
Defect Detection of MEMS Based on Data Augmentation, WGAN-DIV-DC, and a YOLOv5 Model



Abstract
:1. Introduction
1.1. Related Works
1.2. Paper Contribution
2. Method
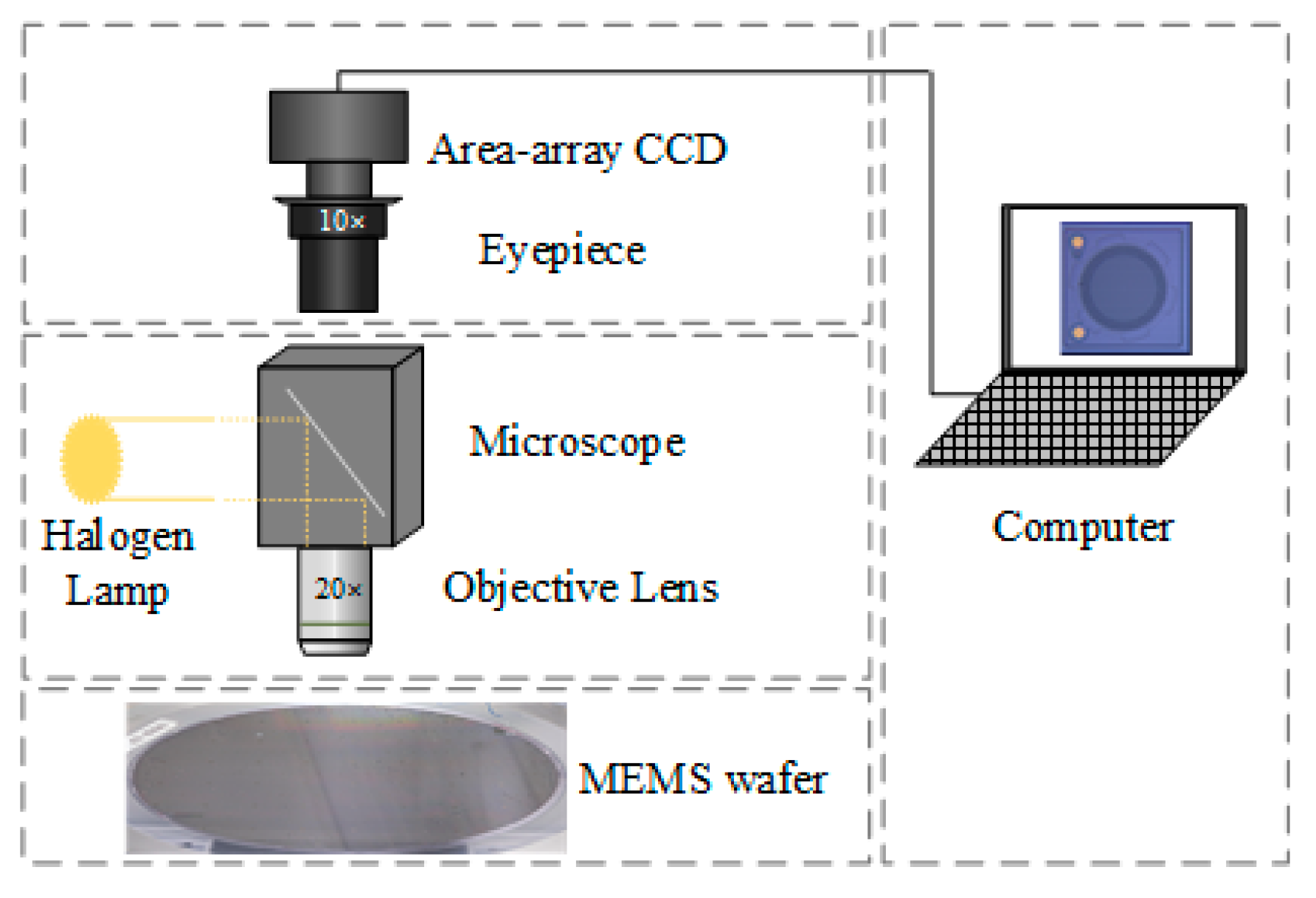
2.1. Dataset Collection
2.2. Data Augmentation
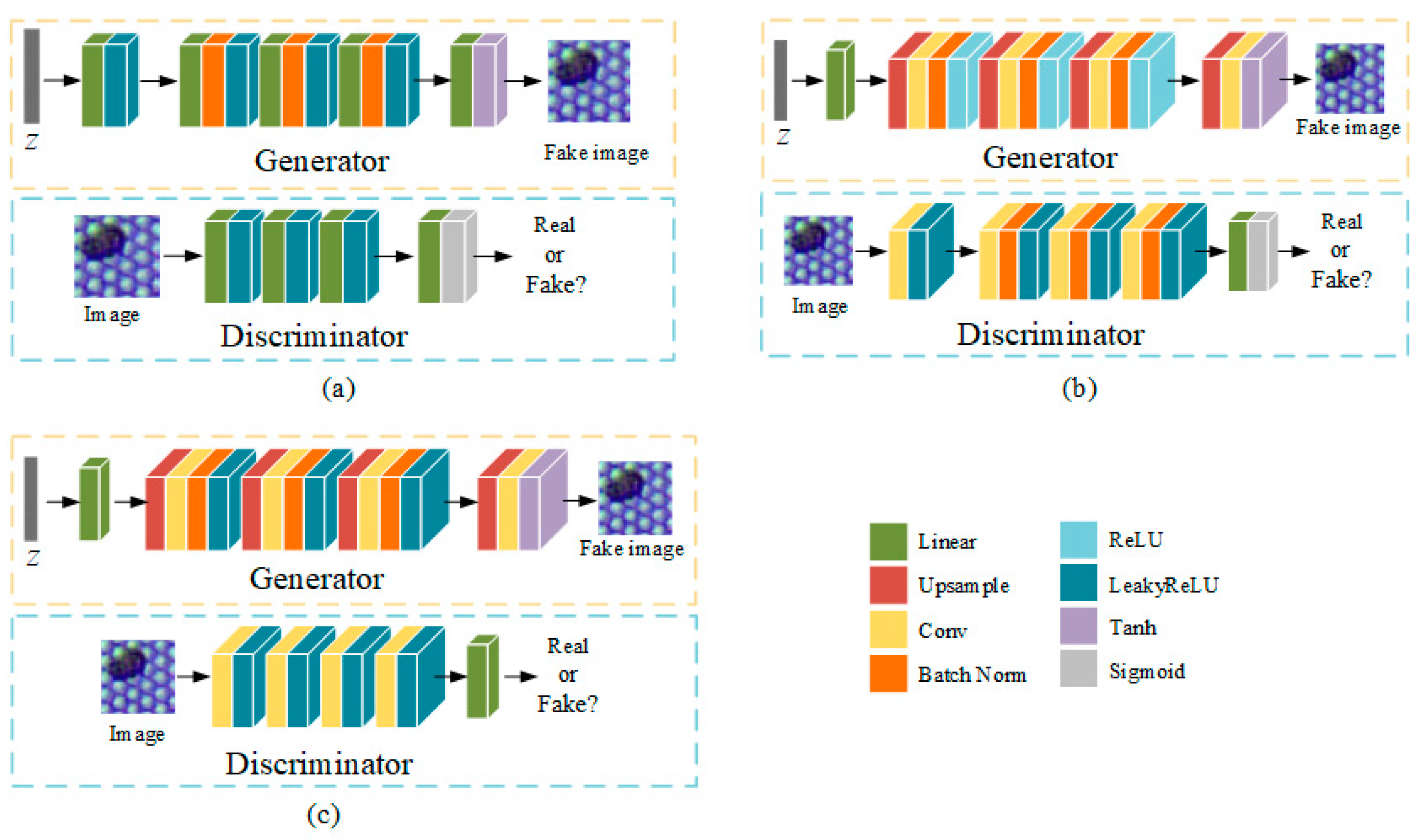
2.2.1. Deep Convolutional Generative Adversarial Network
2.2.2. Wasserstein Generative Adversarial Network
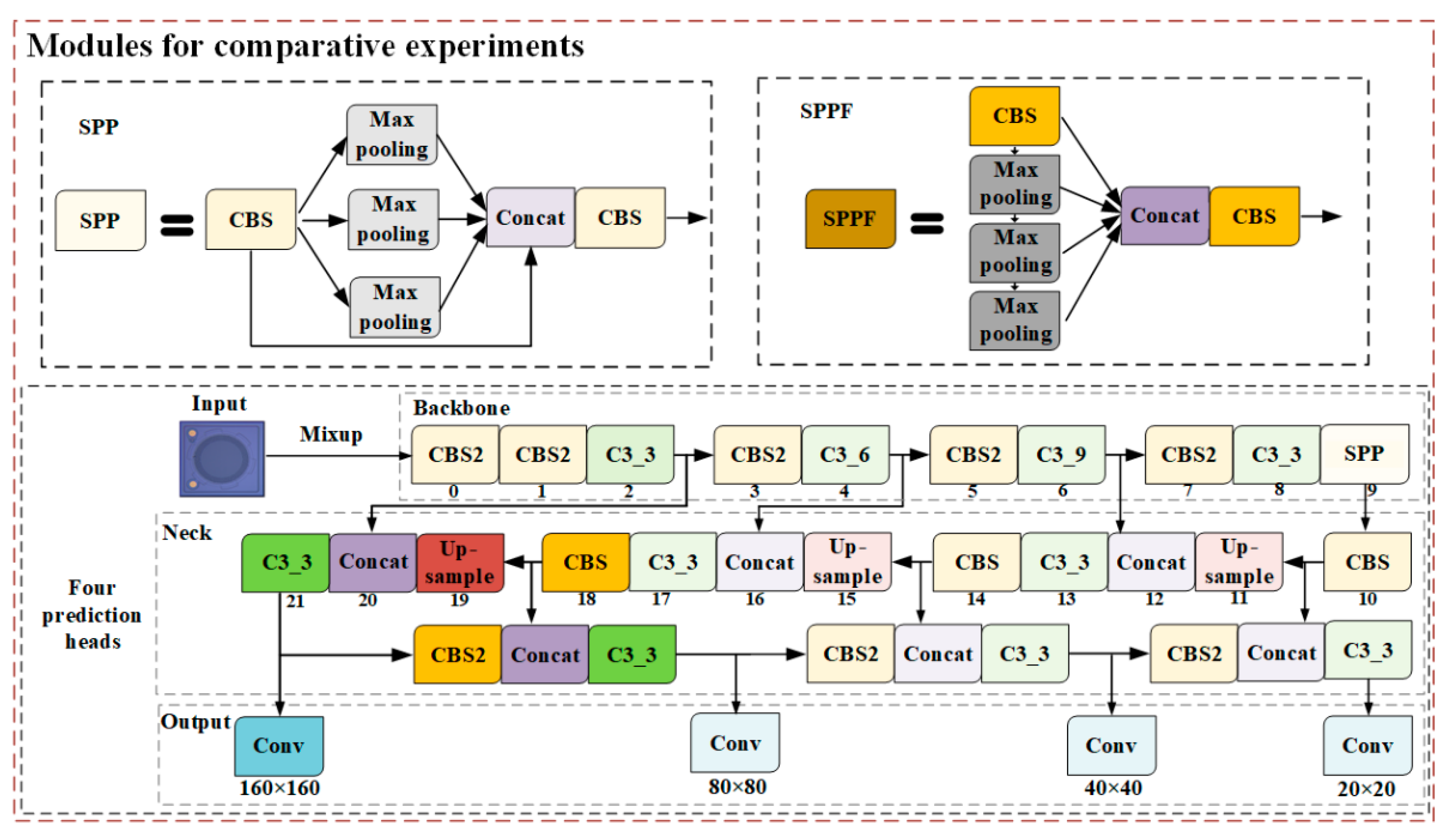
2.3. Yolov5 Algorithm
2.4. Modules for Comparative Experiments
3. Experimental Results and Discussions
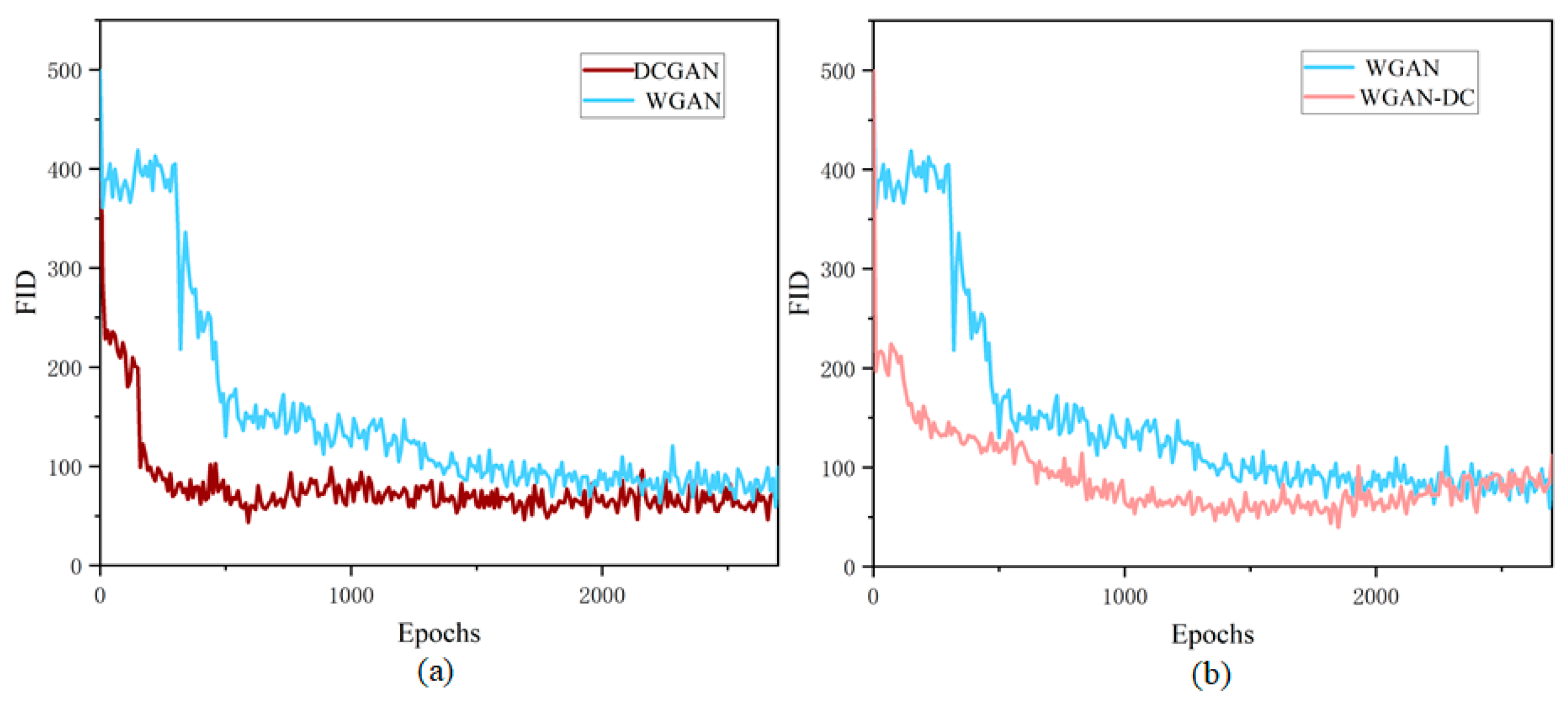
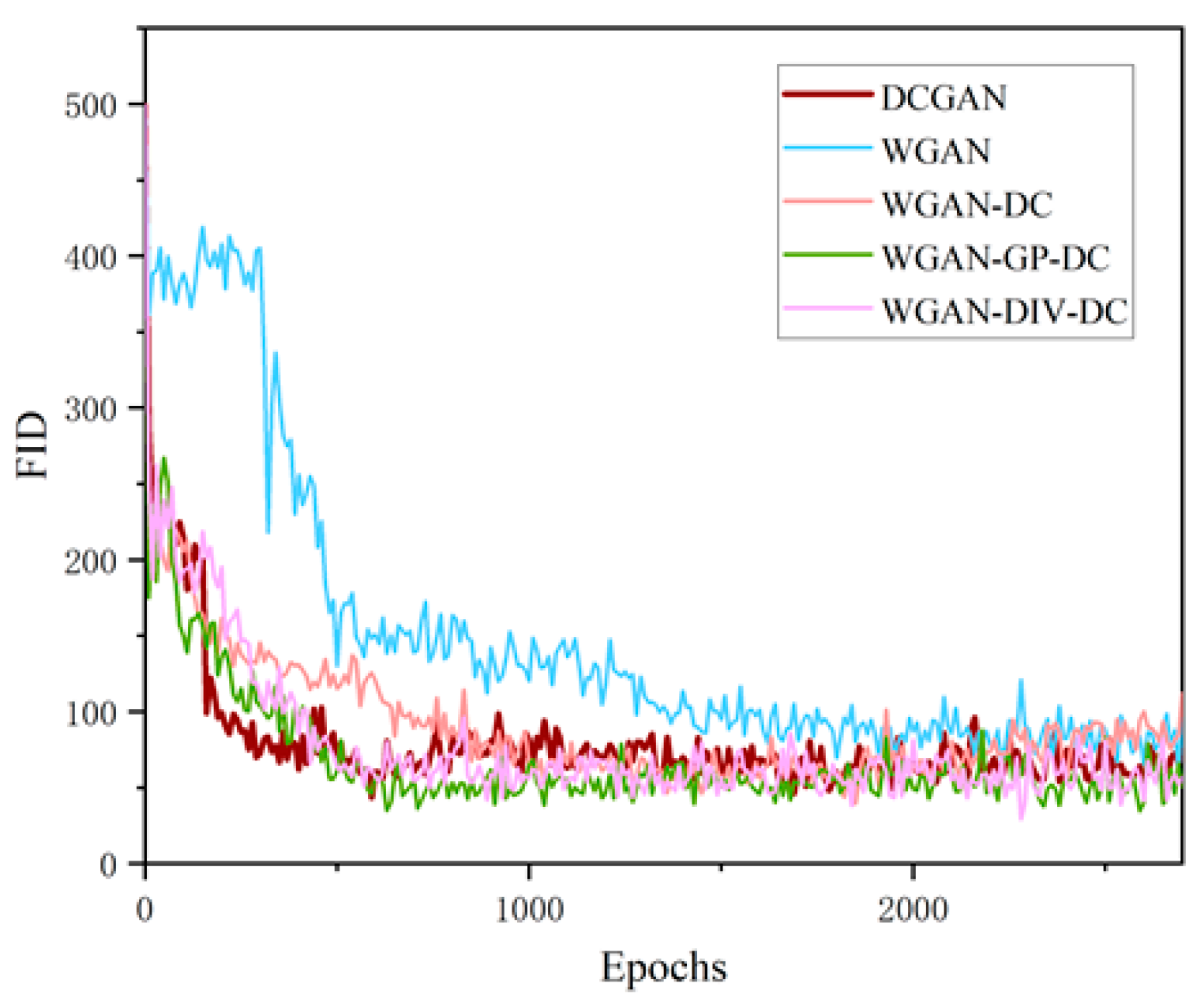
3.1. Data Augmentation
3.2. Detection Performance Comparison
3.2.1. Training Setting
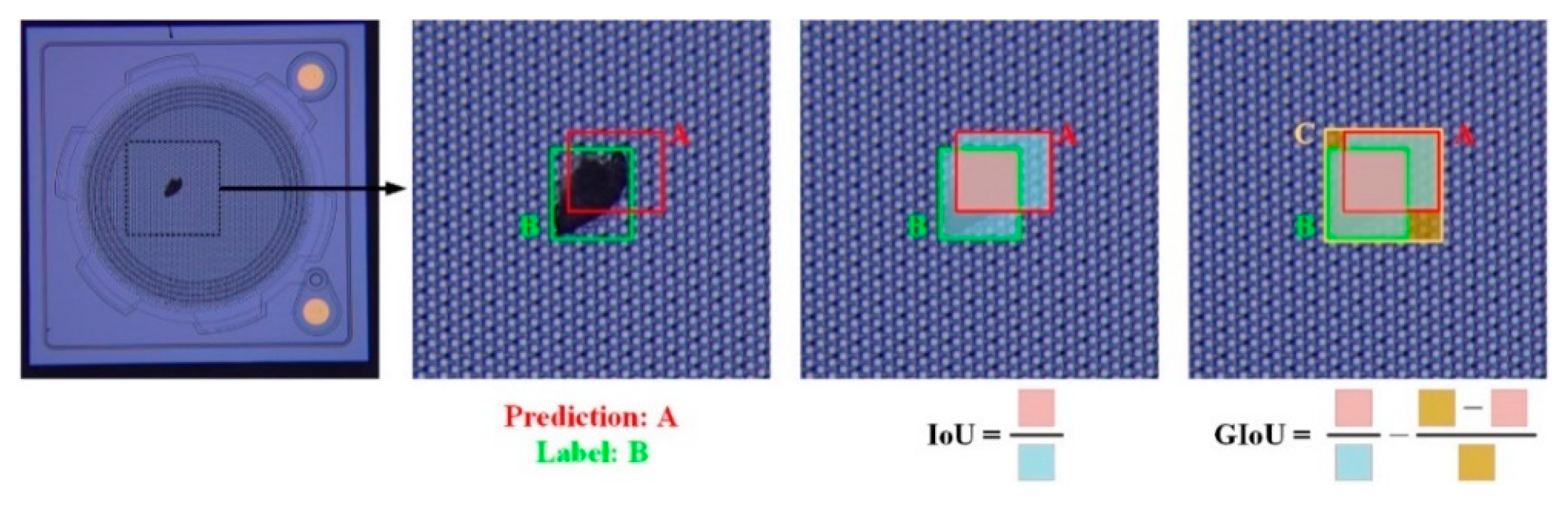
3.2.2. Model Evaluation Metrics
