

CE-BART: Cause-and-Effect BART for Visual Commonsense Generation

Abstract
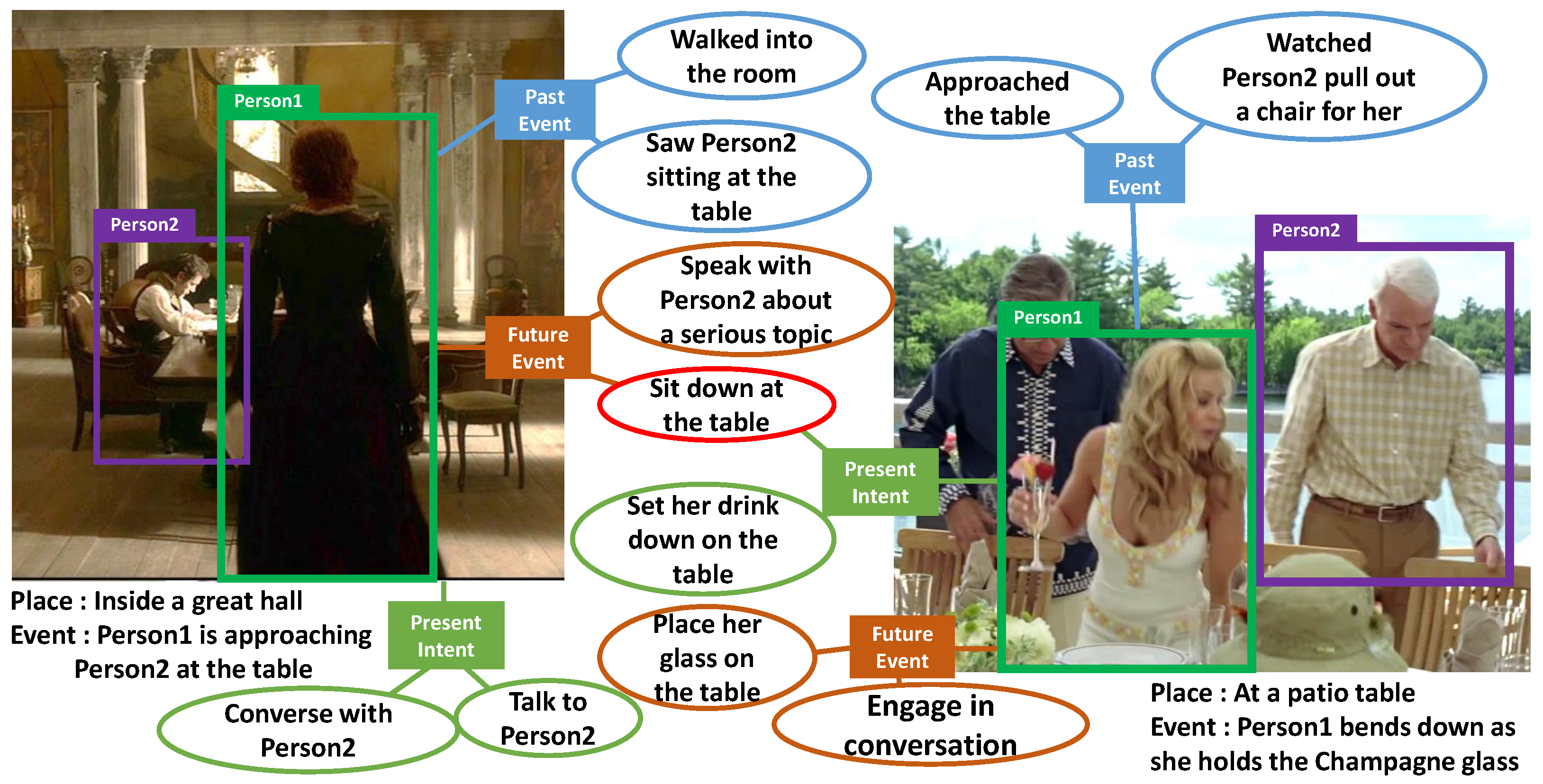
1. Introduction
2. Related Works
2.1. Commonsense Reasoning
2.2. Visual Commonsense Generation
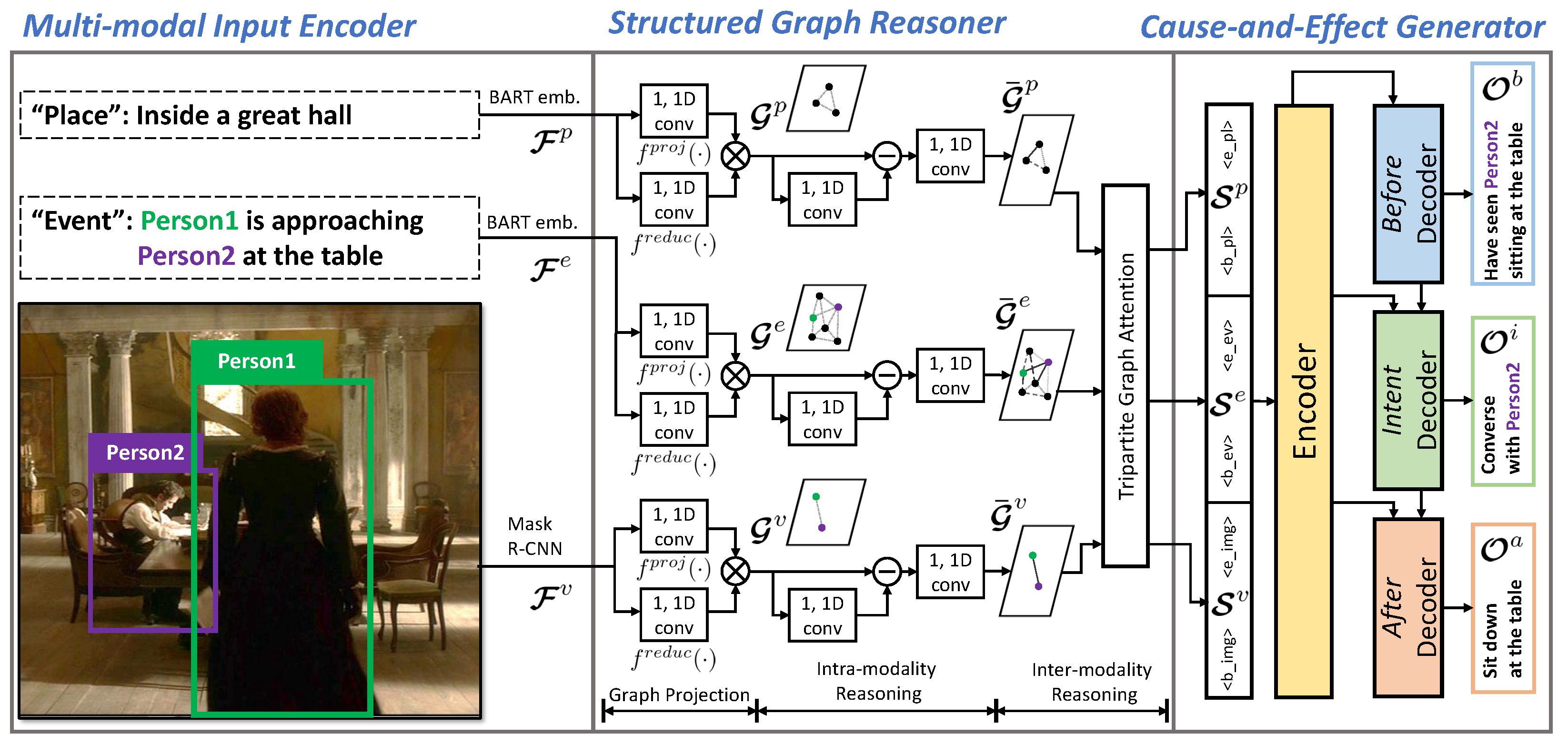
3. Cause-and-Effect BART
3.1. Multimodal Input Encoder
3.2. Structured Graph Reasoner
3.3. Cause-and-Effect Generator
3.3.1. Encoder
3.3.2. Decoder
4. Experiments
4.1. Benchmark Dataset
4.2. Metrics
4.3. Experimental Details
4.4. Experimental Results on VisualCOMET
4.5. Experimental Results on AVSD
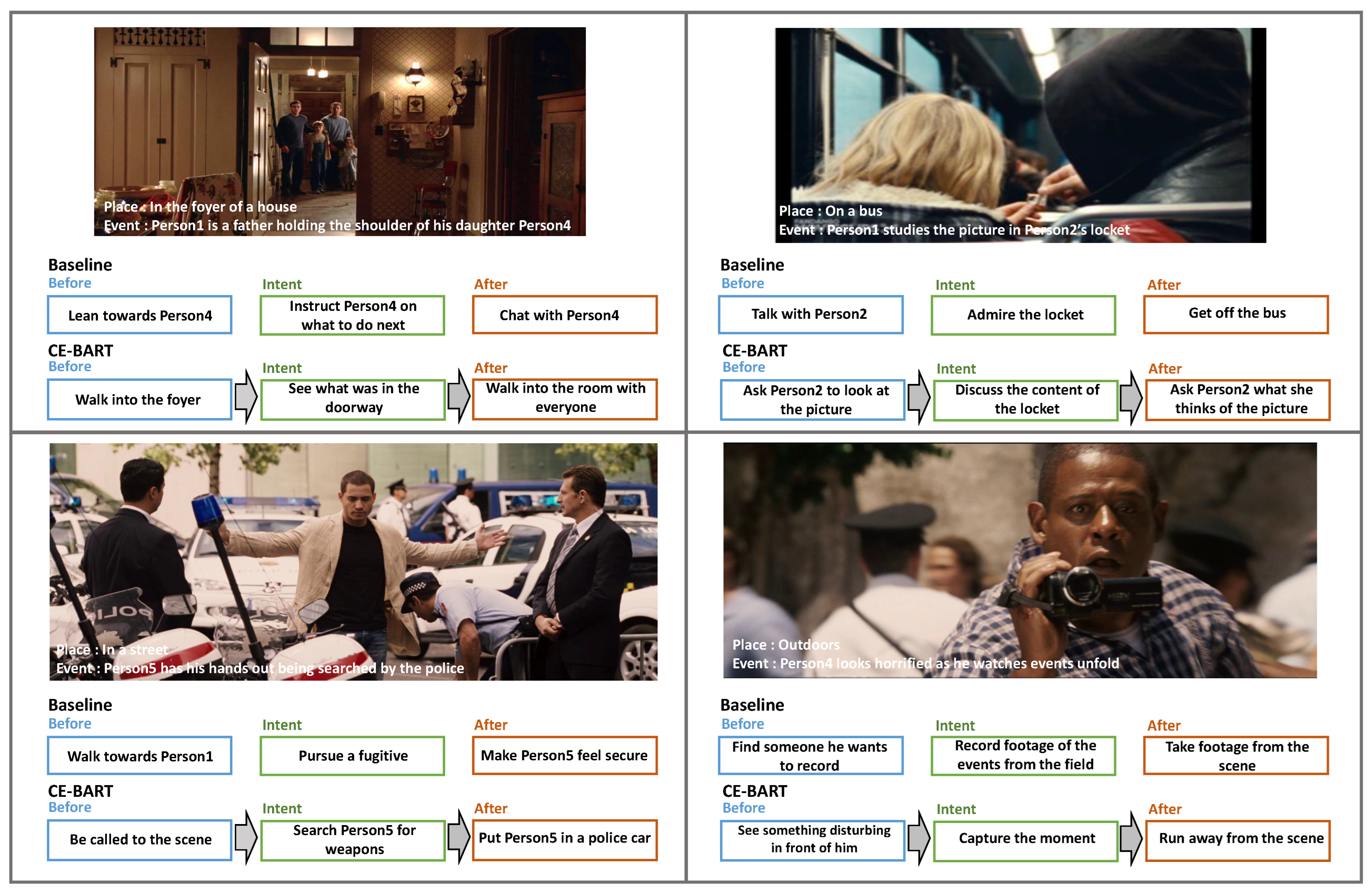
4.6. Qualitative Analysis
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VCG | Visual Commonsense Generation |
| VQA | Visual Question Answering |
| VCR | Visual Commonsense Reasoning |
| CE-BART | Cause-and-Effect BART |
| SGR | Structured Graph Reasoner |
| CEG | Cause-and-Effect Generator |
References
- Park, J.S.; Bhagavatula, C.; Mottaghi, R.; Farhadi, A.; Choi, Y. VisualCOMET: Reasoning about the Dynamic Context of a Still Image. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Lawrence Zitnick, C.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Das, A.; Kottur, S.; Gupta, K.; Singh, A.; Yadav, D.; Moura, J.M.; Parikh, D.; Batra, D. Visual Dialog. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zellers, R.; Bisk, Y.; Farhadi, A.; Choi, Y. From Recognition to Cognition: Visual Commonsense Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June2019. [Google Scholar]
- Piaget, J. The role of action in the development of thinking. In Knowledge and Development; Springer: Berlin/Heidelberg, Germany, 1977; pp. 17–42. [Google Scholar]
