
Free Space Detection Using Camera-LiDAR Fusion in a Bird’s Eye View Plane


Abstract
:1. Introduction
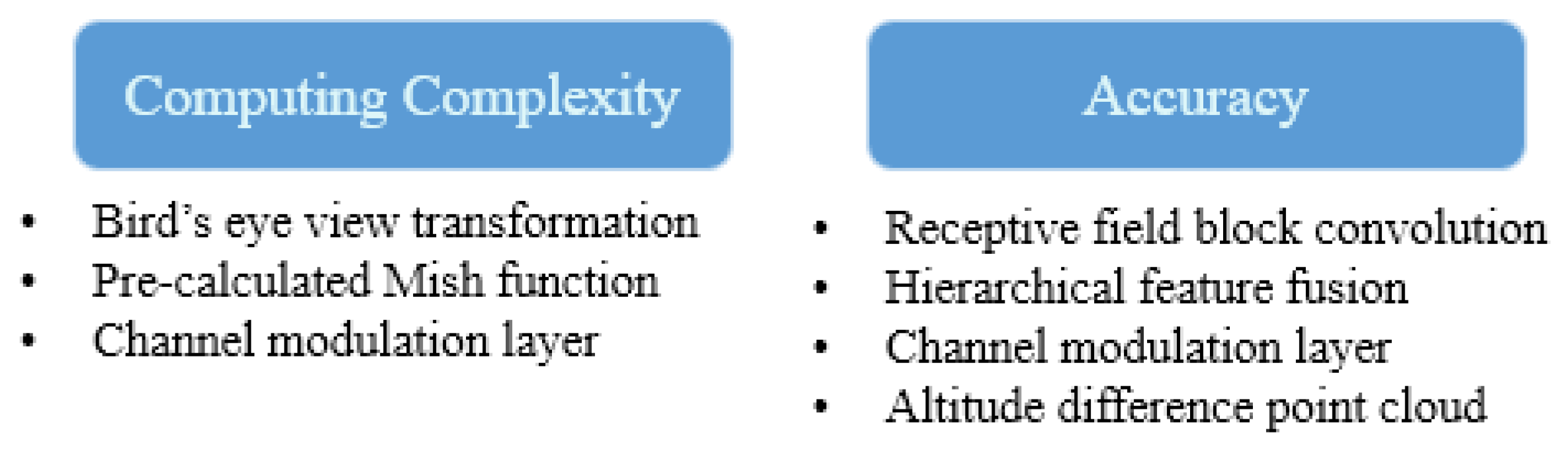
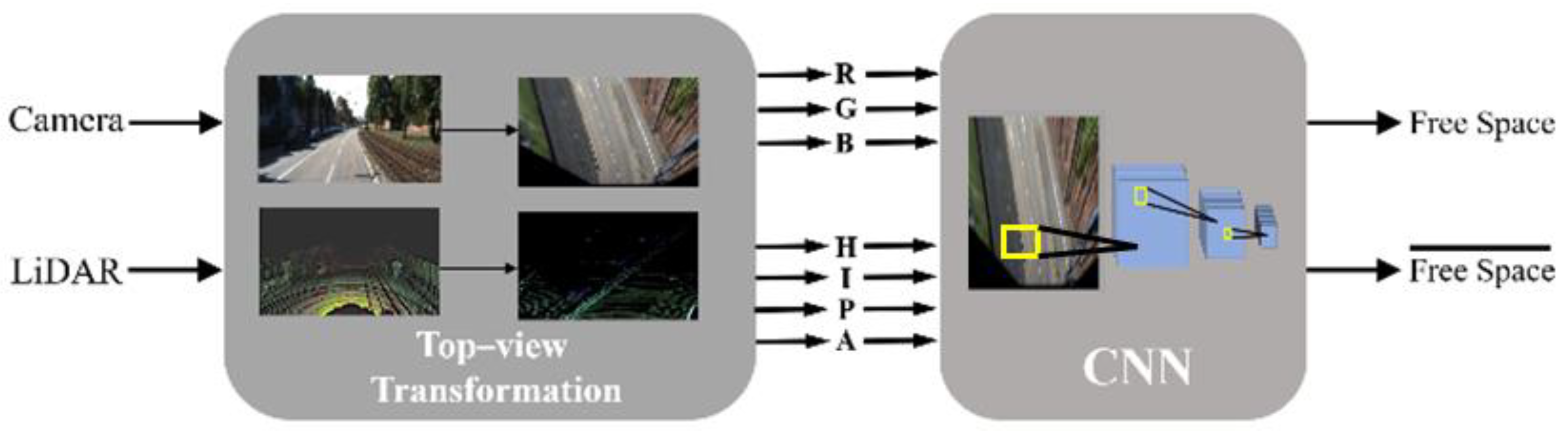
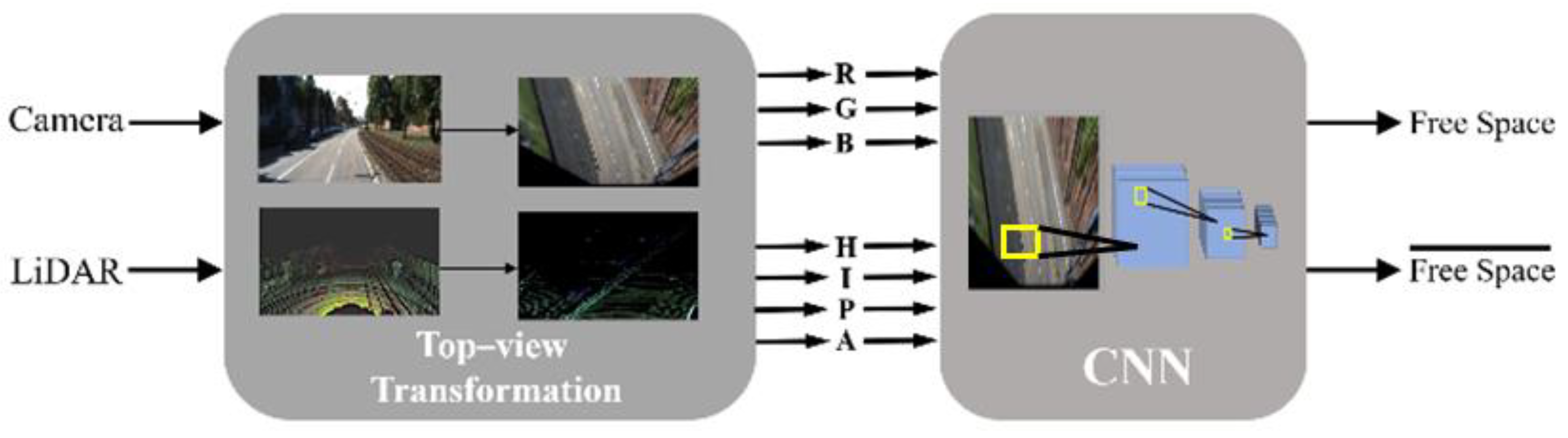
- We employ a data-fusion method that quickly transforms a point cloud to a bird’s eye view rather than projecting it to an image plane, which requires more computational power. Here, the calibration time is reduced by projecting the data onto a plane instead of using a perspective transformation that multiplies several matrices such as sensor coordinate transformation, image plane projection, and undistortion.
2. Related Works
3. Data Transformations
3.1. Perspective Transformation
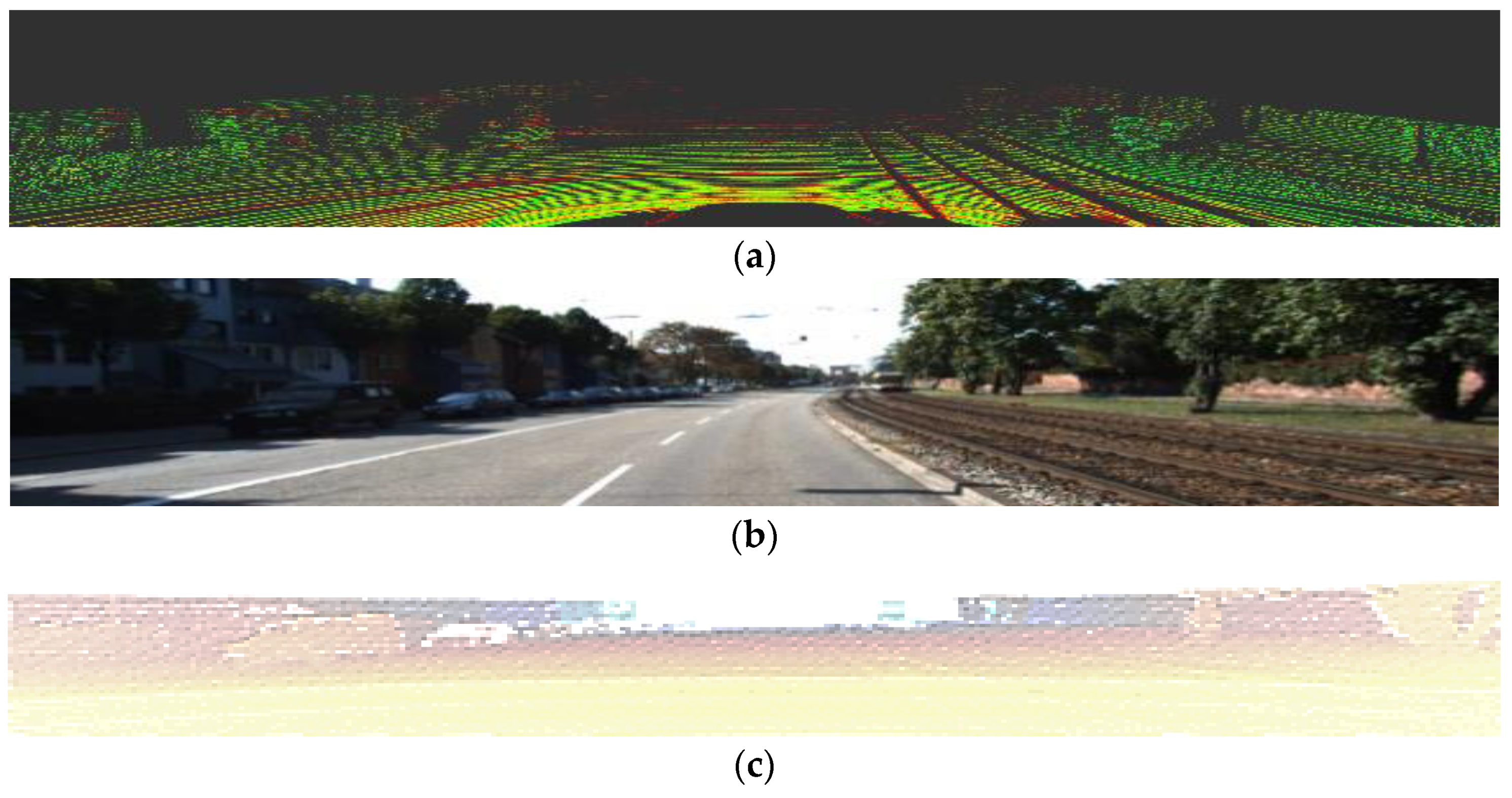
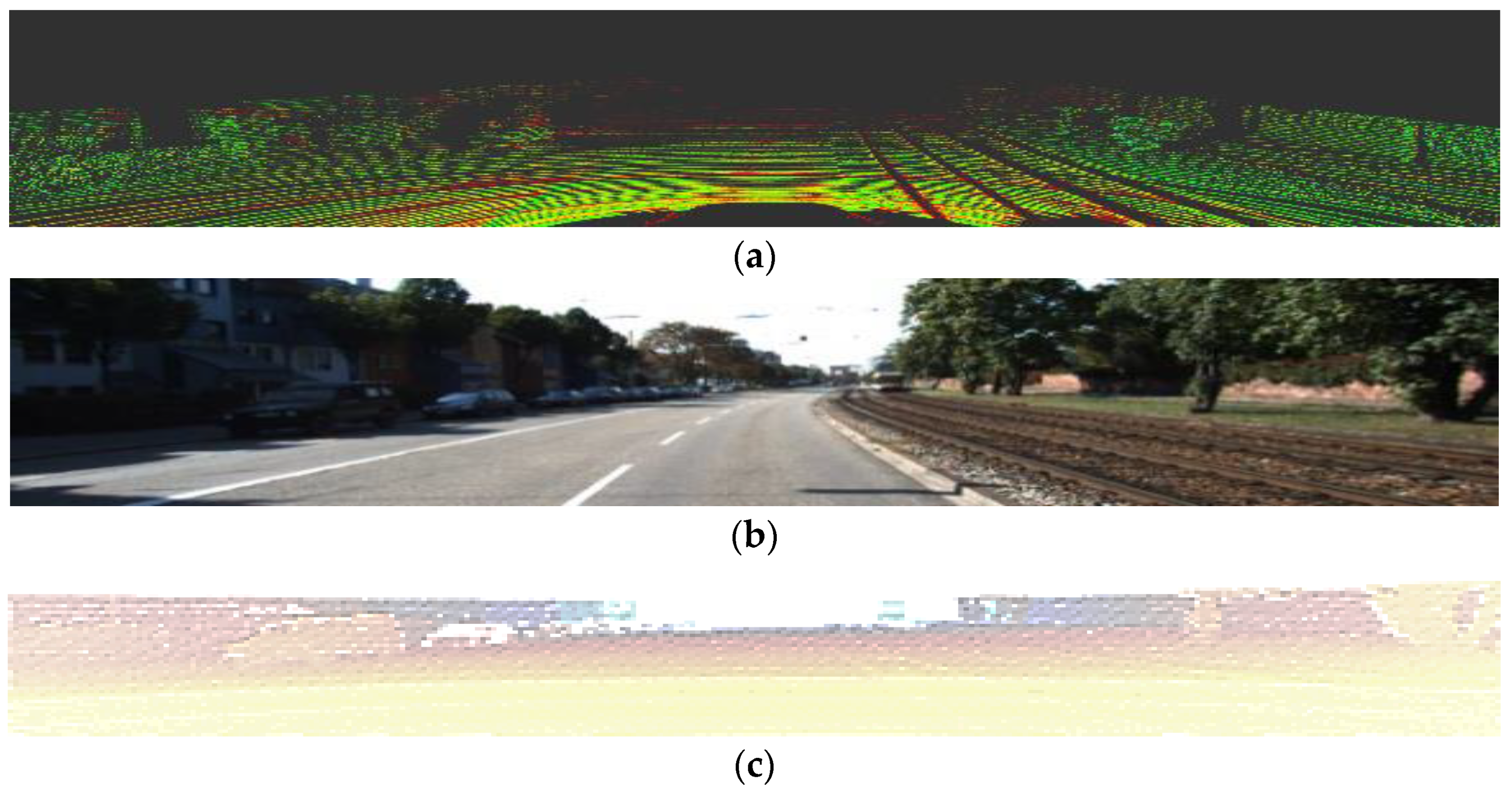
3.2. Bird’s Eye View Transformation
4. Bird’s Eye View Free Space Detection
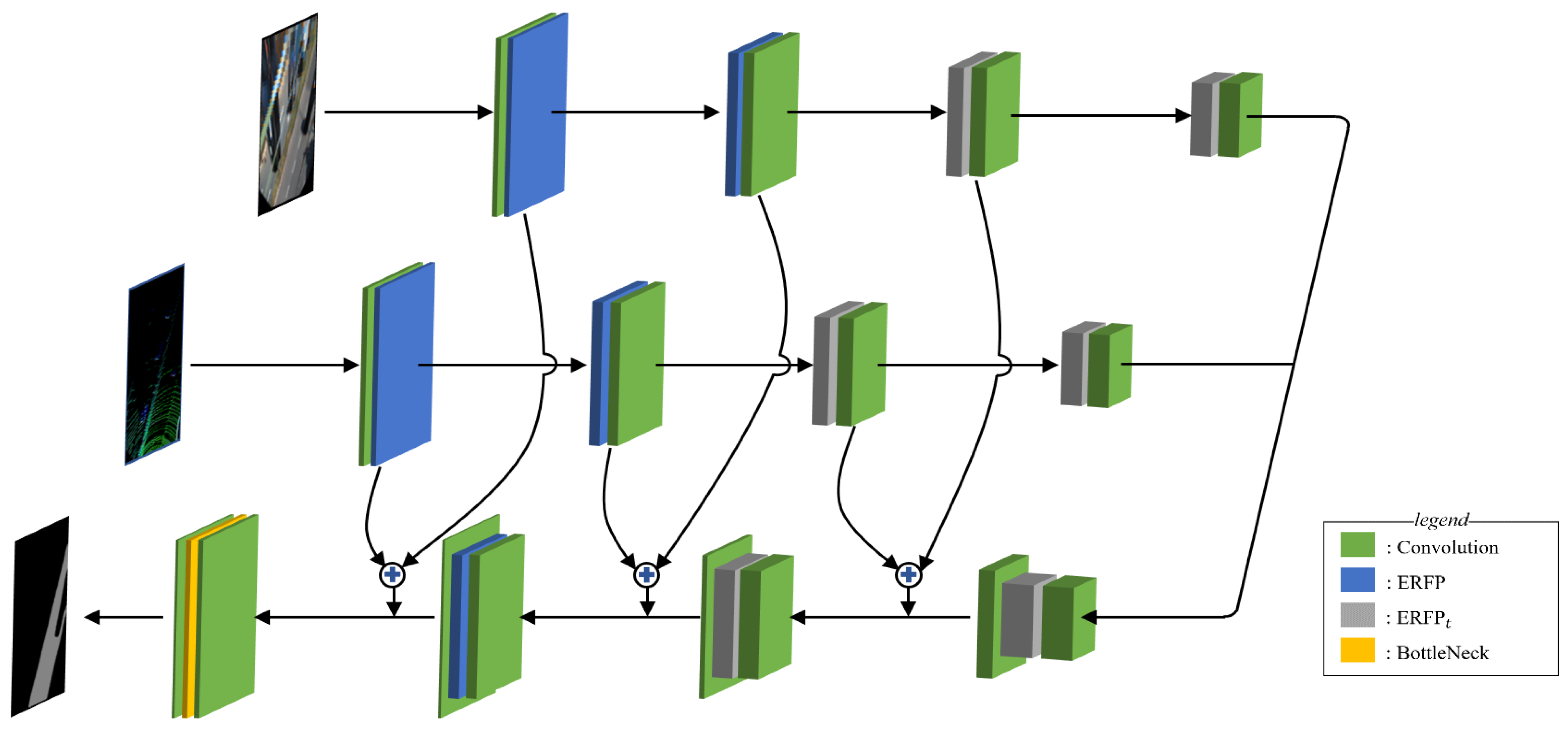
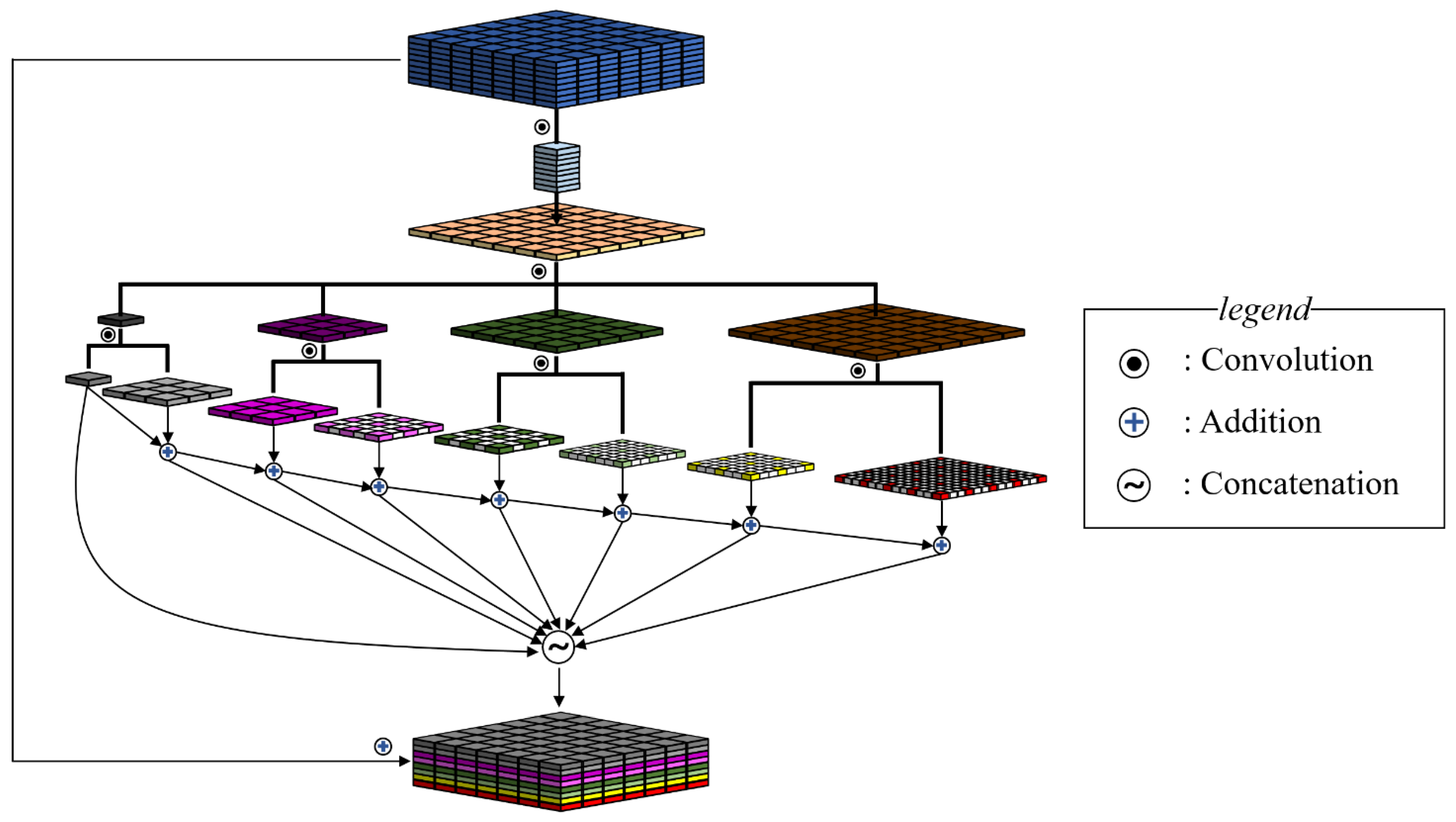
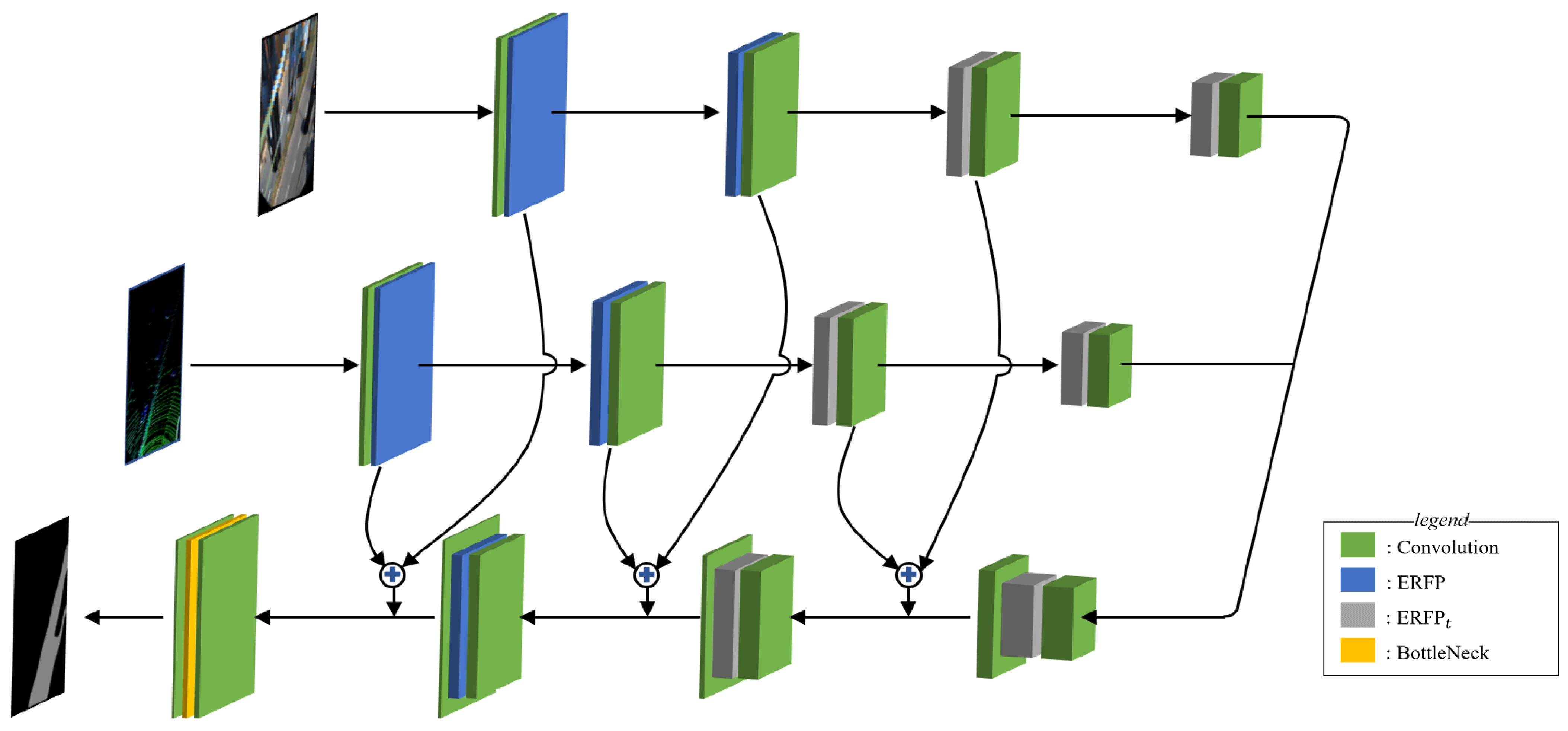
4.1. Efficient Receptive Field Pyramid Module
4.2. Structure of the Network
