3.1. Problem Setting
In cross-domain few-shot object detection (CD-FSOD), the source domain dataset and target domain dataset are defined, where , i.e., the categories of the two are different. contains numerous labeled data with diverse categories, while has fewer categories and only a small amount of labeled data for each category. The label information includes, but is not limited to, category labels and the coordinates of bounding boxes.
Currently, there are two mainstream approaches to solve the CD-FSOD problem, one is “meta-learning”, and the other is “pretraining + fine-tuning”. Our model adopts the latter, and the main processes are as follows: Firstly, a base model is trained in a supervised-learning way using large-scale , and subsequently fine-tunes using to obtain the specialized . The fine-tuning process employs an n-way-k-shot sampling strategy from , as outlined below:
The support set for tuning contains k annotated samples for each of n categories.
The query set for testing comprises unlabeled samples from the same n categories.
Critical constraints are and .
This methodology enables effective adaptation of ’s parameters to novel categories on the target domain while maintaining its fundamental detection capabilities. The limited annotated samples (k per category) in provide sufficient supervisory signals for this specialized adaptation, while the disjoint query set ensures a proper evaluation of the model’s generalization performance on unseen target domain instances.
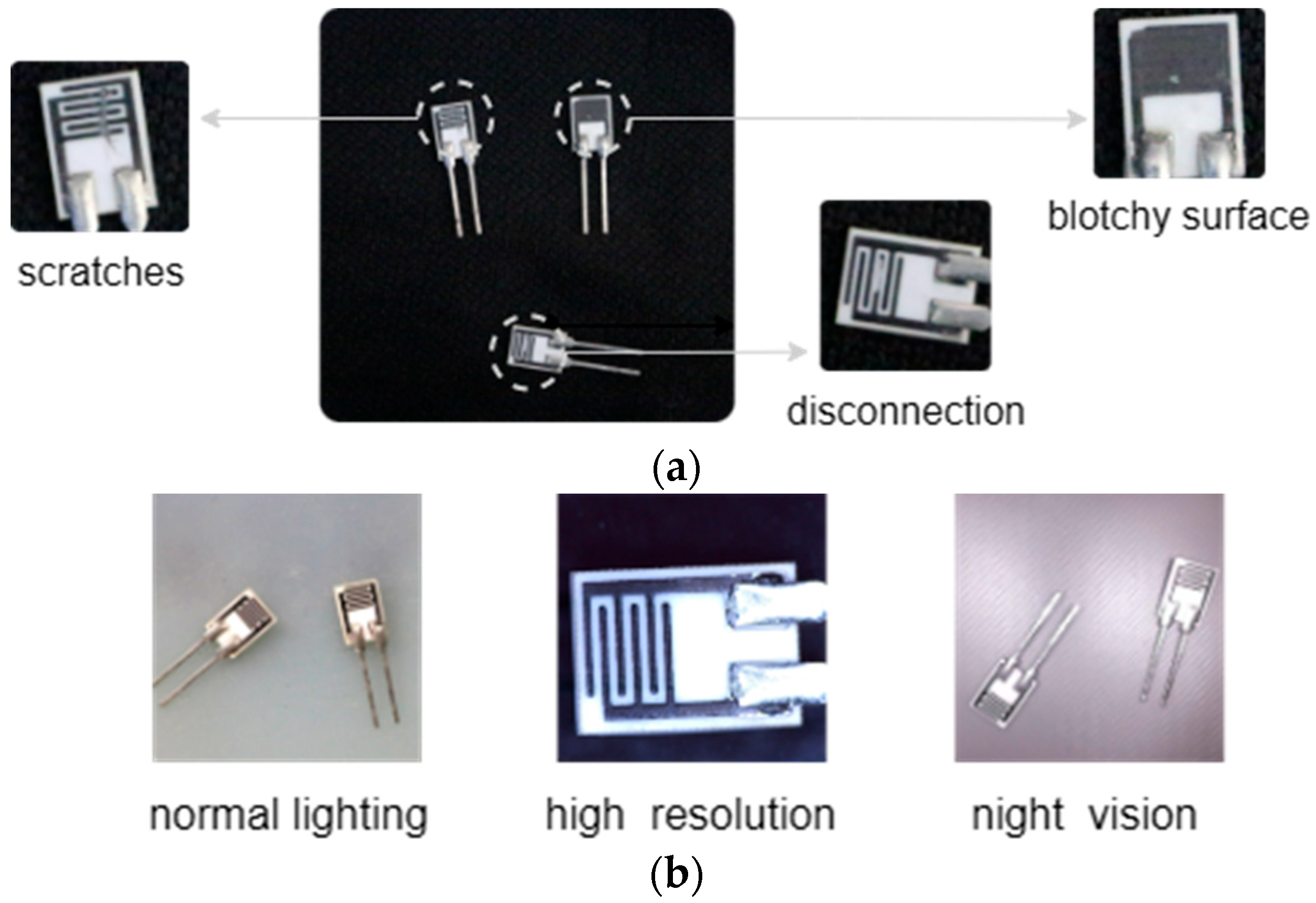
Our research addresses defect detection of a specific type of chip, presenting unique challenges beyond conventional “cross-domain” difficulties. The problem’s complexity manifests through two distinct dimensions: one is significant distributional discrepancies between and , and the other is intrinsic variations within the target domain itself arising from illumination changes, and imaging device diversity. Such multi-faceted scenario variations impose stringent demands on model generalization capabilities.
3.3. Overview of CWCN
The framework of the crossed wavelet convolution network (CWCN) proposed is shown in
Figure 2, which is divided into three parts, including “data preprocessing”, “feature extraction and fusion”, and “detection and loss computation”.
