1. Introduction
Fault detection plays a vital role in maintenance tasks within the railway sector, and has been defined as “the detection of a fault within a prescribed time by a safety mechanism” [
1]. Although railway machinery represents a complex industrial system with a huge variety of components, a train door is a vital subsystem that can lead to service interruptions or failures, resulting in higher operational and maintenance expenses. One report has indicated that the door system accounts for 30–60% of all malfunctions in railway vehicles [
2]. To avoid such failures, predictive maintenance using data-driven methods has recently gained interest from researchers, owing to the vast quantities of monitoring data accessible.
Data-driven approaches for fault detection include traditional machine learning (ML) and deep learning (DL) approaches. Traditional ML approaches necessitate multiple steps such as data preprocessing and feature extraction prior to model development; however, manual feature extraction requires specialised domain expertise, which complicates the use of traditional machine learning methods. In contrast, DL methods allow for the development of fault detection models without the need for manually crafted features by employing a deep network architecture. This represents a notable advantage over traditional ML techniques.
Fault detection methods based on deep learning can be divided into supervised and unsupervised learning approaches. Supervised DL methods require datasets with labels to enable the training of the model. A significant proportion of prior research in the area of fault detection has focused on supervised DL methods, including deep neural networks (DNNs) [
3], two-dimensional convolutional neural networks (2D CNNs) [
4], one-dimensional convolutional neural networks (1D CNNs) [
5], gated recurrent units (GRUs) [
6], and long short-term memory (LSTM) [
7]. However, the need for ample labelled datasets represents a major limitation of supervised methods: faulty data are often scarce, due to the use of conservative maintenance schedules to prevent major incidents. In addition, the imbalance between faulty and healthy data is also problematic when building a classifier. Unlike supervised approaches, unsupervised DL methods do not need datasets with labels, and the aim is to extract the relevant characteristics of the input data. Previous research based on unsupervised learning approaches has included stacked autoencoders [
8], denoising autoencoders [
9], sparse autoencoders [
10], variational autoencoders [
11], and deep belief networks [
12].
Despite the successful outcomes of previous research, one significant drawback of a data-driven fault detection approach is that the fault detection performance may be considerably degraded when the model is applied to actual acquired data rather than training data. The assumption underlying traditional ML and DL approaches is that the distribution of the test data is identical to that of the training data; however, these distributions may differ due to the different operating conditions, components, and detailed specifications of the machinery. This is known as the domain shift problem [
13], which refers to the discrepancy in the feature distribution between two domains. In this case, the training and test data are assumed to be the source and target domains, respectively. Due to the discrepancy between the source and target domains, the accuracy of fault detection in actual industrial data may be worse than anticipated. If the plan is to acquire many types of data beforehand, under different operating conditions and for different components, then the training of the model may be expensive and demanding, meaning that a huge dataset would be required. This strategy is therefore impractical, given that the availability of datasets that include sufficient faulty samples is always limited in industry.
The domain adaptation (DA) technique offers a promising solution for addressing the domain shift problem. DA is an area of machine learning where models are designed to execute tasks in a target domain, using knowledge gained from a similar but distinct source domain. The aim is to address the challenge posed by the distribution shift between the source and target domains. Research into DA has evolved over the years in several areas of study, including computer vision, healthcare, speech recognition, and fault detection. When applied in the context of fault detection, the aim of DA is to align the source and target domain distributions. The aligned source and target features are then used to build a fault detection model. As a result, faults can be detected with almost the same accuracy for both the source and target domains.
Fault detection based on DA can be categorised at the methodological level into network-based, instance-based, mapping-based, and adversarial-based approaches [
14]. Network-based DA involves the direct transfer of certain network parameters that have been pre-trained in the source domain to another model in the target domain, as partial network parameters. The fine-tuning of the network parameters is then conducted using a limited set of labelled data from the target domain [
15,
16]. However, sufficient labelled target domain datasets are necessary for this method, which are often unavailable in the context of fault detection. Instance-based DA involves adjusting the weights of instances in the source domain to assist the classifier in label prediction or using instance statistics to bring the target domain into alignment. These methods include DNNs with a batch normalisation layer (BN) [
17] and adaptive batch normalisation [
18,
19]. However, in order to train the BN layer and set appropriate parameters, a certain amount of normal and faulty target samples is required beforehand.