4.3. Data Augmentation and Learning Details
| Algorithm 1: Implementation of the memory efficient mish |
| ctx: stashed information for backward computation; input: data to be applied to the mish; grad_output: gradient to the precious layer. Class mish is Function forward(ctx, input) is ctx input return input * tanh(softplus(input)) Function backward(ctx, grad_output) is x ← ctx sigmoidX = sigmoid(x) softplusX = softplus(x) tanhX = tanh(softplusX) sechX = 1/cosh(softplusX) return grad_output * (tanhX + x * sigmoidX * sechX2) |
5. Experiments
5.1. Performance Comparison by Sensor Configuration
5.2. Comparison of the Transformation Time
5.3. KITTI Road Benchmark
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. ESPNet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Songtao, L.; Di, H.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 404–419. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Park, J.; Joo, K.; Hu, Z.; Liu, C.; Kweon, I. Non-local spatial propagation network for depth completion. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 120–136. [Google Scholar]
- Cordts, M.; Rehfeld, T.; Schneider, L.; Pfeiffer, D.; Enzweiler, M.; Roth, S.; Pollefeys, M.; Franke, U. The Stixel World: A medium-level representation of traffic scenes. Image Vis. Comput. 2017, 68, 40–52. [Google Scholar] [CrossRef] [Green Version]
- Teichmann, M.; Weber, M.; Zöllner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-time joint semantic reasoning for autonomous driving. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1013–1020. [Google Scholar]
- Mukherjee, S.; Guddeti, R.M.R. A hybrid algorithm for disparity calculation from sparse disparity estimates based on stereo vision. arXiv 2014, arXiv:2001.06967. [Google Scholar]
- Fan, R.; Wang, H.; Cai, P.; Wu, J.; Bocus, J.; Qiao, L.; Liu, M. Learning Collision-Free Space Detection from Stereo Images: Homography Matrix Brings Better Data Augmentation. IEEE ASME Trans. Mechatron 2021. [Google Scholar] [CrossRef]
- Liu, M.; Shan, C.; Zhang, H.; Xia, Q. Stereo Vision Based Road Free Space Detection. In Proceedings of the 2016 9th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 10–11 December 2016; pp. 272–276. [Google Scholar] [CrossRef]
