
Deep Reinforcement Learning-Based Power Allocation for Minimizing Age of Information and Energy Consumption in Multi-Input Multi-Output and Non-Orthogonal Multiple Access Internet of Things Systems

 ,
,  , , and
, , and
Abstract
:1. Introduction
- (1)
- We formulated the joint optimization problem to minimize the AoI and energy consumption of the MIMO-NOMA IoT system by determining the sample selection and power allocation. Specifically, we constructed an MIMO-NOMA channel model and an AoI model to find the relationship between transmission rate and AoI of each device under the SIC mode. Additionally, we constructed an energy consumption model. Then, the joint optimization problem was formulated based on the constructed models.
- (2)
- Then, we simplified the formulated optimization problem to make it suitable for DRL algorithms. In the formulated optimization problem, the sample selection is discrete and power allocation is continuous, which cannot be solved by the traditional DRL method and results in a challenge for optimization. We substituted the energy model and AoI model by the formulated optimization problem, merged the homogeneous terms containing sample selection and simplified the formulated problem to make it suitable to be solved by the traditional continuous-control DRL algorithm.
- (3)
- To solve the formulated optimization problem, we first designed a DRL framework which included the state, action and reward function, and then adopted the DDPG algorithm to obtain the optimal power allocation to minimize the AoI and energy consumption of the MIMO-NOMA IoT system.
- (4)
- Extensive simulations were carried out to demonstrate that the DDPG algorithm successfully optimizes both the AoI and energy consumption compared with other baseline algorithms.
2. Related Work
2.1. AoI in IoT
2.2. MIMO-NOMA IoT System
3. System Model and Problem Formulation
3.1. Scenario Description
3.2. MIMO-NOMA Channel Model
3.3. AoI Model
3.4. Energy Consumption Model
3.5. Problem Formulation
4. DRL Method for Optimization of Power Allocation
4.1. DRL Framework
- Agent: In each slot, the BS determines the transmission power and sample collection commands of each device based on its observation; thus, we consider the BS as the agent.
- State: In the system model, the state observed by the BS in slot t is defined aswhere represents the observation of device m, which is designed asHere, , and can be calculated by the BS from the historical data in slot .
- The two traditional DRL algorithms, namely DDPG and Deep Q-Learning (DQN), are suitable for continuous and discrete action space, respectively. However, and in Equation (16); thus, the space of is discrete while the space of is continuous. Hence, the optimization problem can neither be solved by DQN nor DDPG. Next, we will investigate the relationship between and to handle this dilemma.Substituting Equations (10) and (12) by Equation (13), the optimization objective is rewritten as Equation (17a). Then, substituting Equations (8) and (11) by Equation (17a), we can obtain Equation (17b), where is denoted as to indicate that it is the function of . Then, by reorganizing Equation (17b), we have Equation (17c). The first term of Equation (17c) is related with ; next, we rewrite the first term of Equation (17c) as Equation (18) to investigate the relationship between and . Substituting Equation (6) by Equation (18), we have Equation (18a). Then, by merging the homogeneous terms containing and in Equation (18a), respectively, we have Equation (18b). Let and ; thus, Equation (18b) is rewritten as Equation (18c), where is the coefficient for homogeneous terms containing in Equation (18b), and contains all terms without in Equation (18b).In and , can be calculated by the BS based on the historical data in slot [13] and is known for the BS. In addition, the BS can calculate according to Equations (4) and (5); thus, and can be further calculated according to Equations (7) and (9) given , which means that and depend on and are independent of . Hence, the optimal sample collection commands to minimize , denoted as , are achieved when the term is at its minimum; thus, we haveHence, the optimal sample collection commands can be determined according to Equation (19) when is given and Equation (13) can be rewritten asAccording to Equation (20), the action is only reflected by . Therefore, DDPG, which is suitable for the continuous action space, can be employed as the desired algorithm to solve the optimization problem in Equation (20).
- Reward function: The BS aims to minimize the AoI and energy consumption of the MIMO-NOMA IoT system, and the target of the DDPG algorithm is to maximize the reward function. Therefore, the reward function in slot t can be defined asFurthermore, the expected long-term discounted reward of the system can be defined aswhere is the discounting factor, indicates the action under the state , which is derived through policy . Thus, our objective in this paper becomes finding the optimal policy to minimize .