(1) Data preprocessing. Since our network employs a dual-pipeline feature extraction and fusion mechanism, the dataset requires special processing during model training. Specifically, the original dataset is divided into two subsets, Subset A and Subset B, both of which should contain complete and category-balanced samples. Within the same input batch, images from the two pipelines share the same category labels but exhibit different scenes. This preprocessing strategy facilitates the network in aligning features. Without such alignment, training instability may arise, potentially leading to non-convergence of the model.
(2) Feature extraction and fusion. CWCN employs a novel dual-pipeline crossed wavelet convolution training mechanism, which utilizes wavelet transform convolution (WTConv) instead of conventional convolution for feature extraction. The module also incorporates 3-level crossed wavelet convolution modules (3-Level CWC) to fuse features. The technical details are elaborated in
Section 3.4.
(3) Detection and loss computation. CWCN adopts the Region Proposal Network (RPN) and ROI Pooling from Faster R-CNN [
32] to process dual-pipeline feature maps. The RPN generates target proposal boxes through an anchor mechanism, while ROI Pooling maps the proposals of varying scales onto the feature maps for subsequent classification and regression. During training, the RPN loss function is computed as follows:
where
and
are the number of anchors, and
is a balancing weight.
is the classification loss term,
and
represent the predicted probability and ground -truth label of the
anchor, respectively.
is the regression loss term, where
and
are the predicted and ground-truth bounding box corresponding to the
anchor.
Subsequently, our network concatenates the outputs from two ROI Pooling streams and employs fully connected layers to construct the predictor (consisting of a box classifier and box regressor). This process generates the classification loss
and regression loss
during training:
where
and
are the number of proposal regions,
denotes the predicted class probability of
ROI, and
represents the ground-truth class label. The indicator function
ensures the loss is computed only for foreground samples
. The
is applied to the bounding box parameters, where
and
correspond to the predicted and ground-truth bounding box of
foreground samples.
Additionally, we design a Prototype Similarity Learning (ProSL) module to process the dual-pipeline ROI Pooling outputs, with detailed implementation described in
Section 3.5.