- Han, X.; Wang, H.; Lu, J.; Zhao, C. Road detection based on the fusion of Lidar and image data. Int. J. Adv. Robot. Syst. 2017, 14, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. Lidar-camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef] [Green Version]
- Zhuan, Z.; Li, R.; Jia, K.; Wang, Q.; Li, Y.; Tan, M. Perception-aware Multi-sensor Fusion for 3D LiDAR Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16280–16290. [Google Scholar]
- Caltagirone, L.; Scheidegger, S.; Svensson, L.; Wahde, M. Fast LIDAR-based road detection using fully convolutional neural networks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1019–1024. [Google Scholar]
- Lu, C.; van de Molengraft, M.J.G.; Dubbelman, G. Monocular Semantic Occupancy Grid Mapping with Convolutional Variational Encoder–Decoder Networks. IEEE Robot. Autom. Lett. 2019, 4, 445–452. [Google Scholar] [CrossRef] [Green Version]
- Roddick, T.; Cipolla, R. Predicting Semantic Map Representations from Images Using Pyramid Occupancy Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11138–11147. [Google Scholar]
- Wang, Z.; Zhan, W.; Tomizuka, M. Fusing Bird’s Eye View LIDAR Point Cloud and Front View Camera Image for 3D Object Detection. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Lee, J.-S.; Park, T.-H. Fast Road Detection by CNN-Based Camera–Lidar Fusion and Spherical Coordinate Transformation. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5802–5810. [Google Scholar] [CrossRef]
- Yang, K.; Zhang, J.; Reiß, S.; Hu, X.; Stiefelhagen, R. Capturing Omni-Range Context for Omnidirectional Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1376–1386. [Google Scholar]
- Simon, M.; Milz, S.; Amende, K.; Groß, H. Complex-YOLO: An euler-region-proposal for real-time 3D object detection on point clouds. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 197–209. [Google Scholar]
- Chen, Z.; Zhang, J.; Tao, D. Progressive LiDAR adaptation for road detection. IEEE CAA J. Autom. Sin. 2019, 6, 693–702. [Google Scholar] [CrossRef] [Green Version]