4.2. Optimizing Power Allocation Based on DDPG
| Algorithm 1: Training stage of the DDPG algorithm |
 |
| Algorithm 2: Testing stage of the DDPG algorithm |
 |
4.3. Complexity Investigation
5. Simulation Results and Analysis
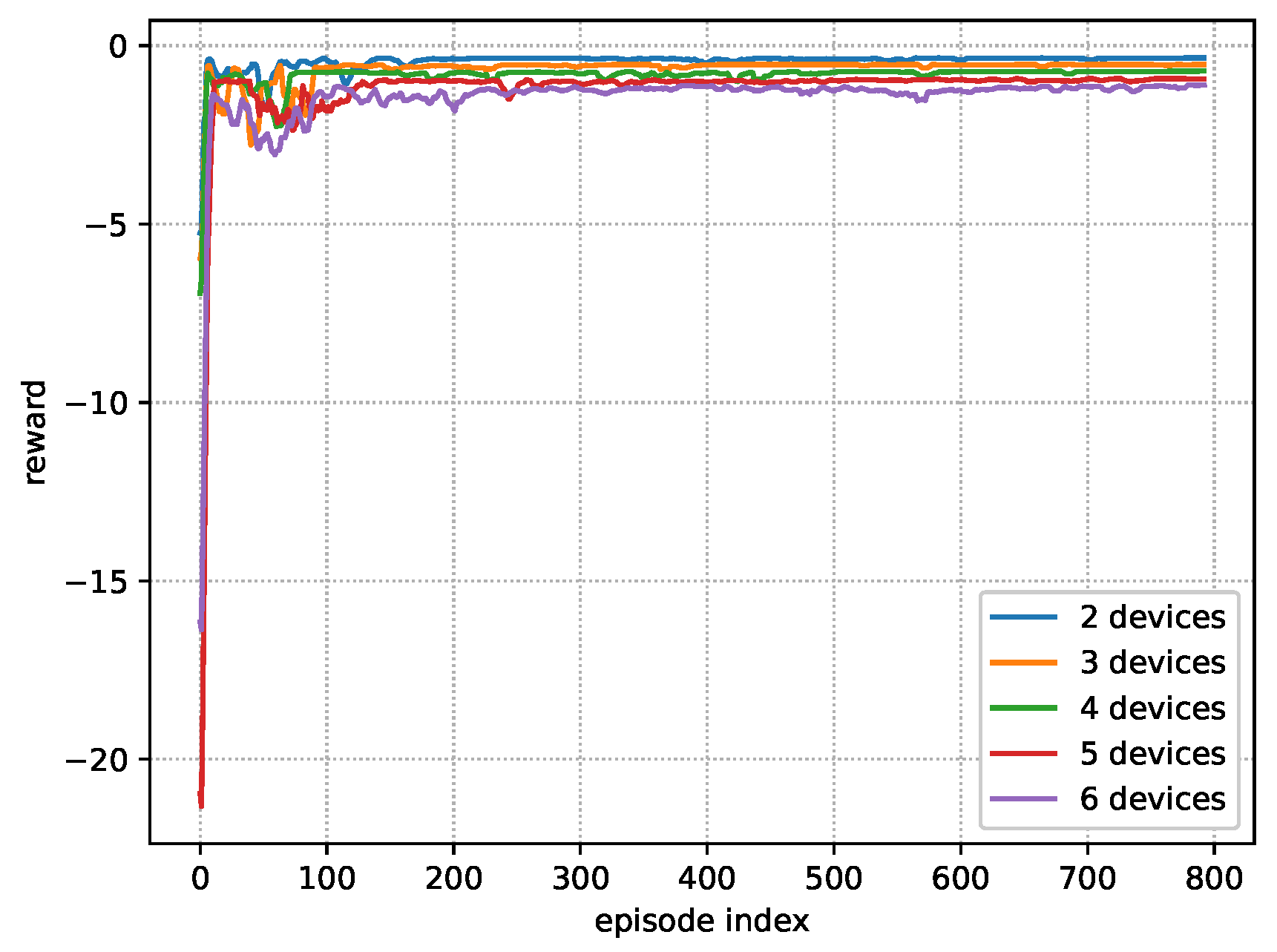
5.1. Training Stage
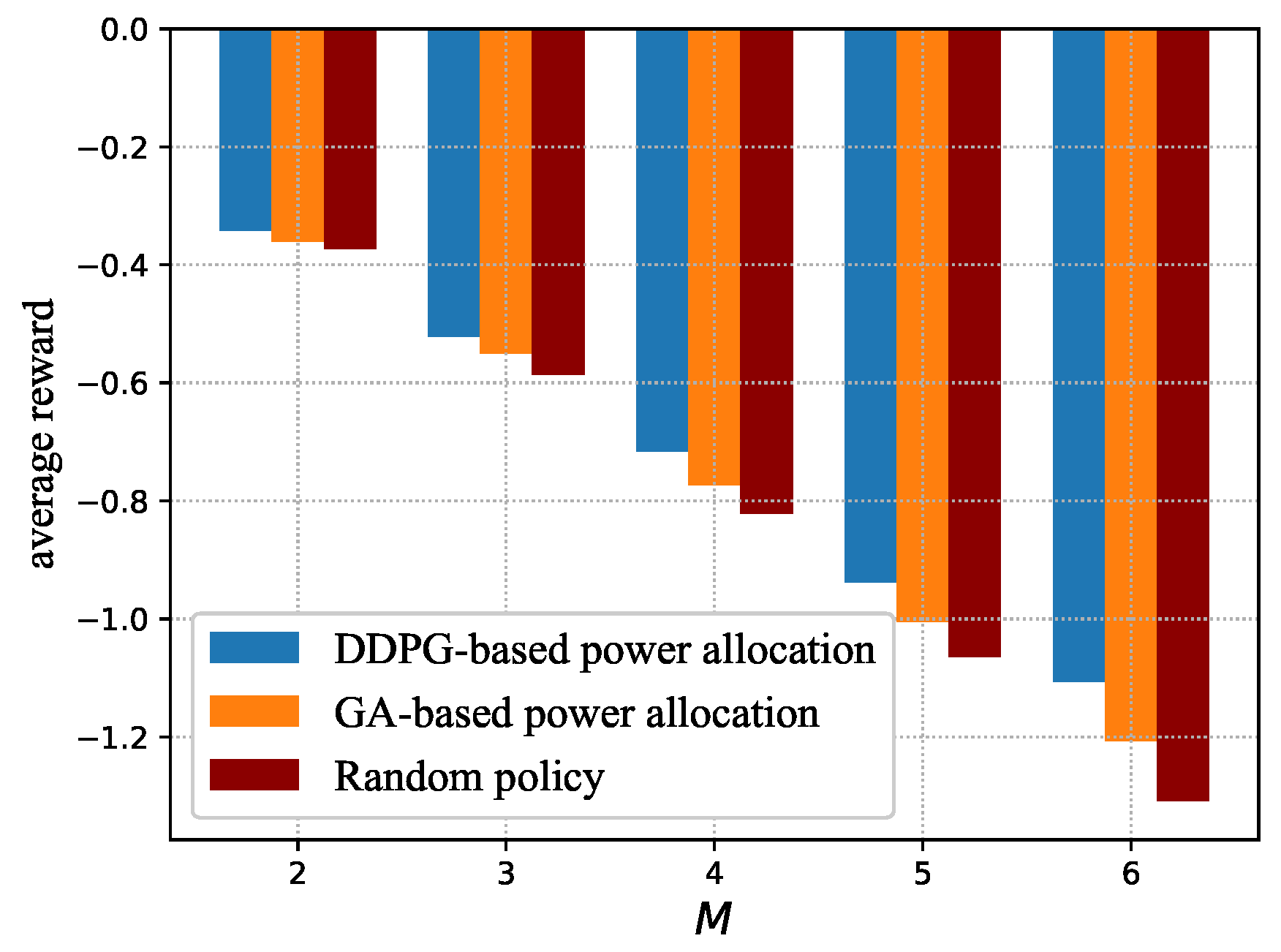
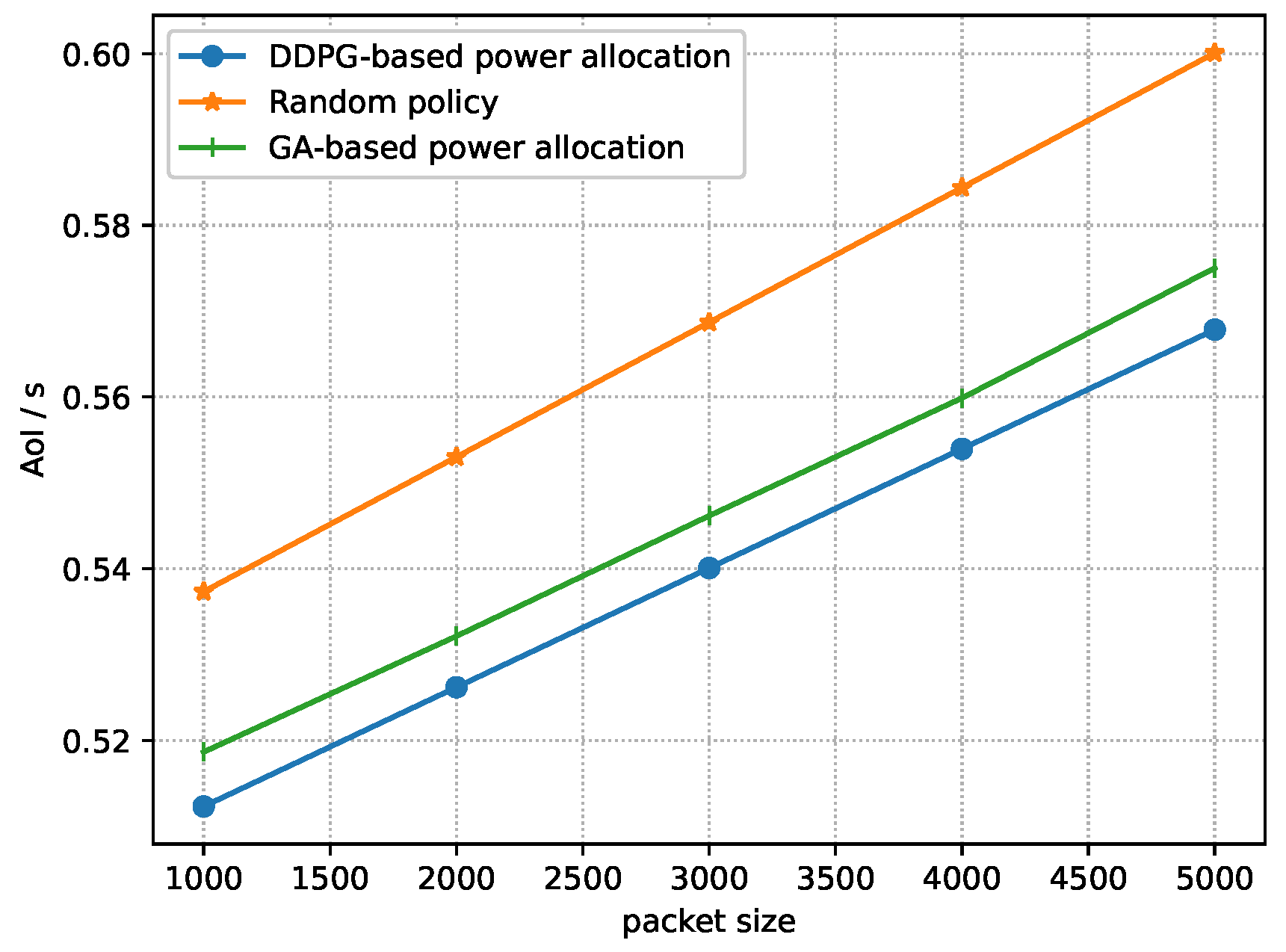
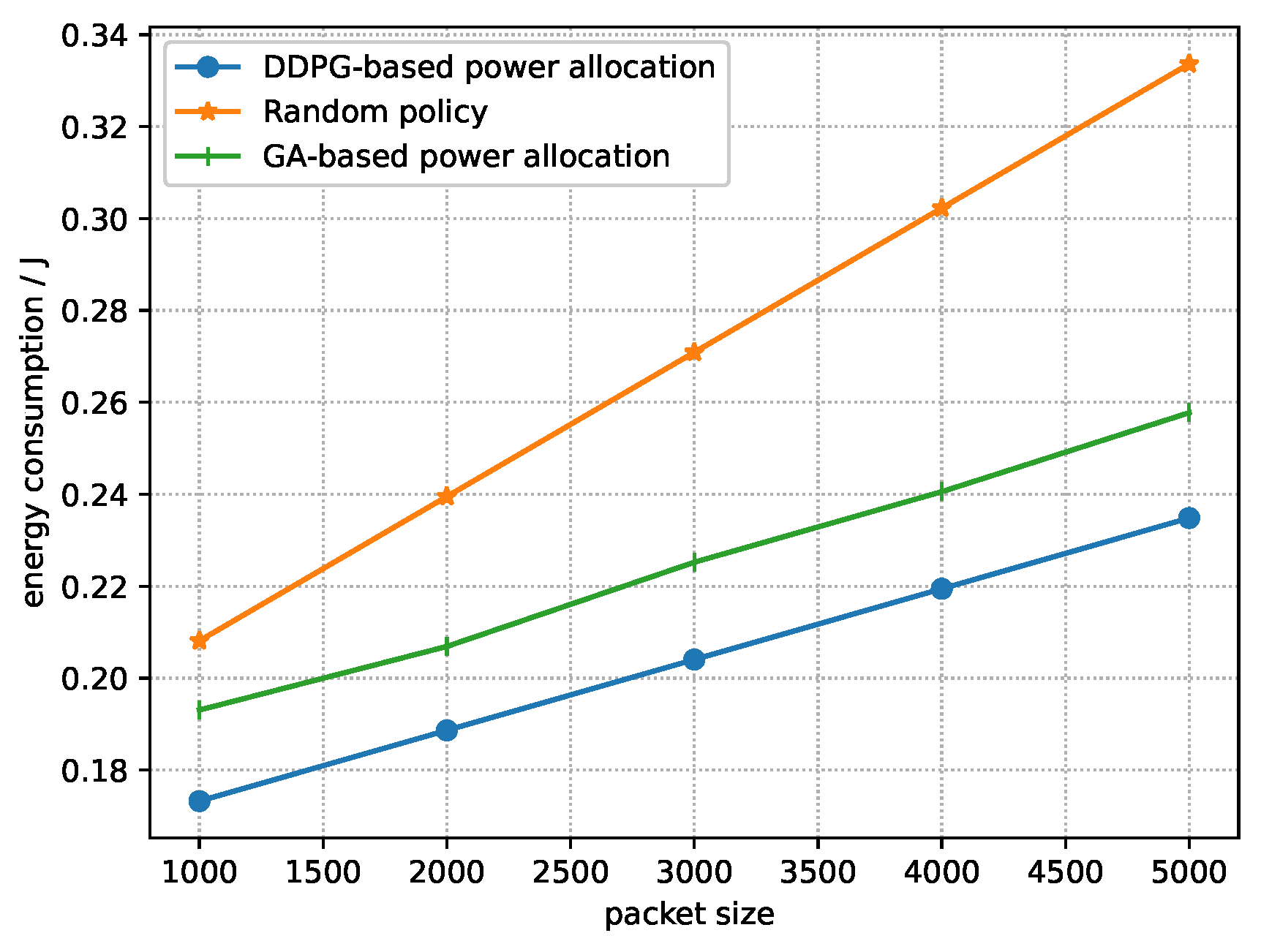
5.2. Testing Stage
- Random policy: Randomly allocate the power of each device m within and the sample collection commands is obtained according to Equation (19).
- GA-based power allocation: In each time slot, the BS randomly generates a population vector according to and a population size B. Each individual element in the population vector stands for the power allocation for all devices. The BS selects the best individuals in the population vector as offspring according to their fitness, i.e., the reward function, of each individual. Then, after evolving for times, for each evolution, the probabilities of crossover and mutation for these offspring become and , respectively, where crossover means that two individuals in the offspring exchange the power allocation of a random device, and mutation means that the power allocation of any device in the offspring is selected within randomly. After that, selecting best individuals from the offspring that has experienced crossover and mutation as the input for the next evolution. After all the evolutions, the best individual from the last offspring, which is the near-optimal power allocation derived by GA, is elected. After that, the BS calculates the optimal sample collection based on the near-optimal power allocation derived by GA according to Equation (19), and then executes the near-optimal power allocation derived by GA and the optimal sample collection. In the end, the BS iterates into the next time slot.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, Q.; Wang, X.; Fan, Q.; Fan, P.; Zhang, C.; Li, Z. High stable and accurate vehicle selection scheme based on federated edge learning in vehicular networks. China Commun. 2023, 20, 1–17. [Google Scholar] [CrossRef]