3.4. DPCWC Module
The dual-pipeline crossed wavelet convolution (DPCWC) training framework proposed employs a WTConv variant as a backbone. The backbone is structured with four ConvStages, each of which contains several ConvBlocks or WTConvBlocks that perform wavelet transform (WT) and inverse wavelet transform (IWT) operations (theoretical details in
Section 3.2). Compared to conventional convolution, our backbone simultaneously captures both low-frequency and high-frequency components of data features, thereby enhancing the model’s ability to perceive both global structures and local details. Unlike single-path designs, this module takes the preprocessed datasets Subset A and Subset B as dual inputs, with features being synchronously extracted through a weight-shared backbone. Consequently, our feature extraction module not only effectively decomposes global contour and local detail information of samples, but also enables the model to capture features from different scenes within the same training phase.
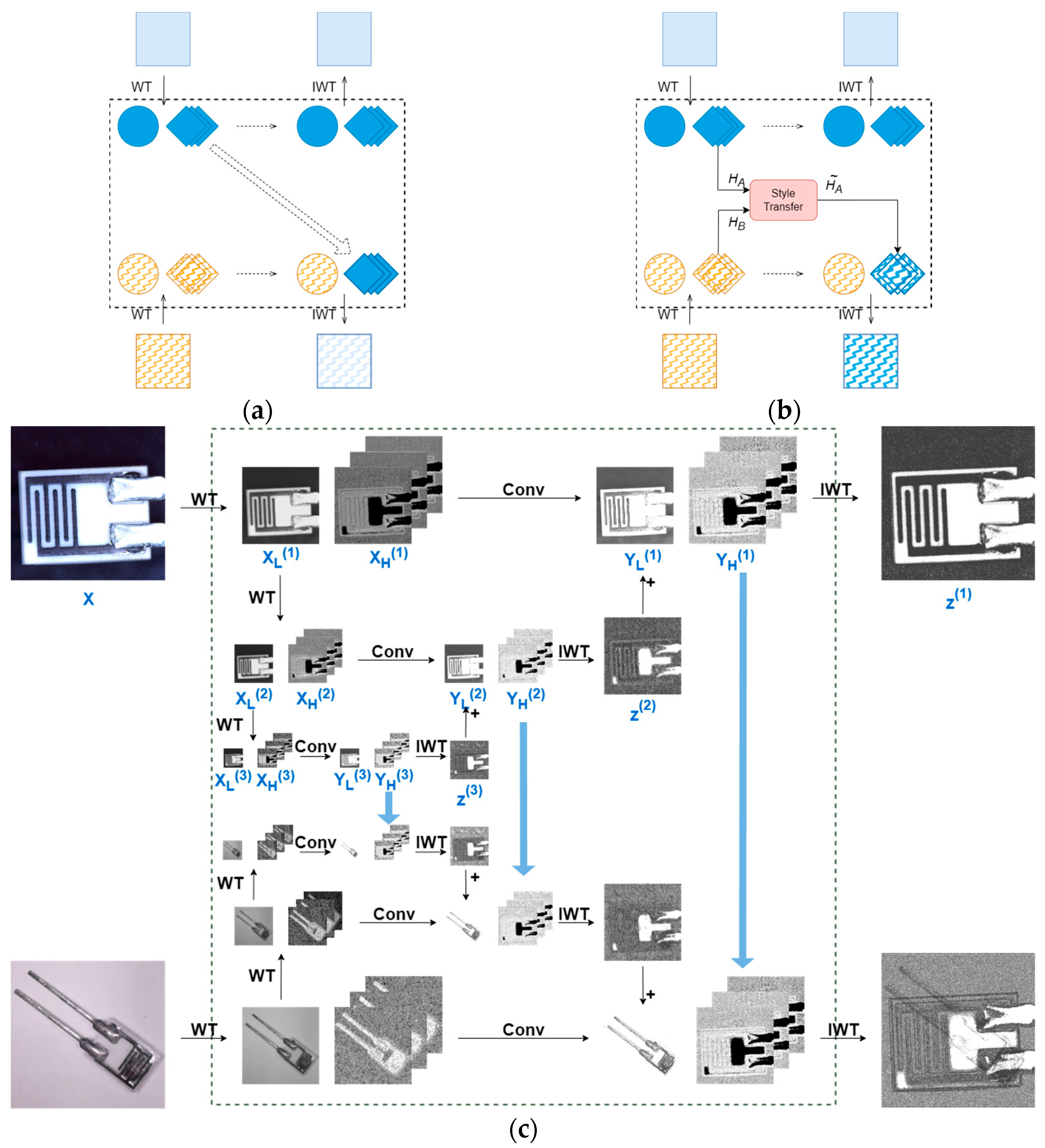
The dual-pipeline feature fusion follows a fundamental principle. Each pipeline preserves its global information through low-frequency components while exchanging local details via high-frequency components. Our implementation employs an alternating fusion strategy across network blocks: after performing WT in the previous block, the high-frequency components from Pipeline B are replaced by the corresponding components of Pipeline A, followed by IWT. In the subsequent block, Pipeline A’s high-frequency components are replaced by Pipeline B’s. This alternating fusion scheme continues iteratively across subsequent WTConvBlocks, where high-frequency components from Pipeline A and Pipeline B are alternately exchanged.
Based on the strategy above, we developed several implementation variants as illustrated in
Figure 3.
For wavelet component processing in the dual-pipeline framework,
Figure 3a demonstrates the direct replacement approach where one pipeline’s high-frequency components are simply substituted from the other.
Figure 3b presents our enhanced method, building upon prior works [
26,
33], which performs style transfer between the high-frequency components using Equation (7) before component substitution:
where
and
denote the mean and variance, respectively, while
and
represent the high-frequency components before and after processing, respectively.
However, we explore that the two methods above fail to adequately account for the importance of multi-scale feature fusion, resulting in significant performance disparities in detecting objects of different sizes (see