The aim of mapping-based DA is to project the original features from both the source and target domains into a new feature space, where the two domain features are aligned using a feature extractor. There are many examples of fault detection using mapping-based DA, including Kullback–Leibler divergence [
20], correlation alignment (CORAL) [
21], maximum mean discrepancy (MMD) [
22,
23], multi-kernel MMD [
24,
25], and joint distribution adaptation [
26]. In contrast, adversarial-based DA uses an adversarial method in which a domain discriminator is used to minimise the discrepancy in the feature distribution between the source and target domains created by a feature extractor. The adversarial network architecture is called a generative adversarial network (GAN). This consists of a pair of networks that are combined to form a generative system, and was initially proposed by Ian Goodfellow in 2014 [
27]. When carrying out domain adaptation with a GAN, the generator is typically employed to map the raw features from both the source and target domains to a new latent feature space, where the alignment of the feature distributions can be achieved. A fault detection model can be built using the aligned features in the latent feature space for both the source and target domains. Examples of adversarial-based DA include the domain adversarial neural network (DANN) [
28,
29], the domain adversarial transfer network [
30], and the Wasserstein distance-based deep transfer network [
31].
Adversarial-based DA can be integrated with mapping-based DA by employing both the adversarial discriminator and an appropriate objective function to minimise the discrepancy between the two domains. Research using both adversarial and mapping-based DA is being widely conducted in relation to fault detection, due to its strong ability to align two domains where only unlabelled target samples are available [
31,
32]. However, these methods still have some impractical aspects, which can be research gaps, as follows:
In a GAN, the feature generator does not take domain-specific decision boundaries into consideration, as the model simply tries to fool the discriminator [
33]. This results in poor performance in terms of detecting faulty samples near the class boundary.
In general, the DA method causes both the source and target domain to be the same in the latent space, meaning that they are treated equally. However, the source domain information needs to be considered with a higher priority than the target domain, as the source domain tends to be a rich dataset that includes more faulty samples than the target domain under actual industrial conditions. The reason for this is that the fault detection model is initially built with a focus on the specific machinery, followed by thorough validation in order to make the model applicable to the actual industrial setting. The model is then applied to another domain.