- Wu, Q.; Wang, S.; Ge, H.; Fan, P.; Fan, Q.; Letaief, K.B. Delay-Sensitive Task Offloading in Vehicular Fog Computing-Assisted Platoons. IEEE Trans. Netw. Serv. Manag. 2023. early access. [Google Scholar] [CrossRef]
- Wu, Q.; Zhao, Y.; Fan, Q.; Fan, P.; Wang, J.; Zhang, C. Mobility-Aware Cooperative Caching in Vehicular Edge Computing Based on Asynchronous Federated and Deep Reinforcement Learning. IEEE J. Sel. Top. Signal Process. 2023, 17, 66–81. [Google Scholar] [CrossRef]
- Gao, Y.; Xia, B.; Xiao, K.; Chen, Z.; Li, X.; Zhang, S. Theoretical Analysis of the Dynamic Decode Ordering SIC Receiver for Uplink NOMA Systems. IEEE Commun. Lett. 2017, 21, 2246–2249. [Google Scholar] [CrossRef]
- Wu, Q.; Shi, S.; Wan, Z.; Fan, Q.; Fan, P.; Zhang, C. Towards V2I Age-aware Fairness Access: A DQN Based Intelligent Vehicular Node Training and Test Method. Chin. J. Electron. 2022, 32, 1–15. [Google Scholar] [CrossRef]
- Bo, Z.; Saad, W. Joint Status Sampling and Updating for Minimizing Age of Information in the Internet of Things. IEEE Trans. Commun. 2019, 67, 7468–7482. [Google Scholar]
- Zhu, H.; Wu, Q.; Wu, X.J.; Fan, Q.; Fan, P.; Wang, J. Decentralized Power Allocation for MIMO-NOMA Vehicular Edge Computing Based on Deep Reinforcement Learning. IEEE Internet Things J. 2022, 9, 12770–12782. [Google Scholar] [CrossRef]
- Long, D.; Wu, Q.; Fan, Q.; Fan, P.; Li, Z.; Fan, J. A Power Allocation Scheme for MIMO-NOMA and D2D Vehicular Edge Computing Based on Decentralized DRL. Sensors 2023, 23, 3449. [Google Scholar] [CrossRef] [PubMed]
- Volodymyr, M.; Koray, K.; David, S.; Rusu, A.A.; Joel, V.; Bellemare, M.G.; Alex, G.; Martin, R.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2019, 518, 529–533. [Google Scholar]
- Zhao, T.; He, L.; Huang, X.; Li, F. DRL-Based Secure Video Offloading in MEC-Enabled IoT Networks. IEEE Internet Things J. 2022, 9, 18710–18724. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, Y.; Yang, B.; Taleb, T. Joint Caching and Computing Service Placement for Edge-Enabled IoT Based on Deep Reinforcement Learning. IEEE Internet Things J. 2022, 9, 19501–19514. [Google Scholar] [CrossRef]