Section 4.5.1 for detailed experimental results). To alleviate this impact, DPCWC adopts the 3-Level CWC method illustrated in
Figure 3c. Our approach modifies the cascaded wavelet transform from [
28] by implementing the following operations:
Multi-level Wavelet Decomposition:
- ■
The input feature map X undergoes 1-level WT, yielding high-frequency component and low-frequency component .
- ■
is further decomposed via 2-level WT to produce and .
- ■
undergoes 3-level WT to generate and .
Convolution in Wavelet Domain:
- ■
Each level’s components perform convolutional operations in wavelet domain using Equation (8), yielding transformed components and , denotes the learnable weight tensor at the level .
Hierarchical Reconstruction:
- ■
and undergo 3-level IWT to reconstruct .
- ■
is combined with through element-wise addition to form the composite low-frequency component at the level
- ■
Feature maps at each level are reconstructed by applying IWT to the composite low-frequency components and corresponding , as formalized in Equation (9).
Cross-pipeline Feature Fusion:
- ■
During synchronous dual-pipeline processing, high-frequency components (, , and ) from one pipeline replace their corresponding counterparts in the other.
- ■
The modified components then undergo cascaded IWT operations.
We also develop a stage-wise fusion strategy, enabling the 3-Level CWC to carry out more effective multi-scale feature fusion and information interaction. Specifically, when applied to shallower network layers, 3-Level CWC excels at integrating fine-grained features, while its application in deeper layers facilitates the fusion of coarse-grained features. However, DPCWC does not employ this fusion operation across all four ConvStages of the backbone but rather selectively implements 3-Level CWC in the second and third ConvStages. This strategic design is based on three key considerations: First, it simultaneously addresses fusion requirements for both shallow and deep network features, ensuring comprehensive multi-scale representation throughout the network hierarchy. Second, it prevents excessive cross-pipeline interference and maintains distinctive feature characteristics in each pipeline, reducing the risk of feature homogenization. Third, it avoids unnecessary parameter proliferation to control model complexity. As evidenced by the experimental results in
Section 4.5.2, our selective fusion approach achieves an optimal balance between representation learning capability and computational efficiency.