Ensuring that DA techniques are robust and reliable for real-world applications is challenging if the method is completely unsupervised. This is because the degree of similarity between the two domains that is required in order to be able to apply the DA method successfully is unclear. However, reliability is crucial for fault detection to avoid catastrophic incidents; hence, real-world implementations of the DA technique are still scarce.
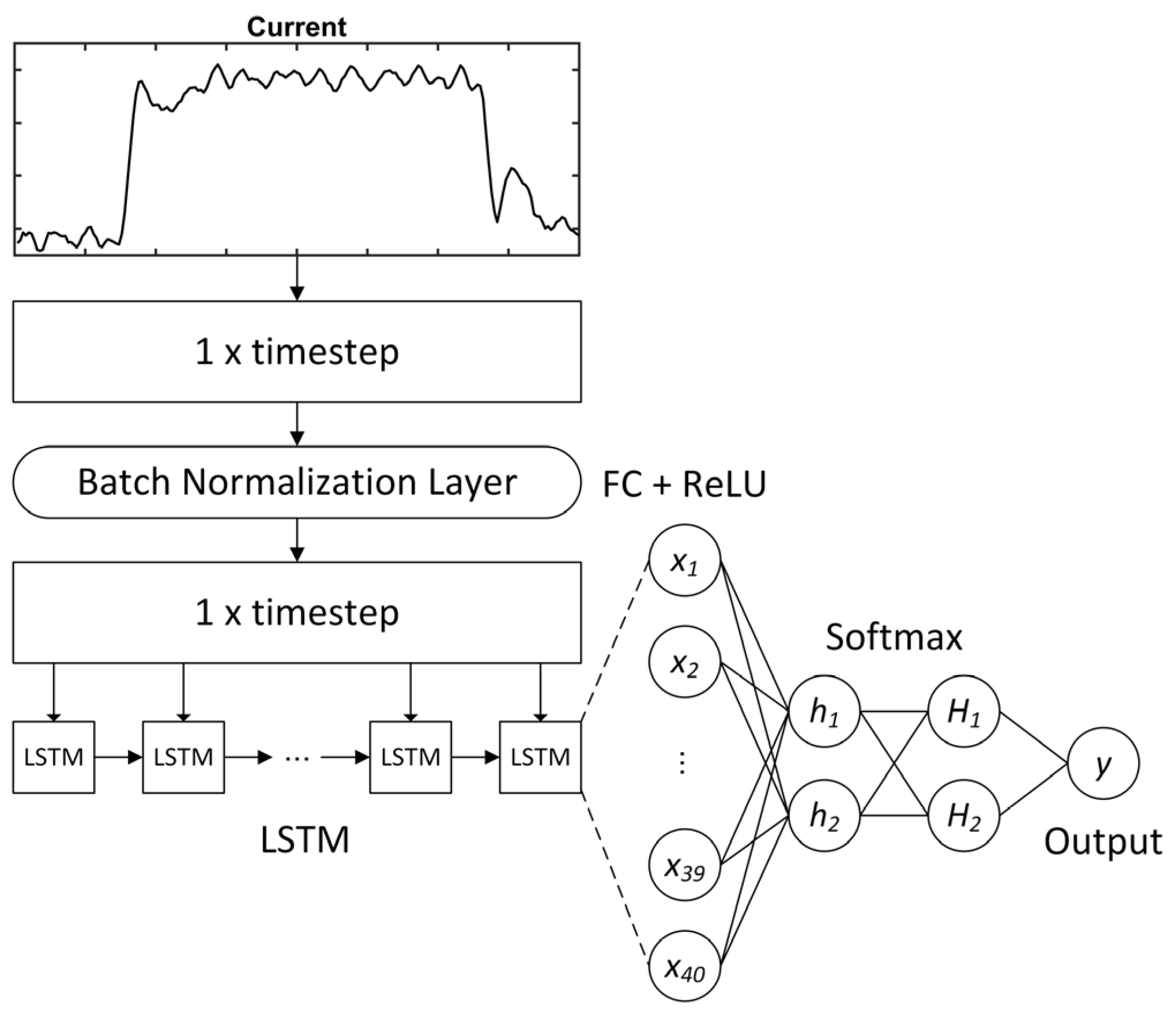
These are major challenges, and few studies can be found that have attempted to overcome these hurdles. In order to tackle these issues, a novel fault detection approach for railway door systems is proposed, based on one-sided DA using GANs. In this study, the source and target domains consist of data from a linear actuator test rig and a real-world railway door, respectively. First, an anomaly detector and a feature generator are trained using label-rich source domain data to generate distinctive source latent features. Next, the target domain data are aligned with the source latent features in a one-sided way. The proposed method enables the faulty target samples to be aligned with the source samples and to be detected accurately by the same anomaly detector, which is built based on rich source data. To the best of our knowledge, this paper is the first to introduce a fault detection method utilising DA specifically for railway door systems. The main contributions of the paper can be summarised as follows:
A fault detection approach is proposed based on one-sided DA with GANs, which can be used for real-world railway door systems.
The proposed one-sided DA from the target to the source domain enables the normal and faulty samples in the target domain to be detected using the same fault detection model, which is trained on a rich source dataset.
Our approach ensures that the two domains can be aligned, despite the low level of similarity between different components, using only a few faulty target samples.
The proposed method is not only the most accurate and robust among comparative models but also bridges the gap between theoretical domain adaptation research and tangible industrial applications.
The proposed approach can also be applied to conventional railway components and various electro-mechanical actuators. This is because the motor current signals considered in this study are primarily obtained from the controller or motor drive, thus eliminating the need for extra sensors.
The remainder of this article is organised as follows.
Section 2 introduces the dataset and the proposed methodology. Some results and a discussion are given in
Section 3. Finally,
Section 4 concludes this article.