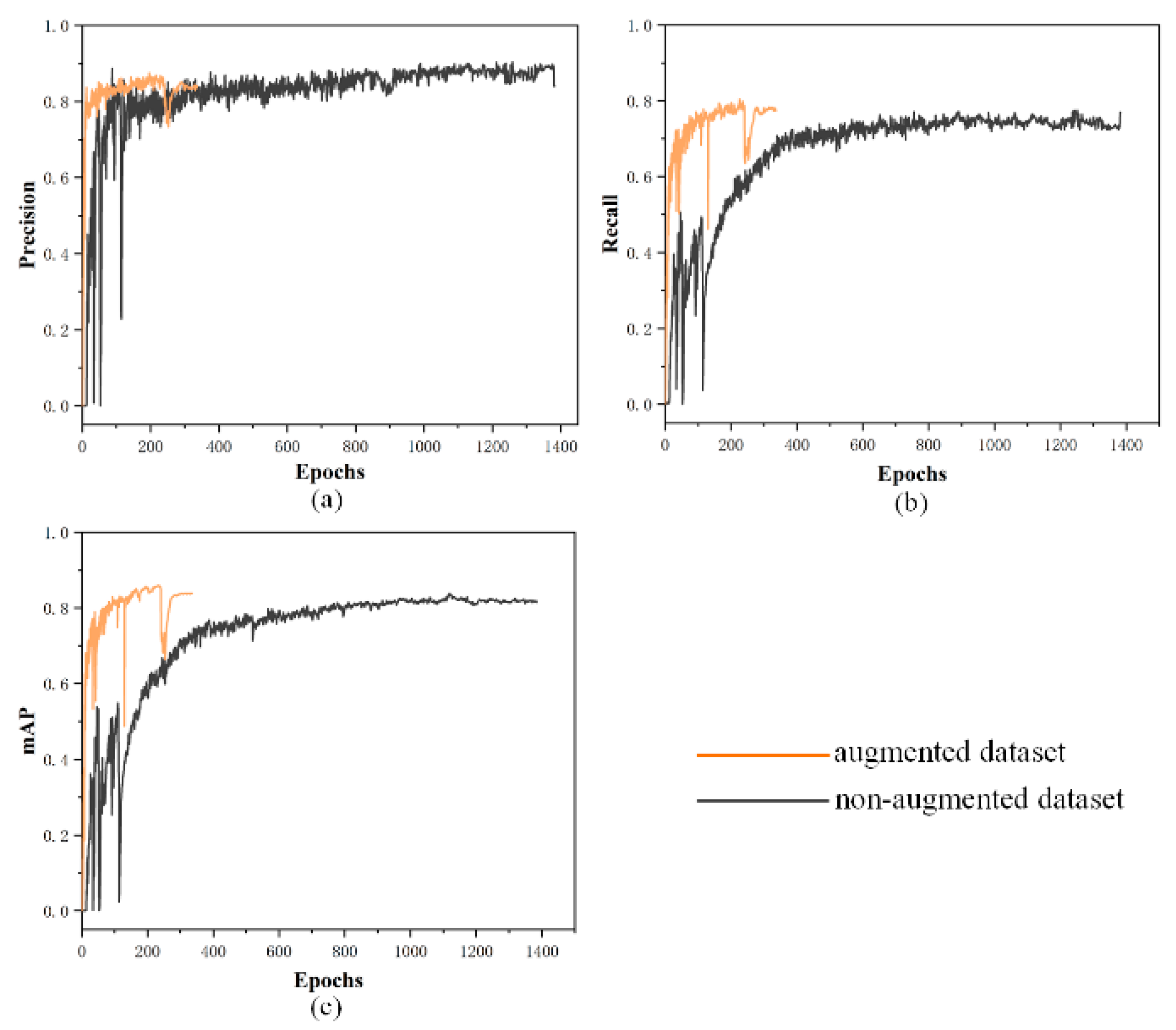
3.2.3. Training Results and Discussions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Narendran, G.; Perumal, D.A.; Gnanasekeran, N. A review of lattice boltzmann method computational domains for micro-and nanoregime applications. Nanosci. Technol. Int. J. 2020, 11, 343–373. [Google Scholar] [CrossRef]
- Liu, H.-F.; Luo, Z.-C.; Hu, Z.-K.; Yang, S.-Q.; Tu, L.-C.; Zhou, Z.-B.; Kraft, M. A review of high-performance MEMS sensors for resource exploration and geophysical applications. Pet. Sci. 2022. [Google Scholar] [CrossRef]
- Wang, X.; Jia, X.; Jiang, C.; Jiang, S. A wafer surface defect detection method built on generic object detection network. Digit. Signal Process. 2022, 130, 103718. [Google Scholar] [CrossRef]