- Iyer, G.; Ram, R.K.; Murthy, J.K.; Krishna, K.M. CalibNet: Geometrically Supervised Extrinsic Calibration using 3D Spatial Transformer Networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1110–1117. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. In Proceedings of the British Machine Vision Virtual Conference (BMVC), Manchester, UK, 7–10 September 2020. [Google Scholar]
- Fritsch, J.; Kühnl, T.; Geiger, A. A new performance measure and evaluation benchmark for road detection algorithms. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1693–1700. [Google Scholar]
- Sun, J.-Y.; Kim, S.-W.; Lee, S.-W.; Kim, Y.-W.; Ko, S.-J. Reverse and Boundary Attention Network for Road Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 876–885. [Google Scholar]
- Wang, H.; Fan, R.; Sun, Y.; Liu, M. Applying Surface Normal Information in Drivable Area and Road Anomaly Detection for Ground Mobile Robots. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 2706–2711. [Google Scholar] [CrossRef]
- Lyu, Y.; Bai, L.; Huang, X. ChipNet: Real-Time LiDAR Processing for Drivable Region Segmentation on an FPGA. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 1769–1779. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Zhang, Z.; Sun, L.; Qin, W. One for All: A Mutual Enhancement Method for Object Detection and Semantic Segmentation. Appl. Sci. 2019, 10, 13. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MaxF (%) | AP (%) | PRE (%) | REC (%) | Runtime (s/Frame) | |
|---|---|---|---|---|---|
| Camera | 94.31 | 92.16 | 98.31 | 90.63 | 0.024 |
| LiDAR | 94.36 | 92.17 | 96.68 | 92.15 | 0.024 |
| Camera + LiDAR | 94.91 | 92.88 | 96.39 | 93.48 | 0.025 |
| Data Format | Transformation Time (ms/Frame) | |
|---|---|---|
| Bird’s Eye View Plane | Image Plane | |
| Image | 0.46 | 0 |
| Point cloud | 10.48 | 146.48 |
| MaxF (%) | AP (%) | PRE (%) | REC (%) | Runtime (ms/Frame) | Operating Complexity | |
|---|---|---|---|---|---|---|
| PLARD [23] | 97.03 | 94.03 | 97.19 | 96.88 | 160 | Heavier network than ours |
| RBANet [29] | 96.30 | 89.72 | 95.14 | 97.50 | 160 | |
| LidCamNet [14] | 96.03 | 93.93 | 96.23 | 95.83 | 150 | |
| NIM-RTFNet [30] | 96.02 | 94.01 | 96.43 | 95.62 | 50 | |