- Grybosi, J.F.; Rebelatto, J.L.; Moritz, G.L. Age of Information of SIC-Aided Massive IoT Networks With Random Access. IEEE Internet Things J. 2022, 9, 662–670. [Google Scholar] [CrossRef]
- Wang, S.; Chen, M.; Yang, Z.; Yin, C.; Saad, W.; Cui, S.; Poor, H.V. Distributed Reinforcement Learning for Age of Information Minimization in Real-Time IoT Systems. IEEE J. Sel. Top. Signal Process. 2022, 16, 501–515. [Google Scholar] [CrossRef]
- Abd-Elmagid, M.A.; Dhillon, H.S.; Pappas, N. AoI-Optimal Joint Sampling and Updating for Wireless Powered Communication Systems. IEEE Trans. Veh. Technol. 2020, 69, 14110–14115. [Google Scholar] [CrossRef]
- Li, C.; Huang, Y.; Li, S.; Chen, Y.; Jalaian, B.A.; Hou, Y.T.; Lou, W.; Reed, J.H.; Kompella, S. Minimizing AoI in a 5G-Based IoT Network Under Varying Channel Conditions. IEEE Internet Things J. 2021, 8, 14543–14558. [Google Scholar] [CrossRef]
- Hatami, M.; Leinonen, M.; Codreanu, M. AoI Minimization in Status Update Control with Energy Harvesting Sensors. IEEE Trans. Wireless Commun. 2021, 69, 8335–8351. [Google Scholar] [CrossRef]
- Sun, M.; Xu, X.; Qin, X.; Zhang, P. AoI-Energy-Aware UAV-assisted Data Collection for IoT Networks: A Deep Reinforcement Learning Method. IEEE Internet Things J. 2021, 8, 17275–17289. [Google Scholar] [CrossRef]
- Hu, H.; Xiong, K.; Qu, G.; Ni, Q.; Fan, P.; Letaief, K.B. AoI-Minimal Trajectory Planning and Data Collection in UAV-Assisted Wireless Powered IoT Networks. IEEE Internet Things J. 2021, 8, 1211–1223. [Google Scholar] [CrossRef]
- Emara, M.; Elsawy, H.; Bauch, G. A Spatiotemporal Model for Peak AoI in Uplink IoT Networks: Time Versus Event-Triggered Traffic. IEEE Internet Things J. 2020, 7, 6762–6777. [Google Scholar] [CrossRef]
- Lyu, L.; Dai, Y.; Cheng, N.; Zhu, S.; Guan, X.; Lin, B.; Shen, X. AoI-Aware Co-Design of Cooperative Transmission and State Estimation for Marine IoT Systems. IEEE Internet Things J. 2021, 8, 7889–7901. [Google Scholar] [CrossRef]