- Xing, Y.; Shi, Z.; Meng, Z.; Ma, Y.; Wattenhofer, R. KM-BART: Knowledge Enhanced Multimodal BART for Visual Commonsense Generation. arXiv 2021, arXiv:2101.00419. [Google Scholar]
- Kim, J.; Yoon, S.; Kim, D.; Yoo, C.D. Structured Co-reference Graph Attention for Video-grounded Dialogue. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Virtually, 2–9 February 2021. [Google Scholar]
- Sap, M.; Shwartz, V.; Bosselut, A.; Choi, Y.; Roth, D. Commonsense Reasoning for Natural Language Processing. In Proceedings of the 58th Annual Meeting of the Association for Computatioonal Linguistics (ACL), Tutorial, Online, 5–10 July 2020. [Google Scholar]
- Hashimoto, C.; Torisawa, K.; Kloetzer, J.; Sano, M.; Varga, I.; Oh, J.H.; Kidawara, Y. Toward Future Scenario Generation: Extracting Event Causality Exploiting Semantic Relation, Context, and Association Features. In Proceedings of the 52th Annual Meeting of the Association for Computatioonal Linguistics (ACL), Baltimore, ML, USA, 23–24 June 2014. [Google Scholar]
- Ning, Q.; Feng, Z.; Wu, H.; Roth, D. Joint Reasoning for Temporal and Causal Relations. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect, 1st ed.; Basic Books, Inc.: New York, NY, USA, 2018. [Google Scholar]
- Li, X.; Taheri, A.; Tu, L.; Gimpel, K. Commonsense Knowledge Base Completion. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Sap, M.; Bras, R.L.; Allaway, E.; Bhagavatula, C.; Lourie, N.; Rashkin, H.; Roof, B.; Smith, N.A.; Choi, Y. ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning. In Proceedings of the 57th Annual Meeting of the Association for Computatioonal Linguistics (ACL), Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Bosselut, A.; Rashkin, H.; Sap, M.; Malaviya, C.; Çelikyilmaz, A.; Choi, Y. COMET: Commonsense Transformers for Automatic Knowledge Graph Construction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), Online, 5–10 July 2020. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. arXiv 2016, arXiv:1602.07332. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, Y.; Rohrbach, M.; Yan, Z.; Shuicheng, Y.; Feng, J.; Kalantidis, Y. Graph-Based Global Reasoning Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Lamb, A.M.; ALIAS PARTH GOYAL, A.G.; Zhang, Y.; Zhang, S.; Courville, A.C.; Bengio, Y. Professor Forcing: A New Algorithm for Training Recurrent Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Alamri, H.; Cartillier, V.; Das, A.; Wang, J.; Cherian, A.; Essa, I.; Batra, D.; Marks, T.K.; Hori, C.; Anderson, P.; et al. Audio Visual Scene-Aware Dialog. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization; Association for Computational Linguistics: Ann Arbor, MI, USA, 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. CIDEr: Consensus-Based Image Description Evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Hori, C.; Alamri, H.; Wang, J.; Wichern, G.; Hori, T.; Cherian, A.; Marks, T.K.; Cartillier, V.; Lopes, R.G.; Das, A.; et al. End-to-end Audio Visual Scene-aware Dialog Using Multimodal Attention-based Video Features. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Geng, S.; Gao, P.; Chatterjee, M.; Hori, C.; Roux, J.; Zhang, Y.; Li, H.; Cherian, A. Dynamic Graph Representation Learning for Video Dialog via Multimodal Shuffled Transformers. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Virtually, 2–9 February 2021. [Google Scholar]