- Ying, X. An Overview of Overfitting and Its Solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- de la Rosa, F.L.; Gómez-Sirvent, J.L.; Sánchez-Reolid, R.; Morales, R.; Fernández-Caballero, A. Geometric transformation-based data augmentation on defect classification of segmented images of semiconductor materials using a ResNet50 convolutional neural network. Expert Syst. Appl. 2022, 206, 117731. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Chen, S.-H.; Kang, C.-H.; Perng, D.-B. Detecting and measuring defects in wafer die using gan and yolov3. Appl. Sci. 2020, 10, 8725. [Google Scholar] [CrossRef]
- Li, W.; Fan, L.; Wang, Z.; Ma, C.; Cui, X. Tackling mode collapse in multi-generator GANs with orthogonal vectors. Pattern Recognit. 2021, 110, 107646. [Google Scholar] [CrossRef]
- Yu, S.; Zhang, K.; Xiao, C.; Huang, J.Z.; Li, M.J.; Onizuka, M. HSGAN: Reducing mode collapse in GANs by the latent code distance of homogeneous samples. Comput. Vis. Image Underst. 2022, 214, 103314. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Xiao, Y.; Wu, J.; Lin, Z. Cancer diagnosis using generative adversarial networks based on deep learning from imbalanced data. Comput. Biol. Med. 2021, 135, 104540. [Google Scholar] [CrossRef] [PubMed]
- Tello, G.; Al-Jarrah, O.Y.; Yoo, P.D.; Al-Hammadi, Y.; Muhaidat, S.; Lee, U. Deep-structured machine learning model for the recognition of mixed-defect patterns in semiconductor fabrication processes. IEEE Trans. Semicond. Manuf. 2018, 31, 315–322. [Google Scholar] [CrossRef]