- Wang, X.; Chen, C.; He, J.; Zhu, S.; Guan, X. AoI-Aware Control and Communication Co-Design for Industrial IoT Systems. IEEE Internet Things J. 2021, 8, 8464–8473. [Google Scholar] [CrossRef]
- Hao, X.; Yang, T.; Hu, Y.; Feng, H.; Hu, B. An Adaptive Matching Bridged Resource Allocation Over Correlated Energy Efficiency and AoI in CR-IoT System. IEEE Trans. Green Commun. Netw. 2022, 6, 583–599. [Google Scholar] [CrossRef]
- Yilmaz, S.S.; Özbek, B.; İlgüy, M.; Okyere, B.; Musavian, L.; Gonzalez, J. User Selection for NOMA based MIMO with Physical Layer Network Coding in Internet of Things Applications. IEEE Internet Things J. 2021, 9, 14998–15006. [Google Scholar] [CrossRef]
- Shi, Z.; Wang, H.; Fu, Y.; Yang, G.; Ma, S.; Hou, F.; Tsiftsis, T.A. Zero-Forcing-Based Downlink Virtual MIMO–NOMA Communications in IoT Networks. IEEE Internet Things J. 2020, 7, 2716–2737. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, Z. Beamforming Optimization and Power Allocation for User-Centric MIMO-NOMA IoT Networks. IEEE Access 2021, 9, 339–348. [Google Scholar] [CrossRef]
- Han, L.; Liu, R.; Wang, Z.; Yue, X.; Thompson, J.S. Millimeter-Wave MIMO-NOMA-Based Positioning System for Internet-of-Things Applications. IEEE Internet Things J. 2020, 7, 11068–11077. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, L.; Luo, H.; Ma, X.; Zhou, S. AoI-Delay Tradeoff in Mobile Edge Caching With Freshness-Aware Content Refreshing. IEEE Trans. Wireless Commun. 2021, 20, 5329–5342. [Google Scholar] [CrossRef]
- Chinnadurai, S.; Yoon, D. Energy Efficient MIMO-NOMA HCN with IoT for Wireless Communication Systems. In Proceedings of the 2018 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 17–19 October 2018; pp. 856–859. [Google Scholar] [CrossRef]
- Gao, J.; Wang, X.; Shen, R.; Xu, Y. User Clustering and Power Allocation for mmWave MIMO-NOMA with IoT devices. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Feng, W.; Zhao, N.; Ao, S.; Tang, J.; Zhang, X.; Fu, Y.; So, D.K.C.; Wong, K.K. Joint 3D Trajectory and Power Optimization for UAV-Aided mmWave MIMO-NOMA Networks. IEEE Trans. Commun. 2021, 69, 2346–2358. [Google Scholar] [CrossRef]