- Le, H.; Sahoo, D.; Chen, N.; Hoi, S.C. Multimodal Transformer Networks for End-to-End Video-Grounded Dialogue Systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Li, W.; Jiang, D.; Zou, W.; Li, X. TMT: A Transformer-based Modal Translator for Improving Multimodal Sequence Representations in Audio Visual Scene-aware Dialog. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Lin, X.; Bertasius, G.; Wang, J.; Chang, S.F.; Parikh, D.; Torresani, L. VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| v | Input image | e | Input event description |
| p | Input place description | Appearance feature | |
| Location feature | Input visual feature | ||
| Input event description feature | Input place description feature | ||
| Image semantic graph | Event semantic graph | ||
| Place semantic graph | Strengthened semantic image feature | ||
| Strengthened semantic event feature | Strengthened semantic place feature | ||
| Before caption | Intent caption | ||
| After caption |
| Methods | Validation Set | Test Set | ||||
|---|---|---|---|---|---|---|
| BLEU2 | METEOR | CIDEr | BLEU2 | METEOR | CIDEr | |
| Baseline [1] | 13.50 | 11.55 | 18.27 | 12.71 | 11.13 | 17.36 |
| KM-BART [6] | 23.47 | 15.02 | 39.76 | - | - | - |
| Variants on CE-BART | ||||||
| BART-base | 22.51 | 14.73 | 37.86 | - | - | - |
| + Proj-SGR | 22.47 | 14.97 | 38.91 | - | - | - |
| + Intra-SGR | 23.85 | 15.72 | 39.59 | - | - | - |
| + Inter-SGR | 25.07 | 18.24 | 41.07 | - | - | - |
| + CEG | 28.60 | 19.32 | 43.58 | - | - | - |