4. Conclusions
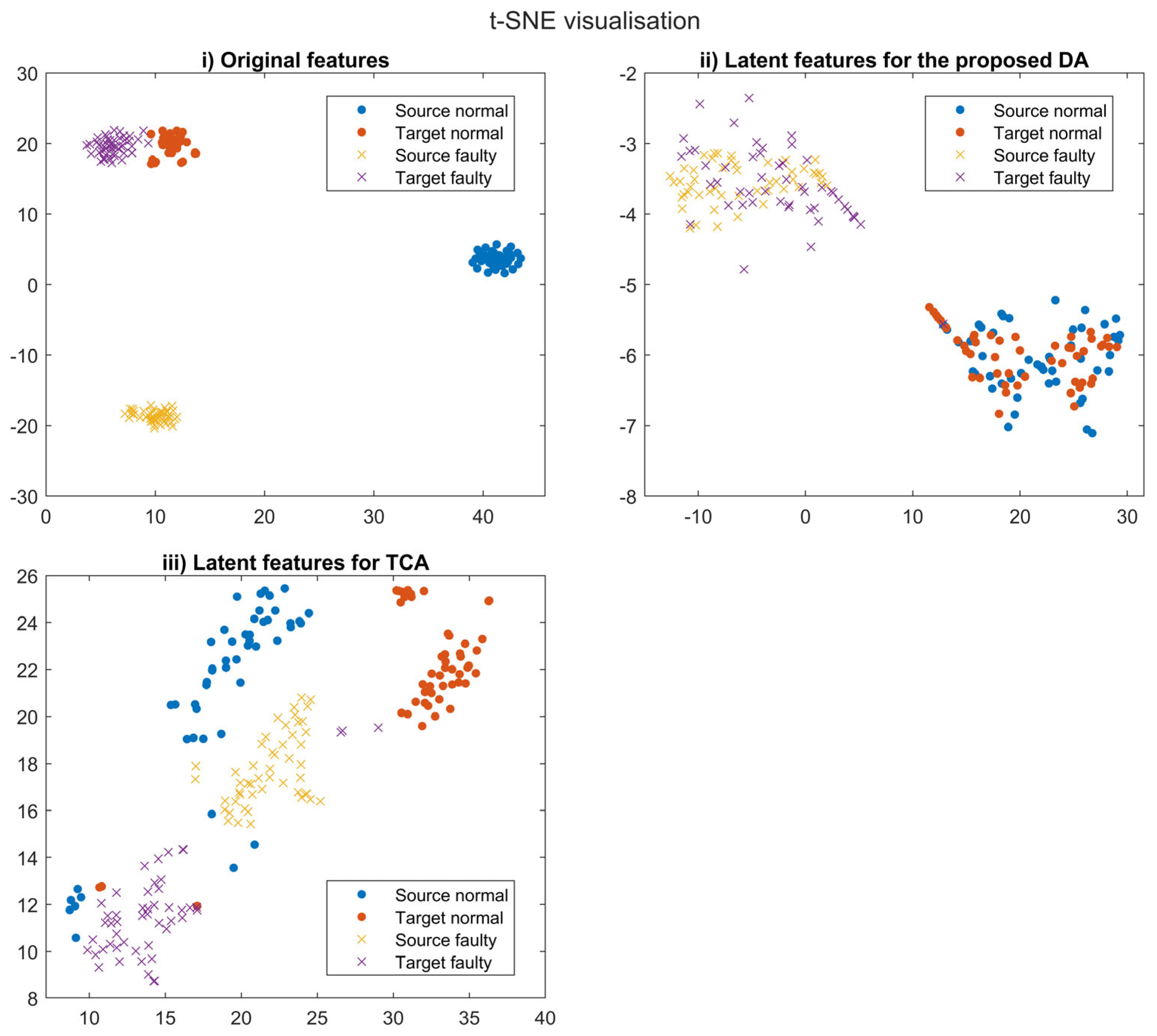
A novel fault detection approach based on one-sided DA using GANs for railway door systems has been proposed. In this study, the source and target domain data were drawn from a linear actuator test rig and a real-world railway door, respectively. Firstly, the anomaly detector and feature generator were trained using the label-rich source domain data to generate distinctive source latent features, and the target domain data were then aligned with the latent source features in a one-sided way. To the best of our knowledge, this is the first paper to propose a fault detection approach based on DA for railway door systems.
