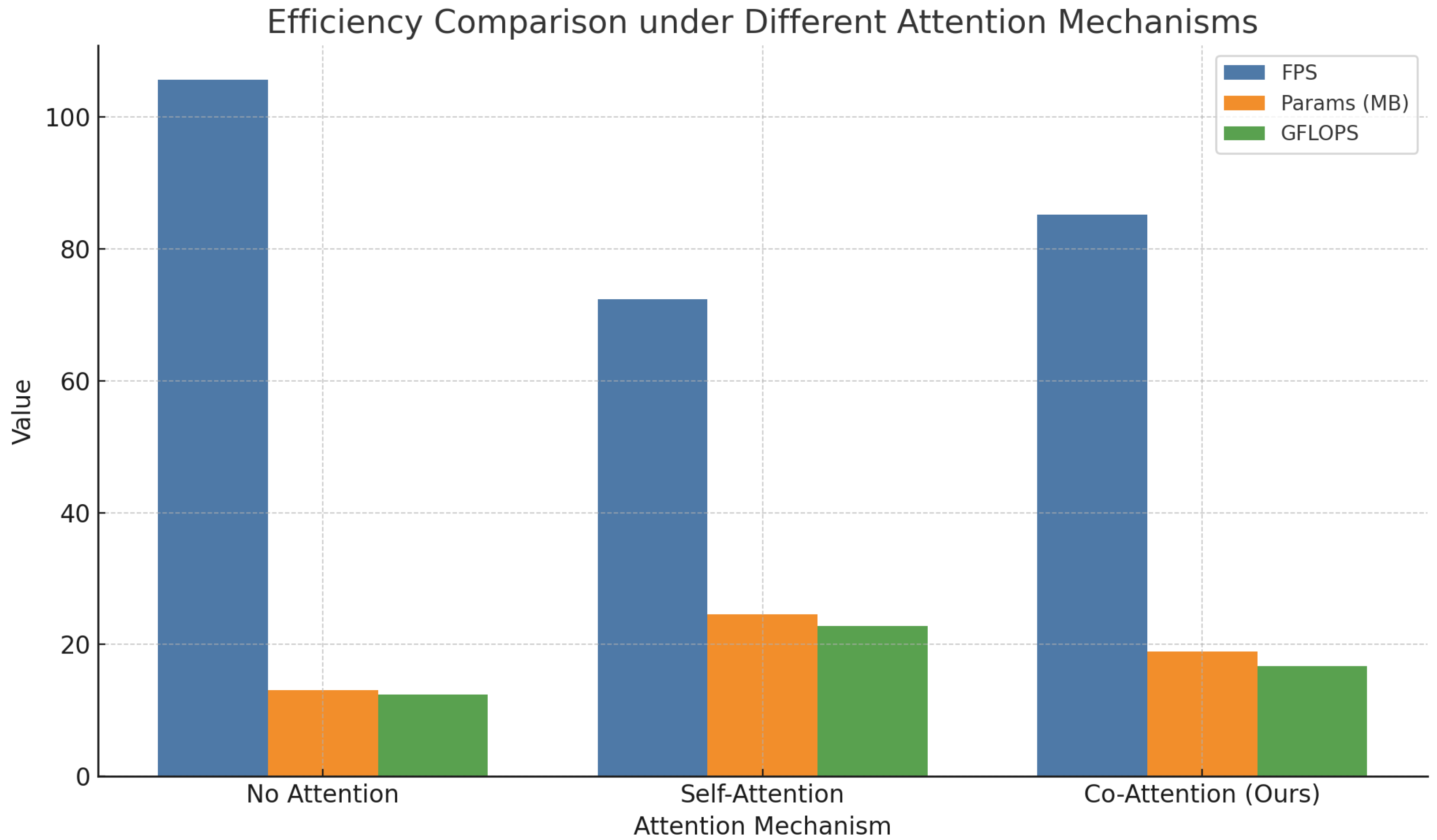
4.2. Ablation Study on Attention Mechanisms
4.3. Generalization Evaluation on Unseen Predator–Pest Combinations
5. Discussion
5.1. Practical Applications and Ecological Value of the Proposed Model
5.2. Limitation and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Julot, J.; Hiller, N. Exploring the Benefits of Biocontrol for Sustainable Agriculture; Institute for European Environmental Policy: Brussels, Belgium, 2021; Available online: https://ieep.eu/ (accessed on 12 May 2022).