- Amini, A.; Kanfoud, J.; Gan, T.-H. An Artificial-Intelligence-Driven Predictive Model for Surface Defect Detections in Medical MEMS. Sensors 2021, 21, 6141. [Google Scholar] [CrossRef] [PubMed]
- Deepan, P.; Sudha, L. Effective utilization of YOLOv3 model for aircraft detection in Remotely Sensed Images. Mater. Today: Proc. 2021, in press. [Google Scholar] [CrossRef]
- Wu, W.-S.; Lu, Z.-M. A Real-Time Cup-Detection Method Based on YOLOv3 for Inventory Management. Sensors 2022, 22, 6956. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2778–2788. [Google Scholar]
- Pacal, I.; Karaman, A.; Karaboga, D.; Akay, B.; Basturk, A.; Nalbantoglu, U.; Coskun, S. An efficient real-time colonic polyp detection with YOLO algorithms trained by using negative samples and large datasets. Comput. Biol. Med. 2022, 141, 105031. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Wu, J.; Huang, Z.; Thoma, J.; Acharya, D.; Van Gool, L. Wasserstein divergence for gans. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 653–668. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv 2017, arXiv:1701.04862. [Google Scholar]
- Wu, P.; Liu, A.; Fu, J.; Ye, X.; Zhao, Y. Autonomous surface crack identification of concrete structures based on an improved one-stage object detection algorithm. Eng. Struct. 2022, 272, 114962. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | The Lowest FID |
|---|---|
| DCGAN | 43.48 |
| WGAN | 54.47 |
| WGAN-DC | 39.55 |
| WGAN-GP-DC | 33.75 |
| WGAN-DIV-DC | 29.44 |
| Data Augmentation | Train | Validation | Test | Total |
|---|---|---|---|---|
| Before | 720 | 240 | 240 | 1200 |
| After | 4000 | 500 | 500 | 5000 |
| System | Ubuntu 18.04 |
|---|---|