- Ding, Z.; Dai, L.; Poor, H.V. MIMO-NOMA Design for Small Packet Transmission in the Internet of Things. IEEE Access 2016, 4, 1393–1405. [Google Scholar] [CrossRef]
- Bulut, I.S.; Ilhan, H. Energy Harvesting Optimization of Uplink-NOMA System for IoT Networks Based on Channel Capacity Analysis Using the Water Cycle Algorithm. IEEE Trans. Green Commun. Netw. 2021, 5, 291–307. [Google Scholar] [CrossRef]
- Ullah, S.A.; Zeb, S.; Mahmood, A.; Hassan, S.A.; Gidlund, M. Deep RL-assisted Energy Harvesting in CR-NOMA Communications for NextG IoT Networks. In Proceedings of the 2022 IEEE Globecom Workshops (GC Wkshps), Rio de Janeiro, Brazil, 4–8 December 2022; pp. 74–79. [Google Scholar] [CrossRef]
- Kang, J.M.; Kim, I.M.; Chun, C.J. Deep Learning-Based MIMO-NOMA With Imperfect SIC Decoding. IEEE Syst. J. 2020, 14, 3414–3417. [Google Scholar] [CrossRef]
- He, X.; Huang, Z.; Wang, H.; Song, R. Sum Rate Analysis for Massive MIMO-NOMA Uplink System with Group-Level Successive Interference Cancellation. IEEE Wirel. Commun. Lett. 2023, 12, 1194–1198. [Google Scholar] [CrossRef]
- Wang, S.; Chen, M.; Saad, W.; Yin, C.; Cui, S.; Poor, H.V. Reinforcement Learning for Minimizing Age of Information under Realistic Physical Dynamics. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Qiao, G.; Leng, S.; Maharjan, S.; Zhang, Y.; Ansari, N. Deep Reinforcement Learning for Cooperative Content Caching in Vehicular Edge Computing and Networks. IEEE Internet Things J. 2020, 7, 247–257. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 2014 International Conference on Machine Learning(ICML), Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Kingma, D.P.; Ba, J. ADAM: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Uhlenbeck, G.E.; Ornstein, L.S. On the Theory of the Brownian Motion. Rev. Latinoam. Microbiol. 1973, 15, 29–35. [Google Scholar] [CrossRef]
- Ngo, H.Q.; Larsson, E.G.; Marzetta, T.L. Energy and Spectral Efficiency of Very Large Multiuser MIMO Systems. IEEE Trans. Commun. 2013, 61, 1436–1449. [Google Scholar] [CrossRef]