- Nchu, F. Sustainable biological control of pests: The way forward. Appl. Sci. 2024, 14, 2669. [Google Scholar] [CrossRef]
- Hoddle, M.; Van Driesche, R. Biological control of insect pests. In Encyclopedia of Insects; Elsevier: Amsterdam, The Netherlands, 2009; pp. 91–101. [Google Scholar]
- Costa, M.; dos Anjos, L. Integrated pest management in a predator-prey system with Allee effects. Neotrop. Entomol. 2015, 44, 385–391. [Google Scholar] [CrossRef] [PubMed]
- Yu, T.; Tian, Y.; Guo, H.; Song, X. Dynamical analysis of an integrated pest management predator–prey model with weak Allee effect. J. Biol. Dyn. 2019, 13, 218–244. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, X. Plant diseases and pests detection based on deep learning: A review. Plant Methods 2021, 17, 22. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wa, S.; Sun, P.; Wang, Y. Pear defect detection method based on resnet and dcgan. Information 2021, 12, 397. [Google Scholar] [CrossRef]
- Chiranjeevi, S.; Saadati, M.; Deng, Z.K.; Koushik, J.; Jubery, T.Z.; Mueller, D.S.; O’Neal, M.; Merchant, N.; Singh, A.; Singh, A.K.; et al. InsectNet: Real-time identification of insects using an end-to-end machine learning pipeline. PNAS Nexus 2025, 4, pgae575. [Google Scholar] [CrossRef] [PubMed]
- Thenmozhi, K.; Reddy, U.S. Crop pest classification based on deep convolutional neural network and transfer learning. Comput. Electron. Agric. 2019, 164, 104906. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-accuracy detection of maize leaf diseases CNN based on multi-pathway activation function module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y.; Ma, X. A new strategy for tuning ReLUs: Self-adaptive linear units (SALUs). In Proceedings of the ICMLCA 2021, 2nd International Conference on Machine Learning and Computer Application, Shenyang, China, 17–19 December 2021; VDE: Osaka, Japan, 2021; pp. 1–8. [Google Scholar]
- Venkateswara, S.M.; Padmanabhan, J. Deep learning based agricultural pest monitoring and classification. Sci. Rep. 2025, 15, 8684. [Google Scholar] [CrossRef] [PubMed]
- Yulita, I.N.; Rambe, M.F.R.; Sholahuddin, A.; Prabuwono, A.S. A convolutional neural network algorithm for pest detection using GoogleNet. AgriEngineering 2023, 5, 2366–2380. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kamsu-Foguem, B.; Kamissoko, D.; Traore, D. Explainable deep convolutional neural networks for insect pest recognition. J. Clean. Prod. 2022, 371, 133638. [Google Scholar] [CrossRef]
- Saranya, T.; Deisy, C.; Sridevi, S. Efficient agricultural pest classification using vision transformer with hybrid pooled multihead attention. Comput. Biol. Med. 2024, 177, 108584. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y. CNN and transformer framework for insect pest classification. Ecol. Inform. 2022, 72, 101846. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, C.; Xiao, D.; Huang, Q. A novel multi-label pest image classifier using the modified Swin Transformer and soft binary cross entropy loss. Eng. Appl. Artif. Intell. 2023, 126, 107060. [Google Scholar] [CrossRef]
- Duan, J.; Ding, H.; Kim, S. A multimodal approach for advanced pest detection and classification. arXiv 2023, arXiv:2312.10948. [Google Scholar] [CrossRef]
- Rahman, C.R.; Arko, P.S.; Ali, M.E.; Khan, M.A.I.; Apon, S.H.; Nowrin, F.; Wasif, A. Identification and recognition of rice diseases and pests using convolutional neural networks. Biosyst. Eng. 2020, 194, 112–120. [Google Scholar] [CrossRef]