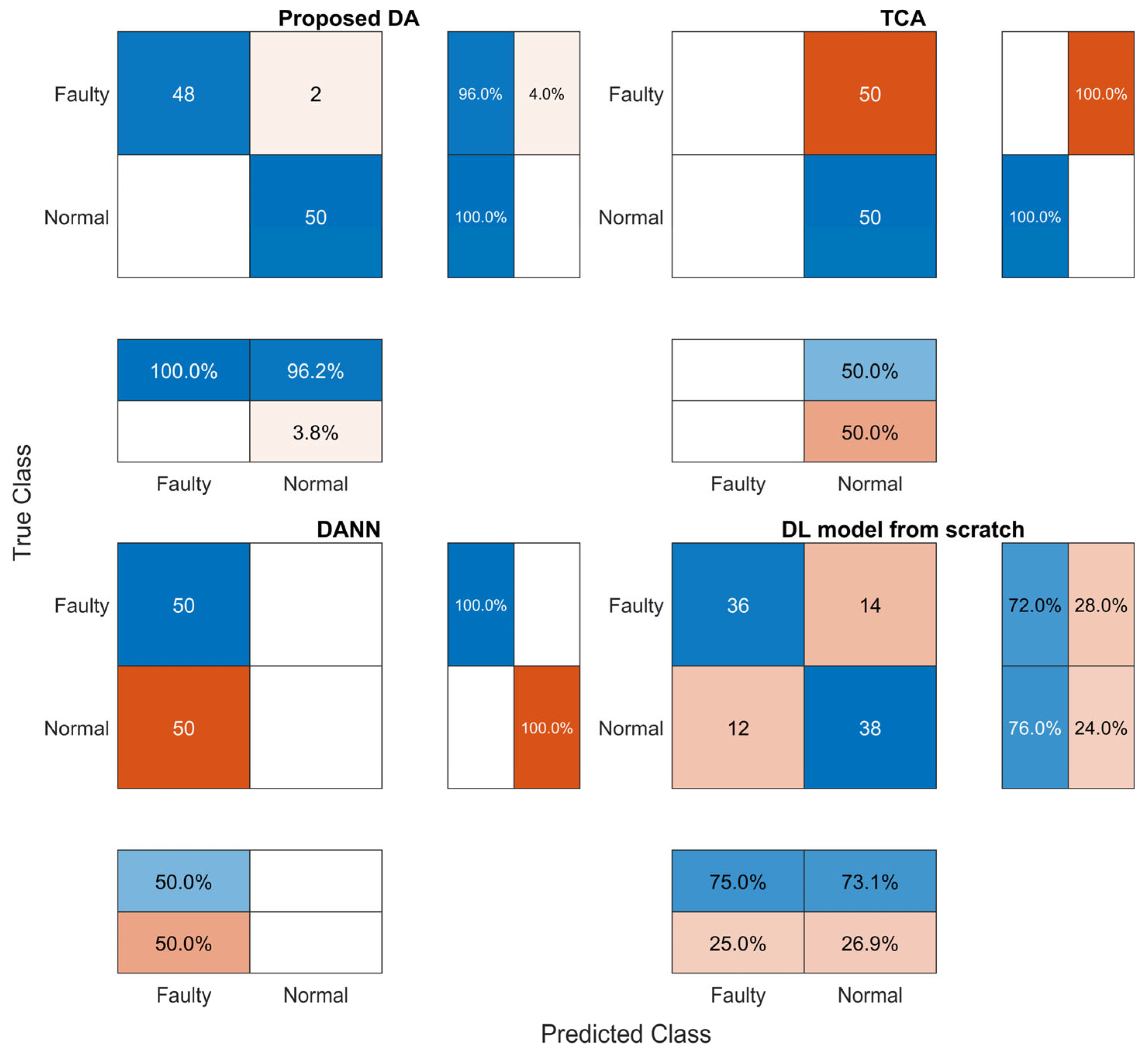
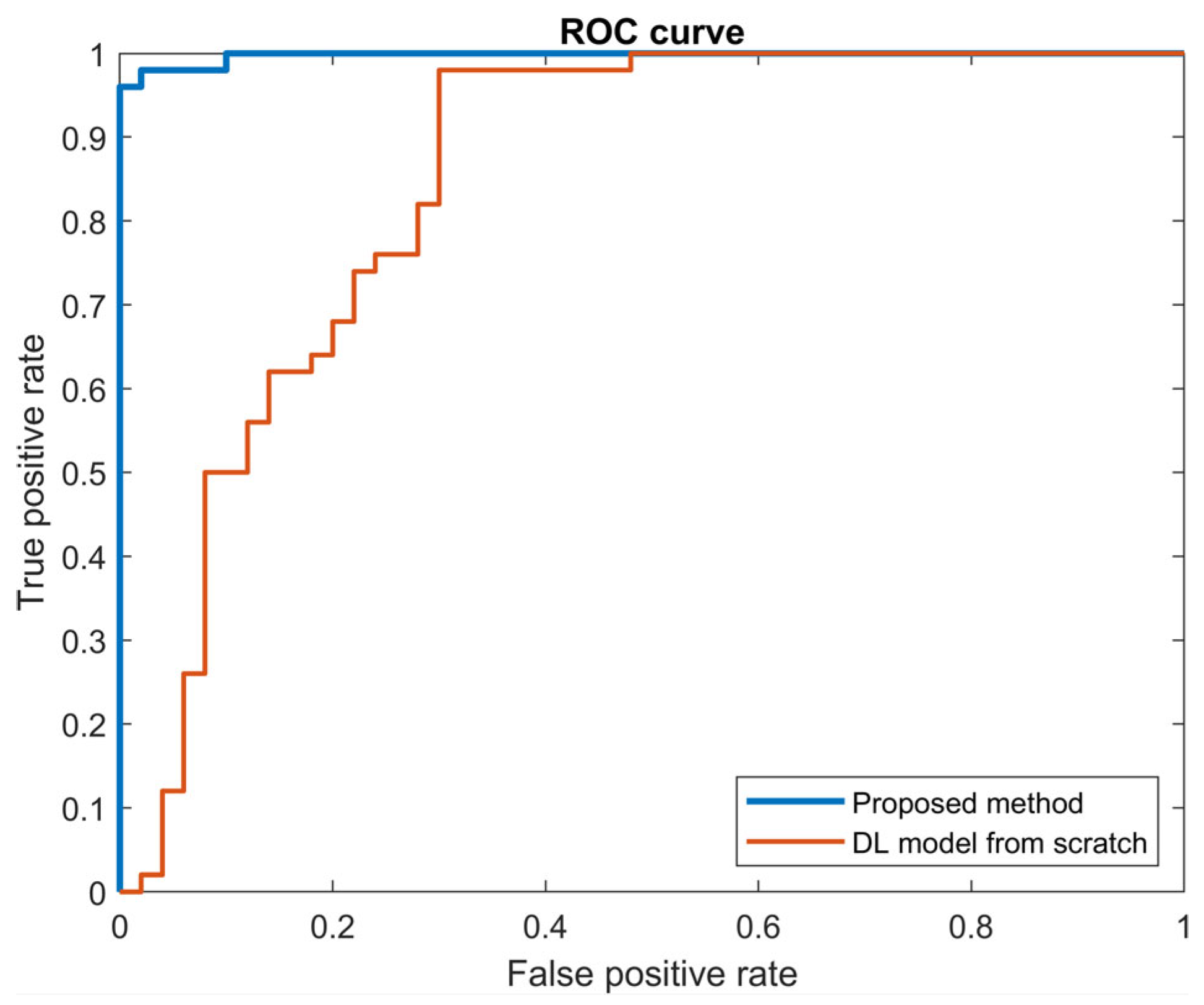
As a result, the performance metrics and sensitivity analysis results showed that the proposed method is the most accurate, with an F1 score of 97.9%, and is also the most robust against variation in the input features. Thus, the proposed method enables faulty target samples to be aligned with the source samples and detected accurately by the same anomaly detector, which is built with rich source data. This results in high reliability of fault detection for real-world applications despite the low level of similarity between different domains. Hence, the proposed method is not only the most accurate and robust compared to alternative models but also bridges the gap between theoretical domain adaptation research and tangible industrial applications.
In future research, it would be valuable to quantify the similarity between domains in order to be able to apply DA methods while maintaining high reliability. This is because the degree of similarity between the two domains that is required in order to be able to apply the DA method successfully is unclear. The method proposed in this research used a few faulty samples from a target domain to tackle this issue; however, even a few faulty samples from a target domain may sometimes be unavailable. An unsupervised DA method would then need to be employed, in which case the required degree of similarity between the two domains would be unknown. Addressing these issues could represent a direction for future work.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}