- Darsena, D.; Gelli, G.; Iudice, I.; Verde, F. A Hybrid NOMA-OMA Scheme for Inter-plane Intersatellite Communications in Massive LEO Constellations. arXiv 2023, arXiv:2307.08340. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | MIMO-NOMA | AoI Minimization | Energy Optimization |
|---|---|---|---|
| [12,15,17,18,19] | × | ✓ | × |
| [13,14,16,22] | × | ✓ | ✓ |
| [25,28,29,32,33] | ✓ | × | ✓ |
| [23,24,26,27] | ✓ | × | × |
| Notation | Description | Notation | Description |
|---|---|---|---|
| B | Population size of genetic algorithm. | The energy consumption to sample fresh information and generate upload packet. | |
| Complex data symbol with 1 as variance. | The communication distance between device m and BS. | ||
| E | Number of episodes. | Probability of offspring in genetic algorithm for crossover/mutation. | |
| Complexity of the primary networks for computing gradients/updating parameters. | The channel vector between device m and BS in slot t. | ||
| i | Index of transition tuples in mini-batch. | I | The number of transition tuples in a mini-batch. |
| The set of devices in which the received power is weaker than device m. | The long-term discounted reward under policy . | ||
| K | The number of antennas equipped in BS. | The transmission delay of device m in slot t. | |
| L | Loss function. | Additive white Gaussian noise. | |
| Evolution times of genetic algorithm | Index/number/set of devices. | ||
| State in slot t of all devices/device m | / | Transmission power of all devices/device m. | |
| Maximum transmission power device m. | Action-value function under and . | ||
| Action-value function under and . | Q | Packet size. | |
| Reward function. | / | Indicator of sample or not for all devices/device m. | |
| / | Indicator of sample or not for all devices/device m. | Complexity of calculating sample decisions based on power allocation. | |
| Complexity of calculating sample decisions based on power allocation. | t/ | Index/set of slot. | |
| The set of undecoded received power of BS. | / | Indicator of transmission success for all devices/device m. | |
| W | Bandwidth of system. | / | Learning rate of actor network/critic network. |