- Guo, Y.; Xu, B.B.; Chen, G.P.; Ding, J.; Yan, Z.Y.; Liang, H.; Wu, C.H. Rice insect pest recognition method based on convolutional neural network. J. Agric. Sci. Technol. 2021, 23, 99–109. [Google Scholar]
- Zhao, S.; Liu, J.; Bai, Z.; Hu, C.; Jin, Y. Crop pest recognition in real agricultural environment using convolutional neural networks by a parallel attention mechanism. Front. Plant Sci. 2022, 13, 839572. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, M.; Ma, X.; Wu, X.; Wang, Y. High-precision wheat head detection model based on one-stage network and GAN model. Front. Plant Sci. 2022, 13, 787852. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Chen, S.; Ren, Y.; Zhang, Y.; Fu, J.; Fan, D.; Lin, J.; Wang, Q. Atrous Pyramid GAN Segmentation Network for Fish Images with High Performance. Electronics 2022, 11, 911. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, X.; Liu, Y.; Zhou, J.; Huang, Y.; Li, J.; Zhang, L.; Ma, Q. A time-series neural network for pig feeding behavior recognition and dangerous detection from videos. Comput. Electron. Agric. 2024, 218, 108710. [Google Scholar] [CrossRef]
- Yaseen, M. What is YOLOv9: An in-depth exploration of the internal features of the next-generation object detector. arXiv 2024, arXiv:2409.07813. [Google Scholar]
- Wei, J.; Gong, H.; Li, S.; You, M.; Zhu, H.; Ni, L.; Luo, L.; Chen, M.; Chao, H.; Hu, J.; et al. Improving the Accuracy of Agricultural Pest Identification: Application of AEC-YOLOv8n to Large-Scale Pest Datasets. Agronomy 2024, 14, 1640. [Google Scholar] [CrossRef]
- Hu, K.; Wang, Z.; Coleman, G.; Bender, A.; Yao, T.; Zeng, S.; Song, D.; Schumann, A.; Walsh, M. Deep learning techniques for in-crop weed recognition in large-scale grain production systems: A review. Precis. Agric. 2024, 25, 1–29. [Google Scholar] [CrossRef]
- Fang, M.; Tan, Z.; Tang, Y.; Chen, W.; Huang, H.; Dananjayan, S.; He, Y.; Luo, S. Pest-ConFormer: A hybrid CNN-Transformer architecture for large-scale multi-class crop pest recognition. Expert Syst. Appl. 2024, 255, 124833. [Google Scholar] [CrossRef]
- Kim, G.E.; Son, C.H. ROI-aware multiscale cross-attention vision transformer for pest image identification. arXiv 2023, arXiv:2312.16914. [Google Scholar] [CrossRef]
- Jeffers, A.; Chong, J.H. Biological Control Strategies in Integrated Pest Management (IPM) Programs; Clemson University Cooperative, Land-Grant Press Clemson Extension, LGP: New York, NY, USA, 2021; Volume 1111, pp. 1–9. [Google Scholar]
- El-Faki, M.S.; Song, Y.; Zhang, N.; El-Shafie, H.A.; Xin, P. Automated detection of parasitized Cadra cautella eggs by Trichogramma bourarachae using machine vision. Int. J. Agric. Biol. Eng. 2018, 11, 94–101. [Google Scholar] [CrossRef]
- Rajabpour, A.; Seraj, A.; Allahyari, H.; Shishehbor, P. Evaluation of Orius laevigatus fiber (Heteroptera: Anthocoridae) for biological control of Thrips tabaci Lindeman (Thysanoptera: Thripidae) on greenhouse cucumber in South of Iran. Asian J. Biol. Sci. 2011, 4, 457–467. [Google Scholar] [CrossRef]
- Wang, D.; Wang, Y.; Li, M.; Yang, X.; Wu, J.; Li, W. Using an improved YOLOv4 deep learning network for accurate detection of whitefly and thrips on sticky trap images. Trans. ASABE 2021, 64, 919–927. [Google Scholar] [CrossRef]
- Gimenez, O.; Kervellec, M.; Fanjul, J.B.; Chaine, A.; Marescot, L.; Bollet, Y.; Duchamp, C. Trade-off between deep learning for species identification and inference about predator-prey co-occurrence: Reproducible R workflow integrating models in computer vision and ecological statistics. arXiv 2021, arXiv:2108.11509. [Google Scholar]