| CPU | Intel Core i7-9700f |
| GPU | 2×NVDIA Geforce RTX 2080 Ti |
| Software | CUDA 10.1; Python 3.9; OpenCV 4.5 |
| Framework | Pytorch 1.9 |
| Baseline Model | The Optimal Model | ||||
|---|---|---|---|---|---|
| Data augmentation with WGAN-DIV-DC | √ | √ | √ | √ | |
| Mosaic | √ | √ | √ | ||
| SPPF | √ | ||||
| One more prediction head | √ | ||||
| Precision | 0.858 | 0.871 | 0.873 | 0.884 | 0.865 |
| Recall | 0.752 | 0.78 | 0.817 | 0.807 | 0.847 |
| mAP | 0.833 | 0.867 | 0.889 | 0.888 | 0.901 |
| F1 score | 0.802 | 0.823 | 0.844 | 0.844 | 0.856 |
| Data augmentation | √ | √ |
| Mosaic | √ | √ |
| SPP | √ | |
| SPPF | √ | |
| Total inference time | 13.4 ms | 13.3 ms |
| Detection speed | 74.6 FPS | 75.1 FPS |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Z.; Sang, M.; Huang, Y.; Xing, L.; Liu, T. Defect Detection of MEMS Based on Data Augmentation, WGAN-DIV-DC, and a YOLOv5 Model. Sensors 2022, 22, 9400. https://doi.org/10.3390/s22239400
Shi Z, Sang M, Huang Y, Xing L, Liu T. Defect Detection of MEMS Based on Data Augmentation, WGAN-DIV-DC, and a YOLOv5 Model. Sensors. 2022; 22(23):9400. https://doi.org/10.3390/s22239400
Chicago/Turabian StyleShi, Zhenman, Mei Sang, Yaokang Huang, Lun Xing, and Tiegen Liu. 2022. "Defect Detection of MEMS Based on Data Augmentation, WGAN-DIV-DC, and a YOLOv5 Model" Sensors 22, no. 23: 9400. https://doi.org/10.3390/s22239400
APA StyleShi, Z., Sang, M., Huang, Y., Xing, L., & Liu, T. (2022). Defect Detection of MEMS Based on Data Augmentation, WGAN-DIV-DC, and a YOLOv5 Model. Sensors, 22(23), 9400. https://doi.org/10.3390/s22239400