| Discounting factor. | , | Weighted factors of reward function. | |
| Received power of BS for device m in slot t. | Exploration noise. | ||
| The energy consumed by device m in slot t. | The average sum energy consumption in slot t. | ||
| / | Parameters of critic-network/target critic-network. | // | Parameters of actor-network/target actor-network/optimal policy. |
| The constant for the update of target networks. | Policy approximated by actor-network with . | ||
| Transmission rate of device m in slot t. | Normalized channel correlation coefficient. | ||
| Variance of received signal’s noise. | / | AoI of device m in slot t on device/BS. | |
| The average sum AoI. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Q.; Zhang, Z.; Zhu, H.; Fan, P.; Fan, Q.; Zhu, H.; Wang, J. Deep Reinforcement Learning-Based Power Allocation for Minimizing Age of Information and Energy Consumption in Multi-Input Multi-Output and Non-Orthogonal Multiple Access Internet of Things Systems. Sensors 2023, 23, 9687. https://doi.org/10.3390/s23249687
Wu Q, Zhang Z, Zhu H, Fan P, Fan Q, Zhu H, Wang J. Deep Reinforcement Learning-Based Power Allocation for Minimizing Age of Information and Energy Consumption in Multi-Input Multi-Output and Non-Orthogonal Multiple Access Internet of Things Systems. Sensors. 2023; 23(24):9687. https://doi.org/10.3390/s23249687
Chicago/Turabian StyleWu, Qiong, Zheng Zhang, Hongbiao Zhu, Pingyi Fan, Qiang Fan, Huiling Zhu, and Jiangzhou Wang. 2023. "Deep Reinforcement Learning-Based Power Allocation for Minimizing Age of Information and Energy Consumption in Multi-Input Multi-Output and Non-Orthogonal Multiple Access Internet of Things Systems" Sensors 23, no. 24: 9687. https://doi.org/10.3390/s23249687
APA StyleWu, Q., Zhang, Z., Zhu, H., Fan, P., Fan, Q., Zhu, H., & Wang, J. (2023). Deep Reinforcement Learning-Based Power Allocation for Minimizing Age of Information and Energy Consumption in Multi-Input Multi-Output and Non-Orthogonal Multiple Access Internet of Things Systems. Sensors, 23(24), 9687. https://doi.org/10.3390/s23249687