| Study method (BJN) | 94.89 | 90.63 | 96.14 | 93.67 | 27 | |
| HA-DeepLab [10] | 94.83 | 93.24 | 94.77 | 94.89 | 60 | Lighter network than ours |
| LoDNN [16] | 94.07 | 920.3 | 92.81 | 95.37 | 18 | |
| ChipNet [31] | 94.05 | 88.59 | 93.57 | 94.53 | 12 | |
| OFANet [32] | 93.74 | 85.37 | 90.36 | 97.38 | 40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, B.; Lee, D.; Lee, J.-S.; Kee, S.-C. Free Space Detection Using Camera-LiDAR Fusion in a Bird’s Eye View Plane. Sensors 2021, 21, 7623. https://doi.org/10.3390/s21227623
Yu B, Lee D, Lee J-S, Kee S-C. Free Space Detection Using Camera-LiDAR Fusion in a Bird’s Eye View Plane. Sensors. 2021; 21(22):7623. https://doi.org/10.3390/s21227623
Chicago/Turabian StyleYu, Byeongjun, Dongkyu Lee, Jae-Seol Lee, and Seok-Cheol Kee. 2021. "Free Space Detection Using Camera-LiDAR Fusion in a Bird’s Eye View Plane" Sensors 21, no. 22: 7623. https://doi.org/10.3390/s21227623
APA StyleYu, B., Lee, D., Lee, J.-S., & Kee, S.-C. (2021). Free Space Detection Using Camera-LiDAR Fusion in a Bird’s Eye View Plane. Sensors, 21(22), 7623. https://doi.org/10.3390/s21227623