- Baltruschat, I.M.; Nickisch, H.; Grass, M.; Knopp, T.; Saalbach, A. Comparison of deep learning approaches for multi-label chest X-ray classification. Sci. Rep. 2019, 9, 6381. [Google Scholar] [CrossRef]
- Yaseen, M. What is YOLOv8: An in-depth exploration of the internal features of the next-generation object detector. arXiv 2024, arXiv:2408.15857. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar] [CrossRef]
- Yoo, S.; Lee, E.Y.J.; Wang, Z.; Wang, X.; Lu, W.D. RN-Net: Reservoir Nodes-Enabled Neuromorphic Vision Sensing Network. arXiv 2024, arXiv:2303.10770. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic DETR: End-to-End Object Detection with Dynamic Attention. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2968–2977. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Type | Image Count | Co-Occurrence Samples |
|---|---|---|---|
| C. septempunctata | Predator | 642 | 412 |
| C. sinica | Predator | 711 | 385 |
| O. sauteri | Predator | 538 | 304 |
| T. chilonis | Predator | 483 | 271 |
| A. gossypii | Pest | 923 | 513 |
| T. tabaci | Pest | 786 | 448 |
| O. furnacalis | Pest | 512 | 276 |
| N. lugens | Pest | 442 | 199 |
| Total | - | 5037 | 2808 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | mAP@50 (%) | mAP@75 (%) |
|---|---|---|---|---|---|
| ResNet-50 (Detection Head) | 78.2 | 74.9 | 76.5 | 73.1 | 62.4 |
| YOLOv8 + Multi-Label Head | 81.5 | 76.3 | 78.8 | 76.9 | 65.7 |
| YOLOv10 + Multi-Label Head | 83.1 | 77.9 | 80.4 | 78.6 | 66.9 |
| YOLOv11 + Multi-Label Head | 84.5 | 79.5 | 81.9 | 80.2 | 68.4 |
| RetinaDet (Multi-Label) | 79.8 | 75.1 | 77.4 | 74.5 | 63.7 |
| DETR (Multi-Label) | 82.4 | 77.3 | 79.8 | 77.9 | 67.2 |
| Vision Transformer (ViT) | 83.6 | 78.4 | 80.9 | 79.4 | 68.1 |
| Ours | 88.9 (+5.3%) | 84.2 (+5.8%) | 86.5 (+5.6%) | 85.1 (+5.7%) | 73.8 (+5.7%) |
| Attention Mechanism | Precision (%) | Recall (%) | F1-Score (%) | mAP@50 (%) | mAP@75 (%) |
|---|---|---|---|---|---|
| No Attention | 82.4 | 77.6 | 79.9 | 76.3 | 65.0 |
| Self-Attention | 85.7 | 80.5 | 83.0 | 80.1 | 68.7 |
| Co-Attention (Ours) | 88.9 | 84.2 | 86.5 | 85.1 | 73.8 |
| Unseen Pair Type | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| T. chilonis-T. tabaci | 81.2 | 76.0 | 78.5 |
| O. sauteri-N. lugens | 83.6 | 78.4 | 80.9 |
| C. septempunctata-O. furnacalis | 79.8 | 74.2 | 76.9 |
| C. sinica-N. lugens | 84.4 | 80.3 | 82.3 |
| Average | 82.3 | 77.2 | 79.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, Y.; Lu, F.; Wang, X.; Wang, Y.; Wang, Z.; Zhu, Y.; Wang, Z.; Dong, M. A CNN-Transformer Hybrid Framework for Multi-Label Predator–Prey Detection in Agricultural Fields. Sensors 2025, 25, 4719. https://doi.org/10.3390/s25154719
Lyu Y, Lu F, Wang X, Wang Y, Wang Z, Zhu Y, Wang Z, Dong M. A CNN-Transformer Hybrid Framework for Multi-Label Predator–Prey Detection in Agricultural Fields. Sensors. 2025; 25(15):4719. https://doi.org/10.3390/s25154719
Chicago/Turabian StyleLyu, Yifan, Feiyu Lu, Xuaner Wang, Yakui Wang, Zihuan Wang, Yawen Zhu, Zhewei Wang, and Min Dong. 2025. "A CNN-Transformer Hybrid Framework for Multi-Label Predator–Prey Detection in Agricultural Fields" Sensors 25, no. 15: 4719. https://doi.org/10.3390/s25154719
APA StyleLyu, Y., Lu, F., Wang, X., Wang, Y., Wang, Z., Zhu, Y., Wang, Z., & Dong, M. (2025). A CNN-Transformer Hybrid Framework for Multi-Label Predator–Prey Detection in Agricultural Fields. Sensors, 25(15), 4719. https://doi.org/10.3390/s25154719