| CE-BART | 28.60 | 19.32 | 43.58 | 28.14 | 18.91 | 42.64 |
| Methods | Before | Intent | After | ||||||
|---|---|---|---|---|---|---|---|---|---|
| B2 | M | C | B2 | M | C | B2 | M | C | |
| w/o CEG | 29.7 | 20.4 | 45.1 | 19.4 | 15.4 | 40.7 | 26.1 | 18.9 | 37.7 |
| w CEG | 30.9 | 20.9 | 45.9 | 25.5 | 16.6 | 42.4 | 29.6 | 20.2 | 41.9 |
| Methods | BLEU1 | BLEU2 | BLEU3 | BLEU4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|
| Baseline [28] | - | - | - | 0.078 | 0.113 | 0.277 | 0.727 |
| STSGR [29] | - | - | - | 0.133 | 0.165 | 0.362 | 1.272 |
| MTN [30] | 0.356 | 0.242 | 0.174 | 0.135 | 0.165 | 0.365 | 1.366 |
| MTN-TMT [31] | - | - | - | 0.142 | 0.171 | 0.371 | 1.357 |
| VX2TEXT [32] | 0.361 | 0.260 | 0.197 | 0.154 | 0.178 | 0.393 | 1.605 |
| CE-BART | 0.364 | 0.266 | 0.203 | 0.158 | 0.181 | 0.400 | 1.681 |
| CE-BART | 0.365 | 0.268 | 0.205 | 0.161 | 0.183 | 0.404 | 1.721 |
| w pre-train |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Hong, J.W.; Yoon, S.; Yoo, C.D. CE-BART: Cause-and-Effect BART for Visual Commonsense Generation. Sensors 2022, 22, 9399. https://doi.org/10.3390/s22239399
Kim J, Hong JW, Yoon S, Yoo CD. CE-BART: Cause-and-Effect BART for Visual Commonsense Generation. Sensors. 2022; 22(23):9399. https://doi.org/10.3390/s22239399
Chicago/Turabian StyleKim, Junyeong, Ji Woo Hong, Sunjae Yoon, and Chang D. Yoo. 2022. "CE-BART: Cause-and-Effect BART for Visual Commonsense Generation" Sensors 22, no. 23: 9399. https://doi.org/10.3390/s22239399
APA StyleKim, J., Hong, J. W., Yoon, S., & Yoo, C. D. (2022). CE-BART: Cause-and-Effect BART for Visual Commonsense Generation. Sensors, 22(23), 9399. https://doi.org/10.3390/s22239399