3.5. ProSL Module
For the cross-scene features from the two pipelines, a dedicated loss computation module is needed to establish and reinforce feature correlations, thereby guiding the model to learn more generalizable feature representations. If our loss computation module appropriately processes the dual ROI Pooling outputs, which contain both categorical and spatial coordinate information from multi-scene, the model can be optimized for category classification and object localization simultaneously.
Inspired by the contrastive learning framework of SimCLR [
34], we initially designed a self-supervised loss computation module. As illustrated in
Figure 4, the module first applies global average pooling (GAP) to reduce dimension and computational complexity. The low-dimensional feature vectors are then used to compute cosine similarity by Equation (10):
where the numerator represents the dot product of the two feature vectors and the denominator is the product of their Euclidean norms. To promote similar feature distributions between the two pipelines, the model optimization aims to minimizes the loss value in Equation (11).
However, this loss computation is inherently limited to contrastive learning between the dual-pipeline features. While the trained model achieves cross-scene feature alignment and effectively determines whether samples from Subset A and B belong to the same category, the inter-class feature clustering relies solely on the Faster R-CNN’s loss computations (Equations (4)–(6)), which leads to insufficient discriminative capability between different categories. In our chip defect detection tasks, this limitation manifests defect misclassification with similar visual characteristics, ultimately failing to address the practical requirements of defect detection.
Building upon the aforementioned loss computation module, we propose Prototype Similarity Learning (ProSL) as illustrated in
Figure 2. ProSL incorporates category label information as prior knowledge to guide model learning, so it falls under the supervised learning (SL) paradigm. The computational details of this module are presented in Algorithm 1.
In ProSL module, the dual-pipeline features from ROI Pooling undergo dimensionality reduction and concatenation, resulting in
which contains features of all ROIs from both Subset A and B.
is then utilized to construct prototypes through the following procedure: features are grouped according to category labels and Intersection over Union (IoU), yielding class-specific features, and then the mean features are computed as prototypes. All the category prototypes including background type are refined using Exponential Moving Average (EMA) as shown in Equation (12):
where
and
denote prototypes of the previous and current batch. In the first batch,
(i.e.,
) is constructed by a pre-trained model and all the support samples.
is an initial model created by the current
.
is the momentum coefficient, whose initial value is 0.1 during the “warm-up” phase and decreases to 0.01. This momentum-based update strategy establishes robust prototypes during initial training epochs while subsequently smoothing the prototype evolution, mitigating excessive fluctuations caused by distribution shifts within individual training batch.
| Algorithm 1. ProSL |
| created by pretrained model and all support samples |
| //Concatenate feature maps to dimension (NA+NB, D) |
| //Group features by annotations for each category, containing background type |
|
|
|
| // Compute the final prototypes for current batch to dimension (K, D) |
|
| //Dimension is (Nj, K) |
|
|
|
Subsequently, the dual-pipeline features
and
are computed similarity with the prototypes
using Equation (10) to obtain
and
, respectively. The final loss objective of ProSL is to minimize the value in Equation (13), where
is 0.1 as a scaling factor,
is the similarity of positive sample and
denotes the similarity for each category.
The loss value is combined with the base losses from Equations (4)–(6) to form the total optimization objective , which is backpropagated to jointly optimize the entire model.
We conducted ablation studies evaluating the effectiveness of different loss functions to identify the optimal module for CWCN (results shown in
Section 4.5.3). Based on the special design of DPCWC, we ultimately adopt the ProSL loss module to strengthen the model’s ability to learn inter-pipeline feature correlations while preserving category discriminability. This option enables the model to better adapt to cross-domain few-shot chip defect detection tasks under multi-scene conditions.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}